1. Introduction
In survival analysis, the time-to-event variable is usually dependent, i.e., a response variable, and describes whether an individual may expect to experience an event of interest and, if so, when they should do it. If an individual does not experience the event of interest for some reason, we call the individual
censored. The event of interest could be whatever defined and detectable event that is not related to censoring [
1].
In statistics and survival analysis, the time-to-event variable is commonly treated as a random variable and modeled using traditional approaches, including estimating, both parametric and non-parametric, of a cumulative distribution function and others, namely survival function and hazard function and its moment characteristics. While the survival function depicts a probability that time to an event of interest is greater than a given time constant, i.e., that an individual would survive a certain time, the hazard function is a rate of probability that the event of interest is registered for in an infinitely short time after a given time period of non-registering the event [
2].
The above-mentioned approach enables the application of statistical inference on the time-to-event variable and its derivations for one or more groups of individuals. Besides survival functions, comparison between groups of individuals, considering explanatory covariates, the hazard function might be modeled within a regression framework using a Cox proportional hazard model [
3].
The Cox proportional hazard model is routinely used for modeling an association between the covariates as independent variables and the hazard function as a dependent variable. However, the Cox model is relatively strictly limited by statistical assumptions [
4]. Supposing that there is a categorical independent variable determining which group an individual belongs to, the limiting fact is that proportions of hazard functions for each pair of groups should be constant across all time points; this is why the Cox model is called “proportional” [
5,
6]. There are several options for how to overcome the violation of non-proportionality of hazard curves, e.g., some covariates in the Cox model may be stratified for different values or groups of individuals that enable the relaxing of the strict assumption that mutual pair hazard curves’ proportions should be equal to one constant [
7,
8]. Even more, if needed, not only time-invariant covariates but also time-variant explanatory variables could be modified in time-varying models [
9], or intervals of time points might be split within time-partitioned models [
10]. Various possibilities of the Cox model assumptions’ violation treatment within the large family of
Cox non-proportional hazard models suggest that not one of them is an optimal “remedy” for all new assumptions coming from them. The Cox non-proportional hazard models are highly complex, usually require a sufficient amount of data and advanced erudition and experience in their usage, and could bring new assumptions, sometimes even more complex [
11]. Besides the Cox models, parametric survival models use log-normal or Weibull baseline hazard function. Although applied to real-world data, these sometimes work better than the Cox regression [
12], some others fail, compared to the Cox model [
13]. The parametric survival models might suffer an initial choice of the baseline hazard function. In addition, even these models assume the proportionality of hazard functions among individuals or cohorts across time points [
14].
In this study, we address the latter issue and propose an alternative to the Cox proportional hazard model that is almost assumption-free. We introduce a principle of time-to-event variable decomposition into two components; first, a time component that is continuous and is used as an explanatory covariate in a machine-learning classification model, and second, an event component that is binary and could be predicted using various classifiers in the classification models, containing, besides others, the time component as an input covariate. Finally, once a classification model is learned and built, then, for a given combination of values of explanatory covariates, including a time point since the time component is one of the covariates, we may predict whether an event of interest is likely to happen for the given covariates’ values combination. The same prediction might be made using the Cox proportional hazard model—the model estimates the posterior distribution of hazard function, which enables obtaining the point estimate of the probability that an individual with given covariates’ values combination would likely experience the event of interest. If the probability is greater than or equal to a defined threshold, we obtain qualitatively the same prediction as using our proposed method. This opens room for comparison of predictive accuracy between our introduced method based on time-to-event variable decomposition and the Cox proportional hazard model. While the Cox proportional hazard model considers the non-experiencing event of interest within a given time scope as the censoring, machine-learning classifiers understand the experiencing and non-experiencing event of interest as two potentially equal states and, thus, might sideline the censoring in this manner. However, if we prefer the prediction paradigm rather than the inference one, censoring as a kind of incomplete information might be sidelined as far as the prediction work with high enough performance.
The first ideas on time-to-event variable decomposition came from the eighties when Blackstone et al. tried to decompose the time-to-event variable into consecutive phases and model a constant hazard function for each phase [
15]. The approach was revisited during the last several years by [
16,
17] since time-varying and time-partitioning models became popular. However, papers dealing with the combination of time-to-event variable decomposition and machine-learning predictions on the components seem to be rare; some initial experiments come from [
18], where authors tried to predict survival in patients with stomach cancer.
The machine-learning classification models might differ in their predictive accuracy; however, regardless of the built classifiers, these are usually assumption-free or assumption-almost-free [
19]. We consider several classification algorithms in the study—multivariate logistic regression, naïve Bayes classifier, decision trees, random forests, and artificial neural networks.
To obtain an idea of how the proposed methodology works on real data, we apply the time-to-event decomposition and ongoing prediction on a dataset of COVID-19 patients that includes, besides others, a variable depicting whether, and if so, when an individual experienced a decrease of their COVID-19 antibody blood level below a laboratory cut-off. Some of the individuals in the dataset did experience the antibody blood level decrease; the other ones did not. Thus, the variable is appropriate to be treated as a time-to-event one. COVID-19 is an infectious disease caused by the virus SARS-CoV-2 that started with the first clinically manifesting cases at the end of the year 2019 and quickly spread worldwide [
20]. Thus, from early 2020 up to the present, there has been more or less a severe long-term pandemic in many regions all around the world [
21,
22]. Individuals’ COVID-19 blood antibodies, particularly IgG antibodies that are more COVID-19-specific, protect them from COVID-19 manifesting disease [
23]. Therefore, if we predict their decrease below laboratory cut-off accurately enough, we can, for instance, quickly, and with no need for extensive or expensive blood testing, preselect which individuals should undergo boosting vaccination first if a new COVID-19 variant would income.
Thus, in this article, we address the following research gap. First, we investigate how possible it is to predict a decrease of antibodies against COVID-19 in time using various individuals’ covariates and a Cox proportional hazard model. Moreover, we introduce a novel method for predicting an event of interest’s occurrence in time using time-to-event decomposition, where the event component is classified using machine-learning classification algorithms. In contrast, the time component is used as one of the covariates. Finally, we compare the predictive performance of Cox regression and our proposed method using predictive accuracy and other metrics.
The paper proceeds as follows. Firstly, in
Section 2, we introduce and explain ideas of our proposed methodology, mostly the logic and principles of the time-to-event decomposition. Then, we illustrate the principles, assumptions, and limitations of the Cox proportional hazard model. In addition, we describe how the prediction of an event of interest’s occurrence could be made using the Cox model. Then, we depict all machine-learning classification algorithms’ principles. Next, in
Section 3, we show the numerical results we have obtained so far and, in particular, compare predictions based on the Cox proportional hazard model with other predictions, using classifiers and time-to-event decomposition. Finally, in
Section 4, we discuss the results, explain them, and last but not least, we highlight important findings in
Section 5.
2. Methodology and Data
A description of the fundamentals of survival variables’ characteristics, the Cox proportional hazard model, the proposed methodology, and the dataset we used for algorithms’ predictive performance, respectively, follow.
2.1. Fundamentals of Survival Variables’ Characteristics
Let us assume that a random variable
T is the survival time, i.e., a length of time an individual does not experience an event of interest [
24]. Firstly, let us define survival function
as a probability that survival time is greater than some time constant
t, so
Let cumulative distribution function
be a probability that survival time
T would not be greater than time constant
t; then, density function
is a derivative of
with respect to
t, so
and also
The hazard function,
, is an instantaneous probability that an individual experiences the event of interest in an indefinitely short time interval
once they survive through time
t up to the beginning of the interval
, so
Since hazard function
describes an instantaneous probability of an event of interest experiencing just after a specific time
t, we could estimate cumulative hazard function
as an accumulation of the hazard of the event of interest over time until constant
t, having estimates
, based e.g., on observed data, for each time point from the beginning to the end of the observed period. That being said,
or more precisely as
which may help us to derive a relationship between the survival function and hazard function as follows:
and since
, we obtain
Finally, by exponentiation of Formula (
6), we obtain a direct relationship between the survival function and cumulative hazard function,
which enables us to predict survival probability for a given time point, based on the Cox proportional hazard model.
2.2. Principles, Assumptions and Limitations of Cox Proportional Hazard Model
The Cox proportional hazard model is frequently used for regression modeling of an association between a hazard function for an event of interest as a dependent variable and multiple independent variables, also called covariates.
Sir Cox [
3] suggested to model the hazard function
in relation to other
covariates
for individual or group
i in the following way:
where
is the baseline hazard function, i.e., the hazard function when each of the covariates is equal to zero;
is a vector of linear coefficients, each matched to an appropriate covariate, and
is a vector of covariates’ values for individual or group
i. The linear coefficients
in the Cox model following Formula (
8) can be estimated using the partial maximum likelihood approach [
25,
26].
By exponentiation Formula (
8), we obtain another form of the Cox model,
Considering the Cox model following Formula (
9) for two groups with indices
r and
s,
we could take a proportion of left-hand and right-hand sides of the equations, obtaining
Assuming the model’s coefficient following Formula (
8) or Formula (
9) are estimated taking into account, for all individuals or groups,
for
, i.e.,
we may derive—using Formula (
10)—that the proportion
of hazard functions for two any groups
is supposed to be constant. This is why the Cox model is called the Cox
proportional hazard model, and the constant proportion of the hazard functions across all time points for any two groups is one of its statistical assumptions. Moreover, if the hazard functions’ ratio should be constant, then also survival functions’ ratio should be constant, as we may see using Formulas (
5) and (
7),
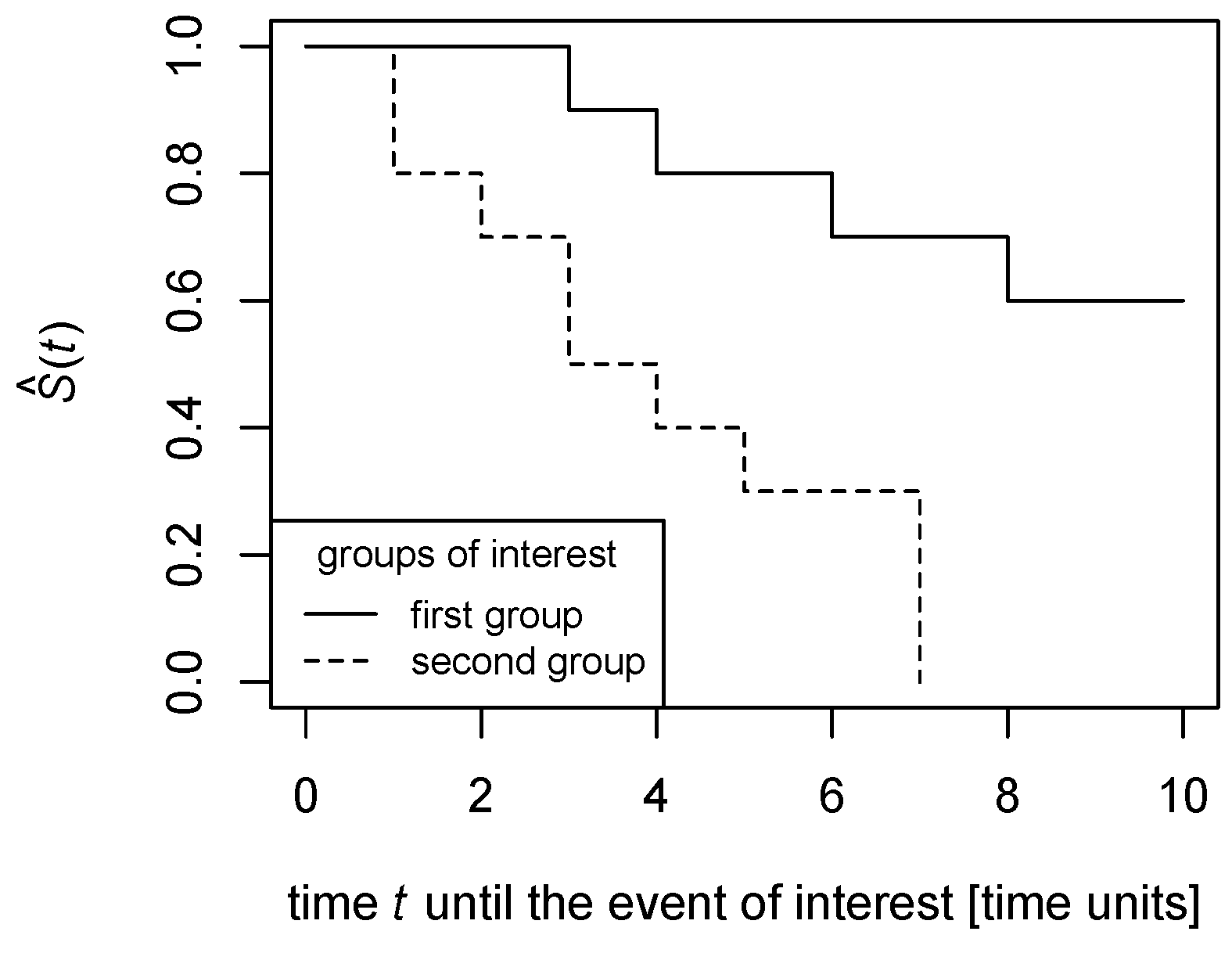
However, real-world data often violate this assumption in practice, as
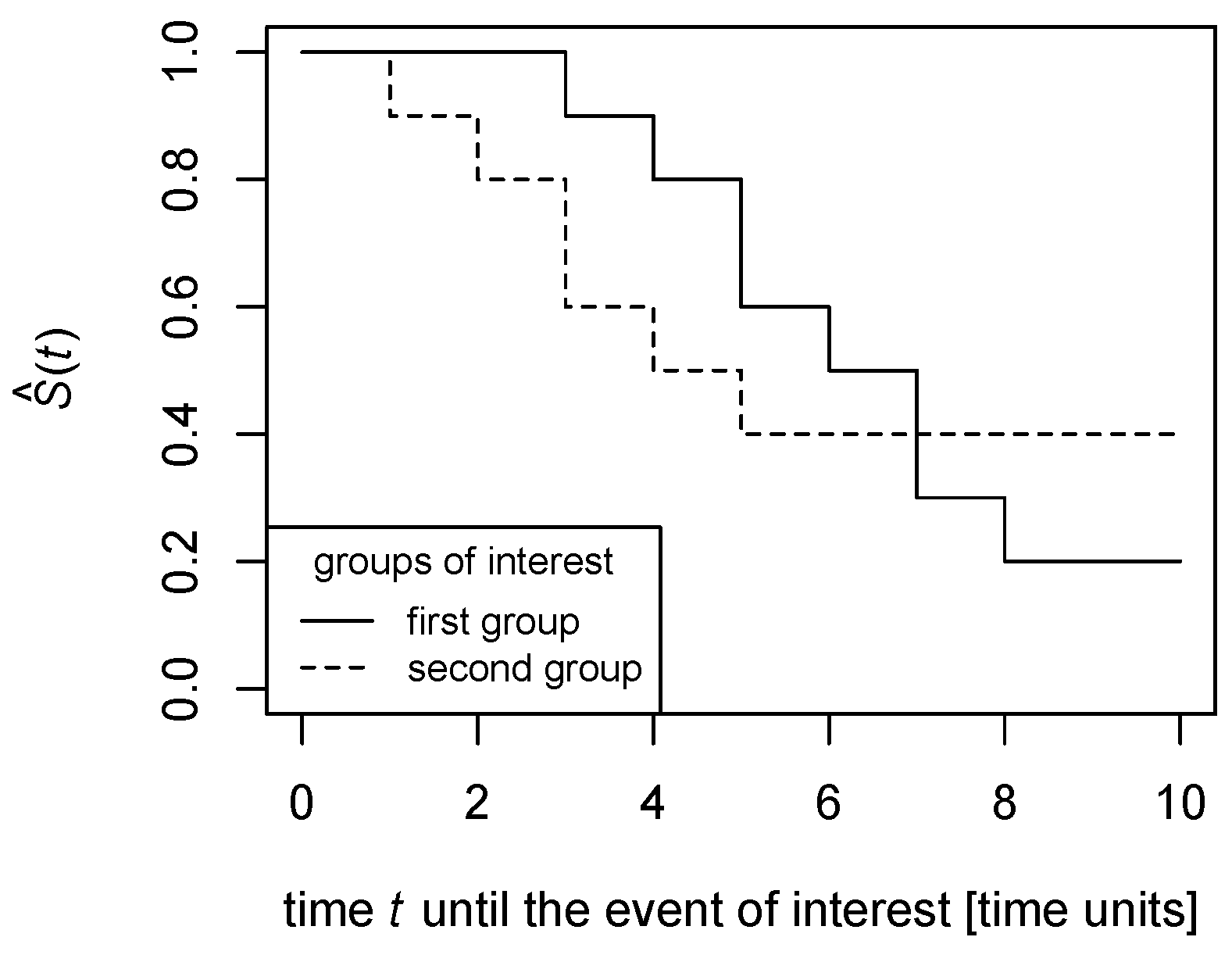
Figure 1 and
Figure 2 illustrate.
In
Figure 1, the survival functions are estimated in a non-parametric way as polygonal chains cross each other; this means that, while the proportion of the survival function for the solid line to the survival function for the dashed line is greater than 1 till the time point of the crossing, it becomes lower than 1 after the crossing. Thus, the survival functions’ proportion could not be constant across all time points.
Similarly, in
Figure 2, the proportion of the survival function for the solid line to the survival function for the dashed line is finite until the time point the dashed line drops to zero, then the proportion becomes infinite. Therefore, the survival functions’ ratio could not be constant across all time points.
Considering the Cox model from Formula (
8) and using Formula (
7), we can predict whether an event of interest is likely to be experienced by an individual from a given group at a given time point. Survival function, i.e., a probability that an individual does not experience the event of interest before time
t, if ever, is
and using estimates coming from the Cox model following Formula (
8),
2.3. Principles of Proposed Time-to-Event Variable Decomposition
and Prediction
The Cox proportional hazard model, following the Formula (
8) or Formula (
9), estimates the posterior hazard function using covariates
, i.e., it models the posterior probability of an event of interest’s occurrence in time [
27].
Let us mark the time to the event of interest for any individual or group as a random variable T, and the occurrence or non-occurrence of the event of interest for any individual or group as a random variable Y. Obviously, , and , or generally considering , for individual or group i, where stands for the event of interest occurrence before time t and stands for the event of interest non-occurrence before time t, respectively.
With respect to the task refining above, the Cox proportional hazard model uses covariates and their values for estimation, a pair for individual or group i, i.e., how likely individual or group i would experience (), or would not experience () the event of interest until time .
Inspecting Formula (
11), we may see that the time
is a parameter of the survival estimate
. However, the event of interest’s occurrence or non-occurrence
requires another derivation. Once the Cox model is built, the coefficients
are estimated using all dataset rows
for
, the survival
might be estimated using Formula (
11). Since
, we may expect that the event of interest does probably not occur before time
t if
is high enough. Let us suppose the event of interest is likely not to happen,
, before time
t, if ever does, whenever
is greater than or equal to a given threshold
; otherwise, the event of interest does probably occur,
, before time
t. Thus,
A natural choice for the threshold seems to be , but may be grid-searched and adjusted, e.g., to maximize the Cox model’s predictive accuracy.
Schematically, the logic of the Cox model is in
Figure 3. Covariates
are on input and make the Cox model’s estimation possible. Once the Cox model is built, we could predict the event of interest occurrence
in time
using Formulas (
11) and (
12). Thus, on the input of the Cox model, there are
k covariates
, and on output, there is the time-to-event pair variable
.
We refine the task of time-to-event prediction the following way. Firstly, we decompose the time-to-event variable into time component
T and event component
Y. The time component
T is continuous and is used as another covariate on input for a machine-learning classification model or, shortly, a classifier. The machine-learning classification model predicts the event component
Y on output, i.e., whether the event of interest likely occurs (
) or not (
) before time
t, using values of covariates
and a value of time
as explanatory variables. Thus, on input of the classifier, there are
covariates
, and on output, there is the event component
Y, as the scheme in
Figure 4 illustrates.
As a classification algorithm, various approaches, such as multivariate logistic regression, naïve Bayes classifiers, decision trees, random forests, or artificial neural networks, might be chosen, e.g., to maximize the model’s predictive accuracy.
2.4. Machine-Learning Classification Algorithms
Following the logic of time-to-event variable decomposition and classification-based prediction of an event of interest’s occurrence as demonstrated in the scheme in
Figure 4, we describe principles of selected classifying algorithms used for the model building and predicting a COVID-19 antibody blood level decrease below laboratory cut-off.
In general, all classifiers listed below employ covariates on input and classify into two classes, either , or of a target variable Y, i.e., an event of interest occurrence or non-occurrence before time t.
2.4.1. Multivariate Logistic Regression
Multivariate logistic regression classifies into one of the classes
, i.e., an event of interest occurrence and non-occurrence, of the target variable
Y using
covariates
. A formula of the multivariate logistic regression [
28] follows for individual
i a form of
where
is an intercept,
are linear coefficients each matched to covariate
for
,
is a linear coefficient matched to time component
T, vector
contains values of appropriate covariates
for individual
i, where
, and
is a residual for individual
i.
The linear coefficients are estimated numerically using maximal likelihood [
29]. Individual
i’s value of variable
Y is classified using a
maximum-a-posteriori principle into final class
so that
2.4.2. Naïve Bayes Classifier
Naïve Bayes classifier also predicts the most likely class
of the target variable
Y, where
stands for the event of interest occurrence and
for the event of interest non-occurrence, respectively [
30]. Once we apply Bayes theorem, we obtain
Assuming we have a given dataset, i.e., a matrix containing
n vectors such as
for
, the probabilities
and
are constant, since
and
Moreover, if the dataset is well balanced, then for
and for
is
. Thus, we may write for
and for
Thus, using Formulas (
14)–(
16), we might rewrite Formula (
13) as follows:
Assuming mutual independence of covariates
, we improve Formula (
17) as
and individual
i’s value of variable
Y is classified into final class
, using the maximum-a-posteriori principle, so
The probabilities
and
for categorical covariates could be estimated as
and
for continuous variables,
and
are estimated [
31] using conditional normal cumulative distribution function
and
, both for small
.
2.4.3. Support Vector Machines
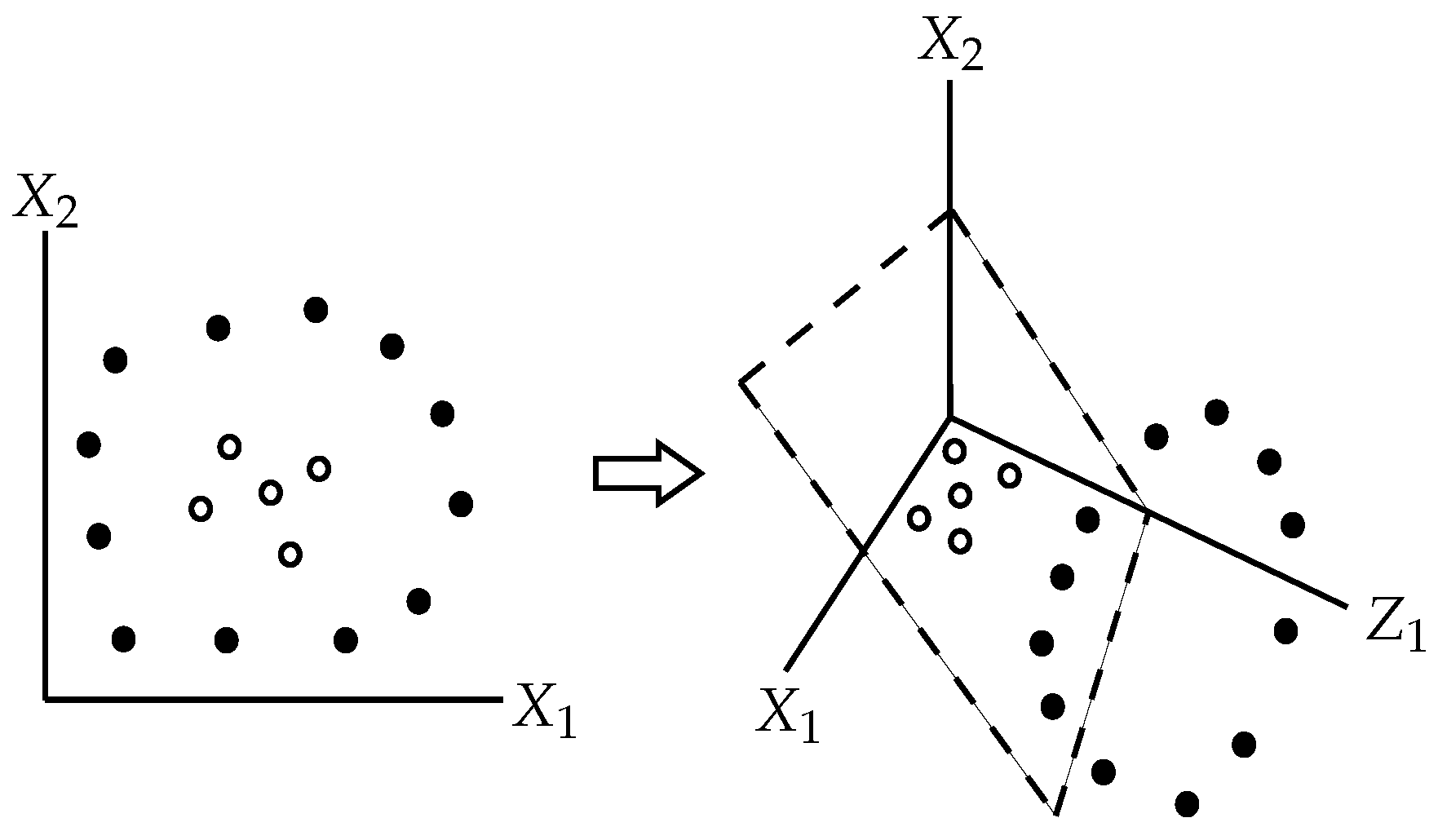
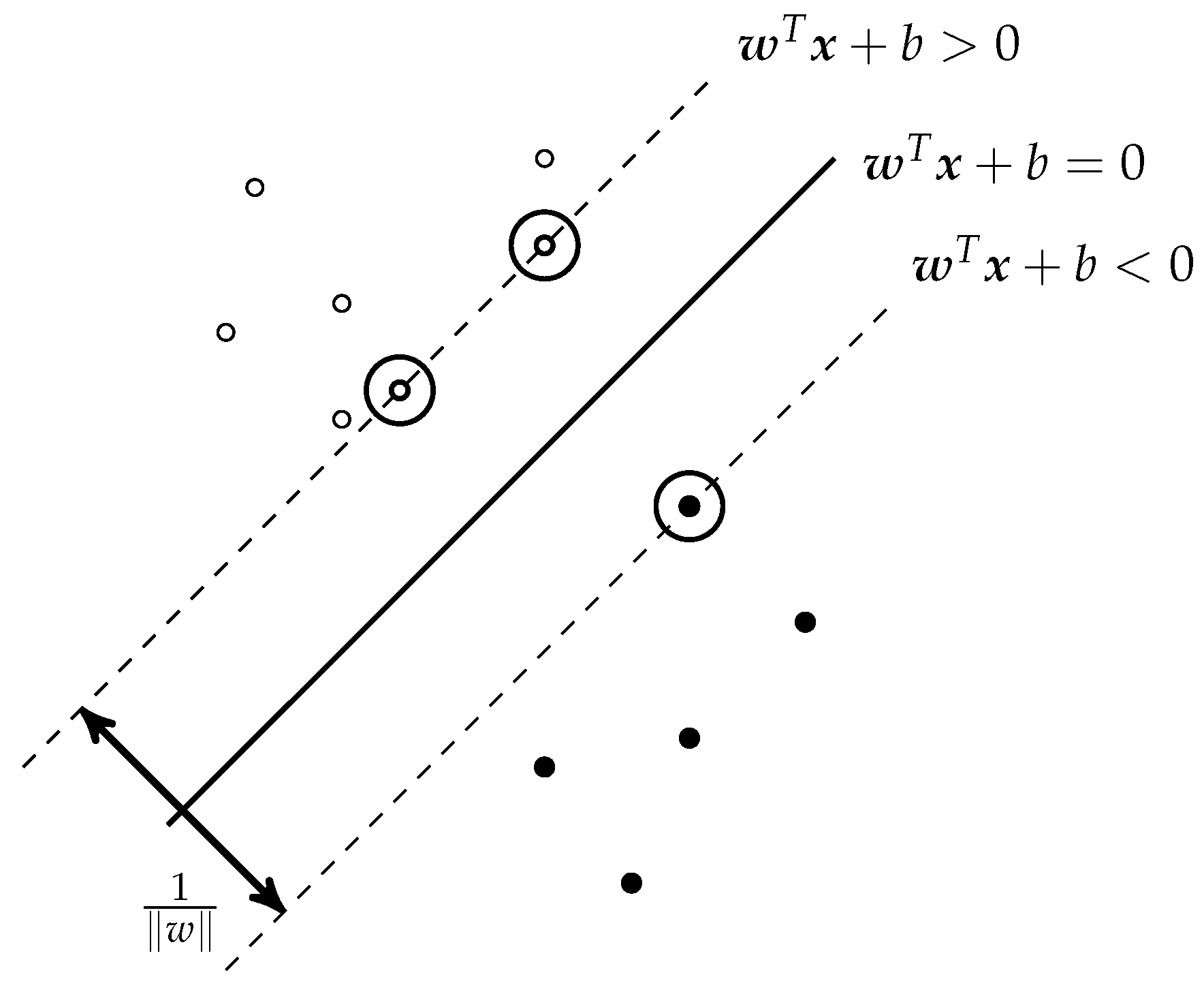
Support vector machines natively split the space of all covariates
into two subspaces by a hyperplane that maximizes the margins between the hyperplane and the points from both subspaces that are the closest to the hyperplane [
32]; see
Figure 5.
More technically, assuming we have vectors such as
, i.e., in other words, these vectors are points in
-dimensional space with coordinates
, that belongs either to class
, or to class
, any hyperplane in the given universe follows a form of
where
is a vector orthonormal, or at least orthogonal to the hyperplane, and
b is a tolerated margin’s width, i.e., a user’s hyperparameter, so that
is the offset of the hyperplane from the universe system of coordinates’ origin along the normal vector
.
The splitting hyperplane follows an equation
. For all points that belong to class
(and are “above” the splitting hyperplane), we suppose to find a boundary hyperplane that is parallel to the splitting hyperplane, so it should have an equation
. Similarly, all remaining points of class
should be on or “below” a boundary hyperplane with equation
. If points of class
are “above” and points of class
are “below” the splitting hyperplane does not matter much and is addressed by
term in other equations. Assuming linear separability of the points from different classes and formally assigning
and
, the distance between these two boundary hyperplanes is equal to
and should be as large as possible, so the searching for max-margin splitting hyperplane means to find
where
term guarantees to work “plus” and “minus” notation if the points of class
or
, respectively, would be “below” or “above” the splitting hyperplane, respectively.
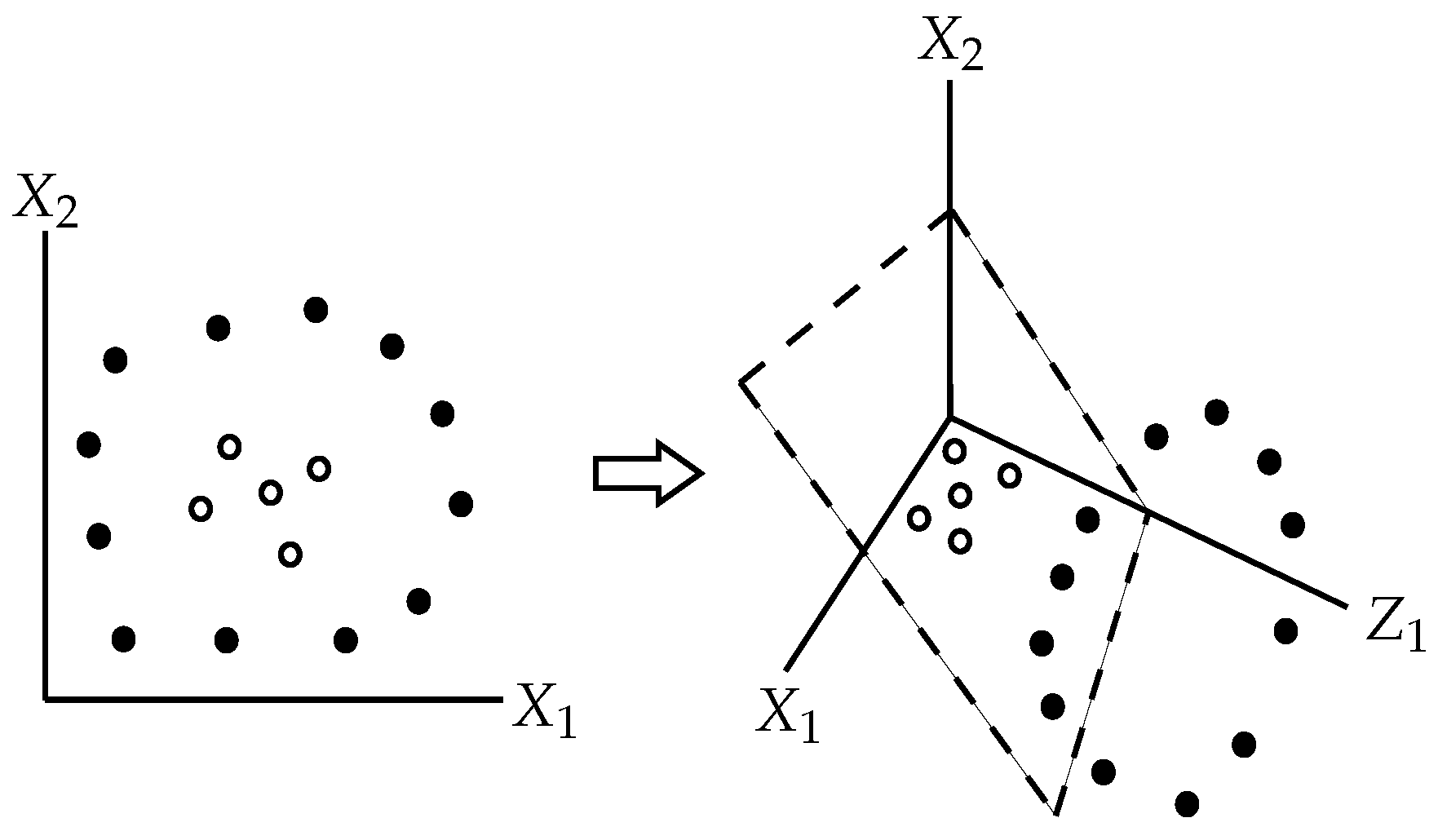
If the points that belong to different classes are not linearly separable, we may use the
kernel trick, i.e., to increase dimensionality of the covariates’ universe
by one or more dimensions that could enable to find a separating hyperplane [
33], as illustrated in
Figure 6.
2.4.4. Decision Trees and Random Forests
Decision trees divide the universe of all covariates
into disjunctive orthogonal subspaces related to maximally probably distribution of individual classes of the target variable
Y, see
Figure 7 for demonstration [
34].
Using node rules employing covariates and their grid-searched thresholds that minimize given criterion, e.g., deviance, entropy, or Gini index, a dataset is repeatedly split into new and new branches, while the tree containing node rules, i.e., logic formulas with the covariates and their thresholds, grows up. Once the tree is completely grown, a set of the tree’s node rules from a root node to leaves enables the classification of an individual into one of the classes or .
More technically spoken, let be a proportion of individuals that belong to class based on node ’s rule.
If node is not a leaf one, then the node rule is created so that an impurity criterion is minimized. The commonly used impurity criterion is
and deviance (cross-entropy),
If node
is a leaf one, then all observations that are constrained by all node rules from root one up to the leaf one
are classified into final class
of target variable
Y, so that
Decision trees natively tend to overfit the classification since, whenever there is at least one leaf node classifying into two or more classes, it is repeatedly split into two branches until each leaf node classifies just into one class. To reduce the overfitting, grown trees are
pruned. A pruned subtree, derived from the grown tree, minimizes the following cost-complexity function,
where
is a set of all nodes in the tree,
is a set of all nodes in the tree structure from the root to the leaf note
, and
is a tuning parameter governing the trade-off between tree complexity and size (low
), and tree reproducibility to other similar data (high
).
Many trees together create a
random forest. To ensure that trees in a random forest are mutually independent and different enough, each tree is grown using a limited number of covariates that are selected for node rules [
35]. Thus, each tree’s node might be determined using only
covariates, which are randomly picked using bootstrap from
, which ensures that trees of one random forest are sufficiently different one from another. A voting scheme determines the final class—an individual
i is classified into class
which a maximum of all trees in the random forest classifies into. If there are two classes with maximum trees voting for, one is picked randomly.
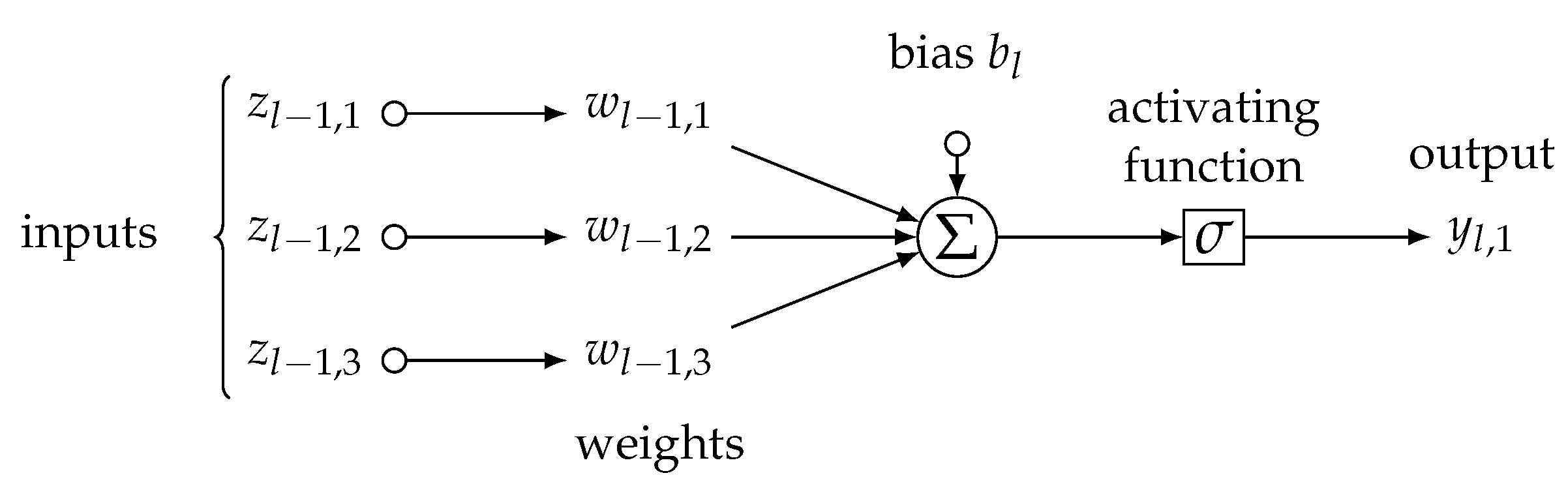
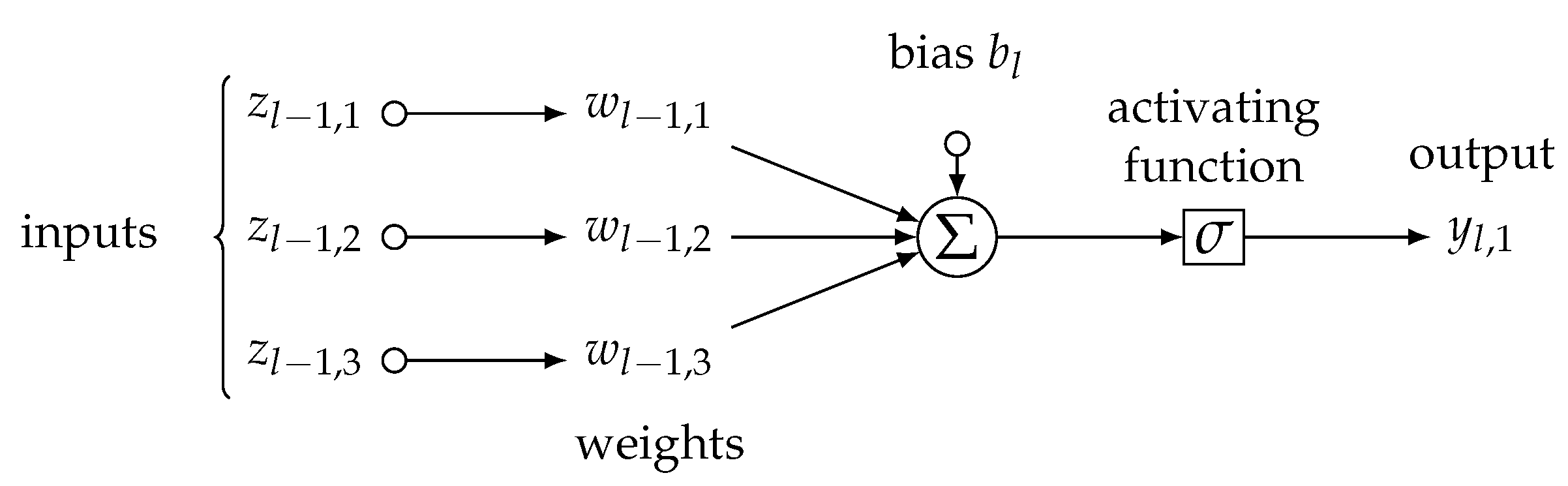
2.4.5. Artificial Neural Networks
Artificial neural networks we used in our study are weighted parallel logistic regression models [
36], called neurons, as in
Figure 8, following an atomic formula:
where
is a signal, i.e., either 0, or 1, of
j-th neuron in
l-th layer of neurons aiming at the next
-th layer,
is sigmoid activating function,
is a vector of weights coming from axons of neurons in the previous
-th layer,
is
l-th layer’s activating threshold, and, finally,
is a vector of incoming signals from
-th layer, i.e., it is either a vector of individual
i’s covariates’ values
when the neurons are of the first layer (
), so it is a vector of signals
coming from
-th layer (
).
A number of layers and neurons in each layer are hyperparameters of the neural network’s architecture and should be chosen by an end user. Within a procedure called
backpropagation, the vectors of weights
are iteratively adjusted by a small gradient per each epoch to minimize loss functions, typically an
or
norm of current and previous neuron’s output
and
, i.e.,
or
, respectively [
37]. The learning rate determines the size of the small gradient adjusting weights in each iteration. Although many exist, the commonly applied activating function is a sigmoid one and follows a form of
In the classification framework, the number of output neurons is equal to the number of classes of target variable
Y; each output neuron
or
represents one of the classes
and final class
is
2.5. Evaluation of Classification Algorithms’ Performance
Considering individual
i’s true value of variable
Y, i.e., either
, or
, an algorithm may predict the true value correctly,
or incorrectly,
. We may evaluate the performance of a classification algorithm using a proportion of a number of predicted classes equal to true classes to a number of all predicted classes. Assuming a confusion matrix [
38] as in
Table 1, the number of correctly predicted classes corresponds to
, while the number of all predictions is
.
Thus, the predictive accuracy of an algorithm, i.e., what is a point estimate of the probability for which an individual’s class would be predicted correctly by the algorithm, is
Even more, assuming that classes
and
are of “positive” meaning or are of our special interest, then [
39], the precision is a point estimate of the probability that an individual classified to
class is truly of class
, so
and the recall is a point estimate of the probability that an individual belonging to class
is classified to class
,
Putting the precision and recall together, so-called F1 score is of form,
and, inspecting Formula (
21) above, since F1 score keeps balance between the precision and recall, it is sometimes considered as a metric of an overall model predictive performance [
39].
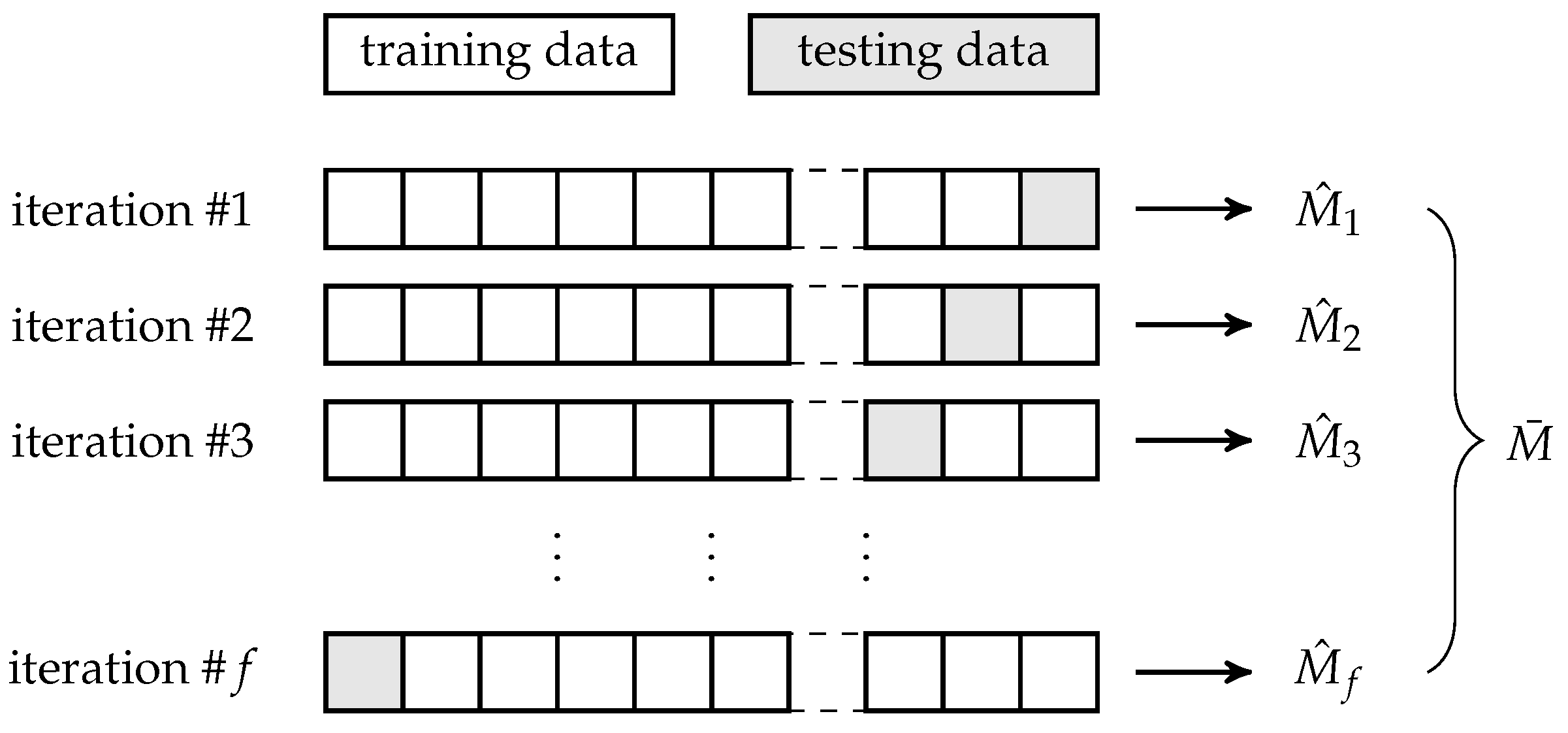
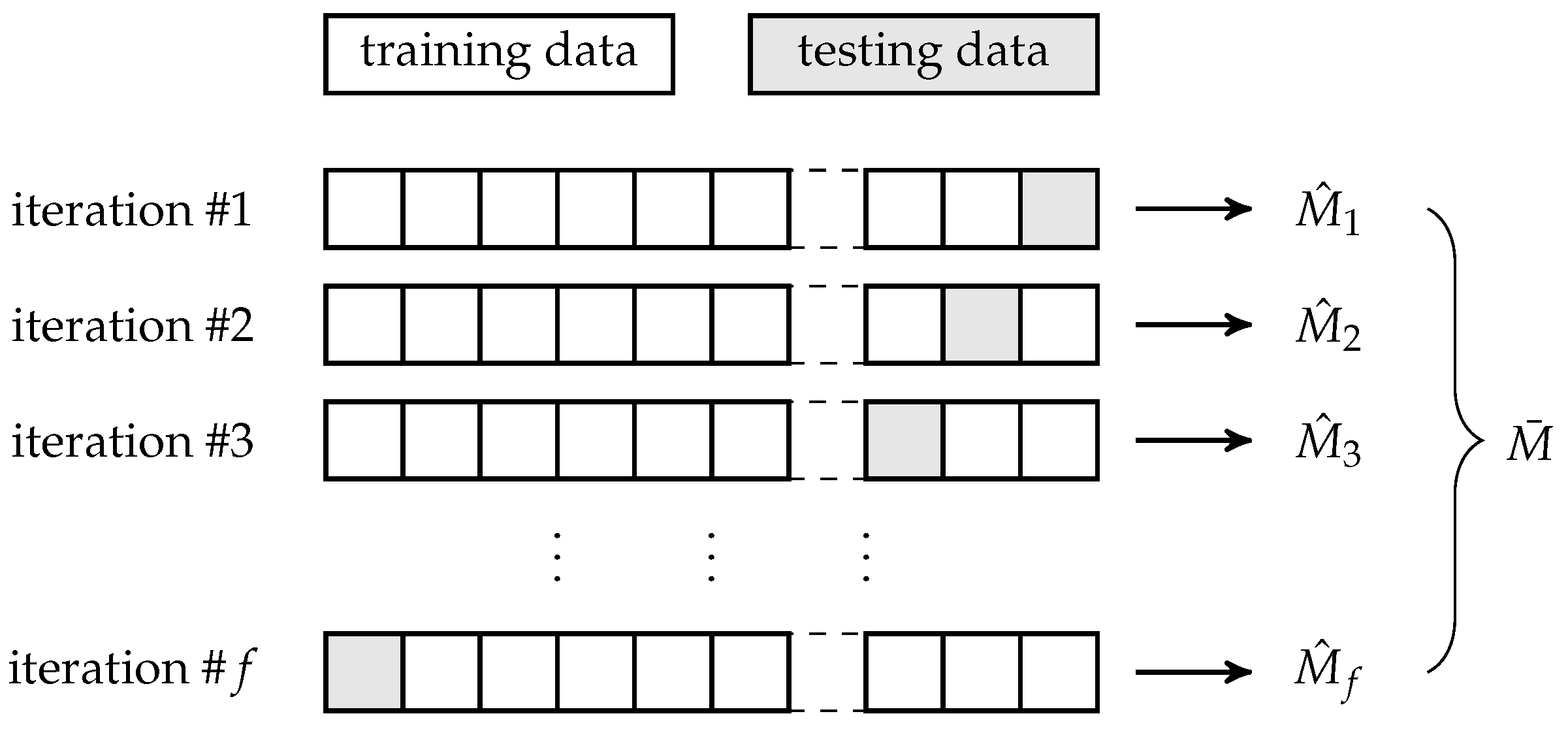
To avoid any bias in the performance measures’ estimation, we estimate them multiple times using
f-fold cross-validation [
40], see
Figure 9. Before each iteration of the
f-fold cross-validation, the entire dataset is split into two parts following a ratio
for training and testing subset, respectively, where
and
. Within each iteration, a portion of
of all data are used for training of an algorithm, while the remaining
portion of all data are used for testing a model based on the trained algorithm.
The
j-th iteration of the
f-fold cross-validation outputs a defined estimate
of a performance metric, so, in our case,
following Formulas (
18)–(
21). The estimates are eventually averaged to obtain a more robust estimate
thus, in our case,
Finally, considering all
f iterations of the
f-fold cross-validation, we also report a confusion matrix containing medians of numbers of matches and mismatches between true classes
Y and predicted ones
. Using the matrix in
Table 1, the
median confusion matrix is the matrix in
Table 2, where
for
and
is median value over all values
from the 1-st, 2-nd, …,
f-th iteration of the
f-fold cross-validation.
Summation of each median confusion matrix should be approximately equal to a portion of all data since each median confusion matrix is produced by the testing, i.e., predicting procedure within an iteration of f-fold cross-validation.
2.6. Asymptotic Time Complexity of Proposed Prediction
Based on Time-to-Event Variable Decomposition
Let us briefly analyze the asymptotic time complexity of the proposed method, i.e., the time-to-event variable decomposition and prediction of an event of interest’s occurrence in time using time and event components, covariates, and machine-learning classification algorithms.
Assuming we have
individuals in a dataset in total, time-to-event variable decomposition is a unit time operation made for each of them, so its asymptotic time complexity, using Bachmann–Landau notation [
41], is
. Picking a machine-learning classifier, let us suppose that it takes
time when training on
n observations (and all their covariates’ values), whereas it takes
time if testing or predicting an output for
n observations (both testing and predicting procedures could be considered the same regarding their asymptotic time complexity since they use a trained model and only output target variable values for input). Firstly, the training, testing, and prediction are linear procedures with respect to a number of observations, i.e., training, testing, or prediction considering
observations would take approximately double the time than considering only
n observations.
however, using Bachmann–Landau logic, linear multipliers do not change asymptotic time complexity, so it is as well
In addition, we may assume that training a model is generally not faster than testing a model or using it for prediction, considering
n observations, so
and neither training nor testing nor even predicting considering
n observations is faster than
n-times performed unit time operation, so
Applying derivations from the previous section, within each iteration of
f-fold cross-validation, we build a model on
portion of the dataset, test it on
portion of the dataset. This is repeated
times since there are
f iterations in the
f-fold cross-validation. Thus, applied to
n observations, the time-to-event variable decomposition,
f-fold cross-validation containing training and testing all
f models and prediction on output, respectively, would asymptotically take
, such that
so, improving Formula (
25), it is obviously
and also
Putting Formulas (
26) and (
27) together, we obtain
thus,
and, finally, asymptotic time complexity
of the time-to-event decomposition, followed by prediction of an event of interest’s occurrence in time using machine-learning classification algorithms is approximately equal to asymptotic time complexity of training of the classification algorithm, regardless of its kind. In other words, the proposed method does not take significantly longer computational time when performed from beginning to end than the classifier used within the technique.
2.7. Description of Used Dataset
The dataset used to confirm the proposed methodology’s feasibility comes from the Department of Occupational Medicine, University Hospital Olomouc. The data contain covariates’ values in about COVID-19 non-vaccinated 663 patients; there are 34 covariates describing COVID-19 antibody blood level values and their decrease below laboratory cut-off for IgG and IgM antibodies in various time points and multiple biometric and other variables, continuous and categorical. All patients have been informed in advance about using their data for the study, following ideas of Helsinki’s declaration [
42].
Regarding the covariates, there are
continuous variables such as age (in years), weight (in kilograms), height (in centimeters), body mass index (in kilogram per squared meters), COVID-19 IgG antibody blood level, COVID-19 IgM antibody blood level, a total count of COVID-19 defined symptoms, the time between beginning and end of COVID-19 symptoms (in days), the time between laboratory-based proof of COVID-19 and antibody blood sampling (in days), the time between COVID-19 symptoms’ offset and antibody blood sampling (in days);
categorical variables such as sex (male/female), COVID-19 IgG antibody blood level decrease below laboratory cut-off (yes/no), COVID-19 IgM antibody blood level decrease below laboratory cut-off (yes/no), COVID-19 defined symptoms such as headache (yes/no), throat pain (yes/no), chest pain (yes/no), muscle pain (yes/no), dyspnea (yes/no), fever (yes/no), subfebrile (yes/no), cough (yes/no), lack of appetite (yes/no), diarrhea (yes/no), common cold (yes/no), fatigue (yes/no), rash (yes/no), loss of taste (yes/no), loss of smell (yes/no), nausea (yes/no), mental troubles (yes/no), and insomnia (yes/no).
As a time-to-event variable, a COVID-19 IgG antibody blood level decrease below the laboratory cut-off or COVID-19 IgM antibody blood level decrease below the laboratory cut-off, respectively, is considered the event component. In contrast, the time between laboratory-based proof of COVID-19 and antibody blood sampling is taken into account for the time component.
3. Results
We applied the Cox proportional hazard model and proposed methodology handling time-to-event decomposition and classification on the dataset as described in the previous sections. All computations were performed using R statistical and programming language [
43].
Firstly, we performed and built the Cox proportional hazard model, considering COVID-19 antibody blood level decrease or non-decrease below laboratory cut-off (for IgG and IgM antibodies, respectively) as an event of interest that does or does not occur when antibody blood sampling is carried out a varying time period after COVID-19 symptoms’ onset is laboratory proven.
Assuming
Cox proportional hazard model for the prediction of COVID-19 IgG antibody blood level decrease or non-decrease below laboratory cut-off, the prediction of IgG antibody decrease below the cut-off was repeated ten times within 10-fold cross-validation and output the predictive accuracy about
, precision about
, recall of
, and F1 score about
; see
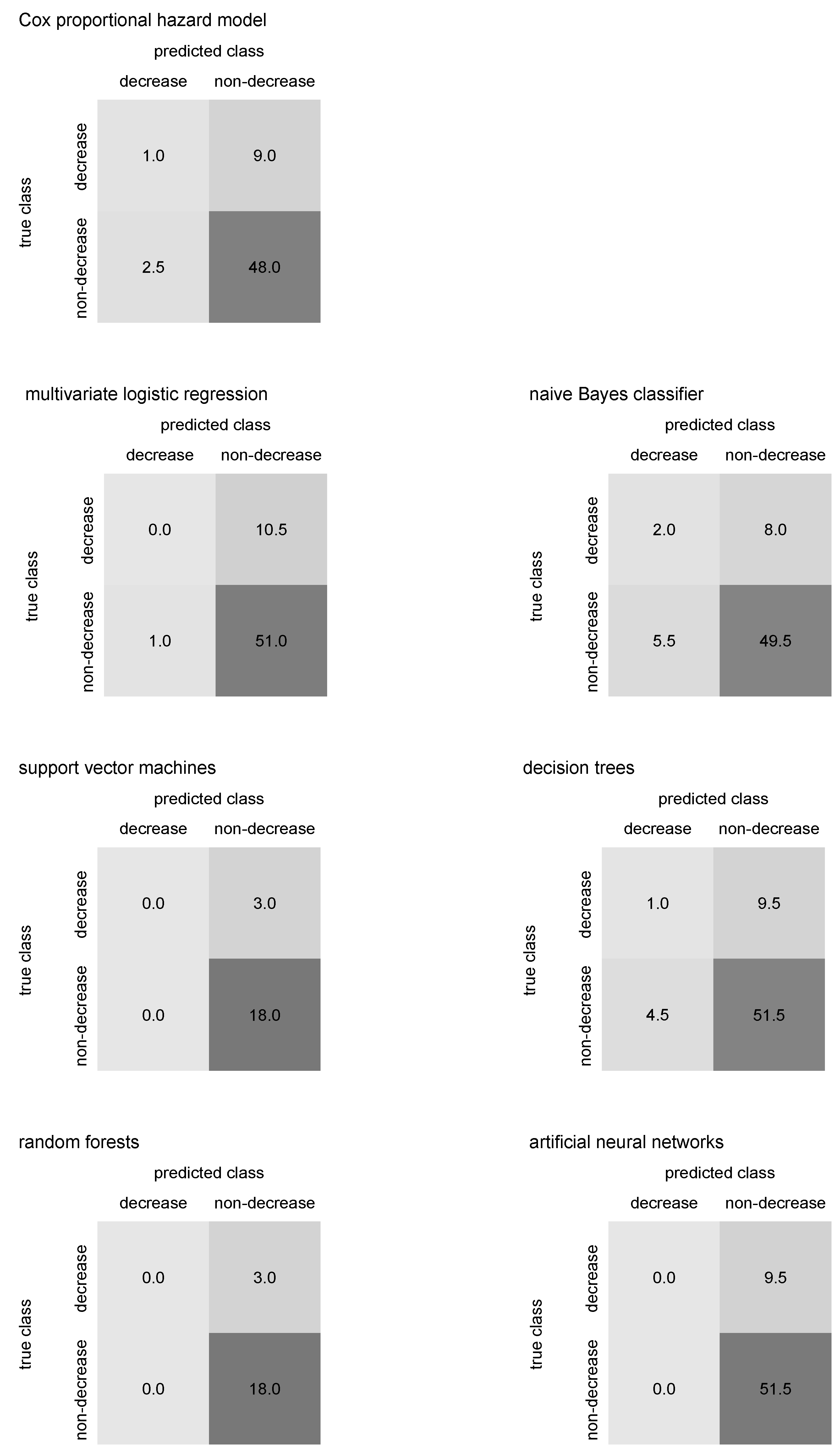
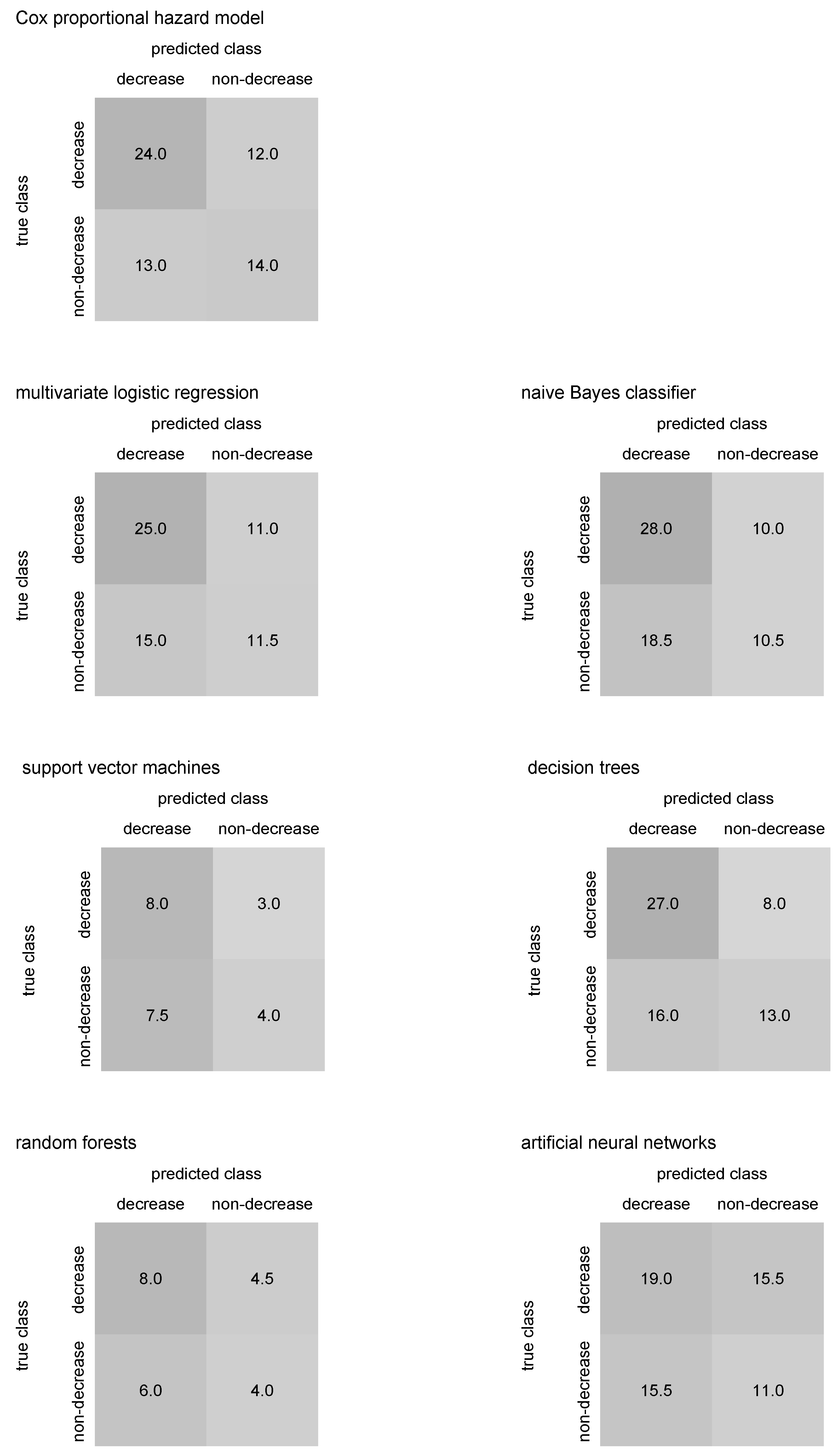
Table 3. The median confusion matrix for Cox proportional hazard model predicting IgG antibody decrease below cut-off is in
Figure 10. An average value of threshold
over all iterations of 10-fold cross-validation for IgG decrease prediction was about
. Cox proportional hazard model predicted COVID-19 IgM antibody blood level decrease or non-decrease below laboratory cut-off with predictive accuracy
, precision of
, recall of
and F1 score about
; see
Table 4. The median confusion matrix for Cox proportional hazard model predicting IgM antibody decrease below cut-off is in
Figure 11. An average threshold
over 10-fold cross-validation’s iterations when IgM decrease predicted was about
.
Let us proceed to the proposed technique. Supposing
multivariate logistic regression as a tool for the prediction of COVID-19 IgG antibody blood level decrease or non-decrease below laboratory cut-off, the prediction of IgG antibody decrease was repeated ten times within 10-fold cross-validation and ended with the predictive accuracy about
, precision about
, recall of
, and F1 score about
, see
Table 3. The median confusion matrix for multivariate logistic regression predicting IgG antibody decrease below cut-off is in
Figure 10. Multivariate logistic regression predicted COVID-19 IgM antibody blood level decrease or non-decrease below laboratory cut-off with predictive accuracy
, precision about
, recall of
, and F1 score about
, see
Table 4. The median confusion matrix for multivariate logistic regression predicting IgM antibody decrease below cut-off is in
Figure 11.
Naïve Bayes classifier, when predicting COVID-19 IgG antibody blood level decrease or non-decrease below laboratory cut-off, was repeated ten times within 10-fold cross-validation and returned the predictive accuracy about
, precision about
, recall of
, and F1 score about
; see
Table 3. The median confusion matrix for the naïve Bayes classifier predicting IgG antibody decrease below cut-off is in
Figure 10. Naïve Bayes classifier predicted COVID-19 IgM antibody blood level decrease or non-decrease below laboratory cut-off with predictive accuracy
, precision about
, recall of
, and F1 score about
, see
Table 4. The median confusion matrix for naïve Bayes classifier predicting IgM antibody decrease below cut-off is in
Figure 11.
When
support vector machines using nonlinear kernel trick were considered for prediction of COVID-19, IgG antibody blood level decrease or non-decrease below laboratory cut-off, the algorithm ended with the predictive accuracy about
, precision about
, recall of
, and F1 score about
; see
Table 3. The median confusion matrix for support vector machines predicting IgG antibody decrease below cut-off is in
Figure 10. Support vector machines predicted COVID-19 IgM antibody blood level decrease or non-decrease below laboratory cut-off with predictive accuracy
, precision about
, recall of
, and F1 score about
; see
Table 4. The median confusion matrix for support vector machines predicting IgM antibody decrease below cut-off is in
Figure 11.
Decision trees predicted COVID-19 IgG antibody blood level decrease or non-decrease below laboratory cut-off using 10-fold cross-validation with the predictive accuracy about
, precision of
, recall of
, and F1 score about
, see
Table 3. The pruning parameter we used for model training has been adopted from default and recommended setting, i.e.,
. The median confusion matrix for decision trees predicting IgG antibody decrease below cut-off is in
Figure 10. Decision trees predicted COVID-19 IgM antibody blood level decrease or non-decrease below laboratory cut-off with predictive accuracy
, precision about
, recall of
, and F1 score about
, see
Table 4. The median confusion matrix for decision trees predicting IgM antibody decrease below cut-off is in
Figure 11.
Random forests were also repeated ten times within 10-fold cross-validation to predict COVID-19 IgG antibody blood level decrease or non-decrease below laboratory cut-off. Each model of the random forests consisted of 1000 decision trees. The random forests’ predictive accuracy of IgG antibody decrease below cut-off is about
, precision about
, recall of
, and F1 score about
; see
Table 3. The median confusion matrix for random forests predicting IgG antibody decrease below cut-off is in
Figure 10. Random forests predicted COVID-19 IgM antibody blood level decrease or non-decrease below laboratory cut-off with predictive accuracy
, precision about
, recall of
, and F1 score about
; see
Table 4. The median confusion matrix for random forests predicting IgM antibody decrease below cut-off is in
Figure 11.
Finally,
artificial neural networks with backpropagation, we performed ten times within 10-fold cross-validation to predict COVID-19 IgG antibody blood level decrease or non-decrease below laboratory cut-off, output the predictive accuracy of IgG antibody decrease below cut-off about
, precision about
, recall of
, and F1 score about
; see
Table 3. For each iteration of the 10-fold cross-validation, we used two hidden layers with 10 and 5 neurons, respectively, and set the learning rate to an interval of approximately
to
. The median confusion matrix for artificial neural networks predicting IgG antibody decrease below cut-off is in
Figure 10. Artificial neural networks predicted COVID-19 IgM antibody blood level decrease or non-decrease below laboratory cut-off with predictive accuracy
precision about
, recall of
, and F1 score about
; see
Table 4. The median confusion matrix for artificial neural networks predicting IgM antibody decrease below cut-off is in
Figure 11.
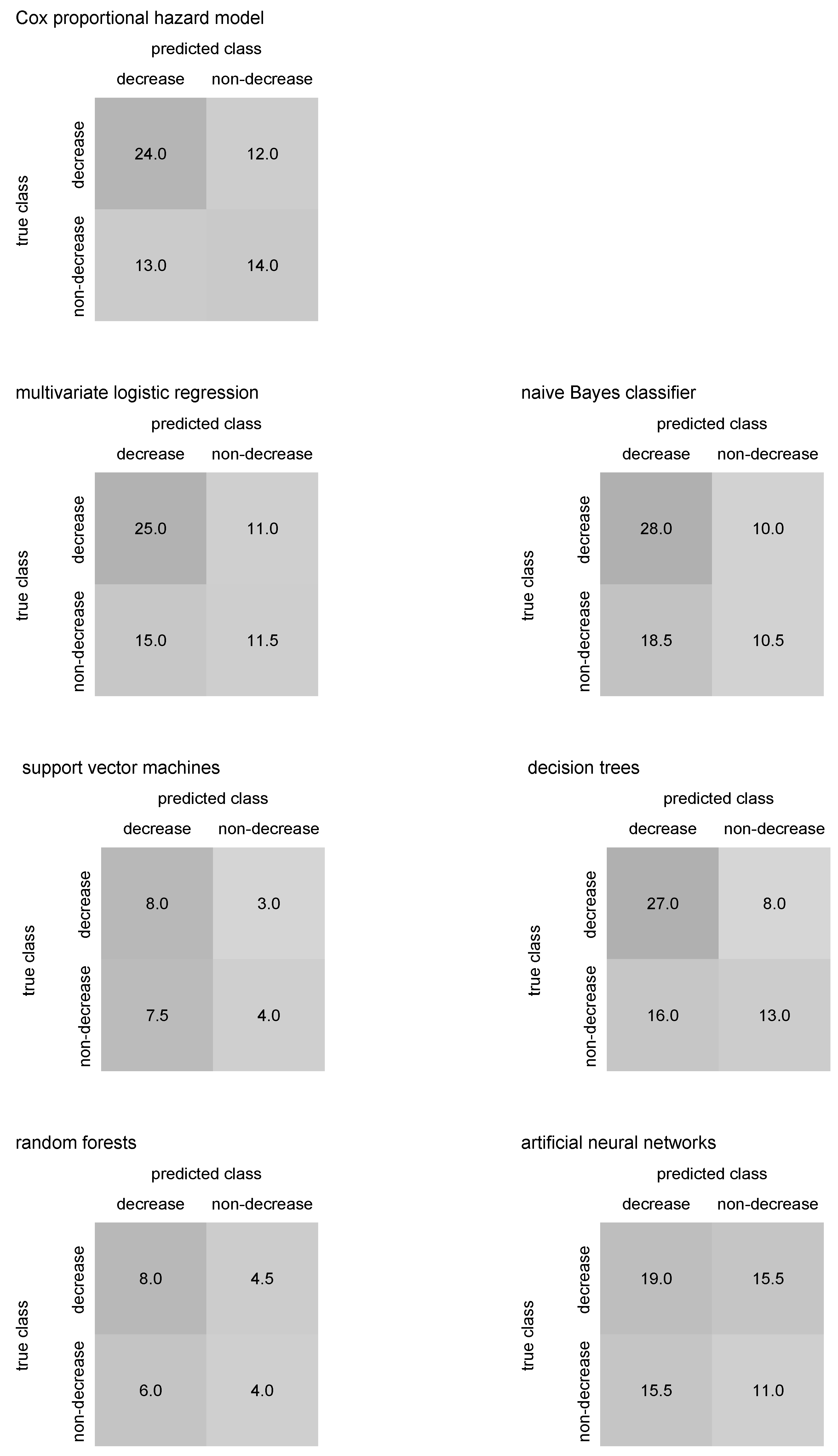
Median confusion matrices in
Figure 10 and
Figure 11 may help to identify whether an algorithm predicting COVID-19 antibody blood level decrease below laboratory cut-off tends to over- or underestimate the antibody decrease. Thus, comparing predicted numbers for antibody blood decrease and non-decrease in the median confusion matrices columns could be useful.
4. Discussion
Prediction of the time period till an event of interest is the most challenging and essential task in statistics, particularly when the event has a significant impact on an individual’s life. Without a doubt, the blood level of antibodies against COVID-19 and their development in time, especially their decrease below laboratory cut-off, also called seronegativity, could determine how an individual would face COVID-19 infection when exposed to it. This is one of the reasons we wanted to compare traditional statistical techniques and machine-learning-based approaches on antibody blood level decrease just for the diagnosis of COVID-19.
Survival analysis provides a toolbox of classical methods that model and predict the time to event. Many methods are commonly used regardless of whether they meet their formal assumptions when applied to real data. Since these methods, including the Cox proportional hazard model for prediction of the time to event, handle the relatively advanced concept of time-to-event modeling, they are limited by relatively strict statistical assumptions. Fortunately, there are various alternatives for how to address the issue of assumptions violation; in the case of the Cox proportional hazard model, we may use rather stratified models that partition an input dataset into multiple parts and build models for them independently, or we might prefer to perform other time-varying and time-partitioning that split the hazard function into several consecutive parts and model the parts individually.
In addition, machine-learning approaches could predict in a time-to-event fashion. A promising fact about the application of machine-learning algorithms not only in survival analysis is that these algorithms usually have very relaxed or not at all prior statistical assumptions. However, the majority of works and papers that employ machine-learning-based techniques for purposes of survival analyses often use mixed methods that combine features from survival analysis and machine-learning, namely scoring and counting models [
44], linear-separating survival models such as survival random forests [
45], or discrete-time survival models [
46]. Nevertheless, if the papers predicted the time to an event of interest and use comparable metrics of performance [
47], regardless of data focus, they usually reach predictive accuracy of about 0.7–0.9. These are similar predictive accuracy values we have obtained using the proposed time-to-event decomposition and ongoing classification too. Besides the Cox proportional hazard model, there are parametric survival models such as Weibull or log-normal ones. Those are flexible and might work well on real-world data; however, they require an initial assumption on the parametric choice of the baseline hazard function. If the assumption is wrong, predictions could fail. For example, Valvo in [
48] predicts COVID-19-related deaths (instead of antibody decrease) using a log-normal survival model with an average error of about 20%, which is, although a different topic, a similar value to our results.
Going deeper into machine learning applied for prediction in COVID-19 diagnosis, many papers deal with predictions of COVID-19 symptoms’ offset, COVID-19 recurrence, long-term COVID-19 disease, post-COVID-19 syndrome [
49,
50,
51]. However, all the mentioned topics of prediction related to COVID-19 manifestation are usually based on datasets that consist of individual observations of symptoms, biometric data, and laboratory or medical imaging data. Thus, very often, the data size is very large, so machine learning is a legit way for how to analyze these kinds of data; a time-to-event variable is generally missing, so such data are not suitable for survival analysis, though. This may be why papers applying machine-learning prediction on survival data related to COVID-19 are not as frequent as we could initially expect, considering the importance of the topic, or publicly available data are usually aggregated up to a higher level, which is generally not an optimal starting point for survival analysis. Furthermore, some publications are still estimating COVID-19 blood antibody level’s development in time [
52,
53,
54], but using traditional methods, so not applying time-to-event decomposition.
Of papers dealing with COVID-19-related predictions using machine-learning techniques, Willette et al. [
55] predicted the risk of COVID-19 severity and risk of hospitalization due to COVID-19, respectively, using discriminant and classification algorithms applied on 7539 observations (!) with variable similar to ours, and received an accuracy of about
and
, respectively. While our dataset is more than ten times smaller, we obtained similar results. Kurano et al. [
56] employed XGBoost (extreme gradient boosting) to classify COVID-19 severity using immunology-related variables. Applied on 134 patients, they received a predictive accuracy between
–
for various lengths of symptoms’ onset. Using standard explanatory variables, Singh et al. [
57] performed support vector machines to determine infectious COVID-19 status on 1063 recipients with final accuracy greater than
. In addition, Rostami and Oussalah [
58] combined feature selectors with explainable trees and others to predict COVID-19 diagnosis. Applied to available 5644 patients’ blood test data containing 111 features, they received an accuracy of about
for XGBoost, about
for support vector machines, about
for neural networks, and
for explainable decision trees, respectively. Cobre at al. [
59] introduced a new method for COVID-19 severity, combining various algorithms such as artificial neural networks, decision trees, discriminant analysis, and
k-nearest neighbor. Applied on biochemical tests of 5643 patients, they obtained a predictive accuracy of about
. Albeit no COVID-19-related predictions, but classification into acute organ injury or non-acute organ injury, Duan et al. [
60] received precision and recall slightly above
, using about 20 features of 339 patients. Thus, the predictive performance we obtained using our proposed method seems comparable with the literature.
However, according to our expectations, when sample sizes, as well as the numbers of features, are enormous and machine-learning algorithms could return outstanding results, as Bhargava et al. [
61] showed when they predicted COVID-19 disease using nine large datasets combining laboratory and imaging data and designed the algorithms in deep-learning fashion. As a result, they received an accuracy above
, or, using ensembled algorithms, even close to
.
Our proposed method, based on time-to-event decomposition and machine-learning classification of individuals to an event of interest’s occurrence or non-occurrence, using the time to event as an explanatory covariate, might contribute to the application of machine-learning for survival-like prediction in COVID-19 patients. Surely we do not want to claim that the method we are introducing in the paper would work on each dataset of similar size; however, thanks to a robust estimate of the predictive accuracy using 10-fold cross-validation, we may believe that the results we have obtained are not only random but supported by sufficient evidence of perfomance metrics and method’s properties.
Considering the IgG antibodies and their blood level decrease below laboratory cut-off in our patients, all performed algorithms show satisfactory performance and output relatively promising results regarding the predictive accuracy, as figured in
Table 3. The Cox proportional hazard model, taking into account as a golden standard, reported similar predictive accuracies such as multivariate logistic regression, naïve Bayes classifier, and decision trees. An assumption of the Cox model that survival curves for various combinations of covariates’ values should be met—particularly, survival curves would not cross each other or drop to zero, as plotted in
Figure 1 and
Figure 2. The multivariate logistic regression is a “baseline” model that performs well in prediction but might suffer from multicollinearity between covariates [
62]. Naïve Bayes classifier is a relatively simple algorithm and often outputs surprisingly good results; however, it depends on only one assumption, but its performance could be ruined if it is violated—explanatory covariates should be independent, as applied in Formula (
17). Decision trees are practically assumption-free [
63] but become more powerful when creating an entire random forest model. Support vector machines and random forests seem to noticeably outperform the Cox model in predictive accuracy, precision, recall, and F1 score—both algorithms reached all metrics higher than Cox’s regression using our dataset. The support vector machines are sophisticated algorithms. Using the kernel trick, these can find a separating hyperplane even for linear non-separable points of different classes. The random forest is the only algorithm among others that is natively ensembled, i.e., consists of a large number of other classification algorithms—decision trees. This is why the random forest typically shows good predictive performance. Among all algorithms applied to the data and predicting IgG antibody decrease, artificial neural networks reported the predictive performance slightly better than the Cox’s model—neural networks are universal classifiers, and their performance could be even improved when larger subsets are used for training, different activating function applied or various architecture of hidden layers investigated. Performance metrics other than predictive accuracy, as listed in
Table 3, are more than satisfying too—and each of them is greater than
.
Prediction of IgM antibody decrease might be tricky since IgM antibodies are less related to a cause it induced their growth, i.e., COVID-19 exposure [
64]. This might be why all algorithms performed mutually similar (and relatively poor) outputs of predictive accuracy and other metrics, as reported in
Table 4.
In the case of IgG decrease prediction, support vector machines, random forest, and neural networks do not predict the decrease class; however, the number of individuals with antibody decrease is significantly lower than those with no antibody decrease, see
Figure 10, so the predictive accuracy is not affected. Still, the possible lack of data in the “IgG decrease” class in training sets could cause the mentioned algorithms to fail to classify a few individuals from the class correctly. Mainly, neural networks are sensitive to this. If the median confusion matrix summation in
Figure 10 and
Figure 11 is lower than approximately one-tenth of the entire dataset size, then the antibody decrease is likely not predicted for some individuals. This could happen due to their missing covariates’ values, which occurred for the three previously mentioned algorithms. Inspecting median confusion matrices in
Figure 11, there seems to be no algorithm that would fail in the prediction of one of the classes in IgM antibody decrease. However, in general, the accuracy of IgM decrease is relatively low, likely caused by the advanced complexity of IgM (!) decrease prediction (compared to IgG decrease prediction).
As for the
limitation of the work, the fact that the proposed methodology works with good performance, particularly for IgG antibody decrease prediction, does not guarantee that it would work on another dataset with similar or even better performance. In addition, classification into classes that stand for an event of interest’s occurrence and non-occurrence consider both classes equal, which sidelines the censoring; however, it seems not to affect prediction performance. In addition, when the classifiers are mutually compared within the proposed method, one should take into account the fact that some of the algorithms did not classify all observations, as we see in
Figure 10 and
Figure 11 (i.e., when the summation of a median confusion matrix is less than one-tenth of the dataset), and consider such a comparison rather only as approximative. Machine-learning classification algorithms within the proposed method may bias any inference potentially carried out using the event of interest’s occurrence estimates [
65]—in this article, we are primarily interested in prediction paradigm and predictive performance. Finally, albeit not a limitation, but rather a note, varying tuning parameters set for classifiers in the introduced method and different sample sizes used for classifiers’ training, testing, and predicting may lead to other predictive performances.
5. Conclusions
Whether an individual would likely experience an event of interest or not, and if so, when exactly, is an essential predictive task in survival analysis. Unfortunately, statistical assumptions often limit methods commonly used to perform this forecasting.
In this work, we address the issue of assumption violation and employ machine learning, usually assumption-free or assumption-relaxed, in the predictive task. We decompose the time-to-event variable into two components—a time and an event one. While the event component is classified using various machine-learning classification algorithms, the time component becomes one of the covariates on the input of the classification models. Classifying into an event of interest’s occurrence and non-occurrence enables us to compare our proposed method with the traditional Cox proportional hazard model.
We apply the introduced methodology to COVID-19 antibody data where we predict IgG and IgM antibody blood level decrease below laboratory cut-off, also considering other explanatory covariates besides the time component.
The asymptotic time complexity of the proposed method equals the computational time of a classifier employed in the method. Compared to the Cox model, the classification does not take into account any censoring and considers both classes, i.e., an event of interest occurrence and non-occurrence, as equal. However, predictive performance measured using predictive accuracy and other metrics is for some models, particularly when IgG antibody decrease is estimated, higher than for the Cox model. Namely, multivariate logistic regression (with an accuracy of ), support vector machines (with an accuracy of ), random forests (with an accuracy of ), and artificial neural networks (with an accuracy of ) seem to outperform the Cox’s regression (with an accuracy of ), applied as classifiers in the proposed method on the COVID-19 data and predicting IgG antibody decrease below the cut-off. The precision, recall, and F1 score of the four named classifiers are constantly high, generally above . Regarding IgM antibody decrease below cut-off, Cox’s regression and the proposed method employing various classifiers perform relatively poorly, likely due to a weak association between COVID-19 exposure and IgM antibody production. In comparison, Cox’s model reached an accuracy of about , and all classifiers within the introduced method predicted with an accuracy of about –.
The proposed method seems to be a promising tool, currently applied to COVID-19 IgG antibody decrease prediction. Since IgG antibodies are closely related to protection against COVID-19 disease, an effective and accurate forecast of their (non-)decrease below laboratory cut-off could help—with no explicit need for time-consuming and expensive blood testing—to early identify COVID-19 non-vaccinated individuals with sufficient antibody level that could not undergo boosting vaccination when new COVID-19 outbreak incomes, or the non-vaccinated with IgG antibody decrease could be detected early as in risk of severe COVID-19, using only the algorithm and variables from their case history.
As for the future outlook, the proposed method could benefit from ensembled classifiers, increasing their predictive accuracy. In addition, various tuning parameters’ settings might improve predictive performance. Probably, the proposed method broadly applies to similar problems based on two-states survival prediction tasks.

 ,
, 

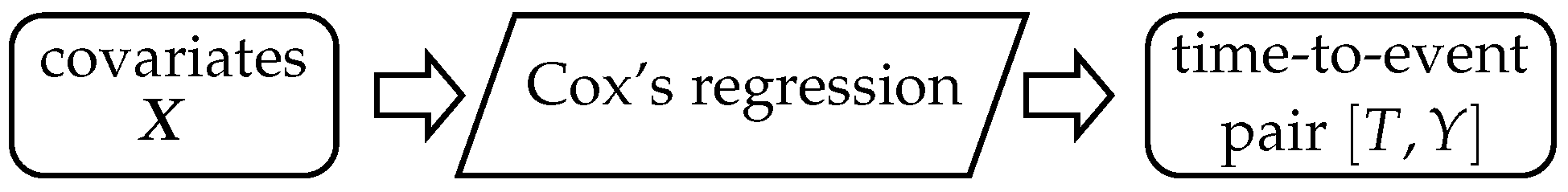


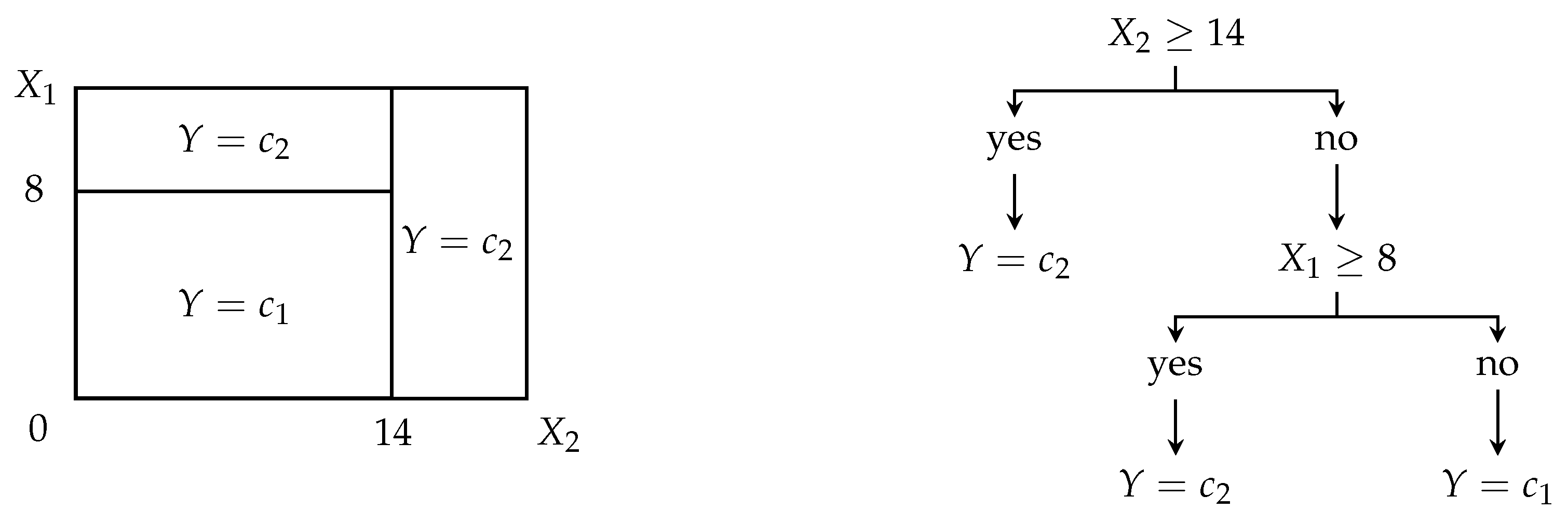


{kind=link}
{kind=link}
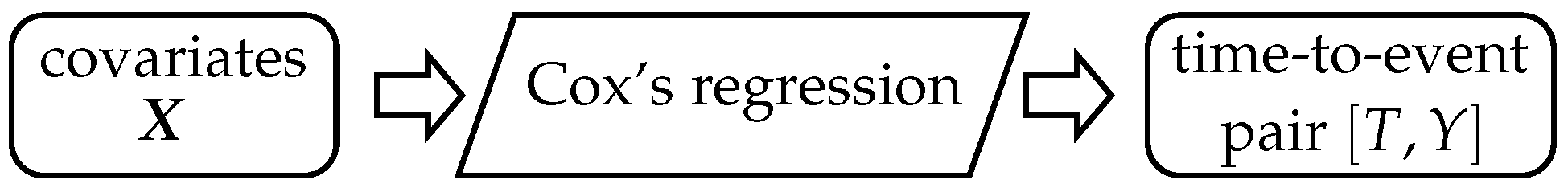{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}