Abstract
This paper introduces a new grammatical framework, Fuzzy Property Grammars (FPGr). This is a model based on Property Grammars and Fuzzy Natural Logic. Such grammatical framework is constraint-based and provides a new way to formally characterize gradience by representing grammaticality degrees regarding linguistic competence (without involving speakers judgments). The paper provides a formal-logical characterization of FPGr. A test of the framework is presented by implementing an FPGr for Spanish. FPGr is a formal theory that may serve linguists, computing scientists, and mathematicians since it can capture infinite grammatical structures within the variability of a language.
MSC:
03B65
1. Introduction
When communicating with each other, we often hesitate over what we are going to say and abandon the discursive thread as well as repeat words and phrases. Hence, as argued by Hayes [1], grammatical niceties are not often respected. Speakers are very rarely ideal in a completely homogeneous speech-community, and very often produce non-canonical inputs regarding natural language. At the same time, the hearers are competent enough to process and interpret ill-formed speech. Thus, a problem arises regarding the discrete conception of language as it cannot describe all natural language productions but only the grammatical ones. Given that humans can decode grammatical deviations in natural language processing, a formal grammar that aims to represent natural language must also do the same.
Many linguists have pointed out to the limits of discrete grammars because of their approach, specifically when it comes to explaining the vague and gradient nature of natural language; see Bolinger [2], Ross [3], Lakoff [4], Manning [5], Aarts et al. [6], Aarts [7], Keller [8,9], Fanselow et al. [10], Prost [11], Bresnan and Nikitina [12], Goldberg [13], Baldwin et al. [14], Lesmo and Torasso [15], Eisenstein [16], Lavie [17], Lau et al. [18], and Blache [19,20]. In linguistics, grammaticality has often been disregarded as an object defined as graded and vague due to Chomsky [21,22]. On the other hand, acceptability has been widely studied as a continuous and graded concept to describe how native speakers judge utterances, as in Keller [8], Lau et al. [18], Sorace and Keller [23], Lau et al. [24]. This research aims to provide a model that can capture grammaticality in its broad sense, from the perfect utterances to the ill-formed ones. This regard may help linguists to explain more accurately how natural language works and how to create an interface which can decode all kinds of natural language inputs.
The direct implication of considering grammaticality as a vague and graded concept is obtaining a model which defines all the linguistic knowledge of a natural language taking into account both prototypical and non-prototypical structures and constraints for generating any grammar with variations, such as grammar for languages, dialects, sociolects, and even idiolects. This research will impact linguistics and society, benefiting linguists and the interdisciplinary collaboration between mathematicians, engineers, linguists, and individuals, as summarized below:
- In linguistics, a model which considers grammaticality as a vague object has to be a fuzzy grammar which defines grammaticality as “knowledge of a grammar for processing language meaning”. This model offers a tool to evaluate complexity and universality in terms of degree. This research direction is already shown in Torrens-Urrutia et al. [25,26].
- For society and individuals, the concept of grammaticality as graded and vague opens the path to developing language software with linguistic explicative capacity. Explicative stands for the notion of explicability as in Floridi et al. [27], that is, combining demands for intelligibility and accountability. Therefore, a software with such characteristics will bare linguistic knowledge that can be incremented or reduced in real-time according to the evolution of natural languages, always displaying the linguistic information as a white-box method. This software could extract information with linguistic explicability in web data mining, in the automatic extraction of other natural language grammars with explicit linguistic information, in self-learning programs, in the developing of computer tools for the automatic detection of language pathologies, etc.
In this paper, we introduce the mechanisms and insights of a new grammatical formal model which can both represent and calculate degrees of grammaticality by considering the notion of gradience as a fuzzy phenomenon in natural language. Our primary aim is to characterize grammaticality using the concepts of fuzzy set theory.
We claim that our model offers a satisfactory alternative solution to account for degrees of grammaticality. This has been possible thanks to the application of notions from fuzzy logic and fuzzy sets theory to a grammar with constraints—a Property Grammar based on Blache [20]. This combination yields a Fuzzy Property Grammar. FPGr accounts for the degrees of grammaticality regarding a natural language grammar (an objective and formal perspective) without involving degrees of acceptability (a subjective and psycho-linguistic perspective) in the measurement of grammaticality. Much literature has been written concerning linguistic gradience and fuzzy grammars. However, to the best of our knowledge, nobody has ever proposed a model of a grammar which would be able to deal with degrees of grammaticality regarding linguistic competence whilst not including acceptability judgments. Consequently, this work presents the first step towards a cross-domain fuzzy grammar which could deal with much more vague phenomena of natural language.
The Fuzzy Property Grammar is a model already shown in Torrens-Urrutia et al. [25] for dealing with vague semantics of evaluative expressions and in Torrens-Urrutia et al. [26] for computing linguistic universality and complexity as a vague concept. However, the details and mechanisms of the model to extract the grammar and to describe grammaticality and its vagueness in terms of degree have not been shown yet.
The paper is organized as follows:
- In Section 2, we present the background of our research with some general ideas regarding key concepts in our framework.
- In Section 3, we lay out the formal prerequisites of our model regarding property grammars and fuzzy natural logic.
- In Section 4, the formal model of Fuzzy Property Grammars is introduced.
- In Section 5, materials and methods for extracting and computing the degrees of grammaticality are presented.
- In Section 6, the results of our research by introducing our Fuzzy Property Grammar of Spanish Language and its idiosyncrasies are shown.
- In Section 7, a theoretical application of the degrees of grammaticality in natural language with examples is displayed.
2. Background
Grammaticality, vagueness, and gradience are key concepts in our formal framework. We treat grammaticality as a continuous concept rather than discrete, uncertain, or predictable, that is, in which degree a linguistic input belongs to a specific grammar. Vagueness and gradience are related to each other since the concept of gradience gathers concepts such as vagueness and uncertainty.
We define grammaticality as a gradient value representing how much a linguistic input is satisfied according to the linguistic knowledge that defines a natural language grammar depicting the competence of a native speaker (Blache [19,20,28]). The linguistic knowledge can be represented in terms of linguistic rules or linguistic constraints. For describing gradient grammaticality, it is necessary to accept the following key aspects:
- (1)
- A grammar represents the linguistic knowledge that a native speaker has regarding a specific natural language. This also concerns the abstract linguistic rules which arrange the surface structures of a particular grammar. Lakoff [4] already strongly claimed that such rules must be considered part of the linguistic competence, and not as part of the linguistic performance (disagreeing with Chomsky [21]).
- (2)
- The linguistic knowledge concerns not only to those rules that can generate perfect grammatical utterances but also to the knowledge that a native speaker has acquired for processing and understanding non-grammatical utterances.
- (3)
- Linguistic knowledge can be defined through linguistic constraints (as a type of linguistic rule) and must tackle the notion of markedness. Therefore, we definitely need to consider canonical, prototypical, and non-canonical, non-prototypical or borderline constraints when defining a grammar.
- –
- The notion of linguistic constraints stands for a relation that puts together two or more linguistic elements. When this relation happens mostly in any context, the linguistic constraint is labeled as canonical or prototypical.
- –
- The notion of markedness stands for non-prototypical linguistic contexts. When a linguistic constraint happens in a marked context, the constraint is labeled as non-canonical, non-prototypical, or borderline.
- –
- The canonical constraints are those ones that definitely belong to a specific grammar. The non-canonical ones, even though they are part of the grammar, are “not definitely” part of it since their belonging to the grammar depends on how marked the linguistic context is.
Taking into account these three features is crucial for the representation of a natural language and its variation since allow us to describe structures that violate prototypical linguistic rules and those which trigger borderline rules, providing a full description of the syntactic mechanisms of a language, for example, I hate cabbage v. Cabbage, I hate. The first one is a prototypical Subject-Verb-Object (SVO) structure that would be acceptable in a range of contexts and would occur relatively frequently; by contrast, the second one is a borderline (non-canonical) Object-Subject-Verb (OSV) structure whose occurrence is much more restricted than its SVO counterpart, and is therefore more marked. For example, in answer to the question Who likes cabbage? the SVO sentence I hate cabbage is fine, but the OSV sentence Cabbage, I hate stands out as non-typical. This does not mean that Cabbage, I hate is not an English sentence that can be understood by a speaker of English. Rather, it represents a marked way of expressing that state of affairs compared to the default SVO construction. Any grammar should capture the fact that Cabbage, I hate is a marked structure for English. This principle is applicable to all languages. Adding this feature to the description of a grammar as linguistic knowledge enables us to capture the continuous, gradient and vague distinction between prototypical structures and their non-prototypical counterparts, whilst situating them both within the grammar. This reflects how native speakers understand and use language on daily basis.
Therefore, the value of grammaticality is fuzzy since it takes into account numerous criteria that make it continuous and vague. The vagueness of the fuzzy value of grammaticality is determined by a value in terms of degrees giving a certain amount of satisfied or violated criteria based on a grammar with constraints. This definition might satisfy many linguistic approaches that distinguish between grammaticality and acceptability.
The degree of grammaticality is the theoretical value resulting from the satisfaction and violation of the linguistic rules that characterize the linguistic knowledge in any linguistic domain (Keller [8], Blache [20], Chomsky [21], Joshi et al. [29]). In contrast, the degree of acceptability is essentially a subjective evaluation (Sorace and Keller [23], Schutze [30]). Additionally, degrees of acceptability are always provided in terms of prediction (Lau et al. [18]), that is, what is the probability that a linguistic input will be acceptable? Consequently, we are interested in determining to which degree an input satisfies a grammar rather than evaluating how much it violates the grammar.
The degree of grammaticality is a positive value (between 0 and 1) as the degree of membership of a linguistic input in a language generated by a specific grammar. Thus, we do not consider negative values representing non-grammaticality (such as saying an input is a quasi-expression (Pullum and Scholz [31]), or an input is −12.293, −02.324, and so on (Keller [8,9], Prost [11])).
Note that we do not mention the notion of correctness. The notion of correctness is related to the notion of satisfying a prescriptive grammar, since there is an incorrect option or an error. Grammaticality belongs to descriptive linguistics and refers to the degree of satisfaction with the rules of an utterance by a specific grammar of a natural language.
Gradience and vagueness characterize the relationship between two categorical objects, that is, each word belongs to “a class in which the transition from membership to non-membership is gradual rather than abrupt” (cf. Zadeh, 1965). This approach can be applied to linguistic gradience to determine the grammaticality of an input. Thus, rather than classifying an utterance as grammatical or non-grammatical if it features some grammatical deviations (“Black-and-white” reasoning; two-valued thinking), it can be classified as more or less grammatical according to the constraints that can be either violated or satisfied (“graded approach”; “fuzzy approach”).
Gradience is a well-known linguistic term. Aarts [32] defines gradience as a term to designate the spectrum of continuous phenomena in language, from categories at the level of grammar to sounds at the level of phonetics. The history of gradience in linguistics is huge. Some of the most distinguished linguists who defended gradient phenomena in language in the past are Bolinger [2], Ross [3], Lakoff [4], Manning [5], Aarts et al. [6], Aarts [7], Keller [8,9], Chomsky [21], Sorace and Keller [23], Lau et al. [24], Aarts [32], Jespersen [33], Curme [34], Wells [35], Crystal [36], Quirk [37], Chomsky [38], Daneš [39], Vachek [40], Neustupnỳ [41], Ross [42,43,44,45,46,47], Lakoff [48], Rosch [49,50,51], Labov [52], Prince and Smolensky [53], Legendre et al. [54], among others.
A grammar on linguistic gradience such as Fuzzy Property Grammar (FPGr) has to tackle all the important features of the gradient approach:
- A framework with constraints: It is necessary to choose a grammar or a model which takes into account constraints.
- Linguistic constraints: The notion of linguistic constraint stands for a relation that puts together two or more linguistic elements. For example, “ἃ Transitive Verb Requires a Subject and an Object”. The linguistic constraint is the “requirement”, and the linguistic elements are “Transitive Verb”. “Subject”, “Object”. Formally, a linguistic constraint is an n-tuple where are linguistic categories. We usually have , as shown in Torrens-Urrutia et al. [25,26].
- Context effects and markedness: The concept of markedness arises to represent the importance of context for a word. A sentence is more marked than a sentence if is acceptable in less contexts than . Müller [55] claimed that markedness can be determined either by the judgments of the speakers or by extracting the number of possible context types for a sentence. Keller [8] points out that “a constraint is context-dependent if the degree of unacceptability triggered by its violation varies from context to context”.
- Constraint ranking: It takes into account how some constraint violations are more significant than the other ones. Constraint ranking is especially essential for representing degrees of acceptability since it seems clear that the speakers find some violations more notable than others.
- Cumulativity: This effect is present in those structures that violate multiple constraints in contrast to those structures that violate a single constraint which is highly ranked.
- Constraint counterbalance: This notion is found in Blache and Prost [56] (p. 7) as an alternative use of cumulativity. Constraint counterbalance claims that “cumulativity must take into account both violated and satisfied constraints; in contrast with standard cumulativity which takes into account only the violated ones.”
- Ganging up effect: This effect shows up when a constraint has been violated multiple times in a structure. Acknowledging this effect allows us to consider that a constraint, which might be ranked below another one, can trigger more unacceptability if it has been violated more repeatedly than that which is ranked higher and violated just a single time.
- Soft and hard constraints are proposed as a paired concept by Keller [8,9]. Both constraints share features such as universal effects of being ranked, being cumulative and performing a ganging up effect. However, they also have features that distinguish them: Hard constraints trigger strong unacceptability when violated, while soft constraints trigger mild violations; hard constraints are independent of their context while soft ones are context dependent; hard constraints are mandatory during the acquisition process of a language as both for a native or as a second language acquisition, while soft constraints display optional traits when they are being acquired.
- Violation position: This notion is also from Blache and Prost [56] (p. 7) and points out how the value of a violation of a constraint might differ from one syntactic structure from another.
- Weights and rules: Linguists who work in gradience weigh constraints according to their ranking, context effect, and how hard and soft they are. The weights of constraints are deeply dependent on the perceived, extracted or intuited impact on native speaker’s acceptability. Usually, the degree of grammaticality and acceptability of a linguistic input is computed as the sum of the weights of the violations triggered by an utterance.
3. Formal Prerrequisites
3.1. Property Grammars
Property Grammars (PG) were introduced by Blache [19], who defined them as a formalism based exclusively on the use of constraints. The framework has been updated several times, most importantly by Blache [28], Blache and Prost [56], Blache and Balfourier [57]. The state-of-the-art in Property Grammars is reported in Blache [20], which provides an extensive explanation of the theory, clarifies the tools available, and describes their potential for linguists who would like to implement them in a natural language grammar. Our proposal is largely based on the newest model proposed in 2016.
Property Grammars is a non-generative theory without hierarchies that approach grammar as a set of statements and describe any kind of input regardless of its form or grammatical violation (Blache [20,28]). Property Grammars define linguistic inputs under several constraints that work as logical operators and are known as properties. The propeties that define the grammatical relations between the parts-of-speech of an input are the following:
- −
- Linearity of precedence order between two elements: A precedes B, in symbols, . Therefore, a violation is triggered when B precedes A. A typical example of this property can be found with the precedence relation between the determiner (DET) and the noun (NOUN) in English: For example, in “The kid”.
- −
- Co-occurrence between two elements: A requires B, in symbols, . A violation is triggered if A occurs, but B does not. A typical example of this property in English is “The woman plays basketball” where . A violation would be “Woman plays basketball”. Moreover, co-occurrence demands at the same time that B requires A. This property is non-hierarchic and non-headed. Therefore, the co-occurrence property must figure in both categories.
- −
- Exclusion between two elements: A and B never appear in co-occurrence in the specified construction, in symbols, , that is, only A or only B occurs. A violation is triggered if both A and B occur. An example of this property in English is the exclusion between the pronoun (PRON) and the noun (NOUN): For example, in “She woman watches a movie”. Unlike co-occurrence, this property does not necessarily figure in both property descriptions.
- −
- Uniqueness means that neither a category nor a group of categories (constituents) can appear more than once in a given construction. For example, in a construction X, . A violation is triggered if one of these constituents is repeated in a construction. A classical example in English is the non-repetition of the determiner and the relative pronoun concerning the nominal construction: In “The the woman that who used to be my partner”, we have a nominal construction: .
- −
- Dependency. An element A has a on an element B, in symbols, . A violation is triggered if the specified dependency does not occur. A classical example in English is the relation between an adjective (ADJ) with the dependency of a modifier, and a noun. For example, in “Colombia is a big country”, . One such violation might be: “Colombia is a big badly”. This property can be perceived as the syntactic property which mixes syntactic features with semantic ones.
Property Grammars are represented on an axis that includes three elements: Constraints with immediate descriptive capacity, the specific notion of construction, and the disconnection of linguistic elements from a hierarchical and derivational point of view. This makes it easier to identify the relationships between words and local language phenomena so that natural language processing can be described. These characteristics mean that property grammars can describe any input and can provide a satisfactory explanation for the different degrees of grammaticality.
Properties define constructions. Constructions are understood as pairs of a form and a function [13,58,59]. Property Grammars borrow the concept of construction from construction grammars, use properties to describe them, and conclude that “in a grammar a construction is equal to set of properties”, as argued by Blache [20] (p. 209). In this sense, a construction is defined as the result of the convergence of many properties, which allows pairing of form and function according to Guénot and Blache [60]. Property Grammars can identify a construction by noticing its properties. Therefore, a construction is a set of categories that are related to a set of properties.
The lexical information in Property Grammars is mostly based on setting up categories for each word or lexical unit. Once the categories for each word are chosen, the properties can be triggered. They can be supported by features that specify when those properties are going to be applied to a category. The typical feature to be represented is a function understood as a subject. For example, a property for an English grammar such as might be inaccurate since the noun can both precede and be preceded by a verb. We can specify functions and other values for a category to provide proper linguistic information thanks to the features. Therefore, Property Grammars can specify that a noun as a subject precedes a verb: N. Features reinforce properties as a tool that can describe linguistic information independently of a context and more precisely represent grammatical knowledge by taking into account linguistic variation.
Property Grammars have considerable potential from a cross-domain point of view. Certainly, this theory has been mostly applied in the syntactic domain. However, Blache and Prévot [61] and Blache et al. [62] have already explored the possibility of a multi-modal annotation. This fits our cross-domain fuzzy grammar approach perfectly, and paves the way for future work on degrees of grammaticality from a multi-modal perspective.
3.2. Fuzzy Natural Logic
There are many different approaches to formalization of natural human reasoning. In our model, we apply Fuzzy Natural Logic (FNL) from Novák [63,64] in order to define a grammar which can capture the vague notion of grammaticality. Fuzzy Natural Logic by Novák is a set of theories formulated in higher-order fuzzy logic (Fuzzy Type Theory (FTT)). The algebra of truth values in this logic is MV-algebra, the models use the standard Łukasiewicz MV-algebra. This mathematical theory is genuinely linguistically motivated and is highly influenced by Lakoff [48] and Montague [65]. It provides models of terms and rules that come with natural language and allow us to reason and argue in it. At the same time, the theory copes with the vagueness of natural language semantics [66,67,68,69,70].
Novák introduced the program of Fuzzy Natural Logic as the program for the development of a mathematical model of human reasoning that is based on the use of natural language. Novák [71] points out the main expected contributions of this theory:
- Development of methods for construction of models of systems and processes on the basis of expert knowledge expressed in genuine natural language.
- Development of algorithms making computer to “understand” natural language and behave accordingly.
- Help to understand the principles of human thinking.
The basic idea in this work is representing grammaticality using methods of fuzzy logic (2).
Vagueness is encountered if we want to group in X certain objects () which have a property
that cannot be precisely specified. For example, let be a property “high tree”. This is a property of trees x and X is a grouping of all high trees. However, this grouping is vaguely delineated since given a tree we cannot unambiguously say whether is has the property or not.
The same has been done with our grammar. We group objects (constraints) (i.e., ) in a linguistic domain (i.e., ) (syntactic domain) solely if they have a certain property (being grammatical). In other words, an object such as a syntactic constraint has the property of being grammatical when it is a constraint in a specific grammar.
Three types of objects can be found when dealing with vagueness: (1) typical or prototypical objects, i.e., the objects that certainly have the property , (2) objects that certainly do not have it, and (3) borderline objects for which it is unclear whether they have or not. Analogously, the fuzzy grammar deals with prototypical constraints (gold standard/canonical constraints) and special/variability constraints.
The second type of objects show up problems for being grouped in a linguistic domain since it is unclear if they have the property . In such a manner, the fuzzy grammar deals with vagueness taking into account the canonical constraints and comparing them with other candidates.
Consequently, a fuzzy grammar takes into account different types of constraints, namely, satisfied constraints, violated constraints, and variability (special, non-canonical) constraints:
- A satisfied constraint is a constraint of a grammar which is found reproduced in a linguistic input.
- A violated constraint is a constraint of a grammar which is found infringed in a linguistic input.
- A variability constraint is a constraint that is triggered when a violation occurs, compensating the final value of grammaticality. Variability rules are found and justified by context effects phenomena. Mainly by the tandem of the linguistic concept of markedness and frequency of appearance, as in the work of Keller [8], Müller [55].
In such a manner, vague linguistic phenomena are captured since a grammar can describe inputs with borderline cases through special constraints, rather than representing inputs which are either fully satisfied or violated.
We refer the reader to the above cited literature in Novák [63,64] for checking the basic concepts of FTT and FNL, and more details.
4. Fuzzy Property Grammars
4.1. Our Basic Idea of Graded Grammaticality
We are convinced that grammaticality has vague character. Therefore, we introduce fuzzy sets as a proper model for its representation. The first idea was to consider a grammar G as a function that assigns a degree of truth from L to each constraint in a set of linguistic inputs I, according to their importance and considering if they have been satisfied or violated:
The idea is that:
- (1)
- Grades can be found in grammar by considering:
- –
- Linguistic constraints that definitely belong to a grammar. Those are labeled as canonical or prototypical constraints.
- –
- Linguistic constraints that belong to the grammar in only marked contexts. Those are labeled as non-canonical, non-prototypical, borderline, or marked constraints.
- (2)
- Graded grammaticality can be found in linguistic inputs (utterances) when describing how many linguistic constraints from a specific linguistic input can be found in a specific grammar. Therefore, a gradient grammar such as a Fuzzy Property Grammar understands grammaticality as the vague relationship between a naturally produced linguistic input and a grammar in gradient terms. This relationship can be expressed in a degree [0, 1] according to how many rules and/or linguistic constraints have been identified by the grammar towards a linguistic input as constraints that are definitely part of the grammar (satisfied and prototypical), partially part of the grammar and satisfied (satisfied and borderline), and definitely not part of the grammar (violated constraints).
In other words, the grammar does not consider every single constraint as 1 or 0 regarding a linguistic input. Instead, the grammar considers if any non-canonical rules are found in a specific linguistic input when some canonical rules are violated, capturing vague linguistic (and borderline) phenomena.
First of all, it is essential to clarify that higher order fuzzy logic is a formalism that allows us to describe a grammar at a higher level (abstractly). It enables us to provide a mathematical formalization of the degrees of grammaticality as a gradient vague objects. In comparison, Property Grammars allow us to describe vague phenomena on a local-sentence level, characterizing the objects (constraints) as prototypical and borderline ones. Therefore, both theories are necessary to be able to build a fuzzy property grammar. It is also important to note that from Section 4.2 to Section 4.3, all the descriptions follow the formalism of fuzzy type theory and fuzzy natural logic. On the other hand, from Section 4.4 to Section 5.3, all the descriptions follow the formalism of Property Grammars. It is also necessary to highlight that we consider the terms linguistic constraints and linguistic rules as synonyms.
4.2. Definition of a Fuzzy Grammar and Fuzzy Property Grammar
The definition of Fuzzy Grammar and Fuzzy Property Grammar has presented changes thorough the literature [25,26,72,73,74]. In the older versions [72,73,74], Fuzzy Grammar and Fuzzy Property Grammar were, in fact, understood as the universe, making the term Fuzzy Property Grammar very misleading since it should be a fuzzy set, or a system of rules which are accompanied by some degree. Therefore, to clarify, we stand with the definitions of Torrens-Urrutia, Novák, and Jiménez-López [25], where the universe and the fuzzy set are clearly distinguished. We display them here to set the basis for the linguistic mechanisms we have integrated into these definitions.
Definition 1.
A Fuzzy Property Grammar () is a couple
where U is a universe
The subscripts denote types and the sets in (4) are sets of the following constraints:
- is the set of constraints that can be determined in phonology.
- is the set of constraints that can be determined in morphology.
- is the set of constraints that characterize syntax.
- is the set of constraints that characterize semantic phenomena.
- is the set of constraints that occur on lexical level.
- is the set of constraints that characterize pragmatics.
- is the set of constraints that can be determined in prosody.
The second component is a function
which can be obtained as a composition of functions , …, . Each of the latter functions characterizes the degree in which the corresponding element x belongs to each of the above linguistic domains (with regards to a specific grammar).
Technically speaking, in (5) is a fuzzy set with the membership function computed as follows:
where .
Let us now consider a set of constraints from an external linguistic input . Each can be observed as an n-tuple . Then, the membership degree is a degree of grammaticality of the given utterance that can be said in arbitrary dialect (of the given grammar).
FPGr operates taking into account the notion of linguistic construction, originally from [58,59]. A linguistic construction is understood as a pair of structure and meaning.
In FPGr, linguistic constructions in written language stands for a simplified version of a because only three linguistic domains are relevant for it, namely the morphological domain (), the syntactical domain (x), and the semantic domain (s), , whereas the others are neglected: .
Definition 2.
A construction is:
Examples of constraints in the linguistic domains in Equation (7):
- The morphological domain, which defines the part-of-speech (or linguistic categories) and the constraints between lexemes and morphemes. For example, in English, the lexeme of a “Regular Verb” ≺ (precedes) the morpheme -ed.
- The syntactical domain, which defines the structure relations between categories in a linguistic construction or phrase. For example, in English, an adverb as a modifier of an adjective is dependent (⇝) of such adjective ().
- The semantic domain, which defines the network-of-meanings of a language and its relation with the syntactical domain. This can be defined with semantic frames [75,76]. It is also responsible for explaining semantic phenomena as metaphorical meaning, metonymy, and semantic implausibility. For example, in English, object (i.e., ) ⇒ (requires) (i.e., ). A metonymy can be triggered with the follow rule: If asking for something to without (i.e., “I am reading R. L. Stevenson”), then is included as a feature in the frame of object as a borderline frame, i.e., .
All the linguistic descriptions from now on are conducted following the framework of Fuzzy Property Grammars.
4.3. A Fuzzy Grammar Computed Using Evaluative Linguistic Expressions
To estimate degree of grammaticality, we can apply fuzzy/linguistic IF-THEN rules. Using them, we can replace the evaluation using numbers by words. For example, insted of “I like your meal in the degree 0.845” we may say “this meal is excellent”. Fuzzy natural logic suggests a mathematical model of the meaning of such expressions, and also enables to reason with them.
Examples of how the degree of grammaticality can be estimated using fuzzy/linguistic IF-THEN rules include the following:
- IF an input is significantly satisfied THEN the degree of grammaticality is high.
- IF an input is quite satisfied THEN the degree of grammaticality is medium.
- IF an input is barely satisfied THEN the degree of grammaticality is low.
Similarly, we can express:
- IF the degree of grammaticality is high THEN the input is significantly grammatical.
- IF the degree of grammaticality is medium THEN the input is quite grammatical.
- IF the degree of grammaticality is low THEN the input is barely grammatical.
The expressions “significantly satisfied, high degree, medium degree”, etc. are called evaluative linguistic expressions. Their formal theory is in detail presented in Novák [66]. The theory of fuzzy/linguistic IF-THEN rules is is described in Novák et al. [77], Novak [78].
The reasoning about grammaticality in the above style is much closer to the natural human reasoning. We will implement such a fuzzy reasoning when we apply our system for the evaluation of the degrees of grammaticality for a linguistic input for suggesting a more natural evaluation. These boundaries have been decided theoretically, and they are a proof-of-concept for the employment of computing grammaticality with words rather than numbers.
4.4. Constraint Behavior
Differently from property grammars, in order to identify degrees of grammaticality in linguistic constructions, we must first identify the most prototypical objects for each construction in a grammar. These prototypical objects would be called canonical constraints or canonical properties. On the other hand, we need to identify the borderline objects for each construction as well. These would be called variability constraints or variability properties. According to this, a list with a definition for each constraint behavior is provided (note: From now, Greek symbols are not related to previous sections, and the formalism is based on the Property Grammars in Section 3.1):
- (a)
- Syntactic Canonical Properties: These are the properties which define the gold standard of the Fuzzy Grammar. These are strictly the most representative constraints, based on both their frequency of occurrence and some theoretical reasons. These properties are represented by the type .
- (b)
- Syntactic Violated Properties: These properties are canonical properties which have been violated regarding a linguistic input or a dialect. Pointing out the violation of a canonical property is necessary in order to trigger the related syntactic variability properties (if it is needed). These properties are represented with the type .
- (c)
- Syntactic Variability Properties: These properties are the core of this framework. These are triggered in the fuzzy grammar only when a violation is identified in an input. Therefore, these are borderline cases in between a violation and a canonical. They explain linguistic variability concerning a fuzzy grammar. When a variability property is satisfied, it triggers a new value over the violated constraint improving its degree of grammaticality. These properties are represented with the type . Variability constraints are found and justified by context effects phenomena. Mainly by the tandem of the linguistic concept of markedness, and frequency of appearance, as in Keller [8], Müller [55].
4.5. Syntactic Variability and xCategory
The syntactic variability properties need another significant effect for triggering variability properties. That is the notion of .
Definition 3.
An is a feature which specifies that a certain category is displaying a syntactic fit from another category, for example, a determiner with a syntactic fit of a pronoun. All the are marked with a x before a prototypical category, i.e., for a pronoun: . The properties of a xCategory are going to be placed in the description of the prototypical category.
Example 1.
Consider the following sentence: “El rojo es mi coche favorito” (“The red is my favourite car”). The determiner “El” is categorized as a determiner; consequently, some violations are triggered, i.e., and . The violations are not erased; in fact, the PG detects the violations. However, once these violations are triggered, a Fuzzy Property Grammar finds a variability constraint in Spanish grammar which links these violations taking into account new constraints for a new fit . If the satisfies the variability constraints from its new fit, the degree of grammaticality will be higher in comparison to its violation.
Thanks to the notion of , we specify a violation and, at the same time, we describe a fuzzy phenomenon such as a determiner performing as a borderline pronoun with its degree of grammaticality. If we consider that a category with a new syntactic fit changes its category, we will admit that there is no violation if the new fit satisfies all the new constraints. Additionally, we would be very discrete, because we would be admitting that a category has to be either this or either that. Therefore, in our framework, the process of categorization is discrete, but a category can be involved in fuzzy features regarding a structure. Consequently, we capture better the fuzzy phenomena involving a category. Additionally, Example 1 shows one of the many different ways of solving this phenomenon. Differently from the proposed solution, another option would be considering that the has a nominal fit (). Therefore, the could specify it. This situation shows how powerful is the notion of in our FPGr since it can provide a satisfactory description attending the different linguistic insights and theoretical perspectives.
Definition 4.
A variability constraint defined in a grammar occurs when a category in a construction has a violated constraint , which is a negated canonical constraint , and implies a variability constraint .
Example 2.
A determiner (DET), in a subject construction (SUBJ), a violation property () has been triggered because a canonical property (), i.e., DET ≺ NOUN, has been unsatisfied , i.e., . This violation implies (⇒) that the input can still trigger another constraint of the grammar, a variability constraint (), i.e., .
In other words, in (9), syntactic variability properties are triggered once a Determiner in Subject Construction violates (¬) the property ; therefore, the input has to satisfy the properties found in the syntactic variability properties of the () either the first one () or () the second one () (). The symbol ⇒ is used to point out that the syntactic variability properties are true only when both elements (the violation and the variability property) co-occur at the same time.
If these variability properties are satisfied, a degree of grammaticality will be provided regarding the value of the satisfied variability property. On the other hand, if this new condition is not satisfied, the violation will remain with the value 0.
Additionally, we want to stress that the relevant part here is how the notion of works, rather than if the phenomenon described in Example 1 and 2 is done in a way that will satisfy most of the linguistic insights (or not). We have chosen what we have considered is one of the most complicated ways to explain the phenomenon of the omission of the NOUN on subject. However, we could easily work it by means of the nominalization.
Following (10), we describe that once there is a violation of a requirement between determiner and noun, the determiner demands another element (X) which can have a nominal fit ().
Therefore, we find that is an essential feature to describe borderline objects in FPGr. Moreover, is a tool to define degrees of grammaticality with respect to a violated property when a variability property is satisfied. In other words, a variability property is a property triggered by a violated property. Both properties are part of a fuzzy grammar, they need each other to be true, and they provide a gradient value for a grammatical violation, which means that a variability property is fuzzy since it is a borderline constraint of a grammar triggered by a violation.
4.6. Constraint Characterization: Part of Speech and Features
Table 1 displays the main elements that are needed to characterize the constraints in a Fuzzy Property Grammar.

Table 1.
Constraint Characterization in FPGr.
- Our part of speech nomenclature for constraint categorization for both words and lexical units takes into account only these 10 categories. The constraints have been extracted by using Universal Dependencies. Therefore, FPGr has based its part of speech in the universal dependencies criteria for future implementations.
- Our construction nomenclature takes into account only these six constructions. These constructions have been found as the most frequent in Spanish while extracting the Universal Dependency corpus (Section 5.1). Therefore, we have considered that those are the most general constructions of Spanish language. Our grammar does not consider more marked structures such as comparatives, superlatives, or widespread idioms yet.
- Our construction nomenclature in Table 1 takes into account three constraint behaviors already mentioned in Section 4.4.
5. Materials and Methods for Extracting and Computing Degrees of Grammaticality
In this section, we show how we have extracted the constraints to build a Fuzzy Property Grammar, and how the degrees of grammaticality are computed in our model.
5.1. Extracting and Placing Constraints
The syntactic properties have been extracted automatically by applying the MarsaGram tool by Blache et al. [79] to the Universal Dependency Spanish Treebank Corpus.
5.1.1. Universal Dependency Spanish Corpus Treebank
Universal Dependency Spanish Corpus Treebank is obtained from the Universal Google Dataset (version 2.0). It consists of 16,006 tree structures and 430,764 tokens and is built from newspaper articles, blogs, and consumer reviews. The parsed sentences are the data that MarsaGram will use in order to automatically extract properties for a PG.
The Spanish Universal Dependency Treebank provides dependency relations, heads, parts of speech, and phrases. Figure 1 is an example of the whole linguistic information regarding a dependency treebank.

Figure 1.
An example of a dependency treebank from Spanish universal dependencies.
Figure 1 shows the sentence “el municipio de Sherman se encuentra ubicado en las coordenadas”, meaning “the municipality of Sherman is located at the coordinates”.
The whole sentences has a root, which is the verb “encuentra” (“located”) (clause 10441:1). This verb receives two clauses (10441:2, 10441:10) and one element (PRON-iobj) as its dependents:
- -
- Clause 10441:2. “El municipio de Sherman” (“The Municipality of Sherman”), as a subject.
- –
- “El” (“The”, masculine and singular) is tagged as a determiner with the dependency of determiner towards the noun “municipio “municipality”.
- –
- “municipio” is tagged as a noun and it is the root of the subject clause (10441:2). It receives as dependents “El” (tagged as determiner), and a proper noun clause (10441:5) headed by “Sherman” as a proper noun. “Sherman” receives as a dependent the adposition “de” (“of”).
- -
- Clause 10441:10. “ubicado en las coordenadas” (“located at the coordinates”) is denoted as a verbal complement.
- –
- “ubicado” (“located”) is tagged as a verb and it is the root of the complement of the verbal clause (10441:10). It receives as dependents a noun clause (10441:12) headed by “coordenadas” (“coordinates”) as a noun. “coordenadas” receives as a dependents the adposition “en” (“in”), and the determiner “las” as (“the feminine and plural”).
- –
- “se” is denoted as an unstressed pronoun since, in this case, the verb “ encuentra” is a pronominal verb which requires the pronoun for expressing such meaning of “finding something or somebody in a location”.
Guidelines for Universal Dependencies can be found in https://universaldependencies.org/guidelines.html, accessed on 29 November 2022. We are using their nomenclature during the process of the extraction of the Spanish properties. Even though most of them are somewhat intuitive, we suggest to check the part of speech tags for morphology https://universaldependencies.org/u/pos/index.html, accessed on 29 November 2022, and the syntactic dependencies https://universaldependencies.org/u/dep/index.html, accessed on 29 November 2022.
Spanish Universal Dependencies take into account more categories and dependency relations than the ones considered in our Fuzzy Property Grammar. Figure 2 displays all the dependencies included in FPGr.

Figure 2.
List of dependencies in property grammar from Blache [20] (p. 195).
In our work, we will adapt the Spanish Universal Dependencies nomenclature to the one proposed in our FPGr (Table 1) for part of speech constructions, and construction features, and to the one proposed in Figure 2 for dependency constraints.
Table 2 contrasts constructions and its expected dependencies between the Spanish universal dependencies and the FPGr.
Table 2.
Contrasting constructions, Universal Dependencies dependencies, and FPGr dependencies.
5.1.2. Spanish Syntactic Properties and MarsaGram
Spanish syntactic properties have been extracted automatically by applying MarsaGram to the Universal Dependency Spanish Corpus Treebank [79]. MarsaGram extracts 7535 rules (constructions) from this Spanish treebank plus 42,235 properties.
The Spanish Universal Dependency Treebank provides dependency relations, heads and parts of speech. On the other hand, MarsaGram ranks each set of constituents with their dependencies by frequency, automatically deducing the most extended constructions and properties, which will be reviewed by the linguist. In this way, this method combines three main types of linguistic information—dependencies, constituency, and syntactic constraints—for building a property grammar.
MarsaGram has essential advantages for linguistic review, that is, it can analyze and simultaneously extract constituency and dependencies by their frequency. These traits allow us to define and characterize Spanish constructions and their properties using an objective data criterion. Once a proper linguistic review has been conducted, this linguistic information is used to define both gradient relations and fuzzy phenomena in syntax.
The advantages that MarsaGram has for linguistic research are the following (this 8-page paper is recommended for further information concerning MarsaGram and its technical details: https://hal.archives-ouvertes.fr/hal-01462181/document, accessed on 29 November 2022):
- (a)
- The corpus allows us to work with linguistic categories and their dependencies to find dependency phrases: Noun phrases, adjective phrases, prepositional phrases, and so on, and their properties. For example, Figure 3 is an example of the as a linguistic category as dependency.
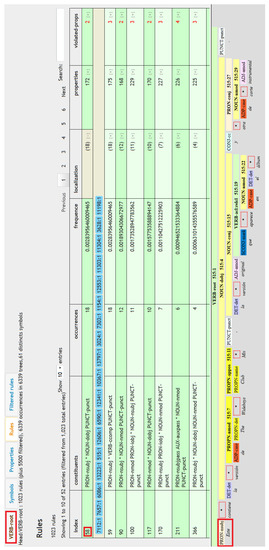 Figure 3. Example of a non-intuitive extraction.
Figure 3. Example of a non-intuitive extraction. - (b)
- We can check the most important/frequent categories for each construction in terms of dependencies and properties. For example, Figure 3 displays the eight phrase structures ranked with an index 58, 59, 90, 100, 117, 170, 211, and 366. They all have low frequency due to the fact that a as a in Spanish is rare. We find the constructions in “constituents”. The constituents in index 58, 59, 90, 170, and 366 display structures where we can find a as a nominal construction of subject, while in index 211 the is on a nominal construction of subject as a passive subject, which can show different properties.
- (c)
- We can apply the notion of construction from Goldberg [80] to the pair of constituency plus dependencies which appear in the RULES section, i.e., a subject construction is a subject dependency-constituency-phrase, a direct object construction is extracted from a direct object dependency-constituency-phrase, and so on. Therefore, we can see which constituents take part in the most common syntactic constructions of Spanish since we operate with an objective statistical frequency number.
- (d)
- MarsaGram provides two weights based on the frequency of each property. is a weight that depends on the number of times a property has been violated, while is a numerical value of the importance of a property in the corpus. This value corresponds to the frequency of a property. Therefore, a property that has never been violated ( as 1) but which has a low numerical value in the corpus ( as 0.001) means that it is either residual or an exception. A property with a high value of importance (), together with a high value of satisfaction (), is a significant property which the speakers tend to respect.
- (e)
- The properties of linearity, co-occurrence, exclusion, and uniqueness have been automatically extracted by MarsaGram. However, particular care needs to be taken with the exclusion property (or it should be disregarded) since it seems that the algorithm over-induces exclusion regarding a category for every other category which does not appear in a construction. MarsaGram makes it possible to check every property extracted in the context of the real sentence.
However, the limitations of MarsaGram are as follows:
- 1.
- The generation of properties depends on the universal dependencies tag. If the latter tag is wrong, it will generate a non-wanted property. For this reason, in general, it is better to always review the properties for each specific construction, its dependencies, and the actual sentence altogether, without implicitly trusting the automatically extracted ones. Therefore, some properties need to be justified with additional theoretical reasons rather than just frequencies.
- 2.
- It is not possible to automatically extract rules or properties for single elements with MarsaGram and universal dependencies. For example, if we want to check a PRON (alone) as a subject such as “Este es mi cuarto” (“This is my bedroom”), we cannot do it checking PRON-nsubj because “Este” (“This”), a appearing alone as a subject, is not extracted as a clause. In order to check so, we have to do it manually. In this case, we would need to check a alone as a subject on the rules and properties extracted from the as of a sentence. This is illustrated in Figure 3.
These limitations of MarsaGram force us to extract properties through category, not words. However, we provide an approach based on syntactic generalities, which is based on the notion of syntactic category, without going deeper on each word details. Therefore, MarsaGram is the perfect tool for our task. Thanks to the extraction of properties regarding syntactic categories, it is possible to represent linguistic variability and its grammaticality taking into account the different properties displayed by each category according to its different fits.
5.1.3. Overview of Spanish Universal Dependencies and MarsaGram Corpus
The first clue given by the corpus is the frequency of appearance of each of the categories in Table 3.
Table 3.
Frequency of occurrence of categories in the corpus.
According to the corpus, the is the most dominating category in terms of occurrences. and follows its domination in terms of occurrences. Given the usual connection between these categories, we can think that in most situations in which a and a appear, they introduce a . Therefore, the number of occurrences of a should be equal to or greater than the number of occurrences of these two elements. The corpus fulfills this logic. The verb is the fourth most frequent element.
These four elements make up 58.06% of the corpus. Consequently, the is the most present element in Spanish language. In short, these four elements, , , , and , perform half of the Spanish grammar.
Otherwise, all the nominal elements, , , and represent the 30.64% of the corpus. In such terms, extracting the properties of the nominal elements, especially the , is a priority since they are the most frequent elements.
On the other hand, each category appears much more frequently regarding some dependencies over the others. In such a way, we could say that each category is more involved in some dependencies over others because those most frequent ones are the canonical dependencies of each category.
5.1.4. Why an Extraction of the Subject Construction?
Spanish language has been chosen since there is no Property Grammar for Spanish yet. More specifically, we extracted constraints regarding the subject construction in Spanish language (standard Spanish/Castilian Spanish).
In Table 4, we can recognize which are the most prototypical categories for each dependency.
Table 4.
Categories and dependencies.
The nominal elements are clearly present in most of the dependencies such as in , , . However, the stands out for having the highest frequency as . As expected, the verb is the element which articulates many other constructions around it. The has a close relationship with the subject construction which is, at the same time, one of the most interesting ones regarding the nominal elements.
Therefore, if we associate dependencies and constructions, we have a clue of those categories which are going to have a critical role for the grammaticality of each construction:
- The categories of , , and are the ones which most perform the categories of subject construction, direct object construction, and indirect object construction.
- , , and (with a preposition) are the categories which mostly introduce a modifier construction.
- The is essential for representing verbal constructions, together with all those other constructions that have requirement relations with it: subject, direct object, and indirect object constructions.
Nevertheless, from all these constructions, the subject construction in Spanish is probably the one where we can find much more linguistic interrelations. A subject construction requires a nominal element, which usually requires a determiner. At the same time, a noun in subject construction can have other nominal modifiers introduced by a preposition. It can also have adjective modifiers. Additionally, it bears the most significant dependency towards the verb. We can find verbs without the need of a direct object, but it is less likely to find verbs without requiring a subject construction. In addition, the subject construction can be complemented by both a conjunctive construction or a subordinate one. Moreover, regarding future work, the properties of the Spanish subject construction are the perfect base for a complete Fuzzy Property Grammar, since it would be straightforward to adapt the nominal properties from the subject to other nominal constructions such as direct or indirect object. Therefore, the subject construction is both the most representative construction of Spanish language and the less isolated one.
For these theoretical reasons, we have extracted a Spanish Property Grammar to define the subject construction in Spanish. The subject construction bears many property relations, and it is the perfect proof-of-concept of the potential of the system that we propose in this work: The combination of both a fuzzy grammar and a Property Grammar for Spanish language.
The subject construction is nominal dependent as shown in Table 5. We acknowledge this by checking the Spanish universal dependencies corpus, which reveals that just the , , and can be categories for a subject construction. The category of with dependency is considered as a part of the . The numerals in Spanish, which are found with a subject dependency, are mostly ordinal numerals and those considered as nouns such as “segundo, primero” (“second, first”).
Table 5.
Frequency within subject construction.
If we compare the three nominal elements in Table 5, it can be seen that the category of the mostly performs the subject. and can introduce a subject construction but with a lower frequency.
Nevertheless, the Subject construction is closely related to the properties of the . Therefore, we need first to describe the in terms of properties.
Once this is accomplished, we will extract the properties from the categories which are mandatory for a subject construction in Spanish: , , and .
As a consequence of these descriptions, other categories will be partially described , , and .
In summary, it would be expected that the properties from the subject construction are not going to be very much different from those which will be displayed in other nominal constructions. Therefore, the extraction of the subject construction is an excellent choice for a proof-of-concept since many other constructions are nominal-dependent such as direct object construction, indirect object construction, and modifier construction with nominal categories.
5.2. Defining Prototypical and Non-Prototypical Fuzzy Constraints
We have applied this new interdisciplinary approach to the description of Spanish syntax. Property Grammars have been used in our work to define the different constructions and linguistic elements of Spanish. Our property grammar has been modified in order to bring up descriptions with fuzzy logic as shown in Section 4.2, Section 4.3, Section 4.4 and Section 4.5. In this way, we have defined a fuzzy grammar that can represent the different gradual phenomena and variability that take place in Spanish.
We provide an example of a Fuzzy Property Grammar in Table 6 in order to clarify how both a Fuzzy Property Grammar description and its constraint interactions are done.
Table 6.
Spanish properties of in subject construction.
Table 6 show the following characteristics which are exclusive from the Fuzzy Property Grammars (these are not present in a standard Property Grammar):
- (a)
- : It assigns to each property a behavior and a number regarding the category in a construction.
- (b)
- Specifications: They can specify features for each category. This trait is handy for those categories which have sub-categories, just like the verbs. We could specify some properties for infinitive verbs (), and others for copulative verbs (), instransitive verbs () and so on.
- (c)
- ∧: This symbol is understood as and. It allows defining a category and its properties concerning many different categories (or features) at the same time. Therefore, all the elements must be satisfied, or it will trigger a violation. This property prevents over-satisfaction, since it groups many categories under the same property. The over-satisfaction mainly occurs concerning the exclusion property. Exclusion property used to involve many categories.
Example 3.
The in Table 6 gives an example. A noun as the subject in a subject construction in Spanish exclude categories such as an adverb, a pronoun, and an infinitive verb: .
If we defined an exclusion separately when one of these excluded categories would occur with the NOUN, such as , the property grammar will label as satisfied the exclusions of the pronoun and the verb in infinitive:
- –
- ;
- –
- ;
- –
- .
We want to evaluate one property one time. Therefore, we are interested in accepting the exclusion property as satisfied just if all the categories are excluded. Otherwise, the over satisfaction of the exclusion property towards the other categories would tell us that exclusion is (paradoxically) satisfied and violated at the same time. Therefore, we define exclusion with ∧, triggering a violation in case any of its categories are not excluded.
- (d)
- ∨: This symbol is understood as or. It allows defining a category and its property concerning many different categories (or features) at the same time. One of the elements regarding ∨ must satisfy the specified property, or a violation will be triggered. This property prevents over-violation.
Example 4.
in Table 6 gives an example. A noun as a subject in Spanish, once is violated, requires a noun as modifier or a proper noun as a modifier or a pronoun as a modifier, or an adjective as a modifier, or a subordinate construction as a modifier: .
With ∨, we specify that one requirement is enough to satisfy this property. If we described this property separately, when a would satisfy the requirement of a noun as modifier (), the property grammar would trigger as a violation that the verb is not satisfying the requirement of the rest of the categories:
- –
- ;
- –
- ;
- –
- ;
- –
- ;
- –
- .
- (e)
- : It allows to specify the properties for the feature within the prototypical category. In Table 6, the constraints for a non-canonical noun with a syntactic fit of a noun can fe found in in .
Example 5.
In Spanish, in “El joven hablaba muy bien” (“The young talked very well”), the adjective “joven” (young) has a syntactic fit as a noun in a Subject construction “joven-”.
5.3. Word Density and Degrees of Grammaticality
In this work, we have considered the following notions for modeling gradient data in order to evaluate grammaticality from a theoretical point of view:
- Context effects: We have extracted the properties according to its frequency and by applying theoretical notions such as the concept of markedness. A value just based on frequencies is avoided, in favor of a value based on a combination of frequencies plus the notion of markedness among other theoretical reason according to context effects. In such manner:
- -
- A theoretical canonical value is understood as 1 ().
- -
- A violated value is understood as 0 ().
- -
- A variability value is understood as a 0.5 ().
- Cumulativity, ganging up effect, constraint counterbalance, and positive ganging up effect. A Property Grammar takes into account different constraint behavior (both violated and satisfied) and the multiple repetitions of both a single violation or various violations for calculating degrees of grammaticality. It also considers the multiple repetitions of both a single satisfaction or various satisfied properties for calculating degrees of grammaticality.
- Density. This notion weights each constraint regarding the number of constraints that defines a category. In our approach, density weights each constraint according to the number of constraints of a category in the construction of an input that are triggered (either satisfied or violated).
The PG is the tool which manages most of the fuzzy details for evaluating grammaticality: It sorts out the types of properties and their behavior, the property interactions and their context effects, and it can easily deal with both cumulativity and ganging up effects for their both positive and violated values.
Density values definitely fit the framework of a PGs since those are based on the part of speech. Therefore, it is necessary to provide tools for extracting the density value for each category. A density value is entirely theoretical which is ideal for using this notion as a weight for representing the degrees of grammaticality regarding linguistic competence.
In what follows, the formulas for representing grammaticality regarding an input for a Fuzzy Grammar are displayed.
Definition 5.
Each category is a word which has a whole full value of grammaticality:
We acknowledge the above because there are not enough theoretical reasons to objectively estimate one word over the other. In the end, if all the constraints of a word are fully satisfied, the word would have a value of grammaticality of 1.
Definition 6.
The canonical value of each constraint of a word () is the value of a canonical property (1) divided by all the triggered constraints of a word ().
Example 6.
A NOUN which triggers 4 constraints will assign a value of 0.25 for each of its canonical constraints.
Definition 7.
The variability value of each constraint of a word () is the value of a variability property (0.5) divided by all the triggered constraints in an word ().
Example 7.
A which triggers 4 variability constraints will assign a value of 0.125 for each of its variability constraints.
Definition 8.
The final grammaticality value of a word () is the addition of all the canonical values of each constraint of a word () plus all the variability values of each constraint of a word () divided by the value of a (11).
Example 8.
A which triggers 3 constraints with an assigned value of 0.33 and satisfies 2 canonical constraints, will have a grammatical word value of 0.66. If the same would satisfy 2 canonical constraints and 1 variability constraint, it would have a grammatical word value of 0.825. In this case, the variability constraint has a special condition in our grammar: will be a satisfied constraint if it fulfils the requirement of satisfying and . These special conditions do not have “a weight” in evaluating grammaticality, since they are merely a condition to check if is satisfied. Because it is so, in this case, is a satisfied constraint with its weight of 0.165. Note that not all variability constraints have special constraints to verify satisfaction or violation of such variability constraint. It could happen that could be either violated or satisfied without further checking. Every FPGr for each construction will specify when these conditions have to be applied.
5.4. Computing the Grammaticality Values from an Input
Once we acknowledge (1) the values of the constraints for each type of constraint in a category and (2) the final grammaticality value of each word, we can extract the grammaticality value of an input. Note that we mention input because this formula is made for evaluating any utterance, construction, or linguistic input in which their words can be identified.
Definition 9.
The value of grammaticality is the result of dividing all the final grammatical values of each word () with all words in an input ():
Example 9.
Table 7.
Example of an input with values of grammaticality and its constraints.
Table 7 shows how an application of all the formulas for extracting grammaticality values would be. It is worth pointing out how all the constraints are enumerated and specified with its behavior.
Formula (16) is very flexible since we can evaluate any input or linguistic construction with it. We do not need to evaluate just phrases, full expressions, and so on. For example, we can consider as an input the full construction in Table 7, the value of such is 0.846. However, if we are interested in finding out the of another construction, such as { and }, we just need to apply the same formula for these two words, and it reveals that their is 0.776:
Moreover, the relation between violated and variability constraints can be seen in . In , three constraints are triggered: 1 violated () and two are satisfied (, ). However, the violated constraints trigger a variability constraint. To add the value of the variability constraint, has to satisfy and . Because all the variability constraints are satisfied, the variability value of 0.165 can be added to . Therefore, the value of grammaticality is more refined, and it softens up the violation. These mechanics contrast with other approaches that would compute the violated constraint as a 0 without considering its fuzzy variability. Therefore, the value of the violated constraint has a degree according to its borderline case. Contrarily, the violated constraints in are violated without the possibility of any compensatory value because, in this case, the grammar does not acknowledge any variability constraint for it.
6. Results
Due to length constraints in this paper, the main result can be seen in Appendix A where all the constraints for a Fuzzy Property Grammar for Spanish Subject Construction can be found.
This grammar has extracted the following cases:
- Thirty-two canonical properties for 6 types of Verb construction. Three variability properties for 6 types of verb construction.
- Five canonical properties for the noun () as subject, and one variability property.
- Seven canonical properties for the adjective (), and one variability property.
- Six canonical properties for the noun () as a modifier and one variability property.
- Three canonical properties for the preposition () as a specifier.
- Two canonical properties for the proper noun () as subject and three variability properties.
- Four canonical properties for the proper noun () as a modifier and three variability properties.
- Five canonical properties for the pronoun () and two variability properties.
- Four canonical properties for the determiner (), and one variability property.
- Five variability properties for .
- Two variability properties for the .
- Two variability properties for the .
Our Fuzzy Property Grammar has extracted a final amount of 68 canonical properties.
Our grammar is fuzzy because we extracted the following borderline cases: 15 variability properties in seven prototypical categories and 9 variability properties in three non-prototypical or borderline : , , and . Therefore, our Fuzzy Property Grammar has extracted the final amount of 24 variability constraints.
Consequently, our Fuzzy Property Grammar has extracted a total amount of 92 properties. The variability properties represent 26,08% of our grammar. Hence, our Fuzzy Property Grammar can capture 26.08% better the linguistic phenomena in natural language in contrast with a discrete grammar. Moreover, it can calculate degrees of grammaticality because of the variability properties which are displayed on it.
All these properties are a proof-of-concept of the linguistic knowledge that a speaker should have for being competent for the acknowledgment of the subject construction in the Spanish Language.
7. Discussion: Theoretical Application of Degrees of Grammaticality in Natural Language Examples
We present some examples of the of implementation to discuss advantages and disadvantages of the model through three examples.
7.1. Example 1: Parsing Constructions with Variability Constraints
In Table 8, we illustrate an example, in natural language, of the variability property in . According to our grammar, the sentence is “not definitely” part of the Fuzzy Property Grammar in Spanish. Such structure is a loan translation of English established in journalistic writing in Spanish. Therefore, any grammar of Spanish should point out its marked structure in contrast with its prototypical counterpart. We do so with the use of canonical and variability properties.
Table 8.
Variability properties of .
- The value of the word “funcionarios” (Public-workers) as a is estimated with the theoretical value of 1: .
- The value of each canonical property of () is calculated dividing all the triggered canonical properties both satisfied () or violated () (4) by our standard value of a canonical property (1). The canonical value of each property in Table 8 is 0.25.
- The value of a variability property ( is calculated by dividing the value of a variability property (0.5) by all triggered satisfied () and violated () constraints in (“funcionarios”). The variability value of each property in Table 8 is 0.125.
- cannot either satisfy or violate because any determiner has appeared. Therefore, our property grammar cannot evaluate its uniqueness in . In this manner, the property is not triggered.
- satisfies 2 canonical properties out of 4. We calculate as 0.5.
- satisfies 1 variability properties out of 1: : ⇒. We calculate as 0.125.
If we did not take into account this variability property, the value of grammaticality of would be 0.5:
In this manner, we could compute the value of grammaticality of this example with words concerning that a value between 0.8 and 0.5 is understood as quite grammatical, and a value of 0.5–0 is understood as barely grammatical.
- The value of grammaticality of the word funcionarios in subject construction in (22) is 0.625. The input is quite grammatical.
- However, the value of grammaticality of in (23) is 0.5. The input displays a borderline case between being quite grammatical and barely grammatical. Because our Fuzzy Property Grammar took into account such variability property as in , we can provide a more fine-grained value such as the one presented in (22).
7.2. Example 2: Mind Which Constraints Shall Be Included in the Grammar
Table 9 and Table 10 show the importance of minding in which constructions and categories every constraint shall be placed. They show a grammatical example in Spanish. The value of grammaticality of has been calculated in both cases using the formulas presented in Section 5.3. Since we cannot be sure about the different weights between categories, we acknowledge the same weight of 1 for all types of words. Therefore, we apply (11) to .
Table 9.
Example of including in .
Table 10.
Example of not including in .
Secondly, we reveal the canonical value of each constraint of () by our standard value of a canonical property (1). We assume that all canonical properties have the same density, which means that no canonical property is more important than another. By assuming this value of 1, we provide a theoretical value for each canonical constraint strictly from the perspective of the syntactic domain, without involving our weights with frequencies, avoiding in such manner the paradoxes of weighting canonical properties by probabilities. This canonical value of 1 is divided by all the triggered constraints of a the (), both satisfied () and violated (). In Table 9, seven constraints have been triggered. In Table 10, five constraints have been triggered. The two additional constraints triggered in Table 9 are those constraints which define the precedence between the noun and the adjective. In (25) and (26), the value of the canonical constraints for Table 9 and Table 10 are respectively calculated following Equation (12):
The violated properties are weighed as 0. Because any variability property is triggered, we already calculate the value of grammaticality of by applying (16). For calculating , we take into account all the canonical weights. In Table 9, the satisfied properties () which keep the value as canonical properties () are displayed in (25). Since all its satisfied constraints are 5 out of 7, we calculate as 0.714. Because there are no variability properties triggered, the value of all variability properties of the is 0: as 0. These both values are divided by the value of which is 1. The final value of grammaticality of in Table 9 is calculated as 0.714 as shown in (27):
In Table 10, the satisfied properties () which keep the value as canonical properties () are displayed in (26). Since all its satisfied constraints are 5 out of 5, we calculate as 1. Because there are no variability properties triggered, the value of all variability properties of is 0: as 0. This both values and are divided by the value of which is 1. The final value of grammaticality of in Table 10 is calculated as 1 as shown in (28):
If we specified the precedence of the noun towards a modifier in , it would trigger a lower degree of grammaticality than what it should be. The properties : and : trigger a violation since the noun is not preceding any adjective, nor modifier, nor conjunction, nor an adjective numeral ordinal and undefined. Because of these violations, a grammatical sentence has 0.284 less grammaticality. Therefore, because we placed these precedence relations in the modifier construction, these properties would only be triggered when an adjective appears, allowing a better calculation for our degrees of grammaticality just as in Table 10.
7.3. Example 3: The Feature xCategory in Processing Natural Language
- “El hombre robot corre” (The robot man runs)
Regarding Table 11, it shows an example of the grammaticality value of a word as a xCategory in Spanish. The value of grammaticality of “robot” has been calculated using the formulas presented in Section 5.3. Again, we point out that since we cannot be sure about the different weights between categories, we acknowledge the same weight of 1 for all types of words. Therefore, we apply (11) to in (29):
Table 11.
in modifier construction as a xADJ.
On one hand, we reveal the canonical value of each constraint of () by our standard value of a canonical property (1). This canonical value of 1 is divided by all the triggered constraints of a the (), both satisfied () and violated (). In Table 11, six constraints (either or ) have been triggered. The variability constraints do not count as an additional triggered constraint since it is a consequence of a violated constraint as seen in (8). In (30), the value of the canonical constraints for in Table 11 is calculated following (12):
On the other hand, we calculate the value of the variability properties triggered as a consequence of the violated canonical properties. The variability triggered properties of the are 1: :. We do not take into account the satisfied variability properties from the since its satisfaction evaluates the possibility of being a with a feature. The variability constraints in the word “robot” as just count as one because the variability rule in specifies that it triggers all the constraints in . Therefore, in case some of the variability constraints would not be satisfied, this variability would not be applied. That is why we separate the constraints which count on calculating grammaticality and the others that just matter for including the variability rule of the , . In other words, if the could not satisfy the variability properties of the , a could not take into account the calculation of the variability property .
In (31), the value of a variability property is calculated by dividing the value of a variability property (0.5) by all triggered all satisfied () and violated () constraints in (“robot”).
Finally, we calculate the value of grammaticality of () by applying (16). For calculating , we take into account all the canonical weights plus all the variability weights of the word “robot” as a . In Table 11, the satisfied properties () which keep the value as canonical properties () are displayed in (30). Since all its satisfied constraints are 3 out of 6, we calculate as 0.498. In Table 11, the variability properties () which keep the value as variability properties () are displayed in (31). Since all its satisfied constraints are 1 out of 1, we calculate as 0.083. The final value of grammaticality of in Table 11 is calculated as 0.581 as shown in (32):
We can compute these values with words following the representation of our Fuzzy Grammar applying approximate reasoning in Section 4.3.
When applying this reasoning to our example, it reveals that the variability property raised the value of grammaticality of enough to be better considered in our Fuzzy Grammar:
- Our Fuzzy Grammar considers a value of 0.581 as an input quite satisfied; therefore, its value of grammaticality is medium. The input is quite grammatical.
- In contrast, the value of the input “robot” as a would be 0.498 without our variability property. In this manner, this input without our variability property in our fuzzy grammar would be computed as an input which is barely satisfied. Therefore, its value of grammaticality would be low. The input would be barely grammatical.
- We recognize that another combination of words for and such as “El hombre paz” (The man peace) or “El cielo hombre” (The sky man) would have the same value of grammaticality regarding the syntactic domain. However, it would not have the same grammaticality value regarding a cross-domain perspective of a Fuzzy Grammar. We state that the combination of and is syntactically possible to a certain degree. However, its degree of grammaticality regarding the other domains (such as semantics) would rely on the satisfaction or the violation of its properties in such domains. Consequently, the final value of grammaticality of two identical syntactic structures might be different in a Fuzzy Property Grammar when we calculate grammaticality of an utterance regarding all the properties in all their domains.
8. Conclusions
The core objective of this paper has been to introduce a formal model which combines fuzzy logic and a grammar with constraints to represent degrees of grammaticality regarding linguistic competence, without involving the speaker’s acceptability judgements, namely, a Fuzzy Property Grammar.
In our model, we claim that data from acceptability judgments cannot model grammaticality since that data are determined by both linguistic and extra-linguistic elements together with the subjective perspective of a speaker. Such features contrast with grammaticality which is a theoretical notion full-based on the satisfaction rule without taking into account extra-linguistic considerations. Grammaticality is a vague concept, so we have used a fuzzy grammar to define it. The degree of grammaticality has a positive value since grammaticality is a vague object which determines the extent to which an input belongs to a grammar in terms of degrees of truth. Consequently, an input is a vague object which is more or less true depending on the number of linguistic elements that it satisfies and violates in a specific grammar.
FPGr can extract values of grammaticality regarding a single word, a construction, or various sentences. It can evaluate any input providing a positive calculation for degrees of grammaticality. We have modeled using approximate reasoning by means of linguistic expressions of grammaticality. This provides a more natural interpretation of the degrees of grammaticality.
Fuzzy Property Grammars consider three types of constraint behaviors: syntactic canonical properties, syntactic violated properties, and syntactic variability properties (these are borderline cases in-between a violation and a canonical use). They explain linguistic variability concerning a fuzzy grammar. When a variability property is satisfied, it triggers a new value over the violated constraint, thus improving its degree of grammaticality. Properties are defined based on theoretical notions for modeling gradient data such as context effects, cumulativity, ganging-up effect, constraint counterbalance and positive ganging-up effect, density and cross-domain values.
We claim that Fuzzy Property Grammars are innovative in contrast to other approaches which treat the gradient phenomena in linguistics, such as optimality theory frameworks, and other grammars with constraints. The reason why our fuzzy grammar works is thanks to the acknowledgment of those variability properties and borderline fits which are known as xCategory.
The fuzzy grammar and the systems proposed have room for uncertainty and predictive tools for a full explanation of natural language inputs. In future work, we will test what happens if we adopt grammatical weights for each constraint according to its occurrences and probabilities, expecting that they would model degrees of acceptability within a fuzzy grammar.
9. Future Work
The future work of the Fuzzy Property Grammars involves, firstly, the creation of a computational model for the induction of both canonical and variability constraints for any natural language.
One of the issues with the Fuzzy Property Grammars is that it is not “friendly” to read when somebody is unfamiliar with it and when a bunch of properties are already being displayed in a short sentence. It would be positive for linguistic analysis to mix our model with a linguistic theory which can represent linguistic constituents with trees and, at the same time, accept constraints in its description. Some of the best candidates for such tasks are the Lexical-Functional Grammar, and the Head-driven Phrase Structure Grammar.
Additionally, we would like to test other methods to check if they can improve the automatization of our model by using new fuzzy systems such as Fault estimation for mode-dependent IT2 fuzzy systems with quantized output signals [81], fuzzy neuronal networks, and XAI (explainable artificial intelligence).
Author Contributions
Conceptualization, A.T.-U., V.N. and M.D.J.-L.; Formal analysis, A.T.-U., V.N. and M.D.J.-L.; Writing—original draft, A.T.-U., V.N. and M.D.J.-L.; Writing—review & editing, A.T.-U., V.N. and M.D.J.-L. All authors have read and agreed to the published version of the manuscript.
Funding
This paper has been supported by the project PID2020-120158GB-I00 funded by MCIN/AEI/10.13039/501100011033.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
This paper has been supported by the project CZ.02.2.69/0.0/0.0/18_053/0017856 “Strengthening scientific capacities OU II”. We wish to thank Philippe Blache for his collaboration and support during this research.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Spanish Fuzzy Property Grammars for Subject Construction
Table A1.
Spanish properties of in subject construction.
Table A1.
Spanish properties of in subject construction.
| : : : : : : |
| Variability Properties |
| : ⇒ |
| : : : : : : |
Table A2.
Spanish properties of in modifier construction.
Table A2.
Spanish properties of in modifier construction.
| : : ≺ : |
| : |
| : |
| : |
| : |
| Variability Properties |
| : |
| : : |
Table A3.
Spanish properties of both in modifier and in specifier construction.
Table A3.
Spanish properties of both in modifier and in specifier construction.
| : : : : : : : |
| Variability Properties of |
| : ⇒ |
| : : ∨V : |
Table A4.
Spanish properties of in subject construction.
Table A4.
Spanish properties of in subject construction.
| : ⊗ |
| : |
| Variability Properties |
| : ¬() ⇒ : ¬() ⇒ : ¬() ⇒ |
Table A5.
in modifier construction.
Table A5.
in modifier construction.
| : : : |
| : |
| Variability Properties |
| : ¬() ⇒ : ¬() ⇒ : ¬() ⇒ |
Table A6.
Spanish properties of .
Table A6.
Spanish properties of .
| : ⊗∧∧∧∧ : ≺ : ⇒ : ⊗∧∧ : V |
| Variability Properties |
| : ¬() ⇒≺ : ¬() ⇒ |
| : ⇒∧≺ |
| : ⇒ { |
Table A7.
Spanish properties of .
Table A7.
Spanish properties of .
| : : : : : |
| Variability Properties |
| : ¬() ⇒ |
Table A8.
Table of Spanish properties of verb in verbal construction.
Table A8.
Table of Spanish properties of verb in verbal construction.
| in |
| : ⇒∨∨ : ⇒∨∨∨∨ : ∨∨≺ : ≺∨∨∨∨ : ≺ : ≺ : ≺ : : : : |
| : : ⇒∨∨ : ∨∨≺ : ≺ : ≺ : : |
| : ⇒∨∨∨ : ⇒∨∨∨∨ : ∨∨≺ : ≺∨∨∨∨ : ∧≺. : : . : |
| : : : : : |
| : : : : |
| : : |
| Variability Properties |
| : ⇒ : ⇒V⇒ : ⇒⇒∨ |
References
- Hayes, P.J. Flexible parsing. Am. J. Comput. Linguist. 1986, 7, 232–242. [Google Scholar] [CrossRef]
- Bolinger, D.L.M. Generality: Gradience and the All-or-None, 14th ed.; Mouton Publishers: The Hague, The Netherlands, 1961. [Google Scholar]
- Ross, J.R. The category squish: Endstation hauptwort. In Papers from the 8th Regional Meeting of the Chicago Linguistic Society; Peranteau, P.M., Levi, J., Phares, G., Eds.; Chicago Linguistic Society: Chicago, IL, USA, 1972; pp. 316–328. [Google Scholar]
- Lakoff, G. Fuzzy grammar and the performance/competence terminology game. In Papers from the Ninth Regional Meeting of the Chicago Linguistic Society; Corum, C.W., Smith-Stark, T.C., Weiser, A., Eds.; Chicago Linguistic Society: Chicago, IL, USA, 1973. [Google Scholar]
- Manning, C.D. Probabilistic syntax. In Probabilistic Linguistics; Bod, R., Hay, J., Jannedy, S., Eds.; MIT Press: Cambridge, UK, 2003; pp. 289–341. [Google Scholar]
- Aarts, B.; Denison, D.; Keizer, E.; Popova, G. (Eds.) Fuzzy Grammar: A Reader; Oxford University Press: Oxford, UK, 2004. [Google Scholar]
- Aarts, B. Conceptions of gradience in the history of linguistics. Lang. Sci. 2004, 26, 343–389. [Google Scholar] [CrossRef]
- Keller, F. Gradience in Grammar: Experimental and Computational Aspects of Degrees of Grammaticality. Ph.D. Thesis, University of Edinburgh, Edinburgh, UK, 2000. [Google Scholar]
- Keller, F. Linear Optimality Theory as a model of gradience in grammar. In Gradience in Grammar: Generative Perspectives; Fanselow, G., Féry, C., Schlesewsky, M., Vogel, R., Eds.; Oxford University Press: Oxford, UK, 2006; pp. 270–287. [Google Scholar] [CrossRef]
- Fanselow, G.; Féry, C.; Vogel, R.; Schlesewsky, M. Gradience in grammar. In Gradience in Grammar: Generative Perspectives; Fanselow, G., Féry, C., Schlesewsky, M., Vogel, R., Eds.; Oxford University Press: Oxford, UK, 2006; pp. 1–23. [Google Scholar]
- Prost, J.P. Modelling Syntactic Gradience with Loose Constraint-Based Parsing. Ph.D. Thesis, Macquarie University, Macquarie Park, NSW, Australia, 2008. [Google Scholar]
- Bresnan, J.; Nikitina, T. The gradience of the dative alternation. In Reality Exploration and Discovery: Pattern Interaction in Language and Life; Uyechi, L., Wee, L.H., Eds.; The University of Chicago Press: Chicago, IL, USA, 2009; pp. 161–184. [Google Scholar]
- Goldberg, A. The nature of generalization in language. Cogn. Linguist. 2009, 20, 1–35. [Google Scholar] [CrossRef]
- Baldwin, T.; Cook, P.; Lui, M.; MacKinlay, A.; Wang, L. How noisy social media text, how diffrnt social media sources? In Proceedings of the Sixth International Joint Conference on Natural Language Processing, Nagoya, Japan, 14–18 October 2013; pp. 356–364. [Google Scholar]
- Lesmo, L.; Torasso, P. Interpreting syntactically ill-formed sentences. In Proceedings of the 10th International Conference on Computational Linguistics and 22nd Annual Meeting on Association for Computational Linguistics, Stanford, CA, USA, 2–6 July 1984; Association for Computational Linguistics: Stanford, CA, USA, 1984; pp. 534–539. [Google Scholar]
- Eisenstein, J. What to do about bad language on the internet. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Rochester, NY, USA, 23–25 April 2013; ACL: Atlanta, GA, USA, 2013; pp. 359–369. [Google Scholar]
- Lavie, A. GLR*: A Robust Grammar-Focused Parser for Spontaneously Spoken Language. Ph.D. Thesis, School of Computer Science, Carnegie Mellon University, Pittsburgh, PE, USA, 1996. [Google Scholar]
- Lau, J.H.; Clark, A.; Lappin, S. Measuring Gradience in Speakers’ Grammaticality Judgements. Proc. Annu. Meet. Cogn. Sci. Soc. 2014, 36, 821–826. [Google Scholar]
- Blache, P. Property grammars and the problem of constraint satisfaction. In Proceedings of the ESSLLI 2000 Workshop on Linguistic Theory and Grammar Implementation, Birmingham, UK, 6–18 August 2000; pp. 47–56. [Google Scholar]
- Blache, P. Representing syntax by means of properties: A formal framework for descriptive approaches. J. Lang. Model. 2016, 4, 183–224. [Google Scholar] [CrossRef]
- Chomsky, N. Aspects of the Theory of Syntax; MIT Press: Cambridge, UK, 1965. [Google Scholar]
- Chomsky, N. The Minimalist Program; MIT Press: Cambridge, UK, 1995. [Google Scholar]
- Sorace, A.; Keller, F. Gradience in linguistic data. Lingua 2005, 115, 1497–1524. [Google Scholar] [CrossRef]
- Lau, J.H.; Clark, A.; Lappin, S. Grammaticality, acceptability, and probability: A probabilistic view of linguistic knowledge. Cogn. Sci. 2017, 41, 1202–1241. [Google Scholar] [CrossRef]
- Torrens-Urrutia, A.; Novák, V.; Jiménez-López, M.D. Describing Linguistic Vagueness of Evaluative Expressions Using Fuzzy Natural Logic and Linguistic Constraints. Mathematics 2022, 10, 2760. [Google Scholar] [CrossRef]
- Torrens-Urrutia, A.; Jiménez-López, M.D.; Brosa-Rodríguez, A.; Adamczyk, D. A Fuzzy Grammar for Evaluating Universality and Complexity in Natural Language. Mathematics 2022, 10, 2602. [Google Scholar] [CrossRef]
- Floridi, L.; Cowls, J.; Beltrametti, M.; Chatila, R.; Chazerand, P.; Dignum, V.; Luetge, C.; Madelin, R.; Pagallo, U.; Rossi, F.; et al. AI4People—An ethical framework for a good AI society: Opportunities, risks, principles, and recommendations. Minds Mach. 2018, 28, 689–707. [Google Scholar] [CrossRef]
- Blache, P. Property grammars: A fully constraint-based theory. In Constraint Solving and Language Processing; Christiansen, H., Skadhauge, P.R., Villadsen, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3438, pp. 1–16. [Google Scholar]
- Joshi, A.K.; Levy, L.S.; Takahashi, M. Tree adjunct grammars. J. Comput. Syst. Sci. 1975, 10, 136–163. [Google Scholar] [CrossRef]
- Schutze, C.T. The Empirical Base of Linguistics: Grammaticality Judgments and Linguistic Methodology; University of Chicago Press: Chicago, IL, USA, 1996. [Google Scholar]
- Pullum, G.K.; Scholz, B.C. On the distinction between model-theoretic and generative-enumerative syntactic frameworks. In Proceedings of the International Conference on Logical Aspects of Computational Linguistics, Le Croisic, France, 27–29 June 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 17–43. [Google Scholar]
- Aarts, B. Modelling linguistic gradience. Stud. Lang. 2004, 28, 1–49. [Google Scholar] [CrossRef]
- Jespersen, O. The Philosophy of Grammar; George Allen and Unwin Ltd.: London, UK, 1924. [Google Scholar]
- Curme, G.O. A Grammar of the English Language, Vol. II: Parts of Speech and Accidence; DC Heath and Co.: Boston, MA, USA, 1935. [Google Scholar]
- Wells, R. Is a structural treatment of meaning possible? In Proceedings of the Eight International Congress of Linguists; Eva, S., Ed.; Oslo University Press: Oslo, Norway, 1958; pp. 636–704. [Google Scholar]
- Crystal, D. English. Lingua 1967, 17, 24–56. [Google Scholar] [CrossRef]
- Quirk, R. Descriptive statement and serial relationship. Language 1965, 41, 205–217. [Google Scholar] [CrossRef]
- Chomsky, N. The Logical Structure of Linguistic Theory; Plenum Press: Aarhus, Denmark, 1975. [Google Scholar]
- Daneš, F. The relation of centre and periphery as a language universal. Trav. Linguist. De Prague 1966, 2, 9–21. [Google Scholar]
- Vachek, J. On the integration of the peripheral elements into the system of language. Trav. Linguist. De Prague 1966, 2, 23–37. [Google Scholar]
- Neustupnỳ, J.V. On the analysis of linguistic vagueness. Trav. Linguist. De Prague 1966, 2, 39–51. [Google Scholar]
- Ross, J.R. Adjectives as noun phrases. In Modern Studies in English; Reibel, D.A., Schane, S.A., Eds.; Prentice-Hall: Englewood Cliffs, NJ, USA, 1969; pp. 352–360. [Google Scholar]
- Ross, J.R. Auxiliaries as main verbs. In Proceedings of the Studies in Philosophical Linguistics. Series I. Great Expectations; Todd, W., Ed.; Great Expectation: Evanston, IL, USA, 1969; pp. 77–102. [Google Scholar]
- Ross, J.R. A fake NP squish. In New Ways of Analyzing Variation in English; Bailey, C.J.N., Shuy, R.W., Eds.; Georgetown University Press: Washington, DC, USA, 1973; pp. 96–140. [Google Scholar]
- Ross, J.R. Nouniness. In Three Dimensions of Linguistic Theory; Kiparsky, P., Fujimura, O., Eds.; TEC Company Ltd.: Tokyo, Japan, 1973; pp. 137–328. [Google Scholar]
- Ross, J.R. Three batons for cognitive psychology. In Cognition and the Symbolic Processes; Weimer, W.B., Palermo, D.S., Eds.; Lawrence Erlbaum: Oxford, UK, 1974; pp. 63–124. [Google Scholar]
- Ross, J.R. The frozeness of pseudoclefts: Towards an inequality-based syntax. In Proceedings of the Papers from the Thirty-Sixth Regional Meeting of the Chicago Linguistic Society, Chicago, IL, USA, 28–30 December 1961; Okrent, A., Boyle, J., Eds.; Chicago Linguistic Society: Chicago, IL, USA, 2000; pp. 385–426. [Google Scholar]
- Lakoff, G. Linguistics and natural logic. Synthese 1970, 22, 151–271. [Google Scholar] [CrossRef]
- Rosch, E. On the internal structure of perceptual and semantic categories. In Cognitive Development and Acquisition of Language; Moore, T.E., Ed.; Academic Press: Amsterdam, The Netherlands, 1973; pp. 111–144. [Google Scholar]
- Rosch, E. Natural categories. Cogn. Psychol. 1973, 4, 328–350. [Google Scholar] [CrossRef]
- Rosch, E. Cognitive representations of semantic categories. J. Exp. Psychol. Gen. 1975, 104, 192. [Google Scholar] [CrossRef]
- Labov, W. The boundaries of words and their meanings. In New Ways of Analyzing Variations in English; Bailey, C., Shuy, R., Eds.; Georgetown University Press: Washington, DC, USA, 1973; pp. 340–373. [Google Scholar]
- Prince, A.; Smolensky, P. Optimality Theory: Constraint Interaction in Generative Grammar; Rutgers University: New Brunswick, NJ, USA, 1993. [Google Scholar]
- Legendre, G.; Miyata, Y.; Smolensky, P. Harmonic Grammar: A formal multi-level connectionist theory of linguistic well-Formedness: An application. In Proceedings of the 12th Annual Conference of the Cognitive Science Society, Cambridge, UK, 25–28 July 1990; Lawrence Erlbaum Associates: Cambridge, UK, 1990; pp. 884–891. [Google Scholar]
- Müller, G. Optimality, markedness, and word order in German. Linguistics 1999, 37, 777–818. [Google Scholar] [CrossRef]
- Blache, P.; Prost, J.P. A quantification model of grammaticality. In Proceedings of the Fifth International Workshop on Constraints and Language Processing (CSLP2008); Villadsen, J., Christiansen, H., Eds.; Computer Science Research Reports; Roskilde University: Roskilde, Denmark, 2008; Volume 122, pp. 5–19. [Google Scholar]
- Blache, P.; Balfourier, J.M. Property Grammars: A Flexible Constraint-Based Approach to Parsing. In Proceedings of the 7th International Conference on Parsing Technologies, IWPT 2001, Beijing, China, 17–19 October 2001. [Google Scholar]
- Fillmore, C.J. The mechanisms of “construction grammar”. In Proceedings of the Fourteenth Annual Meeting of the Berkeley Linguistics Society; Axmaker, S., Jaisser, A., Singmaster, H., Eds.; Berkeley Linguistics Society: Berkeley, CA, USA, 1988; Volume 14, pp. 35–55. [Google Scholar]
- Goldberg, A. Constructions: A new theoretical approach to language. Trends Cogn. Sci. 2003, 7, 219–224. [Google Scholar] [CrossRef] [PubMed]
- Guénot, M.L.; Blache, P. A descriptive and formal perspective for grammar development. In Proceedings of the Foundations of Natural-Language Grammar, Edinburgh, UK, 16–20 August 2005; Available online: https://hal.science/hal-00134236/document (accessed on 29 November 2022).
- Blache, P.; Prévot, L. A formal scheme for multimodal grammars. In Proceedings of the 23rd International Conference on Computational Linguistics: Posters, Association for Computational Linguistics, Beijing, China, 23–27 August 2010; pp. 63–71. [Google Scholar]
- Blache, P.; Bertrand, R.; Ferré, G. Creating and exploiting multimodal annotated corpora: The toma project. In Multimodal Corpora; Kipp, M., Martin, J.C., Paggio, P., Heylen, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; Volume LNAI 5509, pp. 38–53. [Google Scholar]
- Novák, V. Fuzzy Natural Logic: Towards Mathematical Logic of Human Reasoning. In Towards the Future of Fuzzy Logic; Seising, R., Trillas, E., Kacprzyk, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; pp. 137–165. [Google Scholar]
- Novák, V. On Fuzzy Type Theory. Fuzzy Sets Syst. 2005, 149, 235–273. [Google Scholar] [CrossRef]
- Montague, R. Universal grammar. Theoria 1970, 36, 373–398. [Google Scholar] [CrossRef]
- Novák, V. A Comprehensive Theory of Trichotomous Evaluative Linguistic Expressions. Fuzzy Sets Syst. 2008, 159, 2939–2969. [Google Scholar] [CrossRef]
- Novák, V. Mathematical Fuzzy Logic in Modeling of Natural Language Semantics. In Fuzzy Logic—A Spectrum of Theoretical & Practical Issues; Wang, P., Ruan, D., Kerre, E., Eds.; Elsevier: Amsterdam, The Netherlands, 2007; pp. 145–182. [Google Scholar]
- Novák, V.; Lehmke, S. Logical Structure of Fuzzy IF-THEN rules. Fuzzy Sets Syst. 2006, 157, 2003–2029. [Google Scholar] [CrossRef]
- Murinová, P.; Novák, V. Syllogisms and 5-Square of Opposition with Intermediate Quantifiers in Fuzzy Natural Logic. Log. Universalis 2016, 10, 339–357. [Google Scholar] [CrossRef]
- Novák, V. A Formal Theory of Intermediate Quantifiers. Fuzzy Sets Syst. 2008, 159, 1229–1246. [Google Scholar] [CrossRef]
- Novák, V. Fuzzy Natural Logic: Theory and Applications. In Proceedings of the Fuzzy Sets and Their Applications FSTA 2016, Liptovsky Jan, Slovakia, 27 January 2016; Available online: https://irafm.osu.cz/f/Conferences/FSTA2016Sli.pdf (accessed on 29 November 2022).
- Torrens-Urrutia, A. An Approach to Measuring Complexity with a Fuzzy Grammar & Degrees of Grammaticality. In Proceedings of the Workshop on Linguistic Complexity and Natural Language Processing, Santa Fe, NM, USA, 25 August 2018; pp. 59–67. [Google Scholar]
- Torrens-Urrutia, A. An approach to measuring complexity within the boundaries of a natural language fuzzy grammar. In Proceedings of the International Symposium on Distributed Computing and Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2018; pp. 222–230. [Google Scholar]
- Torrens Urrutia, A. A Formal Characterization of Fuzzy Degrees of Grammaticality for Natural Language. Ph.D. Thesis, Universitat Rovira i Virgili, Tarragona, Spain, 2019. [Google Scholar]
- Fillmore, C.J.; Baker, C. A frames approach to semantic analysis. In The Oxford Handbook of Linguistic Analysis; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Goldberg, A. Verbs, constructions and semantic frames. In Syntax, Lexical Semantics, and Event Structure; Oxford University Press: Oxford, UK, 2010; pp. 39–58. [Google Scholar]
- Novák, V.; Perfilieva, I.; Dvorak, A. Insight into Fuzzy Modeling; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Novak, V. Evaluative linguistic expressions vs. fuzzy categories. Fuzzy Sets Syst. 2015, 281, 73–87. [Google Scholar] [CrossRef]
- Blache, P.; Rauzy, S.; Montcheuil, G. MarsaGram: An excursion in the forests of parsing trees. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), Portorož, Slovenia, 23–28 May 2016; pp. 2336–2342. [Google Scholar]
- Goldberg, A. Constructions: A Construction Grammar Approach to Argument Structure; University of Chicago Press: Chicago, IL, USA, 1995. [Google Scholar]
- Sakthivel, R.; Kavikumar, R.; Mohammadzadeh, A.; Kwon, O.M.; Kaviarasan, B. Fault estimation for mode-dependent IT2 fuzzy systems with quantized output signals. IEEE Trans. Fuzzy Syst. 2020, 29, 298–309. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).