In this section, the performance of the GSA-KELM-KF model is evaluated on two publicly benchmark datasets for short-term traffic flow forecasting, e.g., the Amsterdam high-way dataset and England M25 highway dataset. More specific details are given below.
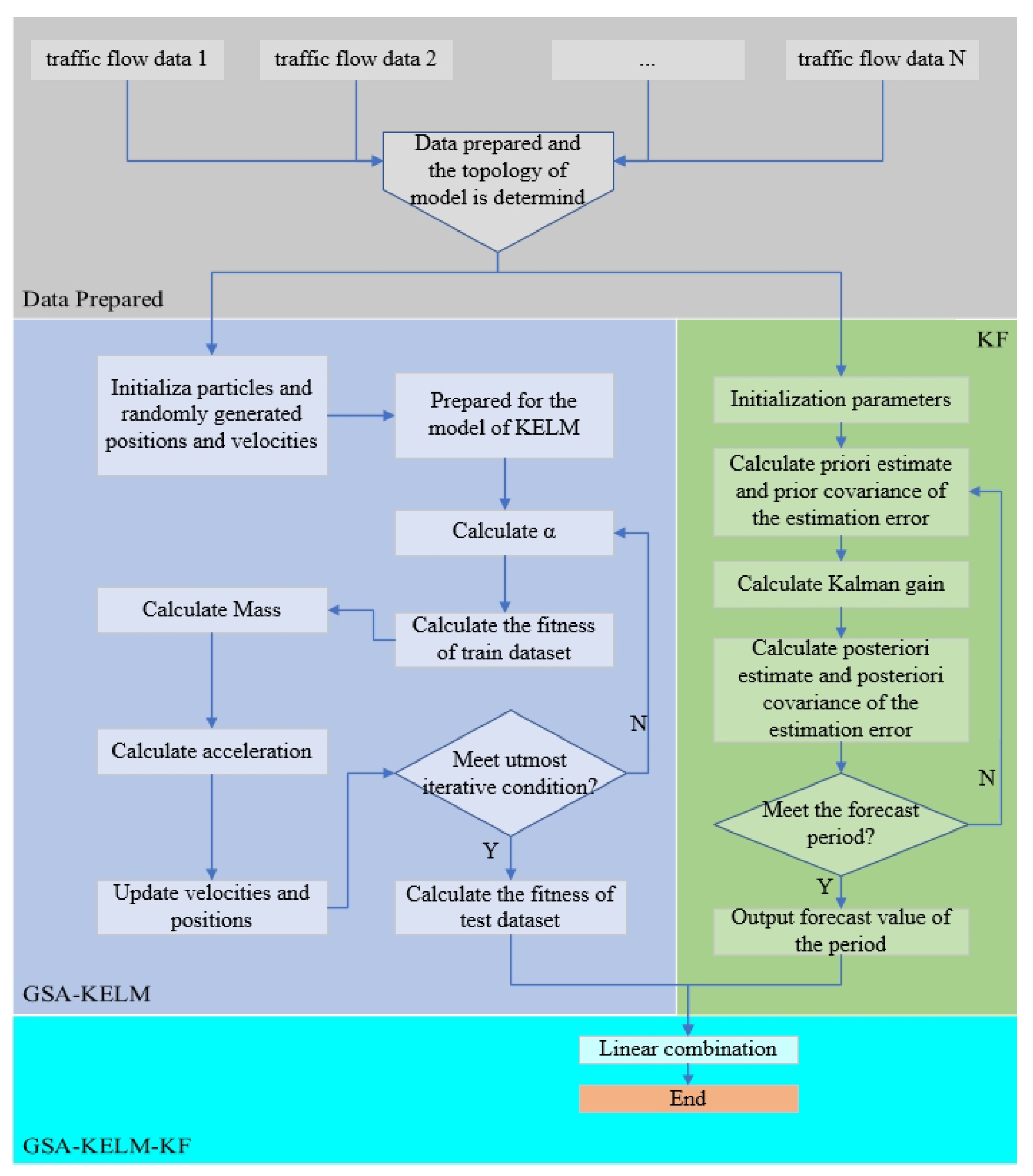
3.3. Experimental Setup
All experiments are compiled and tested on a Linux cluster (CPU: Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50GHz, GPU: NVIDIA GeForce RTX 3070).
For KF, this paper adopts the prediction strategy of predicting the current time from the previous time, so H is set to . F is the identity matrix. And the initialization covariance matrix is consistent with Q.
Amsterdam highway dataset is divided into two parts: the first four weeks for training and the last week for testing. Each input vector contains 12 consecutive data values to forecast the value of the 13th data value. The ranges of the positions and velocities of are set to and , while the ranges of positions and velocities of are and . In KF, the R is set as . Q of dataset A1 is set , and the other settings are . The value of of dataset A1 and dataset A2 is , and the others are .
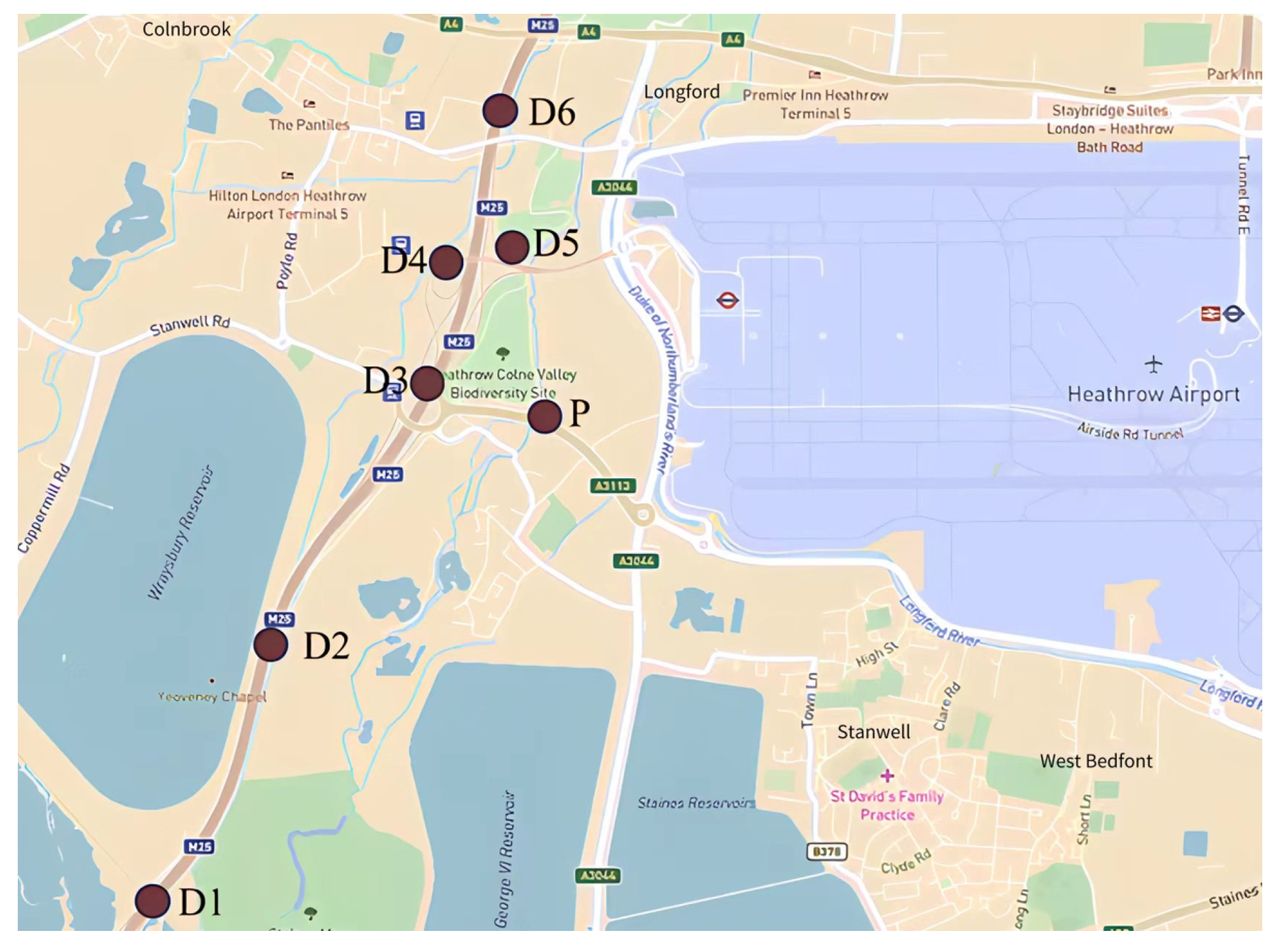
England M25 highway dataset is also split into two parts: the first week for training and the second week for testing. The dimensions of the network are set to 12. In the gravity search algorithm, the maximum number of iterations is set to 50. The ranges of the positions and velcocities of are set to and . and are the ranges of the positions and velocities of . In KF, R and are set to and . Q of datasets D4 and P is set and , respectively, while the other settings are .
To evaluate the performance of the GSA-KELM-KF framework, we compared it with the support vector machine regression, decision tree, artificial neural network, k-nearest neighbour, long short-term memory, noise-immune long short-term memory, extreme learning machine, and kernel extreme learning machine frameworks.
Support vector machine regression (SVR): SVR adds the tolerance deviation of ∈ between the estimated value and the real value to minimize the total deviation of all sample points from the hyperplane. The radial basis function is used as the kernel type, whose regression horizon and the width parameter are set to 8 and . The cost parameter is set to the maximum difference for short-term traffic flow forecasting.
Decision tree (DT): Based on classification and regression tree, DT has strong robustness for missing data and noise without any prior hypothesis [
35].
Artificial neural network (ANN): ANN, a learning model, is generated by the interconnection of a large number of neurons. The number of hidden layers, the mean squared error goal, the spread of radial basis functions, the maximum number of neurons in the hidden layer, and the number of neurons to add between displays based on a default values are set to 1,
, 2000, 40, and 25, respectively [
36].
k-nearest neighbor (kNN) [
37]:
kNN is a machine learning algorithm with a high tolerance for outliers and noise. Predict the properties of a query vector by using the properties of the few vectors closest to the query vector.
Long short-term memory (LSTM) [38]: LSTM is a special kind of recurrent neural network. It is developed to capture time dependence over a long period for traffic flow forecasting. Optimized by grid search, the validation split, the epochs, the batch size, and the hyperparameter units are
, 50, 32, and 256, respectively.
Noise-immune long short-term memory (NiLSTM) [39]: A noise immunity loss function is derived through the maximum correlation entropy of long short-term memory networks. Compared with conventional LSTM, the loss of maximum correlation entropy is a local similarity measure and is not immune to non-Gaussian noise. The length of the input sequence is set to 12, and the range of kernel size is
.
Extreme learning machine (ELM) [40]: ELM is a single-hidden layer feed-forward neural network, which can be directly applied to regression, classification, clustering, and other learning tasks. Both the input weights and the biases of the hidden layer are generated randomly.
Kelnel extreme learning machine (KELM): KELM, as a variety of extended
, improves the generalization of ELM, in which the explicit feature mappings are replaced by kernels according to the kernel method. It is unnecessary to allocate the input weights and biases [
41,
42]. In KELM, the parameters
and
are set to
and {0.01, 0.05, 0.1, 0.3, 0.5, 0.7, 1, 3, 5, 7, 10, 15, 30, 60, 120}.
3.4. Experimental Result
To verify the effectiveness of the proposed models for the randomness and nonlinearity of traffic flow, the experimental scenario in Amsterdam’s ring road dataset is introduced.
Table 1 and
Table 2 indicate the results of
and
separately.
Table 1 shows the comparison of different methods on the A1, A2, A4, and A8 datasets. Our GSA-KELM-KF outperforms typical parametric and non-parametric methods on the
of all datasets, whose results are
,
,
, and
, respectively. For example, compared with LSTM, the RMSE of the GSA-KELM-KF on the A1, A2, A4 and A8 datasets are decreased by
,
,
, and
, respectively. As for ELM, the RMSE of our GSA-KELM-KF are reduced by
,
,
, and
, respectively. Similarly, the RMSE of our GSA-KELM-KF are lower than KELM
,
,
, and
, respectively.
Although RMSE is more suitable for showing larger deviations, MAPE has the simplest interpretation and can be used to compare accuracy between different volumes studied [
43]. Furthermore, MAPE is more suitable for the comparison of long-time series. From
Table 2, we know that our GSA-KELM-KF achieves the best performance on MAPE except for the A8 dataset, with results of
,
,
, and
, respectively. Compared with LSTM, the MAPE of the GSA-KELM-KF decreases by
,
,
, and
on the A1, A2, A4, and A8 datasets, respectively. Compared with ELM, the MAPE of our GSA-KELM-KF on the A1, A2, A4, and A8 datasets decreases by
,
,
, and
, respectively. Similarly, the MAPE of our GSA-KELM-KF is lower than KELM by
,
,
and
, respectively.
The above shows that ELM has the advantages of overcoming the local minimum, and overfitting, while KELM uses the kernel learning function to effectively solve the problem of reduced generalization and stability caused by hidden layer neurons.
Figure 4 shows the visualization result of GSA-KELM-KF. The red line represents the actual truth, and the blue line represents the predicted value of our GSA-KELM-KF. Obviously, our GSA-KELM-KF has excellent fit ability. The related error can be denoted as:
In the early morning and late night, the traffic flow is low, and the error between the predicted value and the actual measured value is small, but the related error becomes larger.
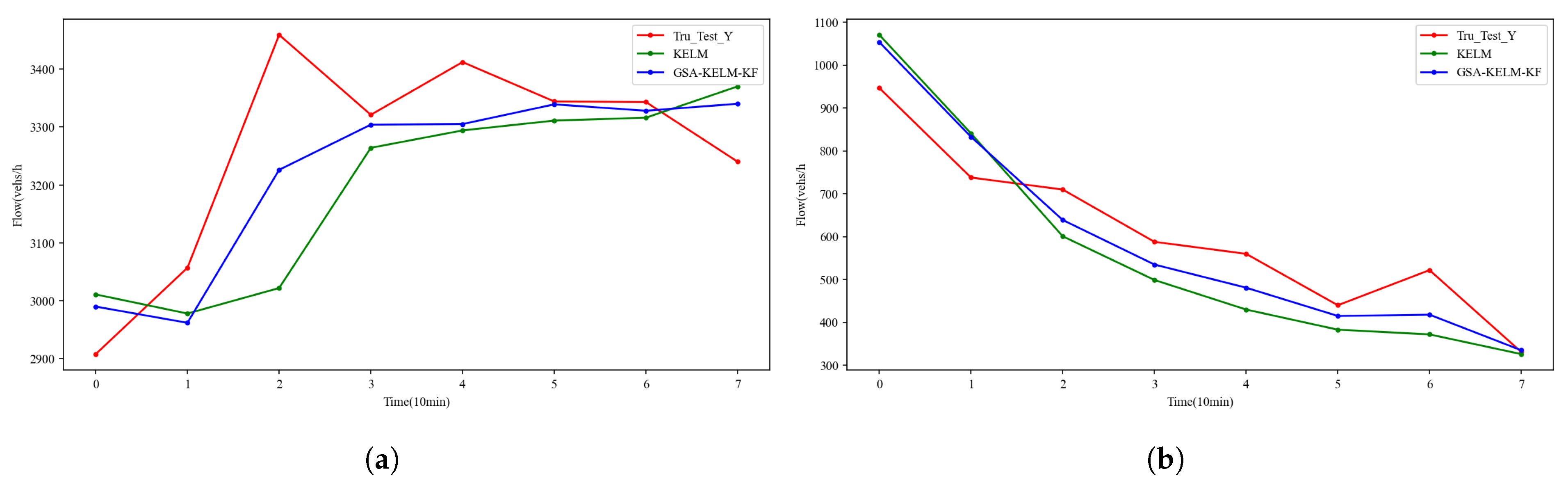
To further illustrate the performance of our model, we also conduct an intuitive comparison with KELM in two representative stages of morning peak passenger flow and nighttime low peak passenger flow in dataset A4.
In
Figure 5a, the morning peak traffic flow ranges from 2900 to 3500 vehicles per hour. Traffic flow fluctuates greatly during this stage, and it is difficult for KELM to capture these rapid fluctuations. In this case, our GSA-KELM-KF prevents KELM from falling behind, effectively mitigating the shortcomings of sudden performance drops due to drastic traffic changes. This is extremely important in intelligent transportation systems and is a key issue in traffic management and traffic information release.
In
Figure 5b, traffic flow gradually decreases at night. In this case, the traffic flow dropped relatively smoothly from 1100 vehicles per hour to 300 vehicles per hour. In this case, our GSA-KELM-KF can predict this change more accurately, prevent KELM from overshooting, and achieve more reasonable predictions.
To sum up, our method has better performances than other state-of-the-art models.
To further confirm the effectiveness of the proposal in different short-term traffic flow prediction tasks, we also compare it with several extreme learning methods on the M25 highway dataset, as summarized in
Table 3.
Due to the zero values of traffic flow at some time on the dataset, the criterion of MAPE is unsuitable as an evaluation criterion. Under the criterion of RMSE, the GSA-KELM-KE achieves the best representation effects on all datasets, whose results are
,
,
,
,
,
, and
on the D1, D2, D3, D4, D5, D6, and P datasets, respectively. Compared with KELM, the RMSE of our GSA-KELM-KF decreases by
,
,
,
,
,
, and
. Similarly, the RMSE of GSA-KELM decreases by
,
,
,
,
,
, and
. Our GSA-KELM-KF model outperforms the ELM, KELM, and GSA-KELM on the England M25 highway dataset, showing the potential for accurate and reliable traffic flow prediction. It can be seen from
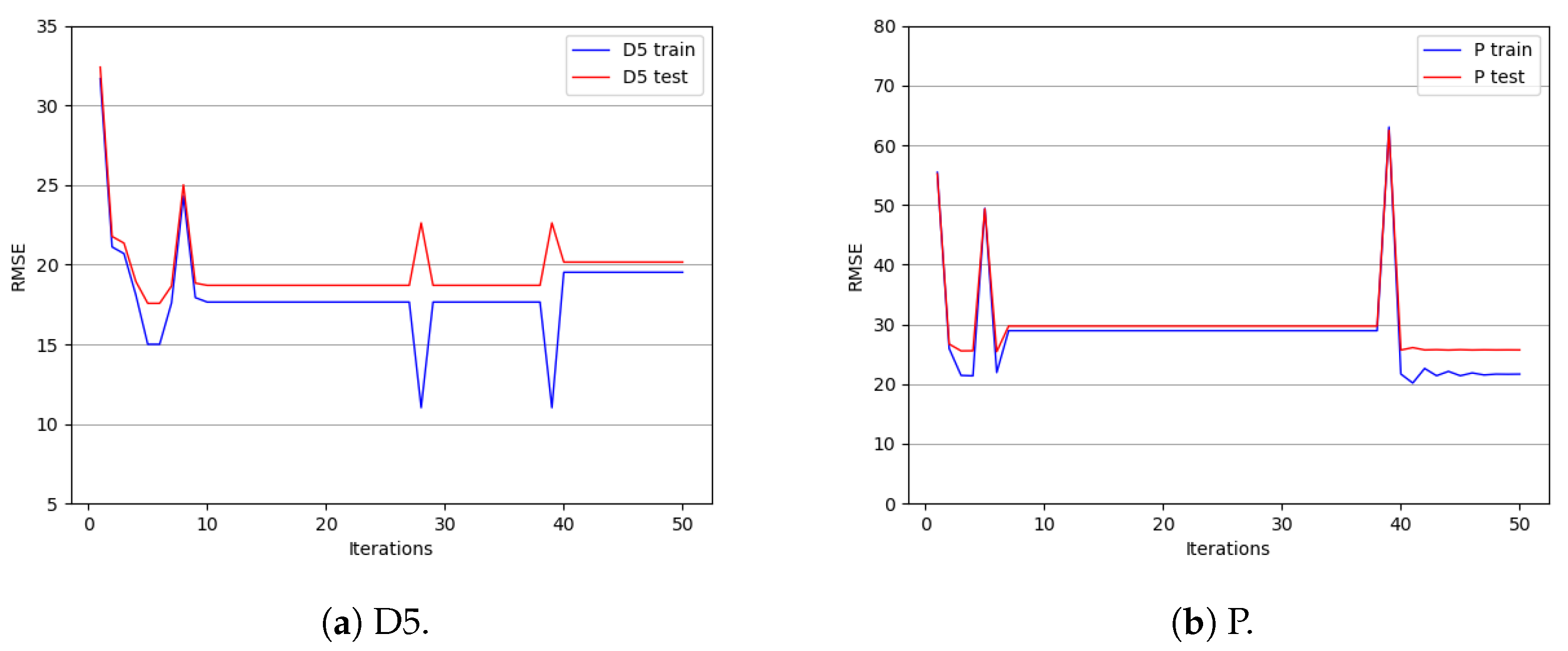
Figure 6 that GSA can automatically break the convergence state after reaching a stable state to reach a new stable state, which provides the possibility of breaking away from the local optimal solution. When particles tend to converge, the state is broken by Equation (
1).
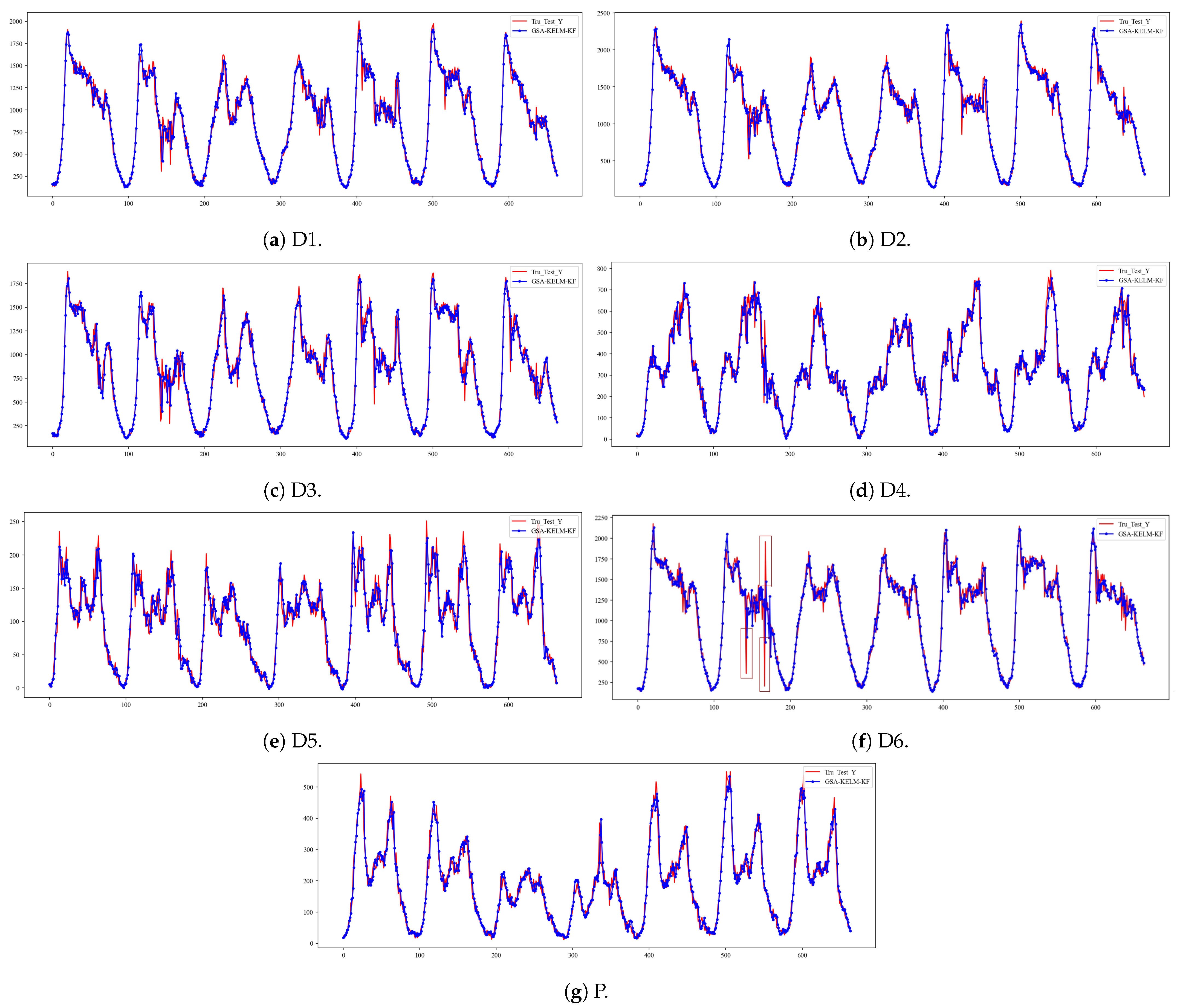
From
Figure 7, our model also has a good fit on the England M25 highway dataset. Particularly, there are three outliers in
Figure 7f, marked by red boxes. However, there is almost no fluctuation in the predicted values for outlier locations, indicating the strong robustness of our model.
3.5. Ablation Study
To verify the effectiveness of different components in our GSA-KELM-KF, we performed ablation experiments on the A1 and A4 datasets, as summarized in
Table 4.
We compare the GSA-KELM-KF with the following several variants: (1) GSA-KELM, in which the variant removes the Kalman filter, which means we optimize KELM using the gravity search algorithm alone; (2) KELM-KF, in which the variant removes the gravity search algorithm, which means we use a grid traversal search algorithm.
From the experimental results, we can see that GSA-KELM-KF outperforms all ablation variants. Compared with the GSA-KELM, the MAPE and RMSE of GSA-KELM-KF on A4 decrease by and , respectively. Correspondingly, the RMSE and MAPE of GSA-KELM-KF are and lower than those of KELM-KF, respectively. The above illustrates the effectiveness of the gravity search algorithm and Kalman filter components. The gravity search algorithm not only avoids manual traversal operations but also automatically searches for better solutions. The Kalman filter module can further reduce the impact of heavy-tail pulse noise interference.
In reality, traffic data always arrives chunk by chunk. We further divide the datasets of A1 and A4 into multiple mini-batches. For the convenience of experiments, we divide the datasets into several mini-batch sizes of 200. We use the first two batches of data for training and test the results on the third batch.
Table 5 shows that GSA-KELM-KF achieves real-time prediction. In
Figure 8, it shows excellent fitting effects. Overall, these findings suggest that our GSA-KELM-KF has promising potential in real-time traffic flow prediction applications.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}