



Region-Aware Deep Feature-Fused Network for Robust Facial Landmark Localization


Abstract
:1. Introduction
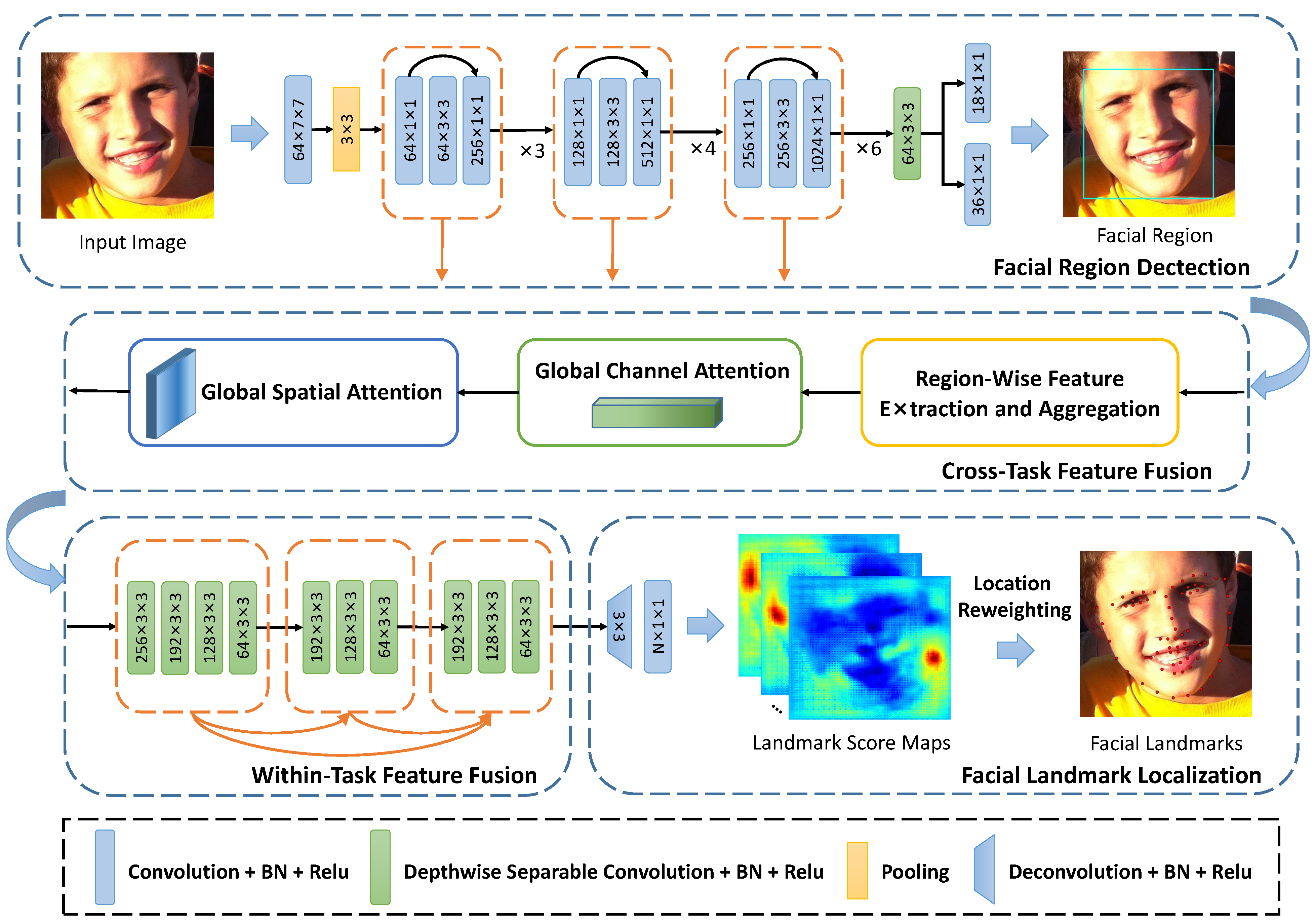
- We present an end-to-end deep convolutional network called region-aware deep feature-fused network (RDFN). The proposed network can simultaneously solve the region initialization problem and the facial landmark localization task.
- In the RDFN, we design two efficient feature fusion schemes to derive the cross-task and within-task feature representations, which further improve the accuracy of facial landmark localization on various unconstrained face images.
- At the inference stage, we introduce a location reweighting strategy to effectively transform the landmark score maps into 2D landmark coordinates.
- We perform extensive experiments to demonstrate the effectiveness of the proposed components and the superior performance of our approach on several challenging datasets, including 300W, AFLW, and COFW.
2. Related Work
3. Methodology
3.1. Motivation and Overview
- The input features are only extracted from the top layer of the network backbone and are weakly discriminative for the fine-grained tasks due to the lack of low-level semantic information from the lower layers.
- In the downstream task, the ability to extract features is further limited by the simple stacked encoding structure of the task-specific subnetwork, which only considers a single gradient flow between network layers.
3.2. Cross-Task Feature Fusion Scheme
3.2.1. Global Channel Attention Block
3.2.2. Global Spatial Attention Block
3.3. Within-Task Feature Fusion Scheme
- Further improvement of gradient flow: In the proposed scheme, layer connections are added when the i-th encoding operation is performed. This feature can further improve the gradient flow of the downstream subnetwork during training.
- Lowerintroduction of model complexity: We replace standard convolutions with depthwise separable convolutions to reduce the overall model complexity of the proposed scheme. Compared to the stacked and dense encoding schemes under the same inputs (), our method can reduce the number of parameters and MACC by about 98.1% and 97.5%, respectively.
- Better capture of multi-scale context: In each encoding operation, the outputs contain the intermediate features with different receptive fields. Taking advantage of the lightweight design, we can perform the proposed encoding operation multiple times to capture more features with different scales of context information.
3.4. Location Reweighting Strategy
3.5. Implementation Detail
4. Experiments
4.1. Datasets and Settings
- 300W [4]: The 300W dataset consists of several popular datasets, such as the HELEN [31], LFPW [32] and AFW [33] datasets, and has been widely used to evaluate the face-alignment algorithms. It contains 3148 training images and 689 test images with 68 annotated landmarks. The test images are divided into the challenge subset (135 images) and the common subset (554 images).
- AFLW [5]: The AFLW dataset is an in-the-wild dataset containing 24,386 faces with large variations in head pose. Following the work [34], the AFLW dataset is split into the AFLW-Full and AFLW-Frontal datasets with 19 reduced landmarks. The AFLW-Full dataset contains 20,000 training images and 4384 test images, of which 1314 near-frontal test images are collected in the AFLW-Frontal dataset.
- COFW [2]: The COFW dataset provides 1852 unconstrained faces with different occlusions, which are divided into 1345 training images and 507 test images. Each face image is annotated with 29 landmarks and the corresponding occlusion state.
4.2. Comparison with Existing Methods on Common Datasets
4.2.1. Results on 300W
4.2.2. Results on AFLW
4.2.3. Results on COFW
4.2.4. Complexity Analysis
4.3. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xiong, X.; De la Torre, F. Supervised descent method and its applications to face alignment. In Proceedings of the CVPR, Portland, OR, USA, 23–28 June 2013; pp. 532–539. [Google Scholar]
- Burgos-Artizzu, X.P.; Perona, P.; Dollár, P. Robust face landmark estimation under occlusion. In Proceedings of the ICCV, Sydney, NSW, Australia, 1–8 December 2013; pp. 1513–1520. [Google Scholar]
- Yan, J.; Lei, Z.; Yi, D.; Li, S. Learn to combine multiple hypotheses for accurate face alignment. In Proceedings of the ICCVW, Washington, DC, USA, 2–8 December 2013; pp. 392–396. [Google Scholar]
- Sagonas, C.; Tzimiropoulos, G.; Zafeiriou, S.; Pantic, M. 300 Faces in-the-wild challenge: The first facial landmark localization challenge. In Proceedings of the ICCVW, Washington, DC, USA, 2–8 December 2013; pp. 397–403. [Google Scholar]
- Koestinger, M.; Wohlhart, P.; Roth, P.M.; Bischof, H. Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 2144–2151. [Google Scholar]
- Ren, S.; Cao, X.; Wei, Y.; Sun, J. Face alignment at 3000 fps via regressing local binary features. In Proceedings of the CVPR, Columbus, OH, USA, 23–28 June 2014; pp. 1685–1692. [Google Scholar]
- Wang, X.; Bo, L.; Fuxin, L. Adaptive wing loss for robust face alignment via heatmap regression. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6971–6981. [Google Scholar]
- Browatzki, B.; Wallraven, C. 3fabrec: Fast few-shot face alignment by reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6110–6120. [Google Scholar]
- Wen, T.; Ding, Z.; Yao, Y.; Wang, Y.; Qian, X. Picassonet: Searching adaptive architecture for efficient facial landmark localization. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–12. [Google Scholar] [CrossRef]
- Kowalski, M.; Naruniec, J.; Trzcinski, T. Deep alignment network: A convolutional neural network for robust face alignment. In Proceedings of the CVPR, Faces-in-the-Wild Workshop/Challenge, Honolulu, HI, USA, 21–26 July 2017; Volume 3, p. 6. [Google Scholar]
- Lin, X.; Liang, Y.; Wan, J.; Lin, C.; Li, S.Z. Region-based Context Enhanced Network for Robust Multiple Face Alignment. IEEE Trans. Multimed. 2019, 21, 3053–3067. [Google Scholar] [CrossRef]
- Xia, J.; Qu, W.; Huang, W.; Zhang, J.; Wang, X.; Xu, M. Sparse Local Patch Transformer for Robust Face Alignment and Landmarks Inherent Relation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4052–4061. [Google Scholar]
- Cao, X.; Wei, Y.; Wen, F.; Sun, J. Face alignment by explicit shape regression. Int. J. Comput. Vis. 2014, 107, 177–190. [Google Scholar] [CrossRef]
- Feng, Z.H.; Hu, G.; Kittler, J.; Christmas, W.; Wu, X.J. Cascaded collaborative regression for robust facial landmark detection trained using a mixture of synthetic and real images with dynamic weighting. IEEE Trans. Image Process. 2015, 24, 3425–3440. [Google Scholar] [CrossRef]
- Zhu, S.; Li, C.; Loy, C.; Tang, X. Face alignment by coarse-to-fine shape searching. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015; pp. 4998–5006. [Google Scholar]
- Trigeorgis, G.; Snape, P.; Nicolaou, M.A.; Antonakos, E.; Zafeiriou, S. Mnemonic descent method: A recurrent process applied for end-to-end face alignment. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 4177–4187. [Google Scholar]
- Xiao, S.; Feng, J.; Xing, J.; Lai, H.; Yan, S.; Kassim, A. Robust facial landmark detection via recurrent attentive-refinement networks. In Proceedings of the ECCV, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 57–72. [Google Scholar]
- Zhang, Z.; Luo, P.; Loy, C.C.; Tang, X. Learning deep representation for face alignment with auxiliary attributes. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 918–930. [Google Scholar] [CrossRef]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-resolution representations for labeling pixels and regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 483–499. [Google Scholar]
- Lin, X.; Zheng, H.; Zhao, P.; Liang, Y. SD-HRNet: Slimming and Distilling High-Resolution Network for Efficient Face Alignment. Sensors 2023, 23, 1532. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Kan, M.; Shan, S.; Chen, X. Occlusion-free face alignment: Deep regression networks coupled with de-corrupt autoencoders. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 3428–3437. [Google Scholar]
- Lv, J.J.; Shao, X.; Xing, J.; Cheng, C.; Zhou, X. A Deep Regression Architecture with Two-Stage Re-initialization for High Performance Facial Landmark Detection. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 4. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Le, V.; Brandt, J.; Lin, Z.; Bourdev, L.; Huang, T.S. Interactive facial feature localization. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 679–692. [Google Scholar]
- Belhumeur, P.N.; Jacobs, D.W.; Kriegman, D.J.; Kumar, N. Localizing parts of faces using a consensus of exemplars. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2930–2940. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Ramanan, D. Face detection, pose estimation, and landmark localization in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2879–2886. [Google Scholar]
- Zhu, S.; Li, C.; Loy, C.C.; Tang, X. Unconstrained face alignment via cascaded compositional learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 3409–3417. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the CVPR, Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar]
- Dong, X.; Yan, Y.; Ouyang, W.; Yang, Y. Style aggregated network for facial landmark detection. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018; Volume 2, p. 6. [Google Scholar]
- Wu, W.; Qian, C.; Yang, S.; Wang, Q.; Cai, Y.; Zhou, Q. Look at Boundary: A Boundary-Aware Face Alignment Algorithm. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2129–2138. [Google Scholar]
- Zhu, M.; Shi, D.; Zheng, M.; Sadiq, M. Robust facial landmark detection via occlusion-adaptive deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3486–3496. [Google Scholar]
- Gao, P.; Lu, K.; Xue, J.; Shao, L.; Lyu, J. A coarse-to-fine facial landmark detection method based on self-attention mechanism. IEEE Trans. Multimed. 2021, 23, 926–938. [Google Scholar] [CrossRef]
- Feng, Z.H.; Kittler, J.; Awais, M.; Huber, P.; Wu, X.J. Wing loss for robust facial landmark localisation with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2235–2245. [Google Scholar]
- Zhang, H.; Li, Q.; Sun, Z.; Liu, Y. Combining data-driven and model-driven methods for robust facial landmark detection. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2409–2422. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Common Subset | Challenging Subset | Full Set | |
|---|---|---|---|---|
| Conventional CSR-Based Method | SDM [1] | 5.57 | 15.40 | 7.50 |
| RCPR [2] | 6.18 | 17.26 | 8.35 | |
| ESR [13] | 5.28 | 17.00 | 7.58 | |
| ERT [35] | - | - | 6.40 | |
| LBF [6] | 4.95 | 11.98 | 6.32 | |
| CFSS [15] | 4.73 | 9.98 | 5.76 | |
| DNN-Based Method w/o Reinitialization | MDM [16] | 4.83 | 10.14 | 5.88 |
| TCDCN [18] | 4.80 | 8.60 | 5.54 | |
| RAR [17] | 4.12 | 8.35 | 4.94 | |
| SAN [36] | 3.34 | 6.60 | 3.98 | |
| LAB [37] | 2.98 | 5.19 | 3.49 | |
| ODN [38] | 3.56 | 6.67 | 4.17 | |
| HRNet [19] | 2.87 | 5.15 | 3.32 | |
| AWing [7] | 2.72 | 4.52 | 3.07 | |
| 3FabRec [8] | 3.36 | 5.74 | 3.82 | |
| LGSA [39] | 2.92 | 5.16 | 3.36 | |
| SD-HRNet [21] | 2.93 | 5.32 | 3.40 | |
| DNN-Based Method w/ Reinitialization | TSR [23] | 4.36 | 7.42 | 4.96 |
| DAN [10] | 3.19 | 5.24 | 3.59 | |
| RCEN [11] | 3.26 | 6.84 | 3.96 | |
| PicassoNet [9] | 3.03 | 5.81 | 3.58 | |
| SLPT [12] | 2.75 | 4.90 | 3.17 | |
| Ours | RDFN | 2.82 | 5.19 | 3.28 |
| RDFN | 2.79 | 5.12 | 3.25 |
| Method | AFLW-Full | AFLW-Frontal | |
|---|---|---|---|
| Conventional CSR-Based Method | SDM [1] | 4.05 | 2.94 |
| RCPR [2] | 3.73 | 2.87 | |
| ERT [35] | 4.35 | 2.75 | |
| LBF [6] | 4.25 | 2.74 | |
| CFSS [15] | 3.92 | 2.68 | |
| CCL [34] | 2.72 | 2.17 | |
| DNN-Based Method w/o Reinitialization | SAN [36] | 1.91 | 1.85 |
| LAB [37] | 1.85 | 1.62 | |
| Wing [40] | 1.65 | - | |
| ODN [38] | 1.63 | 1.38 | |
| AWing [7] | 1.53 | 1.38 | |
| 3FabRec [8] | 1.84 | 1.59 | |
| DNN-Based Method w/Reinitialization | TSR [23] | 2.17 | - |
| RCEN [11] | 2.11 | 1.69 | |
| PicassoNet [9] | 1.59 | 1.30 | |
| Ours | RDFN | 1.48 | 1.25 |
| RDFN | 1.42 | 1.21 |
| Method | NME (%) | FR (%) | |
|---|---|---|---|
| Conventional CSR-Based Method | SDM [1] | 11.14 | - |
| RCPR [2] | 8.50 | 20.00 | |
| ESR [13] | 11.20 | - | |
| DNN-Based Method w/o Reinitialization | TCDCN [18] | 8.05 | - |
| RAR [17] | 6.03 | 4.14 | |
| ECT [41] | 5.98 | 4.54 | |
| LAB [37] | 3.92 | 0.39 | |
| HRNet [19] | 3.45 | 0.19 | |
| LGSA [39] | 3.13 | 0.002 | |
| SD-HRNet [21] | 3.61 | 0.12 | |
| DNN-Based Method w/Reinitialization | DRDA [22] | 6.46 | 6.00 |
| RCEN [11] | 4.44 | 2.56 | |
| SLPT [12] | 3.32 | 0.00 | |
| Ours | RDFN | 3.43 | 0.18 |
| RDFN | 3.36 | 0.10 |
| Method | Backbone | #Params (M) | FLOPs (G) | |
|---|---|---|---|---|
| DNN-Based Method w/o Reinitialization | SAN [36] | ResNet-152 | 57.4 | 10.7 |
| LAB [37] | Hourglass | 25.1 | 19.1 | |
| Wing [40] | ResNet-50 | 25 | - | |
| HRNet [19] | HRNetV2-W18 | 9.3 | 4.3 | |
| AWing [7] | Hourglass | 24.15 | 26.79 | |
| LGSA [39] | Hourglass | 18.64 | - | |
| SD-HRNet [21] | - | 0.98 | 0.59 | |
| DNN-Based Method w/Reinitialization | PicassoNet [9] | - | 1.96 | 0.11 |
| SLPT [12] | HRNetV2-W18 | 13.18 | 5.17 | |
| Ours | RDFN | ResNet-50-C4 | 10.66 | 4.38 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, X.; Liang, Y. Region-Aware Deep Feature-Fused Network for Robust Facial Landmark Localization. Mathematics 2023, 11, 4026. https://doi.org/10.3390/math11194026
Lin X, Liang Y. Region-Aware Deep Feature-Fused Network for Robust Facial Landmark Localization. Mathematics. 2023; 11(19):4026. https://doi.org/10.3390/math11194026
Chicago/Turabian StyleLin, Xuxin, and Yanyan Liang. 2023. "Region-Aware Deep Feature-Fused Network for Robust Facial Landmark Localization" Mathematics 11, no. 19: 4026. https://doi.org/10.3390/math11194026
APA StyleLin, X., & Liang, Y. (2023). Region-Aware Deep Feature-Fused Network for Robust Facial Landmark Localization. Mathematics, 11(19), 4026. https://doi.org/10.3390/math11194026