
Optimizing Variational Quantum Neural Networks Based on Collective Intelligence


Abstract
1. Introduction
2. Physical Model and Methods
2.1. Variational Quantum Neural Networks
2.2. Barren Plateau Problem
2.3. Quantum Optimization Algorithms Simulated by Classical Computers
2.4. Particle Swarm-Based Quantum Optimization Algorithm
- Step1.
- Algorithm initialization. Initially, each parameter is initialized with an initial position and initial velocity, that is each set of parameters is updated to . Apart from the initial condition, individual historical best positions and group best position are also recorded for each parameter. The individual best position is used to optimize individual parameters, while the group best position is responsible for optimizing the global parameter vector. Generally, the more particles initialized, the higher the search efficiency and the better the optimization results. However, when setting a larger number of particles, there will be a problem of high computational cost in evaluating the fitness of each particle. Therefore, a good balance between the number of particles and optimization overhead needs to be considered.
- Step2.
- Optimize swarms. For each parameter vector , its update rule is as followed:
- (a)
- Speed update:
- (b)
- Position update:where w is the inertia weight, usually set between . The larger the inertia weight, the higher the global optimization capability is. In our implementation, we make use of an adaptive weight varying with the number of iterations. For example, suppose the total number of iterations is T, the current iteration is t, then the weight can be updated byand are the weights of the acceleration terms, usually taken as positive values, and and are random numbers between .
- Step3.
- Fitness evaluation. Compute the fitness of each parameter vector, and compare it with the individual historical best position . In case the current position’s fitness is better than the individual historical best position, then update ; otherwise, do not update. The specific fitness function can be characterized using the quantum loss function .
- Step4.
- Global update. Compare the individual historical best positions of all particles with the overall group historical best position. If the individual historical best position of a particle is better than the overall group historical best position, then update the overall group historical best position to the position of that particle.
- Step5.
- Convergence condition. Repeat steps 1–4 until the termination condition is met, such as reaching the maximum number of iterations or satisfying a specific fitness threshold.
3. Results
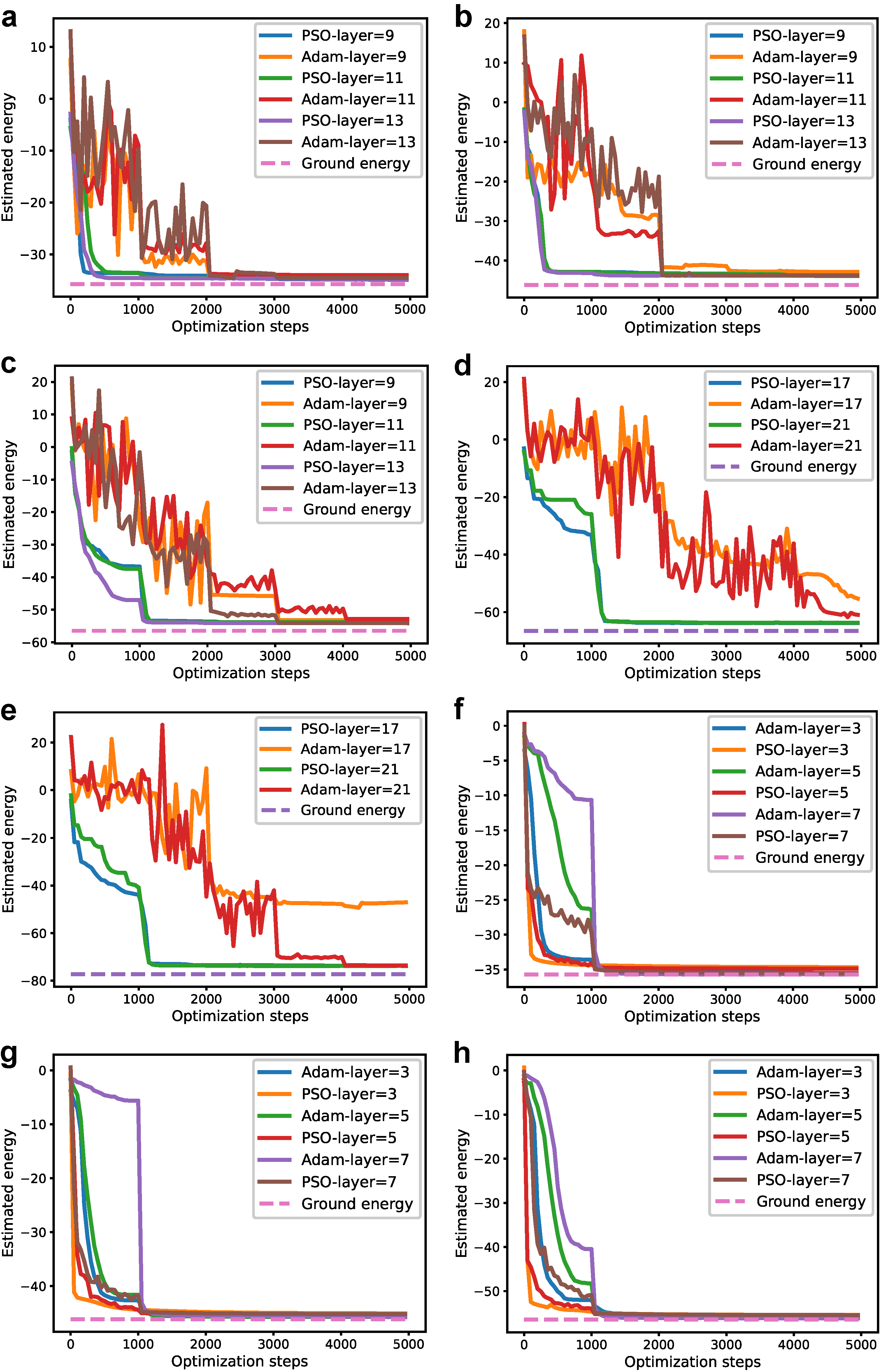
3.1. Solving Ground Energy of a Two-Dimensional Random Hamiltonian
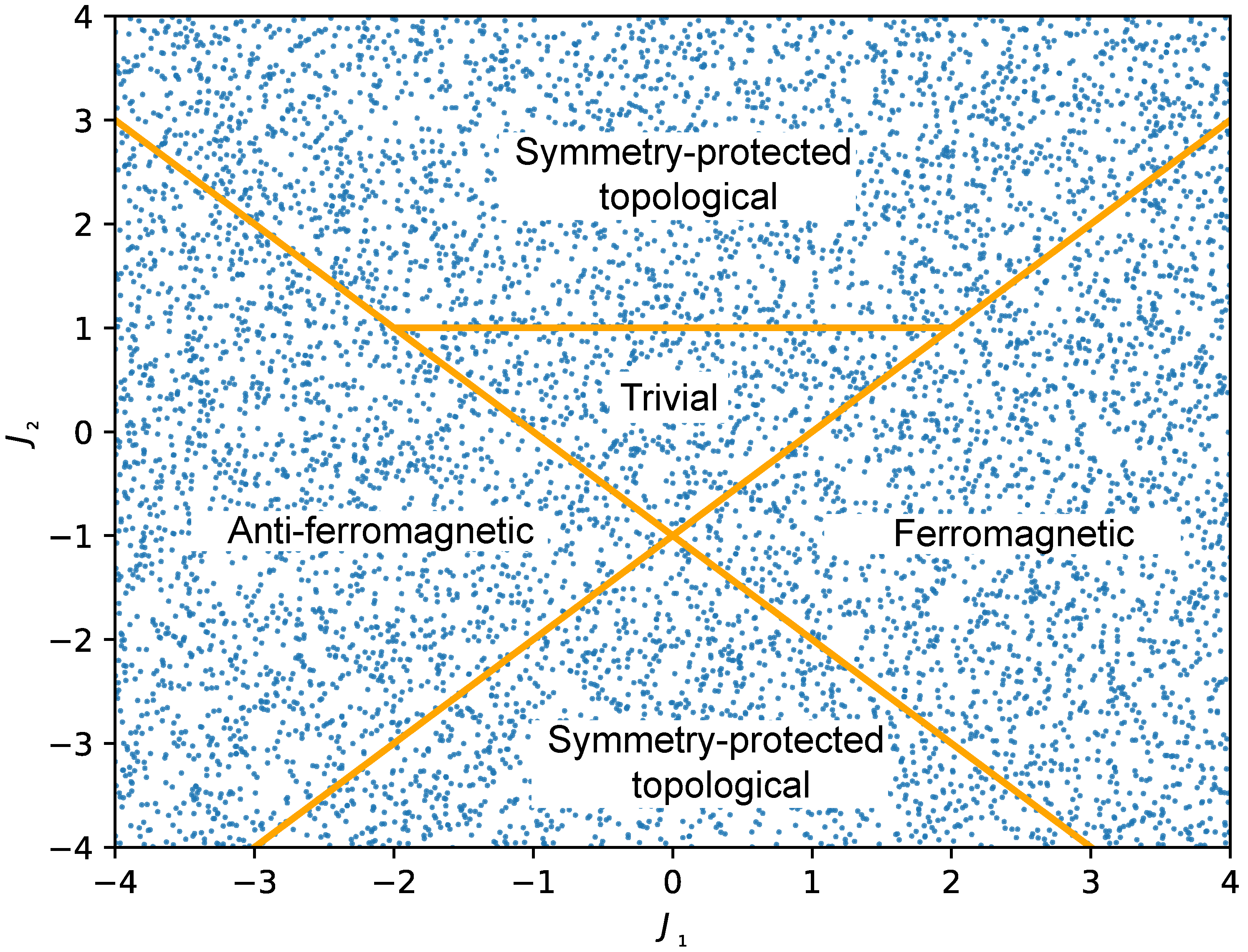
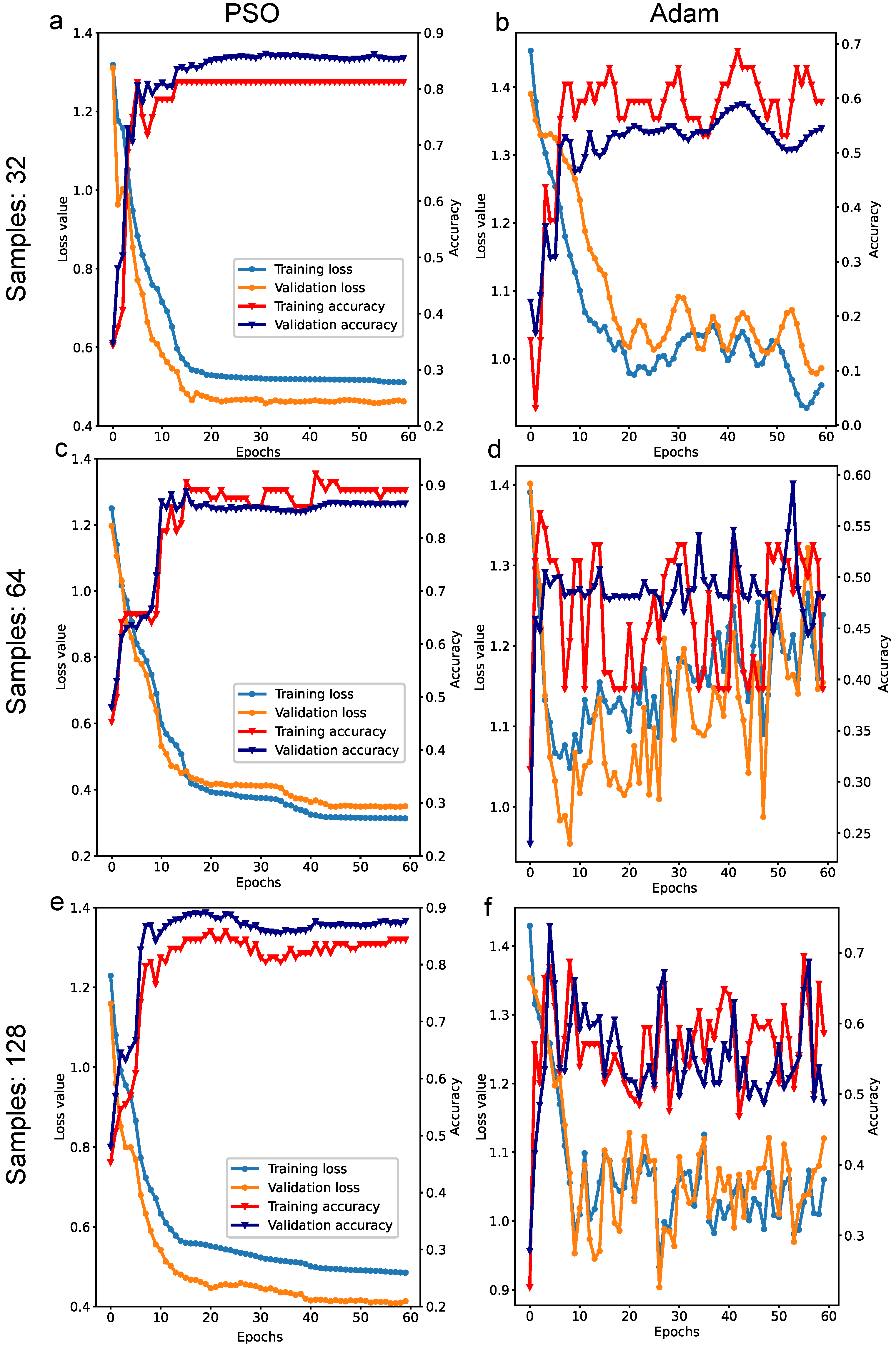
3.2. Quantum Phase Classification
4. Simulation Environment and Hyperparameters
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Preskill, J. Quantum computing in the NISQ era and beyond. arXiv 2018, arXiv:1801.00862v3. [Google Scholar] [CrossRef]
- McClean, J.; Romero, J.; Babbush, R.; Aspuru-Guzik, A. The theory of variational hybrid quantum-classical algorithms. New J. Phys. 2016, 18, 023023. [Google Scholar] [CrossRef]
- Farhi, E.; Goldstone, J.; Gutmann, S. A quantum approximate optimization algorithm. arXiv 2014, arXiv:1411.4028. [Google Scholar] [CrossRef]
- Cao, Y.; Guerreschi, G.G.; Aspuru-Guzik, A. Quantum neuron: An elementary building block for machine learning on quantum computers. arXiv 2017, arXiv:1711.11240. [Google Scholar] [CrossRef]
- McClean, J.R.; Boixo, S.; Smelyanskiy, V.N.; Babbush, R.; Neven, H. Barren plateaus in quantum neural network training landscapes. Nat. Commun. 2018, 9, 4812. [Google Scholar] [CrossRef] [PubMed]
- Arrasmith, A.; Cerezo, M.; Czarnik, P.; Cincio, L.; Coles, P.J. Effect of barren plateaus on gradient-free optimization. Quantum 2021, 5, 558. [Google Scholar] [CrossRef]
- Cheng, B.; Deng, X.-H.; Gu, X.; He, Y.; Hu, G.; Huang, P.; Li, J.; Lin, B.-C.; Lu, D.; Lu, Y. Noisy intermediate-scale quantum computers. Front. Phys. 2023, 18, 21308. [Google Scholar]
- Colless, J.I.; Ramasesh, V.V.; Dahlen, D.; Blok, M.S.; Kimchi-Schwartz, M.E.; McClean, J.R.; Carter, J.; de Jong, W.A.; Siddiqi, I. Computation of molecular spectra on a quantum processor with an error-resilient algorithm. Phys. Rev. X 2018, 8, 011021. [Google Scholar] [CrossRef]
- Holmes, Z.; Sharma, K.; Cerezo, M.; Coles, P.J. Connecting ansatz expressibility to gradient magnitudes and barren plateaus. PRX Quantum 2022, 3, 010313. [Google Scholar] [CrossRef]
- Stokes, J.; Izaac, J.; Killoran, N.; Carleo, G. Quantum natural gradient. Quantum 2020, 4, 269. [Google Scholar] [CrossRef]
- Grant, E.; Wossnig, L.; Ostaszewski, M.; Benedetti, M. An initialization strategy for addressing barren plateaus in parametrized quantum circuits. Quantum 2019, 3, 214. [Google Scholar] [CrossRef]
- Sack, S.H.; Medina, R.A.; Michailidis, A.A.; Kueng, R.; Serbyn, M. Avoiding barren plateaus using classical shadows. PRX Quantum 2022, 3, 020365. [Google Scholar] [CrossRef]
- Chen, S.Y.C.; Huang, C.M.; Hsing, C.W.; Goan, H.S.; Kao, Y.J. Variational quantum reinforcement learning via evolutionary optimization. Mach. Learn. Sci. Technol. 2022, 3, 015025. [Google Scholar] [CrossRef]
- An, A.; Degroote, M.; Aspuru-Guzik, A. Natural evolutionary strategies for variational quantum computation. Mach. Learn. Sci. Technol. 2021, 2, 045012. [Google Scholar]
- Cui, X.; Zhang, W.; Tuske, Z.; Picheny, M. Evolutionary stochastic gradient descent for optimization of deep neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Red Hook, NY, USA, 8 December 2018. [Google Scholar]
- Schuld, M.; Ryan, S.; Johannes Jakob, M. Effect of data encoding on the expressive power of variational quantum-machine-learning models. Phys. Rev. A 2021, 103, 032430. [Google Scholar] [CrossRef]
- Nakaji, K.; Uno, S.; Suzuki, Y.; Raymond, R.; Onodera, T.; Tanaka, T.; Tezuka, H.; Mitsuda, N.; Yamamoto, N. Approximate amplitude encoding in shallow parameterized quantum circuits and its application to financial market indicators. Phys. Rev. Res. 2022, 4, 023136. [Google Scholar] [CrossRef]
- Schreiber, F.J.; Eisert, J.; Meyer, J.J. Classical surrogates for quantum learning models. Phys. Rev. Lett. 2023, 131, 100803. [Google Scholar] [CrossRef] [PubMed]
- Broughton, M.; Verdon, G.; McCourt, T.; Martinez, A.J.; Yoo, J.H.; Isakov, S.V.; Massey, P.; Niu, P.; Halavati, R.; Peters, E.; et al. Tensorflow quantum: A software framework for quantum machine learning. arXiv 2020, arXiv:2003.02989. [Google Scholar]
- Bergholm, V.; Izaac, J.; Schuld, M.; Gogolin, C.; Ahmed, S.; Ajith, V.; Alam, M.S.; Alonso-Linaje, G.; AkashNarayanan, B.; Asadi, A.; et al. Pennylane: Automatic differentiation of hybrid quantum-classical computations. arXiv 2018, arXiv:1811.04968. [Google Scholar]
- Schuld, M.; Bergholm, V.; Gogolin, C.; Izaac, J.; Killoran, N. Evaluating analytic gradients on quantum hardware. Phys. Rev. A 2019, 99, 032331. [Google Scholar] [CrossRef]
- Kennedy, J.; Russell, E. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4. [Google Scholar]
- Schuld, M.; Bocharov, A.; Svore, K.M.; Wiebe, N. Circuit-centric quantum classifiers. Phys. Rev. A 2020, 101, 032308. [Google Scholar] [CrossRef]
- Havlíček, V.; Córcoles, A.D.; Temme, K.; Harrow, A.W.; Kandala, A.; Chow, J.M.; Gambetta, J.M. Supervised learning with quantumenhanced feature spaces. Nature 2019, 567, 209–212. [Google Scholar] [CrossRef] [PubMed]
- Farhi, E.; Neven, H. Classification with quantum neural networks on near term processors. arXiv 2018, arXiv:1802.06002. [Google Scholar] [CrossRef]
- Romero, J.; Olson, J.P.; Aspuru-Guzik, A. Quantum autoencoders for efficient compression of quantum data. Quant. Sci. Technol. 2017, 2, 045001. [Google Scholar] [CrossRef]
- Zhu, D.; Linke, N.M.; Benedetti, M.; Landsman, K.A.; Nguyen, N.H.; Alderete, C.H.; Perdomo-Ortiz, A.; Korda, N.; Garfoot, A.; Brecque, C.; et al. Training of quantum circuits on a hybrid quantum computer. Sci. Adv. 2019, 5, eaaw9918. [Google Scholar] [CrossRef]
- Rad, A.; Seif, A.; Linke, N.M. Surviving the barren plateau in variational quantum circuits with bayesian learning initialization. arXiv 2022, arXiv:2203.02464. [Google Scholar]
- Cong, I.; Choi, S.; Lukin, M.D. Quantum convolutional neural networks. Nat. Phys. 2019, 15, 1273–1278. [Google Scholar] [CrossRef]
- Caro, M.C.; Huang, H.Y.; Cerezo, M.; Sharma, K.; Sornborger, A.; Cincio, L.; Coles, P.J. Generalization in quantum machine learning from few training data. Nat. Commun. 2022, 13, 4919. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.X.; Allcock, J.; Wan, Z.Q.; Liu, S.; Sun, J.; Yu, H.; Yang, X.H.; Qiu, J.; Ye, Z.; Chen, Y.Q.; et al. Tensorcircuit: A quantum software framework for the nisq era. Quantum 2023, 7, 912. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems 32, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Xiao, T.; Huang, J.; Li, H.; Fan, J.; Zeng, G. Intelligent certification for quantum simulators via machine learning. npj Quantum Inf. 2022, 8, 138. [Google Scholar] [CrossRef]
- Xiao, T.; Fan, J.; Zeng, G. Parameter estimation in quantum sensing based on deep reinforcement learning. npj Quantum Inf. 2022, 8, 2. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (PSO) | 0.82 | 0.89 | 0.84 |
| (Adam) | 0.50 | 0.51 | 0.53 |
| (PSO) | 0.86 | 0.87 | 0.873 |
| (Adam) | 0.51 | 0.512 | 0.55 |
| (PSO) | 0.90 | 0.92 | 0.95 |
| (Adam) | 0.53 | 0.537 | 0.544 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Xiao, T.; Deng, X.; Zeng, G.; Li, W. Optimizing Variational Quantum Neural Networks Based on Collective Intelligence. Mathematics 2024, 12, 1627. https://doi.org/10.3390/math12111627
Li Z, Xiao T, Deng X, Zeng G, Li W. Optimizing Variational Quantum Neural Networks Based on Collective Intelligence. Mathematics. 2024; 12(11):1627. https://doi.org/10.3390/math12111627
Chicago/Turabian StyleLi, Zitong, Tailong Xiao, Xiaoyang Deng, Guihua Zeng, and Weimin Li. 2024. "Optimizing Variational Quantum Neural Networks Based on Collective Intelligence" Mathematics 12, no. 11: 1627. https://doi.org/10.3390/math12111627
APA StyleLi, Z., Xiao, T., Deng, X., Zeng, G., & Li, W. (2024). Optimizing Variational Quantum Neural Networks Based on Collective Intelligence. Mathematics, 12(11), 1627. https://doi.org/10.3390/math12111627