


Intelligence in Finance and Economics for Predicting High-Frequency Data

Abstract
1. Introduction
- we evaluate and analyze the performance of the machine learning methods proposed in [18] on one-minute prediction of exchange rate changes for the EUR against the Czech koruna currencies (abbreviated EUR/CZK) for a very large data set,
- we adapt statistical feature selection models (ARMA) to perceptron type neural networks trained by genetic and micro-genetic algorithms, and
- we compare the elapsed time spent using a standard genetic learning algorithm with the time spent using a micro-genetic algorithm.
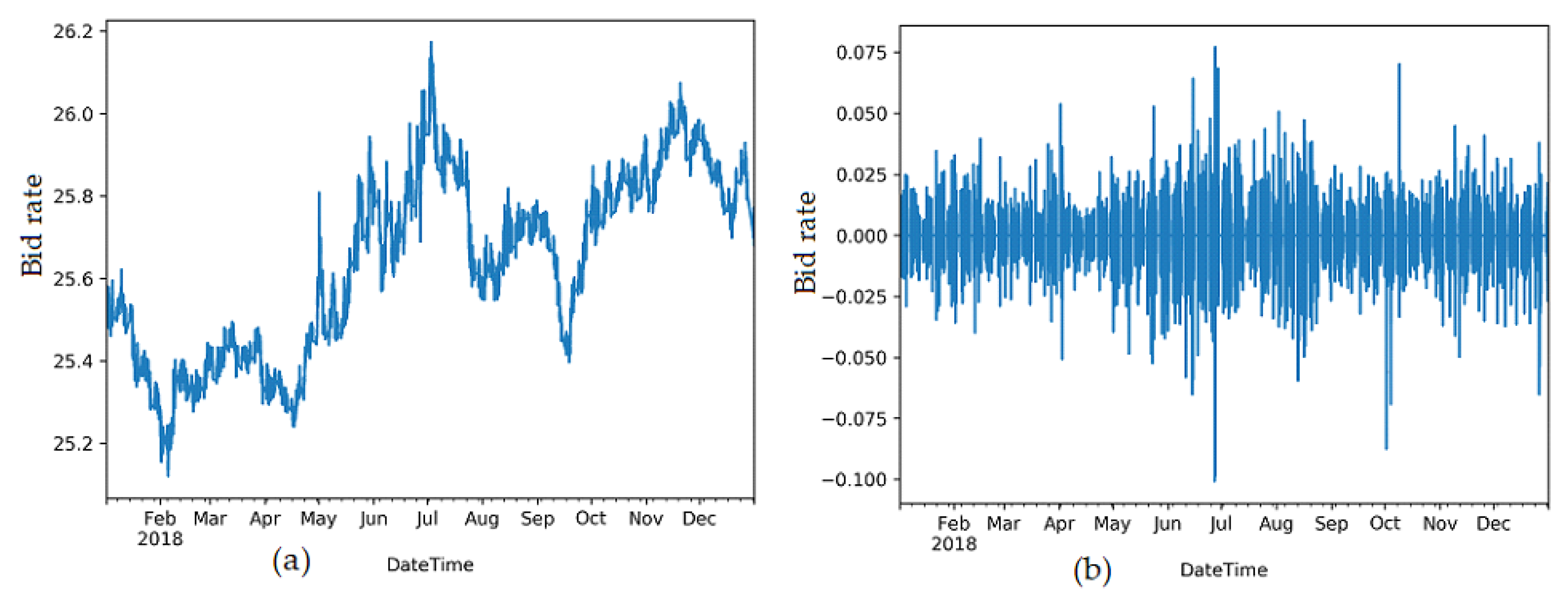
2. Used Data and Its Pre-processing
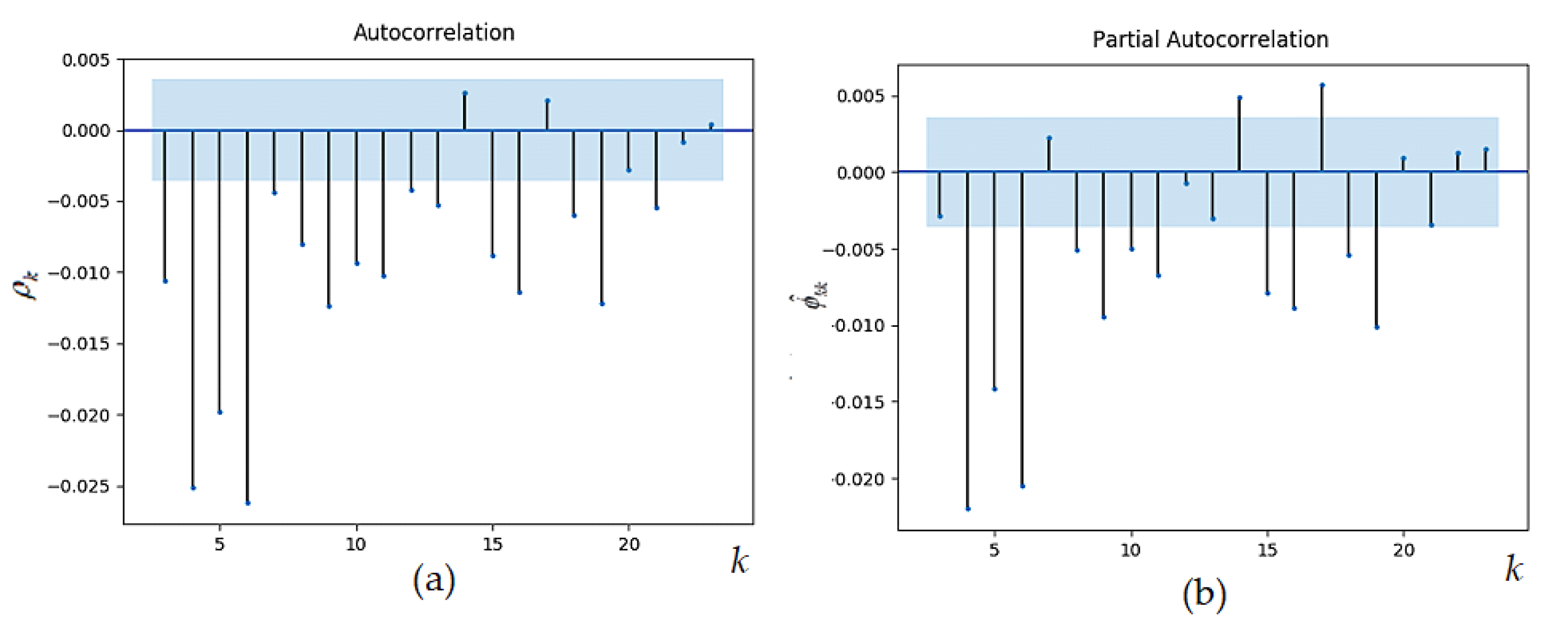
3. Statistical Time Series Analysis and Modelling
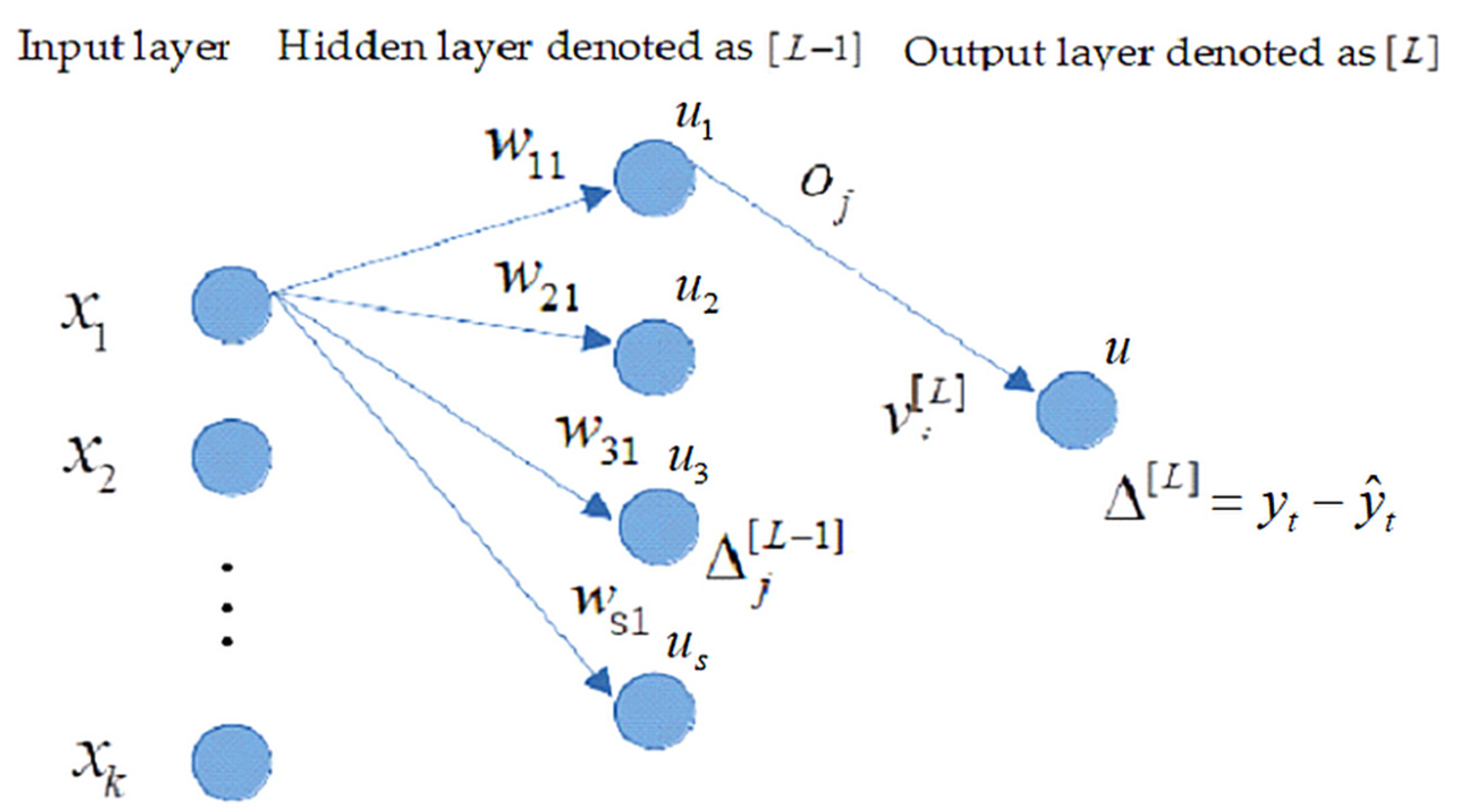
4. The Organizational Dynamics and Implementation of Neural Networks
4.1. Neural Network Implementation Trained by BP Algorithm
- compute the errors for the previous hidden node aswhere is the potential of the previous (hidden) node calculated aswhere denotes the activation function at the previous (hidden) [L-1] layer.
- update the weight for the output neuron aswhere denotes the output from the previous (hidden) layer neurons and represents the learning rate parameter.
- update the weight for the hidden (previous) neurons as
- Convolutional layer, whose task is the extraction of various features from the input feature map.where is a point in the position in input map, similarly, is a point at a position in the output map, is the coefficient at the position in the dimensional kernel used for the input map and is the bias for the output map.
- Pooling layer, which performs the merge operation (11). This operation is essentially the same as in the case of convolutional weaving. The difference lies in the function that is used over a group of points in the local neighborhood. Merging leads to size reduction. In the case of the merging layer, the most used functions are average and maximum. Merging leads to a reduction in the dimensions of maps on other layers, a reduction in the number of synapsis and free parameters.
- Fully-connected layer performs the inner product of the input vector and the transpose weight vector plus bias , i.e.,
- The rectified linear unit layer is vital in CNN architecture and is based on the non-saturation ‘activation function’. Without activating the fields of the convo layers, it increases the decision function’s nonlinear properties by removing the negative values from the activation map and converting them to zero. For example, rectified linear unit ReLU (13) speeds up network training and calculations.
4.2. Neural Network Implementation Trained by Genetic Algorithms
| Algorithm 1. The main steps of MGA algorithm. |
| Step 1. Create a random population with 11 individuals (initialization) and go to Step 3. Step 2. Restart: Create a population with 10 individuals randomly and add the one best individual from previous generation. Step 3. Calculate the fitness of individuals. Step 4. Elitism: Determine the best individual from previous generation and keep it for the next generation. Step 5. Selection: Use the rank selection to select 2 pairs of individuals (parents) for crossover. Step 6. Crossover: Determine the cross and add offspring to the new generation. Step 7: Calculate the fitness of individuals. Step 8: Check if there is a loss of diversity. If not go to Step 4 otherwise go to Step 9. Step 9: If termination criterion was not met, go to Step 2, otherwise Stop. |
5. Experiments and Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Gooijer, J.G. De Gooijer and Rob J. Hyndman. 25 years of time series forecasting. Int. J. Forecast. 2006, 22, 443–473. [Google Scholar] [CrossRef]
- O’Donovan, T.M. Short Term Forecasting: An Introduction to the Box-Jenkins Approach; Wiley: New York, NY, USA, 1983; ISBN1 10: 0471900133. ISBN2 13: 9780471900139. Available online: https://www.amazon.com/Short-Term-Forecasting-Introduction-Box-Jenkins/dp/0471900133 (accessed on 1 January 1983).
- Box, G.E.P.; Jenkins, G.M. Time Series Analysis: Forecasting and Control; Holden Day: San Francisco, CA, USA, 1976. [Google Scholar]
- Ngo, T.H.D.; Bros, W. The Box-Jenkins Methodology for Time Series Models. In SAS Global Forum 2013; Statistics and Data Analysis; Entertainment Group: Burbank, CA, USA, 2013; pp. 201–454. [Google Scholar]
- Engle, R.F. Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdom Inflation. Econom. Econom. Soc. 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Gupta, M.M.; Rao, D.H. On the Principles of Fuzzy Neural Networks. Fuzzy Sets Syst. 1994, 61, 1–18. [Google Scholar] [CrossRef]
- Kecman, V. Learning and soft computing: Support vector machines, neural networks, and fuzzy logic. In Fitting Neural Networks, Scaling of the Inputs, Number of Hidden Units and Layers; The MIT Press: Cambridge, MA, USA, 2001; pp. 353–358. ISBN 9780262527903. [Google Scholar]
- Hornik, K. Some new results on neural network approximation. Neural Netw. 1993, 6, 1069–1072. [Google Scholar] [CrossRef]
- Maciel, L.S.; Ballini, R. Design a Neural Network for Time Series Financial Forecasting: Accuracy and Robustness Analysis. 2008. Available online: https://www.cse.unr.edu/~harryt/CS773C/Project/895-1697-1-PB.pdf (accessed on 1 March 2008).
- Darbellay, G.A.; Slama, M. Forecasting the short-term demand for electricity: Do neural networks stand a better chance? Int. J. Forecast. 2000, 16, 71–83. [Google Scholar] [CrossRef]
- Zhang, G.; Patuvo, B.E.; HU, M.Y. Forecasting with Artificial Neural Networks: The State of the Art. Int. J. Forecast. 1998, 14, 35–62. [Google Scholar] [CrossRef]
- Marcek, D.; Kotillova, A. Statistical and Soft Computing Methods Applied to High Frequency Data. J. Mult.-Valued Log. Soft Comput. 2016, 6, 593–608. [Google Scholar]
- Falat, L.; Marcek, D.; Durisova, M. Intelligent Soft Computing on Forex: Exchange Rates Forecasting with Hybrid Radial Basis Neural Network. Sci. World J. 2016, 2016, 15. [Google Scholar] [CrossRef]
- Marcek, D. Forecasting of Financial Data: A Novel Fuzzy Logic Neural Network Based on Error Correction Concept and Statistics. Complex Intell. Syst. 2018, 4, 95–104. [Google Scholar] [CrossRef]
- Marcek, D.; Babel, J.; Falat, L. Forecasting Currency Pairs with RBF Neural Network Using Activation Function Based on Generalized Normal Distribution Experimental Results. J.Mult.-Valued Log. Soft Comput. 2019, 33, 539–563. [Google Scholar]
- Philip, A.A.; Taofiki, A.A.; Bidemi, A.A. Artificial Neural Network Model for Forecasting Foreign Exchange Rate. Intell. Learn. Syst. Appl. 2011, 3, 57–69. [Google Scholar] [CrossRef]
- Yasir, M.; Mehr, Y.D.; Sitara Afzal, S.; Mazzan, M.; Farhan, A.; Irfan, M.; Seungmin, R. An Intelligent Event-Sentiment-Based Daily Foreign Exchange Rate Forecasting Systém. Appl. Sci. 2019, 9, 2980. [Google Scholar] [CrossRef]
- Marcek, D. Some statistical and CI models to predict chaotic high-frequency financial data. J. Intell. Fuzzy Syst. 2020, 39, 6419–6439. [Google Scholar] [CrossRef]
- Time Series Pack–Reference and Users’s Guide–Wolfram Research. In The Mathematica Applications Library; Wolfram Research, Inc.: Champaign, IL, USA, 1995; pp. 86–99.
- Montgomery, D.C.; Lynwood, A.J.; Gardiner, J.S. Forecasting and time series analysis. In Autoregressive Integrated Moving Average Models; McGraw-Hill, Inc.: New York, NY, USA, 1900. [Google Scholar] [CrossRef]
- Crespo, Á.G.; Palacios, R.C.; Gómez-Berbis, J.M.; Mencke, M. BMR: Benchmarking Metrics Recommender for Personnel issues in Software Development Projects. Int. J. Comput. Intell. Syst. 2009, 2, 250–256. [Google Scholar]
- Available online: https://deeplearrning4j.org (accessed on 18 September 2015).
- Available online: https://clojure.org/ (accessed on 18 September 2015).
- Nielsen, M.A. Neural Networks and Deep Learning. Determination. Press 2015. Available online: http://neuralnetworksanddeeplearning.com/www.deeplearningbook.org (accessed on 22 September 2017).
- Wang, K.; Li, K.; Zhou, L.; Hu, Y.; Cheng, Z.; Liu, J. Multiple convolutional neural networks for multivariate time series prediction. Neurocomputing 2019, 360, 107–119. [Google Scholar] [CrossRef]
- Liu, S.; Ji, H.; Wang, M.C. Non-pooling Convolutional Neural Network Forecasting for Seasonal Time Series With Trends. IEEE Trans. Neural Netw. Learn. 2020, 31, 2879–2888. [Google Scholar] [CrossRef] [PubMed]
- Sze, V.; Chen, Y.H.; Yang, T.T.; Emer, J.S. Efficient processing of deep neural networks: A tutorial and Survay. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]
- Hrabovský, J. Detection of Network Attacks in High-Speed Computer Networks. Ph.D. Thesis, University of Žilina, Faculty of Management Science and Informatics, Žilina, Slovakia, 2019. no.: 28360020193008 (In Slovak). [Google Scholar]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. English (US). In The Handbook of Brain Theory and Neural Networks; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Nag, A.K.; Mitra, A. Forecasting Daily Foreign Exchange Rates Using Genetically Optimized Neural Networks. J. Forecast. 2002, 21, 501–512. [Google Scholar] [CrossRef]
- Saini, N. Review of Selection Methods in Genetic Algorithms. Int. J. Eng. Comput. Sci. 2017, 6, 22261–22263. [Google Scholar] [CrossRef]
- Jebari, K.; Madiafi, M.; Elmoujaid, A. Parent Selection Operators for Genetic Algorithms. Int. J. Eng. Technol. 2013, 2, 1141–1145. [Google Scholar]
- Krishnakumar, K. Micro-genetic Algorithms for Stationary and Non-stationary Function Optimization. In Proceedings of the SPIE Intelligent Control and Adaptive Systems, Philadelphia, PA, USA, 1–3 November 1989; pp. 289–296. [Google Scholar] [CrossRef]
- Alajmi, A.; Wright, J. Selecting the most efficient genetic algorithm sets in solving unconstrained building. optimization problem. Int. J. Sustain. Built Environ. 2014, 1, 18–26. [Google Scholar] [CrossRef]
- Crainic, T. Parallel solution methods for vehicle routing problems. In The Vehicle Routing Problem: Latest Advantages and New Challenges; Golden, B., Raghavan, S., Wasil, E., Eds.; Springer: New York, NY, USA, 2008; pp. 171–198. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Parameter | Coefficient | Stand. Error | z | p > |z| | [0.025 | 0.975] |
|---|---|---|---|---|---|---|
| Bias | 2.278 × 10−6 | |||||
| ar.L1 | −0.9433 | 0.012 | −78.668 | 0.000 | −0.967 | −0.920 |
| ar.L2 | −0.8507 | 0.016 | −53.408 | 0.000 | −0.882 | −0.820 |
| ar.L3 | −0.5851 | 0.017 | −33.628 | 0.000 | −0.619 | −0.551 |
| ar.L4 | −0.7521 | 0.017 | −42.980 | 0.000 | −0.786 | −0.718 |
| ar.L5 | −0.9723 | 0.018 | −55.435 | 0.000 | −1.007 | −0.938 |
| ar.L6 | −0.8592 | 0.020 | −42.317 | 0.000 | −0.899 | −0.819 |
| ar.L7 | −0.8816 | 0.020 | −44.022 | 0.000 | −0.921 | −0.842 |
| ar.L8 | −0.6486 | 0.019 | −33.298 | 0.000 | −0.687 | −0.610 |
| ar.L9 | −0.8109 | 0.018 | −44.858 | 0.000 | −0.846 | −0.775 |
| ar.L10 | −0.8781 | 0.019 | −46.376 | 0.000 | −0.915 | −0.841 |
| ar.L11 | −0.7273 | 0.019 | −38.855 | 0.000 | −0.764 | −0.691 |
| ar.L12 | −0.6489 | 0.018 | −35.296 | 0.000 | −0.685 | −0.613 |
| ar.L13 | −0.8355 | 0.019 | −43.666 | 0.000 | −0.873 | −0.798 |
| ar.L14 | −0.7791 | 0.019 | −41.321 | 0.000 | −0.816 | −0.742 |
| ar.L15 | −0.7226 | 0.019 | −38.984 | 0.000 | −0.759 | −0.686 |
| ar.L16 | −0.6477 | 0.017 | −37.298 | 0.000 | −0.682 | −0.614 |
| ar.L17 | −0.6149 | 0.018 | −35.131 | 0.000 | −0.649 | −0.581 |
| ar.L18 | −0.3127 | 0.015 | −20.642 | 0.000 | −0.342 | −0.283 |
| ar.L19 | 0.0190 | 0.006 | 2.997 | 0.003 | 0.007 | 0.031 |
| ma.L1 | −0.0384 | 0.012 | −3.219 | 0.001 | −0.062 | −0.015 |
| ma.L2 | −0.0605 | 0.012 | −5.189 | 0.000 | −0.083 | −0.038 |
| ma.L3 | −0.2482 | 0.013 | −19.002 | 0.000 | −0.274 | −0.223 |
| ma.L4 | 0.1518 | 0.013 | 12.111 | 0.000 | 0.127 | 0.176 |
| ma.L5 | 0.2349 | 0.013 | 18.316 | 0.000 | 0.210 | 0.260 |
| ma.L6 | −0.0988 | 0.014 | −7.155 | 0.000 | −0.126 | −0.072 |
| ma.L7 | 0.0446 | 0.014 | 3.166 | 0.002 | 0.017 | 0.072 |
| ma.L8 | −0.2270 | 0.018 | −12.707 | 0.000 | −0.262 | −0.192 |
| ma.L9 | 0.1507 | 0.019 | 8.064 | 0.000 | 0.114 | 0.187 |
| ma.L10 | 0.0842 | 0.019 | 4.479 | 0.000 | 0.047 | 0.121 |
| ma.L11 | −0.1315 | 0.019 | −6.750 | 0.000 | −0.170 | −0.093 |
| ma.L12 | −0.0286 | 0.018 | −1.582 | 0.114 | −0.064 | 0.007 |
| ma.L13 | 0.1877 | 0.016 | 12.059 | 0.000 | 0.157 | 0.218 |
| ma.L14 | −0.0507 | 0.015 | −3.428 | 0.001 | −0.080 | −0.022 |
| ma.L15 | −0.0443 | 0.013 | −3.458 | 0.001 | −0.069 | −0.019 |
| ma.L16 | −0.0593 | 0.014 | −4.386 | 0.000 | −0.086 | −0.033 |
| ma.L17 | −0.0065 | 0.013 | −0.492 | 0.623 | −0.033 | 0.020 |
| ma.L18 | −0.2899 | 0.013 | −21.510 | 0.000 | −0.316 | −0.264 |
| ma.L19 | −0.3137 | 0.015 | −21.118 | 0.000 | −0.343 | −0.285 |
| ma.L20 | −0.0509 | 0.020 | −2.518 | 0.012 | −0.090 | −0.011 |
| ma.L21 | −0.0733 | 0.018 | −4.014 | 0.000 | −0.109 | −0.038 |
| Parameter | Standard GA | Micro-GA |
|---|---|---|
| Population | 1000 | 10 |
| Elites | 5 individuals | 1 individual |
| Crossbreds | 220 pairs | 3 pairs |
| Mutants | 1% chance either elite or crossbred | 2% chance either elite or crossbred |
| Randoms | 1000 − (elites + crossbreds + mutants) | 10 − (elites + crossbreds + mutants) |
| Restart | – | Diversity under 75% |
| Parameter | Standard GA 90 Neurons | Standard GA 120 Neurons |
|---|---|---|
| Elapsed time [min] | 4.104 × 103 | 4.350 × 103 |
| MSE on validation data set | 4.51 × 10−6 | 4.47 × 10−6 |
| Number of generations | 3.741 × 103 | 3.550 × 103 |
| Micro-GA | Micro-GA | |
| Elapsed time [min] | 4.70 × 102 | 1.686 × 103 |
| MSE on validation data set | 4.41 × 10−6 | 4.39 × 10−6 |
| Number of generations | 49.567 × 103 | 295.641 × 103 |
| Number of restarts | 2.027 × 103 | 6.965 × 103 |
| Parameter | Standard GA 90 Neurons | Standard GA 120 Neurons | Micro-GA 90 Neurons | Micro GA 120 Neurons |
|---|---|---|---|---|
| Elapsed time | 94% | 100% | 1% | 1% |
| MSE on validation data set | 100% | 99% | 98% | 97% |
| Number of generations | 1% | 1% | 16% | 100% |
| Number of restarts | not applicable | not applicable | 29% | 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Madera, M.; Marcek, D. Intelligence in Finance and Economics for Predicting High-Frequency Data. Mathematics 2023, 11, 454. https://doi.org/10.3390/math11020454
Madera M, Marcek D. Intelligence in Finance and Economics for Predicting High-Frequency Data. Mathematics. 2023; 11(2):454. https://doi.org/10.3390/math11020454
Chicago/Turabian StyleMadera, Martin, and Dusan Marcek. 2023. "Intelligence in Finance and Economics for Predicting High-Frequency Data" Mathematics 11, no. 2: 454. https://doi.org/10.3390/math11020454
APA StyleMadera, M., & Marcek, D. (2023). Intelligence in Finance and Economics for Predicting High-Frequency Data. Mathematics, 11(2), 454. https://doi.org/10.3390/math11020454