Schizophrenia is a relatively serious mental illness, and the specific causes of this disease are currently unclear. In clinical practice, it mainly manifests as disharmony in mental activities and various obstacles in terms of emotions, perception, thinking, and other features. If not promptly and effectively treated, it can lead to mental disabilities. Approximately 80% of patients with schizophrenia may experience mental and behavioral abnormalities that do not meet the diagnostic criteria within 2–5 years of onset. In the diagnosis and treatment of schizophrenia, participants are classified as having first-episode schizophrenia (FES), as healthy controls (HC), or as being clinically high risk for psychosis (CHR). CHR is difficult to determine but it is crucial for diagnosis [
1]. It is not easy to recognize FES or CHR using EEG data, resulting in obstacles in terms of studying the pathology of schizophrenia.
Electroencephalography (EEG) measures electrical fields produced by an active brain. EEG signal analysis has been used as a diagnostic tool both within and outside of the clinical domain for nearly 90 years. However, EEG still requires strict and objective analysis, as it is a non-stationary nonlinear signal and its interpretation mostly remains intuitive and heuristic. In particular, the cross-channel relations of the signal and its reference to the sources, and hence to certain morphological structures, functional brain structures, or both, are not sufficiently understood and therefore remain a matter of intense research [
2]. This study focuses on the application of a resting-state EEG with eyes closed (REC) [
3] during the clinical assistant diagnosis and classification of patients with schizophrenia, in an attempt to establish an effective neuroimaging biomarker from EEG signals.
The signal processing of EEG data faces many challenges. It has been previously observed that EEG data feature low signal-to-noise ratios (SNR), non-stationary signals, and high inter-subject variability, which limit the usefulness of EEG applications [
4]. A common procedure for EEG-based biometrics involves data collection, preprocessing, feature extraction, and pattern recognition [
5]. However, resting-state EEG lacks task-related features, making it difficult to design the best feature for manual extraction. In this study, we considered the non-stationary brain [
6], implying that their tasks change over time. This time interval can be divided into thousands of non-overlapping stationary windows. In this manner, we obtained a set of thousands of matrices. The application of eigenvalues to express features in EEG data has a long history, particularly in relation to the random matrix, which makes the fluctuations in eigenvalues somewhat interpretable [
7].
1.1. Related Works
Of all the clinical manifestations of mental disorders, schizophrenia is the most complex. The severity of schizophrenia is reflected in the complexity of its symptoms. This paper explores EEG data with the aim of finding an effective method by which to diagnose and discriminate between the diverse clinical manifestations of individuals with schizophrenia. Many methods have been developed to understand EEG characteristics in terms of schizophrenia. Early traditional methods have relied on experienced doctors to observe EEG data and provide clinical diagnostic results based on their experience [
8]. However, different doctor make different judgments that are influenced by many factors, such as their understanding of the pathogeny and the patients, and even their personal emotions. Schizophrenia has been hypothesized to be a brain connectivity disorder that results from abnormal structural and functional connectivity networks [
9]. Maran indicated that such abnormalities exist within functional connectivity in resting-state and task-related EEG data [
10]. Statistical methods can be used to detect and visualize brain function dynamics and complexity, so as to then identify abnormal mental disorders [
11]. Conventional univariate statistical methods neglect the highly interrelated nature of the functional and structural aspects of the brain data, as well as the difficulties in dealing with large amounts of EEG data. Choosing the appropriate feature extraction for schizophrenia diagnosis is a challenging task that requires extensive knowledge of signal processing and artificial intelligence.
Machine learning algorithms have been used to diagnose schizophrenia using EEG data. Extensive research has shown that traditional classifiers, such as support vector machines (SVM) [
12], K nearest neighbors (KNN) [
13], Naive Bayes [
14], decision trees [
15], and random forests [
16], are already being used. With the rapid development of artificial intelligence technology, although the classification accuracy of these methods is sufficient enough to provide a clinical reference, their generalization ability needs to be improved. A convolutional neural network (CNN) was used to classify EEG-derived brain connectivity in schizophrenia [
17], which achieved a remarkable accuracy of 93.06% with decision-level fusion. The high accuracy achieved by the CNN could be attributed to its ability in terms of end-to-end learning and utilizing hierarchical structures between data [
18]. Deep learning is also used for identifying individuals with schizophrenia through applying a CNN to capture the unique physical features of resting-state EEG data, reaching a good degree of accuracy at 88% [
19]. However, these works lacked interpretability for clinical applications.
Many classical statistical methods induce large, sometimes intolerable, errors. It is important to develop new approaches to deal with high-dimensional data [
20]. Random matrix theory (RMT) is a very appropriate candidate model, since the classification methods based on RMT rely on singular values of a large-dimension random matrix. RMT originated in physics and is naturally composed by sampling sequences of multiple random variables [
21]. Under some assumption, the eigenvalues or singular values distribution of RMT, spectral statistics, is estimated by the regular form or upper and lower bounds [
22]. For instance, early research on random matrices
XN×T, where
N stands for the number of multivariates and T refers to the sampling length, was introduced when the Chi-square distribution was extended to multivariate random data. If we assume that each dimension of random data is i.i.d. with a mean of zero,
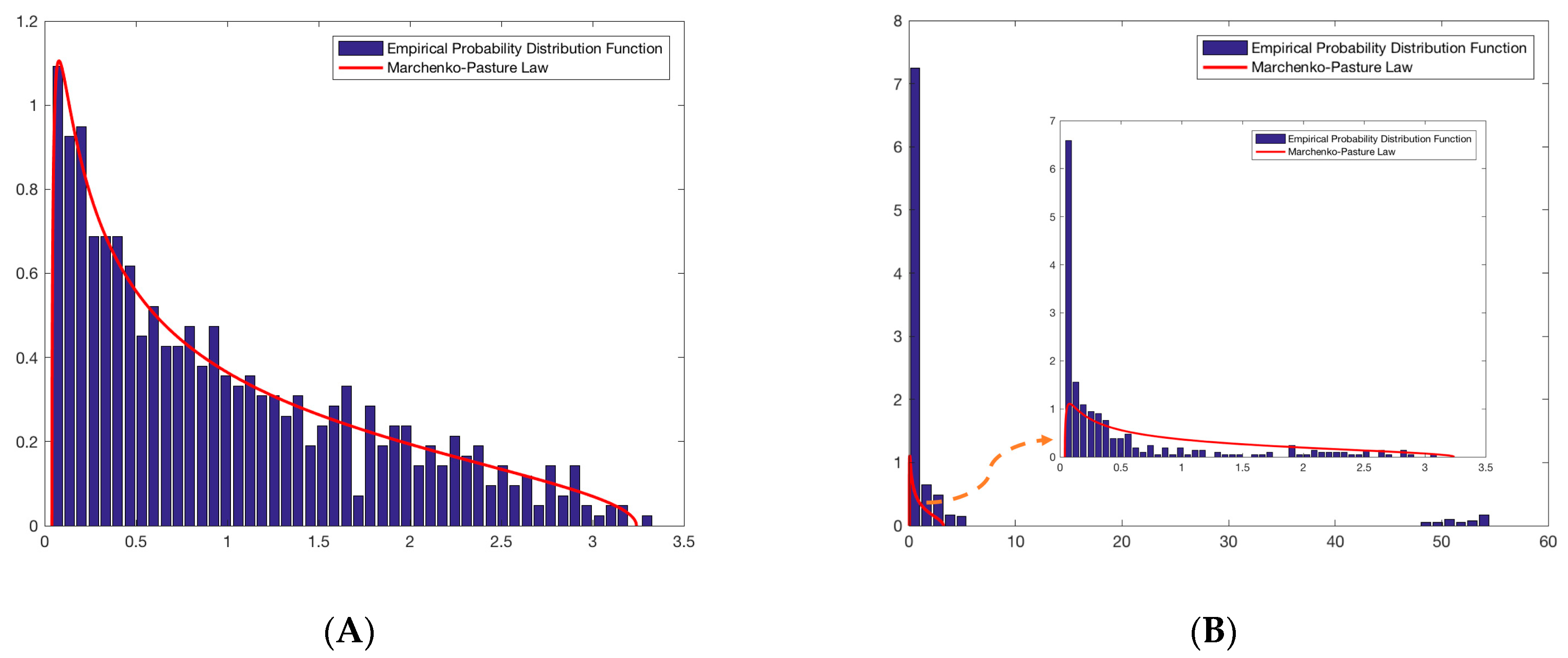
XXT is a p-order symmetric matrix that follows the Wishart distribution. In 1967, Marchenko and Pastur conducted a study of matrices of the order
XTX. When
N is sufficiently large and all variables follow an independent, identically distributed normal distribution variable, its eigenvalue density distribution converges to follow the Marchenko Pastur law [
23]. Today, it is a perspective method widely applied in financial analysis, physics, biological statistics, and computer sciences [
24].
However, each variable does not follow a normal distribution or other standardized distribution assumptions, singular values of
X, or, in other words, the eigenvalues of its covariance matrix of
X are not sufficiently regular as statistical features of multiple random variables. A linear eigenvalues statistic (LES) of
X and LES-associated appropriate test functions can be used to identify the statistical features of the multivariate random matrices
X. Musco provided the theoretical upper and lower bounds of LES with respect to different test functions; for example, the log-determinant, the trace inverse, and the Schatten p-norms [
25]. By introducing a more general assumption of the multivariate variance distribution, the existing bounds of linear eigenvalue statistics for random matrix ensemble were re-established [
26]. For testing the additive effect of the expected familial relatedness, according to a dataset from the UK Biobank, a study was conducted based on LES [
27] where the four test statistics, the likelihood ratio test (LRT), the restricted likelihood ratio test (RLRT), and the sequence kernel association test (SKAT) statistics were employed. For ozone measurements, Han proposed an LES statistical estimation in which the LES-associated test function included a log-determinant, the trace of the matrix inverse, the Estrada index, and the Schatten p-norm to estimate over 6 million variables [
28]. Four test functions were used for anomaly detection in the IEEE 118-bus system, including LRT and Chebyshev Polynomials [
29]. However, there are still very limited applications of RMT in neuroscience. The adoption of RMT in studying EEG data in this research is driven by its ability to provide insights into the statistical properties, noise characteristics, and universal features of the data.
In summary, we can conclude that the different test functions of LES for the same random matrix X have different classification performances. The questions are: which test function is best? Or, how do we find a better one?
In additional, when using EEG data to diagnose schizophrenia, the methods mentioned above focus on the binary classification of FES and HC. Thus far, very little attention has been paid to the role of ternary classifications with the addition of CHR. Distinguishing CHR from HC and FES and preventing the development of CHR in its prodromal stage plays a critical role in treating schizophrenia.
In this paper, we employed LES statistical characteristics, a nonlinear law established for random multivariate, to diagnose schizophrenia, and studied the most appropriate test functions to identify the statistical features of X derived from multivariate random matrices.
1.2. Our Contributions
This study proposes a deep learning method, LES-NN, in which a sequence of LES is the input of a successive deep learning neural network to identify a patient’s mental status in schizophrenia research. The statistical performance of the LES relies on the test function. However, the optimal statistical test function is a functional optimization problem. The proposed LES-based deep learning neural network method involves an iterative learning procedure for the proposed test function optimization problem coupled with the successive parameter optimization of a neural network.
First, EEG data can be divided into matrices, then, the data feature can be characterized using the RMT, within which LES designs are systematically studied. LES is a high-dimensional statistical indicator with different test functions. LES gains insight into systems from different perspectives. In addition, by exploring suitable test functions within the existing functions with physical and statistical significance, it can be found that entropy performs well as a test function for classifying EEG data.
Furthermore, to determine an optimal statistical test function, a functional optimization problem is proposed that relies on the final precision of the model’s output. Finally, we introduce an LES-based deep learning neural network model that synchronously couples the proposed statistical test function functional optimum problem and NN evolution to simultaneously determine the optimal form of the test function and NN parameters. The proposed LES-NN method achieves excellent results for HC, FES, and CHR classification problems. By delving into different instances of schizophrenia, we aim to offer valuable insights into its diagnosis and management.
The paper is organized as follows: The first section includes an introduction to EEG with the prodromal phase of schizophrenia and a learning algorithm with RMT. The second section provides a general overview of the EEG data sources and preprocessing.
Section 3 describes the fundamentals of a RMT and LES.
Section 4 presents the design of the LES test function with machine learning and deep learning neural networks. Finally, the results, discussion, and conclusion are presented in
Section 5 and
Section 6.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}