
Optimal Bandwidth Selection Methods with Application to Wind Speed Distribution



Abstract
:1. Introduction
- Through simulation study comparisons of seven bandwidth selectors, including NS, SRT, DPI, Solve-The-Equation rules (STE), least LSCV, BCV, and SCV are examined. The results show that, among the different bandwidth techniques assessed, the BCV method—particularly for smaller sample sizes—consistently aligns closest with the optimal bandwidth for a majority of the tested normal distributions.
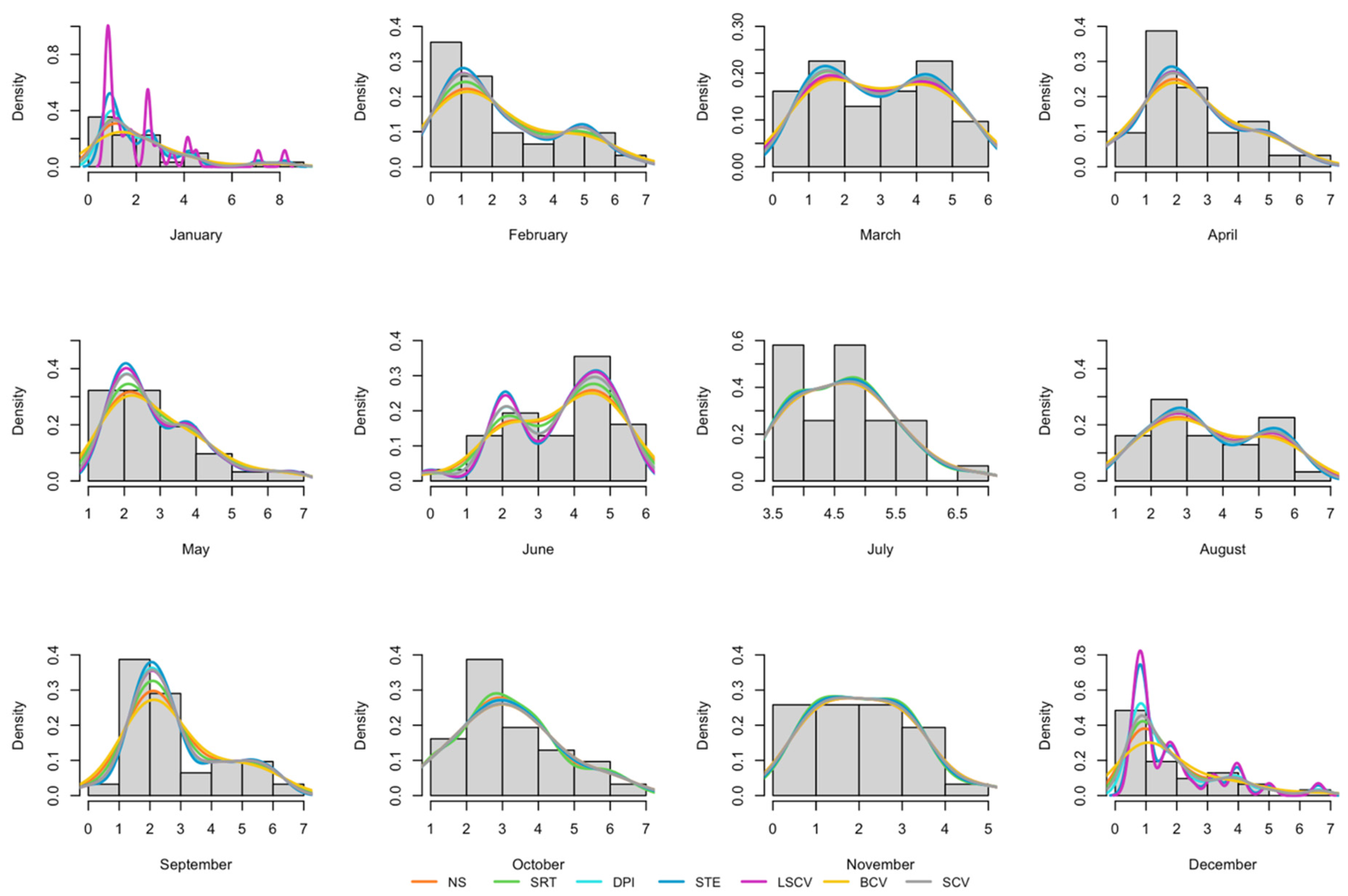
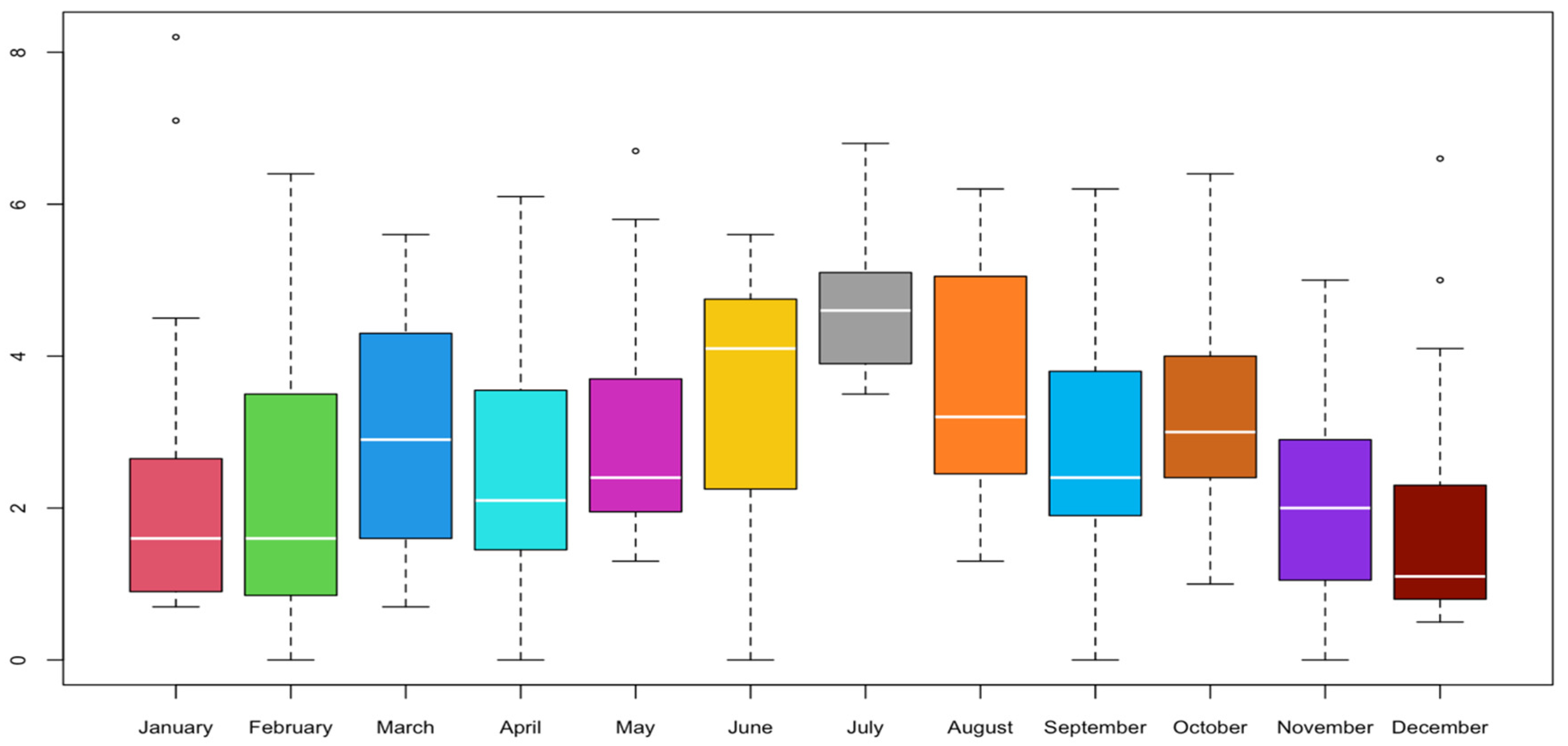
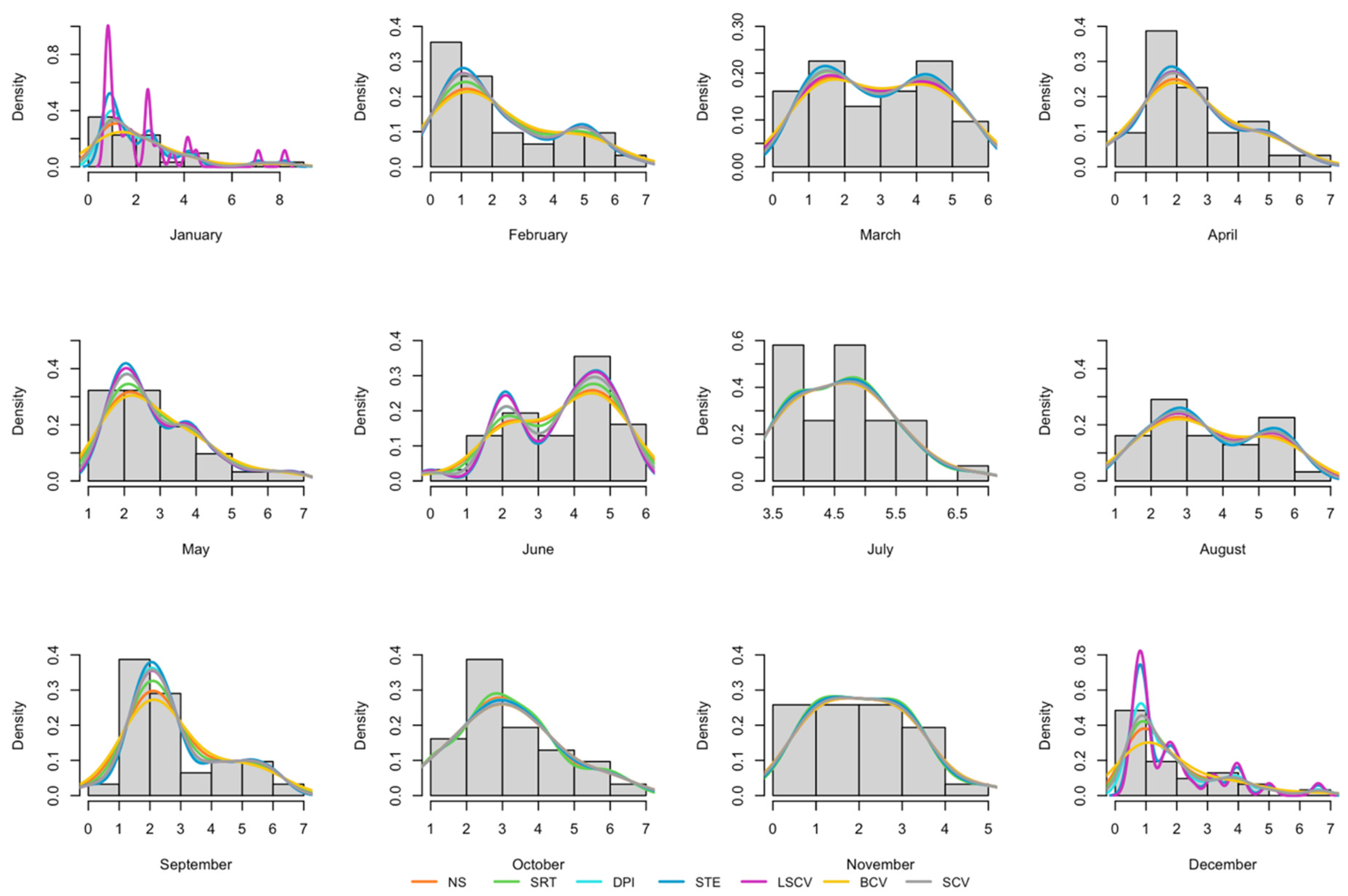
- Wind speed data from Balıkesir, Kepsut region for the year 2022 were employed, with monthly kernel density estimations being conducted using the seven bandwidth selection methods. It was found that the SCV method is convenient for estimating bandwidth for kernel density estimation in most cases with these real-world data.
2. Kernel Density Estimation
3. Bandwidth Selection Methods
3.1. Normal Scale Bandwidth Selection Method
3.2. Silverman’s Rule of Thumb Bandwidth Selection Method
3.3. Direct Plug in Bandwidth Selection Method
3.4. Solve-the-Equation Rules Bandwidth Selection Method
3.5. Least Squares Cross Validation Bandwidth Selection Method
3.6. Bias Cross Validation Bandwidth Selection Method
3.7. Smoothed Cross Validation Bandwidth Selection Method
4. Simulation Study
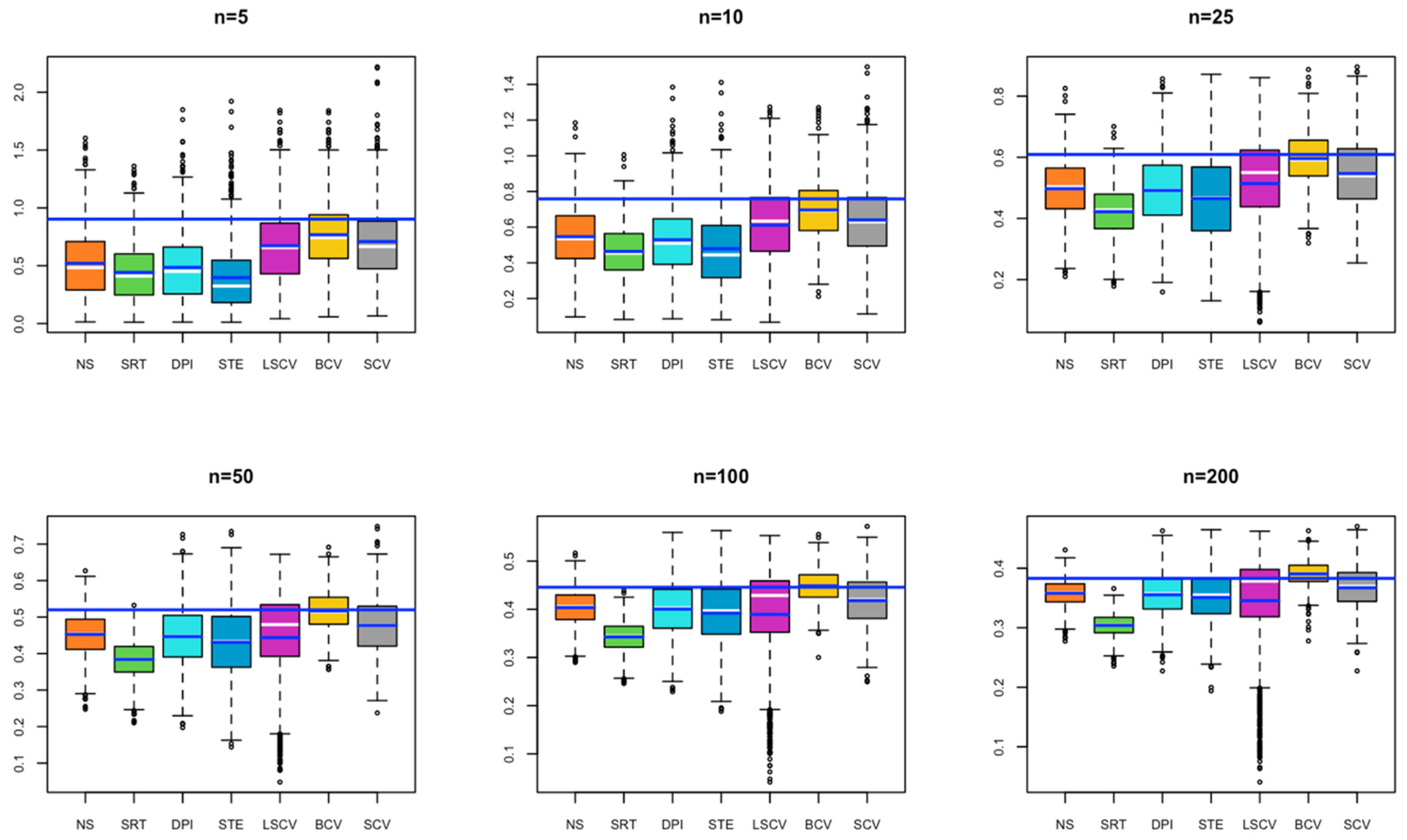
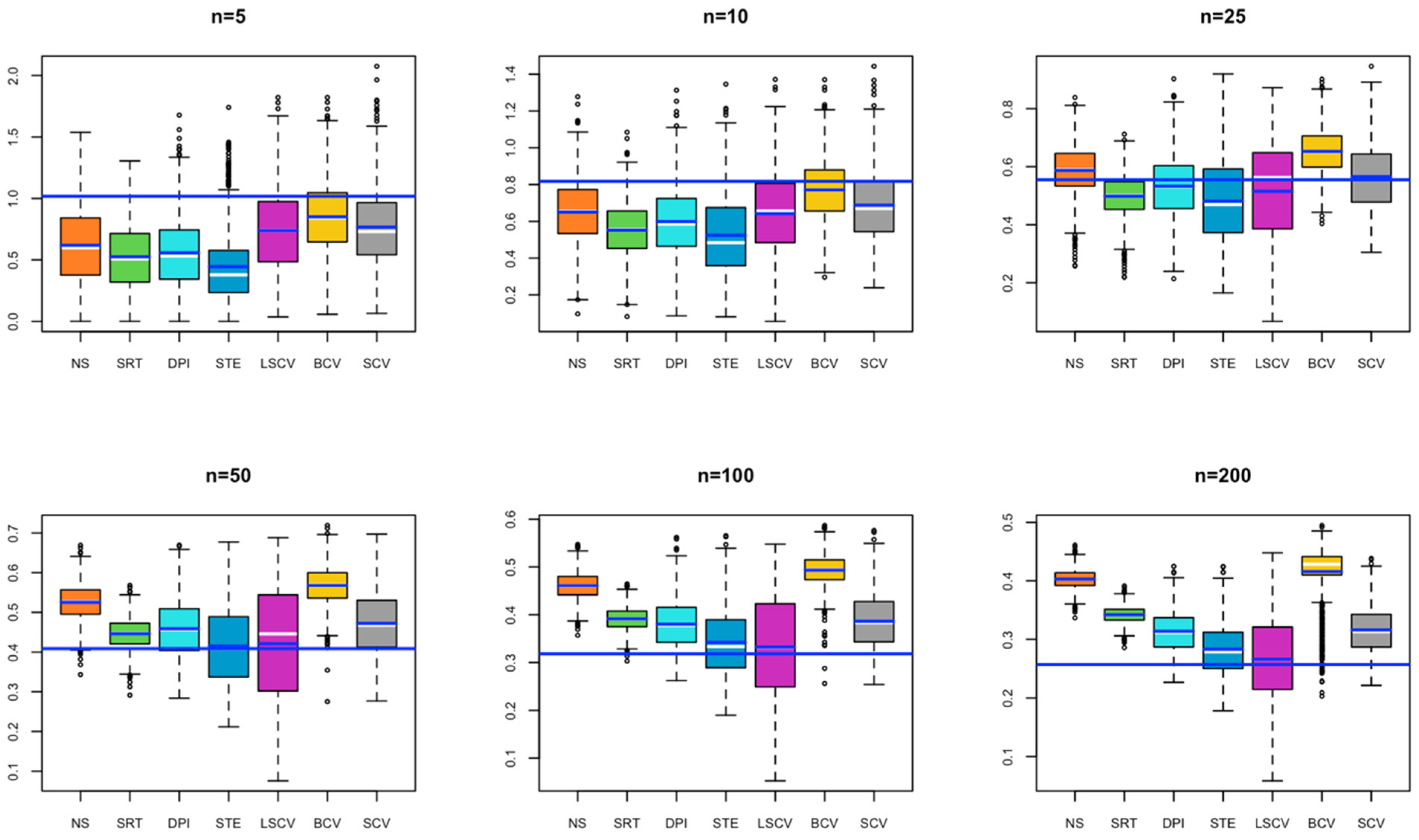
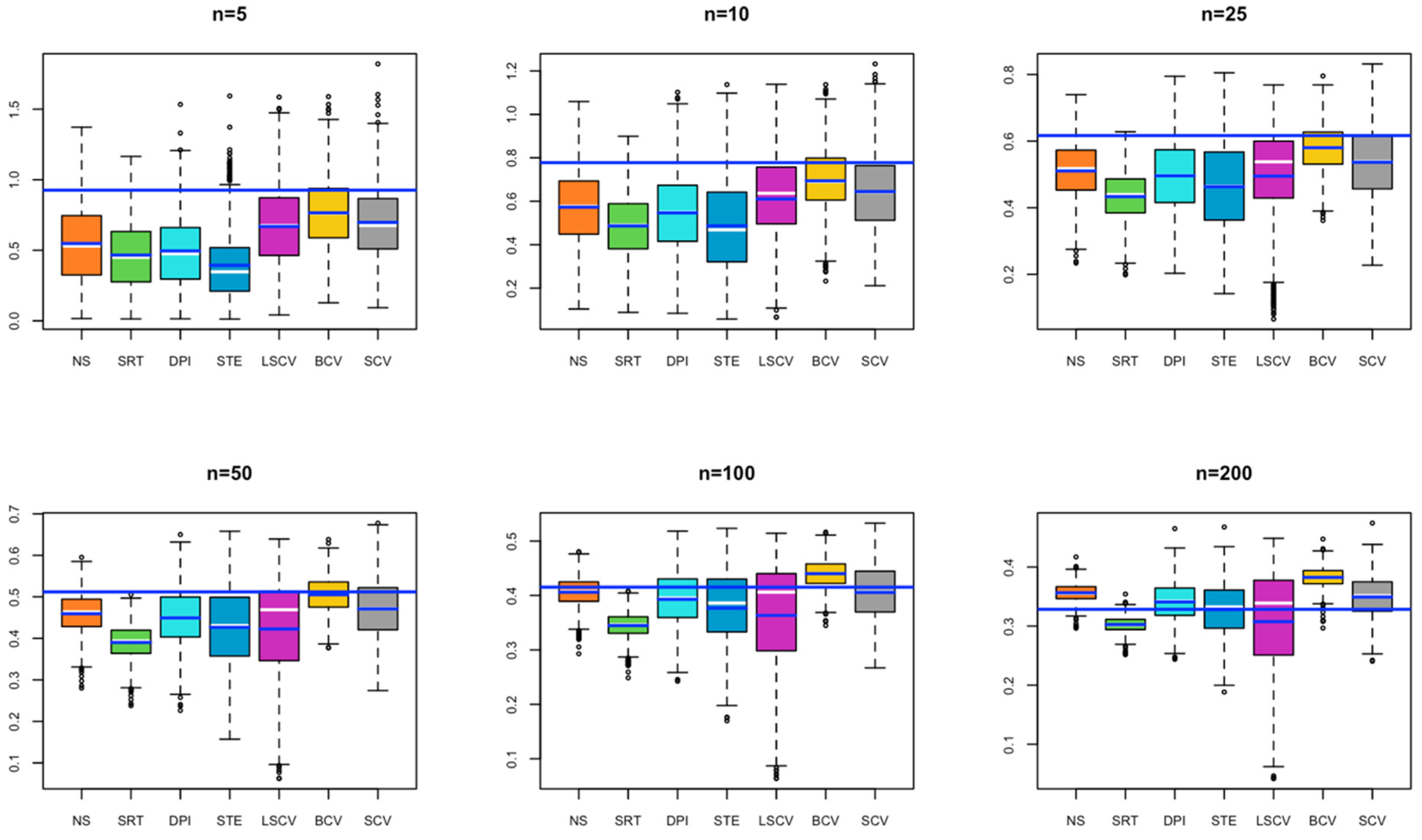
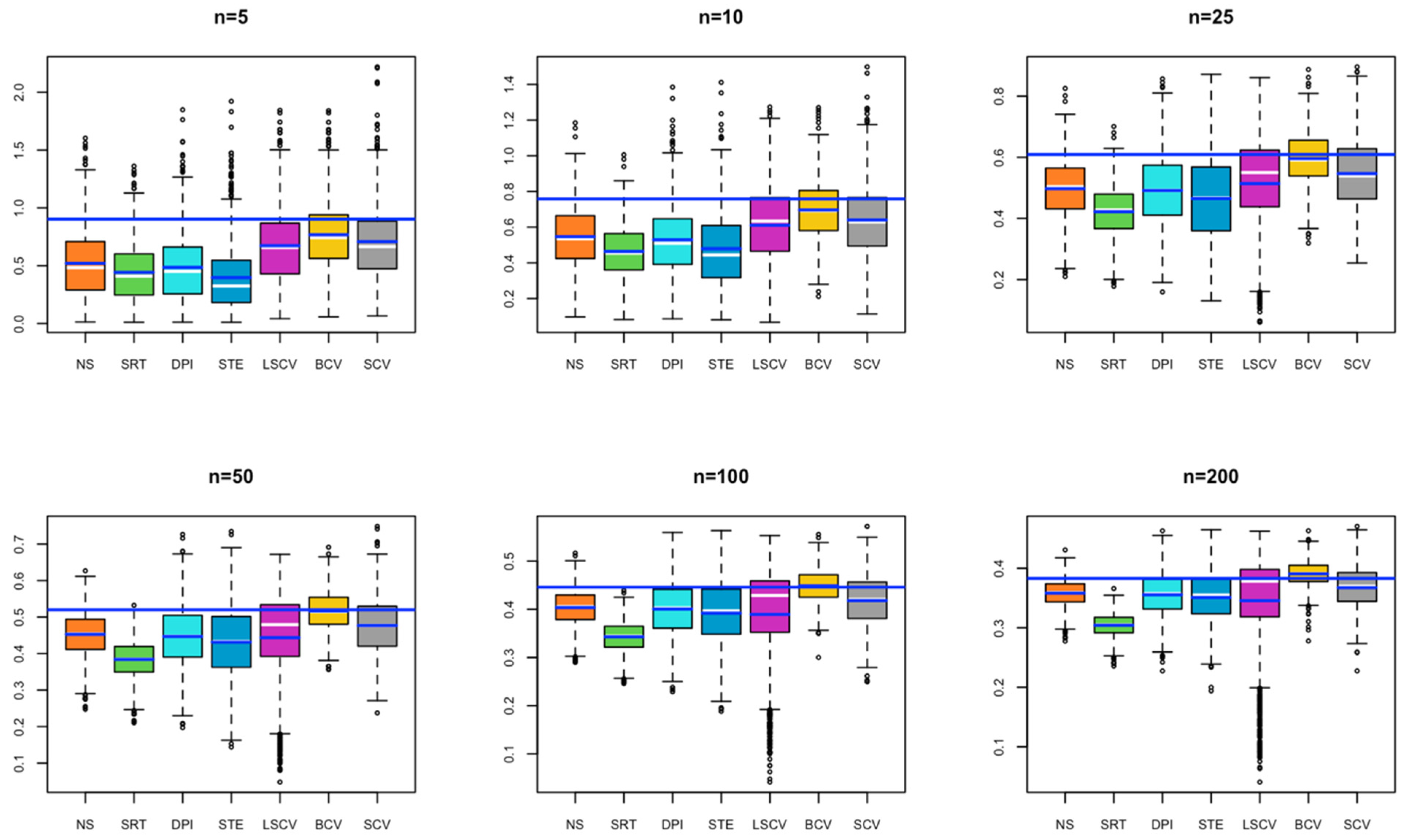
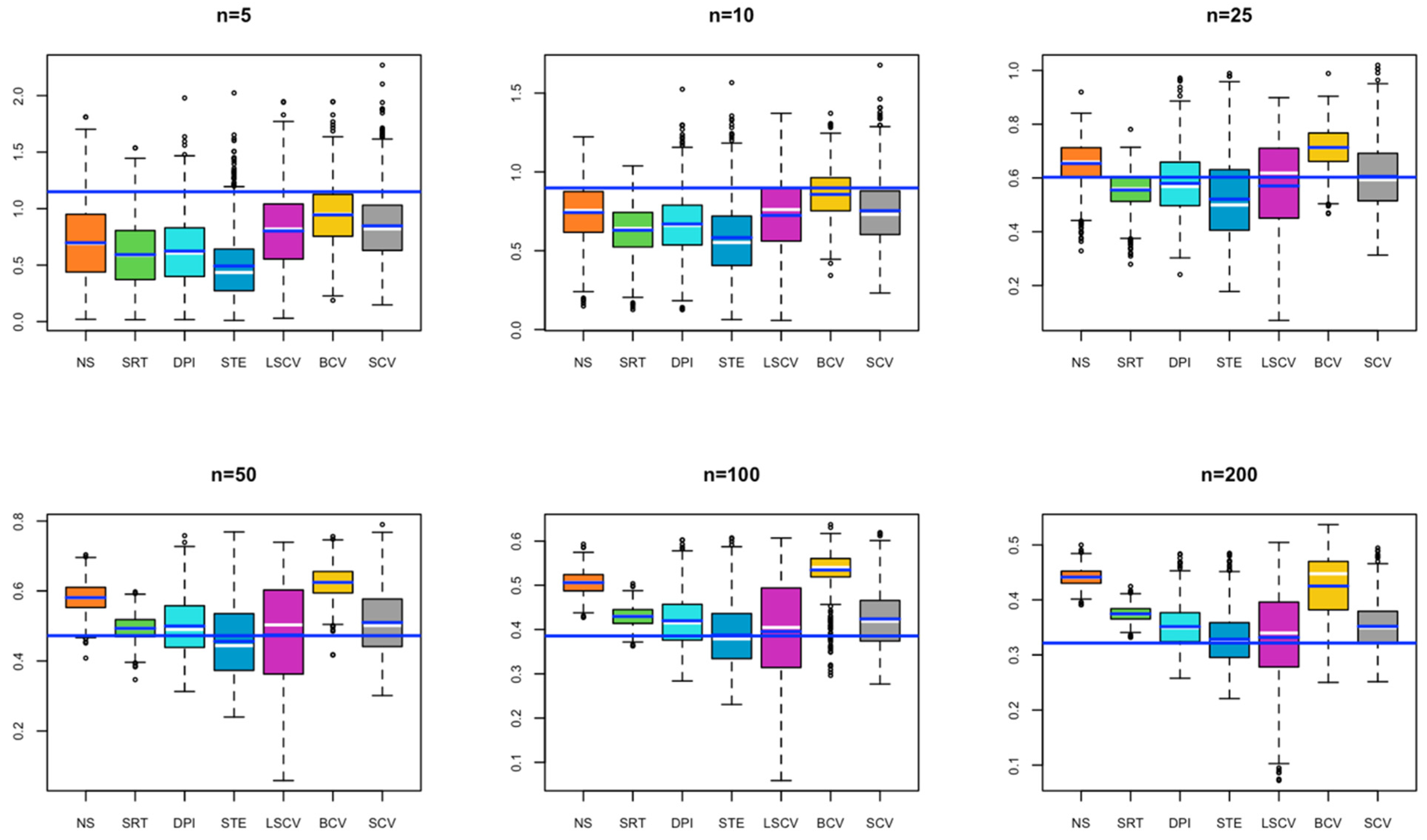
- In Model 1, all estimated bandwidths for small sample size remained below the optimal bandwidth. It is seen that as the sample size increases, the value obtained by the BCV method approaches the optimal bandwidth. In contrast, the bandwidth estimated by the SRT method remains below the optimal bandwidth for each simulated sample size. It may cause under smoothing problems if used in KDE (Figure 1).
- In Model 2, for small sample sizes (n = 5, 10), BCV and SCV occur close to the optimal bandwidth; as the sample size increases, the SCV method is observed to be the closest to the optimal bandwidth (Figure 2).
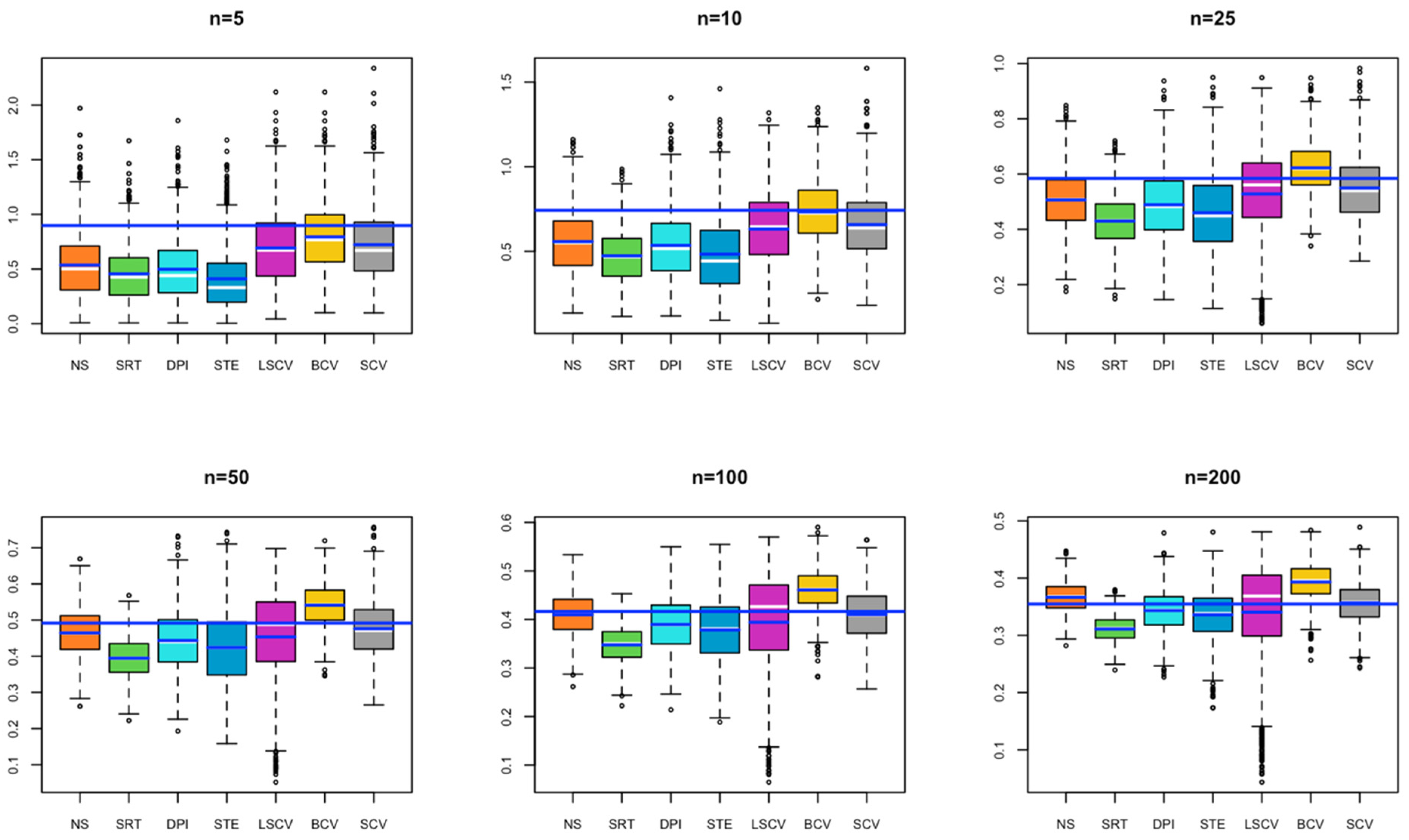
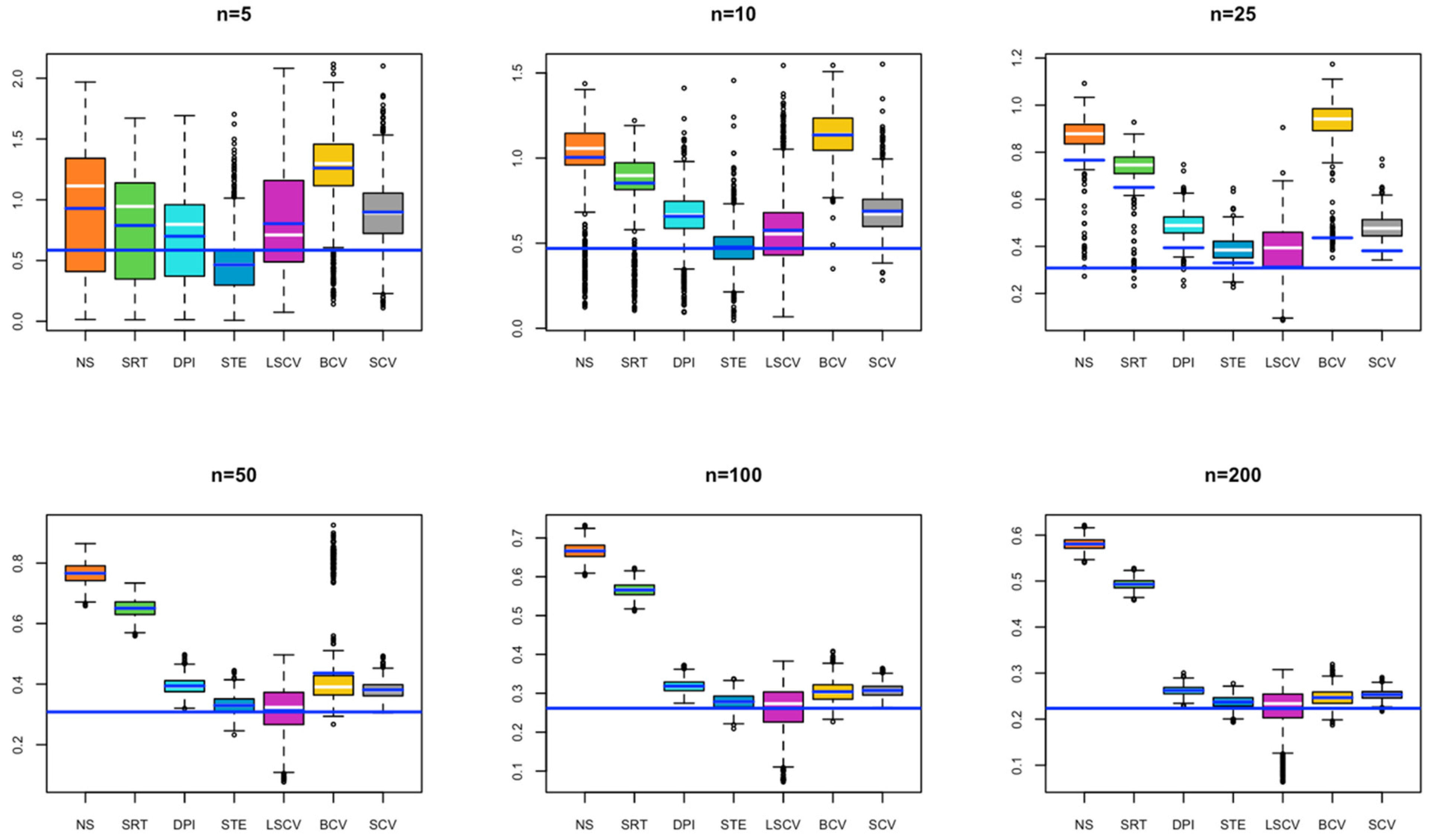
- In Model 3, for a small sample size, the bandwidths estimated by NS, SRT, DPI, STE, and LSCV methods give results close to the optimal bandwidth; as the sample size increases, the bandwidth value estimated by LSCV becomes the closest estimate to the optimal bandwidth (Figure 3).
- In Model 4, for small sample size, the bandwidth estimates estimated by BCV, LSCV, and SCV methods give results close to the optimal bandwidth; as the sample size increases, the bandwidth value estimated by LSCV overlaps with the optimal bandwidth value (Figure 4).
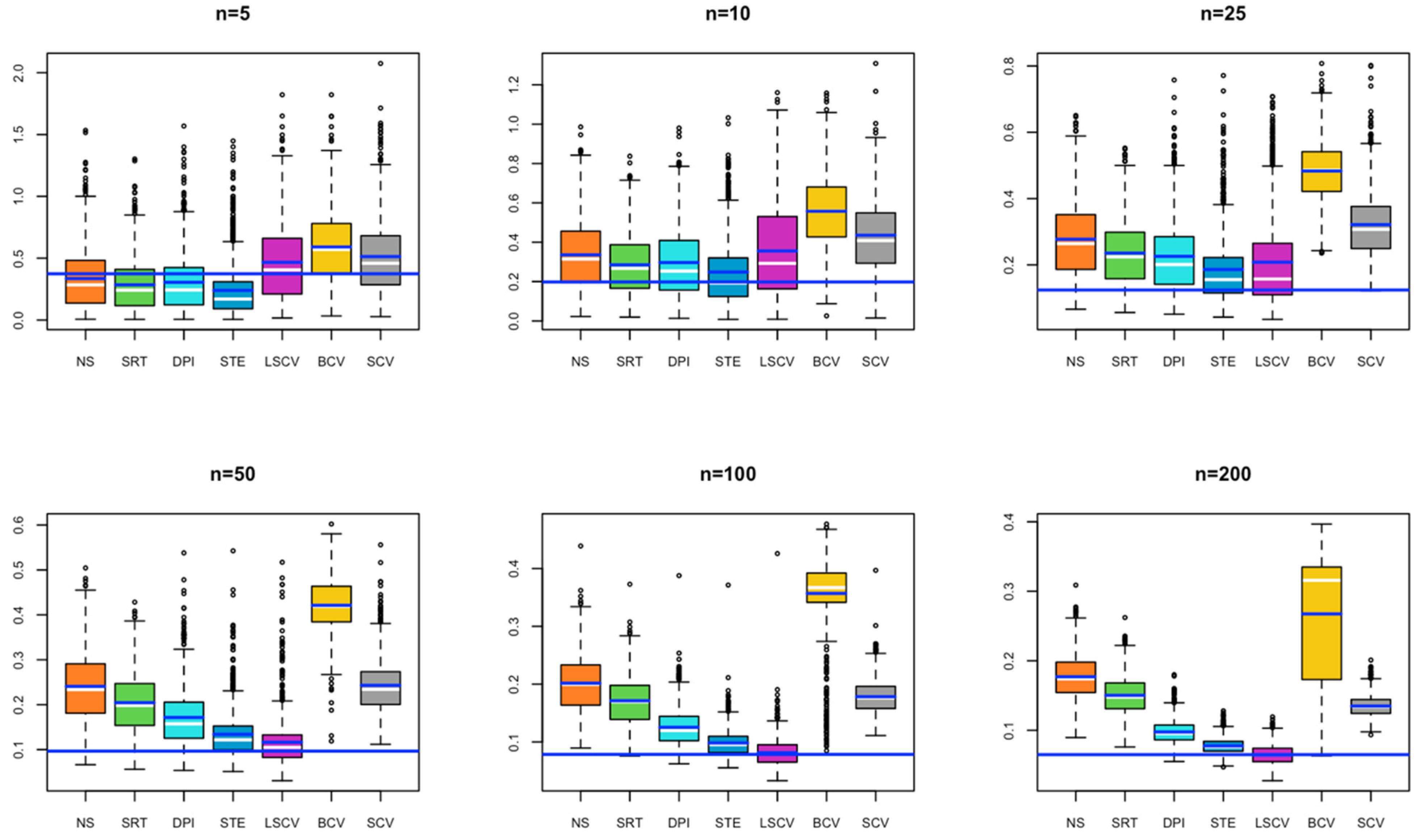
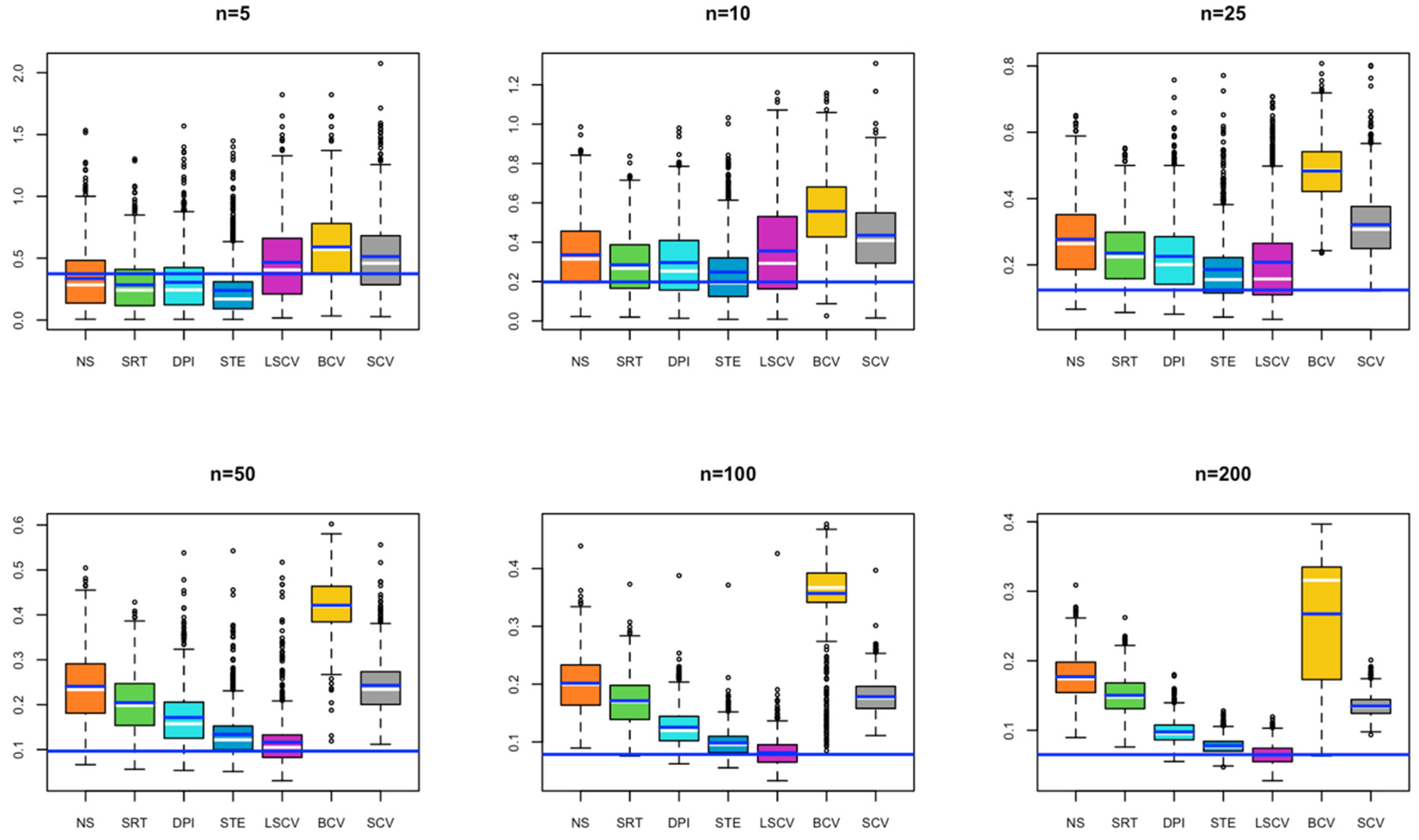
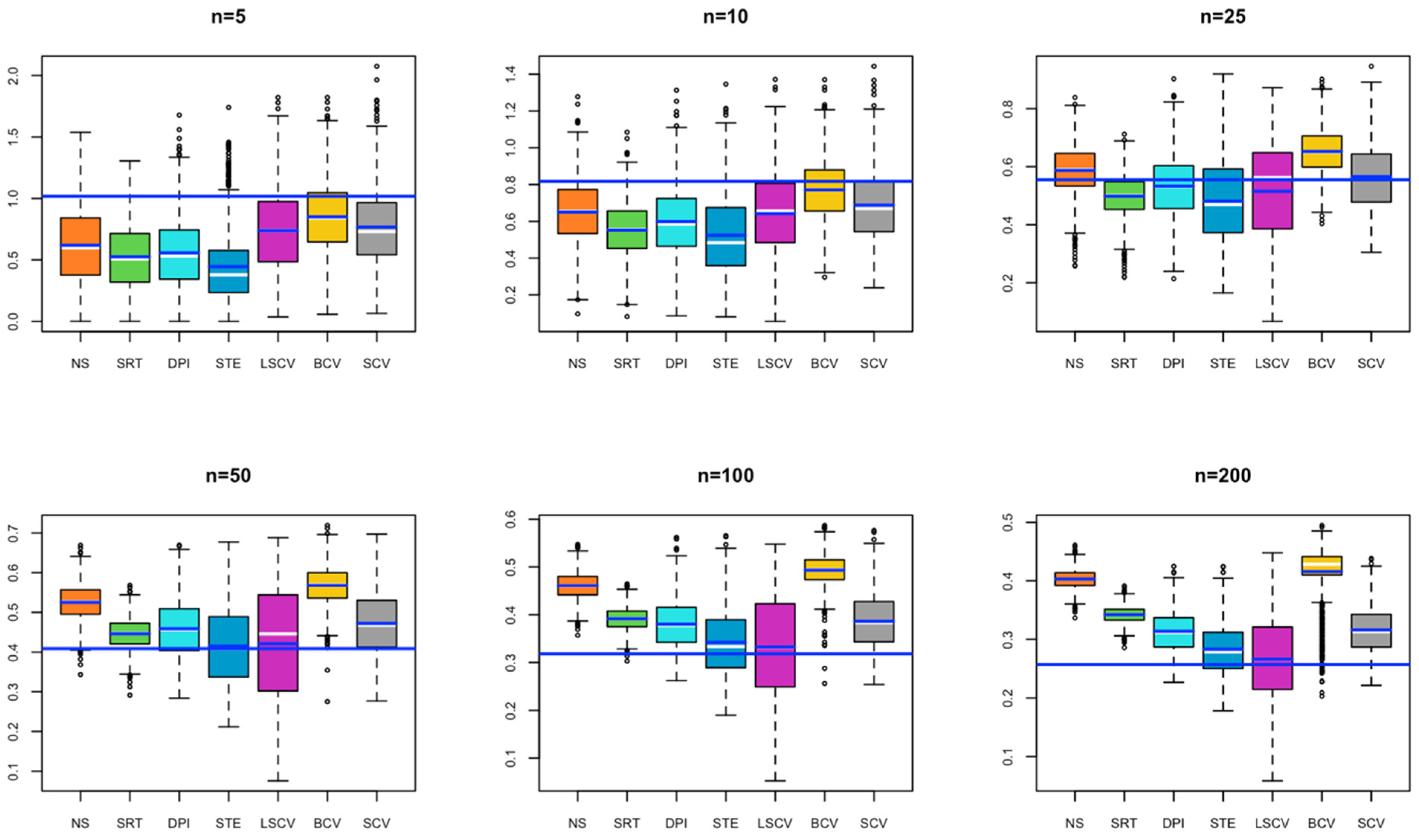
- In Model 5, for a small sample size, the bandwidth estimated by the BCV method captures the closest value to the optimal bandwidth; as the sample size increases, the bandwidth values estimated by SRT, DPI, STE, LSCV, and SCV overlap with the optimal bandwidth value (Figure 5).
- In Model 6, in all cases, the bandwidth estimate by the LSCV method captures the optimal bandwidth value, with the STE bandwidth method following the LSCV bandwidth method (Figure 6).
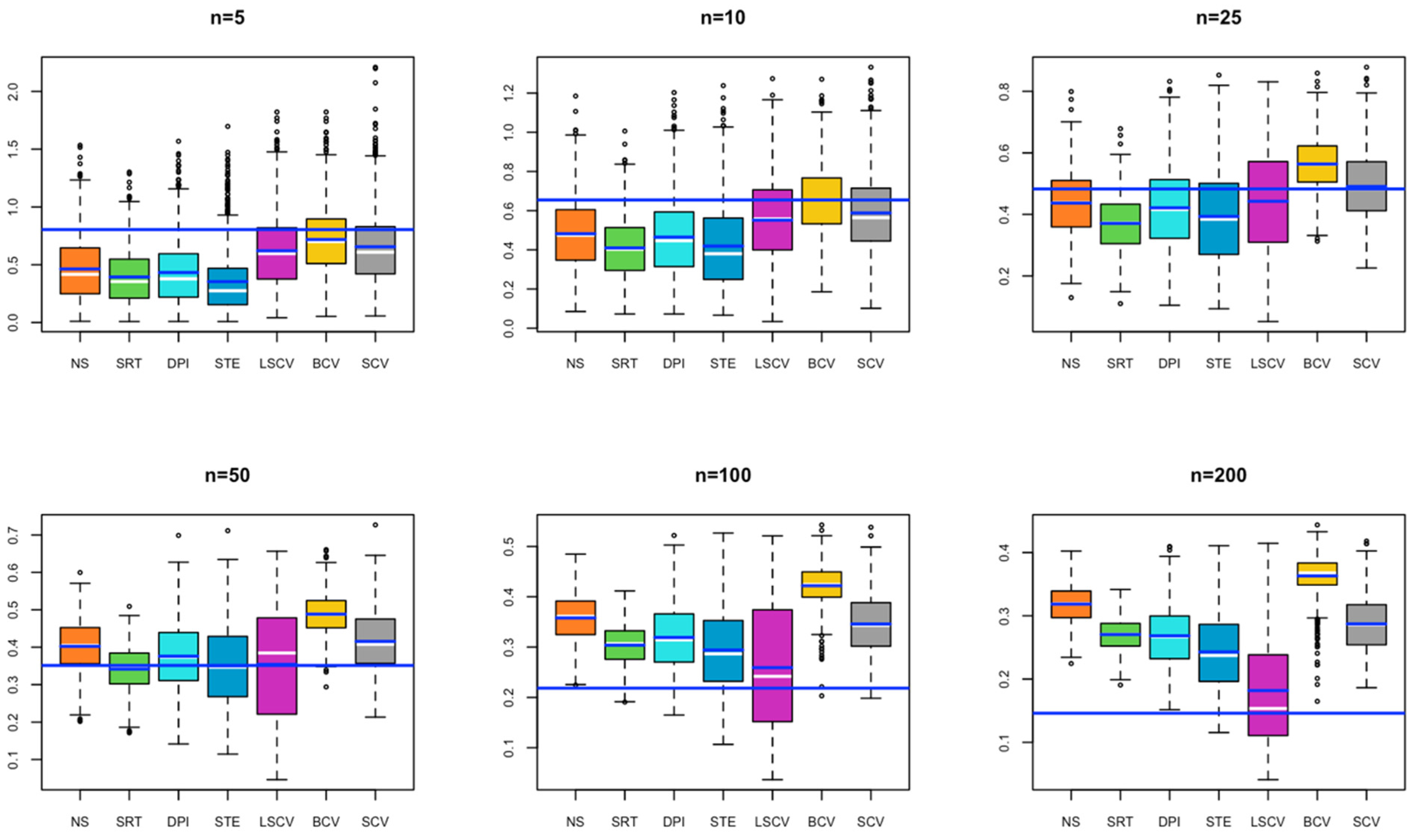
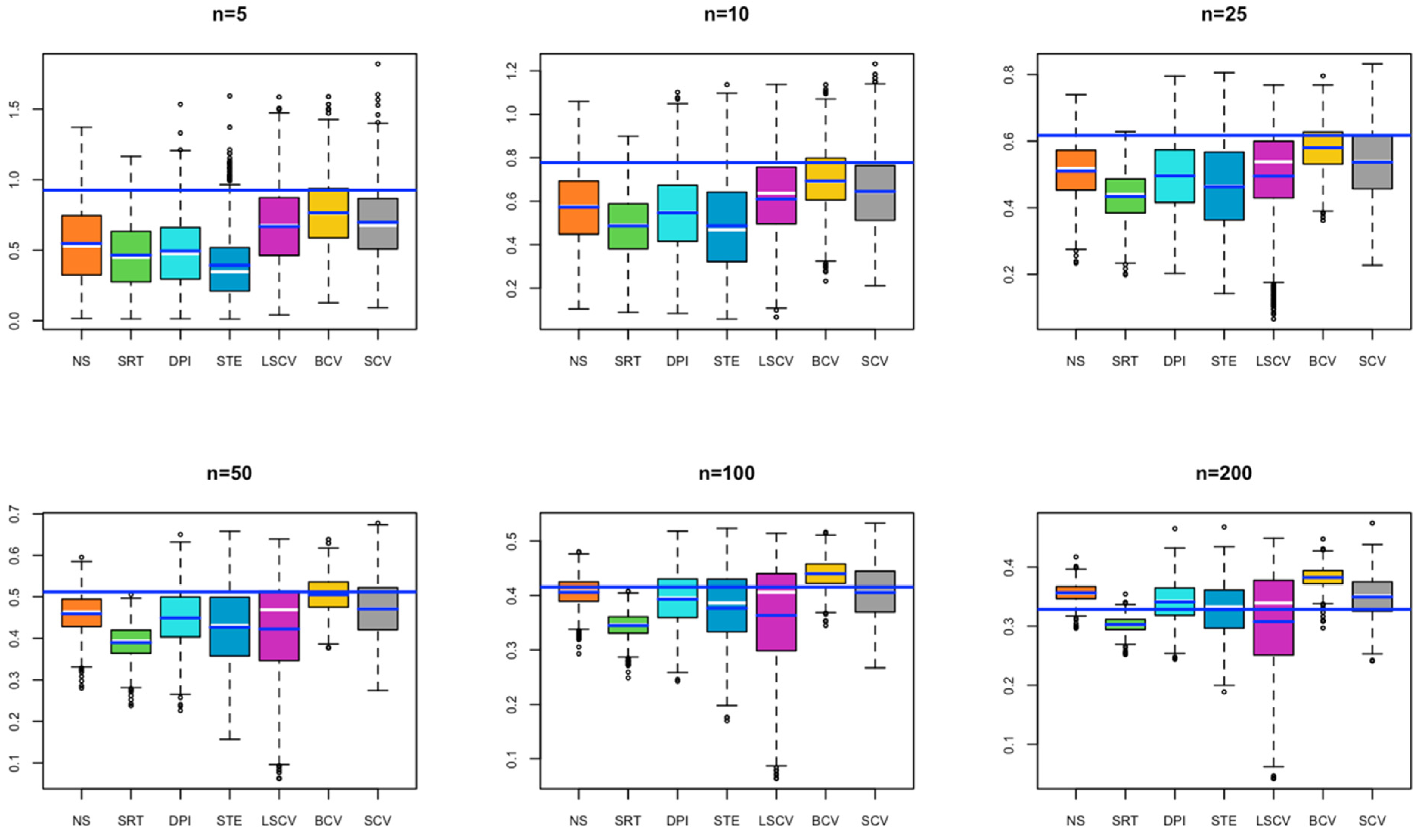
- In Model 7, for a small sample size, although the bandwidth estimate closest to the optimal bandwidth is BCV, as the sample size increases, the bandwidth value estimated by LSCV approaches the optimal bandwidth value (Figure 7).
- In Model 8, for a small sample size, although BCV is the bandwidth estimate closest to the optimal bandwidth, as the sample size increases, the bandwidths estimated by SCV get closer to the optimal bandwidth value (Figure 8).
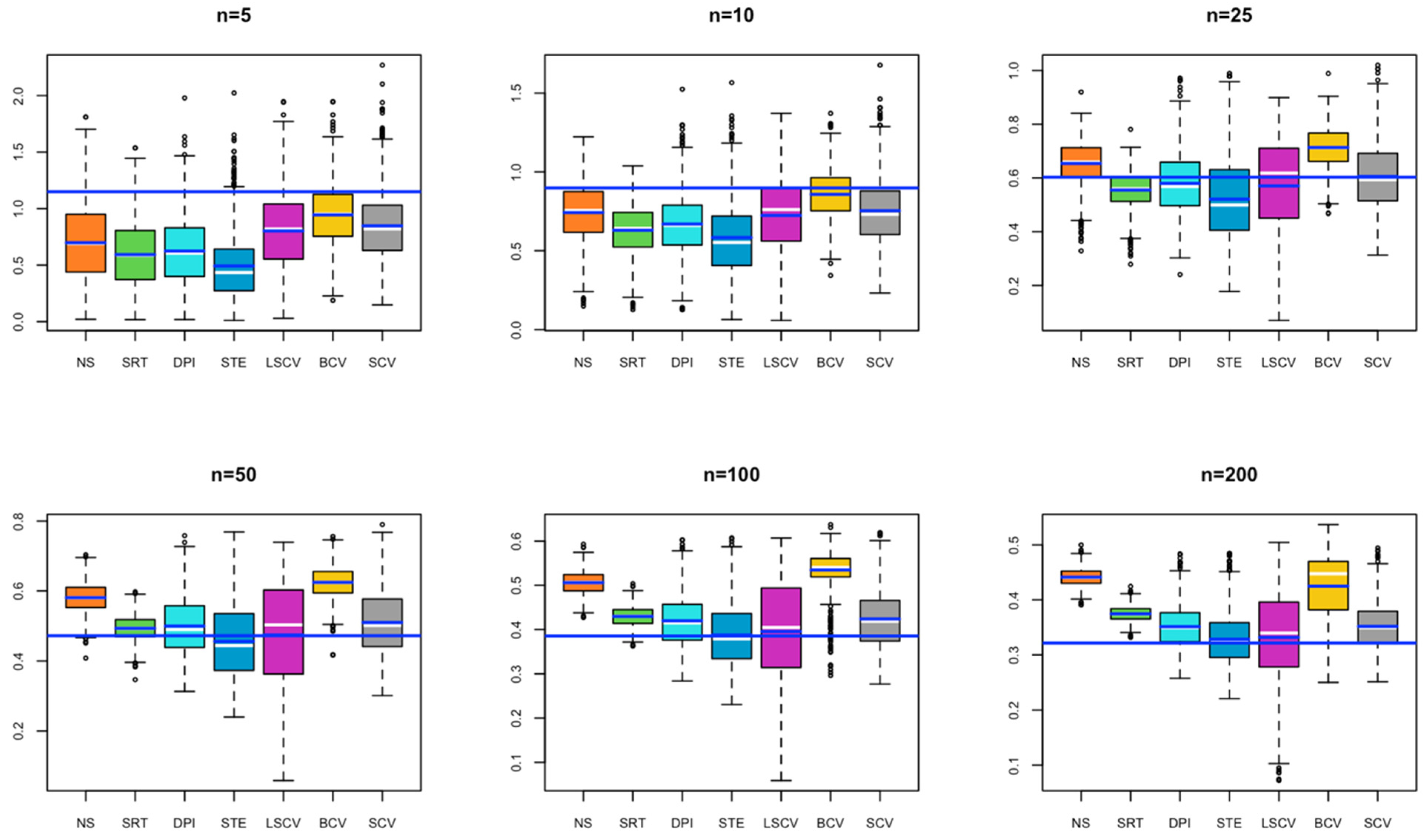
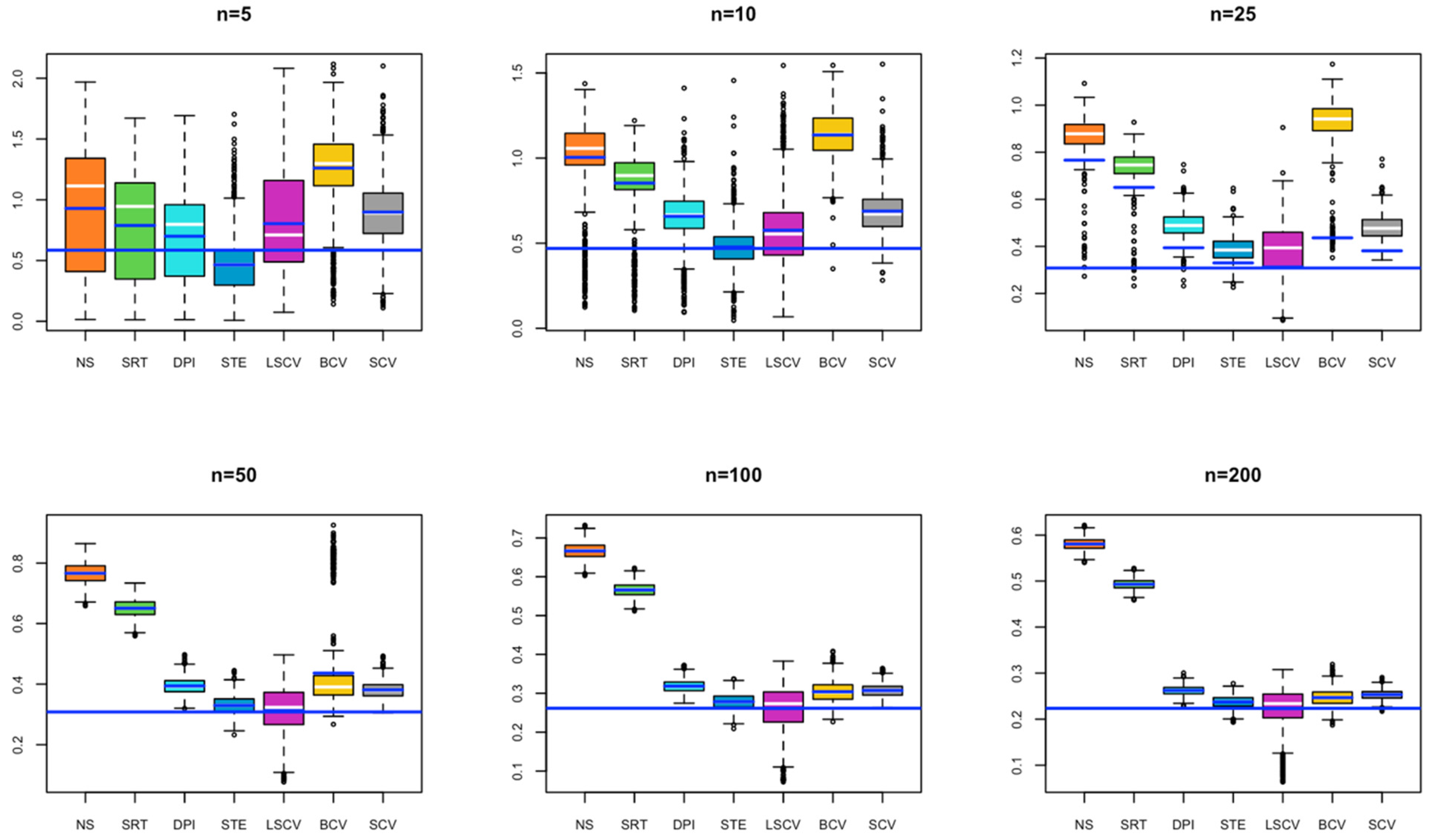
- In Figure S2, for small sample sizes, NS, SRT, DPI, and STE exhibit under smoothing; while as the sample size increases, all bandwidths tend to over smooth.
- In Figure S3, for small sample sizes, SRT, DPI, and STE exhibit under smoothing; while as the sample size increases, all bandwidths tend to over smooth.
- In Figure S4, for small sample sizes, SRT and STE exhibit under smoothing. As the sample size increases, DPI and LCSV also tend to under smooth.
- In Figure S5, for small sample sizes, NS, SRT, DPI, and STE exhibit under smoothing.
- In Figure S6, for small sample sizes, SRT, DPI, and STE exhibit under smoothing; while as the sample size increases, all bandwidths tend to over smooth.
- In Figure S7, for small sample sizes, SRT and DPI exhibit under smoothing; while as the sample size increases, all bandwidths tend to over smooth.
- In Figure S8, as the sample size increases, all bandwidths tend to over smooth.
- In Figure S9, for small sample sizes, NS, SRT, DPI, and STE exhibit under smoothing; while as the sample size increases, all bandwidths tend to over smooth.
5. Application of Real Data
6. Results
- Bandwidths obtained by the NS selection method give the closest results to the optimal bandwidth at low sample size at kurtotic unimodal density and at high sample size at trimodal density.
- The SRT bandwidth selection method does not approach optimal bandwidth at any of the normal mixing densities.
- The DPI bandwidth selection method does not approach optimal bandwidth at any of the normal mixing densities.
- The STE bandwidth selection method gives the closest result to the optimum bandwidth for kurtotic unimodal and separated bimodal density functions at a low sample size.
- The LSCV bandwidth selection method gives the closest result to the optimum bandwidth for large sample sizes in kurtotic unimodal, outlier, separated bimodal and skewed bimodal density functions.
- The BCV bandwidth selection method at all sample sizes at standard normal density; outlier, skewed bimodal, and trimodal density gives the closest result to optimal bandwidth at a small sample size.
- The SCV bandwidth selection method gives the closest result to the optimal bandwidth for all other sample sizes except for a small sample size at skewed unimodal density.
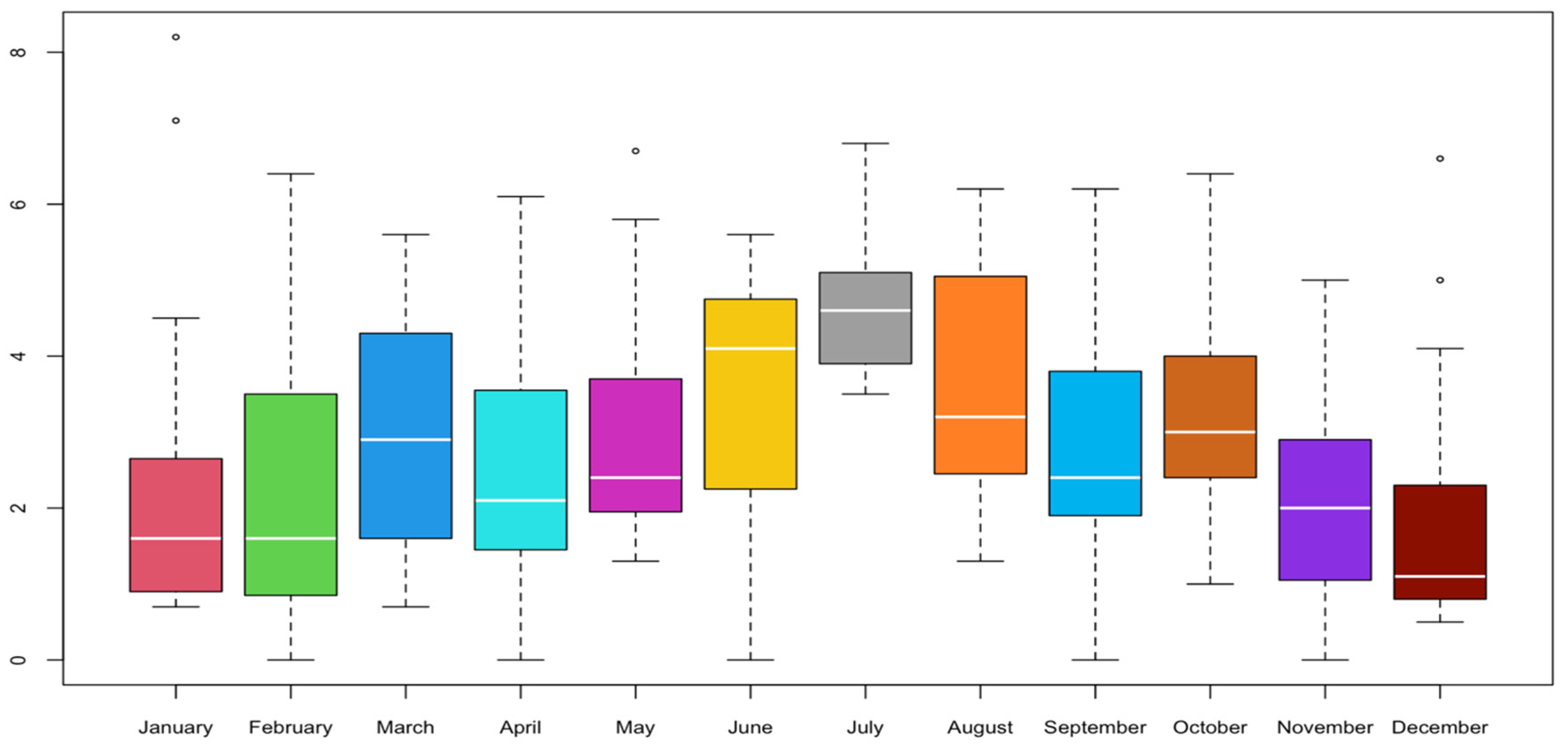
- The BCV bandwidth selection methods have oversmoothed, resulting in high bandwidth in most of the months.
- STE and some of the LSCV bandwidth selection methods have incomplete smoothing, resulting in small bandwidth in some variables.
7. Conclusions
- Geographical viability and terrain analysis: To validate the robustness of the SCV method, future research should extend its investigation across diverse geographical regions and terrain types, considering variations in wind speed data originating from different climatic conditions. Such an approach will help in comprehensively assessing the method’s applicability and ensuring its adaptability across varied environmental contexts.
- Adaptive algorithms and time-series analysis: Leveraging advancements in machine learning and artificial intelligence, a promising avenue for research involves the development of adaptive algorithms capable of dynamically selecting the most suitable bandwidth method based on real-time wind speed data. Additionally, a more detailed time-series analysis should be pursued to uncover diurnal, weekly, and seasonal patterns in wind speed data, further evaluating the performance of bandwidth selectors on these shorter time scales.
- Hybrid bandwidth selection approaches and comparative analysis: Building on the identification of the SCV method as optimal, future investigations can delve into refining its implementation or combining it with other bandwidth methods to create hybrid approaches. These approaches may integrate techniques such as weighted averages, adaptive selection, iterative refinement, data segmentation, bootstrap combination, or a machine learning approach to enhance precision. Furthermore, ongoing studies should continually compare established methods with any emerging contenders to ensure that the most accurate wind speed distribution predictions are achieved in the ever-evolving landscape of technological and mathematical advancements.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Foyhirun, C.; Kongkitkul, D.K.; Ekkawatpanit, C. Performance of Global Climate Model (GCMs) for wind data analysis. E3S Web Conf. 2019, 117, 3–7. [Google Scholar] [CrossRef]
- Donk, P.; Van Uytven, E.; Willems, P. Statistical methodology for on-site wind resource and power potential assessment under current and future climate conditions: A case study of Suriname. SN Appl. Sci. 2019, 1, 846. [Google Scholar] [CrossRef]
- Shi, H.; Dong, Z.; Xiao, N.; Huang, Q. Wind Speed Distributions Used in Wind Energy Assessment: A Review. Front. Energy Res. Wind Energy 2021, 9, 769920. [Google Scholar] [CrossRef]
- Rosenblatt, M. Remarks on Some Nonparametric Estimates of a Density Function. Ann. Stat. 1956, 27, 832–837. [Google Scholar] [CrossRef]
- Parzen, E. On the estimation of a probability density function and the mode. Ann. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis, 1st ed.; Chapman and Hall: London, UK, 1986; pp. 1–48. [Google Scholar]
- Terrell, G.R. The Maximal Smoothing Principle in Density Estimation. J. Am. Stat. Assoc. 1990, 85, 470–477. [Google Scholar] [CrossRef]
- Gramacki, A. Nonparametric Kernel Density Estimation and Its Computational Aspects; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Rudemo, M. Empirical choice of histograms and kernel density estimators. Scand. Stat. Theory Appl. 1982, 9, 65–78. [Google Scholar]
- Bowman, A.W. An alternative method of cross-validation for the smoothing of density estimates. Biometrika 1984, 71, 353–360. [Google Scholar] [CrossRef]
- Scott, D.; Terrell, G. Biased and unbiased cross-validation in density estimation. J. Am. Stat. Assoc. 1987, 82, 1131–1146. [Google Scholar] [CrossRef]
- Sheather, S.J.; Jones, M.C. A Reliable Data-Based Bandwidth Selection Method for Kernel Density Estimation. J. R. Stat. Soc. Ser. B Methodol. 1991, 53, 683–690. [Google Scholar] [CrossRef]
- Cao, R.; Cuevas, A.; Gonzalez Manteiga, W. A comparative study of several smoothing methods in density estimation. Comput. Statist. Data Anal. 1994, 17, 153–176. [Google Scholar] [CrossRef]
- Harpole, J.K. How Bandwidth Selection Algorithms Impact Exploratory Data Analysis Using Kernel Density Estimation. Master’s Thesis, University of Kansas, Lawrence, KS, USA, 2013. [Google Scholar]
- Harpole, J.K.; Woods, C.M.; Rodebaugh, T.L.; Levinson, C.A.; Lenze, E.J. How bandwidth selection algorithms impact exploratory data analysis using kernel density estimation. Psychol. Methods 2014, 9, 428–443. [Google Scholar] [CrossRef] [PubMed]
- Demir, S. Adaptive kernel density estimation with generalized least square cross-validation. Hacet. J. Math. Stat. 2019, 48, 616–625. [Google Scholar] [CrossRef]
- Wallin, G.; Häggström, J.; Wiberg, M. How Important is the Choice of Bandwidth in Kernel Equating? Appl. Psychol. Meas. 2021, 45, 518–535. [Google Scholar] [CrossRef] [PubMed]
- Karakoç, Ş. Çekirdek Düzgünleştirmesiyle Yoğunluk Fonksiyonu Tahmininde Bant Genişliği Seçim Yöntemlerinin Karşılaştırılması. Master’s Thesis, Gazi University, Ankara, Turkey, 2023. [Google Scholar]
- Henderson, D.J.; Papadopoulos, A.; Parmeter, C.F. Bandwidth selection for kernel density estimation of fat-tailed and skewed distributions. J. Stat. Comput. Simul. 2023, 93, 2110–2135. [Google Scholar] [CrossRef]
- Dokur, E.; Kurban, M. Wind Speed Potential Analysis Based on Weibull Distribution. Balk. J. Electr. Comput. Eng. 2015, 3, 231–235. [Google Scholar] [CrossRef]
- Miao, S.; Xie, K.; Yang, H.; Karki, R.; Tai, H.-M.; Chen, T. A mixture kernel density model for wind speed probability distribution estimation. Energy Convers. Manag. 2016, 126, 1066–1083. [Google Scholar] [CrossRef]
- Hu, B.; Li, Y.; Yang, H.; Wang, H. Wind speed model based on kernel density estimation and its application in reliability assessment of generating systems. J. Mod. Power Syst. Clean Energy 2017, 5, 220–227. [Google Scholar] [CrossRef]
- Citakoglu, H.; Aydemir, A. Determination of Monthly Wind Speed of Kayseri Region with Gray Estimation Method. In Proceedings of the 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT), Amman, Jordan, 9–11 April 2019. [Google Scholar] [CrossRef]
- Han, Q.; Ma, S.; Wang, T.; Chu, F. Kernel density estimation model for wind speed probability distribution with applicability to wind energy assessment in China. Renew. Sust. Energ. Rev. 2019, 115, 109387. [Google Scholar] [CrossRef]
- Zhang, L.; Xie, L.; Han, Q.; Wang, Z.; Huang, C. Probability Density Forecasting of Wind Speed Based on Quantile Regression and Kernel Density Estimation. Energies 2020, 13, 6125. [Google Scholar] [CrossRef]
- An, X.-Y.; Yan, Z.; Jia, J.-M. A new distribution for modeling wind speed characteristics and evaluating wind power potential in Xinjiang, China. Energy Sources A Recovery Util. Environ. Eff. 2020, 1, 1556–7036. [Google Scholar] [CrossRef]
- He, Y.-L.; Ye, X.; Huang, D.-F.; Huang, J.Z.; Zhai, J.-H. Novel kernel density estimator based on ensemble unbiased cross-validation. Inf. Sci. 2021, 581, 327–344. [Google Scholar] [CrossRef]
- Jabbar, R.I. Statistical Analysis of Wind Speed Data and Assessment of Wind Power Density Using Weibull Distribution Function (Case Study: Four Regions in Iraq). Phys. Conf. Ser. 2021, 1804, 012010. [Google Scholar] [CrossRef]
- Liu, L.; Wang, J.; Li, J.; Wei, L. Estimation of wind speed distribution with time window and new kernel function. J. Renew. Sustain. Energy 2022, 14, 053307. [Google Scholar] [CrossRef]
- Wahbah, M.; Mohandes, B.; EL-Fouly, T.H.M.; El Moursi, M.S. Unbiased cross-validation kernel density estimation for wind and PV probabilistic modelling. Energy Convers. Manag. 2022, 266, 115811. [Google Scholar] [CrossRef]
- Zhou, S.; Yang, Y.; Gao, Z.; Xi, X.; Duan, Z.; Li, Y. Estimating vertical wind power density using tower observation and empirical models over varied desert steppe terrain in northern China. Atmos. Meas. Tech. 2022, 15, 757–773. [Google Scholar] [CrossRef]
- Silveira, F.; Gomes-silva, F.; Brito, C.; Jale, J.; Gusmão, F.; Xavier-júnior, S.; Rocha, J. Modelling wind speed with a univariate probability distribut ion depending on two baseline functions. Hacet. J. Math. Stat. 2023, 52, 808–827. [Google Scholar] [CrossRef]
- Wand, M.P.; Jones, M.C. Kernel Smoothing, 1st ed.; Chapman & Hall: New York, NY, USA, 1995. [Google Scholar]
- Yolsal, H. Parametrik Olmayan Yoğunluk Tahmincileri ve Regresyon Analizi (Birinci Baskı); Detay Yayıncılık: Ankara, Turkey, 2017. [Google Scholar]
- Sheather, S.J. Density estimation. Stat. Sci. 2004, 19, 558–597. [Google Scholar] [CrossRef]
- Hall, P. Large sample optimality of least squares cross-validation in density estimation. Ann. Stat. 1983, 11, 1156–1174. [Google Scholar] [CrossRef]
- Park, B.; Marron, J. Comparison of data-driven bandwidth selectors. J. Am. Stat. Assoc. 1990, 85, 66–72. [Google Scholar] [CrossRef]
- Jones, C.; Marron, J.; Sheather, S. Progress in data-based bandwidth selection for kernel density estimation. Comput. Stat. 1996, 11, 337–381. [Google Scholar]
- Marron, S.; Wand, M. Exact mean integrated squared error. Ann. Stat. 1992, 20, 712–736. [Google Scholar] [CrossRef]
- Cran.r-project. 2022. Available online: https://cran.rproject.org/web/packages/ks/ks.pdf (accessed on 10 January 2022).
- Turkish State Meteorological Service. Available online: https://mevbis.mgm.gov.tr/mevbis/ui/index.html#/Workspace (accessed on 8 September 2023).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model No. | Densities | |
|---|---|---|
| 1 | Standard Normal (Gaussian) | N (0, 1) |
| 2 | Skewed Unimodal | |
| 3 | Kurtotic Unimodal | |
| 4 | Outlier | |
| 5 | Bimodal | |
| 6 | Separated Bimodal | |
| 7 | Skewed Bimodal | |
| 8 | Trimodal |
| n | B.M. * | ** | SD *** | Bias | MSE | RE | B.M. * | ** | SD *** | Bias | MSE | RE | ||
| 5 | 0.903 | BCV | 0.768 | 0.288 | −0.135 | 0.101 | 0.850 | 0.898 | BCV | 0.793 | 0.313 | −0.105 | 0.109 | 0.883 |
| 10 | 0.758 | BCV | 0.696 | 0.166 | −0.062 | 0.031 | 0.918 | 0.743 | BCV | 0.733 | 0.185 | −0.009 | 0.034 | 0.987 |
| 25 | 0.609 | BCV | 0.596 | 0.085 | −0.014 | 0.007 | 0.979 | 0.584 | SCV | 0.550 | 0.117 | −0.035 | 0.015 | 0.942 |
| 50 | 0.520 | BCV | 0.517 | 0.052 | −0.003 | 0.003 | 0.994 | 0.492 | SCV | 0.476 | 0.080 | −0.016 | 0.007 | 0.967 |
| 100 | 0.445 | BCV | 0.449 | 0.034 | 0.003 | 0.001 | 1.009 | 0.417 | SCV | 0.410 | 0.054 | −0.006 | 0.003 | 0.983 |
| 200 | 0.383 | BCV | 0.391 | 0.022 | 0.008 | 0.001 | 1.021 | 0.355 | SCV | 0.367 | 0.037 | 0.002 | 0.001 | 1.034 |
| n | B.M. * | ** | SD *** | Bias | MSE | RE | B.M. * | ** | SD *** | Bias | MSE | RE | ||
| 5 | 0.374 | NS | 0.335 | 0.248 | −0.038 | 0.063 | 0.896 | 0.804 | BCV | 0.718 | 0.292 | −0.086 | 0.093 | 0.893 |
| 10 | 0.198 | STE | 0.249 | 0.173 | 0.051 | 0.033 | 1.258 | 0.654 | BCV | 0.655 | 0.167 | 0.001 | 0.028 | 1.002 |
| 25 | 0.124 | STE | 0.186 | 0.105 | 0.062 | 0.015 | 1.500 | 0.483 | SCV | 0.491 | 0.114 | 0.008 | 0.013 | 1.017 |
| 50 | 0.097 | LSCV | 0.116 | 0.059 | 0.020 | 0.004 | 1.196 | 0.351 | STE | 0.350 | 0.108 | −0.001 | 0.012 | 0.997 |
| 100 | 0.079 | LSCV | 0.081 | 0.026 | 0.003 | 0.001 | 1.025 | 0.218 | LSCV | 0.259 | 0.123 | 0.041 | 0.017 | 1.188 |
| 200 | 0.065 | LSCV | 0.065 | 0.015 | 0.000 | 0.000 | 1.000 | 0.146 | LSCV | 0.182 | 0.092 | 0.036 | 0.010 | 1.247 |
| n | B.M. * | ** | SD *** | Bias | MSE | RE | B.M. * | ** | SD *** | Bias | MSE | RE | ||
| 5 | 1.149 | BCV | 0.945 | 0.279 | −0.204 | 0.120 | 0.822 | 0.586 | STE | 0.465 | 0.255 | −0.120 | 0.080 | 0.794 |
| 10 | 0.899 | BCV | 0.858 | 0.153 | −0.041 | 0.025 | 0.954 | 0.469 | STE | 0.477 | 0.128 | 0.008 | 0.016 | 1.017 |
| 25 | 0.603 | SCV | 0.606 | 0.125 | 0.003 | 0.016 | 1.005 | 0.366 | LSCV | 0.384 | 0.113 | 0.018 | 0.013 | 1.049 |
| 50 | 0.472 | LSCV | 0.474 | 0.153 | 0.002 | 0.023 | 1.004 | 0.308 | LSCV | 0.312 | 0.082 | 0.004 | 0.007 | 1.013 |
| 100 | 0.385 | STE | 0.388 | 0.073 | 0.002 | 0.005 | 1.008 | 0.262 | LSCV | 0.261 | 0.060 | −0.001 | 0.004 | 0.996 |
| 200 | 0.322 | STE | 0.328 | 0.047 | 0.007 | 0.002 | 1.019 | 0.224 | LSCV | 0.223 | 0.046 | −0.001 | 0.002 | 0.996 |
| n | B.M. * | ** | SD *** | Bias | MSE | RE | B.M. * | ** | SD *** | Bias | MSE | RE | ||
| 5 | 1.017 | BCV | 0.850 | 0.284 | −0.167 | 0.108 | 0.836 | 0.926 | BCV | 0.766 | 0.251 | −0.161 | 0.089 | 0.827 |
| 10 | 0.817 | BCV | 0.771 | 0.164 | −0.046 | 0.029 | 0.944 | 0.778 | BCV | 0.694 | 0.146 | −0.084 | 0.028 | 0.892 |
| 25 | 0.555 | SCV | 0.565 | 0.116 | 0.011 | 0.014 | 1.018 | 0.617 | BCV | 0.580 | 0.071 | −0.036 | 0.006 | 0.940 |
| 50 | 0.408 | STE | 0.415 | 0.099 | 0.007 | 0.010 | 1.017 | 0.512 | BCV | 0.505 | 0.043 | −0.007 | 0.002 | 0.986 |
| 100 | 0.318 | LSCV | 0.333 | 0.109 | 0.015 | 0.012 | 1.047 | 0.415 | NS | 0.406 | 0.028 | −0.009 | 0.001 | 0.978 |
| 200 | 0.258 | LSCV | 0.266 | 0.081 | 0.009 | 0.007 | 1.031 | 0.328 | STE | 0.328 | 0.046 | −0.000 | 0.002 | 1.000 |
| Months | NS | SRT | DPI | STE | LCSV | BCV | SCV |
|---|---|---|---|---|---|---|---|
| January | 0.591 | 0.697 | 0.457 | 0.297 | 0.110 | 1.049 | 0.614 |
| February | 0.830 | 0.978 | 0.682 | 0.598 | 0.679 | 1.050 | 0.687 |
| March | 0.723 | 0.851 | 0.692 | 0.625 | 0.806 | 0.914 | 0.707 |
| April | 0.710 | 0.836 | 0.691 | 0.615 | 0.701 | 0.911 | 0.717 |
| May | 0.591 | 0.697 | 0.487 | 0.398 | 0.438 | 0.752 | 0.491 |
| June | 0.642 | 0.756 | 0.527 | 0.409 | 0.433 | 0.813 | 0.524 |
| July | 0.361 | 0.425 | 0.411 | 0.388 | 0.457 | 0.457 | 0.428 |
| August | 0.685 | 0.806 | 0.633 | 0.554 | 0.685 | 0.866 | 0.642 |
| September | 0.642 | 0.756 | 0.512 | 0.457 | 0.538 | 0.876 | 0.532 |
| October | 0.541 | 0.637 | 0.687 | 0.698 | 0.802 | 0.803 | 0.791 |
| November | 0.518 | 0.610 | 0.587 | 0.560 | 0.656 | 0.655 | 0.613 |
| December | 0.507 | 0.597 | 0.369 | 0.221 | 0.184 | 0.862 | 0.453 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gündüz, N.; Karakoç, Ş. Optimal Bandwidth Selection Methods with Application to Wind Speed Distribution. Mathematics 2023, 11, 4478. https://doi.org/10.3390/math11214478
Gündüz N, Karakoç Ş. Optimal Bandwidth Selection Methods with Application to Wind Speed Distribution. Mathematics. 2023; 11(21):4478. https://doi.org/10.3390/math11214478
Chicago/Turabian StyleGündüz, Necla, and Şule Karakoç. 2023. "Optimal Bandwidth Selection Methods with Application to Wind Speed Distribution" Mathematics 11, no. 21: 4478. https://doi.org/10.3390/math11214478
APA StyleGündüz, N., & Karakoç, Ş. (2023). Optimal Bandwidth Selection Methods with Application to Wind Speed Distribution. Mathematics, 11(21), 4478. https://doi.org/10.3390/math11214478