
Study of a New Software Reliability Growth Model under Uncertain Operating Environments and Dependent Failures

Abstract
:1. Introduction
2. Software Reliability Growth Model
2.1. Nonhomogeneous Poisson Process
2.2. Existing SRGMs
2.3. Proposed Model
3. Sequential Probability Ratio Test
4. Numerical Example
4.1. Datasets
4.2. Criteria
4.3. Results of Goodness of Fit
4.4. Results of SPRT
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Huang, Y.-S.; Chiu, K.-C.; Chen, W.-M. A software reliability growth model for imperfect debugging. J. Syst. Softw. 2022, 188, 111267. [Google Scholar] [CrossRef]
- Luo, H.; Xu, L.; He, L.; Jiang, L.; Long, T. A Novel Software Reliability Growth Model Based on Generalized Imperfect Debugging NHPP Framework. IEEE Access 2023, 11, 71573–71593. [Google Scholar] [CrossRef]
- Chiu, K.C.; Huang, Y.S.; Huang, I.C. A study of software reliability growth with imperfect debugging for time-dependent potential errors. Int. J. Ind. Eng.-Theory Appl. Pract. 2019, 26. [Google Scholar] [CrossRef]
- Gupta, R.; Jain, M.; Jain, A. Software Reliability Growth Model in Distributed Environment Subject to Debugging Time Lag; Springer: Berlin/Heidelberg, Germany, 2019; pp. 105–118. [Google Scholar] [CrossRef]
- Zhang, C.; Yuan, Y.; Jiang, W.; Sun, Z.; Ding, Y.; Fan, M.; Li, W.; Wen, Y.; Song, W.; Liu, K. Software Reliability Model Related to Total Number of Faults under Imperfect Debugging; Springer: Berlin/Heidelberg, Germany, 2022; pp. 48–60. [Google Scholar] [CrossRef]
- Nguyen, H.C.; Huynh, Q.T. New non-homogeneous Poisson process software reliability model based on a 3-parameter S-shaped function. IET Softw. 2022, 16, 214–232. [Google Scholar] [CrossRef]
- Pradhan, V.; Dhar, J.; Kumar, A.; Bhargava, A. An S-Shaped Fault Detection and Correction SRGM Subject to Gamma-Distributed Random Field Environment and Release Time Optimization; Springer: Berlin/Heidelberg, Germany, 2020; pp. 285–300. [Google Scholar]
- Pradhan, S.K.; Kumar, A.; Kumar, V. A Testing Coverage Based SRGM Subject to the Uncertainty of the Operating Environment. In Proceedings of the 1st International Online Conference on Mathematics and Applications, online, 1–15 May 2023; MDPI: Basel, Switzerland, 2023; p. 44. [Google Scholar]
- Pradhan, S.K.; Kumar, A.; Kumar, V. A New Software Reliability Growth Model with Testing Coverage and Uncertainty of Operating Environment. Comput. Sci. Math. Forum. 2023, 7, 44. [Google Scholar] [CrossRef]
- Pradhan, V.; Dhar, J.; Kumar, A. Testing coverage-based software reliability growth model considering uncertainty of operating environment. Syst. Eng. 2023, 26, 449–462. [Google Scholar] [CrossRef]
- Haque, M.A.; Ahmad, N. Software reliability modeling under an uncertain testing environment. Int. J. Model. Simul. 2023, 1–7. [Google Scholar] [CrossRef]
- Chatterjee, S.; Saha, D.; Sharma, A.; Verma, Y. Reliability and optimal release time analysis for multi up-gradation software with imperfect debugging and varied testing coverage under the effect of random field environments. Ann. Oper. Res. 2022, 312, 65–85. [Google Scholar] [CrossRef]
- Lee, D.H.; Chang, I.H.; Pham, H. Software Reliability Model with Dependent Failures and SPRT. Mathematics 2020, 8, 1366. [Google Scholar] [CrossRef]
- Kim, Y.S.; Song, K.Y.; Pham, H.; Chang, I.H. A Software Reliability Model with Dependent Failure and Optimal Release Time. Symmetry 2022, 14, 343. [Google Scholar] [CrossRef]
- Raheem, A.R.; Akthar, S.; Rafi, S.M. An Imperfect Debugging Software Reliability Growth Model: Optimal Release Problems through Warranty Period based on Software Maintenance Cost Model. Rev. Geintec 2021, 11, 4623–4631. [Google Scholar] [CrossRef]
- Minamino, Y.; Inoue, S.; Yamada, S. Change-point–based software reliability modeling and its application for software development management. In Recent Advancements in Software Reliability Assurance; CRC Press: Boca Raton, FL, USA, 2019; pp. 59–92. [Google Scholar]
- Ke, S.Z.; Huang, C.Y. Software reliability prediction and management: A multiple change-point model approach. Qual. Reliab. Eng. Int. 2020, 36, 1678–1707. [Google Scholar] [CrossRef]
- Saxena, P.; Kumar, V.; Ram, M. A novel CRITIC-TOPSIS approach for optimal selection of software reliability growth model (SRGM). Qual. Reliab. Eng. Int. 2022, 38, 2501–2520. [Google Scholar] [CrossRef]
- Kumar, V.; Saxena, P.; Garg, H. Selection of optimal software reliability growth models using an integrated entropy–Technique for Order Preference by Similarity to an Ideal Solution (TOPSIS) approach. In Mathematical Methods in the Applied Sciences; Wiley: Hoboken, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Garg, R.; Raheja, S.; Garg, R.K. Decision Support System for Optimal Selection of Software Reliability Growth Models Using a Hybrid Approach. IEEE Trans. Reliab. 2022, 71, 149–161. [Google Scholar] [CrossRef]
- Yaghoobi, T. Selection of optimal software reliability growth model using a diversity index. Soft Comput. 2021, 25, 5339–5353. [Google Scholar] [CrossRef]
- Zhu, M. A new framework of complex system reliability with imperfect maintenance policy. Ann. Oper. Res. 2022, 312, 553–579. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, C. Software reliability prediction using a deep learning model based on the RNN encoder–decoder. Reliab. Eng. Syst. Saf. 2018, 170, 73–82. [Google Scholar] [CrossRef]
- San, K.K.; Washizaki, H.; Fukazawa, Y.; Honda, K.; Taga, M.; Matsuzaki, A. Deep Cross-Project Software Reliability Growth Model Using Project Similarity-Based Clustering. Mathematics 2021, 9, 2945. [Google Scholar] [CrossRef]
- Li, L. Software reliability growth fault correction model based on machine learning and neural network algorithm. Microprocess. Microsyst. 2021, 80, 103538. [Google Scholar] [CrossRef]
- Banga, M.; Bansal, A.; Singh, A. Implementation of machine learning techniques in software reliability: A framework. In Proceedings of the 2019 International Conference on Automation, Computational and Technology Management (ICACTM), London, UK, 24–26 April 2019; IEEE: New York, NY, USA, 2019; pp. 241–245. [Google Scholar] [CrossRef]
- Wald, A. Sequential Analysis; Dover Publications: Mineola, NY, USA, 2004; ISBN 978-0-486-61579-0. [Google Scholar]
- Stieber, H.A. Statistical quality control: How to detect unreliable software components. In Proceedings of the Eighth International Symposium on Software Reliability Engineering, Albuquerque, NM, USA, 2–5 November 1997; IEEE Computer Society: Washington, DC, USA, 1997; pp. 8–12. [Google Scholar]
- Pham, H. System Software Reliability; Springer: London, UK, 2006. [Google Scholar]
- Pham, H.; Nordmann, L.; Zhang, X. A general imperfect-software-debugging model with S-shaped fault-detection rate. IEEE Trans. Reliab. 1999, 48, 169–175. [Google Scholar] [CrossRef]
- Pham, H. A new software reliability model with Vtub-shaped fault-detection rate and the uncertainty of operating environments. Optimization 2014, 63, 1481–1490. [Google Scholar] [CrossRef]
- Yamada, S.; Ohba, M.; Osaki, S. S-shaped reliability growth modeling for software fault detection. IEEE Trans. Reliab. 1983, 32, 475–484. [Google Scholar] [CrossRef]
- Goel, A.L.; Okumoto, K. Time-Dependent Error-Detection Rate Model for Software Reliability and Other Performance Measures. IEEE Trans. Reliab. 1979, 28, 206–211. [Google Scholar] [CrossRef]
- Yamada, S.; Ohba, M.; Osaki, S. S-shaped Software Reliability Growth Models and Their Applications. IEEE Trans. Reliab. 1984, 33, 289–292. [Google Scholar] [CrossRef]
- Yamada, S.; Tokuno, K.; Osaki, S. Imperfect debugging models with fault introduction rate for software reliability assessment. Int. J. Syst. Sci. 1992, 23, 2241–2252. [Google Scholar] [CrossRef]
- Pham, H.; Zhang, X. An NHPP Software Reliability Model and Its Comparison. Int. J. Reliab. Qual. Saf. Eng. 1997, 04, 269–282. [Google Scholar] [CrossRef]
- Chang, I.H.; Pham, H.; Lee, S.W.; Song, K.Y. A testing-coverage software reliability model with the uncertainty of operating environments. Int. J. Syst. Sci. Oper. Logist. 2014, 1, 220–227. [Google Scholar] [CrossRef]
- Song, K.Y.; Chang, I.H.; Pham, H. A software reliability model with a Weibull fault detection rate function subject to operating environments. Appl. Sci. 2017, 7, 983. [Google Scholar] [CrossRef]
- Li, Q.; Pham, H. A testing-coverage software reliability model considering fault removal efficiency and error generation. PLoS ONE 2017, 12, e0181524. [Google Scholar] [CrossRef]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Automat. Contr. 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Pillai, K.; Sukumaran Nair, V.S. A model for software development effort and cost estimation. IEEE Trans. Softw. Eng. 1997, 23, 485–497. [Google Scholar] [CrossRef]
- Anjum, M.; Haque, M.A.; Ahmad, N. Analysis and ranking of software reliability models based on weighted criteria value. Int. J. Inf. Technol. Comput. Sci. 2013, 5, 1–14. [Google Scholar] [CrossRef]
- Wood, A. Software Reliability Growth Models; TANDEM Technical Report; Tandem Computers: Cupertino, CA, USA, 1996; Volume 96. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Model | ||
|---|---|---|---|
| 1 | DPF1 [13] (dependent failure model 1) | ||
| 2 | DPF2 [14] (dependent failure model 2) | ||
| 3 | DS [32] (delayed S-shaped model) | ||
| 4 | GO [33] (by Goel–Okumoto) | ||
| 5 | IS [34] (inflection S-shaped model) | ||
| 6 | YID [35] (imperfect debugging model by Yamada) | ||
| 7 | PNZ [30] (by Pham–Nordmann–Zhang) | ||
| 8 | PZ [36] (by Pham–Zhang) | ||
| 9 | TC [37] (testing coverage model) | ||
| 10 | VTUB [31] (VTUB model) | ||
| 11 | NEW |
| Time | Failures | Cumulative Failures | Time | Failures | Cumulative Failures |
|---|---|---|---|---|---|
| 1 | 10 | 10 | 7 | 4 | 40 |
| 2 | 2 | 12 | 8 | 3 | 43 |
| 3 | 4 | 16 | 9 | 1 | 44 |
| 4 | 6 | 22 | 10 | 6 | 50 |
| 5 | 6 | 28 | 11 | 1 | 51 |
| 6 | 8 | 36 | 12 | 4 | 55 |
| Time | Failures | Cumulative Failures | Time | Failures | Cumulative Failures |
|---|---|---|---|---|---|
| 1 | 27 | 27 | 14 | 5 | 111 |
| 2 | 16 | 43 | 15 | 5 | 116 |
| 3 | 11 | 54 | 16 | 6 | 122 |
| 4 | 10 | 64 | 17 | 0 | 122 |
| 5 | 11 | 75 | 18 | 5 | 127 |
| 6 | 8 | 83 | 19 | 1 | 128 |
| 7 | 1 | 84 | 20 | 1 | 129 |
| 8 | 5 | 89 | 21 | 2 | 131 |
| 9 | 3 | 92 | 22 | 1 | 132 |
| 10 | 1 | 93 | 23 | 2 | 134 |
| 11 | 4 | 97 | 24 | 1 | 135 |
| 12 | 7 | 104 | 25 | 1 | 136 |
| 13 | 2 | 106 |
| No. | Criteria | |
|---|---|---|
| 1 | Mean-square error (MSE) [29] | |
| 2 | Predictive ratio risk (PRR) [29] | |
| 3 | Predictive power (PP) [29] | |
| 4 | Sum of absolute errors (SAE) [38] | |
| 5 | R-square () [39] | |
| 6 | Akaike’s information criterion (AIC) [40] | |
| 7 | Predicted relative variation (PRV) [41] | |
| 8 | Root-mean-square prediction error (RMSPE) [41] | |
| 9 | Mean absolute error (MAE) [42] | |
| 10 | Mean error of prediction (MEOP) [42] | |
| No. | Model | ||||||
|---|---|---|---|---|---|---|---|
| 1 | GO | 94.344 | 0.0733 | - | - | - | - |
| 2 | DS | 57.478 | 0.344 | - | - | - | - |
| 3 | IS | 65.781 | 0.206 | - | 1.293 | - | - |
| 4 | PNZ | 64.922 | 0.208 | 0.001 | 1.286 | - | - |
| 5 | PZ | 7.617 | 0.210 | 0.005 | 1.321 | - | 64.992 |
| 6 | TC | 0.005 | 1.075 | 2001.000 | 84.681 | 80.373 | - |
| 7 | VTUB | 5.0693 | 1.793 | 0.0181 | 0.0004 | 57.6685 | - |
| 8 | DPF1 | 55.893 | 0.004 | - | - | - | 0.548 |
| 9 | DPF2 | 56.058 | 0.008 | - | - | - | 0.093 |
| 10 | NEW | - | 1.490 | 43.371 | 2.098 | 83.496 | 17.472 |
| No. | Model | ||||||
|---|---|---|---|---|---|---|---|
| 1 | GO | 135.800 | 0.139 | - | - | - | - |
| 2 | DS | 124.630 | 0.357 | - | - | - | - |
| 3 | IS | 136.090 | 0.138 | - | 0.0001 | - | - |
| 4 | PNZ | 80.564 | 0.347 | 0.034 | 0.0001 | - | - |
| 5 | PZ | 0.0002 | 0.139 | 10,000 | 0.0001 | - | 135.800 |
| 6 | TC | 0.9920 | 0.716 | 0.468 | 4.740 | 335.580 | - |
| 7 | VTUB | 1.5416 | 0.70439 | 0.2943 | 0.6996 | 187.0933 | - |
| 8 | DPF1 | 136.830 | 0.001 | - | - | - | 0.724 |
| 9 | DPF2 | 137.416 | 0.007 | - | - | - | 4.477 |
| 10 | NEW | - | 6.571 | 0.480 | 0.484 | 232.760 | 0.010 |
| Model | MSE | PRR | PP | SAE | R2 | AIC | PRV | RMSPE | MAE | MEOP |
|---|---|---|---|---|---|---|---|---|---|---|
| GO | 4.0245 | 0.2932 | 0.1627 | 19.4170 | 0.9855 | 57.7076 | 58.6775 | 1.9120 | 1.9127 | 1.9417 |
| DS | 8.2096 | 7.3679 | 0.6177 | 20.9540 | 0.9704 | 69.6251 | 70.5950 | 2.6305 | 2.7236 | 2.0954 |
| IS | 4.0555 | 0.4815 | 0.1905 | 17.0520 | 0.9868 | 60.1451 | 61.5998 | 1.8126 | 1.8208 | 1.8947 |
| PNZ | 4.5632 | 0.4818 | 0.1906 | 17.0566 | 0.9868 | 62.1389 | 64.0786 | 1.8128 | 1.8210 | 2.1321 |
| PZ | 5.2153 | 0.4890 | 0.1917 | 17.0459 | 0.9868 | 64.1689 | 66.5934 | 1.8125 | 1.8210 | 2.4351 |
| TC | 5.6420 | 0.4307 | 0.1888 | 18.3723 | 0.9857 | 64.2519 | 66.6765 | 1.8906 | 1.8945 | 2.6246 |
| VTUB | 2.9516 | 0.0320 | 0.0296 | 12.6030 | 0.9925 | 59.5514 | 61.9760 | 1.3688 | 1.3704 | 1.8004 |
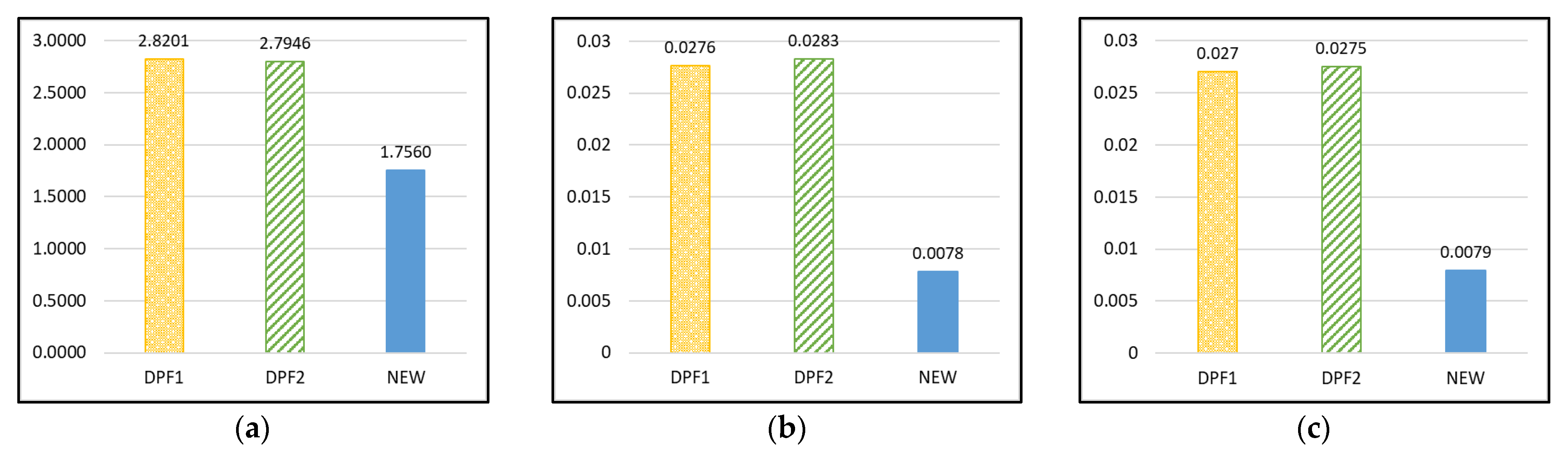
| DPF1 | 2.8201 | 0.0276 | 0.0270 | 12.7389 | 0.9919 | 58.6958 | 60.6354 | 1.4321 | 1.4321 | 1.5924 |
| DPF2 | 2.7946 | 0.0283 | 0.0275 | 12.7515 | 0.9919 | 58.6274 | 60.5670 | 1.4256 | 1.4256 | 1.5939 |
| NEW | 1.7560 | 0.0078 | 0.0079 | 9.0969 | 0.9956 | 57.1869 | 59.6115 | 1.0571 | 1.0571 | 1.2996 |
| Model | MSE | PRR | PP | SAE | R2 | AIC | PRV | RMSPE | MAE | MEOP |
|---|---|---|---|---|---|---|---|---|---|---|
| GO | 33.8121 | 0.4650 | 0.2567 | 119.2816 | 0.9658 | 122.0078 | 124.4456 | 5.6246 | 5.6897 | 5.1862 |
| DS | 134.5741 | 12.6273 | 1.1757 | 239.4995 | 0.8641 | 210.6486 | 213.0863 | 11.1425 | 11.3479 | 10.4130 |
| IS | 35.3621 | 0.4784 | 0.2614 | 118.4177 | 0.9658 | 123.8758 | 127.5324 | 5.6203 | 5.6905 | 5.3826 |
| PNZ | 9.8972 | 0.0324 | 0.0293 | 60.7847 | 0.9909 | 118.4497 | 123.3252 | 2.9414 | 2.9427 | 2.8945 |
| PZ | 38.8875 | 0.4653 | 0.2567 | 119.2828 | 0.9658 | 128.0082 | 134.1026 | 5.6246 | 5.6899 | 5.9641 |
| TC | 7.6738 | 0.0200 | 0.0201 | 47.3312 | 0.9933 | 116.9172 | 123.0116 | 2.5288 | 2.5288 | 2.3666 |
| VTUB | 7.7044 | 0.0223 | 0.0226 | 47.6464 | 0.9932 | 116.8753 | 122.9696 | 2.5337 | 2.5338 | 2.3823 |
| DPF1 | 27.9981 | 0.1921 | 0.3654 | 86.1298 | 0.9742 | 141.7791 | 146.6546 | 4.9481 | 4.9495 | 4.1014 |
| DPF2 | 29.5188 | 0.2080 | 0.3988 | 84.9504 | 0.9728 | 143.8089 | 148.6844 | 5.0737 | 5.0819 | 4.0453 |
| NEW | 7.2890 | 0.0163 | 0.0161 | 45.6681 | 0.9936 | 116.7360 | 122.8303 | 2.4646 | 2.4646 | 2.2834 |
| Parameter | (30 Cases) |
|---|---|
| = 1.490 × 0.01, = 1.490 × 0.02, = 1.490 × 0.03, …, = 1.490 × 0.28, = 1.490 × 0.29, = 1.490 × 0.30 | |
| = 43.371 × 0.01, = 43.371 × 0.02, = 43.371 × 0.03, …, = 43.371 × 0.28, = 43.371 × 0.29, = 43.371 × 0.30 | |
| = 17.472 × 0.01, = 17.472 × 0.02, = 17.472 × 0.03, …, = 17.472 × 0.28, = 17.472 × 0.29, = 17.472 × 0.30 |
| T | Data | Case 1 | Case 2 | Case 3 | Case 4 | Case 5 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| B | A | B | A | B | A | B | A | B | A | ||
| 1 | 10 | −91.6485 | 111.9572 | −40.7429 | 61.0500 | −23.7732 | 44.0777 | −15.2878 | 35.5887 | −10.1965 | 30.4928 |
| 2 | 12 | −63.4548 | 86.9885 | −25.8408 | 49.3760 | −13.3007 | 36.8385 | −7.0287 | 30.5700 | −3.2636 | 26.8096 |
| 3 | 16 | −37.5227 | 69.4399 | −10.7830 | 42.7032 | −1.8689 | 33.7940 | 2.5897 | 29.3425 | 5.2665 | 26.6746 |
| 4 | 22 | −27.5646 | 72.2082 | −2.6239 | 47.2618 | 5.6860 | 38.9424 | 9.8369 | 34.7784 | 12.3229 | 32.2753 |
| 5 | 28 | −24.5062 | 82.1106 | 2.1452 | 55.4461 | 11.0220 | 46.5477 | 15.4519 | 42.0875 | 18.1005 | 39.4000 |
| 6 | 36 | −23.4268 | 92.2987 | 5.5017 | 63.3539 | 15.1360 | 53.6925 | 19.9426 | 48.8478 | 22.8150 | 45.9266 |
| 7 | 40 | −22.9201 | 101.2277 | 8.1138 | 70.1761 | 18.4491 | 59.8111 | 23.6054 | 54.6134 | 26.6865 | 51.4790 |
| 8 | 43 | −22.6278 | 108.8320 | 10.2339 | 75.9518 | 21.1782 | 64.9767 | 26.6384 | 59.4733 | 29.9013 | 56.1548 |
| 9 | 44 | −22.4486 | 115.3179 | 11.9897 | 80.8607 | 23.4592 | 69.3597 | 29.1818 | 63.5929 | 32.6019 | 60.1160 |
| 10 | 50 | −22.3433 | 120.8964 | 13.4632 | 85.0707 | 25.3887 | 73.1133 | 31.3391 | 67.1181 | 34.8956 | 63.5040 |
| 11 | 51 | −22.2903 | 125.7391 | 14.7136 | 88.7159 | 27.0381 | 76.3591 | 33.1879 | 70.1642 | 36.8639 | 66.4301 |
| 12 | 55 | −22.2751 | 129.9798 | 15.7851 | 91.9001 | 28.4617 | 79.1912 | 34.7875 | 72.8201 | 38.5691 | 68.9802 |
| Continue | Continue | Continue | Continue | Continue | |||||||
| T | Data | Case 6 | Case 7 | Case 8 | Case 9 | Case 10 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| B | A | B | A | B | A | B | A | B | A | ||
| 1 | 10 | −6.8025 | 27.0931 | −4.3786 | 24.6624 | −2.5613 | 22.8372 | −1.14839 | 21.41546 | −0.0188 | 20.2760 |
| 2 | 12 | −0.7517 | 24.3033 | 1.0442 | 22.5140 | 2.3929 | 21.1729 | 3.44359 | 20.13081 | 4.2858 | 19.2981 |
| 3 | 16 | 7.0530 | 24.8990 | 8.3312 | 23.6337 | 9.2920 | 22.6877 | 10.04157 | 21.95486 | 10.6435 | 21.3715 |
| 4 | 22 | 13.9757 | 30.6019 | 15.1516 | 29.4019 | 16.0287 | 28.4971 | 16.70621 | 27.78849 | 17.2434 | 27.2169 |
| 5 | 28 | 19.8563 | 37.5968 | 21.1001 | 36.2971 | 22.0223 | 35.3105 | 22.72883 | 34.53135 | 23.2831 | 33.8961 |
| 6 | 36 | 24.7175 | 43.9644 | 26.0635 | 42.5480 | 27.0597 | 41.4705 | 27.82083 | 40.61732 | 28.4158 | 39.9195 |
| 7 | 40 | 28.7271 | 49.3734 | 30.1705 | 47.8530 | 31.2385 | 46.6962 | 32.05422 | 45.77975 | 32.6915 | 45.0298 |
| 8 | 43 | 32.0626 | 53.9257 | 33.5915 | 52.3165 | 34.7230 | 51.0923 | 35.58749 | 50.12279 | 36.2631 | 49.3296 |
| 9 | 44 | 34.8675 | 57.7810 | 36.4707 | 56.0957 | 37.6575 | 54.8140 | 38.56454 | 53.79936 | 39.2739 | 52.9697 |
| 10 | 50 | 37.2520 | 61.0773 | 38.9198 | 59.3262 | 40.1549 | 57.9950 | 41.09925 | 56.94153 | 41.8382 | 56.0806 |
| 11 | 51 | 39.2999 | 63.9232 | 41.0244 | 62.1147 | 42.3019 | 60.7404 | 43.27912 | 59.65319 | 44.0442 | 58.7651 |
| 12 | 55 | 41.0753 | 66.4027 | 42.8500 | 64.5438 | 44.1650 | 63.1314 | 45.17131 | 62.01465 | 45.9596 | 61.1028 |
| Continue | Continue | Continue | Continue | Continue | |||||||
| T | Data | Case 11 | Case 12 | Case 13 | Case 14 | Case 15 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| B | A | B | A | B | A | B | A | B | A | ||
| 1 | 10 | 0.9045 | 19.3416 | 1.6731 | 18.5610 | 2.3225 | 17.8985 | 2.8781 | 17.3287 | 3.3586 | 16.8329 |
| 2 | 12 | 4.9765 | 18.6179 | 5.5537 | 18.0521 | 6.0437 | 17.5744 | 6.4652 | 17.1661 | 6.8321 | 16.8132 |
| 3 | 16 | 11.1384 | 20.8971 | 11.5532 | 20.5046 | 11.9066 | 20.1753 | 12.2119 | 19.8959 | 12.4789 | 19.6564 |
| 4 | 22 | 17.6783 | 26.7445 | 18.0360 | 26.3461 | 18.3340 | 26.0045 | 18.5850 | 25.7072 | 18.7981 | 25.4452 |
| 5 | 28 | 23.7255 | 33.3645 | 24.0831 | 32.9097 | 24.3745 | 32.5130 | 24.6132 | 32.1613 | 24.8089 | 31.8448 |
| 6 | 36 | 28.8886 | 39.3332 | 29.2682 | 38.8293 | 29.5751 | 38.3874 | 29.8237 | 37.9933 | 30.0246 | 37.6362 |
| 7 | 40 | 33.1975 | 44.3994 | 33.6035 | 43.8570 | 33.9311 | 43.3811 | 34.1959 | 42.9560 | 34.4093 | 42.5704 |
| 8 | 43 | 36.7997 | 48.6630 | 37.2305 | 48.0897 | 37.5784 | 47.5868 | 37.8598 | 47.1377 | 38.0867 | 46.7305 |
| 9 | 44 | 39.8377 | 52.2728 | 40.2907 | 51.6738 | 40.6570 | 51.1487 | 40.9537 | 50.6801 | 41.1935 | 50.2556 |
| 10 | 50 | 42.4260 | 55.3578 | 42.8987 | 54.7370 | 43.2815 | 54.1932 | 43.5921 | 53.7084 | 43.8436 | 53.2694 |
| 11 | 51 | 44.6532 | 58.0200 | 45.1435 | 57.3804 | 45.5410 | 56.8205 | 45.8640 | 56.3218 | 46.1262 | 55.8706 |
| 12 | 55 | 46.5875 | 60.3381 | 47.0935 | 59.6822 | 47.5042 | 59.1084 | 47.8384 | 58.5976 | 48.1102 | 58.1359 |
| Continue | Continue | Continue | Continue | Continue | |||||||
| T | Data | Case 16 | Case 17 | Case 18 | Case 19 | Case 20 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| B | A | B | A | B | A | B | A | B | A | ||
| 1 | 10 | 3.7780 | 16.3971 | 4.1469 | 16.0107 | 4.4737 | 15.6653 | 4.7649 | 15.3544 | 5.0258 | 15.0727 |
| 2 | 12 | 7.1545 | 16.5056 | 7.4406 | 16.2352 | 7.6962 | 15.9959 | 7.9264 | 15.7829 | 8.1349 | 15.5922 |
| 3 | 16 | 12.7150 | 19.4497 | 12.9257 | 19.2699 | 13.1153 | 19.1127 | 13.2874 | 18.9747 | 13.4446 | 18.8529 |
| 4 | 22 | 18.9802 | 25.2116 | 19.1368 | 25.0014 | 19.2718 | 24.8106 | 19.3887 | 24.6360 | 19.4901 | 24.4751 |
| 5 | 28 | 24.9691 | 31.5563 | 25.0995 | 31.2903 | 25.2045 | 31.0426 | 25.2875 | 30.8097 | 25.3516 | 30.5891 |
| 6 | 36 | 30.1858 | 37.3084 | 30.3133 | 37.0037 | 30.4120 | 36.7175 | 30.4856 | 36.4460 | 30.5372 | 36.1863 |
| 7 | 40 | 34.5797 | 42.2158 | 34.7138 | 41.8856 | 34.8165 | 41.5748 | 34.8918 | 41.2794 | 34.9430 | 40.9961 |
| 8 | 43 | 38.2682 | 46.3561 | 38.4112 | 46.0076 | 38.5209 | 45.6795 | 38.6016 | 45.3676 | 38.6567 | 45.0686 |
| 9 | 44 | 41.3858 | 49.8655 | 41.5378 | 49.5027 | 41.6551 | 49.1613 | 41.7421 | 48.8371 | 41.8023 | 48.5264 |
| 10 | 50 | 44.0459 | 52.8664 | 44.2065 | 52.4919 | 44.3311 | 52.1400 | 44.4243 | 51.8059 | 44.4899 | 51.4860 |
| 11 | 51 | 46.3377 | 55.4568 | 46.5061 | 55.0725 | 46.6376 | 54.7117 | 46.7368 | 54.3695 | 46.8075 | 54.0421 |
| 12 | 55 | 48.3300 | 57.7128 | 48.5057 | 57.3202 | 48.6435 | 56.9519 | 48.7483 | 56.6029 | 48.8239 | 56.2693 |
| Continue | Continue | Continue | Continue | Continue | |||||||
| T | Data | Case 21 | Case 22 | Case 23 | Case 24 | Case 25 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| B | A | B | A | B | A | B | A | B | A | ||
| 1 | 10 | 5.2607 | 14.8159 | 5.4729 | 14.5805 | 5.6654 | 14.3638 | 5.8406 | 14.1631 | 6.0004 | 13.9767 |
| 2 | 12 | 8.3249 | 15.4207 | 8.4990 | 15.2658 | 8.6592 | 15.1253 | 8.8072 | 14.9975 | 8.9446 | 14.8808 |
| 3 | 16 | 13.5891 | 18.7453 | 13.7228 | 18.6499 | 13.8470 | 18.5651 | 13.9631 | 18.4897 | 14.0721 | 18.4226 |
| 4 | 22 | 19.5781 | 24.3260 | 19.6547 | 24.1871 | 19.7213 | 24.0570 | 19.7791 | 23.9346 | 19.8292 | 23.8192 |
| 5 | 28 | 25.3990 | 30.3786 | 25.4317 | 30.1766 | 25.4512 | 29.9817 | 25.4591 | 29.7928 | 25.4564 | 29.6089 |
| 6 | 36 | 30.5691 | 35.9361 | 30.5835 | 35.6935 | 30.5821 | 35.4568 | 30.5662 | 35.2248 | 30.5371 | 34.9965 |
| 7 | 40 | ||||||||||
| 12 | 55 | ||||||||||
| Reject | Reject | Reject | Reject | Reject | |||||||
| T | Data | Case 26 | Case 27 | Case 28 | Case 29 | Case 30 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| B | A | B | A | B | A | B | A | B | A | ||
| 1 | 10 | 6.1466 | 13.8027 | 6.2806 | 13.6396 | 6.4036 | 13.4863 | 6.5167 | 13.3417 | 6.6209 | 13.2047 |
| 2 | 12 | 9.0727 | 14.7739 | 9.1923 | 14.6758 | 9.3045 | 14.5856 | 9.4099 | 14.5023 | 9.5093 | 14.4254 |
| 3 | 16 | 14.1747 | 18.3628 | 14.2718 | 18.3095 | 14.3640 | 18.2621 | 14.4517 | 18.2199 | 14.5353 | 18.1823 |
| 4 | 22 | 19.8727 | 23.7098 | 19.9102 | 23.6060 | 19.9424 | 23.5071 | 19.9701 | 23.4128 | 19.9937 | 23.3227 |
| 5 | 28 | 25.4443 | 29.4293 | 25.4237 | 29.2535 | 25.3953 | 29.0810 | 25.3599 | 28.9113 | 25.3182 | 28.7442 |
| 6 | 36 | 30.4958 | 34.7708 | 30.4433 | 34.5472 | 30.3803 | 34.3251 | 30.3077 | 34.1038 | 30.2260 | 33.8831 |
| 7 | 40 | ||||||||||
| 12 | 55 | ||||||||||
| Reject | Reject | Reject | Reject | Reject | |||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, D.; Chang, I.; Pham, H. Study of a New Software Reliability Growth Model under Uncertain Operating Environments and Dependent Failures. Mathematics 2023, 11, 3810. https://doi.org/10.3390/math11183810
Lee D, Chang I, Pham H. Study of a New Software Reliability Growth Model under Uncertain Operating Environments and Dependent Failures. Mathematics. 2023; 11(18):3810. https://doi.org/10.3390/math11183810
Chicago/Turabian StyleLee, Dahye, Inhong Chang, and Hoang Pham. 2023. "Study of a New Software Reliability Growth Model under Uncertain Operating Environments and Dependent Failures" Mathematics 11, no. 18: 3810. https://doi.org/10.3390/math11183810
APA StyleLee, D., Chang, I., & Pham, H. (2023). Study of a New Software Reliability Growth Model under Uncertain Operating Environments and Dependent Failures. Mathematics, 11(18), 3810. https://doi.org/10.3390/math11183810