

Research Progress of Complex Network Modeling Methods Based on Uncertainty Theory

 ,
, 

Abstract
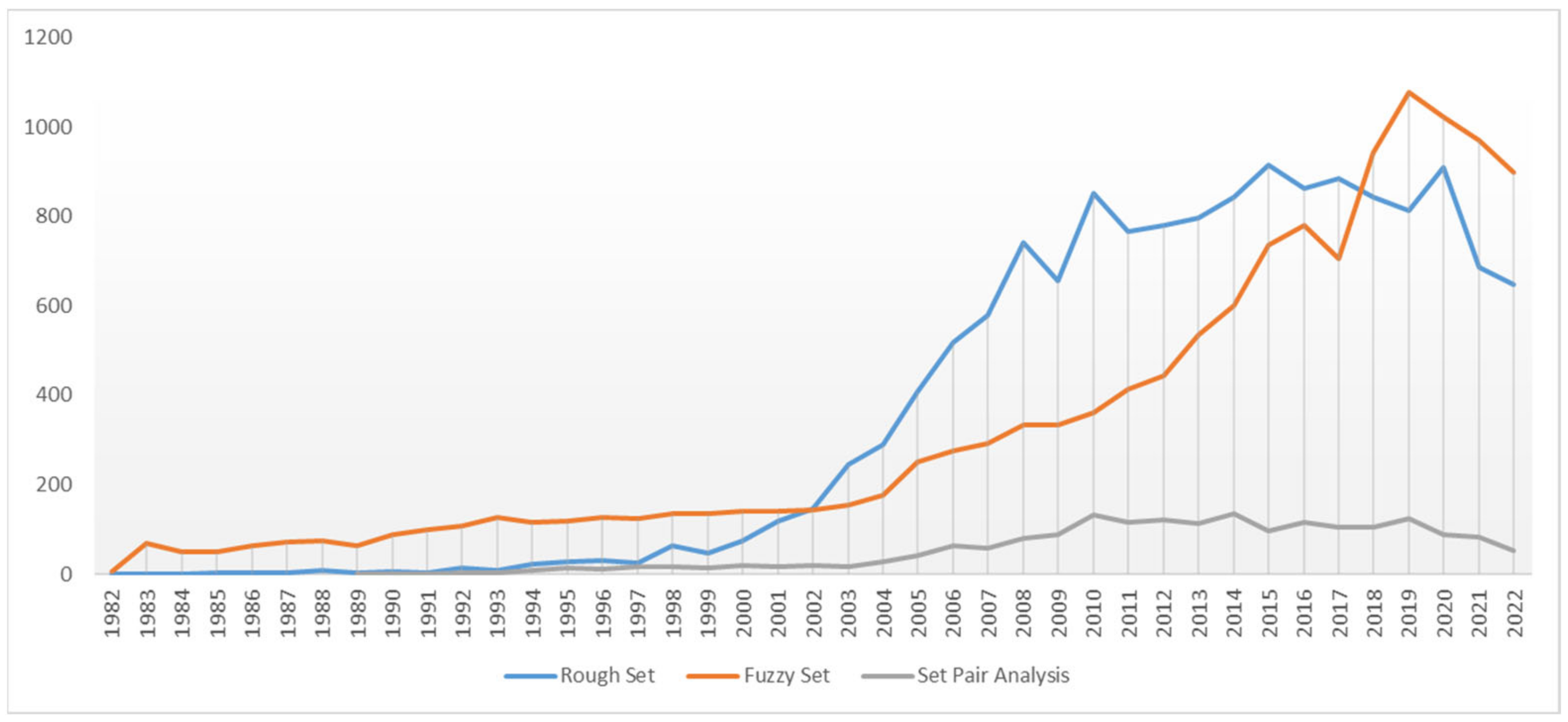
1. Introduction
- (1)
- The theoretical basis of complex network modeling research around set pair analysis and rough set and fuzzy set fusion includes: using a set pair connection degree to measure the similarity between complex network vertices and modeling complex networks based on set pair similarity; using rough sets with upper and lower approximate sets to construct a complex network of rough vertices (edges); using three-way decision methods (probabilistic rough sets) to model a complex network; and using the fuzzy set membership degree to describe the relationship between vertices and cliques or between cliques and then to model complex networks.
- (2)
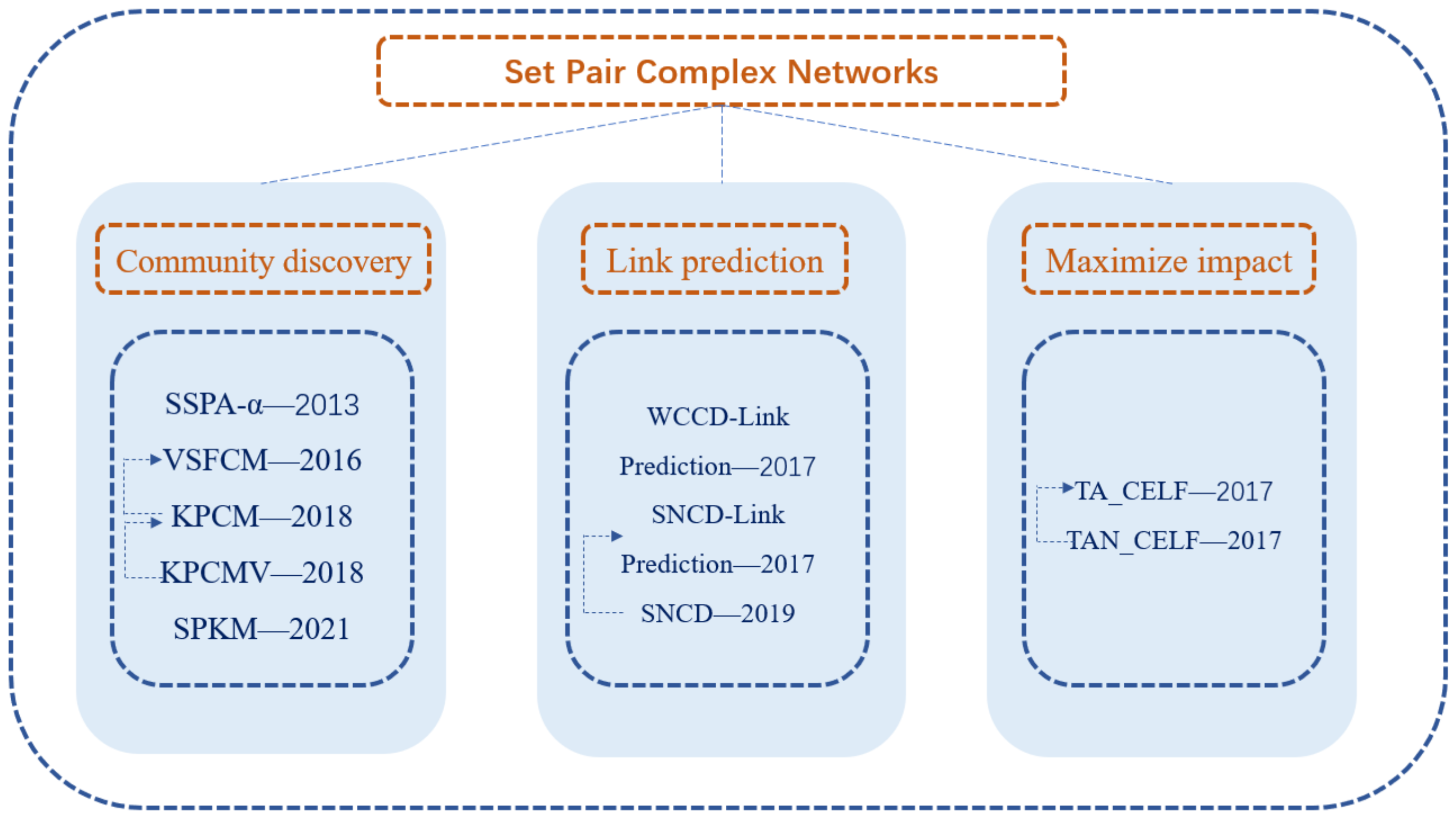
- The modeling methods and applications of set pair analysis, rough set theory and fuzzy set theory in complex networks are summarized and analyzed, including: community discovery, link prediction, influence maximization and decision-making problems. A typical algorithm and an innovative algorithm are analyzed and compared.
- (3)
- The prospect of uncertainty theory in complex network modeling research and its possible extension in the field of uncertain hypergraphs is put forward.
2. SPA-Based Complex Network Modeling
2.1. Theoretical Basis of Set Pair Modeling for Complex Networks
2.1.1. The Basis of Set Pair Analysis
2.1.2. Set Pair Similarity Measure between Complex Network Vertices
2.1.3. Complex Network Set Pair Relationship Matrix
2.1.4. Set Pair Relationship Community Description
2.2. SPA-Based Complex Network Modeling and Application
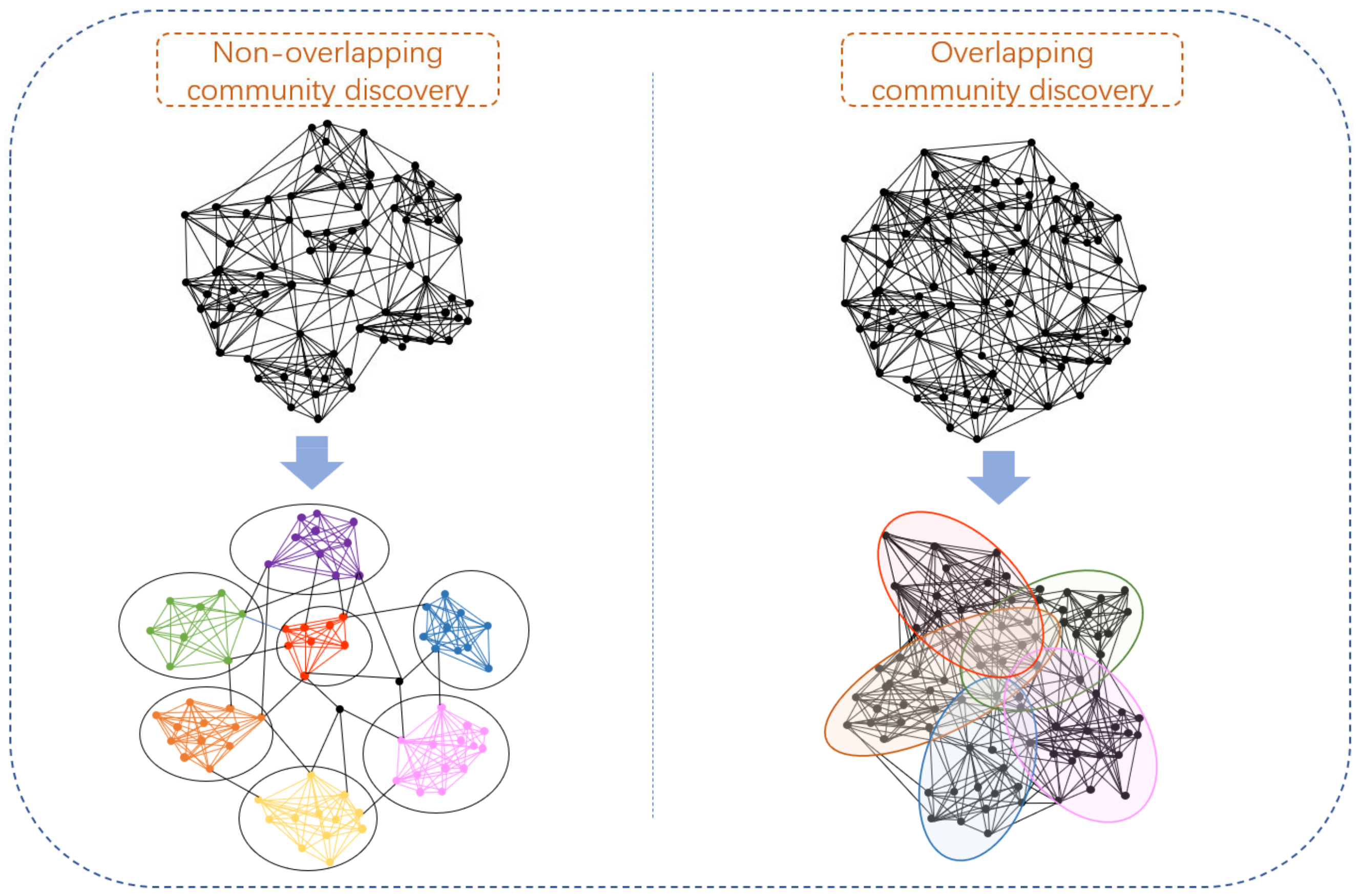
2.2.1. Community Discovery
- (1)
- Static community discovery
- (2)
- Dynamic community discovery
- (3)
- Overlapping community discovery
2.2.2. Link Prediction
2.2.3. Maximizing Impact
2.2.4. Other Problems
3. Complex Network Modeling Based on RS
3.1. Basics of RS Modeling Complex Network
3.1.1. Basic Theory of RS
3.1.2. RS Complex Network
3.1.3. Rough Complex Network Accuracy Metrics
3.1.4. Coarse Clustering Coefficients for Rough Complex Network
3.2. Rough Set Modeling Method for Complex Networks
3.2.1. Rough Decision-making Model
- (1)
- Rough path and defensive decision making
- (2)
- Rough and complex network decision-making method
3.2.2. Community Discovery
- (1)
- Non-overlapping community discovery
- (2)
- Overlapping community discovery
3.2.3. Other Problems
4. Modeling Method Based on Fuzzy Set Theory
4.1. Fuzzy Set Theory Modeling Basis
4.1.1. Fuzzy Membership Function
- (1)
- The membership function must have an upper bound of 1 and a lower bound of 0. That is, the value range of the membership function is [0,1];
- (2)
- For each sample, its membership must be unique. That is, for a fuzzy set, an element can only correspond to one degree of membership.
4.1.2. Fuzzy Clustering Algorithm
- (1)
- Initialization: take the fuzzy weighting index m = 2, the number of clusters C (2 ≤ C ≤ n), where n is the number of data sample points, the iteration stop threshold is , the initial cluster center value is P(0), and the number of iterations l = 0;
- (2)
- Calculate the partition matrix U composed of the values of membership degrees U(l):For any i, k, represents the distance between the sample point and the i-th class. If , then the membership degree of the sample point and the i-th class is:
- (3)
- Update the cluster center value:
- (4)
- If , the algorithm stops; otherwise, go to step (2).
4.1.3. Modularity
4.2. Fuzzy Set Theory Modeling Method
4.2.1. Community Discovery
- (1)
- Topological structure
- (2)
- Fuzzy clustering
4.2.2. Other Problems
5. Challenges and Prospects
- (1)
- In traditional graph theory, an edge can only connect two vertices, and it is impossible to model and analyze higher-dimensional situations. A hypergraph is a graph model whose edges can connect multiple vertices. Now, some scholars have constructed an uncertain hypergraph model and applied it to the research of practical problems. However, research in this area still has a number of areas for development;
- (2)
- A three-way decision is an effective rough decision-making model, and the current research on this is far from sufficient. The question of how to reduce time complexity and space complexity as much as possible while ensuring high precision will be a long-term research hotspot;
- (3)
- Some scholars have combined rough set theory and fuzzy set theory to propose a series of models and algorithms. However, the cross-integration of other uncertainty theories and their modeling in complex networks remains to be studied.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Albert, R.; Barabasi, A.L. Statistical mechanics of complex network. Rev. Mod. Phys. 2002, 74, 47. [Google Scholar] [CrossRef]
- Bollacker, K.; Evans, C.; Pariyosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; ACM: New York, NY, USA, 2008; pp. 1247–1250. [Google Scholar]
- West, R.; Gabrilovich, E.; Murphy, K.; Sun, S.; Gupta, R. Knowledge base completion via search-based question answering. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Republic of Korea, 8 April 2014; ACM: New York, NY, USA, 2014; pp. 515–526. [Google Scholar]
- Gu, Y. Research on Modeling Activity-Travel Behavior Considering Uncertainties in Transportion Network. Master’s Thesis, Southeast University, Dhaka, Bangladesh, 2018. [Google Scholar] [CrossRef]
- Nimmegeers, P.; Telen, D.; Logist, F.; Impe, J.V. Dynamic optimization of biological network under parametric uncertainty. BMC Syst. Biol. 2016, 10, 86. [Google Scholar] [CrossRef] [PubMed]
- Peng, J.; Zhang, B.; Sugeng, K.A. Uncertain Hypergraphs: A Conceptual Framework and Some Topological Characteristics Indexes. Symmetry 2022, 14, 330. [Google Scholar] [CrossRef]
- Zhang, L.Y.; Guo, J.F.; Wang, J.Z.; Wang, J.; Li, S.S.; Zhang, C.Y. Hypergraph and Uncertain Hypergraph Representation Learning Theory and Methods. Mathematics 2022, 10, 1921. [Google Scholar] [CrossRef]
- Hu, Z.Y. Dynamic Analysis of Uncertain Complex Network. Master’s Thesis, Huazhong University of Science and Technology, Wuhan, China, 2008. [Google Scholar]
- Dong, Y.H.; Liu, Y.; Zhong, M.Y. Sensor Fault for Complex Network with Uncertain Coupling Occurrence Probabilities. J. Shandong Univ. Sci. Technol. Nat. Sci. 2020, 39, 77–85. [Google Scholar] [CrossRef]
- Jiang, J.; Wang, R.; Pezeril, M.; Wang, Q.A. Application of varentropy as a measure of probabilistic uncertainty for complex network. Chin. Sci. Bull. 2011, 56, 3677–3682. [Google Scholar] [CrossRef]
- Qun, L.; Wei, W.; Li, X.L.; Yang, Y.X.; Peng, H.P. Adaptive synchronization research on the uncertain complex network with time-delay. Acta Phys. Sin. 2008, 57, 1529–1534. [Google Scholar] [CrossRef]
- Ortega, O.O.; Ozen, M.; Wilson, B.A.; Pino, J.C.; Irvin, M.W.; Ildefonso, G.V.; Garbett, S.P.; Lopez, C.F. Probability-based mechanisms in biological network with parameter uncertainty. bioRxiv 2022. [Google Scholar] [CrossRef]
- Wei, X.X.; Li, Y.; Bian, C.Z.; Lu, H.P. A Survey of Research on Uncertain Network Design Models. Highw. Eng. 2014, 39, 171–176. [Google Scholar]
- Wang, H.W.; Liu, D.; Zhao, P.; Chen, X. Review on Hierarchical Task Network Planning under Uncertainty. Acta Autom. Sin. 2016, 42, 655–667. [Google Scholar] [CrossRef]
- Zhang, C.Y.; Guo, J.F. The α Relational Communities of Set Pair Social Network and Its Dynamic Mining Algorithms. Chin. J. Comput. 2013, 36, 1682–1692. [Google Scholar] [CrossRef]
- Chen, X. Study on the Measure Methods of Similarity between Vertices in Network. Ph.D. Thesis, Yanshan University, Qinhuangdao, China, 2017. [Google Scholar]
- Zhang, C.Y.; Liang, R.T.; Liu, L. Set pair social network analysis model and its application. J. Hebei Union Univ. Nat. Sci. Ed. 2011, 33, 99–103. [Google Scholar]
- Zhang, C.Y.; Liang, R.T.; Liu, L. Set Pair Social Network Analysis Model and Information Mining. In Proceedings of the International Conference on Electronic Commerce, Web Application, and Communication, Guangzhou, China, 16–17 April 2011; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Chunying, Z.; Ruitao, L.; Lu, L.; Jing, W. Set Pair Community Mining and Situation Analysis Based on Web Social Network. Procedia Eng. 2011, 15, 3456–3460. [Google Scholar] [CrossRef]
- Zhang, J.Z. Research on Community Detection Algorithm Based on the Measure of Set Pair Similarity. Master’s Thesis, Yanshan University, Qinhuangdao, China, 2016. [Google Scholar]
- Hao, D.D.; Guo, J.F.; Wang, Y.J. Research on community discovery based on k-shell. J. Hebei Acad. Sci. 2018, 35, 18–29. [Google Scholar] [CrossRef]
- Chen, X.; Guo, J.F.; Zhang, C.Y. Measuring Similarity Between Vertices and Its Application in Social Network. J. Front. Comput. Sci. Technol. 2017, 11, 1629–1641. [Google Scholar]
- Chen, X.; Guo, J.F.; Fan, C.Z. Research on Network Community Discovery Methods Based on Topic Concern. Comput. Eng. Appl. 2017, 53, 85–93. [Google Scholar]
- Chen, X.; Guo, J.F.; Tian, K.L.; Fan, C.Z.; Pan, X. A Study on the Influence Propagation Model in Topic Attention Network. Int. J. Perform. Eng. 2017, 13, 721. [Google Scholar] [CrossRef]
- Guo, J.F.; Dong, H.; Zhang, T.W.; Chen, X. Representation learning of the topic-attention network. J. Comput. Appl. 2020, 40, 441–447. [Google Scholar]
- Gao, R.Y. Research and Application of Three-way Clustering Based on Set Pair Information Granule. Master’s Thesis, North China University of Science and Technology, Qinhuangdao, China, 2021. [Google Scholar] [CrossRef]
- Zhang, W.Y.; Wu, B.; Liu, Y. Cluster-level trust prediction based on multi-modal social networks. Neurocomputing 2016, 210, 206–216. [Google Scholar] [CrossRef]
- Chen, X.; Guo, J.F.; Pan, X.; Zhang, C.Y. Link prediction in signed network based on connection degree. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 1747–1757. [Google Scholar] [CrossRef]
- Cao, L.X. Research on the Statistical Characteristics and Definition of the Complex Network with Uncertainty. J. Northwest Norm. Univ. 2018, 54, 28–33+43. [Google Scholar] [CrossRef]
- Wang, C.Z. Research on Complex Network Attack Modeling and Security Assessment Method. Ph.D. Thesis, Xi’an University of Architecture and Technology, Xi’an, China, 2011. [Google Scholar]
- Bao, Z.K.; Yang, S.L. Rough Decision Analysis Model Based on New Feature Dominance Relationship. Stat. Decis. 2015, 41–44. [Google Scholar] [CrossRef]
- Cao, L.X.; Huang, G.Q. Concept design and construction algorithm of rough complex network. J. Intell. Fuzzy Syst. 2017, 33, 1441–1451. [Google Scholar] [CrossRef]
- Cao, L.X.; Huang, G.Q.; Chai, W. A knowledge discovery model for third-party payment network based on rough set theory. J. Intell. Fuzzy Syst. 2017, 33, 413–421. [Google Scholar] [CrossRef]
- Cao, L.X.; Huang, G.Q.; Li, Y. Decision Methods and Applications of Rough Complex Network Based on Network-Based. J. Front. Comput. Sci. Technol. 2016, 10, 1601. [Google Scholar]
- Cao, L.X. Research on Risk Analysis and Decision Models of the Third-party Payment Rough Network. Ph.D. Thesis, Xi’an University of Architecture and Technology, Xi’an, China, 2016. [Google Scholar]
- Cao, L.X.; Fu, W.Q. Benefit Risk Evaluation of Third-party Payment Network Based on Rough Set. Comput. Technol. Dev. 2019, 29, 149–153. [Google Scholar]
- Liu, Y.L.; Pan, L.; Jia, X.Y.; Wang, C.J.; Xie, J.Y. Three-way decision based overlapping community detection. Rough Sets Knowl. Technol. 2013, 8171, 279–290. [Google Scholar]
- Fang, L.D.; Zhang, Y.P.; Chen, J.; Wang, Q.Q.; Liu, F.; Wang, G. Three-way Decision Based on Non-overlapping Community Division. Caai Transctions Intell. Syst. 2017, 12, 293–300. [Google Scholar]
- Fang, L.D. Research on Non-overlapping Community Division Based on Three-way Decision Theory. Master’s Thesis, Anhui University, Hefei, China, 2018. [Google Scholar]
- Chen, J.; Li, Y.; Yang, X.; Zhang, Y. VGHC: A variable granularity hierarchical clustering for community detection. Granul. Comput. 2019, 6, 37–46. [Google Scholar] [CrossRef]
- Zhu, W.Q. Application of Rough Set and Ant Colony Algorithm on Community Discovery. Master’s Thesis, Soochow University, New Taipei, Taiwan, 2011. [Google Scholar]
- Liu, L.A. Research of Community Mining in Social Network Based on Granular Computing. Master’s Thesis, Nanchang University, Nanchang, China, 2014. [Google Scholar]
- Zhang, Q.; Chen, H.M.; Feng, Y.F. A Research of Community Mining in Social Network Based on Granular Computing. Comput. Sci. 2020, 47, 72–78. [Google Scholar]
- Zhang, Q.; Chen, H.M.; Feng, Y.F. Overlapping Community Detection Method Based on Rough Set and Distance Dynamic Model. Comput. Sci. 2020, 47, 75–82. [Google Scholar]
- Zhang, Q. Research on Overlapping Community Detection Algorithm Based on Rough Set. Master’s Thesis, Southwest Jiaotong University, Chengdu, China, 2020. [Google Scholar] [CrossRef]
- Gupta, S.; Kumar, P.; Bhasker, B. A rough connectedness algorithm for mining communities in complex network. In Proceedings of the International Conference on Big Data Analytics and Knowledge Discovery, San Francisco, CA, USA, 13–17 August 2016; Springer: Cham, Switzerland, 2016; pp. 34–48. [Google Scholar]
- Gupta, S.; Kumar, P. An overlapping community detection algorithm based on rough clustering of links. Data Knowl. Eng. 2020, 125, 101777. [Google Scholar] [CrossRef]
- Fuentes, I.; Pina, A.; Nápoles, G.; Arco, L.; Vanhoof, K. Rough Net Approach for Community Detection Analysis in Complex Network. In Rough Sets: International Joint Conference, IJCRS 2020, Havana, Cuba, 29 June–3 July 2020; Springer: Cham, Switzerland, 2020; pp. 401–415. [Google Scholar]
- Gregory, S. Fuzzy overlapping communities in network. J. Stat. Mech. Theory Exp. 2011, 2011, P02017. [Google Scholar] [CrossRef]
- Hu, L.; Chan, K.C. Fuzzy clustering in a complex network based on content relevance and link structures. IEEE Trans. Fuzzy Syst. 2015, 24, 456–470. [Google Scholar] [CrossRef]
- Xu, J.X.; Han, Z.H.; Gu, H.J. Overlapping Community Detection with Node Struture and Attribute. Appl. Res. Comput. 2016, 33, 3615–3619. [Google Scholar]
- Duan, Z.X. Automatic Detection and Simulation of Complex Network Fuzzy Overlapping Community Structure. Comput. Simul. 2020, 37, 352–356. [Google Scholar]
- Tao, L.; Li, W.; Jin, Y.; Yin, S. Community discovery of complex network based on fuzzy density peak clustering algorithm. In Proceedings of the 2018 13th IEEE Conference on Industrial Electronics and Applications (ICIEA), Wuhan, China, 31 May–2 June 2018; pp. 531–536. [Google Scholar]
- Yang, X. Research on Density Peaks Clustering and Application in Community Detection. Master’s Thesis, Southwest University, El Paso, TX, USA, 2022. [Google Scholar] [CrossRef]
- Zhan, H.; Chen, P.; Zhang, X.F. Overlapping Community Division Based on Rough Fuzzy Clustering Algorithm. Syst. Eng. 2020, 89–90. [Google Scholar]
- Chen, W.J.; Wen, Y.; Yang, N. Fuzzy Overlapping Community Partitioning Algorithm Based on Vertex Vector Representation. Data Anal. Knowl. Discov. 2021, 5, 41–50. [Google Scholar]
- Li, H.W.; Wei, T.H. Research on Design of Fuzzy Clustering Algorithm Based on Q Function Optimization for Weighted Directed Complex Network. Guangdong Technol. 2016, 25, 54–56. [Google Scholar]
- Shi, F.J.; Chen, J.Z.; Zhao, K.; Huang, H.; Li, W.G. Fuzzy Analysis and Information Mining on Overlapping Communities in Directed Network Based on Matrix Decomposition. Electron. Des. Eng. 2019, 27, 20–25. [Google Scholar] [CrossRef]
- Liu, J.X. A Summary of Complex Network and Their Research Progress in China. J. Syst. Sci. 2009, 17, 31–37. [Google Scholar]
- Sheng, X. A Review of the Development of Complex Network Models. J. Chifeng Univ. (Nat. Sci. Ed.) 2016, 32, 8–10. [Google Scholar] [CrossRef]
- An, S.H.; Yu, R.H. A Survey of Research on Complex Network Theory. Comput. Syst. Appl. 2020, 29, 26–31. [Google Scholar] [CrossRef]
- Zhao, K.Q. Set Pair Analysis and Its Preliminary Application. Discov. Nat. 1994, 12, 67–72. [Google Scholar]
- Zhang, X.; Cheng, X.; Qi, X. Analysis of Assessment of Power Grid Corp Asset Management Based on Set Pair Analysis Model. For. Chem. Rev. 2021, 1119–1132. [Google Scholar]
- Liu, S.; Liu, H.; Chen, J.; Wu, Z.; Liang, N.; Guo, G.; Qiu, H.; Deng, B. Evaluation Method for Insulation State of Cable Intermediate Joint based on Variable Weight and Set Pair Analysis. In Proceedings of the 2022 IEEE 5th International Conference on Automation, Electronics and Electrical Engineering (AUTEEE), Shenyang, China, 18–20 November 2022. [Google Scholar]
- Zhang, C.Y. Research on Modeling and Situation Analysis Theory of Social Network Based on Attribute Graph. Ph.D. Thesis, Yanshan University, Qinhuangdao, China, 2013. [Google Scholar]
- Liu, F.C.; Zhang, C.Y.; Wang, J. The Static a Relationship Mining of Social Network. Int. J. Adv. Comput. Technol. 2012, 4, 188–195. [Google Scholar]
- Wang, X.L. Mathematical Statistics Model for Similarity of Uncertain Complex Network Nodes. Electron. Des. Eng. 2020, 28, 89–92. [Google Scholar] [CrossRef]
- Zhang, C.; Ren, J.; Liu, L.; Liu, S.; Li, X.; Wang, L. Set pair three-way overlapping community discovery algorithm for weighted social internet of things. Digit. Commun. Netw. 2022, in press. [Google Scholar] [CrossRef]
- Li, H.; Zhang, R.; Zhao, Z. An Efficient Influence Maximization Algorithm Based on Clique in Social Networks. IEEE Access 2019, 7, 141083–141093. [Google Scholar] [CrossRef]
- Tian, J.T.; Wang, Y.T.; Feng, X.J. A New Hybrid Algorithm for Influence Maximization in Social Network. Chin. J. Comput. 2011, 34, 1956–1965. [Google Scholar] [CrossRef]
- Cao, J.X.; Min, H.Y.; Xu, S.; Liu, B. Mixed Heuristic and Greedy Strategies Based Algorithm for Influence Maximization in Social Network. J. Southeast Univ. Nat. Sci. Ed. 2016, 46, 950–956. [Google Scholar]
- Zhang, W.; Li, R.W.; Shi, X.W.; Shi, Y.J.; Gu, X.J. Dynamic Mining Method of Manufacturing Services Demand Based on Set Pair. Comput. Integr. Manuf. Syst. 2016, 22, 62–69. [Google Scholar] [CrossRef]
- Zhao, G.H. Research on the Emotional Analysis Based on Set Pair-Information Entropy in Social Network. Master’s Thesis, Yanshan University, Qinhuangdao, China, 2018. [Google Scholar]
- He, T.; Lu, C.J.; Shi, K.Q. Rough Graph and Its Structure. J. Shandong Univ. (Nat. Sci.) 2006, 41, 46–50. [Google Scholar]
- Zhang, C.Y.; Guo, J.F. The Rough Attribute Graph Model of Web Social Network and Its Application. Comput. Eng. Sci. 2014, 36, 517–523. [Google Scholar]
- Pawlak, Z. Rough sets. Int. J. Inf. Comput. Sci. 1982, 11, 314–356. [Google Scholar] [CrossRef]
- Jiang, Y.W.; Jia, C.Y.; Yu, J. An efficient community detection method based on rand centrality. Phys. A Stat. Mech. Its Appl. 2013, 392, 2182–2194. [Google Scholar] [CrossRef]
- Yao, Y. Decision-theoretic rough set models. In Proceedings of the International Conference on Rough Set and Knowledge Technology, Toronto, Canada, 14–16 May 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 1–12. [Google Scholar]
- Liu, D.; Li, T.R.; Li, X.H. Rough Set Theory: A Three-way Decisions Perspective. J. Nanjing Univ. Nat. Sci. Nat. Sci. 2013, 49, 574–581. [Google Scholar] [CrossRef]
- Pancerz, K. Quantitative assessment of ambiguities in plasmodium propagation in terms of complex network and rough set. In Proceedings of the 10th EAI International Conference on Bio-Inspired Information and Communications Technologies. European Alliance for Innovation, Hoboken, NJ, USA, 15–16 March 2017. [Google Scholar]
- Ji, Z.; Fu, Z.Q.; Zhang, S.T. Fault Diagnosis of Diesel Generator Set Based on Optimized NRS and Complex Network. J. Vib. Shock 2020, 39, 246–251. [Google Scholar] [CrossRef]
- Li, X.Y.; Li, X.W.; Jiang, J. Multi objective rough set attribute reduction algorithm based on characteristics of knowledge granularity. Control. Decis. 2021, 36, 196–205. [Google Scholar] [CrossRef]
- Jaskula, B.; Szkola, J.; Pancerz, K.; Derkacz, A. Eye-tracking data, complex network and rough set: An attempt toward combining them. In Proceedings of the 9th EAI International Conference on Bio-inspired Information and Communications Technologies (formerly BIONETICS), New York, NY, USA, 3–5 December 2016; pp. 167–173. [Google Scholar]
- Zadeh, L.A. Fuzzy set. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Ye, H.J. The Research on Fuzzy Clustering Analysis Technology and Its Application. Master’s Thesis, Hefei University of Technology, Hefei, China, 2006. [Google Scholar]
- Newman, M.E.; Girvan, M. Finding and evaluating community structure in network. Phys. Rev. E 2004, 69, 026113. [Google Scholar] [CrossRef] [PubMed]
- Newman, M.E. Modularity and community structure in network. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef] [PubMed]
- Xiao, J.; Zhang, Y.J.; Xu, X.K. Research Progress of Fuzzy Overlapping Community Detection in Complex Network. Complex Syst. Complex. Sci. 2017, 14, 8–29. [Google Scholar] [CrossRef]
- Nepusz, T.; Petróczi, A.; Négyessy, L.; Bazsó, F. Fuzzy communities and the concept of bridgeness in complex network. Phys. Rev. E 2008, 77, 016107. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, R.S.; Zhang, X.S. Identification of overlapping community structure in complex network using fuzzy c-means clustering. Phys. A Stat. Mech. Its Appl. 2007, 374, 483–490. [Google Scholar] [CrossRef]
- Zhao, K.; Zhang, S.W.; Pan, Q. Fuzzy Clustering and Information Mining in Complex Network. Appl. Res. Comput. 2010, 27, 2452–2454. [Google Scholar]
- Zhao, K.; Zhang, S.W.; Pan, Q. Identification of Overlapping Clusters in Complex Network Using Symmetrical Nonnegative Matrix Factorization. Comput. Meas. Control 2010, 18, 2872–2874+2878. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, R.S.; Zhang, X.S. Uncovering fuzzy community structure in complex network. Phys. Rev. E 2007, 76, 046103. [Google Scholar] [CrossRef]
- Wang, D.; Wu, M.D. Rough Fuzzy C-Means Algorithm and Its Application to Image Clustering. J. Natl. Univ. Def. Technol. 2007, 29, 76–80. [Google Scholar]
- Liu, P. Risk Assessment of Power Grid Based on Complex Network and Fuzzy Theory. Master’s Thesis, Tianjin University, Tianjin, China, 2012. [Google Scholar]
- Zhang, H.; Hu, Y.; Lan, X.; Mahadevan, S.; Deng, Y. Fuzzy fractal dimension of complex network. Appl. Soft Comput. 2014, 25, 514–518. [Google Scholar] [CrossRef]
- Zhou, X.X. Construction Method and Application of Complex Network based on Fuzzy Clustering. Master’s Thesis, Jiangsu University, Zhenjiang, China, 2015. [Google Scholar]
- Wang, X.; Park, J.H.; Yang, H.; Zhang, X.; Zhong, S. Delay-dependent fuzzy sampled-data synchronization of T–S fuzzy complex network with multiple couplings. IEEE Trans. Fuzzy Syst. 2019, 28, 178–189. [Google Scholar] [CrossRef]
- Zhang, X.; Huang, C. Synchronization Analysis for Fuzzy Complex Network with Reaction-Diffusion Terms. J. N. Univ. China 2020, 41, 11–18+23. [Google Scholar]
- Zhang, X. Synchronization Analysis for Fuzzy Complex Network with Reaction-Diffusion Terms. Master’s Thesis, Taiyuan University of Technology, Taiyuan, China, 2020. [Google Scholar]
- Huang, C.; Zhang, X.; Lam, H.K.; Tsai, S.H. Synchronization analysis for nonlinear complex network with reaction-diffusion terms using fuzzy-model-based approach. IEEE Trans. Fuzzy Syst. 2020, 29, 1350–1362. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper Title | Years | Major Contributions |
|---|---|---|
| Set Pair Social Network Analysis Model and Its Application [17] | 2011 | For the first time, set pair analysis was used in a social network, and a set pair social network analysis model and its related theorems are proposed. |
| Set Pair Community Mining and Situation Analysis Based on Web Social Network [19] | 2011 | The set pair connection degree was used in analyzing the sameness, difference and opposites of neighbor nodes, and a set pair community mining algorithm for context analysis is proposed. |
| The α Relational Communities of Set Pair Social Network and Its Dynamic Mining Algorithms [15] | 2013 | In the set pair social network, the concept of α-relation community with a given threshold was proposed, and the static and dynamic α-relation community mining algorithms based on set pair analysis theory are given, respectively. |
| Research on Community Detection Algorithm Based on the Measure of Set Pair Similarity [20] | 2016 | A similarity measurement method between vertices based on the weighted aggregation coefficient connection degree and a new similarity-based hierarchical clustering algorithm VSFCM were proposed, which are used in the algorithm research of community discovery. |
| Research on Community Discovery Based on k-shell [21] | 2018 | Aiming at the problems existing in the VSFCM algorithm, combining the k-shell decomposition method with set pair analysis, the algorithm KPCM and the algorithm KPCMV were proposed and applied to community discovery. |
| Measuring Similarity Between Vertices and Its Application in Social Network [22] | 2017 | A new metric, the weighted aggregation coefficient connection degree, was proposed for a traditional social network and applied to social network link prediction and community discovery. The symbolic network is characterized as a system of similarities, differences and antithesis, and a new measure of similarity between vertices was proposed, which is applied to link prediction and dynamic community discovery in a symbolic network. Using the connection degree to describe the similarities, differences and antithesis between vertices of the topic attention network, a new measure of similarity between vertices was proposed and applied to the community discovery and influence maximization research of a topic-attention network. |
| Study on the Measure Methods of Similarity between Vertices in Network [16] | ||
| Research on Network Community Discovery Methods Based on Topic Concern [23] | 2017 | A topic attention model was constructed, and the similarity between vertices of the model is characterized using the set pair connection degree. With a focus on the characteristics of the topic-attention network, a new measure of similarity between vertices, TANCD, was proposed, and a topic community discovery algorithm based on TANCD was proposed. Combining deep-learning technology with natural language processing, a topic community discovery algorithm based on representation learning was proposed. |
| A Study on the Influence Propagation Model in Topic Attention Network [24] | 2017 | |
| Study on the Measure Methods of Similarity between Vertices in Network [16] | 2017 | |
| Representation Learning of the Topic-Attention Network [25] | 2019 | |
| Research and Application of Three-way Clustering Based on Set Pair Information Granule [26] | 2021 | This paper constructs a three-way clustering algorithm SPKM based on set pair information granules and applies the set pair three-way clustering algorithm to community mining in a complex network. |
| Paper Title | Years | Major Contributions |
|---|---|---|
| Research on Complex Network Attack Modeling and Security Assessment Method [30] | 2013 | A rough path generation algorithm is proposed. On this basis, the ant colony algorithm is used to further mine k key vulnerable paths to the attack target. |
| Rough Decision Analysis Model Based on New Feature Dominance Relationship [31] | 2015 | A decision analysis model based on an extended rough set is constructed, the rough approximation relationship of decision classes is obtained under the new feature of relationship, and the classification decision rules are given. |
| Decision Methods and Applications of Rough Complex Network Based on Network-Based [34] | 2016 | Combining rough set theory with complex networks for the first time, the concept of the rough complex network is proposed, and the concepts of positive field, negative field and boundary field of the rough complex network are given. A scale-free benefit risk assessment model is constructed, combined with game theory, to conduct a game analysis of the third-party payment rough network operation risk. A decision method of rough and complex networks is given by defining the network basis of rough and complex networks, and it is used to solve the operation risk decision analysis of third-party payment rough and complex networks. |
| Research on Risk Analysis and Decision Models of the Third-party Payment Rough Network [35] | 2016 | |
| A Knowledge Discovery Model for Third-party Payment Network based on Rough Set Theory [33] | 2017 | |
| Concept Design and Construction Algorithm of Rough Complex Network [32] | 2017 | |
| Benefit Risk Evaluation of Third-party Payment Network Based on Rough Set [36] | 2018 | |
| Research on the Statistical Characteristics and Definition of the Complex Network with Uncertainty [29] | 2018 |
| Paper Title | Years | Mean Work |
|---|---|---|
| Three-way Decision-based Overlapping Community Detection [37] | 2017 | Using the idea of a three-way decision, a non-overlapping community and overlapping community discovery algorithm based on a three-way decision is proposed [37]. A three-way division [38] is performed for the overlapping communities that appear during the granulation process to obtain non-overlapping communities; aiming at the problem of community merging in the process of hierarchical clustering, a community discovery method based on variable granularity hierarchical clustering is proposed. |
| Three-way Decision Based on Non-overlapping Community Division [38] | 2017 | |
| Research on Non-overlapping Community Division Based on Three-way Decision Theory [39] | 2018 | |
| VGHC: A Variable Granularity Hierarchical Clustering for Community Detection [40] | 2020 | |
| Application of Rough Set and Ant Colony Algorithm on Community Discovery [41] | 2012 | A model of network community structure discovery is constructed based on a rough set, and information centrality is used to measure the relationship between vertices. |
| Research of Community Mining in Social Network Based on Granular Computing [42] | 2015 | Based on granular computing of a rough set model, a community mining algorithm based on granular computing is constructed. |
| Research of Community Mining in Social Network Based on Granular Computing [43] | 2020 | An overlapping community discovery algorithm is proposed based on a rough set and density peaks [43]; an overlapping community discovery algorithm is proposed based on a rough set and distance dynamic models [44]. |
| Overlapping Community Detection Method Based on Rough Set and Distance Dynamic Model [44] | 2020 | |
| Research on Overlapping Community Detection Algorithm Based on Rough Set [45] | 2021 | |
| A Rough Connectedness Algorithm for Mining Communities in Complex Network [46] | 2016 | A new algorithm based on a rough set is proposed to detect disjointed, overlapping and hierarchically nested communities in a network by constructing the granularity of neighborhood vertices and representing them as a rough set [46]; an overlapping community detection algorithm is proposed based on link granularity information and a rough set [47]. |
| An Overlapping Community Detection Algorithm Based on Rough Clustering of Links [47] | 2020 | |
| Rough Net Approach for Community Detection Analysis in Complex Network [48] | 2020 | A new rough network model is constructed, and new quality measures are proposed for exploratory analysis of a community structure in a single network and multiple networks. |
| Paper Title | Years | Mean Work |
|---|---|---|
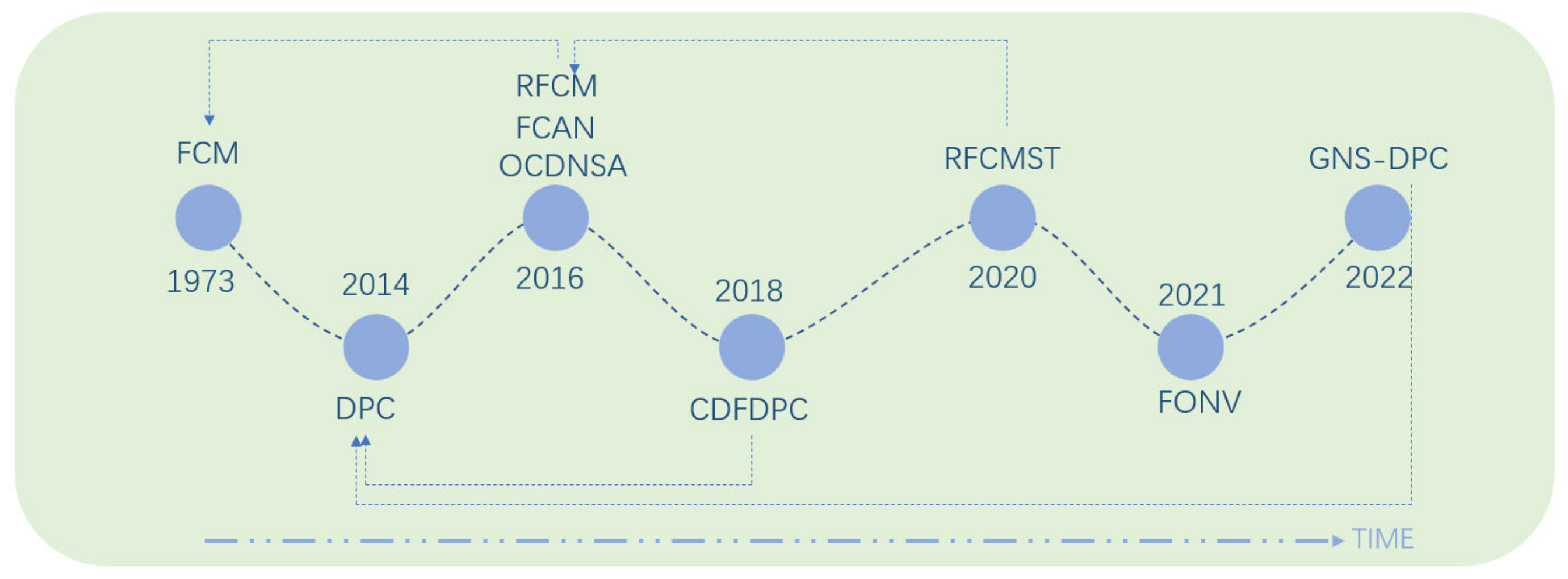
| Fuzzy Overlapping Communities in Network [49] | 2011 | The concept of a fuzzy overlapping partition is proposed. |
| Fuzzy Clustering in a Complex Network Based on Content Relevance and Link Structures [50] | 2016 | Considering the membership degree of the cluster to which the vertex belongs, a clustering algorithm (FCAN) based on fuzzy set theory is proposed. |
| Overlapping Community Detection with Node Structure and Attribute [51] | 2016 | Reference [51] proposed a complex network fuzzy overlapping community structure detection method based on vertex topology. However, the average execution time of this algorithm is slightly longer, and it is more suitable for sparse networks. Therefore, the literature [52] proposed a fuzzy overlapping community structure detection model based on two-stage clustering to solve the above problems. |
| Automatic Detection and Simulation of Complex Network Fuzzy Overlapping Community Structure [52] | 2020 | |
| Community Discovery of Complex Network Based on Fuzzy Density Peak Clustering Algorithm [53] | 2018 | In [53], a community discovery algorithm based on the clustering of fuzzy density peaks (CDFDPC) was proposed. The algorithm uses the F_DPC algorithm to determine the core community, and then the fuzzy clustering idea is used to determine the membership degree of each point to complete the distribution of the remaining vertices. Reference [54] proposed a density peak clustering algorithm based on generalized nearest neighbor similarity and designed a multi-step assignment strategy. This strategy effectively avoids the associated errors in the data point allocation process of the traditional DPC algorithm and increases the robustness of the algorithm. |
| Research on Density Peaks Clustering and Application in Community Detection [54] | 2022 | |
| Overlapping Community Division Based on Rough Fuzzy Clustering Algorithm [55] | 2020 | Based on the rough fuzzy clustering algorithm, combined with the concept of signal transmission, an overlapping community structure mining algorithm, RFCMST, based on rough fuzzy clustering and signal transmission is proposed. |
| Fuzzy Overlapping Community Partitioning Algorithm Based on Vertex Vector Representation [56] | 2021 | A fuzzy community partition algorithm based on vertex vector representation is proposed. |
| Research on Design of Fuzzy Clustering Algorithm Based on Q Function Optimization for Weighted Directed Complex Network [57] | 2016 | On the basis of the traditional algorithm, a new Q function suitable for fuzzy partitioning of a weighted directed complex network is constructed, a fuzzy clustering algorithm for a complex network is designed, and the algorithm is improved for the unstable results of the FCM clustering algorithm. |
| Fuzzy Analysis and Information Mining on Overlapping Communities in Directed Network Based on Matrix Decomposition [58] | 2019 | In order to develop a fuzzy community analysis method for a directed network, a new fuzzy metric that can describe the association of directed point groups is introduced, and a new modular index suitable for fuzzy structures of a directed network is constructed. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Wang, J.; Guo, J.; Wang, L.; Zhang, C.; Liu, B. Research Progress of Complex Network Modeling Methods Based on Uncertainty Theory. Mathematics 2023, 11, 1212. https://doi.org/10.3390/math11051212
Wang J, Wang J, Guo J, Wang L, Zhang C, Liu B. Research Progress of Complex Network Modeling Methods Based on Uncertainty Theory. Mathematics. 2023; 11(5):1212. https://doi.org/10.3390/math11051212
Chicago/Turabian StyleWang, Jing, Jing Wang, Jingfeng Guo, Liya Wang, Chunying Zhang, and Bin Liu. 2023. "Research Progress of Complex Network Modeling Methods Based on Uncertainty Theory" Mathematics 11, no. 5: 1212. https://doi.org/10.3390/math11051212
APA StyleWang, J., Wang, J., Guo, J., Wang, L., Zhang, C., & Liu, B. (2023). Research Progress of Complex Network Modeling Methods Based on Uncertainty Theory. Mathematics, 11(5), 1212. https://doi.org/10.3390/math11051212