

A Study of Multifactor Quantitative Stock-Selection Strategies Incorporating Knockoff and Elastic Net-Logistic Regression

Abstract
1. Introduction
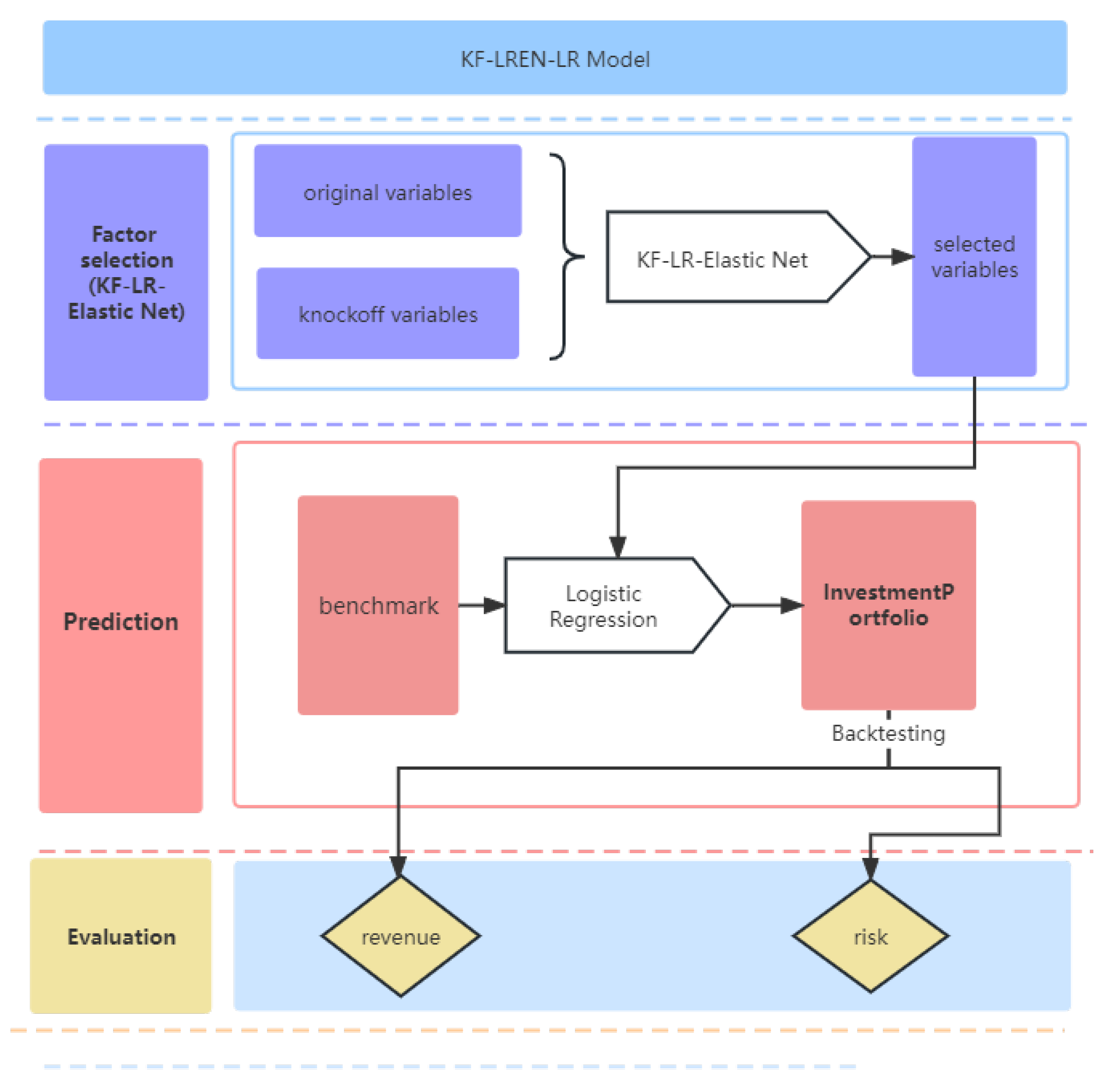
2. Factor-Selection Model: KF-LR-Elastic Net
2.1. Model Construction: LR-Elastic Net
2.1.1. General Logistic Regression
2.1.2. Lasso/Ridge-Logistic Regression Model
2.1.3. LR-Elastic Net
2.2. Model Construction: KF-LR-Elastic Net
2.2.1. The Main Idea of Knockoff
2.2.2. Knockoff Variable Creation
2.2.3. KF-LR-Elastic Net
2.3. Prediction Model: Logistic Regression
3. Empirical Analysis
3.1. Data Collection and Processing
3.1.1. Data Selection
3.1.2. ADF Test
3.1.3. Data Processing
- (1)
- Missing value processing. The number of factors selected in this study is large, so the processing of missing values is divided into two steps: deletion and interpolation. In the first step, we remove the records with missing returns and then remove the records with missing factor indicators greater than 15% and those with missing factor values over 10%. In the second step, the missing values are interpolated in two situations: if a stock’s data on a factor are partially missing, they are filled by linear interpolation in the time series; if they are entirely missing, they are either replaced by the average values of the data of the stocks in the same industry as the stock or filled by interpolation.
- (2)
- Normalization. This may have a negative effect on the subsequent factor selection and may slow down the convergence of the machine learning model during the training process because the magnitudes of the factors in different categories vary, which may result in significant differences in the magnitudes of the factors. Therefore, each factor is standardized by using the following equation:where and are the mean and standard deviation of the variable x, respectively.
- (3)
- Neutralizing. Similar to purging the factors and roughly resolving the interfactor correlation, the neutralization procedure’s goal is to eliminate the bias and duplication that are inherent in the factors. A multifactor stock-selection model’s return volatility and stability will both rise if it contains factors that mostly carry repeating information. The PE of the banking industry is incredibly low whereas the PE ratio of the internet industry is the reverse as most stock factors have evident industry and market capitalization characteristics. In this study, we use market capitalization and industry neutralization to process the factor data and, after removing any exposure to incorrect factors, arrive at the pure factors.
3.2. Comparison Model and Evaluation Index
3.2.1. Model Prediction Classification Evaluation Metrics
3.2.2. Factor Selection Based on KF-LR-Elastic Net
3.3. Model Prediction Classification Evaluation
3.4. Stock-Selection Strategy and Backtest Analysis
3.4.1. Investment Strategy Building
3.4.2. Backtest Analysis of Multifactor Quantitative Stock-Selection Strategies under Different Market Environments
3.4.3. Backtest Analysis in an Uptrend
3.4.4. Backtest Analysis in a Downtrend
3.4.5. Backtest Analysis in a Shock Trend
4. Conclusions and Prospect
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Markowitz, H.M. Portfolio selection. J. Financ. 1952, 7, 77–91. [Google Scholar] [CrossRef]
- Sharpe, W.F. Capital asset prices: A theory of market equilibrium under conditions of risk. J. Financ. 1964, 19, 425–442. [Google Scholar] [CrossRef]
- Ross, S.A. The arbitrage theory of capital asset pricing. J. Econ. Theory 1976, 13, 341–360. [Google Scholar] [CrossRef]
- Fama, E.F.; French, K.R. Common risk factors in the returns on stocks and bonds. J. Financ. Econ. 1993, 33, 3–56. [Google Scholar] [CrossRef]
- Carhart, M.M. On persistence in mutual fund performance. J. Financ. 1997, 52, 57–82. [Google Scholar] [CrossRef]
- Fama, E.F.; French, K.R. A five-factor asset pricing model. J. Financ. Econ. 2015, 116, 1–22. [Google Scholar] [CrossRef]
- Stambaugh, R.F.; Yuan, Y. Mispricing factors. Rev. Financ. Stud. 2017, 30, 1270–1315. [Google Scholar] [CrossRef]
- Asness, C.S. The interaction of value and momentum strategies. Financ. Anal. J. 1997, 53, 29–36. [Google Scholar] [CrossRef]
- Fan, J.; Lv, J. A selective overview of variable selection in high dimensional feature space. Stat. Sin. 2010, 4, 101–148. [Google Scholar] [CrossRef][Green Version]
- Hastie, T.; Tibshirani, R. Generalized Additive Models. Stat. Sci. 1986, 1, 297–318. [Google Scholar] [CrossRef]
- Lin, Y.; Zhang, H.H. Component selection and smoothing in multivariate nonparametric regression. Ann. Stat. 2006, 34, 2272–2297. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Y.; Zheng, F.; Deng, C.; Huang, H. Sparse modal additive model. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 2373–2387. [Google Scholar] [CrossRef] [PubMed]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Yuan, M.; Lin, Y. Model selection and estimation in regression with grouped variables. J. R. Stat. Soc. Ser. B 2006, 68, 49–67. [Google Scholar] [CrossRef]
- Bach, F.R. Consistency of the group lasso and multiple kernel learning. J. Mach. Learn. Res. 2008, 9, 1179–1225. [Google Scholar] [CrossRef]
- Lemhadri, I.; Ruan, F.; Tibshirani, R. Lassonet: Neural networks with feature sparsity. Mach. Learn. Res. 2019, 130, 10–18. [Google Scholar] [CrossRef]
- Ravikumar, P.; Liu, H.; Lafferty, J.; Wasserman, L.A. SpAM: Sparse Additive Models. J. R. Stat. Soc. Ser. Stat. Methodol. 2009, 71, 1009–1030. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Wang, X.C. Construction of quantitative trading intelligence System based on LASSO and neural network–Shanghai and Shenzhen 300 stock index futures as an example. Investig. Res. 2014, 33, 23–29. https://doi.org/CNKI:SUN:TZYJ.0.2014-09-003.
- Li, B.; Shao, X.; Li, Y. Research on fundamental quantitative investment driven by Machine learning. China’s Ind. Econ. 2019, 8, 61–79. [Google Scholar] [CrossRef]
- Shu, S.; Li, L. Regular sparse multi-factor quantitative stock selection Strategy. Comput. Eng. Appl. 2021, 10, 110–117. [Google Scholar] [CrossRef]
- Jagannathan, R.; Ma, T. Risk reduction in large portfolios: Why imposing the wrong constraints helps. J. Financ. 2003, 58, 1651–1683. [Google Scholar] [CrossRef]
- Benjamini, Y.; Hochberg, Y. Controlling the false discovery rate: A practical and powerful approach to multiple testing. J. R. Stat. Soc. Ser. B 1995, 57, 289–300. [Google Scholar] [CrossRef]
- Barber, R.F.; Candes, E.J. Controlling the False Discovery Rate Via Knockoffs. Ann. Stat. 2015, 43, 2055–2085. [Google Scholar] [CrossRef]
- Candes, E.; Fan, Y.; Janson, L.; Lv, J. Panning for gold: Model-x knockoffs for high-dimensional controlled variable selection. J. R. Stat. Soc. Ser. B Stat. 2018, 80, 551–577. [Google Scholar] [CrossRef]
- Fan, Y.; Demirkaya, E.; Lv, J. Nonuniformity of p-values can occur early in diverging dimensions. J. Mach. Learn. Res. 2019, 20, 2849–2881. [Google Scholar] [CrossRef]
- Gégout-Petit, A.; Gueudin-Muller, A.; Karmann, C. The revisited knockoffs method for variable selection in L 1-penalized regressions. Commun.-Stat.-Simul. Comput. 2020, 51, 5582–5595. [Google Scholar] [CrossRef]
- Katsevich, E.; Sabatti, C. Multilayer knockoff filter: Controlled variable selection at multiple resolutions. Ann. Appl. Stat. 2019, 13, 1–33. [Google Scholar] [CrossRef]
- Barber, R.F.; Candès, E.J. A knockoff filter for high-dimensional selective inference. Ann. Stat. 2019, 5, 2504–2537. [Google Scholar] [CrossRef]
- Liu, W.; Ke, Y.; Liu, J.; Li, R. Model-Free Feature Screening and F DR Control with Knockoff Features. J. Am. Stat. Assoc. 2022, 117, 428–443. [Google Scholar] [CrossRef]
- Dai, R.; Barber, R. The knockoff filter for FDR control in group-sparse and multitask regression. JMLR 2016, 47, 1851–1859. [Google Scholar] [CrossRef]
- Srinivasan, A.; Xue, L.; Zhan, X. Compositional knockoff filter for high-dimensional regression analysis of microbiome data. Biometrics 2021, 77, 984–995. [Google Scholar] [CrossRef] [PubMed]
- Zhu, G.; Zhao, T. Deep-gknock: Nonlinear group-feature selection with deep neural networks. Neural Networks. Neural Netw. 2021, 135, 139–147. [Google Scholar] [CrossRef] [PubMed]
- Hoerl, A.E.; Kennard, R.W. Ridge Regression: Applications to Nonorthogonal Problems. Technometrics 1970, 12, 69–82. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization, 1st ed.; Cambridge University Press: Cambridge, UK, 2004; pp. 127–189. [Google Scholar] [CrossRef]
- Zhang, H.; Shen, H.; Liu, Y. The study on multi-factor quantitative stock selection based on self-attention neural network. J. Appl. Stat. Manag. 2020, 29, 556–570. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title | Value |
|---|---|
| Test Statistic | −1.6165 |
| p-value | 0.7407 |
| Lags Used | 11 |
| Number of observations used | 1703 |
| Critical Value (1%) | −3.2125 |
| Critical Value (5%) | −2.2354 |
| Critical Value (10%) | −2.1583 |
| KF-LR-Elastic Net | KF-LR-Elastic Net | LR-Elastic Net | KF-LR-Lasso |
|---|---|---|---|
| PB | PB | PB | PB |
| PE | PE | PE | PE |
| - | - | LFLO | LFLO |
| ARTRate | - | ARTRate | ARTRate |
| GrossIncomeRatio | GrossIncomeRatio | GrossIncomeRatio | GrossIncomeRatio |
| ROE | ROE | ROE | ROE |
| NetProfitGrowRate | NetProfitGrowRate | NetProfitGrowRate | NetProfitGrowRate |
| FSALESG | FSALESG | FSALESG | FSALESG |
| DVRAT | DVRAT | HBETA | DVRAT |
| SKEW | SKEW | SKEW | SKEW |
| DDNBT | DDNBT | DDNBT | DDNBT |
| - | - | - | DDNSR |
| DDNSR | - | TOBT | TOBT |
| FiftyTwoweekHigh | FiftyTwoweekHigh | FiftyTwoweekHigh | FiftyTwoweekHigh |
| EARNMOM | EARNMOM | EARNMOM | EARNMOM |
| - | MACD | MACD | MACD |
| Hurst | Hurst | Hurst | Hurst |
| DHILO | DHILO | DHILO | DHILO |
| BIAS5 | BIAS5 | BIAS5 | BIAS5 |
| VR | VR | VR | VR |
| - | - | ADX | ADX |
| GREV | GREV | GREV | GREV |
| SFY12P | SFY12P | SFY12P | SFY12P |
| GSREV | - | - | GSREV |
| - | - | OBV6 | OBV6 |
| Prediction Model | Factor-Selection Model | Accuracy | Recall | Precision | F1 |
|---|---|---|---|---|---|
| LR | KF-LR-Elastic Net | 75.45% | 71.55% | 75.30% | 73.38% |
| KF-LR-Elastic Net | 75.48% | 71.56% | 75.37% | 73.42% | |
| LR-Elastic Net | 74.35% | 70.86% | 72.84% | 71.84% | |
| KF-LR-Lasso | 74.77% | 71.13% | 73.78% | 72.43% |
| Factor-Selection Model | Prediction Model | Accuracy | Recall | Precision | F1 |
|---|---|---|---|---|---|
| KF-LR-Elastic Net | LR | 75.45% | 71.55% | 75.30% | 73.38% |
| SVM | 74.44% | 70.92% | 73.04% | 71.96% | |
| RF | 74.45% | 70.93% | 73.07% | 71.99% | |
| LSTM | 75.31% | 71.46% | 74.98% | 73.18% |
| Index | Annual Rate of Return | CSI 300 Return | Beta | Information Ratio | Sharpe |
|---|---|---|---|---|---|
| Value | 21.45% | −21.63% | 0.48 | 1.52 | 0.61 |
| Index | Winning percentage | Profit and loss ratio | Alpha | Maximum pullback | |
| Value | 0.53 | 2.09 | 0.30 | 17.67% |
| Category | Up | Down | Volatile |
|---|---|---|---|
| Backtest period | 4.26–6.28 | 7.4–10.11 | 10.17–12.30 |
| Benchmark return | 17.71 | −16.55 | 2.89 |
| Tactics return | 21.56 | 1.86 | 0.60 |
| Annual rate of return | 219.71 | 7.24 | 3.74 |
| Beta | 0.97 | 0.79 | 0.55 |
| Alpha | 0.60 | 0.46 | 0.09 |
| Sharpe ratio | 8.33 | 0.12 | −0.01 |
| Winning percentage | 0.75 | 0.46 | 0.40 |
| Profit and loss ratio | 5.14 | 3.87 | 1.79 |
| Information ratio | 3.05 | 2.40 | −0.66 |
| Maximum pullback | 2.96 | 9.92 | 9.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, Y.; Tang, G.; Li, X.; Chen, X. A Study of Multifactor Quantitative Stock-Selection Strategies Incorporating Knockoff and Elastic Net-Logistic Regression. Mathematics 2023, 11, 3502. https://doi.org/10.3390/math11163502
Ren Y, Tang G, Li X, Chen X. A Study of Multifactor Quantitative Stock-Selection Strategies Incorporating Knockoff and Elastic Net-Logistic Regression. Mathematics. 2023; 11(16):3502. https://doi.org/10.3390/math11163502
Chicago/Turabian StyleRen, Yumei, Guoqiang Tang, Xin Li, and Xuchang Chen. 2023. "A Study of Multifactor Quantitative Stock-Selection Strategies Incorporating Knockoff and Elastic Net-Logistic Regression" Mathematics 11, no. 16: 3502. https://doi.org/10.3390/math11163502
APA StyleRen, Y., Tang, G., Li, X., & Chen, X. (2023). A Study of Multifactor Quantitative Stock-Selection Strategies Incorporating Knockoff and Elastic Net-Logistic Regression. Mathematics, 11(16), 3502. https://doi.org/10.3390/math11163502