

A Semantics-Based Clustering Approach for Online Laboratories Using K-Means and HAC Algorithms



Abstract
:1. Introduction
2. Related Work
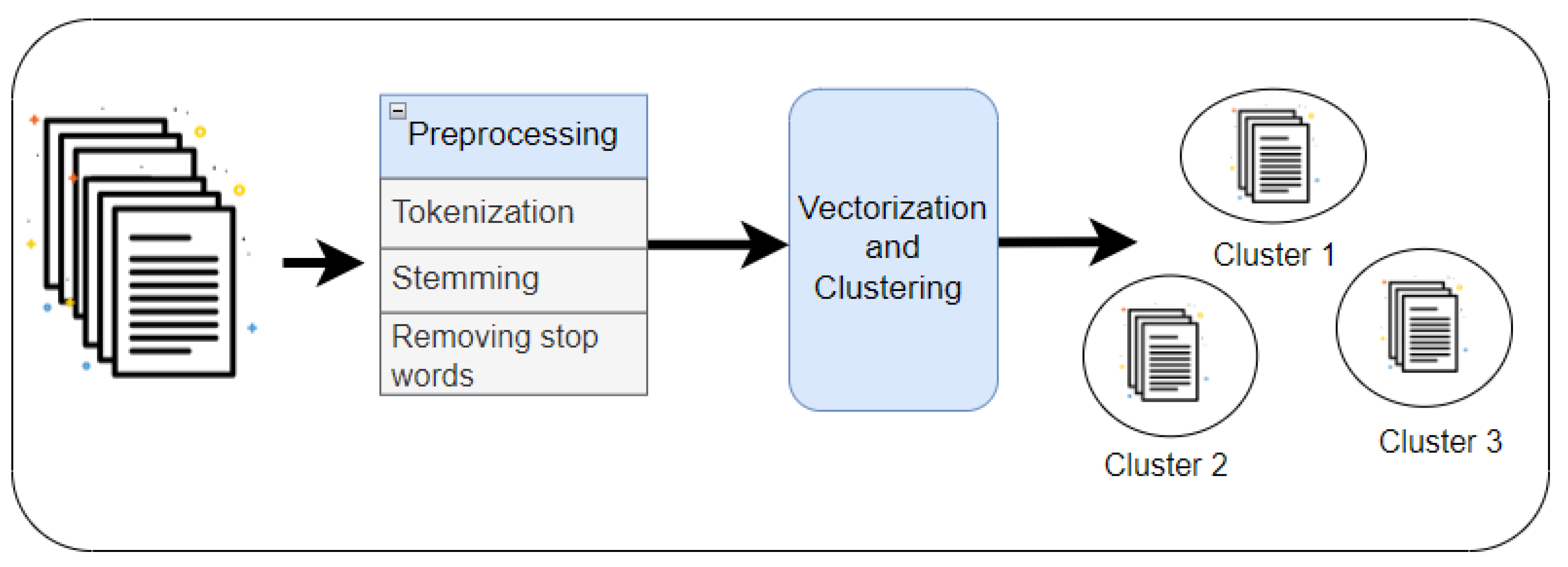
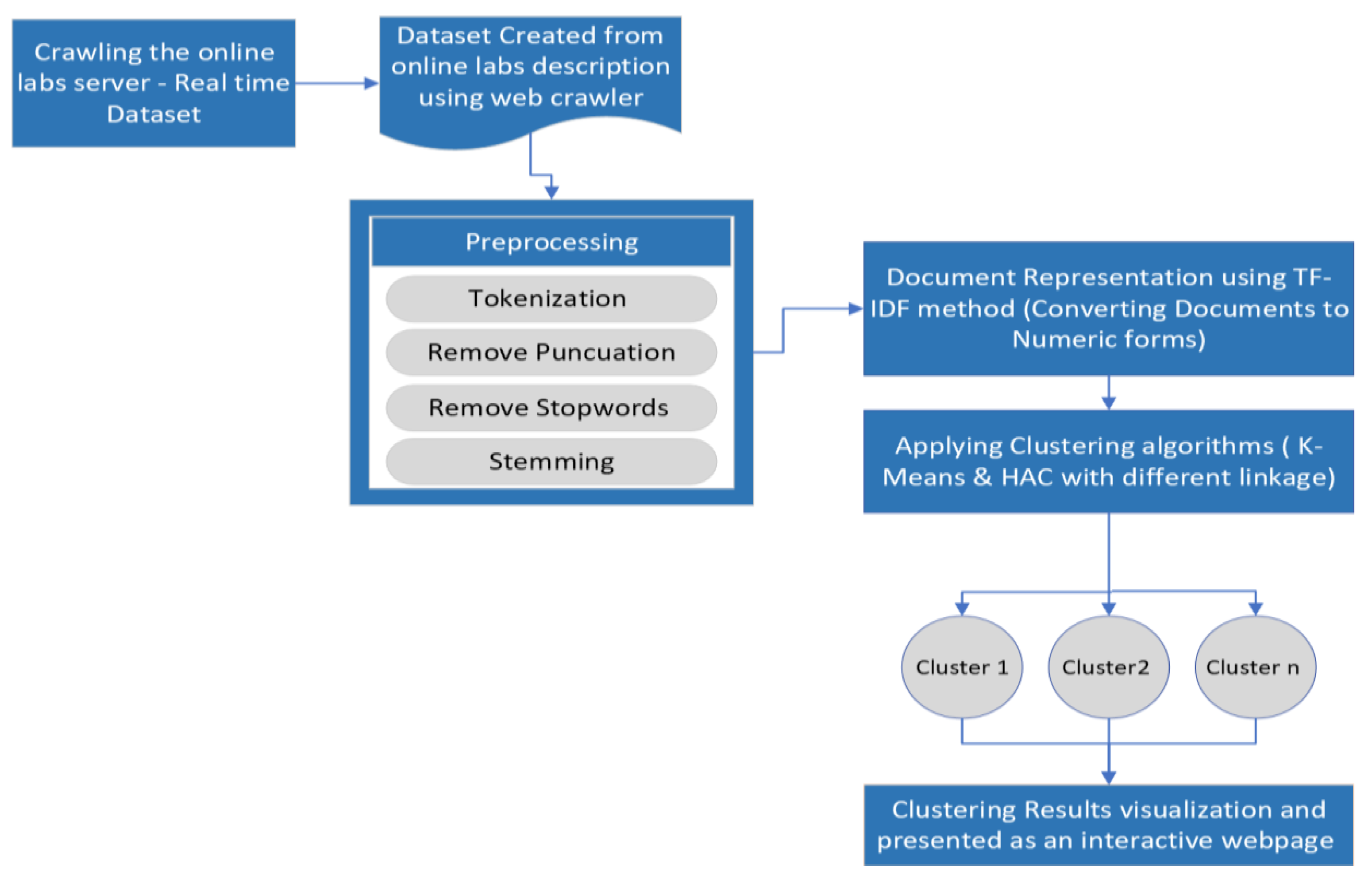
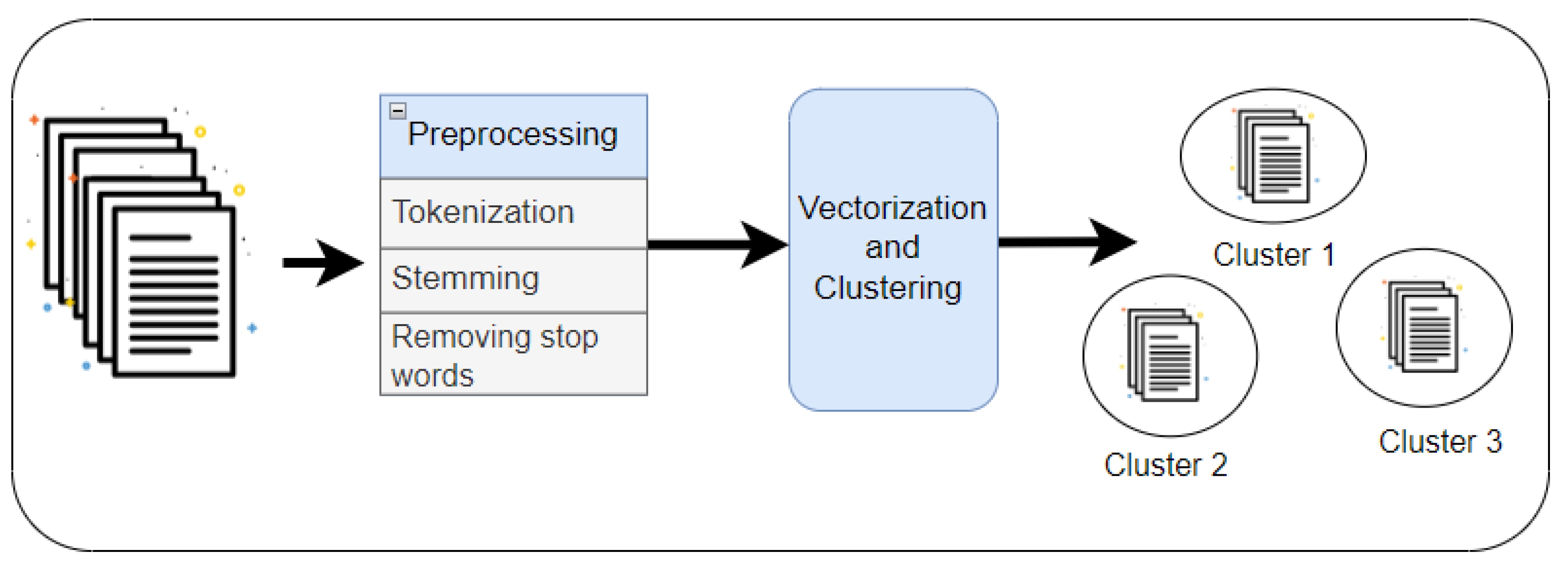
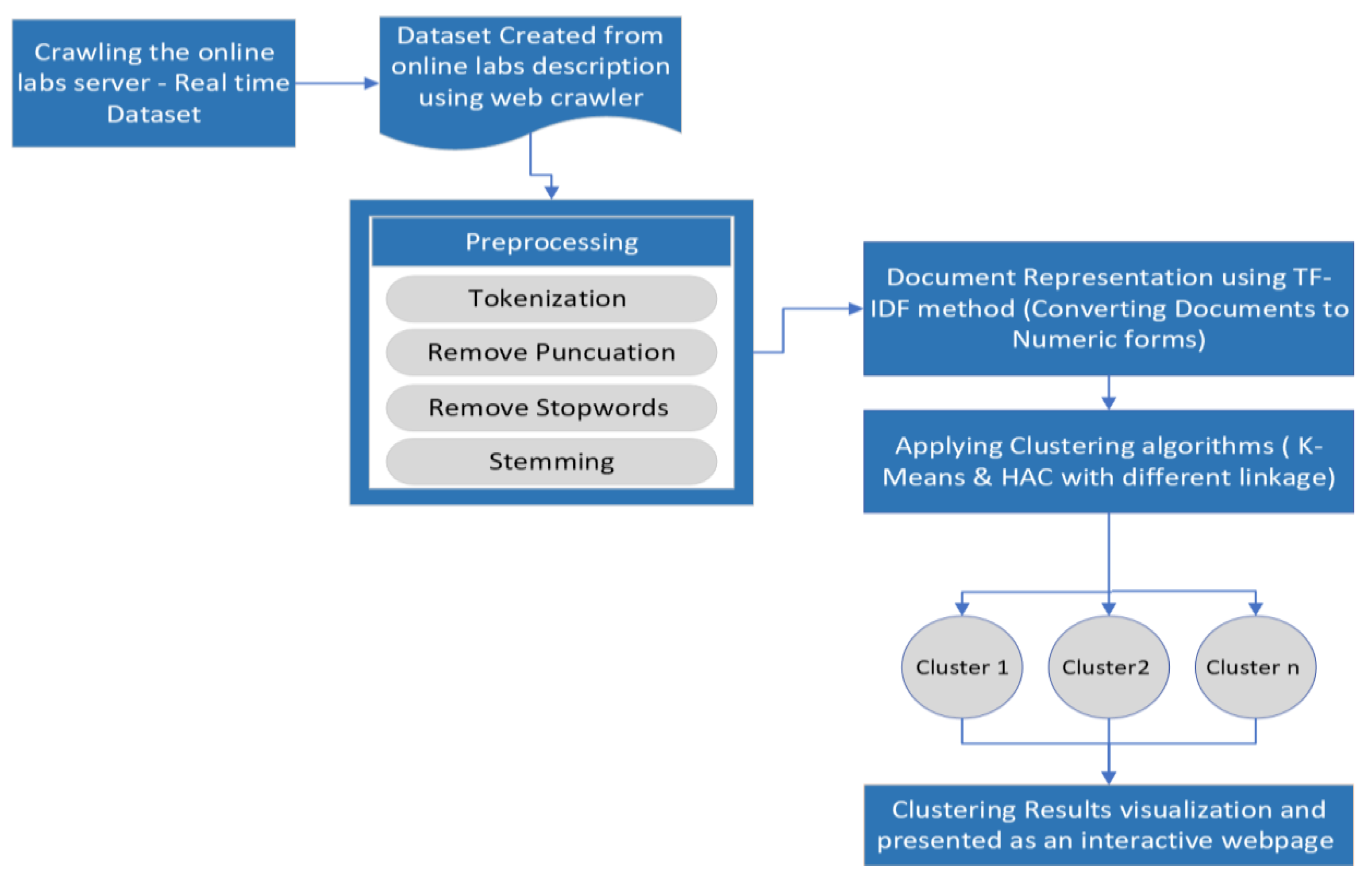
3. The Methodology of Proposed work
3.1. Data Gathering and Crawling
3.2. Document Preparation
3.3. Representing Document
3.4. Using the K-Means and HAC Clustering Algorithms
3.4.1. K-Means Algorithm
- Determine the number of clusters by selecting value K.
- Select K points or centroids randomly.
- Assign each data point to its nearest centroid, so constructing the K clusters specified in advance.
- Determine the variance and add a new centroid to each cluster.
- Repeat the third step, this time reassigning each data point to the cluster’s new nearest centroid.
- Proceed to step 4 if reassignment occurs; otherwise, proceed to FINISH.
- The model is complete.
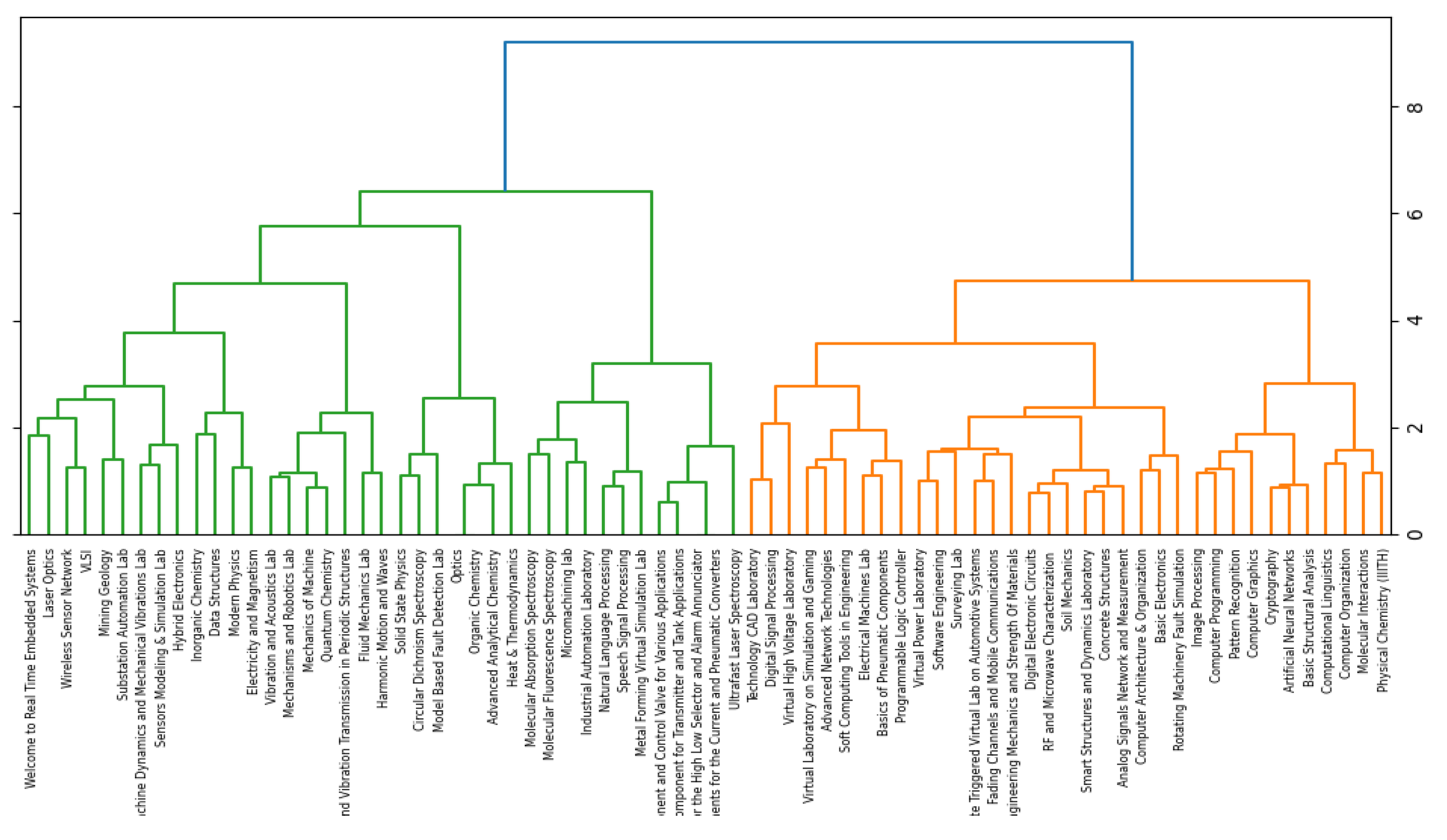
3.4.2. Agglomerative Hierarchical Clustering (HAC)
- Each data point is assigned to one cluster.
- Determine the measurement of distance and compute the distance matrix.
- Identify the “linkage” criteria for combining the clusters.
- Updated the distance matrix
- Repeat the procedure until each data point is represented by a single cluster.
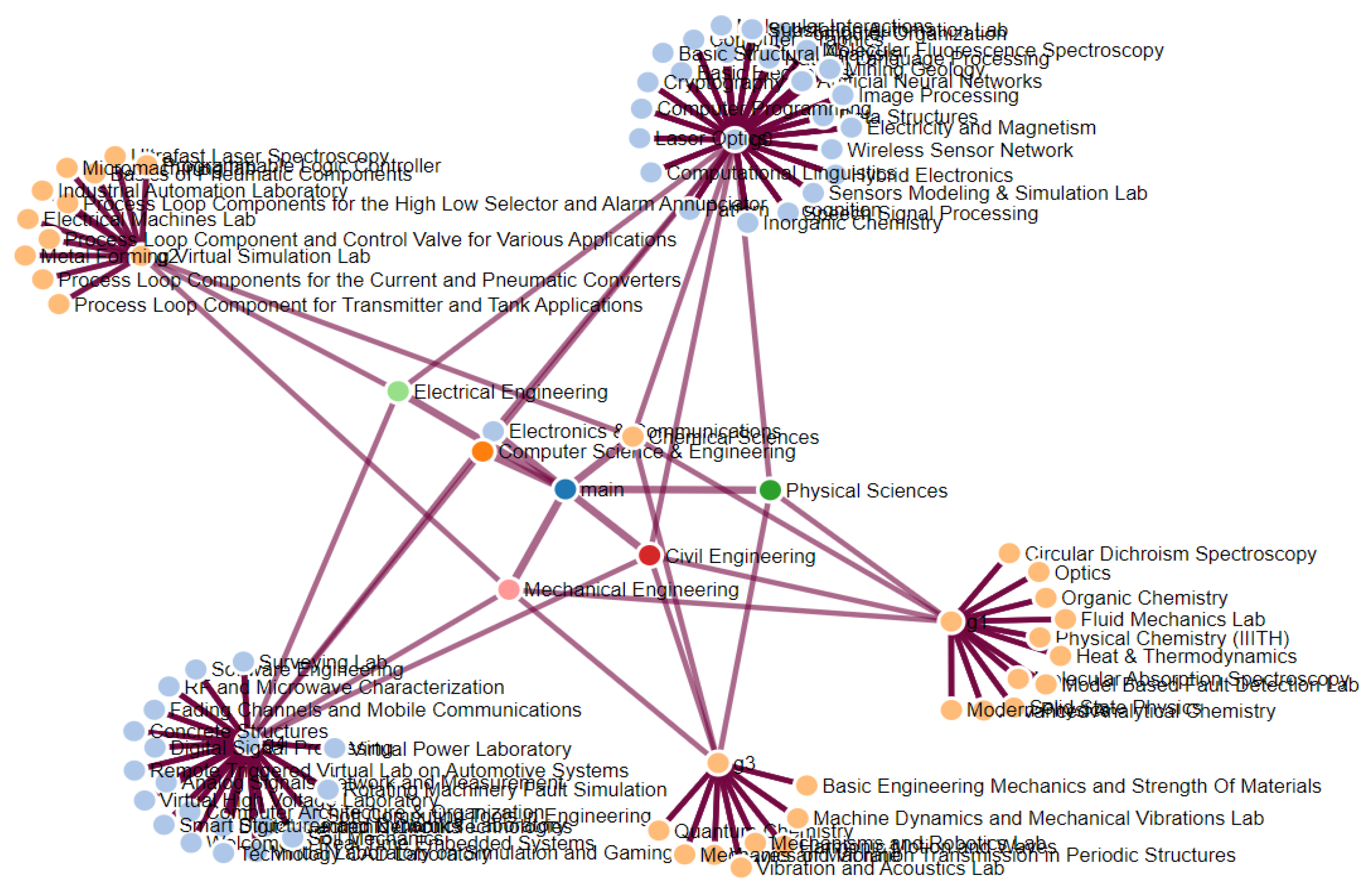
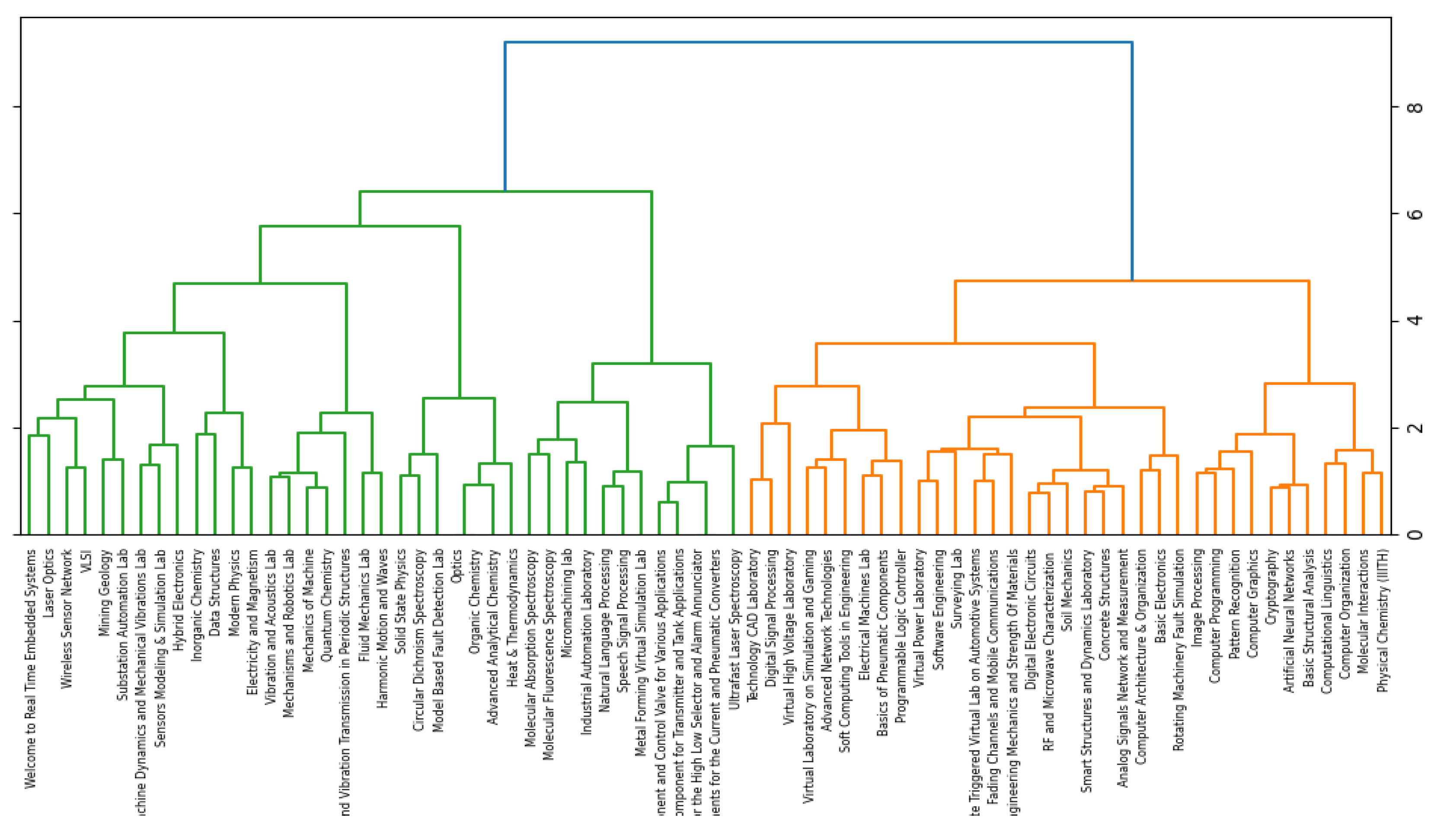
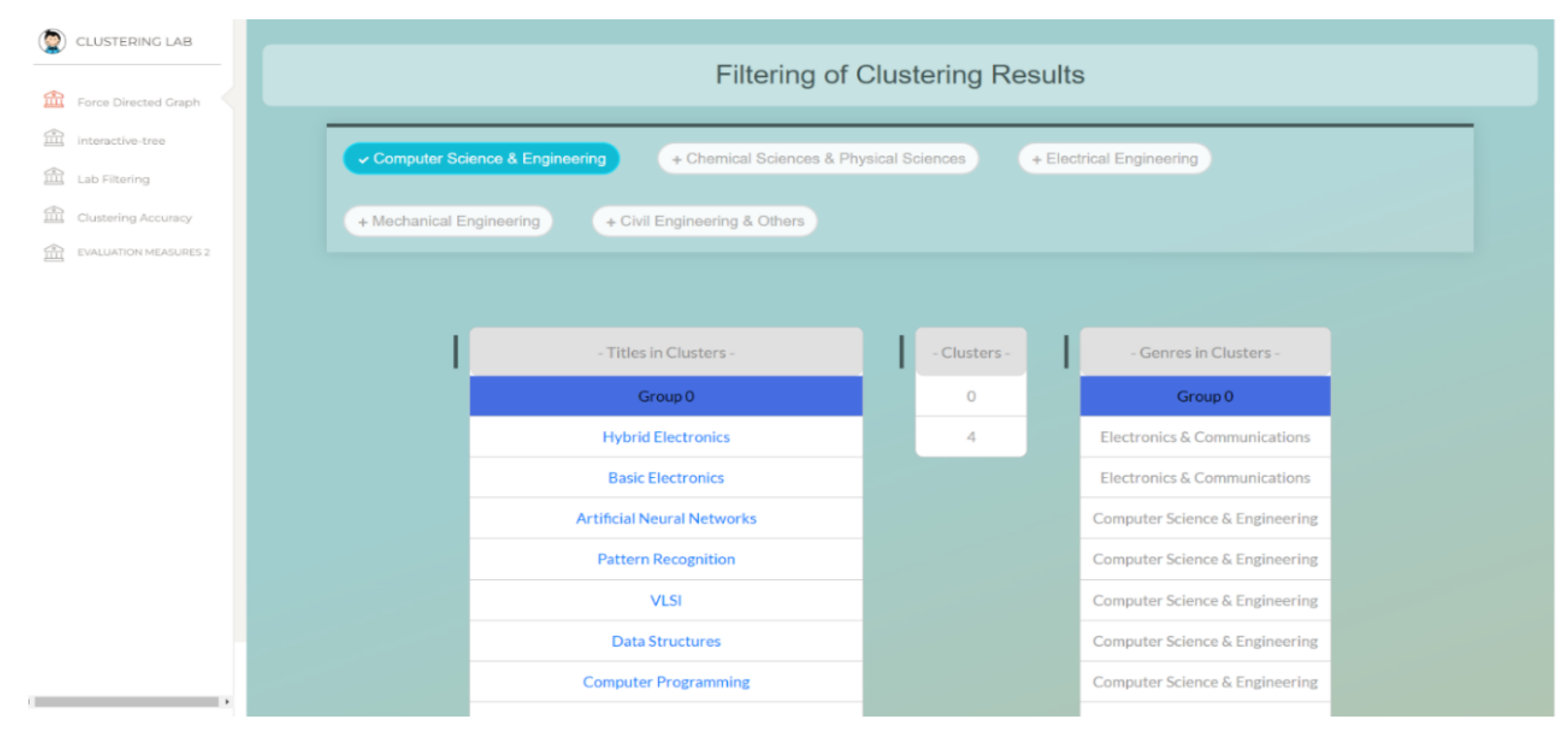
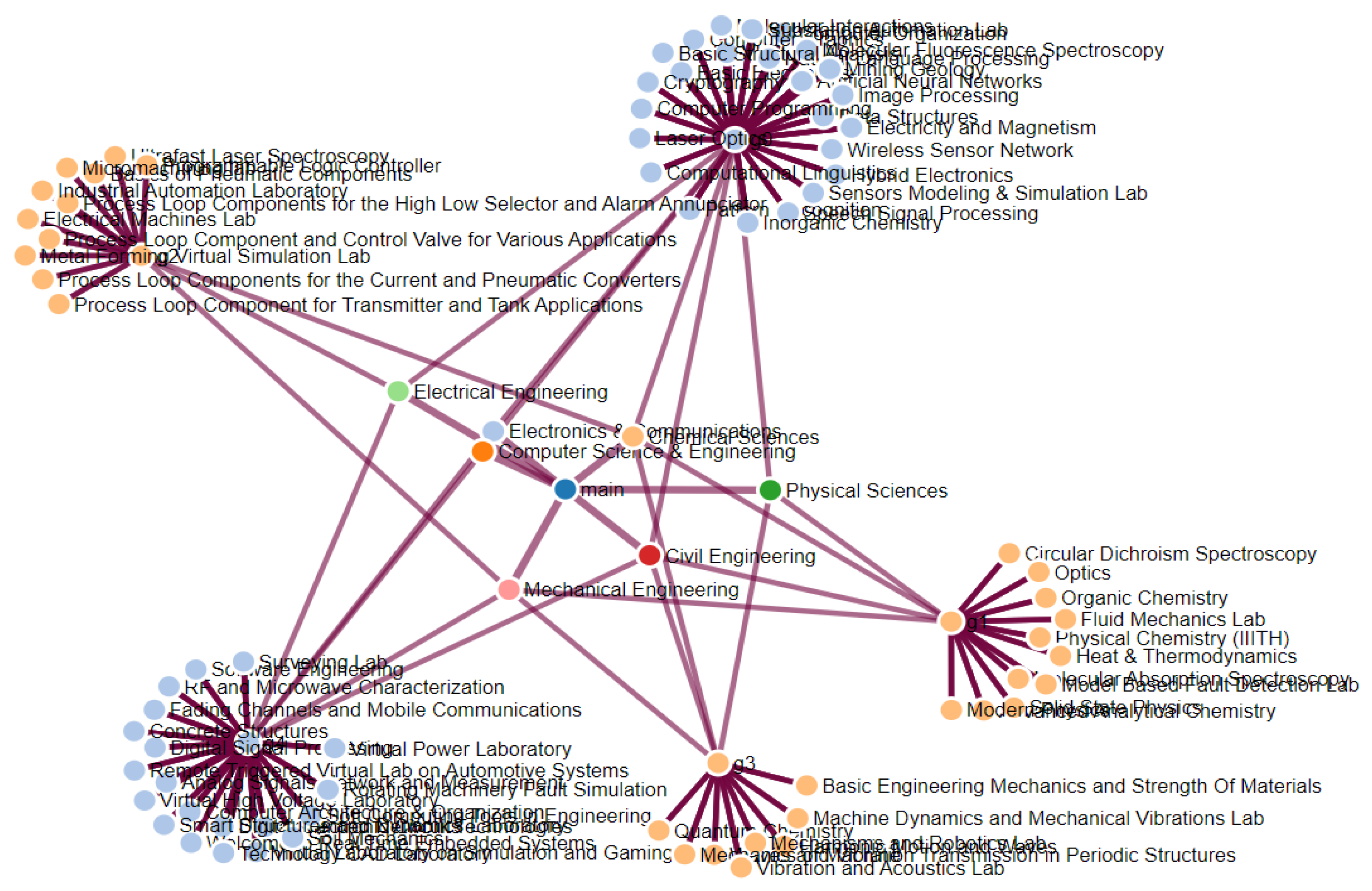
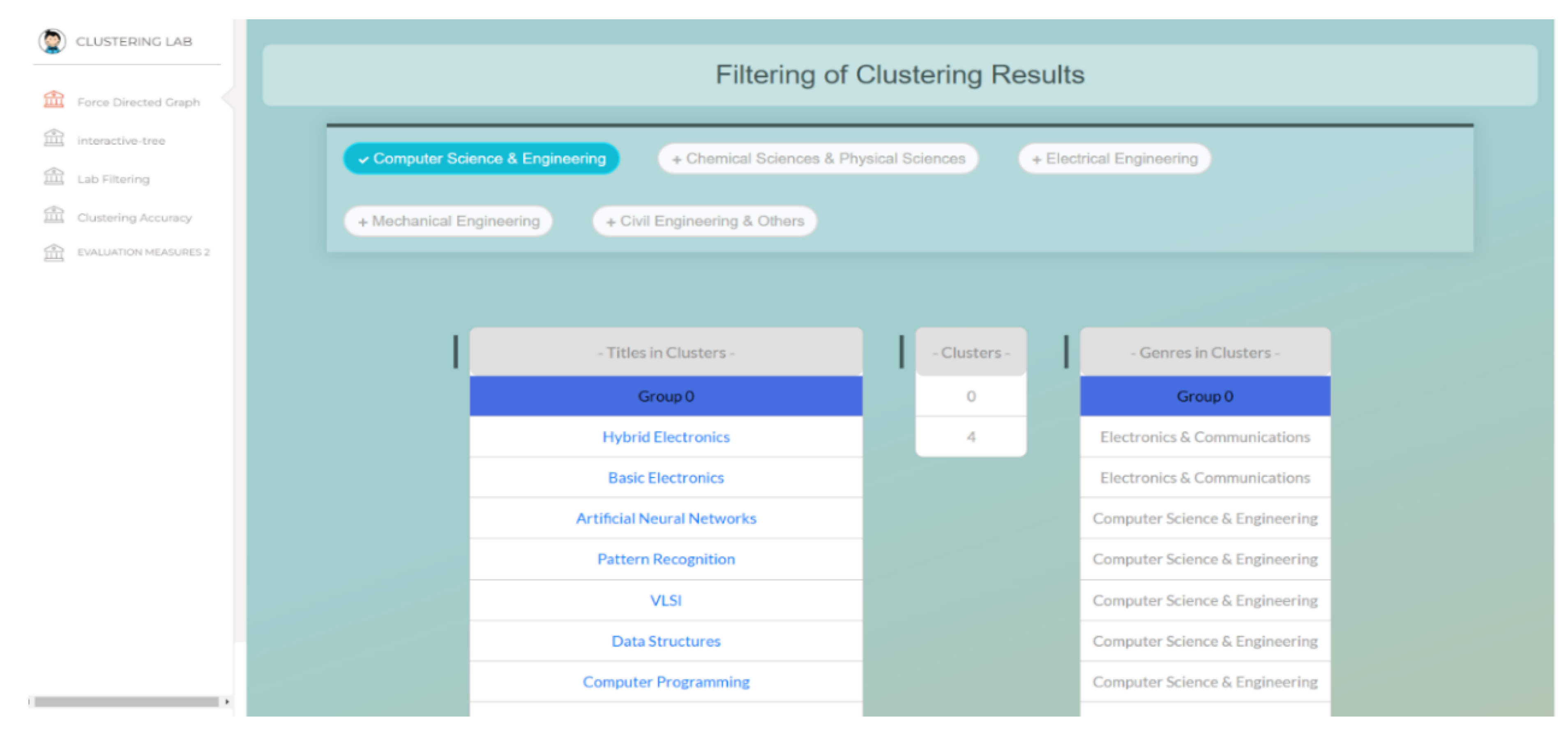
4. Clustering Result Representation
5. Experimental Results and Implementation
5.1. Datasets
- NLTK_Reuters: Reuters-21578 is the most frequent dataset used to evaluate document categorization and document clustering. It has 19,715 unique documents.
- NLTK_Brown: The corpus comprises one million words of American English writing published in 1961 and comprises 500 unique documents.
- Txt-Sentoken: Including negative and positive folders of review movies, this medium-sized dataset has 2000 unique documents.
- 20 Newsgroups: This is a highly frequent and valid dataset containing 18,846 unique documents and is used to test numerous data mining methods, text application and machine learning methods, etc.
- Online Labs: This is a small dataset which contains the descriptions of 95 online laboratories obtained by crawling the short real-time description of the online laboratories’ repository from the online laboratories’ servers. Each lab’s titles, genres and descriptions are included.
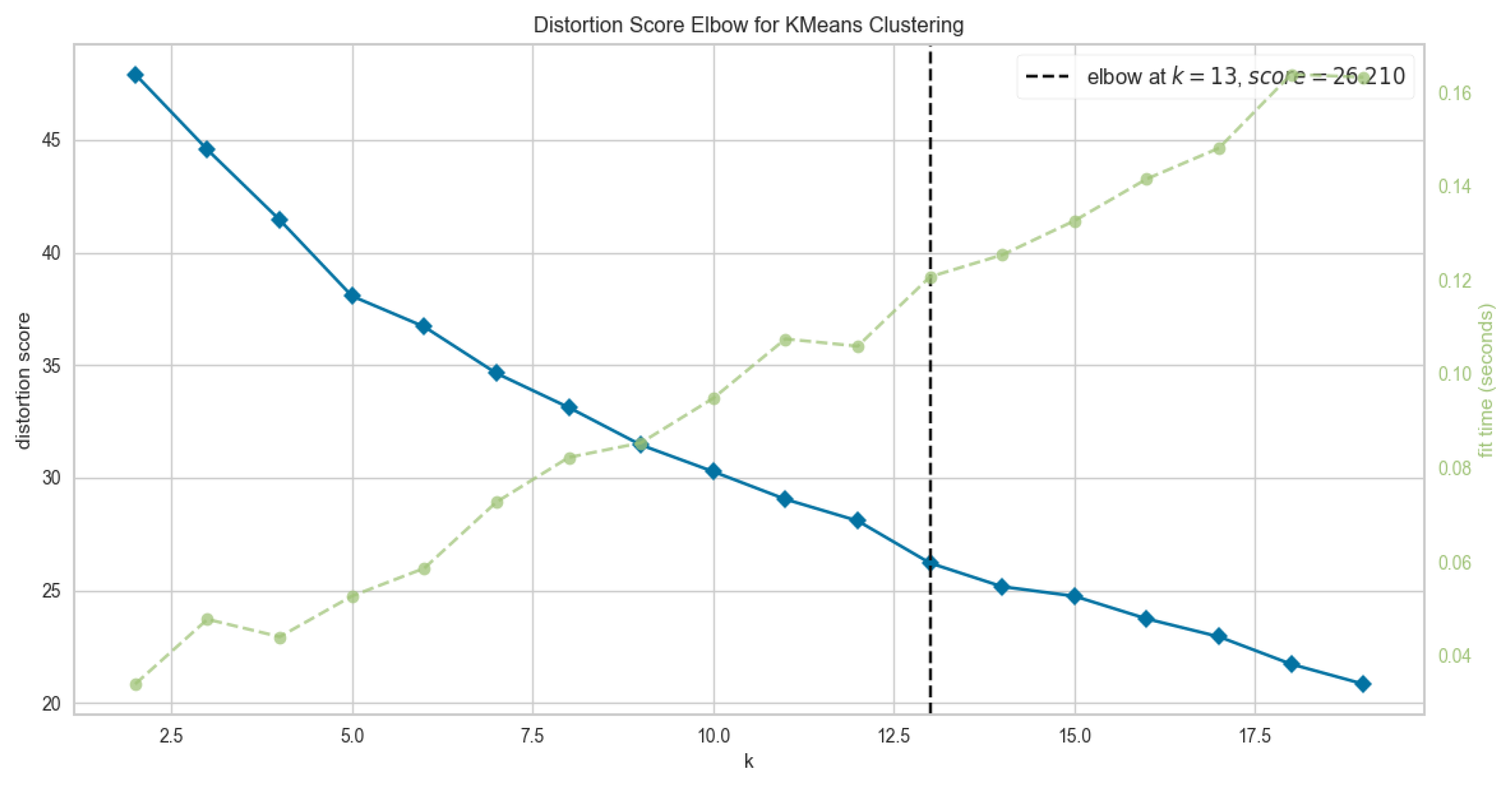
5.2. Optimal Cluster Number
5.3. Evaluation Measures
6. Results and Discussion
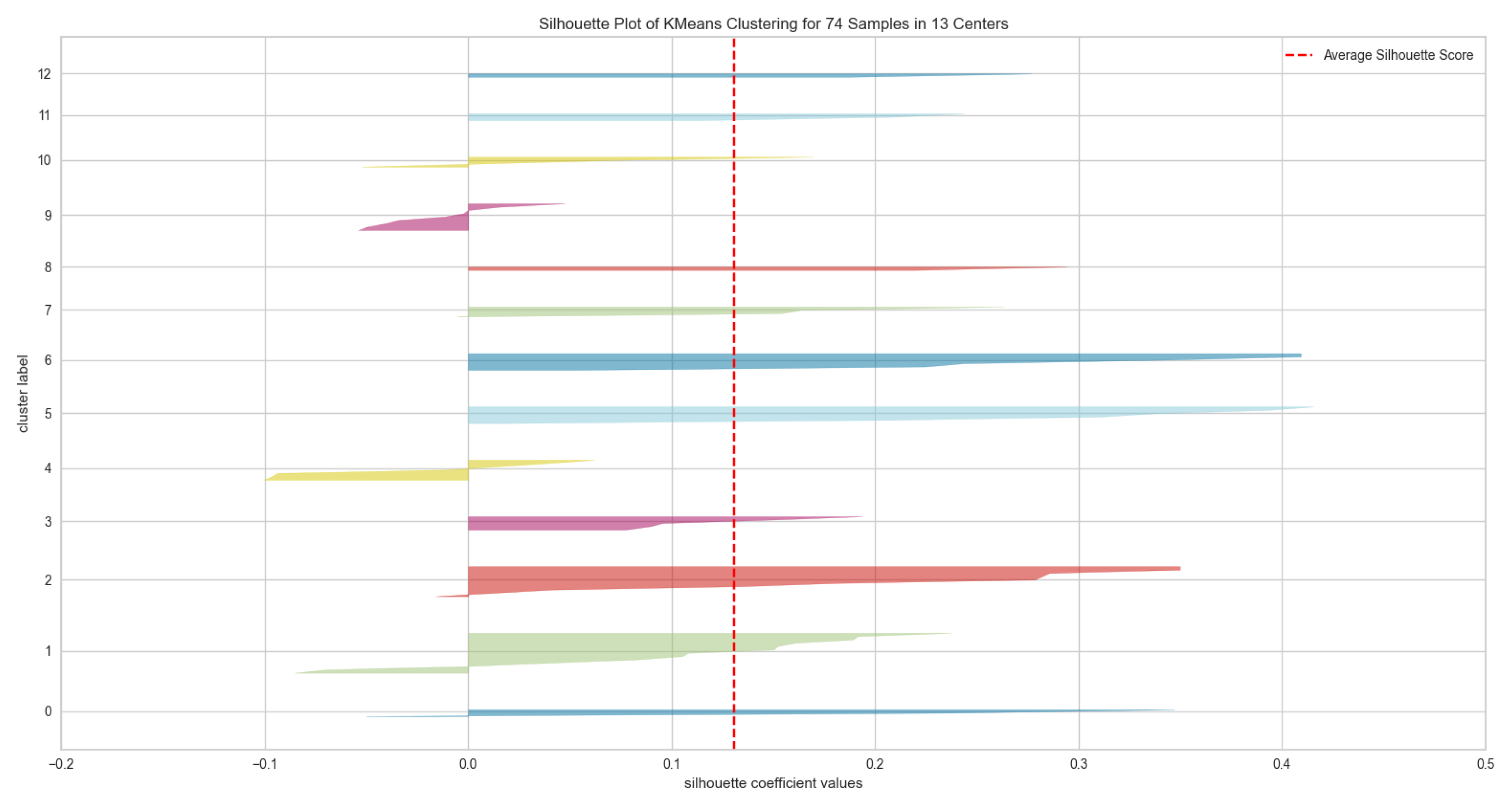
6.1. Internal Evaluation for the Proposed System
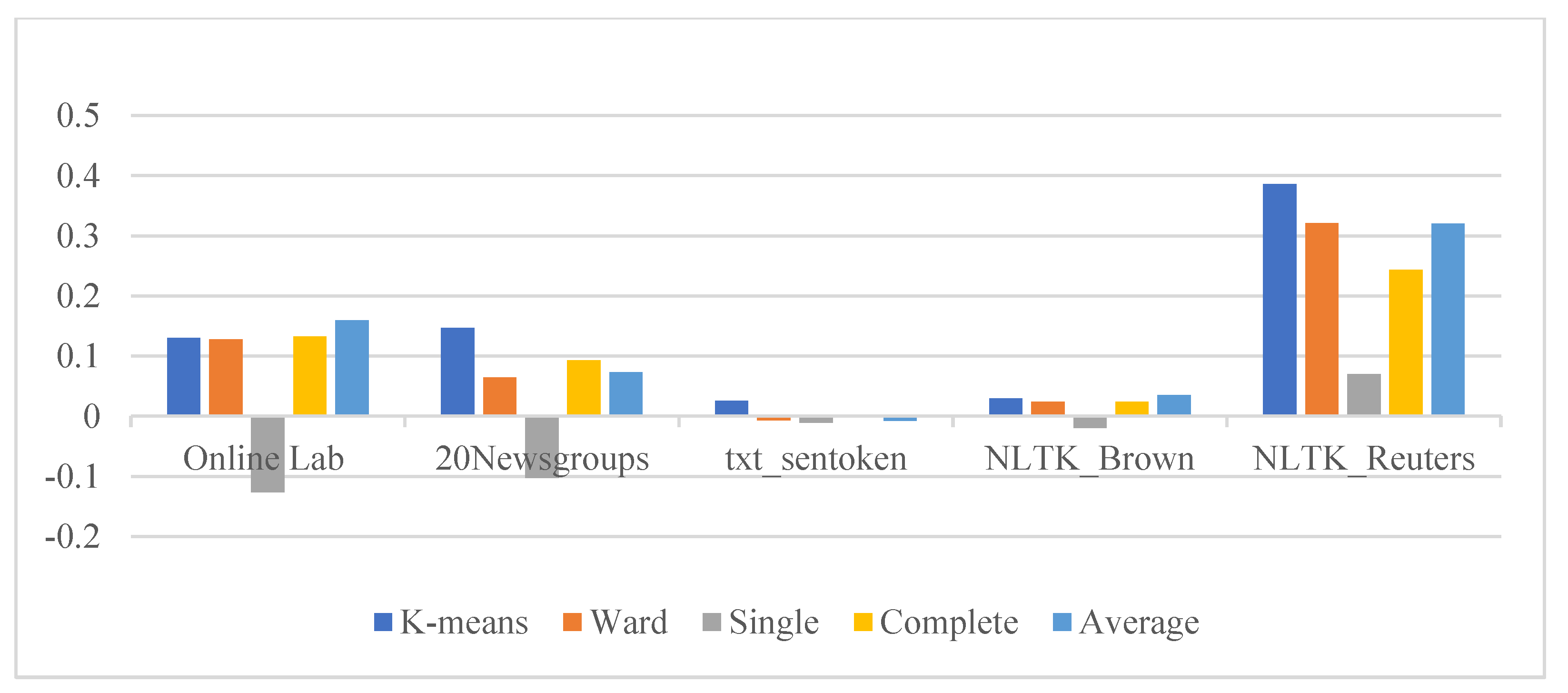
6.2. External Evaluation for the Proposed System
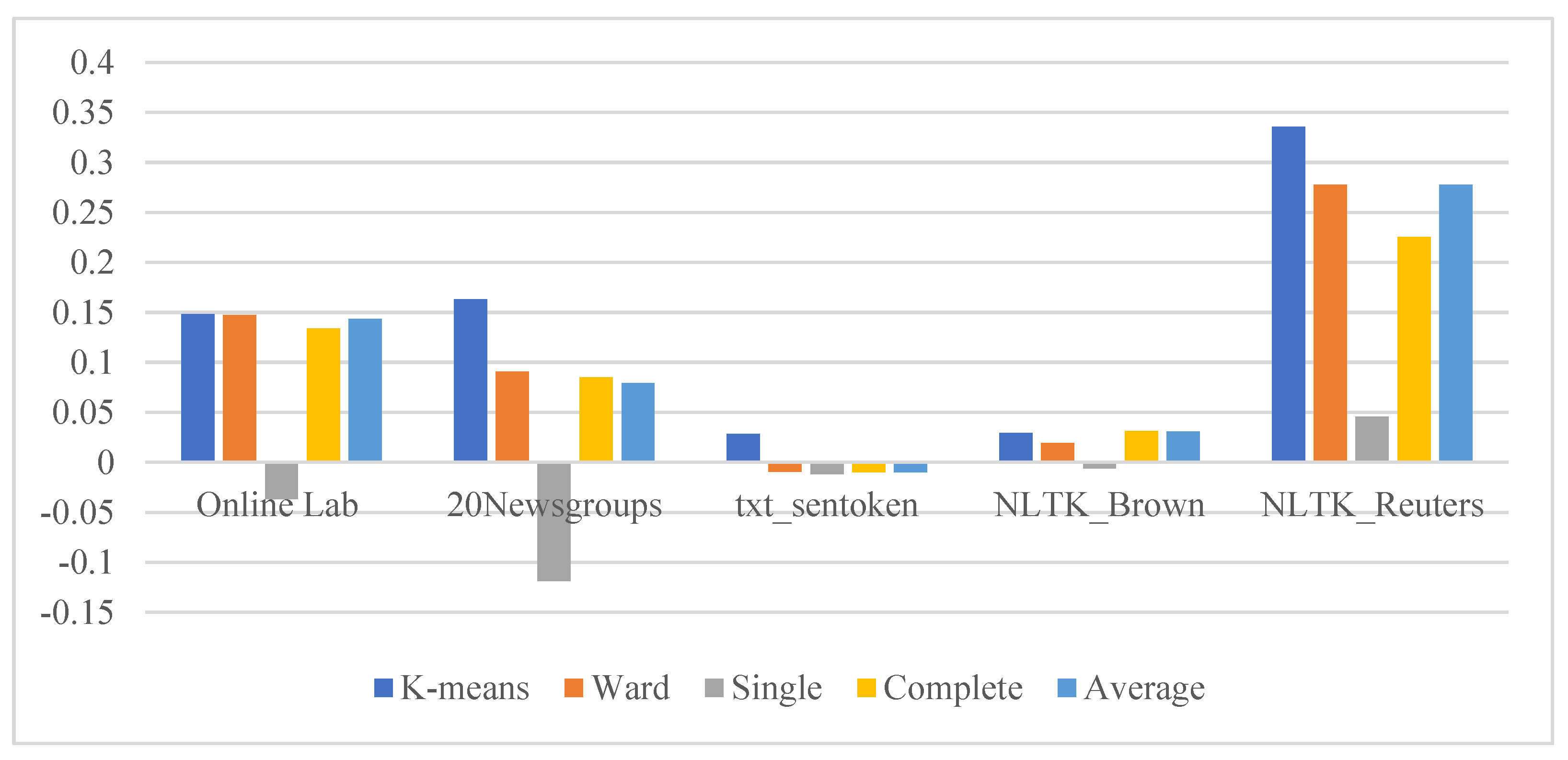
- Evaluation metrics for the K-Means algorithm of optimal cluster number K = 13 as shown in Table 2:
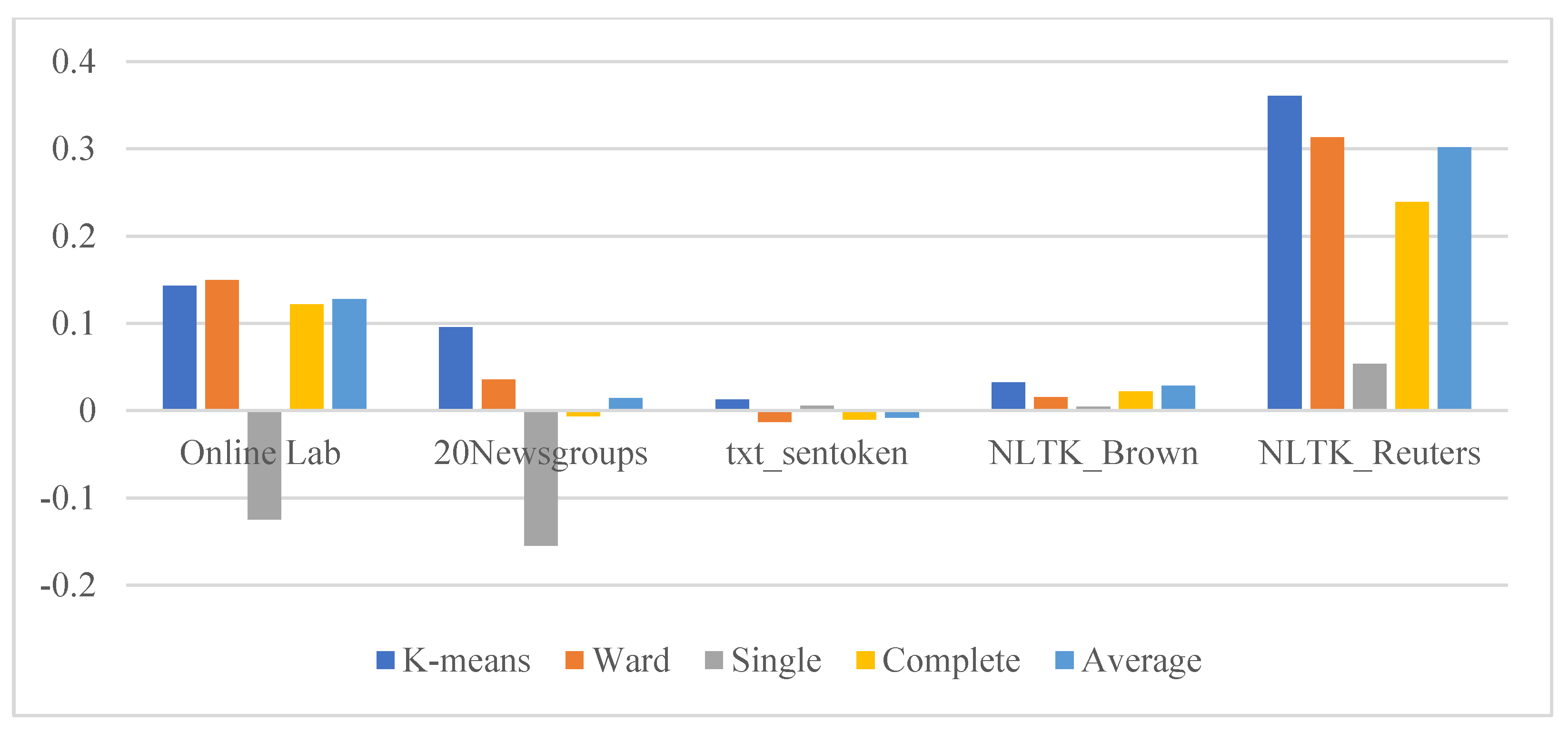
- Evaluation metrics for the HAC (Ward method) algorithm of optimal cluster number K = 13 as shown in Table 2:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | Scenarios | Datasets | Purity | V-Measure | F-Measure | Accuracy | Homogeneity | Completeness | NMI-Score |
|---|---|---|---|---|---|---|---|---|---|
| K-Means | WoPP | Online Lab | 0.462162162 | 0.345549506 | 0.014574899 | 0.024324324 | 0.397271606 | 0.305743723 | 0.345549506 |
| 20 Newsgroups | 0.102408999 | 0.043879554 | 0.036345756 | 0.047808554 | 0.039965172 | 0.048643981 | 0.043879554 | ||
| txt_sentoken | 0.6075 | 0.019775376 | 0.016650513 | 0.0635 | 0.045449135 | 0.012636911 | 0.019775376 | ||
| NLTK_Brown | 0.36 | 0.326133575 | 0.057811277 | 0.06 | 0.320056571 | 0.332445818 | 0.326133575 | ||
| NLTK_Reuters | 0.542404301 | 0.134296242 | 0.001147675 | 0.025210863 | 0.148022042 | 0.122899964 | 0.134296242 | ||
| PPWoS | Online Lab | 0.445946 | 0.33343 | 0.062572 | 0.094595 | 0.383353 | 0.295011 | 0.33343 | |
| 20 Newsgroups | 0.104266 | 0.042329 | 0.043036 | 0.058633 | 0.038738 | 0.046653 | 0.042329 | ||
| txt_sentoken | 0.611 | 0.021128 | 0.015683 | 0.057 | 0.048037 | 0.013542 | 0.021128 | ||
| NLTK_Brown | 0.342 | 0.339315 | 0.06665 | 0.096 | 0.336702 | 0.34197 | 0.339315 | ||
| NLTK_Reuters | 0.534202 | 0.124766 | 0.003014 | 0.046992 | 0.138458 | 0.113538 | 0.124766 | ||
| PPwS | Online Lab | 0.554054 | 0.438731 | 0.081511 | 0.108108 | 0.501941 | 0.389661 | 0.438731 | |
| 20 Newsgroups | 0.109201 | 0.052181 | 0.048011 | 0.065266 | 0.047916 | 0.05728 | 0.052181 | ||
| txt_sentoken | 0.6135 | 0.027836 | 0.018374 | 0.0685 | 0.064871 | 0.01772 | 0.027836 | ||
| NLTK_Brown | 0.368 | 0.372691 | 0.016878 | 0.024 | 0.365426 | 0.380252 | 0.372691 | ||
| NLTK_Reuters | 0.535082 | 0.124158 | 0.002725 | 0.062656 | 0.137668 | 0.113062 | 0.124158 | ||
| HAC (Ward) | WoPP | Online Lab | 0.513513514 | 0.387974527 | 0.060164835 | 0.094594595 | 0.448631654 | 0.341766126 | 0.387974527 |
| 20 Newsgroups | 0.105752 | 0.044192 | 0.035488 | 0.051682 | 0.039858 | 0.049583 | 0.044192 | ||
| txt_sentoken | 0.593 | 0.022797 | 0.033348 | 0.151 | 0.046642 | 0.015085 | 0.022797 | ||
| NLTK_Brown | 0.358 | 0.328791 | 0.098994 | 0.184 | 0.310418 | 0.349476 | 0.328791 | ||
| NLTK_Reuters | 0.536287 | 0.125513 | 0.002942 | 0.067708 | 0.136927 | 0.115856 | 0.125513 | ||
| PPWoS | Online Lab | 0.4864865 | 0.3583059 | 0.0508277 | 0.0810811 | 0.4107279 | 0.3177507 | 0.3583059 | |
| 20 Newsgroups | 0.0984294 | 0.0358565 | 0.043526 | 0.0579964 | 0.032702 | 0.0396845 | 0.0358565 | ||
| txt_sentoken | 0.591 | 0.0182871 | 0.0672182 | 0.3495 | 0.0349447 | 0.0123839 | 0.0182871 | ||
| NLTK_Brown | 0.366 | 0.3403492 | 0.0095858 | 0.012 | 0.3214758 | 0.3615769 | 0.3403492 | ||
| NLTK_Reuters | 0.5352674 | 0.1268945 | 0.0049828 | 0.0910186 | 0.1391429 | 0.116628 | 0.1268945 | ||
| PPwS | Online Lab | 0.5945946 | 0.4435351 | 0.0390575 | 0.0675676 | 0.5098827 | 0.3924661 | 0.4435351 | |
| 20 Newsgroups | 0.1034702 | 0.0418827 | 0.0374483 | 0.0497718 | 0.0383529 | 0.0461281 | 0.0418827 | ||
| txt_sentoken | 0.568 | 0.0207478 | 0.0403083 | 0.216 | 0.0398396 | 0.0140262 | 0.0207478 | ||
| NLTK_Brown | 0.354 | 0.3190606 | 0.0273966 | 0.038 | 0.3056518 | 0.3336998 | 0.3190606 | ||
| NLTK_Reuters | 0.5359626 | 0.1304612 | 0.0017955 | 0.0375846 | 0.1441178 | 0.1191688 | 0.1304612 |
7. Comparison with Existing Studies
8. Conclusions
- Enlarge the system by including more clustering algorithms and approaches for small datasets such as Optics, Affinity propagation and K-Medoids.
- Applying these algorithms on other Virtual Learning Environments.
- Using word embedding methods such as Glove or Word2vec for word representation instead of the TF-IDF method.
Author Contributions
Funding
Conflicts of Interest
References
- Huang, A. Similarity Measures for Text Document Clustering. In Proceedings of the New Zealand Computer Science Research Student Conference (NZCSRSC), Christchurch, New Zealand, 14–18 April 2008. [Google Scholar]
- Fatimi, S.; El, C.; Alaoui, L. A Framework for Semantic Text Clustering. IJACSA 2020, 11, 451–459. [Google Scholar] [CrossRef]
- Djenouri, Y.; Belhadi, A.; Djenouri, D.; Lin, J.C.-W. Cluster-based information retrieval using pattern mining. Appl. Intell. 2021, 51, 1888–1903. [Google Scholar] [CrossRef]
- Haji, S.H.; Abdulazeez, A.M.; Zeebaree, D.Q.; Ahmed, F.Y.H.; Zebari, D.A. The Impact of Different Data Mining Classification Techniques in Different Datasets. In Proceedings of the 2021 IEEE Symposium on Industrial Electronics & Applications (ISIEA), Virtual Event, 10–11 July 2021; IEEE: Langkawi Island, Malaysia, 2021; pp. 1–6. [Google Scholar]
- ADC: Advanced document clustering using contextualized representations. Expert Syst. Appl. 2019, 137, 157–166. [CrossRef]
- Shan, C.; Du, Y. A Web Service Clustering Method Based on Semantic Similarity and Multidimensional Scaling Analysis. Sci. Program. 2021, 2021, 1–12. [Google Scholar] [CrossRef]
- Lwin, W. Impressive Approach for Documents Clustering Using Semantics Relations in Feature Extraction. In Proceedings of the 2019 the 9th International Workshop on Computer Science and Engineering, WCSE, Changsha, China, 18–20 October 2019. [Google Scholar]
- Absalom, E.; Ezugwu, A.M.I. A Comprehensive Survey of Clustering Algorithms: State-Of-The-Art Machine Learning Applications, Taxonomy, Challenges, And Future Research Prospects. Sci. Direct 2022, 110, 165–193. [Google Scholar]
- Al-Azzawy, D.S.; Al-Rufaye, F.M.L. Arabic words clustering by using K-means algorithm. In Proceedings of the 2017 Annual Conference on New Trends in Information & Communications Technology Applications (NTICT), Baghdad, Iraq, 7–9 March 2017; IEEE: Baghdad, Iraq, 2017; pp. 263–267. [Google Scholar]
- Bafna, P.; Pramod, D.; Vaidya, A. Document Clustering: TF-IDF Approach. In Proceedings of the 2016 International Conference on Electrical, Electronics, and Optimization Techniques (ICEEOT), Chennai, India, 3–5 March 2016; IEEE: New York, NY, USA, 2016; pp. 61–66. [Google Scholar]
- Shaban, K. A Semantic Approach for Document Clustering. JSW 2009, 4, 391–404. [Google Scholar] [CrossRef]
- Nair, S.R.; Gokul, G.; Vadakkan, A.A.; Pillai, A.G.; Thushara, M. Clustering of Research Documents—A Survey on Semantic Analysis and Keyword Extraction. In Proceedings of the 2021 6th International Conference for Convergence in Technology (I2CT), Maharashtra, India, 2–4 April 2021; IEEE: Maharashtra, India, 2021; pp. 1–6. [Google Scholar]
- Alian, M.; Awajan, A. Arabic Semantic Similarity Approaches—Review. In Proceedings of the 2018 International Arab Conference on Information Technology (ACIT), Werdanye, Lebanon, 28–30 November; IEEE: Werdanye, Lebanon, 2018; pp. 1–6. [Google Scholar]
- Ibrahim, R.K.; Zeebaree, S.R.M.; Jacksi, K.; Sadeeq, M.A.M.; Shukur, H.M.; Alkhayyat, A. Clustering Document based Semantic Similarity System using TFIDF and K-Mean. In Proceedings of the 2021 International Conference on Advanced Computer Applications (ACA), Maysan, Iraq, 25–26 July 2021; IEEE: Maysan, Iraq, 2021; pp. 28–33. [Google Scholar]
- Mohammed, S.M.; Jacksi, K.; Zeebaree, S.R.M. Glove Word Embedding and DBSCAN algorithms for Semantic Document Clustering. In Proceedings of the 2020 International Conference on Advanced Science and Engineering (ICOASE), Duhok, Iraq, 23–24 December 2020. [Google Scholar]
- Zhou, Y. Application of K-Means Clustering Algorithm in Energy Data Analysis. Wirel. Commun. Mob. Comput. 2022, 2022, 1–8. [Google Scholar] [CrossRef]
- Jacksi, K.; Ibrahim, R.K.; Zeebaree, S.R.M.; Zebari, R.R.; Sadeeq, M.A.M. Clustering Documents based on Semantic Similarity using HAC and K-Mean Algorithms. In Proceedings of the 2020 International Conference on Advanced Science and Engineering (ICOASE), Duhok, Iraq, 23–24 December 2020; IEEE: Duhok, Iraq, 2020; pp. 205–210. [Google Scholar]
- Salah, R.M.; Alves, G.R.; Abdulazeez, D.H.; Guerreiro, P.; Gustavsson, I. Why VISIR? Proliferative activities and collaborative work of VISIR system. In Proceedings of the 7th International Conference on Education and New Learning Technologies (EDULEARN15), Barcelona, Spain, 7–8 July 2015. [Google Scholar]
- Radhamani, R.; Kumar, D.; Nizar, N.; Achuthan, K.; Nair, B.; Diwakar, S. What virtual laboratory usage tells us about laboratory skill education pre- and post-COVID-19: Focus on usage, behavior, intention and adoption. Educ. Inf. Technol. 2021, 26, 7477–7495. [Google Scholar] [CrossRef] [PubMed]
- Qona’ah, N.; Devi, A.R.; Dana, I.M.G.M. Laboratory Clustering using K-Means, K-Medoids, and Model-Based Clustering. IJAS 2020, 3, 64. [Google Scholar] [CrossRef]
- Salih, N.M.; Jacksi, K. Semantic Document Clustering using K-means algorithm and Ward’s Method. In Proceedings of the 2020 International Conference on Advanced Science and Engineering (ICOASE), Duhok, Iraq, 23–24 December 2020. [Google Scholar]
- Jalal, A.A.; Ali, B.H. Text documents clustering using data mining techniques. IJECE 2021, 11, 664. [Google Scholar] [CrossRef]
- Mehta, V.; Bawa, S.; Singh, J. Stamantic clustering: Combining statistical and semantic features for clustering of large text datasets. Expert Syst. Appl. 2021, 174, 114710. [Google Scholar] [CrossRef]
- Ma, L.; Zhang, Y. Using Word2Vec to process big text data. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 29 October–1 November 2015; IEEE: Santa Clara, CA, USA, 2015; pp. 2895–2897. [Google Scholar]
- Adebiyi, M.O.; Adigun, E.B.; Ogundokun, R.O.; Adeniyi, A.E.; Ayegba, P.; Oladipupo, O.O. Semantics-based clustering approach for similar research area detection. TELKOMNIKA 2020, 18, 1874. [Google Scholar] [CrossRef]
- Stanchev, L. Semantic Document Clustering Using a Similarity Graph. In Proceedings of the 2016 IEEE Tenth International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, 4–6 February 2016; IEEE: Laguna Hills, CA, USA, 2016; pp. 1–8. [Google Scholar]
- Vinoth, D.; Prabhavathy, P. A Short Text Clustering Approaches in Social Media. ECS Trans. 2022, 107, 1375–1386. [Google Scholar] [CrossRef]
- Zandieh, P.; Shakibapoor, E. Clustering Data Text Based on Semantic. Int. J. Comput. 2017, 26, 8. [Google Scholar]
- Huang, S.; Kang, Z.; Xu, Z.; Liu, Q. Robust deep k-means: An effective and simple method for data clustering. Pattern Recognit. 2021, 117, 107996. [Google Scholar] [CrossRef]
- Liu, L.; Mosavat-Jahromi, H.; Cai, L.; Kidston, D. Hierarchical Agglomerative Clustering and LSTM-based Load Prediction for Dynamic Spectrum Allocation. In Proceedings of the 2021 IEEE 18th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2021; IEEE: Las Vegas, NV, USA, 2021; pp. 1–6. [Google Scholar]
- Das, T.; Paitnaik, S.; Mishra, S.P. Identification of the Optimal Number of Clusters in Textual Data. In Advances in Distributed Computing and Machine Learning; Sahoo, J.P., Tripathy, A.K., Mohanty, M., Li, K.-C., Nayak, A.K., Eds.; Lecture Notes in Networks and Systems; Springer: Singapore, 2022; Volume 302, pp. 215–225. ISBN 9789811648069. [Google Scholar]


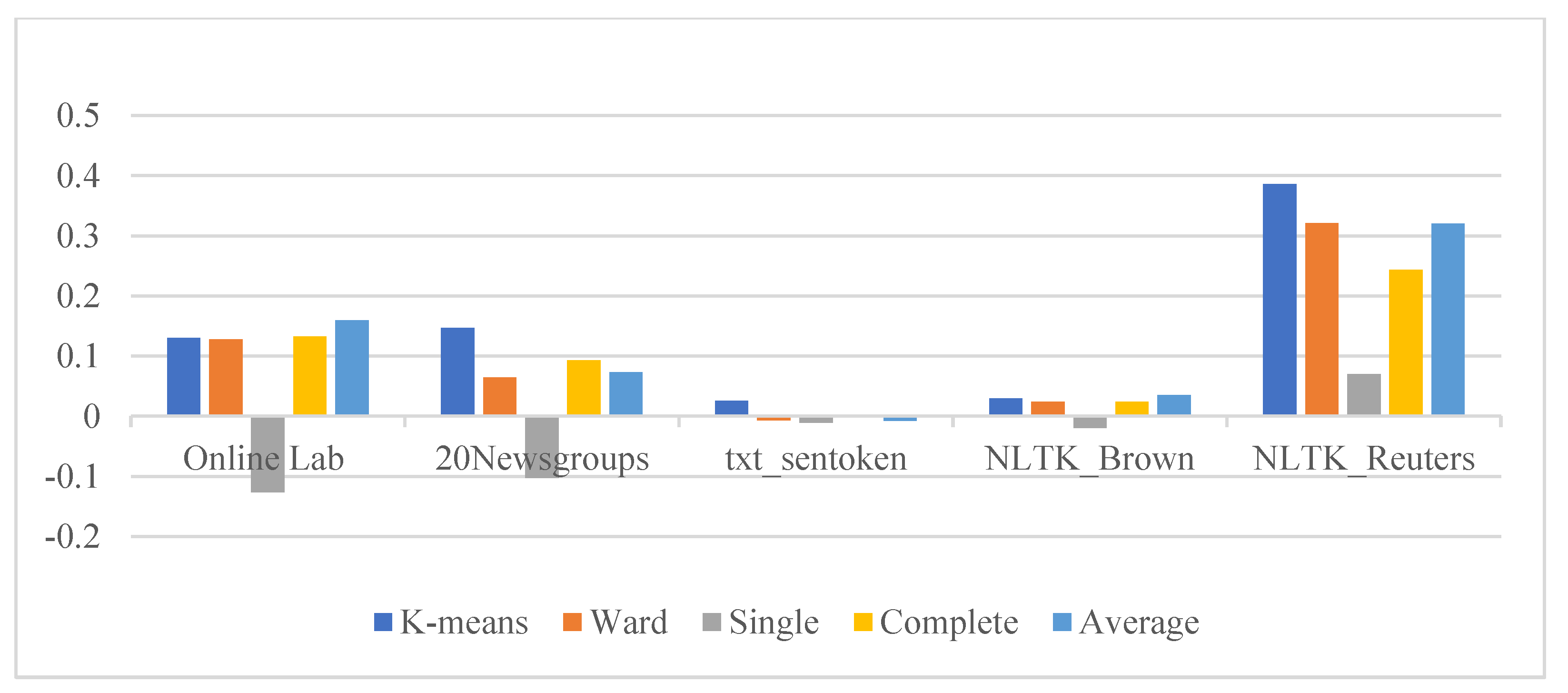
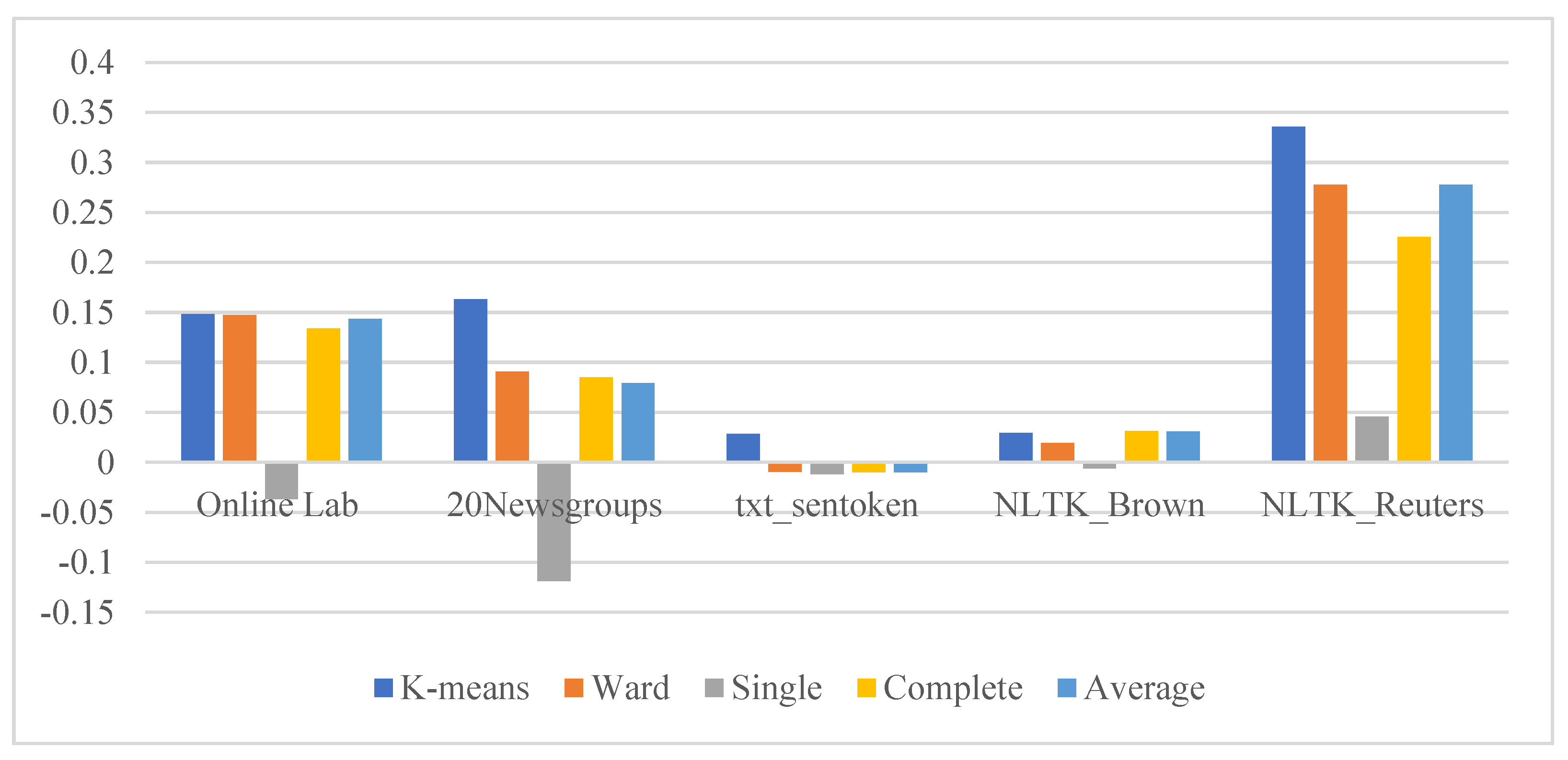

| Scenarios | Datasets | Partitioning Clustering | HAC Algorithm | |||
|---|---|---|---|---|---|---|
| K-Means | Ward | Single | Complete | Average | ||
| WoPP | Online Lab | 0.130429856 | 0.1281765 | −0.1262827 | 0.1327986 | 0.1600882 |
| 20 Newsgroups | 0.14729813 | 0.0646622 | −0.1027132 | 0.0934307 | 0.0732552 | |
| txt_sentoken | 0.025685631 | −0.0067918 | −0.0107076 | −0.001784 | −0.0072473 | |
| NLTK_Brown | 0.029879957 | 0.0241643 | −0.0196633 | 0.0243814 | 0.0353152 | |
| NLTK_Reuters | 0.385767347 | 0.3211324 | 0.0703577 | 0.2430639 | 0.320531 | |
| PPWoS | Online Lab | 0.14830793 | 0.1472155 | −0.0367298 | 0.134025 | 0.1433745 |
| 20 Newsgroups | 0.163033891 | 0.0910541 | −0.1187512 | 0.0851621 | 0.0791069 | |
| txt_sentoken | 0.028361561 | −0.0095231 | −0.0115982 | −0.009855 | −0.0096819 | |
| NLTK_Brown | 0.02926897 | 0.0194938 | −0.006007 | 0.0313465 | 0.0311442 | |
| NLTK_Reuters | 0.335450842 | 0.2775758 | 0.0457569 | 0.225533 | 0.2775008 | |
| PPwS | Online Lab | 0.142849649 | 0.1494705 | −0.1247673 | 0.1216341 | 0.1274566 |
| 20 Newsgroups | 0.095702334 | 0.0355147 | −0.1545218 | −0.00648 | 0.0144914 | |
| txt_sentoken | 0.012576785 | −0.0126844 | 0.0057517 | −0.010246 | −0.0079978 | |
| NLTK_Brown | 0.032447364 | 0.0152929 | 0.0046581 | 0.0218663 | 0.0286168 | |
| NLTK_Reuters | 0.360457389 | 0.3131754 | 0.0532977 | 0.239106 | 0.3018736 | |
| Reference | Date | Semantic Approach | Dataset | Similarity Measures | Clustering Algorithms | Other Measures |
|---|---|---|---|---|---|---|
| Jalal and Ali [22] | 2021 | Text clustering based on semantic similarity | Research papers in BEEI journal | Precision and Recall | Cosine similarity | TF-IDF |
| Mehta et al. [23] | 2021 | Clustering large text datasets | Newsgroup, Reuters, Classic3 | Silhouette coefficient, Purity, AMI, | K-Means | TF-IDF, WordNet |
| Salih and Jacksi, [21] | 2020 | Movies Clustering based on semantic similarity | IMDB and Wikipedia | Silhouette score, purity, V-Measure, F1-Measure, accuracy, homogeneity, completeness, NMI-Score | K-Means and HAC (Ward method) | TF-IDF |
| Jacksi et al. [5] | 2020 | Document clustering based on semantic approach | IMDB and Wikipedia | Purity, accuracy, F1-measure, NMI, Silhouette score | K-Means and HAC | TF-IDF |
| Adebiyi et al. [25] | 2020 | Research document Clustering | Publications from Nigerian universities | Silhouette analysis | K-Means | TF-IDF and WordNet |
| Mohammed et al. [15] | 2020 | Document Clustering based on semantic similarity | IMDB and Wikipedia | Silhouette average, purity, accuracy, F1, completeness, homogeneity and NMI score | DBSCAN, K-Means | Glove |
| Ma and Zhang, 2015 [24] | 2015 | Cluster large text dataset | 20 Newsgroups | F1-micro score | K-Means | Word2Vec |
| Proposed system | 2022 | Online laboratorial document clustering based on semantic approach | Realtime educational online labs | Silhouette score, purity, V-Measure, F1-Measure, accuracy, homogeneity, completeness, NMI-Score | K-Means and HAC with different linkages (Single, Complete, Average, Ward) | TF-IDF |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haji, S.H.; Jacksi, K.; Salah, R.M. A Semantics-Based Clustering Approach for Online Laboratories Using K-Means and HAC Algorithms. Mathematics 2023, 11, 548. https://doi.org/10.3390/math11030548
Haji SH, Jacksi K, Salah RM. A Semantics-Based Clustering Approach for Online Laboratories Using K-Means and HAC Algorithms. Mathematics. 2023; 11(3):548. https://doi.org/10.3390/math11030548
Chicago/Turabian StyleHaji, Saad Hikmat, Karwan Jacksi, and Razwan Mohmed Salah. 2023. "A Semantics-Based Clustering Approach for Online Laboratories Using K-Means and HAC Algorithms" Mathematics 11, no. 3: 548. https://doi.org/10.3390/math11030548
APA StyleHaji, S. H., Jacksi, K., & Salah, R. M. (2023). A Semantics-Based Clustering Approach for Online Laboratories Using K-Means and HAC Algorithms. Mathematics, 11(3), 548. https://doi.org/10.3390/math11030548