1. Introduction
Capital allocation proposed by Dhaene et al. [
1] is a key concept in economics and finance. Although they are related, the meaning of capital allocation is slightly different in these two research fields. In economics, capital allocation is related to the allocation of limited resources (capital) to the most-efficient alternatives [
2,
3,
4,
5,
6]. In financial and actuarial applications, capital allocation is associated with the individual risk contribution to an aggregate risk [
7]. Our study focuses on capital allocation from a financial and actuarial perspective. Risk in quantitative risk management is defined as a random variable (r.v.) associated with costs or losses [
8,
9,
10]. Capital allocation problems arise when a total amount associated with the aggregate risk has to be distributed across the multiple units of risk that make it up [
11,
12]. The total capital amount to allocate across the individual risks is usually calculated by means of a risk measure, such as the Value-at-Risk (VaR) or the Tail-Value-at-Risk (TVaR) [
13]. A capital allocation principle is the set of guidelines that indicates how the total capital must be allocated across the individual risks. The resulting capital allocations reflect the contributions of the individual risks to the total risk evaluated under that capital allocation principle.
There is an extensive amount of studies in the literature dealing with capital allocation problems. Examples of capital allocation problems can be found, for instance, in asset allocation strategies for portfolio selection [
14,
15,
16,
17,
18,
19], the allocation of the total solvency capital requirement across business lines [
20,
21,
22,
23], or when distributing total claim costs across the coverage of an insurance policy [
24], among others. A comparative analysis of alternative capital allocation principles can be found in Xu and Hu [
25] and Balog et al. [
26].
Although capital allocation problems have mainly been analysed from a static approach and only one organisation level [
1,
27,
28,
29], some studies have included a time-dependent perspective taking into account dynamics in capital risk allocations [
17,
30,
31,
32,
33], and other studies have dealt with hierarchical corporate structures at two or more organisational levels in which a given total capital must be allocated among business lines and also their sub-business lines [
34,
35]. A standard assumption in the literature is that the aggregate risk is formed as linear combinations of individual risks, but there are some attempts to investigate capital allocation for portfolios with nonlinear aggregation [
36].
There are two main streams to motivate capital allocation principles. Some capital allocation principles have been motivated based on game theory in which capital allocation problems are interpreted as coalition games [
37,
38,
39,
40]. In that context, the Aumann–Shapley value is one of the most-popular capital allocation rules [
37,
41,
42]. An alternative approach to derive capital allocation principles emerges from the economy theory. Capital allocation problems are interpreted as optimisation problems in which a loss function of particular interest for risk managers is minimised [
7,
43,
44,
45,
46,
47]. Under this second approach, Dhaene et al. [
1] provided a unified theoretical framework in which a capital allocation principle is the outcome of a particular optimisation problem. This framework was later generalised by Zaks and Tsanakas [
34] considering a hierarchical corporate structure, and more recently, Cai and Wang [
35] considered different loss functions for capital shortfall risk and capital surplus risk.
The goal of this study is to complement and generalise the unified capital allocation framework provided by Dhaene et al. [
1] in order to overcome some of the drawbacks of their allocation setting. Dhaene et al. [
1] showed that their unified capital allocation framework has a unique allocation solution when the quadratic optimisation criterion is considered. The authors argued that most of the capital allocation principles used in practice can be accommodated by that framework, but the haircut allocation principle did not seem to be reconcilable with that setting ([
1] Table 1). The contribution of our study is twofold. First, we provide an alternative approach to solve the quadratic optimisation problem, which is, in our opinion, easier to follow and understand by researchers and practitioners. Second, we prove that the haircut allocation principle can be accommodated by that quadratic optimisation setting by relaxing one of the original constraints. Therefore, we extend the number of capital allocations principles represented by that unified capital allocation framework.
In the optimisation setting proposed by Dhaene et al. [
1], the solution of the quadratic allocation criterion is derived via a geometric proof. In this article, we provide an alternative proof of the solution to the quadratic allocation problem based on the Lagrangian method. To our knowledge, this proof has not been previously provided in the literature. Dhaene et al. [
1] and Zaks and Tsanakas [
34] followed geometric approaches to obtain solutions to their quadratic optimisation problems. On the other hand, Cai and Wang [
35] used the Lagrangian method, but their optimisation problem was based on the absolute allocation criterion. That is, their loss function was based on absolute deviations, allowing for different weighting functions to apply to positive and negative deviations.
A second contribution here is that we accommodate the haircut allocation principle into the capital allocation setting provided by Dhaene et al. [
1]. The haircut allocation principle has been widely used in the industry due to its simplicity [
1,
22] (pp. 6, 750). Under the haircut allocation principle, the portion of the aggregate capital allocated to a risk unit is computed as the proportion that the VaR associated with this risk unit represents in relation to the sum of VaRs for all risk units. In this paper, we prove that the haircut allocation principle can be accommodated by the quadratic optimisation criterion by relaxing one of the original conditions of Dhaene et al. [
1]. The general optimisation framework of Dhaene et al. [
1] depends on a set of non-negative auxiliary random variables with the expected value equal to one, which are used as weight factors to the (scaled) deviations between losses and allocated risk capitals. Previously, Belles-Sampera et al. [
24] suggested a mechanism to accommodate the haircut allocation principle into the quadratic optimisation framework by allowing auxiliary random variables to take negative values. However, as appointed by Cai and Wang [
35], when the auxiliary random variables take negative values, the loss function could be concave and the optimisation problem may not have minimisers. In addition, the proof of Proposition 1 of Belles-Sampera et al. [
24] was based on Theorem 1 of Dhaene et al. [
1], which can only be applied to non-negative auxiliary random variables with the expected value equal to one. Inspired by Belles-Sampera et al. [
24], we here define a particular form of the auxiliary random variables from which the haircut allocation principle is derived. We show that the solution exists and it is unique. Therefore, we demonstrate that the haircut allocation principle can be understood as the solution of a quadratic optimisation problem. Finally, two particular examples are provided where the haircut allocation principle is obtained.
The paper is structured as follows. The general optimal capital allocation framework is defined in the next section, and the proof of the solution of the quadratic allocation criterion via the Lagrangian method is shown.
Section 3 provides the steps to accommodate the haircut allocation principle into this framework, as the solution to a quadratic optimisation problem. Two examples are provided in
Section 4. An illustrative application is given in
Section 5.
Section 6 concludes.
2. Risk Capital Allocation as a Quadratic Optimisation Problem
The optimal allocation framework introduced in this section may be used to describe capital allocation principles as solutions to optimisation problems. We assumed that all components and concepts of the optimisation setting exist and are mathematically well-defined. For instance, the existence of moments of a specific order of the random variables involved in the allocation setting will be assumed when it would be required to prove a proposition.
Assume that a capital
has to be allocated across
n business units denoted by
. The random variable
with finite expectation refers to the loss associated with the
jth business. Based on the capital allocation framework given by Dhaene et al. [
1], we argue that most capital allocation problems can be described as the optimisation problem given by
with the following characterising elements:
- (a)
A function ;
- (b)
A set of positive values , ;
- (c)
A set of random variables such that , .
The optimisation framework given in (
1) is more general than the original optimisation framework proposed by Dhaene et al. [
1] (see Remark 2 for a description of the original setting). Note that, if
is selected, then the optimisation criterion in (
1) is called the
quadratic optimisation criterion. The explicit and unique solution to the quadratic minimisation problem is given in the following proposition.
Proposition 1. Assume that random variables , , and have finite moments of first and second order, . Then, the solution of the minimisation problem proposed in the general framework defined in (1) under the quadratic optimisation criterion is Proof of Proposition 1. Let us rewrite expression (
1) when
in the following way:
Now, let
and
for all
, so
for all
j. The expression (
3) can be rewritten as
Note that
is a random variable, while
is a constant. A similar procedure inspired by the proof of Theorem 1 by Dhaene et al. [
1] is followed. Let us consider that
The last two elements do not depend on
. Therefore, the minimisation problem in (
4) is equivalent to
Following a similar strategy to Zaks et al. [
44], the notation
is introduced (
is properly defined since
). Note that
so the optimisation problem (
5) is equivalent to
The selected method to solve problem (
6) is the Lagrange multipliers’ method. Following the notation of Magnus and Neudecker [
48] (Ch. 7), both
and
are suitable for the application of this optimisation method because
is differentiable at any
,
g is twice differentiable at any
, and the
Jacobian matrix of
g has full rank 1. Consider the Lagrangian function:
The partial derivatives of function
with respect to
and
are
By equalling the first partial derivative (
7) to zero, we obtain
Then,
, and from (
8) equal to zero, we obtain
then substituting in (
9),
The objective function and constraints in (
6) are convex functions, so the solution is unique. Changing the notation from (
6) to (
5), then (
10) can be expressed as
The solution to problems (
4) and (
5) is
Finally, the solution of problem (
3) is
□
A proof that the solution
in (
10) is a minimum is provided. According to Magnus and Neudecker [
48], the bordered Hessian matrix of
,
is:
The characteristics of the
matrix do not depend either on
or on
. As stated in (Magnus and Neudecker [
48] p. 156), the point
with
for all
i,
, is a minimum if all minors
:
of
have their sign equal to
for
. As is shown in
Appendix A,
are equal to:
Therefore, it is satisfied that
for all
, because
for all
due to
for all
j. Therefore,
is a minimum in (
6).
An alternative proof can be given following the strategy in Dhaene et al. [
1]. The problem (
6) can be understood as finding the closest point to the origin (with respect to the Euclidean distance) that belongs to the hyperplane:
From this point of view, the solution
in (
10) is unique and a minimum.
Remark 1. The proof of Proposition 1 requires that , . This is satisfied with Conditions (b) and (c). However, a more-general framework may be defined with the conditions (b) and (c) expressed as follows:
- (b)
A set of weights , ;
- (c)
A set of random variables , , with .
The proof of the proposition still holds. However, the interpretation of a negative weight and a negative expected value of in the context of risk management is not as straightforward as with positive values.
Remark 2. The original allocation problem proposed by Dhaene et al. [1] considered (b) and (c) in (1) as follows: - (b)
A set of non-negative weights , , such that ;
- (c)
A set of non-negative random variables , , with .
Under these constraints, the solution (2) can be simplified as 5. Illustrative Application
This section illustrates a financial application to compute the haircut allocation principle in the context of the market risk for a portfolio of stocks. All calculations were carried out in the R software (version R 4.3.1) [
49].
Let us suppose that we are U.S. institutional investors and we have to analyse a set of investment funds in order to increase the value of the assets of the institution that we represent. Once a week, we have to report the value of our assets to the institution’s management board. We do not invest in assets denominated in currencies other than USD, so the investment funds under analysis are not subject to currency risk. We considered four funds that have the goal of beating the following indexes, respectively: the S&P500, the NASDAQ, the Dow Jones Industrial Average Index, and the NYSE Composite Index (the NYSE tickers for this indexes are, respectively, the following: GSPC, IXIC, DJI, and NYA). We want to analyse the risk of each investment fund, on a weekly basis, if no additional information other than the index of reference is available. In addition, we are interested in ranking the investment funds based on their relative riskiness. As is shown hereinafter, these objectives may be reached with the application of the haircut capital allocation principle.
First, it should be determined what risk is under analysis and how it is measured. Any monetary amount invested in a fund during a period of interest can increase or decrease depending on the return of the fund for that period: a positive return generates an increase of the assets’ value (profit), while a negative return generates a decrease of the assets’ value (loss). Therefore, the random variables that represent the risks in our analysis should be linked to the returns of the funds. As we report on a weekly basis to the management board, weekly returns seem a natural choice. Note that, in the capital allocation framework described in (
1), a positive value of the risk random variable is considered a loss, so weekly returns of the funds with a negative sign were selected as the risk random variables in this illustration (see [
8] (Section 1.2.1) for details about the ‘asset side’ risk perspective versus the ‘liability side’ risk perspective). To measure the risk, we considered the Value-at-Risk (VaR) with a confidence level
equal to 51/52 (≃98.08%) because the information of this risk measure value is easy to communicate to the institution’s management board, i.e.,
“with a frequency of one week in a year, losses in terms of returns can be higher than the VaR”. There are alternative methods to estimate the VaR [
50,
51,
52]. In this application, we selected the empirical
-quantile of the historical returns of the fund (known as the
historical VaR). The last element to perform the haircut capital allocation exercise is to determine the
aggregate risk capital to be allocated among the four individual funds. We are only interested in the relative riskiness of each investment fund, so we can set any amount as the total risk capital to allocate. For instance,
K is equal to 1000 risk units.
Summarising, the risk of the four investment funds is measured by the historical VaR of negative weekly returns. The relative risk of the investment funds is computed by means of a haircut allocation principle, in which a total amount of 1000 risk units is distributed among the four funds based on their riskiness. Now, the dataset is created. The dataset consists of negative discrete weekly returns of the indexes linked to the four investment funds and covers the observational period from 6 August 2018 to 31 July 2023 (data were obtained from the web
https://es.finance.yahoo.com, accessed on 31 August 2023). In terms of (
12),
,
for
(one
i for each investment fund),
t and
are consecutive weeks,
is the level of the index of reference for the
ith fund in week
t,
, and
. The samples of
,
contain 261 observations, and
is estimated as
. The results are shown in
Table 2. To ease the analysis, the funds will be named by the name of their index of reference and expressions such as
the return (or the risk) of the fund will be used to refer to the return (or the risk) of the index of reference of the fund.
Investment funds can be ranked based on the risk measure value displayed in
Table 2. The NASDAQ fund is the riskiest fund, and the S&P500 fund is the fund with the lowest risk. The DJI fund is riskier than the NYA fund. The haircut allocation principle proportionally distributes the 1000 risk units among the investment funds based on their relative risk (
). Note that there is a trade-off between risk and return. For instance, if the ratio between the VaR and the expected return is considered
, the ranking of funds remarkably varies. Now, the NASDAQ fund would be the most-attractive investment option in terms of the trade-off between risk and return (
), although it is the riskiest fund, as stated before. The less-attractive investment option would be the NYA fund (
), followed by the DJI fund (
) and the S&P500 fund (
).
In
Section 4, two examples of
are provided in which the haircut allocation principle is accommodated by the general optimisation framework proposed in (
1).
Table 3 and
Table 4 show the expressions of
,
, in this illustration when the definitions proposed in Example 1 and Example 2 are considered, respectively. The sample means of
and
were estimated for each
i in both examples and were equal to 1 and
, respectively, as expected according to Lemma 1.
It is worth noting that the random variables in
Table 3 always take positive values, so the first example in this application would fit the original optimisation framework proposed by Dhaene et al. [
1]. The positiveness of
in Example 1 for this application can be deduced from Remark 3. For example, let us select the NASDAQ fund (
), which was the riskiest investment fund. The sample values of the
weighted random variable
for the two examples are shown in
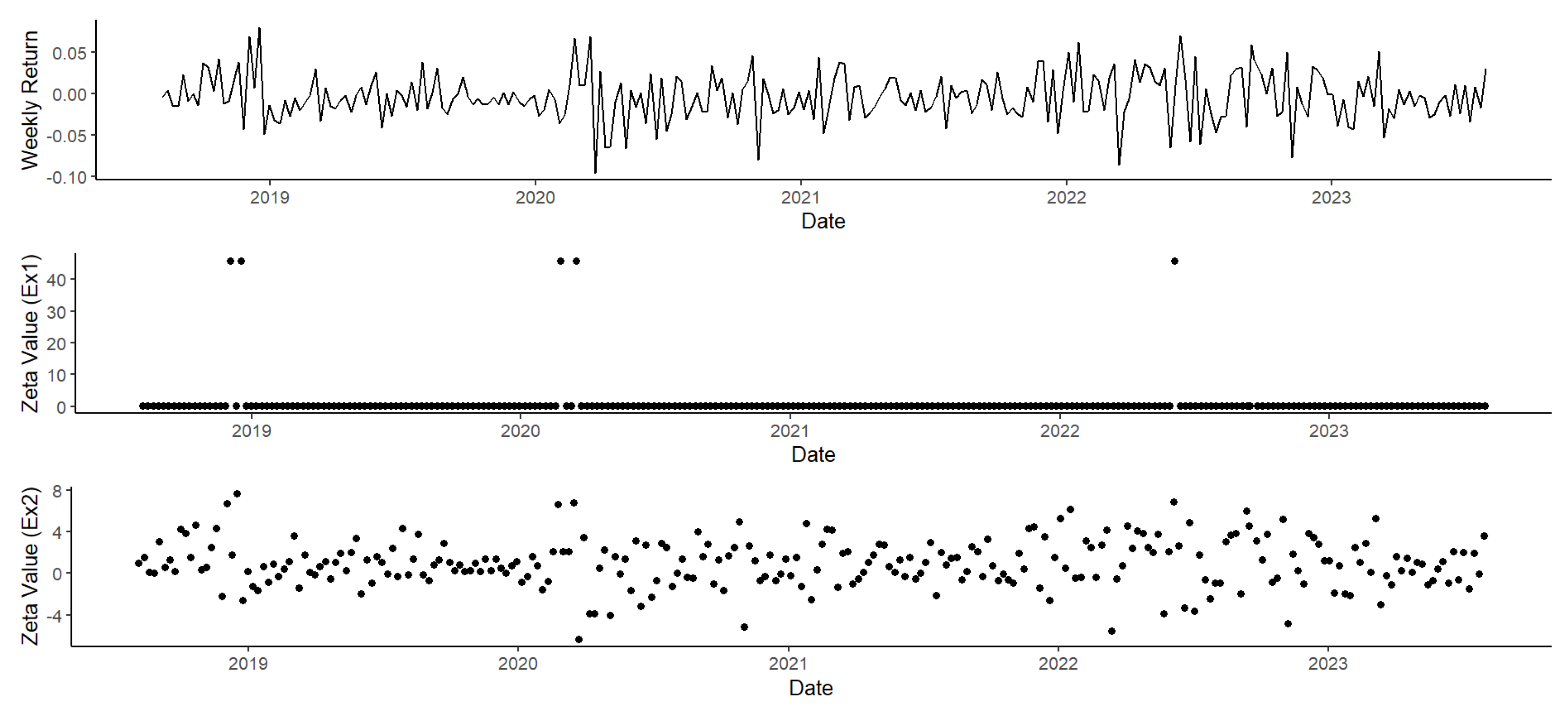
Figure 1. The
in Example 1 has
associated, and the approximated value of
is
, so
. Recalling that
, now, we have to determine the sign of
. The sign of the sample value of this expression is negative,
. According to
Table 1,
is negative only when
. However, this is not feasible since
takes only two values (0 or 1), and both are smaller than
. The same reasoning can be followed by the rest of the funds in Example 1.
Figure 1 shows that sample values of
for Example 1 take only positive values. By contrast, the random variables in
Table 4 may take positive and negative values, as shown in
Figure 1 for the sample values of
of Example 2. Therefore, the second example in this application would fit the generalised optimisation framework (
1), but not the original setting (see Remark (6)).
6. Conclusions
In this paper, we generalised the capital allocation framework proposed by Dhaene et al. [
1]. We proved that the haircut capital allocation principle can now be accommodated by that general optimisation framework. Under this general capital allocation setting, we provide an alternative and interpretable form to obtain the optimal solution to the quadratic optimisation problem that complements the existing geometrical proof. All required steps to obtain the optimal solution to that capital allocation framework were described in order to be easy to follow by a broad (not necessarily expert) audience. We argue that the majority of relevant scenarios from a risk management perspective can be represented in our capital allocation framework.
The theoretical findings were complemented with a financial illustration to evaluate the market risk for a set of investment funds. We showed how the haircut capital allocation principle can be applied in a real context to analyse the risk of each investment fund and to rank them based on their relative riskiness. The two examples of weighted random variables proposed in the study to define the haircut capital allocation principle as a quadratic optimisation problem were estimated in the illustration. We showed that the weighting random variable involved in the first example only took positive values in the illustration and, therefore, would fit the optimisation setting of Dhaene et al. [
1]. By contrast, the weighted random variable involved in the second example took positive and negative values in the illustration and, therefore, would fit the generalised optimisation framework proposed in this study, but not the optimisation setting of Dhaene et al. [
1].
To conclude, capital allocation principles defined as the outcomes of optimisation problems contribute to a deeper understanding of the implications and limitations of using a particular capital allocation principle. Providing a unified optimisation setting of capital allocation principles is useful for risk managers to select the most-adequate allocation principle in a specific risk context. The availability of a unified optimisation framework eases the risk management’s task of comparison between capital allocation principles. The generalised optimisation framework defined in our study includes the widely used haircut capital allocation principle in the unified optimisation setting. It, therefore, represents an improvement from a risk management point of view. However, our study is not without limitations. The analysis was carried out considering the quadratic optimisation criterion in a hierarchical corporate structure with one organisational level. A natural extension of our study is to consider other optimisation criteria, such as the absolute deviation criterion and hierarchical corporate structures with two or more organisational levels. Another potential future line of research is to consider the haircut capital allocation principle in portfolios with nonlinear risk aggregation.





{kind=link}