1. Introduction
Nearing the end of the twentieth century, the accelerated development of artificial intelligence (especially machine learning methods) rekindled the idea that good results are obtainable in a much faster way and in many engineering spheres, including language modeling. In practice, it was established that one of the biggest disadvantages of formal grammar (language modeling state-of-the-art at the time) was the high cost of their creation. The extraction of grammatical rules from the corpus of texts can, of course, be carried out simply by making a list, but this leads to the problem of over-fitting the model, where individual rules are taken for general ones and the broader picture is lost. On the other hand, the derivation of general rules from individuals must be carried out carefully and requires an enormous amount of time. With new technological developments, however, the researchers began to investigate the creation of completely new probability-based models, which emulate automata and rule-based grammars. Instead of assigning a Boolean response to input strings, these new systems, called language models, assign probabilities based on a previously observed textual (training) corpus (
Figure 1).
Language models are thus defined as systems that assign probabilities to strings (based on the context in which they occur), and the models are based on the previously collected corpus. Input strings refer to sequences of tokens , usually representing n-grams of words or characters.
In the previous couple of decades, language modeling was developed primarily using artificial neural networks (ANNs), according to the inspiring idea of Elman [
1,
2], who, while experimenting with time series as input data for machine learning (ML) models, constructed an artificial neural network whose goal was to predict the next element in a sequence. Although the potential of using ANNs for language modeling was recognized early on, the limitations imposed by this approach caused a stagger in development. A large amount of training data necessary for the correct generalization of grammatical rules, as well as satisfactory computing resources (especially working memory and processing power), were not available (at least not to the general public) at the time of the methodology’s development. In addition, the problem of the vanishing gradient, a consequence of backpropagation when training multi-layer and recurrent ANNs, was observed often in practice [
3], especially on the task of natural language modeling.
Nevertheless, the exponential growth in the PC computing power that followed, as well as the exponential increase in the amount of data available (via the Big Data phenomenon), enabled the theory to finally be technologically supported, triggering a new wave of fresh research, based on the idea of deep learning [
4], which is currently the most represented sub-field of machine learning research, and artificial intelligence in general. The use of the long short-term memory method (LSTM) [
5] in language modeling solved the problem of the vanishing gradient at first glance, while also providing previously unattainable results.
1.1. State-of-the-Art
Only with the emergence of the Transformer architecture by Google [
6], as an adequate alternative to LSTM models, a new step forward was made in the field of natural language modeling. The main difference between transformers and LSTM models is that transformers do not rely on recurrent structures, but have an improved model for
attention, a special parameter propagated during learning, which serves to separate relevant from irrelevant information. Today, the most significant and widespread language models are built using this architecture, i.e., an encoder-decoder structure for model training, supported by pre-trained word vectorizations (word embeddings) for preprocessing.
The first outstandingly influential of the type models were BERT (
bidirectional encoder representations from transformers) by Google [
7] and GPT (
generative pre-trained transformer) by OpenAI [
8,
9]. The former is an encoder-based model used primarily for text annotation and classification and the latter is a decoder-based model used primarily for language generation (prediction of the next token for some given left context). Fast forward to today, decoder-based language models are most prominent in the field, with the OpenAI GPT models (now in the fourth generation) being especially popular for instruction tuning [
10]. However, their last model published in open code (and also the latest one available for Serbian) is still GPT-2 [
11], with the efforts still being focused mainly on the development of encoder-based models both for Serbian [
12] and similar Slavic languages [
13,
14,
15,
16].
1.2. Text Quality Evaluation and Perplexity
With the beginning of the twenty-first century and the emergence of the Big Data phenomenon, the necessity to separate significant, quality data from unusable or non-quality data became even more apparent. Machine-based classification methods that rely on automatically collected attributes such as user ratings or predefined expressions (e.g., [
17]) are widely used today and represent the basis for web-originated data analysis.
Classical assessment methods such as evaluation by users or experts tend to be subjective, but an adequate alternative still does not exist. Evaluating the quality of a stimulus (irrelevant of its nature) must be subjective because different people perceive it differently. The evaluation metrics vary depending on the natural language processing (NLP) task, the phase (the model building, deployment, production phase), the focus (intrinsic and extrinsic, ML and business), etc. [
18]. The extrinsic metric focuses on evaluating performance on the final objective of the concrete NLP task, while the intrinsic focuses on intermediary objectives.
Intrinsic evaluation metrics have the advantage of not relying on specific tasks or reference texts, but rather on the (language) models previously trained on reference texts, which are taken as the gold standard. A typical application of intrinsic metrics is to compare two models and analyze how likely they are to generate the same text. The most common intrinsic metric used in computational linguistics is
perplexity, a measure of how much the model is surprised by seeing new input text. Another way to think about perplexity is to treat it as the
weighted average branching factor of a language, i.e., the average number of possible next words that can follow any word [
19].
Definition 1. Let be a language model. Perplexity () of a language model on a string of tokens (sentence, text) is defined as the inverse probability that a model will generate W, normalized by the number of tokens n. Accordingly, perplexity is calculated as follows:where is the probability that a model will generate W. If represents language generated by model and P is a probability function, then This implies that the higher the value of perplexity, the poorer the fit of the tested input string and the model. If we have text that is taken as a gold standard, we can use perplexity as a measure of the quality of a model, or we can measure the quality of the generated text if we take a model as the gold standard. In both cases, we want the measure of perplexity to be as low as possible. In the worst case, if the model is completely unprepared and the probability for each token is the same, then the perplexity is equal to the size of the lexicon of tokens.
The aforementioned properties allow for perplexity to be used for automatically distinguishing between the high- and low-quality data [
20], with one of the motives being the selection of data used to train new language models [
21]. Perplexity can also be used for text classification based on language [
22], the detection of harmful content [
23], and fact checking [
24].
1.3. Research Questions, Aims, Means, and Novelty
Recent developments in NLP (primarily statistically based language models) have brought us numerous new methods and technologies of language modeling [
25], with new and arguably better language models appearing every so often. This paper constitutes an expansion of prior scholarly investigations dedicated to processing and evaluating texts written in arbitrary highly inflective and morphology-rich natural language, particularly Serbian. Two prior investigations considering (Serbian) language processing tasks are revisited, specifically, part-of-speech tagging [
26] and literature authorship attribution [
27] in order to inspect advantages of using composite language models. In these papers, several feature combination techniques were tested (e.g., voting, weighted voting, bidding), but it was concluded that the trained stacked classifier is the optimal method of feature combination, with the main advantage of distinguishing between quality and noise-inducing features. Additionally, if the trained stacked classifier’s complexity is kept low, their explicitness is reasonable and the risk of overfitting them is minimal. The specific aim of this research is to further develop the methodology for the creation of composite intelligent systems to aid in solving the task of language modeling, particularly focusing on the tasks of perplexity-based text evaluation and classification [
20]. The main motivation of the experiment was to support the distinction between high-quality and low-quality text, particularly that acquired from the web, in order to secure the integrity of automatically constructed corpora.
In order to achieve this goal, a group of
standalone transformer-based language models (GPT-2), previously trained on a corpus of texts in Serbian [
28], were used to develop several different
composite language models. The expediency of the models will be illustrated in the example of solving two binary classification tasks:
- C1
Detection of low-quality sentences;
- C2
Machine translation detection.
The first classification task was chosen because of its direct alignment with the goal of the research (distinguishing between high-quality and low-quality text), while the second task was chosen as an alternative, which is more difficult benchmark, especially with the recent advances in the field of machine translation [
29]. The ability of the standalone models to classify the sentences will be tested using only the sentence perplexity value outputted by the model. The obtained results will be used as a baseline for the evaluation of the composite models. The first of the two envisioned composite models,
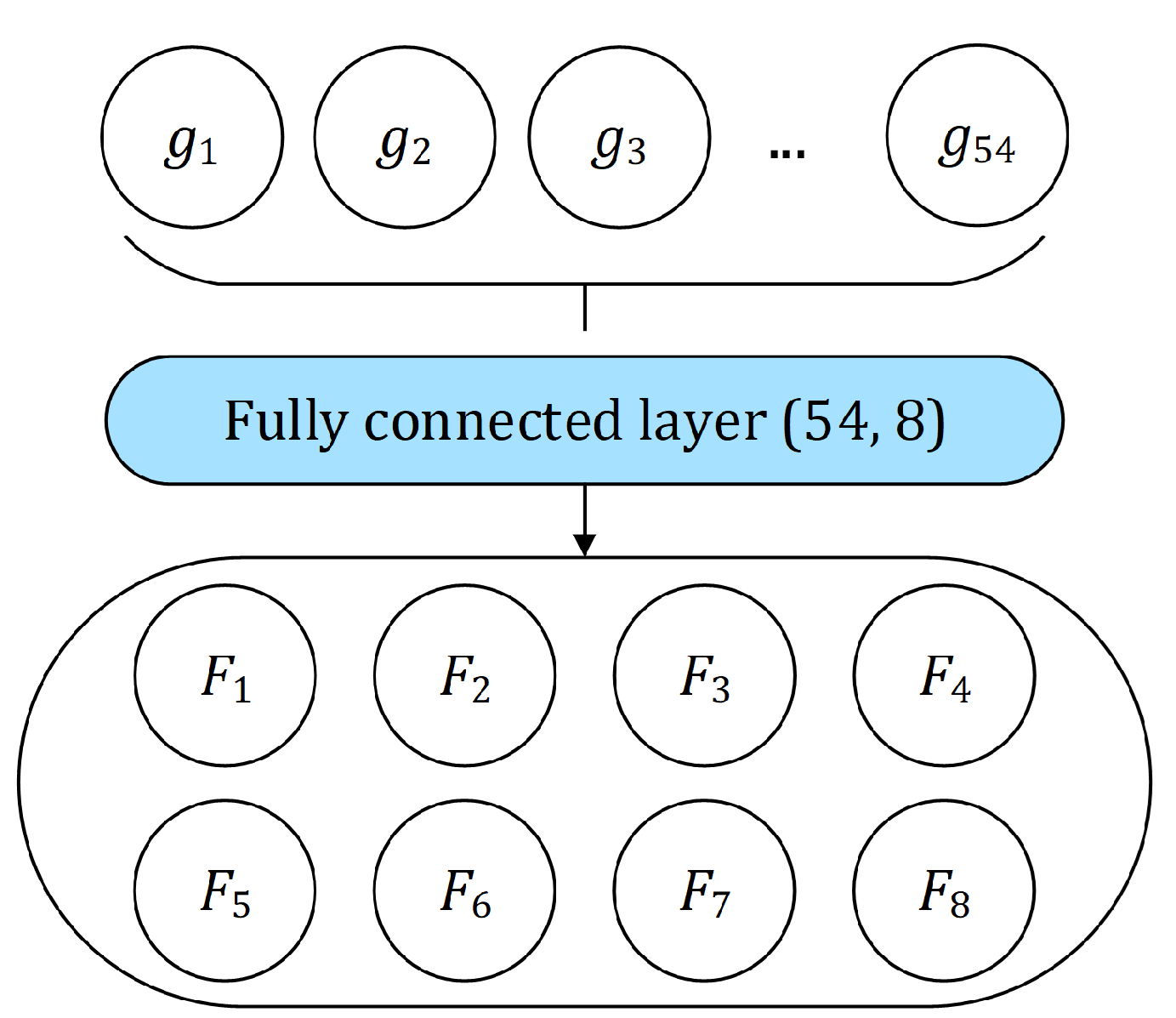
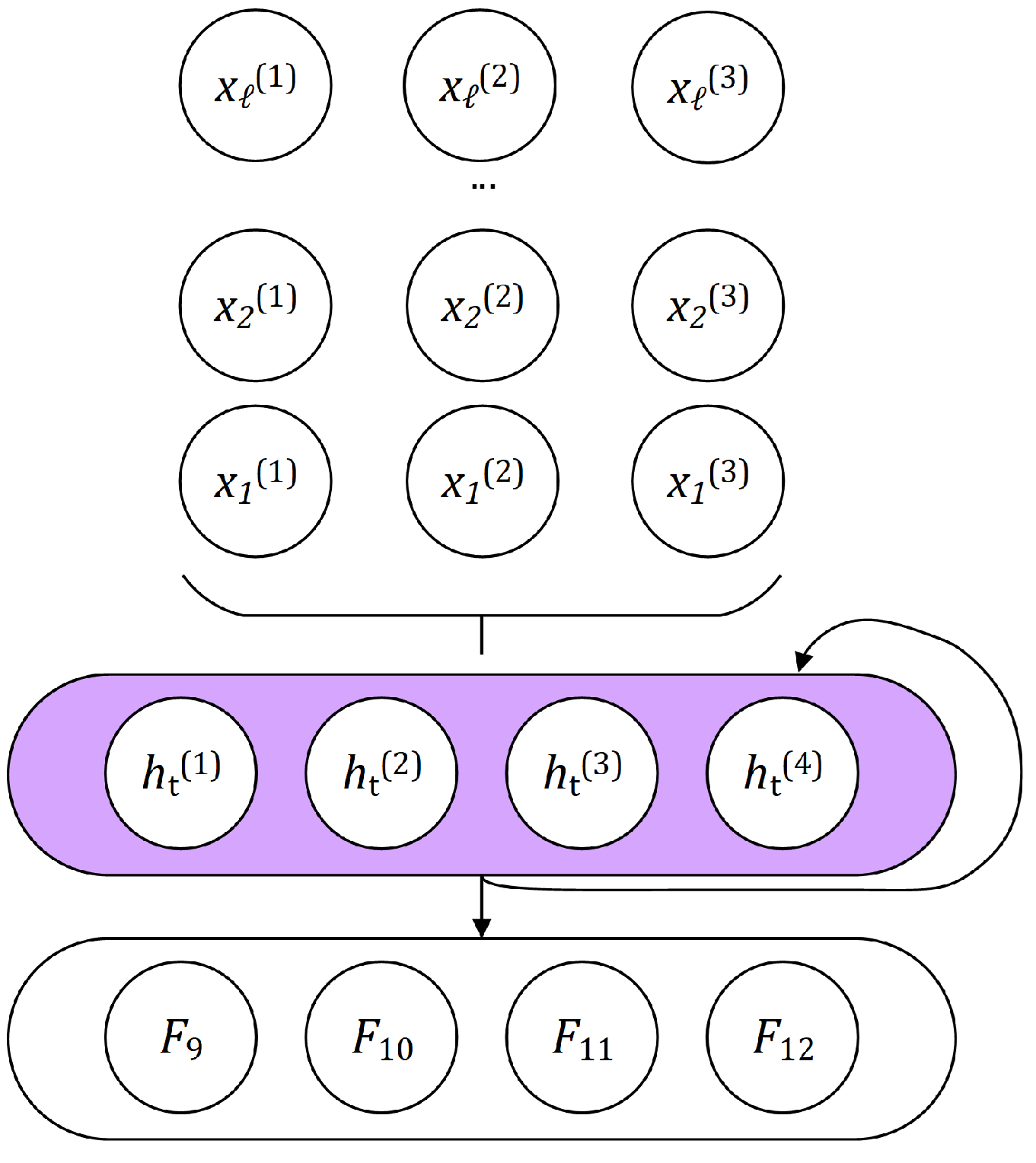
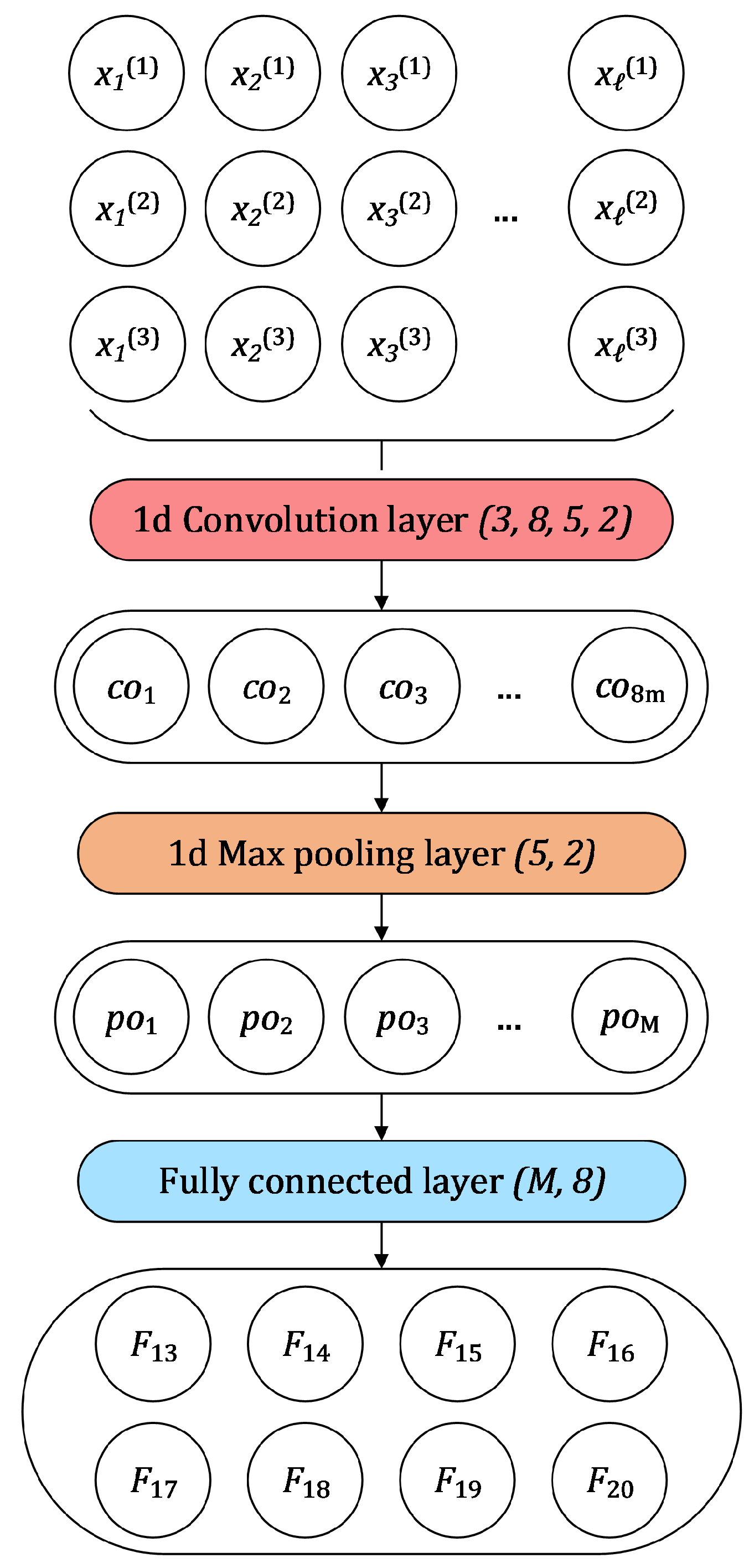
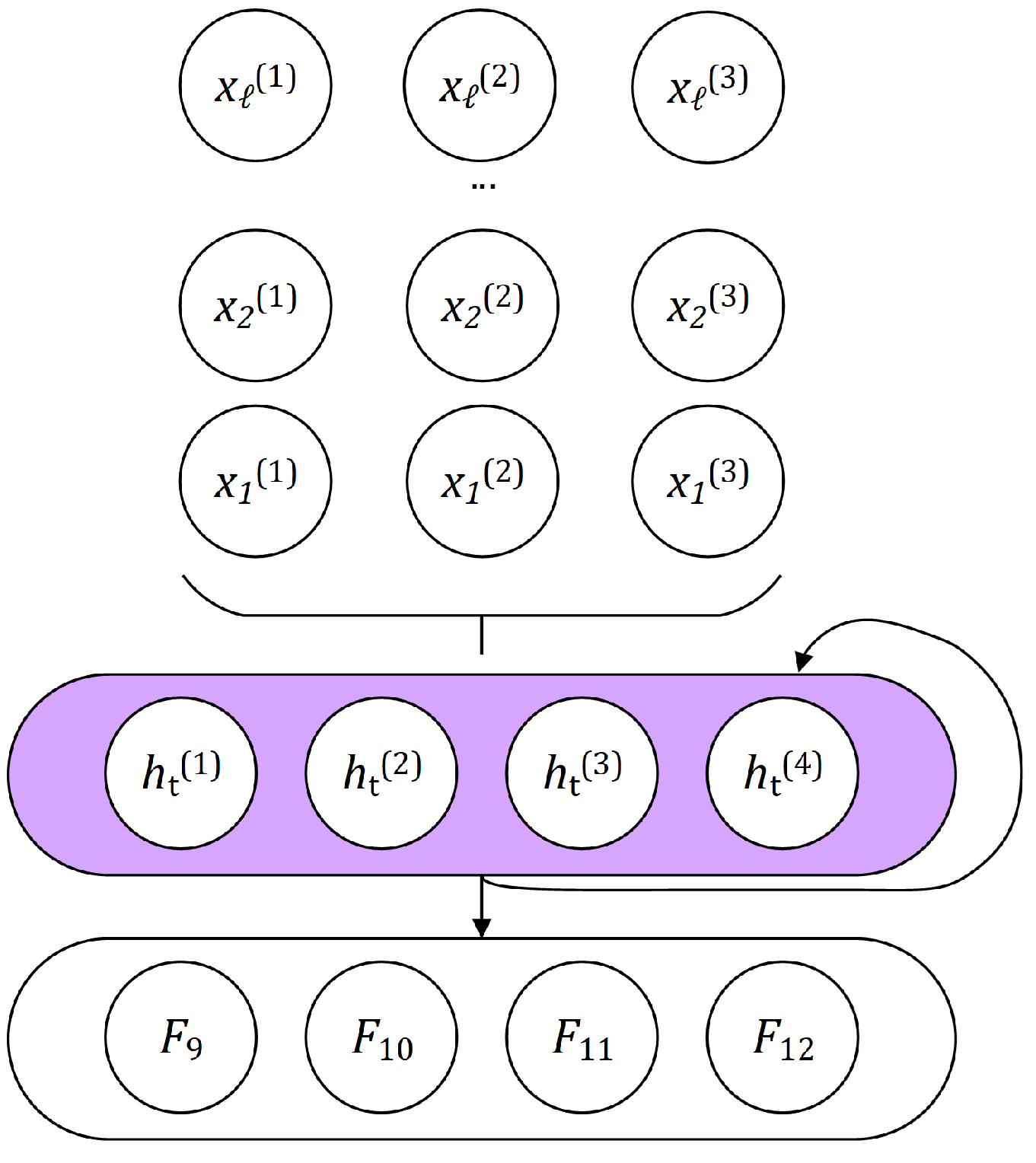
, will use sentence perplexities outputted by each of the three standalone models (
M1,
M2, and
M3,
Section 2.1) as classification features. Besides the
features, the second composite model,
, will use additional features extracted from standalone models
M1,
M2, and
M3.
This paper will address three research questions:
- RQ1
Are semantic and syntactic models justified tools to use for sentence classification tasks, e.g., low-quality sentence or machine translation detection?
- RQ2
Can composite language models based on outputted perplexities and the wisdom of crowds-based compositions improve on the accuracy of standalone models on classification tasks?
- RQ3
Can features extracted from perplexity vectors be used to further improve the classification accuracy of composite models?
The main contributions of this research are:
Development of a perplexity-based dataset for testing and validation of composite and standalone language models using existing models and parallel language corpora;
Development of a detailed model of the composite systems for parallel unification of created models (which can be applied to both future models and other languages);
Creation of composite Serbian language models that can be used in natural language processing tasks, including document classification and text evaluation;
Evaluation of created models on two well-known binary classification problems.
The developed composite model architectures are to enable a more precise calculation of fitness between models and texts (i.e., a more precise calculation of perplexity) which could also induce performance improvement for generative language models. Additionally, the knowledge gathered through the inspection of the results should enable researchers to further develop the methodology of composite intelligent systems creation.
Section 2 of this paper will present the creation of the main evaluation dataset and its merits, and
Section 3 will describe the process of feature extraction and model compositions.
Section 4 will present the evaluation process and the results obtained, which will be followed by the discussion and concluding remarks, together with plans for future research in
Section 5.
2. Dataset
The dataset used to evaluate the proposed methodology approach for this experiment is envisioned as a series of matrices containing perplexity values obtained through standalone language model evaluation. In order to prepare the dataset, several standalone language models (M1, M2, and M3) that output different perplexity values for the same text were needed, and also several series of textual sentences (T1, T2, and T3) not previously used for the training or fine-tuning of M1, M2, and M3. The final dataset is obtained by evaluation of M1, M2, and M3 using T1, T2, and T3 as the test sets.
The textual dataset T was envisioned as a list of three separate sets:
- T1
High-quality sentences in Serbian, obtained from the expert translation of appraised novels written in other languages;
- T2
List of low-quality sentences, i.e., a list of sentences from the dataset T1 corrupted using several different methods in order to make them semantically or syntactically incorrect;
- T3
List of machine translations of the original literary sentences, as opposed to the expert translations from the dataset (T1).
The final dataset D was generated by recording the perplexity values of prepared language models against the prepared sets of sentences, and it was used to evaluate the methodology on both envisioned classification tasks. The detection of low-quality sentences (C1) is summed up as the classification between datasets T1 and T2, and the detection of machine translations (C2) as the classification between datasets T1 and T3. The complete process of the dataset generation can be summed up in three steps:
Preparation of pre-trained language models for Serbian that tend to output different perplexity measures for textual input (M1, M2, and M3);
Preparation of textual data T1, T2, and T3 (based on text not used for the training or fine-tuning of aforementioned language models), which will be used for the creation of evaluation dataset for both classification tasks (C1 and C2);
Generation of the final dataset, based on perplexity outputs obtained via evaluation of the prepared sentences from the previous step (T1, T2, and T3) using prepared language models from the first step (M1, M2, and M3).
2.1. Language Models
A total of three standalone language models that were previously trained [
28] on a collected corpus of Serbian texts and based on a second-generation generative pre-trained transformers architecture (GPT2, 137 million parameters) were used for this research:
- M1
Control model trained using a standard corpus of contemporary Serbian texts (1 billion tokens), and standard training configuration for GPT2-based models;
- M2
Experimental semantic model, trained on a specially prepared corpus representation, i.e., a corpus processed using latent semantic analysis methods [
30], namely removal of stop words and lemmatization;
- M3
Experimental syntactic model, trained on a different corpus representation that was processed using morphological dictionaries in such a way that the content words [
31] were replaced with their grammatical category.
The two experimental models were supposed to model two complementary aspects of the text in natural language (semantics and syntax) and therefore produce potentially different perplexities when faced with the same piece of input text. It should be noted that when calculating perplexity using these models, input text must be preprocessed using the same transformation that was used for the generation of the training corpus data for the respective model in order to obtain correct readings. All three of these models are available in open access on the
Huggingface platform and linked in the Data Availability Statement at the end of the paper. See
Appendix A for the implementation details.
2.2. Textual Data
Textual data used to build the evaluation dataset for this research is based on a parallel corpus of literary texts (novels originally written in German and Italian and their expert translations into the Serbian language). The bigger share of the texts was pooled from parallel Serbian–German corpus,
SrpNemKor [
32], where only the novels originally written in German were used. The rest of the textual data represent the parallel translation of the third part of the
Naples stories series [
33,
34], prepared as the part of the parallel Serbian–Italian corpus within the It-Sr-Ner project (supported by CLARIN ERIC “Bridging Gaps Call 2022”) [
35]. A total of seven novel translations were used (
Table 1).
The first envisioned set of sentences (a set of expert translations, ) was created by simply extracting sentences from the translations listed in novels. The set contains tokens (about per sentence) and has a type-token ratio of .
The second set (low-quality sentences, ) was created by taking each sentence from the first set and applying one of the following transformations at random:
Lemmatization: Each word in the sentence is replaced with its lemma based on Serbian Morphological Dictionaries, to make the sentences prone to morphosyntactic incorrectness. Although it is possible that the lemmatized sentence is equal to the original one (in case all words in the original sentence were already lemmas), a simple equality comparison between them calculated that this happens less than 0.8% of the time;
Random mixing of word order within a sentence: A sentence was transformed into a list of words and punctuation marks, which was then randomly shuffled and put back together into text. This was also conducted to make the sentences prone to syntactical incorrectness, especially regarding the position of prepositions and adjectives. As in the previous case, this does not necessarily mean that the sentences are incorrect, but a manual evaluation of a set of 400 sentences found that this happens in less than 0.6% of the cases;
Random replacement of words in the sentence: namely, each word in the sentence is replaced by another, random word of the same grammatical category from the Serbian Morphological dictionaries, in order to make it prone to semantic incorrectness.
The application of these transformations does not affect sentence lengths, but the type-token ratio is decreased to (due to the lemmatization of one part of the sentences).
The third set of sentences (machine translations, ) was obtained by running the original sentences (in German and Italian) through the Google Translate service and translating them into Serbian. Another simple equality comparison revealed that they differ from expert translations about of the time. These sentences are somewhat shorter (average of tokens per sentence and total), but the type-token ratio of is quite similar to the one of the first set.
The complete textual dataset is a sequence comprising sentences divided into three subsequences of equal size .
2.3. Sentence Perplexities and Perplexity Vectors
Definition 2. Let . Integer interval is defined as .
Definition 3. Let and . The vector is the element-wise inverse (also called Hadamard inverse) of vector x.
Definition 4. Perplexity vector () [36] of a language model on a sentence is calculated applying the Equation (
1)
to each N-gram of tokens within a sentence (N fixed, ): Size is used during this experiment. The size of for a given sentence s is and therefore varies depending on the number of tokens n in s.
Let , , . The final dataset D consists of:
- D1
Subset containing three sequences of inverse perplexity triples, one for each dataset
, i.e.,
where
represents perplexity of the model
on the
kth sentence in the dataset
, calculated using (
1). See
Appendix A for the implementation details.
- D2
The subset comprised three sequences, one for each dataset
, where every sequence element is a triple containing the Hadamard inverse of perplexity vectors, i.e.,
and
represents the perplexity vector of the model
on the
kth sentence in the dataset
, calculated using (
3).
Values stored in sets
and
were used to measure the classification performance of (both standalone and composite) language models on the tasks of detecting low-quality sentences and machine translations (see
Section 4).
Definition 5. Let and be two sequences of length n. The Pearson linear correlation coefficient r is defined aswhere represents the mean of x and analogously for . Let
and
be a sequence
such that
, i.e., a sequence of perplexity values obtained for sentences of dataset
using model
. In order to ensure that the perplexity values differ between both different models and different textual datasets, the Pearson coefficients
were calculated using (
6), as the primary measure of linear correlation between every two pairs
and
, where pairs share either a model (
) or a dataset (
).
Table 2 and
Table 3 contain the resulting
coefficients between
pairs, where pairs share the same dataset in
Table 2, while pairs in
Table 3 share the same model.
The results presented in
Table 2 confirm the uniqueness of perplexities outputted using the prepared models, with the highest correlation coefficient being 0.265 between the models
M1 (control) and
M2 (semantic) and all of the other correlation coefficients being less than 0.05. On the other hand, the much higher correlation was apparent in
Table 3, averaging at about 0.56, indicating that the models have trouble differing between the datasets, especially model
M2 between the datasets
T1 and
T2 (inability to distinguish the control set from the artificially-defected, low-quality sentences), with a correlation coefficient of over 0.8. In
Section 3, we introduce composite models as a form of overcoming this insufficiency.
Once the data were confirmed to be of value, all of the perplexity values in sets
D1 and
D2 were converted to their inverse value, which concluded the creation of the dataset
D according to Equations (
4) and (
5). This was carried out for the sake of their easier input into the machine learning algorithms afterwards in the experiment.
4. Results
For the evaluation, we used five-fold cross-validation over dataset
D, for which both subsets were split into five (nearly) equal, class-balanced chunks. For each of the five folds, a different chunk was used for testing, while the other four were used to train ten classifiers, including five for each classification task (
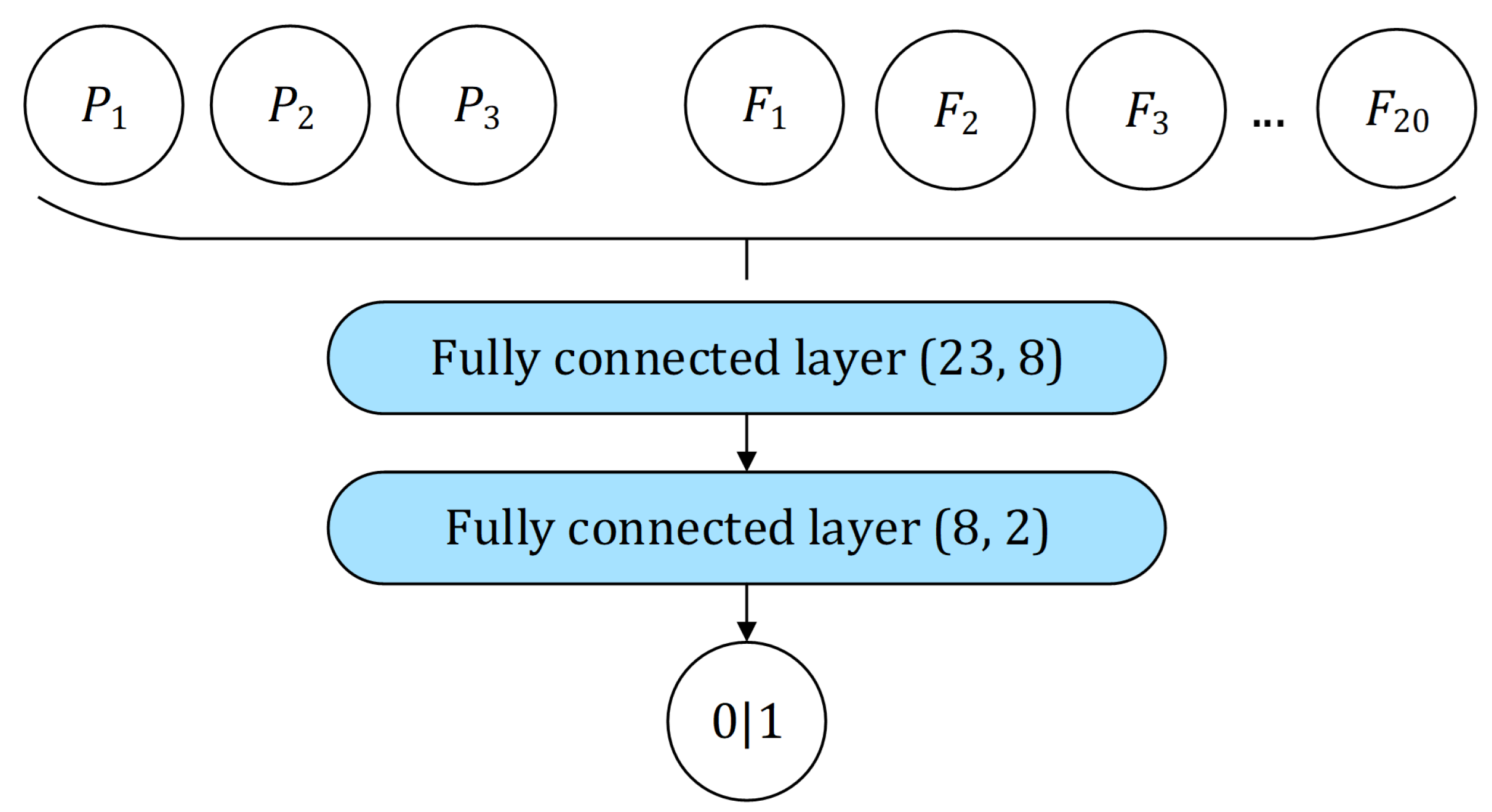
,
). Three
simple classifiers were based directly on standalone models (
,
, and
), while two
composite classifiers (
and
) were trained on top of all three standalone models. Different training procedures were deployed depending on the classifier being trained, where different levels of input data complexity influenced the complexity of the models (
Table 4).
For each training session, the Adam optimizer [
41] with a learning rate of
and a batch size of 64 was used, and the number of training epochs was limited to 50. In order to measure the improvements achieved using the proposed composite models, the results achieved using the standalone models (
M1,
M2, and
M3) were marked as the baseline. More precisely, the baseline was defined as the best result achieved by any of these
,
for each classification task
and
. The experiment was conducted to explore whether the composite models would achieve a statistically significant improvement.
As already mentioned, during the preparation of the five data chunks for each of the two binary classification tests, an equal number of samples for both classes (
and
for task
or
and
for task
) was prepared by stratifying the already balanced data according to the output class. This resulted not only in the effective training but also in the accuracy always being equal to the
score. For that reason, we will focus on the classification accuracy metric when presenting the results of the cross-validation, or relative accuracy increase when depicting the improvements the composite models achieved over the baseline. The results of the evaluation will be presented in
Section 4.1.
4.1. Quantitative Results
The cross-validation accuracy of all of the five inspected models (
,
,
,
and
) on the task of low-quality sentence detection (
), as well as the highest achieved accuracy and mean accuracy, are presented in
Table 5. The accuracy results of the same models, but on the task of machine translation detection (
), are presented in the same manner in
Table 6.
The average relative accuracy increase (RAI) and average error rate reduction (ERR) compared to the baseline are calculated for both composite models (
and
) on both classification tasks (
and
) using the equations:
and
where
a is the baseline accuracy and
is the alleged improved accuracy.
These results, aiming to give a definite answer to the research questions
RQ1–
RQ3, are presented in
Table 7.
4.2. Qualitative Results
The improvement achieved by the composite model
over the baseline (2.06% relative accuracy increase on
and 6.88% relative accuracy increase on
) is probably not due to mere chance, but despite that, we cannot ascertain the statistical significance via simple comparison. In order to check the integrity of the results, we used the
corrected repeated k-fold cross-validation test [
42] to determine the actual statistical significance of the achieved improvements. The
t-score was calculated as:
where
k is the number of cross-validation folds (
),
the baseline accuracy at fold
i,
the improved accuracy at fold
i,
r the size ratio of test and training sets (
), and
the variance of the difference of
a and
across folds.
For each composite model (
,
) and for each classification task (
,
), we calculate the
t-score using Equation (
34) and from it the
p-value using
Student’s Cumulative distribution function [
43]. These results are presented in
Table 8. Here, we observe a high statistical significance of the accuracy increase in three out of four cases with the
p-values being below 0.05, in accordance with the standard confidence level of 0.95. The only outlier represents what the improvements classifier
achieved over the baseline for task
(machine translation detection),
, in which case the
null hypothesis (stating that no statistical significance exists) cannot be rejected.
5. Discussion
In this paper, we experiment with two separate classification tasks: low-quality sentence detection () and machine translation detection (). On both tasks, we test the improvements achieved using composite language models (built upon perplexity outputs of several language models) over the accuracy of standalone models, which is taken as a baseline.
From the results presented in previous section, precisely
Table 5 (cross-validation results on task
), the following observations are made:
- Q1
Model is the best standalone model for low-quality sentence detection (average accuracy of 84.88%), and should thus be taken as the baseline for ;
- Q2
Composite model outperforms this baseline on each cross-validation fold (with an average accuracy of 85.69%;
- Q3
Composite model outperforms the composite model across all cross-validation folds with an average accuracy of 86.63%.
Additionally, from the results presented in
Table 6 (cross-validation on task
), we note the following observations:
- Q4
Model (syntactic) is the best-performing standalone model for machine-translation detection and should thus be taken as the baseline for , although with an accuracy of only 50.9%;
- Q5
None of the other standalone models managed to surpass the 50% accuracy score (on any fold), indicating that perplexities outputted by the control () and semantic model () are not indicators for machine translation detection;
- Q6
Composite model slightly outperforms the baseline on four out of five cross-validation folds, and also on average (accuracy of 51.71%);
- Q7
Composite model outperforms the baseline, as well as composite model across all cross-validation folds, with an average accuracy of 54.4%.
Lastly, from the results presented in
Table 7 (average relative accuracy increase and error rate reduction per composite model and per task) and
Table 8 (statistical significance of achieved accuracy improvements per composite model and per task), the following is observed:
- Q8
Composite model achieved the average RAI of 0.95% for classification task and 1.59% for classification task . The former is deemed statistically significant for a confidence level of 95% (), while the latter is deemed statistically insignificant ();
- Q9
Composite model achieved the average RAI of 2.06% for , 6.88% for , error rate reduction of 11.57% for , and 7.13% for . Both improvements are deemed statistically significant for a confidence level of 95% ( and , respectively);
- Q10
The results achieved by all tested models, and especially
,
, and
, are comparable to the state-of-the-art results achieved for low-quality sentence detection for the English language [
20].
Based on the collected cues, primarily and , we conclude that there is indeed a use for semantic and syntactic models in sentence classification. While the positive results achieved using composite classifiers that incorporate these models indicate their importance for refinement of the classification, the fact that syntactic model outperformed the control model for classification task indicates a positive answer to the research question RQ1:
RQ1: Are semantic and syntactic models justified tools to use for sentence classification tasks, e.g., low-quality sentence or machine translation detection?
This notion that models and provide additional information despite being trained on the same text (just different representation) is additionally apparent through results achieved by composite model (, , ). While there is not definite statistical significance in its improvements over the baseline for the task (), it definitely improved over the baseline on the task () as evident in , confirming a positive answer to the first research question and imploring a positive answer to the research question RQ2:
RQ2: Can composite language models based on outputted perplexities and the wisdom of crowds-based compositions improve on the accuracy of standalone models on classification tasks?
Finally, the improvements the composite model achieved over both the standalone models (, , and ) and the composite model (, , ) undoubtedly provide a positive answer to the final research question RQ3:
RQ3: Can features extracted from perplexity vectors be used to further improve the classification accuracy of composite models?
This also furthers the indication of the value of semantic and syntactic models, but most of all, it affirms the value of perplexity vectors [
36] in perplexity-based sentence classification.
If we revisit the results for low-quality sentence detection task (, , ), we conclude that for the task, while partially solvable using a standard language model, with an accuracy of nearly 85%, a significant improvement can be made via incorporating other language models and perplexity vectors. No statistically significant improvements over the baseline were found using the model for this task, which is probably caused by the poor performance of the semantic and syntactic model (average accuracy of 55.84% and 61.75% compared to the baseline of 84.88%). Due to this fact, we must contribute the improvements achieved by model (total error rate reduction of over 11%, ) to the usage of perplexity vectors, indicating that low-quality sentences are detectable via features contained within them.
As for the task of machine translation detection () and the observed results on it (, , , ), it is apparent that its difficulty is much higher. Two out of three standalone models failed to outperform the 50% accuracy mark, which can be attributed to random selection. The only standalone model that could even slightly differentiate between the expert and machine translations was the syntactic one (but with very low accuracy), which could mean that expert and machine translations differ mostly in the syntax used. However, model which uses all three achieved better results (average accuracy of 51.71%) and the improvements were found to be statistically significant, indicating that the combination of syntax and semantics is a better indicator. Lastly, the results achieved by the model (relative accuracy increase of 6.88% and error rate reduction of 7.13%, ), despite the somewhat low achieved accuracy of 54.4%, indicate a high improvement through the usage of features extracted from perplexity vectors for this quite difficult task.
In conclusion, composite models are shown to improve on the accuracy of standalone models for classification tasks, with a composite language model based on a stacked classifier architecture that uses properties extracted from perplexity vectors as features being singled out as the best option for detection of both machine translations (low accuracy) and low-quality sentences (high accuracy). It should be noted that the drawback of composite models is higher training complexity and higher execution time. In future work, they should also be compared to bigger standalone models, i.e., whether the composition of a few smaller models is better than a large standalone model in terms of both training and execution speed, as well as in accuracy. If composite models are shown to be feasible, the research should focus on improving their quality through the improvement of the standalone models that they are composed of.
Perplexity vectors are shown to mitigate the main limitation of perplexity-based classification (the lack of dimensionality), but their limitations (aside from slightly higher execution time) are yet to be determined through future research. For example, features analysis should disclose the highest-value features of perplexity vectors, e.g., features extracted using RNN or features extracted from frequency-domain-based properties of perplexity vectors.
An inspection of further usages of both composite language models and perplexity vectors should be performed in order to expand on the idea of this research. Lastly, other methods should be tested for the examined tasks for the Serbian language, and a comparative study should be performed for a better understanding of both previously achieved and future results. Most prominently, BERT or a RoBERTa-based model for Serbian should be fine-tuned for the aforementioned tasks and tested on the prepared dataset.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}