
ClueCatcher: Catching Domain-Wise Independent Clues for Deepfake Detection



Abstract
:1. Introduction
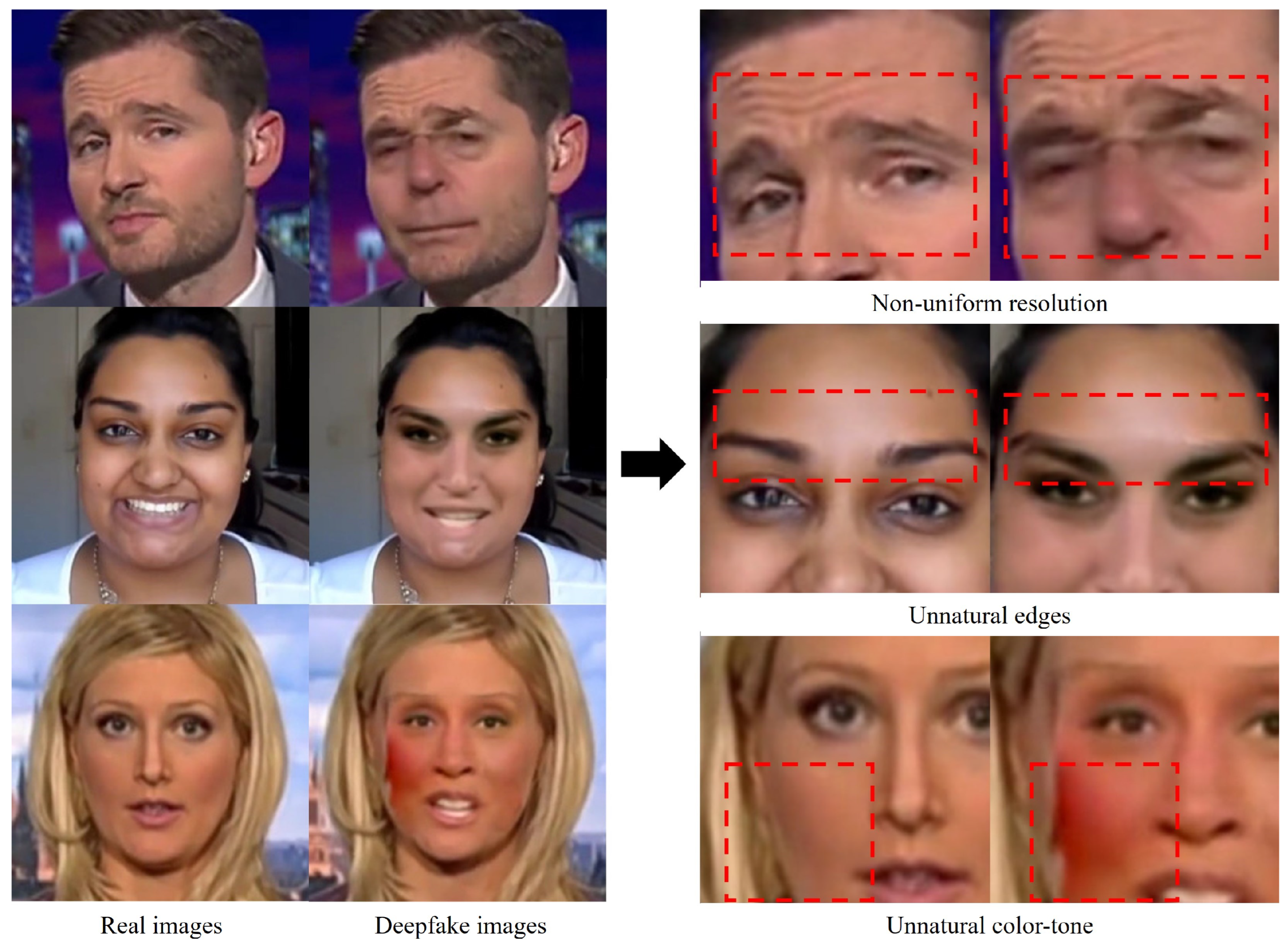
- We observe a common characteristic of images with face forgery applied: a quality difference between patches corresponding to facial and nonfacial regions where the technique is not applied.
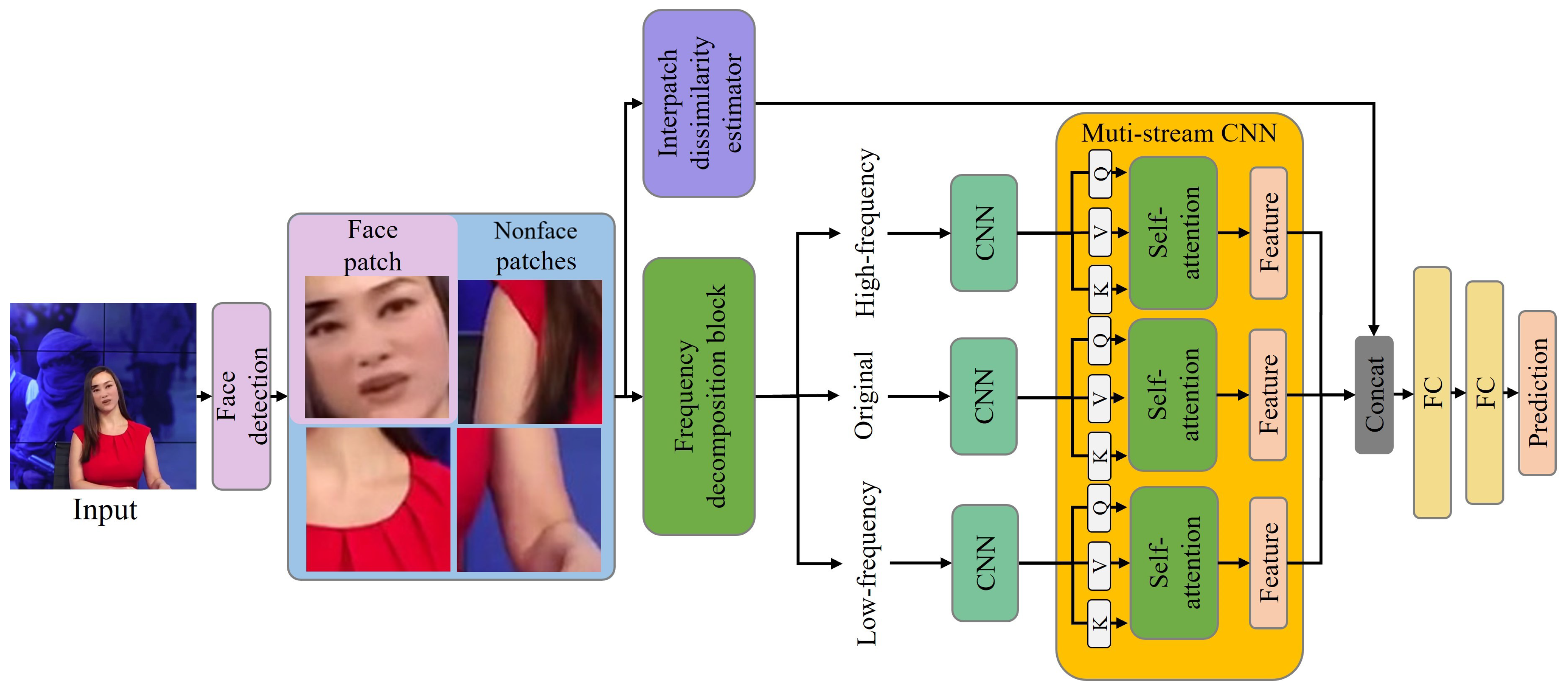
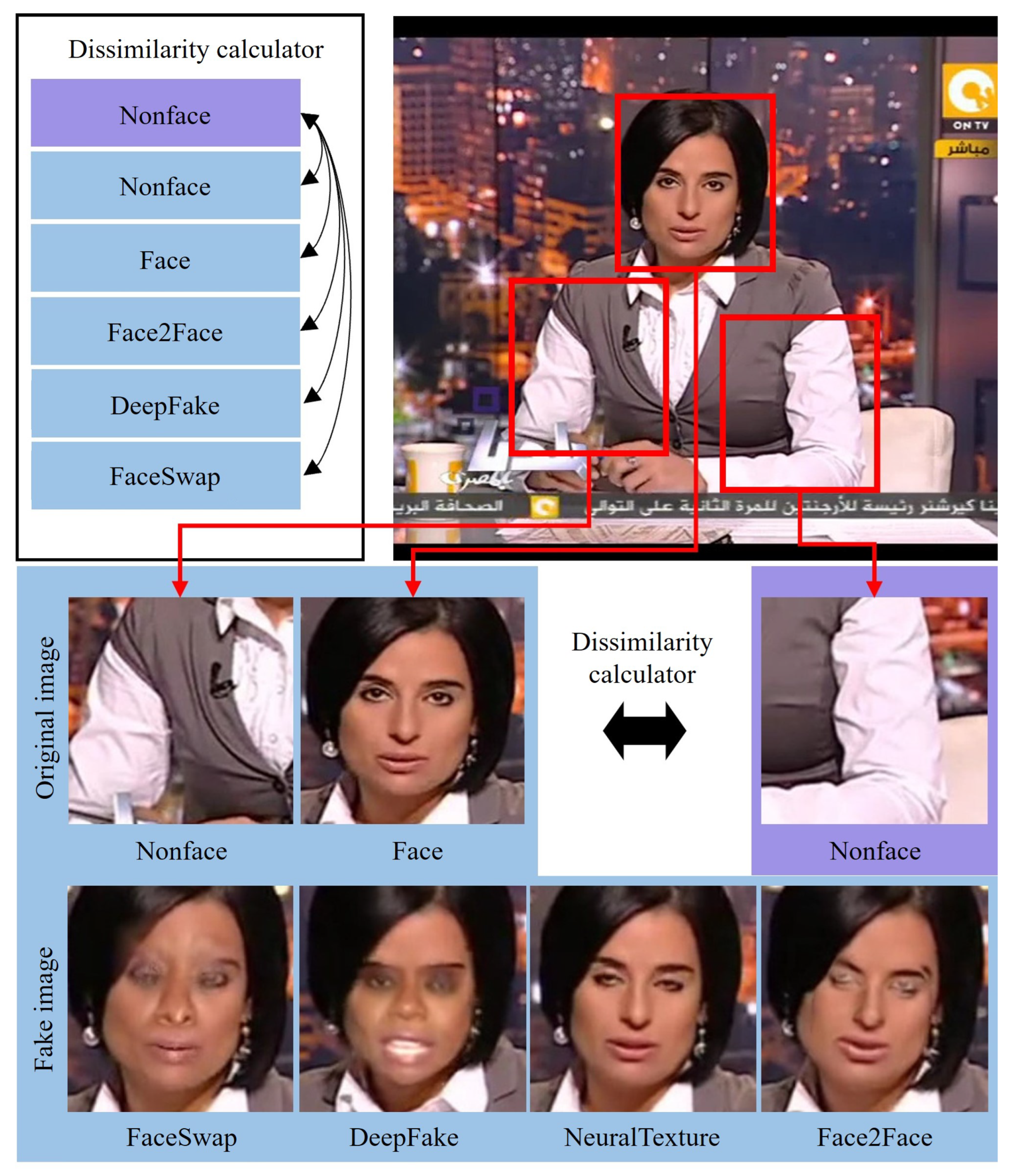
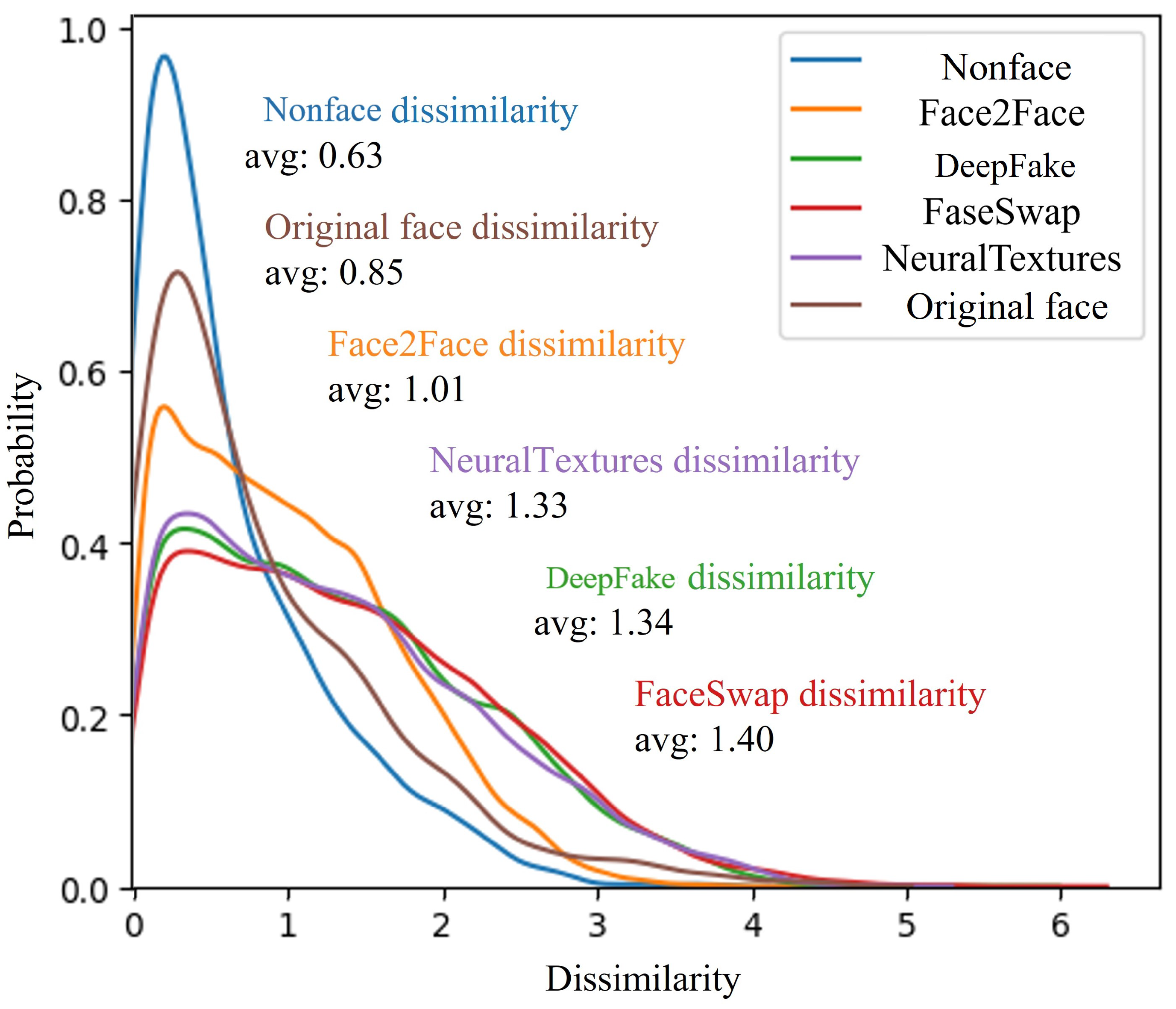
- We employ the interpatch dissimilarity estimator within a frame to capture quality differences between patches to enhance the performance and generalizability of deepfake detection.
- We use a multistream CNN that uses high and low frequencies and the original image streams to capture deepfake clues unique to each feature.
2. Related Work
2.1. Deepfake Generation
2.2. Deepfake Detection
2.3. No-Reference Image Quality Assessment
3. Methods
3.1. Observation
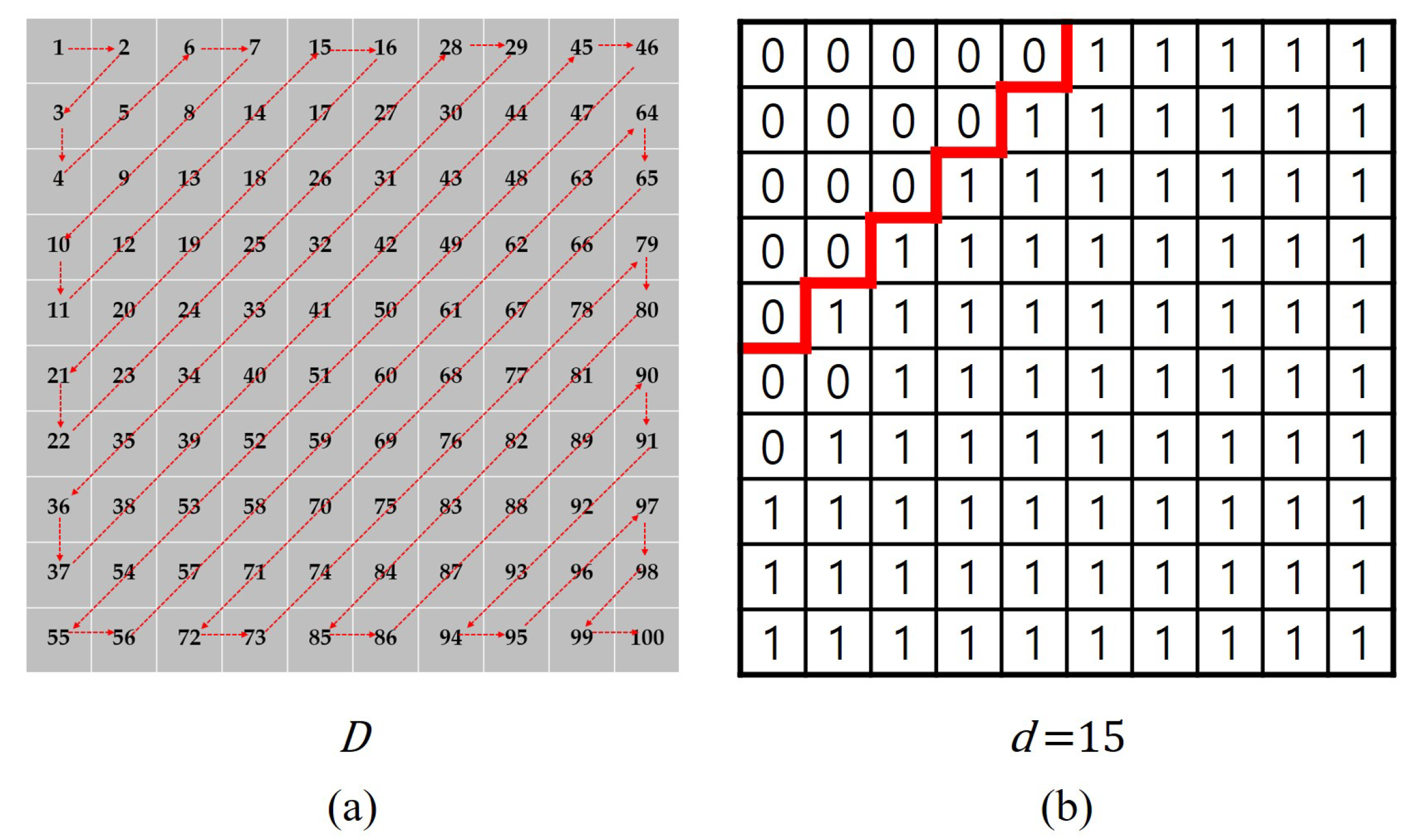
3.2. Interpatch Dissimilarity Estimator
3.3. Frequency Decomposition Block
3.4. Multi-Stream Convolution Neural Network
4. Experiments
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Implementation Details
4.1.3. Evaluation Metrics
4.2. Comparison with Previous Methods
4.3. Generalizability Evaluation
4.4. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Morales, A.; Ortega-Garcia, J. Deepfakes and beyond: A survey of face manipulation and fake detection. Inf. Fusion 2020, 64, 131–148. [Google Scholar] [CrossRef]
- Bitouk, D.; Kumar, N.; Dhillon, S.; Belhumeur, P.N.; Nayar, S.K. Face Swapping: Automatically Replacing Faces in Photographs. ACM SIGGRAPH 2008, 27, 1–8. [Google Scholar] [CrossRef]
- Korshunova, I.; Shi, W.; Dambre, J.; Theis, L. Fast face-swap using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 22–25 July 2017; pp. 3677–3685. [Google Scholar]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-df: A large-scale challenging dataset for deepfake forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3207–3216. [Google Scholar]
- Lee, I.; Lee, E.; Yoo, S.B. Latent-OFER: Detect, mask, and reconstruct with latent vectors for occluded facial expression recognition. arXiv 2023, arXiv:2307.11404. [Google Scholar]
- Nirkin, Y.; Keller, Y.; Hassner, T. Fsgan: Subject agnostic face swapping and reenactment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 7184–7193. [Google Scholar]
- Liu, K.; Perov, I.; Gao, D.; Chervoniy, N.; Zhou, W.; Zhang, W. Deepfacelab: Integrated, flexible and extensible face-swapping framework. Pattern Recognit. 2023, 141, 109628. [Google Scholar] [CrossRef]
- Vahdat, A.; Kautz, J. NVAE: A deep hierarchical variational autoencoder. Adv. Neural Inf. Process. Syst. 2020, 33, 19667–19679. [Google Scholar]
- Hong, Y.; Kim, M.J.; Lee, I.; Yoo, S.B. Fluxformer: Flow-Guided Duplex Attention Transformer via Spatio-Temporal Clustering for Action Recognition. IEEE Robot. Autom. Lett. 2023, 8, 6411–6418. [Google Scholar] [CrossRef]
- Choi, Y.; Uh, Y.; Yoo, J.; Ha, J.W. Stargan v2: Diverse image synthesis for multiple domains. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8188–8197. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Thies, J.; Zollhofer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2face: Real-time face capture and reenactment of rgb videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2387–2395. [Google Scholar]
- Masood, M.; Nawaz, M.; Malik, K.M.; Javed, A.; Irtaza, A.; Malik, H. Deepfakes generation and detection: State-of-the-art, open challenges, countermeasures, and way forward. Appl. Intell. 2023, 53, 3974–4026. [Google Scholar] [CrossRef]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. Mesonet: A compact facial video forgery detection network. In Proceedings of the IEEE International Workshop on Information Forensics and Security, Hong Kong, China, 10–13 December 2018; pp. 1–7. [Google Scholar]
- Wang, R.; Juefei-Xu, F.; Ma, L.; Xie, X.; Huang, Y.; Wang, J.; Liu, Y. Fakespotter: A simple yet robust baseline for spotting ai-synthesized fake faces. arXiv 2019, arXiv:1909.06122. [Google Scholar]
- Bonettini, N.; Cannas, E.D.; Mandelli, S.; Bondi, L.; Bestagini, P.; Tubaro, S. Video face manipulation detection through ensemble of cnns. In Proceedings of the 2020 25th International Conference on Pattern Recognition, Milano, Italy, 10–15 January 2021; pp. 5012–5019. [Google Scholar]
- Li, Y.; Lyu, S. Exposing deepfake videos by detecting face warping artifacts. arXiv 2018, arXiv:1811.00656. [Google Scholar]
- Kim, M.H.; Yun, J.S.; Yoo, S.B. Multiregression spatially variant blur kernel estimation based on inter-kernel consistency. Electron. Lett. 2023, 59, e12805. [Google Scholar] [CrossRef]
- Yang, J.; Xiao, S.; Li, A.; Lu, W.; Gao, X.; Li, Y. MSTA-Net: Forgery detection by generating manipulation trace based on multi-scale self-texture attention. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4854–4866. [Google Scholar] [CrossRef]
- Li, L.; Bao, J.; Zhang, T.; Yang, H.; Chen, D.; Wen, F.; Guo, B. Face x-ray for more general face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5001–5010. [Google Scholar]
- Durall, R.; Keuper, M.; Pfreundt, F.J.; Keuper, J. Unmasking deepfakes with simple features. arXiv 2019, arXiv:1911.00686. [Google Scholar]
- Le, M.B.; Woo, S. ADD: Frequency attention and multi-view based knowledge distillation to detect low-quality compressed deepfake images. Proc. Aaai Conf. Artif. Intell. 2022, 36, 122–130. [Google Scholar]
- Giudice, O.; Guarnera, L.; Battiato, S. Fighting deepfakes by detecting gan dct anomalies. J. Imaging 2021, 7, 128. [Google Scholar] [CrossRef] [PubMed]
- Jeong, Y.; Kim, D.; Ro, Y.; Choi, J. FrePGAN: Robust deepfake detection using frequency-level perturbations. Proc. Aaai Conf. Artif. Intell. 2022, 36, 1060–1068. [Google Scholar] [CrossRef]
- Yun, J.S.; Na, Y.; Kim, H.H.; Kim, H.I.; Yoo, S.B. HAZE-Net: High-Frequency Attentive Super-Resolved Gaze Estimation in Low-Resolution Face Images. In Proceedings of the Asian Conference on Computer Vision, Macau, China, 4–8 December; pp. 3361–3378.
- Tian, C.; Luo, Z.; Shi, G.; Li, S. Frequency-Aware Attentional Feature Fusion for Deepfake Detection. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing, Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Kohli, A.; Gupta, A. Detecting deepfake, faceswap and face2face facial forgeries using frequency cnn. Multimed. Tools Appl. 2021, 80, 18461–18478. [Google Scholar] [CrossRef]
- Li, J.; Xie, H.; Li, J.; Wang, Z.; Zhang, Y. Frequency-aware discriminative feature learning supervised by single-center loss for face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 6458–6467. [Google Scholar]
- Qian, Y.; Yin, G.; Sheng, L.; Chen, Z.; Shao, J. Thinking in frequency: Face forgery detection by mining frequency-aware clues. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 86–103. [Google Scholar]
- Younus, M.A.; Hasan, T.M. Effective and fast deepfake detection method based on haar wavelet transform. In Proceedings of the 2020 International Conference on Computer Science and Software Engineering, Duhok, Iraq, 16–18 April 2020; pp. 186–190. [Google Scholar]
- Wang, B.; Wu, X.; Tang, Y.; Ma, Y.; Shan, Z.; Wei, F. Frequency domain filtered residual network for deepfake detection. Mathematics 2023, 11, 816. [Google Scholar] [CrossRef]
- Wolter, M.; Blanke, F.; Heese, R.; Garcke, J. Wavelet-packets for deepfake image analysis and detection. Mach. Learn. 2022, 111, 4295–4327. [Google Scholar] [CrossRef]
- Lee, I.; Yun, J.S.; Kim, H.H.; Na, Y.; Yoo, S.B. LatentGaze: Cross-Domain Gaze Estimation through Gaze-Aware Analytic Latent Code Manipulation. In Proceedings of the Asian Conference on Computer Vision, Macau, China, 4–8 December 2022; pp. 3379–3395. [Google Scholar]
- Abdul, J.V.; Janet, B. Deep fake video detection using recurrent neural networks. Int. J. Sci. Res. Comput. Sci. Eng. 2021, 9, 22–26. [Google Scholar]
- Masi, I.; Killekar, A.; Mascarenhas, R.M.; Gurudatt, S.P.; AbdAlmageed, W. Two-branch recurrent network for isolating deepfakes in videos. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 667–684. [Google Scholar]
- Sabir, E.; Cheng, J.; Jaiswal, A.; AbdAlmageed, W.; Masi, I.; Natarajan, P. Recurrent convolutional strategies for face manipulation detection in videos. Interfaces 2019, 3, 80–87. [Google Scholar]
- De L., O.; Franklin, S.; Basu, S.; Karwoski, B.; George, A. Deepfake detection using spatiotemporal convolutional networks. arXiv 2020, arXiv:2006.14749. [Google Scholar]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Two-stream neural networks for tampered face detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1831–1839. [Google Scholar]
- Nguyen, H.H.; Fang, F.; Yamagishi, J.; Echizen, I. Multi-task learning for detecting and segmenting manipulated facial images and videos. In Proceedings of the 2019 IEEE 10th International Conference on Biometrics Theory, Applications and Systems, Tampa, FL, USA, 23–26 September 2019; pp. 1–8. [Google Scholar]
- Rana, M.S.; Nobi, M.N.; Murali, B.; Sung, A.H. Deepfake detection: A systematic literature review. IEEE Access 2022, 10, 25494–25513. [Google Scholar] [CrossRef]
- Zhao, T.; Xu, X.; Xu, M.; Ding, H.; Xiong, Y.; Xia, W. Learning self-consistency for deepfake detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 19–21 June 2021; pp. 15023–15033. [Google Scholar]
- Chen, L.; Zhang, Y.; Song, Y.; Liu, L.; Wang, J. Self-supervised learning of adversarial example: Towards good generalizations for deepfake detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18710–18719. [Google Scholar]
- Nadimpalli, A.V.; Rattani, A. On improving cross-dataset generalization of deepfake detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 91–99. [Google Scholar]
- Ke, J.; Wang, Q.; Wang, Y.; Milanfar, P.; Yang, F. Musiq: Multi-scale image quality transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 5148–5157. [Google Scholar]
- Yang, S.; Wu, T.; Shi, S.; Lao, S.; Gong, Y.; Cao, M.; Wang, J.; Yang, Y. Maniqa: Multi-dimension attention network for no-reference image quality assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1191–1200. [Google Scholar]
- Jinjin, G.; Haoming, C.; Haoyu, C.; Xiaoxing, Y.; Ren, J.S.; Chao, D. Pipal: A large-scale image quality assessment dataset for perceptual image restoration. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 633–651. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 1–11. [Google Scholar]
- Ahmed, N.; Natarajan, T.; Rao, K.R. Discrete cosine transform. IEEE Trans. Comput. 1974, 100, 90–93. [Google Scholar] [CrossRef]
- Bazarevsky, V.; Kartynnik, Y.; Vakunov, A.; Raveendran, K.; Grundmann, M. Blazeface: Sub-millisecond neural face detection on mobile gpus. arXiv 2019, arXiv:1907.05047. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Capsule-forensics: Using capsule networks to detect forged images and videos. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 12–17 May 2019; pp. 2307–2311. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | FF++ | Celeb-DF |
|---|---|---|
| MesoNet [14] | 84.70 | 68.50 |
| FWA [17] | 80.15 | - |
| Xception-c23 [4] | 99.75 | 99.47 |
| MesoInception4 [14] | 83.05 | 72.67 |
| Two-stream [38] | 70.10 | - |
| Multi-task [39] | 76.35 | - |
| Capsule [54] | 96.60 | 98.84 |
| DSP-FWA [17] | 93.02 | - |
| Two Branch [35] | 93.14 | 93.10 |
| -Net [29] | 98.10 | 99.86 |
| EfficientNet-B4 [16] | 99.70 | 99.48 |
| ClueCatcher (Ours) | 99.33 | 99.98 |
| Methods | Celeb-DF | FPS |
|---|---|---|
| Meso4 [14] | 54.88 | - |
| FWA [17] | 56.92 | - |
| Xception-c23 [4] | 65.33 | 62 |
| MesoInception4 [14] | 53.67 | - |
| Two-stream [38] | 53.87 | - |
| Multi-task [39] | 54.35 | - |
| Capsule [54] | 57.52 | 41 |
| DSP-FWA [17] | 64.60 | 29 |
| Two Branch [35] | 73.40 | - |
| -Net [29] | 65.14 | 26 |
| EfficientNet-B4 [16] | 64.29 | 39 |
| EfficientNet-PPO [43] | 66.91 | - |
| ClueCatcher (Ours) | 76.50 | 18 |
| Method | Training Set | Testing Set | Cross Avg. | |||
|---|---|---|---|---|---|---|
| DF | F2F | FS | NT | |||
| EfficientNet-B4 [16] | 96.88 | 59.46 | 42.00 | 65.00 | 65.84 | |
| Xception-c23 [4] | DF | 98.85 | 64.95 | 42.54 | 64.27 | 67.65 |
| ClueCatcher (Ours) | 98.75 | 68.71 | 47.70 | 69.73 | 71.22 | |
| EfficientNet-B4 [16] | 82.90 | 95.14 | 60.24 | 65.31 | 75.90 | |
| Xception-c23 [4] | F2F | 82.67 | 99.70 | 54.48 | 58.97 | 73.96 |
| ClueCatcher (Ours) | 84.40 | 98.32 | 56.29 | 66.09 | 76.28 | |
| EfficientNet-B4 [16] | 46.92 | 52.32 | 93.65 | 45.00 | 59.47 | |
| Xception-c23 [4] | FS | 56.10 | 51.35 | 98.99 | 45.28 | 62.93 |
| ClueCatcher (Ours) | 45.59 | 56.60 | 98.01 | 53.86 | 63.26 | |
| EfficientNet-B4 [16] | 92.33 | 77.11 | 49.18 | 99.07 | 79.42 | |
| Xception-c23 [4] | NT | 87.45 | 79.92 | 50.15 | 99.96 | 79.37 |
| ClueCatcher (Ours) | 92.84 | 79.92 | 54.74 | 98.89 | 81.59 | |
| Frequency Components | Interpatch Dissimilarity | FaceForensics++ | |||
|---|---|---|---|---|---|
| DF | F2F | FS | NT | ||
| - | - | 98.56 | 97.74 | 98.28 | 93.97 |
| ✓ | - | 99.68 | 98.42 | 99.71 | 97.53 |
| - | ✓ | 99.72 | 99.49 | 98.59 | 96.44 |
| ✓ | ✓ | 99.76 | 99.70 | 99.87 | 98.66 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, E.-G.; Lee, I.; Yoo, S.-B. ClueCatcher: Catching Domain-Wise Independent Clues for Deepfake Detection. Mathematics 2023, 11, 3952. https://doi.org/10.3390/math11183952
Lee E-G, Lee I, Yoo S-B. ClueCatcher: Catching Domain-Wise Independent Clues for Deepfake Detection. Mathematics. 2023; 11(18):3952. https://doi.org/10.3390/math11183952
Chicago/Turabian StyleLee, Eun-Gi, Isack Lee, and Seok-Bong Yoo. 2023. "ClueCatcher: Catching Domain-Wise Independent Clues for Deepfake Detection" Mathematics 11, no. 18: 3952. https://doi.org/10.3390/math11183952
APA StyleLee, E.-G., Lee, I., & Yoo, S.-B. (2023). ClueCatcher: Catching Domain-Wise Independent Clues for Deepfake Detection. Mathematics, 11(18), 3952. https://doi.org/10.3390/math11183952