


Transformer Models and Convolutional Networks with Different Activation Functions for Swallow Classification Using Depth Video Data
 , ,
, ,  and
and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Participant Recruitment
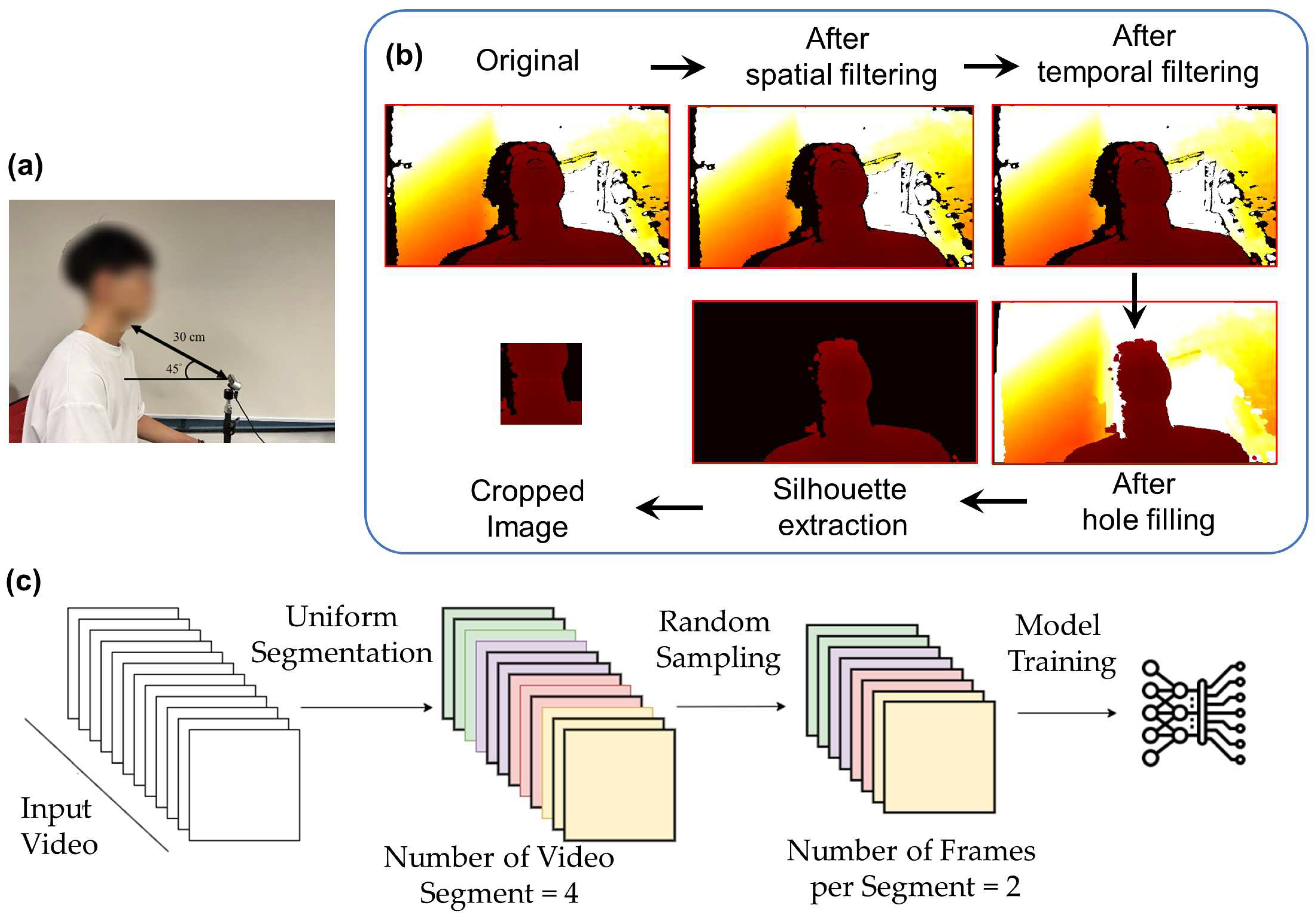
2.2. System Setup
2.3. Experimental Procedure
2.4. Data Processing
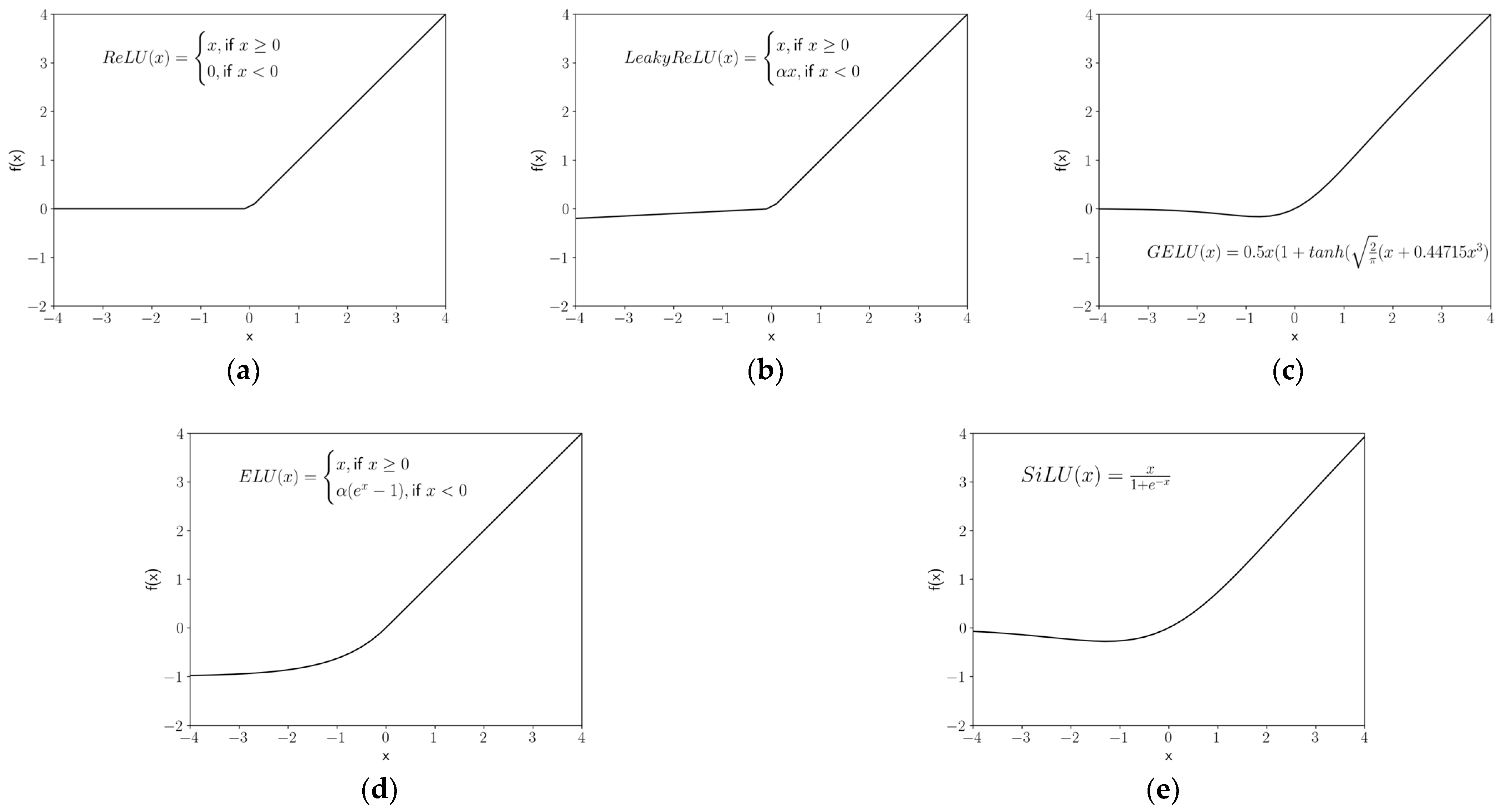
2.5. Activation Functions
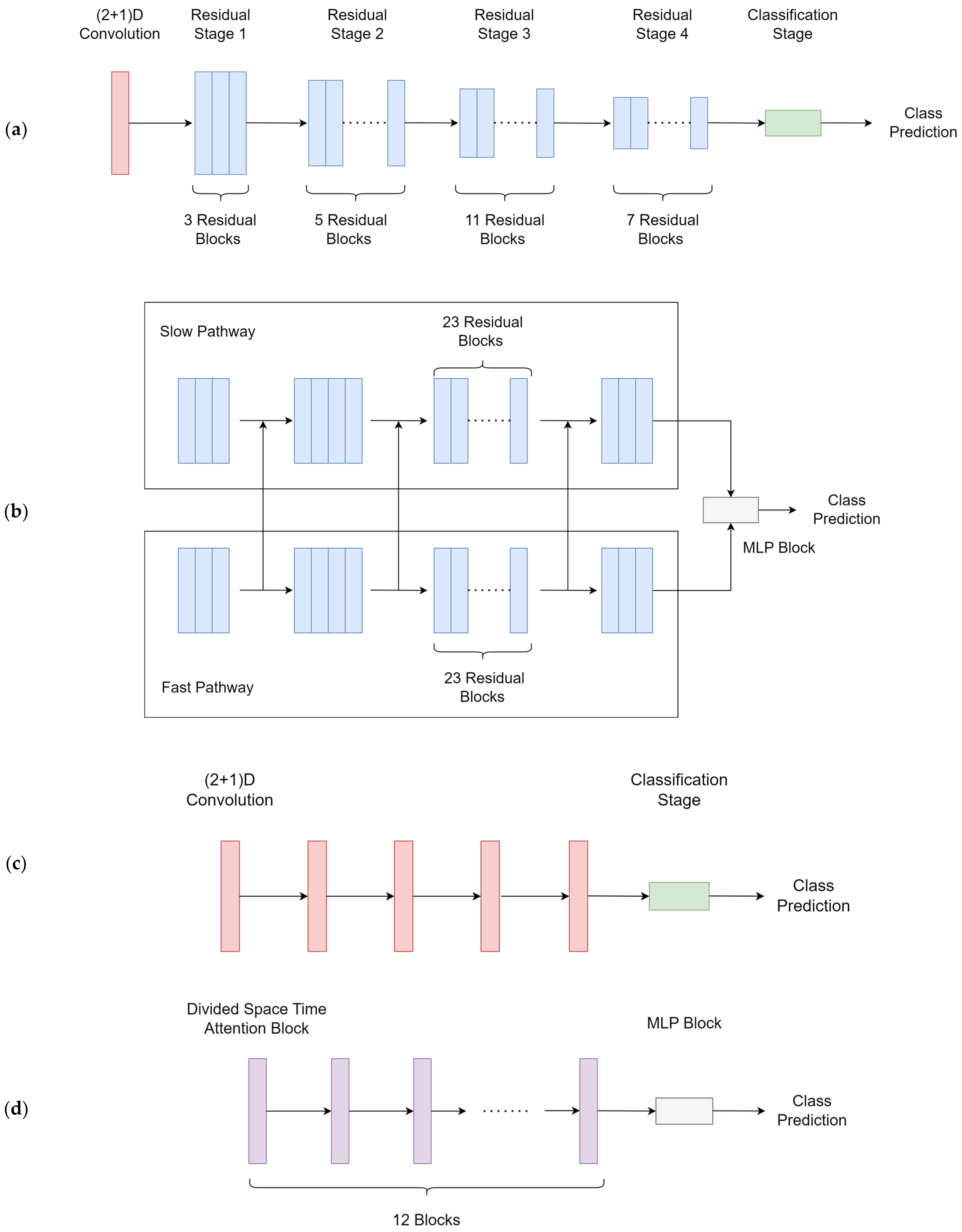
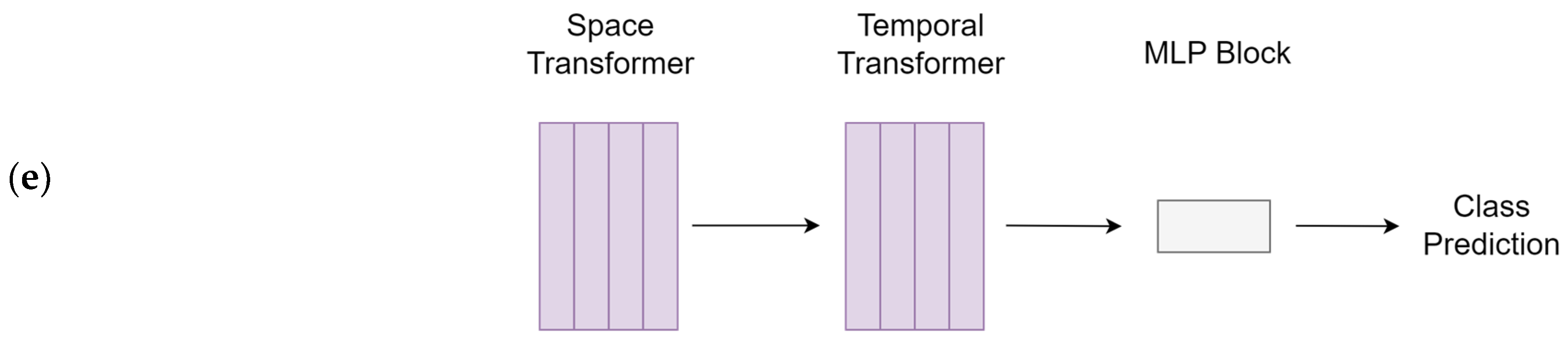
2.6. Model Training
2.7. Outcome Measures and Data Analysis (Model Evaluation)
3. Results
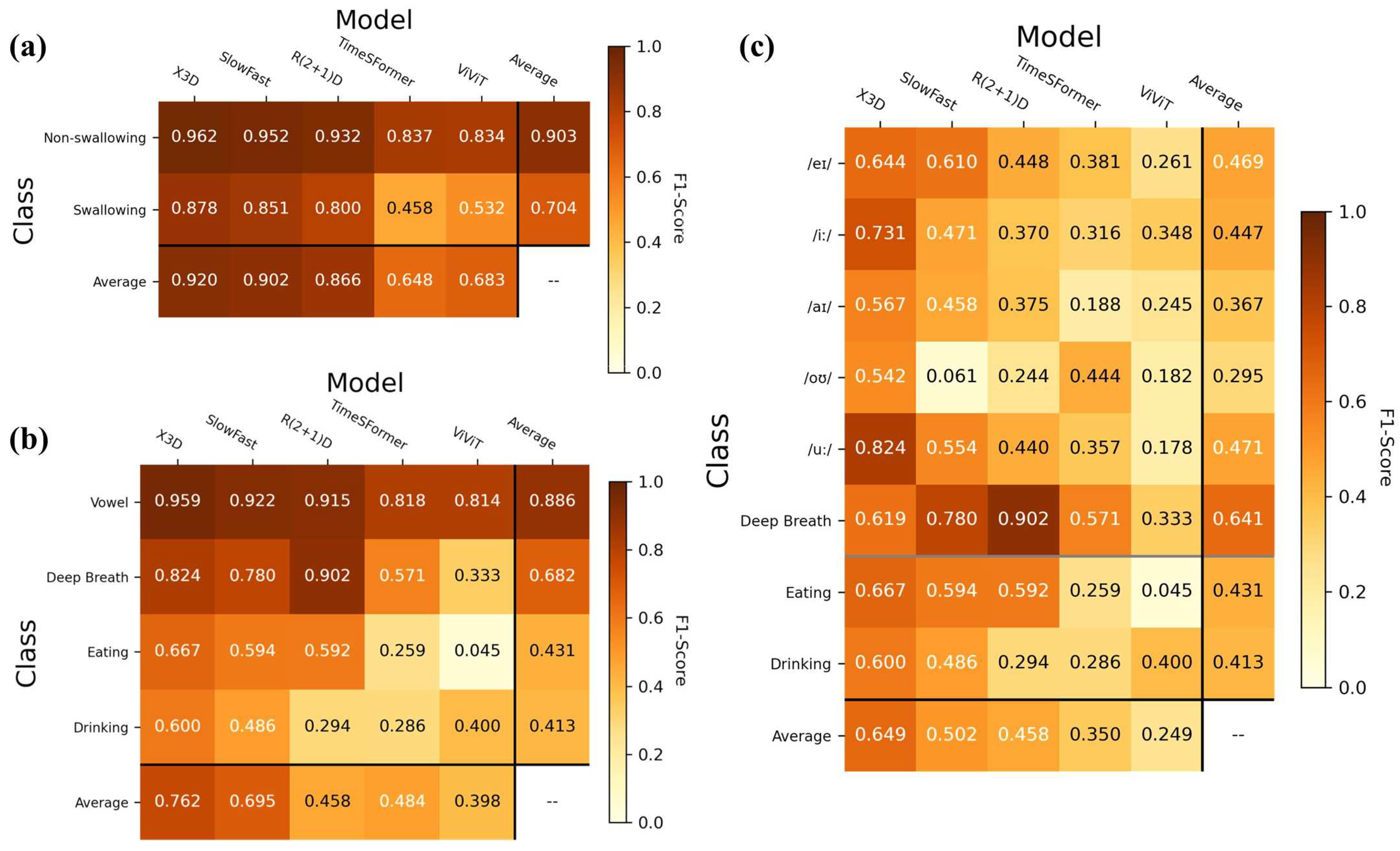
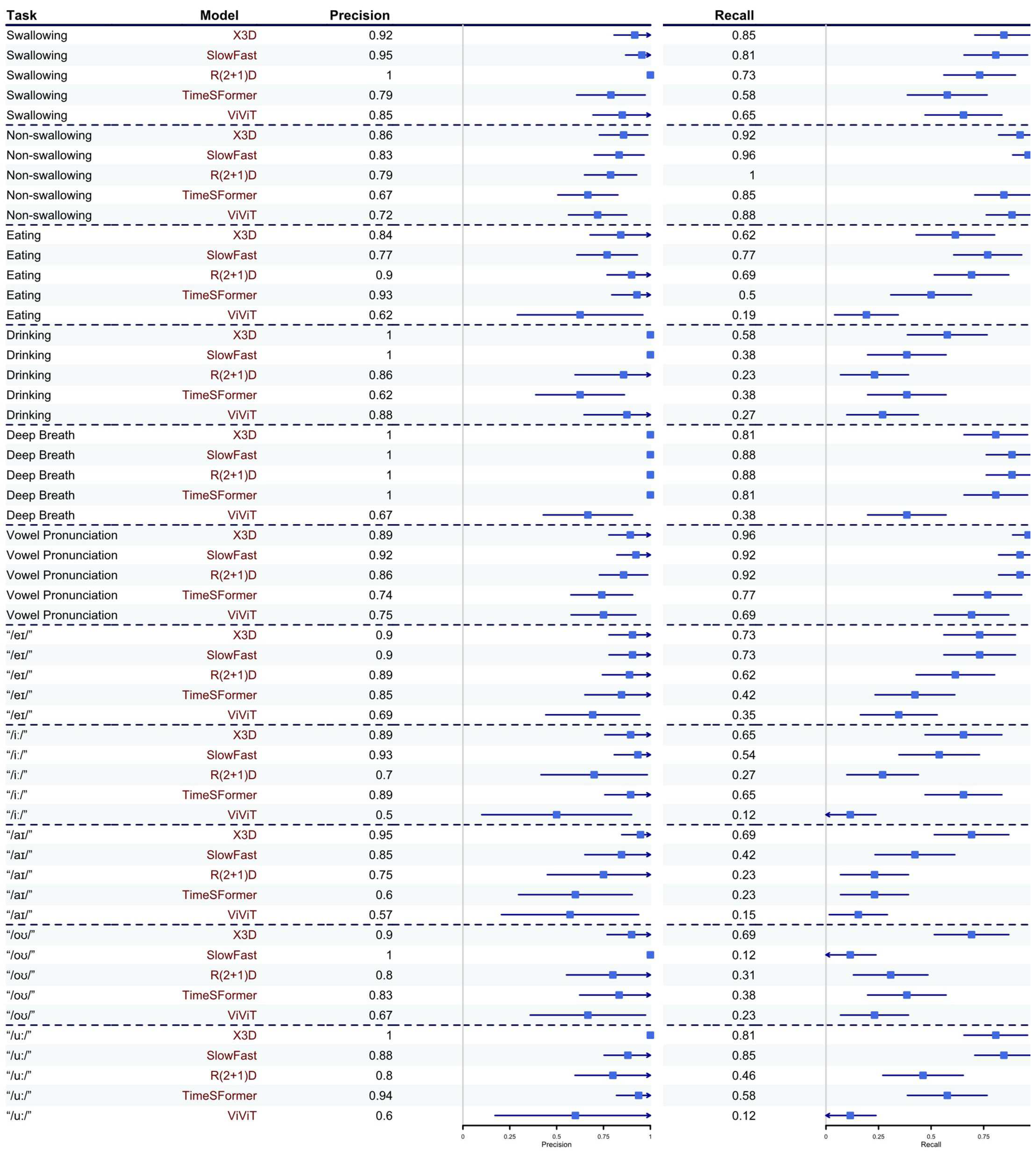
3.1. Model Performance
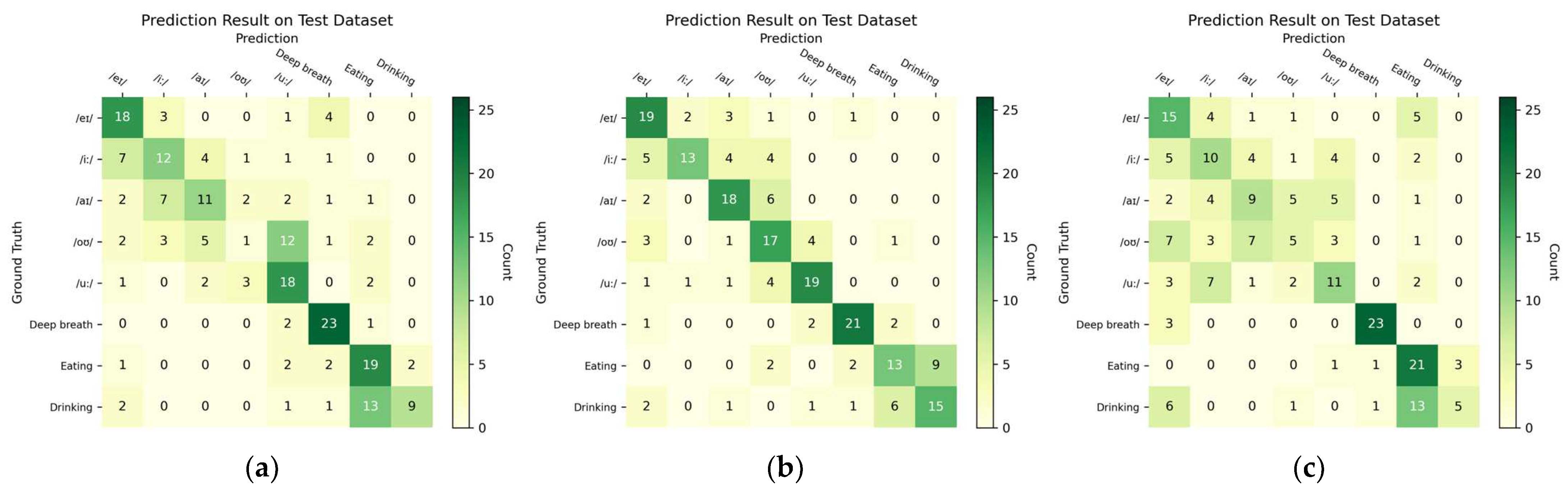
3.2. Task Prediction Performance
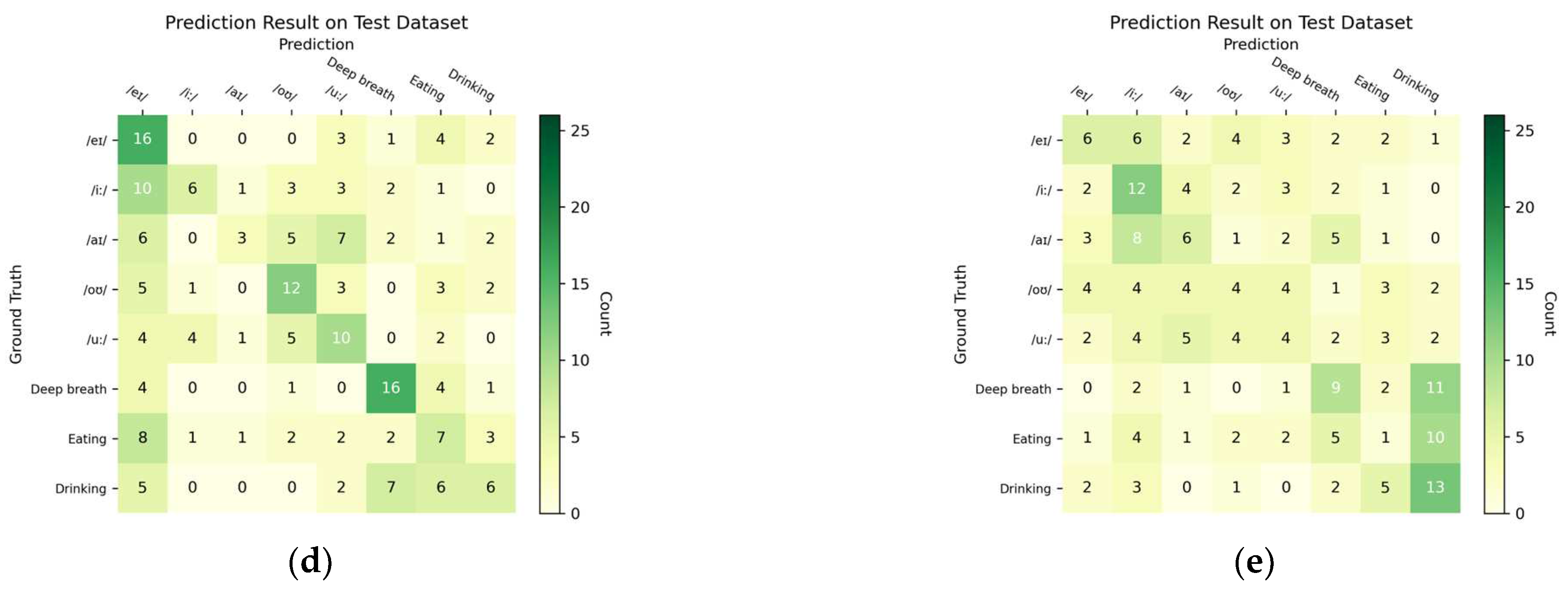
3.3. Evaluation of Activation Functions on the Best Model
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
| Algorithm A1: The pseudocode of the video frame sampling | |
| 1: | Input: V, the input video withnumber of frames |
| 2: | s, the number of segments |
| 3: | n, the number of frames per segments |
| 4: | Output: Array of sampled video frames |
| 5: | (Compute distance between segments that are approximately evenly spread across the video frames) |
| 6: | Initialized array A [0 … s*n] |
| 7: | for each segment in video segment to where k from 0. s do |
| 8: | (Get the start index of the segment) |
| 9: | for j in 0 … n do |
| 10: | (Append sampled frames to the array) |
| 11: | end for |
| 12: | end for |
| 13: | return A |
| Algorithm A2: The pseudocode of Adam optimization method | |
| 1: | Input: , learning rate |
| 2: | , exponential decay rates for the moment estimates |
| 3: | , stochastic objective function with parameters |
| 4: | , initial parameter vector |
| 5: | , small value to prevent division by zero |
| 6: | Output: , resulting parameter vector after t timesteps |
| 7: | |
| 8: | |
| 9: | |
| 10: | while not converged do |
| 11: | |
| 12: | (Compute gradient for the parameters) |
| 13: | (Update biased first moment estimate) |
| 14: | (Update biased second raw moment estimate) |
| 15: | (Compute bias-corrected first moment estimate) |
| 16: | (Compute bias-corrected second raw moment estimate) |
| 17: | ) (Update parameters) |
| 18: | end while |
| 19: | return |
| Algorithm A3: The pseudocode of Bootstrapping | |
| 1: | Input: , dataset of depth videos with label a |
| 2: | , dataset of depth videos without label a |
| 3: | , size of each bootstrap sample |
| 4: | Output: B, array containing the bootstrap samples |
| 5: | Initialize empty array B |
| 6: | For t from 0 to n − 1 do |
| 7: | Randomly select an index from |
| 8: | Add the depth video with index i in to B |
| 9: | Randomly select an index from |
| 10: | Add the depth video with index i in to B |
| 11: | end for |
| 12: | return B |
References
- Patel, D.; Krishnaswami, S.; Steger, E.; Conover, E.; Vaezi, M.; Ciucci, M.; Francis, D. Economic and survival burden of dysphagia among inpatients in the United States. Dis. Esophagus 2018, 31, 131. [Google Scholar] [CrossRef]
- Rogus-Pulia, N.; Malandraki, G.A.; Johnson, S.; Robbins, J. Understanding dysphagia in dementia: The present and the future. Curr. Phys. Med. Rehabil. Rep. 2015, 3, 86–97. [Google Scholar] [CrossRef]
- Smukalla, S.M.; Dimitrova, I.; Feintuch, J.M.; Khan, A. Dysphagia in the elderly. Curr. Treat. Options Gastroenterol. 2017, 15, 382–396. [Google Scholar] [CrossRef]
- Warnecke, T.; Labeit, B.; Schroeder, J.; Reckels, A.; Ahring, S.; Lapa, S.; Claus, I.; Muhle, P.; Suntrup-Krueger, S.; Dziewas, R. Neurogenic dysphagia: Systematic review and proposal of a classification system. Neurology 2021, 96, e876–e889. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. The ICD-10 Classification of Mental and Behavioural Disorders: Clinical Descriptions and Diagnostic Guidelines; World Health Organization: Geneva, Switzerland, 1992. [Google Scholar]
- Malagelada, J.-R.; Bazzoli, F.; Boeckxstaens, G.; De Looze, D.; Fried, M.; Kahrilas, P.; Lindberg, G.; Malfertheiner, P.; Salis, G.; Sharma, P. World gastroenterology organisation global guidelines: Dysphagia—Global guidelines and cascades update September 2014. J. Clin. Gastroenterol. 2015, 49, 370–378. [Google Scholar] [CrossRef]
- Crary, M.A.; Carnaby, G.D.; Sia, I.; Khanna, A.; Waters, M.F. Spontaneous swallowing frequency has potential to identify dysphagia in acute stroke. Stroke 2013, 44, 3452–3457. [Google Scholar] [CrossRef]
- Auyeung, M.; Tsoi, T.; Mok, V.; Cheung, C.; Lee, C.; Li, R.; Yeung, E. Ten year survival and outcomes in a prospective cohort of new onset Chinese Parkinson’s disease patients. J. Neurol. Neurosurg. Psychiatry 2012, 83, 607–611. [Google Scholar] [CrossRef]
- Takizawa, C.; Gemmell, E.; Kenworthy, J.; Speyer, R. A systematic review of the prevalence of oropharyngeal dysphagia in stroke, Parkinson’s disease, Alzheimer’s disease, head injury, and pneumonia. Dysphagia 2016, 31, 434–441. [Google Scholar] [CrossRef] [PubMed]
- Baijens, L.W.; Clavé, P.; Cras, P.; Ekberg, O.; Forster, A.; Kolb, G.F.; Leners, J.-C.; Masiero, S.; Mateos-Nozal, J.; Ortega, O. European Society for Swallowing Disorders–European Union Geriatric Medicine Society white paper: Oropharyngeal dysphagia as a geriatric syndrome. Clin. Interv. Aging 2016, 11, 1403. [Google Scholar] [CrossRef] [PubMed]
- Ekberg, O.; Hamdy, S.; Woisard, V.; Wuttge-Hannig, A.; Ortega, P. Social and psychological burden of dysphagia: Its impact on diagnosis and treatment. Dysphagia 2002, 17, 139–146. [Google Scholar] [CrossRef] [PubMed]
- Bhattacharyya, N. The prevalence of dysphagia among adults in the United States. Otolaryngol. Head Neck Surg. 2014, 151, 765–769. [Google Scholar] [CrossRef] [PubMed]
- Warnecke, T.; Dziewas, R.; Langmore, S. FEES and Other Instrumental Methods for Swallowing Evaluation. In Neurogenic Dysphagia; Warnecke, T., Dziewas, R., Langmore, S., Eds.; Springer: Boston, MA, USA, 2021; pp. 55–107. [Google Scholar]
- Kertscher, B.; Speyer, R.; Palmieri, M.; Plant, C. Bedside screening to detect oropharyngeal dysphagia in patients with neurological disorders: An updated systematic review. Dysphagia 2014, 29, 204–212. [Google Scholar] [CrossRef] [PubMed]
- Maccarini, A.R.; Filippini, A.; Padovani, D.; Limarzi, M.; Loffredo, M.; Casolino, D. Clinical non-instrumental evaluation of dysphagia. Acta Otorhinolaryngol. Ital. 2007, 27, 299–305. [Google Scholar]
- Suiter, D.M.; Leder, S.B. Clinical utility of the 3-ounce water swallow test. Dysphagia 2008, 23, 244–250. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.Y.; Kim, D.-K.; Seo, K.M.; Kang, S.H. Usefulness of the simplified cough test in evaluating cough reflex sensitivity as a screening test for silent aspiration. Ann. Rehabil. Med. 2014, 38, 476. [Google Scholar] [CrossRef] [PubMed]
- O’Horo, J.C.; Rogus-Pulia, N.; Garcia-Arguello, L.; Robbins, J.; Safdar, N. Bedside diagnosis of dysphagia: A systematic review. J. Hosp. Med. 2015, 10, 256–265. [Google Scholar] [CrossRef]
- So, B.P.-H.; Chan, T.T.-C.; Liu, L.; Yip, C.C.-K.; Lim, H.-J.; Lam, W.-K.; Wong, D.W.-C.; Cheung, D.S.K.; Cheung, J.C.-W. Swallow Detection with Acoustics and Accelerometric-Based Wearable Technology: A Scoping Review. Int. J. Environ. Res. Public Health 2023, 20, 170. [Google Scholar] [CrossRef]
- Lai, D.K.-H.; Cheng, E.S.-W.; Lim, H.-J.; So, B.P.-H.; Lam, W.-K.; Cheung, D.S.K.; Wong, D.W.-C.; Cheung, J.C.-W. Computer-aided screening of aspiration risks in dysphagia with wearable technology: A Systematic Review and meta-analysis on test accuracy. Front. Bioeng. Biotechnol. 2023, 11, 1205009. [Google Scholar] [CrossRef]
- Zahnd, E.; Movahedi, F.; Coyle, J.L.; Sejdić, E.; Menon, P.G. Correlating Tri-Accelerometer Swallowing Vibrations and Hyoid Bone Movement in Patients with Dysphagia. In Proceedings of the ASME 2016 International Mechanical Engineering Congress and Exposition, Phoenix, AZ, USA, 11–17 November 2016. [Google Scholar]
- Päßler, S.; Wolff, M.; Fischer, W.-J. Food intake monitoring: An acoustical approach to automated food intake activity detection and classification of consumed food. Physiol. Meas. 2012, 33, 1073. [Google Scholar] [CrossRef]
- Kuramoto, N.; Ichimura, K.; Jayatilake, D.; Shimokakimoto, T.; Hidaka, K.; Suzuki, K. Deep Learning-Based Swallowing Monitor for Realtime Detection of Swallow Duration. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 4365–4368. [Google Scholar]
- Dudik, J.M.; Coyle, J.L.; El-Jaroudi, A.; Mao, Z.-H.; Sun, M.; Sejdić, E. Deep learning for classification of normal swallows in adults. Neurocomputing 2018, 285, 1–9. [Google Scholar] [CrossRef]
- Taniwaki, M.; Kohyama, K. Fast fourier transform analysis of sounds made while swallowing various foods. J. Acoust. Soc. Am. 2012, 132, 2478–2482. [Google Scholar] [CrossRef]
- Farooq, M.; Fontana, J.M.; Sazonov, E. A novel approach for food intake detection using electroglottography. Physiol. Meas. 2014, 35, 739. [Google Scholar] [CrossRef]
- Tajitsu, Y.; Suehiro, A.; Tsunemine, K.; Katsuya, K.; Kawaguchi, Y.; Kuriwaki, Y.; Sugino, Y.; Nishida, H.; Kitamura, M.; Omori, K. Application of piezoelectric braided cord to dysphagia-detecting system. Jpn. J. Appl. Phys. 2018, 57, 11UG02. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Cohen, E.; Pourhomayoun, M.; Alshurafa, N. SwallowNet: Recurrent neural network detects and characterizes eating patterns. In Proceedings of the 2017 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Kona, HI, USA, 13–17 March 2017; pp. 401–406. [Google Scholar]
- Cheung, J.C.-W.; So, B.P.-H.; Ho, K.H.M.; Wong, D.W.-C.; Lam, A.H.-F.; Cheung, D.S.K. Wrist accelerometry for monitoring dementia agitation behaviour in clinical settings: A scoping review. Front. Psychiatry 2022, 13, 913213. [Google Scholar] [CrossRef] [PubMed]
- Tam, A.Y.-C.; Zha, L.-W.; So, B.P.-H.; Lai, D.K.-H.; Mao, Y.-J.; Lim, H.-J.; Wong, D.W.-C.; Cheung, J.C.-W. Depth-Camera-based Under-blanket Sleep Posture Classification using Anatomical Landmark-guided Deep Learning Model. Int. J. Environ. Res. Public Health 2022, 19, 13491. [Google Scholar] [CrossRef] [PubMed]
- Tam, A.Y.-C.; So, B.P.-H.; Chan, T.T.-C.; Cheung, A.K.-Y.; Wong, D.W.-C.; Cheung, J.C.-W. A Blanket Accommodative Sleep Posture Classification System Using an Infrared Depth Camera: A Deep Learning Approach with Synthetic Augmentation of Blanket Conditions. Sensors 2021, 21, 5553. [Google Scholar] [CrossRef] [PubMed]
- Bian, Z.-P.; Hou, J.; Chau, L.-P.; Magnenat-Thalmann, N. Fall detection based on body part tracking using a depth camera. IEEE J. Biomed. Health Inform. 2014, 19, 430–439. [Google Scholar] [CrossRef]
- Procházka, A.; Charvátová, H.; Vyšata, O.; Kopal, J.; Chambers, J. Breathing analysis using thermal and depth imaging camera video records. Sensors 2017, 17, 1408. [Google Scholar] [CrossRef]
- An, K.; Zhang, Q.; Kwong, E. ViscoCam: Smartphone-based Drink Viscosity Control Assistant for Dysphagia Patients. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 3. [Google Scholar] [CrossRef]
- Yoshida, J.; Kozawa, K.; Moritani, S.; Sakamoto, S.-I.; Sakai, O.; Miyagi, S. Detection of Swallowing Times Using a Commercial RGB-D Camera. In Proceedings of the 2019 IEEE 8th Global Conference on Consumer Electronics (GCCE), Osaka, Japan, 15–18 October 2019; pp. 1154–1155. [Google Scholar]
- Sugimoto, C.; Masuyama, Y. Elevation Measurement of Laryngeal Prominence from Depth Images for Evaluating Swallowing Function. In Proceedings the of 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 1562–1565. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Dubey, S.R.; Singh, S.K.; Chaudhuri, B.B. Activation Functions in Deep Learning: A Comprehensive Survey and Benchmark. arXiv 2021, arXiv:2109.14545. [Google Scholar] [CrossRef]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation Functions: Comparison of trends in Practice and Research for Deep Learning. arXiv 2018, arXiv:1811.03378. [Google Scholar] [CrossRef]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. arXiv 2016, arXiv:1608.00859. [Google Scholar] [CrossRef]
- Gastal, E.S.L.; Oliveira, M.M. Domain transform for edge-aware image and video processing. ACM Trans. Graph. 2011, 30, 69. [Google Scholar] [CrossRef]
- Fukushima, K. Cognitron: A self-organizing multilayered neural network. Biol. Cybern. 1975, 20, 121–136. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. arXiv 2015, arXiv:1502.01852. [Google Scholar] [CrossRef]
- Hendrycks, D.; Gimpel, K. Gaussian Error Linear Units (GELUs). arXiv 2016, arXiv:1606.08415. [Google Scholar] [CrossRef]
- Clevert, D.-A.; Unterthiner, T.; Hochreiter, S. Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs). arXiv 2015, arXiv:1511.07289. [Google Scholar] [CrossRef]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef] [PubMed]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language Modeling with Gated Convolutional Networks. arXiv 2016, arXiv:1612.08083. [Google Scholar] [CrossRef]
- Varshney, M.; Singh, P. Optimizing nonlinear activation function for convolutional neural networks. Signal Image Video Process. 2021, 15, 1323–1330. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Bertasius, G.; Wang, H.; Torresani, L. Is Space-Time Attention All You Need for Video Understanding? arXiv 2021, arXiv:2102.05095. [Google Scholar] [CrossRef]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. ViViT: A Video Vision Transformer. arXiv 2021, arXiv:2103.15691. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast Networks for Video Recognition. arXiv 2018, arXiv:1812.03982. [Google Scholar] [CrossRef]
- Feichtenhofer, C. X3D: Expanding Architectures for Efficient Video Recognition. arXiv 2020, arXiv:2004.04730. [Google Scholar] [CrossRef]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A Closer Look at Spatiotemporal Convolutions for Action Recognition. arXiv 2017, arXiv:1711.11248. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar] [CrossRef]
- Saito, T.; Rehmsmeier, M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef]
- Fortuna-Cervantes, J.M.; Ramírez-Torres, M.T.; Mejía-Carlos, M.; Murguía, J.S.; Martinez-Carranza, J.; Soubervielle-Montalvo, C.; Guerra-García, C.A. Texture and Materials Image Classification Based on Wavelet Pooling Layer in CNN. Appl. Sci. 2022, 12, 3592. [Google Scholar] [CrossRef]
- So, B.P.-H.; Lai, D.K.-H.; Cheung, D.S.-K.; Lam, W.-K.; Cheung, J.C.-W.; Wong, D.W.-C. Virtual Reality-Based Immersive Rehabilitation for Cognitive-and Behavioral-Impairment-Related Eating Disorders: A VREHAB Framework Scoping Review. Int. J. Environ. Res. Public Health 2022, 19, 5821. [Google Scholar] [CrossRef]
- Imperatori, C.; Mancini, M.; Della Marca, G.; Valenti, E.M.; Farina, B. Feedback-based treatments for eating disorders and related symptoms: A systematic review of the literature. Nutrients 2018, 10, 1806. [Google Scholar] [CrossRef] [PubMed]
- Selva, J.; Johansen, A.S.; Escalera, S.; Nasrollahi, K.; Moeslund, T.B.; Clapés, A. Video Transformers: A Survey. arXiv 2022, arXiv:2201.05991. [Google Scholar] [CrossRef] [PubMed]
- Park, N.; Kim, S. How do vision transformers work? arXiv 2022, arXiv:2202.06709. [Google Scholar]
- Bedri, A.; Li, R.; Haynes, M.; Kosaraju, R.P.; Grover, I.; Prioleau, T.; Beh, M.Y.; Goel, M.; Starner, T.; Abowd, G. EarBit: Using wearable sensors to detect eating episodes in unconstrained environments. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 1–20. [Google Scholar] [CrossRef]
- Noiray, A.; Cathiard, M.A.; Ménard, L.; Abry, C. Test of the movement expansion model: Anticipatory vowel lip protrusion and constriction in French and English speakers. J. Acoust. Soc. Am. 2011, 129, 340–349. [Google Scholar] [CrossRef]
- Yadav, M.; Alam, M.A. Dynamic time warping (dtw) algorithm in speech: A review. Int. J. Res. Electron. Comput. Eng. 2018, 6, 524–528. [Google Scholar]
- Joseph, V.R. Optimal ratio for data splitting. Stat. Anal. Data Min. ASA Data Sci. J. 2022, 15, 531–538. [Google Scholar] [CrossRef]
- Dubbs, A. Test Set Sizing Via Random Matrix Theory. arXiv 2021, arXiv:2112.05977. [Google Scholar] [CrossRef]
- Amari, S.; Murata, N.; Muller, K.R.; Finke, M.; Yang, H.H. Asymptotic statistical theory of overtraining and cross-validation. IEEE Trans. Neural Netw. 1997, 8, 985–996. [Google Scholar] [CrossRef]
- Guyon, I.M. A Scaling Law for the Validation-Set Training-Set Size Ratio. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.33.1337&rep=rep1&type=pdf (accessed on 9 July 2023).
- Afendras, G.; Markatou, M. Optimality of Training/Test Size and Resampling Effectiveness of Cross-Validation Estimators of the Generalization Error. arXiv 2015, arXiv:1511.02980. [Google Scholar] [CrossRef]
- Xu, Y.; Goodacre, R. On Splitting Training and Validation Set: A Comparative Study of Cross-Validation, Bootstrap and Systematic Sampling for Estimating the Generalization Performance of Supervised Learning. J. Anal. Test. 2018, 2, 249–262. [Google Scholar] [CrossRef] [PubMed]
- Erickson, B.J.; Korfiatis, P.; Kline, T.L.; Akkus, Z.; Philbrick, K.; Weston, A.D. Deep learning in radiology: Does one size fit all? J. Am. Coll. Radiol. 2018, 15, 521–526. [Google Scholar] [CrossRef] [PubMed]
- Marcu, D.C.; Grava, C. The impact of activation functions on training and performance of a deep neural network. In Proceedings of the 2021 16th International Conference on Engineering of Modern Electric Systems (EMES), Oradea, Romania, 10–11 June 2021. [Google Scholar] [CrossRef]
- Farzad, A.; Mashayekhi, H.; Hassanpour, H. A comparative performance analysis of different activation functions in LSTM networks for classification. Neural Comput. Appl. 2019, 31, 2507–2521. [Google Scholar] [CrossRef]
- Marchisio, A.; Abdullah Hanif, M.; Rehman, S.; Martina, M.; Shafique, M. A Methodology for Automatic Selection of Activation Functions to Design Hybrid Deep Neural Networks. arXiv 2018, arXiv:1811.03980. [Google Scholar] [CrossRef]
- Basirat, M.; Roth, P.M. The Quest for the Golden Activation Function. arXiv 2018, arXiv:1808.00783. [Google Scholar] [CrossRef]
- Jagtap, A.D.; Kawaguchi, K.; Karniadakis, G.E. Adaptive activation functions accelerate convergence in deep and physics-informed neural networks. J. Comput. Phys. 2020, 404, 109136. [Google Scholar] [CrossRef]
- Parhi, R.; Nowak, R.D. The role of neural network activation functions. IEEE Signal Process. Lett. 2020, 27, 1779–1783. [Google Scholar] [CrossRef]
- Hayou, S.; Doucet, A.; Rousseau, J. On the Selection of Initialization and Activation Function for Deep Neural Networks. arXiv 2018, arXiv:1805.08266. [Google Scholar] [CrossRef]
- Dushkoff, M.; Ptucha, R. Adaptive activation functions for deep networks. In Proceedings of the IS&T International Symposium on Electronic Imaging, San Francisco, CA, USA, 14–18 February 2016; pp. COIMG-149.1–COIMG-149.5. [Google Scholar]
- Li, B.; Li, Y.; Rong, X. The extreme learning machine learning algorithm with tunable activation function. Neural Comput. Appl. 2013, 22, 531–539. [Google Scholar] [CrossRef]
- Mao, Y.-J.; Zha, L.-W.; Tam, A.Y.-C.; Lim, H.-J.; Cheung, A.K.-Y.; Zhang, Y.-Q.; Ni, M.; Cheung, J.C.-W.; Wong, D.W.-C. Endocrine Tumor Classification via Machine-Learning-Based Elastography: A Systematic Scoping Review. Cancers 2023, 15, 837. [Google Scholar] [CrossRef]
- Mao, Y.-J.; Lim, H.-J.; Ni, M.; Yan, W.-H.; Wong, D.W.-C.; Cheung, J.C.-W. Breast tumour classification using ultrasound elastography with machine learning: A systematic scoping review. Cancers 2022, 14, 367. [Google Scholar] [CrossRef]
- Solares, J.R.A.; Raimondi, F.E.D.; Zhu, Y.; Rahimian, F.; Canoy, D.; Tran, J.; Gomes, A.C.P.; Payberah, A.H.; Zottoli, M.; Nazarzadeh, M. Deep learning for electronic health records: A comparative review of multiple deep neural architectures. J. Biomed. Inform. 2020, 101, 103337. [Google Scholar] [CrossRef] [PubMed]
- Ebrahimi, A.; Wiil, U.K.; Schmidt, T.; Naemi, A.; Nielsen, A.S.; Shaikh, G.M.; Mansourvar, M. Predicting the risk of alcohol use disorder using machine learning: A systematic literature review. IEEE Access 2021, 9, 151697–151712. [Google Scholar] [CrossRef]
- Artetxe, A.; Beristain, A.; Grana, M. Predictive models for hospital readmission risk: A systematic review of methods. Comput. Methods Programs Biomed. 2018, 164, 49–64. [Google Scholar] [CrossRef] [PubMed]
- Paganelli, A.I.; Mondéjar, A.G.; da Silva, A.C.; Silva-Calpa, G.; Teixeira, M.F.; Carvalho, F.; Raposo, A.; Endler, M. Real-time data analysis in health monitoring systems: A comprehensive systematic literature review. J. Biomed. Inform. 2022, 127, 104009. [Google Scholar] [CrossRef] [PubMed]
- Ling, C.X.; Sheng, V.S. Cost-sensitive learning and the class imbalance problem. Encycl. Mach. Learn. 2008, 2011, 231–235. [Google Scholar]
- Sinha, S.; Ohashi, H.; Nakamura, K. Class-wise difficulty-balanced loss for solving class-imbalance. arXiv 2020, arXiv:2010.01824. [Google Scholar]
- Abd Elrahman, S.M.; Abraham, A. A review of class imbalance problem. J. Netw. Innov. Comput. 2013, 1, 332–340. [Google Scholar]
- Lei, J. Cross-validation with confidence. J. Am. Stat. Assoc. 2020, 115, 1978–1997. [Google Scholar] [CrossRef]
- Lim, H.-J.; Lai, D.K.-H.; So, B.P.-H.; Yip, C.C.-K.; Cheung, D.S.K.; Cheung, J.C.-W.; Wong, D.W.-C. A Comprehensive Assessment Protocol for Swallowing (CAPS): Paving the Way towards Computer-Aided Dysphagia Screening. Int. J. Environ. Res. Public Health 2023, 20, 2998. [Google Scholar] [CrossRef]
- Tay, Y.; Dehghani, M.; Abnar, S.; Shen, Y.; Bahri, D.; Pham, P.; Rao, J.; Yang, L.; Ruder, S.; Metzler, D. Long range arena: A benchmark for efficient transformers. arXiv 2020, arXiv:2011.04006. [Google Scholar]
- Feng, S.Y.; Gangal, V.; Wei, J.; Chandar, S.; Vosoughi, S.; Mitamura, T.; Hovy, E. A survey of data augmentation approaches for NLP. arXiv 2021, arXiv:2105.03075. [Google Scholar]
- Dawar, N.; Ostadabbas, S.; Kehtarnavaz, N. Data Augmentation in Deep Learning-Based Fusion of Depth and Inertial Sensing for Action Recognition. IEEE Sens. Lett. 2019, 3, 7101004. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. arXiv 2011, arXiv:1106.1813. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| X3D | SlowFast | R(2+1)D | TimeSFormer | ViViT | |
|---|---|---|---|---|---|
| Total parameters | 2.99 M | 6.19 M | 31.51 M | 121.26 M | 3.05 M |
| Training speed | 35 s/epoch | 51 s/epoch | 70 s/epoch | 94 s/epoch | 37 s/epoch |
| X3D | SlowFast | R(2+1)D | TimeSFormer | ViViT | |
|---|---|---|---|---|---|
| Coarse Classification | |||||
| Swallowing | 0.880 | 0.875 | 0.844 | 0.667 | 0.739 |
| Non-swallowing | 0.889 | 0.893 | 0.881 | 0.746 | 0.793 |
| Coarse Average: | 0.885 | 0.884 | 0.863 | 0.707 | 0.766 |
| Fine-grained Classification | |||||
| Eating | 0.711 | 0.769 | 0.783 | 0.650 | 0.294 |
| Drinking | 0.732 | 0.556 | 0.364 | 0.476 | 0.412 |
| Deep Breathing | 0.894 | 0.939 | 0.939 | 0.894 | 0.488 |
| Vowel Pronunciation | 0.926 | 0.923 | 0.889 | 0.755 | 0.720 |
| Pronouncing “/eɪ/” | 0.809 | 0.809 | 0.727 | 0.564 | 0.462 |
| Pronouncing “/iː/” | 0.756 | 0.683 | 0.389 | 0.756 | 0.188 |
| Pronouncing “/aɪ/” | 0.800 | 0.564 | 0.353 | 0.333 | 0.242 |
| Pronouncing “/oʊ/” | 0.783 | 0.207 | 0.444 | 0.526 | 0.343 |
| Pronouncing “/u:/” | 0.894 | 0.863 | 0.585 | 0.714 | 0.194 |
| 4-class Average: | 0.816 | 0.797 | 0.744 | 0.694 | 0.479 |
| 8-class Average: | 0.797 | 0.674 | 0.573 | 0.614 | 0.328 |
| ReLU (Default) | LeakyReLU | GELU | ELU | GLU | SiLU | |
|---|---|---|---|---|---|---|
| Coarse Classification | ||||||
| Swallowing | 0.962 | 0.807 | 0.681 | 0.673 | 0.906 | 0.925 |
| Non-swallowing | 0.878 | 0.927 | 0.911 | 0.899 | 0.763 | 0.750 |
| Coarse Average: | 0.920 | 0.867 | 0.796 | 0.786 | 0.835 | 0.838 |
| Fine-grained Classification | ||||||
| Eating | 0.667 | 0.551 | 0.418 | 0.407 | 0.488 | 0.593 |
| Drinking | 0.600 | 0.578 | 0.458 | 0.462 | 0.250 | 0.429 |
| Deep Breathing | 0.619 | 0.816 | 0.760 | 0.627 | 0.800 | 0.857 |
| Vowel Pronunciation | 0.959 | 0.925 | 0.895 | 0.839 | 0.895 | 0.924 |
| Pronouncing “/eɪ/” | 0.644 | 0.644 | 0.543 | 0.462 | 0.654 | 0.538 |
| Pronouncing “/iː/” | 0.731 | 0.596 | 0.519 | 0.545 | 0.596 | 0.378 |
| Pronouncing “/aɪ/” | 0.567 | 0.723 | 0.578 | 0.585 | 0.510 | 0.500 |
| Pronouncing “/oʊ/” | 0.542 | 0.591 | 0.474 | 0.500 | 0.511 | 0.341 |
| Pronouncing “/u:/” | 0.824 | 0.750 | 0.506 | 0.516 | 0.588 | 0.429 |
| 4-class Average: | 0.711 | 0.718 | 0.633 | 0.584 | 0.608 | 0.701 |
| 8-class Average: | 0.649 | 0.656 | 0.532 | 0.513 | 0.550 | 0.508 |
| Tan18° | Tan15° | Tan12° | Tan9° | Tan6° | Tan3° | Tan0° | ||
|---|---|---|---|---|---|---|---|---|
| F1 | Pronouncing “/eɪ/” | 0.585 | 0.585 | 0.667 | 0.548 | 0.543 | 0.677 | 0.644 |
| Pronouncing “/iː/” | 0.577 | 0.510 | 0.750 | 0.578 | 0.605 | 0.681 | 0.731 | |
| Pronouncing “/aɪ/” | 0.711 | 0.627 | 0.846 | 0.621 | 0.698 | 0.650 | 0.567 | |
| Pronouncing “/oʊ/” | 0.667 | 0.625 | 0.708 | 0.486 | 0.625 | 0.679 | 0.542 | |
| Pronouncing “/u:/” | 0.742 | 0.632 | 0.691 | 0.698 | 0.808 | 0.727 | 0.824 | |
| Deep breathing | 0.939 | 0.826 | 0.830 | 0.894 | 0.902 | 0.816 | 0.619 | |
| Eating | 0.691 | 0.607 | 0.571 | 0.679 | 0.692 | 0.571 | 0.667 | |
| Drinking | 0.600 | 0.476 | 0.510 | 0.549 | 0.652 | 0.553 | 0.600 | |
| 8-class Average | 0.689 | 0.611 | 0.697 | 0.632 | 0.691 | 0.669 | 0.649 | |
| Precision | Pronouncing “/eɪ/” | 0.487 | 0.487 | 0.588 | 0.472 | 0.400 | 0.583 | 0.576 |
| Pronouncing “/iː/” | 0.577 | 0.520 | 0.818 | 0.684 | 0.765 | 0.762 | 0.731 | |
| Pronouncing “/aɪ/” | 0.842 | 0.640 | 0.846 | 0.562 | 0.882 | 0.929 | 0.500 | |
| Pronouncing “/oʊ/” | 0.727 | 0.682 | 0.773 | 0.818 | 0.682 | 0.667 | 0.591 | |
| Pronouncing “/u:/” | 0.639 | 0.581 | 0.655 | 0.595 | 0.808 | 0.690 | 0.840 | |
| Deep breathing | 1.000 | 0.950 | 0.815 | 1.000 | 0.920 | 0.870 | 0.813 | |
| Eating | 0.655 | 0.567 | 0.609 | 0.667 | 0.692 | 0.486 | 0.643 | |
| Drinking | 0.857 | 0.625 | 0.520 | 0.560 | 0.750 | 0.619 | 0.625 | |
| 8-class Average | 0.723 | 0.632 | 0.703 | 0.670 | 0.737 | 0.701 | 0.665 | |
| Recall | Pronouncing “/eɪ/” | 0.731 | 0.731 | 0.769 | 0.654 | 0.846 | 0.808 | 0.731 |
| Pronouncing “/iː/” | 0.577 | 0.500 | 0.692 | 0.500 | 0.500 | 0.615 | 0.731 | |
| Pronouncing “/aɪ/” | 0.615 | 0.615 | 0.846 | 0.692 | 0.577 | 0.500 | 0.654 | |
| Pronouncing “/oʊ/” | 0.615 | 0.577 | 0.654 | 0.346 | 0.577 | 0.692 | 0.500 | |
| Pronouncing “/u:/” | 0.885 | 0.692 | 0.731 | 0.846 | 0.808 | 0.769 | 0.808 | |
| Deep breathing | 0.885 | 0.731 | 0.846 | 0.808 | 0.885 | 0.769 | 0.500 | |
| Eating | 0.731 | 0.654 | 0.538 | 0.692 | 0.692 | 0.692 | 0.692 | |
| Drinking | 0.462 | 0.385 | 0.500 | 0.538 | 0.577 | 0.500 | 0.577 | |
| 8-class Average | 0.688 | 0.611 | 0.697 | 0.635 | 0.683 | 0.668 | 0.649 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lai, D.K.-H.; Cheng, E.S.-W.; So, B.P.-H.; Mao, Y.-J.; Cheung, S.M.-Y.; Cheung, D.S.K.; Wong, D.W.-C.; Cheung, J.C.-W. Transformer Models and Convolutional Networks with Different Activation Functions for Swallow Classification Using Depth Video Data. Mathematics 2023, 11, 3081. https://doi.org/10.3390/math11143081
Lai DK-H, Cheng ES-W, So BP-H, Mao Y-J, Cheung SM-Y, Cheung DSK, Wong DW-C, Cheung JC-W. Transformer Models and Convolutional Networks with Different Activation Functions for Swallow Classification Using Depth Video Data. Mathematics. 2023; 11(14):3081. https://doi.org/10.3390/math11143081
Chicago/Turabian StyleLai, Derek Ka-Hei, Ethan Shiu-Wang Cheng, Bryan Pak-Hei So, Ye-Jiao Mao, Sophia Ming-Yan Cheung, Daphne Sze Ki Cheung, Duo Wai-Chi Wong, and James Chung-Wai Cheung. 2023. "Transformer Models and Convolutional Networks with Different Activation Functions for Swallow Classification Using Depth Video Data" Mathematics 11, no. 14: 3081. https://doi.org/10.3390/math11143081
APA StyleLai, D. K.-H., Cheng, E. S.-W., So, B. P.-H., Mao, Y.-J., Cheung, S. M.-Y., Cheung, D. S. K., Wong, D. W.-C., & Cheung, J. C.-W. (2023). Transformer Models and Convolutional Networks with Different Activation Functions for Swallow Classification Using Depth Video Data. Mathematics, 11(14), 3081. https://doi.org/10.3390/math11143081