

Contextual Urdu Lemmatization Using Recurrent Neural Network Models

 , , ,
, , , 
Abstract
1. Introduction
- An Urdu lemmatization algorithm based on four RNN models, namely BiLSTM, BiGRU, BiGRNN, and AFED, is presented.
- Lemmatization is performed to find the accurate and legitimate lemma from the two Urdu corpora.
- Semantic and syntactic embeddings are created using the Word2Vec model and edit trees are generated from the word lemma pairs available in the input file.
- The proposed approach successfully handles proper nouns, inflectional and derivational morphemes, stop words, loan words, and diacritized Urdu words.
- Accuracy, precision, recall, and F-score evaluation measures are used to evaluate the performance of the proposed approach.
2. Related Work
3. Morphologically of Urdu Language
3.1. Vowels in Urdu
3.2. Spellings in Urdu
| میری لکھائی بہت خوبصورت ہے |
| (My handwriting is very beautiful) |
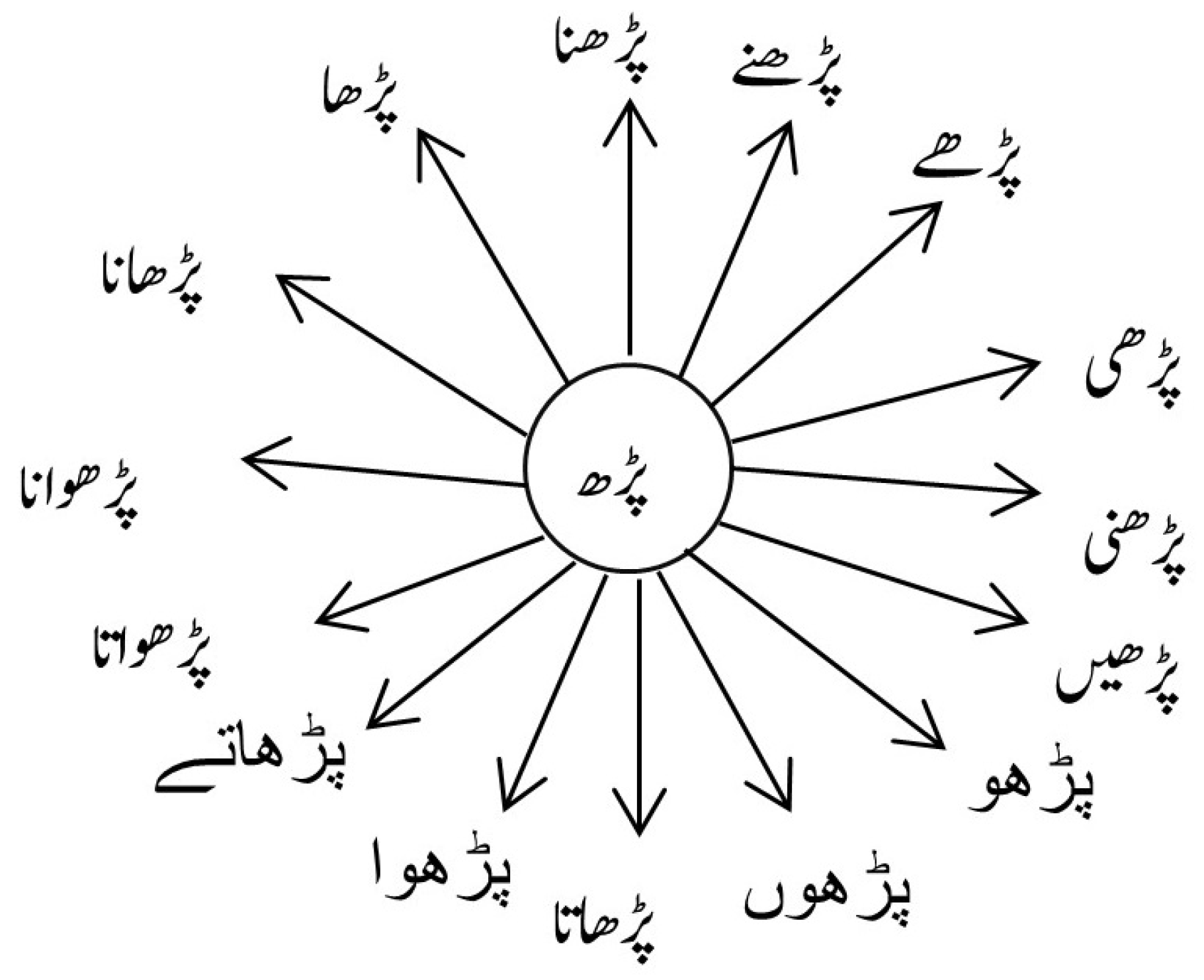
3.3. Inflections and Derivations in Urdu
3.4. Loan Words in Urdu
3.5. Nouns and Verbs in Urdu
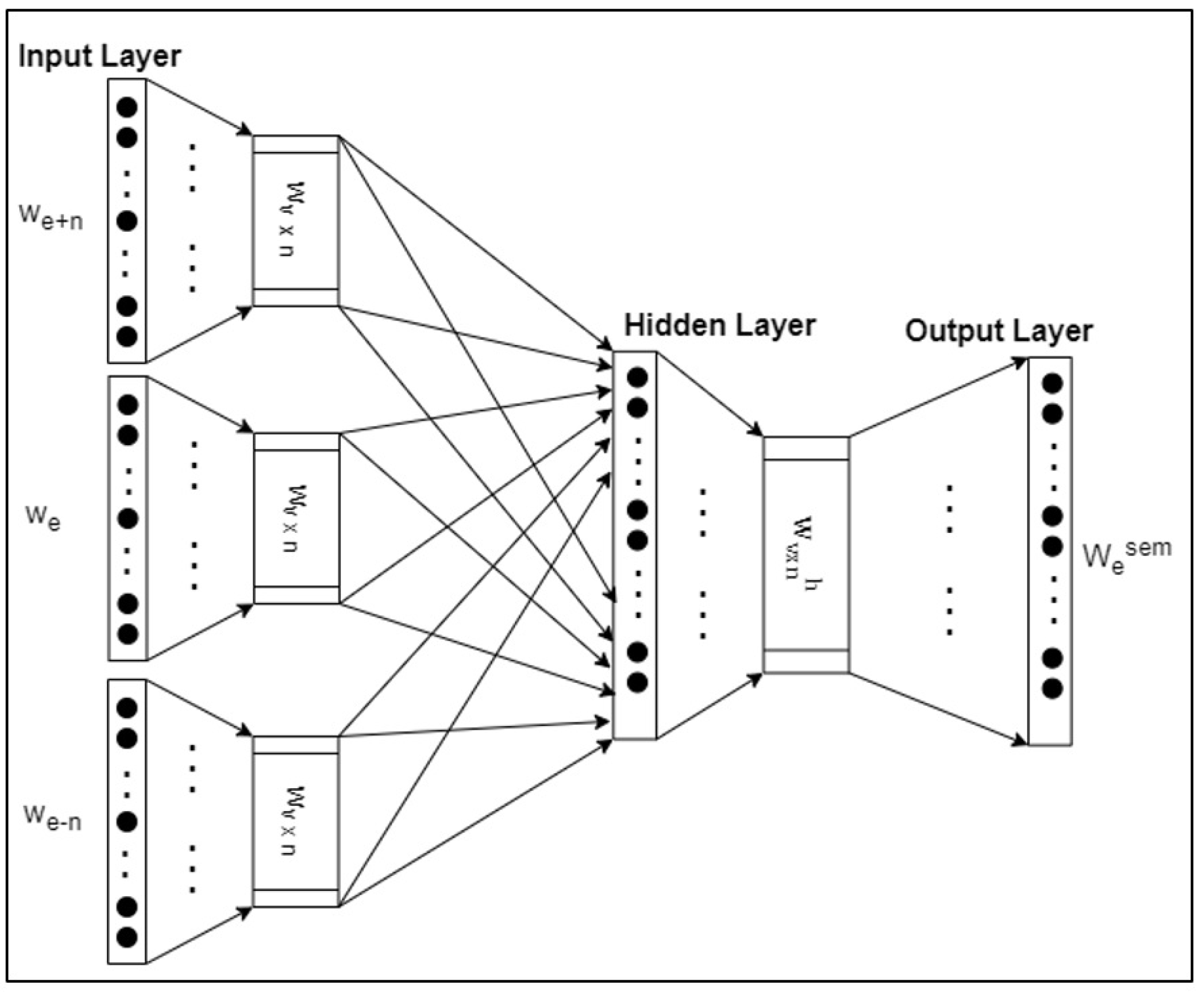
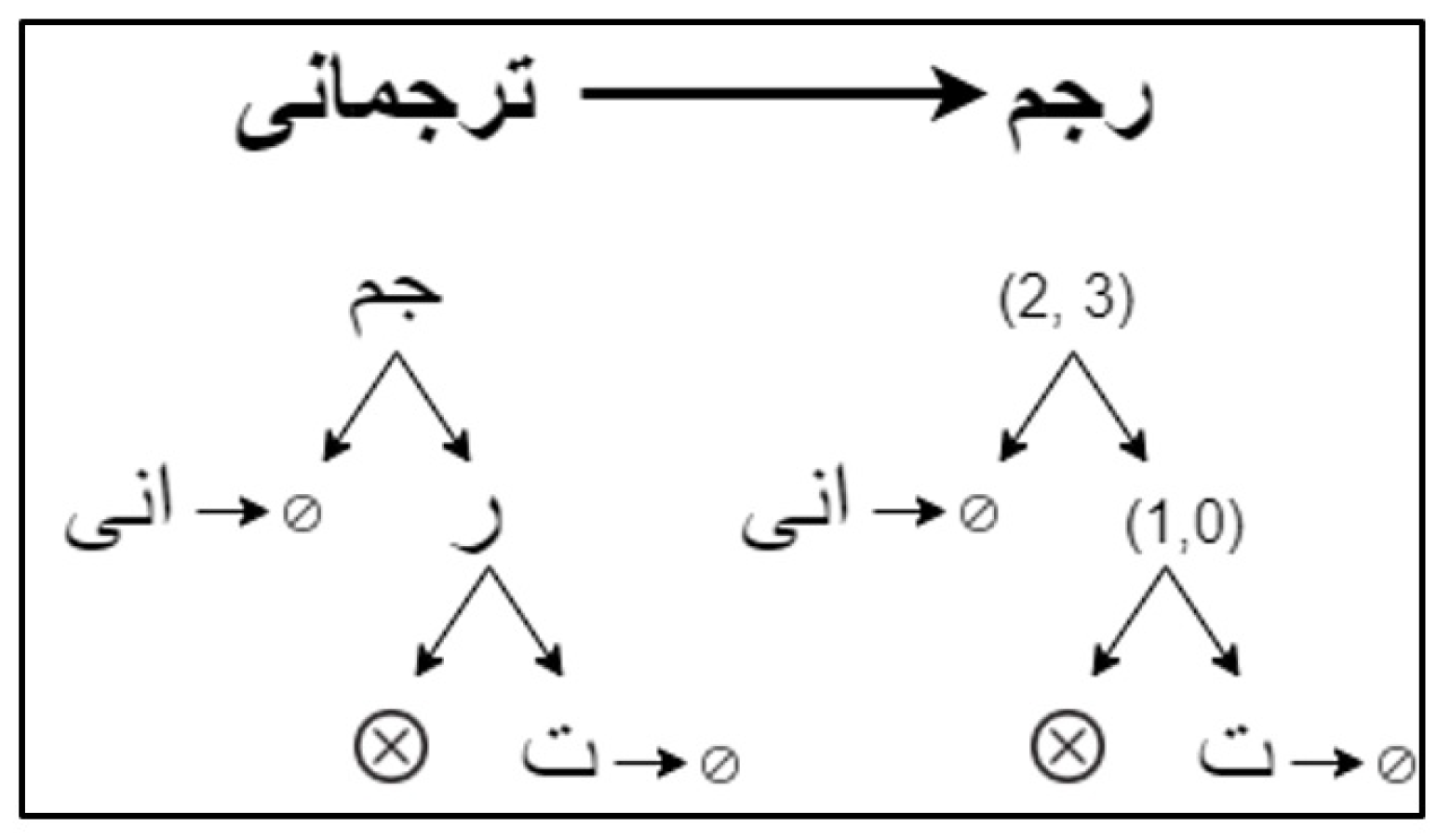
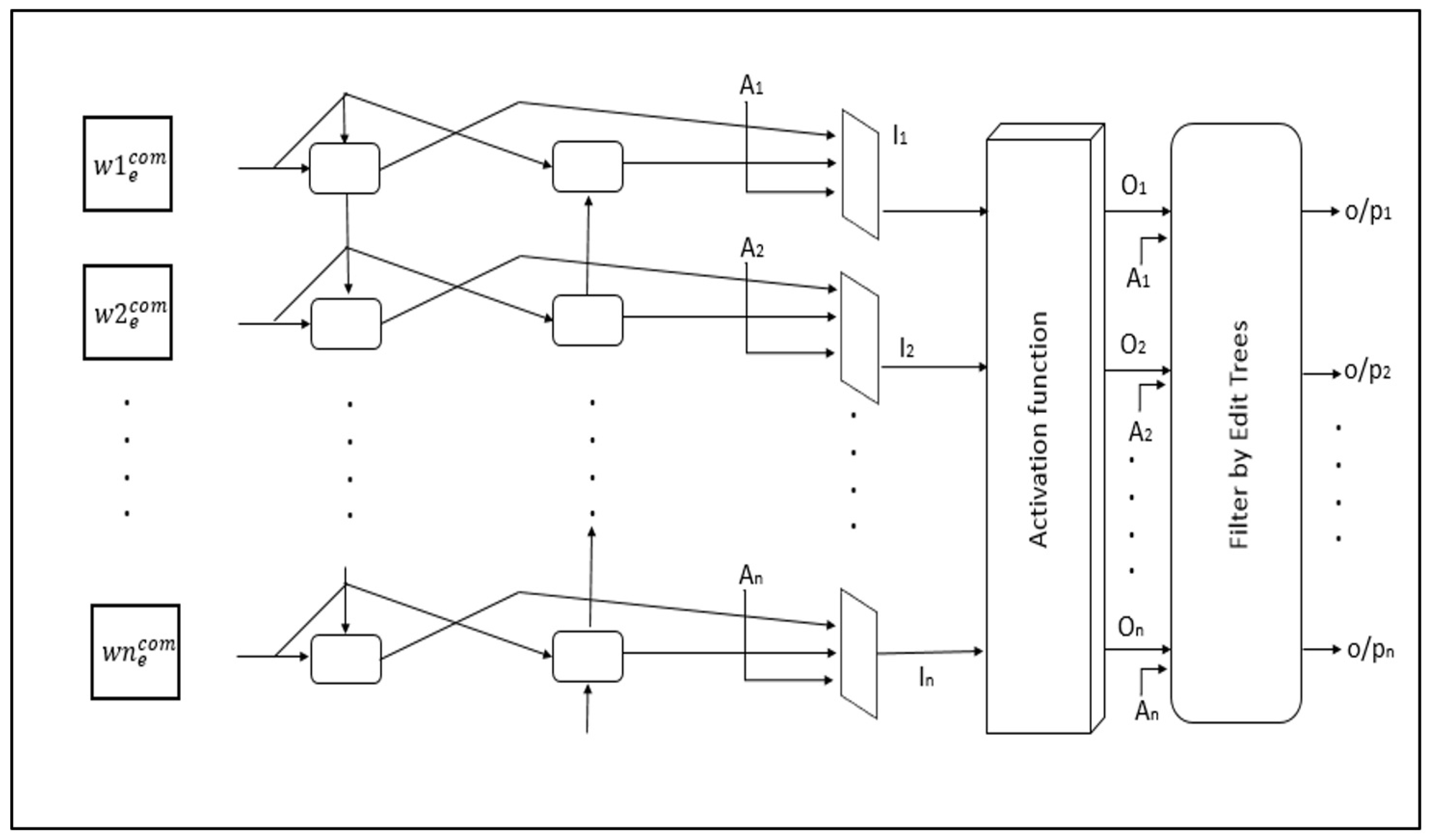
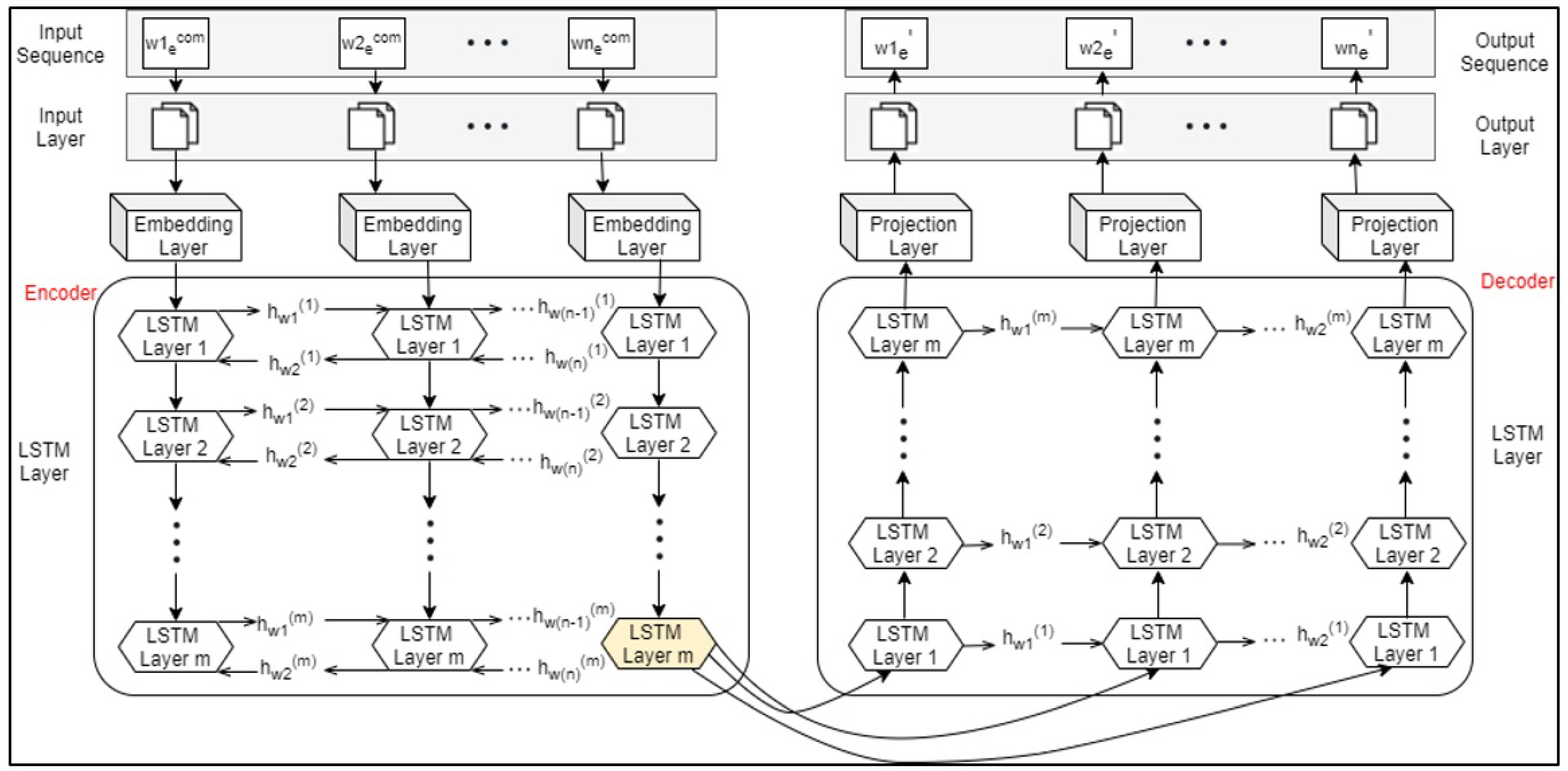
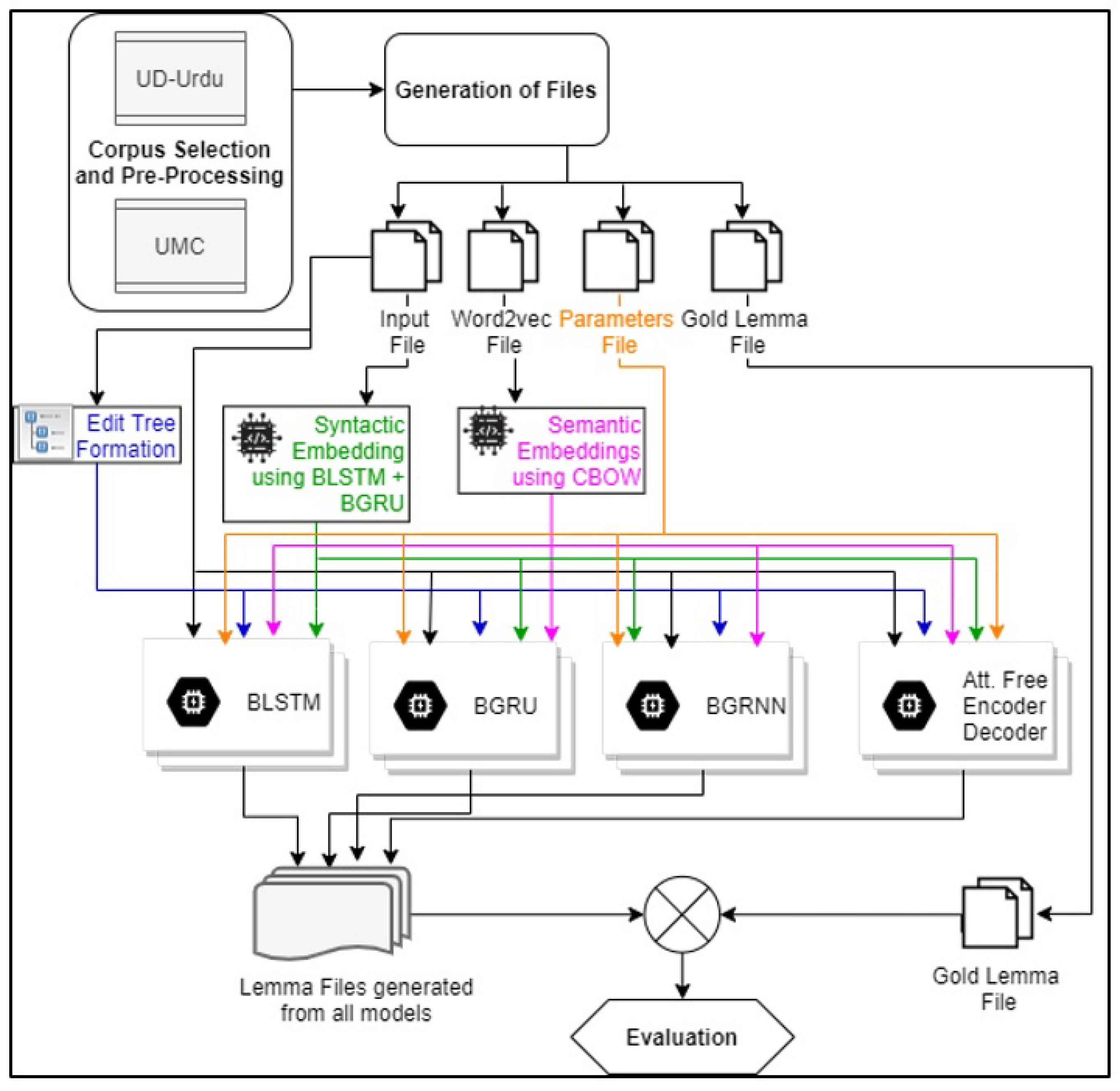
4. Proposed Methodology
4.1. Corpus Selection and Preprocessing
4.2. Experimental Design and Setup
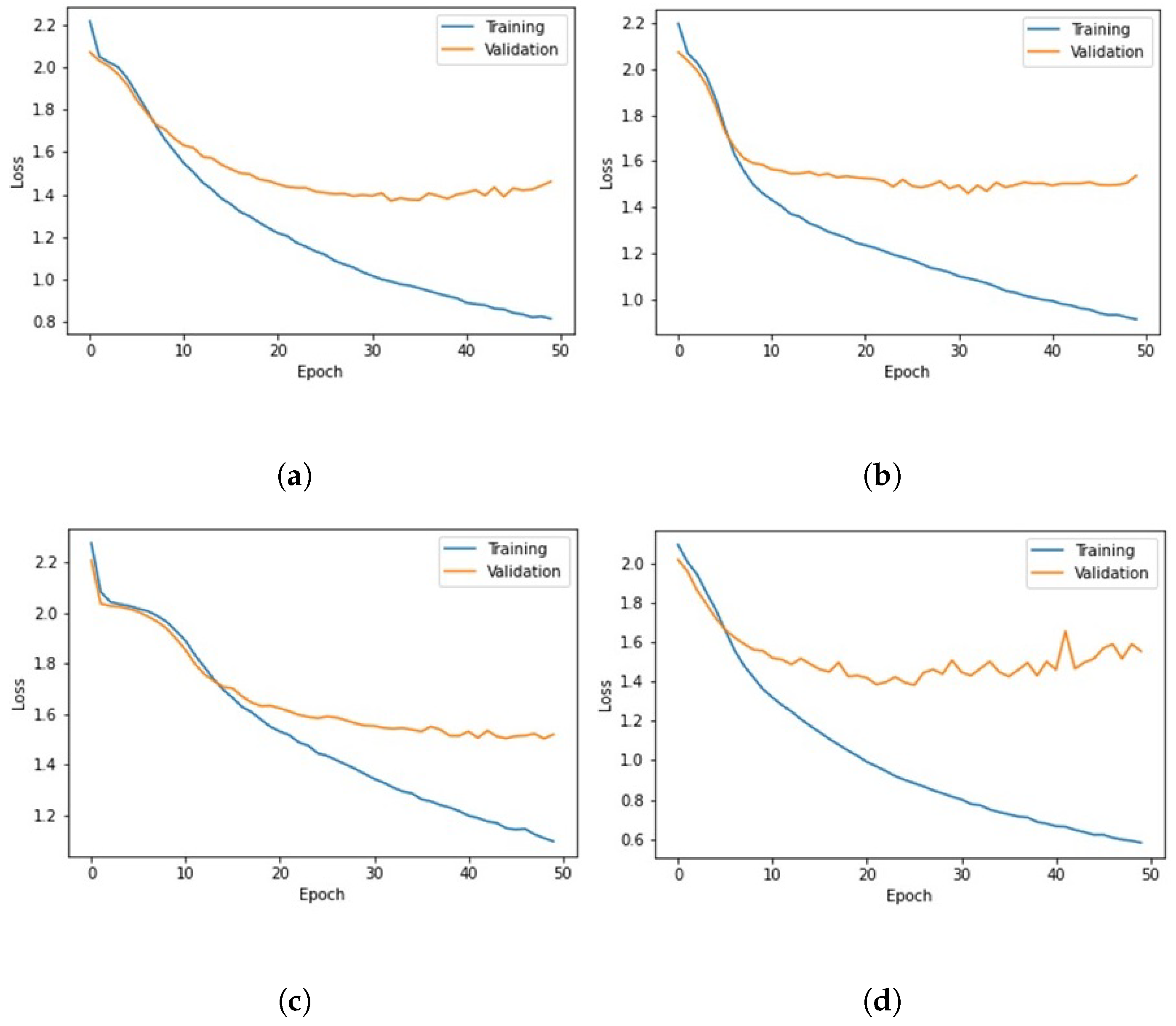
5. Results and Discussions
| پری گل، علی اور پارسا نے امتحانات میں اعلیٰ نمبر حاصل کیے۔ |
| (Pari Gul, Ali, and Parsa achieved good marks in the exams.) |
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Included Stop Words



References
- Sychev, O.A.; Penskoy, N.A. Method of lemmatizer selections in multiplexing lemmatization. IOP Conf. Ser. Mater. Sci. Eng. 2019, 483, 012091. [Google Scholar] [CrossRef]
- Boudchiche, M.; Mazroui, A. A hybrid approach for Arabic lemmatization. Int. J. Speech Technol. 2019, 22, 563–573. [Google Scholar] [CrossRef]
- Samir, A.; Lahbib, Z. Stemming and lemmatization for information retrieval systems in amazigh language. In Proceedings of the International Conference on Big Data, Cloud and Applications, Kenitra, Morocco, 4–5 April 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 222–233. [Google Scholar]
- Fatima, T.; Islam, R.U.; Anwar, M.W.; Jamal, M.H.; Chaudhry, M.T.; Gillani, Z. STEMUR: An Automated Word Conflation Algorithm for the Urdu Language. Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 21, 1–20. [Google Scholar] [CrossRef]
- Jabbar, A.; Iqbal, S.; Khan, M.U.G.; Hussain, S. A survey on Urdu and Urdu like language stemmers and stemming techniques. Artif. Intell. Rev. 2018, 49, 339–373. [Google Scholar] [CrossRef]
- Manjavacas, E.; Kádár, Á.; Kestemont, M. Improving lemmatization of non-standard languages with joint learning. arXiv 2019, arXiv:1903.06939. [Google Scholar]
- Gupta, V.; Joshi, N.; Mathur, I. Design and development of a rule-based Urdu lemmatizer. In Proceedings of the Proceedings of International Conference on ICT for Sustainable Development, Ahmedabad, India, 3–4 July 2015; Springer: Berlin/Heidelberg, Germany, 2016; pp. 161–169. [Google Scholar]
- Paul, S.; Tandon, M.; Joshi, N.; Mathur, I. Design of a rule based Hindi lemmatizer. In Proceedings of the Third International Workshop on Artificial Intelligence, Soft Computing and Applications, Chennai, India, 13–15 July 2013; Springer Nature: Singapore, 2013; Volume 2, pp. 67–74. [Google Scholar]
- Khaltar, B.O.; Fujii, A. A lemmatization method for modern mongolian and its application to information retrieval. In Proceedings of the the Third International Joint Conference on Natural Language Processing: Volume-I, Hyderabad, India, 7–12 January 2008. [Google Scholar]
- Khaltar, B.O.; Fujii, A.; Ishikawa, T. Extracting loanwords from Mongolian corpora and producing a Japanese-Mongolian bilingual dictionary. In Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, Sydney, Australia, 17–21 July 2006; pp. 657–664. [Google Scholar]
- Suhartono, D. Lemmatization technique in bahasa: Indonesian. J. Softw. 2014, 9, 1203. [Google Scholar] [CrossRef]
- Plisson, J.; Lavrac, N.; Mladenic, D. A rule based approach to word lemmatization. In Proceedings of the 7th International Multiconference Information Society IS 2004 Ljubljana, Slovenia, 2004., 13–14 October.
- Freihat, A.A.; Abbas, M.; Bella, G.; Giunchiglia, F. Towards an optimal solution to lemmatization in Arabic. Procedia Comput. Sci. 2018, 142, 132–140. [Google Scholar] [CrossRef]
- Chakrabarty, A.; Garain, U. Benlem (a bengali lemmatizer) and its role in wsd. ACM Trans. Asian Low-Resour. Lang. Inf. Process. (TALLIP) 2016, 15, 1–18. [Google Scholar] [CrossRef]
- Chakrabarty, A.; Chaturvedi, A.; Garain, U. A neural lemmatizer for bengali. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 2558–2561. [Google Scholar]
- Pütz, T.; De Kok, D.; Pütz, S.; Hinrichs, E. Seq2seq or perceptrons for robust lemmatization. An empirical examination. In Proceedings of the 17th International Workshop on Treebanks and Linguistic Theories (TLT 2018), Oslo, Norway, 13–14 December 2018; Linköping University Electronic Press: Linköping, Sweden, 2018; pp. 193–207. [Google Scholar]
- Kondratyuk, D.; Gavenčiak, T.; Straka, M.; Hajič, J. LemmaTag: Jointly tagging and lemmatizing for morphologically-rich languages with BRNNs. arXiv 2018, arXiv:1808.03703. [Google Scholar]
- Humayoun, M.; Yu, H. Analyzing pre-processing settings for Urdu single-document extractive summarization. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 3686–3693. [Google Scholar]
- Alam, M.; ul Hussain, S. Sequence to sequence networks for Roman-Urdu to Urdu transliteration. In Proceedings of the 2017 International Multi-topic Conference (INMIC), Lahore, Pakistan, 24–26 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–7. [Google Scholar]
- Jawaid, B.; Kamran, A.; Bojar, O. Urdu Monolingual Corpus; LINDAT/CLARIAH-CZ Digital Library at the Institute of Formal and Applied Linguistics (ÚFAL), Faculty of Mathematics and Physics, Charles University: Prague, Czechia, 2014. [Google Scholar]
- Bhat, R.A.; Bhatt, R.; Farudi, A.; Klassen, P.; Narasimhan, B.; Palmer, M.; Rambow, O.; Sharma, D.M.; Vaidya, A.; Ramagurumurthy Vishnu, S.; et al. The hindi/urdu treebank project. In Handbook of Linguistic Annotation; Springer: Berlin/Heidelberg, Germany, 2017; pp. 659–697. [Google Scholar]
- Palmer, M.; Bhatt, R.; Narasimhan, B.; Rambow, O.; Sharma, D.M.; Xia, F. Hindi syntax: Annotating dependency, lexical predicate-argument structure, and phrase structure. In Proceedings of the The 7th International Conference on Natural Language Processing, Dalian, China, 24–27 September 2009; pp. 14–17. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 2, 3111–3119. [Google Scholar]
- Boroş, T.; Dumitrescu, Ş.D.; Burtica, R. NLP-Cube: End-to-end raw text processing with neural networks. In Proceedings of the CoNLL 2018 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies, Brussels, Belgium, 31 October–1 November 2018; pp. 171–179. [Google Scholar]
- Müller, T.; Cotterell, R.; Fraser, A.; Schütze, H. Joint lemmatization and morphological tagging with lemming. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2268–2274. [Google Scholar]
- Chrupala, G.; Dinu, G.; van Genabith, J. Learning Morphology with Morfette. In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC’08), Marrakech, Morocco, 28–30 May 2008; European Language Resources Association (ELRA): Marrakech, Morocco, 2008. [Google Scholar]
- Yildiz, E.; Tantuğ, A.C. Morpheus: A neural network for jointly learning contextual lemmatization and morphological tagging. In Proceedings of the 6th Workshop on Computational Research in Phonetics, Phonology, and Morphology, Florence, Italy, 2 August 2019; pp. 25–34. [Google Scholar]
- Chakrabarty, A.; Pandit, O.A.; Garain, U. Context sensitive lemmatization using two successive bidirectional gated recurrent networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1481–1491. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Techniques | Benefits | Drawbacks | Language |
|---|---|---|---|
| Statistical task-based using hidden Markov models | Higher accuracy as the model has the ability to learn complex patterns and dependencies existing between inflected forms of a word and its lemma. | Requires large-annotated training data, which is not readily available, to learn the probabilistic relationships between the different word forms and their lemmas. | Arabic [2] |
| Efficiently handles large datasets, making them well-suited for lemmatization tasks where the goal is to process a large amount of text. | Agnostic of the context in which a word appears, hence unable to accurately lemmatize words having multiple possible lemmas depending on the context. | ||
| Language-agnostic which helps build a lemmatizer for any language provided there is enough training data available. | Based on probabilistic models of word form and lemma relationships, hence unable to handle unusual or unexpected word forms, leading to errors/inaccuracies in lemmatization. | ||
| Rule-based approach | Higher accuracy as it is based on pre-defined rules, list of lemmas and their corresponding inflected forms. | Lacks generalization, as it is dependent on the list of rules that requires comprehensive knowledge of the language. | Hindi [8] Mongolian [9,10] Bahasa Indonesia [11] Slovene [12] Urdu [7,18] |
| Does not require model training like ML-based techniques. | Error-prone to rare or unusual inflections because of predefined rules. Therefore, should be used in conjunction with other techniques, such as stemming. | ||
| Customizable to specific languages/domains, allowing for greater control over the stemming or lemmatization process. | It is time-consuming as it requires defining a predefined list of rules and a set of suffixes for each language. | ||
| Agnostics to the context of the word and cannot accurately lemmatize words that may have different meanings in different contexts. | |||
| Has limited coverage as it is unable to handle a wide range of inflections and derivations, leading to inaccurate lemmatization for words that are not covered by the rules. | |||
| Not adaptable to new words or changes in the language. | |||
| Unable to capture the full range of variations and complexities of a language, leading to lower stemming and lemmatization accuracy. | |||
| Machine and deep learning based approach | Neural networks can learn complex patterns and relationships in data, leading to improved accuracy in lemmatization. | Neural network-based lemmatization can be complex and resource-intensive, requiring significant computational power and memory. | Bengali [14,15] German [16] Arabic, German, Czech [17] |
| Well-suited to train and test large data, hence practical choice for lemmatization on even very large corpora. | Neural network-based lemmatization requires a large amount of annotated training data to learn the patterns and relationships between word forms and lemmas. If enough annotated data are not available, the accuracy of the lemmatization may be limited. | ||
| Can consider the context in which a word appears, leading to improved accuracy of lemmatization for words with multiple possible lemmas depending on the context. | Dependent on the choice of hyperparameters. | ||
| Able to handle a wide range of inflections as it learns from the data rather than relying on predefined rules. | Less practical choice for tasks where computational resources are limited. | ||
| Can generalize well to new data, as it is able to learn patterns in the data rather than memorizing specific examples. | |||
| Hybrid approach | Useful in cases where rule-based or machine and deep learning approach alone is not sufficient to accurately stem a wide range of words. | More complex to implement and understand, and requires more computational resources than a single technique, as it involves combining multiple techniques. | Arabic [13] Urdu [5] |
| Often achieves higher accuracy than a single technique, as it takes advantage of the strengths of multiple techniques. | Less practical choice for tasks where computational resources are limited. | ||
| More robust since it can use the dictionary to derive a word’s lemma even if the word is not seen during training. | |||
| Can be customized to handle specific inflections or words by adding them to the dictionary. |
| Long Vowel | Short Vowel | Diacritic | |||
|---|---|---|---|---|---|
| Symbol | Example | Symbol | Example | Symbol | Example |
| اُ | اُو-/O | َ | پَاک-/Pak | ں | میں -/Maine |
 |  -/Aye -/Aye | ئ | ولئ کامل-/Wali-e-Kaamil | ء | إِسماعيل -/Ismail |
| اِ | اِی-/E | ۓ | روئے زمین-/Ru-e-Zameen | ْ | بنْت-/Bint |
| او | آو-/Aao | ُ | حُسن-/Husn | ّ | مدرسّہ-/Madrasa |
| Word | Type | Discussion |
|---|---|---|
 | Inflectional | Both end with “ی”, making them feminine but in reality, they are masculine in nature. |
 | Derivational | These masculine abstract nouns are the resultant of causative verbs when their roots are attached with “ؤ”. |
| Loan Language | Loan Words | |||
|---|---|---|---|---|
| Persian | نمائندگان | ہم نفس | دانشور | دستِ بازو |
| Arabic | مساجد | مفتاح | علماِ دین | لا قانونیت |
| English | کالم (Column) | انجن (Engine) | سائیکل (Cycle) | ہیٹر (Heater) |
| Turkish | امداد | بدترین | مرکب | مراسم |
| Models | UMC Dataset | UDC Dataset | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F-Score | Accuracy | Precision | Recall | F-Score | |
| BiLSTM | 91.6% | 88.4% | 86.4% | 89.4% | 95.4% | 91.7% | 92.3% | 91.3% |
| BiGRU | 92.5% | 90.4% | 89.9% | 91.5% | 95.7% | 94.1% | 93.5% | 94.6% |
| BiGRRN | 91.8% | 87.8% | 88.3% | 88.7% | 94.7% | 91.8% | 92.6% | 92.1% |
| AFED | 94.3% | 91.7% | 91.4% | 92.6% | 96.3% | 95.2% | 94.9% | 95.1% |
| Words | Lemma |
|---|---|
| شُمَالی (Northern) | شمال (North) |
| چوٹِیوں (Hills) | چوٹی (Hill) |
| آبشَاروں (Waterfalls) | آبشار (Waterfall) |
| Words | Loan Language | In Urdu | Lemma |
|---|---|---|---|
| All ambulances | English | تمام ایمبولینسیں | ایمبولینس |
| Am’dad | Turkish | امداد | مدد |
| Bad’tareen | Turkish | بد ترین | بد تر |
| Ayaat | Arabic | آیات | آیت |
| Inflectional Urdu Words | Derivational Urdu Words | ||
|---|---|---|---|
| Words | Lemma | Word | Lemma |
| برسات (N) | برس (N) | آبادی (N) | آباد (Adj) |
| حمایتی (N) | حمایت (N) | حیادار (Adj) | حیا (N) |
| حلف نامہ (N) | حلف (N) | خاردار (N) | خار (Adj) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hafeez, R.; Anwar, M.W.; Jamal, M.H.; Fatima, T.; Espinosa, J.C.M.; López, L.A.D.; Thompson, E.B.; Ashraf, I. Contextual Urdu Lemmatization Using Recurrent Neural Network Models. Mathematics 2023, 11, 435. https://doi.org/10.3390/math11020435
Hafeez R, Anwar MW, Jamal MH, Fatima T, Espinosa JCM, López LAD, Thompson EB, Ashraf I. Contextual Urdu Lemmatization Using Recurrent Neural Network Models. Mathematics. 2023; 11(2):435. https://doi.org/10.3390/math11020435
Chicago/Turabian StyleHafeez, Rabab, Muhammad Waqas Anwar, Muhammad Hasan Jamal, Tayyaba Fatima, Julio César Martínez Espinosa, Luis Alonso Dzul López, Ernesto Bautista Thompson, and Imran Ashraf. 2023. "Contextual Urdu Lemmatization Using Recurrent Neural Network Models" Mathematics 11, no. 2: 435. https://doi.org/10.3390/math11020435
APA StyleHafeez, R., Anwar, M. W., Jamal, M. H., Fatima, T., Espinosa, J. C. M., López, L. A. D., Thompson, E. B., & Ashraf, I. (2023). Contextual Urdu Lemmatization Using Recurrent Neural Network Models. Mathematics, 11(2), 435. https://doi.org/10.3390/math11020435