1. Introduction
The vehicle routing problem is an interesting and well-studied research topic due to its growing impact on real-world industrial processes [
1]. Well-planned vehicle routes can significantly reduce overall costs and resource requirements in the transportation sector. Simple optimization objectives, such as minimizing transportation distances or reducing fuel consumption by taking faster routes, can make a significant difference and result in highly efficient systems. However, since these objectives are often not sufficient, more advanced methods incorporate additional constraints. Some of these include balancing the workload among vehicles [
2], coordinating adjacent shifts [
3], avoiding traffic congestion [
4], and dynamically updating vehicle routes [
5]. The optimization objectives depend on the specific problem and customer requirements, and there are numerous different objectives that often need to be balanced [
6]. Furthermore, in such problems, we are often faced with different kinds of uncertainties that also need to be taken into account, and develop approaches that can work with them need to be developed [
7]. In addition to substantial financial benefits, effective route and shift planning can improve driver safety and job satisfaction, reducing the number of vehicles and minimizing the environmental impact. Therefore, companies whose business operations involve the transportation of goods have great interest in this topic to leverage the benefits of optimization.
A concrete example is the Ningbo port on the coast of the East China Sea, which holds the status of the world’s largest port in terms of cargo throughput. In 2021, the port handled 1.224 billion tons of cargo (
https://www.nbport.com.cn/gfww/, accessed on 13 July 2023). This figure represents a significant logistical challenge as such a large volume of cargo requires excellent organization and transportation planning. In addition to route planning, it is necessary to coordinate all related processes, such as vehicle preparation and maintenance, traffic updates, and vehicle location monitoring. At the same time, there is a great opportunity for cost savings as even small improvements in the system can lead to significant cost reductions overall. In such cases, it is crucial to minimize the resources consumed in transporting goods.
All of the above calls for the development of a system aimed at optimizing vehicle routing. The described problem is a well-known vehicle routing problem (VRP) that has been studied for over 60 years since it was first mentioned by Dantzig and Ramser [
8]. Over the years, VRP has been successfully integrated with other technologies to develop so-called “smart cities” and “smart ports” (
https://commission.europa.eu/eu-regional-and-urban-development/topics/cities-and-urban-development/city-initiatives/smart-cities_en, 13 July 2023). The idea behind such projects is to develop highly efficient systems that seek to optimize, among other things, the transportation of people and goods to increase the satisfaction and safety of citizens or employees. These systems utilize various technologies to collect as much data as possible, including GPS, radar and sensor technology, 5G networks, and Internet of Things (IoT)-connected technologies. Subsequently, through the analysis of big data, these data are transformed into valuable information used to assess transportation needs. A good vehicle routing algorithm forms the core of such a system and is essential for a successful end product. In this regard, there are different variants of VRP, depending on the specific constraints that the algorithm must consider, such as time windows (VRPTWs) [
9], time-dependent travel duration (TDVRP) [
10], pickup and deliveries (VRPPDs) [
11], fleets with electric vehicles [
12,
13], and many others [
14,
15,
16].
In the particular case of the Ningbo port, we are dealing with the open periodic vehicle routing problem with time windows (OPVRPTWs). The network of each maritime port consists of several surrounding nodes (cities) between which container transportation is required. This transportation from the origin location to the destination is constructed as a single task that has a start and end time within which the goods need to be transported (thus, the problem includes time windows). Furthermore, since the transportation tasks are specified across several periods (shifts) and in some shifts the vehicle does not need to return to the depot, it is an open and periodic problem. These additional properties introduce additional constraints that need to be considered when constructing a solution.
In order to deal with the previously described problem, we propose a novel variable neighborhood search (VNS) algorithm that uses several neighborhood structures from the literature and applies them in several layers during the execution, depending on whether the algorithm is focused on exploitation or exploration. Additionally, we introduce a tabu list into the algorithm to help the algorithm avoid areas of the search space that it already visited. Furthermore, to gain additional performance improvements, the neighborhood search is parallelized. We denote the resulting algorithm as VNTS and evaluate its performance on a set of real-world and artificially generated instances for OPVRPTWs based on the real-world logistics problem from the Ningbo port. Certain algorithm design choices are evaluated and the algorithm is compared to the state-of-the-art results from the literature. The experimental study demonstrates that the proposed algorithm achieves slightly better results than an existing algorithm from the literature, but in a significantly smaller amount of time.
The rest of the paper is organized as follows. The next section provides a short overview of the literature dealing with VRS, specifically with OPVRPTWs.
Section 3 provides the description of the problem under consideration.
Section 4 describes the proposed method used to solve the routing problem. The experimental setup is described in
Section 5, whereas the results of the executed experiments are summarized in
Section 6. Finally,
Section 7 concludes the paper and outlines possible future research directions.
2. Literature Review
VRP is of great interest due to the significant advantages it offers through the implementation of an effective system. The opportunity for resource savings attracts many researchers and industry leaders to explore and improve existing methods. This leads to a large number of research studies in this field, each taking different approaches due to the various variants of the problem and the different optimization objectives and constraints involved [
6,
17]. Since finding the optimal solution for the most challenging instances of this problem is extremely difficult (if not impossible) within a reasonable time frame, the challenge lies in evaluating what constitutes “good” solutions. However, the term “good” can have subjective meanings, especially in this context. Therefore, it is important to compare different approaches and understand the strengths and weaknesses of each. There is no universal approach that can solve all such problems in the best possible way (as stated in the “No Free Lunch” theorem).
The nature of the problem itself excludes an exact approach due to the large search space. Even in small instances, existing deterministic methods cannot provide high-quality solutions within a reasonable time [
18]. Each day requires the transportation of hundreds of containers, with their time windows spanning across several possible shifts [
19]. An exact, deterministic approach is only feasible for smaller problems or comparison purposes when time is not a crucial factor [
20,
21]. The reality is that such cases are in the minority, making it necessary to find more advanced approaches capable of solving real-world complex problems.
Therefore, evolutionary approaches have received significant attention throughout history as they can relatively successfully find “good enough” solutions within a reasonable time frame. However, these approaches also have limitations, particularly for very large instances, but their inefficiency is often highlighted as a significant drawback [
22]. Poorly implemented evolutionary algorithms can be highly inefficient if the search is not directed effectively, resulting in suboptimal solutions, despite having ample time available. If time is critical in problem-solving, we need an approach that can search the space of possible solutions relatively quickly and efficiently.
It has been shown that population-based approaches are not the most efficient for solving problems with a large search space since adding complexity (the number of solutions in one generation) to the system significantly slows down the algorithm [
18]. On the other hand, if time is not a crucial factor, slower but ultimately better solutions are more interesting. In this regard, population-based approaches can still be a good option depending on the complexity of the problem and the implementation. For example, refs [
23,
24] successfully implement genetic algorithms for solving simpler problems, while the authors of [
25,
26] implement ant colony algorithms for solving VRP. These algorithms are relatively effective in this context as they address smaller-scale problems that are less common in today’s world.
As for the initialization of the initial solution, there is a well-known technique called “insertion” that was introduced by Clarke and Wright [
27]. Over the years, other initialization techniques have been developed that are faster and simpler. It has been shown that a good initial solution does not necessarily result in a better final solution, so researchers often opt for the simplest and fastest initialization option to reduce the algorithm’s complexity [
18]. Efficiently initializing a good solution is, therefore, the foundation of a good system that can quickly find a “good enough” solution for the given problem. In addition, complexity is of utmost importance because there is constantly updated real-time information about the location of vehicles, and these systems often have graphical interfaces through which vehicles and routes are observed, requiring fast execution. Additionally, there may be a need to gradually update routes based on various situations, such as traffic congestion, road works, obstacles, etc. In [
28], the authors discuss the impact of complex constraints on the complexity of initialization for the general VRP case and propose an efficient insertion heuristic with a complexity of
and, in some rare cases,
. This is a significant improvement compared to the usual approach with a complexity of
. Reducing complexity offers exactly what was described earlier: efficient initialization and the possibility of iterative improvement using an evolutionary approach and/or local search if necessary.
Because of the previous reasons, recent research has dominantly applied various kinds of local search and variable neighborhood methods to solve various VRPs [
18,
29,
30]. This is also the case with the OPVRPTW problem considered in this paper. The problem of routing trucks in a maritime port based on the example of the Ningbo port was first considered in [
19]. The authors provide a formal definition of the newly proposed problem and also design a two-stage algorithm in order to solve the proposed problem. In the first stage, a simple initial solution method is used to construct the initial solution, which is then improved with a VNS algorithm in the second phase. The results demonstrate that the proposed algorithm achieved a performance improvement of 5–10% when compared to the results in practice, thus demonstrating the benefit of applying such approaches.
Within the scope of [
31], the neighborhood is examined, and path weights are updated as a measure of goodness to find better solutions to the traveling salesman problem in combination with a genetic algorithm. The neighborhood refers to solutions that can be obtained by making certain changes to the current solution. In the context of vehicle routing, these changes often involve destroying a certain number of routes and inserting the corresponding tasks at different locations within the solution. Additionally, smaller changes are possible, such as altering the order of tasks within a route or changing the location of a task to a different route. In [
32], an adaptive variable neighborhood search technique is used, and a set of solution destruction and repair operators that have proven successful are proposed to create the neighborhood. The obtained results demonstrate that the proposed algorithm can further improve the best solutions obtained for the problem. A bi-objective variant of the problem is investigated in [
33], in which the total travel distance and driver payment criteria are minimized. The authors propose the application of a hyper-heuristic approach to solve this problem variant, in which five heuristics with different levels of perturbations are used. The results outline that the algorithm is able to obtain Pareto fronts of good final quality, better than other state-of-the-art algorithms when tested on this problem. In [
18], a common variable neighborhood search technique is employed along with a more advanced search routing system. The algorithm examines neighboring states (solutions) and updates certain parameters based on them to guide further searches. If the neighboring states are promising, it indicates that the current solution is in a high-quality search space and that the algorithm continues searching in the same direction. However, if the neighboring states around the current one are of low quality, the search direction is changed to explore a sub-space of better quality. This approach has shown promise, although the large number of parameters requires careful tuning.
The existence of a large number of completely different algorithms that can relatively successfully solve variants of similar problems further confirms that there is no universal approach that efficiently solves all of these problems. However, numerous research studies and advancements in the field have led to more robust approaches that, through data analysis (e.g., the network for distributing goods, frequency of container transfers on specific routes, weather forecasts, road conditions, etc.), can gain valuable insights into the problem and adapt the approach and specific parameters to better fit the given problem. This increases the efficiency of the algorithm and ultimately leads to better final solutions.
3. Open Periodic Vehicle Routing Problem with Time Windows
3.1. Problem Description
The problem under consideration can be classified as an open periodic vehicle routing problem with time windows (OPVRPTWs) that is modeled based on a practical problem from the real world encountered at the Ningbo port, one of the largest ports in China [
19].
In the considered problem, a certain number of containers needs to be transported between cities within the network. Each container
i has a time window
associated with it, which defines the earliest time from which the container can be picked up from the source destination (
) and the latest that the container has to be delivered to the destination (
). The vehicle fleet owned by Ningbo port consists of 100 identical vehicles [
19] that can transport only one container at a time. Adhering to local labor laws, shifts for task execution are divided into two shift types, day and night shifts, each lasting 12 h. Therefore, the first shift of the day starts at 08:00 a.m., and the second shift starts at 08:00 p.m. The shifts are indexed in chronological order, with odd indices representing day shifts and even indices representing night shifts. The analysis of task deadlines has shown that the majority of these deadlines fall within day shifts. However, most tasks have a wide range of possible shifts, so it is possible to distribute tasks equally between day and night shifts. During these shifts, drivers carry out tasks by transporting containers from one city to another. It is important to note that vehicles do not return to the central warehouse at the end of the day shift; they only do so at the end of the night shift. Therefore, the idea when creating the route for the day shift is to construct a path that takes into account the next shift and ends at the node (city) where the next shift begins, thus making these two shift types a kind of unity. This reduces the proportion of so-called empty trips, during which vehicles do not carry cargo but only travel to the location that represents the source of the next task. Such parts of the route represent a significant cost since no work is performed within them; the driver only prepares the vehicle for the next task.
Since the total distance of cargo transportation is fixed (determined by the predefined tasks), the main goal of the problem is to minimize the proportion of empty trips. This is used as an indicator of solution quality and can be abbreviated as the
LDR (loaded distance rate), which is a commonly used measure in the logistics sector. If the cargo transportation distance is expressed by the measured
LD (loaded distance) and the distance of empty trips is expressed by the measured
UD (unloaded distance),
LDR can be calculated as follows:
Since this metric measures the proportion of the distance traveled with the load in the total traveled distance, it needs to be maximized. When presenting the results and comparing different methods, the LDR metric will be used to assess the quality of the results.
Therefore, individual tasks have time windows within which they must be completed, and vehicles must return to the warehouse at the end of every second shift. This means that this is an open problem of vehicle routing with time windows (OPVRPTWs). The described problem differs from the classical VRP because goods are transported between all nodes, not just from a central warehouse to other nodes. The problem has elements of pickup and delivery vehicle routing (VRP with PD), but it differs in that the vehicle’s capacity is only one container, and the vehicle can perform only one job at a time. (The vehicle never transports goods to two different destinations at the same time.) The analysis of specific problem instances has shown that the frequency of routes between all nodes is equal, which means that all nodes are equally important (except for vehicle storage, where the central warehouse is the only option). However, special attention should be paid to the node that connects the day shift with the night shift. As mentioned, in the ideal situation, the destination of the last task of the day shift is the same as the source of the first task of the night shift. This outcome is desirable because the shift change does not involve an empty trip, but it may not always be possible to achieve. In cases where such vehicle routing is not possible, the following approach is taken. If the driver of the day shift has time during their working hours to prepare the vehicle for the first task of the night shift, they will drive an empty vehicle from the destination of their last task to that node. If the driver cannot do this before the end of their working hours, they will leave the vehicle at the destination of their last completed task. The driver of the night shift will then have to perform an empty trip as the first part of their route to reach the source of their first task.
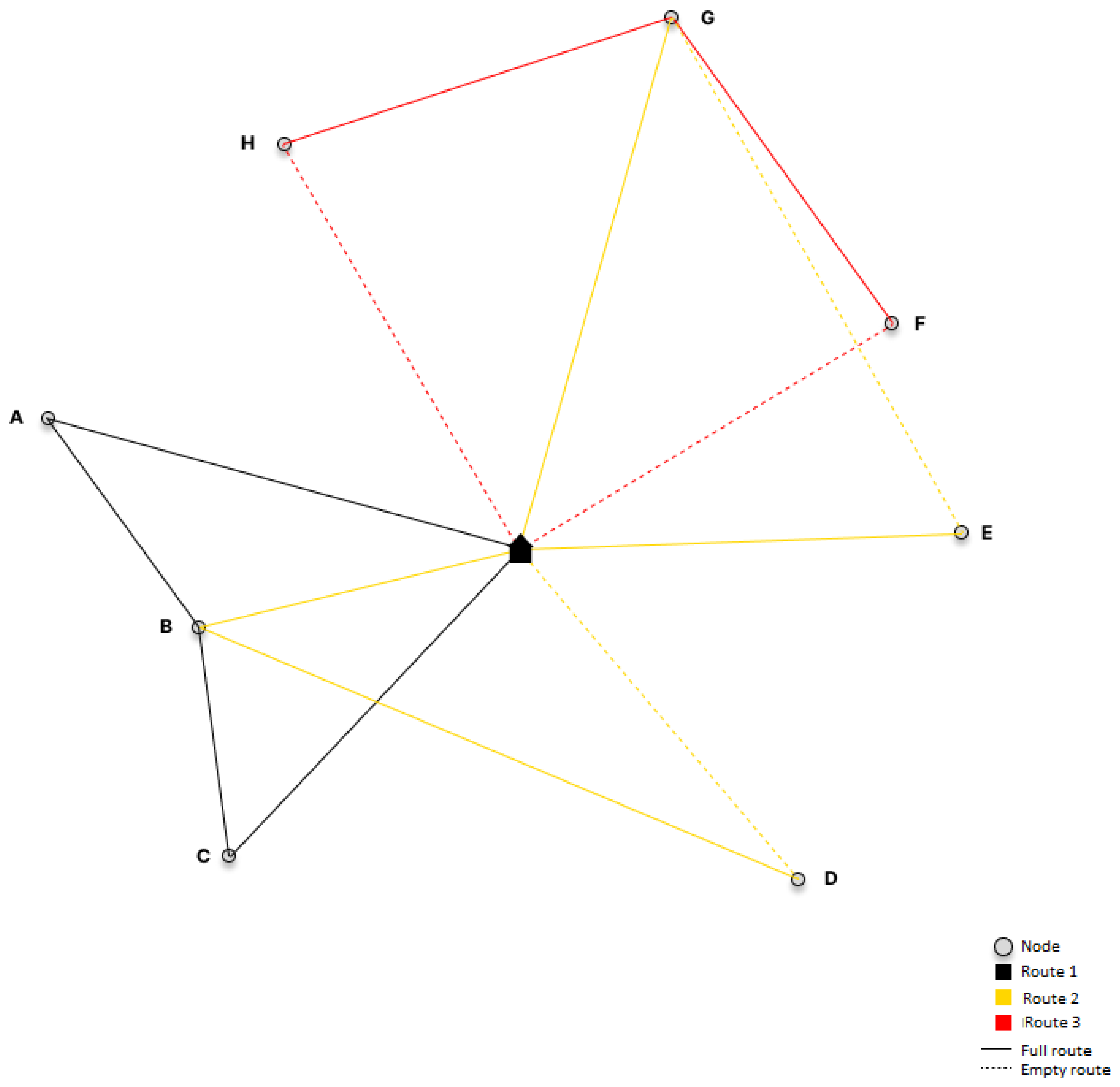
Figure 1 shows an example of created routes for three vehicles in two shifts. Each color represents a route performed by one vehicle. At the beginning of the day shift, the vehicle starts from the warehouse (located at the center) and performs tasks. When it is time for the shift change, the vehicle is taken over by the driver responsible for the night shift and continues with the tasks. At the end of their shift, the driver must return the vehicle to the warehouse. Let us consider the quality of each route. If we know that solid lines represent parts of routes where tasks are performed, and dashed lines represent empty trips during which vehicles do not perform any work, it is evident that the black route is the most efficient as it has no empty trips. On the other hand, the red route is not of good quality as it has a significant proportion of empty trips. Furthermore, as we can see, each node can be visited several times by vehicles, which is determined by the number of tasks that have that node as a source or destination.
Because vehicles return to the warehouse at the end of every second shift, the algorithm searches for routes rather than cycles, as in the case of the classical VRP. However, this problem is not the same as the school bus routing problem, where the day and night routes are identical. In fact, the two routes of a single vehicle belonging to the day shift and the next night shift do not have to be identical and usually will not be. Furthermore, in many VRP cases, the loading and unloading times of goods can be ignored since they are relatively short compared to the transportation time of goods. However, here it is not the case. The loading and unloading times of goods are significant and must be taken into account in the time calculations. The cities are relatively close, and the transportation time of goods is not significantly longer than the loading and unloading times.
3.2. Problem Definition
Table 1 presents the notations used to define the mathematical model, which was defined in [
18,
33]. The purpose of this definition is to clearly indicate all constraints and the optimization objective.
The number of vehicles K represents the size of a homogeneous fleet of vehicles available in each shift. Each individual vehicle can transport a maximum of one container at a time. Containers are transported between nodes N, and for each node, the loading and unloading times for one container are known. The days within the horizon of a specific instance are denoted as D and indexed sequentially starting from one. Each day has a day shift () and/or a night shift (), depending on the exact horizon boundary, i.e., whether the respective shift falls within the horizon where tasks T need to be performed. However, the boundary days may not have both shifts if they do not belong to the horizon where tasks need to be performed. Each shift has its start and end time, which is equal to the start and end time of the driver’s work shift assigned to that shift. Each task has a source and destination city and the earliest possible start time and latest time for starting the task.
It is important to note that if a vehicle arrives at the task’s source node before its time window, it must wait until
. Tasks that involve multiple containers are divided into multiple smaller tasks so that each individual task only requires the transportation of one container. This simplification facilitates the problem formulation and improves the efficiency of the proposed algorithm by making task allocation easier. Furthermore, the task execution time
includes loading at the source, transportation to the destination, and unloading at the destination. The travel time and distance between two nodes are represented by
and
, respectively. For the purpose of defining constraints, the start time of task
i is denoted by
. The travel time is expressed in minutes, which is important for calculating the feasibility of solutions, while travel distances are expressed in kilometers. However, the unit of distance can be ignored because the evaluation of the solution quality is based on the proportion of the transportation distance to the total sum of vehicle routes (transportation and empty trips). Finally, the binary decision variable
indicates whether a specific task with origin
i and destination
j is performed in shift
s. These notations are also used in [
18], with minor modifications.
Using the notation introduced above, we can now define the mathematical optimization problem that needs to be solved:
The objective function denoted as 1 signifies that the goal is to minimize the total route distance of all vehicles. Since the distance of cargo transportation is fixed and determined by the specific tasks that constitute the instance, the objective is to minimize the proportion of empty trips, in other words, to maximize the LDR while respecting all given constraints. Constraints 2 and 3 indicate that each task is performed exactly once and that all tasks are completed. Constraint 4 ensures that work on each task starts within its time window. Constraints 5 and 6 specify that the work of a single vehicle is performed within the time window of one shift. This is done by using to filter the corresponding starting or ending time of the shift to which the task is associated, and checking whether the starting and completion times of the task are within them. Constraint 7 states that the decision variable is binary, meaning it can only take values of one or zero. Again, in this OVRP, vehicles return to the warehouse at the end of every second shift. This is ensured by defining constraints 8 (for the day shift) and 9 (for the night shift). Additionally, these constraints ensure compliance with the constraints on the maximum number of vehicles in a shift.
The conclusion from the analysis and formal problem definition is that this is a nonlinear constrained problem with a vast search space. The size of the search space is determined by the length of the horizon
, the number of vehicles
, and the number of tasks
. Since the total number of possible routes in the solution is equal to
, and the number of task permutations is
, the size of the search space is
[
18]. Therefore, it is logical to conclude that a high-quality algorithm is necessary to find a relatively good solution by effectively navigating the search space.
4. Variable Neighborhood Search with Tabu List and Iterated Local Search
To solve the previously outlined OPVRPTW problem, we propose a novel variable neighborhood search (VNS) method that includes a tabu list and iterates a local search procedure, denoted as the variable neighborhood tabu search (VNTS). The parameters that control the behaviors of the algorithm are outlined in
Table 2. Some parameters are adaptable and change during the execution of the algorithm so that it can better adapt to the current conditions of the search. The parameters that change during the execution of the algorithm are the route and task multipliers, which control how much of the solution will be destroyed to construct a new solution, as well as the number of neighborhood layers and neighbors generated in each layer, the values of which must be within the interval specified by the user. The remaining parameters are fixed through the entire execution of the algorithm.
The general outline of the VNTS algorithm is given in Algorithm 1. At the start of the algorithm, the previously outlined parameters have to be set by the user. After that, and depending on the problem instance that is solved, an initial solution is constructed using a certain heuristic procedure. Selected potential procedures to construct the initial solution are described in
Section 4.1. After the parameter and solution initialization process, the main loop of the algorithm is executed until a given termination criterion is reached, which in this case will be the amount of the elapsed time.
In the main loop of the algorithm, the first operation is the adaptation of certain algorithm parameters, depending on the recent history of the search, in order to facilitate either intensification or diversification. The update process of the parameters is outlined in
Section 4.2. After the algorithm parameters have been updated, a neighborhood search is performed through several layers that control the intensity of operators that are used to perturb the solution. Depending on the current value of respective parameters, the algorithm will perform a broad or restricted search in the neighborhood of the current solution. Both the number of neighbors and the extent to which the current solution will be perturbed depend on the current neighborhood layer and the appropriate multiplier parameters. The number of neighbors (NN) that will be constructed in a certain layer is calculated as
where
i denotes the index of the current layer. Furthermore, the route and task numbers that are removed from the current solution when generating neighbors are
where
denotes the number of tasks that will be removed from the solution,
denotes the number of routes that will be removed, and
i denotes the index of the current neighborhood layer. In this way, each subsequent layer not only generates more neighbors, it also generates more distinct neighbors as it will introduce larger perturbations in the current solution. Based on these parameters, the neighborhood of the current solution is generated as explained in
Section 4.3.
Out of the generated neighborhood, the best solution that is not in the tabu list is selected. This solution is then set as the current solution since it was found to be better to accept every new solution rather than accepting only better solutions. In this way, the algorithm has more of a chance to escape the local optima and the algorithm introduces more diversity in its search process. In the final step, an additional local search procedure, described in
Section 4.4, is applied to the current solution to further intensify the search. The complexity of one iteration of the algorithm in the notion of generated neighbors is equal to
, where
L is the number of layers and
N represents the number of neighbors generated in each iteration. However, as the number of layers and neighbors is adaptable during the algorithm execution, this can affect the amount of the computation performed in the individual iterations and is not constant during the entire execution of the algorithm.
| Algorithm 1 VNTS algorithm outline |
|
1: | ▹ Parameter initialization |
|
2: | ▹ Initialise starting solution |
|
3: | ▹ Iteration counter |
|
4: | ▹ Iteration of last improvement |
|
5: while do |
| 6:
| ▹ Adjust current parameter values |
|
7: while do |
| 8: |
|
9: | ▹ Number of neighbors to generate
|
|
10: | ▹ Number of tasks to remove |
|
11: | ▹ Number of routes to remove |
|
12: |
|
13: for do | ▹ Find the best neighbor not in the tabu list |
|
14: if && ! then |
|
15: |
|
16: end if |
|
17: end for |
|
18: if then | ▹ Determine if solution improved or not |
|
19: |
|
20: end if |
|
21: | ▹ Accept the neighbor and add it to the tabu list |
|
22: |
|
23: end while |
|
24: | ▹ Perform additional local search for intensification |
|
25: end while |
|
26: return Best found solution
|
4.1. Solution Initialization
The initialization of the initial feasible solution is the first step of the algorithm. Several initialization types are well-known in this field. However, it has been shown that this aspect of the algorithm is not necessarily crucial because a better initial solution does not necessarily lead to a better final solution, so the fastest or simplest method of initialization is usually chosen. However, as mentioned, the complexity of the approach and the quality of the quickly generated solution are important aspects of today’s systems, so numerous initialization methods have been tested. First, the Clarke–Wright initialization method was tested, which assigns one route to each vehicle and then attempts to reduce the number of routes by merging existing routes in a way that maximally improves routing (greedy approach). This approach is well-known and frequently used in the literature. This paper will not examine it in more detail because it has been found to be slower than other methods and the obtained solution tends to get stuck in a local optimum.
A new type of initialization is proposed that creates cycles instead of routes. The method considers each daily and the following nightly shift as a whole and creates a route for that unit. This approach still respects all daily constraints (it is trivial to divide such a route into a daily and nightly shift), but it significantly simplifies the implementation and the search space exploration. Additionally, this approach implicitly aims to minimize the proportion of empty paths between the mentioned two shift types, which further enhances the quality of the solution. Furthermore, it is required to define in which order the tasks are selected in the initialization process. Here, we use three heuristic rules:
Urgency-based insertion heuristic (UBIH)—The initialization that first assigns tasks with the earliest deadlines.
Width-based insertion heuristic (WBIH)—The initialization method that first assigns tasks with the narrowest time windows.
Random shuffle insertion heuristic (RSIH)—The initialization that assigns tasks in random order.
During the insertion of each task, it deliberately does not place the task in the optimal position to avoid becoming stuck in the local optimum. All mentioned initialization methods result in feasible solutions. Although it is possible to generate higher-quality initial solutions, it was not done so because it was found that good initial solutions do not necessarily lead to better final solutions. Moreover, high-quality initial solutions can quickly become trapped in a local optimum. Therefore, the priority is the speed of initialization while respecting the constraints.
4.2. Parameter Update
In each iteration of the algorithm, some parameters are updated based on the state of the search. The procedure by which the parameters are updated is outlined in Algorithm 2. In the case that the number of iterations without improvement is larger than the threshold specified by the incumbent improvement parameter (IM), the algorithm is likely stuck in the local optima, i.e., stagnation is detected. Therefore, the parameters are adjusted in a way to facilitate diversification, i.e., to explore the search for a wider region of solutions. First of all, the number of neighborhood layers is incremented if it is still lower than the allowed maximum value. Furthermore, the multipliers for task and route removal are also incremented, which will mean that a larger portion of the current solution is destroyed, thus facilitating more diversification in the newly created neighbors. However, this is done only if a certain number of iterations has elapsed since the last diversification, which is controlled by the diversification period (DP) parameter.
| Algorithm 2 Parameter update procedure |
| 1: Input:parameters P, current iteration iter, iteration of last improvement last_improve |
|
2: if && then | ▹ If stagnation was detect |
|
3: |
|
4: |
|
5: |
|
6: |
|
7: | ▹ Store when the last diversification happened |
|
8: else if then | ▹ If improvement was detected |
|
9: |
|
10: |
|
11: |
|
12: |
|
13: end if |
On the other hand, when an improvement in the solution is observed, the route and task multipliers are reset to 1. With this, the perturbations in the solution are again smaller; therefore, the goal is again to search for a closer neighborhood to the current solution. Furthermore, the number of layers in the neighborhood search is decremented and the tasks are once again inserted into the routes optimally. With this, it reduces the number of neighbors that will be examined in each iteration. In this way, the algorithm balances between the exploration and exploitation of the search space so that when good solutions are found, only a very close neighborhood near to the current solution is examined, whereas in cases when no improvement is observed for a longer time, the search area is expanded, and more distant areas to that of the current solution are investigated.
4.3. Neighborhood Generation and Search
In each iteration of the algorithm, a certain number of neighbors is constructed. The neighbors are created through several layers, where these layers control the number of neighbors being generated and the intensity of modifications that are applied to the current solution. As such, a smaller number of neighbors with minor modifications is introduced in the earlier layers, whereas more neighbors with larger modifications are generated in later layers. The motivation for this is to first start the search in the vicinity of the current solution and gradually expand it to solutions that are further away. Each layer controls how many routes and tasks will be removed from the solution, by increasing the values of the corresponding parameters in each subsequent layer. For example, this means that in the second layer, these parameters will be two times larger than in the first one, or that in the third layer, they will be three times larger, and so on. This is done by multiplying the route and task multiplier parameters with the index of the current layer, as outlined in Algorithm 1. With this, it is possible to search over a wider range of the solution space, thus facilitating diversification. During the neighborhood search in each of the layers, all neighbors are collected in the set and at the end of the neighborhood search in this layer, the best solution not contained in the tabu list is selected. The selected solution is used to update the current solution and is also added to the tabu list to prevent the search from revisiting this solution in the immediate future.
The procedure for generating neighbors from the current solution is outlined in Algorithm 3. This procedure creates the required number of neighbors from the current solution by using different operators that are outlined in
Table 3. The first two sets of operators outlined in the table are tasked with the destruction of a solution, i.e. with the removal of certain parts of the solution. The first group of operators removes a selected route from the solution, whereas the second group removes a selected task from the solution. Since the first group of operators is more destructive, it is applied only in cases when the algorithm is directed toward diversification, as it will make large changes to solutions. The second group of operators is always applied as it removes only a single task and, thus, introduces small changes to the solution.
| Algorithm 3 Neighborhood generation procedure |
| 1: Input:current solution S, parameters P |
|
2: |
| 3: | ▹ Empty set of neighbors |
|
4: while do |
|
5: |
|
6: if then | ▹ Remove routes only when diversification is performed |
|
7: |
|
8: while do |
|
9: |
|
10: |
| 11: end while |
|
12: end if |
|
13: |
|
14: while do | ▹ Tasks are always removed from the solution |
|
15: |
|
16: |
|
17: end while |
|
18: | ▹ Reinsert the removed tasks into the solution |
|
19: | ▹ add the generated neighbor |
|
20: end while |
|
21: return neighborhood
|
In both cases, five operators are used, depending on how the routes or tasks that should be removed from the solution are selected. For the first group of operators, these include selecting a random route, the longest or shortest route, and the route that is the most full or most empty, in the sense that it contains the lowest or highest percentage of empty travels within it. In the second group of operators, the task can be selected either randomly from all routes or from the shortest route, the most costly or least costly task in the sense that it leads to the largest or lowest increase in the LDR, and the most disconnected task that is not connected with other tasks and is further away from them. Each time a route or task needs to be removed from the solution, one of the previously outlined operators is randomly selected to determine which task or route will be removed. The task and route numbers that will be removed are defined by the and parameters, which are controlled by the current layer and the multipliers defined for the task and route removal.
The third group of operators selects how the removed tasks are inserted back into the solution to reconstruct a complete solution. The tasks can be inserted back into the solution either randomly or at the optimal place. The optimal insertion strategy inserts the tasks at the position that leads to the highest increase in the LDR metric. In any case, insertion operators always insert tasks into a feasible position. If no such position exists, a new route is constructed only with that task to ensure the feasibility of solutions.
The required neighbors that need to be generated are specified by the parameter, which again depends on the current layer. When the required neighbors are generated, the set of all neighbors created during the search is returned as the result.
4.4. Local Search
The final step in each iteration of the algorithm is the execution of an additional local search on the current solution. Since it is possible that after the neighborhood search the current solution is replaced by a solution with worse quality, it is useful to improve it before searching through its neighborhood in the next iteration. The general outline of the local search procedure is outlined in Algorithm 4. This local search procedure is aimed exclusively at improving the current solution, so it uses a slightly different strategy compared to the one that is used at the beginning of each iteration. In the local search, a certain number of iterations are performed and in each iteration, a neighbor is created. The neighbor is created by always applying both route and task removal operators from
Table 3. However, in this case, only the operator that removes empty routes is applied from the first group, as well as only operators that remove disconnected or costly tasks (collectively denoted as expensive tasks). The reason for this is to try and remove parts of the solution that can be considered inefficient and whose modifications could potentially lead to better solutions. Finally, the tasks are inserted using only the greedy strategy that attempts to place them at the “optimal” place in the solution. This local search can be considered greedy as it tries to insert the tasks in the best possible places. The procedure is repeated until there is no improvement in the quality of the solution in several consecutive iterations. The final solution is returned and becomes the current solution of the algorithm, which is used in the next iteration to generate the neighborhood. Since the local search procedure accepts only a better solution than the current one, the solution it returns will either be better than the starting solution or the starting solution itself if no better solutions are found.
| Algorithm 4 Local search procedure |
|
1: Input: current solution S, parameters P |
|
2: |
|
3: |
|
4: | ▹ Number of iterations that elapsed since the last improvement |
|
5: while do |
| 6: |
|
7: |
| 8: |
▹ Insert the tasks into the optimal places |
|
9: if then | ▹ Count iterations without improvement for termination |
|
10: |
|
11: |
|
12: else |
|
13: |
|
14: end if |
|
15: end while |
|
16: return |
7. Conclusions
This study deals with the OPVRPTW that was inspired by a real-world transportation problem found in the Ningbo port. Due to the large volume of goods being transported through the port, it is important to design solution methods that can efficiently obtain good quality solutions for the considered problem. For that reason, we propose the VNTS algorithm to efficiently solve the considered problem. The algorithm searches through several neighborhood layers using various operators and integrates a tabu list to avoid searching over already-visited areas in the solution space. Furthermore, the algorithm uses a simple parallelization to further improve its performance.
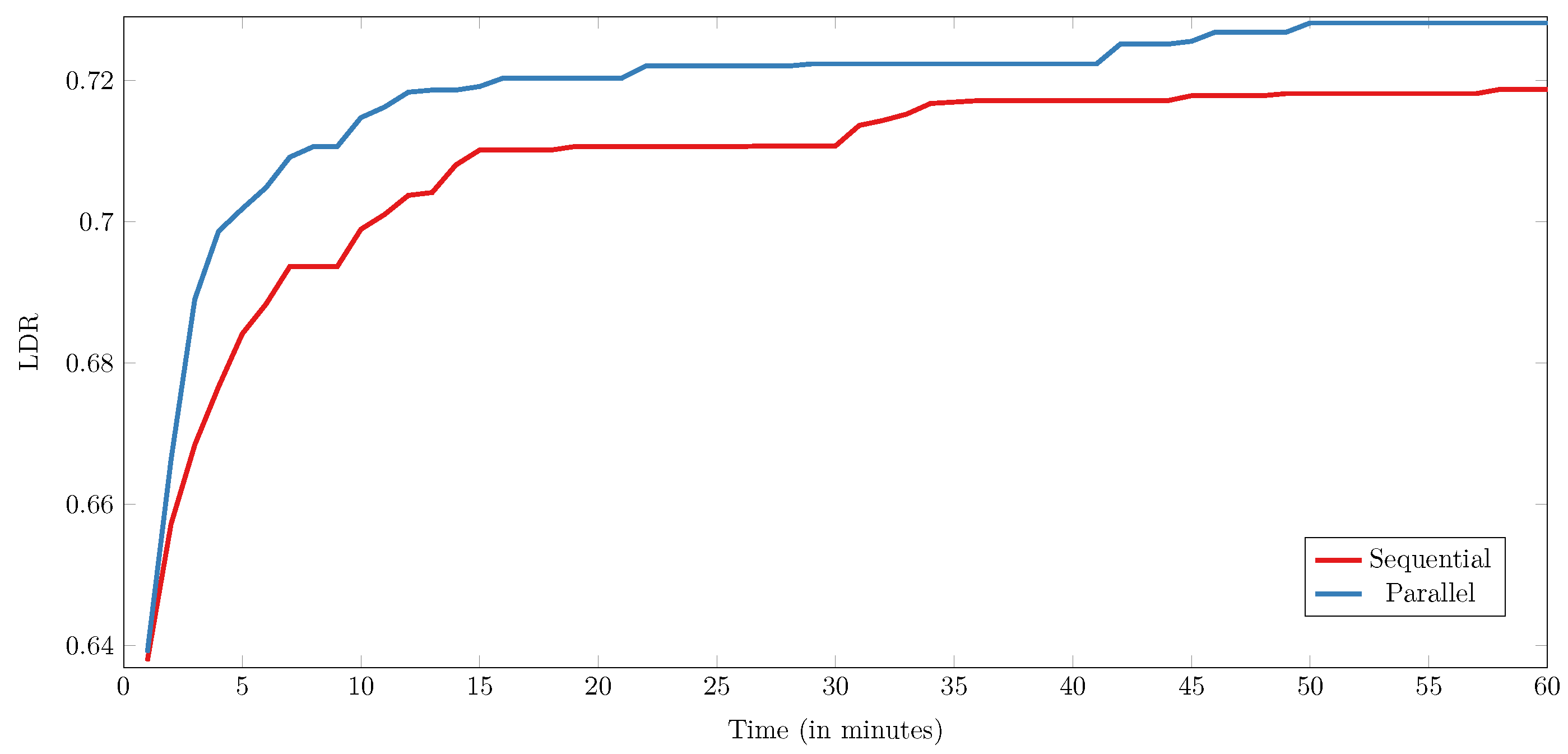
The performance of the proposed VNTS algorithm was examined across a set of real-world and synthetic benchmark instances. The results show that the algorithm performs best when the initial solution is generated with a random initialization strategy and that using parallelization leads to a significant improvement of the results in the same amount of time. By comparing the results of VNTS with those of the existing VNS-RLS algorithm from the literature, which represents the current state of the art, we found that neither algorithm consistently outperforms the other, but rather that each of the algorithms performs better for half of the instances. This shows that no single method is superior across different problems. However, it should be noted that the proposed method obtains such results in one hour, which is considerably lower than the runtime of the VNS-RLS method, which was usually an order of magnitude larger.
In future work, we plan to extend the algorithm with more complex neighborhood operators, which could help to improve the exploitation of good solutions. Furthermore, the algorithm will be extended with concepts from similar methods, such as simulated annealing or path re-linking. We also intended to extend the considered problem to include additional constraints, such as using a fleet of electric vehicles that is becoming more prominent, and adapt the algorithm to efficiently solve such problems as well. Finally, it should be noted that truck scheduling between ports is not an isolated problem, but rather is closely connected to other problems encountered in container yard terminals [
34,
35,
36] and it is intended to consider more realistic scenarios that consider solving several of such problems jointly [
37].




{kind=link}
{kind=link}