
Intelligent Image Super-Resolution for Vehicle License Plate in Surveillance Applications

 , ,
, ,  ,
,  ,
, 

Abstract
:1. Introduction
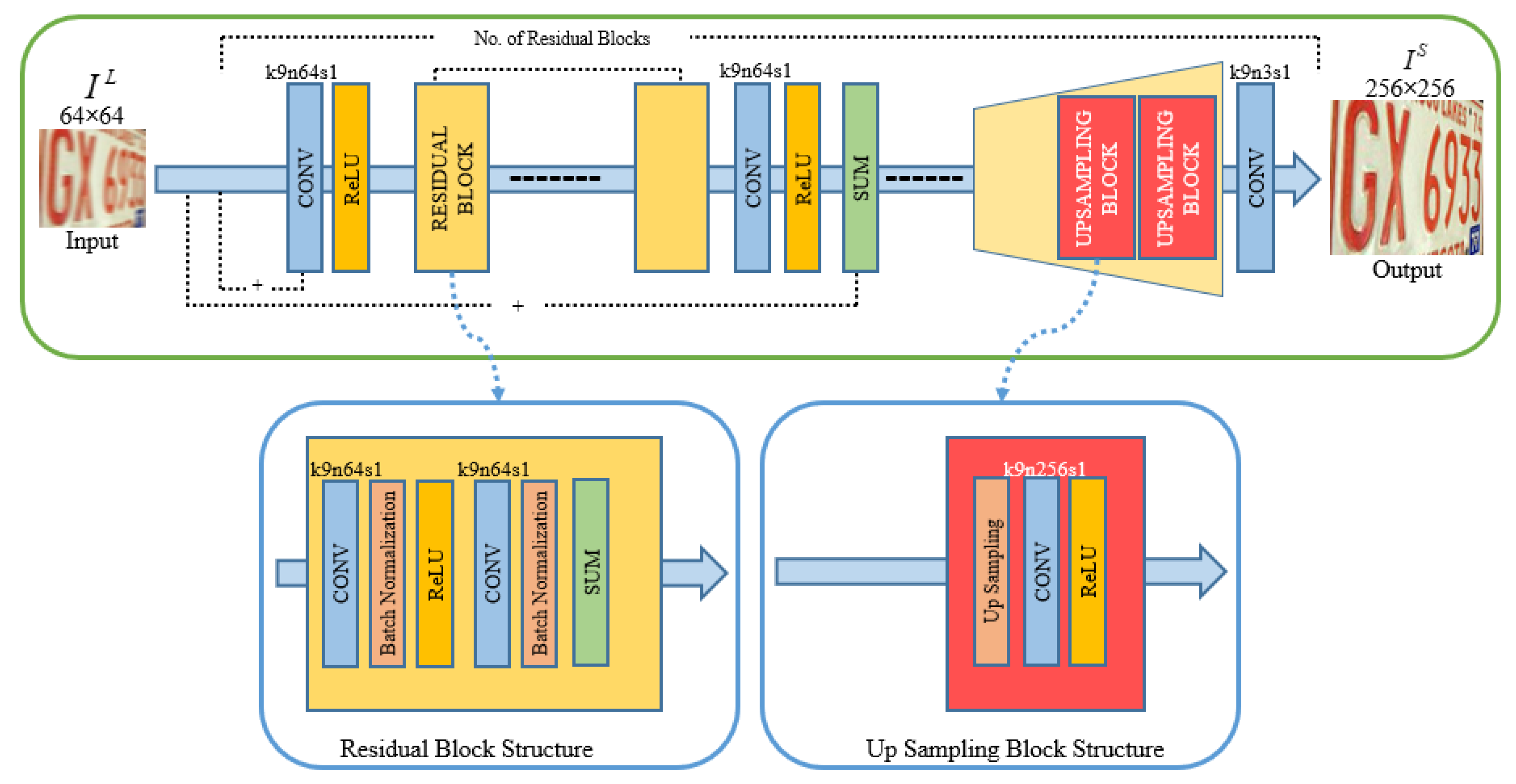
- In light of the usefulness of SRGAN in the current literature, we incorporated motion deblurring in its architecture, thus achieving good-quality HR and deblurred images.
- We reduced the size of the original SRGAN by reducing the number of residual blocks in the generator network from 16 to 8, consequently achieving less inference time while preserving the same performance.
- We developed a comprehensive and new domain-specific dataset that originally contains 3112 images of different regions and color patterns. Furthermore, we diversified the angles of the images and increased the size of the dataset to 12,388 using different augmentation techniques.
2. Related Work
2.1. Image Super Resolution and Deblurring
2.2. License Plate Super Resolution and Deblurring
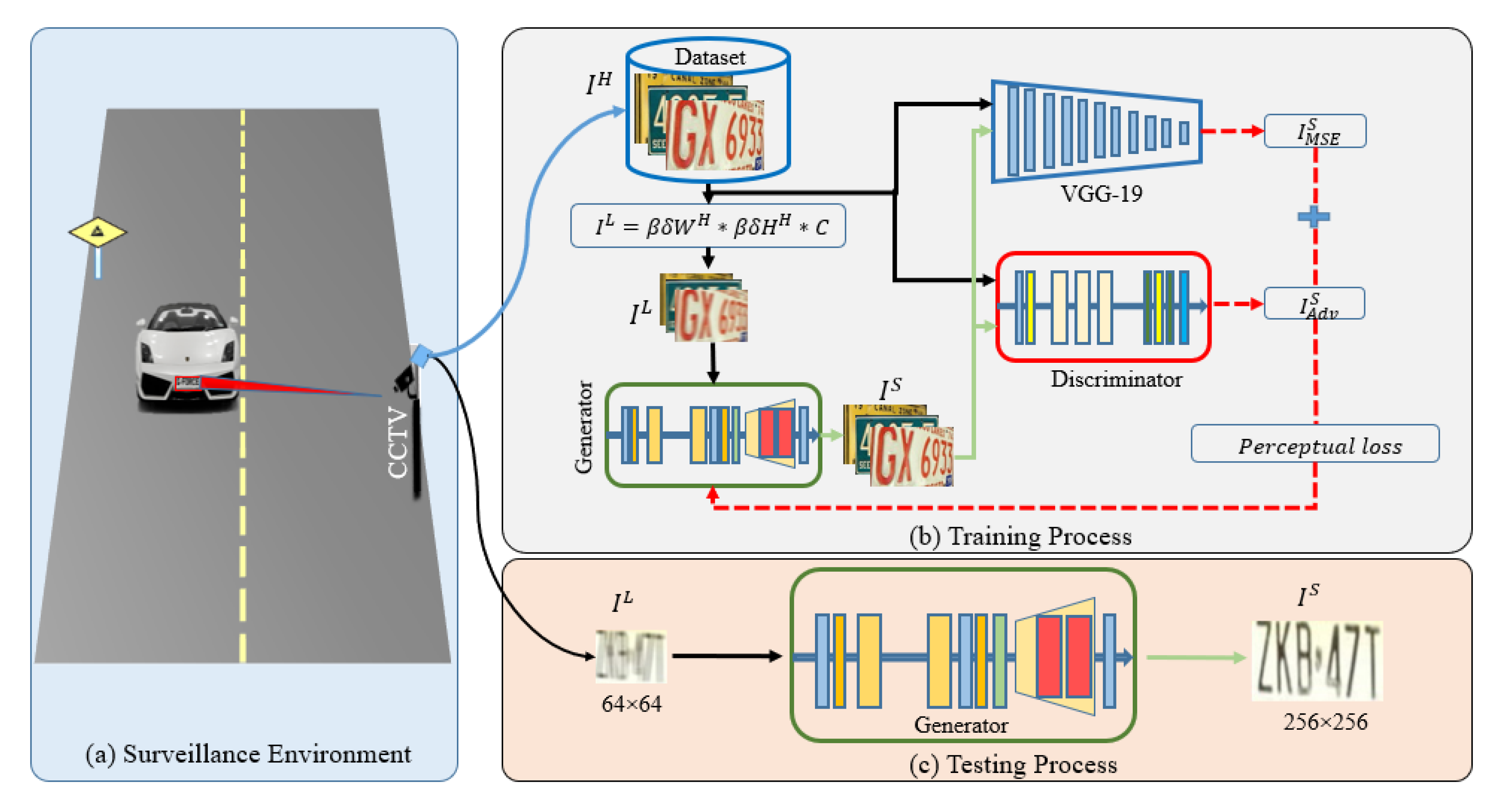
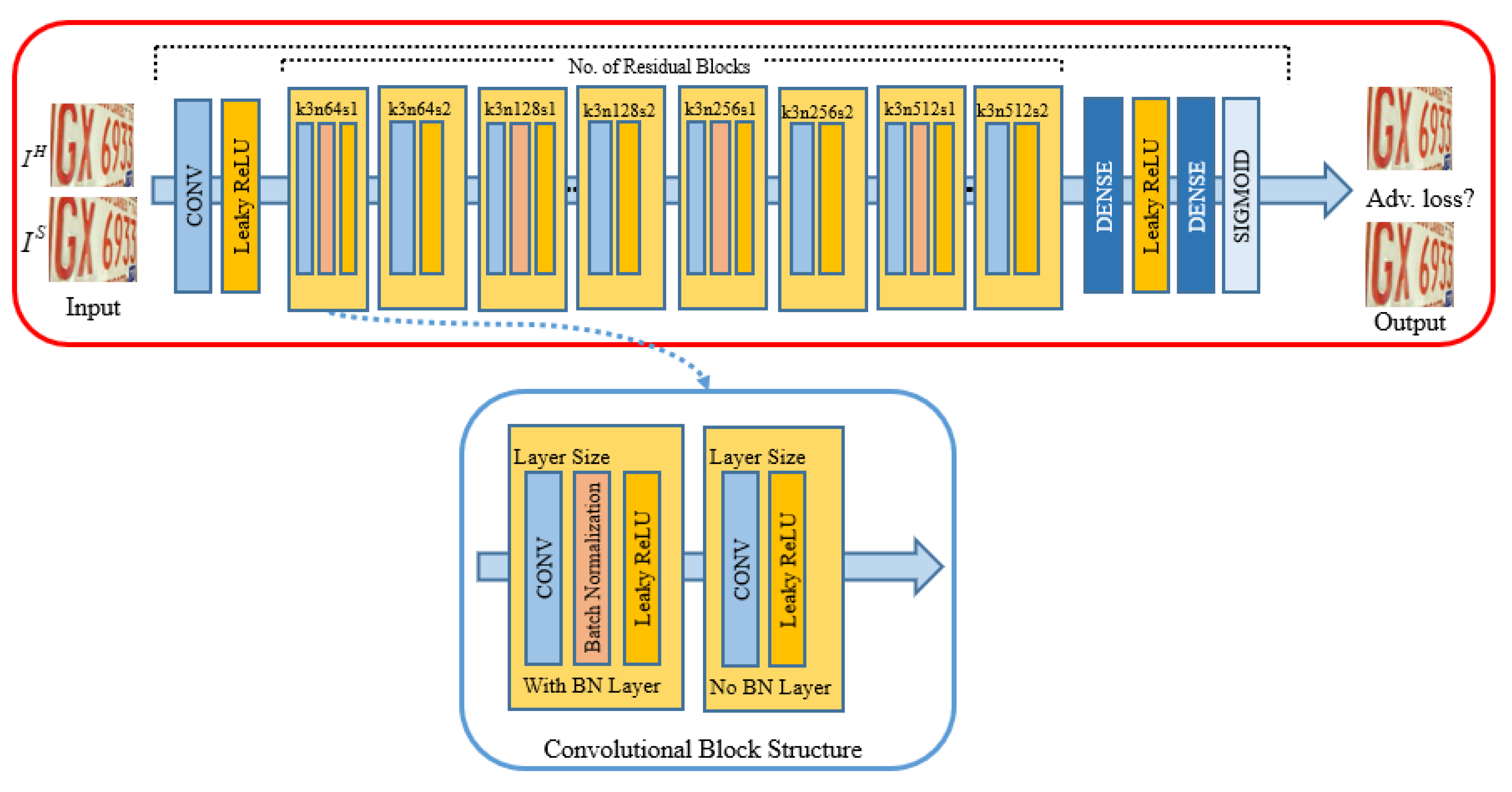
3. Proposed Methodology
3.1. Adversarial Loss Function
3.2. Content Loss Function
3.3. Perceptual Loss Function
4. Results and Discussion
4.1. Dataset Acquisition
4.2. Experimental Setup
4.3. Performance Evaluation
4.3.1. Quantitative Evaluation
4.3.2. Evaluation Using Inference Time
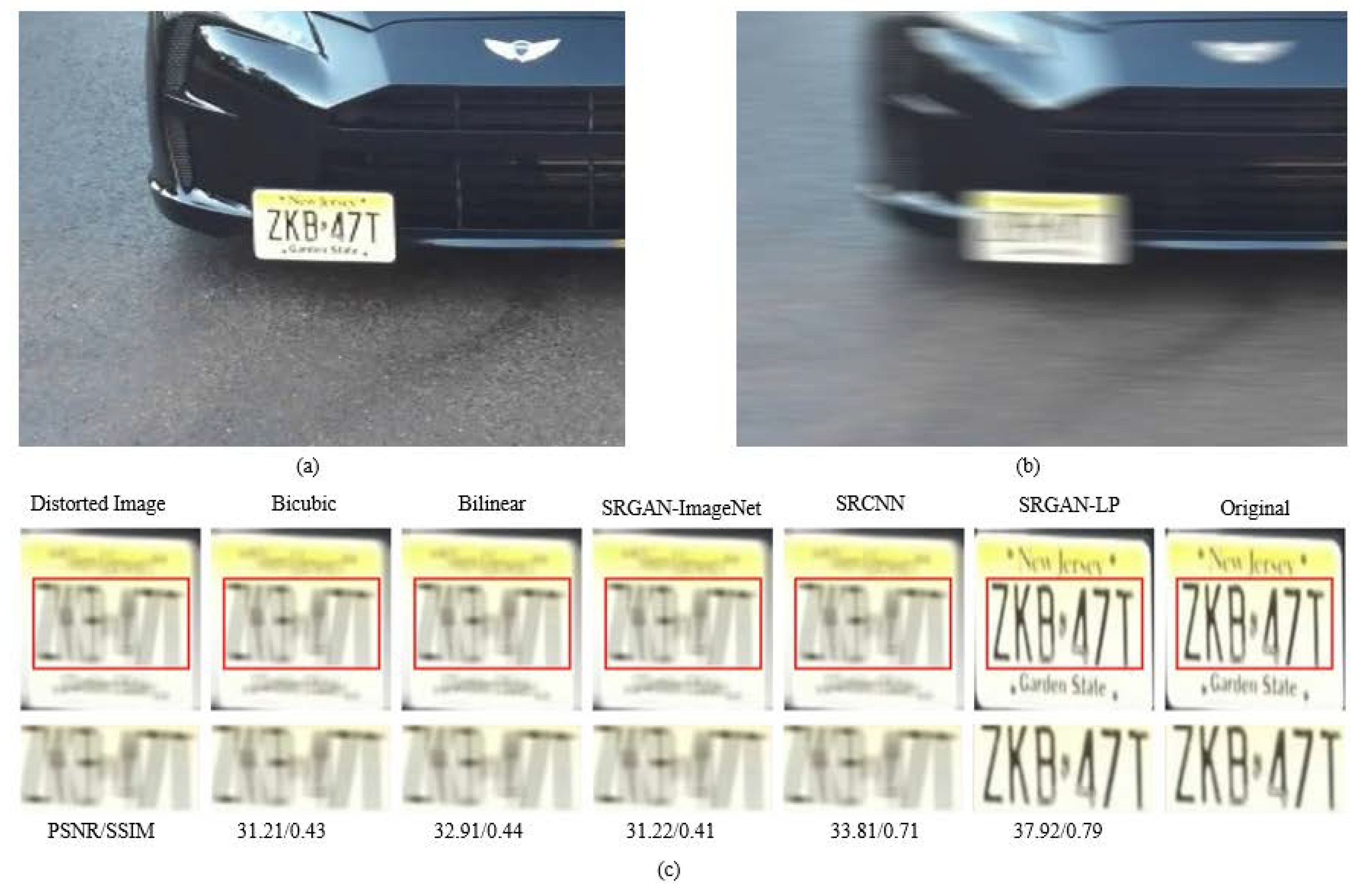
4.3.3. Qualitative Evaluation
4.3.4. Evaluation Using OCR
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abuelsamid, S.; Alexander, D.; Jerram, L. Navigant Research Leaderboard Report: Automated Driving; Navigant: Chicago, IL, USA, 2017. [Google Scholar]
- Aung, N.; Zhang, W.; Sultan, K.; Dhelim, S.; Ai, Y. Dynamic traffic congestion pricing and electric vehicle charging management system for the internet of vehicles in smart cities. Digit. Commun. Netw. 2021, 7, 492–504. [Google Scholar] [CrossRef]
- Dong, R.; Zhang, L.; Fu, H. RRSGAN: Reference-based super-resolution for remote sensing image. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5601117. [Google Scholar] [CrossRef]
- Qu, L.; Zhu, X.; Zheng, J.; Zou, L. Triple-attention-based parallel network for hyperspectral image classification. Remote Sens. 2021, 13, 324. [Google Scholar]
- Xue, J.; Zhao, Y.-Q.; Bu, Y.; Liao, W.; Chan, J.C.-W.; Philips, W. Spatial-spectral structured sparse low-rank representation for hyperspectral image super-resolution. IEEE Trans. Image Process. 2021, 30, 3084–3097. [Google Scholar]
- Lei, M.; Li, J.; Li, M.; Zou, L.; Yu, H. An Improved UNet++ Model for Congestive Heart Failure Diagnosis Using Short-Term RR Intervals. Diagnostics 2021, 11, 534. [Google Scholar] [CrossRef]
- Yan, J.; Zhang, T.; Broughton-Venner, J.; Huang, P.; Tang, M.-X. Super-resolution ultrasound through sparsity-based deconvolution and multi-feature tracking. IEEE Trans. Med. Imaging 2022, 41, 1938–1947. [Google Scholar] [PubMed]
- Li, Y.; Sixou, B.; Peyrin, F. A review of the deep learning methods for medical images super resolution problems. Irbm 2021, 42, 120–133. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Christensen-Jeffries, K.; Couture, O.; Dayton, P.A.; Eldar, Y.C.; Hynynen, K.; Kiessling, F.; O’Reilly, M.; Pinton, G.F.; Schmitz, G.; Tang, M.-X. Super-resolution ultrasound imaging. Ultrasound Med. Biol. 2020, 46, 865–891. [Google Scholar] [CrossRef]
- Afrakhteh, S.; Jalilian, H.; Iacca, G.; Demi, L. Temporal super-resolution of echocardiography using a novel high-precision non-polynomial interpolation. Biomed. Signal Process. Control 2022, 78, 104003. [Google Scholar]
- Li, J.; Pei, Z.; Zeng, T. From beginner to master: A survey for deep learning-based single-image super-resolution. arXiv 2021, arXiv:2109.14335. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Cho, S.-J.; Ji, S.-W.; Hong, J.-P.; Jung, S.-W.; Ko, S.-J. Rethinking coarse-to-fine approach in single image deblurring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4641–4650. [Google Scholar]
- Hwang, J.W.; Lee, H.S. Adaptive image interpolation based on local gradient features. IEEE Signal Process. Lett. 2004, 11, 359–362. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, BC, Canada, 8–13 December 2014; Volume 7. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Wang, T.-C.; Liu, M.-Y.; Zhu, J.-Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. Deblurgan: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8183–8192. [Google Scholar]
- Wang, L.; Li, Y.; Wang, S. DeepDeblur: Fast one-step blurry face images restoration. arXiv 2017, arXiv:1711.09515. [Google Scholar]
- Nah, S.; Hyun Kim, T.; Mu Lee, K. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar]
- Gou, C.; Wang, K.; Yao, Y.; Li, Z. Vehicle license plate recognition based on extremal regions and restricted Boltzmann machines. IEEE Trans. Intell. Transp. Syst. 2015, 17, 1096–1107. [Google Scholar]
- Li, H.; Shen, C. Reading car license plates using deep convolutional neural networks and LSTMs. arXiv 2016, arXiv:1601.05610. [Google Scholar]
- Guo, J.-M.; Liu, Y.-F. License plate localization and character segmentation with feedback self-learning and hybrid binarization techniques. IEEE Trans. Veh. Technol. 2008, 57, 1417–1424. [Google Scholar]
- Jiao, J.; Ye, Q.; Huang, Q. A configurable method for multi-style license plate recognition. Pattern Recognit. 2009, 42, 358–369. [Google Scholar] [CrossRef]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Bakurov, I.; Buzzelli, M.; Schettini, R.; Castelli, M.; Vanneschi, L. Structural similarity index (SSIM) revisited: A data-driven approach. Expert Syst. Appl. 2022, 189, 116087. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 184–199. [Google Scholar]
- Plate Recognizer, Version 1.26.0; ParkPow, Inc.: Budapest, Hungary, 2021. Available online: https://platerecognizer.com/(accessed on 25 January 2023).
- Jiang, C.; Zhang, B. Weakly-supervised vehicle detection and classification by convolutional neural network. In Proceedings of the 2016 9th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Datong, China, 15–17 October 2016; pp. 570–575. [Google Scholar]
- Lu, W.; Zhao, H.; He, Q.; Huang, H.; Jin, X. Category-consistent deep network learning for accurate vehicle logo recognition. Neurocomputing 2021, 463, 623–636. [Google Scholar]
- Tafazzoli, F.; Frigui, H.; Nishiyama, K. A large and diverse dataset for improved vehicle make and model recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Nashville, TN, USA, 15–19 June 2021; pp. 1–8. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description | Symbol | Description |
|---|---|---|---|
| D | Discriminator model | G | Generator model |
| Discriminator parameterized by | Generator parameterized by | ||
| A | A variable parameter in leaky ReLU used in D | θ | Model parameters |
| IH | High-resolution image | IS | Super-resolution image |
| C | Color channels | IL | Low-resolution image |
| w | Weights of layers | b | Biases of layers |
| δ | Scaling factor | β | Motion blur |
| Λ | Number of residual blocks | Q | Batch size |
| k | Number of filters in a layer | s | Stride of a convolution filter |
| lS | Perceptual loss | N | Total number of images in dataset |
| Bilinear [15] | Bicubic [15] | SRCNN [8] | SRGAN-ImageNet [13] | SRGAN-LP | |
|---|---|---|---|---|---|
| PSNR | 29.16 | 28.03 | 29.38 | 30.11 | 41.24 |
| SSIM | 0.39 | 0.42 | 0.52 | 0.40 | 0.81 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hijji, M.; Khan, A.; Alwakeel, M.M.; Harrabi, R.; Aradah, F.; Cheikh, F.A.; Sajjad, M.; Muhammad, K. Intelligent Image Super-Resolution for Vehicle License Plate in Surveillance Applications. Mathematics 2023, 11, 892. https://doi.org/10.3390/math11040892
Hijji M, Khan A, Alwakeel MM, Harrabi R, Aradah F, Cheikh FA, Sajjad M, Muhammad K. Intelligent Image Super-Resolution for Vehicle License Plate in Surveillance Applications. Mathematics. 2023; 11(4):892. https://doi.org/10.3390/math11040892
Chicago/Turabian StyleHijji, Mohammad, Abbas Khan, Mohammed M. Alwakeel, Rafika Harrabi, Fahad Aradah, Faouzi Alaya Cheikh, Muhammad Sajjad, and Khan Muhammad. 2023. "Intelligent Image Super-Resolution for Vehicle License Plate in Surveillance Applications" Mathematics 11, no. 4: 892. https://doi.org/10.3390/math11040892
APA StyleHijji, M., Khan, A., Alwakeel, M. M., Harrabi, R., Aradah, F., Cheikh, F. A., Sajjad, M., & Muhammad, K. (2023). Intelligent Image Super-Resolution for Vehicle License Plate in Surveillance Applications. Mathematics, 11(4), 892. https://doi.org/10.3390/math11040892