
Improved Hybrid Firefly Algorithm with Probability Attraction Model


Abstract
1. Introduction
- According to the uniformity and diversity of the initial population generated by different initialization methods, the best method of population uniformity and diversity is selected as the population initialization method.
- A probabilistic attraction model is proposed for the problems of various attraction models.
- A firefly position update formula with an adaptive change in relative attraction is proposed to improve the convergence speed and solution quality of FA.
- A combined mutation operator based on selection probability is proposed, which can adaptively select a single mutation operator with strong exploration ability and exploitation ability.
- A remove similarity operation is added to the algorithm to enhance the exploration ability of the algorithm and maintain the diversity of the population.
- The proposed IHFAPA is compared with other improved algorithms in the literature in parameter optimization, such as reducer and cantilever beam. IHFAPA is superior to them in solution quality.
2. Related Works
2.1. Firefly Algorithm
| Algorithm 1: Pseudo code of FA |
| Input: The population size of the population is n, and the dimension of the variable is D, T is maximum number of iterations; |
| Output: The final population; |
| Randomly generate n initial fireflies; Calculate the fitness value of all initial fireflies; Parameter initialization, population size, maximum attraction and light attraction coefficient; let t = 0; |
| While t ≤ T do t←t + 1; |
| for i = 1 to n do |
| for j = 1 to n do |
| If firefly j is brighter than firefly i then |
| Generate a new firefly according to Equation (3); |
| Evaluate the new solution; |
| End if |
| End for |
| End for |
| Rank the fireflies and find the current best; |
| End While End |
2.2. Brief Review of FA
2.2.1. Adaptive Adjustment of Parameters
2.2.2. Improved Location-Update Method
2.2.3. Improvement in Attraction Model
2.2.4. Hybrid Firefly Algorithm
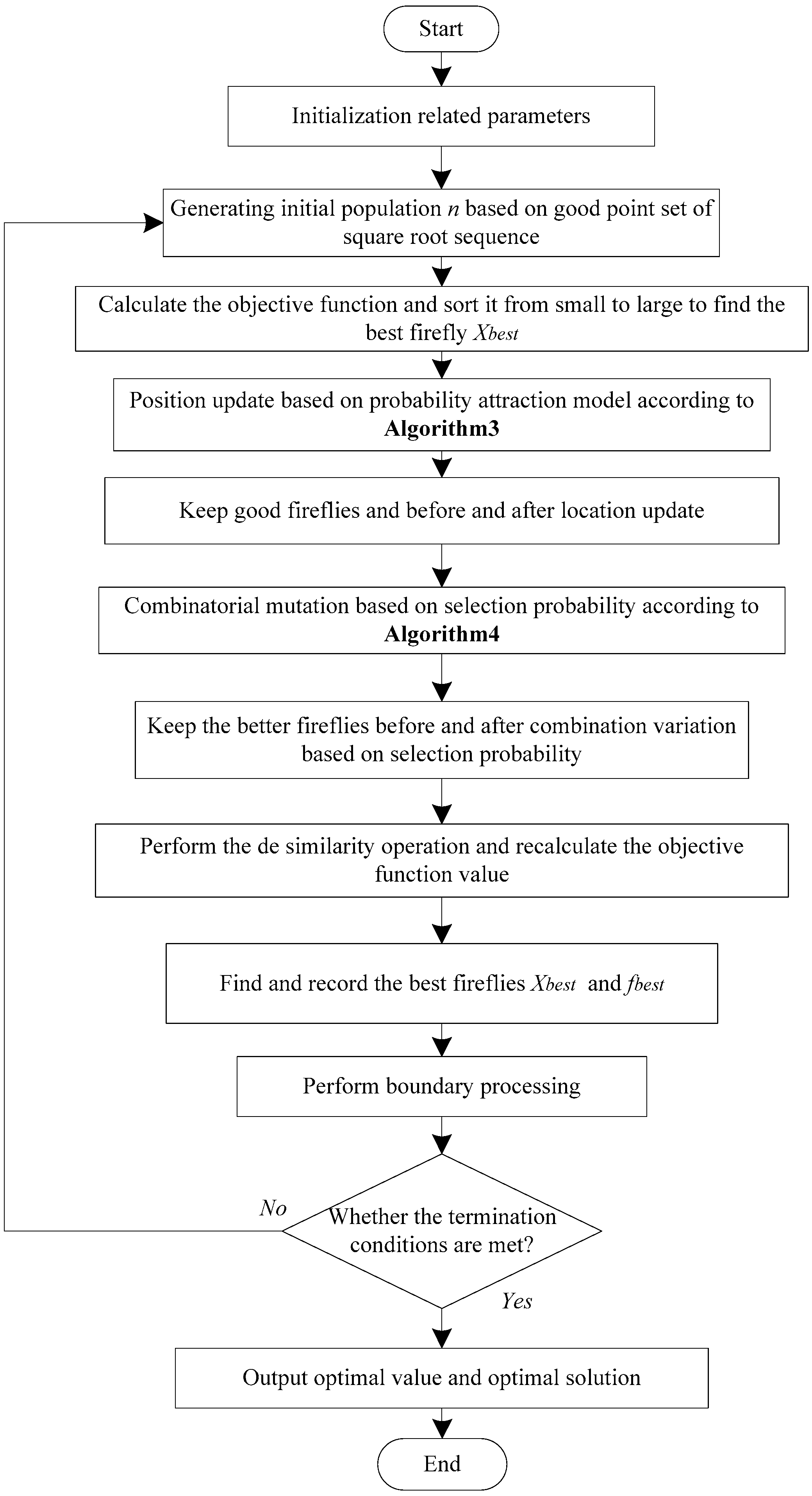
3. Proposed Methods
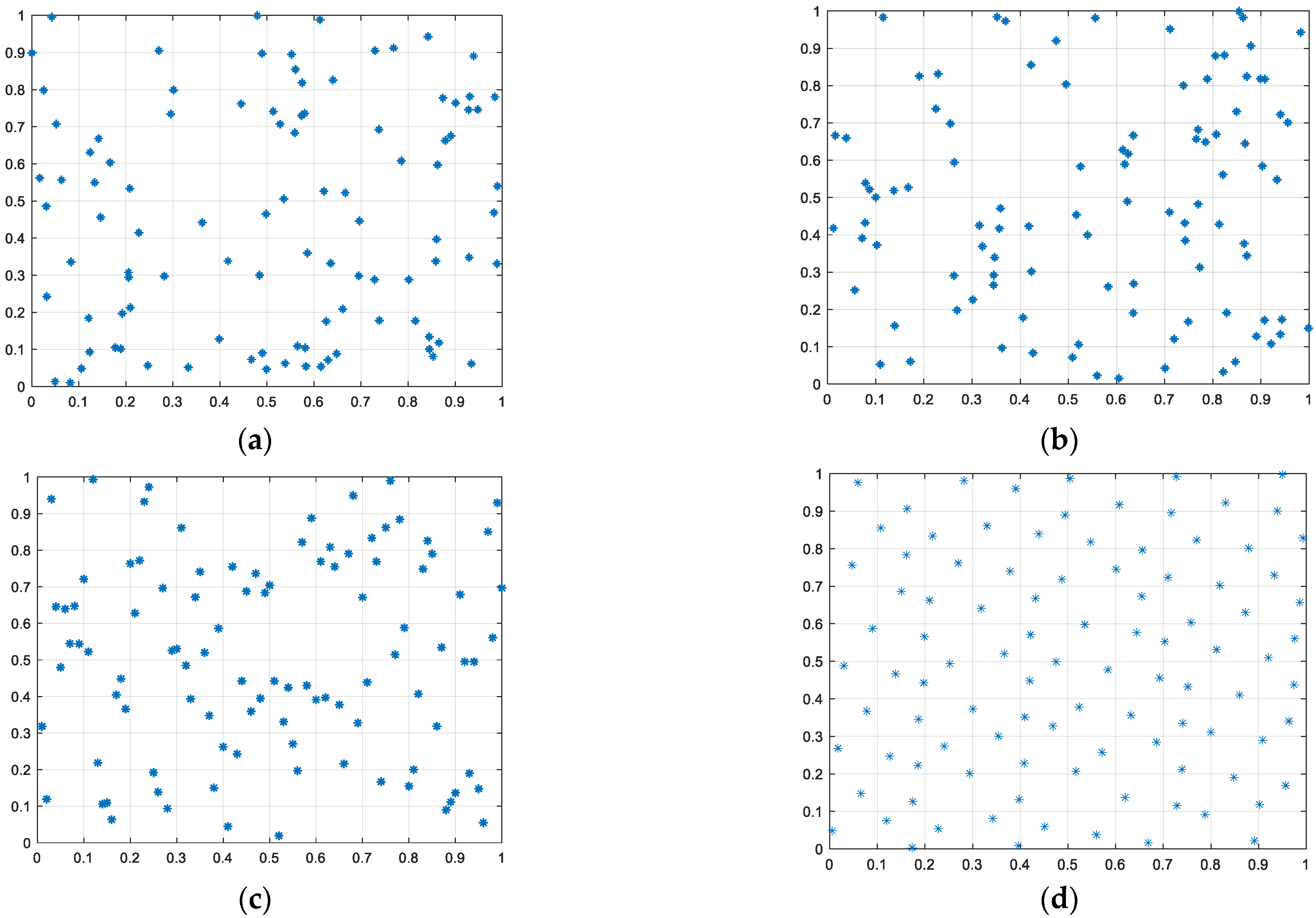
3.1. Population Initialization
3.1.1. Initial Population Generation Method Based on Square-Root Sequence Method
| Algorithm 2: Initial population generated based on the square-root sequence good point set method |
| Input: The population size of the population is n, and the dimension of the variable is D; Output: The initial population of the population; |
| Produce the first good point r1: |
| Generate a good point set according to Equation (4) Pn |
| for I = 1 to n do |
| The individual generating the initial population according to Equation (5) Xi: |
| end for |
3.1.2. Compare Different Population Initialization Methods
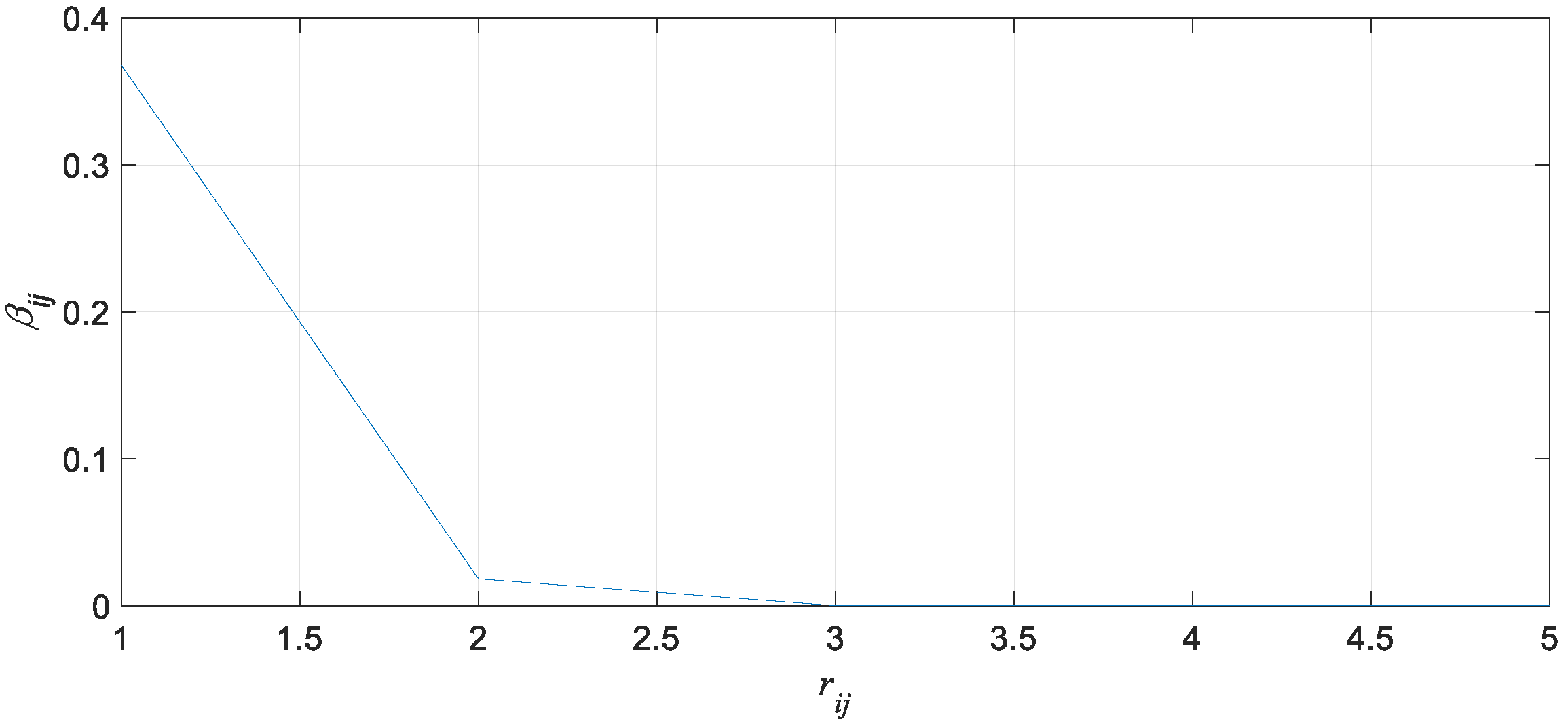
3.2. Probability Attraction Model
3.2.1. Common Attraction Model
3.2.2. Probability Attraction Model
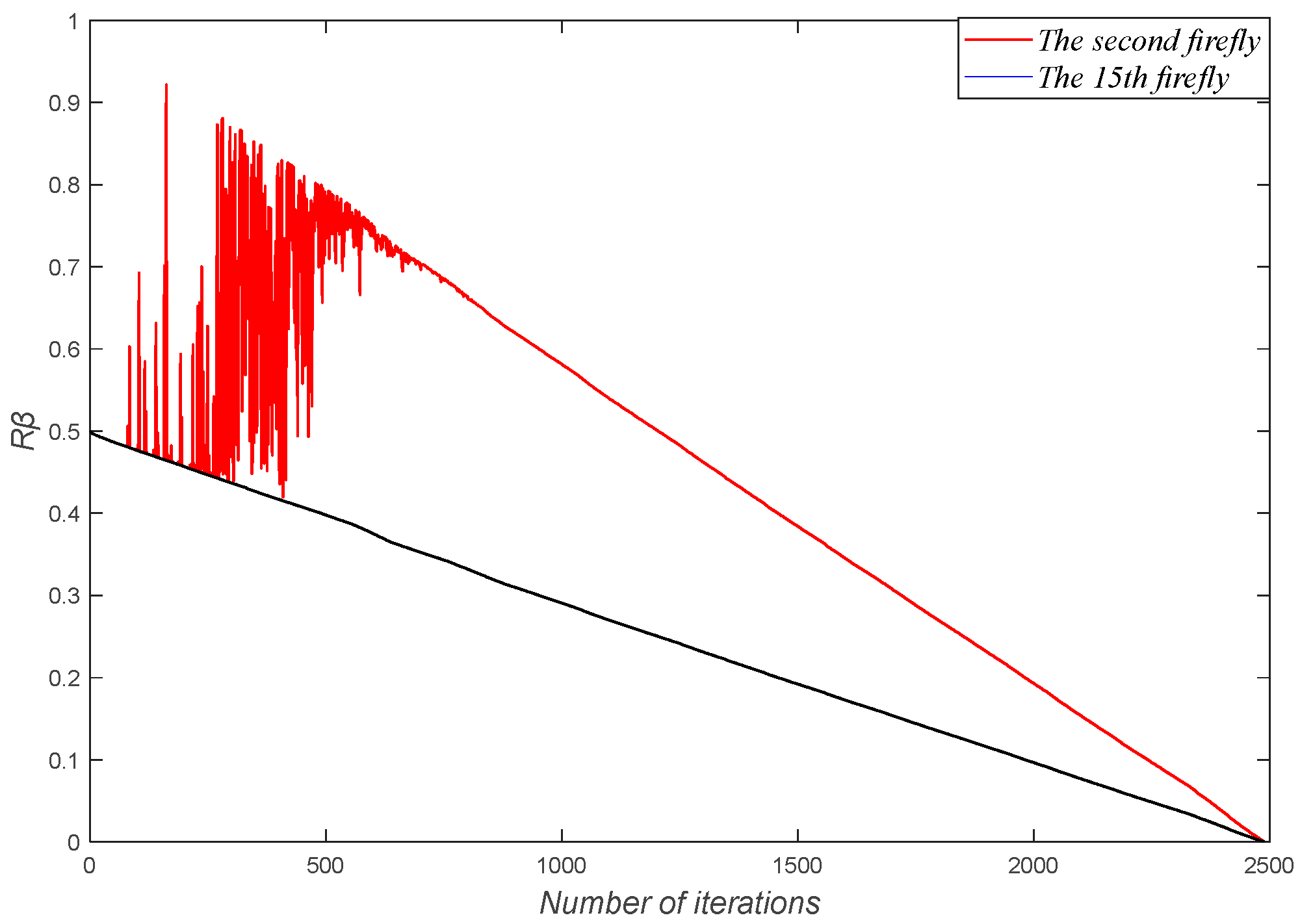
3.3. Improved Location-Update Method
| Algorithm 3: Improved position update based on probability attraction model |
| Input: individual fireflies of the population; Output: the updated firefly population; |
| Calculation of the OFV for fireflies in the current population; |
| The fireflies in the population are sorted according to their OFV from small to large; |
| Recording the best firefly Xbest and its OFV fbest; |
| for i = 2 to n do |
| Update Xi(t) and Xbest according to Equation (14); |
| End for |
3.4. Combined Mutation Operator Based on Selection Probability
| Algorithm 4: Combined mutation operation based on selection probability |
| Input: Firefly individuals in the population; Output: Firefly individuals in the population after combined mutation operation; |
| Calculate the value of scaling factor f according to Equation (22); |
| for i = 1 to n |
| if rand < P1 |
| if rand ≤ 0.5 |
| Generate a new solution Xi(t + 1) according to Equation (18); |
| else |
| Generate a new solution Xi(t + 1) according to Equation (19); |
| else |
| Else rand ≤ 0.5 |
| Generate a new solution Xi(t + 1) according to Equation (20); |
| else |
| Generate a new solution Xi(t + 1) according to Equation (21); |
| End if End if |
| End for |
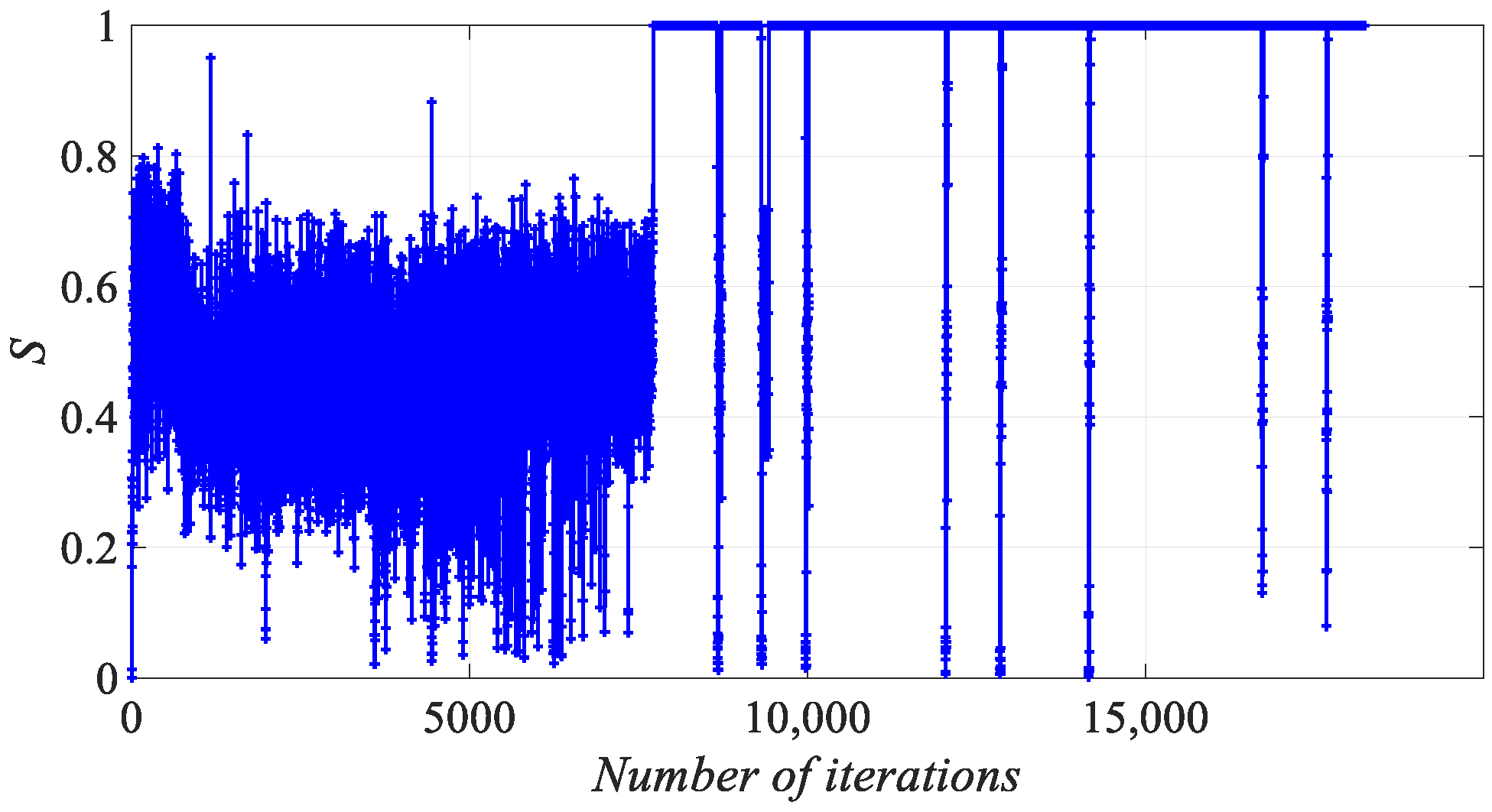
3.5. Remove Similarity Operation
3.6. The Evolutionary Strategy of IHFAPA
| Algorithm 5: IHFAPA |
| Input: population size n, initial values of S1, F1, S2 and F2, and step size α0, maximum attraction βmax, minimum attraction βmin Output: optimal solution x and optimal value f(x); |
|
4. Numerical Experiment and Result Analysis
4.1. Selection of Test Function
4.2. Evaluation Method of Algorithm Performance
4.2.1. Algorithm Performance Evaluation Indicators
- Mean value
- Standard deviation
- w/t/l indicators
- Friedman rank ranking
- Each algorithm is run R times independently on each test function, and the optimal value of each run is retained.
- Record the optimal value obtained from R runs and calculate the average value of R optimal values according to the following formula:where m is the number of algorithms participating in the comparison, k is the number of test functions and R is the number of independent runs. meanfij represents the average value of the optimal value obtained by the i-th algorithm independently running on the j-th test function for R times.
- For each test function, all the algorithms participating in the comparison are sorted in the order of meanfij from small to large and give the algorithm rank ranking rankij (i = 1, 2, …, m; j = 1, 2, …, k). If the average value of the optimal value of the comparison algorithm is the same, then take the average of the ranking position as the rank ranking. To explain the calculation method of ranking and rank ranking, suppose there are five algorithms involved in the comparison. For a certain test function, if the average value of the optimal value obtained by the algorithm participating in the comparison is 1, 3, 3, 2 and 4, respectively, since the average of the optimal values found by the second and third algorithms are the same, then the ranking of the two algorithms are 3 and 4, respectively. Take the average of the ranking positions of these two algorithms ((3 + 4) / 2 = 3.5) as the rank ranking of the algorithm. Therefore, the rank rankings corresponding to the five algorithms are 1, 3.5, 3.5, 2 and 5. The results of the rank ranking are shown in Table 4.
- Calculate the average of the rank ranking of each algorithm Averanki.where m is the number of participating comparison algorithms and k is the number of test functions.
- Rank according to the average value Averanki of the rank ranking of each algorithm from small to large, the result of the sorting is the final ranking Finalranki of various algorithms.
4.2.2. Algorithm Performance Difference Significance Test
- The original hypothesis, opposite hypothesis and significance level of Friedman test are given α.
- 2.
- Calculate the rank of each algorithm corresponding to each test function rankji(1 ≤ I ≤ m, 1 ≤ j ≤ k).
- 3.
- Calculate the sum of rank ranking of each test function corresponding to each algorithm sunranki; the sunranki calculation formula is sunranki:
- 4.
- Calculate the Friedman test value χ2. The calculation formula of χ2 is:
- 5.
- According to the pre-determined significance level α and degrees of freedom (m − 1). Critical values can be obtained from the table of critical values of the Chi-square test χ2α[m − 1], if
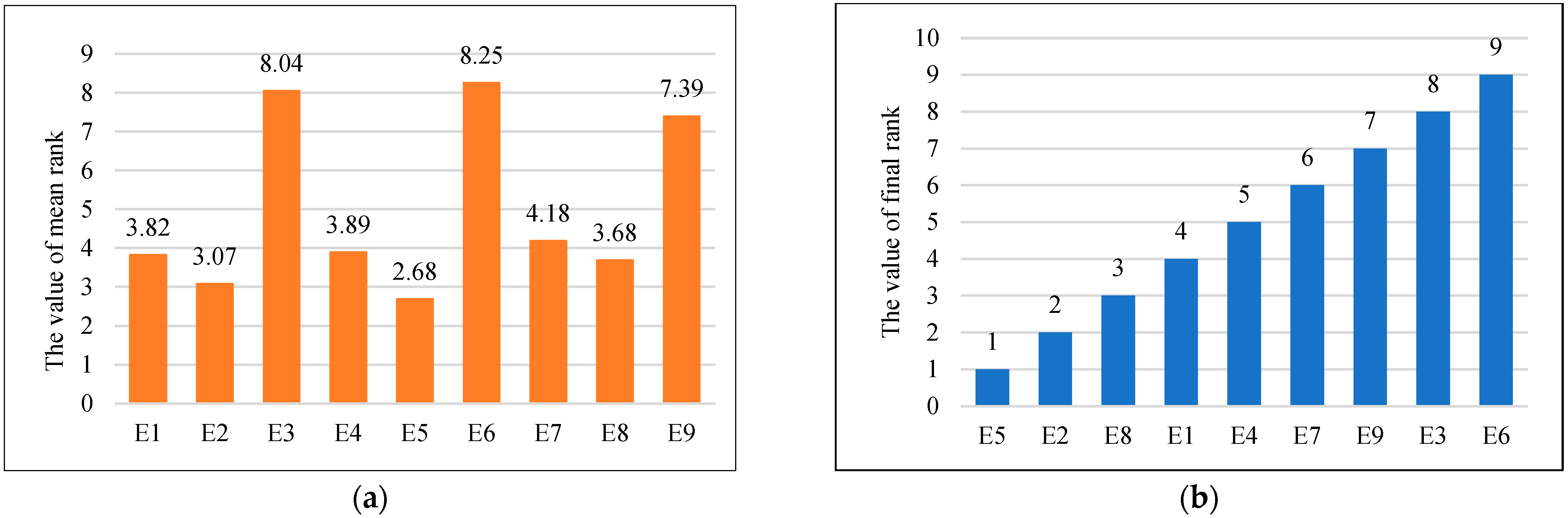
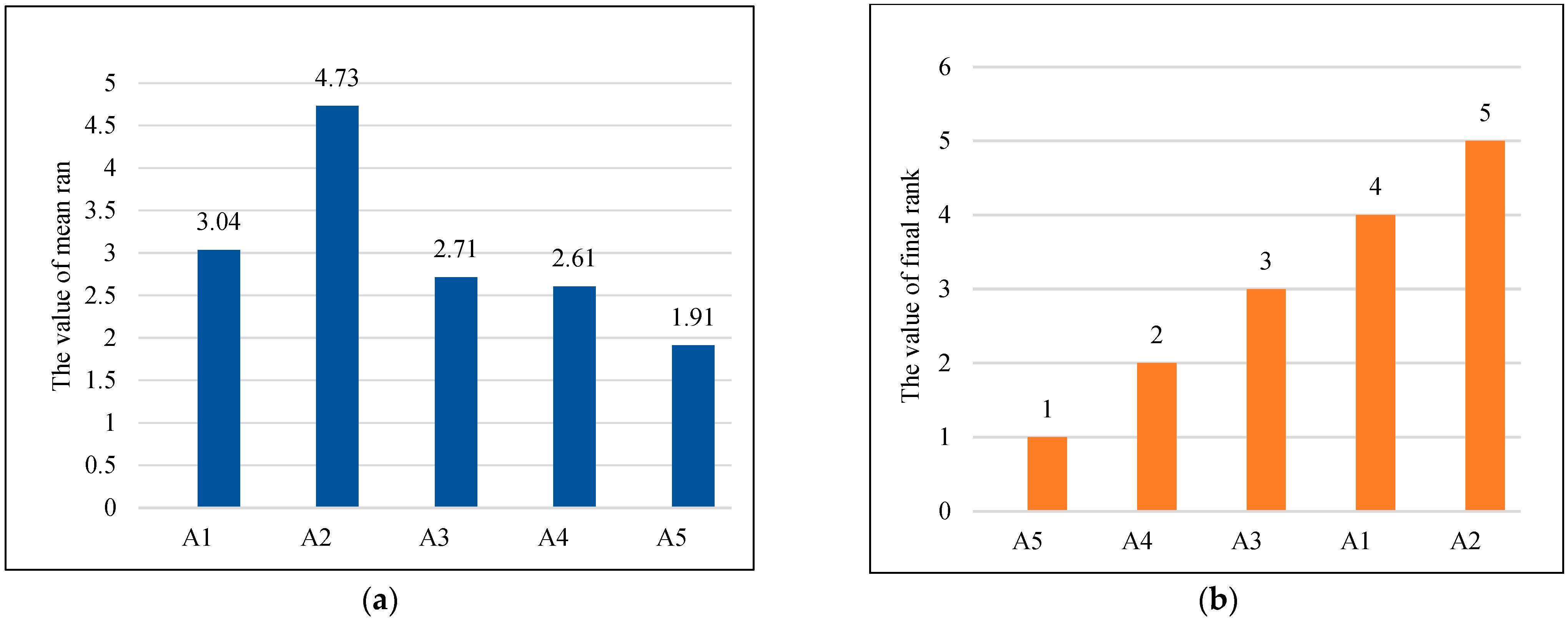
4.3. Obtain the Optimal Parameter Combination through Orthogonal Experiments
4.4. Termination Condition of Algorithm Iteration
- Taking the maximum number of iterations as the iteration termination condition, it is unfair to the algorithms that participate in the comparison. Let the time required for an iteration of algorithm A be t1, the time required for one iteration of algorithm B is t2, and t1 > t2. Let t1 = 1.2t2, t2 = 0.005 s, the maximum number of iterations is 1000. When both algorithm A and algorithm B reach the maximum number of iterations, algorithm A needs 6 s and algorithm B needs 5 s. The running time of A is 1 s longer than the running time of B. If the solution quality of A is better than that of B, it cannot be said that the performance of algorithm A is better than that of algorithm B. Because the running time of A is long, if algorithm B runs for another 1 s, the quality of the solution from algorithm B is not necessarily worse than that of algorithm A.
- Taking the maximum evaluation times of the objective function as the termination condition of the algorithm iteration, it is also unfair to the algorithms involved in the comparison. The main reasons are: some algorithms in an iteration process, although the evaluation times of the objective function are few, the running time of the program is very long; some algorithms in an iteration process, although there are many evaluation times of the objective function, but the running time of the program is very short. Therefore, taking the maximum evaluation times of the objective function as the iteration termination condition is unfair to some algorithms.
4.5. Performance Comparison of Different Attraction Models
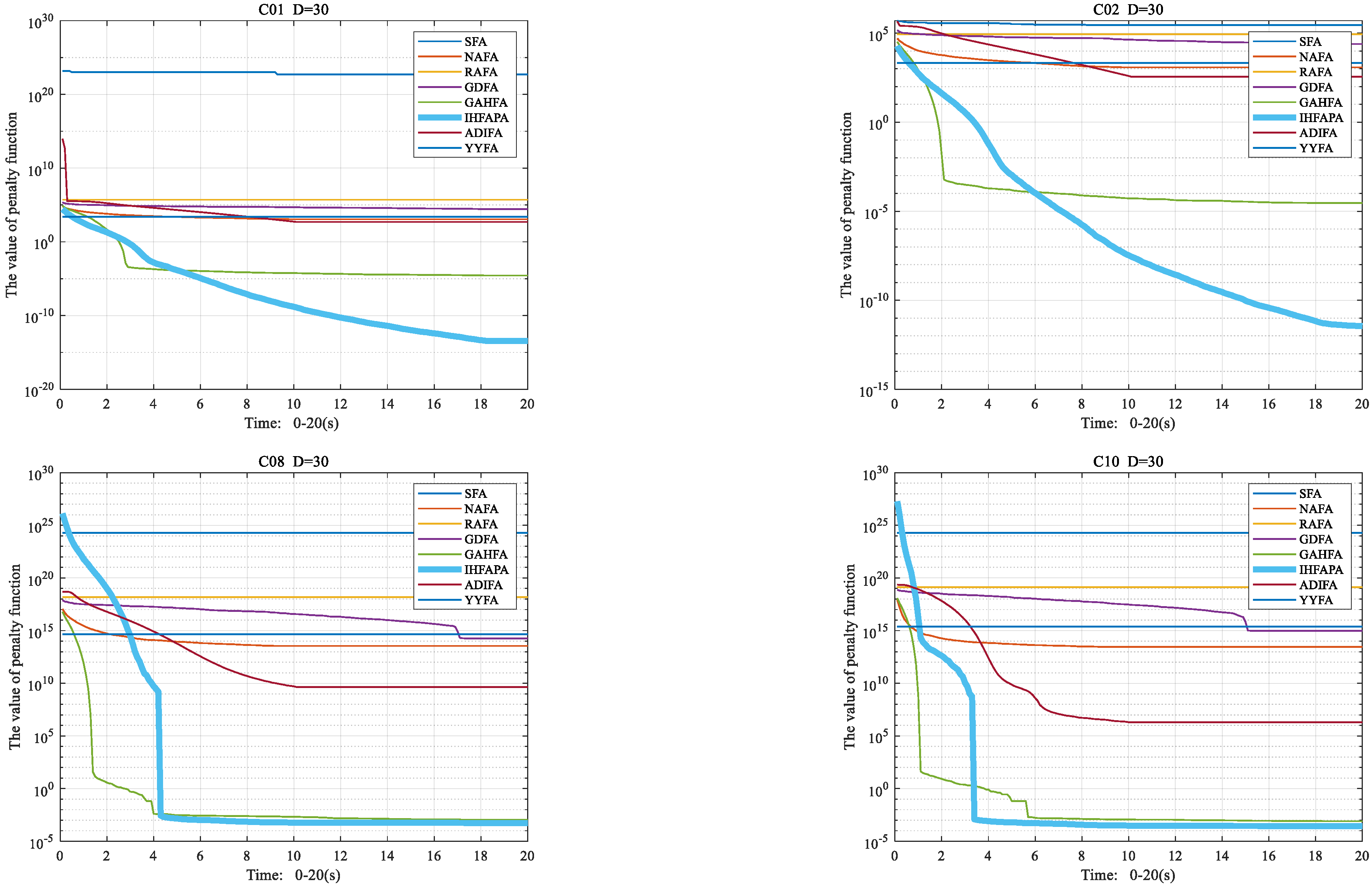
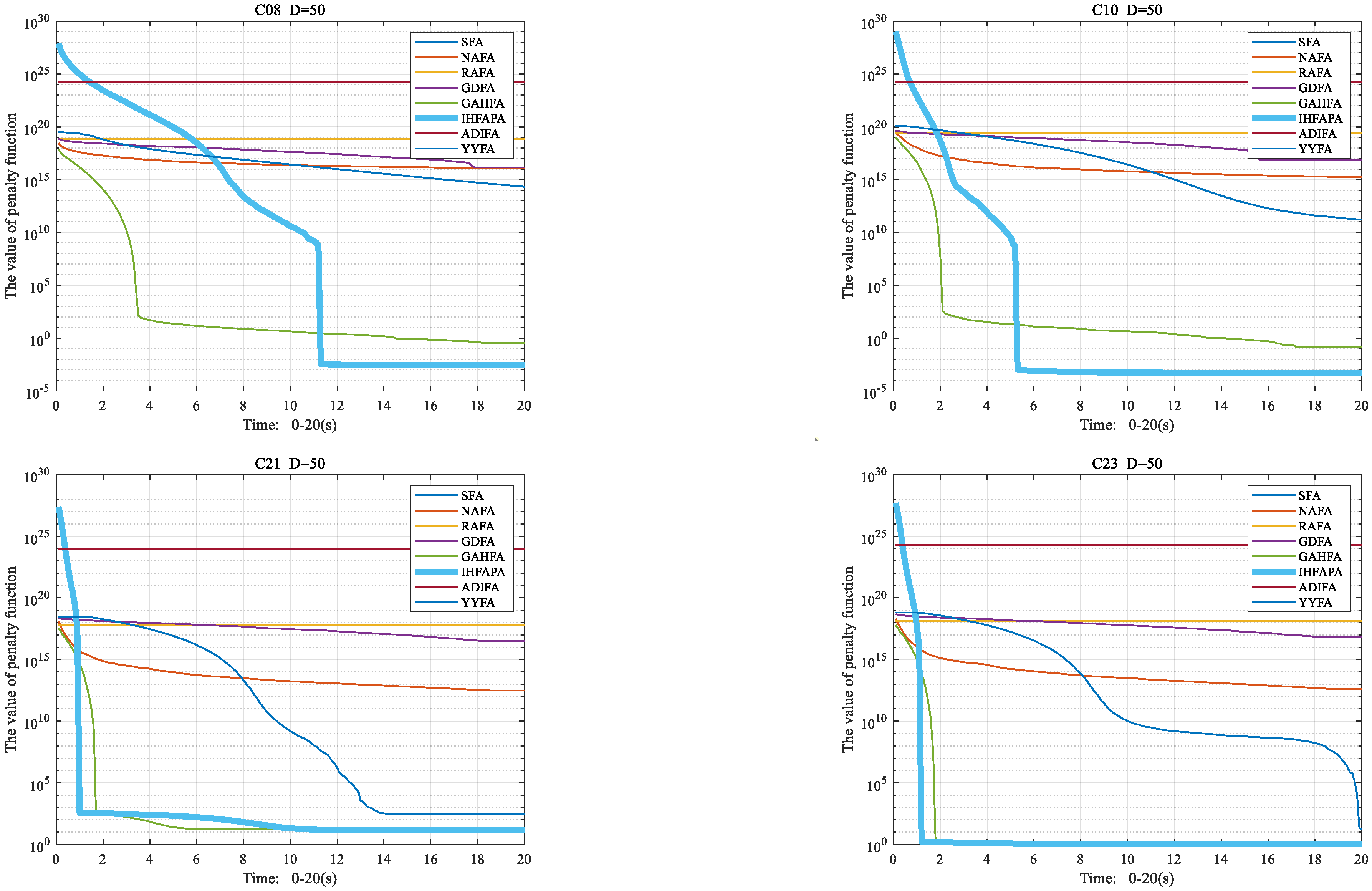
4.6. Performance Comparison between IHFAPA and Other FAs
- Standard firefly algorithm (SFA) [6];
- Random-attracting firefly algorithm (RaFA) [19];
- Neighborhood-attracting firefly algorithm (NaFA) [42];
- Gender-difference firefly algorithm (GDFA) [47];
- An adaptive Log Spiral levy firefly algorithm (ADIFA) [29];
- Cauchy mutation of the Yin and Yang firefly algorithm (YYFA) [36];
- Group-attraction hybrid firefly algorithm (GAHFA) [20].
4.6.1. Parameter Settings
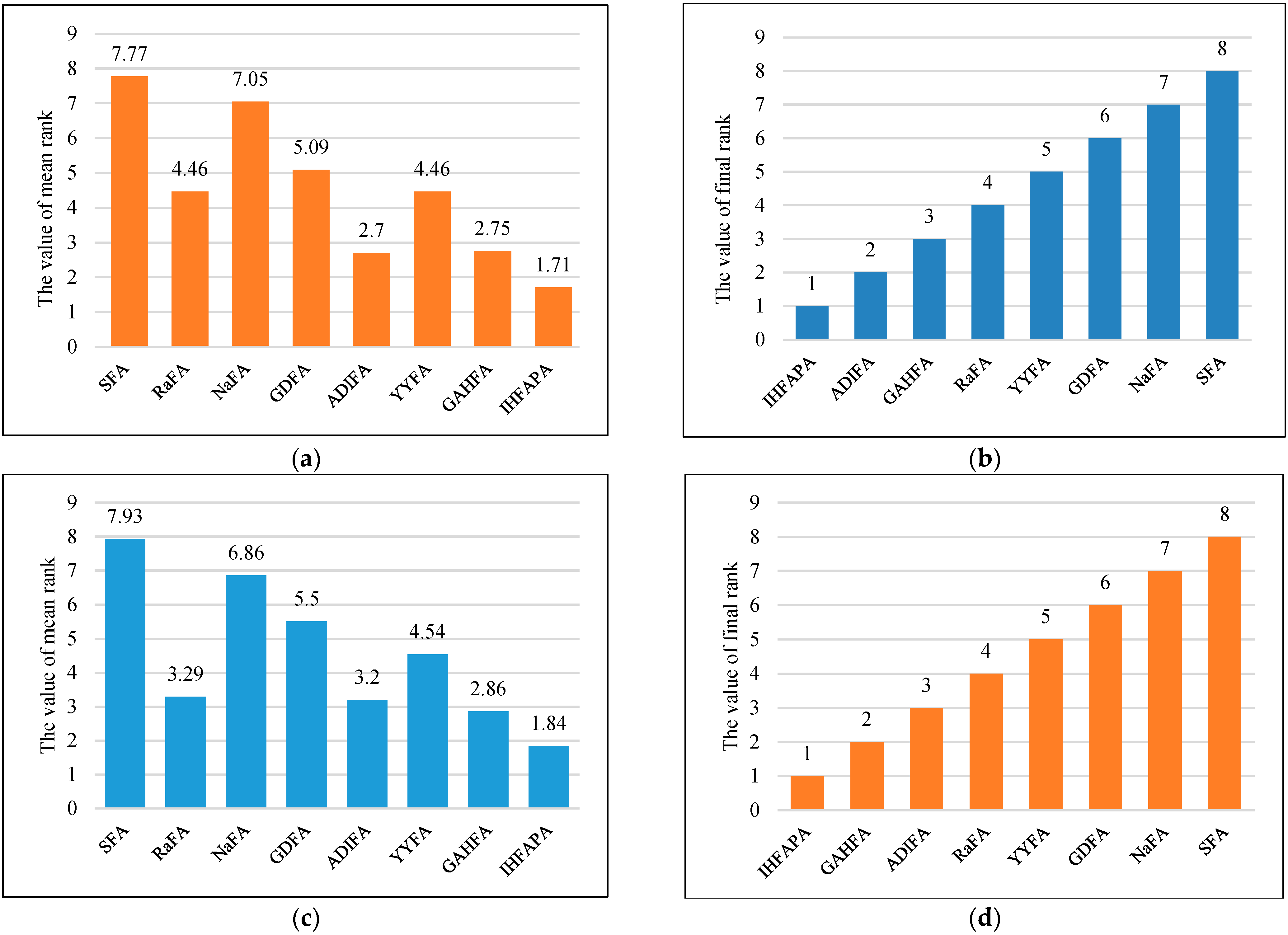
4.6.2. Statistical Results and Analysis
- Statistical results
- 2.
- Result analysis
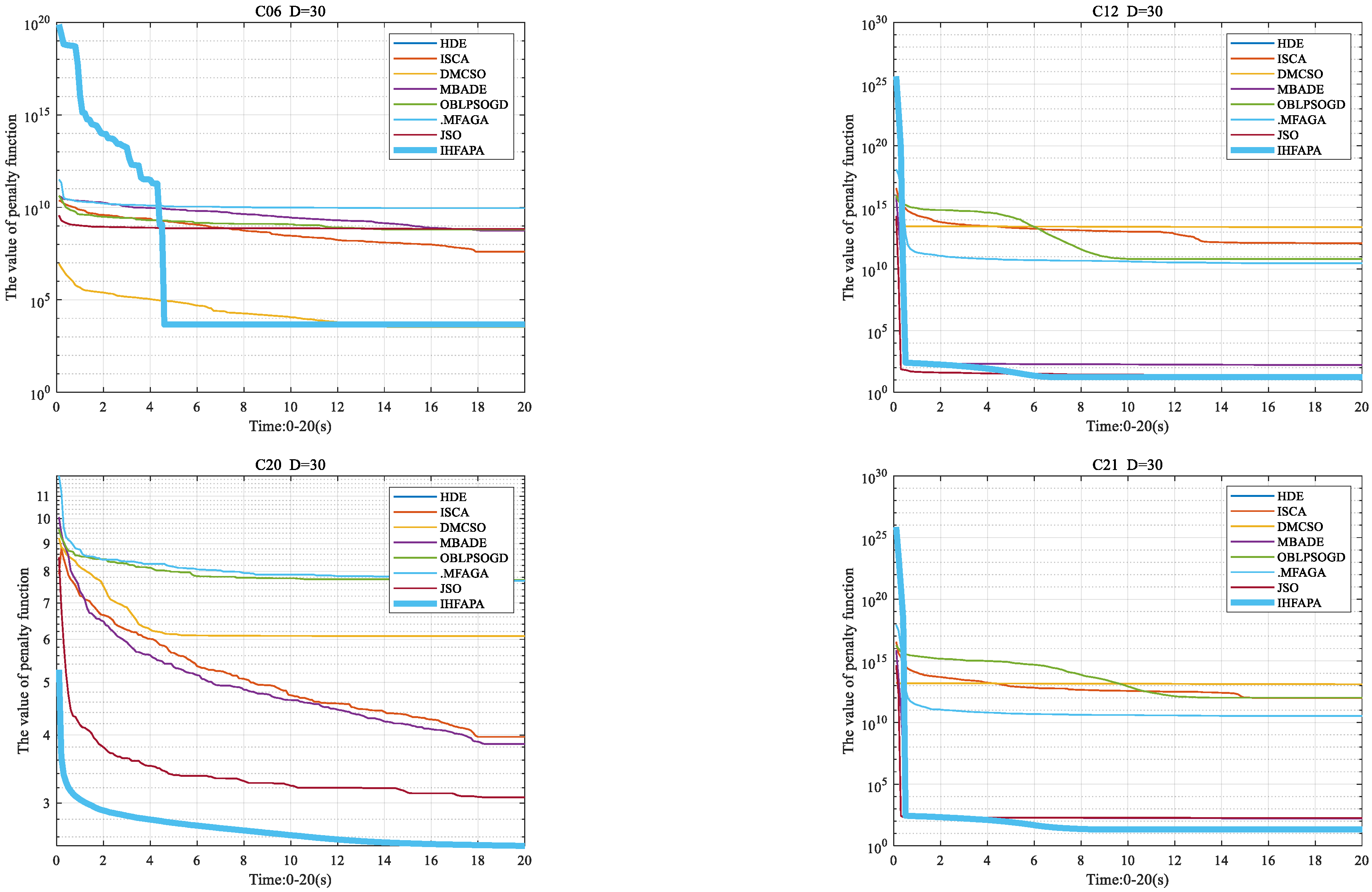
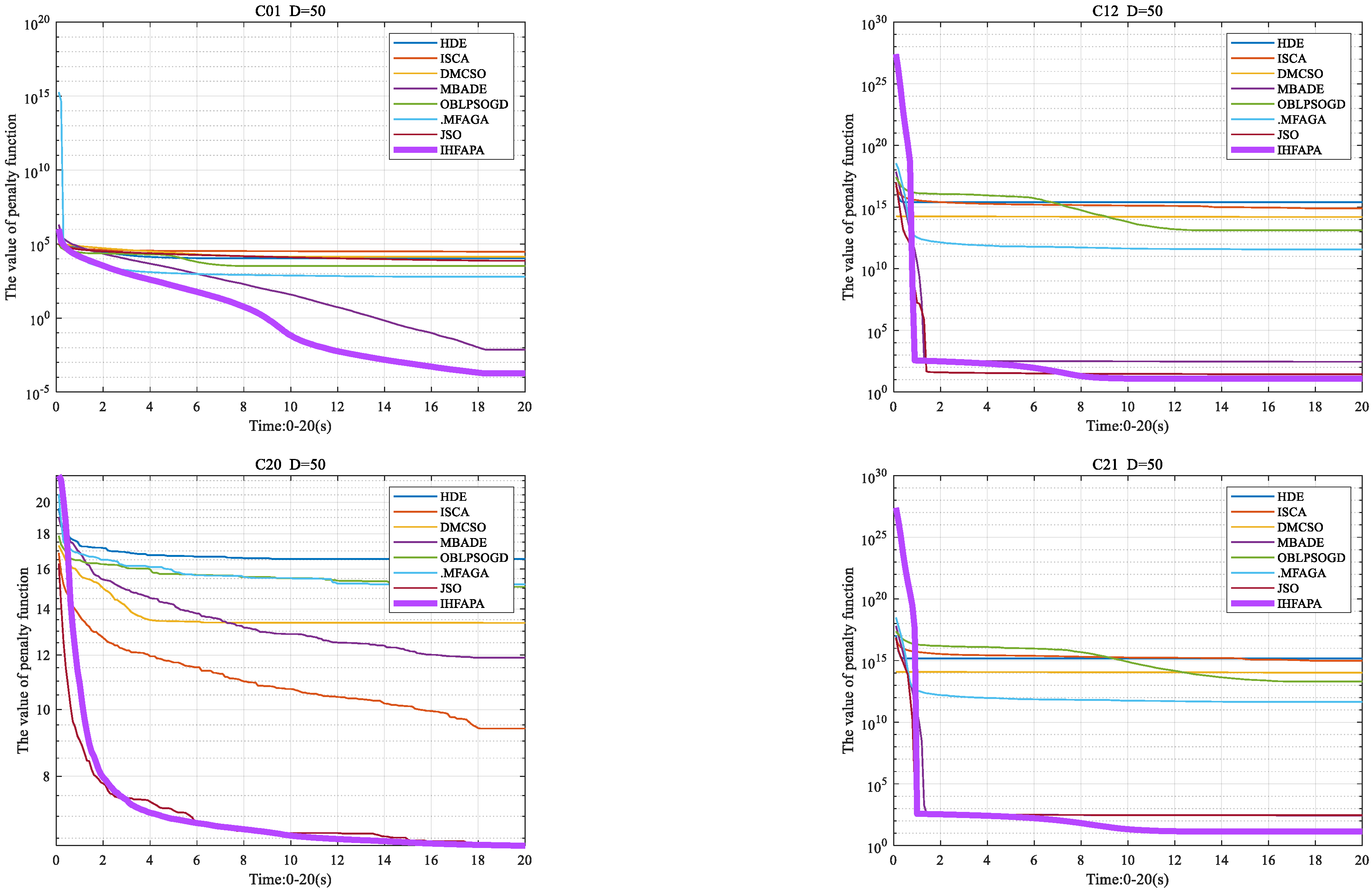
4.6.3. Convergence Curve of Firefly Algorithm
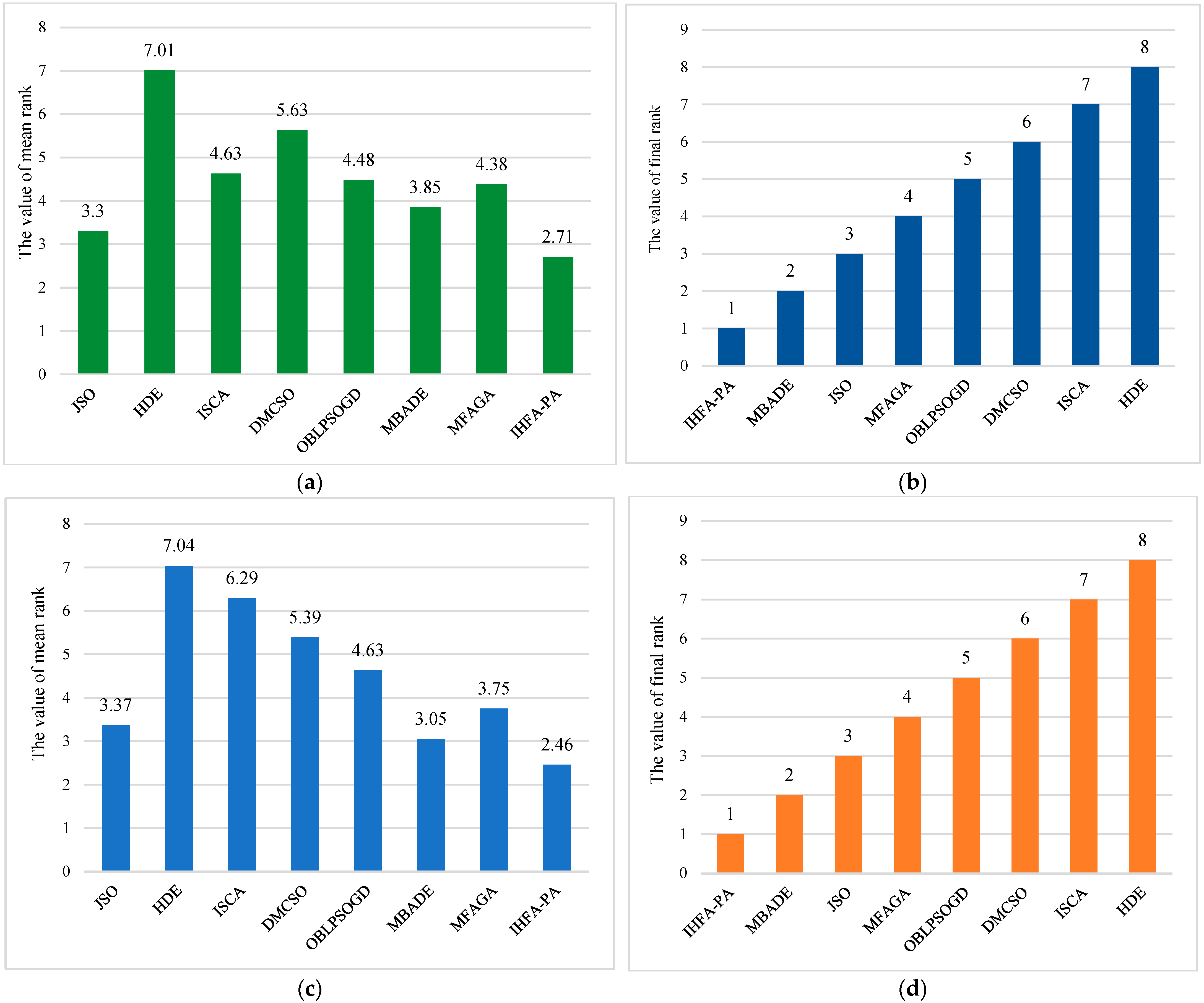
4.7. Comparison of IHFAPA and Other Improved Algorithms
- Adaptive differential evolution algorithm (HDE) [47];
- Improved sine and cosine algorithm with crossover operator (ISCA) [48];
- Hybrid chicken swarm algorithm based on differential mutation (DMCSO) [49];
- Particle swarm optimization based on oppositional group decision learning (OBLPSOGD) [50];
- Hybrid algorithm of improved bat algorithm and differential evolution algorithm (MBADE) [51];
- Firefly single-objective genetic optimization algorithm based on partition and unity (MFAGA) [52];
- Single-objective real-parameter optimization: Algorithm Jso (JSO) [53];
4.7.1. Parameter Setting
4.7.2. Statistical Results and Analysis
- 1.
- Statistical results
- 2.
- Results analysis
4.7.3. Convergence Curve of the Proposed Algorithm
5. Application to Engineering Problems
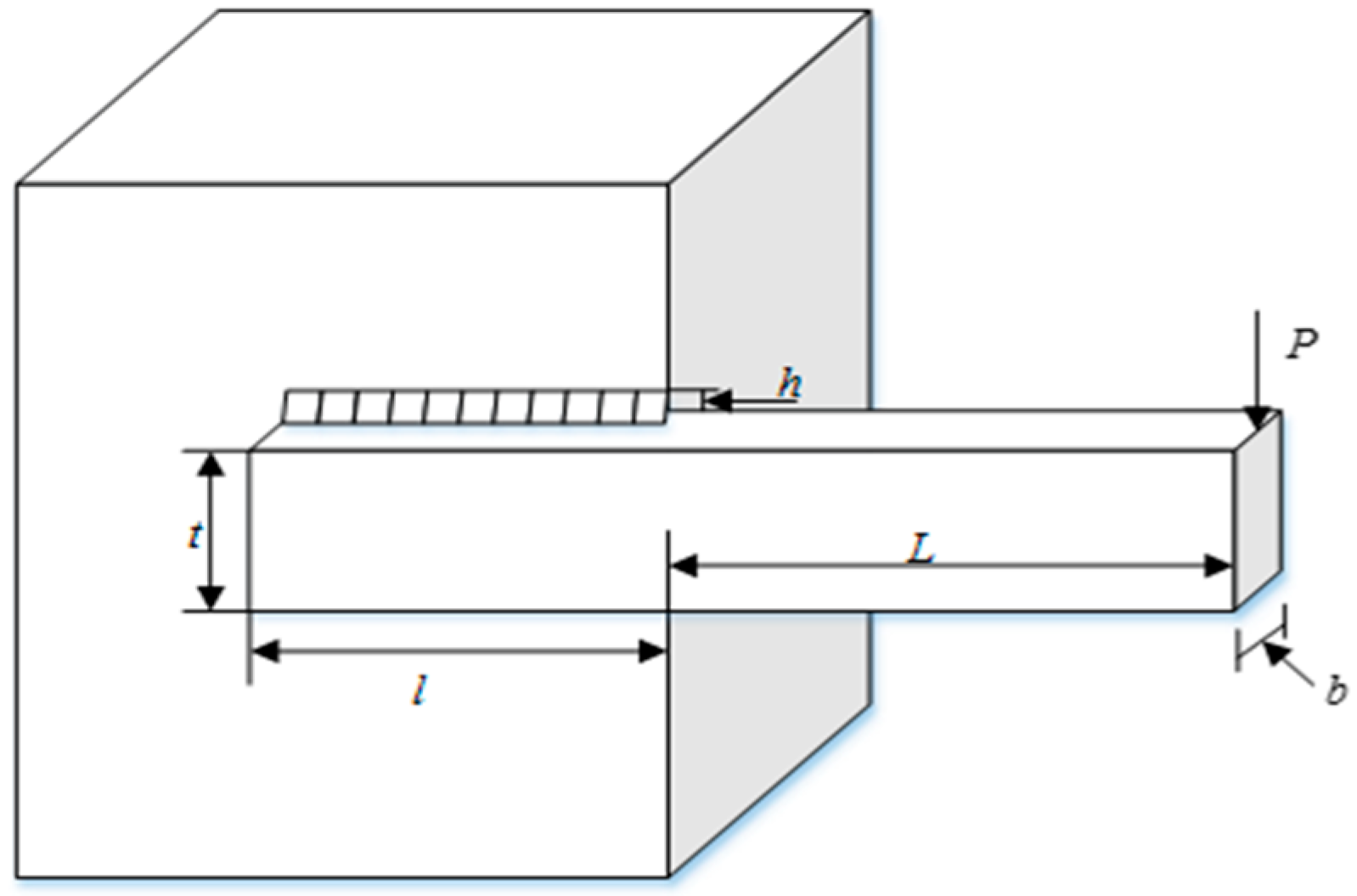
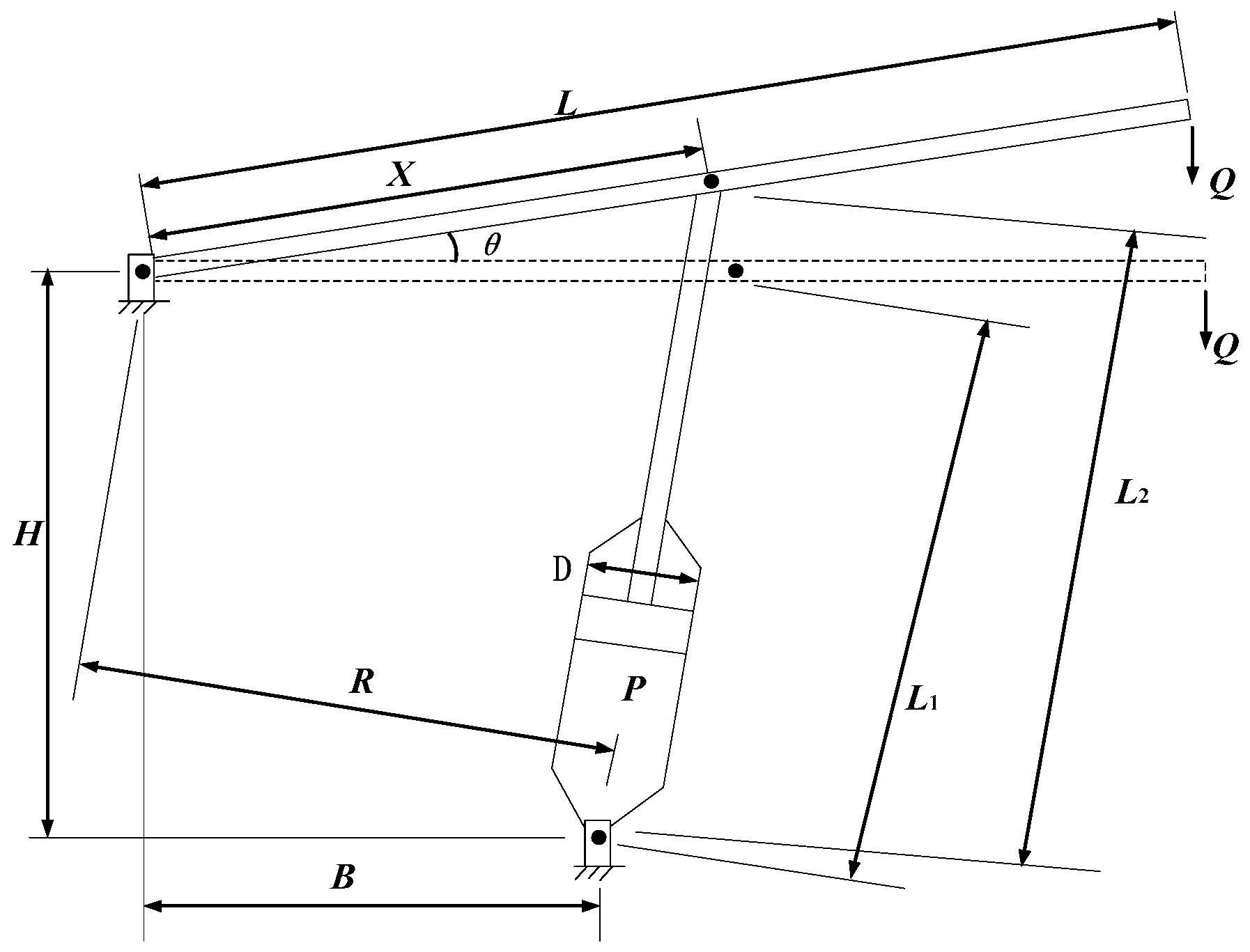
5.1. Optimization Design of Cantilever Beam [28]
5.2. Optimization Design of Welded Beam [54]
5.3. Optimization Design of Piston Rod [55]
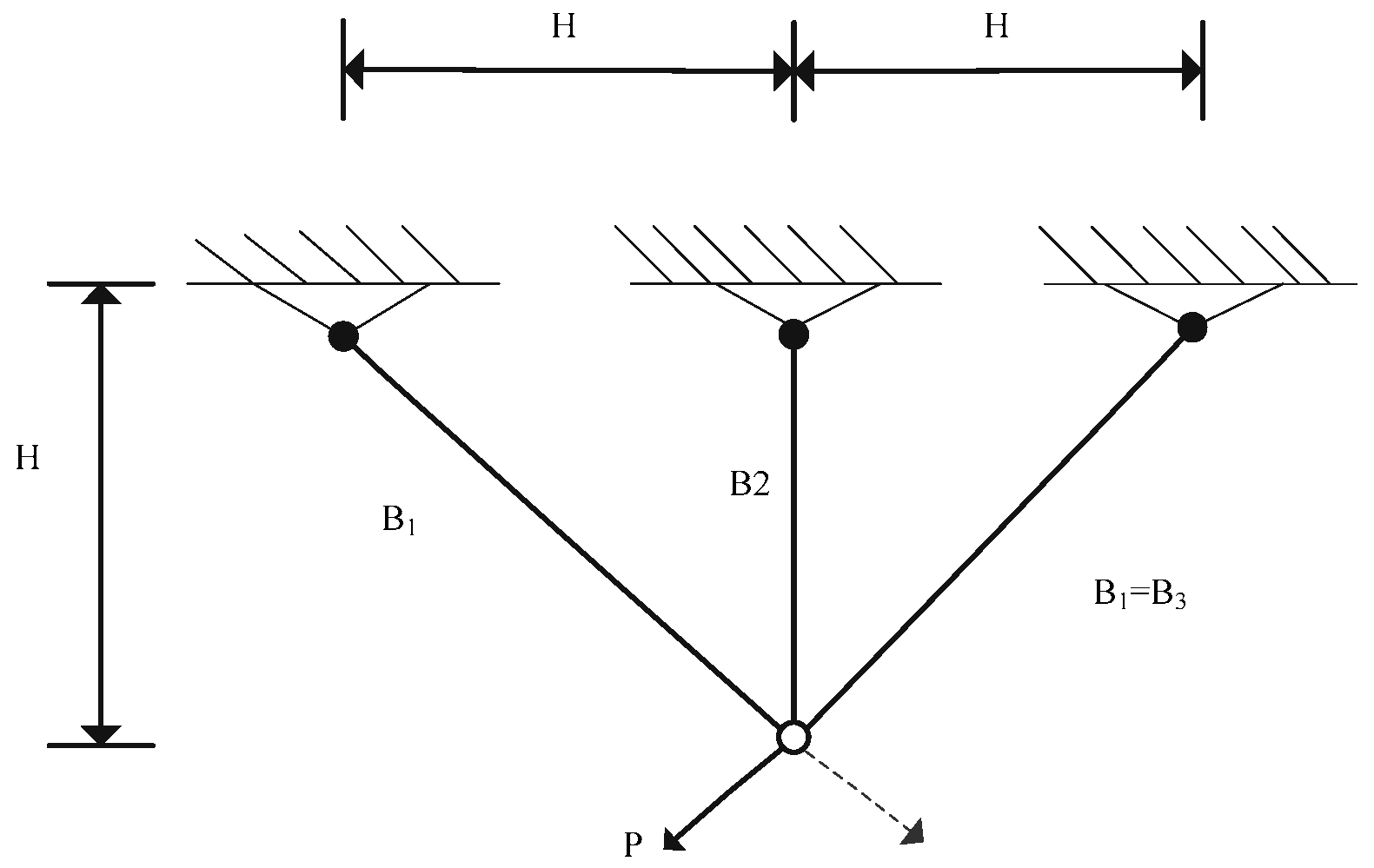
5.4. Optimization Design of Three-Bar Truss [55]
5.5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bhanu, B.; Lee, S.; Ming, J. Adaptive image segmentation using a genetic algorithm. IEEE Trans. Syst. Man Cybern. 1995, 25, 1543–1567. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential Evolution—A Simple and Efficient Heuristic for global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Gao, W.F.; Liu, S.Y.; Huang, L.L. Particle swarm optimization with chaotic opposition-based population initialization and stochastic search technique. Commun. Nonlinear Sci. Numer. Simul. 2012, 17, 4316–4327. [Google Scholar] [CrossRef]
- Wang, H.; Zhou, X.Y.; Sun, H.; Yu, X.; Zhao, J.; Zhang, H.; Cui, L.Z. Firefly algorithm with adaptive control parameters. Soft Comput. 2017, 21, 5091–5102. [Google Scholar] [CrossRef]
- Karaboga, D.; Basturk, B. A powerful and efficient algorithm for numerical function optimization: Artificial bee colony (ABC) algorithm. J. Glob. Optim. 2007, 39, 459–471. [Google Scholar] [CrossRef]
- Yang, X.S. Nature-Inspired Metaheuristic Algorithms; Luniver Press: Bristol, UK, 2008. [Google Scholar]
- Mishra, S.P.; Dash, P.K. Short-term prediction of wind power using a hybrid pseudo-inverse Legendre neural network and adaptive firefly algorithm. Neural Comput. Appl. 2019, 31, 2243–2268. [Google Scholar] [CrossRef]
- Huang, H.C.; Lin, S.K. A Hybrid Metaheuristic Embedded System for Intelligent Vehicles Using Hypermutated Firefly Algorithm Optimized Radial Basis Function Neural Network. IEEE Trans. Ind. Inform. 2019, 15, 1062–1069. [Google Scholar] [CrossRef]
- Dhal, K.G.; Das, A.; Ray, S.; Galvez, J. Randomly Attracted Rough Firefly Algorithm for histogram based fuzzy image clustering. Knowl. Based Syst. 2021, 216, 106814. [Google Scholar] [CrossRef]
- Agarwal, V.; Bhanot, S. Radial basis function neural network-based face recognition using firefly algorithm. Neural Comput. Appl. 2018, 30, 2643–2660. [Google Scholar] [CrossRef]
- Kaya, S.; Gumuscu, A.; Aydilek, I.B.; Karacizmeli, I.H.; Tenekeci, M.E. Solution for flow shop scheduling problems using chaotic hybrid firefly and particle swarm optimization algorithm with improved local search. Soft Comput. 2021, 25, 7143–7154. [Google Scholar] [CrossRef]
- Ewees, A.A.; Al-qaness, M.A.A.; Abd Elaziz, M. Enhanced salp swarm algorithm based on firefly algorithm for unrelated parallel machine scheduling with setup times. Appl. Math. Model. 2021, 94, 285–305. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, J.; Sun, L.; Mao, J.; Sun, J. A Novel Firefly Algorithm for Scheduling Bag-of-Tasks Applications Under Budget Constraints on Hybrid Clouds. IEEE Access 2019, 7, 151888–151901. [Google Scholar] [CrossRef]
- He, L.F.; Huang, S.W. Modified firefly algorithm based multilevel thresholding for color image segmentation. Neurocomputing 2017, 240, 152–174. [Google Scholar] [CrossRef]
- Pitchaimanickam, B.; Murugaboopathi, G. A hybrid firefly algorithm with particle swarm optimization for energy efficient optimal cluster head selection in wireless sensor networks. Neural Comput. Appl. 2020, 32, 7709–7723. [Google Scholar] [CrossRef]
- Yogarajan, G.; Revathi, T. Nature inspired discrete firefly algorithm for optimal mobile data gathering in wireless sensor networks. Wirel. Netw. 2018, 24, 2993–3007. [Google Scholar] [CrossRef]
- Pakdel, H.; Fotohi, R. A firefly algorithm for power management in wireless sensor networks (WSNs). J. Supercomput. 2021, 77, 9411–9432. [Google Scholar] [CrossRef]
- Wang, H.; Wang, W.J.; Cui, L.Z.; Sun, H.; Zhao, J.; Wang, Y.; Xue, Y. A hybrid multi-objective firefly algorithm for big data optimization. Appl. Soft Comput. 2018, 69, 806–815. [Google Scholar] [CrossRef]
- Wang, H.; Wang, W.J.; Sun, H.; Rahnamayan, S. Firefly algorithm with random attraction. Int. J. Bio-Inspired Comput. 2016, 8, 33–41. [Google Scholar] [CrossRef]
- Cheng, Z.W.; Song, H.H.; Wang, J.Q.; Zhang, H.Y.; Chang, T.Z.; Zhang, M.X. Hybrid firefly algorithm with grouping attraction for constrained optimization problem. Knowl.-Based Syst. 2021, 220, 30. [Google Scholar] [CrossRef]
- Coelho, L.D.; Mariani, V.C. Firefly algorithm approach based on chaotic Tinkerbell map applied to multivariable PID controller tuning. Comput. Math. Appl. 2012, 64, 2371–2382. [Google Scholar] [CrossRef]
- Rizk-Allah, R.M.; Zaki, E.M.; El-Sawy, A.A. Hybridizing ant colony optimization with firefly algorithm for unconstrained optimization problems. Appl. Math. Comput. 2013, 224, 473–483. [Google Scholar] [CrossRef]
- Liang, R.H.; Wang, J.C.; Chen, Y.T.; Tseng, W.T. An enhanced firefly algorithm to multi-objective optimal active/reactive power dispatch with uncertainties consideration. Int. J. Electr. Power Energy Syst. 2015, 64, 1088–1097. [Google Scholar] [CrossRef]
- Banerjee, A.; Ghosh, D.; Das, S. Modified firefly algorithm for area estimation and tracking of fast expanding oil spills. Appl. Soft Comput. 2018, 73, 829–847. [Google Scholar] [CrossRef]
- Zhang, J.; Teng, Y.F.; Chen, W. Support vector regression with modified firefly algorithm for stock price forecasting. Appl. Intell. 2019, 49, 1658–1674. [Google Scholar] [CrossRef]
- Ball, A.K.; Roy, S.S.; Kisku, D.R.; Murmu, N.C.; Coelho, L.d.S. Optimization of drop ejection frequency in EHD inkjet printing system using an improved Firefly Algorithm. Appl. Soft Comput. 2020, 94, 106438. [Google Scholar] [CrossRef]
- Zhang, L.; Srisukkham, W.; Neoh, S.C.; Lim, C.P.; Pandit, D. Classifier ensemble reduction using a modified firefly algorithm: An empirical evaluation. Expert Syst. Appl. 2018, 93, 395–422. [Google Scholar] [CrossRef]
- Wang, C.F.; Song, W.X. A novel firefly algorithm based on gender difference and its convergence. Appl. Soft Comput. 2019, 80, 107–124. [Google Scholar] [CrossRef]
- Wu, J.R.; Wang, Y.G.; Burrage, K.; Tian, Y.C.; Lawson, B.; Ding, Z. An improved firefly algorithm for global continuous optimization problems. Expert Syst. Appl. 2020, 149, 113340. [Google Scholar] [CrossRef]
- Chen, K.; Zhou, Y.; Zhang, Z.; Dai, M.; Chao, Y.; Shi, J. Multilevel Image Segmentation Based on an Improved Firefly Algorithm. Math. Probl. Eng. 2016, 2016, 1–12. [Google Scholar] [CrossRef]
- Huang, S.J.; Liu, X.Z.; Su, W.F.; Yang, S.H. Application of Hybrid Firefly Algorithm for Sheath Loss Reduction of Underground Transmission Systems. IEEE Trans. Power Deliv. 2013, 28, 2085–2092. [Google Scholar] [CrossRef]
- Verma, O.P.; Aggarwal, D.; Patodi, T. Opposition and dimensional based modified firefly algorithm. Expert Syst. Appl. 2016, 44, 168–176. [Google Scholar] [CrossRef]
- Dash, J.; Dam, B.; Swain, R. Design of multipurpose digital FIR double-band filter using hybrid firefly differential evolution algorithm. Appl. Soft Comput. 2017, 59, 529–545. [Google Scholar] [CrossRef]
- Aydilek, I.B. A Hybrid Firefly and Particle Swarm Optimization Algorithm for Computationally Expensive Numerical Problems. Appl. Soft Comput. 2018, 66, 232–249. [Google Scholar] [CrossRef]
- Li, G.C.; Liu, P.; Le, C.Y.; Zhou, B.D. A Novel Hybrid Meta-Heuristic Algorithm Based on the Cross-Entropy Method and Firefly Algorithm for Global Optimization. Entropy 2019, 21, 494. [Google Scholar] [CrossRef]
- Wang, W.C.; Xu, L.; Chau, K.W.; Xu, D.M. Yin-Yang firefly algorithm based on dimensionally Cauchy mutation. Expert Syst. Appl. 2020, 150, 18. [Google Scholar] [CrossRef]
- Hua, L.K.; Wang, Y.J.S.B.H. Applications of Number Theory to Numerical Analysis; Springer: Berlin/Heidelberg, Germany, 1972. [Google Scholar]
- Sayadi, M.K.; Hafezalkotob, A.; Naini, S.G.J. Firefly-inspired algorithm for discrete optimization problems: An application to manufacturing cell formation. J. Manuf. Syst. 2013, 32, 78–84. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, Y.; Liu, K.; Chen, Y. Chaos Pseudo Parallel Genetic Algorithm and Its Application on Fire Distribution Optimization. J. Beijing Inst. Technol. 2005, 25, 1047–1051. [Google Scholar]
- Rahnamayan, S.; Tizhoosh, H.R.; Salama, M.M.A. Opposition versus randomness in soft computing techniques. Appl. Soft Comput. 2008, 8, 906–918. [Google Scholar] [CrossRef]
- Tizhoosh, H.R. Opposition-Based Learning: A New Scheme for Machine Intelligence. In Proceedings of the International Conference on International Conference on Computational Intelligence for Modelling, Control & Automation, Vienna, Austria, 28–30 November 2005; pp. 695–701. [Google Scholar]
- Wang, H.; Wang, W.; Zhou, X.; Sun, H.; Zhao, J.; Yu, X.; Cui, Z. Firefly algorithm with neighborhood attraction. Inf. Sci. 2016, 382–383, 374–387. [Google Scholar] [CrossRef]
- Mishra, A.; Agarwal, C.; Sharma, A.; Bedi, P. Optimized gray-scale image watermarking using DWT–SVD and Firefly Algorithm. Expert Syst. Appl. 2014, 41, 7858–7867. [Google Scholar] [CrossRef]
- Zhu, L.; Zhang, Z.; Wang, Y. A Pareto firefly algorithm for multi-objective disassembly line balancing problems with hazard evaluation. Int. J. Prod. Res. 2018, 56, 7354–7374. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, M.; Song, H.; Cheng, Z.; Chang, T.; Bi, Y.; Sun, K. Improvement and Application of Hybrid Firefly Algorithm. IEEE Access 2019, 7, 165458–165477. [Google Scholar] [CrossRef]
- Holm, S. A simple sequentially rejective multiple test procedure. Scand. J. Stat. 1979, 6, 65–70. [Google Scholar]
- Anh, H.P.H.; Son, N.N.; Van Kien, C.; Ho-Huu, V. Parameter identification using adaptive differential evolution algorithm applied to robust control of uncertain nonlinear systems. Appl. Soft Comput. 2018, 71, 672–684. [Google Scholar] [CrossRef]
- Gupta, S.; Deep, K. Improved sine cosine algorithm with crossover scheme for global optimization. Knowl.-Based Syst. 2019, 165, 374–406. [Google Scholar] [CrossRef]
- Han, M. Hybrid chicken swarm algorithm with dissipative structure and differential mutation. J. ZheJiang Univ. (Sci. Ed.) 2018, 45, 272–283. [Google Scholar] [CrossRef]
- Wang, S.J.; Gao, X.Z. A survey of research on firefly algorithm. Microcomput. Its Appl. 2015, 34, 8–11. [Google Scholar]
- Ylidizdan, G.; Baykan, O.K. A novel modified bat algorithm hybridizing by differential evolution algorithm. Expert Syst. Appl. 2020, 141, 19. [Google Scholar] [CrossRef]
- Gupta, D.; Dhar, A.R.; Roy, S.S. A partition cum unification based genetic- firefly algorithm for single objective optimization. Sādhanā 2021, 46, 121. [Google Scholar] [CrossRef]
- Brest, J.; Maucec, M.S.; Boskovic, B. Single objective real-parameter optimization: Algorithm jSO. In Proceedings of the 2017 IEEE Congress on Evolutionary Computation (CEC), Donostia, Spain, 5–8 June 2017. [Google Scholar]
- Cheng, Z.; Song, H.; Chang, T.; Wang, J. An improved mixed-coded hybrid firefly algorithm for the mixed-discrete SSCGR problem. Expert Syst. Appl. 2022, 188, 116050. [Google Scholar] [CrossRef]
- Gandomi, A.H.; Yang, X.S.; Alavi, A.H. Cuckoo search algorithm: A metaheuristic approach to solve structural optimization problems. Eng. Comput. 2013, 29, 17–35. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Population Initialization Method | Diversity |
|---|---|
| Random initialization method | 0.48 |
| Based on Tent chaotic mapping method | 0.49 |
| Reverse learning method | 0.49 |
| Good point set method based on square-root sequence | 0.54 |
| Attraction Model | T1 | t1 | T2 | t2 |
|---|---|---|---|---|
| CAM | n(n − 1)/2 | (n − 1)/2 | n(n − 1) | n − 1 |
| RAM | ≤n | ≤1 | n | 1 |
| NAM | kn | k | 2kn | 2k |
| GAM | n − 1 | (n − 1)/n | n − 1 | (n − 1)/n |
| Probability attraction Model | n − 1 | (n − 1)/n | n − 1 | (n − 1)/n |
| Function | Search Range | Type of Objective | Number of Constraints | |
|---|---|---|---|---|
| E | I | |||
| C01 | [−100,100] D | Non-Separable | 0 | 1 Separable |
| C02 | [−100,100] D | Non-Separable Rotated | 0 | 1 Non-Separable, Rotated |
| C03 | [−100,100] D | Non-Separable | 1 Separable | 1 Separable |
| C04 | [−10,10] D | Separable | 0 | 2 Separable |
| C05 | [−10,10] D | Non-Separable | 0 | 2 Non-Separable, Rotated |
| C06 | [−20,20] D | Separable | 6 | 0 Separable |
| C07 | [−20,20] D | Separable | 2 Separable | 0 |
| C08 | [−100,100] D | Separable | 2 Non-Separable | 0 |
| C09 | [−10,10] D | Separable | 2 Non-Separable | 0 |
| C10 | [−100,100] D | Separable | 2 No Separable | 0 |
| C11 | [−100,100] D | Separable | 1 Separable | 1 Non Separable |
| C12 | [−100,100] D | Separable | 0 | 2 Separable |
| C13 | [−100,100] D | Non-Separable | 0 | 3 Separable |
| C14 | [−100,100] D | Non-Separable | 1 Separable | 1 Separable |
| C15 | [−100,100] D | Separable | 1 | 1 |
| C16 | [−100,100] D | Separable | 1 Non-Separable | 1 Separable |
| C17 | [−100,100] D | Non-Separable | 1 | 1 Separable |
| C18 | [−100,100] D | Separable | 0 | 2 Non-Separable |
| C19 | [−50,50] D | Separable | 0 | 2 Non-Separable |
| C20 | [−100,100] D | Non-Separable | 0 | 2 |
| C21 | [−100,100] D | Rotated | 0 | 2 Rotated |
| C22 | [−100,100] D | Rotated | 1 Rotated | 3 Rotated |
| C23 | [−100,100] D | Rotated | 1 Rotated | 1 Rotated |
| C24 | [−100,100] D | Rotated | 1 Rotated | 1 Rotated |
| C25 | [−100,100] D | Rotated | 1 Rotated | 1 Rotated |
| C26 | [−100,100] D | Rotated | 1 Rotated | 1 Rotated |
| C27 | [−100,100] D | Rotated | 1 Rotated | 2 Rotated |
| C28 | [−50,50] D | Rotated | 0 | 2 Rotated |
| The j-th Test Function | Algorithm 1 | Algorithm 2 | Algorithm 3 | Algorithm 4 | Algorithm 5 |
|---|---|---|---|---|---|
| Average of optimal values | 1 | 3 | 3 | 2 | 4 |
| Ranking position | 1 | 3 | 4 | 2 | 5 |
| Ranking rankij | 1 | 3.5 | 3.5 | 2 | 5 |
| Value | Factor A(ζ) | Factor B(n) |
|---|---|---|
| Level 1 | 0.3 | 0.95 |
| Level 2 | 0.4 | 0.97 |
| Level 3 | 0.5 | 0.98 |
| Experiment Number | Factors | |
|---|---|---|
| A(ζ) | B(n) | |
| E1 | Level 1 | Level 1 |
| E2 | Level 1 | Level 2 |
| E3 | Level 1 | Level 3 |
| E4 | Level 2 | Level 1 |
| E5 | Level 2 | Level 2 |
| E6 | Level 2 | Level 3 |
| E7 | Level 3 | Level 1 |
| E8 | Level 3 | Level 2 |
| E9 | Level 3 | Level 3 |
| Function | Evaluation Indicator | E1 | E2 | E3 | E4 | E5 | E6 | E7 | E8 | E9 |
|---|---|---|---|---|---|---|---|---|---|---|
| C01 | Mean | 7.05 × 10−13 | 1.50 × 10−15 | 5.22 × 1027 | 6.72 × 10−14 | 6.17 × 10−15 | 2.51 × 1027 | 3.30 × 10−13 | 4.04 × 10−13 | 1.24 × 1027 |
| Std. | 1.30 × 10−12 | 1.86 × 10−15 | 8.43 × 1027 | 1.01 × 10−13 | 8.21 × 10−15 | 2.88 × 1027 | 7.05 × 10−13 | 3.53 × 10−13 | 1.84 × 1027 | |
| C02 | Mean | 3.80 × 10−13 | 8.11 × 10−14 | 2.29 × 1027 | 4.18 × 10−13 | 2.52 × 10−14 | 3.76 × 1027 | 3.88 × 10−12 | 1.27 × 10−11 | 9.05 × 1026 |
| Std. | 5.10 × 10−13 | 2.12 × 10−13 | 2.59 × 1027 | 5.53 × 10−13 | 5.99 × 10−14 | 6.54 × 1027 | 6.59 × 10−12 | 2.48 × 10−11 | 1.31 × 1027 | |
| C03 | Mean | 6.93 × 109 | 9.14 × 109 | 4.43 × 1027 | 2.29 × 109 | 9.86 × 109 | 3.13 × 1027 | 8.24 × 1010 | 5.33 × 1010 | 2.25 × 1027 |
| Std. | 2.19 × 1010 | 3.67 × 1010 | 6.09 × 1027 | 7.23 × 109 | 2.60 × 1010 | 7.30 × 1027 | 2.17 × 1011 | 1.68 × 1011 | 2.87 × 1027 | |
| C04 | Mean | 4.11 × 102 | 4.09 × 102 | 1.89 × 1018 | 3.62 × 102 | 3.77 × 102 | 2.51 × 1020 | 4.42 × 102 | 4.10 × 102 | 1.14 × 1019 |
| Std. | 7.13 × 101 | 6.05 × 101 | 5.91 × 1018 | 4.03 × 101 | 6.23 × 101 | 6.87 × 1020 | 9.32 × 101 | 6.26 × 101 | 2.34 × 1019 | |
| C05 | Mean | 2.14 × 101 | 1.89 × 101 | 3.65 × 1023 | 2.60 × 101 | 1.88 × 101 | 2.96 × 1023 | 2.81 × 101 | 2.39 × 101 | 1.35 × 1023 |
| Std. | 5.65 × 101 | 5.44 × 101 | 4.85 × 1023 | 1.56 × 101 | 4.17 × 101 | 5.70 × 1023 | 1.95 × 101 | 5.46 × 101 | 2.02 × 1023 | |
| C06 | Mean | 4.11 × 1018 | 9.90 × 1012 | 8.61 × 1021 | 6.17 × 103 | 5.58 × 103 | 1.70 × 1022 | 5.27 × 103 | 4.44 × 103 | 7.76 × 1021 |
| Std. | 1.23 × 1019 | 4.43 × 1013 | 6.56 × 1021 | 1.55 × 103 | 1.03 × 103 | 1.23 × 1022 | 7.52 × 102 | 8.20 × 102 | 6.83 × 10 21 | |
| C07 | Mean | 3.69 × 1021 | 2.08 × 1021 | 1.71 × 1025 | 4.31 × 1021 | −1.48 × 102 | 1.32 × 1025 | 1.27 × 1021 | 1.22 × 1021 | 1.15 × 1025 |
| Std. | 5.18 × 1021 | 4.23 × 1021 | 3.71 × 1024 | 1.03 × 1022 | 2.78 × 1021 | 5.07 × 1024 | 2.10 × 1021 | 1.92 × 1021 | 7.45 × 1024 | |
| C08 | Mean | 7.43 × 10−4 | 2.99 × 10−4 | 3.98 × 1030 | 4.15 × 10−4 | 4.49 × 10−4 | 4.53 × 1030 | 4.91 × 10−4 | 4.11 × 10−4 | 2.36 × 1030 |
| Std. | 3.68 × 10−4 | 1.77 × 10−4 | 6.99 × 1030 | 1.37 × 10−4 | 2.76 × 10−4 | 5.74 × 1030 | 2.23 × 10−4 | 2.45 × 10−4 | 1.86 × 1030 | |
| C09 | Mean | 5.65 × 101 | 4.38 × 101 | 1.23 × 1039 | 7.76 × 101 | 5.45 × 101 | 7.66 × 1038 | 8.71 × 101 | 7.24 × 101 | 3.00 × 1036 |
| Std. | 3.41 × 101 | 3.09 × 101 | 3.88 × 1039 | 2.58 × 101 | 3.34 × 101 | 2.42 × 1039 | 4.49 × 101 | 3.64 × 101 | 7.15 × 1036 | |
| C10 | Mean | 2.71 × 10−4 | 2.88 × 10−4 | 5.62 × 1031 | 2.55 × 10−4 | 2.22 × 10−4 | 1.13 × 1032 | 2.40 × 10−4 | 2.71 × 10−4 | 2.62 × 1031 |
| Std. | 9.89 × 10−5 | 1.09 × 10−4 | 6.58 × 1031 | 6.51 × 10−5 | 1.16 × 10−4 | 2.65 × 1032 | 6.58 × 10−5 | 8.95 × 10−5 | 2.35 × 1031 | |
| C11 | Mean | 1.58 × 1020 | 2.08 × 1020 | 1.43 × 10119 | 6.95 × 1019 | 8.64 × 1019 | 1.29 × 10124 | 6.65 × 1018 | 1.01 × 1020 | 1.40 × 10 126 |
| Std. | 2.03 × 1020 | 5.87 × 1020 | 4.51 × 10119 | 8.82 × 1019 | 1.92 × 1020 | 4.08 × 10124 | 1.34 × 1019 | 1.70 × 1020 | 4.41 × 10 126 | |
| C12 | Mean | 2.11 × 101 | 1.73 × 101 | 3.81 × 1028 | 2.50 × 101 | 4.00 × 10−1 | 3.78 × 1028 | 1.50 × 101 | 1.25 × 101 | 3.71 × 1028 |
| Std. | 1.32 × 101 | 1.02 × 101 | 1.50 × 1028 | 1.59 × 101 | 1.21 × 101 | 1.66 × 1028 | 9.72 × 101 | 4.47 × 101 | 1.34 × 1028 | |
| C13 | Mean | 6.51 × 1022 | 4.21 × 1022 | 2.99 × 1028 | 7.12 × 1022 | 4.64 × 1022 | 3.48 × 1028 | 6.64 × 1022 | 6.41 × 1022 | 3.43 × 1028 |
| Std. | 4.74 × 1022 | 4.26 × 1022 | 1.09 × 1028 | 6.24 × 1022 | 3.88 × 1022 | 1.56 × 1028 | 3.85 × 1022 | 3.48 × 1022 | 1.70 × 1028 | |
| C14 | Mean | 1.41 × 101 | 1.42 × 101 | 7.02 × 1028 | 1.41 × 101 | 1.41 × 101 | 8.18 × 1028 | 1.42 × 101 | 1.41 × 101 | 5.92 × 1028 |
| Std. | 2.24 × 10−13 | 3.18 × 10−2 | 2.69 × 1028 | 1.26 × 10−13 | 3.77 × 10−14 | 3.25 × 1028 | 2.75 × 10−2 | 9.62 × 10−13 | 1.87 × 1028 | |
| C15 | Mean | 2.03 × 101 | 2.06 × 101 | 3.27 × 1028 | 2.21 × 101 | 1.96 × 101 | 3.48 × 1028 | 2.25 × 101 | 2.12 × 101 | 3.28 × 1028 |
| Std. | 2.98 × 101 | 2.19 × 101 | 1.41 × 1028 | 3.33 × 101 | 3.75 × 101 | 1.09 × 1028 | 3.69 × 101 | 4.91 × 101 | 9.69 × 1028 | |
| C16 | Mean | 1.84 × 102 | 1.61 × 102 | 3.71 × 1028 | 1.82 × 102 | 1.65 × 102 | 3.25 × 1028 | 1.89 × 102 | 1.81 × 102 | 2.74 × 1028 |
| Std. | 1.62 × 101 | 2.11 × 101 | 1.57 × 1028 | 1.84 × 101 | 1.99 × 101 | 1.25 × 1028 | 1.00 × 101 | 1.86 × 101 | 1.00 × 1028 | |
| C17 | Mean | 9.61 × 1020 | 9.61 × 1020 | 3.99 × 1028 | 9.61 × 1020 | 9.61 × 1020 | 4.05 × 1028 | 9.61 × 1020 | 9.61 × 1020 | 3.09 × 1028 |
| Std. | 0 | 0 | 1.69 × 1028 | 0 | 0 | 1.31 × 1028 | 0 | 0 | 1.27 × 1028 | |
| C18 | Mean | 4.91 × 1022 | 5.92 × 1022 | 9.95 × 1040 | 4.86 × 1022 | 3.65 × 101 | 6.05 × 1040 | 8.93 × 1022 | 5.57 × 1022 | 6.46 × 1040 |
| Std. | 1.21 × 1023 | 1.24 × 1023 | 4.81 × 1040 | 1.33 × 1023 | 1.24 × 1023 | 4.54 × 1040 | 1.69 × 1023 | 1.32 × 1023 | 5.26 × 1040 | |
| C19 | Mean | 1.84 × 1027 | 1.84 × 1027 | 1.85 × 1027 | 1.84 × 1027 | 1.84 × 1027 | 1.85 × 1027 | 1.84 × 1027 | 1.84 × 1027 | 1.85 × 1027 |
| Std. | 1.67 × 1024 | 1.96 × 1024 | 1.47 × 1023 | 1.77 × 1024 | 1.72 × 1024 | 5.70 × 1023 | 1.29 × 1024 | 8.66 × 1023 | 3.52 × 10 23 | |
| C20 | Mean | 2.98 × 101 | 2.51 × 101 | 3.19 × 1017 | 2.64 × 101 | 2.48 × 101 | 1.80 × 1017 | 2.70 × 101 | 2.77 × 101 | 1.20 × 101 |
| Std. | 5.29 × 101 | 3.78 × 10−1 | 6.85 × 1017 | 3.78 × 10−1 | 2.76 × 10−1 | 5.69 × 1017 | 3.73 × 10−1 | 5.49 × 10−1 | 1.72 × 101 | |
| C21 | Mean | 1.71 × 101 | 2.16 × 101 | 2.29 × 1028 | 2.46 × 101 | 1.45 × 101 | 3.00 × 1028 | 1.86 × 101 | 2.11 × 101 | 2.41 × 1028 |
| Std. | 7.92 × 101 | 1.24 × 101 | 6.66 × 1027 | 1.29 × 101 | 9.78 × 101 | 1.25 × 1028 | 1.16 × 101 | 1.32 × 101 | 1.17 × 1028 | |
| C22 | Mean | 4.67 × 1020 | 4.88 × 1020 | 2.60 × 1028 | 5.54 × 1020 | 7.41 × 1020 | 3.96 × 1028 | 4.55 × 1020 | 4.29 × 1020 | 2.02 × 1028 |
| Std. | 3.00 × 1020 | 4.12 × 1020 | 1.71 × 1028 | 6.33 × 1020 | 5.04 × 1020 | 1.13 × 1028 | 3.76 × 1020 | 2.70 × 1020 | 7.96 × 1027 | |
| C23 | Mean | 1.41 × 101 | 1.41 × 101 | 4.62 × 1028 | 1.41 × 101 | 1.41 × 101 | 5.08 × 1028 | 1.41 × 101 | 1.42 × 101 | 5.59 × 1028 |
| Std. | 7.60 × 10−13 | 1.94 × 10−2 | 1.38 × 1028 | 9.67 × 10−13 | 1.94 × 10−2 | 2.344 × 1028 | 1.21 × 10−11 | 2.75 × 10−2 | 1.54 × 1028 | |
| C24 | Mean | 2.06 × 101 | 2.01 × 101 | 2.374 × 1028 | 2.18 × 101 | 1.95 × 101 | 2.564 × 1028 | 2.12 × 101 | 2.06 × 101 | 2.104 × 1028 |
| Std. | 1.99 × 101 | 2.55 × 101 | 1.05 × 1028 | 2.89 × 101 | 2.38 × 101 | 1.01 × 1028 | 2.57 × 101 | 1.99 × 101 | 1.01 × 1028 | |
| C25 | Mean | 1.82 × 102 | 1.77 × 102 | 2.65 × 1028 | 1.91 × 102 | 1.66 × 102 | 2.07 × 1028 | 1.92 × 102 | 1.83 × 102 | 2.27 × 1028 |
| Std. | 2.45 × 101 | 1.34 × 101 | 1.26 × 1028 | 2.24 × 101 | 1.49 × 101 | 8.76 × 1027 | 1.67 × 101 | 1.26 × 101 | 8.05 × 1027 | |
| C26 | Mean | 9.61 × 1020 | 9.61 × 1020 | 2.60 × 1028 | 9.61 × 1022 | 9.61 × 1020 | 2.24 × 1028 | 9.61 × 1020 | 9.61 × 1020 | 2.49 × 1028 |
| Std. | 0 | 0 | 1.29 × 1028 | 0 | 0 | 3.77 × 1027 | 0 | 0 | 1.04 × 1028 | |
| C27 | Mean | 6.55 × 1023 | 5.70 × 1022 | 5.51 × 1040 | 9.31 × 1022 | 3.65 × 101 | 6.38 × 1040 | 7.71 × 1022 | 1.15 × 1023 | 6.07 × 1040 |
| Std. | 1.08 × 1023 | 1.19 × 1023 | 3.45 × 1040 | 1.77 × 1023 | 1.60 × 1023 | 4.76 × 1040 | 1.18 × 1023 | 1.70 × 1023 | 3.61 × 1040 | |
| C28 | Mean | 1.85 × 1027 | 1.85 × 1027 | 1.85 × 1027 | 1.85 × 1027 | 1.85 × 1027 | 1.85 × 1027 | 1.85 × 1027 | 1.85 × 1027 | 1.85 × 1027 |
| Std. | 1.49 × 1024 | 1.70 × 1023 | 4.75 × 1023 | 6.63 × 1023 | 1.63 × 1024 | 3.01 × 1023 | 1.14 × 1024 | 1.19 × 1024 | 5.28 × 1023 |
| Dimension | Significant Level | k | χ2 | χ2α[k−1] | p-Value | Null Hypothesis | Alternative Hypothesis |
|---|---|---|---|---|---|---|---|
| D = 30 | A = 0.05 | 9 | 160.54 | 15.51 | 1.23487 × 10−30 | Reject | Accept |
| Test Functions | Performance Indicators | Complete Attraction Model | Random Attraction Model | Neighborhood Attraction Model | Grouping Attraction Model | Probability Attraction Model |
|---|---|---|---|---|---|---|
| C01 | Mean | 7.10 × 101 | 9.49 × 103 | 1.98 × 10−2 | 1.08 × 101 | 6.17 × 10−15 |
| Std | 5.79 × 103 | 4.47 × 104 | 5.63 × 10−2 | 2.06 × 102 | 8.21 × 10−15 | |
| C02 | Mean | 2.36 × 101 | 9.52 × 103 | 2.58 × 10−2 | 3.29 × 101 | 2.52 × 10−14 |
| Std | 3.03 × 103 | 2.58 × 104 | 1.07 × 10−1 | 8.15 × 101 | 5.99 × 10−14 | |
| C03 | Mean | 9.34 × 104 | 2.67 × 106 | 3.38 × 105 | 9.99 × 105 | 9.86 × 109 |
| Std | 3.41 × 106 | 5.89 × 106 | 1.90 × 1010 | 4.80 × 106 | 2.60 × 1010 | |
| C04 | Mean | 2.34 × 102 | 4.07 × 102 | 1.21 × 102 | 5.33 × 102 | 3.77 × 102 |
| Std | 5.88 × 102 | 6.63 × 102 | 2.22 × 102 | 6.62 × 102 | 6.23 × 101 | |
| C05 | Mean | 1.85 × 101 | 2.54 × 102 | 2.18 × 101 | 1.55 × 101 | 1.88 × 101 |
| Std | 7.52 × 101 | 5.40 × 103 | 1.01 × 102 | 2.30 × 101 | 1.17 × 101 | |
| C06 | Mean | 2.42 × 1012 | 3.44 × 103 | 4.36 × 1013 | 3.91 × 103 | 5.58 × 103 |
| Std | 9.93 × 1012 | 3.20 × 1011 | 1.56 × 1018 | 2.26 × 1020 | 1.03 × 103 | |
| C07 | Mean | 6.17 × 1021 | 1.20 × 1021 | −1.43 × 102 | −1.93 × 102 | −1.48 × 102 |
| Std | 7.58 × 1020 | 1.01 × 1024 | 9.70 × 1022 | 9.17 × 1023 | 2.78 × 1021 | |
| C08 | MEan | 7.02 × 10−4 | 1.87 × 1025 | 2.58 × 1013 | 5.22 × 1016 | 4.49 × 10−4 |
| Std | 4.80 × 1020 | 3.27 × 1026 | 3.63 × 1014 | 3.65 × 1018 | 2.76 × 10−4 | |
| C09 | Mean | 2.28 × 101 | 3.79 × 101 | 6.65 × 101 | −2.65 × 10−3 | 5.45 × 101 |
| Std | 1.50 × 101 | 1.99 × 1018 | 1.91 × 101 | 1.40 × 101 | 1.34 × 101 | |
| C10 | Mean | 3.50 × 10−4 | 2.73 × 1026 | 4.64 × 1012 | 2.61 × 10−4 | 2.22 × 10−4 |
| Std | 6.75 × 10−4 | 4.06 × 1027 | 3.60 × 1013 | 8.60 × 10−4 | 1.16 × 10−4 | |
| C11 | Mean | 6.74 × 1015 | 1.01 × 1026 | 1.04 × 1016 | 5.62 × 1019 | 8.64 × 1019 |
| Std | 1.26 × 1025 | 3.51 × 1027 | 8.81 × 1020 | 7.25 × 1022 | 1.92 × 1020 | |
| C12 | Mean | 4.00 × 101 | 2.73 × 1023 | 1.69 × 102 | 4.00 × 101 | 4.00 × 101 |
| Std | 3.97 × 101 | 2.65 × 1025 | 2.50 × 102 | 3.97 × 101 | 1.21 × 101 | |
| C13 | Mean | 2.71 × 1023 | 4.27 × 1025 | 4.85 × 102 | 8.35 × 1022 | 4.64 × 1022 |
| Std | 2.37 × 1024 | 2.73 × 1026 | 7.45 × 1021 | 1.59 × 1024 | 3.88 × 1022 | |
| C14 | Mean | 1.41 × 101 | 1.69 × 1024 | 1.90 × 101 | 1.41 × 101 | 1.41 × 101 |
| Std | 1.50 × 101 | 7.77 × 1025 | 2.32 × 101 | 1.50 × 101 | 3.77 × 10−4 | |
| C15 | Mean | 1.81 × 101 | 1.81 × 101 | 1.49 × 101 | 1.81 × 101 | 1.96 × 101 |
| Std | 3.06 × 101 | 6.63 × 1024 | 1.81 × 101 | 3.06 × 101 | 1.75 × 101 | |
| C16 | Mean | 1.76 × 102 | 2.20 × 102 | 6.91 × 101 | 2.07 × 102 | 1.65 × 102 |
| Std | 2.40 × 102 | 1.63 × 1025 | 1.19 × 102 | 2.47 × 102 | 1.99 × 101 | |
| C17 | Mean | 9.61 × 1020 | 2.76 × 1024 | 9.61 × 1020 | 9.61 × 1020 | 9.61 × 1020 |
| Std | 9.61 × 1020 | 4.46 × 1026 | 9.61 × 1020 | 9.61 × 1020 | 0 | |
| C18 | Mean | 3.65 × 101 | 1.01 × 1027 | 5.59 × 1014 | 3.65 × 101 | 3.65 × 101 |
| Std | 2.75 × 1025 | 6.34 × 1035 | 2.57 × 1025 | 2.39 × 1026 | 1.24 × 1027 | |
| C19 | Mean | 1.84 × 1027 | 1.85 × 1027 | 1.84 × 1027 | 1.85 × 1027 | 1.84 × 1027 |
| Std | 1.85 × 1027 | 1.85 × 1027 | 1.85 × 1027 | 1.85 × 1027 | 1.72 × 1024 | |
| C20 | Mean | 2.05 × 101 | 2.59 × 101 | 2.48 × 101 | 2.07 × 101 | 2.01 × 101 |
| Std | 3.97 × 101 | 5.18 × 101 | 4.97 × 101 | 3.40 × 101 | 2.76 × 10−1 | |
| C21 | Mean | 4.00 × 101 | 1.69 × 1024 | 1.81 × 102 | 4.00 × 101 | 1.45 × 101 |
| Std | 3.97 × 101 | 6.98 × 1025 | 3.00 × 102 | 3.97 × 102 | 9.78 × 101 | |
| C22 | Mean | 3.56 × 1023 | 5.42 × 1025 | 2.91 × 104 | 5.63 × 1022 | 7.41 × 1020 |
| Std | 3.02 × 1024 | 3.17 × 1026 | 5.11 × 1021 | 1.33 × 1024 | 5.04 × 1022 | |
| C23 | Mean | 1.41 × 101 | 4.65 × 1024 | 1.95 × 101 | 1.41 × 101 | 1.41 × 101 |
| Std | 1.50 × 101 | 1.22 × 1026 | 2.33 × 101 | 1.41 × 101 | 1.94 × 10−2 | |
| C24 | Mean | 1.81 × 101 | 2.12 × 101 | 1.18 × 101 | 1.81 × 101 | 1.95 × 101 |
| Std | 2.75 × 101 | 3.95 × 1025 | 1.81 × 101 | 3.06 × 101 | 2.38 × 101 | |
| C25 | Mean | 1.88 × 102 | 2.26 × 102 | 7.54 × 101 | 1.95 × 102 | 1.66 × 102 |
| Std | 2.45 × 102 | 1.40 × 1025 | 1.45 × 102 | 2.51 × 102 | 1.49 × 101 | |
| C26 | Mean | 9.61 × 1020 | 5.52 × 1027 | 9.61 × 1020 | 9.61 × 1020 | 9.61 × 1020 |
| Std | 9.61 × 1020 | 2.71 × 1026 | 9.61 × 1020 | 9.61 × 1020 | 0 | |
| C27 | Mean | 3.66 × 101 | 1.20 × 1033 | 3.83 × 1015 | 3.65 × 101 | 3.65 × 101 |
| Std | 3.35 × 1026 | 5.39 × 1035 | 3.08 × 1025 | 3.09 × 1026 | 1.60 × 1023 | |
| C28 | Mean | 1.84 × 1027 | 1.85 × 1027 | 1.84 × 1027 | 1.85 × 1027 | 1.85 × 1027 |
| Std | 1.85 × 1027 | 1.85 × 1027 | 1.85 × 1027 | 1.85 × 1027 | 1.63 × 1025 | |
| w/t/l | 25/0/3 | 23/0/5 | 26/0/2 | 25/0/3 | - | |
| Dimension | Significance Level | k | χ2 | χ2α[k − 1] | p-Value | Null Hypothesis | Alternative Hypothesis |
|---|---|---|---|---|---|---|---|
| D = 30 | α = 0.05 | 5 | 26.07 | 9.49 | 3.05747 × 10−5 | Reject | Accept |
| Algorithm | Reference | Years | Parameters |
|---|---|---|---|
| SFA | [6] | 2008 | α = 0.2, β0 = 1, γ = 1.0 |
| RaFA | [19] | 2016 | α ∈ [0,1], β0 = 1, γ = 1 |
| NaFA | [42] | 2017 | α = 0.5, γ = 1, βmin = 0.2, β0 = 1.0, k = 3 |
| GDFA | [47] | 2019 | β0 = 1, γ = 1 |
| ADIFA | [29] | 2020 | a (0) = 0.2, β0 = 1, γ = 1 |
| YYFA | [36] | 2020 | a (0) = 0.2, βmin = 0.2, β0 = 1, γ = 1, L = 800 |
| GAHFA | [20] | 2021 | α0 = 0.3, φ0 = 0.9, pm = 0.7, Fmax = 0.9, Fmin = 0.1 |
| IHFAPA | - | - | N = 40, α0 = 0.1, ϕ0 = 0.9, βmax = 1, βmin = 0.5, γ = 1, Pm = 1 |
| Test Functions | Performance Indicators | SFA | RaFA | NaFA | GDFA | ADIFA | YYFA | GAHFA | IHFAPA |
|---|---|---|---|---|---|---|---|---|---|
| C01 | Mean | 6.48 × 105 | 9.23 × 102 | 5.12 × 105 | 2.90 × 104 | 5.12 × 102 | 2.59 × 103 | 3.00 × 10−5 | 6.17 × 10−15 |
| Std | 0 | 1.92 × 102 | 4.25 × 105 | 3.95 × 103 | 1.70 × 102 | 2.24 × 103 | 6.73 × 10−6 | 8.21 × 10−15 | |
| C02 | Mean | 3.18 × 105 | 1.06 × 103 | 9.08 × 104 | 2.61 × 104 | 3.58 × 102 | 2.44 × 103 | 3.01 × 10−5 | 2.52 × 10−14 |
| Std | 1.25 × 105 | 3.95 × 102 | 5.26 × 104 | 3.20 × 103 | 9.42 × 101 | 2.24 × 103 | 5.66 × 10−6 | 5.99 × 10−14 | |
| C03 | Mean | 1.08 × 1024 | 9.18 × 105 | 3.83 × 106 | 1.34 × 105 | 4.86 × 105 | 1.70 × 106 | 3.70 × 104 | 9.86 × 109 |
| Std | 2.77 × 1023 | 6.53 × 105 | 1.36 × 106 | 5.94 × 106 | 2.37 × 105 | 1.30 × 106 | 1.04 × 104 | 2.60 × 1010 | |
| C04 | Mean | 1.11 × 103 | 5.20 × 102 | 8.00 × 102 | 3.09 × 102 | 2.48 × 102 | 5.57 × 102 | 6.23 × 102 | 3.77 × 102 |
| Std | 8.90 × 101 | 8.15 × 101 | 8.61 × 101 | 2.90 × 101 | 1.89 × 101 | 8.22 × 101 | 6.63 × 101 | 6.23 × 101 | |
| C05 | Mean | 6.71 × 106 | 1.73 × 105 | 1.32 × 106 | 1.98 × 105 | 4.02 × 101 | 4.94 × 103 | 7.71 × 101 | 1.88 × 101 |
| Std | 1.13 × 106 | 1.02 × 105 | 3.01 × 105 | 6.21 × 104 | 1.45 × 101 | 7.65 × 103 | 4.83 × 101 | 4.17 × 101 | |
| C06 | Mean | 4.36 × 1024 | 9.76 × 109 | 6.85 × 1010 | 7.15 × 109 | 4.01 × 108 | 1.72 × 1010 | 5.42 × 103 | 5.58 × 103 |
| Std | 4.90 × 1023 | 1.84 × 109 | 5.01 × 1010 | 3.28 × 109 | 1.75 × 108 | 7.55 × 1010 | 1.35 × 103 | 1.03 × 103 | |
| C07 | Mean | 2.00 × 1024 | 6.66 × 1012 | 5.97 × 1014 | 9.80 × 1012 | 8.85 × 104 | 9.03 × 1012 | 1.85 × 1012 | −1.48 × 102 |
| Std | 3.86 × 1018 | 6.73 × 1012 | 1.08 × 1014 | 1.84 × 1013 | 1.29 × 104 | 2.28 × 1012 | 4.73 × 1012 | 2.78 × 1021 | |
| C08 | Mean | 2.00 × 1024 | 3.30 × 1013 | 1.58 × 1018 | 2.10 × 1014 | 4.69 × 109 | 4.76 × 1014 | 1.16 × 103 | 4.49 × 10−4 |
| Std | 0 | 1.32 × 1013 | 1.99 × 1018 | 9.03 × 1013 | 7.47 × 108 | 7.02 × 1014 | 3.07 × 10−4 | 2.76 × 10−4 | |
| C09 | Mean | 1.00 × 1024 | 1.71 × 1012 | 3.00 × 1015 | 1.25 × 106 | 1.29 × 105 | 6.95 × 101 | 1.62 × 106 | 5.45 × 101 |
| Std | 1.02 × 1020 | 1.37 × 1012 | 1.89 × 1015 | 1.14 × 106 | 5.76 × 104 | 6.25 × 10−1 | 8.10 × 106 | 3.34 × 101 | |
| C10 | Mean | 2.02 × 1024 | 2.20 × 1013 | 1.32 × 1019 | 1.14 × 1015 | 2.08 × 106 | 3.22 × 1015 | 8.66 × 10−4 | 2.22 × 10−4 |
| Std | 5.20 × 1021 | 6.18 × 1012 | 1.95 × 1019 | 5.77 × 1014 | 4.96 × 106 | 9.17 × 1015 | 1.42 × 10−4 | 1.16 × 10−4 | |
| C11 | Mean | 1.00 × 1024 | 4.20 × 1013 | 9.66 × 1017 | 7.20 × 1014 | 1.70 × 1011 | 6.03 × 1014 | 1.32 × 106 | 8.64 × 1019 |
| Std | 5.74 × 1020 | 4.09 × 1013 | 2.92 × 1017 | 2.55 × 1014 | 7.07 × 1010 | 1.64 × 1015 | 6.24 × 106 | 1.92 × 1020 | |
| C12 | Mean | 1.00 × 1024 | 7.96 × 1011 | 3.26 × 1017 | 5.10 × 1013 | 2.05 × 102 | 5.23 × 1013 | 1.89 × 101 | 1.00 × 101 |
| Std | 2.26 × 1020 | 1.54 × 1011 | 8.73 × 1016 | 1.95 × 1013 | 9.29 × 10−1 | 2.45 × 1014 | 1.25 × 101 | 1.21 × 101 | |
| C13 | Mean | 1.32 × 1024 | 1.11 × 1013 | 3.67 × 1017 | 7.08 × 1015 | 1.08 × 1012 | 3.54 × 1011 | 3.10 × 1015 | 4.64 × 1022 |
| Std | 4.76 × 1023 | 4.05 × 1012 | 7.39 × 1016 | 1.87 × 1015 | 1.70 × 1011 | 5.19 × 1012 | 1.91 × 1015 | 3.88 × 1022 | |
| C14 | Mean | 2.00 × 1024 | 1.32 × 1012 | 6.63 × 1017 | 1.07 × 1014 | 2.12 × 101 | 4.52 × 1013 | 1.41 × 101 | 1.40 × 101 |
| Std | 6.45 × 1020 | 3.79 × 1011 | 1.67 × 1017 | 6.01 × 1013 | 5.04 × 10−1 | 1.72 × 1013 | 1.74 × 10−1 | 3.77 × 10−14 | |
| C15 | Mean | 1.00 × 1024 | 2.55 × 101 | 2.82 × 1017 | 1.93 × 101 | 2.39 × 101 | 3.13 × 101 | 2.47 × 101 | 1.96 × 101 |
| Std | 3.32 × 1020 | 3.77 × 101 | 6.66 × 1017 | 4.22 × 101 | 1.50 × 101 | 8.75 × 101 | 3.99 × 101 | 3.75 × 101 | |
| C16 | Mean | 1.00 × 1024 | 2.34 × 102 | 3.17 × 1017 | 1.70 × 102 | 1.56 × 102 | 3.16 × 1013 | 2.39 × 102 | 1.65 × 102 |
| Std | 1.84 × 1020 | 1.00 × 101 | 6.46 × 1016 | 2.34 × 101 | 1.86 × 101 | 1.58 × 1014 | 1.10 × 101 | 1.99 × 101 | |
| C17 | Mean | 2.00 × 1024 | 9.69 × 1010 | 3.53 × 1017 | 4.89 × 1015 | 9.61 × 1010 | 3.34 × 1012 | 9.61 × 1010 | 9.61 × 1020 |
| Std | 2.41 × 1020 | 1.28 × 109 | 9.45 × 1016 | 1.28 × 1015 | 3.58 × 10−2 | 1.52 × 1013 | 4.75 × 10−2 | 0 | |
| C18 | Mean | 1.14 × 1030 | 9.73 × 1019 | 5.06 × 1028 | 3.84 × 1024 | 6.95 × 1011 | 3.21 × 1017 | 2.55 × 1011 | 3.65 × 101 |
| Std | 4.99 × 1029 | 2.05 × 1020 | 1.92 × 1028 | 2.38 × 1024 | 9.18 × 1010 | 1.47 × 1018 | 1.00 × 1012 | 1.24 × 1024 | |
| C19 | Mean | 1.00 × 1024 | 1.84 × 1017 | 1.85 × 1017 | 1.85 × 1017 | 1.84 × 1017 | 1.84 × 1017 | 1.85 × 1017 | 1.84 × 1027 |
| Std | 6.60 × 1016 | 7.59 × 1013 | 3.76 × 1013 | 3.92 × 1013 | 4.58 × 1013 | 6.94 × 1013 | 1.06 × 1013 | 1.72 × 1024 | |
| C20 | Mean | 8.40 × 101 | 8.87 × 101 | 3.03 × 101 | 6.04 × 101 | 3.63 × 101 | 9.18 × 101 | 2.36 × 101 | 2.48 × 101 |
| Std | 4.67 × 10−1 | 2.44 × 10−1 | 5.45 × 10−1 | 1.09 × 101 | 1.27 × 10−1 | 4.96 × 10−1 | 3.41 × 10−1 | 2.76 × 10−1 | |
| C21 | Mean | 1.00 × 1024 | 6.03 × 1011 | 1.62 × 1017 | 3.82 × 1013 | 2.06 × 102 | 9.40 × 1013 | 1.61 × 101 | 1.45 × 101 |
| Std | 2.11 × 1020 | 1.97 × 1011 | 3.75 × 1016 | 2.03 × 1012 | 1.39 × 101 | 4.35 × 1013 | 1.14 × 101 | 9.78 × 101 | |
| C22 | Mean | 1.00 × 1024 | 1.06 × 1013 | 1.91 × 1017 | 8.16 × 1015 | 1.53 × 1013 | 5.92 × 1012 | 2.44 × 1015 | 7.41 × 1022 |
| Std | 2.92 × 1020 | 3.56 × 1013 | 5.36 × 1016 | 1.92 × 1013 | 3.34 × 1012 | 8.28 × 1012 | 8.79 × 1014 | 5.04 × 1022 | |
| C23 | Mean | 2.00 × 1024 | 1.39 × 1012 | 2.85 × 1017 | 6.03 × 1014 | 2.07 × 101 | 5.48 × 101 | 1.41 × 101 | 1.40 × 101 |
| Std | 6.22 × 1020 | 4.88 × 1011 | 7.02 × 1016 | 2.94 × 1014 | 5.75 × 10−2 | 1.31 × 1014 | 1.74 × 10−2 | 1.94 × 10−2 | |
| C24 | Mean | 1.00 × 1024 | 1.44 × 102 | 1.50 × 1017 | 2.08 × 101 | 1.78 × 101 | 2.02 × 101 | 2.32 × 101 | 1.95 × 101 |
| Std | 2.61 × 1020 | 9.23 × 101 | 3.83 × 1016 | 2.91 × 101 | 9.63 × 10−1 | 3.23 × 101 | 3.94 × 101 | 2.38 × 101 | |
| C25 | Mean | 1.00 × 1024 | 2.57 × 102 | 1.51 × 1017 | 1.91 × 102 | 2.11 × 102 | 1.33 × 102 | 2.40 × 102 | 1.66 × 102 |
| Std | 2.11 × 1020 | 4.09 × 101 | 3.32 × 1016 | 1.89 × 101 | 1.23 × 101 | 3.02 × 101 | 1.52 × 101 | 1.49 × 101 | |
| C26 | Mean | 2.00 × 1024 | 9.63 × 1010 | 1.58 × 1017 | 5.19 × 1014 | 9.61 × 1014 | 2.39 × 1012 | 9.61 × 1010 | 9.61 × 1020 |
| Std | 2.15 × 1020 | 2.60 × 108 | 4.21 × 1016 | 1.56 × 1014 | 3.05 × 10−1 | 1.14 × 1013 | 9.87 × 10−3 | 0 | |
| C27 | Mean | 5.19 × 1029 | 6.63 × 1019 | 1.75 × 1028 | 9.08 × 1024 | 9.06 × 1011 | 5.25 × 1019 | 7.26 × 1011 | 3.65 × 101 |
| Std | 2.22 × 1029 | 1.41 × 1020 | 9.03 × 1027 | 7.87 × 1024 | 1.31 × 1012 | 2.08 × 1020 | 1.61 × 1012 | 1.60 × 1024 | |
| C28 | Mean | 1.00 × 1024 | 1.85 × 1017 | 1.85 × 1017 | 1.85 × 1017 | 1.85 × 1017 | 1.85 × 1017 | 1.85 × 1017 | 1.85 × 1027 |
| Std | 6.50 × 1016 | 1.73 × 1014 | 6.35 × 1013 | 3.81 × 1013 | 5.57 × 1014 | 1.22 × 1014 | 1.61 × 1014 | 1.63 × 1024 | |
| w/t/l | 28/0/0 | 28/0/0 | 28/0/0 | 27/0/1 | 16/0/12 | 25/0/3 | 20/0/10 | - | |
| Test Functions | Performance Indicators | SFA | RaFA | NaFA | GDFA | ADIFA | YYFA | GAHFA | IHFAPA |
|---|---|---|---|---|---|---|---|---|---|
| C01 | Mean | 1.52 × 106 | 1.69 × 104 | 1.02 × 106 | 1.07 × 105 | 1.77 × 104 | 9.27 × 103 | 3.68 × 10−4 | 1.21 × 10−5 |
| Std | 0 | 3.24 × 103 | 8.28 × 105 | 1.15 × 104 | 1.18 × 103 | 4.17 × 103 | 5.81E × 10−5 | 1.10 × 10−5 | |
| C02 | Mean | 1.18 × 106 | 1.66 × 104 | 4.65 × 105 | 1.09 × 105 | 1.67 × 104 | 7.38 × 103 | 4.31 × 10−4 | 6.35 × 10−5 |
| Std | 8.20 × 105 | 3.43 × 103 | 2.00 × 105 | 1.73 × 104 | 2.54 × 103 | 3.29 × 103 | 8.41 × 10−5 | 5.02 × 10−5 | |
| C03 | Mean | 1.16 × 1024 | 1.69 × 106 | 1.32 × 107 | 5.52 × 105 | 1.05 × 106 | 8.78 × 106 | 1.31 × 105 | 2.15 × 105 |
| Std | 3.74 × 1023 | 9.10 × 105 | 1.50 × 107 | 2.79 × 105 | 4.44 × 105 | 8.51 × 106 | 6.00 × 104 | 4.47 × 104 | |
| C04 | Mean | 2.13 × 103 | 9.81 × 102 | 1.33 × 103 | 8.34 × 102 | 5.69 × 102 | 1.31 × 103 | 1.07 × 103 | 8.71 × 102 |
| Std | 1.21 × 102 | 6.675 × 101 | 8.11 × 101 | 5.305 × 101 | 1.625 × 101 | 8.135 × 101 | 1.83 × 102 | 1.36 × 102 | |
| C05 | Mean | 1.76 × 107 | 4.26 × 103 | 3.37 × 106 | 1.66 × 106 | 3.40 × 105 | 4.38 × 104 | 4.22 × 101 | 5.345 × 101 |
| Std | 1.95 × 106 | 3.72 × 103 | 3.08 × 105 | 2.87 × 105 | 1.68 × 106 | 4.78 × 104 | 1.655 × 101 | 2.845 × 101 | |
| C06 | Mean | 4.52 × 1024 | 8.67 × 103 | 8.11 × 1010 | 1.30 × 1010 | 9.97 × 108 | 3.32 × 1010 | 9.12 × 103 | 7.85 × 106 |
| Std | 5.10 × 1023 | 1.96 × 103 | 4.19 × 1010 | 5.32 × 109 | 4.53 × 108 | 1.37 × 1010 | 2.29 × 103 | 3.92 × 107 | |
| C07 | Mean | 2.00 × 1024 | 3.05 × 1016 | 2.32 × 1015 | 1.36 × 1015 | 9.01 × 107 | 4.58 × 1013 | 2.54 × 1013 | 5.41 × 1011 |
| Std | 5.94 × 1018 | 7.59 × 1010 | 2.28 × 1014 | 1.94 × 1014 | 1.18 × 108 | 1.16 × 1013 | 4.33 × 1013 | 5.91 × 1011 | |
| C08 | Mean | 2.01 × 1024 | 4.96 × 1015 | 6.94 × 1018 | 1.56 × 1016 | 8.44 × 1013 | 4.33 × 1015 | 4.49 × 10−1 | 2.31 × 10−3 |
| Std | 4.72 × 1021 | 1.56 × 1015 | 4.88 × 1018 | 3.59 × 1015 | 1.12 × 1013 | 4.57 × 1015 | 8.67 × 10−1 | 3.72 × 10−4 | |
| C09 | Mean | 1.00 × 1024 | 4.77 × 101 | 1.90 × 1016 | 2.27 × 1010 | 8.42 × 106 | 1.47 × 107 | 3.03 × 101 | 2.32 × 101 |
| Std | 1.90 × 1020 | 1.77 × 101 | 1.06 × 1016 | 1.29 × 1010 | 2.16 × 106 | 2.20 × 107 | 1.40 × 101 | 8.08 × 101 | |
| C10 | Mean | 2.03 × 1024 | 1.91 × 1014 | 2.75 × 1019 | 7.96 × 1016 | 6.96 × 1010 | 1.88 × 1016 | 1.21 × 10−1 | 6.4 × 10−4 |
| Std | 6.03 × 1021 | 8.75 × 1013 | 1.38 × 1019 | 1.57 × 1016 | 1.05 × 1010 | 3.76 × 1016 | 4.27 × 10−1 | 1.29 × 10−4 | |
| C11 | Mean | 1.01 × 1024 | 3.64 × 1014 | 3.81 × 1018 | 1.22 × 1016 | 2.58 × 1012 | 3.53 × 1015 | 1.24 × 1010 | 2.33 × 1012 |
| Std | 1.01 × 1021 | 1.70 × 1014 | 7.93 × 1017 | 3.73 × 1015 | 5.14 × 1011 | 1.13 × 1016 | 2.36 × 1010 | 3.14 × 1012 | |
| C12 | Mean | 1.00 × 1024 | 1.47 × 102 | 1.09 × 1018 | 1.50 × 1015 | 3.36 × 102 | 3.90 × 1014 | 1.65 × 101 | 1.62 × 101 |
| Std | 3.64 × 1020 | 3.87 × 101 | 1.66 × 1017 | 4.34 × 1014 | 1.64 × 101 | 1.24 × 1015 | 1.11 × 101 | 1.14 × 101 | |
| C13 | Mean | 1.17 × 1024 | 9.25 × 1013 | 1.07 × 1018 | 1.46 × 1017 | 1.86 × 1013 | 2.34 × 1014 | 9.83 × 1015 | 8.65 × 1013 |
| Std | 3.74 × 1023 | 4.85 × 1013 | 2.13 × 1017 | 3.51 × 1016 | 1.44 × 1012 | 5.75 × 1014 | 4.23 × 1015 | 4.13 × 1013 | |
| C14 | Mean | 2.01 × 1024 | 1.17 × 101 | 2.16 × 1018 | 3.05 × 1015 | 2.21 × 105 | 8.66 × 1013 | 1.11 × 101 | 1.10 × 101 |
| Std | 8.08 × 1020 | 6.23 × 10−2 | 3.09 × 1017 | 1.14 × 1015 | 3.33 × 105 | 1.91 × 1014 | 7.98 × 10−6 | 8.51 × 10−9 | |
| C15 | Mean | 1.00 × 1024 | 2.46 × 101 | 9.37 × 1017 | 5.53 × 106 | 2.64 × 101 | 3.96 × 101 | 2.69 × 101 | 1.22 × 101 |
| Std | 4.52 × 1020 | 3.00 × 101 | 1.46 × 1017 | 2.76 × 107 | 1.71 × 101 | 9.58 × 101 | 4.71 × 101 | 1.68 × 101 | |
| C16 | Mean | 1.00 × 1024 | 3.94 × 102 | 9.97 × 1017 | 3.92 × 102 | 2.78 × 102 | 2.22 × 102 | 3.98 × 102 | 2.83 × 102 |
| Std | 3.16 × 1020 | 2.28 × 101 | 2.13 × 1017 | 4.82 × 101 | 1.38 × 101 | 3.78 × 101 | 1.66 × 101 | 2.62 × 101 | |
| C17 | Mean | 2.00 × 1024 | 2.64 × 1011 | 1.10 × 1018 | 2.23 × 1017 | 2.60 × 1011 | 3.49 × 1014 | 2.60 × 1011 | 2.60 × 1011 |
| Std | 2.91 × 1020 | 2.20 × 10−3 | 1.52 × 1017 | 3.43 × 1016 | 1.44 × 10−2 | 8.21 × 1014 | 4.73 × 10−3 | 1.11 × 10−2 | |
| C18 | Mean | 4.25 × 1030 | 5.38 × 1018 | 1.54 × 1029 | 2.53 × 1027 | 1.95 × 1013 | 3.49 × 1019 | 4.00 × 1012 | 5.43 × 101 |
| Std | 1.55 × 1030 | 1.81 × 1019 | 4.31 × 1028 | 9.33 × 1026 | 2.96 × 1012 | 1.16 × 1020 | 1.23 × 1013 | 5.36 × 101 | |
| C19 | Mean | 1.00 × 1024 | 5.27 × 1017 | 5.28 × 1017 | 5.28 × 1017 | 5.28 × 1017 | 5.28 × 1017 | 5.28 × 1017 | 5.27 × 1017 |
| Std | 6.48 × 1016 | 2.99 × 1014 | 1.10 × 1014 | 5.24 × 1013 | 9.26 × 1013 | 1.64 × 1015 | 3.06 × 1014 | 4.02 × 101 | |
| C20 | Mean | 1.65 × 101 | 3.84 × 101 | 1.89 × 101 | 1.63 × 101 | 7.73 × 101 | 7.75 × 101 | 1.19 × 101 | 5.34 × 101 |
| Std | 4.28 × 10−1 | 5.03 × 10−1 | 1.02 × 101 | 5.83 × 10−1 | 1.47 × 101 | 6.47 × 10−1 | 7.98 × 10−1 | 2.07 × 10−1 | |
| C21 | Mean | 1.00 × 1024 | 3.49 × 106 | 7.12 × 1017 | 3.49 × 1016 | 3.35 × 102 | 1.12 × 1014 | 1.98 × 101 | 1.61 × 101 |
| Std | 3.93 × 1020 | 1.74 × 107 | 1.20 × 1017 | 7.00 × 1015 | 1.21 × 101 | 3.95 × 1014 | 1.18 × 101 | 1.14 × 101 | |
| C22 | Mean | 1.00 × 1024 | 8.59 × 1013 | 7.49 × 1017 | 1.44 × 1017 | 1.01 × 1014 | 1.88 × 1014 | 8.99 × 1015 | 8.50 × 1013 |
| Std | 4.63 × 1020 | 1.85 × 1013 | 1.36 × 1017 | 2.44 × 1016 | 1.02 × 1013 | 4.51 × 1014 | 4.19 × 1015 | 4.86 × 1013 | |
| C23 | Mean | 2.01 × 1024 | 3.64 × 108 | 1.43 × 1017 | 7.53 × 1016 | 1.86 × 101 | 1.67 × 1014 | 1.10 × 101 | 1.10 × 101 |
| Std | 8.48 × 1020 | 1.05 × 109 | 2.46 × 1017 | 1.43 × 1016 | 7.82 × 10−1 | 3.57 × 1014 | 6.74 × 10−6 | 2.48 × 10−8 | |
| C24 | Mean | 1.00 × 1024 | 2.39 × 101 | 6.44 × 1017 | 2.01 × 102 | 1.96 × 101 | 2.33 × 101 | 2.52 × 101 | 2.30 × 101 |
| Std | 3.90 × 1020 | 2.54 × 101 | 1.44 × 1017 | 3.93 × 102 | 1.53 × 101 | 3.60 × 101 | 3.33 × 101 | 3.28 × 101 | |
| C25 | Mean | 1.00 × 1024 | 3.96 × 102 | 6.57 × 1017 | 1.19 × 103 | 3.64 × 102 | 3.09 × 102 | 3.99 × 102 | 2.94 × 102 |
| Std | 3.87 × 1020 | 1.62 × 101 | 1.28 × 1017 | 1.33 × 103 | 9.95 × 101 | 3.47 × 101 | 1.39 × 102 | 2.10 × 101 | |
| C26 | Mean | 2.00 × 1024 | 2.60 × 1011 | 7.07 × 1017 | 2.16 × 1017 | 2.61 × 1011 | 6.59 × 1013 | 2.616 × 1011 | 2.60 × 1011 |
| Std | 2.94 × 1020 | 1.73 × 10−3 | 1.33 × 1017 | 3.92 × 1016 | 9.79 × 10−1 | 1.86 × 1014 | 4.78 × 10−3 | 2.40 × 10−3 | |
| C27 | Mean | 2.47 × 1030 | 3.42 × 1020 | 1.05 × 1029 | 2.63 × 1027 | 2.69 × 1013 | 1.40 × 1022 | 4.83 × 1010 | 2.48 × 1012 |
| Std | 1.01 × 1030 | 6.20 × 1020 | 3.46 × 1028 | 8.19 × 1026 | 4.92 × 1012 | 5.71 × 1022 | 1.34 × 1011 | 1.23 × 1013 | |
| C28 | Mean | 1.00 × 1024 | 5.28 × 1017 | 5.28 × 1017 | 5.28 × 1017 | 5.28 × 1017 | 5.28 × 1017 | 5.28 × 1017 | 5.28 × 1017 |
| Std | 6.31 × 1016 | 2.56 × 1014 | 1.37 × 1014 | 7.90 × 1013 | 7.17 × 1013 | 2.19 × 1014 | 3.17 × 1014 | 2.90 × 1014 | |
| w/t/l | 28/0/0 | 28/0/0 | 28/0/0 | 27/0/1 | 25/0/3 | 27/0/1 | 16/0/12 | - | |
| Dimension | Significance Level | k | χ2 | χ2α[k − 1] | p-Value | Null Hypothesis | Alternative Hypothesis |
|---|---|---|---|---|---|---|---|
| D = 30 | α = 0.05 | 8 | 148.47 | 14.07 | 8.51889 × 10−29 | Reject | Accept |
| Dimension | Significance Level | k | χ2 | χ2α[k − 1] | p-Value | Null Hypothesis | Alternative Hypothesis |
|---|---|---|---|---|---|---|---|
| D = 50 | α = 0.05 | 8 | 151.31 | 14.07 | 2.15923 × 10−29 | Reject | Accept |
| Comparison | Unadjusted p-Value | Adjusted p-Value |
|---|---|---|
| IHFAPA vs. SFA | 3.28 × 10−7 | 4.69 × 10−8 |
| IHFAPA vs. RaFA | 1.92 × 10−2 | 9.60 × 10−3 |
| IHFAPA vs. NaFA | 1.00 × 10−3 | 2.00 × 10−4 |
| IHFAPA vs. GDFA | 8.00 × 10−3 | 2.67 × 10−3 |
| IHFAPA vs. ADIFA | 1.00 × 10−5 | 1.67 × 10−6 |
| IHFAPA vs. YYFA | 1.60 × 10−3 | 4.00 × 10−4 |
| IHFAPA vs. GAHFA | 8.43 × 10−2 | 8.43 × 10−2 |
| Comparison | Unadjusted p-Value | Adjusted p-Value |
|---|---|---|
| IHFAPA vs. SFA | 4.06 × 10−14 | 5.80 × 10−15 |
| IHFAPA vs. RaFA | 3.02 × 10−3 | 7.55 × 10−4 |
| IHFAPA vs. NaFA | 8.38 × 10−13 | 1.40 × 10−13 |
| IHFAPA vs. GDFA | 6.01 × 10−9 | 1.20 × 10−9 |
| IHFAPA vs. ADIFA | 1.36 × 10−2 | 4.53 × 10−3 |
| IHFAPA vs. YYFA | 4.82 × 10−2 | 2.41 × 10−2 |
| IHFAPA vs. GAHFA | 9.34 × 10−2 | 9.34 × 10−2 |
| Algorithm | Reference | Years | Parameters |
|---|---|---|---|
| JSO | [53] | 2017 | MF = 0.5, MCR = 0.8. |
| HDE | [47] | 2018 | F = [0.7,1], CR = [0.4,1]. |
| ISCA | [48] | 2019 | CR = 0.3. |
| DMCSO | [49] | 2019 | RN = 0.2n, HN = 0.6n, CN = 0.2n, MN = 0.1n, FL ∈ [0.4,1], G = 10. |
| OBLPSOGD | [50] | 2019 | P0 = 0.3, α = 3.2, k = 15, σ = 0.3, wmin = 0.4, wmax = 0.9. |
| MBADE | [51] | 2020 | A0 = 0.9, r0 = 0.5, fmax = 2, fmin = 0, α = γ = 0.9. |
| MFAGA | [52] | 2021 | α = 4, β0 = 1, γ = 2, w = 0.7. |
| IHFAPA | - | - | n = 40, α0 = 0.1, ϕ0 = 0.9, βmax = 1, βmin = 0.5, γ = 1, Pm = 1. |
| Test Functions | Performance Indicators | JSO | HDE | ISCA | DMCSO | OBLPSOGD | MBADE | MFAGA | IHFAPA |
|---|---|---|---|---|---|---|---|---|---|
| C01 | Mean | 3.77 × 101 | 4.41 × 103 | 5.97 × 103 | 5.49 × 103 | 1.51 × 102 | 3.05 × 103 | 7.94 × 101 | 6.17 × 10−15 |
| Std | 9.50 × 101 | 1.60 × 103 | 2.08 × 103 | 2.22 × 103 | 9.09 × 101 | 6.61 × 10−4 | 1.80 × 101 | 8.21 × 10−15 | |
| C02 | Mean | 2.01 × 101 | 3.67 × 103 | 4.86 × 103 | 3.81 × 103 | 3.30 × 102 | 2.03 × 103 | 8.06 × 101 | 2.52 × 10−14 |
| Std | 5.64 × 101 | 1.47 × 103 | 1.35 × 103 | 1.69 × 103 | 1.19 × 102 | 2.32 × 10−4 | 2.28 × 101 | 5.99 × 10−14 | |
| C03 | Mean | 5.39 × 105 | 3.22 × 105 | 8.41 × 104 | 5.00 × 104 | 6.92 × 104 | 9.86 × 104 | 8.33 × 107 | 1.56 × 105 |
| Std | 3.73 × 105 | 5.13 × 105 | 2.66 × 104 | 1.25 × 104 | 4.05 × 104 | 2.18 × 104 | 4.15 × 107 | 1.74 × 105 | |
| C04 | Mean | 1.46 × 102 | 7.04 × 101 | 6.04 × 101 | 3.97 × 102 | 5.45 × 102 | 5.37 × 101 | 3.66 × 102 | 4.84 × 102 |
| Std | 6.81 × 101 | 1.98 × 101 | 1.12 × 101 | 6.04 × 101 | 6.27 × 101 | 1.42 × 101 | 1.83 × 101 | 6.23 × 101 | |
| C05 | Mean | 1.18 × 101 | 3.09 × 104 | 2.04 × 102 | 3.82 × 104 | 3.49 × 102 | 5.89 × 102 | 7.23 × 103 | 7.64 × 101 |
| Std | 7.78 × 101 | 5.61 × 104 | 1.80 × 102 | 4.30 × 104 | 3.29 × 102 | 1.53 × 101 | 1.83 × 103 | 4.17 × 101 | |
| C06 | Mean | 1.81 × 1010 | 4.96 × 109 | 4.40 × 107 | 3.62 × 103 | 1.14 × 109 | 5.05 × 109 | 8.76 × 109 | 4.10 × 103 |
| Std | 7.48 × 109 | 2.28 × 109 | 4.93 × 107 | 9.95 × 102 | 2.55 × 109 | 1.04 × 103 | 7.01 × 109 | 1.03 × 103 | |
| C07 | Mean | 1.55 × 1012 | 8.79 × 109 | 4.48 × 102 | 2.18 × 109 | −1.77 × 102 | 4.85 × 1011 | 7.51 × 1012 | −1.48 × 102 |
| Std | 4.76 × 1011 | 1.46 × 1010 | 1.03 × 103 | 5.96 × 109 | 1.61 × 102 | 1.12 × 109 | 5.23 × 1012 | 2.78 × 1011 | |
| C08 | Mean | 1.98 × 101 | 7.44 × 1015 | 1.43 × 1015 | 1.75 × 1013 | 3.58 × 1011 | 1.88 × 1015 | 2.69 × 1011 | 3.15 × 10−3 |
| Std | 5.20 × 101 | 4.92 × 1015 | 1.20 × 1015 | 6.57 × 1012 | 3.47 × 1011 | 1.43 × 10−3 | 1.57 × 1011 | 2.76 × 10−4 | |
| C09 | Mean | 4.86 × 101 | 4.09 × 1011 | 1.23 × 101 | 1.04 × 1010 | 1.89 × 1011 | 6.10 × 101 | 6.37 × 109 | 9.16 × 101 |
| Std | 1.50 × 101 | 1.64 × 1012 | 1.56 × 101 | 2.68 × 1010 | 4.12 × 1011 | 2.61 × 101 | 6.40 × 109 | 3.34 × 101 | |
| C10 | Mean | 6.25 × 10−4 | 3.43 × 1016 | 3.28 × 1015 | 4.49 × 1014 | 2.88 × 1012 | 3.19 × 1015 | 1.05 × 1012 | 7.23 × 10−4 |
| Std | 4.33 × 10−4 | 5.05 × 1016 | 4.40 × 1015 | 1.40 × 1014 | 8.26 × 1012 | 4.51 × 10−4 | 2.81 × 1011 | 1.16 × 10−4 | |
| C11 | Mean | 2.49 × 1011 | 8.86 × 1014 | 2.78 × 1013 | 3.65 × 1013 | 2.94 × 1016 | 3.79 × 1014 | 2.05 × 1012 | 4.64 × 1011 |
| Std | 4.21 × 1011 | 1.39 × 1015 | 5.57 × 1013 | 3.77 × 1013 | 2.05 × 1016 | 6.97 × 1017 | 1.57 × 1012 | 1.92 × 1014 | |
| C12 | Mean | 2.15 × 102 | 1.69 × 1014 | 1.26 × 1012 | 2.61 × 1013 | 5.471010 | 2.37 × 102 | 2.77 × 1010 | 4.00 × 101 |
| Std | 1.95 × 101 | 1.58 × 1014 | 2.57 × 1012 | 1.81 × 1013 | 7.471010 | 1.58 × 101 | 9.19 × 109 | 1.21 × 101 | |
| C13 | Mean | 5.601010 | 3.71 × 1014 | 2.81 × 1012 | 2.28 × 1013 | 3.66 × 1012 | 1.86 × 1013 | 3.59 × 1012 | 5.06 × 1012 |
| Std | 1.04 × 1011 | 4.53 × 1014 | 6.41 × 1012 | 1.47 × 1013 | 3.39 × 1012 | 9.18 × 1013 | 9.56 × 1011 | 3.88 × 1012 | |
| C14 | Mean | 2.17 × 101 | 6.85 × 1014 | 3.64 × 1013 | 3.86 × 1013 | 8.041010 | 2.94 × 107 | 7.23 × 1010 | 1.41 × 101 |
| Std | 7.04 × 10−2 | 8.40 × 1014 | 1.09 × 1014 | 2.01 × 1013 | 1.09 × 1011 | 2.06 × 10−7 | 2.30 × 1010 | 3.77 × 10−4 | |
| C15 | Mean | 1.71 × 101 | 8.08 × 1013 | 2.40 × 101 | 1.54 × 1013 | 1.40 × 101 | 2.12 × 101 | 1.78 × 101 | 1.49 × 101 |
| Std | 2.59 × 101 | 3.20 × 1014 | 5.04 × 101 | 1.42 × 1013 | 1.65 × 101 | 5.10 × 101 | 1.93 × 101 | 3.75 × 101 | |
| C16 | Mean | 1.65 × 102 | 3.08 × 1012 | 1.74 × 102 | 2.15 × 1013 | 1.35 × 102 | 2.16 × 102 | 1.57 × 102 | 1.90 × 102 |
| Std | 1.38 × 101 | 1.00 × 1013 | 1.25 × 101 | 1.49 × 1013 | 9.81 × 101 | 1.74 × 101 | 2.06 × 101 | 1.99 × 101 | |
| C17 | Mean | 9.611010 | 4.12 × 1014 | 1.58 × 1014 | 2.42 × 1013 | 9.611010 | 9.61 × 1010 | 9.61 × 1010 | 9.611010 |
| Std | 3.53 × 101 | 6.49 × 1014 | 6.57 × 1014 | 1.56 × 1013 | 2.12 × 10−2 | 5.53 × 10−2 | 3.14 × 103 | 0 | |
| C18 | Mean | 5.10 × 1010 | 4.07 × 1025 | 1.19 × 1020 | 1.84 × 1024 | 7.19 × 1017 | 8.77 × 1014 | 2.98 × 1016 | 3.65 × 101 |
| Std | 1.61 × 1011 | 1.05 × 1026 | 2.46 × 1020 | 1.77 × 1024 | 1.68 × 1018 | 1.24 × 1011 | 2.28 × 1016 | 1.24 × 1011 | |
| C19 | Mean | 1.83 × 1017 | 1.85 × 1017 | 1.83 × 1017 | 9.21 × 1013 | 1.84 × 1017 | 1.83 × 1017 | 1.85 × 1017 | 1.84 × 1017 |
| Std | 2.27 × 103 | 1.01 × 1014 | 1.59 × 1014 | 8.29 × 1010 | 1.98 × 1014 | 6.26 × 1013 | 1.67 × 1014 | 1.72 × 1014 | |
| C20 | Mean | 8.45 × 101 | 8.65 × 101 | 4.18 × 101 | 6.31 × 101 | 8.08 × 101 | 7.82 × 101 | 7.90 × 101 | 3.54 × 101 |
| Std | 7.25 × 10−1 | 5.34 × 10−1 | 2.77 × 10−1 | 7.15 × 10−1 | 4.30 × 10−1 | 1.35 × 101 | 6.00 × 10−1 | 2.76 × 10−1 | |
| C21 | Mean | 2.13 × 102 | 9.32 × 1013 | 1.00 × 1012 | 1.32 × 1013 | 1.16 × 1012 | 3.30 × 102 | 3.241010 | 1.46 × 101 |
| Std | 2.59 × 101 | 1.08 × 1014 | 1.88 × 1012 | 7.07 × 1012 | 2.72 × 1012 | 3.08 × 101 | 1.01010 | 9.78 × 101 | |
| C22 | Mean | 4.51 × 1011 | 3.43 × 1014 | 9.88 × 1012 | 9.44 × 1012 | 1.88 × 1013 | 1.45 × 1013 | 3.67 × 1012 | 1.25 × 1012 |
| Std | 2.01 × 1011 | 5.12 × 1014 | 9.30 × 1012 | 4.02 × 1012 | 1.34 × 1013 | 4.78 × 1013 | 1.32 × 1012 | 5.04 × 1012 | |
| C23 | Mean | 2.01 × 101 | 3.19 × 1014 | 2.73 × 1012 | 2.52 × 1013 | 3.47 × 1012 | 8.25 × 101 | 7.56 × 1012 | 1.41 × 101 |
| Std | 7.06 × 10−2 | 3.18 × 1014 | 5.63 × 1012 | 1.24 × 1013 | 6.38 × 1012 | 1.40 × 10−1 | 2.68 × 1012 | 1.94 × 10−2 | |
| C24 | Mean | 1.82 × 101 | 7.27 × 1012 | 1.71 × 101 | 1.03 × 1013 | 1.54 × 101 | 1.81 × 101 | 1.85 × 101 | 1.81 × 101 |
| Std | 1.54 × 101 | 3.21 × 1013 | 1.79 × 101 | 5.70 × 1012 | 1.91 × 101 | 2.67 × 101 | 1.64 × 101 | 2.38 × 101 | |
| C25 | Mean | 1.72 × 102 | 2.78 × 1013 | 1.95 × 102 | 9.87 × 1012 | 1.42 × 102 | 1.95 × 102 | 1.47 × 102 | 1.82 × 102 |
| Std | 1.50 × 101 | 9.57 × 1013 | 1.78 × 101 | 8.68 × 1012 | 1.25 × 101 | 2.21 × 101 | 1.78 × 101 | 1.49 × 101 | |
| C26 | Mean | 9.61 × 1010 | 1.52 × 1014 | 1.39 × 1012 | 1.30 × 1013 | 1.45 × 1011 | 9.61 × 1012 | 9.61 × 1012 | 9.61 × 1012 |
| Std | 2.76 × 101 | 2.54 × 1014 | 3.54 × 1012 | 6.46 × 1012 | 2.24 × 1011 | 4.06 × 10−3 | 1.43 × 103 | 0.00 × 101 | |
| C27 | Mean | 4.50 × 1013 | 3.57 × 1022 | 1.61 × 1018 | 2.22 × 1023 | 6.85 × 1017 | 1.66 × 1016 | 1.32 × 1016 | 3.65 × 101 |
| Std | 1.10 × 1014 | 8.85 × 1022 | 3.86 × 1018 | 3.66 × 1023 | 1.59 × 1018 | 2.06 × 1013 | 9.40 × 1015 | 1.60 × 1013 | |
| C28 | Mean | 1.84 × 1017 | 1.85 × 1017 | 1.84 × 1017 | 9.23 × 1013 | 1.84 × 1017 | 1.84 × 1017 | 1.85 × 1017 | 1.85 × 1017 |
| Std | 4.59 × 1014 | 6.40 × 1013 | 1.49 × 1014 | 4.69 × 1012 | 3.39 × 1014 | 1.88 × 1014 | 2.05 × 1014 | 1.63 × 1014 | |
| w/t/l | 25/0/3 | 28/0/0 | 26/0/2 | 25/0/3 | 23/0/5 | 26/0/2 | 25/0/3 | - | |
| Test Functions | Performance Indicators | JSO | HDE | ISCA | DMCSO | OBLPSOGD | MBADE | MFAGA | IHFAPA |
|---|---|---|---|---|---|---|---|---|---|
| C01 | Mean | 2.37 × 102 | 1.86 × 1016 | 1.61 × 1016 | 9.82 × 1013 | 7.46 × 1013 | 2.81 × 109 | 4.65 × 1012 | 1.21 × 10−5 |
| Std | 3.43 × 102 | 1.16 × 1013 | 7.94 × 107 | 1.91 × 1011 | 1.72 × 1012 | 9.51 × 101 | 2.91 × 1011 | 1.10 × 10−5 | |
| C02 | Mean | 1.62 × 103 | 3.51 × 1013 | 2.04 × 108 | 2.00 × 1011 | 2.90 × 1012 | 3.82 × 101 | 2.47 × 1011 | 6.35 × 10−5 |
| Std | 2.41 × 103 | 1.80 × 1017 | 4.40 × 1017 | 2.80 × 1015 | 1.08 × 1014 | 6.11 × 102 | 1.52 × 1013 | 5.02 × 10−5 | |
| C03 | Mean | 1.31×16 | 1.05 × 1017 | 1.83 × 1017 | 9.29 × 1014 | 1.83 × 1014 | 1.63 × 103 | 4.89 × 1012 | 1.15 × 103 |
| Std | 7.10 × 105 | 6.43 × 1015 | 1.89 × 1015 | 2.61 × 1014 | 1.91 × 1017 | 1.45 × 1010 | 2.50 × 1013 | 4.47 × 104 | |
| C04 | Mean | 3.20 × 102 | 7.11 × 1015 | 2.04 × 1015 | 1.70 × 1014 | 7.90 × 1016 | 1.55 × 1010 | 1.51 × 1013 | 8.71 × 102 |
| Std | 1.16 × 102 | 1.83 × 1015 | 1.15 × 1015 | 1.67 × 1014 | 1.24 × 1013 | 1.28 × 102 | 3.60 × 1011 | 1.36 × 102 | |
| C05 | Mean | 8.23 × 101 | 1.86 × 1015 | 1.35 × 1015 | 5.62 × 1013 | 1.38 × 1013 | 5.16 × 101 | 8.08 × 1010 | 5.34 × 101 |
| Std | 4.57 × 101 | 2.02 × 1015 | 3.48 × 1015 | 1.25 × 1014 | 1.78 × 1014 | 1.65 × 1015 | 2.70 × 1013 | 2.84 × 101 | |
| C06 | Mean | 4.69 × 101 | 1.96 × 1015 | 4.30 × 1015 | 5.42 × 1013 | 1.13 × 1014 | 1.30 × 1015 | 3.42 × 1012 | 7.85 × 106 |
| Std | 1.13 × 101 | 3.16 × 1015 | 2.45 × 1015 | 3.68 × 1014 | 2.05 × 1013 | 1.20 × 101 | 7.87 × 1011 | 3.92 × 107 | |
| C07 | Mean | 6.69 × 1012 | 2.29 × 1015 | 2.01 × 1015 | 9.99 × 1013 | 1.53 × 1013 | 8.69 × 10−2 | 1.22 × 1011 | 5.41 × 1011 |
| Std | 9.39 × 1011 | 4.60 × 1012 | 2.17 × 1013 | 1.37 × 1014 | 1.93 × 101 | 3.24 × 101 | 2.11 × 101 | 5.91 × 1011 | |
| C08 | Mean | 7.74 × 1014 | 1.35 × 1013 | 9.70 × 1013 | 5.41 × 1013 | 2.44 × 101 | 5.24 × 101 | 2.54 × 101 | 2.31 × 10−3 |
| Std | 1.50 × 1015 | 8.01 × 1013 | 4.33 × 1013 | 1.45 × 1014 | 2.78 × 102 | 3.44 × 102 | 2.82 × 102 | 3.72 × 10−4 | |
| C09 | Mean | 6.23 × 109 | 2.56 × 1014 | 1.90 × 1014 | 4.02 × 1013 | 1.37 × 101 | 2.16 × 101 | 2.81 × 101 | 1.32 × 101 |
| Std | 1.95 × 1010 | 2.48 × 1015 | 1.82 × 1015 | 1.98 × 1014 | 1.51 × 1013 | 2.60 × 1011 | 2.60 × 1011 | 8.08 × 101 | |
| C10 | Mean | 2.26 × 1010 | 2.56 × 1015 | 2.20 × 1015 | 5.12 × 1013 | 1.29 × 1013 | 4.54 × 10−2 | 1.04 × 104 | 6.47 × 10−4 |
| Std | 7.14 × 1010 | 3.24 × 1026 | 1.39 × 1025 | 1.64 × 1025 | 6.38 × 1020 | 1.60 × 1011 | 1.23 × 1018 | 1.29 × 10−4 | |
| C11 | Mean | 8.68 × 1012 | 5.47 × 1026 | 2.30 × 1025 | 7.03 × 1024 | 8.68 × 1020 | 2.01 × 1011 | 1.88 × 1018 | 2.33 × 1012 |
| Std | 1.63 × 1013 | 5.28 × 1017 | 5.25 × 1017 | 2.64 × 1014 | 5.26 × 1017 | 5.22 × 1017 | 5.27 × 1017 | 3.14 × 1012 | |
| C12 | Mean | 3.07 × 102 | 2.94 × 1014 | 2.95 × 1014 | 1.32 × 1011 | 2.78 × 1014 | 1.28 × 1014 | 3.18 × 1014 | 1.62 × 101 |
| Std | 3.70 × 101 | 1.75 × 101 | 1.03 × 101 | 1.41 × 101 | 1.59 × 101 | 1.29 × 101 | 1.59 × 101 | 1.14 × 101 | |
| C13 | Mean | 1.73 × 1012 | 5.59 × 10−1 | 6.98 × 10−1 | 1.19 × 101 | 5.07 × 10−1 | 3.00 × 101 | 6.79 × 10−1 | 8.65 × 1013 |
| Std | 9.82 × 1011 | 1.63 × 1015 | 9.51 × 1014 | 1.15 × 1014 | 2.39 × 1013 | 2.80 × 102 | 4.05 × 1011 | 4.13 × 1013 | |
| C14 | Mean | 6.40 × 104 | 1.56 × 1015 | 8.48 × 1014 | 3.03 × 1013 | 1.94 × 1013 | 4.08 × 101 | 1.13 × 1011 | 1.10 × 101 |
| Std | 1.46 × 105 | 2.07 × 1015 | 1.45 × 1015 | 1.18 × 1014 | 3.96 × 1014 | 3.91 × 1015 | 2.62 × 1013 | 8.51 × 10−9 | |
| C15 | Mean | 2.01 × 101 | 1.72 × 1015 | 9.71 × 1014 | 4.11 × 1013 | 1.88 × 1014 | 3.24 × 1015 | 6.20 × 1012 | 2.22 × 101 |
| Std | 1.31 × 101 | 3.07 × 1015 | 2.04 × 1015 | 2.49 × 1014 | 5.46 × 1013 | 1.54 × 101 | 7.97 × 1011 | 2.68 × 101 | |
| C16 | Mean | 3.22 × 102 | 2.78 × 1015 | 1.98 × 1015 | 6.78 × 1013 | 8.09 × 1013 | 6.49 × 10−2 | 1.75 × 1011 | 2.83 × 102 |
| Std | 1.51 × 101 | 1.55 × 1014 | 6.46 × 1011 | 9.51 × 1013 | 1.82 × 101 | 2.65 × 101 | 2.04 × 101 | 2.62 × 101 | |
| C17 | Mean | 2.60 × 1011 | 4.61 × 1014 | 2.89 × 1012 | 3.07 × 1013 | 1.43 × 101 | 4.34 × 101 | 1.68 × 101 | 2.60 × 1011 |
| Std | 4.11 × 101 | 2.70 × 1013 | 2.77 × 1012 | 9.08 × 1013 | 2.89 × 102 | 3.88 × 102 | 2.91 × 102 | 1.11 × 10−2 | |
| C18 | Mean | 3.05 × 1015 | 9.14 × 1013 | 8.70 × 1012 | 3.33 × 1013 | 1.36 × 101 | 2.42 × 101 | 2.66 × 101 | 5.43 × 101 |
| Std | 9.65 × 1015 | 1.07 × 1015 | 1.35 × 1015 | 1.24 × 1014 | 8.67 × 1014 | 2.60 × 1011 | 2.60 × 1011 | 5.36 × 101 | |
| C19 | Mean | 5.22 × 1017 | 7.57 × 1014 | 1.71 × 1015 | 3.88 × 1013 | 4.27 × 1014 | 2.40 × 10−3 | 1.19 × 104 | 5.27 × 1017 |
| Std | 1.44 × 1013 | 7.56 × 1023 | 6.36 × 1023 | 5.72 × 1024 | 2.50 × 1021 | 9.11 × 1010 | 5.27 × 1018 | 4.02 × 1014 | |
| C20 | Mean | 1.72 × 101 | 1.68 × 1024 | 1.08 × 1024 | 4.52 × 1024 | 2.94 × 1021 | 1.96 × 1011 | 4.46 × 1018 | 5.34 × 101 |
| Std | 6.51 × 10−1 | 5.28 × 1017 | 5.27 × 1017 | 2.64 × 1014 | 5.27 × 1017 | 5.26 × 1017 | 5.28 × 1017 | 2.07 × 101 | |
| C21 | Mean | 3.33 × 102 | 1.28 × 1014 | 4.47 × 1014 | 7.44 × 1010 | 2.05 × 1014 | 4.11 × 1014 | 3.46 × 1014 | 1.61 × 101 |
| Std | 2.66 × 101 | 1.86 × 1016 | 1.61 × 1016 | 9.82 × 1013 | 7.46 × 1013 | 2.81 × 109 | 4.65 × 1012 | 1.14 × 101 | |
| C22 | Mean | 8.80 × 1012 | 1.16 × 1013 | 7.94 × 107 | 1.91 × 1011 | 1.72 × 1012 | 9.51 × 101 | 2.91 × 1011 | 8.50 × 1013 |
| Std | 4.02 × 1012 | 3.51 × 1013 | 2.04 × 108 | 2.00 × 1011 | 2.90 × 1012 | 3.82 × 101 | 2.47 × 1011 | 4.86 × 1013 | |
| C23 | Mean | 1.63 × 101 | 1.80 × 1017 | 4.40 × 1017 | 2.80 × 1015 | 1.08 × 1014 | 6.11 × 102 | 1.52 × 1013 | 1.10 × 101 |
| Std | 6.93 × 10−2 | 1.05 × 1017 | 1.83 × 1017 | 9.29 × 1014 | 1.83 × 1014 | 1.63 × 103 | 4.89 × 1012 | 2.48 × 10−8 | |
| C24 | Mean | 2.23 × 101 | 6.43 × 1015 | 1.89 × 1015 | 2.61 × 1014 | 1.91 × 1017 | 1.45 × 1010 | 2.50 × 1013 | 2.30 × 101 |
| Std | 1.31 × 101 | 7.11 × 1015 | 2.04 × 1015 | 1.70 × 1014 | 7.90 × 1016 | 1.55 × 1010 | 1.51 × 1013 | 3.28 × 101 | |
| C25 | Mean | 3.15 × 102 | 1.83 × 1015 | 1.15 × 1015 | 1.67 × 1014 | 1.24 × 1013 | 1.28 × 102 | 3.60 × 1011 | 2.94 × 102 |
| Std | 6.68 × 101 | 1.86 × 1015 | 1.35 × 1015 | 5.62 × 1013 | 1.38 × 1013 | 5.16 × 101 | 8.08 × 1010 | 2.10 × 101 | |
| C26 | Mean | 2.60 × 1011 | 2.02 × 1015 | 3.48 × 1015 | 1.25 × 1014 | 1.78 × 1014 | 1.65 × 1015 | 2.70 × 1013 | 2.60 × 1011 |
| Std | 9.40 × 101 | 1.96 × 1015 | 4.30 × 1015 | 5.42 × 1013 | 1.13 × 1014 | 1.30 × 1015 | 3.42 × 1012 | 2.40 × 10−3 | |
| C27 | Mean | 6.21 × 1012 | 3.16 × 1015 | 2.45 × 1015 | 3.68 × 1014 | 2.05 × 1013 | 1.20 × 101 | 7.87 × 1011 | 2.48 × 1012 |
| Std | 1.37 × 1013 | 2.29 × 1015 | 2.01 × 1015 | 9.99 × 1013 | 1.53 × 1013 | 8.69 × 10−2 | 1.22 × 1011 | 1.23 × 1013 | |
| C28 | Mean | 5.25 × 1017 | 4.60 × 1012 | 2.17 × 1013 | 1.37 × 1014 | 1.93 × 101 | 3.24 × 101 | 2.11 × 101 | 5.28 × 1017 |
| Std | 1.38 × 1015 | 1.35 × 1013 | 9.70 × 1013 | 5.41 × 1013 | 2.44 × 101 | 5.24 × 101 | 2.54 × 101 | 2.90 × 1014 | |
| w/t/l | 25/0/3 | 28/0/0 | 28/0/0 | 28/0/0 | 23/0/5 | 18/0/10 | 26/0/2 | - | |
| Dimension | Significance Level | k | χ2 | χ2α[k − 1] | p-Value | Null Hypothesis | Alternative Hypothesis |
|---|---|---|---|---|---|---|---|
| D = 30 | α = 0.05 | 8 | 118.68 | 14.07 | 1.4438 × 10−22 | Reject | Accept |
| Dimension | Significance Level | k | χ2 | χ2α[k − 1] | p-Value | Null Hypothesis | Alternative Hypothesis |
|---|---|---|---|---|---|---|---|
| D = 50 | α = 0.05 | 8 | 173.61 | 14.07 | 4.3532 × 10−34 | Reject | Accept |
| Comparison | Unadjusted p-Value | Adjusted p-Value |
|---|---|---|
| IHFAPA vs. JSO | 3.56 × 10−1 | 3.56 × 10−1 |
| IHFAPA vs. HDE | 5.23 × 10−10 | 7.47 × 10−11 |
| IHFAPA vs. ISCA | 4.99 × 10−5 | 9.98 × 10−6 |
| IHFAPA vs. DMCSO | 7.45 × 10−8 | 1.24 × 10−8 |
| IHFAPA vs. OBLPSOGD | 9.39 × 10−4 | 3.13 × 10−4 |
| IHFAPA vs. MBADE | 3.67 × 10−2 | 1.84 × 10−2 |
| IHFAPA vs. MFAGA | 6.85 × 10−4 | 1.71 × 10−4 |
| Comparison | Unadjusted p-Value | Adjusted p-Value |
|---|---|---|
| IHFAPA vs. JSO | 3.70 × 10−3 | 7.47 × 10−11 |
| IHFAPA vs. HDE | 1.34 × 10−14 | 1.91 × 10−15 |
| IHFAPA vs. ISCA | 1.23 × 10−13 | 2.04 × 10−14 |
| IHFAPA vs. DMCSO | 4.45 × 10−12 | 8.89 × 10−13 |
| IHFAPA vs. OBLPSOGD | 6.23 × 10−8 | 1.56 × 10−8 |
| IHFAPA vs. MBADE | 1.49 × 10−1 | 1.49 × 10−1 |
| IHFAPA vs. MFAGA | 2.55 × 10−5 | 8.50 × 10−6 |
| Algorithm | x1 | x2 | x3 | x4 | x5 | f(X) |
|---|---|---|---|---|---|---|
| SFA | 5.378221 | 5.196736 | 5.352442 | 33.838475 | 1.509515 | 31.913801 |
| RaFA | 27.867726 | 19.660745 | 11.522870 | 4.807659 | 8.096651 | 44.785197 |
| NaFA | 5.822165 | 4.833300 | 4.296618 | 3.704691 | 2.380659 | 13.093698 |
| GDFA | 5.995532 | 4.712419 | 4.524987 | 3.592656 | 2.135814 | 13.046380 |
| ADIFA | 5.812717 | 4.894457 | 4.637111 | 3.486921 | 2.130079 | 13.046305 |
| YYFA | 5.974240 | 4.872583 | 4.427257 | 3.513410 | 2.164964 | 13.040808 |
| GAHFA | 6.013024 | 4.733404 | 4.514108 | 3.525513 | 2.164763 | 13.039888 |
| JSO | 5.978223 | 4.876190 | 4.466096 | 3.479479 | 2.139142 | 13.032515 |
| HDE | 5.980548 | 4.884228 | 4.459534 | 3.482497 | 2.132448 | 13.032592 |
| ISCA | 5.980177 | 4.873386 | 4.469500 | 3.477099 | 2.138981 | 13.032522 |
| DMCSO | 5.976299 | 4.877723 | 4.466438 | 3.478975 | 2.139698 | 13.032516 |
| MBADE | 5.978223 | 4.876190 | 4.466096 | 3.479479 | 2.139142 | 13.032514 |
| MFAGA | 5.978223 | 4.876190 | 4.466096 | 3.479479 | 2.139142 | 13.032514 |
| IHFAPA | 5.978223 | 4.876190 | 4.466096 | 3.479479 | 2.139142 | 13.032514 |
| Algorithm | Best | Worst | Mean | Std |
|---|---|---|---|---|
| SFA | 31.91380143 | 95.41133362 | 72.02906616 | 1.73 × 101 |
| RaFA | 44.78519656 | 98.22406344 | 78.05979901 | 1.30 × 101 |
| NaFA | 13.09369793 | 14.01238482 | 13.46412795 | 2.55 × 10−1 |
| GDFA | 13.04638006 | 13.137194 | 13.08140472 | 2.80 × 10−2 |
| ADIFA | 13.04630463 | 23.70457178 | 15.15767351 | 2.59 |
| YYFA | 13.04080799 | 13.20624313 | 13.11404444 | 3.81 × 10−2 |
| GAHFA | 13.03988751 | 14.23777192 | 13.53016911 | 4.17 × 10−1 |
| JSO | 13.03251551 | 13.03251551 | 13.03251551 | 2.19 × 10−15 |
| HDE | 13.03259225 | 13.03320678 | 13.0327743 | 1.77 × 10−4 |
| ISCA | 13.03252229 | 14.2417099 | 13.21728098 | 2.62 × 10−1 |
| DMCSO | 13.03251606 | 13.03256694 | 13.03253796 | 1.43 × 10−5 |
| MBADE | 13.03251427 | 13.03251427 | 13.03251427 | 5.88 × 10−15 |
| MFAGA | 13.03251422 | 13.03251422 | 13.03251422 | 1.82 × 10−15 |
| IHFAPA | 13.03251422 | 13.03251422 | 13.03251422 | 1.82 × 10−15 |
| Algorithm | x1 | x2 | x3 | x4 | f(X) |
|---|---|---|---|---|---|
| SFA | 0.205142 | 3.286062 | 9.040616 | 0.205725 | 1.699504 |
| RaFA | 0.152123 | 4.864129 | 9.337794 | 0.217702 | 1.969270 |
| NaFA | 0.343650 | 2.812506 | 7.196487 | 0.426302 | 2.848371 |
| GDFA | 0.203523 | 3.278857 | 9.114596 | 0.205344 | 1.705893 |
| ADIFA | 0.207075 | 3.229328 | 9.036616 | 0.205730 | 1.702817 |
| YYFA | 0.206911 | 3.232201 | 9.036624 | 0.205730 | 1.819633 |
| GAHFA | 0.252491 | 2.581204 | 9.036624 | 0.205730 | 1.695247 |
| JSO | 0.205730 | 3.253120 | 9.036624 | 0.205730 | 1.695247 |
| HDE | 0.327076 | 2.308069 | 7.180879 | 0.326335 | 2.111363 |
| ISCA | 0.205180 | 3.262910 | 9.036821 | 0.205736 | 1.695851 |
| DMCSO | 0.187914 | 4.153360 | 8.537442 | 0.230493 | 1.880627 |
| MBADE | 0.205730 | 3.253120 | 9.036624 | 0.205730 | 1.695247 |
| MFAGA | 0.127434 | 5.184727 | 9.958296 | 0.298460 | 1.820290 |
| IHFAPA | 0.205730 | 3.253109 | 9.036624 | 0.205730 | 1.695247 |
| Algorithm | Best | Worst | Mean | Std |
|---|---|---|---|---|
| SFA | 1.699504131 | 1.703915182 | 1.701907472 | 1.76 × 10−3 |
| RaFA | 1.969269943 | 2.360207438 | 2.183403881 | 1.70 × 10−1 |
| NaFA | 2.848370826 | 6.543512806 | 4.44958705 | 1.04 |
| GDFA | 1.705892603 | 1.794671332 | 1.750032772 | 2.62 × 10−2 |
| ADIFA | 1.702817329 | 1.710019138 | 1.705453849 | 3.97 × 10−3 |
| YYFA | 1.819633196 | 2.040470288 | 1.917570624 | 1.13 × 10−1 |
| GAHFA | 1.695247121 | 1.695247121 | 1.695247121 | 2.22 × 10−16 |
| JSO | 1.695247547 | 1.695247547 | 1.695247547 | 1.00 × 10−11 |
| HDE | 2.111363368 | 3.326935976 | 2.647398239 | 4.80 × 10−1 |
| ISCA | 1.695850898 | 2.062965308 | 1.828526064 | 1.76 × 10−1 |
| DMCSO | 1.880626824 | 2.659265752 | 2.288024928 | 3.04 × 10−1 |
| MBADE | 1.695247165 | 1.695247165 | 1.695247165 | 2.72 × 10−16 |
| MFAGA | 1.820289796 | 2.261054896 | 2.008538645 | 1.08 × 10−1 |
| IHFAPA | 1.695246726 | 1.695246726 | 1.695246726 | 1.70 × 10−11 |
| Algorithm | x1 | x2 | x3 | x4 | f(X) |
|---|---|---|---|---|---|
| SFA | 323.248363 | 445.241380 | 0.769432 | 100.504978 | 33.017971 |
| RaFA | 495.290074 | 499.715164 | 2.217472 | 60.012207 | 168.239426 |
| NaFA | 104.240204 | 86.759338 | 0.482788 | 61.045700 | 8.485409 |
| GDFA | 0.575958 | 4.047767 | 4.526363 | 98.406522 | 18.808499 |
| ADIFA | 472.995123 | 498.160365 | 2.257819 | 60.584553 | 174.903047 |
| YYFA | 0.050070 | 2.146217 | 4.091046 | 119.970691 | 8.862098 |
| GAHFA | 500.000000 | 500.000000 | 2.211110 | 60.000000 | 8.412698 |
| JSO | 5.834864 | 8.515579 | 5.181083 | 82.183156 | 122.517700 |
| HDE | 350.423154 | 499.875433 | 2.435342 | 60.161549 | 189.607904 |
| ISCA | 0.050000 | 2.041532 | 4.083032 | 120.000000 | 8.412792 |
| DMCSO | 0.088350 | 2.800421 | 5.317896 | 68.916930 | 20.295798 |
| MBADE | 255.964175 | 499.721801 | 2.719571 | 60.145636 | 8.412698 |
| MFAGA | 0.071040 | 2.571204 | 4.486615 | 98.392004 | 12.985521 |
| IHFAPA | 0.050000 | 2.041514 | 4.083027 | 120.000000 | 8.412698 |
| Algorithm | Best | Worst | Mean | Std |
|---|---|---|---|---|
| SFA | 33.0179706 | 655683.391233 | 174576.900399 | 2.80 × 105 |
| RaFA | 168.2394257 | 171.464577 | 169.316744 | 1.46 |
| NaFA | 8.4854092 | 63459.882063 | 24002.590167 | 2.44 × 104 |
| GDFA | 18.8084987 | 203.436288 | 108.714651 | 1.01 × 102 |
| ADIFA | 174.9030473 | 237.515228 | 210.815755 | 2.39 × 101 |
| YYFA | 8.8620984 | 173.613805 | 63.925947 | 9.50 × 101 |
| GAHFA | 8.4126983 | 167.472730 | 135.660724 | 7.11 × 101 |
| JSO | 122.517700 | 167.472700 | 164.607900 | 1.02 × 101 |
| HDE | 189.6079044 | 22916.006641 | 3369.843019 | 7.93 × 103 |
| ISCA | 8.4127921 | 8.413036 | 8.412932 | 1.14 × 10−4 |
| DMCSO | 20.2957982 | 290.999882 | 176.624502 | 9.77 × 101 |
| MBADE | 8.4126981 | 167.472730 | 135.660724 | 7.11 × 101 |
| MFAGA | 12.9855210 | 543.823923 | 228.069099 | 1.54 × 102 |
| IHFAPA | 8.4126981 | 167.472730 | 91.123915 | 8.11 × 101 |
| Algorithm | x1 | x2 | f(x) |
|---|---|---|---|
| SFA | 0.787926 | 0.410374 | 263.896446 |
| RaFA | 0.785019 | 0.419141 | 263.950917 |
| NaFA | 0.786150 | 0.416532 | 264.010146 |
| GDFA | 0.788675 | 0.408248 | 263.895843 |
| ADIFA | 0.788664 | 0.408279 | 263.895844 |
| YYFA | 0.788660 | 0.408292 | 263.895844 |
| GAHFA | 0.788675 | 0.408248 | 263.895843 |
| JSO | 0.788675 | 0.408248 | 263.895843 |
| HDE | 0.783659 | 0.422625 | 263.914661 |
| ISCA | 0.788465 | 0.408844 | 263.895903 |
| DMCSO | 0.788675 | 0.408248 | 263.895843 |
| MBADE | 0.788675 | 0.408248 | 263.895843 |
| MFAGA | 0.787865 | 0.410557 | 263.897624 |
| IHFAPA | 0.788675 | 0.408248 | 263.895843 |
| Algorithm | Best | Worst | Mean | Std |
|---|---|---|---|---|
| SFA | 263.8964457 | 263.8999999 | 263.8979033 | 9.28 × 10−4 |
| RaFA | 263.9509171 | 265.2151988 | 264.3419885 | 3.17 × 10−1 |
| NaFA | 264.0101463 | 269.4611471 | 265.7919397 | 1.55 |
| GDFA | 263.8958434 | 263.896638 | 263.8958931 | 1.76 × 10−4 |
| ADIFA | 263.8958435 | 263.895876 | 263.8958504 | 7.81 × 10−6 |
| YYFA | 263.8958436 | 267.4844861 | 264.4581455 | 9.68 × 10−1 |
| GAHFA | 263.8958434 | 263.8958434 | 263.8958434 | 4.02 × 10−14 |
| JSO | 263.8958534 | 263.8958434 | 263.8958544 | 7.20 × 10−410 |
| HDE | 263.9146614 | 265.2142127 | 264.251843 | 4.03 × 10−1 |
| ISCA | 263.8959028 | 263.9135898 | 263.8975107 | 3.85 × 10−3 |
| DMCSO | 263.8958434 | 264.2691155 | 263.9251508 | 8.45 × 10−2 |
| MBADE | 263.8958434 | 263.8958434 | 263.8958434 | 4.02 × 10−14 |
| MFAGA | 263.8976237 | 263.9835232 | 263.9164881 | 2.33 × 10−2 |
| IHFAPA | 263.8958434 | 263.8958434 | 263.8958434 | 4.02 × 10−14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bei, J.-L.; Zhang, M.-X.; Wang, J.-Q.; Song, H.-H.; Zhang, H.-Y. Improved Hybrid Firefly Algorithm with Probability Attraction Model. Mathematics 2023, 11, 389. https://doi.org/10.3390/math11020389
Bei J-L, Zhang M-X, Wang J-Q, Song H-H, Zhang H-Y. Improved Hybrid Firefly Algorithm with Probability Attraction Model. Mathematics. 2023; 11(2):389. https://doi.org/10.3390/math11020389
Chicago/Turabian StyleBei, Jin-Ling, Ming-Xin Zhang, Ji-Quan Wang, Hao-Hao Song, and Hong-Yu Zhang. 2023. "Improved Hybrid Firefly Algorithm with Probability Attraction Model" Mathematics 11, no. 2: 389. https://doi.org/10.3390/math11020389
APA StyleBei, J.-L., Zhang, M.-X., Wang, J.-Q., Song, H.-H., & Zhang, H.-Y. (2023). Improved Hybrid Firefly Algorithm with Probability Attraction Model. Mathematics, 11(2), 389. https://doi.org/10.3390/math11020389