1. Introduction
Many classification methods have been proposed in the literature and in a vast array of applications, among them a popular approach called support vector machine based on quadratic programming (QP) [
1,
2,
3]. The difficulty in the implementation of SVMs on massive datasets lies in the fact that the quantity of storage memory required for a regular QP solver increases by an exponential magnitude as the problem size expands.
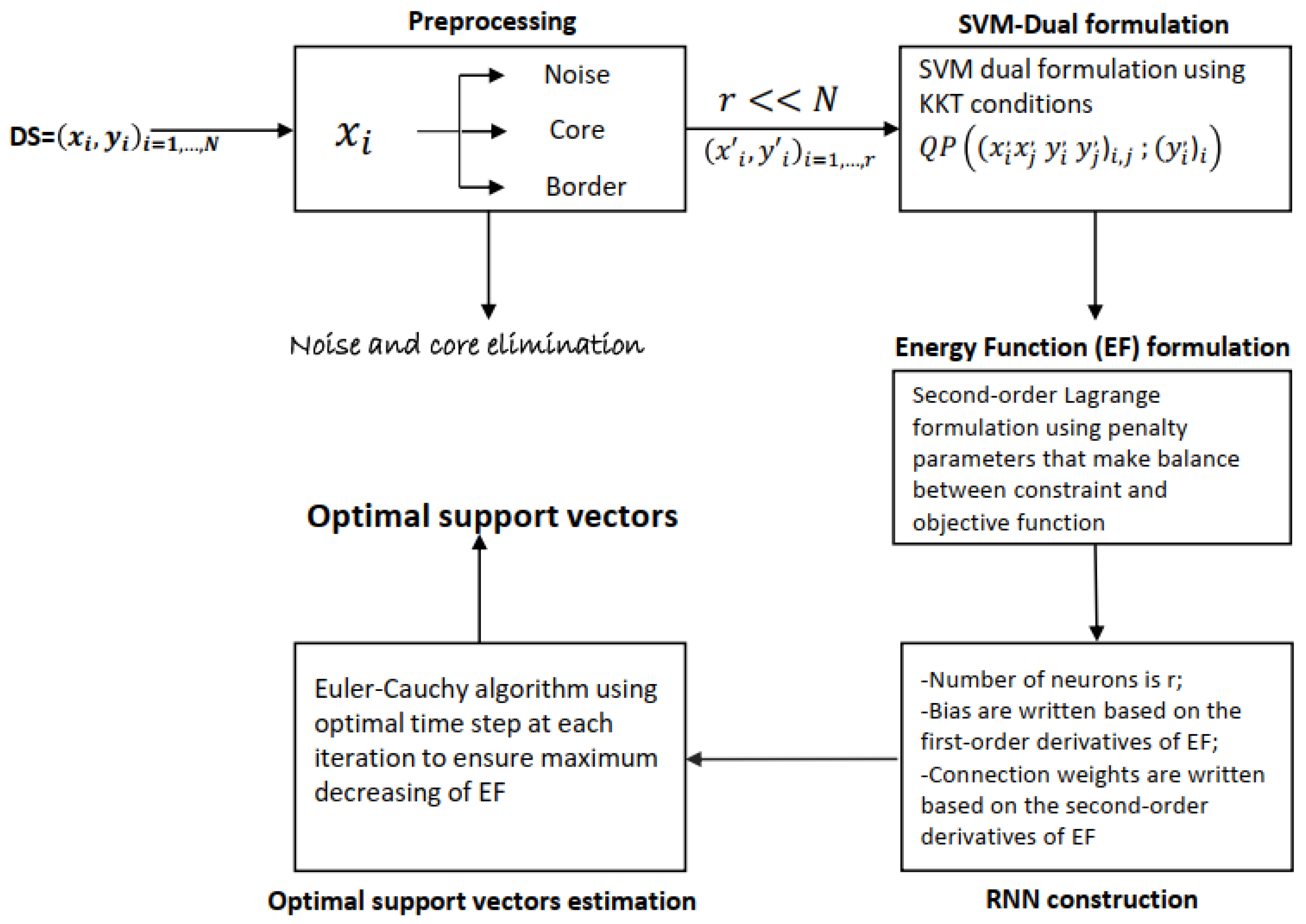
This paper introduces a new type of SVM that implements a preprocessing filter and a recurrent neural network, called the Optimal Recurrent Neural Network and Density-Based Support Vector Machine (Opt-RNN-DBSVM).
SVM approaches are based on the existence of a linear separator, which can be obtained by transforming the data in a higher-dimensional space through appropriate kernel functions. Among all possible hyperplanes, the SVM searches for the one with the most confident separation margin for good generalization. This issue takes the form of a nonlinear constrained optimization problem that is usually handled using optimization methods. Thanks to the Kuhen–Tuker conditions [
4], all these methods transform the primal mathematical model into the dual version and use optimization methods to find the support vectors on which the optimal margin is built. Unfortunately, the complexity in time and memory grows exponentially with the size of the datasets; in addition, the number of local minima grows too, which influences the location of the separation margin and the quality of the predictions.
A primary area of research in learning from empirical data through support vector machines (SVMs) and addressing classification and regression issues is the development of incremental learning schemes when the size of the training dataset is massive [
5]. Out of many possible candidates, avoiding the usage of regular quadratic programming (QP) solvers, the two learning methods gaining attention recently are iterative single-data algorithms (ISDA) and sequential minimal optimization (SMO) [
6,
7,
8,
9]. ISDAs operate from a single sample at hand (pattern-based learning) towards the best fit solution. The Kernel-Adatron (KA) is the primary ISDA for SVMs, using kernel functions to map data to the high-dimensional character space of SVMs [
10] and conducting Adatron [
11] processing in the character space. Platt’s SMO algorithm is an outlier among the so-called decomposition approaches introduced in [
12,
13], operating on a two-sample workset of samples at a time. Because the decision for the two-point workset may be determined analytically, the SMO does not require the involvement of standard QP solvers. Due to it being analytically driven, the SMO has been especially popular and is the most commonly utilized, analyzed, and further developed approach. Meanwhile, KA, while yielding somewhat comparable performance (accuracy and computational time) in resolving classification issues, has not gained as much traction. The reason for this is twofold. First, until recently [
14], KA appeared to be restricted to classification tasks; second, it lacks the qualities of a robust theoretical framework. KA employs a gradient ascent procedure, and this fact also may have caused some researchers to be suspicious of the challenges posed by gradient ascent techniques in the presence of a perhaps ill-conditioned core array. In [
15], lacking bias parameter b, the authors derive and demonstrate the equality of two apparently dissimilar ISDAs, namely a KA approach and an unbiased variant of the SMO training scheme [
9], when constructing SVMs possessing positive definite kernels. The equivalence is applicable to both classification and regression tasks and gives additional insights into these apparently dissimilar methods of learning. Despite the richness of the toolbox set up to solve the quadratic programs from SVMs, and with the large amount of data generated by social networks, medical and agricultural fields, etc., the amount of computer memory required for a QP solver from the dual-SVM grows hyper-exponentially, and additional methods implementing different techniques and strategies are more than necessary.
Classical algorithms, namely ISDAs and SMO, do not distinguish between different types of samples (noise, border, and core), which causes searches in unpromising areas. In this work, we introduce a hybrid method to overcome these shortcomings, namely the Optimal Recurrent Neural Network Density-Based Support Vector Machine (Opt-RNN-DBSVM). This method proceeds in four steps: (a) the characterization of different samples based on the density of the datasets (noise, core, and border), (b) the elimination of samples with a low probability of being a support vector, namely core samples that are very far from the borders of different components of different classes, (c) the construction of an appropriate recurrent neural network based on an original energy function, ensuring a balance between the dual-SVM components (constraints and objective function) and ensuring the feasibility of the network equilibrium points [
16,
17], and (d) the solution of the system of differential equations, managing the dynamics of the RNN, using the Euler–Cauchy method involving an optimal time step. Density-based preprocessing reduces the number of local minima in the dual-SVM. The RNN’s recurrent architecture avoids the need to examine previously visited areas; this behavior is similar to a taboo search, which prohibits certain moves for a few iterations [
18]. In addition, the optimal time step of the Euler–Cauchy algorithm speeds up the search for an optimal decision margin. On one hand, two main interesting fundamental results are demonstrated: the convergence of the RNN-SVM to feasible solutions, and the fact that Opt-RNN-DBSVM has very low time complexity compared to Const-RNN-SVM, SMO-SVM, ISDA-SVM, and L1QP-SVM. On the other hand, several experimental studies are conducted based on well-known datasets. Based on several performance measures (accuracy, F1-score, precision, recall), Opt-RNN-DBSVM outperforms recurrent neural network–SVM with a constant time step, the Kernel-Adatron algorithm–SVM family, and well-known non-kernel models. In fact, Opt-RNN-DBSVM improves the accuracy, the F1-score, the precision, and the recall. Moreover, the proposed method requires a very small number of support vectors.
The rest of this paper is organized as follows.
Section 2 presents the flowchart of the proposed method.
Section 3 gives the outline of our recent SVM version called Density-Based Support Vector Machine.
Section 4 presents, in detail, the construction of the recurrent neural network associated with the dual-SVM and the Euler–Cauchy algorithm that implements an optimal time step.
Section 5 gives some experimental results.
Section 6 presents some conclusions and future extensions of Opt-RNN-DBSVM.
3. Density-Based Support Vector Machine
In the following, let us denote by the set of N samples labeled, respectively, by , distributed via K class . In our case, K=2 and .
3.1. Classical Support Vector Machine
The hyperplane that the SVM searches must satisfy the equation
, where
w is the weight that defines this SVM separator that satisfies the constraint family given by
. To ensure the maximum margin, we need to maximize
. As the patterns are not linearly separable, the kernel function
K is introduced (which satisfies the Mercer conditions [
25]) to transform the data into an appropriate space.
By introducing the Lagrange relaxation and using the Kuhn–Tuker conditions, we obtain a quadratic optimization problem with a single linear constraint that must be solved to determine the support vectors [
26].
To address the problem of saturated constraints, some researchers have added the notion of a soft margin [
27]. They employ
N supplementary slack variables
at every constraint
. The sum of the relaxed variables is weighted and included in the cost function:
Here,
represents the transformation function derived from the function kernel
K. The following dual problem is obtained:
Several methods can be used to solve this optimization problem: gradient methods, linearization methods, the Frank–Wolf method, the generation column method, the Newton method applied to the Kuhn system, sub-gradient methods, the Dantzig algorithm, the Uzawa algorithm [
4], recurrent neural networks [
28], hill climbing, simulated annealing, search by calf, A*, genetic algorithms [
29], ant colony, and the particle swarm optimization method [
30], etc.
Several versions of SVMs are proposed in the literature, e.g., the least squares support vector machine classifiers (LS-SVM) introduced in [
21], generalized support vector machine (G-SVM) [
22], fuzzy support vector machine [
31,
32], one-class support vector machine (OC-SVM) [
26,
33], total support vector machine (T-SVM) [
34], weighted support vector machine (W-SVM) [
35], granular support vector machine (G-SVM) [
36], smooth support vector machine (S-SVM) [
37], proximity support vector machine classifiers (P-SVM) [
23], multisurface proximal support vector machine classification via generalized eigenvalues (GEP-SVM) [
24], and twin support vector machine (T-SVM) [
38], etc.
3.2. Density-Based Support Vector Machine (DBSVM)
In this section, a short description of the DBVSM method is given. Let us introduce a real number
and the integer
, called min-points, and three types of samples are defined: noise points, border points, and interior points (or core points). It is possible to show that the interior points do not change their nature even when they are projected into another space by the kernel functions. Furthermore, such points cannot be selected as support vectors [
19].
Definition 1. Let . A point is said to be an interior point (or core point) of S if there exists an such that . The set of all interior points of S is denoted by or .
Definition 2. For a given dataset , a non-negative real r, and an integer , there exist three types of samples.
- 1.
A sample x is called a -noise point if .
- 2.
A sample x is called a -core point if and
- 3.
A sample x is called a -border point if and there exists a -core point y such as .
Let K be a kernel function allowing us to move from the space to the space using the transformation (here, ).
Lemma 1 ([
19])
. If a is a -core point for a given ϵ and min-points (mp), then is also a -core point with an appropriate and the same min-points (mp). Theorem 1 ([
19])
. A core point is either a noise point or a border point. Proposition 1 ([
19])
. Let be a real number. The core point set corePoints (minPoints) is a decreasing function for the inclusion operator. Let = be the set of the Lagrange multipliers, where , , and are the Lagrange multipliers of the border samples, core samples, and noise samples, respectively.
As the elements of
and
cannot be selected to be support vectors, the reduced dual problem is given by
In this work, as the RD problem is quadratic with linear constraints, in order to solve this, we use a continuous Hopfield network by proposing an original energy function in the following section [
39].
4. Recurrent Neural Network to Find Optimal Support Vectors
The continuous Hopfield network consists of interconnected neurons with a smooth sigmoid activation function (usually a hyperbolic tangent). The differential equation that governs the dynamics of the CHN is
where
u,
,
W, and
I are, respectively, the vectors of neuron states, the outputs, the weight matrix, and the biases. For a CHN of
N neurons, the state
and output
of the neuron
i are given by the equation
.
For an initial vector state
, a vector
is called an equilibrium point of the system
1, if and only if
, such as
. It should be noted that if the energy function (or Layapunov function) exists, the equilibrium point exists as well. Hopfield proved that the symmetry of the matrix of the weight is a sufficient condition for the existence of the Lyapunov function [
40].
4.1. Continuous Hopfield Network Based on Original Energy Function
To solve the obtained dual problem via a recurrent neural network [
39,
41,
42], we propose the following energy function:
To determine the vector of the neurons’ biases, we calculate the partial derivatives of
E:
The components of the bias vector are given by
To determine the connection weights W between each neuron pair, the second partial derivative of E is calculated: .
The components of the weight W matrix are given by .
To calculate the equilibrium point of the proposed recurrent neural network, we use the Euler–Cauchy iterative method:
- (1)
Initialization: and the step are randomly chosen;
- (2)
Given and the step , the step is chosen such that is the maximum and are calculated using
Then, are calculated using the activation function f: .
Then, the are given by , where P is the projection operator on the set .
- (3)
Return to (1) until , where .
Figure 2 shows the connection weights W between each pair of neurons.
Theorem 2. If , else , where .
Proof of Theorem 2. We have and .
Then, because .
Thus .
Finally, for , , and for . □
Concerning the constraint family satisfaction
, the activation function is used:
where
is supposed to be a very large positive real number, which ensures that
.
Let us consider a kernel function K such that .
Theorem 3. A continuous Hopfield network has an equilibrium point if and .
Theorem 4. If , then CHN-SVM has an equilibrium point.
Proof of Theorem 4. We have and because K is symmetric.
Then, CHN-SVM has an equilibrium point. □
4.2. Continuous Hopfield Network with Optimal Time Step
In this section, we chose, mathematically, the optimal time size in each iteration of the Euler–Cauchy method to solve the dynamical equation of the recurrent neural network proposed in this paper. At the end of the
iteration, we know
and let
be the next step size, which permits us to calculate
using the formula
and
must be chosen such as
at the maximum.
As the activation function of the proposed neural network is the , then .
The matrix form of the energy function is
where
,
, and
for all
i and
j.
At the
iteration, the state
is known, and
is calculated by
where
is the actual time step that must be optimal. To this end,
is substituted by
in
:
where
,
,
.
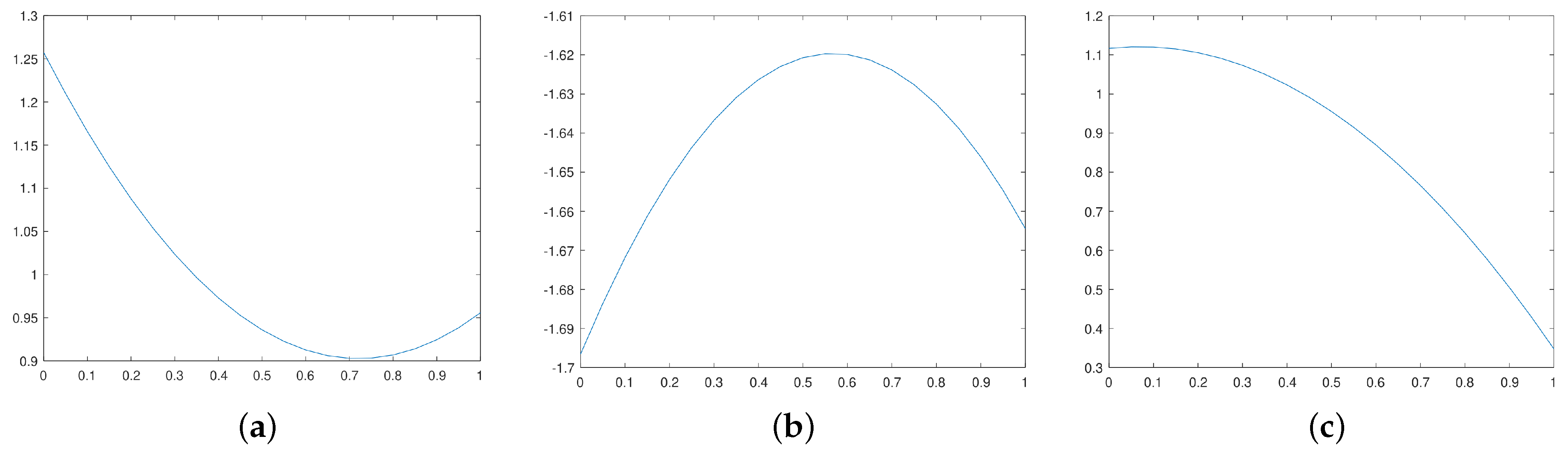
Thus, the best time step is the minimum of
.
Figure 3a–c gives different cases.
4.3. Opt-RNN-DBSVM Algorithm
The inputs of Algorithm 1 are the radius
r (the size of the neighborhood of the current sample), the minimum of samples
into
(which determines the type of this sample), the three Lagrangian parameters
(which allow a compromise between the dual components), the bound
C of the SVM [
19], and the number of iterations (which represents artificial convergence).
Algorithm 1 processes in three macro-steps: data preprocessing, RNN-SVM construction, and RNN-SVM equilibrium point estimation. The input of the first phase is the initial dataset with labeled samples. Based on
r and
, the algorithm determines the types of different samples based on the value of the current sample neighborhood’s discrete size. The output of this phase is a reduced sub-dataset (the initial dataset minus the core samples). The inputs of the second phase are the reduced dataset, the Lagrangian parameters
,
,
, and the SVM bound
C. Based on the energy function built in
Section 4.1 and on the first and second derivatives, the architecture of CHN-SVM is constructed; the bias and connection weights, which represent the output of this phase, are calculated. These later represent the input of the third phase and the Euler–Cauchy algorithm is used to calculate the degree of membership of different samples in the set of support vectors; to ensure an optimal decrease in the energy function, at each iteration, an optimal step is determined by solving a quadratic one-dimension optimization problem; see
Section 4.2. At convergence, the proposed algorithm produces the support vectors based on which Opt-RNN-DBSVM can predict the class of unseen samples.
| Algorithm 1 Opt-RNN-DBSVM |
Require: Ensure: % Density based preprocessing: for all s in DS do if then else if then else end if end for % RNN-Building: % Optimal Euler–Cauchy to RNN stability: for k = 1, …, ITER do end for
|
Proposition 2. If N, r, and represent, respectively, the size of a labeled dataset , the number of remaining samples (output of the preprocessing phase), and the number of iterations, then the complexity of Algorithm 1 is .
Proof. First, in the preprocessing phase, we calculate, for each sample , the distance and execute N comparisons to determine the type of each sample; thus, the complexity of this phase is .
Second, during iterations, the activation of each neuron is updated using the activation of all the other neurons to solve the reduced dual-SVM; thus, the third phase has complexity of .
Finally, the complexity of Algorithm 1 is . Let us denote Const-RNN-SVM as the SVM version that implements a recurrent neural network based on a constant time step. Following the same reasoning, the complexity of Const-RNN-SVM is .
Notes: As the Kernel-Adatron algorithm (KA) is the kernel version of SMO and ISDA, and KA implements two embedded N-loops in each iteration, then the complexity of SMO and ISDA is of [
10]. In addition, it is considered that L1QP-SVM implements the numerical linear algebra Gauss–Seidel method [
43], which implements two embedded N-loops in each iteration, and thus the complexity of SMO and ISDA is of
. □
For a very large and high-density labeled dataset, we have ; thus,
and and .
Thus, and , and .
Firstly, preprocessing the database reduces the number of local minima in the dual-SVM. Secondly, this reduction enables real-time decision making in big data problems. Finally, the optimal time step of the Euler–Cauchy algorithm speeds up the search for an optimal decision margin.
5. Experimentation
In this section, Opt-RNN-DBSVM is compared to several classifiers, Const-RNN-SVM (RNN-SVM using a constant Euler–Cauchy time step), SMO-SVM, ISDA-SVM, L1QP-SVM, and some non-kernel classifiers (Naive Bayes (NB), MLP, KNN, AdaBoostM1 (ABM1), Nearest Center Classifier (NCC), Decision Tree (DT), SGD Classifier (SGDC)). The classifiers were tested on several datasets: IRIS, ABALONE, WINE, ECOLI, BALANCE, LIVER, SPECT, SEED, and PIMA (collected from the University of California at Irvine (UCI) repository [
44]). The performance measures used in this study are the accuracy, F1-score, precision, and recall.
5.1. Opt-RNN-DBSVM vs. Const-CHN-SVM
In this subsection, Opt-RNN-DBSVM is compared to Const-RNN-SVM by considering different values of the Euler–Cauchy time step
s ∈ {0.1, 0.2, …, 0.9}.
Table 1 and
Table 2 show the different values of accuracy, F1-score, precision, and recall on the considered datasets. These results show the superiority of Opt-RNN-DBSVM over Const-CHN-SVM (
step∈
STEP = {0.1, 0.2, …, 0.9}). In fact, this superiority is quantified as follows:
where
is the set of different considered data. These results are not unexpected, because Opt-RNN-SVM ensures an optimal decrease in the CHN energy function at each step. This superiority is normal, since a single time step of the Euler–Cauchy algorithm does not explore all the regions of the solution space of the dual problem associated with the SVM, and it also causes premature convergence to a poor local solution. On the other hand, the variable optimal time step of this algorithm allowed a higher-order decay in the energy function of the RNN associated with the dual-SVM.
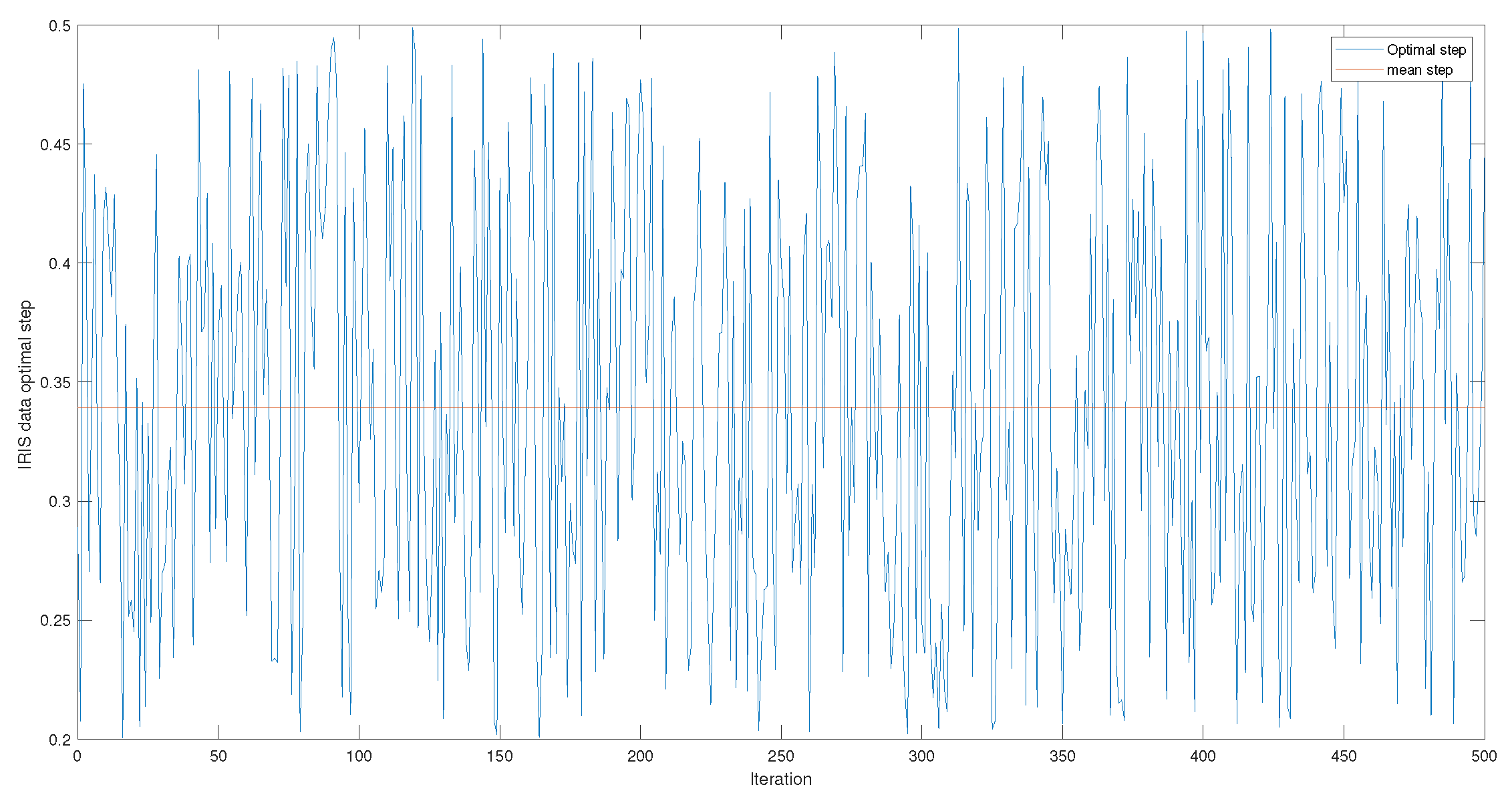
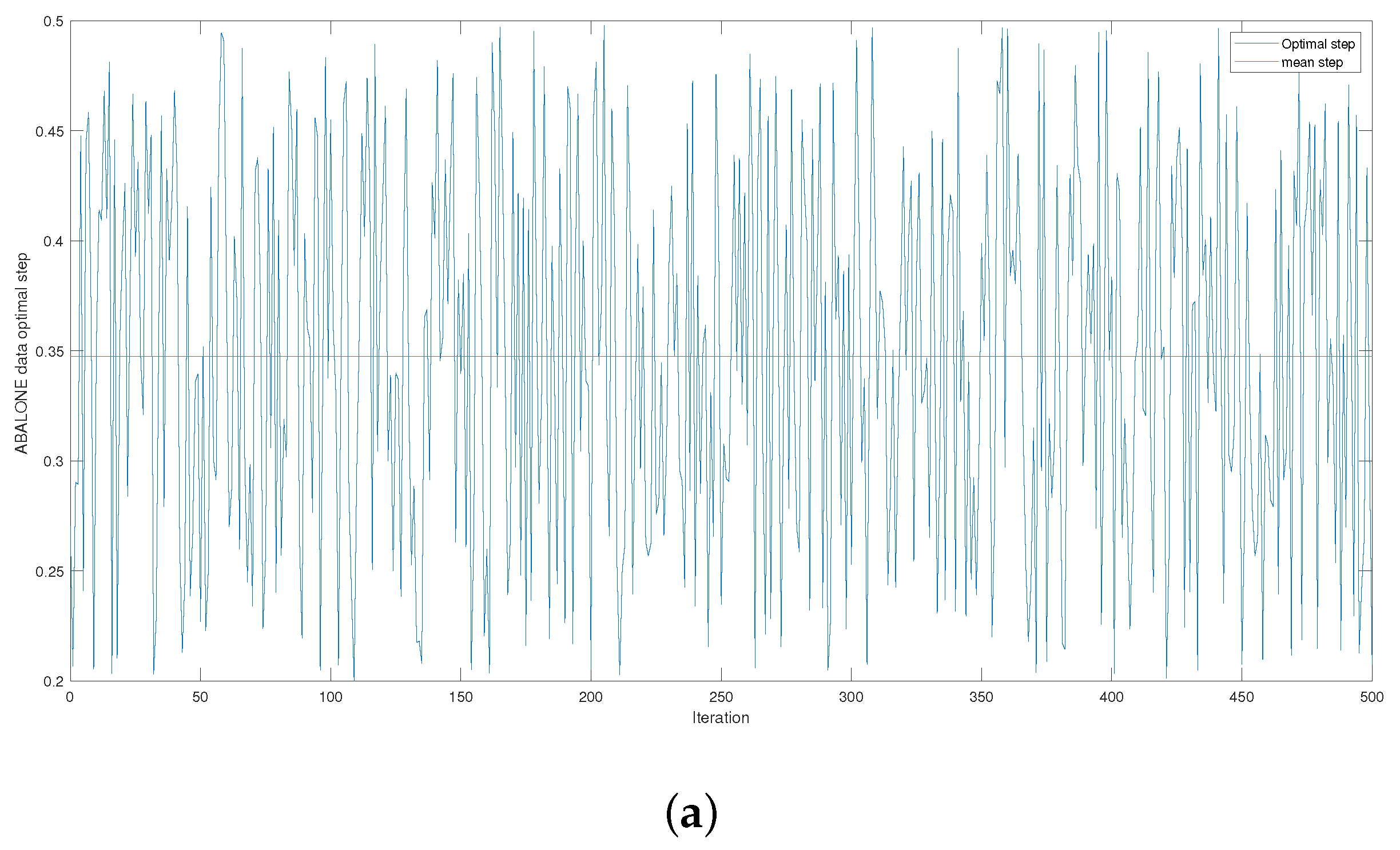
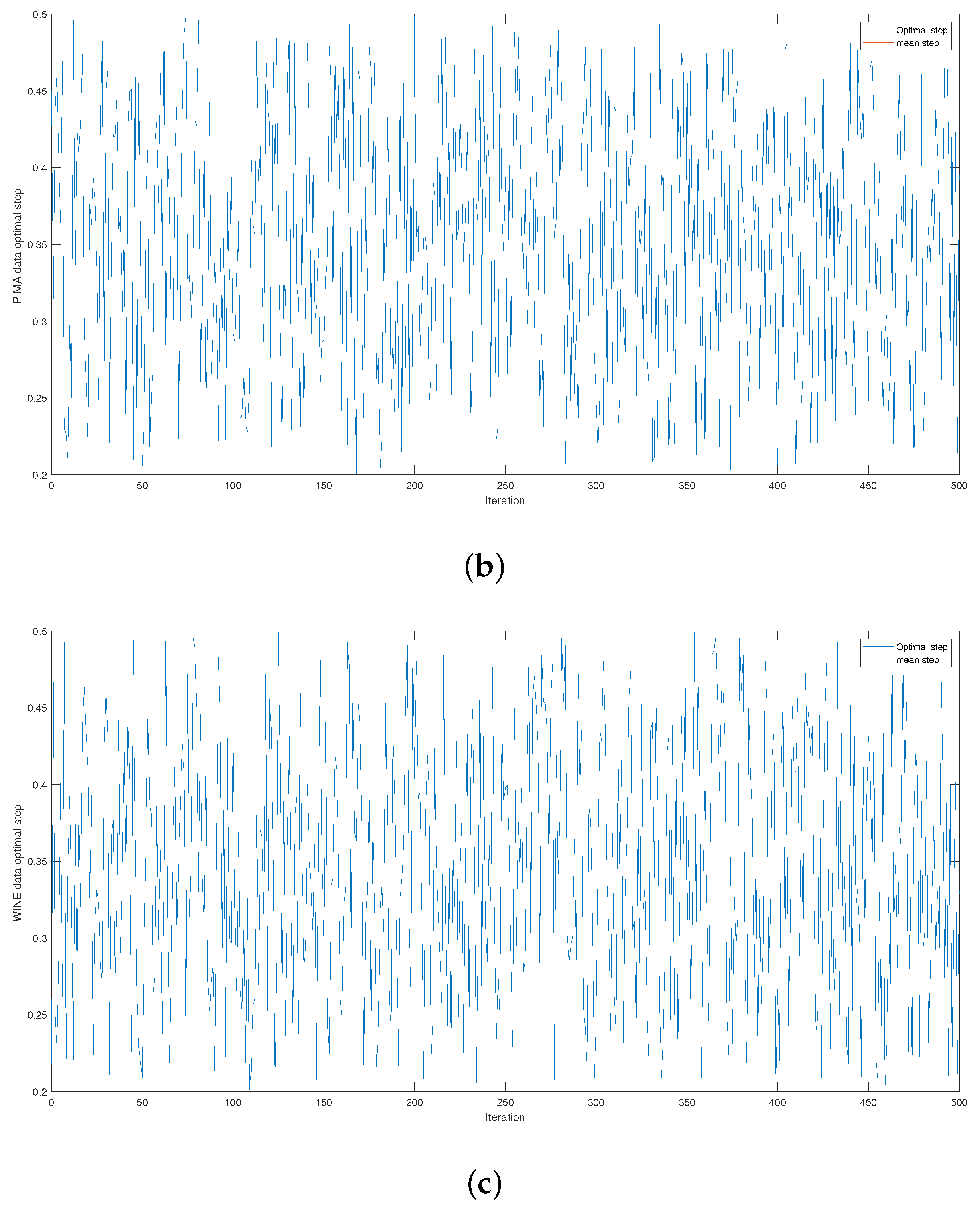
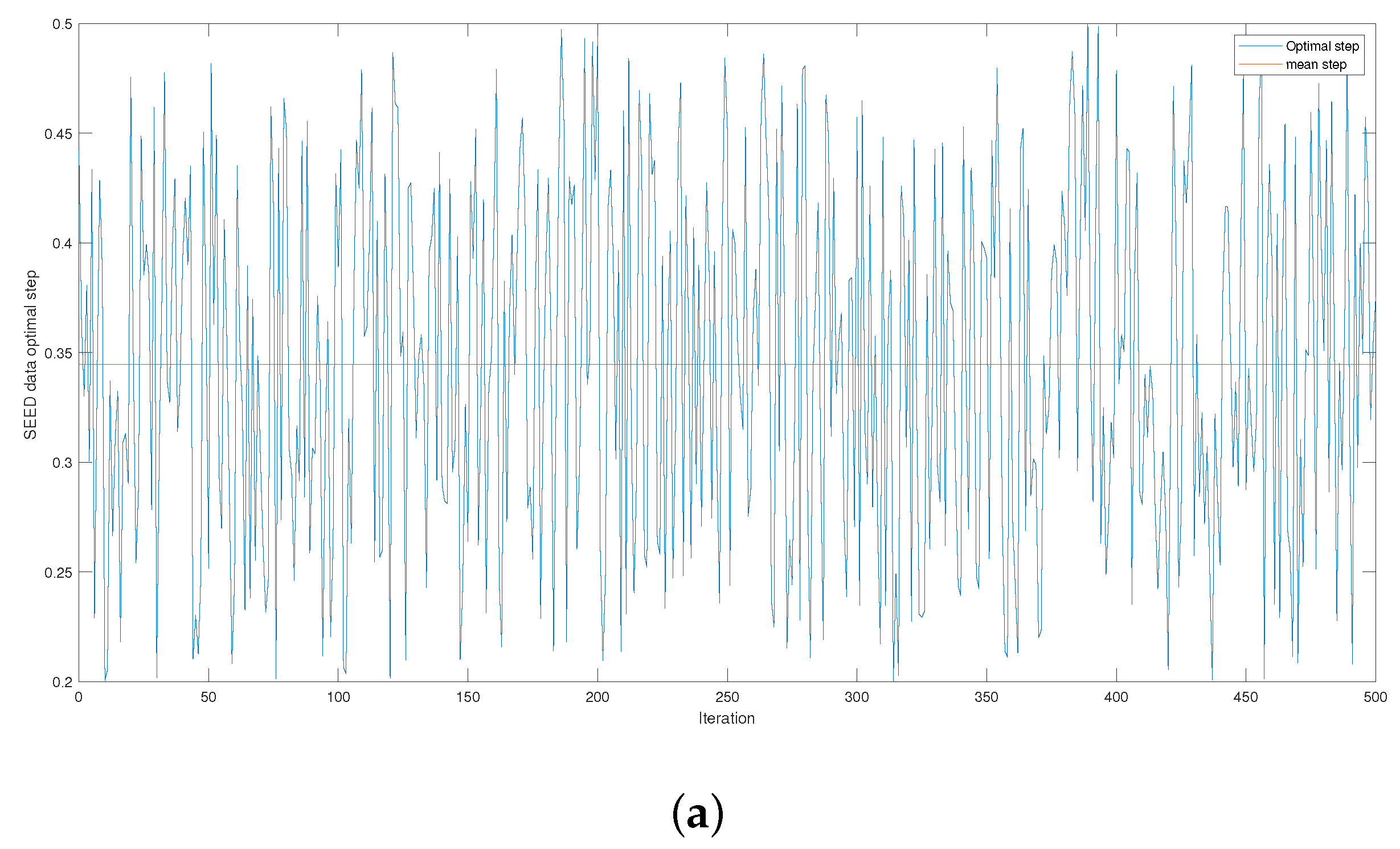
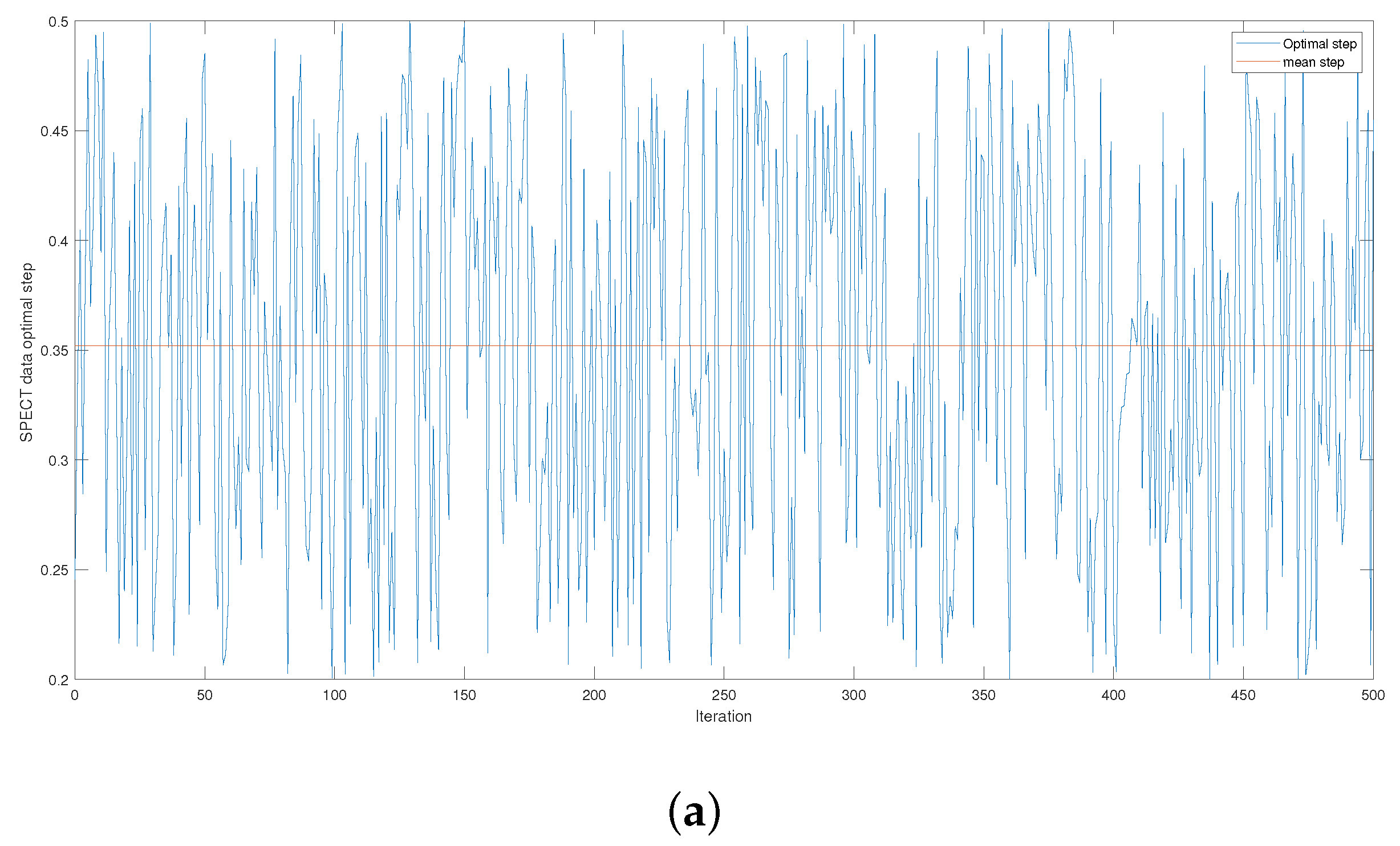
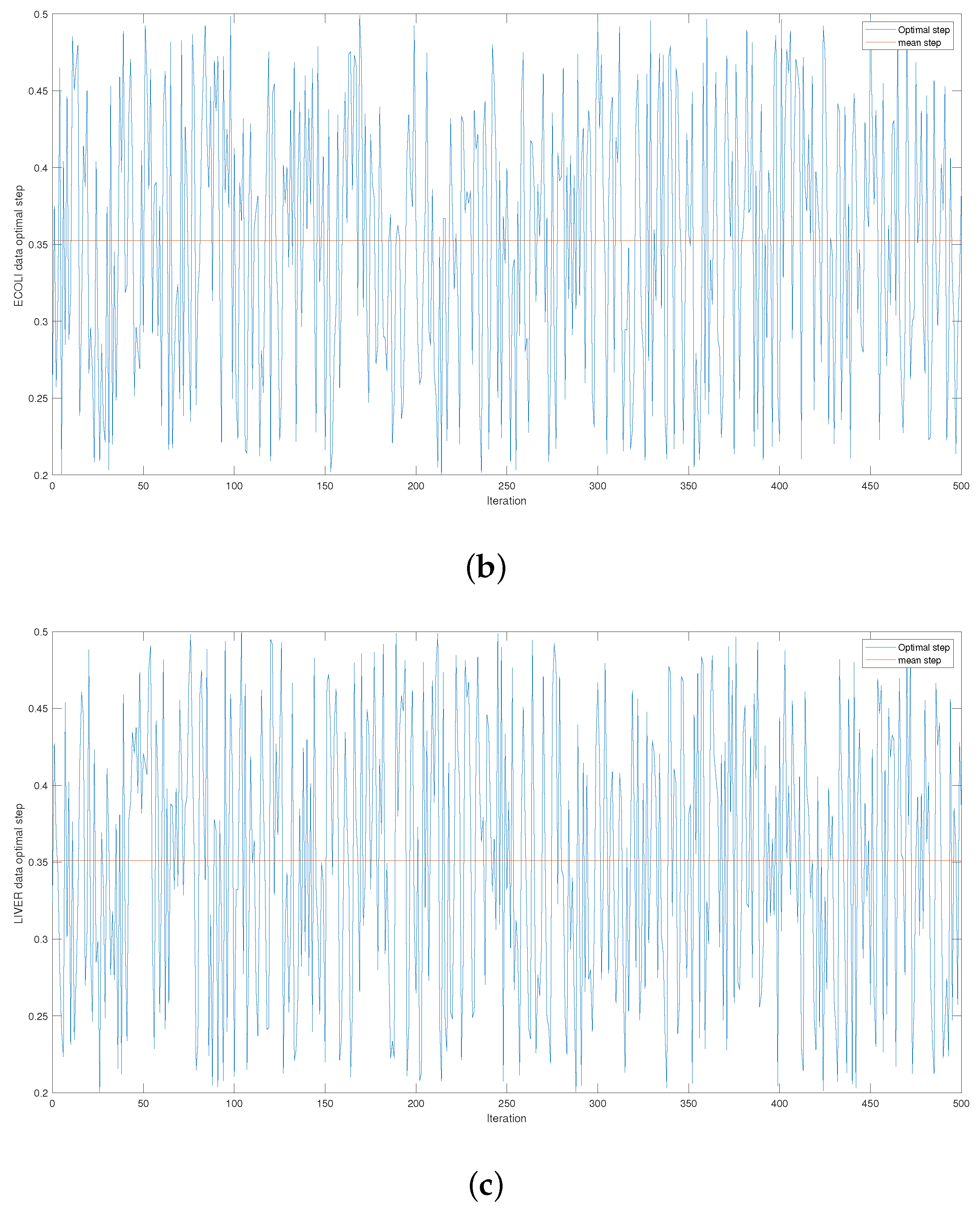
Figure 4 and
Figure A1,
Figure A2 and
Figure A3 give the series of optimal steps generated by Opt-RNN-DBSVM during iterations for different datasets. It is noted that all the optimal steps are taken from the interval
, which explains why a single constant time step of the Euler–Cauchy algorithm can never produce satisfactory support vectors compared to Opt-RNN-DBSVM. However, this simulation provides an optimal domain for those using a CHN based on a constant time step instead of taking a random time step from
.
5.2. Opt-RNN-DBSVM vs. Classical Optimizer–SVM
In this section, we give the performance of different Classical Optimizer–SVM models (L1QP-SVM, ISDA-SVM, and SMO-SVM) applied to several datasets and compare the number of support vectors obtained by the different Classical Optimizer–SVM models and Opt-RNN-SVM.
Table 3 gives the values of accuracy, F1-score, precision, and recall for Classical Optimizer–SVM on different datasets. The results show the superiority of Opt-RNN-DBSVM. Indeed, when considering each of the performance measures, the proposed method achieves remarkable improvements of 30% for accuracy and F1-score, 50% for precision, and 40% for recall.
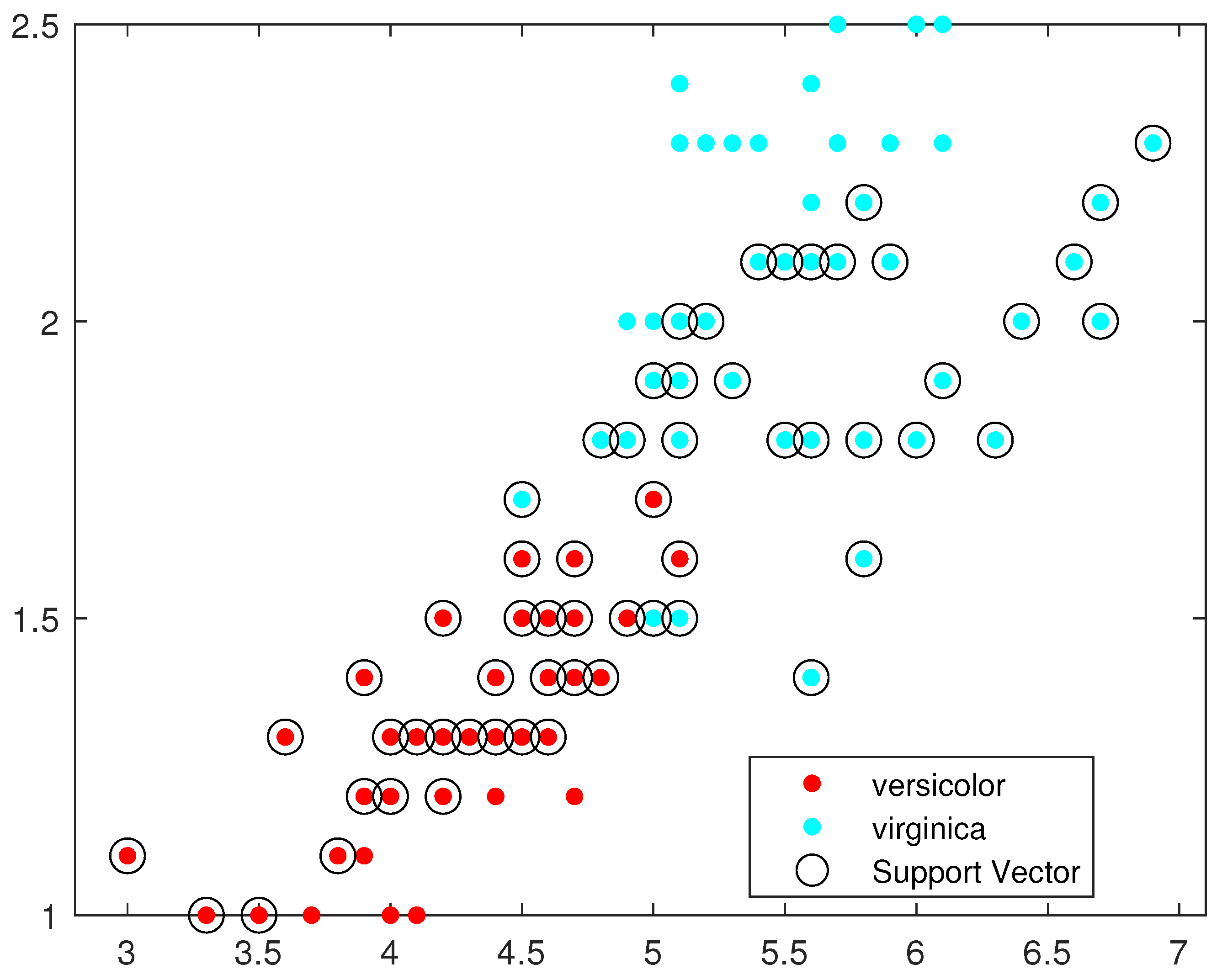
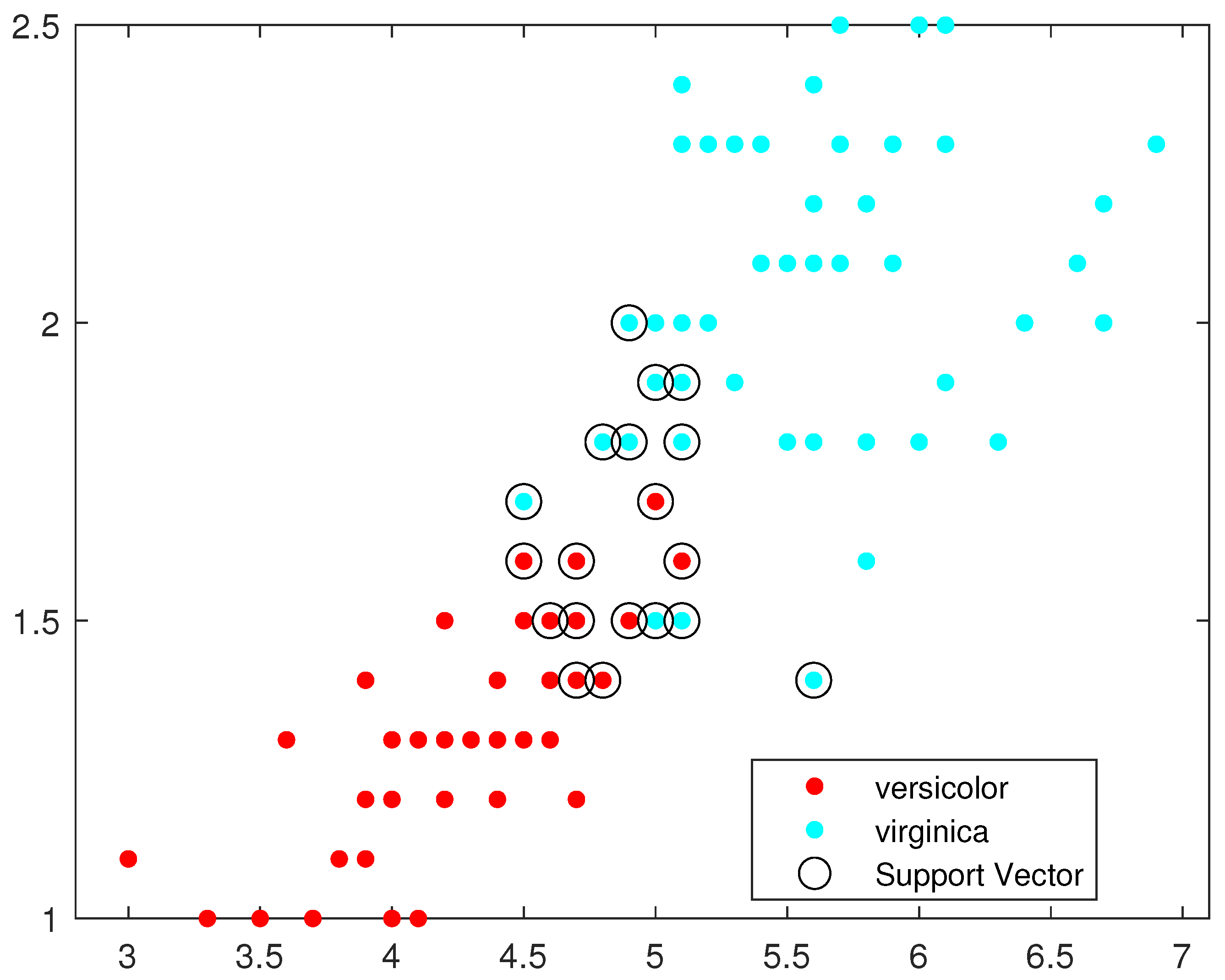
Figure 5,
Figure 6,
Figure 7 and
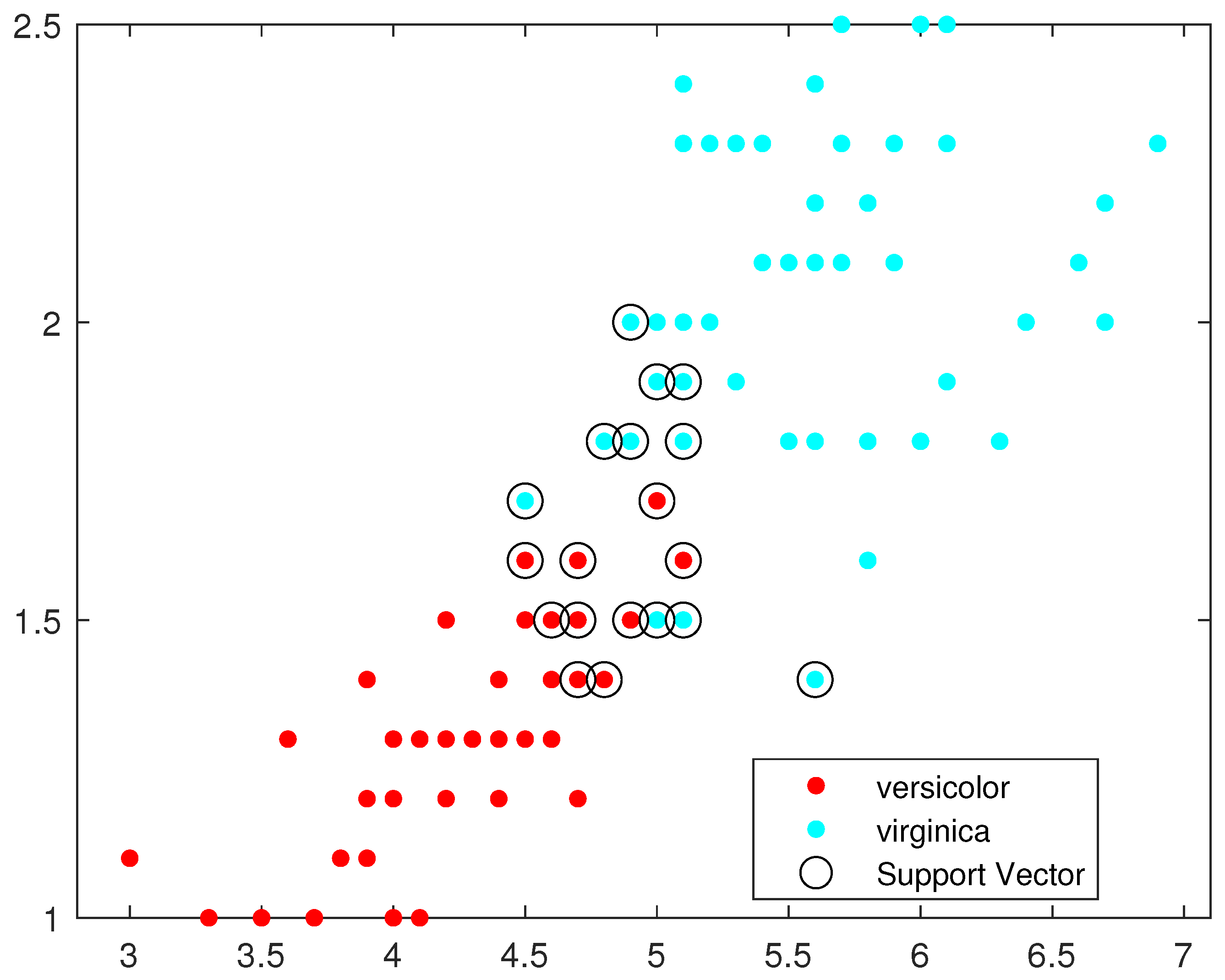
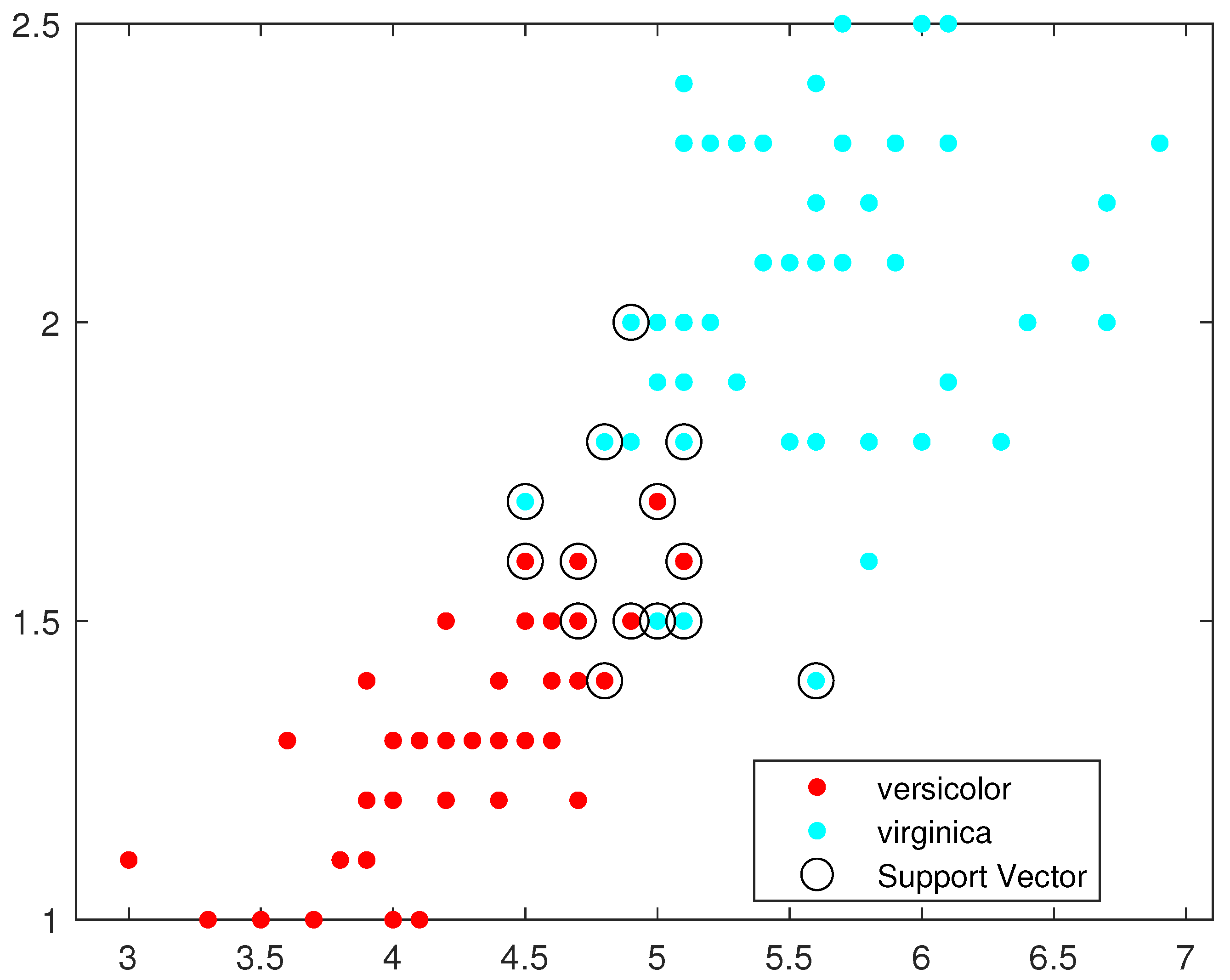
Figure 8 illustrate, respectively, the support vectors obtained using L1QP-SVM, L1QP-SVM, SMO-SVM, and Opt-RNN-SVM applied to the IRIS data. We note that (a) ISDA considers more than
as support vectors, which is an exaggeration; (b) L1QP and SMO use a reasonable number of samples as support vectors, but most of them are duplicated; and (c) thanks to the preprocessing, Opt-RNN can reduce the number of support vectors by more than
, compared to SMO and L1QP, which allows it to overcome the over-learning phenomenon encountered with SMO and L1QP. In this sense, this reasonable number of support vectors used by Opt-RNN-DBSVM will speed up the online predictions of systems that implement these support vectors, especially with regard to to sentiment analysis, which manipulates very long texts.
To analyze these results further and to evaluate the performance of multiple kernel classifiers, regardless of the data type, we perform the Friedman test to verify the statistical significance of the proposed method compared to other methods with respect to the derived mean rankings [
11]. The null hypothesis is given by
, i.e., “The kernel classifiers Opt-RNN-DB, SMO, ISDA, and L1QP perform similarly in mean rankings without a significant difference”. The considered degree of freedom of the Friedman test is 3 (number of kernel classifiers −1). The significance level is 0.05 and the considered confidence interval is 95%. Three performance measures are considered (accuracy, F1-score, precision).
Considering the accuracy measure, the average rank of the four kernel methods is given in brackets: Opt-RNN-DB(4), SMO(2.06), and L1QP(2.06), and ISDA(1.89). Opt-RNN-DB has the highest ranking, followed by SMO and L1QP. Considering the F1-score, the average rank of the four kernel methods is given in brackets: Opt-RNN-DB(4), ISDA(2.11), SMO(1.94), and L1QP(1.94). Opt-RNN-DB has the highest ranking, followed by ISDA. Considering the precision measure, the average rank of the four kernel methods is given in brackets: Opt-RNN-DB(4), ISDA(2.11), SMO(1.94), and L1QP(1.94). Opt-RNN-DB has the highest ranking, followed by ISDA.
Table 4 gives the results of the Friedman test on the kernel SVM classifiers (SOM, L1QP, ISDA) considering different performance measures. The null hypothesis
is rejected for all these kernel classifiers at a significance level of
= 0.05, indicating that the proposed hybrid classifier outperforms all other kernel classifiers. In this regard, the performance of ISDA-SVM is the closest to that of the Opt-RNN-DBSVM classifier.
5.3. Opt-RNN-DBSVM vs. Non-Kernel Classifiers
In this section, we compare Opt-RNN-DBSVM to several non-kernel classifiers, namely Naive Bayes [
45], MLP [
46], KNN [
47], AdaBoostM1 [
48], Decision Tree [
49], SGD Classifier [
50], Nearest Centroid Classifier [
50], and Classical SVM [
51].
Table A1,
Table A2,
Table A3,
Table A4,
Table A5 give the values of the measures accuracy, F1-score, precision, and recall for the considered datasets. Considering each of these performance measures, Opt-RNN-DBSVM permits remarkable improvements and clearly outperforms the other methods. The large number of classifiers and datasets makes it difficult to demonstrate this superiority without employing statistical methods.
To analyze these results further and to evaluate the performance of non-kernel classifiers (Naive Bayes (NB), MLP, KNN, AdaBoostM1 (ABM1), Nearest Centroid Classifier (NCC), Decision Tree (DT), SGD Classifier (SGDC)) compared to Opt-RNN DBSVM, regardless of the data type, we perform the Friedman test to verify the statistical significance of the proposed method compared to other methods with respect to the derived mean rankings. Three performance measures are considered (accuracy, F1-score, precision).
The null hypothesis is given by , i.e., “The classifiers NB, MLP, KNN, ABM1, NCC, DT, SGDC, Opt-RNN-DBSVM perform similarly in mean rankings without a significant difference”.
The considered degree of freedom of the Friedman test is 7 (number of non-kernel classifiers −1). The significance level is 0.05 and the considered confidence interval is 95%.
Considering the accuracy measure, the average rank of the four kernel methods is given in brackets: Opt-RNN-DBSVM(7.80), ABM1(5.2), KNN(5.2), NB(4.4), NCC(3.95), SGDC(3.55), DT(3.5), and MLP(2.4). Opt-RNN-DB has the highest ranking, followed by ABM1(5.2) and KNN(5.2). Considering the F1-score, the average rank of the four kernel methods is given in brackets: Opt-RNN-DBSVM(7.1), ABM1(5.2), KNN(5.05), NB(4.8), SGDC(4.6), NCC(4.05), DT(3.1), and MLP(2.1). Opt-RNN-DB has the highest ranking, followed by ABM1 and KNN. Considering the precision measure, the average rank of the four kernel methods is given in brackets: Opt-RNN-DBSVM(7.1), NCC(5.3), ABM1(5.15), KNN(4.9), NB(4.25), SGDC(3.95), DT(3.25), and MLP(2.1). Opt-RNN-DB has the highest ranking, followed by NCC and ABM1.
Table 5 gives the results of the Friedman test on the non-kernel classifiers (NB, MLP, KNN, ABM1, NCC, DT, and SGDC) considering three performance measures (accuracy, F1-score, and precision). The null hypothesis
is rejected for all these classifiers at a significance level of
= 0.05, indicating that the proposed hybrid classifier outperforms all other non-kernel classifiers. In this regard, the performance of ABM1 is the closest to that of the Opt-RNN-DBSVM classifier.
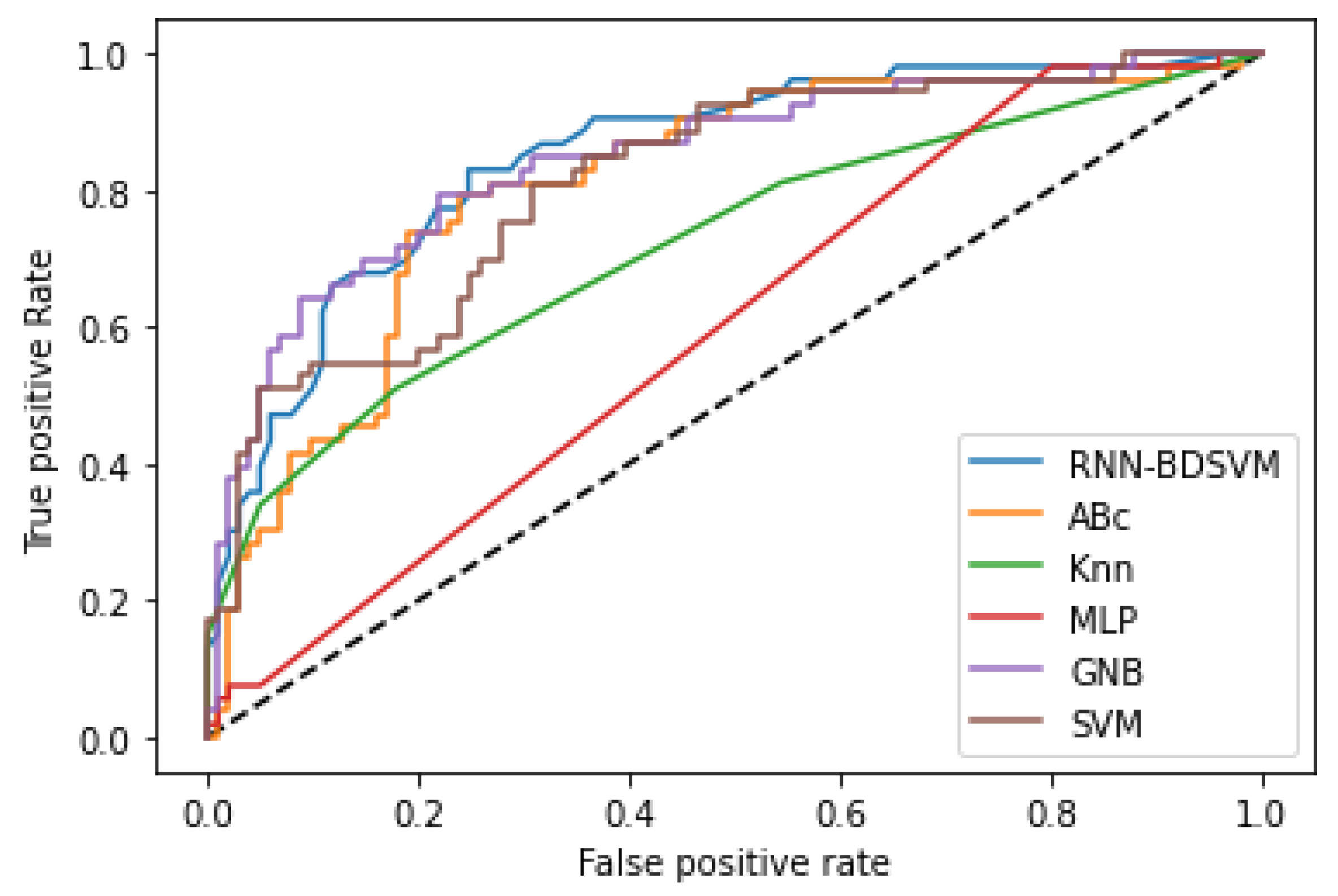
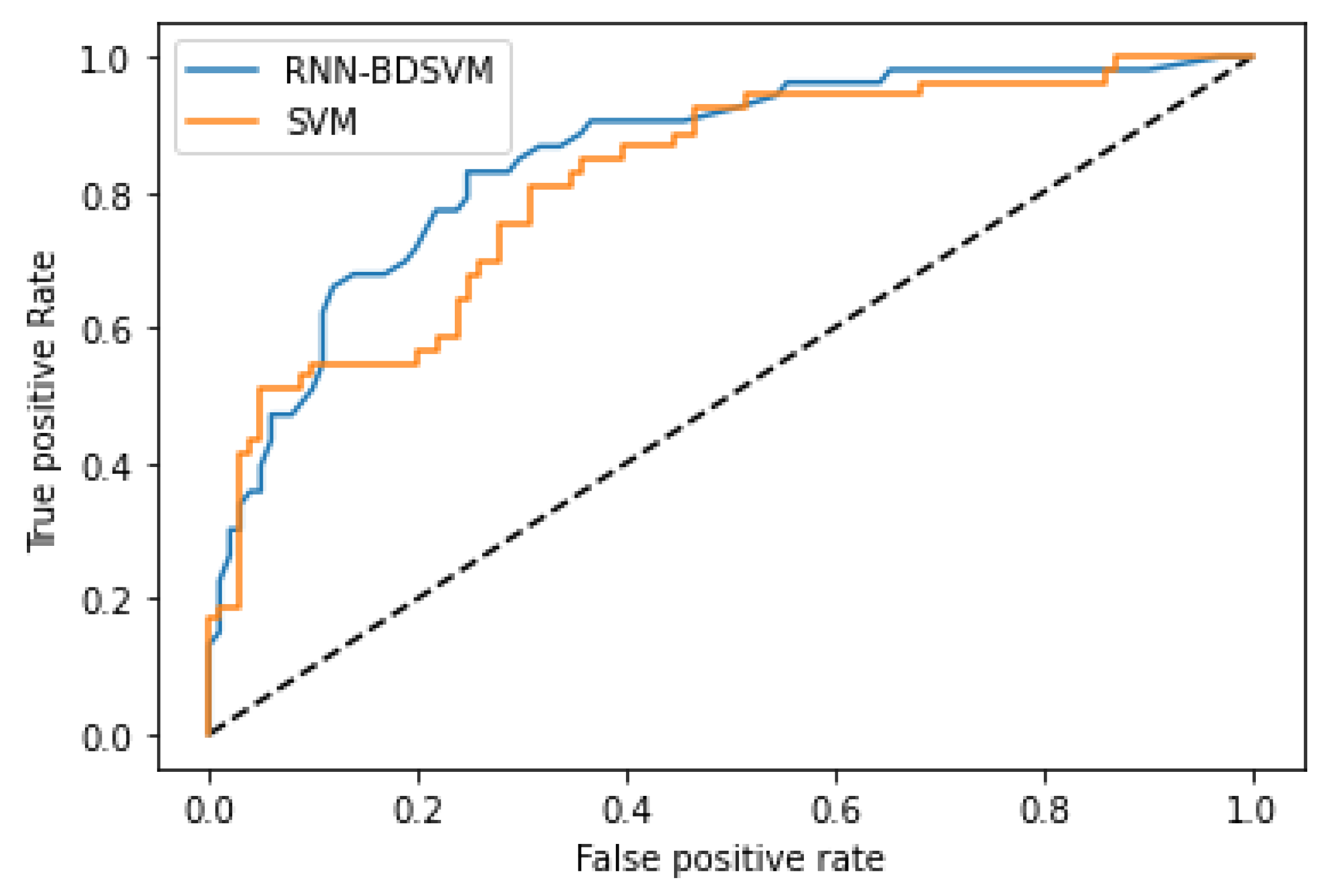
Additional comparison studies were performed on the PIMA and Germany Diabetes datasets and the ROC curves were used to calculate the AUC for the best performance obtained from each non-kernel classifier.
Figure A4 and
Figure A6 show the comparison of the ROC curves of the classifiers DT, KNN, MLP, NB, etc., and the Opt-RNN-DBSVM method, evaluated on the PIMA dataset. We point out that Opt-RNN-DBSVM quickly converges to the best results and obtains more true positives and a smaller number of false positives compared to several other classification methods.
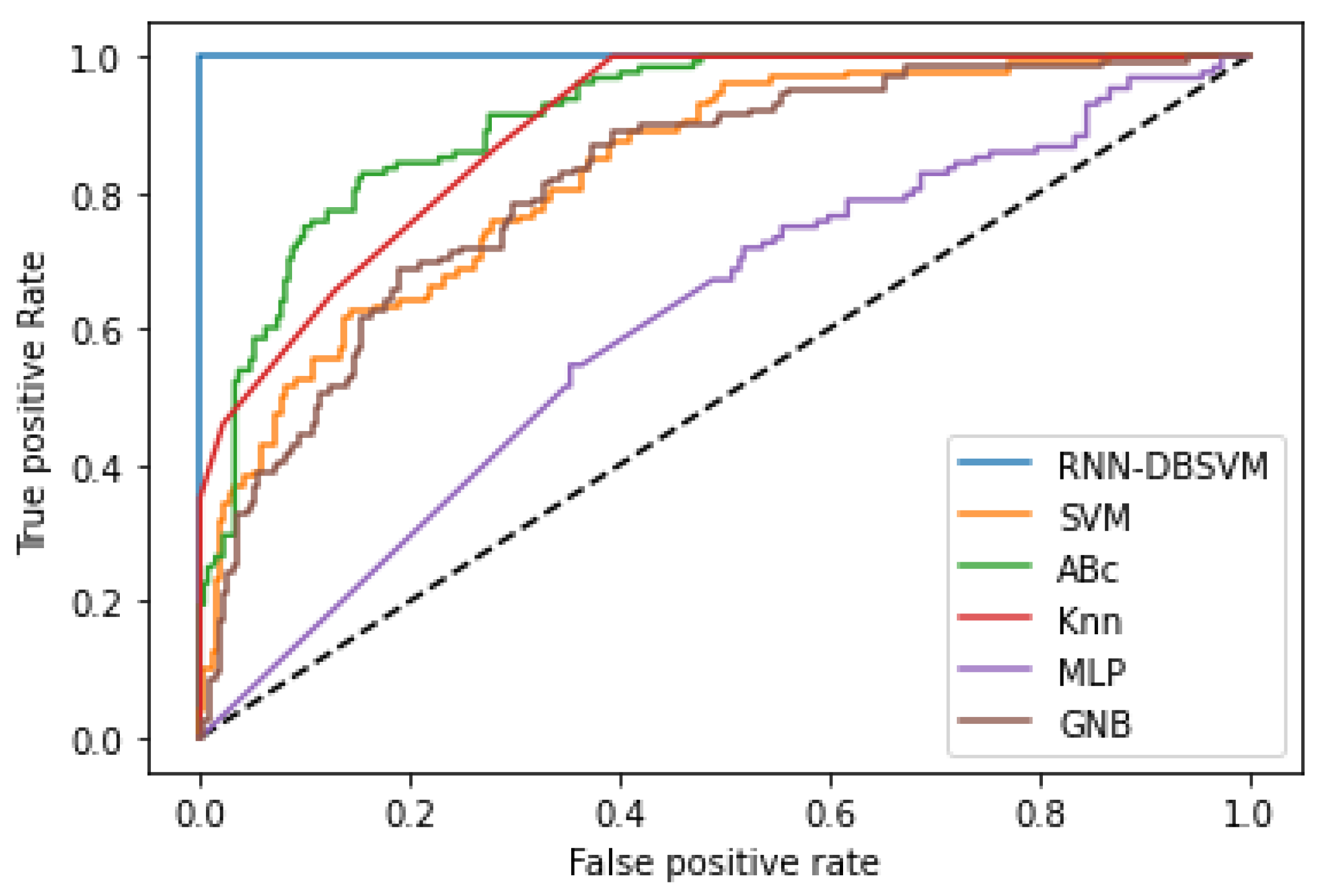
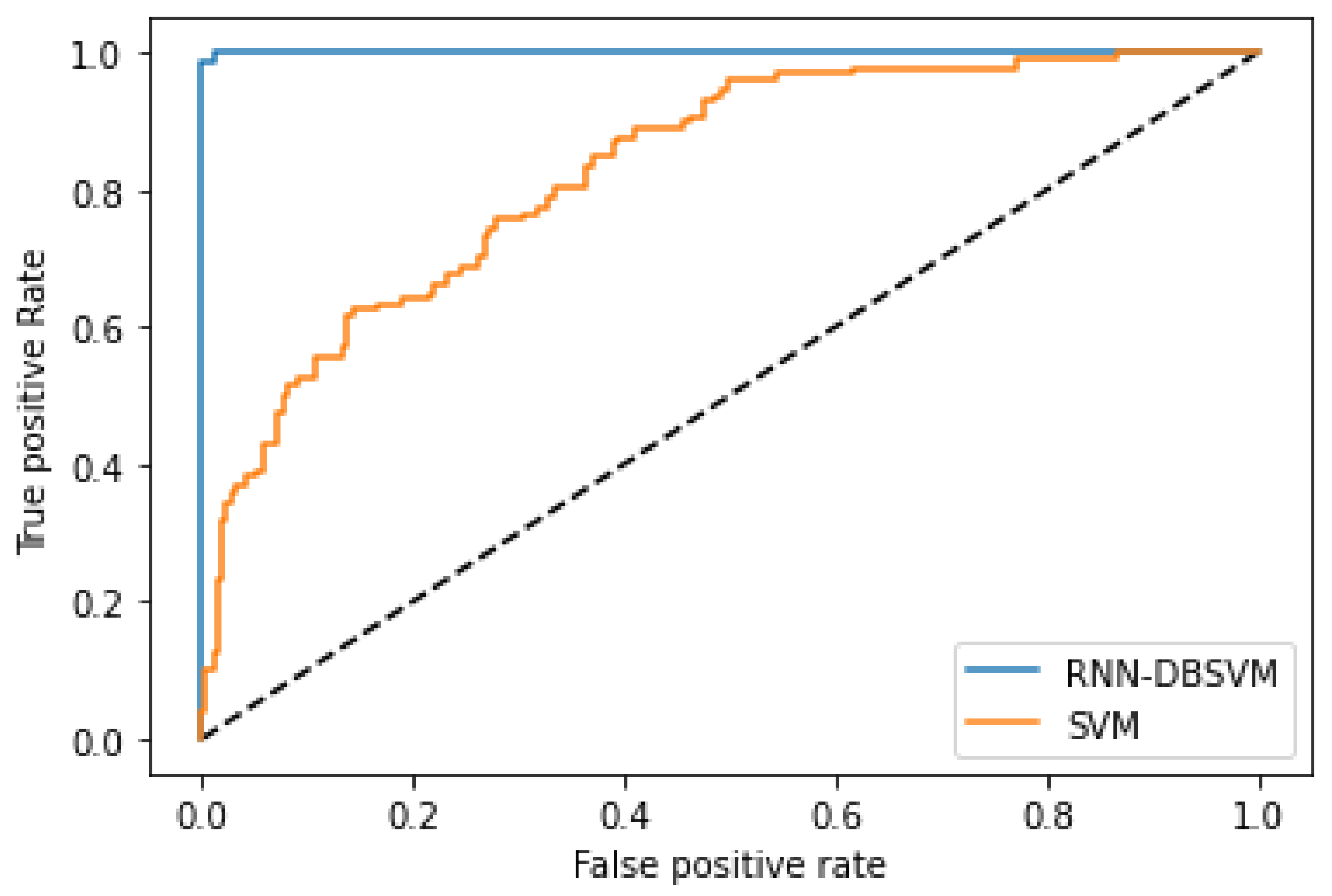
More comparisons are given in
Appendix B;
Figure A5 and
Figure A7 show the comparison of the ROC curves of the classical SVM and Opt-RNN-DBSVM methods, evaluated on the Germany Diabetes dataset. More specifically, considering the performance measures “false positive rate” and “true positive rate”, predictions based on support vectors produced by Opt-RNN-DBSVM dominate predictions based on support vectors produced by other non-kernel classifiers.
6. Conclusions
The main challenges of SVM implementation are the number of local minima and the amount of computer memory required to solve the dual-SVM, which increase exponentially with respect to the size of the dataset. The Kernel-Adatron family of algorithms, ISDA and SMO, has handled very large classification and regression problems. However, these methods treat noise, boundary, and kernel samples in the same way, resulting in a blind search in unpromising areas. In this paper, we have introduced a hybrid approach to deal with these drawbacks, namely Optimal Recurrent Neural Network and Density-Based Support Vector Machine (Opt-RNN-DBSVM), which performs in six phases: the characterization of different samples, the elimination of samples having a weak probability of being support vectors, building an appropriate recurrent neural network based on an original energy function, and solving the differential equation system governing the RNN dynamics, using the Euler–Cauchy method implementing an optimal time step. Data preprocessing reduces the number of local minima in the dual-SVM; this reduction enables real-time decision making in big data problems. The RNN’s recurring architecture avoids the need to explore recently visited areas; this is an implicit tabu search. With the optimal time step, the search moves from the current vectors to the best neighboring support vectors. On one hand, two main, interesting fundamental results were demonstrated: the convergence of RNN-SVM to feasible solutions and the fact that Opt-RNN-DBSVM has very low time complexity compared to Const-RNN-SVM, SMO-SVM, ISDA-SVM, and L1QP-SVM. On the other hand, several experimental studies were conducted based on well-known datasets (IRIS, ABALONE, WINE, ECOLI, BALANCE, LIVER, SPECT, SEED, PIMA). Based on popular performance measures (accuracy, F1-score, precision, recall), Opt-RNN-DBSVM outperformed Const-RNN-SVM, KA-SVM, and some non-kernel models (cited in
Table A1). In fact, Opt-RNN-DBSVM improved the accuracy by up to 3.43%, F1-score by up to 2.31%, precision by up to 7.52%, and recall by up to 6.5%. In addition, compared to SMO-SVM, ISDA-SVM, and L1QP-SVM, Opt-RNN-DBSVM provides a reduction in the number of support vectors by up to 32%, which permits us to save memory for large applications that implement several machine learning models. The main problem encountered in the implementation of Opt-RNN-DBSVM is the determination of the Lagrange parameters involved in the SVM energy function. In this sense, a genetic strategy will be introduced to determine these parameters considering each dataset. In future work, extensions of this method may include combining Opt-RNN-DBSVM with big data technologies to accelerate classification tasks on big data and introducing hybrid versions based on Opt-RNN, deep learning, and fuzzy-SVM.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}