
LASFormer: Light Transformer for Action Segmentation with Receptive Field-Guided Distillation and Action Relation Encoding



Abstract
:1. Introduction
- We propose a light yet effective transformer framework for action segmentation called LASFormer, which can be effective in learning temporal structure representation with lower computational costs and is thus more efficient for handling long video sequences.
- We propose receptive field-guided distillation (RFD) to realize mode reduction, which can overcome more generally the gap in semantic feature structure between the intermediate features of teacher and student by the aggregated temporal dilation convolution (ATDC).
- We propose the SIA and SICA, which can replace SA and CA, respectively, thus reducing the inference latency. Also, we propose an ARE embedded after the decoder, which utilizes the designed TGR and CMF to excavate contextual relations among actions more accurately, reducing over-segmentation errors.
- Our approach achieves state-of-the-art performance in accuracy, edit score, and F1 score on three popular benchmarks, 50Salads, GTEA, and Breakfast, and LASFormer is demonstrated to be more efficient than existing transformer-based methods in the number of model parameters, FLOPs, and GPU memory cost.
2. Related Work
2.1. Action Segmentation
2.2. Study on Efficient Transformers
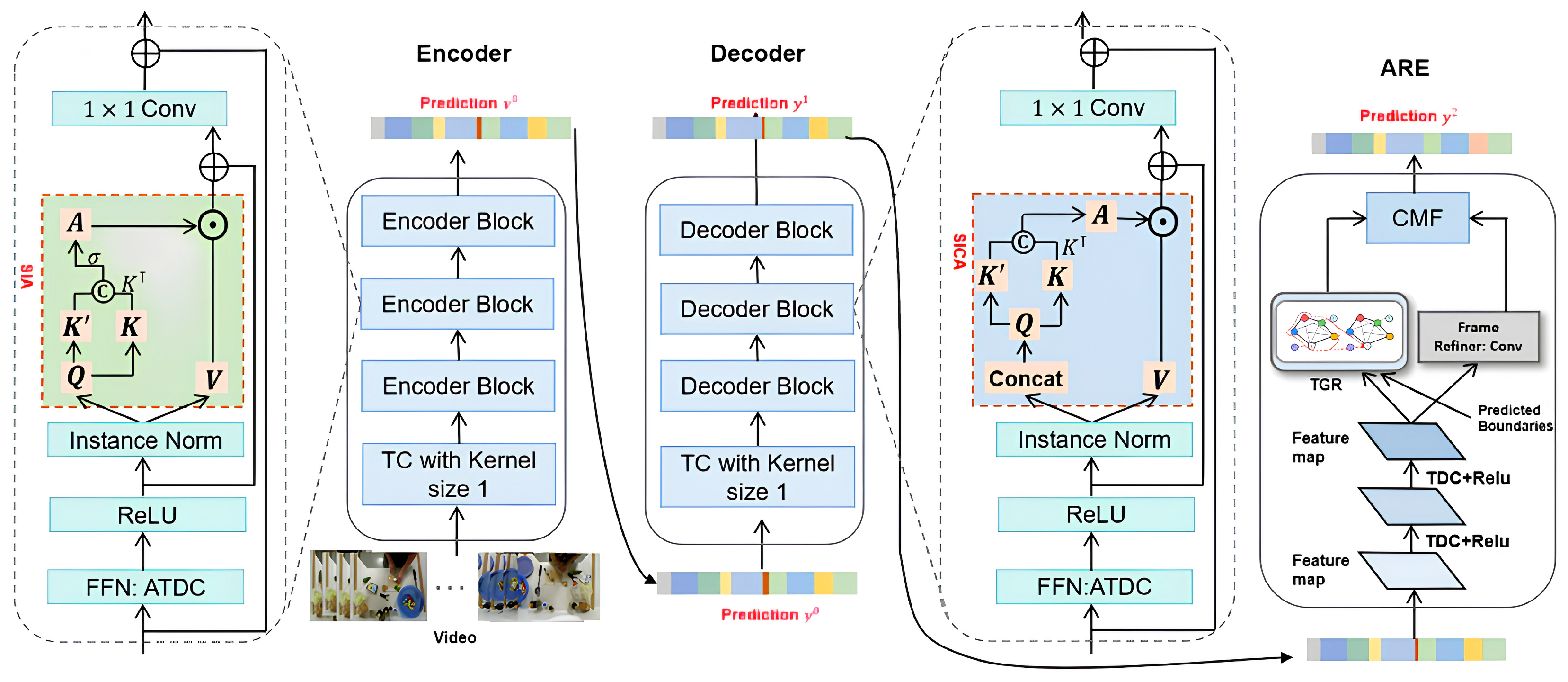
3. Methods
3.1. Overview
3.1.1. Main Components
3.1.2. The Pipeline of Proposed Framework
3.2. Encoder Block
3.3. Decoder Block
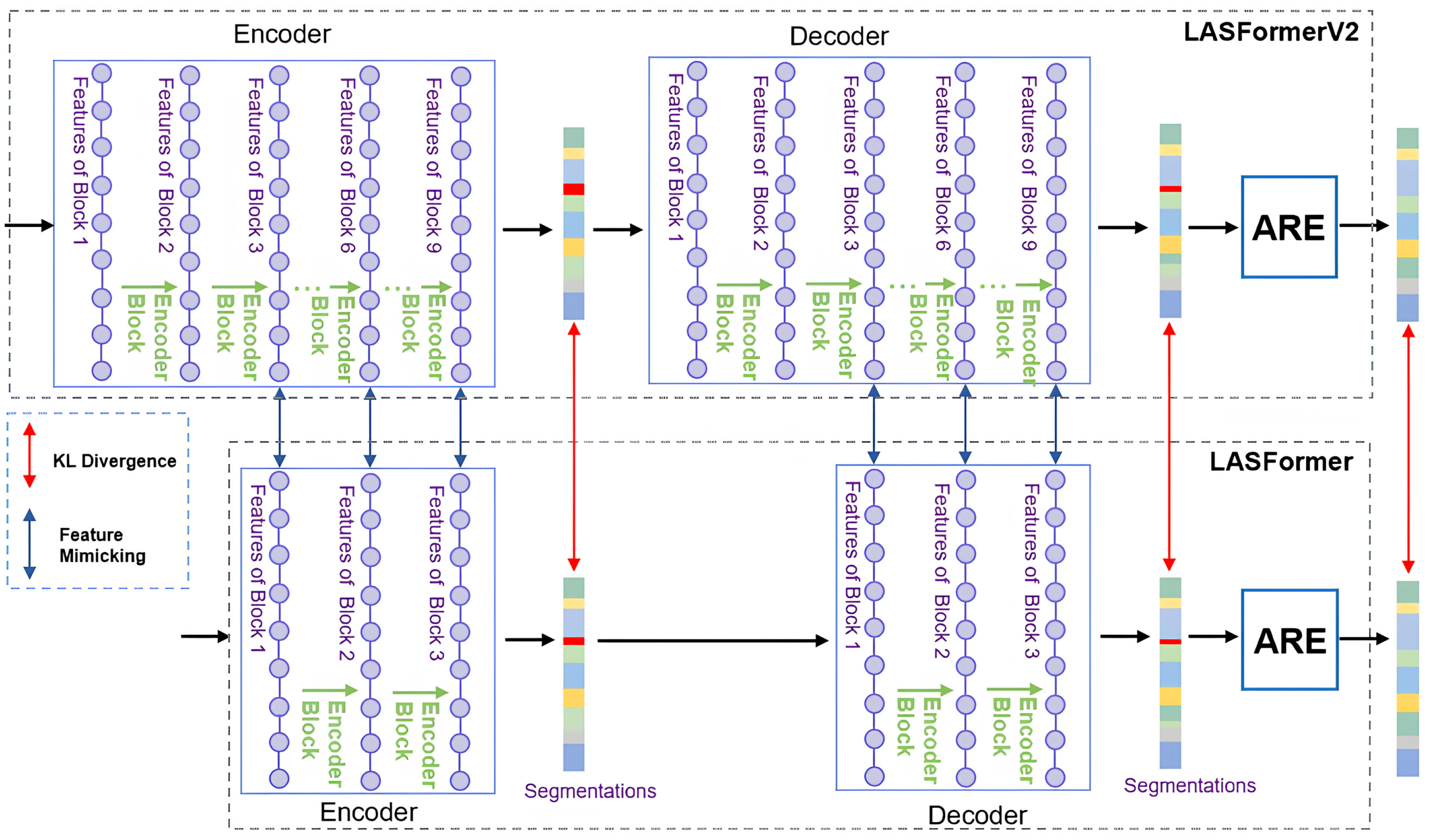
3.4. Receptive Field-Guided Distillation
3.5. Action Relation Encoding
3.5.1. Temporal Graph Reasoning
3.5.2. Cross-Model Fusion
4. Experiments and Discussion
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
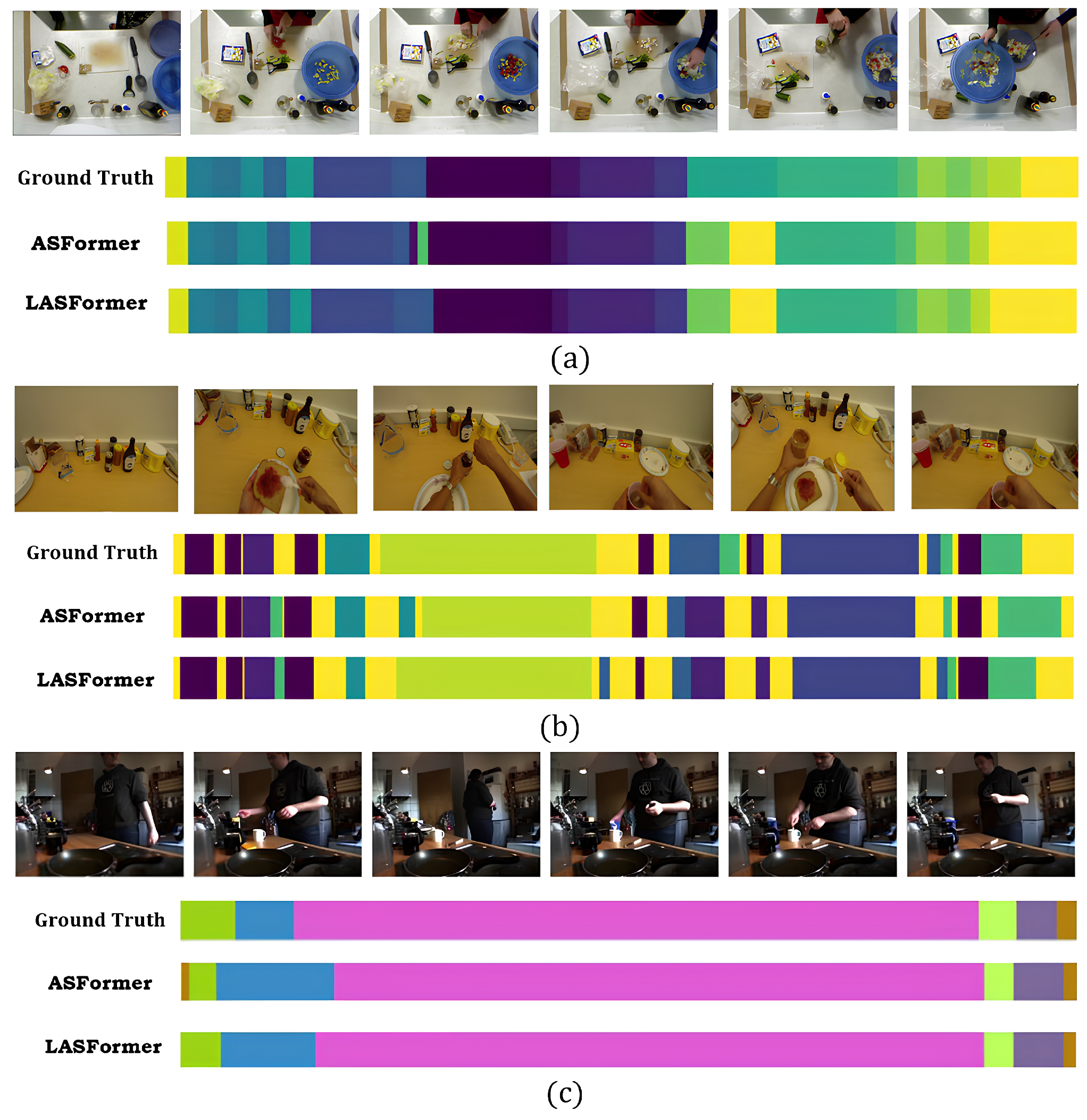
4.3. Compared with State-of-the-Art Methods
4.4. Ablation Study
4.4.1. Overall Analysis of the Effect of Three Main Components
4.4.2. Ablations of the Receptive Field-Guided Distillation
4.4.3. Analysis of Simplified Implicit Attention and Cross-Attention
4.4.4. Analysis of the Action Relation Encoding and the Number of Decoders
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, D.; Li, Q.; Jiang, T.; Wang, Y.; Miao, R.; Shan, F.; Li, Z. Towards Unified Surgical Skill Assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Computer Vision Foundation, IEEE, Nashville, TN, USA, 20–25 June 2021; pp. 9522–9531. [Google Scholar] [CrossRef]
- Chen, M.H.; Li, B.; Bao, Y.; AlRegib, G.; Kira, Z. Action Segmentation With Joint Self-Supervised Temporal Domain Adaptation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9451–9460. [Google Scholar] [CrossRef]
- Chen, W.; Chai, Y.; Qi, M.; Sun, H.; Pu, Q.; Kong, J.; Zheng, C. Bottom-up improved multistage temporal convolutional network for action segmentation. Appl. Intell. 2022, 52, 14053–14069. [Google Scholar] [CrossRef]
- Gao, S.H.; Han, Q.; Li, Z.Y.; Peng, P.; Wang, L.; Cheng, M.M. Global2Local: Efficient Structure Search for Video Action Segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16800–16809. [Google Scholar] [CrossRef]
- Farha, Y.A.; Gall, J. MS-TCN: Multi-Stage Temporal Convolutional Network for Action Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–19 June 2019; pp. 3570–3579. [Google Scholar] [CrossRef]
- Li, S.J.; AbuFarha, Y.; Liu, Y.; Cheng, M.M.; Gall, J. MS-TCN++: Multi-Stage Temporal Convolutional Network for Action Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 45, 6647–6658. [Google Scholar] [CrossRef] [PubMed]
- Yi, F.; Wen, H.; Jiang, T. ASFormer: Transformer for Action Segmentation. In Proceedings of the The British Machine Vision Conference, London, UK, 20–25 November 2021. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Zhou, Q.; Li, X.; He, L.; Yang, Y.; Cheng, G.; Tong, Y.; Ma, L.; Tao, D. TransVOD: End-to-End Video Object Detection with Spatial-Temporal Transformers. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 7853–7869. [Google Scholar] [CrossRef] [PubMed]
- Kim, B.; Lee, J.; Kang, J.; Kim, E.; Kim, H.J. HOTR: End-to-End Human-Object Interaction Detection With Transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Virtual Event, Nashville, TN, USA, 20–25 June 2021; pp. 74–83. [Google Scholar] [CrossRef]
- Bao, L.; Zhou, X.; Zheng, B.; Yin, H.; Zhu, Z.; Zhang, J.; Yan, C. Aggregating transformers and CNNs for salient object detection in optical remote sensing images. Neurocomputing 2023, 553, 126560. [Google Scholar] [CrossRef]
- Vecchio, G.; Prezzavento, L.; Pino, C.; Rundo, F.; Palazzo, S.; Spampinato, C. MeT: A graph transformer for semantic segmentation of 3D meshes. Comput. Vis. Image Underst. 2023, 235, 103773. [Google Scholar] [CrossRef]
- Du, D.; Su, B.; Li, Y.; Qi, Z.; Si, L.; Shan, Y. Do we really need temporal convolutions in action segmentation? arXiv 2022, arXiv:cs.CV/2205.13425. [Google Scholar]
- Fayyaz, M.; Koohpayegani, S.A.; Jafari, F.R.; Sengupta, S.; Joze, H.R.V.; Sommerlade, E.; Pirsiavash, H.; Gall, J. Adaptive Token Sampling for Efficient Vision Transformers. In Proceedings of the Computer Vision—ECCV 2022—17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Volume 13671, pp. 396–414. [Google Scholar] [CrossRef]
- Tang, Y.; Han, K.; Wang, Y.; Xu, C.; Guo, J.; Xu, C.; Tao, D. Patch Slimming for Efficient Vision Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition CVPR, New Orleans, LA, USA, 18–24 June 2022; pp. 12155–12164. [Google Scholar] [CrossRef]
- Yin, H.; Vahdat, A.; Álvarez, J.M.; Mallya, A.; Kautz, J.; Molchanov, P. A-ViT: Adaptive Tokens for Efficient Vision Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10799–10808. [Google Scholar] [CrossRef]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the Design of Spatial Attention in Vision Transformers. In Proceedings of the Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, Vancouver, BC, Canada, 6–21 December 2021; pp. 9355–9366. [Google Scholar]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. MetaFormer is Actually What You Need for Vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10809–10819. [Google Scholar] [CrossRef]
- Li, K.; Wang, Y.; Gao, P.; Song, G.; Liu, Y.; Li, H.; Qiao, Y. UniFormer: Unified Transformer for Efficient Spatial-Temporal Representation Learning. In Proceedings of the the Tenth International Conference on Learning Representations, ICLR, Virtual, 25–29 April 2022. [Google Scholar]
- Pan, J.; Bulat, A.; Tan, F.; Zhu, X.; Dudziak, L.; Li, H.; Tzimiropoulos, G.; Martínez, B. EdgeViTs: Competing Light-Weight CNNs on Mobile Devices with Vision Transformers. In Proceedings of the Computer Vision—ECCV 2022—17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G.J., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Volume 13671, pp. 294–311. [Google Scholar] [CrossRef]
- Behrmann, N.; Golestaneh, S.A.; Kolter, Z.; Gall, J.; Noroozi, M. Unified Fully and Timestamp Supervised Temporal Action Segmentation via Sequence to Sequence Translation. In Proceedings of the Computer Vision—ECCV 2022—17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Volume 13695, pp. 52–68. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, Y.; Yin, Z.; Gao, C. Unsupervised video segmentation for multi-view daily action recognition. Image Vis. Comput. 2023, 134, 104687. [Google Scholar] [CrossRef]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar] [CrossRef]
- Kuehne, H.; Richard, A.; Gall, J. A Hybrid RNN-HMM Approach for Weakly Supervised Temporal Action Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 765–779. [Google Scholar] [CrossRef]
- Richard, A.; Kuehne, H.; Gall, J. Weakly Supervised Action Learning with RNN Based Fine-to-Coarse Modeling. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1273–1282. [Google Scholar] [CrossRef]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal Convolutional Networks for Action Segmentation and Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1003–1012. [Google Scholar] [CrossRef]
- Lei, P.; Todorovic, S. Temporal Deformable Residual Networks for Action Segmentation in Videos. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6742–6751. [Google Scholar] [CrossRef]
- Ishikawa, Y.; Kasai, S.; Aoki, Y.; Kataoka, H. Alleviating Over-segmentation Errors by Detecting Action Boundaries. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Montreal, QC, Canada, 10–17 October 2021; pp. 2321–2330. [Google Scholar] [CrossRef]
- Zhang, Y.; Tang, S.; Muandet, K.; Jarvers, C.; Neumann, H. Local Temporal Bilinear Pooling for Fine-Grained Action Parsing. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 11997–12007. [Google Scholar] [CrossRef]
- Ahn, H.; Lee, D. Refining Action Segmentation with Hierarchical Video Representations. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 16282–16290. [Google Scholar] [CrossRef]
- Li, M.; Chen, L.; Duan, Y.; Hu, Z.; Feng, J.; Zhou, J.; Lu, J. Bridge-Prompt: Towards Ordinal Action Understanding in Instructional Videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE, New Orleans, LA, USA, 18–24 June 2022; pp. 19848–19857. [Google Scholar] [CrossRef]
- Chen, L.; Li, M.; Duan, Y.; Zhou, J.; Lu, J. Uncertainty-Aware Representation Learning for Action Segmentation. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI-22, Vienna, Austria, 23–29 July 2022; pp. 820–826. [Google Scholar] [CrossRef]
- Wang, Z.; Gao, Z.; Wang, L.; Li, Z.; Wu, G. Boundary-Aware Cascade Networks for Temporal Action Segmentation. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; pp. 34–51. [Google Scholar] [CrossRef]
- Long, F.; Yao, T.; Qiu, Z.; Tian, X.; Luo, J.; Mei, T. Gaussian Temporal Awareness Networks for Action Localization. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 344–353. [Google Scholar] [CrossRef]
- Huang, Y.; Sugano, Y.; Sato, Y. Improving Action Segmentation via Graph-Based Temporal Reasoning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 14021–14031. [Google Scholar] [CrossRef]
- Kong, Z.; Dong, P.; Ma, X.; Meng, X.; Niu, W.; Sun, M.; Shen, X.; Yuan, G.; Ren, B.; Tang, H.; et al. SPViT: Enabling Faster Vision Transformers via Latency-Aware Soft Token Pruning. In Proceedings of the Computer Vision—ECCV 2022—17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Volume 13671, pp. 620–640. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE, New Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar] [CrossRef]
- Mehta, S.; Rastegari, M. MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer. In Proceedings of the The Tenth International Conference on Learning Representations, ICLR, Virtual, 25 April 2022. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Heo, B.; Kim, J.; Yun, S.; Park, H.; Kwak, N.; Choi, J.Y. A Comprehensive Overhaul of Feature Distillation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1921–1930. [Google Scholar] [CrossRef]
- Stein, S.; Mckenna, S.J. Combining Embedded Accelerometers with Computer Vision for Recognizing Food Preparation Activities. In Proceedings of the the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Zurich, Switzerland, 8–12 September 2013; Volume 33, pp. 3281–3288. [Google Scholar]
- Fathi, A.; Ren, X.; Rehg, J.M. Learning to recognize objects in egocentric activities. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3281–3288. [Google Scholar] [CrossRef]
- Kuehne, H.; Arslan, A.; Serre, T. The Language of Actions: Recovering the Syntax and Semantics of Goal-Directed Human Activities. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 780–787. [Google Scholar] [CrossRef]
- Kuehne, H.; Gall, J.; Serre, T. An end-to-end generative framework for video segmentation and recognition. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems 32, Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Wang, D.; Hu, D.; Li, X.; Dou, D. Temporal Relational Modeling with Self-Supervision for Action Segmentation. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 2729–2737. [Google Scholar]
- Xu, Z.; Rawat, Y.S.; Wong, Y.; Kankanhalli, M.S.; Shah, M. Don’t Pour Cereal into Coffee: Differentiable Temporal Logic for Temporal Action Segmentation. In Proceedings of the NeurIPS, New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Yang, D.; Cao, Z.; Mao, L.; Zhang, R. A temporal and channel-combined attention block for action segmentation. Appl. Intell. 2023, 53, 2738–2750. [Google Scholar] [CrossRef]
- Tian, X.; Jin, Y.; Tang, X. TSRN: Two-stage refinement network for temporal action segmentation. Pattern Anal. Appl. 2023, 26, 1375–1393. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| 50Salads | GTEA | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method | F1@{10,25,50} | Edit | Acc | F1@{10,25,50} | Edit | Acc | ||||
| MSTCN + DTGRM [47] | 79.1 | 75.9 | 66.1 | 72.0 | 80.0 | 87.8 | 86.6 | 72.9 | 83.0 | 77.6 |
| MSTCN + GTRM [36] | 75.4 | 72.8 | 63.9 | 67.5 | 82.6 | - | - | - | - | - |
| ASFormer [7] | 85.1 | 83.4 | 76.0 | 79.6 | 85.6 | 90.1 | 88.8 | 79.2 | 84.6 | 79.7 |
| MSTCN [5] | 76.3 | 74.0 | 64.5 | 67.9 | 80.7 | 87.5 | 85.4 | 74.6 | 81.4 | 79.2 |
| MSTCN++ [6] | 80.7 | 78.5 | 70.1 | 74.3 | 83.7 | 88.8 | 85.7 | 76.0 | 83.5 | 80.1 |
| BCN [34] | 82.3 | 81.3 | 74.0 | 74.3 | 84.4 | 88.5 | 87.1 | 77.3 | 84.4 | 79.8 |
| SSTDA [2] | 83.0 | 81.5 | 73.8 | 75.8 | 83.2 | 90.0 | 89.1 | 78.0 | 86.2 | 79.8 |
| Global2Local [4] | 80.3 | 78.0 | 69.8 | 73.4 | 82.2 | 89.9 | 87.3 | 75.8 | 84.6 | 78.5 |
| MSTCN + HASR [31] | 83.4 | 81.8 | 71.9 | 77.4 | 81.7 | 89.2 | 87.3 | 73.2 | 85.4 | 77.4 |
| UARL + MSTCN++ [33] | 80.8 | 78.7 | 69.5 | 74.6 | 82.7 | 90.1 | 87.8 | 76.5 | 84.9 | 78.8 |
| BUIMS-TCN [3] | 81.1 | 79.8 | 72.4 | 74.0 | 83.9 | 89.4 | 86.6 | 76.6 | 85.0 | 80.6 |
| MSTCN + DTL [48] | 78.3 | 76.5 | 67.6 | 70.5 | 81.5 | - | - | - | - | - |
| BCN + MTA + CHA [49] | 83.0 | 81.7 | 76.1 | 75.9 | 84.3 | 90.6 | 89.5 | 78.2 | 86.0 | 81.2 |
| ASFormer + KARI + BEP [50] | 85.4 | 83.8 | 77.4 | 79.9 | 85.3 | - | - | - | - | - |
| TSRN [50] | 84.9 | 83.5 | 77.3 | 79.3 | 84.5 | 89.4 | 87.8 | 80.1 | 84.9 | 80.6 |
| Ours | 85.0 | 83.5 | 78.1 | 80.5 | 85.1 | 90.1 | 88.5 | 79.7 | 86.0 | 81.9 |
| Method | F1@{10,25,50} | Edit | Acc | ||
|---|---|---|---|---|---|
| DTGRM | 68.7 | 61.9 | 46.6 | 68.9 | 68.3 |
| GTRM | 57.5 | 54.0 | 43.3 | 58.7 | 65.0 |
| MSTCN | 52.6 | 48.1 | 37.9 | 61.7 | 66.3 |
| MSTCN++ | 64.1 | 58.6 | 45.9 | 65.6 | 67.6 |
| BCN | 68.7 | 65.5 | 55 | 66.2 | 70.4 |
| SSTDA | 75.0 | 69.1 | 55.2 | 73.7 | 70.2 |
| BUIMS-TCN | 71.0 | 65.2 | 50.6 | 70.2 | 68.7 |
| UARL + MSTCN++ | 65.2 | 59.4 | 47.4 | 66.2 | 67.8 |
| ASFormer | 76.0 | 70.6 | 57.4 | 75.0 | 73.5 |
| MSTCN + DTL | 73.0 | 67.7 | 54.4 | 71.6 | 72.3 |
| BCN + MTA + CHA | 70.8 | 67.7 | 57.9 | 68.0 | 72.2 |
| TSRN | 75.4 | 70.3 | 56.2 | 75.0 | 71.6 |
| Ours | 77.5 | 72.3 | 59.5 | 76.7 | 73.7 |
| Models | F1@{10,25,50} (%) | Edit (%) | Acc (%) | Pam (M) | FLOPs | GPU (G) | Latency (ms) | ||
|---|---|---|---|---|---|---|---|---|---|
| ASFormer | 85.1 | 83.4 | 76.0 | 79.6 | 85.6 | 1.146 | 7.5 G | ∼ 2.7 | 525 |
| LASFormerV2 | 85.7 | 84.2 | 78.3 | 80.9 | 85.2 | 0.766 | 4.8 G | ∼ 1.6 | 261 |
| LASFormerV1 | 85.4 | 83.9 | 77.9 | 80.3 | 85.0 | 0.666 | 4.3 G | ∼ 1.9 | 121 |
| LASFormer | 85.0 | 83.5 | 78.1 | 80.5 | 85.1 | 0.667 | 4.1 G | ∼ 1.9 | 56 |
| UARL+MSTCN++ | 80.8 | 78.7 | 69.5 | 74.6 | 82.7 | 0.980 | 5.2 G | ∼ 3.2 | 43 |
| ASFormer+KARI+BEP | 85.4 | 83.8 | 77.4 | 79.9 | 85.3 | 1.146+ | 7.5+ G | 2.7+ | 525+ |
| ATDC | Fea-mim | Log-dis | F1@{10,25,50} | Edit | Acc | ||
|---|---|---|---|---|---|---|---|
| − | − | − | 72.5 | 68.2 | 57.3 | 73.4 | 72.8 |
| − | − | ✔ | 73.2 | 68.8 | 57.8 | 73.7 | 72.3 |
| − | ✔ | ✔ | 73.5 | 69.3 | 58.1 | 73.8 | 73.1 |
| ✔ | ✔ | ✔ | 77.5 | 72.3 | 59.5 | 76.7 | 73.7 |
| 50Salads | GTEA | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1@{10,25,50} (%) | Edit (%) | Acc (%) | GPU (G) | Pam (M) | F1@{10,25,50} (%) | Edit (%) | Acc (%) | GPU (G) | Pam (M) | |||||
| − | 85.1 | 83.4 | 76.0 | 79.6 | 85.6 | ∼2.7 | 1.146 | 90.1 | 88.8 | 79.2 | 84.6 | 79.7 | ∼1.5 | 0.746 |
| 3 | 85.0 | 83.5 | 78.1 | 80.5 | 85.1 | ∼2.0 | 0.667 | 90.1 | 88.5 | 79.7 | 86.0 | 81.9 | ∼0.88 | 0.600 |
| 2 | 84.1 | 81.9 | 75.7 | 79.7 | 83.3 | ∼1.7 | 0.573 | 89.4 | 88.6 | 80.4 | 85.0 | 81.3 | ∼0.87 | 0.571 |
| Methods | 50Salads | GTEA | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SIA | SICA | F1@{10,25,50} (%) | Edit (%) | Acc (%) | Latency (ms) | F1@{10,25,50} (%) | Edit (%) | Acc (%) | Latency (ms) | ||||
| − | − | 85.4 | 83.9 | 77.9 | 80.3 | 85.0 | 121 | 89.8 | 88.5 | 78.6 | 86.0 | 81.8 | 64 |
| ✔ | ✔ | 85.0 | 83.5 | 78.1 | 80.5 | 85.1 | 56 | 90.1 | 88.5 | 79.7 | 86.0 | 81.9 | 46 |
| Methods | F1@{10,25,50} (%) | Edit (%) | Acc (%) | Pam (M) | FLOPs | GPU (G) | ||
|---|---|---|---|---|---|---|---|---|
| 1 Decoder | 79.5 | 77.4 | 71.6 | 71.5 | 86.8 | 0.605 | 4.1 G | ∼1.4 |
| 3 Decoders | 85.1 | 83.4 | 76.0 | 79.6 | 85.6 | 1.146 | 7.5 G | ∼2.7 |
| 2 Decoders + ARE | 83.2 | 81.0 | 74.5 | 77.5 | 85.5 | 1.030 | 6.5 G | ∼1.9 |
| 1 Decoder + ARE | 85.7 | 84.2 | 78.3 | 80.9 | 85.1 | 0.766 | 4.8 G | ∼1.6 |
| 50Salads | GTEA | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method | F1@{10,25,50} | Edit | Acc | F1@{10,25,50} | Edit | Acc | ||||
| Stacking TDC | 81.0 | 78.7 | 71.5 | 74.4 | 85.6 | 88.8 | 87.1 | 78.9 | 84.3 | 81.2 |
| TGR+ADD | 83.2 | 81.2 | 75.4 | 78.9 | 84.1 | 89.1 | 88.4 | 79.2 | 84.9 | 81.3 |
| TGR+CMF | 85.0 | 83.5 | 78.1 | 80.5 | 85.1 | 90.1 | 88.5 | 79.7 | 86.0 | 81.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Z.; Li, K. LASFormer: Light Transformer for Action Segmentation with Receptive Field-Guided Distillation and Action Relation Encoding. Mathematics 2024, 12, 57. https://doi.org/10.3390/math12010057
Ma Z, Li K. LASFormer: Light Transformer for Action Segmentation with Receptive Field-Guided Distillation and Action Relation Encoding. Mathematics. 2024; 12(1):57. https://doi.org/10.3390/math12010057
Chicago/Turabian StyleMa, Zhichao, and Kan Li. 2024. "LASFormer: Light Transformer for Action Segmentation with Receptive Field-Guided Distillation and Action Relation Encoding" Mathematics 12, no. 1: 57. https://doi.org/10.3390/math12010057
APA StyleMa, Z., & Li, K. (2024). LASFormer: Light Transformer for Action Segmentation with Receptive Field-Guided Distillation and Action Relation Encoding. Mathematics, 12(1), 57. https://doi.org/10.3390/math12010057