
3D Multi-Organ and Tumor Segmentation Based on Re-Parameterize Diverse Experts


Abstract
:1. Introduction

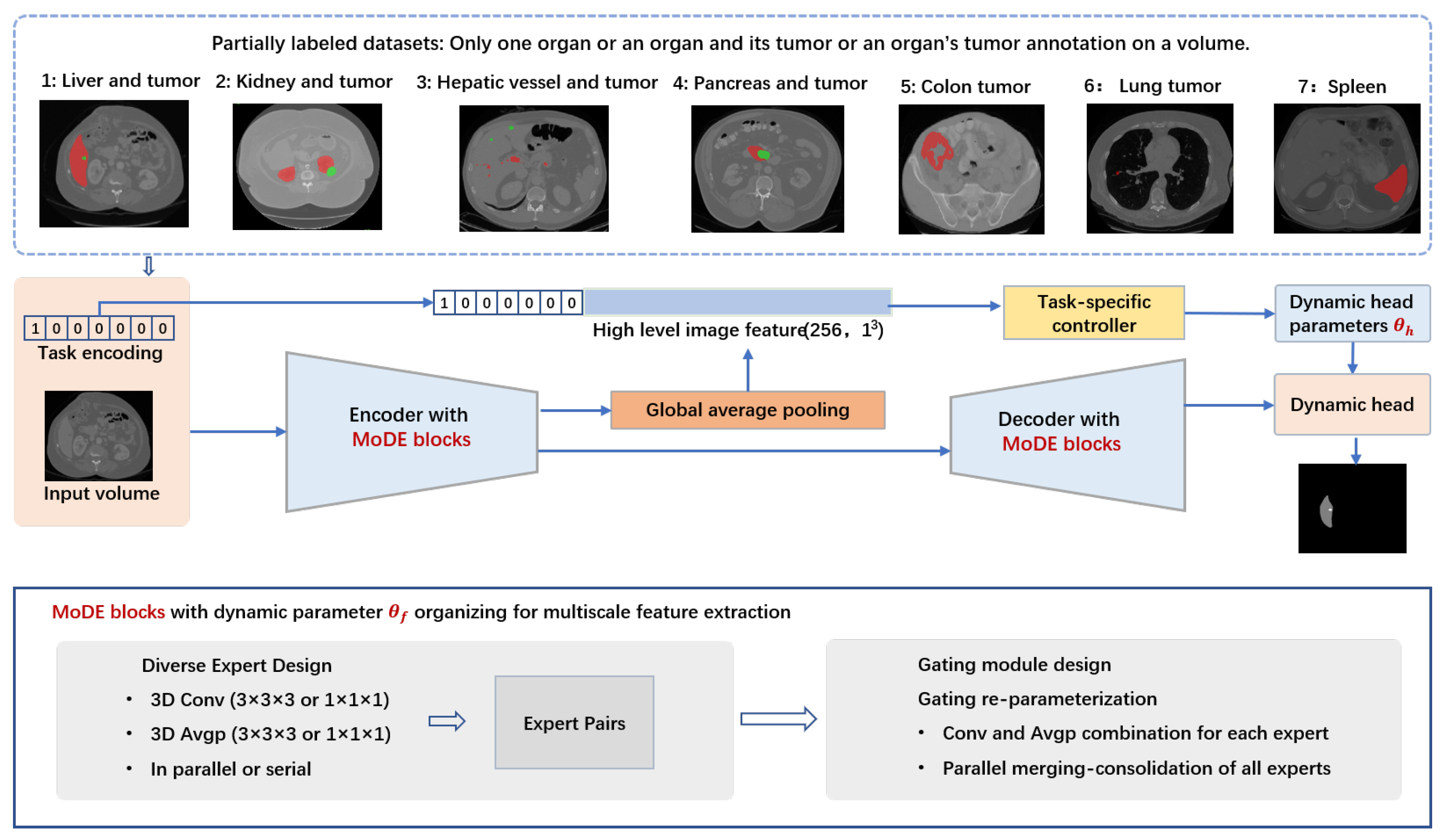{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Methods | Datasets |
|---|---|---|
| Zhang, L. et al. [15] | A multi-teacher knowledge distillation framework leveraging the soft labels | KiTS [22], MSD Spleen and Pancreas [23], TCIA [24], BTCV [25] |
| Shi, G. et al. [17] | Design of jointly optimized marginal loss and exclusion loss | BTCV [25], MSD Liver, MSD Spleen, MSD Pancreas [23], KiTS [22] |
| Chen., S. et al. [20] | Multi-head: transfer learning | LIDC [26], LiTS [27] |
| Fang, X. et al. [28] | Multi-head: pyramid input pyramid output feature abstraction network and a target adaptive loss | BTCV [25], LiTS [27], KiTS [22] and MSD Spleen [23] |
| Zhang, G. et al. [29] | Single network: conditional nnU-Net with a conditioning strategy for the decoder | LiTS [27], MSD Pancreas, MSD Spleen [23], KiTS [22], SLIVER07 [30], NIH pancreas [31], BTCV [25] |
| Zhang, J. et al. [18] | Single network: with dynamic heads leveraging one-hot task embedding | MOTS including LiTS [27], KiTS [22], and MSD Hepatic vessel and tumor, MSD Pancreas and tumor, MSD Colon tumor, MSD Lung tumor and MSD Spleen [23] |
| Liu, J. et al. [19] | Single network: with dynamic heads leveraging task embedding from Clip | MSD [23] and BTCV [25] |
2. Materials and Methods
2.1. Problem Definition
2.2. Network Architecture
2.3. Mixture-of-Diverse-Experts Block
3. Results
3.1. Datasets
3.2. Implementation Details
3.3. Performance Metrics
3.4. Comparisons with State-of-the-Art Approaches
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Y.; Zhou, Y.; Shen, W.; Park, S.; Fishman, E.K.; Yuille, A.L. Abdominal multi-organ segmentation with organ-attention networks and statistical fusion. Med. Image Anal. 2019, 55, 88–102. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Zhang, D.; Ge, R. Eye-Guided Dual-Path Network for Multi-organ Segmentation of Abdomen. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Vancouver, BC, Canada, 8–12 October 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 23–32. [Google Scholar]
- Bilic, P.; Christ, P.; Li, H.B.; Vorontsov, E.; Ben-Cohen, A.; Kaissis, G.; Szeskin, A.; Jacobs, C.; Mamani, G.E.H.; Chartrand, G.; et al. The liver tumor segmentation benchmark (lits). Med. Image Anal. 2023, 84, 102680. [Google Scholar] [CrossRef]
- Antonelli, M.; Reinke, A.; Bakas, S.; Farahani, K.; Kopp-Schneider, A.; Landman, B.A.; Litjens, G.; Menze, B.; Ronneberger, O.; Summers, R.M.; et al. The medical segmentation decathlon. Nat. Commun. 2022, 13, 4128. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Isensee, F.; Petersen, J.; Klein, A.; Zimmerer, D.; Jaeger, P.F.; Kohl, S.; Wasserthal, J.; Koehler, G.; Norajitra, T.; Wirkert, S.; et al. nnu-net: Self-adapting framework for u-net-based medical image segmentation. arXiv 2018, arXiv:1809.10486. [Google Scholar]
- Taghanaki, S.A.; Abhishek, K.; Cohen, J.P.; Cohen-Adad, J.; Hamarneh, G. Deep semantic segmentation of natural and medical images: A review. Artif. Intell. Rev. 2020, 54, 137–178. [Google Scholar] [CrossRef]
- Tajbakhsh, N.; Jeyaseelan, L.; Li, Q.; Chiang, J.N.; Wu, Z.; Ding, X. Embracing imperfect datasets: A review of deep learning solutions for medical image segmentation. Med. Image Anal. 2020, 63, 101693. [Google Scholar] [CrossRef] [PubMed]
- Suganyadevi, S.; Seethalakshmi, V.; Balasamy, K. A review on deep learning in medical image analysis. Int. J. Multimed. Inf. Retr. 2022, 11, 19–38. [Google Scholar] [CrossRef] [PubMed]
- Qureshi, I.; Yan, J.; Abbas, Q.; Shaheed, K.; Riaz, A.B.; Wahid, A.; Khan, M.W.J.; Szczuko, P. Medical image segmentation using deep semantic-based methods: A review of techniques, applications and emerging trends. Inf. Fusion 2023, 90, 316–352. [Google Scholar] [CrossRef]
- Heller, N.; Isensee, F.; Maier-Hein, K.H.; Hou, X.; Xie, C.; Li, F.; Nan, Y.; Mu, G.; Lin, Z.; Han, M.; et al. The state of the art in kidney and kidney tumor segmentation in contrast-enhanced CT imaging: Results of the KiTS19 challenge. Med. Image Anal. 2021, 67, 101821. [Google Scholar] [CrossRef]
- Gul, S.; Khan, M.S.; Bibi, A.; Khandakar, A.; Ayari, M.A.; Chowdhury, M.E. Deep learning techniques for liver and liver tumor segmentation: A review. Comput. Biol. Med. 2022, 147, 105620. [Google Scholar] [CrossRef]
- Dutande, P.; Baid, U.; Talbar, S. Deep residual separable convolutional neural network for lung tumor segmentation. Comput. Biol. Med. 2022, 141, 105161. [Google Scholar] [CrossRef]
- Ghorpade, H.; Jagtap, J.; Patil, S.; Kotecha, K.; Abraham, A.; Horvat, N.; Chakraborty, J. Automatic Segmentation of Pancreas and Pancreatic Tumor: A Review of a Decade of Research. IEEE Access 2023, 11, 108727–108745. [Google Scholar] [CrossRef]
- Zhang, L.; Feng, S.; Wang, Y.; Wang, Y.; Zhang, Y.; Chen, X.; Tian, Q. Unsupervised Ensemble Distillation for Multi-Organ Segmentation. In Proceedings of the 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI), Kolkata, India, 28–31 March 2022; pp. 1–5. [Google Scholar]
- Li, W.H.; Liu, X.; Bilen, H. Learning multiple dense prediction tasks from partially annotated data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18879–18889. [Google Scholar]
- Shi, G.; Xiao, L.; Chen, Y.; Zhou, S.K. Marginal loss and exclusion loss for partially supervised multi-organ segmentation. Med. Image Anal. 2021, 70, 101979. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, Y.; Xia, Y.; Shen, C. DoDNet: Learning to segment multi-organ and tumors from multiple partially labeled datasets. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 1195–1204. [Google Scholar]
- Liu, J.; Zhang, Y.; Chen, J.N.; Xiao, J.; Lu, Y.; A Landman, B.; Yuan, Y.; Yuille, A.; Tang, Y.; Zhou, Z. Clip-driven universal model for organ segmentation and tumor detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 21152–21164. [Google Scholar]
- Chen, S.; Ma, K.; Zheng, Y. Med3d: Transfer learning for 3d medical image analysis. arXiv 2019, arXiv:1904.00625. [Google Scholar]
- Zhou, D.; Gu, C.; Xu, J.; Liu, F.; Wang, Q.; Chen, G.; Heng, P.A. RepMode: Learning to Re-parameterize Diverse Experts for Subcellular Structure Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 3312–3322. [Google Scholar]
- Available online: https://kits19.grand-challenge.org/data/ (accessed on 18 June 2022).
- Available online: http://medicaldecathlon.com/ (accessed on 12 July 2021).
- Clark, K.; Vendt, B.; Smith, K.; Freymann, J.; Kirby, J.; Koppel, P.; Moore, S.; Phillips, S.; Maffitt, D.; Pringle, M.; et al. The Cancer Imaging Archive (TCIA): Maintaining and operating a public information repository. J. Digit. Imaging 2013, 26, 1045–1057. [Google Scholar] [CrossRef] [PubMed]
- Landman, B.; Xu, Z.; Igelsias, J.E.; Styner, M.; Langerak, T.R.; Klein, A. 2015 miccai multi-atlas labeling beyond the cranial vault workshop and challenge. In Proceedings of the MICCAI Multi-Atlas Labeling Beyond Cranial Vault—Workshop Challenge, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Armato III, S.G.; McLennan, G.; McNitt-Gray, M.F.; Meyer, C.R.; Yankelevitz, D.; Aberle, D.R.; Henschke, C.I.; Hoffman, E.A.; Kazerooni, E.A.; MacMahon, H.; et al. Lung image database consortium: Developing a resource for the medical imaging research community. Radiology 2004, 232, 739–748. [Google Scholar] [CrossRef] [PubMed]
- Available online: https://competitions.codalab.org/competitions/17094 (accessed on 22 July 2019).
- Fang, X.; Yan, P. Multi-organ segmentation over partially labeled datasets with multi-scale feature abstraction. IEEE Trans. Med Imaging 2020, 39, 3619–3629. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.; Yang, Z.; Huo, B.; Chai, S.; Jiang, S. Multiorgan segmentation from partially labeled datasets with conditional nnU-Net. Comput. Biol. Med. 2021, 136, 104658. [Google Scholar] [CrossRef] [PubMed]
- Heimann, T.; van Ginneken, G.; Styner, M. Available online: http://www.sliver07.org (accessed on 20 June 2019).
- Roth, H.R.; Lu, L.; Farag, A.; Shin, H.C.; Liu, J.; Turkbey, E.B.; Summers, R.M. Deeporgan: Multi-level deep convolutional networks for automated pancreas segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015. Proceedings, Part I 18. pp. 556–564. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Diverse branch block: Building a convolution as an inception-like unit. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10886–10895. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Chen, Q.; Xu, J.; Koltun, V. Fast image processing with fully-convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2497–2506. [Google Scholar]
- Dmitriev, K.; Kaufman, A.E. Learning multi-class segmentations from single-class datasets. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9501–9511. [Google Scholar]
- Ganaie, M.A.; Hu, M.; Malik, A.; Tanveer, M.; Suganthan, P. Ensemble deep learning: A review. Eng. Appl. Artif. Intell. 2022, 115, 105151. [Google Scholar] [CrossRef]
- Alsubai, S.; Khan, H.U.; Alqahtani, A.; Sha, M.; Abbas, S.; Mohammad, U.G. Ensemble deep learning for brain tumor detection. Front. Comput. Neurosci. 2022, 16, 1005617. [Google Scholar] [CrossRef]
- Tandel, G.S.; Tiwari, A.; Kakde, O.G.; Gupta, N.; Saba, L.; Suri, J.S. Role of Ensemble Deep Learning for Brain Tumor Classification in Multiple Magnetic Resonance Imaging Sequence Data. Diagnostics 2023, 13, 481. [Google Scholar] [CrossRef] [PubMed]

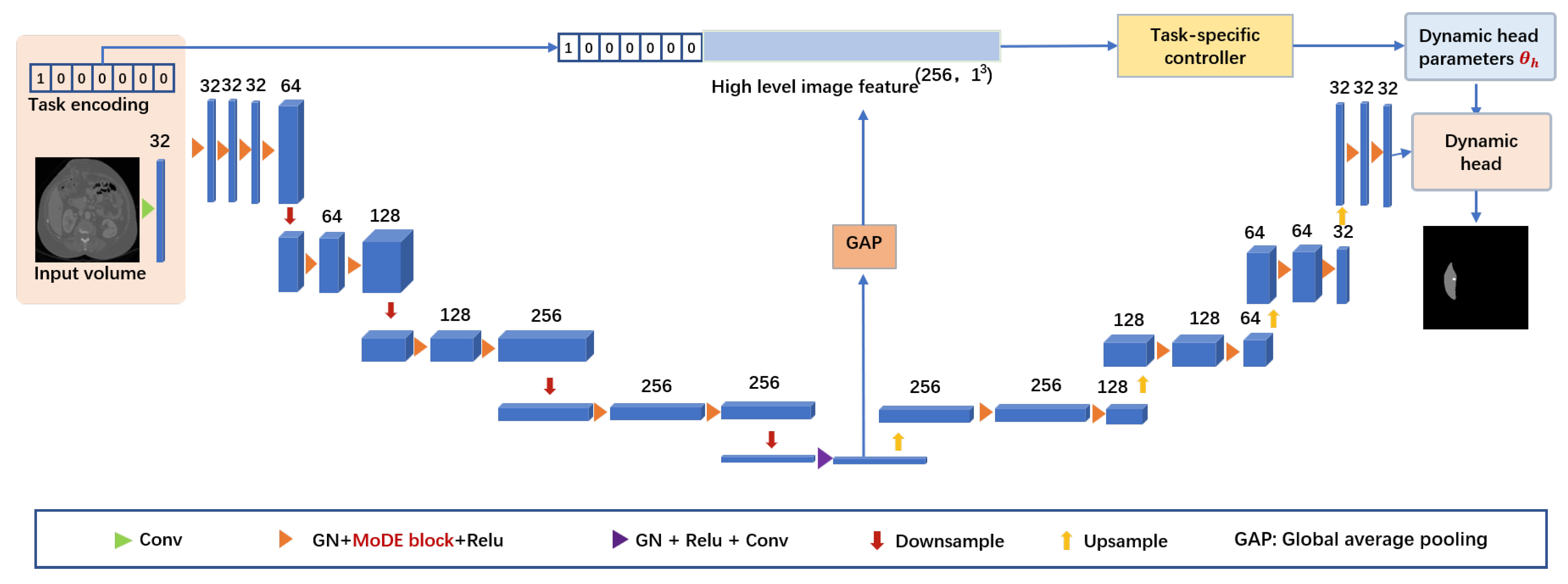


| Stage | Layer Name | In Channel Size | Out Channel Size | Stride | Output Size |
|---|---|---|---|---|---|
| Encoder | Input | 1 | - | - | |
| Conv1 | 1 | 32 | |||
| Layer0 | 32 | 32 | |||
| Layer1 | 32 | 64 | |||
| Layer2 | 64 | 128 | |||
| Layer3 | 128 | 256 | |||
| Layer4 | 256 | 256 | |||
| fusionConv | 256 | 256 | |||
| Decoder | GAP | 256 | - | - | |
| Controller | 256 + 7 | 162 | |||
| 8resb | 256 | 128 | |||
| 4resb | 128 | 64 | |||
| 2resb | 64 | 32 | |||
| 1resb | 32 | 32 | |||
| preclsConv | 32 | 8 | |||
| SegHead | 32 | 8 |
| Methods | Task 1: Liver | Task 2: Kidney | Task 3: Hepatic Vessel | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dice | HD | Dice | HD | Dice | HD | |||||||
| Organ | Tumor | Organ | Tumor | Organ | Tumor | Organ | Tumor | Organ | Tumor | Organ | Tumor | |
| Multi-Nets | 96.61 | 61.65 | 4.25 | 41.16 | 96.52 | 74.89 | 1.79 | 11.19 | 63.04 | 72.19 | 13.73 | 50.70 |
| TAL [28] | 96.18 | 60.82 | 5.99 | 38.87 | 95.95 | 75.87 | 1.98 | 15.36 | 61.90 | 72.68 | 13.86 | 43.57 |
| Multi-Head [20] | 96.75 | 64.08 | 3.67 | 45.68 | 96.60 | 79.16 | 4.69 | 13.28 | 59.49 | 69.64 | 19.28 | 79.66 |
| Cond-NO | 69.38 | 47.38 | 37.79 | 109.65 | 93.32 | 70.40 | 8.68 | 24.37 | 42.27 | 69.86 | 93.35 | 70.34 |
| Cond-Input [34] | 96.68 | 65.26 | 6.21 | 47.61 | 96.82 | 78.41 | 1.32 | 10.10 | 62.17 | 73.17 | 13.61 | 43.32 |
| Cond-Dec [35] | 95.27 | 63.86 | 5.49 | 36.04 | 95.07 | 79.27 | 7.21 | 8.02 | 61.29 | 72.46 | 14.05 | 65.57 |
| DoDNet [18] | 96.87 | 65.47 | 3.35 | 36.75 | 96.52 | 77.59 | 2.11 | 8.91 | 62.42 | 73.39 | 13.49 | 53.56 |
| DoDNet 1 | 96.78 | 63.56 | 4.52 | 32.97 | 96.26 | 80.06 | 3.87 | 11.99 | 62.55 | 74.87 | 13.76 | 40.9 |
| DoDRepNet [21,32,33] | 96.99 | 66.69 | 3.29 | 25.31 | 96.89 | 82.68 | 1.97 | 14.61 | 63.6 | 76.65 | 13.45 | 29.06 |
| Methods | Task 4: Pancreas | Task 5: Colon | Task 6: Lung | Task 7: Spleen | Average score | |||||||
| Dice | HD | Dice | HD | Dice | HD | Dice | HD | Dice↑ | HD↓ | |||
| Organ | Tumor | Organ | Tumor | Tumor | Tumor | Tumor | Tumor | Organ | Organ | |||
| Multi-Nets | 82.53 | 58.36 | 9.23 | 26.13 | 34.33 | 103.91 | 54.51 | 53.68 | 93.76 | 2.65 | 71.67 | 28.95 |
| TAL [28] | 81.35 | 59.15 | 9.02 | 21.07 | 48.08 | 66.42 | 61.85 | 39.92 | 93.01 | 3.10 | 73.35 | 23.56 |
| Multi-Head [20] | 83.49 | 61.22 | 6.40 | 18.66 | 50.89 | 59.00 | 64.75 | 34.22 | 94.01 | 3.86 | 74.55 | 26.22 |
| Cond-NO | 65.31 | 46.24 | 36.06 | 76.26 | 42.55 | 76.14 | 57.67 | 102.92 | 59.68 | 38.11 | 60.37 | 61.24 |
| Cond-Input [34] | 82.53 | 61.20 | 8.09 | 31.53 | 51.43 | 44.18 | 60.29 | 58.02 | 93.51 | 4.32 | 74.68 | 24.39 |
| Cond-Dec [35] | 77.24 | 55.69 | 17.60 | 48.47 | 51.80 | 63.67 | 57.68 | 53.27 | 90.14 | 6.52 | 72.71 | 29.63 |
| DoDNet [18] | 82.64 | 60.45 | 7.88 | 15.51 | 51.55 | 58.89 | 71.25 | 10.37 | 93.91 | 3.67 | 75.64 | 19.50 |
| DoDNet 1 | 82.54 | 59.82 | 8.61 | 28.56 | 48.86 | 58.88 | 61.5 | 18.5 | 94.74 | 2.13 | 74.54 | 20.66 |
| DoDRepNet [21,32,33] | 83.67 | 61.22 | 7.48 | 34.07 | 45.17 | 70.94 | 65.82 | 47.61 | 94.18 | 2.68 | 75.78 | 22.77 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, P.; Gu, C.; Wu, B.; Liao, X.; Qian, Y.; Chen, G. 3D Multi-Organ and Tumor Segmentation Based on Re-Parameterize Diverse Experts. Mathematics 2023, 11, 4868. https://doi.org/10.3390/math11234868
Liu P, Gu C, Wu B, Liao X, Qian Y, Chen G. 3D Multi-Organ and Tumor Segmentation Based on Re-Parameterize Diverse Experts. Mathematics. 2023; 11(23):4868. https://doi.org/10.3390/math11234868
Chicago/Turabian StyleLiu, Ping, Chunbin Gu, Bian Wu, Xiangyun Liao, Yinling Qian, and Guangyong Chen. 2023. "3D Multi-Organ and Tumor Segmentation Based on Re-Parameterize Diverse Experts" Mathematics 11, no. 23: 4868. https://doi.org/10.3390/math11234868
APA StyleLiu, P., Gu, C., Wu, B., Liao, X., Qian, Y., & Chen, G. (2023). 3D Multi-Organ and Tumor Segmentation Based on Re-Parameterize Diverse Experts. Mathematics, 11(23), 4868. https://doi.org/10.3390/math11234868