
The Application of the Random Time Transformation Method to Estimate Richards Model for Tree Growth Prediction


Abstract
1. Introduction
2. Data and Fit of the Model
3. Richards Model
4. Estimation of the Richards Model
5. The Likelihood Function
- is updated by minimizing the mean squared error between the observed data and the predicted data;
- is updated by maximizing the likelihood function;
- is updated by minimizing the Kullback–Leibler divergence between the prior and the posterior distribution.
Strategies to Estimate the Parameters
- (a)
- SubstitutionFor the function defined by (17), we find that the maximum of , with respect to , is given byand replacing this value in , we haveOn the other hand, given thatand supposing increments of real-time , we obtain that is given byWe notice that the estimate of will be available when have been estimated.
- (b)
- SubstitutionLet then we obtainwhere Note that when maximizing with respect to , it is equivalent to minimise the first term in brackets of Equation (23)Thus, the optimum of (24) is reached inWe obtain, in this form, the estimate of , which is a function of and .
- (c)
- SubstitutionLet us define We want to find the maximum of with respect to . However, this is equivalent to minimizing the denominator of Thus, the following function is minimisedNevertheless, reaches the global minimum when that is,Moreover, neither delta nor the other parameters can be estimated. However, the minimisation method available in MATLAB converge to a local minimum where the initial point is not close to The problem is that is unbounded as an function and the maximum does not exist. In this case, we solve a constraint problem every time that reaches the maximum of It is not difficult to show that the likelihood function is unbounded for
- (d)
- EstimateWe define Then, this function is maximised and is obtained. With this, is a numeric value, and is a function of y, from which we obtain Moreover, in this stage, we recover as and later as
6. Results
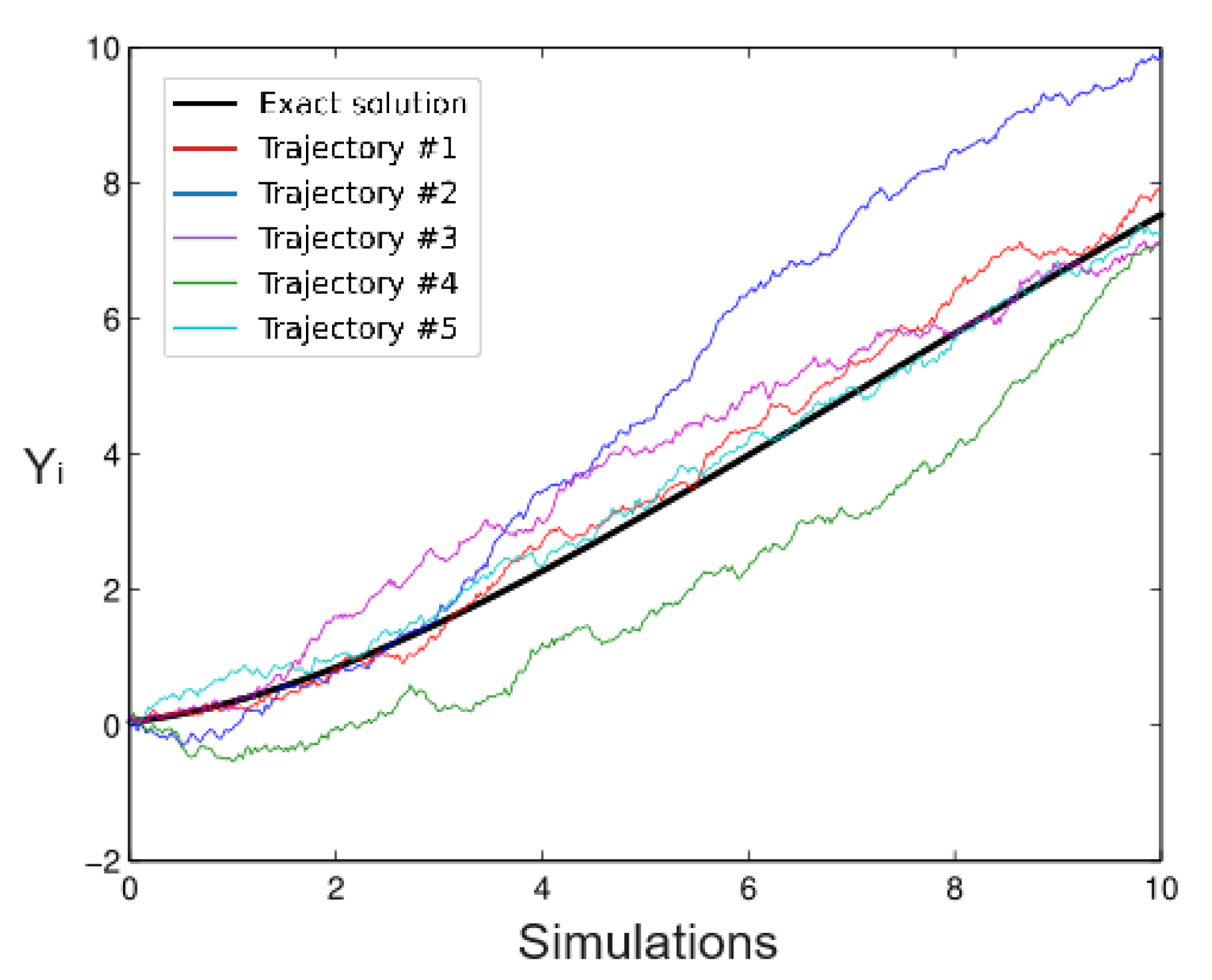
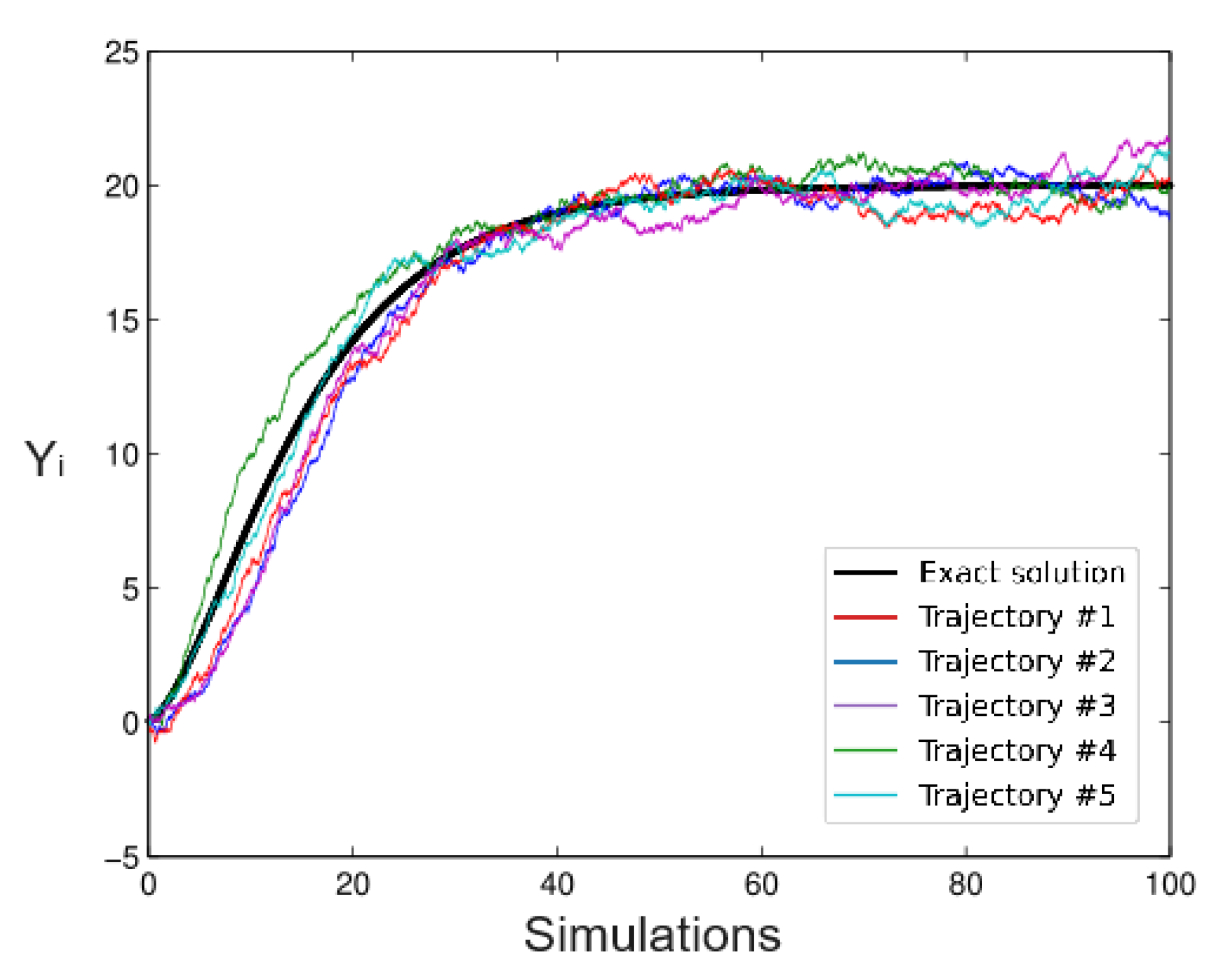
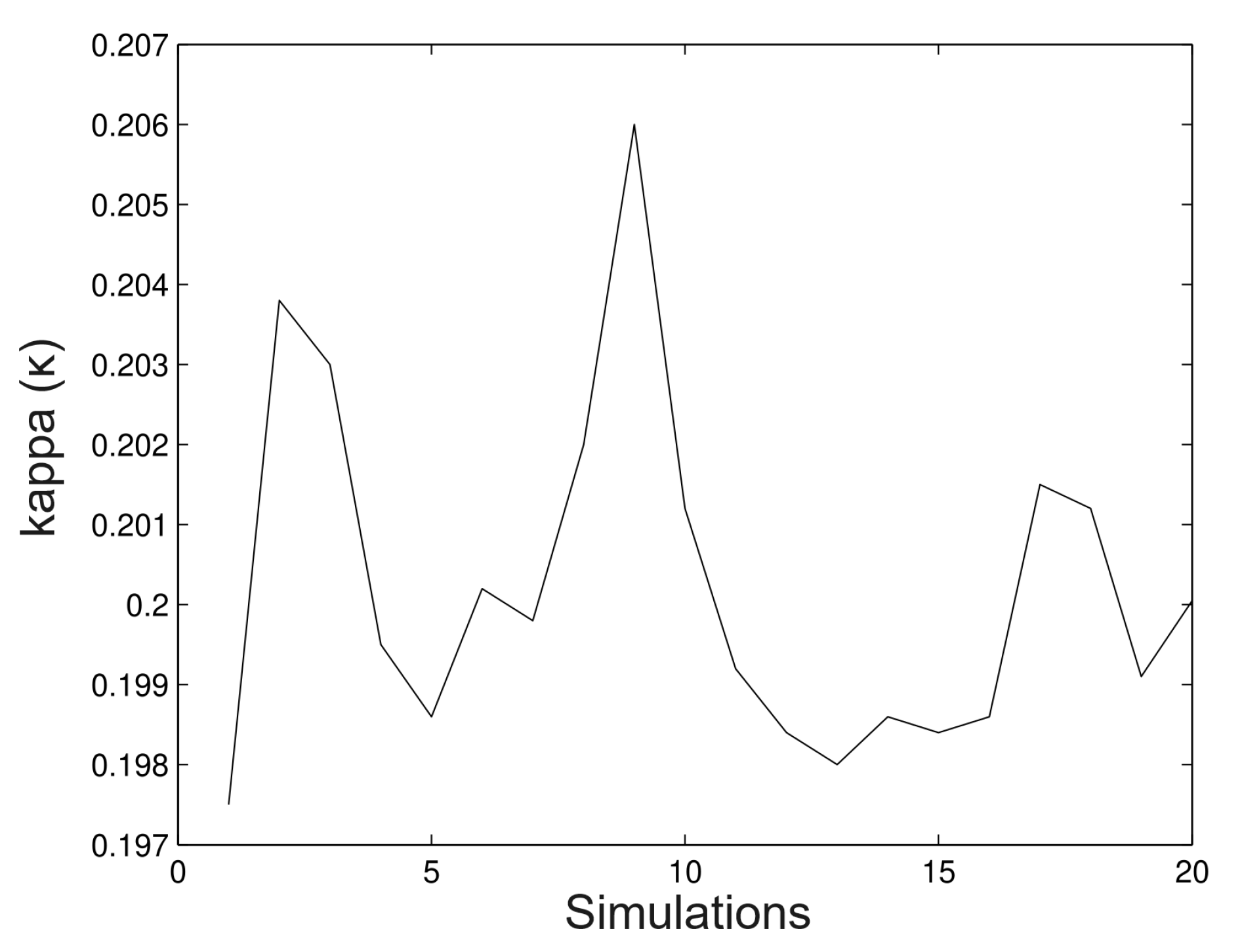
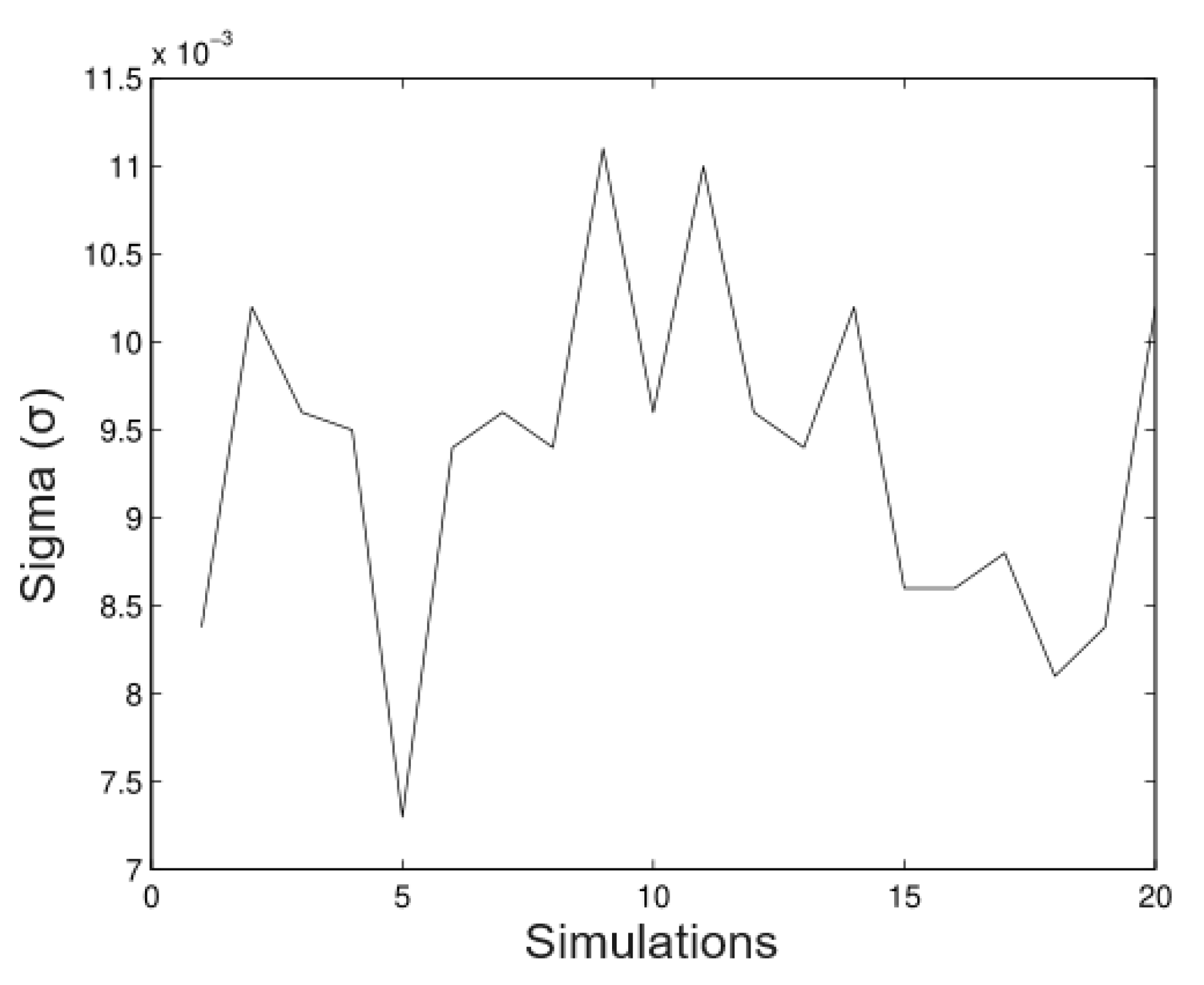
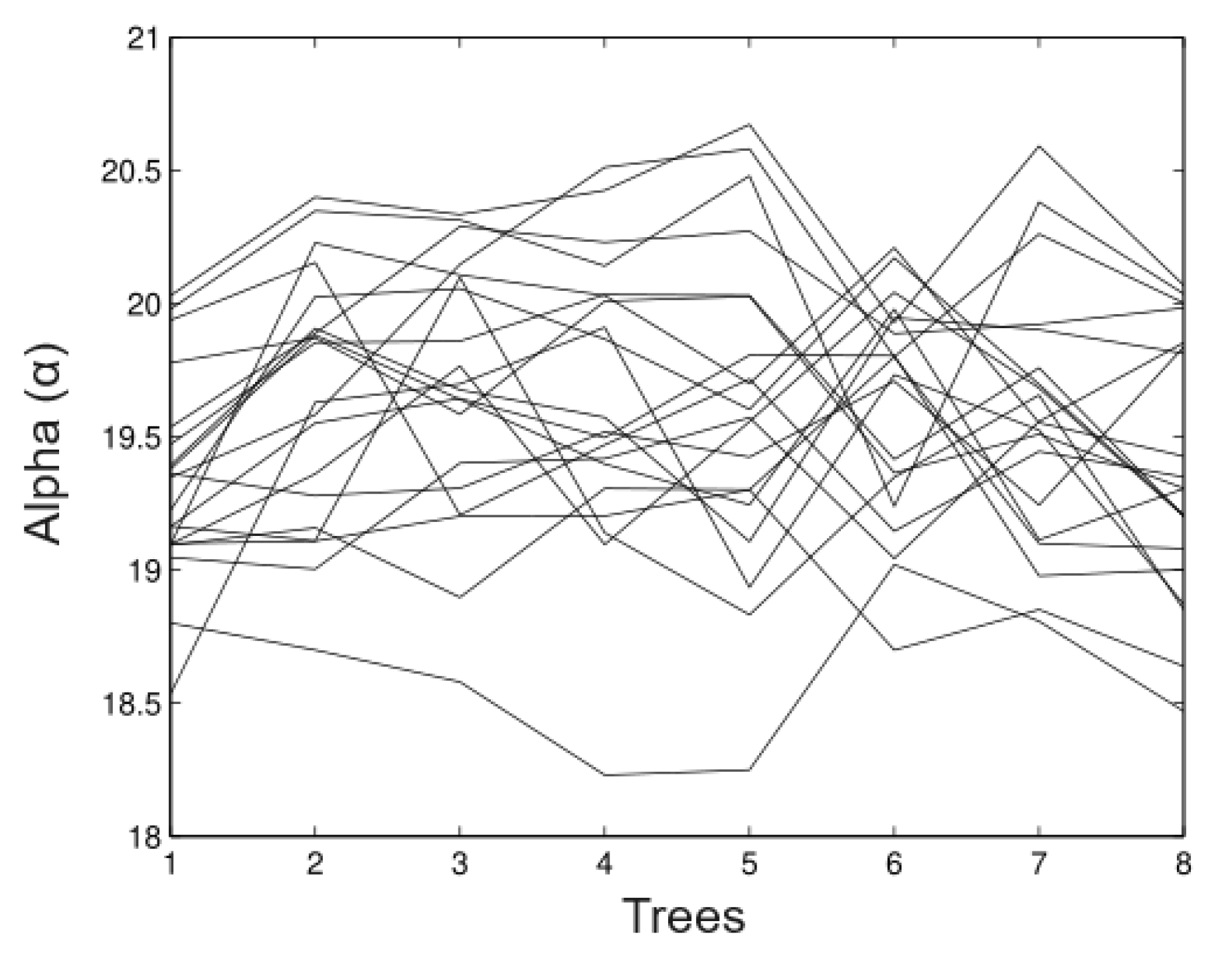
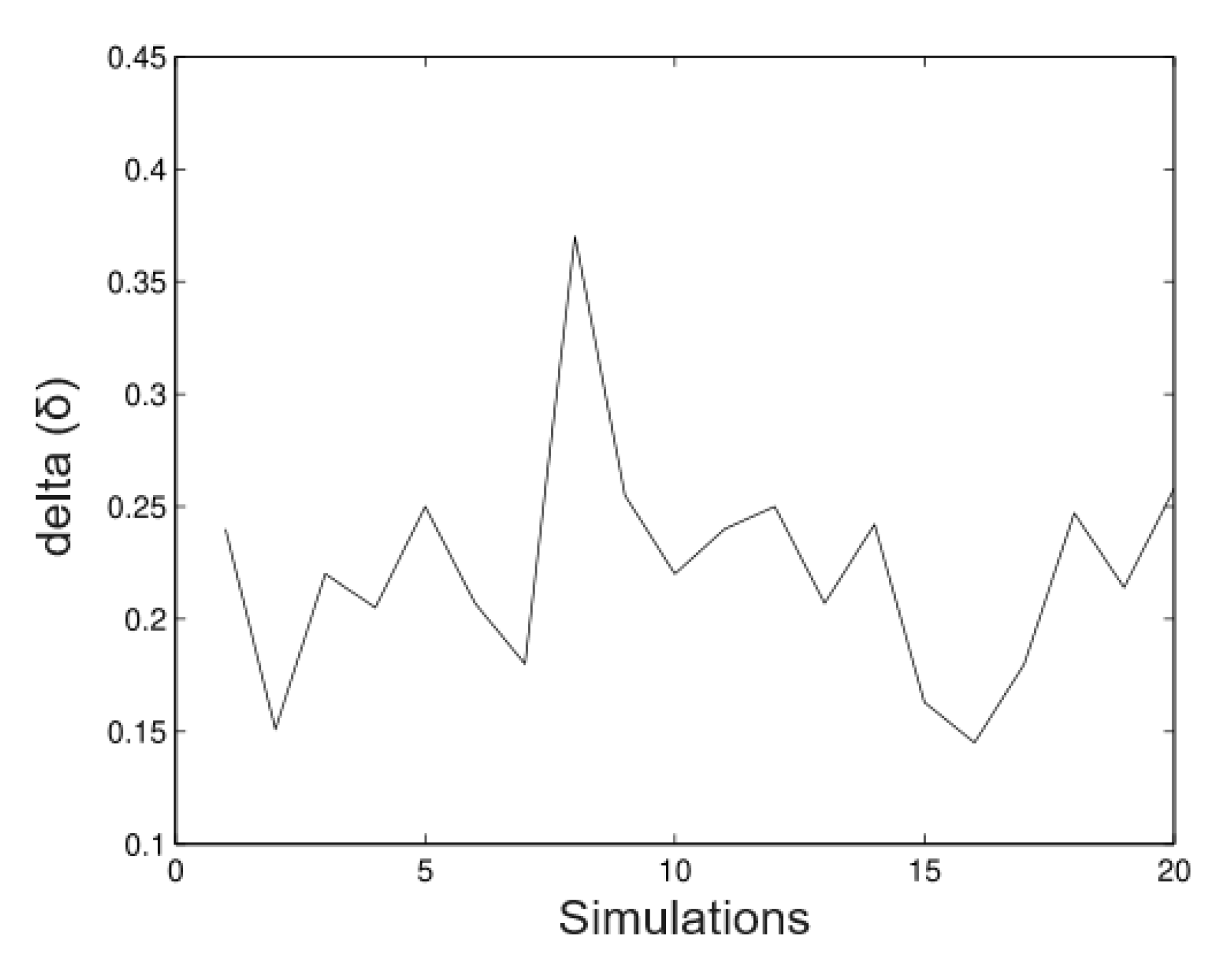
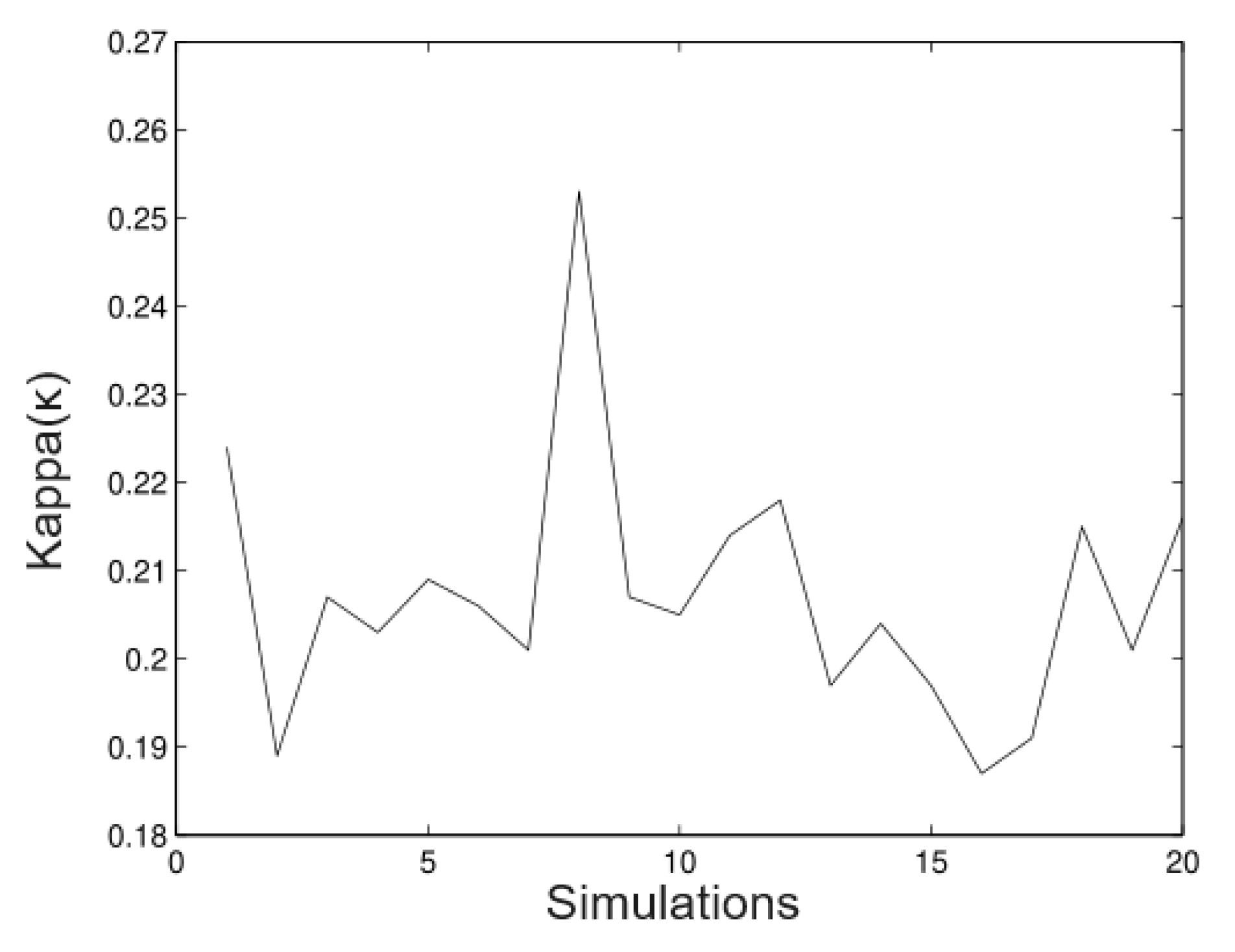
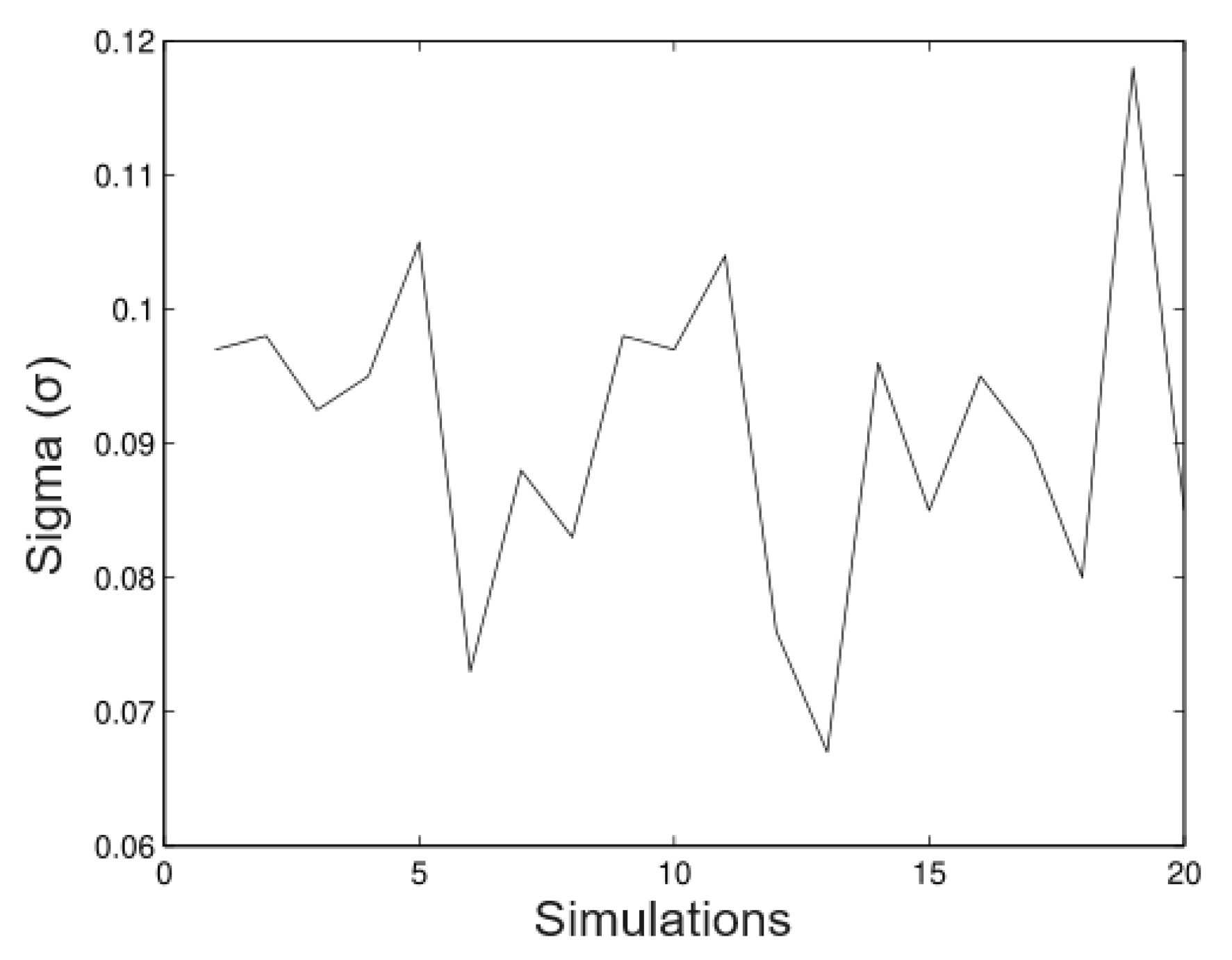
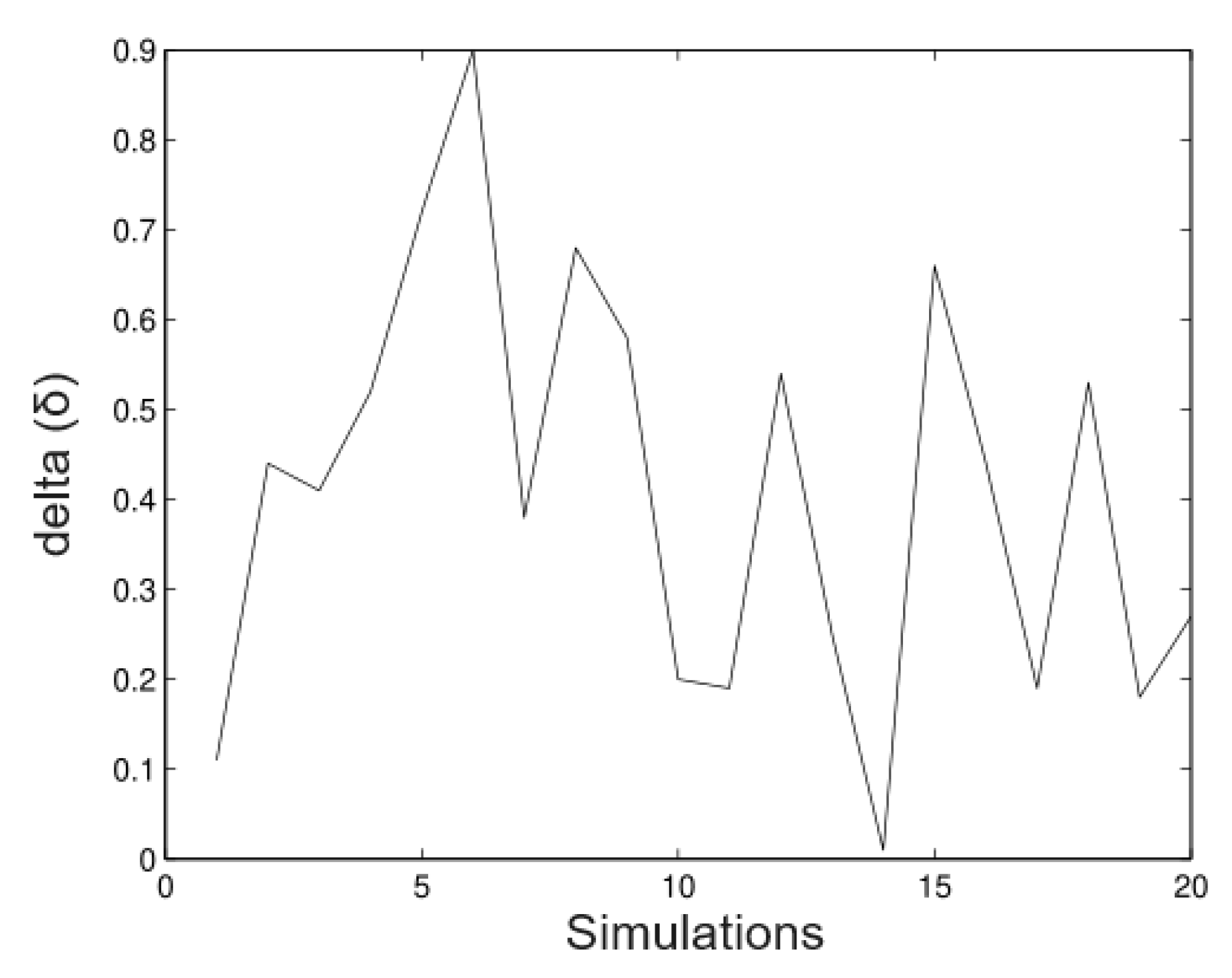
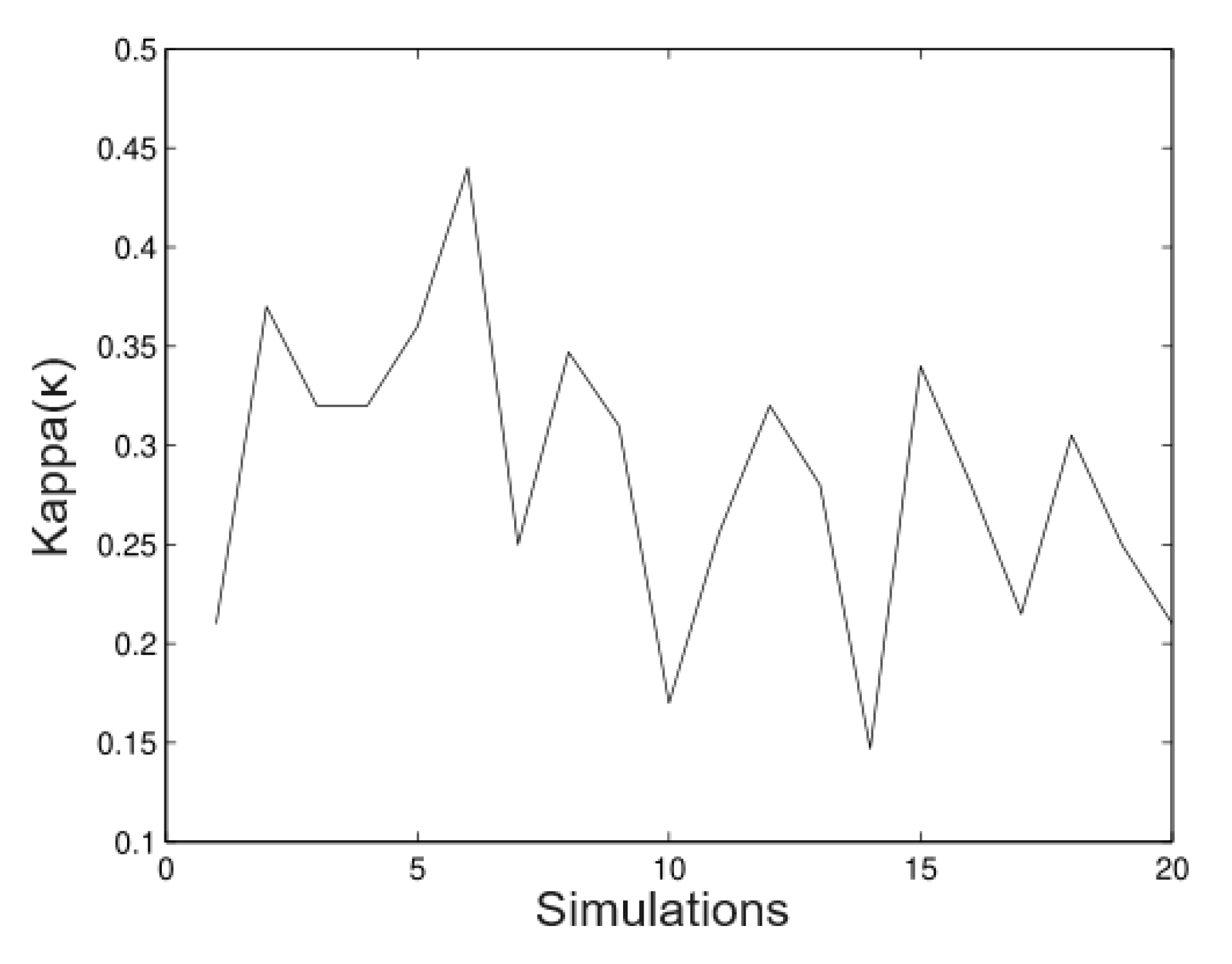
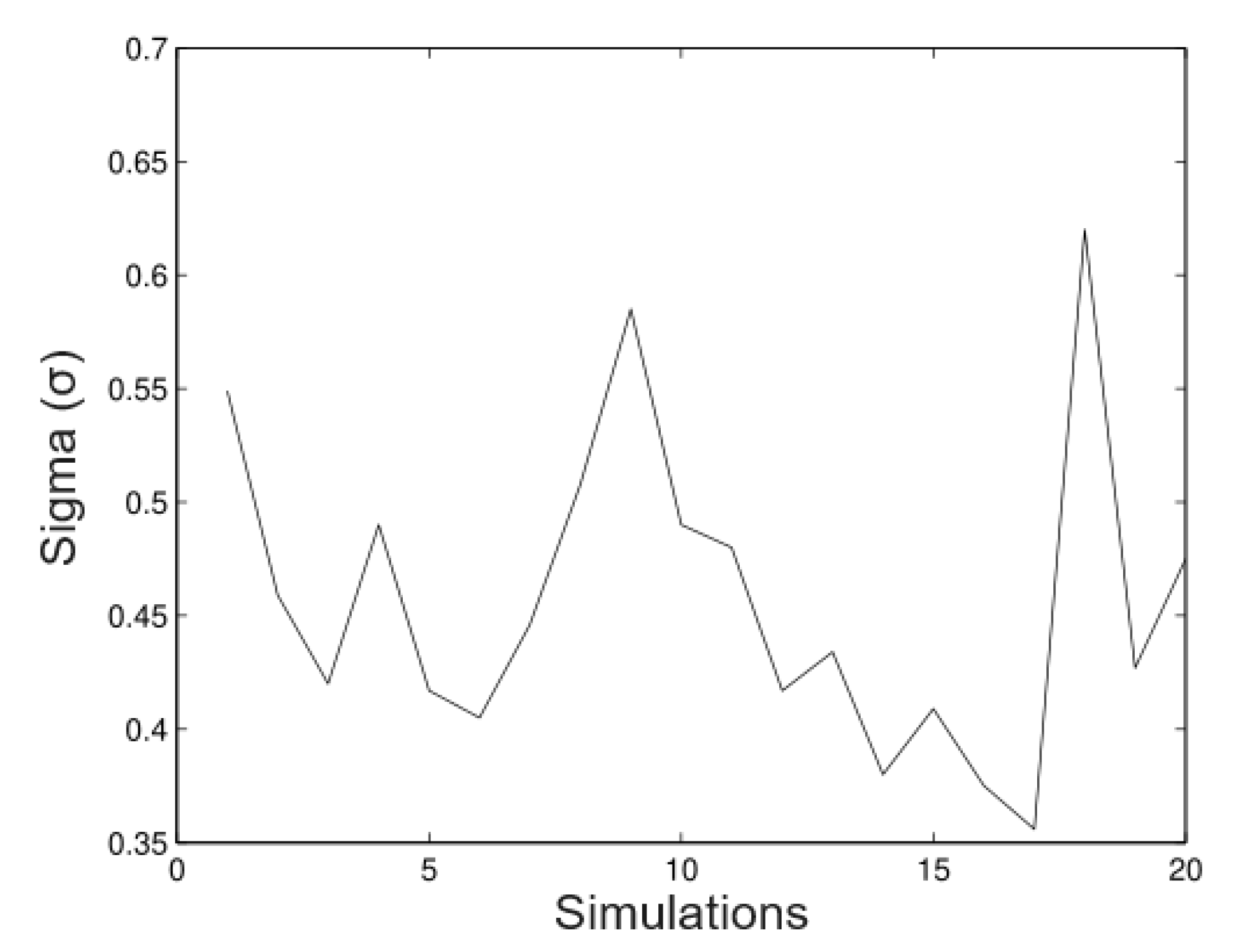
6.1. Simulated Data
- Simulation 1: = 20 (all trees), = 0.2, = 0.2, and = 0.01
- 2.
- Simulation 2: Alfa = 20 (all trees),
- 3.
- Simulation 3: Alfa = 20 (all trees),
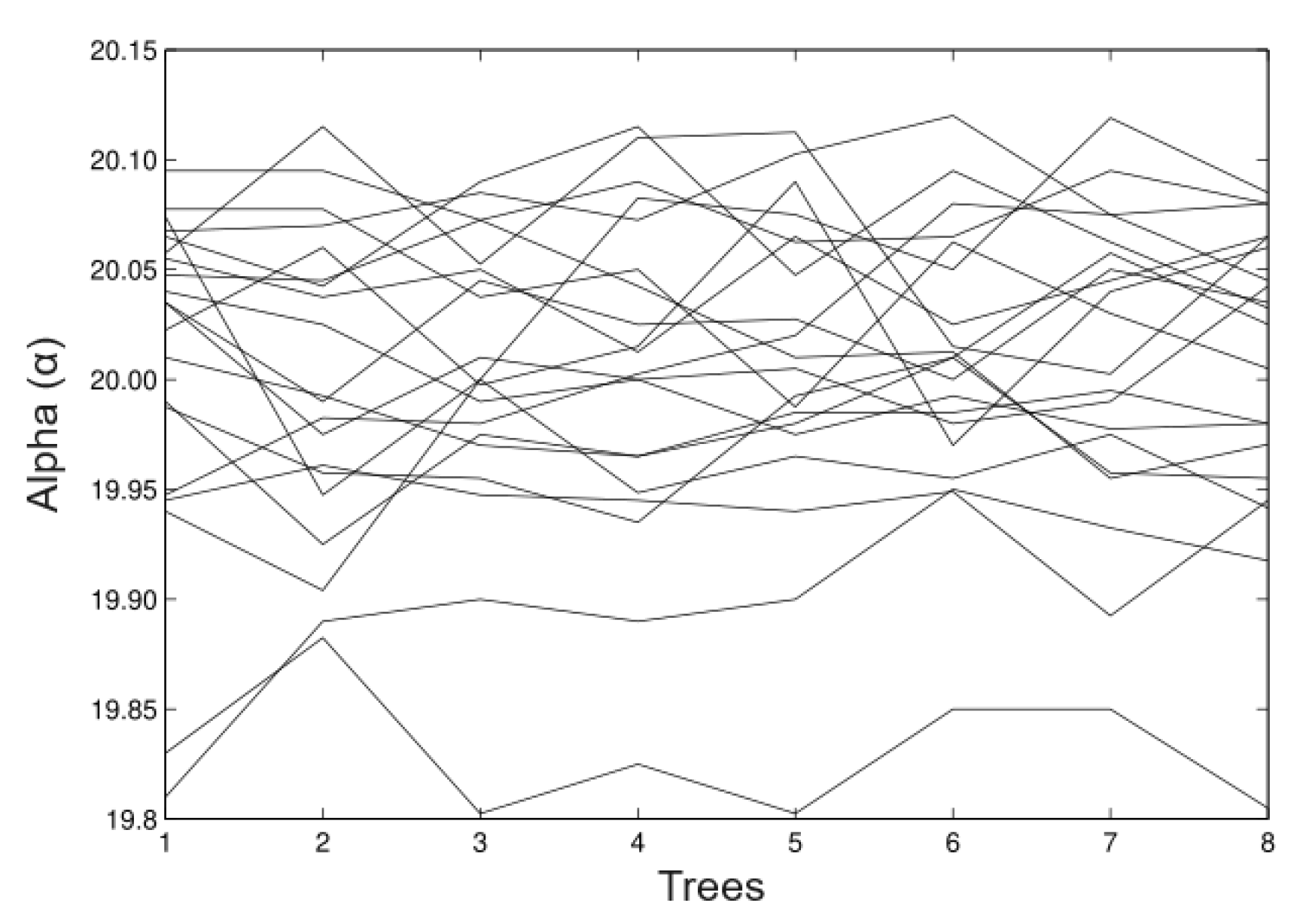
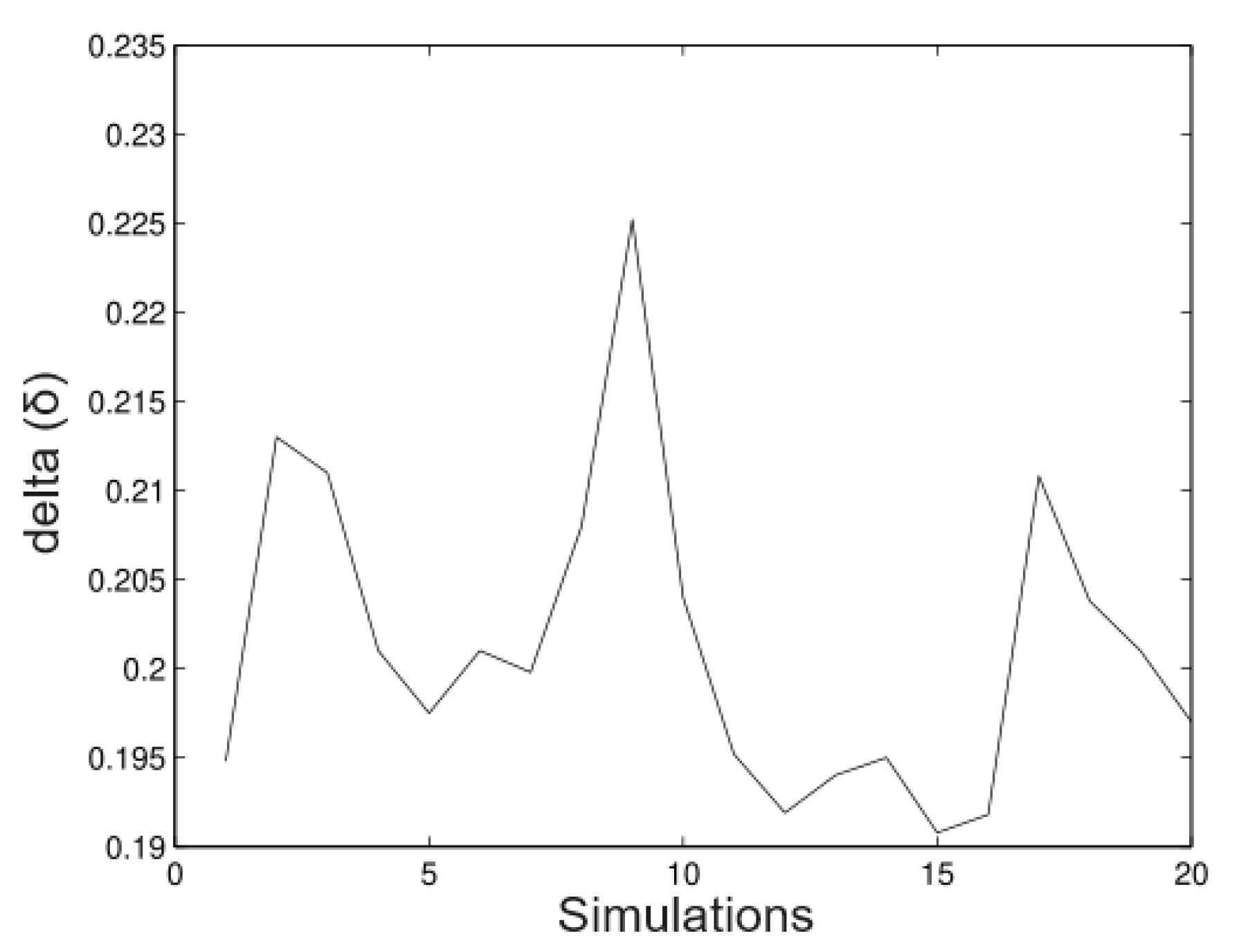
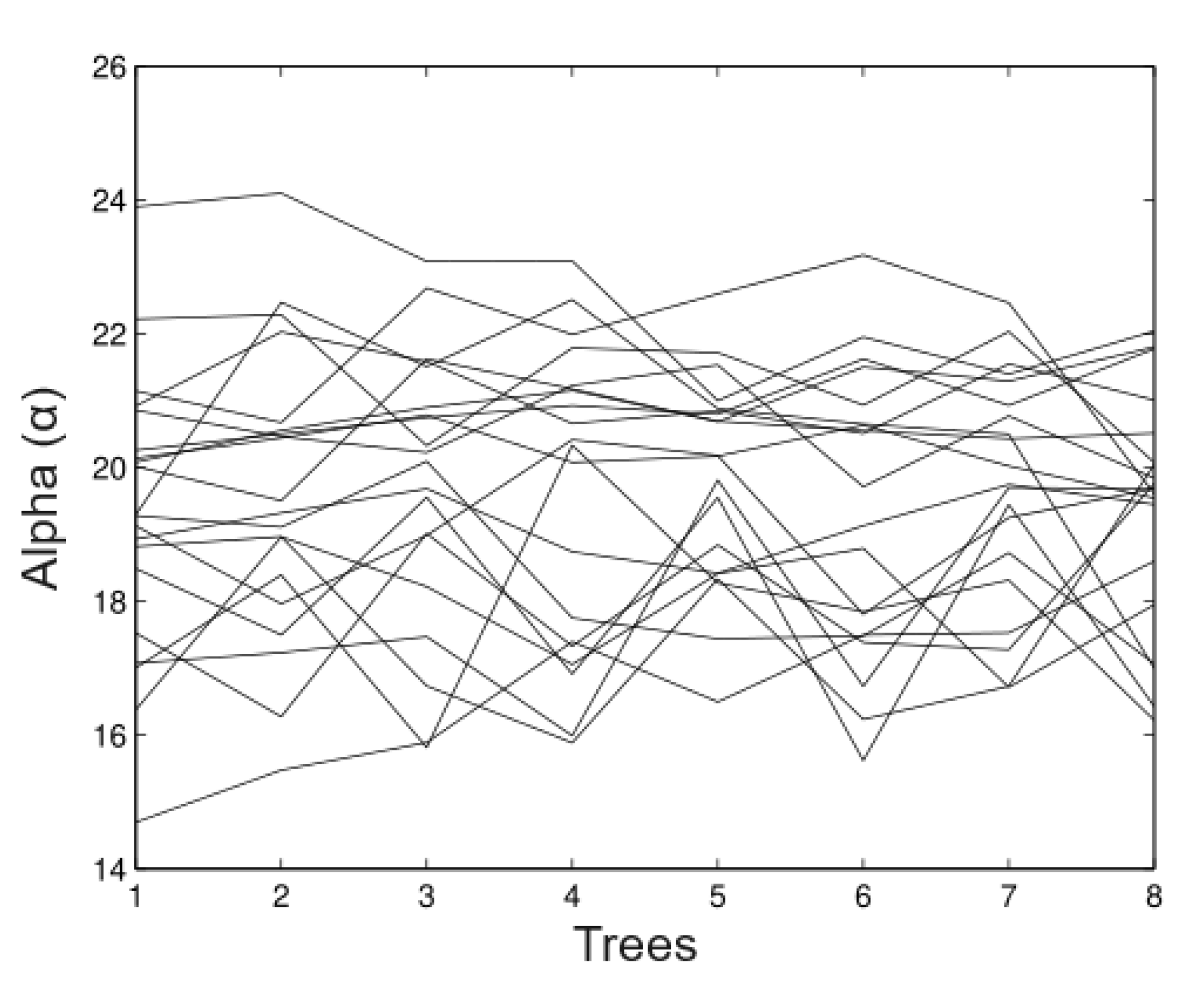
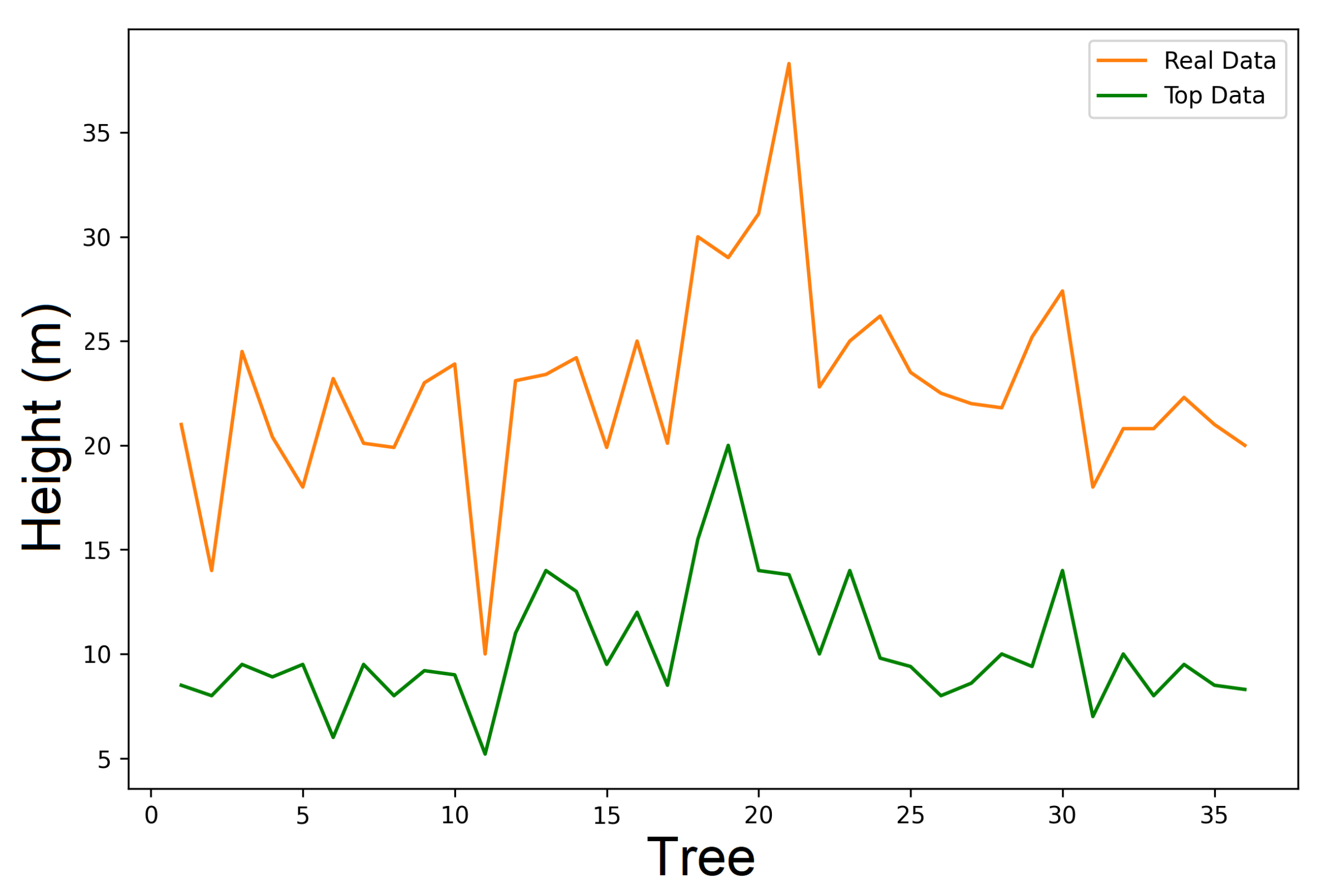
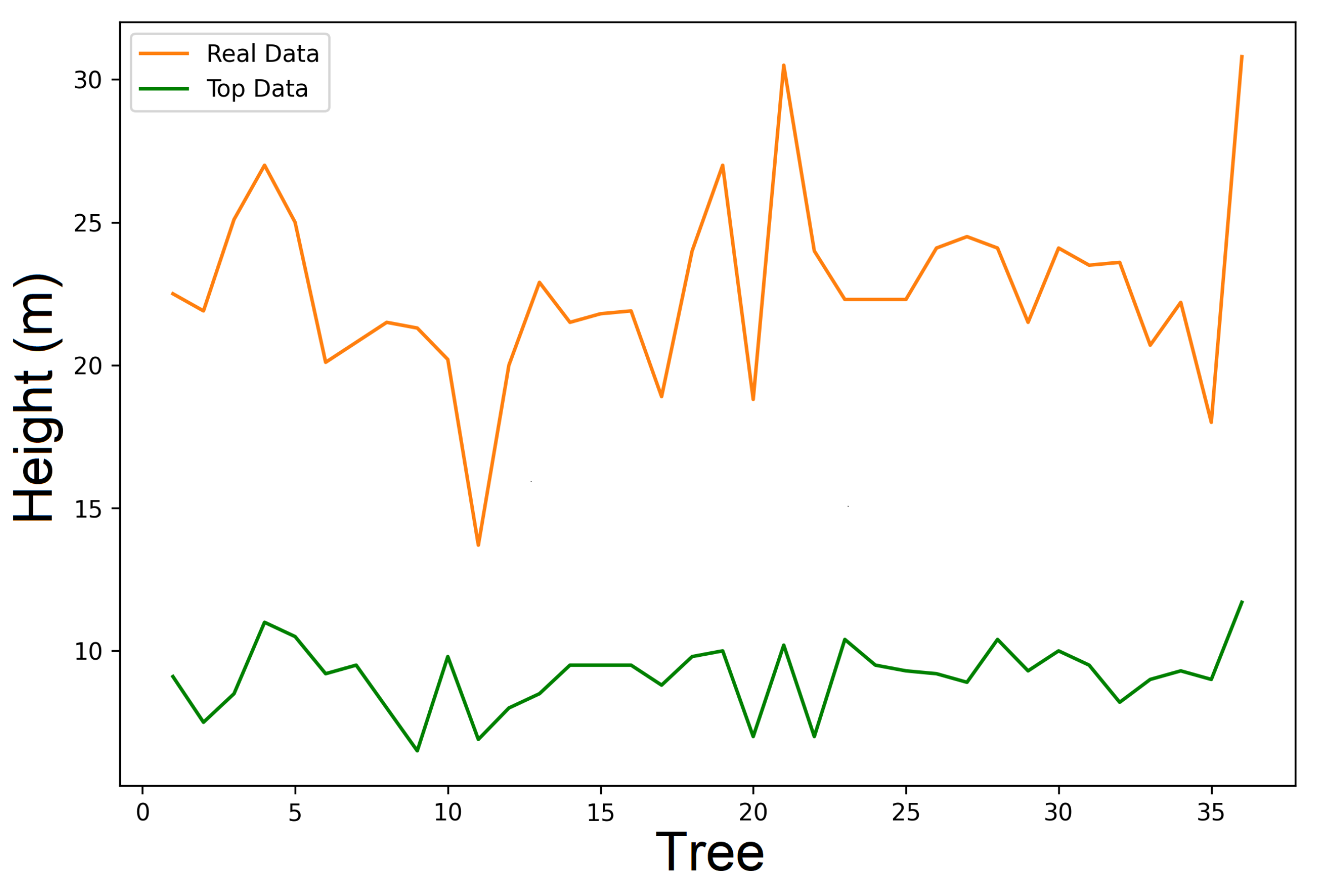
6.2. Real Data
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Delattre, M.; Genon-Catalot, V.; Samson, A. Estimation of Population Parameters in Stochastic Differential Equations with Random Effects in the Diffusion Coefficient. ESAIM Probab. Stat. 2015, 19, 671–688. [Google Scholar] [CrossRef][Green Version]
- Garcí a, O. A Stochastic Differential Equation: Model for the Height Growth of Forest Stand. Biometrics 1983, 39, 1059–1072. [Google Scholar] [CrossRef]
- Garcí a, O.; Ruiz, F. A Growth Model for Eucalypt in Galicia, Spain. For. Ecol. Manag. 2003, 173, 49–62. [Google Scholar] [CrossRef]
- Gushchin, A.; Kuchler, U. Asymptotic Inference for a Linear Stochastic Differential Equation with Time Delay. Bernoulli 1999, 5, 1059–1098. [Google Scholar] [CrossRef]
- Iacus, S. Simulation and Inference for Stochastic Differential Equations with R Examples; Springer Series in Statistics; Springer: New York, NY, USA, 2008. [Google Scholar]
- Kloeden, P.; Platen, E. Numerical Solution of Stochastics Differential Equations; Springer: Berlin/Heidelberg, Germany, 1992. [Google Scholar]
- Kloeden, P.; Platen, E.; Schurz, H.; Sorensen, M. On effects of Discretization on Estimators of Drift Parameters for Diffusion Processes. J. Appl. Probab. 1996, 33, 1061–1076. [Google Scholar] [CrossRef]
- Seber, G.A.E.; Wild, C.J. Nonlinear Regression; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1989. [Google Scholar]
- Kashyap, R.; Ramachandra Rao, A. Dynamic Stochastic Models from Empirical Data; Academic Press: Cambridge, MA, USA, 1976. [Google Scholar]
- Liang, Y.; Wang, W.; Metzler, R.; Cherstvy, A.G. Anomalous diffusion, nonergodicity, non-Gaussianity, and aging of fractional Brownian motion with nonlinear clocks. Phys. Rev. E 2023, 108, 034113. [Google Scholar] [CrossRef]
- Von Bertalanffy, L. A Quantitative Theory of Organic Growth. Hum. Biol. 1938, 10, 181–213. [Google Scholar]
- Von Bertalanffy, L. Quantitative Laws in Metabolism and Growth. Q. Rev. Biol. 1957, 32, 217–231. [Google Scholar] [CrossRef]
- Richards, F.J. A Flexible Growth for Empirical Use. J. Exp. Bot. 1959, 10, 290–300. [Google Scholar] [CrossRef]
- Aikman, D.P.; Benjamin, L.R. A Model for Plant and Crop Growth, Allowing for Competition for Light by the Use of Potential and Restricted Projected Crown Zone Areas. Ann. Bot. 1994, 73, 185–194. [Google Scholar] [CrossRef]
- Hunt, R. Plant Growth Curves; E. Arnold Publishers: London, UK, 1982; pp. 16–85. [Google Scholar]
- Jorve, E.; Jorve, K. A unified approach to the Richards-model family for use in growth analyses: Why we need only two model forms. J. Theor. Biol. 2010, 267, 417–425. [Google Scholar]
- Larsen, R.U. Plant Grow Modelling by Light and Temperature. Acta Hortic. 1990, 272, 235–242. [Google Scholar] [CrossRef]
- Ramachandra Prasad, T.V.; Krishnamurthy, K.; Kaislam, C. Functional Crop and Cob Growth Models of Maize (Zea mays L.) Cultivars. J. Agron. Crop Sci. 1992, 168, 208–212. [Google Scholar] [CrossRef]
- Fowler, C.W. Density Dependence as Related to Life History Strategy. Ecology 1981, 62, 602–610. [Google Scholar] [CrossRef]
- Sibly, R.M.; Barker, D.; Denham, M.C.; Hone, J.; Pagel, M. On the Regulation of Populations of Mammals, Birds, Fish, and Insects. Science 2005, 309, 607–610. [Google Scholar] [CrossRef]
- Ghosh, H.; Prajneshu. Optimum Fitting of Richards Growth Model in Random Environment. J. Stat. Theory Pract. 2019, 13, 6. [Google Scholar] [CrossRef]
- Dennis, J.E.; Schnabel, R.B. Numerical Methods for Unconstrained Optimization and Nonlinear Equations; SIAM: Philadelphia, PA, USA, 1996. [Google Scholar]
- Jukic, D. Necessary and Sufficient Criteria for the Existence of the Least Squares Estimate for a 3-parametric Exponential Regression Model. Appl. Math. Comput. 2004, 147, 1–17. [Google Scholar]
- Jukic, D.; Scitovski, R. The Best Least Squares Approximation Problem for a 3-parametric Exponential Regression Model, Austral. N. Z. Ind. Appl. Math. J. 2000, 42, 254–266. [Google Scholar]
- White, G.C.; Brishin, I.L. Estimation and Comparison of Parameters in Stochastic Growth Models for Barn Owls. Growth 1980, 44, 97–111. [Google Scholar]
- Bassan, B.; Marcus, R.; Talpaz, H.; Meilijson, I. Parameter Estimation in Diferential Equations, using Random Time Transformation. J. Ital. Statist. Soc. 1997, 2, 77–99. [Google Scholar]
- Adler, R.L.; Shields, P. Skew Products of Bernoulli Shifts with Rotations. Isr. J. Math. 1972, 12, 215–222. [Google Scholar] [CrossRef]
- Alon, N.; Meilijson, I. Random time transformation analysis of Covid19. MedRxiv 2020. [Google Scholar] [CrossRef]
- Lipser, R.; Shiryayev, A. Statistics of Random Process I; Springer: Berlin/Heidelberg, Germany, 1977. [Google Scholar]
- Ratkowsky, D.A. Nonlinear Regression Modeling: A Unified Practical Approach; Marcel Dekker, Inc.: New York, NY, USA, 1983. [Google Scholar]
- Román-Román, P.; Torres-Ruiz, F. A stochastic model related to the Richards-type growth curve.Estimation by means of simulated annealing and variable neighborhood search. Appl. Math. Comput. 2015, 266, 579–598. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Zone | |||
|---|---|---|---|
| Expo1 | 0.1365 | 0.3538 | 0.4460 |
| Expo2 | 0.0930 | 0.3263 | 0.4223 |
| Seccos | 0.1271 | 0.3798 | 0.4221 |
| Secint | 0.0830 | 0.2395 | 0.4525 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cornejo, Ó.; Muñoz-Herrera, S.; Baesler, F.; Rebolledo, R. The Application of the Random Time Transformation Method to Estimate Richards Model for Tree Growth Prediction. Mathematics 2023, 11, 4233. https://doi.org/10.3390/math11204233
Cornejo Ó, Muñoz-Herrera S, Baesler F, Rebolledo R. The Application of the Random Time Transformation Method to Estimate Richards Model for Tree Growth Prediction. Mathematics. 2023; 11(20):4233. https://doi.org/10.3390/math11204233
Chicago/Turabian StyleCornejo, Óscar, Sebastián Muñoz-Herrera, Felipe Baesler, and Rodrigo Rebolledo. 2023. "The Application of the Random Time Transformation Method to Estimate Richards Model for Tree Growth Prediction" Mathematics 11, no. 20: 4233. https://doi.org/10.3390/math11204233
APA StyleCornejo, Ó., Muñoz-Herrera, S., Baesler, F., & Rebolledo, R. (2023). The Application of the Random Time Transformation Method to Estimate Richards Model for Tree Growth Prediction. Mathematics, 11(20), 4233. https://doi.org/10.3390/math11204233