

Driver Distraction Detection Based on Cloud Computing Architecture and Lightweight Neural Network


 ,
, 
Abstract
:1. Introduction
- This paper uses the advantages of cloud computing architecture in big data processing and edge computing deployment to propose a driver distraction behavior detection method that supports cloud and fog computing. By training deep learning models in a cloud computing environment, and then deploying the trained models to edge devices with limited computing resources, the model is updated and optimized on edge devices through a two-level optimization path of data-driven and model-driven devices.
- The Progressive Scalable Detection Network (PSDNet) is introduced, which fuses a multi-branch scalable perceptual backbone network and a lightweight progressive feature pyramid, aiming to decouple the training time and inference time of the model by employing structural reparameterization and simultaneously quantizing the scalable network to improve detection accuracy and efficiency.
- A model-driven approach based on the performance-aware approximation integrating a sequential greedy channel pruning algorithm and a performance-aware prediction criterion is proposed. Experimental results show that the proposed model-driven approach can reduce FLOPs and parameters by more than 30% with small performance degradation and achieve 1.2× to 2.0× speedups on cloud and edge mobile platforms.
2. Related Work
2.1. Driving Distraction Detection
2.2. Cloud Computing in Driving Distraction Detection
3. The Proposed Method
3.1. Progressive Scalable Detection Networks
3.1.1. Overall Architecture
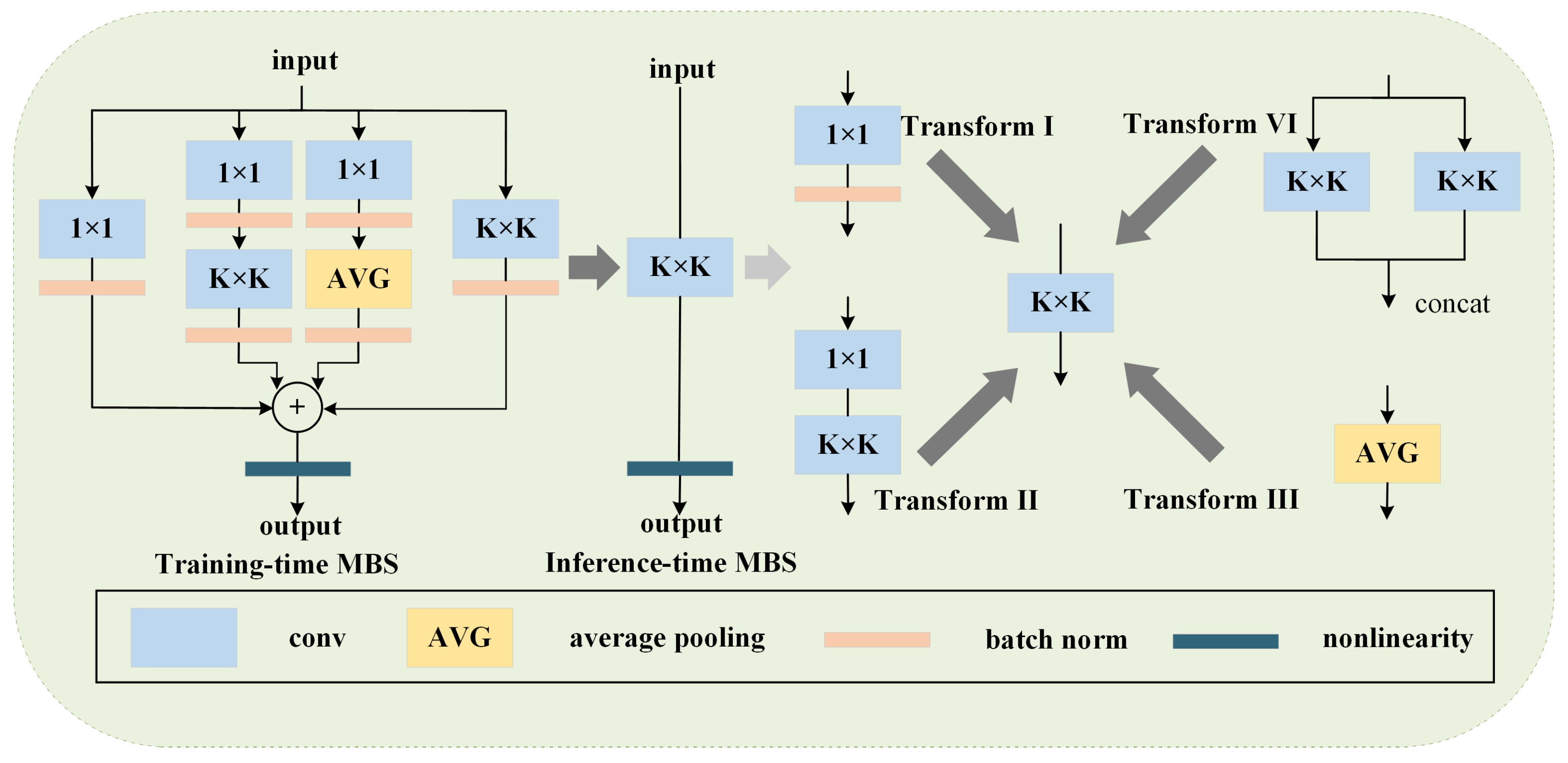
3.1.2. Multi-Branch Scalable Sensing Backbone
3.1.3. Lightweight Asymptotic Feature Pyramid Network
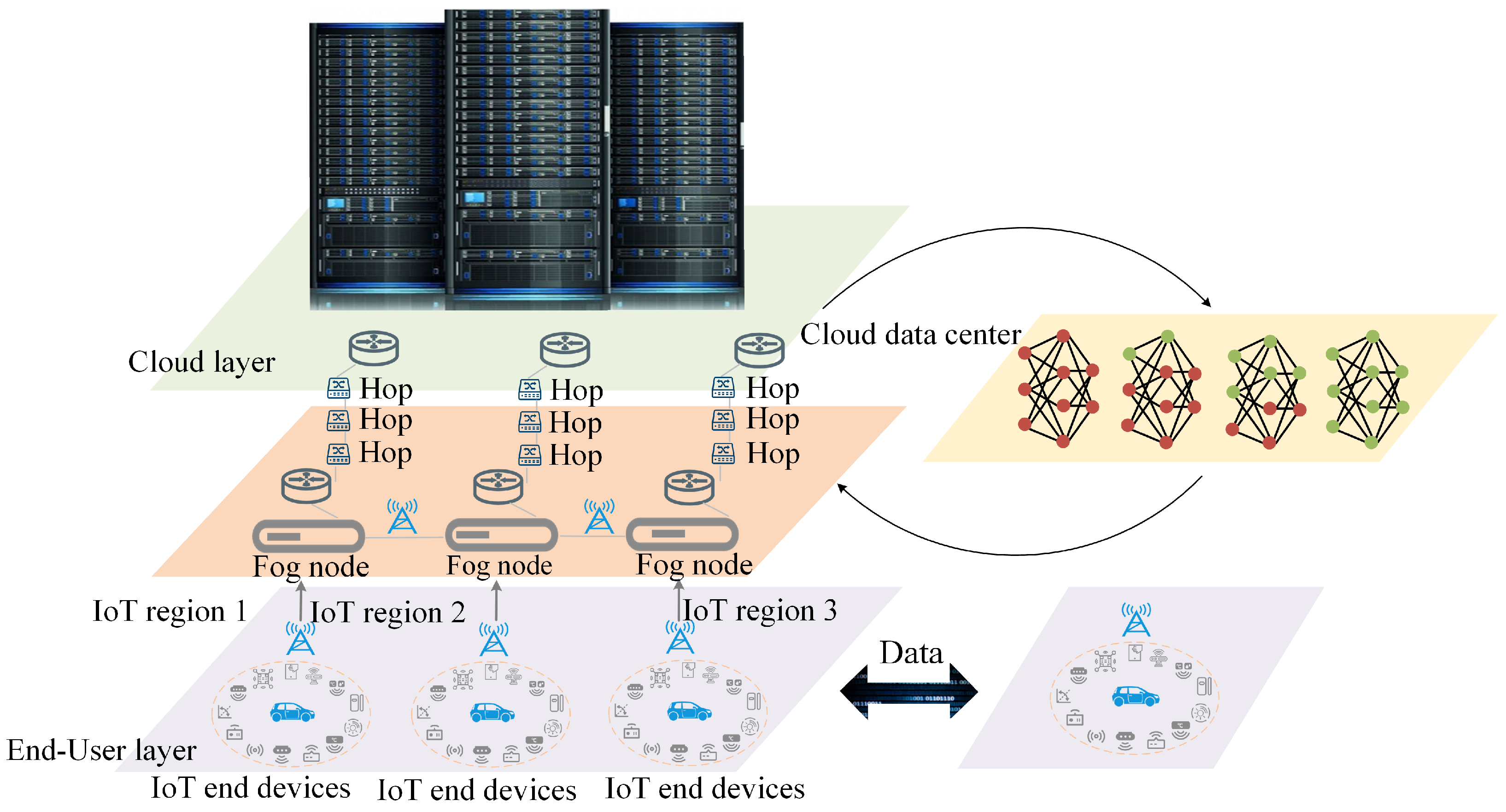
3.2. Deployment Strategies Based on Cloud–Fog Computing Architecture
| Algorithm 1 The proposed framework. |
| Input: The pretrained model , dataset D, reserved ratio of FLOPs or parameters, performance drop threshold , initial drop threshold , masking ratio of filters, and filtering ratio P of pruning layers. Output: The compressed model satisfying the compression requirements .
|
4. Experiments
4.1. Datasets
4.2. Experiment Details
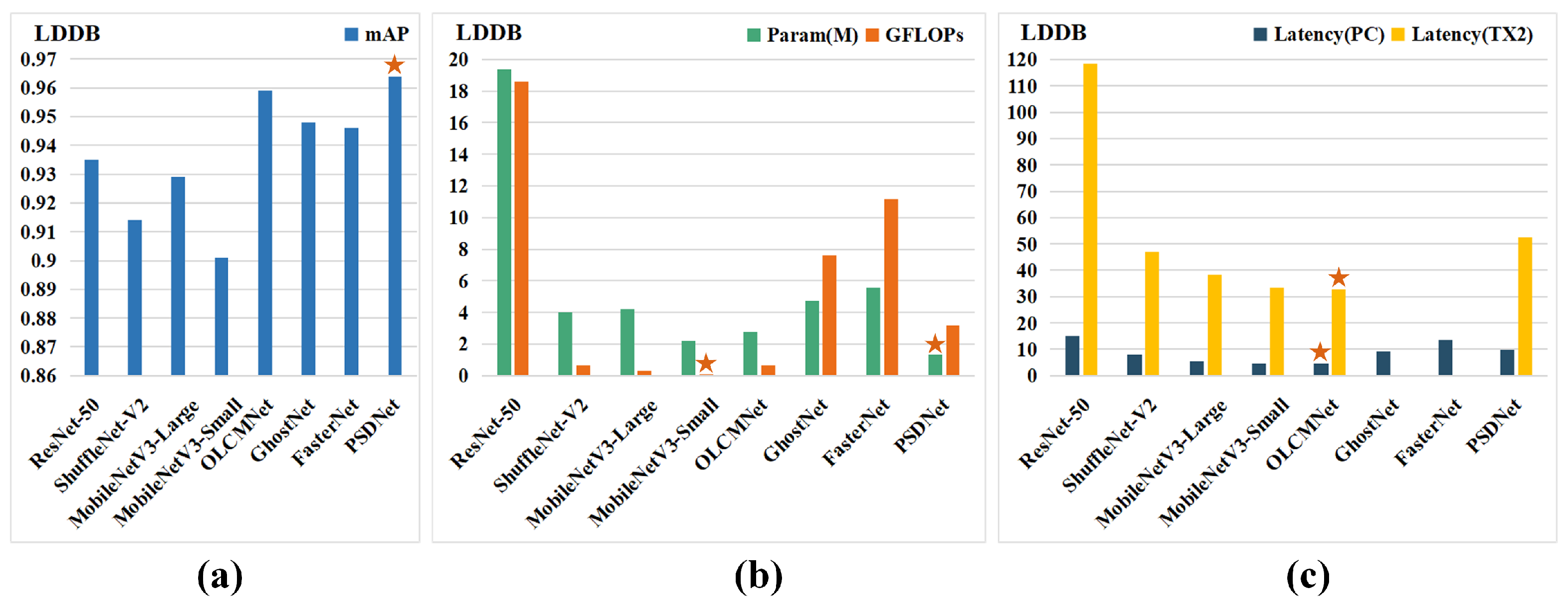
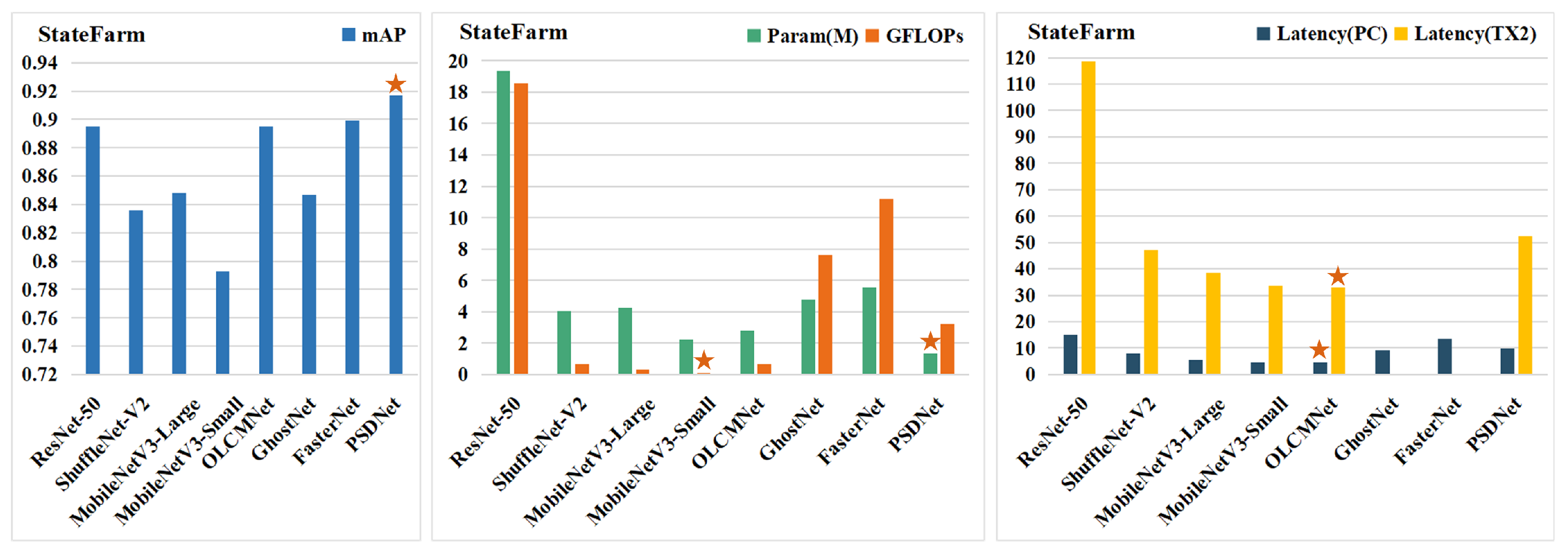
4.3. Comparative Experiments
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chhabra, R.; Verma, S.; Krishna, C.R. A survey on driver behavior detection techniques for intelligent transportation systems. In Proceedings of the 2017 7th International Conference on Cloud Computing, Data Science & Engineering-Confluence, Noida, India, 12–13 January 2017; pp. 36–41. [Google Scholar]
- Kim, W.; Choi, H.K.; Jang, B.T.; Lim, J. Driver distraction detection using single convolutional neural network. In Proceedings of the 2017 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Republic of Korea, 18–20 October 2017; pp. 1203–1205. [Google Scholar]
- Qi, G.; Wang, H.; Haner, M.; Weng, C.; Chen, S.; Zhu, Z. Convolutional neural network based detection and judgement of environmental obstacle in vehicle operation. CAAI Trans. Intell. Technol. 2019, 4, 80–91. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, S.; Gu, S.; Li, Y.; Li, J.; Shuai, L.; Qi, G. Driver distraction detection based on lightweight networks and tiny object detection. Math. Biosci. Eng. 2023, 20, 18248–18266. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, Y. Real-time forest smoke detection using hand-designed features and deep learning. Comput. Electron. Agric. 2019, 167, 105029. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 11–18 October 2018; pp. 116–131. [Google Scholar]
- Zhang, Z.; Zhang, H.; Wang, Y.; Liu, T.; He, Y.; Tian, Y. Underwater Sea Cucumber Target Detection Based on Edge-Enhanced Scaling YOLOv4. J. Beijing Inst. Technol. 2023, 32, 328–340. [Google Scholar]
- Li, Y.; Xu, P.; Zhu, Z.; Huang, X.; Qi, G. Real-time driver distraction detection using lightweight convolution neural network with cheap multi-scale features fusion block. In Proceedings of the 2021 Chinese Intelligent Systems Conference, Fuzhou, China, 16–17 October 2021; Springer: Berlin/Heidelberg, 2022; Volume II, pp. 232–240. [Google Scholar]
- Jadeja, Y.; Modi, K. Cloud computing-concepts, architecture and challenges. In Proceedings of the 2012 International Conference on Computing, Electronics and Electrical Technologies (ICCEET), Nagercoil, India, 21–22 March 2012; pp. 877–880. [Google Scholar]
- Murthy, C.V.B.; Shri, M.L.; Kadry, S.; Lim, S. Blockchain based cloud computing: Architecture and research challenges. IEEE Access 2020, 8, 205190–205205. [Google Scholar] [CrossRef]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2736–2744. [Google Scholar]
- Ye, H.; Zhang, B.; Chen, T.; Fan, J.; Wang, B. Performance-aware Approximation of Global Channel Pruning for Multitask CNNs. IEEE Trans. Pattern Anal. Mach. Intell. 2023. [Google Scholar] [CrossRef] [PubMed]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713. [Google Scholar]
- Nascimento, M.G.d.; Fawcett, R.; Prisacariu, V.A. Dsconv: Efficient convolution operator. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5148–5157. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2820–2828. [Google Scholar]
- Chen, J.; Kao, S.h.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Qi, G.; Zhang, Y.; Wang, K.; Mazur, N.; Liu, Y.; Malaviya, D. Small object detection method based on adaptive spatial parallel convolution and fast multi-scale fusion. Remote Sens. 2022, 14, 420. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7036–7045. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Diverse branch block: Building a convolution as an inception-like unit. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10886–10895. [Google Scholar]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. AFPN: Asymptotic Feature Pyramid Network for Object Detection. arXiv 2023, arXiv:2306.15988. [Google Scholar]
- Yan, C.; Sheng, S. Research on behavior element decision of cloud edge collaboration capability based on 5g automatic driving scene. In Proceedings of the 2021 IEEE 5th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Xi’an, China, 15–17 October 2021; Volume 5, pp. 1787–1790. [Google Scholar]
- Xun, Y.; Qin, J.; Liu, J. Deep learning enhanced driving behavior evaluation based on vehicle-edge-cloud architecture. IEEE Trans. Veh. Technol. 2021, 70, 6172–6177. [Google Scholar] [CrossRef]
- Khan, M.A.; Nawaz, T.; Khan, U.S.; Hamza, A.; Rashid, N. IoT-Based Non-Intrusive Automated Driver Drowsiness Monitoring Framework for Logistics and Public Transport Applications to Enhance Road Safety. IEEE Access 2023, 11, 14385–14397. [Google Scholar] [CrossRef]
- Abouelnaga, Y.; Eraqi, H.M.; Moustafa, M.N. Real-time distracted driver posture classification. arXiv 2017, arXiv:1706.09498. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 1314–1324. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 6023–6032. [Google Scholar]
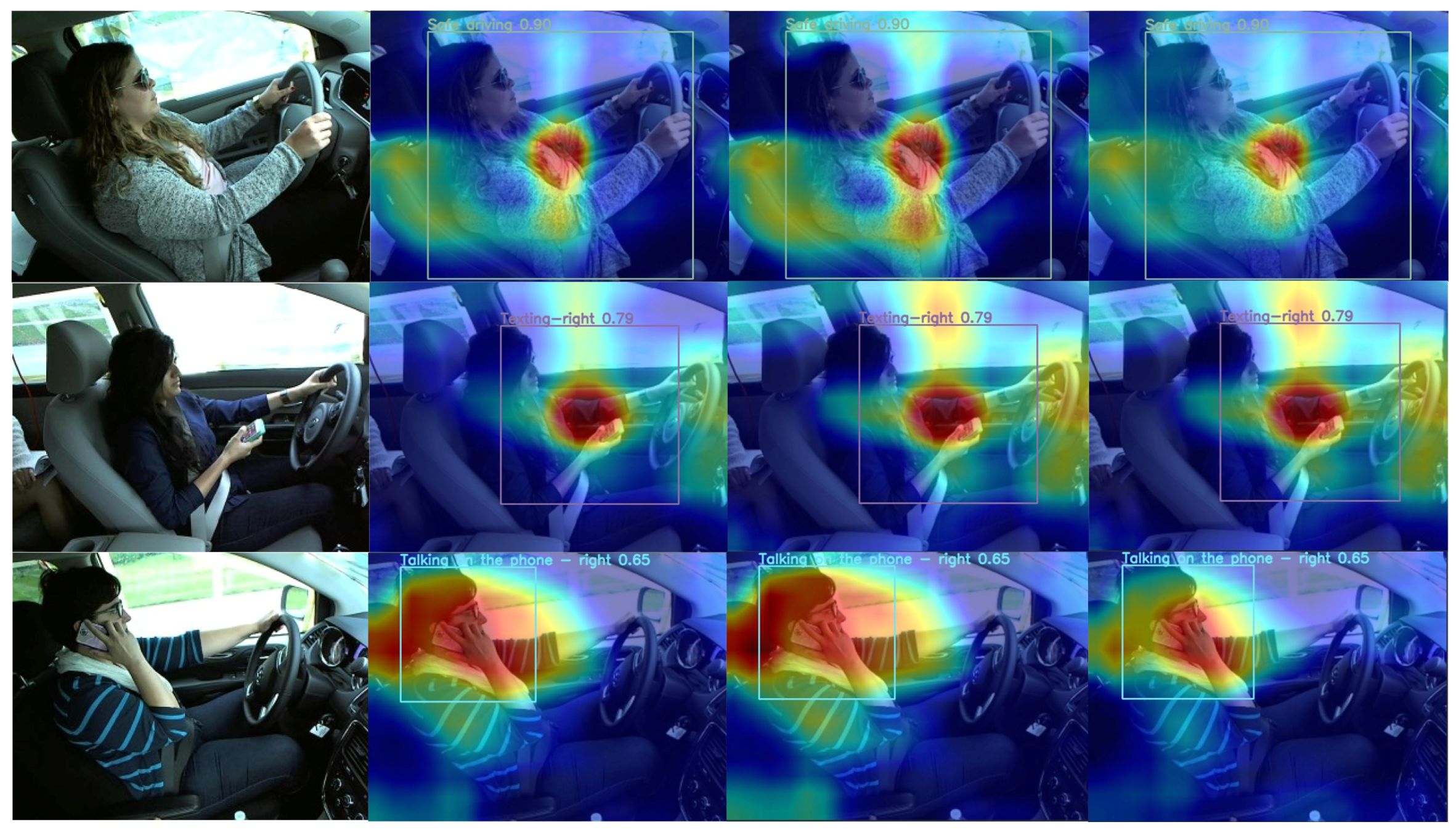
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. [Google Scholar]
- Fu, R.; Hu, Q.; Dong, X.; Guo, Y.; Gao, Y.; Li, B. Axiom-based grad-cam: Towards accurate visualization and explanation of cnns. arXiv 2020, arXiv:2008.02312. [Google Scholar]
- Li, P.; Yang, Y.; Grosu, R.; Wang, G.; Li, R.; Wu, Y.; Huang, Z. Driver distraction detection using octave-like convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2021, 23, 8823–8833. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | mAP | Param (M) | GFLOPs | Latency (PC) | Latency (TX2) |
|---|---|---|---|---|---|
| ResNet-50 [7] | 0.935 | 19.35 | 18.58 | 15.2 ± 1.2 | 118.5 ± 2.2 |
| ShuffleNet-V2 [29] | 0.914 | 4.02 | 0.64 | 8.0 ± 0.9 | 47.1 ± 6.1 |
| MobileNetV3-Large [30] | 0.929 | 4.23 | 0.30 | 5.6 ± 0.7 | 38.4 ± 7.9 |
| MobileNetV3-Small [30] | 0.901 | 2.21 | 0.09 | 4.7 ± 0.8 | 33.5 ± 7.3 |
| OLCMNet [35] | 0.959 | 2.78 | 0.68 | 4.7 ± 0.5 | 32.8 ± 4.6 |
| GhostNet [36] | 0.948 | 4.75 | 7.6 | 9.3 ± 1.1 | - |
| FasterNet [19] | 0.946 | 5.55 | 11.2 | 13.5 ± 0.2 | - |
| PSDNet | 0.964 | 1.33 | 3.2 | 9.9 ± 0.5 | 52.5 ± 6.2 |
| Models | mAP | Param (M) | GFLOPs | Latency (PC) | Latency (TX2) |
|---|---|---|---|---|---|
| ResNet-50 [7] | 0.895 | 19.35 | 18.58 | 15.2 ± 1.2 | 118.5 ± 2.2 |
| ShuffleNet-V2 [29] | 0.836 | 4.02 | 0.64 | 8.0 ± 0.9 | 47.1 ± 6.1 |
| MobileNetV3-Large [30] | 0.848 | 4.23 | 0.30 | 5.6 ± 0.7 | 38.4 ± 7.9 |
| MobileNetV3-Small [30] | 0.793 | 2.21 | 0.09 | 4.7 ± 0.8 | 33.5 ± 7.3 |
| OLCMNet [35] | 0.895 | 2.78 | 0.68 | 4.7 ± 0.5 | 32.8 ± 4.6 |
| GhostNet [36] | 0.847 | 4.75 | 7.6 | 9.3 ± 1.1 | - |
| FasterNet [19] | 0.899 | 5.55 | 11.2 | 13.5 ± 0.2 | - |
| PSDNet | 0.917 | 1.33 | 3.2 | 9.9 ± 0.5 | 52.5 ± 6.2 |
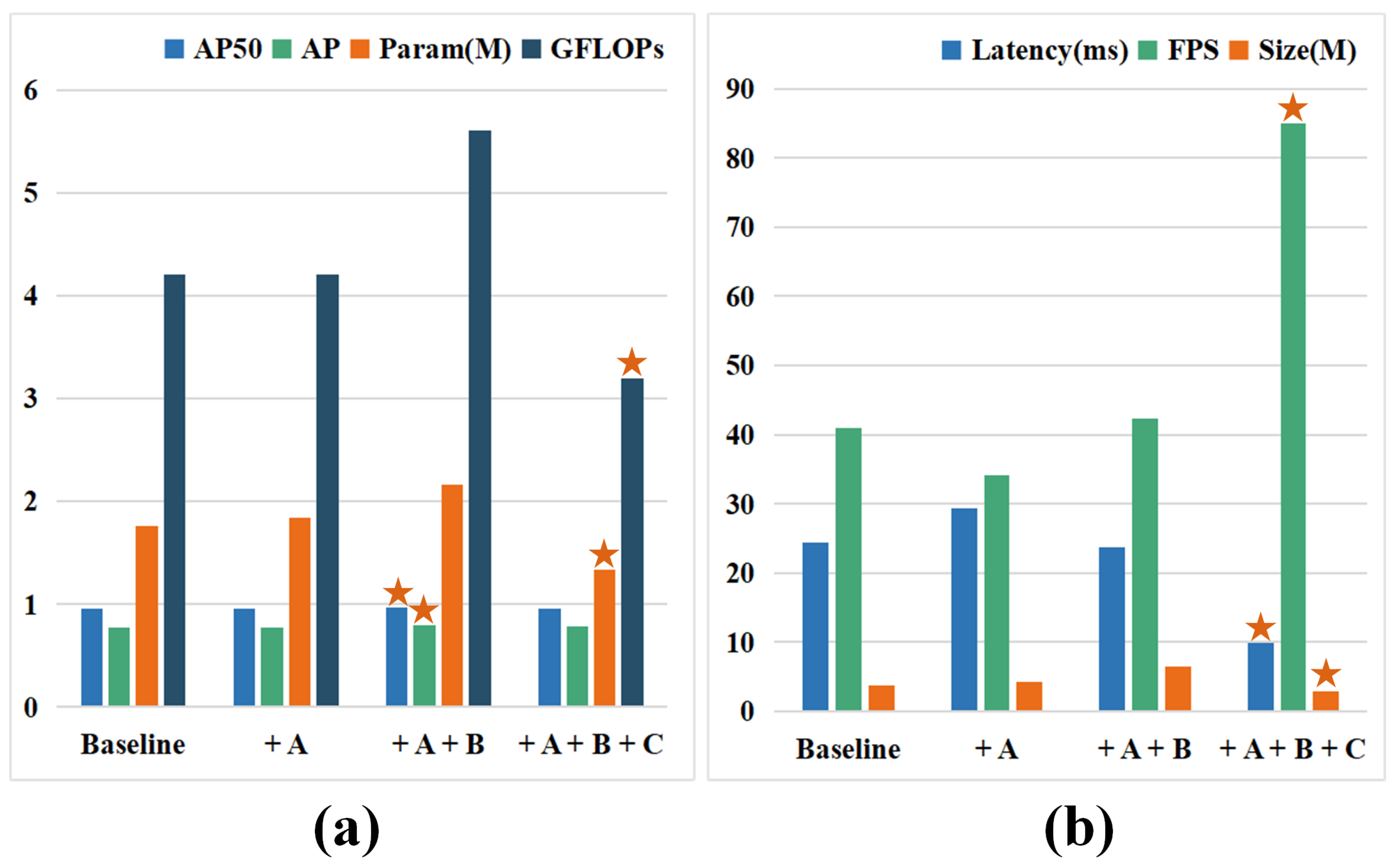
| Models | AP50 | AP | Param (M) | GFLOPs | Latency (ms) | FPS | Size (M) |
|---|---|---|---|---|---|---|---|
| Baseline | 0.951 | 0.771 | 1.76 | 4.2 | 24.4 | 40.98 | 3.73 |
| + A | 0.954 | 0.775 | 1.84 | 4.2 | 29.3 | 34.09 | 4.34 |
| + A + B | 0.964 | 0.794 | 2.16 | 5.6 | 23.7 | 42.26 | 6.44 |
| + A + B + C | 0.960 | 0.788 | 1.33 | 3.2 | 9.9 | 84.98 | 2.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Wang, S.; Qi, G.; Zhu, Z.; Li, Y.; Shuai, L.; Wen, B.; Chen, S.; Huang, X. Driver Distraction Detection Based on Cloud Computing Architecture and Lightweight Neural Network. Mathematics 2023, 11, 4862. https://doi.org/10.3390/math11234862
Huang X, Wang S, Qi G, Zhu Z, Li Y, Shuai L, Wen B, Chen S, Huang X. Driver Distraction Detection Based on Cloud Computing Architecture and Lightweight Neural Network. Mathematics. 2023; 11(23):4862. https://doi.org/10.3390/math11234862
Chicago/Turabian StyleHuang, Xueda, Shaowen Wang, Guanqiu Qi, Zhiqin Zhu, Yuanyuan Li, Linhong Shuai, Bin Wen, Shiyao Chen, and Xin Huang. 2023. "Driver Distraction Detection Based on Cloud Computing Architecture and Lightweight Neural Network" Mathematics 11, no. 23: 4862. https://doi.org/10.3390/math11234862
APA StyleHuang, X., Wang, S., Qi, G., Zhu, Z., Li, Y., Shuai, L., Wen, B., Chen, S., & Huang, X. (2023). Driver Distraction Detection Based on Cloud Computing Architecture and Lightweight Neural Network. Mathematics, 11(23), 4862. https://doi.org/10.3390/math11234862