
Learning Wasserstein Contrastive Color Histogram Representation for Low-Light Image Enhancement

Abstract
:1. Introduction
- A novel WCR framework is proposed for LLIE, which regularizes the CH representation of the restored image in Wasserstein space to keep its color consistency while removing residual noise;
- A DCHM was designed that can be readily injected into the network to learn the image CH representation in an end-to-end mode;
- We constructed a WCR loss that introduces low-light images as negative samples for CL, which effectively reduces the residual noise.
2. Related Work
2.1. Low-Light Image Enhancement
2.2. Contrastive Learning
3. Methodology
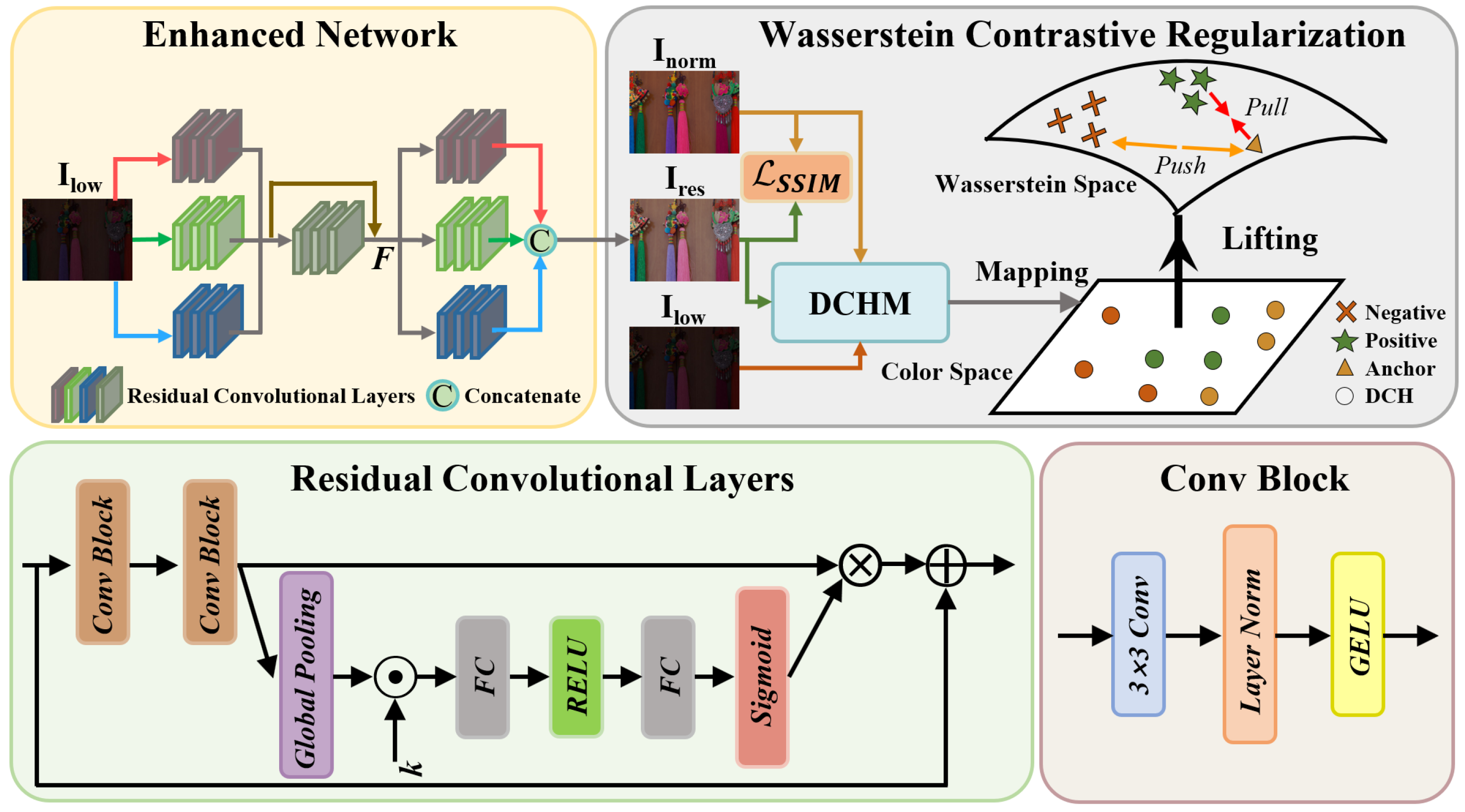
3.1. Overall Pipeline
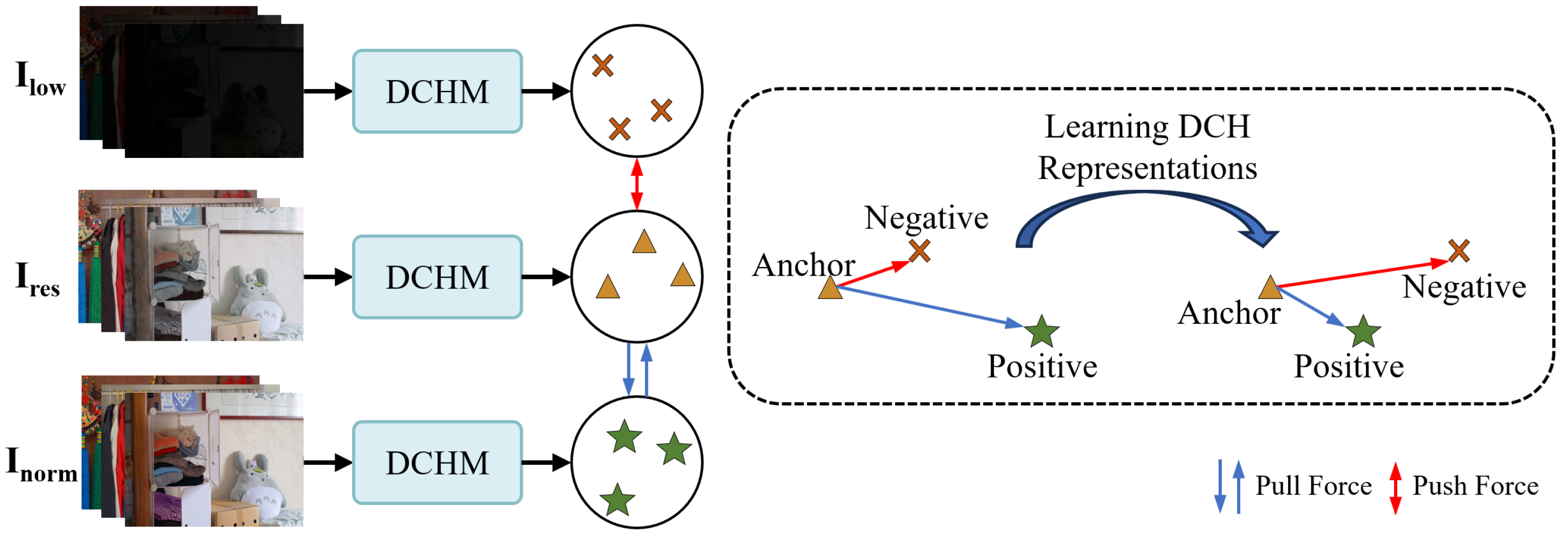
3.2. DCHM
3.3. WCR Loss
3.4. Total Loss
4. Experiments
4.1. Implementation Details
4.2. Evaluation Datasets and Metrics
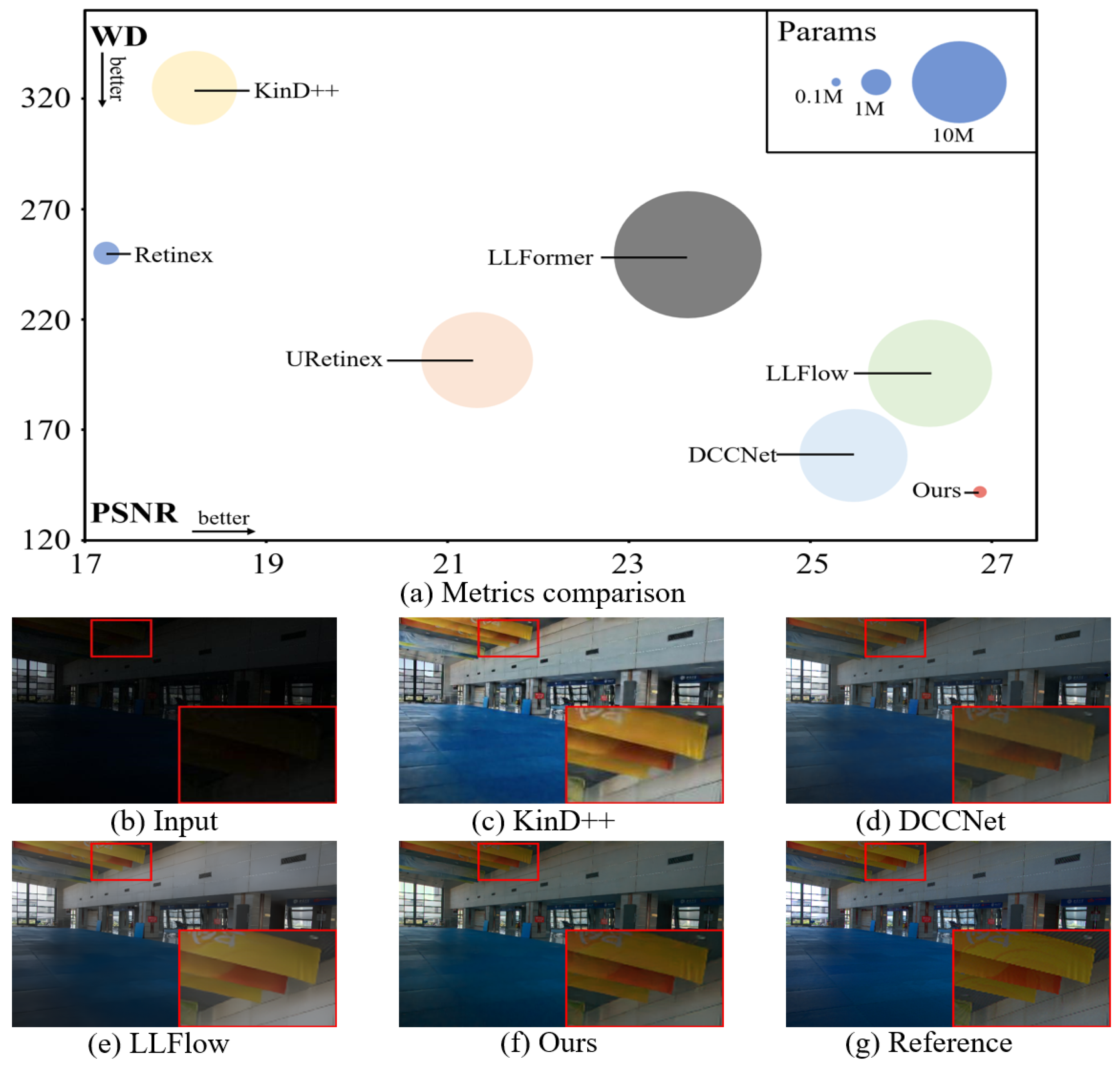
4.3. Quantitative Enhancement Results
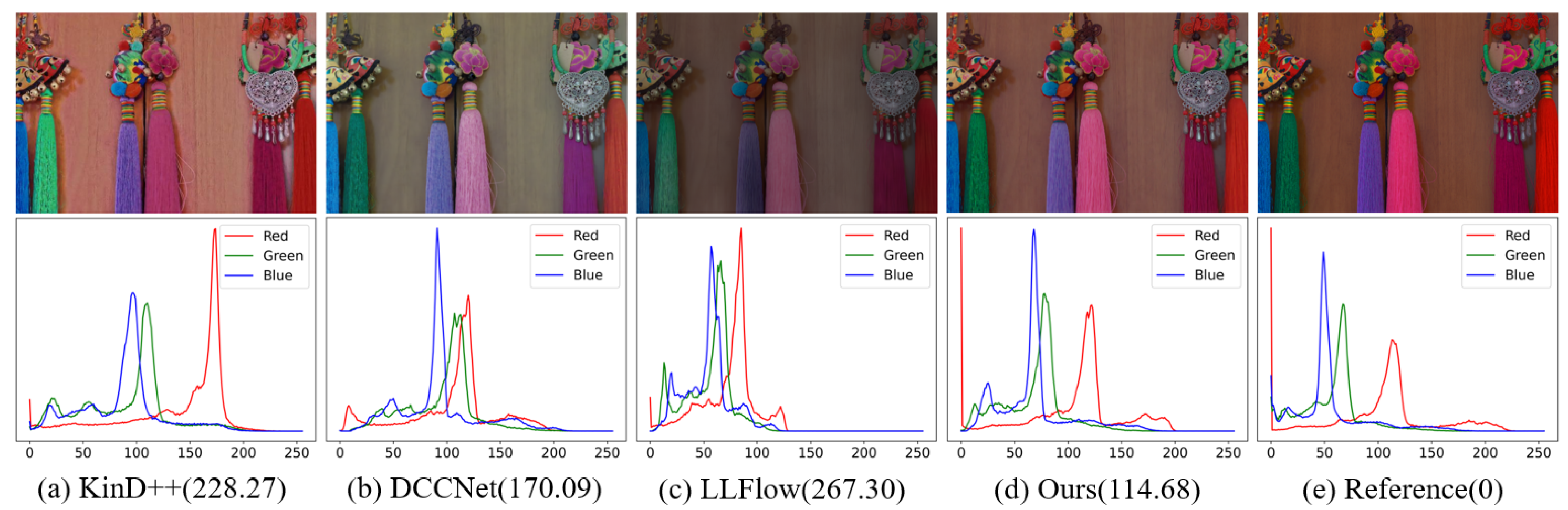
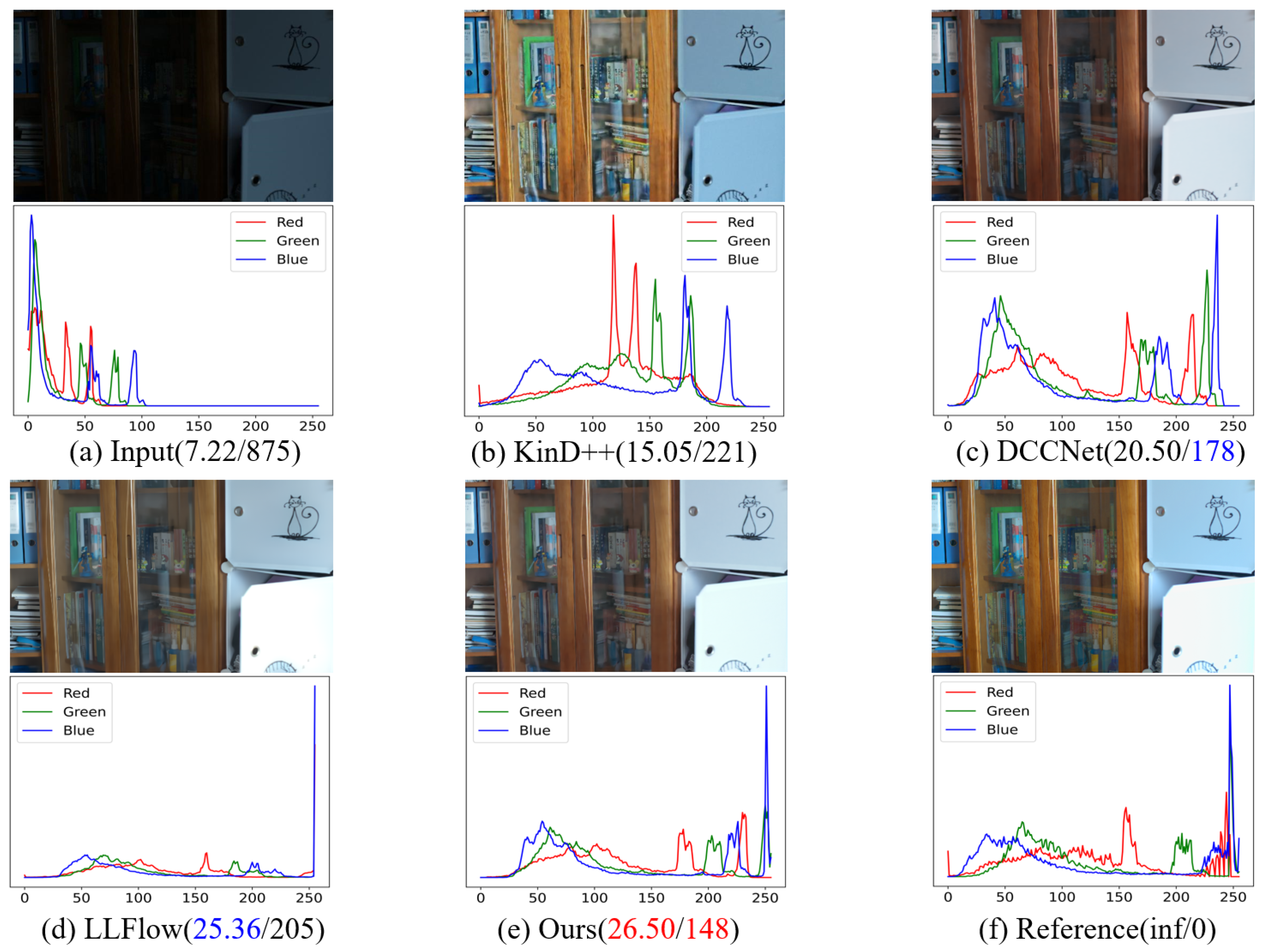
4.4. Visual Image Analysis and Evaluations
4.5. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6479–6488. [Google Scholar]
- Lamba, M.; Rachavarapu, K.K.; Mitra, K. Harnessing multi-view perspective of light fields for low-light imaging. IEEE Trans. Image Process. 2020, 30, 1501–1513. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Yang, W.; Liu, J. Hla-face: Joint high-low adaptation for low light face detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16195–16204. [Google Scholar]
- Liang, J.; Wang, J.; Quan, Y.; Chen, T.; Liu, J.; Ling, H.; Xu, Y. Recurrent exposure generation for low-light face detection. IEEE Trans. Multimed. 2021, 24, 1609–1621. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, X.; Ma, J.; Liu, W.; Zhang, J. Beyond brightening low-light images. Int. J. Comput. Vis. 2021, 129, 1013–1037. [Google Scholar] [CrossRef]
- Wang, Y.; Wan, R.; Yang, W.; Li, H.; Chau, L.P.; Kot, A. Low-light image enhancement with normalizing flow. In Proceedings of the AAAI Conference on Artificial Intelligence, Pomona, CA, USA, 24–28 October 2022; Volume 36, pp. 2604–2612. [Google Scholar]
- Zhang, Z.; Zheng, H.; Hong, R.; Xu, M.; Yan, S.; Wang, M. Deep Color Consistent Network for Low-Light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1899–1908. [Google Scholar]
- Kim, B.; Lee, S.; Kim, N.; Jang, D.; Kim, D.S. Learning color representations for low-light image enhancement. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 1455–1463. [Google Scholar]
- Wu, Y.; Pan, C.; Wang, G.; Yang, Y.; Wei, J.; Li, C.; Shen, H.T. Learning Semantic-Aware Knowledge Guidance for Low-Light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 1662–1671. [Google Scholar]
- Yeganeh, H.; Ziaei, A.; Rezaie, A. A novel approach for contrast enhancement based on histogram equalization. In Proceedings of the 2008 International Conference on Computer and Communication Engineering, Kuala Lumpur, Malaysia, 13–15 May 2008; pp. 256–260. [Google Scholar]
- Wang, S.; Zheng, J.; Hu, H.M.; Li, B. Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans. Image Process. 2013, 22, 3538–3548. [Google Scholar] [CrossRef] [PubMed]
- Ren, X.; Yang, W.; Cheng, W.H.; Liu, J. LR3M: Robust low-light enhancement via low-rank regularized retinex model. IEEE Trans. Image Process. 2020, 29, 5862–5876. [Google Scholar] [CrossRef] [PubMed]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Wu, W.; Weng, J.; Zhang, P.; Wang, X.; Yang, W.; Jiang, J. URetinex-Net: Retinex-Based Deep Unfolding Network for Low-Light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5901–5910. [Google Scholar]
- Li, C.; Guo, J.; Porikli, F.; Pang, Y. LightenNet: A convolutional neural network for weakly illuminated image enhancement. Pattern Recognit. Lett. 2018, 104, 15–22. [Google Scholar] [CrossRef]
- Zhang, F.; Li, Y.; You, S.; Fu, Y. Learning temporal consistency for low light video enhancement from single images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4967–4976. [Google Scholar]
- Jiang, H.; Zheng, Y. Learning to see moving objects in the dark. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7324–7333. [Google Scholar]
- Wang, Y.; Cao, Y.; Zha, Z.J.; Zhang, J.; Xiong, Z.; Zhang, W.; Wu, F. Progressive retinex: Mutually reinforced illumination-noise perception network for low-light image enhancement. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2015–2023. [Google Scholar]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Dobrushin, R.L. Prescribing a system of random variables by conditional distributions. Theory Probab. Its Appl. 1970, 15, 458–486. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Bychkovsky, V.; Paris, S.; Chan, E.; Durand, F. Learning Photographic Global Tonal Adjustment with a Database of Input/Output Image Pairs. In Proceedings of the The Twenty-Fourth IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-Light Image/Video Enhancement Using CNNs. In Proceedings of the BMVC, Newcastle, UK, 3–6 September 2018; Volume 220, p. 4. [Google Scholar]
- Wang, T.; Zhang, K.; Shen, T.; Luo, W.; Stenger, B.; Lu, T. Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method. arXiv 2022, arXiv:2212.11548. [Google Scholar]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1632–1640. [Google Scholar]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1780–1789. [Google Scholar]
- Li, C.; Guo, C.; Loy, C.C. Learning to enhance low-light image via zero-reference deep curve estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4225–4238. [Google Scholar]
- Ma, L.; Ma, T.; Liu, R.; Fan, X.; Luo, Z. Toward fast, flexible, and robust low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5637–5646. [Google Scholar]
- Xie, E.; Ding, J.; Wang, W.; Zhan, X.; Xu, H.; Sun, P.; Li, Z.; Luo, P. Detco: Unsupervised contrastive learning for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 8392–8401. [Google Scholar]
- Wei, F.; Gao, Y.; Wu, Z.; Hu, H.; Lin, S. Aligning pretraining for detection via object-level contrastive learning. Adv. Neural Inf. Process. Syst. 2021, 34, 22682–22694. [Google Scholar]
- Hu, H.; Cui, J.; Wang, L. Region-aware contrastive learning for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 16291–16301. [Google Scholar]
- Wu, H.; Qu, Y.; Lin, S.; Zhou, J.; Qiao, R.; Zhang, Z.; Xie, Y.; Ma, L. Contrastive learning for compact single image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10551–10560. [Google Scholar]
- Huang, S.; Wang, K.; Liu, H.; Chen, J.; Li, Y. Contrastive semi-supervised learning for underwater image restoration via reliable bank. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 18145–18155. [Google Scholar]
- Liang, D.; Li, L.; Wei, M.; Yang, S.; Zhang, L.; Yang, W.; Du, Y.; Zhou, H. Semantically contrastive learning for low-light image enhancement. In Proceedings of the AAAI Conference on Artificial Intelligence, Pomona, CA, USA, 24–28 October 2022; Volume 36, pp. 1555–1563. [Google Scholar]
- Fu, H.; Zheng, W.; Meng, X.; Wang, X.; Wang, C.; Ma, H. You Do Not Need Additional Priors or Regularizers in Retinex-Based Low-Light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 18125–18134. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Avi-Aharon, M.; Arbelle, A.; Raviv, T.R. Differentiable Histogram Loss Functions for Intensity-based Image-to-Image Translation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 11642–11653. [Google Scholar] [CrossRef]
- Villani, C. Optimal Transport: Old and New; Springer: Berlin/Heidelberg, Germany, 2009; Volume 338. [Google Scholar]
- Cuturi, M. Sinkhorn distances: Lightspeed computation of optimal transport. Adv. Neural Inf. Process. Syst. 2013, 26, 2292–2300. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Tu, Z.; Talebi, H.; Zhang, H.; Yang, F.; Milanfar, P.; Bovik, A.; Li, Y. Maxim: Multi-axis mlp for image processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5769–5780. [Google Scholar]
- Fu, Z.; Wang, W.; Huang, Y.; Ding, X.; Ma, K.K. Uncertainty Inspired Underwater Image Enhancement. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XVIII. Springer: Berlin/Heidelberg, Germany, 2022; pp. 465–482. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Massey, F.J. The Kolmogorov-Smirnov Test for Goodness of Fit. J. Am. Stat. Assoc. 1951, 46, 68–78. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Learning enriched features for real image restoration and enhancement. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 492–511. [Google Scholar]
- Fu, X.; Zhuang, P.; Huang, Y.; Liao, Y.; Zhang, X.P.; Ding, X. A retinex-based enhancing approach for single underwater image. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 4572–4576. [Google Scholar]
- Peng, Y.T.; Cosman, P.C. Underwater image restoration based on image blurriness and light absorption. IEEE Trans. Image Process. 2017, 26, 1579–1594. [Google Scholar] [PubMed]
- Lim, S.; Kim, W. DSLR: Deep stacked Laplacian restorer for low-light image enhancement. IEEE Trans. Multimed. 2020, 23, 4272–4284. [Google Scholar] [CrossRef]
- Chen, Y.S.; Wang, Y.C.; Kao, M.H.; Chuang, Y.Y. Deep photo enhancer: Unpaired learning for image enhancement from photographs with gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6306–6314. [Google Scholar]
- Berman, D.; Treibitz, T.; Avidan, S. Non-local Image Dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1674–1682. [Google Scholar]
- Zhao, L.; Lu, S.P.; Chen, T.; Yang, Z.; Shamir, A. Deep symmetric network for underexposed image enhancement with recurrent attentional learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 12075–12084. [Google Scholar]
- Jiang, N.; Chen, W.; Lin, Y.; Zhao, T.; Lin, C.W. Underwater image enhancement with lightweight cascaded network. IEEE Trans. Multimed. 2021, 24, 4301–4313. [Google Scholar] [CrossRef]
- Zhang, F.; Zeng, H.; Zhang, T.; Zhang, L. CLUT-Net: Learning Adaptively Compressed Representations of 3DLUTs for Lightweight Image Enhancement. In Proceedings of the 30th ACM International Conference on Multimedia, Lisbon, Portugal, 10–14 October 2022; pp. 6493–6501. [Google Scholar]
- Li, C.; Anwar, S.; Hou, J.; Cong, R.; Guo, C.; Ren, W. Underwater image enhancement via medium transmission-guided multi-color space embedding. IEEE Trans. Image Process. 2021, 30, 4985–5000. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PSNR↑ | SSIM↑ | LPIPS↓ | WD↓ | Params (M)↓ | FLOPs (G)↓ |
|---|---|---|---|---|---|---|
| Retinex(BMVC’18) [13] | 18.04 | 0.67 | 0.389 | 250.07 | 0.84 | 587.47 |
| KinD(ACMMM’19) [27] | 18.15 | 0.82 | 0.131 | 261.55 | 8.16 | 356.72 |
| KinD++(IJCV’21) [5] | 18.21 | 0.83 | 0.148 | 264.91 | 8.28 | 2532 |
| MIRNet(ECCV’20) [48] | 23.91 | 0.88 | 0.093 | 152.42 | 31.79 | 2882.24 |
| URetinex(CVPR’22) [14] | 21.33 | 0.88 | 0.096 | 201.64 | 15.10 | - |
| MAXIM(CVPR’22) [44] | 25.73 | 0.89 | 0.075 | 158.42 | 14.14 | 216 |
| LLFormer(AAAI’23) [26] | 23.65 | 0.87 | 0.107 | 160.37 | 24.52 | - |
| DCC(CVPR’22) [7] | 25.48 | 0.89 | 0.091 | 148.25 | 13.19 | 270.47 |
| LLFLow(AAAI’22) [6] | 26.32 | 0.91 | 0.092 | 195.62 | 17.42 | 1050 |
| Ours | 26.87 | 0.90 | 0.083 | 141.80 | 0.24 | 55.3 |
| Methods | FiveK | Methods | UIEB | ||
|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | ||
| MBLLEN(BMVC’18) [25] | 19.78 | 0.83 | ReUIE(ICIP’14) [49] | 17.53 | 0.77 |
| KinD(ACMMM’19) [27] | 14.54 | 0.74 | IBLA(TIP’17) [50] | 18.51 | 0.76 |
| DSLR(TMM’20) [51] | 16.63 | 0.78 | WaterNet(TIP’19) [24] | 19.81 | 0.86 |
| DPE(CVPR’18) [52] | 24.08 | 0.92 | Haze-line(TPAMI’20) [53] | 14.97 | 0.67 |
| IRN(ICCV’21) [54] | 24.27 | 0.90 | LC-Net(TMM’21) [55] | 18.54 | 0.84 |
| CLUT(ACMMM’22) [56] | 25.55 | 0.93 | Ucolor(TIP’21) [57] | 21.65 | 0.84 |
| MAXIM(CVPR’22) [44] | 26.15 | 0.95 | PUIE(ECCV’22) [45] | 21.86 | 0.87 |
| Ours | 26.66 | 0.96 | Ours | 22.32 | 0.90 |
| Method | S (R) | C (R) | S (G) | C (G) | S (B) | C (B) |
|---|---|---|---|---|---|---|
| LLFlow | 0.1250 | 0.0365 | 0.0781 | 0.4160 | 0.1289 | 0.0283 |
| DCCNet | 0.1133 | 0.0748 | 0.0625 | 0.7004 | 0.1523 | 0.0052 |
| Our | 0.0781 | 0.4160 | 0.0703 | 0.5524 | 0.0977 | 0.1741 |
| Module Variants | PSNR↑ | SSIM↑ | LPIPS↓ | WD↓ | |||
|---|---|---|---|---|---|---|---|
| ✓ | 22.73 | 0.83 | 0.157 | 207.34 | |||
| ✓ | ✓ | 24.37 | 0.86 | 0.104 | 151.17 | ||
| ✓ | ✓ | ✓ | 25.98 | 0.87 | 0.083 | 144.12 | |
| ✓ | 23.34 | 0.85 | 0.138 | 199.96 | |||
| ✓ | ✓ | 25.46 | 0.88 | 0.090 | 146.76 | ||
| ✓ | ✓ | ✓ | 26.87 | 0.90 | 0.083 | 141.80 | |
| Model | PSNR↑ | SSIM↑ | LPIPS↓ | WD↓ |
|---|---|---|---|---|
| Unet [58] w/o WCR | 17.74 | 0.83 | 0.164 | 254.36 |
| Unet w WCR | 19.52 (+1.78) | 0.85 | 0.137 | 200.94 (−53.42) |
| LLFormer [26] w/o WCR | 23.65 | 0.87 | 0.107 | 160.37 |
| LLFormer w WCR | 25.17 (+1.52) | 0.88 | 0.094 | 133.58 (−26.79) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Z.; Hu, S.; Song, H.; Liang, P. Learning Wasserstein Contrastive Color Histogram Representation for Low-Light Image Enhancement. Mathematics 2023, 11, 4194. https://doi.org/10.3390/math11194194
Sun Z, Hu S, Song H, Liang P. Learning Wasserstein Contrastive Color Histogram Representation for Low-Light Image Enhancement. Mathematics. 2023; 11(19):4194. https://doi.org/10.3390/math11194194
Chicago/Turabian StyleSun, Zixuan, Shenglong Hu, Huihui Song, and Peng Liang. 2023. "Learning Wasserstein Contrastive Color Histogram Representation for Low-Light Image Enhancement" Mathematics 11, no. 19: 4194. https://doi.org/10.3390/math11194194
APA StyleSun, Z., Hu, S., Song, H., & Liang, P. (2023). Learning Wasserstein Contrastive Color Histogram Representation for Low-Light Image Enhancement. Mathematics, 11(19), 4194. https://doi.org/10.3390/math11194194