
Ensemble Learning for Multi-Label Classification with Unbalanced Classes: A Case Study of a Curing Oven in Glass Wool Production

 , , , ,
, , , ,
Abstract
:1. Introduction
- It introduces a comprehensive framework to address the significant challenges of exploiting the Industrial Internet of Things (IIoT). It focuses explicitly on handling outliers, missing data, unbalanced class classification, and the emergence of new classes.
- It analyzes the effects of missing data and a comparative evaluation of various imputation methods for addressing this issue.
- It examines the performance of diverse classifiers within the ensemble learning framework to handle the imbalanced class classification problem. The study proposes a new mixture design weight ensemble to optimize the contribution of classifiers in ensemble learning.
- It applies the proposed approaches to an industrial real-world case study that exemplifies the implementation and effectiveness of the proposed methods and techniques.
2. State of the Art
2.1. How to Deal with Poor Quality Data?
2.1.1. Dealing with Outliers
2.1.2. From Missing Data to Imputation Methods
- K-nearest neighbors imputation: A non-parametric approach using observations in the neighborhood to impute missing values [25].
- Density estimation imputation: For each variable, a probability density is estimated based on observed values. Then, missing values are imputed by a value generated from the estimated probability density function [26].
- EM (Expectation Maximization) algorithm for Gaussian mixture imputation: A multivariate imputation requires the estimation of a finite Gaussian mixture model (GMM) parameter in the presence of missing data. The Gaussian mixture models can fit the distribution of a multi-dimensional dataset. An Expectation Maximization algorithm estimates the parameters of GMM.The EM algorithm consists of two iterative steps. The expectation step consists of computing the complete data likelihood conditional on the observed data, using the current estimates of the parameters. The maximization step consists of estimating new parameters by maximizing the expected likelihood estimated in the E step. E steps and M steps are applied iteratively until convergence [27].
- Random forest imputation (missForest): Random forest (RF) is an ensemble of decision trees. Each decision tree has a different set of hyper-parameters and is trained on a different subset of data. In the first step, the approach trains an RF on observed values. Then, it predicts the missing values using the trained RF. The imputation procedure is processed iteratively until a stopping criterion is met [28].
- Stochastic regression imputation: Uses regression techniques to impute missing data. First, for each unobserved value, the approach uses mean imputation. Then, each feature is regressed on the other features. Based on the regression model, it predicts each incomplete value using the observed value of the other features. The method adds (or subtracts) a random value to each imputation to integrate the stochastic aspect. It samples the random value of a normal distribution with mean 0 and standard deviation equal to the uncertainty of the regression imputation model [29].
2.2. How to Handle the Imbalance Problem in Multi-Label Classification?
- Resampling methods aim to rebalance the class distribution by resampling the data space [37]. These techniques can be categorized into three main groups. Undersampling methods eliminate samples associated with the majority class [38]. Meanwhile, oversampling methods create new samples associated with the minority class [39]. Last but not least, hybrid approaches take undersampling and oversampling simultaneously. Within these categories, resampling methods can further be divided into two sub-categories based on how the samples are added or removed: random methods and heuristic-based methods.
- –
- Random resampling aims to balance class distribution by randomly choosing the samples to be deleted or produced associated with a specific class. Random undersampling is a simple method for adjusting the balance of the original dataset. However, the major inconvenience is that it can discard potentially essential data on the majority class. On the other hand, random oversampling can lead to overfitting since it only duplicates existing instances.
- –
- Heuristic-based resampling aims to carefully select instances to be deleted or duplicated instead of randomly choosing.
- ∗
- In the case of undersampling, it tries to eliminate the least significant samples of the majority class to minimize the risk of information loss. Popular heuristics in this category include the MLeNN heuristic [40] and the MLTL heuristic [41]. To select samples to remove from the majority class, MLeNN utilizes the Edited Nearest-Neighbor rule; meanwhile, MLTL utilizes the classic Tomek Link algorithm.Space-filling designs of experiments are also good techniques to minimize the loss of information. In the computer experiment setting, space-filling designs aim to spread the points evenly throughout the response region. Then a subset of points is chosen to reconstruct the response region sufficiently and efficiently. This concept can be applied to undersampling the majority class by selecting a subset of representative samples located near the class boundary or within the class envelope. This approach helps to retain as much class-specific information as possible [42]. Space-filling designs include low-discrepancy sequences [43], good lattice points [44], Latin Hypercubes [45], and orthogonal Latin Hypercubes [46].
- ∗
- In the case of oversampling, the synthetic minority oversampling technique (SMOTE) and its modified versions are popular methods with great success in various applications [47]. SMOTE interpolates several minority class samples that lie together to create new examples. First, it randomly selects one (or more depending on the oversampling ratio) of the k nearest neighbors of a minority class sample. Then, it randomly interpolates both samples to create the new instance values. This procedure is repeated to generate as many synthetic instances for the minority class as required.The approach is effective because new synthetic samples are relatively close in feature space to existing examples from the minority class. However, SMOTE may increase the occurrence of overlaps between classes because it generates new synthetic samples for each original minority instance without consideration of neighboring instances [48]. Various modified versions of SMOTE have been proposed to overcome this limitation. The representative approaches are Borderline-SMOTE [49], Radius-SMOTE [50], and Adaptive Synthetic Sampling (ADASYN) [51] algorithms. Unlike SMOTE, Borderline-SMOTE only generates synthetic instances for minority samples that are “closer” to the border. On the other hand, Radius-SMOTE aims to correctly select initial samples in the minority class based on a safe radius distance. Therefore, new synthetic data are prevented from overlapping in the opposite class with the safe radius distance. Regarding ADASYN, this approach is similar to SMOTE, but it adaptively creates different amounts of synthetic samples as a function of their distributions.
- Classifier adaptation adapts the existing machine learning algorithms to directly learn the imbalance distribution from the classes in the datasets [36]. There are representative multi-label methods adapted to deal with imbalance, such as [52], which applies the enrichment process for neural network training to address the multi-label and unbalanced data problems. First, they group similar instances to obtain a balanced representation by clustering resampling. This balanced representation forms an initial subset of training data. Then, during the neural network classifier training process, they continuously add and remove samples from the training set with respect to their prevalence. They repeat the incremental data modification process until it reaches a predefined number of iterations or the stop condition.The work done in [53] adapts radial basis neural networks to construct an unbalanced multi-instance multi-label radial basis function neural network (IMIMLRBF). First, according to the number of samples of each label, IMIMLRBF computes the number of units in the hidden layer. Then, based on the label frequencies, it adjusts the weights associated with the links between the hidden and output layers.The authors in [54] address class imbalance in multi-label learning via a two-stage multi-label hyper network. In their approach, according to label imbalance ratios, labels are divided into two groups: unbalanced labels and common labels. First, the approach trains a multi-label hyper network to produce preliminary predictions for all labels. Then, it utilizes the correlation between common and unbalanced labels to refine the initial predictions, improving the learning performance of unbalanced labels.
- Ensemble approaches use multiple base classifiers to obtain better predictive performance than could be obtained from any single classifier. The idea is to combine different options of the constituent classifiers to derive a consensus decision. This approach is beneficial if classifiers are different [58]. Apart from using different base classifiers, the difference can also be achieved by training on different, randomly selected datasets [59,60], as well as by using different feature sets [61].Ensemble methods first train several multi-label classifiers. These trained classifiers are different and, thus, can provide diverse multi-label predictions. Then, they combine the outputs of these classifiers to obtain the final prediction. There are various classifier combination schemes, such as voting [62], stacking [63], bagging, and adaptive boosting [64].
- Cost-sensitive learning methods apply different cost metrics to handle unbalanced data. In traditional classification, the misclassification costs are equal for all classes. In the cost-sensitive approaches, classifiers consider higher costs for the misclassification of minority instances compared to majority instances [65]. The representative studies that migrate the cost-sensitive methods to handle the class imbalance problem are [66,67].
2.3. How to Combine Multi-Classifier Results to Improve the Global Classification Performance?
2.3.1. Voting Ensemble
- Hard voting first sums the predictions for each class and then predicts the class with the largest sum of votes from classifiers.
- Soft voting sums the predicted probabilities for each class label and then predicts the class with the largest summed probability.
2.3.2. Dynamic Weight Ensemble
2.3.3. Stacking Ensemble
- In the first level, various single classifiers, such as k-NN, SVM, and decision tree, are trained in parallel with the training dataset.
- In the second level, the approach uses the predictions made by the base classifiers in the first level to train a meta-learner, such as logistic regression. It takes the predictions of based classifiers as inputs of the meta-learner. With the expected label, it obtains the input and output pairs of the training dataset to fit the meta-learner. It is worth noting that the meta-learner is trained on a different dataset to the examples used to train the base classifier in the first level to avoid overfitting.
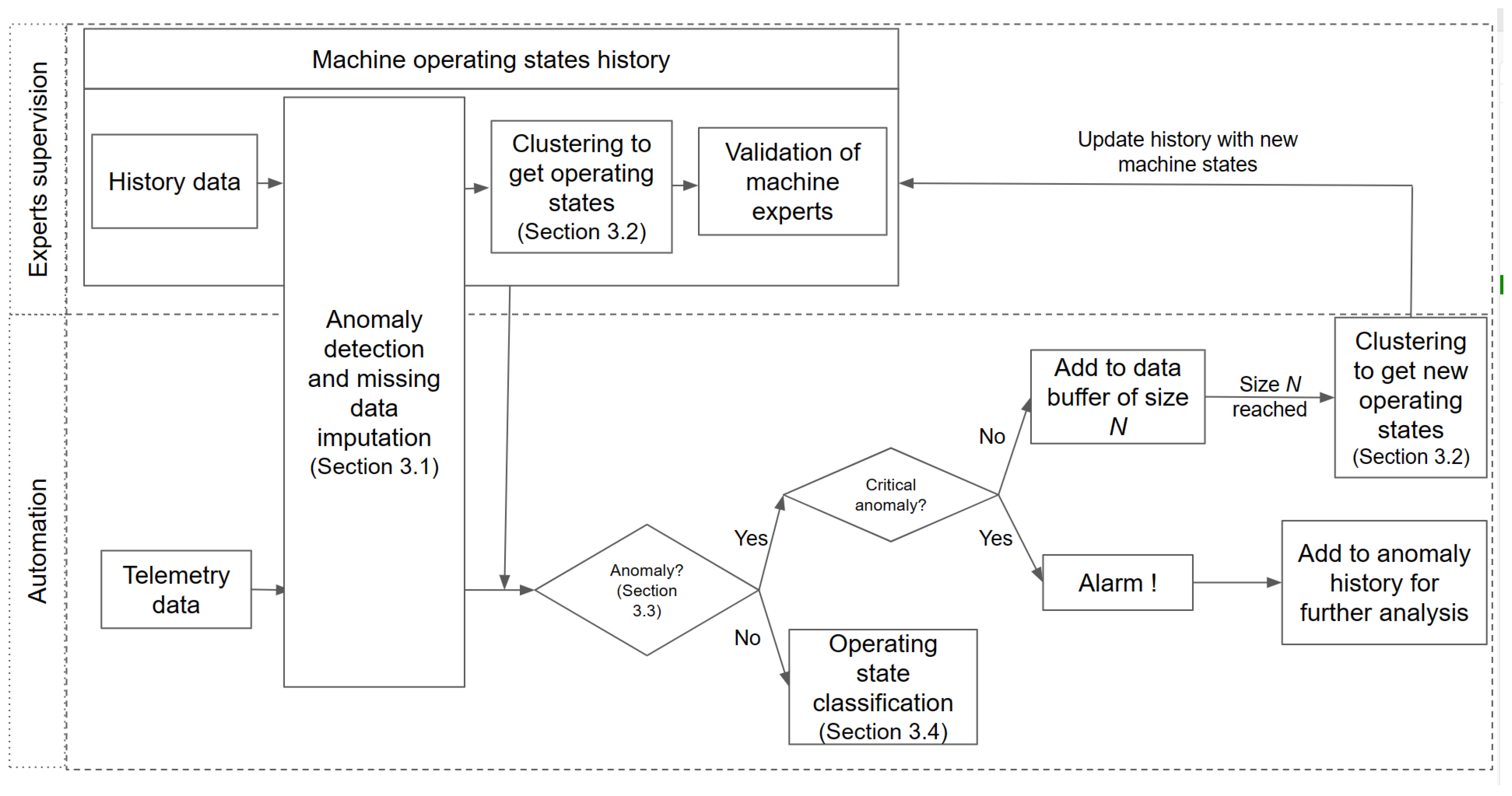
3. Proposed Methodology
- The learning phase focuses on establishing the first reference machines’ operating states from historical data. This phase is also called “Experts supervision level”, where discussions and validations from the machine experts are needed in some analyses. This part preprocesses and clusters history data to obtain a proposal of machine operating states. The machine experts then review, adjust, and validate the proposal to obtain the machine operating states.
- The second part, “real-time exploitation”, or “Automation level”, is almost entirely automated. Telemetry data come from sensors, PLC, etc. The imputation module (“Anomaly Detection and Missing Data”) fills in missing data if necessary. Then, based on historical data, if the telemetry data have abnormal behavior (“Anomaly detection” module, Section 3.3), the procedure classifies it as a candidate for new operating states or triggers an alarm depending on the severity. These anomalies will be added to anomaly history for further analysis. On the other hand, if the telemetry data have normal behavior, the classification module will tag it into one of the historical operating states. Because the real-word dataset has unbalanced class problems, the module “Operating state classification” (Section 3.4) consists of ensemble learning classifiers to enhance the accuracy of the classification.
3.1. Missing Data Imputation Module
3.2. Identification of the Process Reference States
3.2.1. Dimensionality Reduction
3.2.2. Machine Operational Regimes
3.3. Anomaly Detection and History Updating—Novel Class Detection
- Critical outliers are considered as “danger” or “fault” for the machine operating state. Such outliers are considered as early signs of failure that usually lead to faults or machine breakdown.
- Novel class outliers contain outliers having strong cohesion among themselves. They possess the potential to form a new class regarding “concept-evolution”.
- Statistics-based approaches construct a model that represents the normal behavior of the dataset. The new incoming data are considered anomalous if they do not match the model or have a very low probability of corresponding to the model [78].
- Clustering and the nearest neighbors approach use the proximity between observations to detect abnormal data. The clustering approach splits the dataset into different clusters as a function of the similarity between the data. Then, it considers the most distant cluster as an anomaly cluster [79]. The nearest neighbors approach calculates the distance between all of the observations in the dataset. It considers new incoming data as an anomaly if it is far from its k nearest neighbors [80] or has the fewest neighbors in a predefined radius r [81].
- The isolation-based approach aims to isolate abnormal observations from the dataset. The anomalous data have two characteristics. First, they have significantly different behavior compared to normal data. Second, they have a very small proportion in the whole dataset. So, the anomalies are likely to be rapidly isolated from the normal dataset [82].
3.4. Operational State Classification Using Ensemble Learning
3.4.1. Unbalanced Classes
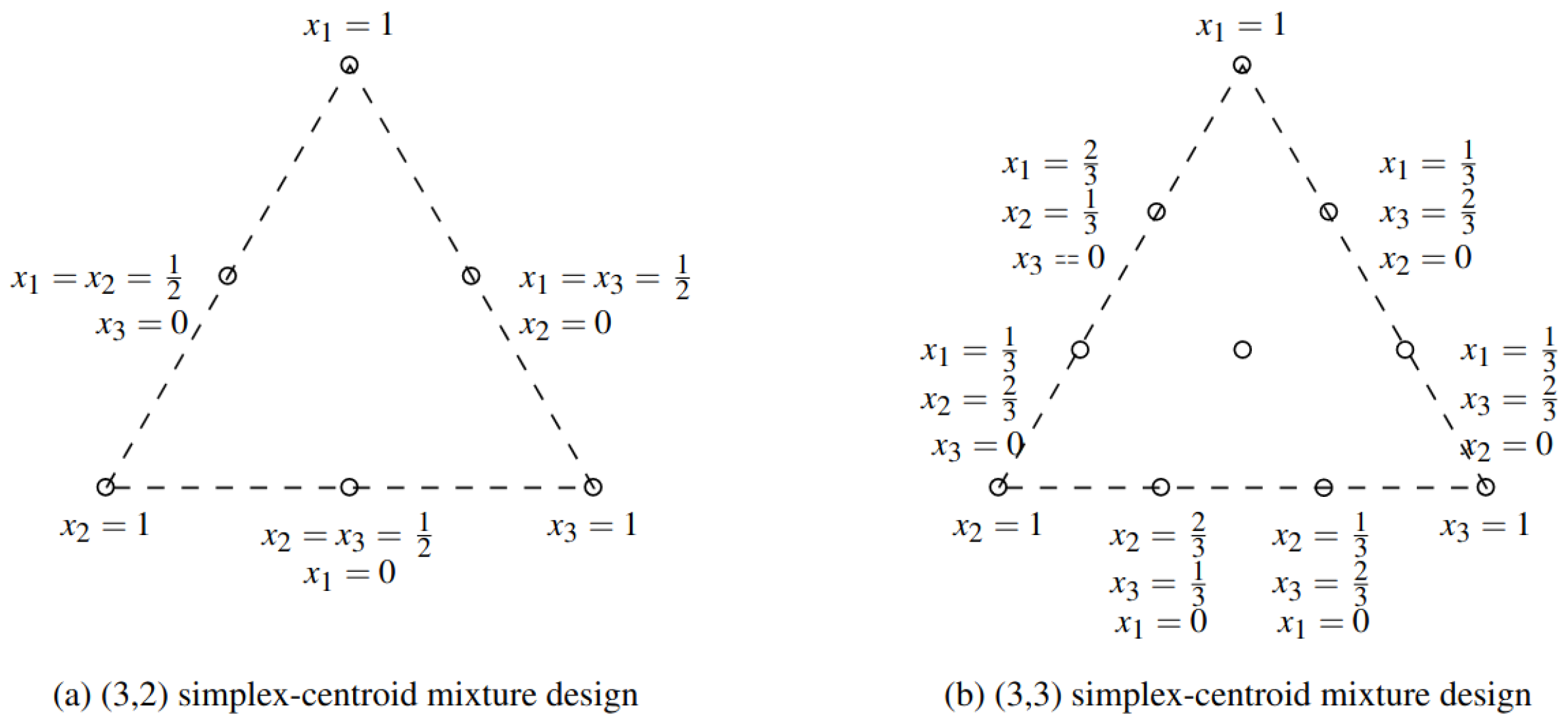
3.4.2. Mixture Design Weight Ensemble
3.4.3. Operating State Classification Module
- KNN classifier: It works on the premise that data points having similar attributes will be located closer to each other than data points having dissimilar characteristics. For each query, KNN estimates its relative distances from a specified number of neighboring data points (K) closest to the query. Then, KNN sorts the K-nearest neighboring data points in ascending order of their distances from the query point and classifies the query points according to the mode of the K-nearest data point labels [87].
- SVM classifier: It creates and uses hyperplanes as a decision boundary to be able to classify a query into its correct category class. The hyperplanes are the extreme cases of each data class (known as support vectors), which help define the class boundary. The algorithm attaches a penalty to every point located on the other side of its class across a particular hyperplane. It then explores several hyperplane solutions and selects the best class boundary that maximizes the separation margin between classes [88].
- RF classifier: It consists of multiple decision trees. A decision tree is a set of hierarchical decisions that leads to a classification result. The tree has “root” nodes at the top. Then, it splits into branches based on certain feature-based conditions. Each branch may further split into sub-branches based on more specific sub-feature conditions. The splitting of branches may continue until they reach the leaf node, which is the final classification decision, and no further splitting is needed. For each query, each decision tree in the random forest votes for one of the classes to which the input belongs. Then, the RF will take the vote for the class with the most occurrence as the final prediction [89].
- It combines the classification output of KNN, SVM, and RF using three voting ensemble approaches—hard voting, soft voting, and mixture design weights—to obtain three classifiers, called “HARD_VOTING”, “SOFT_VOTING”, and “MIXTURE_VOTING”, respectively.
- It uses SMOTE to oversample minority classes, then trains KNN, SVM, and RF on the oversampled complete dataset to obtain three classifiers, “KNN_SMOTE”, “SVM_SMOTE”, and “RF_SMOTE”, respectively.
- It applies cost-sensitive learning methods on SVM and RF to obtain “SVM_COST” and “RF_COST”, respectively. The classifiers put higher costs for misclassifying minority classes than majority classes.
4. Application to Industrial Manufacturing: Glass Wool Production
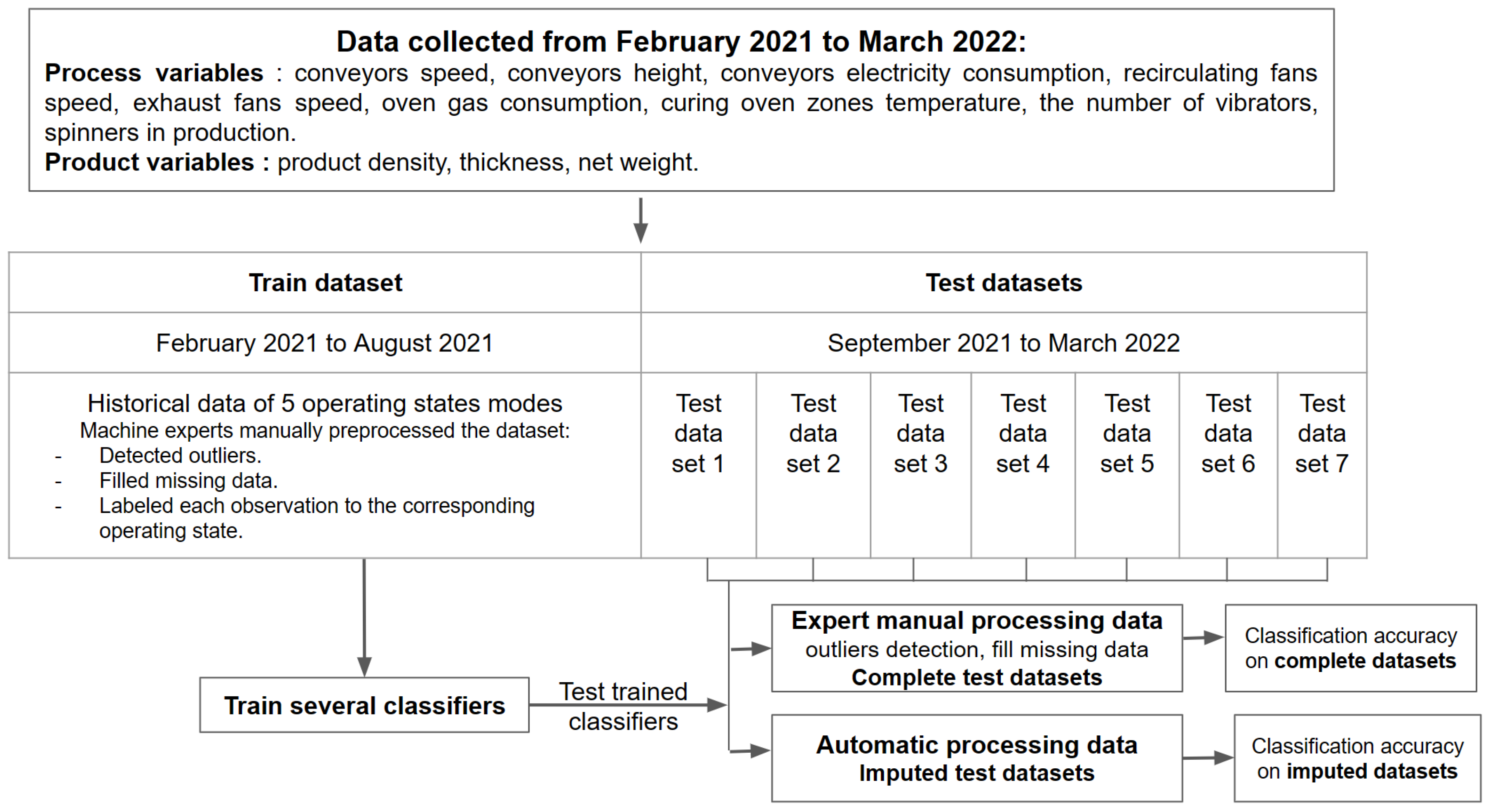
4.1. Data Acquisition
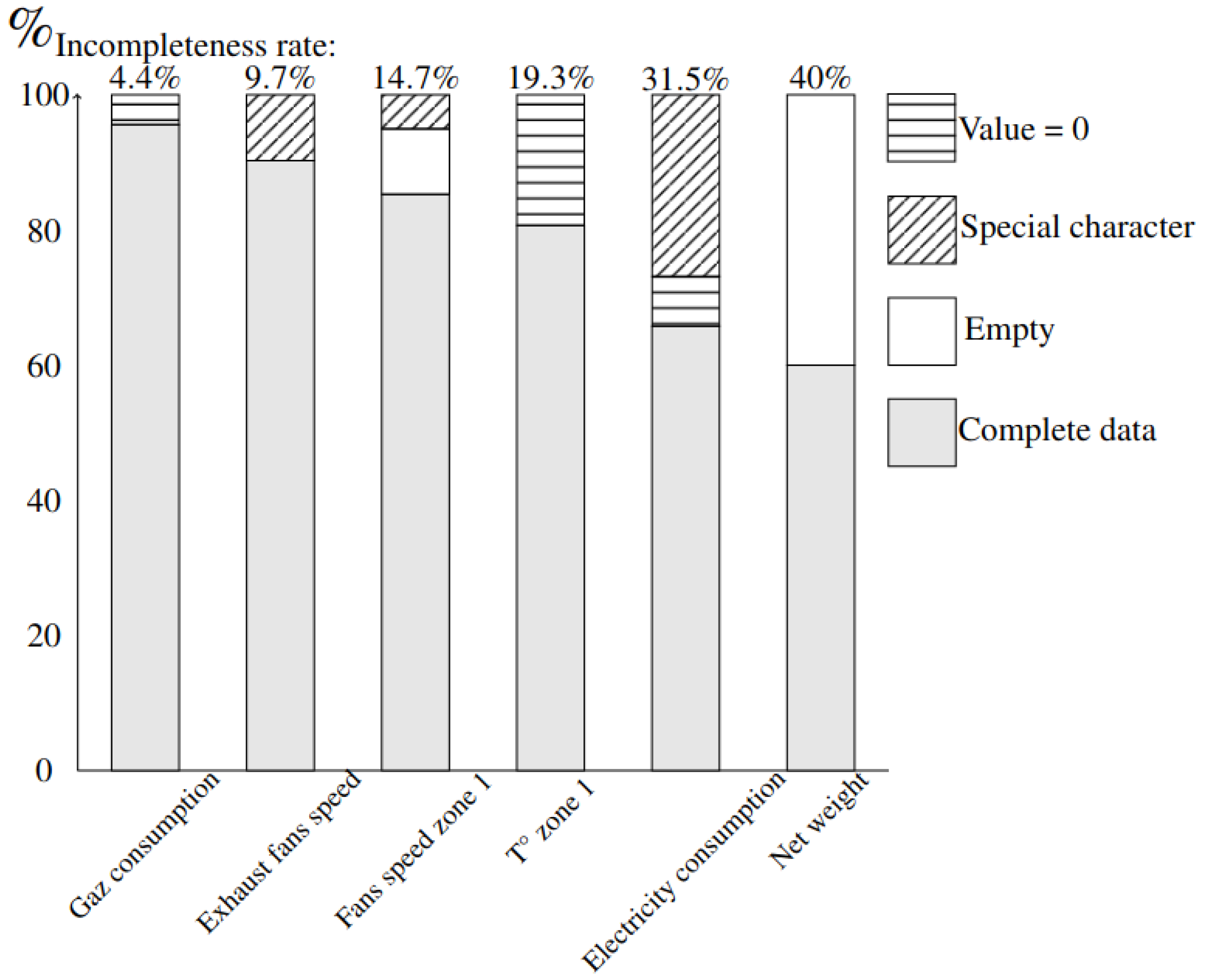
4.1.1. Missing Data
4.1.2. Application of the Proposed Framework to the Curing Oven
4.2. Numerical Results and Discussions
- Weighted Accuracy is the overall accuracy score that takes into account class weights.
- , , …, are the weights assigned to each class. These weights are often calculated as the proportion of instances in each class relative to the total number of instances in the dataset.
- Accuracy, Accuracy, …, Accuracy are the accuracy scores for each class, calculated as the ratio of true positives for that class to the total number of instances in that class.
- n is the total number of classes.
4.2.1. The Effect of Missing Data
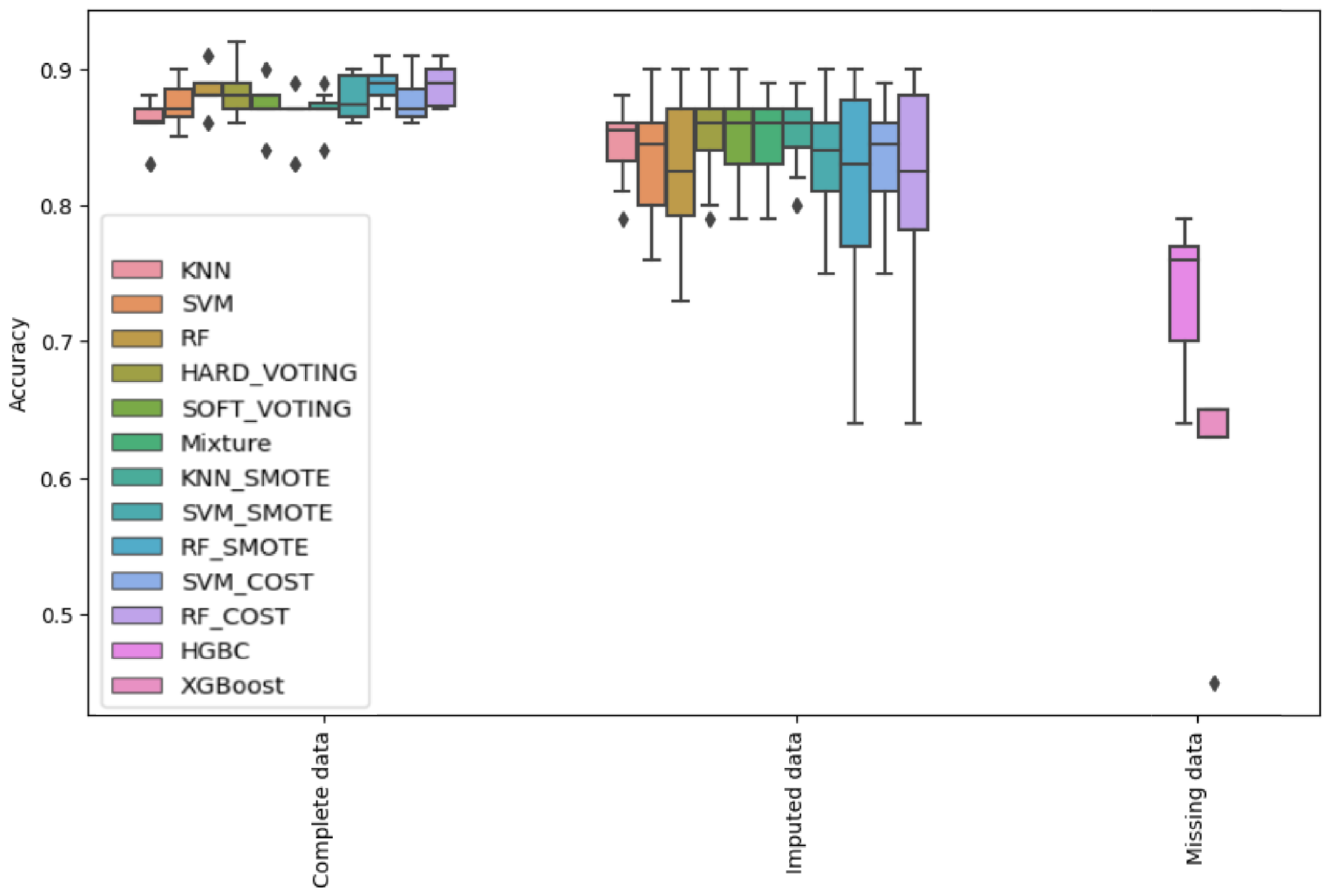
- All classifiers have high classification accuracy when using the “Complete” test datasets. Their accuracies are at least , and in some test datasets, the accuracy is up to for the “HARD_VOTING”. The “RF_SMOTE” and the “RF_COST” box plot show that there is an improvement in the overall classification accuracies of unbalanced classes by using SMOTE and cost-sensitive learning methods in the “Complete” datasets.
- There is a significant performance decrease when using “Imputed” datasets. Most classification accuracies for using “Imputed” datasets are between and . For some classifiers, the accuracy decreases to , such as for “RF_SMOTE” and “RF_COST”. These two classifiers have high accuracy with the “Complete” dataset. However, their performances fall considerably in cases of imputed data.The decrease in performance of RF COST and RF SMOTE can be attributed to multiple factors. RF SMOTE’s synthetic samples can introduce complexity and noise into the dataset, reducing accuracy. RF COST may underperform when the cost matrix is inaccurately defined, failing to reflect true misclassification costs. Both techniques are also prone to overfitting and model complexity issues, especially with high-dimensional or noisy data. These complexities can reduce their accuracy.
- Despite the ability of HGBC and XGBoost to handle incomplete data directly, their performance is significantly inferior to that of other methods. The classification accuracy achieved by these two classifiers varies, frequently falling below , and, in the case of XGBoost, declining even to under . This observation strongly emphasizes the requirement for employing data imputation methods to address incomplete data before the classification process.
4.2.2. Improvement of Classification Accuracy Using Imputation Methods
- The “Complete” dataset gives the best classification results. On the other hand, the imputed datasets can be divided into three groups according to their performances. The first group comprised methods with the highest accuracy, albeit with a significant computational time requirement. The second group featured methods with slightly lower accuracy but reduced computational demands compared to the first group. The third group encompassed methods that prioritized computational efficiency over accuracy.
- The first group consists of two imputation methods, KNN and RF. They provide accuracy as close as the “Complete” dataset. RF imputation is slightly better than KNN imputation. However, as shown in Table 2, the required execution time of the RF imputation method is nearly twice as long as that required by KNN. Therefore, the KNN imputation method has more performance and time requirement advantages.
- The second group consists of Median imputation, Stochastic regression imputation (S_regression), and EM imputation. Imputation by median value is a straightforward approach. However, in our experiments, its accuracy is as good as with other techniques: S_regression imputation and EM imputation. These three approaches require less execution time and provide over classification accuracy.
- The kernel imputation method provides the worst accuracy among imputation methods. In some datasets, the accuracy may fall to . In addition, it is the third most time-consuming approach in our experiments.
- The “Missing data” box plot combines the accuracy results of HGBC and XGBoost when classifying data directly from the incomplete dataset. Despite their computational speed advantages, as demonstrated in the missing data box plot, HGBC and XGBoost often yield accuracy below . This observation again emphasizes data imputation methods’ essential role in addressing incomplete data before the classification process.
4.2.3. Ensemble Learning Classifier Performances
- The “Complete” dataset gives the best accuracy. “HARD_VOTING”, “RF_SMOTE”, and “RF_SENSITIVE” handle better the unbalanced class classification problem.
- The KNN classifier is more robust to missing data. As can been seen in the KNN columns, there are fewer variations in the box plots than for other classifiers, regardless of imputation methods.
- The KNN and RF imputation approaches give classification accuracies as close as using the “Complete” dataset. These methods ensure the best classification accuracy in the case of missing data. However, their time requirements are significant.
- The Median imputation and Stochastic regression imputation are rapid techniques to handle the missing data in our experiments. They provide over classification accuracies in a short execution time.
5. Conclusions and Perspectives
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rüßmann, M.; Lorenz, M.; Gerbert, P.; Waldner, M.; Justus, J.; Engel, P.; Harnisch, M. Industry 4.0: The future of productivity and growth in manufacturing industries. Boston Consult. Group 2015, 9, 54–89. [Google Scholar]
- Shahin, K.I.; Simon, C.; Weber, P.; Theilliol, D. Input-Output Hidden Markov Model for System Health Diagnosis Under Missing Data. In Proceedings of the 2020 28th Mediterranean Conference on Control and Automation (MED), Saint-Raphaël, France, 15–18 September 2020; pp. 556–561. [Google Scholar]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Gama, J.; Žliobaitė, I.; Bifet, A.; Pechenizkiy, M.; Bouchachia, A. A survey on concept drift adaptation. ACM Comput. Surv. (CSUR) 2014, 46, 1–37. [Google Scholar] [CrossRef]
- Tan, X.; Gao, C.; Zhou, J.; Wen, J. Three-way decision-based co-detection for outliers. Int. J. Approx. Reason. 2023, 160, 108971. [Google Scholar] [CrossRef]
- Iglewicz, B.; Hoaglin, D.C. Volume 16: How to Detect and Handle Outliers; Quality Press: Milwaukee, WI, USA, 1993. [Google Scholar]
- Whaley, D.L., III. The Interquartile Range: Theory and Estimation. Electronic Theses and Dissertations, East Tennessee State University, Johnson City, TN, USA, 2005. [Google Scholar]
- Yang, X.; Latecki, L.J.; Pokrajac, D. Outlier detection with globally optimal exemplar-based GMM. In Proceedings of the 2009 SIAM International Conference on Data Mining, Sparks, NV, USA, 30 April–2 May 2009; pp. 145–154. [Google Scholar]
- Degirmenci, A.; Karal, O. Efficient density and cluster based incremental outlier detection in data streams. Inf. Sci. 2022, 607, 901–920. [Google Scholar] [CrossRef]
- He, Z.; Xu, X.; Deng, S. Discovering cluster-based local outliers. Pattern Recognit. Lett. 2003, 24, 1641–1650. [Google Scholar] [CrossRef]
- Angiulli, F.; Pizzuti, C. Fast outlier detection in high dimensional spaces. In Proceedings of the European Conference on Principles of Data Mining and Knowledge Discovery, Helsinki, Finland, 19–23 August 2002; pp. 15–27. [Google Scholar]
- Zhang, K.; Hutter, M.; Jin, H. A new local distance-based outlier detection approach for scattered real-world data. In Proceedings of the 13th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD-09), Bangkok, Thailand, 27–30 April 2009; pp. 813–822. [Google Scholar]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; pp. 93–104. [Google Scholar]
- Tang, J.; Chen, Z.; Fu, A.W.C.; Cheung, D.W. Enhancing effectiveness of outlier detections for low density patterns. In Proceedings of the 6th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining, Taipei, Taiwan, 6–8 May 2002; pp. 535–548. [Google Scholar]
- Kriegel, H.P.; Kröger, P.; Schubert, E.; Zimek, A. LoOP: Local outlier probabilities. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; pp. 1649–1652. [Google Scholar]
- Tang, B.; He, H. A local density-based approach for outlier detection. Neurocomputing 2017, 241, 171–180. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar]
- Blomberg, L.C.; Ruiz, D.D.A. Evaluating the influence of missing data on classification algorithms in data mining applications. In Proceedings of the Anais do IX Simpósio Brasileiro de Sistemas de Informação (SBC), João Pessoa, Brazil, 22–24 May 2013; pp. 734–743. [Google Scholar]
- Acuna, E.; Rodriguez, C. The treatment of missing values and its effect on classifier accuracy. In Classification, Clustering, and Data Mining Applications: Proceedings of the Meeting of the International Federation of Classification Societies (IFCS), Illinois Institute of Technology, Chicago, IL, USA, 15–18 July 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 639–647. [Google Scholar]
- Farhangfar, A.; Kurgan, L.; Dy, J. Impact of imputation of missing values on classification error for discrete data. Pattern Recognit. 2008, 41, 3692–3705. [Google Scholar] [CrossRef]
- Twala, B. An empirical comparison of techniques for handling incomplete data using decision trees. Appl. Artif. Intell. 2009, 23, 373–405. [Google Scholar] [CrossRef]
- Buczak, P.; Chen, J.J.; Pauly, M. Analyzing the Effect of Imputation on Classification Performance under MCAR and MAR Missing Mechanisms. Entropy 2023, 25, 521. [Google Scholar] [CrossRef]
- Gabr, M.I.; Helmy, Y.M.; Elzanfaly, D.S. Effect of missing data types and imputation methods on supervised classifiers: An evaluation study. Big Data Cogn. Comput. 2023, 7, 55. [Google Scholar] [CrossRef]
- Brown, R.L. Efficacy of the indirect approach for estimating structural equation models with missing data: A comparison of five methods. Struct. Equ. Model. Multidiscip. J. 1994, 1, 287–316. [Google Scholar] [CrossRef]
- Tutz, G.; Ramzan, S. Improved methods for the imputation of missing data by nearest neighbor methods. Comput. Stat. Data Anal. 2015, 90, 84–99. [Google Scholar] [CrossRef]
- Titterington, D.; Sedransk, J. Imputation of missing values using density estimation. Stat. Probab. Lett. 1989, 8, 411–418. [Google Scholar] [CrossRef]
- Di Zio, M.; Guarnera, U.; Luzi, O. Imputation through finite Gaussian mixture models. Comput. Stat. Data Anal. 2007, 51, 5305–5316. [Google Scholar] [CrossRef]
- Stekhoven, D.J.; Bühlmann, P. MissForest—Non-parametric missing value imputation for mixed-type data. Bioinformatics 2012, 28, 112–118. [Google Scholar] [CrossRef]
- Little, R.J.; Rubin, D.B. Statistical Analysis with Missing Data; John Wiley & Sons: Hoboken, NJ, USA, 2019; Volume 793. [Google Scholar]
- Lim, H. Low-rank learning for feature selection in multi-label classification. Pattern Recognit. Lett. 2023, 172, 106–112. [Google Scholar] [CrossRef]
- Priyadharshini, M.; Banu, A.F.; Sharma, B.; Chowdhury, S.; Rabie, K.; Shongwe, T. Hybrid Multi-Label Classification Model for Medical Applications Based on Adaptive Synthetic Data and Ensemble Learning. Sensors 2023, 23, 6836. [Google Scholar] [CrossRef]
- Teng, Z.; Cao, P.; Huang, M.; Gao, Z.; Wang, X. Multi-label borderline oversampling technique. Pattern Recognit. 2024, 145, 109953. [Google Scholar] [CrossRef]
- Lin, I.; Loyola-González, O.; Monroy, R.; Medina-Pérez, M.A. A review of fuzzy and pattern-based approaches for class imbalance problems. Appl. Sci. 2021, 11, 6310. [Google Scholar] [CrossRef]
- Wong, W.Y.; Hasikin, K.; Khairuddin, M.; Salwa, A.; Razak, S.A.; Hizaddin, H.F.; Mokhtar, M.I.; Azizan, M.M. A Stacked Ensemble Deep Learning Approach for Imbalanced Multi-Class Water Quality Index Prediction. Comput. Mater. Contin. 2023, 76, 1361–1384. [Google Scholar]
- Asselman, A.; Khaldi, M.; Aammou, S. Enhancing the prediction of student performance based on the machine learning XGBoost algorithm. Interact. Learn. Environ. 2023, 31, 3360–3379. [Google Scholar] [CrossRef]
- Tarekegn, A.N.; Giacobini, M.; Michalak, K. A review of methods for imbalanced multi-label classification. Pattern Recognit. 2021, 118, 107965. [Google Scholar] [CrossRef]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Liu, X.Y.; Wu, J.; Zhou, Z.H. Exploratory undersampling for class-imbalance learning. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2008, 39, 539–550. [Google Scholar]
- Castellanos, F.J.; Valero-Mas, J.J.; Calvo-Zaragoza, J.; Rico-Juan, J.R. Oversampling imbalanced data in the string space. Pattern Recognit. Lett. 2018, 103, 32–38. [Google Scholar] [CrossRef]
- Charte, F.; Rivera, A.J.; Jesus, M.J.d.; Herrera, F. MLeNN: A first approach to heuristic multilabel undersampling. In Proceedings of the International Conference on Intelligent Data Engineering and Automated Learning, Salamanca, Spain, 10–12 September 2014; pp. 1–9. [Google Scholar]
- Pereira, R.M.; Costa, Y.M.; Silla, C.N., Jr. MLTL: A multi-label approach for the Tomek Link undersampling algorithm. Neurocomputing 2020, 383, 95–105. [Google Scholar] [CrossRef]
- Santiago, J.; Claeys-Bruno, M.; Sergent, M. Construction of space-filling designs using WSP algorithm for high dimensional spaces. Chemom. Intell. Lab. Syst. 2012, 113, 26–31. [Google Scholar] [CrossRef]
- Sobol’, I.M. On the distribution of points in a cube and the approximate evaluation of integrals. Zhurnal Vychislitel’Noi Mat. Mat. Fiz. 1967, 7, 784–802. [Google Scholar] [CrossRef]
- Bakhvalov, N.S. On the approximate calculation of multiple integrals. J. Complex. 2015, 31, 502–516. [Google Scholar] [CrossRef]
- Butler, N.A. Optimal and orthogonal Latin hypercube designs for computer experiments. Biometrika 2001, 88, 847–857. [Google Scholar] [CrossRef]
- Raghavarao, D.; Preece, D. Combinatorial analysis and experimental design: A review of “Constructions and Combinatorial Problems in Design of Experiments” by Damaraju Raghavarao. J. R. Stat. Soc. Ser. D (Stat.) 1972, 21, 77–87. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Wang, B.X.; Japkowicz, N. Imbalanced data set learning with synthetic samples. In Proceedings of the IRIS Machine Learning Workshop, Ottawa, ON, Canada, 9 June 2004; Volume 19, p. 435. [Google Scholar]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In Proceedings of the International Conference on Intelligent Computing, Hefei, China, 23–26 August 2005; pp. 878–887. [Google Scholar]
- Pradipta, G.A.; Wardoyo, R.; Musdholifah, A.; Sanjaya, I.N.H. Radius-SMOTE: A new oversampling technique of minority samples based on radius distance for learning from imbalanced data. IEEE Access 2021, 9, 74763–74777. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Tepvorachai, G.; Papachristou, C. Multi-label imbalanced data enrichment process in neural net classifier training. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1301–1307. [Google Scholar]
- Zhang, M.L. ML-RBF: RBF neural networks for multi-label learning. Neural Process. Lett. 2009, 29, 61–74. [Google Scholar] [CrossRef]
- Sun, K.W.; Lee, C.H. Addressing class-imbalance in multi-label learning via two-stage multi-label hypernetwork. Neurocomputing 2017, 266, 375–389. [Google Scholar] [CrossRef]
- Pouyanfar, S.; Wang, T.; Chen, S.C. A multi-label multimodal deep learning framework for imbalanced data classification. In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019; pp. 199–204. [Google Scholar]
- Sozykin, K.; Protasov, S.; Khan, A.; Hussain, R.; Lee, J. Multi-label class-imbalanced action recognition in hockey videos via 3D convolutional neural networks. In Proceedings of the 2018 19th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Busan, Republic of Korea, 27–29 June 2018; pp. 146–151. [Google Scholar]
- Li, C.; Shi, G. Improvement of Learning Algorithm for the Multi-instance Multi-label RBF Neural Networks Trained with Imbalanced Samples. J. Inf. Sci. Eng. 2013, 29, 765–776. [Google Scholar]
- Kittler, J.; Hatef, M.; Duin, R.P.; Matas, J. On combining classifiers. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 226–239. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Ho, T.K.; Hull, J.J.; Srihari, S.N. Decision combination in multiple classifier systems. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 66–75. [Google Scholar]
- Kuncheva, L.I.; Rodríguez, J.J. A weighted voting framework for classifiers ensembles. Knowl. Inf. Syst. 2014, 38, 259–275. [Google Scholar] [CrossRef]
- Yin, X.; Liu, Q.; Pan, Y.; Huang, X.; Wu, J.; Wang, X. Strength of stacking technique of ensemble learning in rockburst prediction with imbalanced data: Comparison of eight single and ensemble models. Nat. Resour. Res. 2021, 30, 1795–1815. [Google Scholar] [CrossRef]
- Winata, G.I.; Khodra, M.L. Handling imbalanced dataset in multi-label text categorization using Bagging and Adaptive Boosting. In Proceedings of the 2015 International Conference on Electrical Engineering and Informatics (ICEEI), Denpasar, Bali, Indonesia, 10–11 August 2015; pp. 500–505. [Google Scholar]
- Sun, Y.; Kamel, M.S.; Wong, A.K.; Wang, Y. Cost-sensitive boosting for classification of imbalanced data. Pattern Recognit. 2007, 40, 3358–3378. [Google Scholar] [CrossRef]
- Cao, P.; Liu, X.; Zhao, D.; Zaiane, O. Cost sensitive ranking support vector machine for multi-label data learning. In Proceedings of the International Conference on Hybrid Intelligent Systems, Seville, Spain, 18–20 April 2016; pp. 244–255. [Google Scholar]
- Wu, G.; Tian, Y.; Liu, D. Cost-sensitive multi-label learning with positive and negative label pairwise correlations. Neural Netw. 2018, 108, 411–423. [Google Scholar] [CrossRef] [PubMed]
- Witten, I.H.; Frank, E. Data mining: Practical machine learning tools and techniques with Java implementations. Acm Sigmod Rec. 2002, 31, 76–77. [Google Scholar] [CrossRef]
- Kim, H.; Kim, H.; Moon, H.; Ahn, H. A weight-adjusted voting algorithm for ensembles of classifiers. J. Korean Stat. Soc. 2011, 40, 437–449. [Google Scholar] [CrossRef]
- Cheon, Y.; Kim, D. Natural facial expression recognition using differential-AAM and manifold learning. Pattern Recognit. 2009, 42, 1340–1350. [Google Scholar] [CrossRef]
- Sun, B.; Xu, F.; Zhou, G.; He, J.; Ge, F. Weighted joint sparse representation-based classification method for robust alignment-free face recognition. J. Electron. Imaging 2015, 24, 013018. [Google Scholar] [CrossRef]
- Lu, W.; Wu, H.; Jian, P.; Huang, Y.; Huang, H. An empirical study of classifier combination based word sense disambiguation. IEICE Trans. Inf. Syst. 2018, 101, 225–233. [Google Scholar] [CrossRef]
- Ren, F.; Li, Y.; Hu, M. Multi-classifier ensemble based on dynamic weights. Multimed. Tools Appl. 2018, 77, 21083–21107. [Google Scholar] [CrossRef]
- Peng, T.; Ye, C.; Chen, Z. Stacking Model-based Method for Traction Motor Fault Diagnosis. In Proceedings of the 2019 CAA Symposium on Fault Detection, Supervision and Safety for Technical Processes (SAFEPROCESS), Xiamen, China, 5–7 July 2019; pp. 850–855. [Google Scholar]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Jain, A.K.; Dubes, R.C. Algorithms for Clustering Data; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1988. [Google Scholar]
- Togbe, M.U.; Chabchoub, Y.; Boly, A.; Barry, M.; Chiky, R.; Bahri, M. Anomalies detection using isolation in concept-drifting data streams. Computers 2021, 10, 13. [Google Scholar] [CrossRef]
- Yamanishi, K.; Takeuchi, J.I.; Williams, G.; Milne, P. On-line unsupervised outlier detection using finite mixtures with discounting learning algorithms. Data Min. Knowl. Discov. 2004, 8, 275–300. [Google Scholar] [CrossRef]
- Masud, M.; Gao, J.; Khan, L.; Han, J.; Thuraisingham, B.M. Classification and novel class detection in concept-drifting data streams under time constraints. IEEE Trans. Knowl. Data Eng. 2010, 23, 859–874. [Google Scholar] [CrossRef]
- Angiulli, F.; Fassetti, F. Detecting distance-based outliers in streams of data. In Proceedings of the Sixteenth ACM Conference on Conference on Information and Knowledge Management, Lisbon, Portugal, 6–10 November 2007; pp. 811–820. [Google Scholar]
- Pokrajac, D.; Lazarevic, A.; Latecki, L.J. Incremental local outlier detection for data streams. In Proceedings of the 2007 IEEE Symposium on Computational Intelligence and Data Mining, Honolulu, HI, USA, 1–5 April 2007; pp. 504–515. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation-based anomaly detection. ACM Trans. Knowl. Discov. Data (TKDD) 2012, 6, 1–39. [Google Scholar] [CrossRef]
- Dangut, M.D.; Skaf, Z.; Jennions, I. Rescaled-LSTM for predicting aircraft component replacement under imbalanced dataset constraint. In Proceedings of the 2020 Advances in Science and Engineering Technology International Conferences (ASET), Dubai, United Arab Emirates, 4 February–9 April 2020; pp. 1–9. [Google Scholar]
- Scheffé, H. Experiments with mixtures. J. R. Stat. Soc. Ser. B (Methodol.) 1958, 20, 344–360. [Google Scholar] [CrossRef]
- Montgomery, D.C. Design and Analysis of Experiments; John Wiley & Sons: Hoboken, NJ, USA, 2017. [Google Scholar]
- Khuri, A.I.; Mukhopadhyay, S. Response surface methodology. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 128–149. [Google Scholar] [CrossRef]
- Lopez-Bernal, D.; Balderas, D.; Ponce, P.; Molina, A. Education 4.0: Teaching the basics of KNN, LDA and simple perceptron algorithms for binary classification problems. Future Internet 2021, 13, 193. [Google Scholar] [CrossRef]
- Chapelle, O.; Haffner, P.; Vapnik, V.N. Support vector machines for histogram-based image classification. IEEE Trans. Neural Netw. 1999, 10, 1055–1064. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Ho, M.H.; Ponchet Durupt, A.; Boudaoud, N.; Vu, H.C.; Caracciolo, A.; Sieg-Zieba, S.; Xu, Y.; Leduc, P. An Overview of Machine Health Management in Industry 4.0. In Proceedings of the 31st European Safety and Reliability Conference, ESREL 2021, Angers, France, 19–23 September 2021; Research Publishing Services: Singapore, 2021; pp. 433–440. [Google Scholar]
- Alfi. The ALFI Technologies Group: Turnkey Solutions FOR the Intralogistics and the Production of Building Materials. 2021. Available online: http://www.alfi-technologies.com/en/alfi-technologies/le-groupe/ (accessed on 1 June 2021).
- Cetim. Mission—Cetim—Technical Centre for Mechanical Industry. 2021. Available online: https://www.cetim.fr/en/About-Cetim/Mission (accessed on 1 June 2021).
- Lin, T.H. A comparison of multiple imputation with EM algorithm and MCMC method for quality of life missing data. Quality Quant. 2010, 44, 277–287. [Google Scholar] [CrossRef]
- Lee, J.M.; Yoo, C.; Choi, S.W.; Vanrolleghem, P.A.; Lee, I.B. Nonlinear process monitoring using kernel principal component analysis. Chem. Eng. Sci. 2004, 59, 223–234. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Gaz Consumpt | Exhaust Fan Speed | Fan Speed Zone 1 | T° Zone 1 | Electricity Consumpt | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Missing | Longest | Missing | Longest | Missing | Longest | Missing | Longest | Missing | Longest | |
| Train | 4.5 | 0.55 | 4.5 | 3.2 | 12.4 | 2.3 | 3 | 0.5 | 28.5 | 2.47 |
| Test 1 | 5.5 | 0.6 | 7.8 | 3.1 | 11.1 | 2.2 | 5 | 1.1 | 12.5 | 5 |
| Test 2 | 4.4 | 0.5 | 9.7 | 2.5 | 14.7 | 2.9 | 19.3 | 1.5 | 31.5 | 3.3 |
| Test 3 | 6.75 | 0.65 | 3.29 | 0.5 | 7 | 1.2 | 11.5 | 2.5 | 12.3 | 3.2 |
| Test 4 | 15.5 | 0.59 | 8.5 | 3.1 | 13.9 | 3.1 | 6.3 | 0.4 | 13.7 | 4.3 |
| Test 5 | 5.9 | 0.7 | 5.8 | 1.2 | 10.1 | 2.8 | 2.5 | 0.4 | 15.7 | 2.5 |
| Test 6 | 3.13 | 0.41 | 3.5 | 0.9 | 12.3 | 3.6 | 17.1 | 2.1 | 14.5 | 2.3 |
| Test 7 | 2.7 | 0.64 | 5.1 | 2.2 | 8.2 | 1.1 | 1.7 | 0.1 | 17.5 | 3.1 |
| Method | KNN | Kernel | EM | RF | S_Regression |
|---|---|---|---|---|---|
| Max | 5567.00 | 2800.00 | 806.00 | 10,406.00 | 61.00 |
| Mean | 4426.86 | 2311.86 | 696.00 | 8834.43 | 42.10 |
| 1106.70 | 478.16 | 100.53 | 1319.03 | 13.59 | |
| Min | 2973.00 | 1531.00 | 535.00 | 7256.00 | 21.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ho, M.H.; Ponchet Durupt, A.; Vu, H.C.; Boudaoud, N.; Caracciolo, A.; Sieg-Zieba, S.; Xu, Y.; Leduc, P. Ensemble Learning for Multi-Label Classification with Unbalanced Classes: A Case Study of a Curing Oven in Glass Wool Production. Mathematics 2023, 11, 4602. https://doi.org/10.3390/math11224602
Ho MH, Ponchet Durupt A, Vu HC, Boudaoud N, Caracciolo A, Sieg-Zieba S, Xu Y, Leduc P. Ensemble Learning for Multi-Label Classification with Unbalanced Classes: A Case Study of a Curing Oven in Glass Wool Production. Mathematics. 2023; 11(22):4602. https://doi.org/10.3390/math11224602
Chicago/Turabian StyleHo, Minh Hung, Amélie Ponchet Durupt, Hai Canh Vu, Nassim Boudaoud, Arnaud Caracciolo, Sophie Sieg-Zieba, Yun Xu, and Patrick Leduc. 2023. "Ensemble Learning for Multi-Label Classification with Unbalanced Classes: A Case Study of a Curing Oven in Glass Wool Production" Mathematics 11, no. 22: 4602. https://doi.org/10.3390/math11224602
APA StyleHo, M. H., Ponchet Durupt, A., Vu, H. C., Boudaoud, N., Caracciolo, A., Sieg-Zieba, S., Xu, Y., & Leduc, P. (2023). Ensemble Learning for Multi-Label Classification with Unbalanced Classes: A Case Study of a Curing Oven in Glass Wool Production. Mathematics, 11(22), 4602. https://doi.org/10.3390/math11224602