
Application of SVM and Chi-Square Feature Selection for Sentiment Analysis of Indonesia’s National Health Insurance Mobile Application



Abstract
:1. Introduction
1.1. Problem Statement
- How does sentiment analysis of user reviews for the Mobile JKN application using SVM classification and Chi-Square feature selection method work?
- How well does the model’s performance using SVM classification and the Chi-Square feature selection method fare in conducting sentiment analysis of user reviews for the Mobile JKN application?
- What is the optimal value of the regularized constant hyperparameter for the SVM method in sentiment analysis of user reviews for the Mobile JKN application, as determined by the F1-Score metric?
1.2. Model Limitation
- The method employed includes Chi-Square feature selection and the SVM classification method;
- The data used comprise reviews of the Mobile JKN application from the Indonesian Google Play Store, with a total of 7020 reviews collected through scraping between 1 February 2023, and 20 March 2023;
- Sentiment analysis is performed by categorizing review data into two classes: positive sentiment and negative sentiment;
- Sentiment analysis and computations are conducted using the Python programming language with an interpreter in the DataSpell IDE;
- Model performance improvement is based on the F1-Score metric with hyperparameter tuning for the regularized constant and the “linear” kernel.
1.3. Broad Objectives
- Obtain sentiment analysis results of user reviews for the Mobile JKN application;
- Attain model performance for sentiment analysis of user reviews for the Mobile JKN application;
- Determine the optimal value of the regularized constant hyperparameter for sentiment analysis of user reviews for the Mobile JKN application.
1.4. Contributions of This Work
- Advanced Framework Integration: This study pioneers the integration of Support Vector Machine (SVM) classification and Chi-Square feature selection within a unified framework. This innovative amalgamation aims to harness the strengths of both techniques, leading to improved sentiment analysis accuracy and robustness;
- Hyperparameter-Tuned Model: A significant contribution lies in the introduction of hyperparameter tuning, specifically optimizing the regularized constant, to tailor the SVM model’s performance for sentiment analysis. This strategic optimization, based on the F1-Score metric, showcases a commitment to refining model predictions for imbalanced datasets;
- Focused Domain Application: The applicability of this approach extends to user-generated content by employing a dataset of Mobile JKN application reviews. This application-focused approach addresses the nuances and challenges unique to sentiment analysis in the context of real-world user reviews;
- Clear Experimental Insights: This study provides a clear and detailed overview of the experimental methodology, encompassing text preprocessing, feature selection, model training, and performance evaluation. By elucidating each step, it offers insights into the mechanics and effectiveness of the approach;
- Model Limitations and Significance: Recognizing the boundaries of this work, a dedicated section on model limitations is presented. This candid exploration of potential constraints contributes to a well-rounded understanding of the scope and implications of the research.
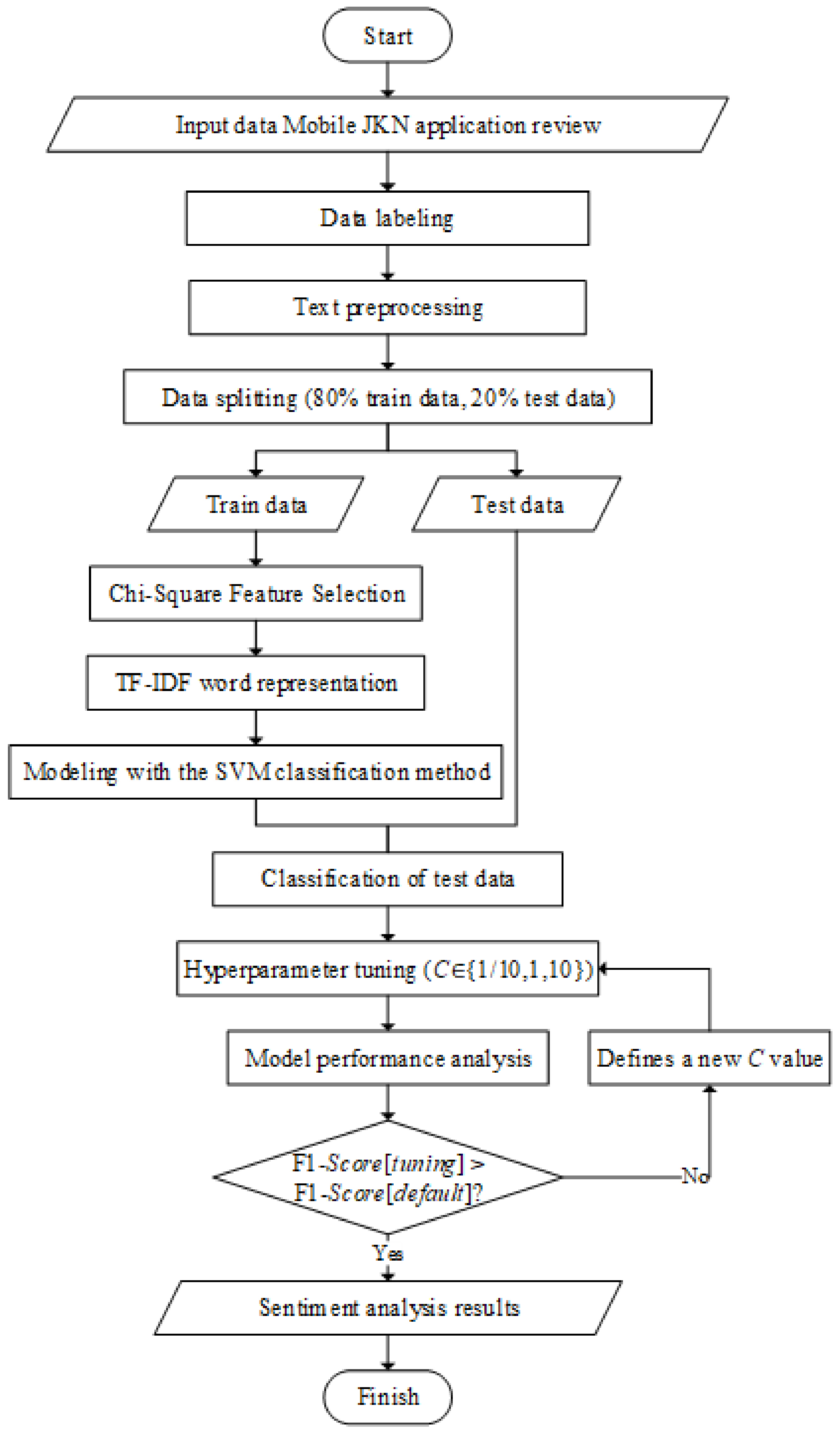
2. Materials and Methods
2.1. Data Collection
2.2. Text Preprocessing
- Case folding is the process of converting all letters to lowercase;
- Stopword filtering is the process of removing meaningless words. For example, words like “malah,” “adalah,” “di,” “ke,” and “yang” will be eliminated in this stage.
- Tokenizing is the process of splitting sentences into several words. Typically, each word is separated by a space delimiter, so in this case, a space delimiter will be used;
- Stemming is the process of extracting or reducing affixes to obtain the base form of words.
2.3. Chi-Square Feature Selection
2.4. TF-IDF Word Representation
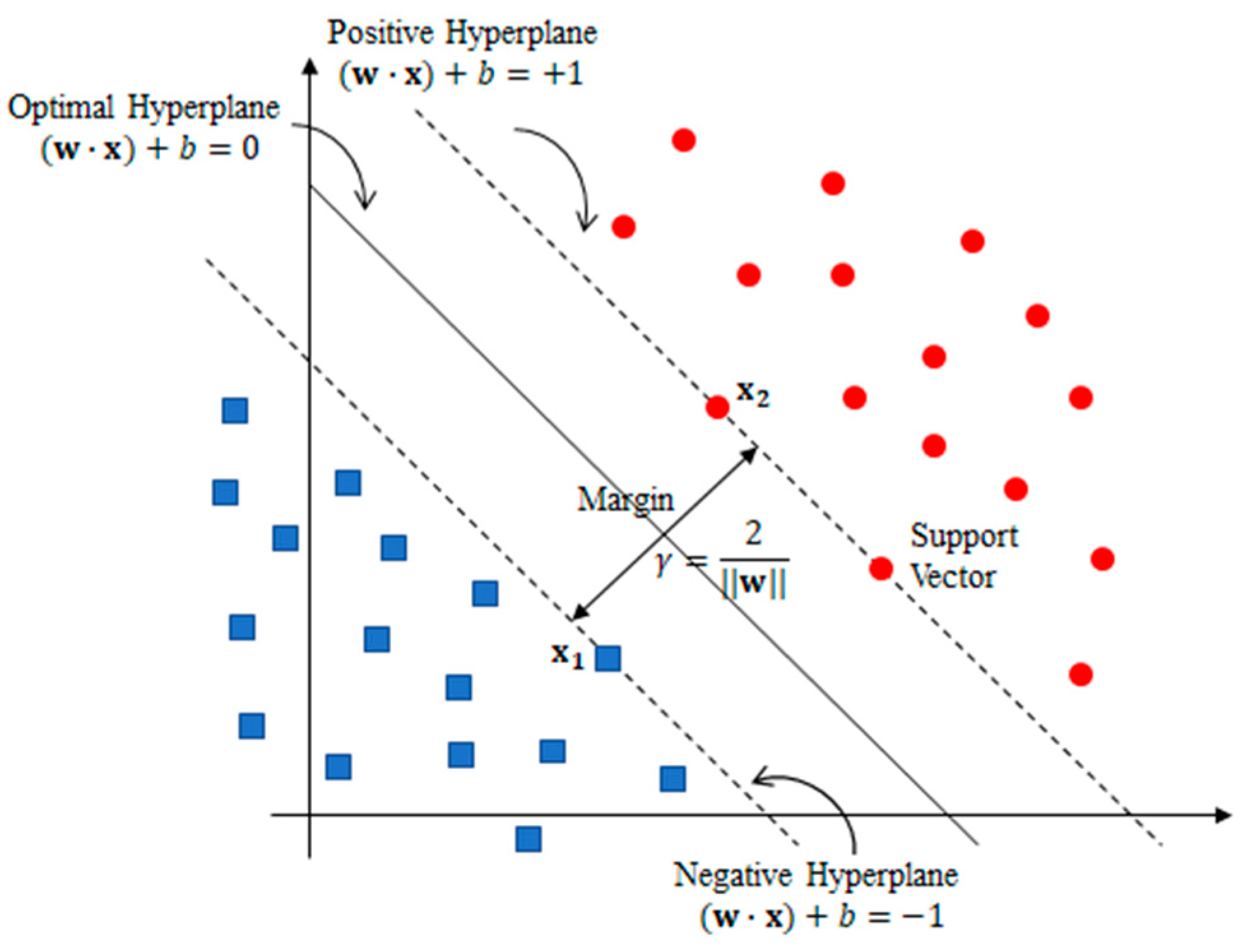
2.5. SVM Classification Model
2.6. Confusion Matrix
- True Positives (TPs) are the number of positive class data correctly predicted as positive;
- True Negatives (TNs) are the number of negative class data correctly predicted as negative;
- False Positives (FPs) are the number of negative class data wrongly predicted as positive;s
- False Negatives (FNs) are the number of positive class data wrongly predicted as negative.
2.7. Performance Metrics
- Precision
- 2.
- Recall
- 3.
- F1-Score
- 4.
- Accuracy
2.8. Hyperparameter Tuning
3. Results
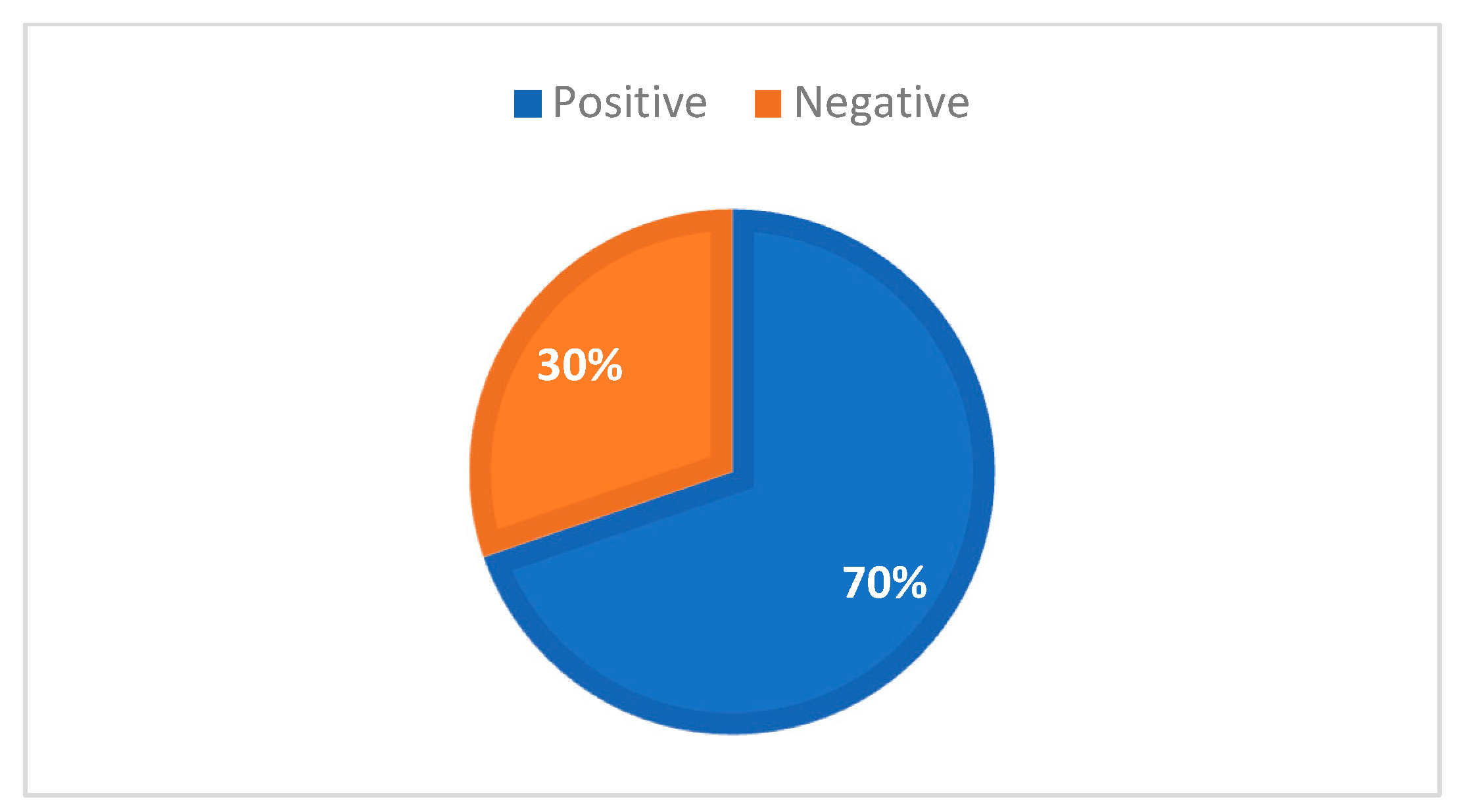
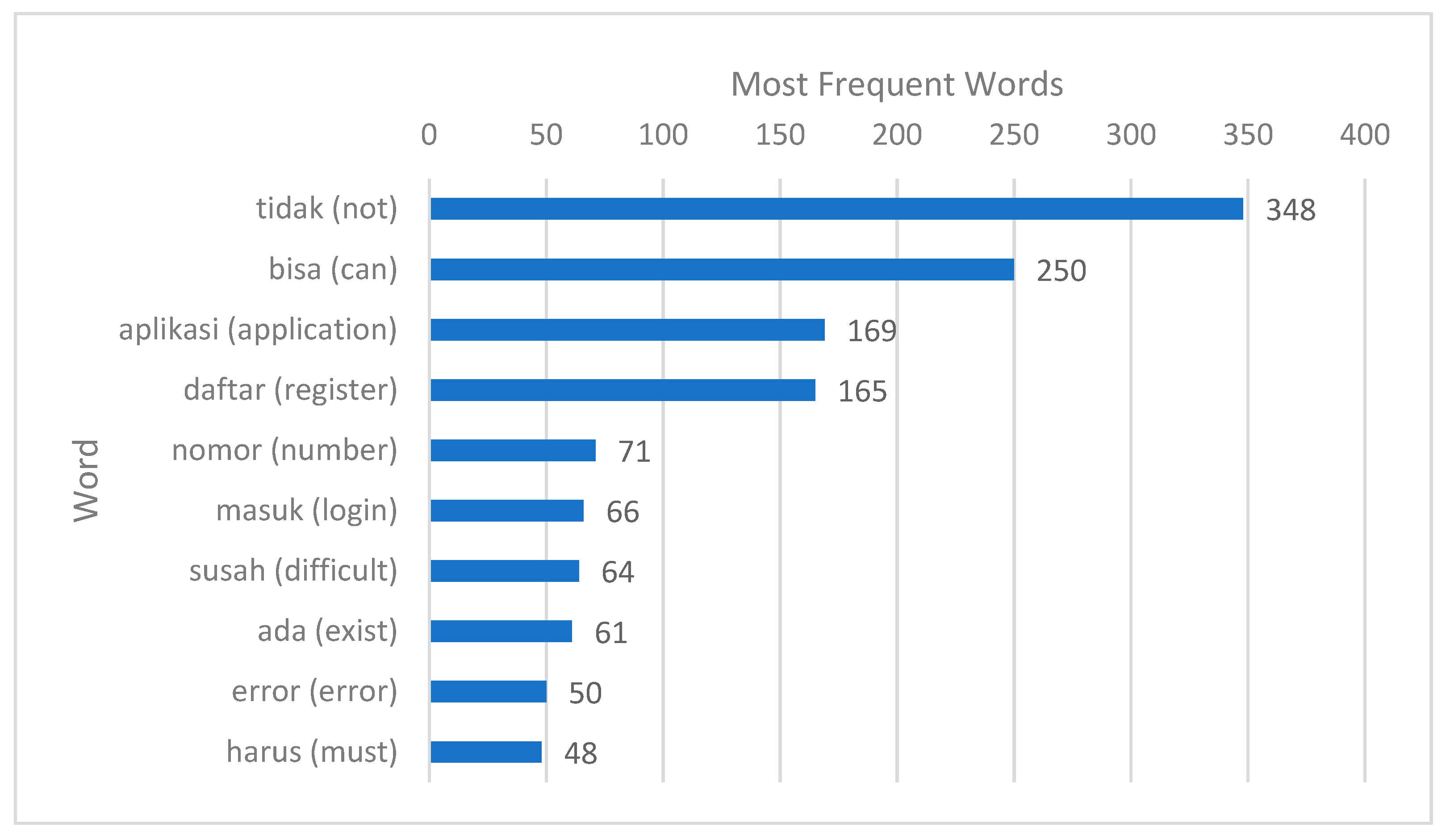
3.1. Data
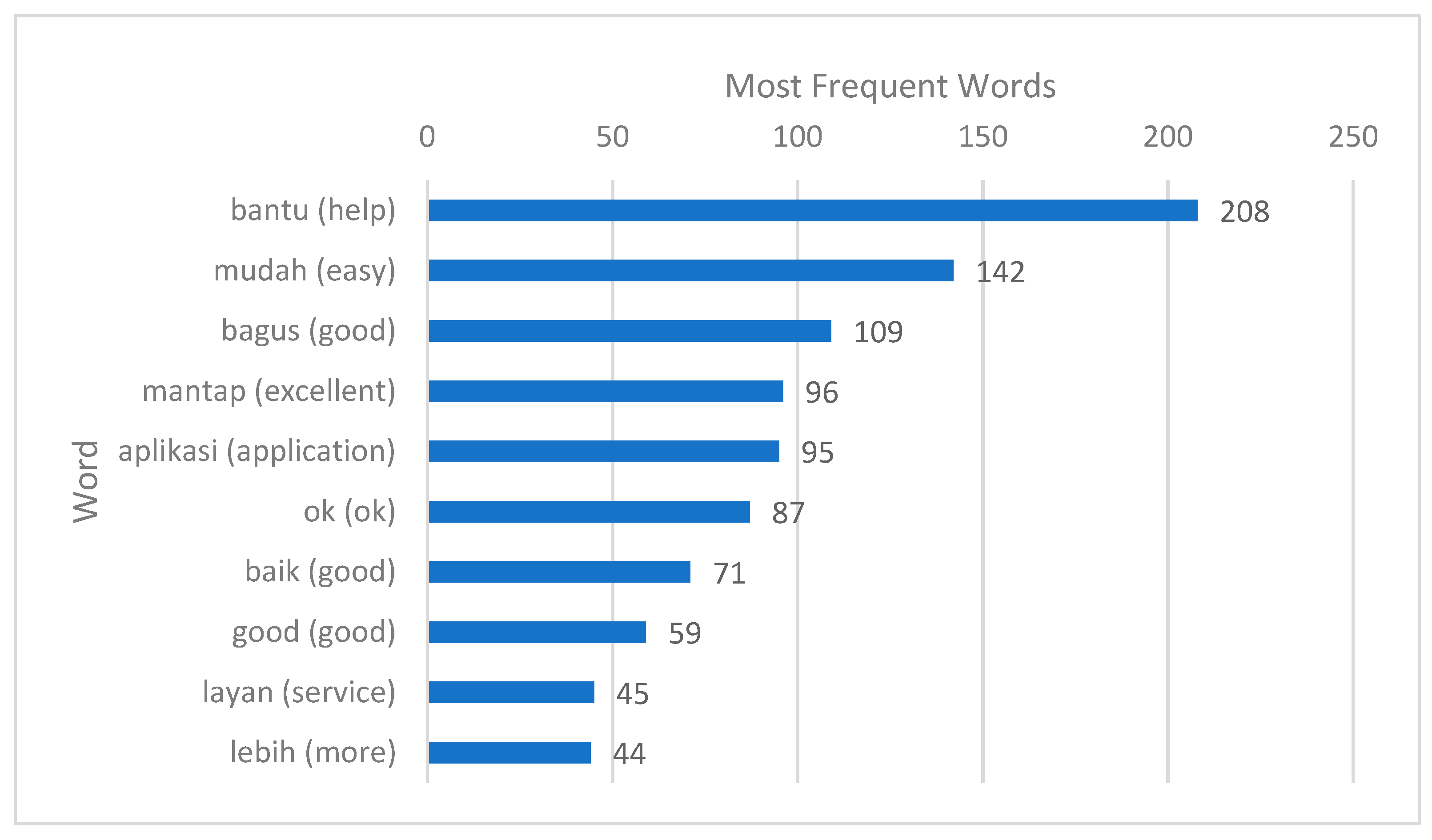
3.2. Preprocessed Data
3.3. Chi-Square Feature Selection
3.4. SVM Classification Model and Hyperparameter Tuning
3.5. Label Prediction
3.5.1. Positive Reviews Data
3.5.2. Negative Reviews Data
4. Computation Complexity Analysis
4.1. Data Preprocessing
- Time: 236.8210 s
- Memory: 119,472 bytes
4.2. Feature Selection
- Time: 68.3171 s
- Memory: 26,088 bytes
4.3. Word Representation
- All 2996 features:Time: 0.0346 sMemory: 48 bytes
- Selected 1000 Features:Time: 0.0317 sMemory: 48 bytes
4.4. Model Training
- All 2996 features:Time: 0.6502 sMemory: 48 bytes
- Selected 1000 Features:Time: 0.5037 sMemory: 48 bytes
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kementrian Kesehatan Republik Indonesia. Profil Kesehatan Indonesia Tahun 2021; Sibuea, F., Hardhana, B., Widiantini, W., Eds.; Kementerian Kesehatan Republik Indonesia: Jakarta, Indonesia, 2022. [Google Scholar]
- Agustina, R.; Dartanto, T.; Sitompul, R.; Susiloretni, K.A.; Achadi, E.L.; Taher, A.; Wirawan, F.; Sungkar, S.; Sudarmono, P.; Shankar, A.H.; et al. Universal Health Coverage in Indonesia: Concept, Progress, and Challenges. Lancet 2019, 393, 75–102. [Google Scholar] [CrossRef] [PubMed]
- Anam, K. Pandemi Dorong Inovasi Layanan Digital BPJS Kesehatan. Available online: https://news.detik.com/berita/d-5758142/pandemi-dorong-inovasi-layanan-digital-bpjs-kesehatan (accessed on 15 February 2023).
- Humas BPJS Kesehatan Ikuti Perkembangan Zaman, Mobile JKN Satu Genggaman Untuk Berbagai Kemudahan. Available online: https://www.bpjs-kesehatan.go.id/bpjs/post/read/2020/1671/Ikuti-Perkembangan-Zaman-Mobile-JKN-Satu-Genggaman-Untuk-Berbagai-Kemudahan (accessed on 3 March 2023).
- Nasukawa, T.; Yi, J. Sentiment Analysis: Capturing Favorability Using Natural Language Processing. In Proceedings of the 2nd International Conference on Knowledge Capture, Sanibel Island, FL, USA, 23–25 October 2003; pp. 70–77. [Google Scholar]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment Analysis Algorithms and Applications: A Survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef]
- Shaik, T.; Tao, X.; Dann, C.; Xie, H.; Li, Y.; Galligan, L. Sentiment Analysis and Opinion Mining on Educational Data: A Survey. Nat. Lang. Process. J. 2022, 2, 100003. [Google Scholar] [CrossRef]
- Wu, S.; Fei, H.; Ren, Y.; Ji, D.; Li, J. Learn from Syntax: Improving Pair-Wise Aspect and Opinion Terms Extractionwith Rich Syntactic Knowledge. arXiv 2021, arXiv:210502520. [Google Scholar]
- Tian, Y.; Chen, W.; Hu, B.; Song, Y.; Xia, F. End-to-End Aspect-Based Sentiment Analysis with Combinatory Categorial Grammar. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; pp. 13597–13609. [Google Scholar]
- Li, Z.; Zou, Y.; Zhang, C.; Zhang, Q.; Wei, Z. Learning Implicit Sentiment in Aspect-Based Sentiment Analysis with Supervised Contrastive Pre-Training. arXiv 2021, arXiv:211102194. [Google Scholar]
- Shi, W.; Li, F.; Li, J.; Fei, H.; Ji, D. Effective Token Graph Modeling Using a Novel Labeling Strategy for Structured Sentiment Analysis. arXiv 2022, arXiv:220310796. [Google Scholar]
- Fei, H.; Chua, T.-S.; Li, C.; Ji, D.; Zhang, M.; Ren, Y. On the Robustness of Aspect-Based Sentiment Analysis: Rethinking Model, Data, and Training. ACM Trans. Inf. Syst. 2022, 41, 1–32. [Google Scholar] [CrossRef]
- Huang, J.; Meng, Y.; Guo, F.; Ji, H.; Han, J. Weakly-Supervised Aspect-Based Sentiment Analysis via Joint Aspect-Sentiment Topic Embedding. arXiv 2020, arXiv:201006705. [Google Scholar]
- Li, B.; Fei, H.; Wu, Y.; Zhang, J.; Wu, S.; Li, J.; Liu, Y.; Liao, L.; Chua, T.-S.; Li, F.; et al. Diaasq: A Benchmark of Conversational Aspect-Based Sentiment Quadruple Analysis. arXiv 2022, arXiv:221105705. [Google Scholar]
- Fei, H.; Zhang, Y.; Ren, Y.; Ji, D. Latent Emotion Memory for Multi-Label Emotion Classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; 2020; Volume 34, pp. 7692–7699. [Google Scholar]
- Uysal, A.K.; Gunal, S. The Impact of Preprocessing on Text Classification. Inf. Process. Manag. 2014, 50, 104–112. [Google Scholar] [CrossRef]
- Şahin, D.Ö.; Klç, E. Two New Feature Selection Metrics for Text Classification. Autom. Časopis Za Autom. Mjer. Elektron. Račun. Komun. 2019, 60, 162–171. [Google Scholar] [CrossRef]
- Padurariu, C.; Breaban, M.E. Dealing with Data Imbalance in Text Classification. Procedia Comput. Sci. 2019, 159, 736–745. [Google Scholar] [CrossRef]
- Mantovani, R.G.; Rossi, A.L.D.; Alcobaça, E.; Vanschoren, J.; de Carvalho, A.C. A Meta-Learning Recommender System for Hyperparameter Tuning: Predicting When Tuning Improves SVM Classifiers. Inf. Sci. 2019, 501, 193–221. [Google Scholar] [CrossRef]
- Sari, E.D.N.; Irhamah, I. Analisis Sentimen Nasabah Pada Layanan Perbankan Menggunakan Metode Regresi Logistik Biner, Naïve Bayes Classifier (NBC), Dan Support Vector Machine (SVM). J. Sains Dan Seni ITS 2020, 8, D177–D184. [Google Scholar] [CrossRef]
- Mahendrajaya, R.; Buntoro, G.A.; Setyawan, M.B. Analisis Sentimen Pengguna Gopay Menggunakan Metode Lexicon Based Dan Support Vector Machine. KOMPUTEK 2019, 3, 52–63. [Google Scholar] [CrossRef]
- Cahyono, Y.; Unpam, T.I. Analisis Sentiment Pada Sosial Media Twitter Menggunakan Naïve Bayes Classifier Dengan Feature Selection Particle Swarm Optimization Dan Term Frequency. METODE 2017, 81, 67. [Google Scholar] [CrossRef]
- Septiana, R.D.; Susanto, A.B.; Tukiyat, T. Analisis Sentimen Vaksinasi Covid-19 Pada Twitter Menggunakan Naive Bayes Classifier Dengan Feature Selection Chi-Squared Statistic Dan Particle Swarm Optimization. J. SISKOM-KB Sist. Komput. Dan Kecerdasan Buatan 2021, 5, 49–56. [Google Scholar] [CrossRef]
- Luthfiana, L.; Young, J.C.; Rusli, A. Implementasi Algoritma Support Vector Machine Dan Chi Square Untuk Analisis Sentimen User Feedback Aplikasi. Ultim. J. Tek. Inform. 2020, 12, 125–126. [Google Scholar] [CrossRef]
- Pelayanan Peserta BPJS Kesehatan. Panduan Layanan Bagi Peserta JKN-KIS Tahun 2022; Humas BPJS Kesehatan: Jakarta, Indonesia, 2022. [Google Scholar]
- Bahri, S.; Amri, A.; Siregar, A.A. Analisis Kualitas Pelayanan Aplikasi Mobile JKN BPJS Kesehatan Menggunakan Metode Service Quality (SERVQUAL). Ind. Eng. J. 2022, 11, 12–18. [Google Scholar] [CrossRef]
- Alam, S.; Yao, N. The Impact of Preprocessing Steps on the Accuracy of Machine Learning Algorithms in Sentiment Analysis. Comput. Math. Organ. Theory 2019, 25, 319–335. [Google Scholar] [CrossRef]
- Putra, O.V.; Wasmanson, F.M.; Harmini, T.; Utama, S.N. Sundanese Twitter Dataset for Emotion Classification. In Proceedings of the 2020 International Conference on Computer Engineering, Network, and Intelligent Multimedia (CENIM), Surabaya, Indonesia, 17–18 November 2020; pp. 391–395. [Google Scholar]
- HaCohen-Kerner, Y.; Miller, D.; Yigal, Y. The Influence of Preprocessing on Text Classification Using a Bag-of-Words Representation. PLoS ONE 2020, 15, e0232525. [Google Scholar] [CrossRef] [PubMed]
- Amrullah, A.Z.; Anas, A.S.; Hidayat, M.A.J. Analisis Sentimen Movie Review Menggunakan Naive Bayes Classifier Dengan Seleksi Fitur Chi Square. J. Bumigora Inf. Technol. BITe 2020, 2, 40–44. [Google Scholar]
- Suharno, C.F.; Fauzi, M.A.; Perdana, R.S. Klasifikasi Teks Bahasa Indonesia Pada Dokumen Pengaduan Sambat Online Menggunakan Metode K-Nearest Neighbors Dan Chi-Square. J. Pengemb. Teknol. Inf. Dan Ilmu Komput. E-ISSN 2017, 2548, 964X. [Google Scholar] [CrossRef]
- Saraswati, N.W.S. Text Mining Dengan Metode Naïve Bayes Classifier Dan Support Vector Machines Untuk Sentiment Analysis. Univ. Udayana Tek. Elektro Denpasar Univ. Udayana 2011, 1, 45–48. [Google Scholar]
- Kraiklang, R.; Chueadee, C.; Jirasirilerd, G.; Sirirak, W.; Gonwirat, S. A Multiple Response Prediction Model for Dissimilar AA-5083 and AA-6061 Friction Stir Welding Using a Combination of AMIS and Machine Learning. Computation 2023, 11, 100. [Google Scholar] [CrossRef]
- Ariyanto, R.A.; Chamidah, N. Sentiment Analysis for Zoning System Admission Policy Using Support Vector Machine and Naive Bayes Methods. J. Phys. Conf. Ser. 2021, 1776, 12058. [Google Scholar] [CrossRef]
- Hadna, N.M.S.; Santosa, P.I.; Winarno, W.W. Studi Literatur Tentang Perbandingan Metode Untuk Proses Analisis Sentimen Di Twitter. In Proceedings of the Seminar Nasional Teknologi Informasi dan Komunikasi 2016, Yogyakarta, Indonesia, 18–19 March 2016; Volume 2016, pp. 57–64. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Arifin, N.; Enri, U.; Sulistiyowati, N. Penerapan Algoritma Support Vector Machine (SVM) Dengan TF-IDF N-Gram Untuk Text Classification. STRING Satuan Tulisan Ris. Dan Inov. Teknol. 2021, 6, 129–136. [Google Scholar] [CrossRef]
- Gifari, O.I.; Adha, M.; Hendrawan, I.R.; Durrand, F.F.S. Analisis Sentimen Review Film Menggunakan TF-IDF Dan Support Vector Machine. J. Inf. Technol. 2022, 2, 36–40. [Google Scholar] [CrossRef]
- Elgeldawi, E.; Sayed, A.; Galal, A.R.; Zaki, A.M. Hyperparameter Tuning for Machine Learning Algorithms Used for Arabic Sentiment Analysis. Informatics 2021, 8, 79. [Google Scholar] [CrossRef]
- Phongying, M.; Hiriote, S. Diabetes Classification Using Machine Learning Techniques. Computation 2023, 11, 96. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predict: Positive | Predict: Negative | |
|---|---|---|
| Actual: Positive | TP | FN |
| Actual: Negative | FP | TN |
| Sample Reviews | English Translation | Label |
|---|---|---|
| aplikasi nya susah, captcha untuk login ngk keluar2 | The application is hard to use and the captcha for login doesn’t appear. | Negative |
| G bisa update ...lelet tiap mlm | Cannot update… very slow every night. | Negative |
| Mempermudah masyarakt | Facilitate society | Positive |
| Bagus ada peningkatan | It’s good to see improvement. | Positive |
| Raw Reviews | Preprocessed Reviews |
|---|---|
| aplikasi nya susah, captcha untuk login ngk keluar2 | “aplikasi”, “susah”, “captcha”, “login”, “ngk”, “keluar” |
| G bisa update ...lelet tiap mlm | “tidak”, “bisa”, “update”, “lambat”, “mlm’ |
| Mempermudah masyarakt | “mudah”, “masyarakat” |
| Bagus ada peningkatan | “bagus”, “ada”, “tingkat” |
| No. | ||
|---|---|---|
| 1 | tidak | 3944.972542 |
| 2 | bisa | 2575.768594 |
| 3 | daftar | 2391.238341 |
| 4 | aplikasi | 1227.094684 |
| ⋮ | ⋮ | ⋮ |
| 2995 | putar | 0.000943121 |
| 2996 | aktip | 0.000943121 |
| C | TP | TN | FP | FN | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|---|---|
| 0.1 | 927 | 384 | 29 | 35 | 95.35% | 96.97% | 96.36% | 96.66% |
| 1 | 932 | 380 | 33 | 30 | 95.42% | 96.58% | 96.88% | 96.73% |
| 10 | 930 | 384 | 29 | 32 | 95.56% | 96.98% | 96.67% | 96.82% |
| 100 | 931 | 375 | 38 | 31 | 94.98% | 96.08% | 96.78% | 96.43% |
| Sample Reviews | English Translation | ActualLabel | Predicted Label |
|---|---|---|---|
| mantap,,semakin mudah…. | Great, it’s becoming easier… | positive | positive |
| Mantabbb, TPI sayang untuk perubahan faskesnya lama bgt harus nunggu 3 bulan 🤦 | Great, but it’s unfortunate that it takes a long time to wait for the change of healthcare facility, have to wait for 3 months 🤦. | positive | positive |
| Paket lengkap, segala nya jadi mudah tinggal klik klik klik, terima kasih BPJS | Complete package, everything becomes easy, just a few clicks, thank you BPJS. | positive | positive |
| Semoga lebih baek aja kedapnnya | Hopefully, the quality of their services improves. | positive | positive |
| Bagus | Good | positive | positive |
| ⋮ | ⋮ | ⋮ | ⋮ |
| Saya ngak bisa menambah kan anak saya lewat mobile JKN BG mana cara nya mohon informasi | I’m unable to add my child through Mobile JKN. Can you please provide me with information on how to do it? | negative | negative |
| Simple no ribet | Simple, not complicated. | positive | positive |
| kenapa sehabis di-update tidak bisa daftar antrian onlain di faskes pertama...?? | Why can’t I register for an online queue at the first healthcare facility after updating it? | negative | negative |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hokijuliandy, E.; Napitupulu, H.; Firdaniza. Application of SVM and Chi-Square Feature Selection for Sentiment Analysis of Indonesia’s National Health Insurance Mobile Application. Mathematics 2023, 11, 3765. https://doi.org/10.3390/math11173765
Hokijuliandy E, Napitupulu H, Firdaniza. Application of SVM and Chi-Square Feature Selection for Sentiment Analysis of Indonesia’s National Health Insurance Mobile Application. Mathematics. 2023; 11(17):3765. https://doi.org/10.3390/math11173765
Chicago/Turabian StyleHokijuliandy, Ewen, Herlina Napitupulu, and Firdaniza. 2023. "Application of SVM and Chi-Square Feature Selection for Sentiment Analysis of Indonesia’s National Health Insurance Mobile Application" Mathematics 11, no. 17: 3765. https://doi.org/10.3390/math11173765
APA StyleHokijuliandy, E., Napitupulu, H., & Firdaniza. (2023). Application of SVM and Chi-Square Feature Selection for Sentiment Analysis of Indonesia’s National Health Insurance Mobile Application. Mathematics, 11(17), 3765. https://doi.org/10.3390/math11173765