1. Introduction
Entity Linking (EL) is a critical task in the field of Natural Language Processing (NLP), whose core goal is to associate entity mentions appearing in a document (e.g., names of people, places, organizations, etc.) with their referent entity in a knowledge base (e.g., Wikipedia, Freebase, etc.). The EL task generally consists of the following main steps: entity detection, candidate entity generation, and candidate entity ranking. It should be noted that the specific steps and methods of EL tasks may vary in different application scenarios and tasks. In some tasks, entity detection may not be necessary because the entities in the text are already explicitly labeled. However, in an end-to-end EL task [
1,
2], it is usually necessary to include all of these steps to complete the entity linking process. EL has received much attention due to its wide range of applications in various tasks, including information retrieval [
3], content analysis [
4], etc. However, significant progress has been made in building EL systems, and most of the existing research works [
5,
6] are based on the assumption that entity sets are shared between the train and test sets. However, in practice, textual data may come from different domains, topics, and sources, thus presenting diversity and heterogeneity in the data distribution. It also means that the train and test sets may come from different domain distributions, ultimately leading to disjointed entity sets in different domains. This situation highlights the need and importance of zero-shot entity linking [
7,
8].
The main goal of zero-shot EL is to address two aspects of the problem. Firstly, it aims to deal with unknown entities, having the ability to successfully link entities that have never been seen in the training data to the correct entities in the knowledge graph or entity repository. Secondly, it aims to build EL models that are more general so that they can be adapted to the challenges of different domains, topics, and data distributions, thus increasing the generality and robustness of the models to satisfy the information needs of multiple domains. However, labeled data are often costly to produce or difficult to access in certain specialist areas (e.g., legal). To delve deeper into this problem, Ref. [
8] constructed the Zeshel dataset, containing 16 specialized domains, divided into 8 domains for training and 4 domains each for validation and testing, which covers rich textual content for mentions and entities. Without adopting resources (e.g., structured knowledge base) or assumptions (e.g., labeled mentions, a shared entity set), they expand the scope of zero-shot EL to promote the generalizability of the EL system on unseen domains.
To date, a body of work [
9,
10,
11,
12,
13] has emerged on zero-shot EL, most of which uses BERT [
14] as the base encoder. These research efforts have mainly focused on the candidate generation phase, which has a crucial impact on the candidate ranking in EL systems. Ref. [
11] was based on encoding mentions and entities using a Biencoder [
9] architecture, followed by a Sum-Of-Max (SOM) score function, to compute the similarity between them and training the model using either hard negative sampling or mixed-p negative sampling. Ref. [
13] proposed a Transformational Biencoder, which introduced a transformation into the Biencoder to encode mentions and entities and adopted an In-Domain negative sampling strategy, in which they sorted all entities in the golden entity domain over a training period to take the top-k entities as hard negatives.
Concerning current negative sampling methods in the field of zero-shot EL, we note that they generally employ an extractive strategy, resulting in a lack of diversity in the selected negative samples, thus limiting the ability of the model to acquire richer knowledge. Furthermore, hard negative sampling aims to select more challenging negative samples to expose the model to more challenging tasks. However, the negative samples selected by the current hard negative sampling strategy are still not challenging enough. Another problem is that the current zero-shot EL task is usually divided into two phases: candidate entity generation and ranking. These two phases of the task usually take a significant amount of time. Therefore, in the candidate entity generation phase, we believe that not only do we need to improve the recall of candidate entities to provide a richer pool of candidates for the candidate entity ranking phase, but we also need to improve the accuracy so that the model can match the ultimately correct entities in the candidate entity generation phase. These improvements will help to increase the performance and efficiency of the zero-shot EL system.
In this paper, we propose an adaptive_mixup_hard generative negative sampling method based on the hard negative sampling method. The main innovation of the method is to generate more difficult negative samples by fusing the positive sample features of the current mention with negative sample features. In the generation process, a transformable adaptivity parameter W is introduced, which enables the model to generate rich and diverse negative samples during the training process to compensate for the shortcomings of the existing extractive negative sampling methods. In addition, this method inherits the feature that the negative entities selected by hard negative sampling and is semantically different from the golden entities but closer in the embedding space, which helps to improve the differentiation between the golden entity and the negative entities. Therefore, we combine this negative sampling method with the Biencoder architecture to form a new model Biencoder_AMH. In the model, we adopt three different score functions (DUAL, Pooling Mean, and SOM) for similarity calculation. Through the validation of a large number of experiments, our model achieves a certain amount of improvement in the top-64 recalls and accuracy compared to previous work, which makes an essential contribution to the research of matching to the final correct entity in the candidate entity generation stage. Notably, our model achieves different degrees of improvement in each of the r@k (k = 4, 8, 16, 32, 64) metrics, which indicates that our approach not only improves the performance but also provides a strong support for the research in the candidate entity ranking stage. More importantly, we show results at a finer granularity, demonstrating that the improvement in model performance is not limited to a single domain in the test set but grows on multiple domains, which is more in line with the context and goal of zero-shot entity linking.
Our contributions can be summarized as follows:
We propose an adaptive_mixup_hard negative sampling, a method variant on hard negative sampling that enables the model to cope with more demanding challenges. Subsequently, we merge this method with the Biencoder [
9] architecture to construct a new model, Biencoder_AMH.
Our negative sampling method is a generative approach that generates a diversity of negative samples, which helps the model to learn the data distribution more comprehensively and reduces the potential risk of overfitting, improving the model’s generalization performance.
After extensive experimental validation, our method achieves not only a significant improvement in top-64 recalls but also a certain degree of improvement in accuracy when compared with other negative sampling strategies (Random, Hard, Mixed-p) under three different score functions (DUAL, Pooling Mean, SOM).
2. Related Works
We discuss related work to better contextualize our contributions. The entity linking task can be divided into candidate generation and ranking. Previous work has used frequency information, alias tables, and TF-IDF-based methods to generate candidates. For candidate ranking, Refs. [
5,
15,
16,
17,
18] have established state-of-the-art (SOTA) results using neural networks to model context word, span, and information helps to link [
19,
20,
21].
In the EL domain, negative sampling strategies aim to efficiently select negative samples to optimize the performance of EL tasks. Ref. [
8] proposed the zero-shot entity linking task. Recently, the strategy of negative sampling has been widely used in the candidate generation phase in the domain of zero-shot entity linking. Ref. [
9] followed [
22] by using hard negatives in training. They obtained hard negatives by finding the top 10 predicted entities for each training example and added these extra hard negatives to the random in-batch negatives. Ref. [
11] demonstrated the results obtained with different negative sampling strategies (Random, Hard, and Mixed-p) on different architectures and showed theoretically and empirically that hard negative mining always improves performance for all architectures. Ref. [
13] suggested that negatives that are lexically similar, semantically different, and close to the golden entity representation are more difficult. As a result, they considered the domain of the golden entity. They sorted all entities in the golden entity domain over a training period to take the top-k entities as hard negatives. However, the negatives generated by the above methods are not difficult enough. Therefore, we generate more difficult negatives based on hard negative sampling by incorporating the features of the golden entity, allowing the model to face more difficult challenges.
In the candidate generation, Ref. [
8] used BM25, a variant of TF-IDF, to measure the similarity between mentions with their contexts and candidate entities with their descriptions. Numerous applications to the Zeshel dataset have sprung up following this work. Among them, BERT [
14] is found to be a highly regarded encoder. Ref. [
9] proposed a Biencoder architecture in which textual descriptions of mentions and entities are encoded using two independent BERT encoders. Then, the dot product is used as a scorer and is referred to by [
11] as DUAL. Due to BERT, the Biencoder provides a robust baseline for the task. In the study by [
10], they used repeated location embedding based on the BERT architecture to address the problem of remote modeling in entity text description. Ref. [
11] used the Biencoder framework. However, they used the more expressive SOM [
23] score function to measure the correlation between mentions and entities and, as a result, achieved better results on the task. Ref. [
13] proposed a Transformational Biencoder, which introduced a transformation into the Biencoder [
9] to improve the generalization performance of zero-shot EL over unknown domains. Accordingly, we also combined our negative sampling approach with the Biencoder architecture and notably achieved some improvements to three different score functions (DUAL, Pooling Mean, and SOM).
3. Methodology
In this section, we describe our adaptive_mixup_hard negative sampling strategy, a method variant on hard negative sampling, inspired via [
24]. We then combine our negative sampling approach with the Biencoder [
9] and multiple similarity calculations (DUAL, Pooling Mean, and SOM) to propose our model Biencoder_AMH. First, we formally present the task definition in
Section 3.1. Next, in
Section 3.2, we introduce the Biencoder. Then, we describe our adaptive_mixup_hard negative sampling strategy in
Section 3.3. Finally, we present our model Biencoder_AMH in
Section 3.4. The structure of our model is shown in
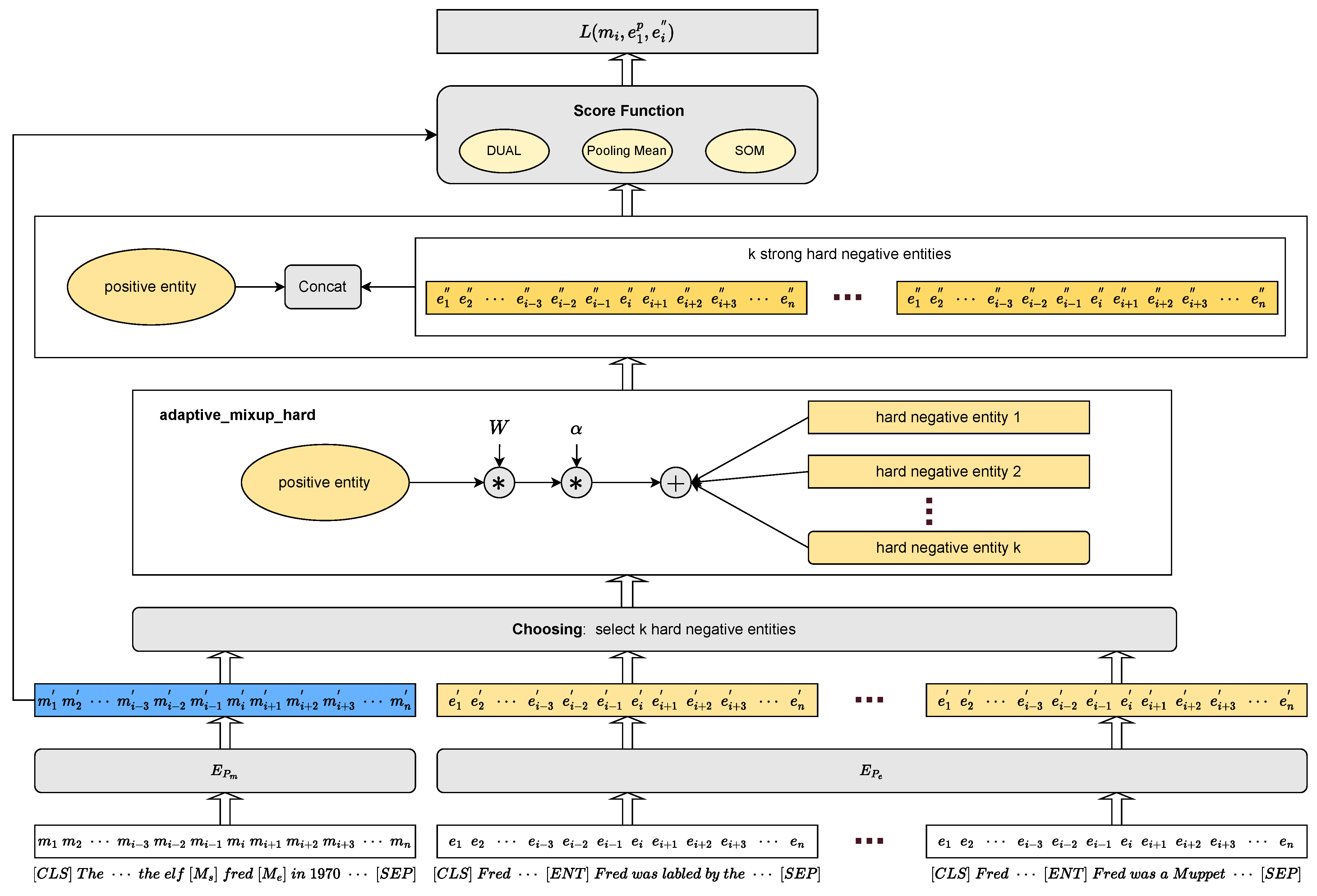
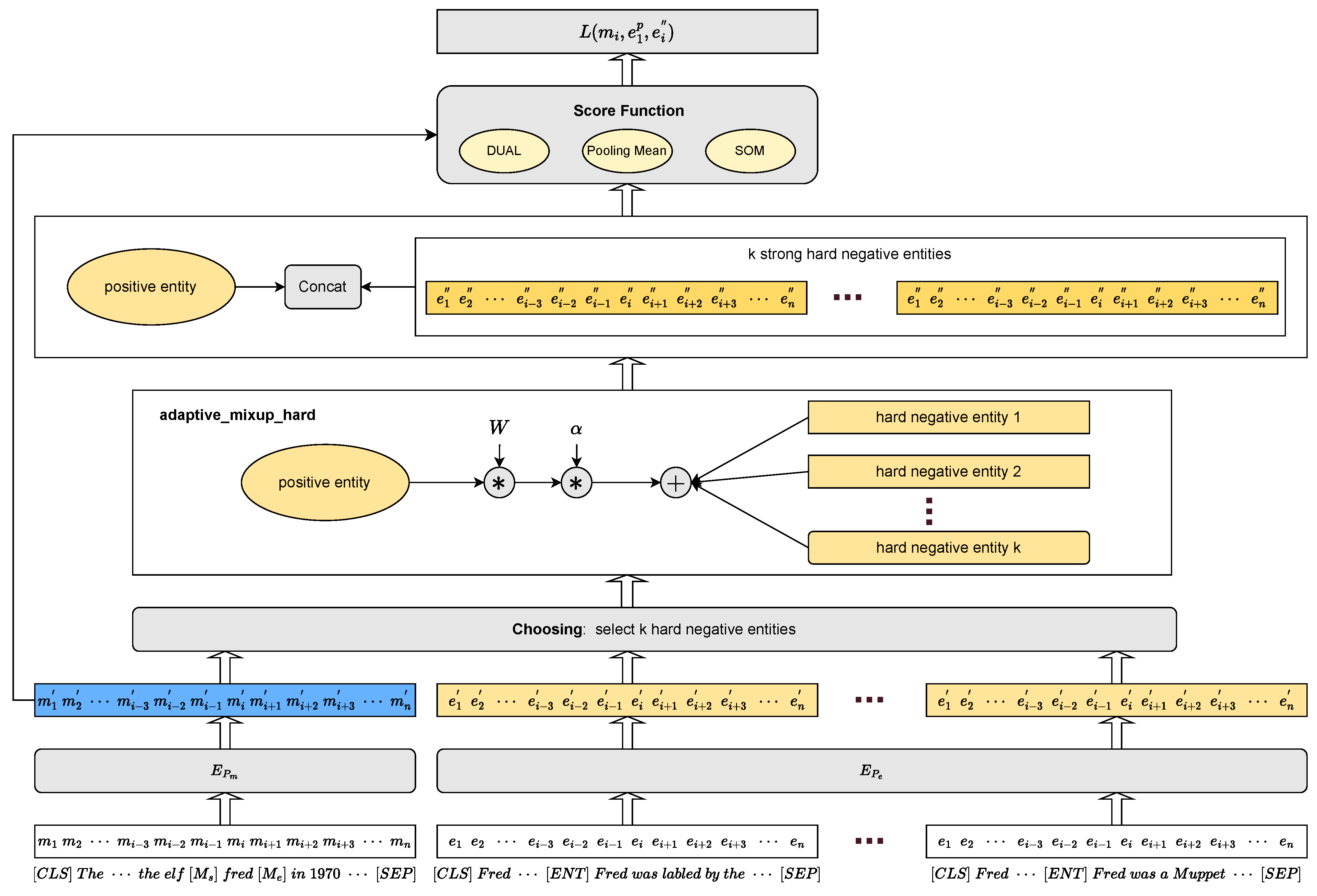
Figure 1.
3.1. Task Definition
The entity linking task is expressed as follows. Given a mention
m in a document and a set of entities
, EL aims to identify the referring entity
that corresponds to the mention
m. The goal is to obtain an EL model on the training set of mention–entity pairs
that correctly labels mentions in the test set
.
and
are usually assumed to be from the same domain. We assume that the title and description of the entities are available, which is a common setting in entity linking [
5,
8].
In this paper, we focus on the study of the zero-shot EL [
8], where both
and
are found to contain multiple sub-datasets from different domains. At the same time, the knowledge base is separated into training and test time. Formally, denote
and
to be the knowledge base in training and test, and we require
. The collection of text documents, mentions, and entity dictionaries are separated for training and testing, so linked entities are not visible during the test.
Below, we will describe the three negative sampling methods that are already available.
Random: The negatives are sampled uniformly at random from all entities of a batch in training data. It can help the model to deal with unknown entities in various situations but may lead to a training process that lacks guidance for specific textual contexts.
Hard: This is a more challenging strategy that tries to select semantically similar negatives to positive examples. In this way, the model will face incredibly greater difficulty in learning and will need a better understanding of the meaning of the entity in different contexts. It aims to help models to capture semantic information better, but it can also lead to a more strenuous training process.
Mixed-p:
p percent of the negatives are hard, the rest are random. It maintains a degree of diversity in the training process while introducing a degree of challenge. Previous works have shown that such a combination of random and hard negatives can be effective. Ref. [
11] finds that the performance is not sensitive to the value of
p, In this paper, We choose a
p-value of 50%.
3.2. Biencoder
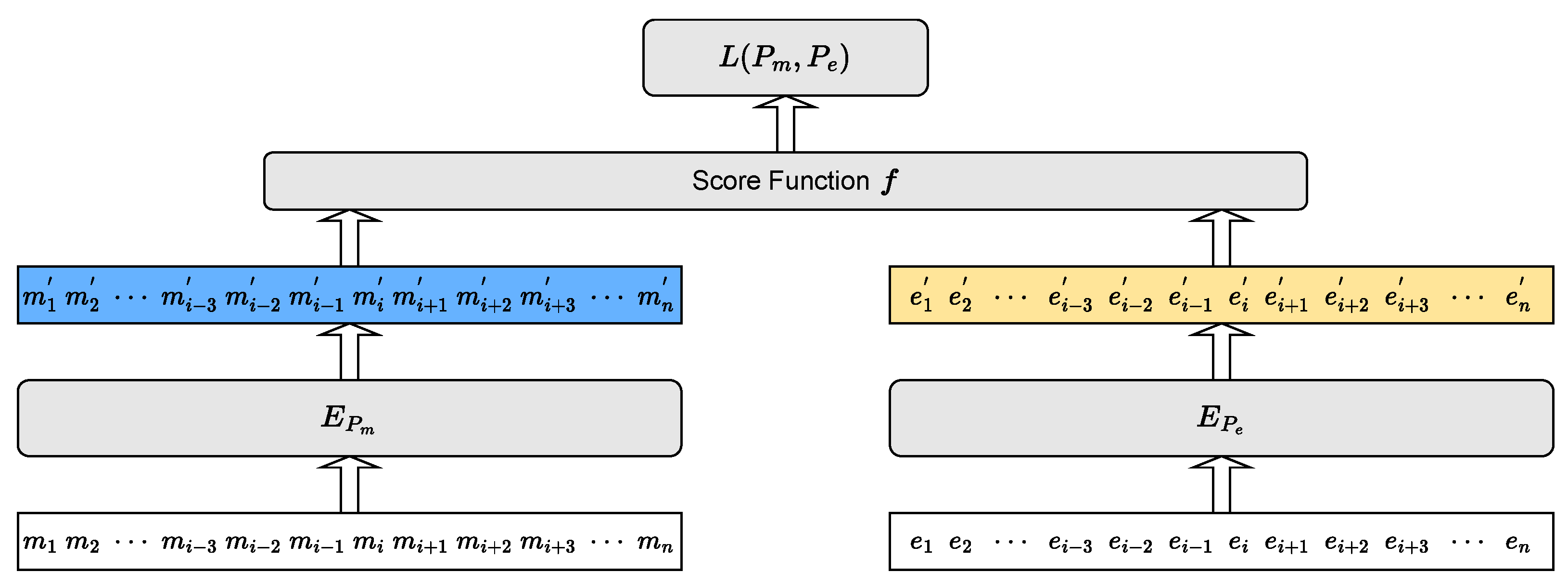
Our model is based on the Biencoder [
9], which independently embeds mentions and corresponding entities into the same representation space. As shown in
Figure 2, the Biencoder comprises a text encoder
for encoding mentions, a text encoder
for encoding entities, and a score function
f for calculating the relevant scores for mention–entity pairs.
and
share the same architecture but have independent parameters,
and
, and BERT [
14] is employed to model
and
. This approach allows for real-time reasoning because candidate representations can be cached.
Given a pair of the mention–entity
, the representation of mention
m is composed of the left context
and right context
of the mention, as well as the mention itself. Specifically, we construct the input for each mention
m as:
Likewise, the entity representation
e is also composed of word pieces of the entity title and description. Therefore, the input to our entity
e is:
where [CLS], [Ms], [Me], [ENT], and [SEP] are special tokens to mark the boundaries of the different pieces of information. For instance, [ENT] is a special token to separate the entity title and description representation. More specifically, the input of mention
m is represented after tokenization as
and the entity
e is denoted as
. Then, both input context
and candidate entity
are encoded into vectors
and
.
where
d denotes the dimension of representations.
The problem of the entity linking is then reduced to using a score function f, i.e., , to quantify the similarity between and . In the current mention–entity pair , if the entity e is the golden entity, the score should be high, or low if otherwise.
As shown in
Figure 3, we will introduce the three existing score functions. Ref. [
9] defines a DUAL score function that chooses the
representations
and
of the respective representations
and
to compute the score
.
Pooling Mean can be used to average pool the embeddings in a text fragment of the mention and entity to obtain an overall representation of the text fragment. Doing so allows the text snippet to be represented as a vector, reflecting the average features. Pooling Mean computes as follows.
In addition, Ref. [
11] followed the architecture of [
9] and presented that the SOM scorer [
23] produces better results than DUAL. However, it is worth noting that the SOM scorer comes at the cost of increased computational cost due to considering all hidden states of
and
in the scorer. It means that SOM takes more time than DUAL and Pooling Mean in the training and prediction phases. SOM computes
as follows.
Eventually, the network is trained to maximize the score of the correct entity relative to the (randomly sampled) entities of the same batch ([
25,
26]). Concretely, the total loss
is computed as:
where
are golden mention–entity pairs in the training set, and
are
negative entities for the
i-th mention in a batch.
3.3. Adaptive_Mixup_Hard
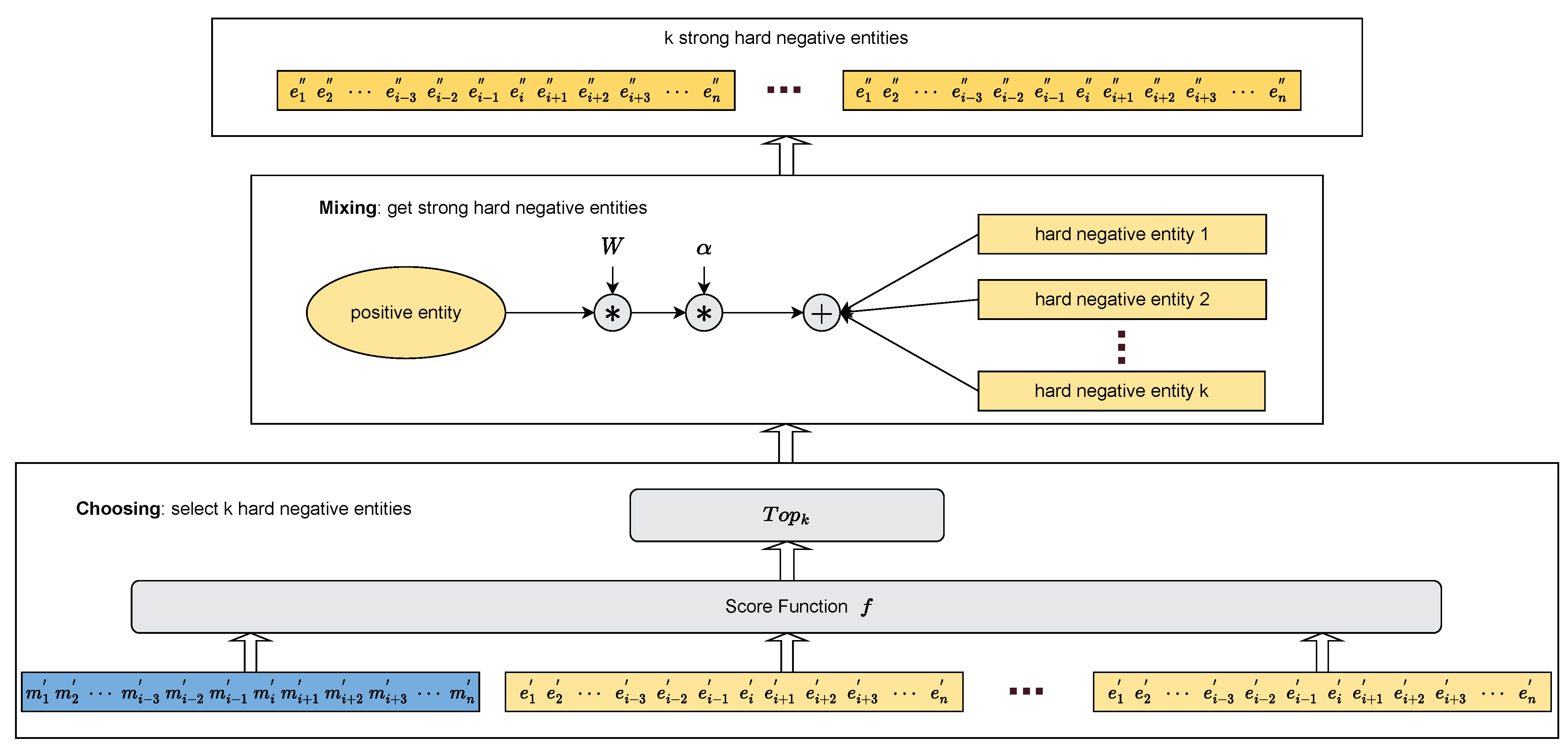
It is known that hard negative sampling makes it more difficult for the model to learn, allowing it to better understand the meaning of entities in different contexts. However, the negative samples obtained under this sampling are still not challenging enough for zero-shot entity linking. Therefore, as shown in
Figure 4, we propose the adaptive_mixup_hard (AMH) negative sampling, a method variant on hard negative sampling following a two-stage pipeline: choosing and mixing. This method improves the robustness of the model by fusing the features of positive entities
and negative entities
to obtain more difficult negative samples (strong hard negatives), enabling the model to face more complicated tasks.
Below, we will describe the two-stage process of the AMH negative sampling and present its algorithmic process in Algorithm 1.
| Algorithm 1 The process of AMH negative sampling |
Require: Mention–entity pairs in a batch, Mention encoder , Entity encoder , score function , a parameter to control the difficulty of synthesizing new negative entities for to B do Construct the input for each mention and entity as and by ( 1) and ( 2). Obtain the mention and entity embeddings and using and by ( 3). Obtain one positive entity and the rest are its corresponding negative entities for each mention in a batch. if is DUAL then Compute the scores of the mention with its corresponding negative entities by ( 4). else if is Pooling Mean then Compute the scores by ( 5). else if is SOM then Compute the scores by ( 6). end if Select the top k highest scores among the negative entities as the hard negative entities by ( 8). Calculate an adaptive parameter by ( 9). Obtain the final strong hard negative entity by ( 10). end for
|
Choosing: For the mention–entity pairs
in a batch, they are encoded into vectors
. Then, for each mention
m in a batch, there is one positive entity
and the rest are its corresponding negative entities
. Next, we use the scoring function
f to compute the scores of the mentions with their corresponding negative entities. According to hard negative sampling, we select the top
k highest scores among the negative entities as the hard negative entities
. The hard negative entities are computed as:
Mixing: This process is crucial to our approach and aims to synthesize strong, hard negative entities to improve the robustness of the model. Considering that it may be counterproductive to train the model if it is too difficult to fuse the negative entities of the positive entity features at the beginning, we introduce an adaptive parameter
. Its calculation is as follows:
During the training process,
W will increase to progressively increase the difficulty of negative entities, which allows the model to learn more diverse representations. It is worth noting that
W will eventually increase to 1. Therefore, we also introduce an additional hyper-parameter
to control the difficulty of synthesizing new negative entities. The strong hard negative entity
is computed as:
It is worth noting that for different score functions, different
values cause the model to perform differently and that there is a critical value at which the model performs best. We will describe this in more detail in
Section 4.5.
3.4. Biencoder_AMH
Eventually, we combine the Biencoder, Adaptive_mixup_hard, and the score function to form our new model Biencoder_AMH. More specifically, we form the new model Biencoder_AMH_DUAL using DUAL as the score function. Similarly, depending on the different score functions Pooling Mean and SOM, we will also form Biencoder_AMH_Pooling_Mean and Biencoder_AMH_SOM, respectively. Because, depending on the scoring function f, our negative sampling strategy AMH has different rules for the first stage of choosing.
As shown in
Figure 1, first, we follow the Biencoder architecture and use BERT [
14] to encode mentions with their contexts and entities with their descriptive information to obtain their encoded representations
and
, respectively. Then, according to our method AMH, we first filter a batch to obtain
K hard negative entities
and one positive entity
corresponding to the current mention
m, and finally fuse the features of each negative entity with those of the positive entity to obtain
K strong hard negative entities
. Finally, we input
,
and
into the scoring function
f and use BCEWithLogitsLoss to calculate the loss
. Concretely, for each training pair
in a batch of B pairs, the loss is computed as:
where
indicates the code corresponding to the current mention
m.
and
denote the coding of the positive entity and strong hard negative entity corresponding to
m, respectively.
is a function that maps the model’s output to the probability space, facilitating probability estimation and the computation of cross-entropy loss.
5. Discussion
With respect to current negative sampling methods in the zero-shot EL domain, we note that these methods typically employ an extraction strategy that results in a lack of diversity in the negative samples selected, thus limiting the ability of the model to acquire richer knowledge. Furthermore, hard negative sampling aims to select more challenging negative samples, exposing the model to more challenging tasks. However, the negative samples selected by current hard negative sampling strategies are not challenging enough. Therefore, we propose an adaptive_mixup_hard generative negative sampling method based on the hard negative sampling method. This method introduces a transformable adaptivity parameter W, enabling the model to generate rich and diverse negative samples and also generates more difficult negatives by fusing the positive sample features of the current mention with negative sample features.
However, due to the limited hardware resources, we were only able to set the batch size to 64. For the consideration of time and computational cost, we did not compare our method with other negative sampling methods under the Poly-Encoder [
26] and Multi-Vector Encoder [
28] architectures. In addition, during the experimental phase of the hyper-parameter, we did not perform a comprehensive search for all score functions. Finally, in the fusion of features of positive and negative samples, we currently only consider the control of the weights of features of positive samples, so we are thinking about whether we need to control the weights of negative samples simultaneously. Therefore, future work includes:
To enhance the reliability of our method by comparing it with other negative sampling methods under the Poly-Encoder and Multi-Vector Encoder architectures.
Analyze our method in terms of gradient and loss to make it theoretically interpretable.
Control the weights of positive and negative samples simultaneously for further improvement.
Research into end-to-end zero-shot entity linking models: joint models for mention detection and entity linking.



 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}