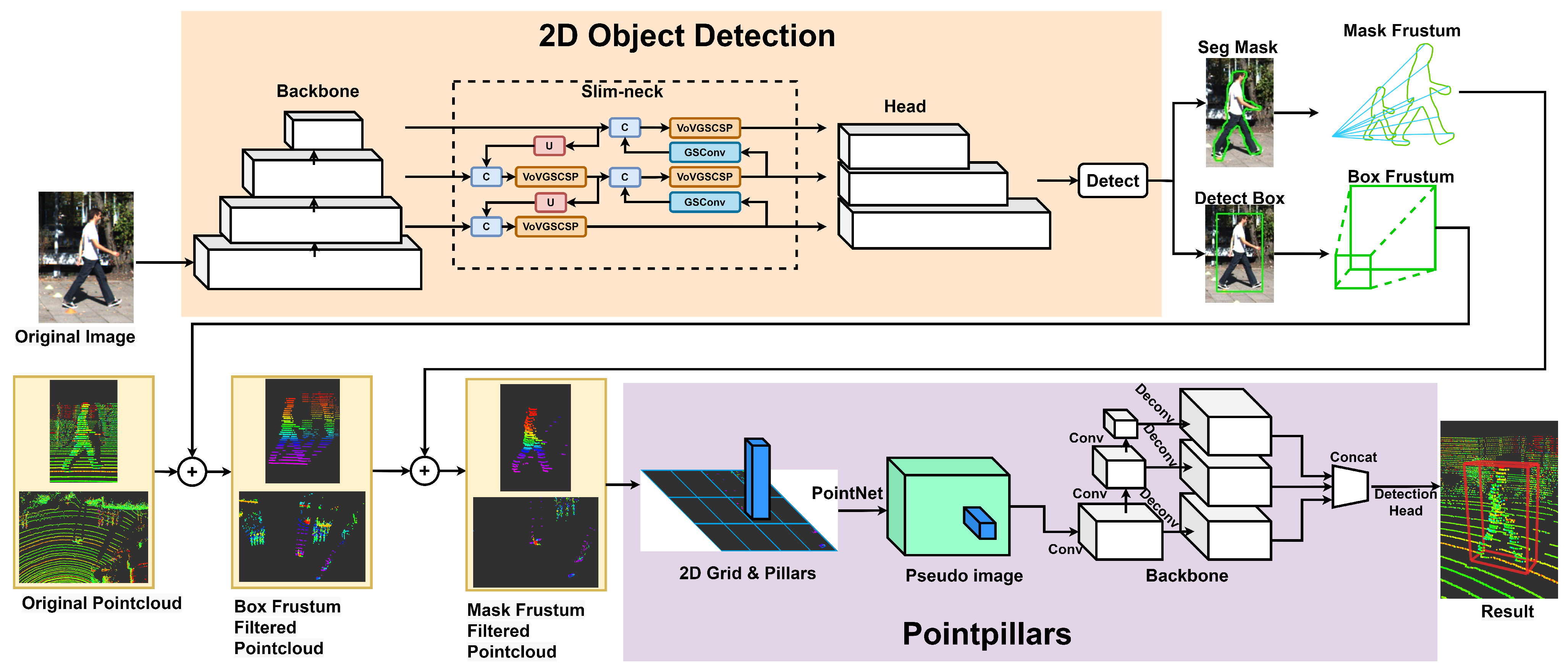
In this section, we present the ISF–PointPillars method, as depicted in
Figure 1. The RGB image is initially fed into the 2D target detection network, thus generating multiple-scale feature maps via the backbone. Subsequently, multilevel features are fused through the slim-neck structure. The outputs, including the bounding box and instance segmentation mask, are then generated via the target detection head and instance segmentation head, respectively. The bounding box is extended to 3D space to generate a frustum, and the point data are roughly filtered. Then, the instance mask is extended to 3D space to generate an instance contour frustum, and the point cloud is finely filtered again. After undergoing two filtering processes, the remaining point count is significantly reduced. Finally, the remaining point cloud is fed into the enhanced PointPillars network for inference, thereby yielding information about the object’s category, scale, position, and orientation.
The algorithm proposed in this study is validated for 2D and 3D detection performance on the KITTI dataset. Qualitative and ablation experiments are conducted to verify the effectiveness of each step in the proposed workflow. The experimental results demonstrate that the innovative contributions introduced in this study effectively enhanced detection accuracy.
2.1. Instance Frustum Filter
This section introduces an effective method to significantly reduce the quantity of 3D spatial point cloud data while maximally preserving the points belonging to target objects. In the 3D LiDAR point cloud, the points belonging to the objects of interest, such as cars, cyclists, and pedestrians, are referred to as “foreground points”, while the points belonging to areas of disinterest such as roads, buildings, and green spaces are termed “background points”.
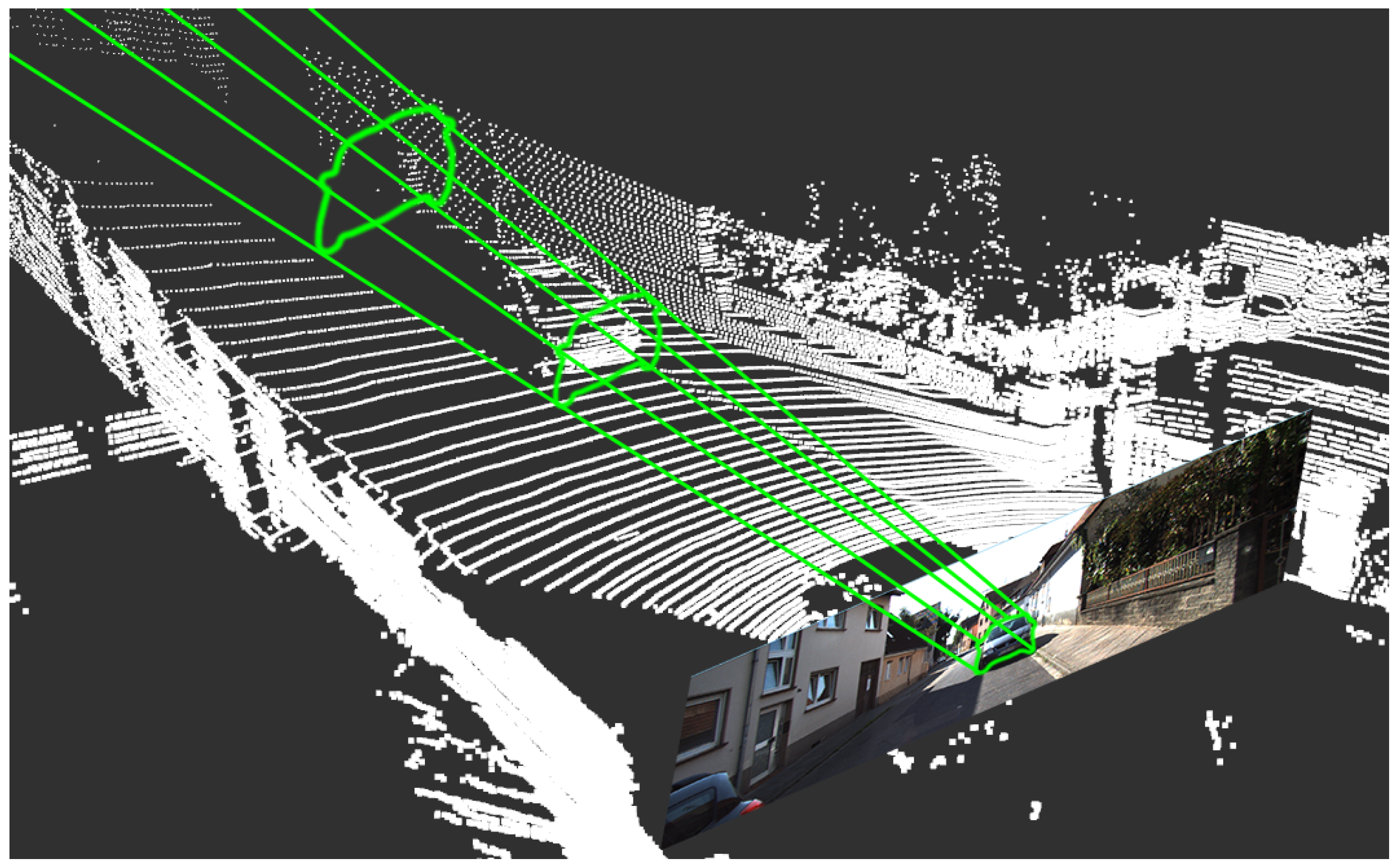
We drew inspiration from the method of generating frustums using rectangular bounding boxes [
32] and introduced innovative modifications to it. By extending the boundaries of 2D image instance segmentation into 3D frustums, as illustrated in
Figure 2, and employing the ray casting algorithm [
34], we could effectively filter out nearly all background points located outside these frustums. This results in a reduced data volume sent into the 3D network and improved object detection accuracy.
It is worth noting that our point cloud segmentation algorithm has apparent advantages over traditional ones. First, our method can accurately identify and remove background points, thereby retaining more useful information. In contrast, voxel downsampling and random downsampling may lose some important point cloud details. Moreover, our method eliminates the need for additional parameter settings. In contrast, techniques such as voxel downsampling and random downsampling may necessitate adjustments to parameters, such as the voxel size or sampling ratio. Additionally, ground segmentation algorithms may require tuning multiple parameters based on specific environments, which is a time-consuming and labor-intensive process. Furthermore, our method does not depend on the structure and density of the point cloud, thus making it applicable to a wider range of scenarios.
The specific implementation process of the algorithm is as follows:
First, we establish the corresponding relationship between 3D LiDAR points and 2D RGB images. Mapping any point
in 3D LiDAR point cloud space to its corresponding point
on the camera image can be achieved using the following equation:
where
is the rectified projection matrix of the
ith camera, and
is the rectified rotation matrix. Here,
has been expanded into a
matrix by appending a fourth zero row and column and by setting
.
is the transformation matrix from 3D LiDAR points to the camera. The specific expression of the matrix is as follows:
where
represents the distance from the reference camera at 0,
and
represent the focus distance expressed in pixels,
and
are the offsets of the coordinate values relative to the origin of the image,
is the rotation matrix from LiDAR to camera, and
is the translation matrix from LiDAR to camera.
Second, we compare the points in the project matrix with the 2D rectangular bounding boxes and only retain the points within the rectangular frame to achieve preliminary filtering. Since only four values (Xmin, Xmax, Ymin, and Ymax) are considered for each rectangular box, the projected 2D image of the point cloud can be processed using a vectorization operation, which performs the same logical operation on the whole array without using explicit loops, thus speeding up the computation.
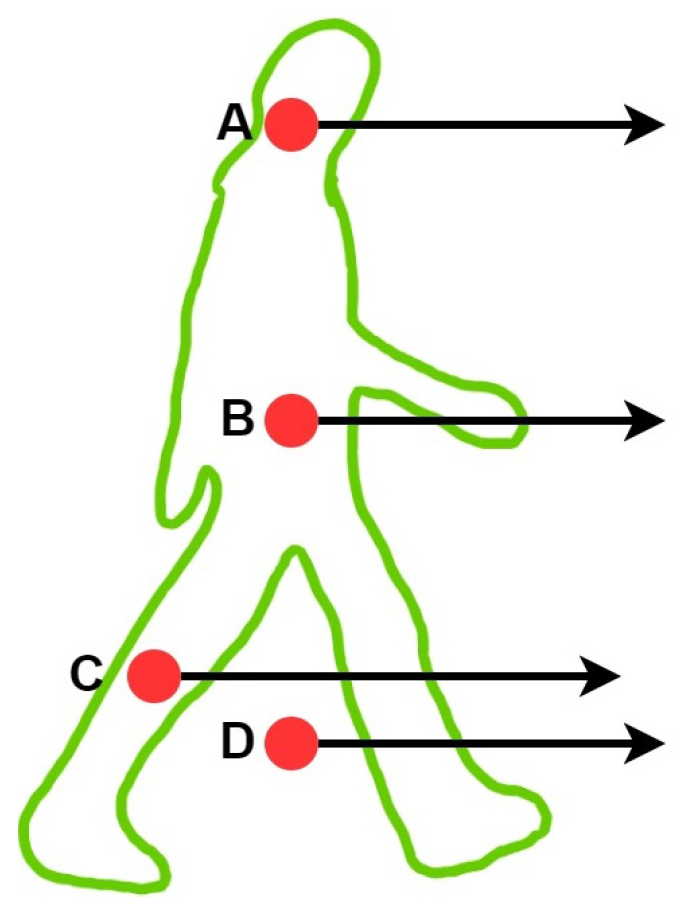
Third, we use the ray casting method to determine whether the remaining point cloud is located in the instance segment frustum region and then filter the point cloud again. The ray casting method is a detection algorithm for judging whether a point is within a polygonal area. As shown in
Figure 3, a ray is emitted from any arbitrary point, thus passing through the polygonal region. If the number of intersection points within the area is even, the point is considered outside the polygonal area; if it is odd, the point is deemed inside the polygonal region.
The pseudocode of the point cloud filtering process is shown in Algorithm 1.
| Algorithm 1 Mapping 3D points onto 2D plane and removing points outside the frustum |
| Input: 3D point cloud data: ; bounding boxes: ; instance edge contours: |
| Output: Filtered point cloud: |
| 1: for each single bounding box in do |
| 2: Expand box into 3D space to form frustum ; |
| 3: Perform vectorized operations using numpy to determine whether points are inside ; |
| 4: Point cloud after initial filtering is saved as ; |
| 5: end for |
| 6: for each instance counter ins in Ins do |
| 7: Expand ins into 3D space to form frustum ; |
| 8: for each point p in do |
| 9: Use Ray Casting algorithm to determine whether p is inside ; |
| 10: if p is inside an instance frustum then |
| 11: Add p to point cloud after second filtering ; |
| 12: end if |
| 13: end for |
| 14: end for |
| 15: return |
In summary, our algorithm facilitates both preliminary and detailed point cloud filtering. This is achieved by extending 2D bounding boxes into 3D frustums and, in the subsequent step, leveraging instance contours for further refinement. Rather than directly applying the instance contour filter to the raw point cloud, the decision to divide the filtering process into two stages is grounded in the considerable volume of points in 3D space, thereby often reaching the hundreds of thousands. The direct application of the ray casting algorithm to raw point clouds could impose undue strain on CPUs.
Figure 4 depicts two road scenes arranged in two columns. The three rows of images correspond, from top to bottom, to the visual data of the original point cloud, the point cloud filtered via the box frustum, and the remaining point cloud filtered via the instance mask frustum, respectively. After two rounds of filtering, the background points are filtered out, and the target object points are retained.
2.2. Improving 2D Object Detection Networks
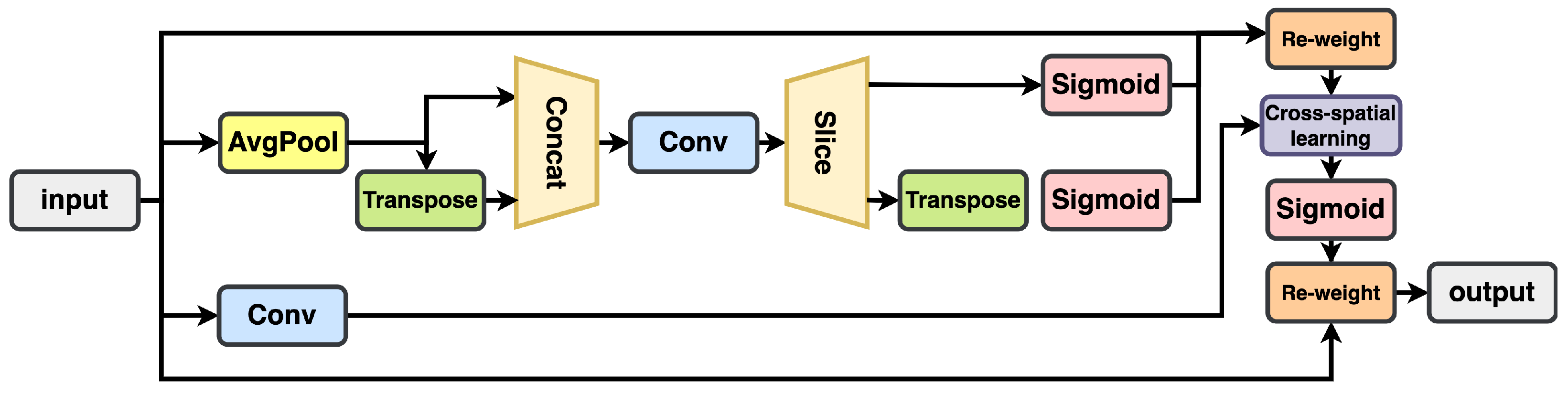
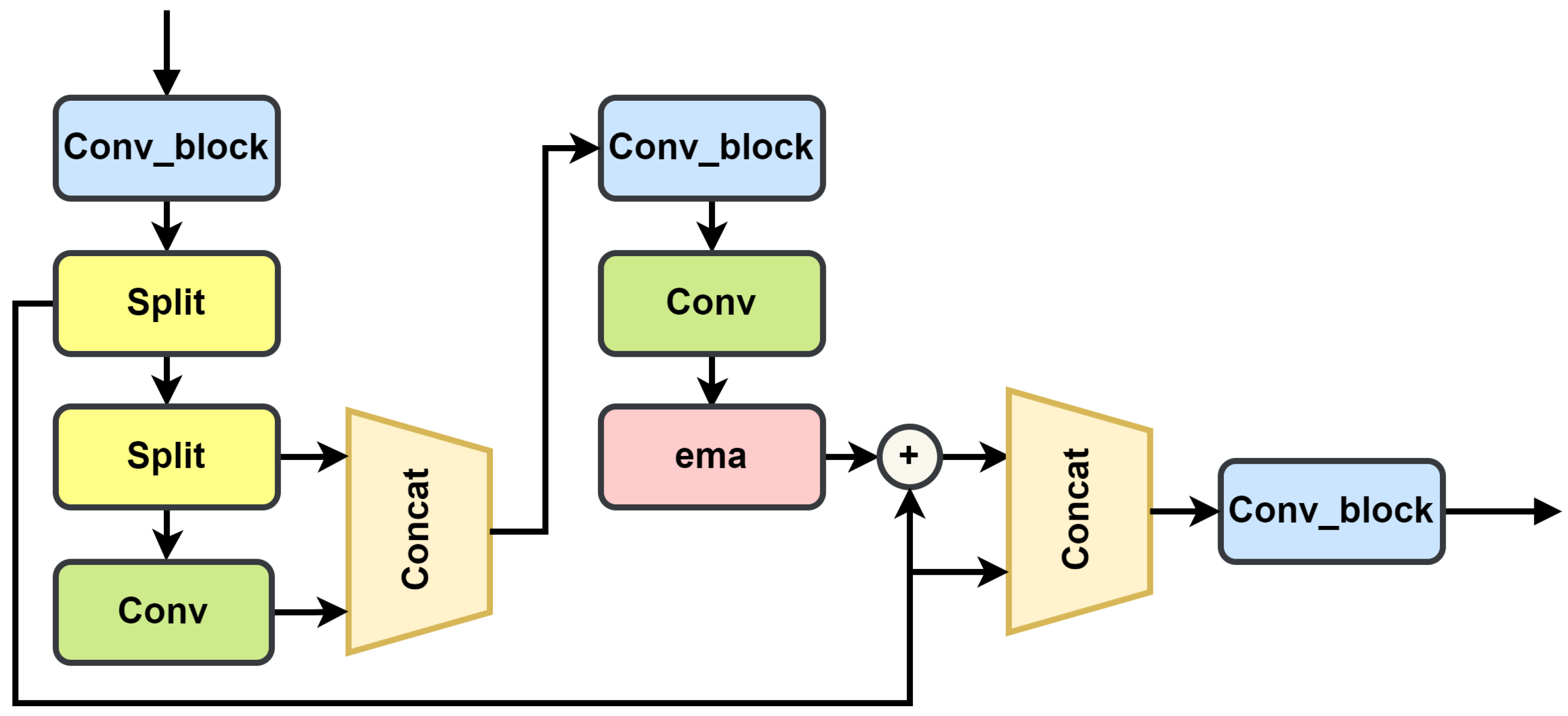
In order to improve the detection accuracy of RGB images in autonomous driving scenarios, enhance real-time performance, and reduce the amount of model calculations, we modified the 2D network. We introduced the EMA attention mechanism, which is shown in
Figure 5, and the FasterNet [
35] structure based on partial convolution (PConv) to reduce the number of model parameters while maintaining algorithm accuracy. These components are integrated into the C2F-FE module, as shown in
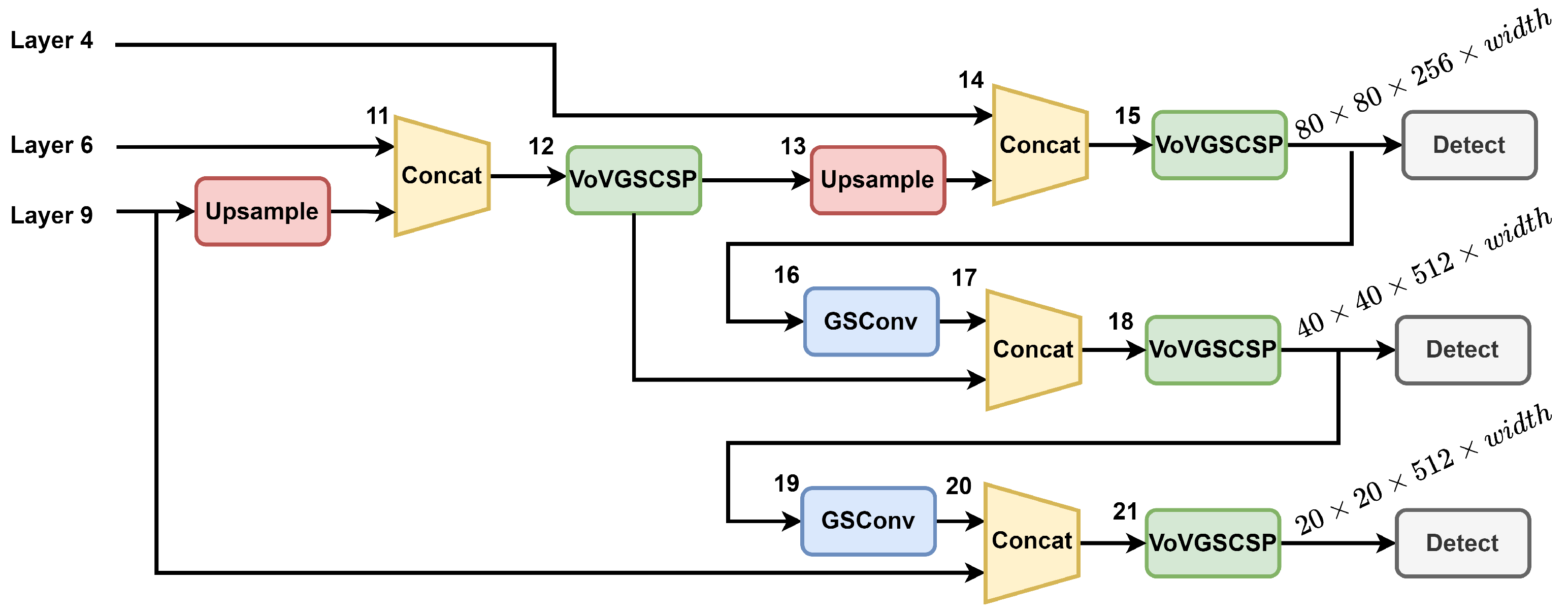
Figure 6. This module replaces the C2F (the faster implementation of the cross-stage partial bottleneck with two convolutions) module in the YOLOv8 backbone. Subsequently, we employed the slim-neck [
36] architecture to replace the head layer, as illustrated in
Figure 7.
The C2F module was extensively employed within the YOLOv8 backbone network. The C2F module design draws inspiration from the C2 module, formally known as the ‘Cross-Stage Partial (CSP) bottleneck with two convolutions’. The C2 module serves as a foundational component within the YOLOv8 architecture. C2F is an optimized version of C2 that focuses on improving execution speed without sacrificing accuracy. To further enhance the network speed, we introduced partial convolution (PConv) to more efficiently extract spatial features by reducing redundant calculations and simultaneous storage access. This improvement enhances FLOPS, boosts GPU throughput, and conserves CPU computing time.
In order to retain the information on each channel and reduce computational overhead, we introduced the EMA module and integrated it into the C2F-Faster structure, thus ultimately forming the C2F-FE module.
To further minimize the number of model parameters, we made modifications to the YOLOv8 head. We replaced the original Conv module with GSConv [
36] and substituted the C2F module with VoVGSCSP [
36], thereby creating a slim-neck structure.
We also adjusted the computation of the loss function. The overall loss function for 2D detection consists of three components: bounding box loss, segment loss, and classification loss. Segment loss (
) uses crossentropy loss [
37] to calculate instance segment loss, and the formula is as follows:
where
represents the hyperparameters of the bounding box;
N denotes the batch size;
is the ground truth label of instance segmentation mask, which takes the value 0 or 1;
represents the predicted instance segmentation score, with its value ranging is between
; and
indicates the sigmoid function. Classification loss (
) adopts the binary crossentropy loss function.
where
represents the predicted value of the model, and
represents the true value (0 or 1) of the ground truth.
represents the sigmoid function, thereby mapping
x to the interval
. The computation of
involves the use of the complete intersection over union (CIOU) function, which combines IoU and distance loss. The formulation is as follows:
where the CIoU computation formula involves various components. There is the IoU, which denotes the intersection over union of rectangular boxes, and it is defined as
. The parameter
is employed to compute the distance between the center points of the predicted box
p and the ground truth box
. Meanwhile,
c signifies the distance between the farthest vertices of the two rectangular boxes. The parameter
can be tuned to facilitate the transition from CIoU to DIoU when the IoU falls below 0.5.
To quantify the extent of overlap between the bounding box and the ground truth box generated by the model, we introduced the bounding box loss function (
) to optimize the model’s predictive performance:
where
W is a hyperparameter used to control the weight, and
represents the sum of confidences for all prediction results.
The distribution focal loss (DFL) function aids the network in more accurately localizing object boundaries, particularly in complex scenes:
where
N represents the batch size,
represents the predicted probability of the true class,
is a balanced parameter associated with class
t, and
is a parameter controlling the focusing effect.
The overall loss function of the 2D object detection model is as follows:
where the coefficient
is the gain of bounding box loss,
is the gain of segmentation loss,
is the gain of classification loss, and
is the gain of DFL loss. Adjusting these coefficients can affect the weight of each loss function in the total loss.
2.3. Three-Dimensional Detection Method
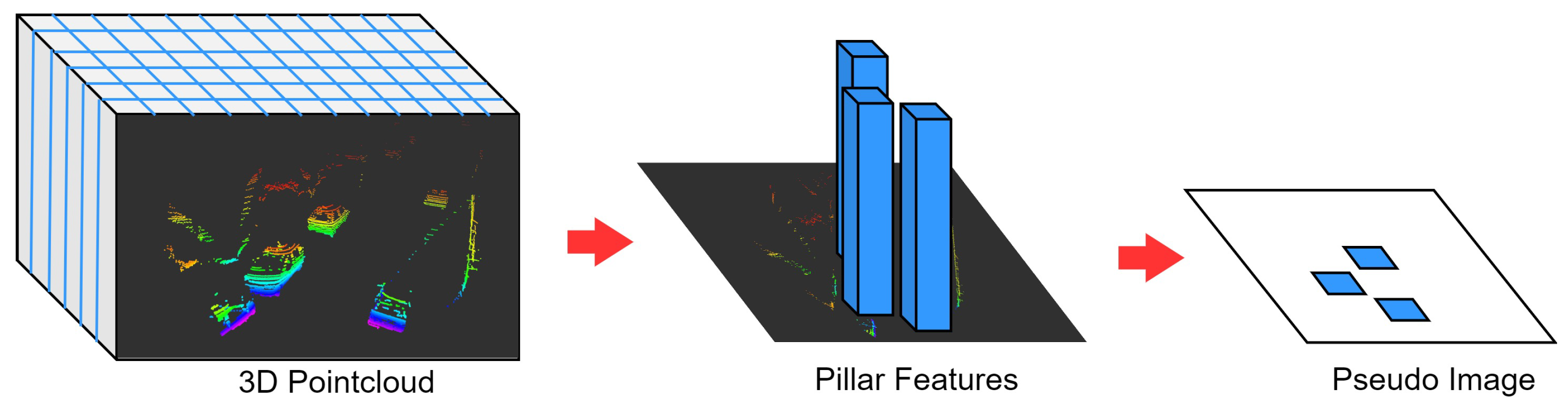
Our 3D object detection method is based on the PointPillars network. PointPillars transforms 3D point clouds into 2D BEV feature maps, as illustrated in
Figure 8. First, draw a grid on the x–y plane, divide the point cloud into several pillars, and then extract features from the points in each pillar through operations such as linear, batch norm, ReLU, and max polling. All the features form a pseudoimage and are then processed via 2D CNN. This approach is distinguished by its rapid processing speed and minimal hardware requirements, thereby making it well suited for deployment in real-time detection scenarios. To further enhance the efficiency of point cloud data computation and foster seamless integration between the 3D network and the 2D detection method, we have implemented the following enhancements.
2.3.1. Encoder
The PointPillars network, implemented within the MMDetection3D [
38] framework, employs PillarFeatureNet [
39] to compute features for points within each voxel. Subsequently, PointPillarsScatter [
24] is utilized to generate pseudoimages. To further improve the detection performance of PointPillars in autonomous driving scenarios, we made modifications. The original point cloud data include coordinates
and LiDAR reflectivity. However, we replaced
with radius, thus representing the second norm of
:
Since the LiDAR point cloud is annularly projected and reflects from surrounding objects with the current vehicle as the center, we combined into a variable . In this way, we can replace the original with to reduce data dimensionality. This operation significantly diminishes the number of computations in subsequent pipelines, thereby enhancing the overall efficiency of the algorithm.
2.3.2. Loss Function
The original PointPillars method uses focal loss to calculate classification loss, which requires presetting the hyperparameters
and
to adjust the effect of the loss function:
However, the utilization of the weighted softmax function, with distinct weights assigned to various categories, yields improved generalization and enhanced detection performance:
In Equation (
11),
represents the estimated probability of class
i,
signifies the weights associated with different classes, and
C represents the total number of categories. Additionally, we drew inspiration from SECOND [
40] for the design of the localization loss function:
Among them, represents the boxes in three-dimensional space; is the difference between the predicted box and the ground truth box, wherein the boxes possess attributes of that represent the three-dimensional coordinates, size, and orientation angle of the boxes; and is a loss function used for target detection regression problems.
Finally, but equally as significant, we introduced the direction loss function to prevent 180-degree misjudgments of the target. This follows the approach used in SECOND, where softmax classification loss was also introduced:
where
C is the total number of categories, x is the representation vector of each sample,
and
represent parameters for sample x belonging to the
ith class, and
k represents the currently predicted category.
The final 3D target detection total loss function is as follows:
where
is the weight of the classification loss function,
is the weight of the localization loss function, and
is the weight of the direction loss function.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}