
ADDA: An Adversarial Direction-Guided Decision-Based Attack via Multiple Surrogate Models


Abstract
:1. Introduction
- We design a simple yet novel algorithm called ADDA based on the random search mechanism via exploiting multiple pretrained white-box surrogate models, drastically reducing the query amount while achieving a high fooling rate.
- We explore the geometric properties of three large classification models trained on the ImageNet dataset along adversarial directions generated through different reference models. The results reveal several interesting findings, such as that the adversarial directions always outperform the random directions in both targeted and untargeted settings.
- We demonstrate the superior efficiency and effectiveness of our algorithm over several state-of-the-art decision-based attacks through comprehensive experiments. Our source code is publicly available at (https://github.com/whitevictory9/ADDA, accessed on 1 July 2023).
- Our approach is able to successfully fool Google Cloud Vision, a black-box machine learning commercial system, while using an unprecedentedly low number of queries.
2. Related Work
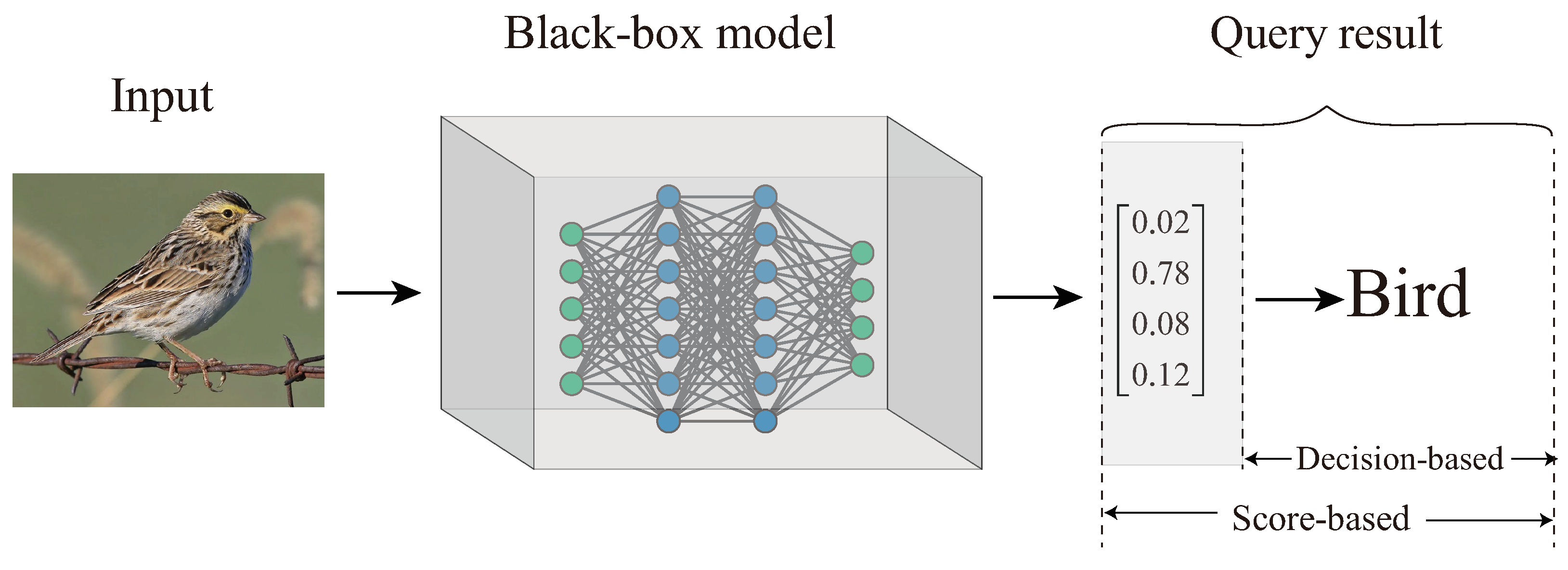
3. Problem Formulation
4. Our Approach
4.1. Basic Idea
4.2. Exploration of Different Adversarial Directions
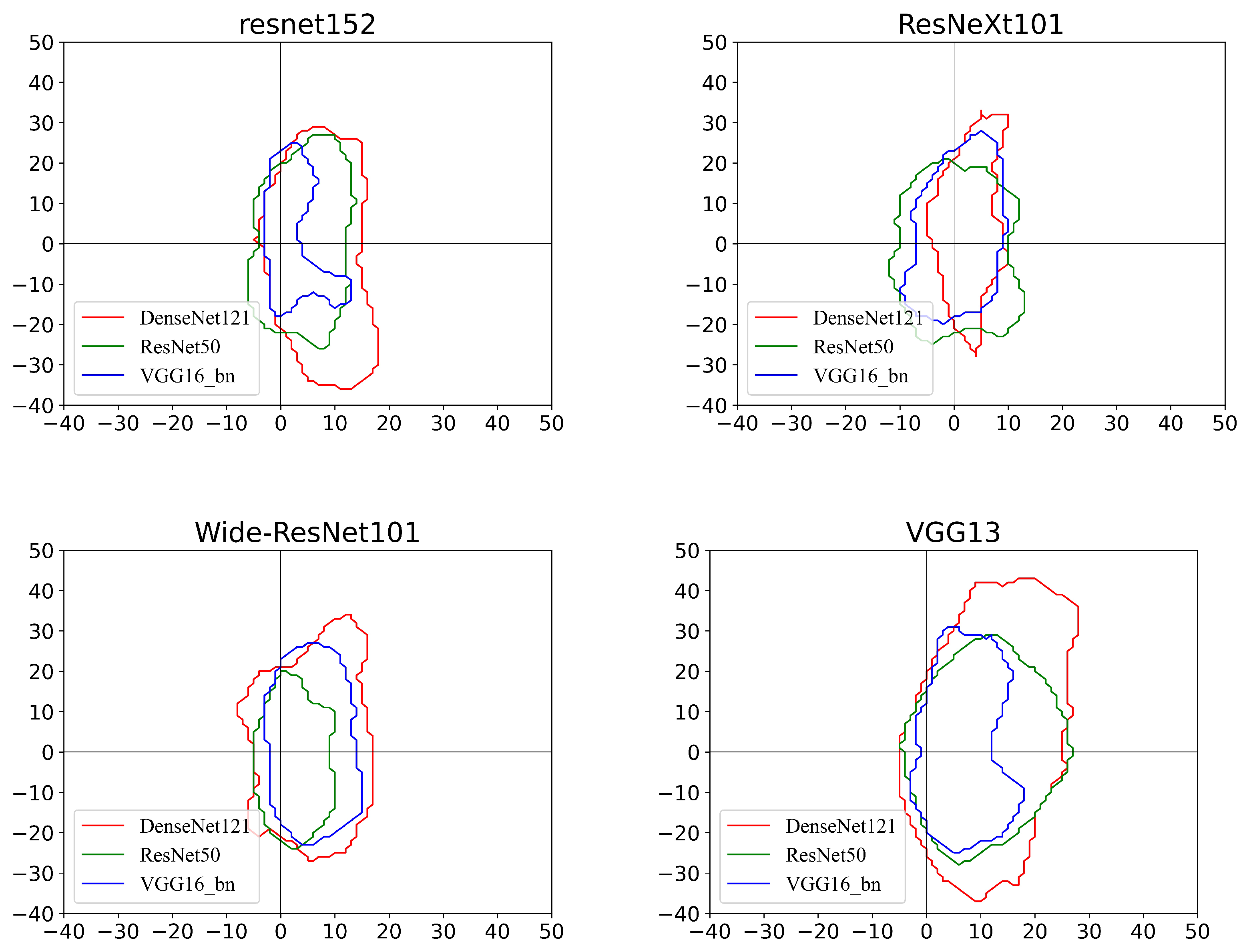
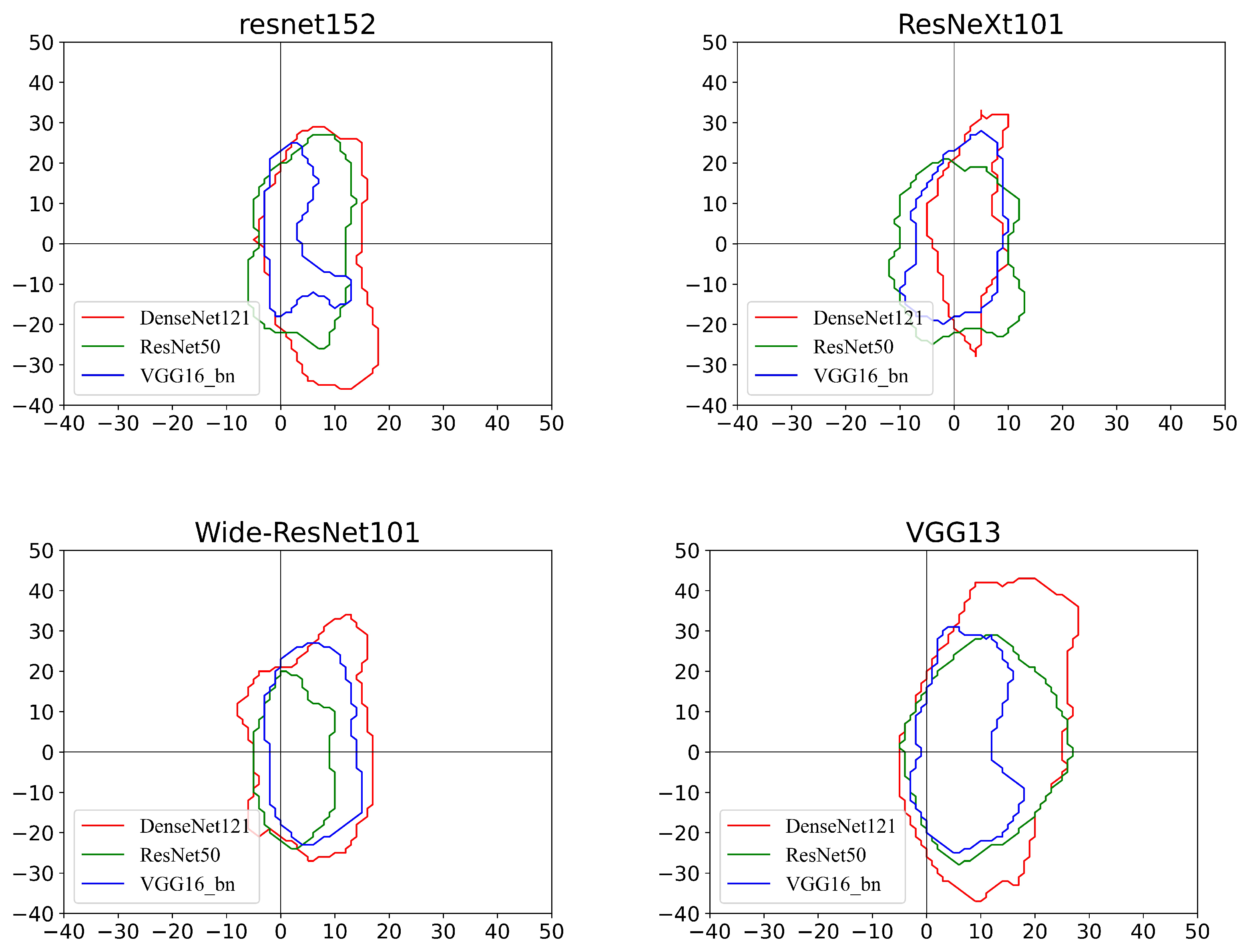
- For all victim models, the area where each model can correctly predict the image is limited to the middle region. In addition, the decision boundary of each model is within a small closed curve. The models are quickly misled along the untargeted adversarial direction (e.g., negative gradient direction). This partially explains the feasibility of the non-targeted attack approach presented in Section 4.1.
- The distance to the boundary along the non-targeted adversarial direction is less than along other directions. Note that this conclusion holds for different planes; that is, even if the reference model provides a direction that is not optimal for searching for adversarial samples, it is still better than a random direction. For example, for the ResNet50 model, using the ResNeXt101 surrogate model as the direction guide is slower to reach the boundary than following the directions provided by other substitute models, but is faster than the random directions. Therefore, it can be concluded that the reference model can provide useful guidance in searching for adversarial examples even when it is not optimal.
- Using different surrogate models, the distance to the boundary along the non-targeted adversarial direction is unequal. For an attacker, the ideal situation is to reach the boundary in the shortest distance. This means that only a very small perturbation is needed in order for the victim model to be misclassified. Specifically, among the four substitute models, when the reference model ResNeXt101 is used as the direction guidance the number of steps to move out of the ground-truth region of the DenseNet121 model is the least. Thus, intuitively, if we can take advantage of this optimal situation it will greatly improve the efficiency of the adversarial attack.
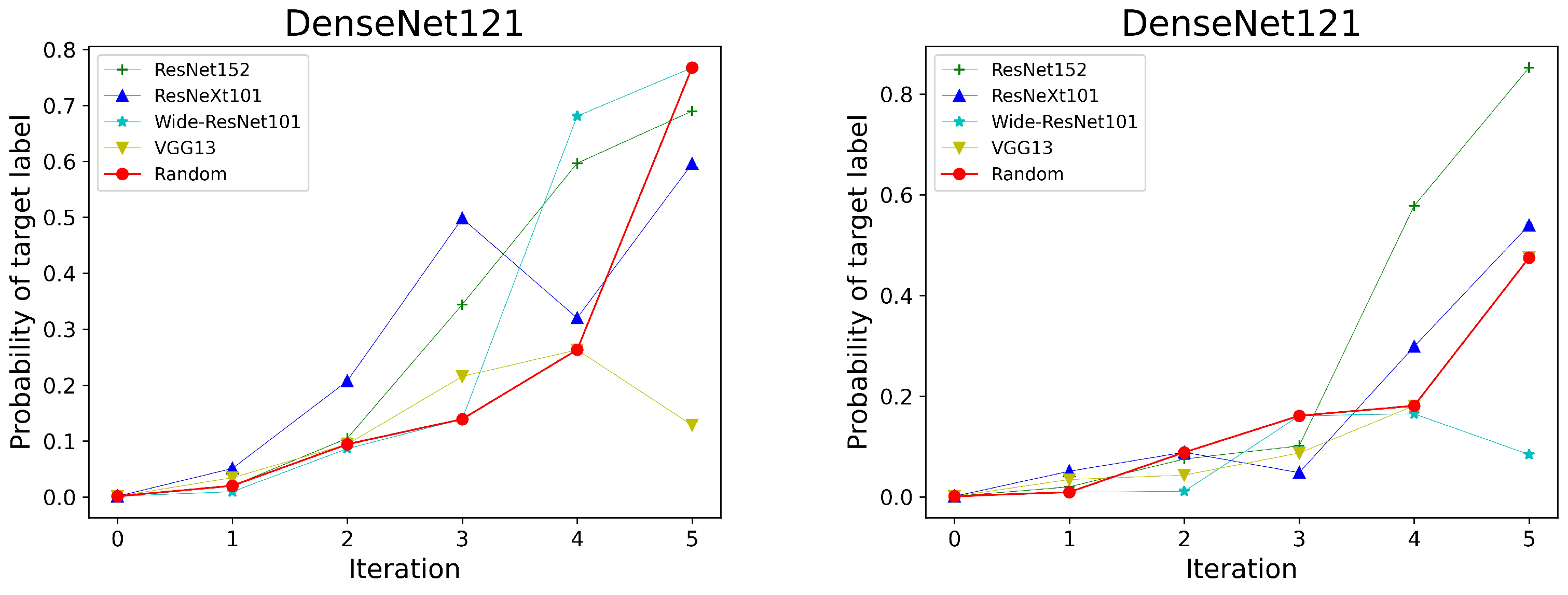
- With the guidance of the targeted adversarial direction, each victim model finds the target area within which all points are predicted as the target class. However, certain targeted regions are very small, and each of the centers deviates from the x-axis (i.e., the targeted adversarial direction). This may be due to the inaccurate targeted adversarial direction provided by the surrogate model, such as the other three cases when the victim model is ResNet50, excluding Wide ResNet101 used as the reference model. Obviously, compared with the other three surrogate models, the success probability of the targeted adversarial attack is higher along the adversarial direction generated by Wide ResNet101. In contrast, for the DenseNet121 model, it is possible to reach the targeted regions faster along the other three adversarial directions. Therefore, the optimal adversarial direction is different for different victim models.
- Another interesting finding is that certain victim models appear to have multiple target regions in the plane. This may be attributed to the nonlinearity of the function , i.e., the gradient direction may change significantly when the distortion is large [37]. In this situation, moving along the direction of the original adversarial gradient no longer increases the probability of being classified as the target label.
4.3. Adversarial Direction-Guided Decision-Based Attack (ADDA)
| Algorithm 1 ADDA Algorithm |
|
5. Experiments
5.1. Experimental Setup
5.2. Untargeted Attacks on ImageNet
5.3. Targeted Attacks on ImageNet
5.4. Attacks on Google Cloud Vision
6. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gayathri, J.L.; Abraham, B.; Sujarani, M.S.; Nair, M.S. A computer-aided diagnosis system for the classification of COVID-19 and non-COVID-19 pneumonia on chest X-ray images by integrating CNN with sparse autoencoder and feed forward neural network. Comput. Biol. Med. 2022, 141, 105134. [Google Scholar]
- Wang, D.; Yu, H.; Wang, D.; Li, G. Face recognition system based on CNN. In Proceedings of the 2020 International Conference on Computer Information and Big Data Applications (CIBDA), Guiyang, China, 17–19 April 2020; pp. 470–473. [Google Scholar]
- Aladem, M.; Rawashdeh, S.A. A single-stream segmentation and depth prediction CNN for autonomous driving. IEEE Intell. Syst. 2020, 36, 79–85. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Athalye, A.; Carlini, N.; Wagner, D. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 274–283. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 506–519. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial machine learning at scale. arXiv 2016, arXiv:1611.01236. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2574–2582. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Artificial Intelligence Safety and Security; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018; pp. 99–112. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I. Transferability in machine learning: From phenomena to black-box attacks using adversarial samples. arXiv 2016, arXiv:1605.07277. [Google Scholar]
- Liu, Y.; Chen, X.; Liu, C.; Song, D. Delving into Transferable Adversarial Examples and Black-box Attacks. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Chen, P.Y.; Zhang, H.; Sharma, Y.; Yi, J.; Hsieh, C.J. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 15–26. [Google Scholar]
- Ilyas, A.; Engstrom, L.; Athalye, A.; Lin, J. Black-box adversarial attacks with limited queries and information. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 2137–2146. [Google Scholar]
- Ilyas, A.; Engstrom, L.; Madry, A. Prior convictions: Black-box adversarial attacks with bandits and priors. arXiv 2018, arXiv:1807.07978. [Google Scholar]
- Tu, C.C.; Ting, P.; Chen, P.Y.; Liu, S.; Zhang, H.; Yi, J.; Hsieh, C.-J.; Cheng, S.M. Autozoom: Autoencoder-based zeroth order optimization method for attacking black-box neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 742–749. [Google Scholar]
- Brendel, W.; Rauber, J.; Bethge, M. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models. arXiv 2017, arXiv:1712.04248. [Google Scholar]
- Cheng, M.; Le, T.; Chen, P.Y.; Yi, J.; Zhang, H.; Hsieh, C.J. Query-efficient hard-label black-box attack: An optimization-based approach. arXiv 2018, arXiv:1807.04457. [Google Scholar]
- Brunner, T.; Diehl, F.; Le, M.T.; Knoll, A. Guessing smart: Biased sampling for efficient black-box adversarial attacks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4958–4966. [Google Scholar]
- Chen, J.; Jordan, M.I.; Wainwright, M.J. Hopskipjumpattack: A query-efficient decision-based attack. In Proceedings of the 2020 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 18–21 May 2020; pp. 1277–1294. [Google Scholar]
- Shukla, S.N.; Sahu, A.K.; Willmott, D.; Kolter, Z. Simple and efficient hard label black-box adversarial attacks in low query budget regimes. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual, 14–18 August 2021; pp. 1461–1469. [Google Scholar]
- Cheng, S.; Dong, Y.; Pang, T.; Su, H.; Zhu, J. Improving black-box adversarial attacks with a transfer-based prior. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Huang, Z.; Zhang, T. Black-box adversarial attack with transferable model-based embedding. arXiv 2019, arXiv:1911.07140. [Google Scholar]
- Guo, Y.; Yan, Z.; Zhang, C. Subspace attack: Exploiting promising subspaces for query-efficient black-box attacks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Shi, Y.; Han, Y.; Tian, Q. Polishing decision-based adversarial noise with a customized sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1030–1038. [Google Scholar]
- Cheng, M.; Singh, S.; Chen, P.; Chen, P.Y.; Liu, S.; Hsieh, C.J. Sign-opt: A query-efficient hard-label adversarial attack. arXiv 2019, arXiv:1909.10773. [Google Scholar]
- Maho, T.; Furon, T.; Le Merrer, E. Surfree: A fast surrogate-free black-box attack. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10430–10439. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble adversarial training: Attacks and defenses. arXiv 2017, arXiv:1705.07204. [Google Scholar]
- Yang, J.; Jiang, Y.; Huang, X.; Ni, B.; Zhao, C. Learning black-box attackers with transferable priors and query feedback. Adv. Neural Inf. Process. Syst. 2020, 33, 12288–12299. [Google Scholar]
- Suya, F.; Chi, J.; Evans, D.; Tian, Y. Hybrid batch attacks: Finding black-box adversarial examples with limited queries. In Proceedings of the 29th USENIX Security Symposium, Boston, MA, USA, 12–14 August 2020; pp. 1327–1344. [Google Scholar]
- Ma, C.; Chen, L.; Yong, J.H. Simulating unknown target models for query-efficient black-box attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11835–11844. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part IV 14. pp. 630–645. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attack | DenseNet121 | ResNet50 | VGG16_bn | |||
|---|---|---|---|---|---|---|
| ASR (%) | Avg. Q | ASR (%) | Avg. Q | ASR (%) | Avg. Q | |
| Sign-opt | 6.29 | 475.08 | 5.59 | 455.76 | 10.40 | 478.87 |
| HJSA | 9.65 | 165.37 | 11.09 | 144.14 | 16.14 | 159.76 |
| Bayes attack | 61.53 | 52.33 | 61.10 | 64.18 | 74.50 | 56.30 |
| ADDA | 99.58 | 7.70 | 99.89 | 5.50 | 98.21 | 7.37 |
| Threat Model | Attack | ASR (%) | Avg. Q | ASR (%) | Avg. Q | ASR (%) | Avg. Q |
|---|---|---|---|---|---|---|---|
| DenseNet121 | Sign-opt | 7.45 | 698.18 | 18.47 | 703.06 | 39.65 | 702.37 |
| HJSA | 11.75 | 466.29 | 24.24 | 441.48 | 47.53 | 416.91 | |
| Bayes attack | 17.73 | 110.59 | 35.46 | 86.20 | 67.05 | 50.43 | |
| SurFree | 28.54 | 413.30 | 49.21 | 348.18 | 75.13 | 270.41 | |
| ADDA | 96.96 | 16.65 | 99.16 | 8.83 | 99.90 | 8.85 | |
| ResNet50 | Sign-opt | 7.04 | 673.78 | 18.43 | 688.97 | 42.44 | 700.10 |
| HJSA | 10.66 | 451.74 | 24.43 | 444.04 | 49.38 | 405.17 | |
| Bayes attack | 15.94 | 109.01 | 33.99 | 91.56 | 67.25 | 63.20 | |
| SurFree | 26.09 | 406.97 | 48.24 | 359.46 | 75.57 | 264.85 | |
| ADDA | 98.86 | 11.65 | 99.69 | 7.16 | 99.90 | 6.55 | |
| VGG16_bn | Sign-opt | 11.24 | 654.14 | 26.58 | 671.87 | 58.36 | 680.88 |
| HJSA | 14.48 | 479.80 | 29.34 | 440.92 | 64.98 | 386.72 | |
| Bayes attack | 17.82 | 90.23 | 39.85 | 89.72 | 74.40 | 45.70 | |
| SurFree | 43.84 | 401.77 | 67.19 | 315.18 | 90.64 | 210.01 | |
| ADDA | 95.38 | 17.65 | 98.53 | 10.07 | 99.68 | 9.06 | |
| Treat Model | ASR (%) | Avg. Q | ASR (%) | Avg. Q |
|---|---|---|---|---|
| DenseNet121 | 85.83 | 90.40 | 90.10 | 61.26 |
| ResNet50 | 95.24 | 54.95 | 97.62 | 44.67 |
| VGG16_bn | 72.58 | 110.67 | 84.24 | 94.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Liu, X. ADDA: An Adversarial Direction-Guided Decision-Based Attack via Multiple Surrogate Models. Mathematics 2023, 11, 3613. https://doi.org/10.3390/math11163613
Li W, Liu X. ADDA: An Adversarial Direction-Guided Decision-Based Attack via Multiple Surrogate Models. Mathematics. 2023; 11(16):3613. https://doi.org/10.3390/math11163613
Chicago/Turabian StyleLi, Wanman, and Xiaozhang Liu. 2023. "ADDA: An Adversarial Direction-Guided Decision-Based Attack via Multiple Surrogate Models" Mathematics 11, no. 16: 3613. https://doi.org/10.3390/math11163613
APA StyleLi, W., & Liu, X. (2023). ADDA: An Adversarial Direction-Guided Decision-Based Attack via Multiple Surrogate Models. Mathematics, 11(16), 3613. https://doi.org/10.3390/math11163613