
STAB-GCN: A Spatio-Temporal Attention-Based Graph Convolutional Network for Group Activity Recognition


Abstract
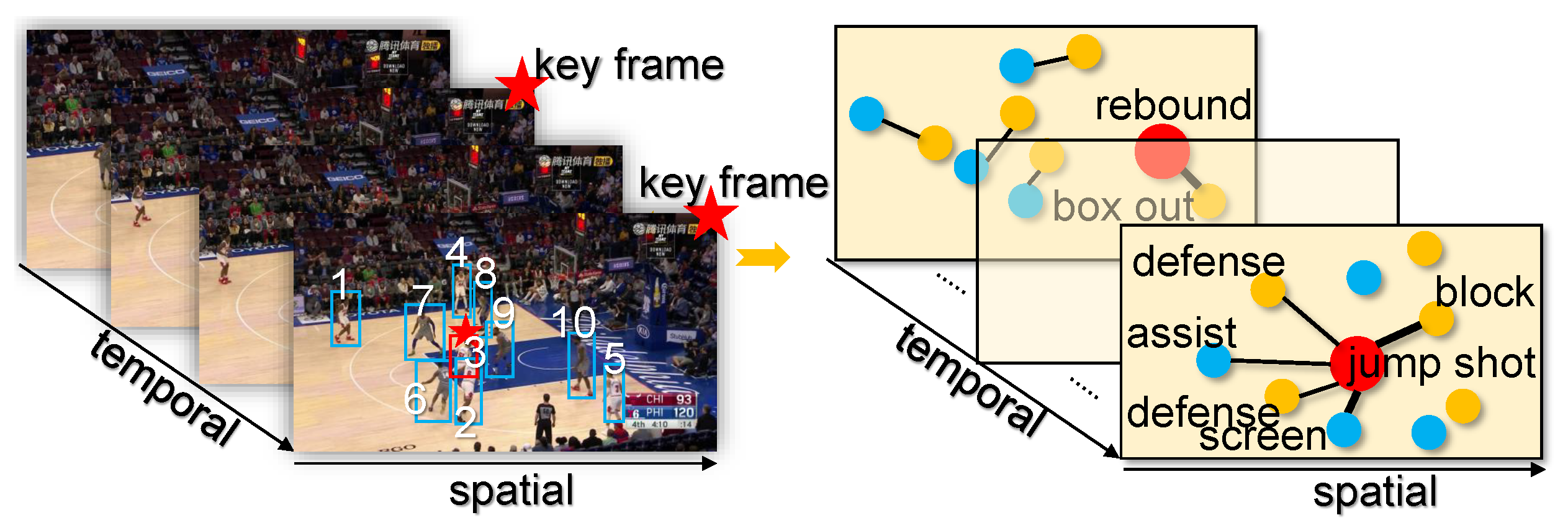
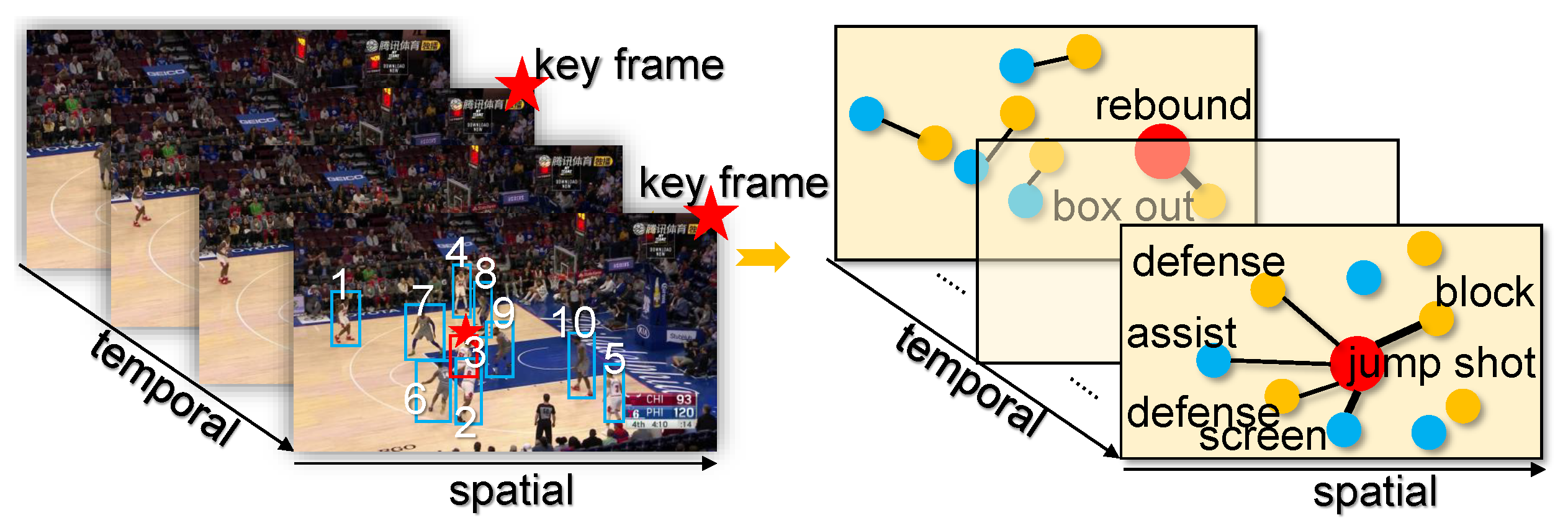
:1. Introduction
- We propose the novel STAB-GCN that uses the GCN with a spatio-temporal attention mechanism, which learns how to selectively attend to the features in videos. Our STAB-GCN model employs a multilayer structure to yield better graph embedding.
- We build elastic and effective actor relation graphs to capture key actors and the latent relations between actors in multi-person scenarios. It leverages an attention mechanism to dynamically embed the relationship strength between actors and yields multiple actor relation graphs of different structures with the evolution of the spatio-temporal dimension, thus effectively recognizing different group activities.
- The proposed model achieves state-of-the-art performance on the available datasets, i.e., the NBA dataset, the Volleyball dataset, and the Collective Activity dataset. Experimental results demonstrate that our STAB-GCN is efficient and effective in embedding spatio-temporal actor relations in GAR.
2. Related Work
2.1. Group Activity Recognition
2.2. Transformer Models
3. Methodology
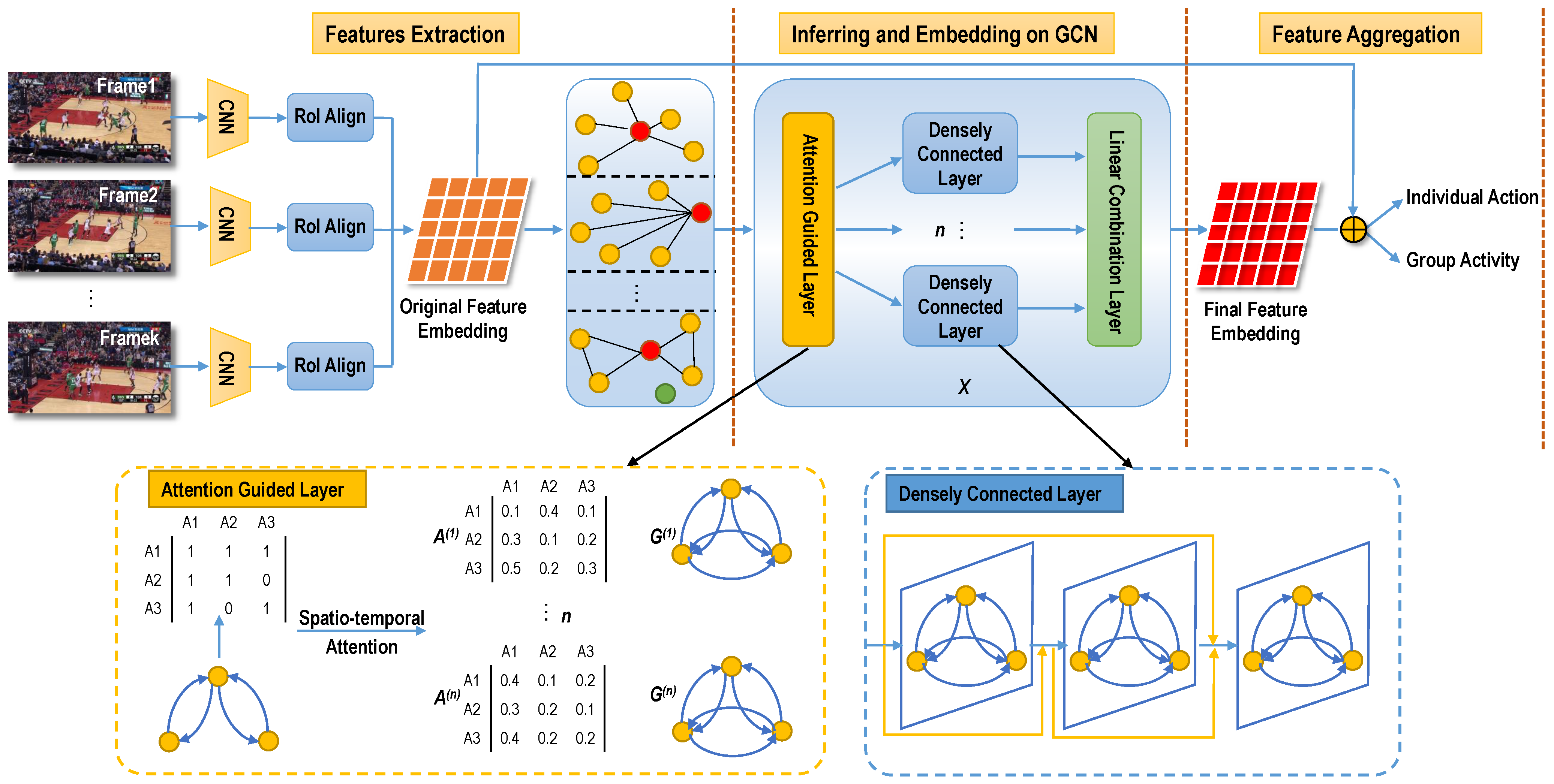
3.1. The Model of STAB-GCN
3.2. Spatio-Temporal Attention Mechanism
3.2.1. Spatial Attention Unit
3.2.2. Temporal Attention Unit
3.2.3. Spatio-Temporal Actor Relation Embedding
3.3. Embedding on Graph Convolutional Network
3.4. Training Objective
4. Experiments
4.1. Datasets
4.2. Implementation Details
4.3. Comparison with Up-to-Date Methods
4.4. Ablation Study
4.4.1. Multiple Sub-Layers
4.4.2. Effectiveness of Spatio-Temporal Attention-Based GCN
4.4.3. Scene Information
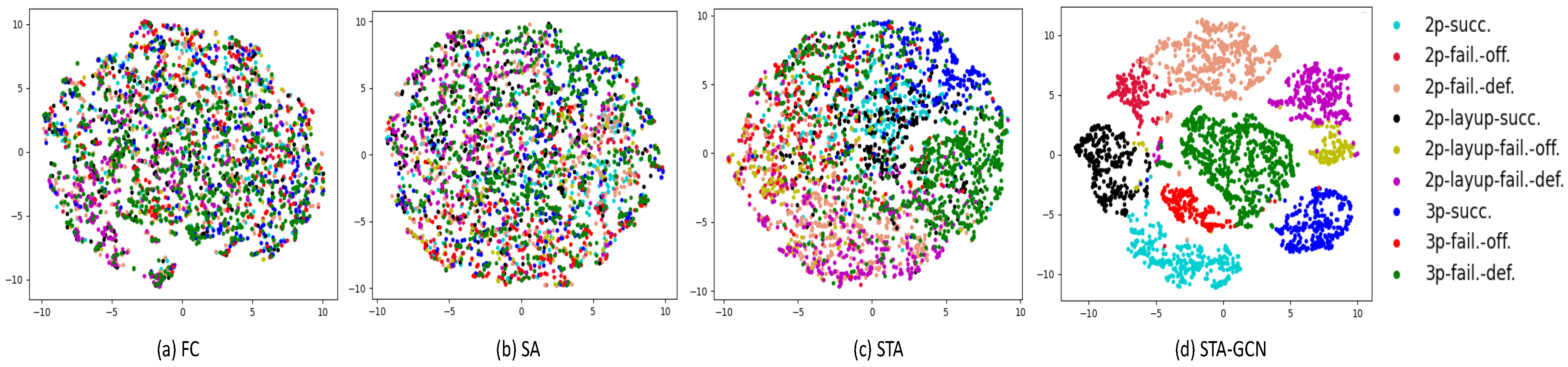
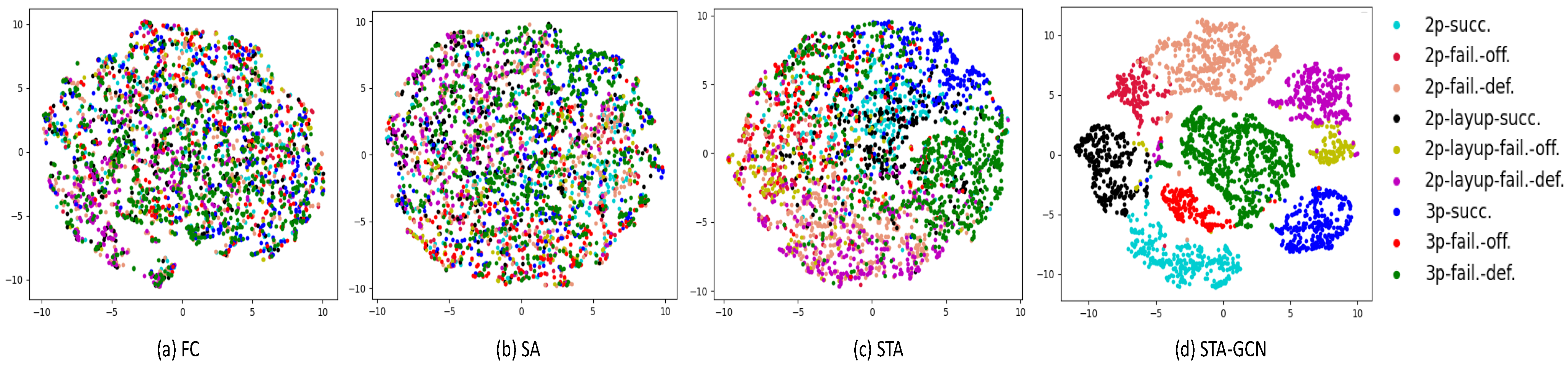
4.5. Visualization Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Han, M.F.; Zhang, D.J.; Wang, Y.L.; Yan, R.; Yao, L.N.; Chang, X.J.; Qiao, Y. Dual-AI: Dual-path Actor Interaction Learning for Group Activity Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 2980–2989. [Google Scholar]
- Wu, J.C.; Wang, L.M.; Wang, L.; Guo, J.; Wu, G.S. Learning actor relation graphs for group activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 9964–9974. [Google Scholar]
- Choi, W.G.; Shahid, K.; Savarese, S. What are they doing? Collective activity classification using spatio-temporal relationship among people. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Kyoto, Japan, 29 September–2 October 2009; pp. 1282–1289. [Google Scholar]
- Yu, S.; Xia, F.; Li, S.H.; Hou, M.L.; Sheng, Q.Z. Spatio-Temporal Graph Learning for Epidemic Prediction. ACM Trans. Intell. Syst. Technol. 2023, 14, 1–25. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Hawash, H.; Chang, V.; Chakrabortty, R.K.; Ryan, M. Deep Learning for Heterogeneous Human Activity Recognition in Complex IoT Applications. IEEE Internet Things J. 2022, 9, 5653–5665. [Google Scholar] [CrossRef]
- Kong, L.; Pei, D.; He, R.; Huang, D.; Wang, Y. Spatio-Temporal Player Relation Modeling for Tactic Recognition in Sports Videos. IEEE Trans. Circ. Syst. Video Technol. 2022, 32, 6086–6099. [Google Scholar] [CrossRef]
- Bourached, A.; Gray, R.; Griffiths, R.R.; Jha, A.; Nachev, P. Hierarchical graph-convolutional variational autoencoding for generative modelling of human motion. arXiv 2022, arXiv:2111.12602. [Google Scholar]
- Li, K.C.; Wang, Y.L.; Zhang, J.H.; Gao, P.; Song, G.L.; Liu, Y.; Li, H.S.; Qiao, Y. Uniformer: Unifying convolution and self-attention for visual recognition. arXiv 2022, arXiv:2201.09450. [Google Scholar]
- Yu, S.; Xia, F.; Wang, Y.R.; Li, S.H.; Febrinanto, F.G.; Chetty, M.H. PANDORA: Deep Graph Learning Based COVID-19 Infection Risk Level Forecasting. IEEE Trans. Comput. Soc. Syst. 2022, 1–14. [Google Scholar] [CrossRef]
- Bagautdinov, T.; Alahi, A.; Fleuret, F.; Fua, P.; Savarese, S. Social scene understanding: End-to-end multiperson action localization and collective activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4315–4324. [Google Scholar]
- Ibrahim, M.S.; Muralidharan, S.; Deng, Z.W.; Vahdat, A.; Mori, G. A hierarchical deep temporal model for group activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1971–1980. [Google Scholar]
- Deng, Z.W.; Vahdat, A.; Hu, H.X.; Mori, G. Structure inference machines: Recurrent neural networks for analyzing relations in group activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4772–4781. [Google Scholar]
- Ibrahim, M.S.; Mori, G. Hierarchical relational networks for group activity recognition and retrieval. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 721–736. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Yan, R.; Xie, L.X.; Tang, J.H.; Shu, X.B.; Tian, Q. Social Adaptive Module for Weakly-Supervised Group Activity Recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 208–224. [Google Scholar]
- Li, X.; Chuah, M.C. Sbgar: Semantics based group activity recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22 October 2017; pp. 2876–2885. [Google Scholar]
- Kumar, A.; Rawat, Y.S. End-to-End Semi-Supervised Learning for Video Action Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 14680–14690. [Google Scholar]
- Shu, T.M.; Xie, D.; Rothrock, B.; Todorovic, S.; Zhu, S.C. Joint inference of groups, events and human roles in aerial videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4576–4584. [Google Scholar]
- Yan, R.; Shu, X.; Yuan, C.; Tian, Q.; Tang, J. Position-Aware Participation-Contributed Temporal Dynamic Model for Group Activity Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 7574–7588. [Google Scholar] [CrossRef] [PubMed]
- Tang, J.; Shu, X.; Yan, R.; Zhang, L. Coherence Constrained Graph LSTM for Group Activity Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 636–647. [Google Scholar] [CrossRef] [PubMed]
- Pramono, R.R.A.; Chen, Y.T.; Fang, W.H. Empowering relational network by self-attention augmented conditional random fields for group activity recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 5 March 2020; pp. 71–90. [Google Scholar]
- Gavrilyuk, K.; Sanford, R.; Javan, M.; Snoek, C.G. Actor-transformers for group activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–20 June 2020; pp. 839–848. [Google Scholar]
- Li, S.C.; Cao, Q.G.; Liu, L.B.; Yang, K.L.; Liu, S.N.; Hou, J.; Yi, S. Groupformer: Group activity recognition with clustered spatial-temporal transformer. In Proceedings of the IEEE Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 13668–13677. [Google Scholar]
- Pramono, R.R.A.; Fang, W.H.; Chen, Y.T. Relational reasoning for group activity recognition via self-attention augmented conditional random field. IEEE Trans. Image Process. 2021, 20, 4752–4768. [Google Scholar] [CrossRef] [PubMed]
- Yuan, H.J.; Ni, D. Learning visual context for group activity recognition. In Proceedings of the Conference on Association for the Advance of Artificial Intelligence (AAAI), Online, 2–9 February 2021; pp. 3261–3269. [Google Scholar]
- Bertasius, G.; Wang, H.; Torresani, L. Is space-time attention all you need for video understanding? In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021. [Google Scholar]
- Fan, H.Q.; Xiong, B.; Mangalam, K.; Li, Y.H.; Yan, Z.C.; Malik, J.; Feichtenhofer, C. Multiscale vision transformers. In Proceedings of the International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 6804–6815. [Google Scholar]
- Patrick, M.; Campbell, D.; Asano, Y.M.; Metze, I.M.F.; Feichtenhofer, C.; Vedaldi, A.; Henriques, J. Keeping your eye on the ball: Trajectory attention in video transformers. In Proceedings of the Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 6–14 December 2021. [Google Scholar]
- He, K.M.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2961–2969. [Google Scholar]
- Qi, M.; Wang, Y.; Qin, J.; Li, A.; Luo, J.; Gool, L.V. StagNet: An Attentive Semantic RNN for Group Activity and Individual Action Recognition. IEEE Trans. Circ. Syst. Video Technol. 2020, 30, 549–565. [Google Scholar] [CrossRef]
- Yuan, H.J.; Ni, D.; Wang, M. Spatio-temporal dynamic inference network for group activity recognition. In Proceedings of the IEEE conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 7456–7465. [Google Scholar]
- Shu, T.M.; Todorovic, S.; Zhu, A.C. CERN: Confidence-energy recurrent network for group activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4255–4263. [Google Scholar]
- Yan, R.; Tang, J.H.; Shu, X.B.; Li, Z.C.; Tian, Q. Participation-contributed temporal dynamic model for group activity recognition. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1292–1300. [Google Scholar]
- Hu, G.Y.; Cui, B.; He, Y.; Yu, S. Progressive relation learning for group activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–20 June 2020; pp. 980–989. [Google Scholar]
- Tang, Y.S.; Wang, Z.A.; Li, P.Y.; Lu, J.W.; Yang, M.; Zhou, J. Mining semantics-preserving attention for group activity recognition. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1283–1291. [Google Scholar]
- Azar, S.M.; Atigh, M.G.; Nickabadi, A.; Alahi, A. Convolutional relational machine for group activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 7892–7901. [Google Scholar]
- Yan, R.; Xie, L.X.; Tang, J.H.; Shu, X.B.; Tian, Q. Higcin: Hierarchical graph-based cross inference network for group activity recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 6955–6968. [Google Scholar] [CrossRef] [PubMed]
- Lin, J.; Gan, C.; Han, S. Tsm: Temporal shift module for efficient video understanding. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–3 November 2019; pp. 7083–7093. [Google Scholar]
- Kim, D.K.; Lee, J.S.; Cho, M.S.; Kwak, S. Detector-Free Weakly Supervised Group Activity Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 20083–20093. [Google Scholar]
- Maaten, L.V.; Hinton, G. Visualizing data using t-sne. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Individual Action | Group Activity |
|---|---|---|---|
| HDTM [11] | AlexNet | - | 81.9 |
| CERN [32] | VGG-16 | - | 83.3 |
| StagNet [30] | VGG-16 | - | 89.3 |
| HRN [13] | VGG-19 | - | 89.5 |
| AFormer [22] | I3D | - | 91.4 |
| DIN [31] | ResNet-18 | - | 93.1 |
| SSU [10] | Inception-v3 | 81.8 | 90.6 |
| ARG [2] | Inception-v3 | 83.0 | 92.5 |
| TCE + STBiP [25] | Inception-v3 | - | 93.3 |
| GFormer [23] | Inception-v3 | 83.7 | 94.1 |
| Dual [1] | Inception-v3 | 84.4 | 94.4 |
| STAB-GCN | Inception-v3 | 82.9 | 94.8 |
| STAB-GCN | ResNet-18 | 84.3 | 92.2 |
| Method | Backbone | Group Activity |
|---|---|---|
| SIM [12] | AlexNet | 81.2 |
| HDTM [11] | AlexNet | 87.5 |
| PCTDM [33] | AlexNet | 92.2 |
| CERN [32] | VGG-16 | 87.2 |
| StagNet [30] | VGG-16 | 89.1 |
| PRL [34] | VGG-16 | 93.8 |
| SPA + KD [35] | VGG-16 | 92.5 |
| CRM [36] | I3D | 94.2 |
| ARG [2] | ResNet-18 | 91.0 |
| DIN [31] | ResNet-18 | 95.3 |
| HiGCIN [37] | ResNet-18 | 93.0 |
| TCE + STBiP [25] | Inception-v3 | 95.1 |
| SBGAR [16] | Inception-v3 | 86.1 |
| Dual [1] | ResNet-18 | 95.2 |
| STAB-GCN | Inception-v3 | 92.1 |
| STAB-GCN | ResNet-18 | 96.5 |
| Method | Backbone | Group Activity |
|---|---|---|
| SACRF [24] | Inception-v3 | 56.3 |
| TSM [38] | Inception-v1 | 66.6 |
| AFormer [22] | ResNet-18 | 47.1 |
| DIN [31] | ResNet-18 | 61.6 |
| SAM [15] | ResNet-18 | 54.3 |
| ARG [2] | Inception-v3 | 59.0 |
| DFW [39] | ResNet-18 | 75.8 |
| Dual [1] | Inception-v3 | 50.2 |
| STAB-GCN | Inception-v3 | 78.1 |
| STAB-GCN | ResNet-18 | 78.4 |
| Sub-Layer | 1 | 4 | 8 | 16 | 32 |
| Accuracy | 75.3 | 78.4 | 78.1 | 77.5 | 76.8 |
| Method | NBA | Volleyball |
|---|---|---|
| None | 74.2 | 90.6 |
| SA | 75.9 | 92.4 |
| STA | 77.6 | 93.2 |
| STAB-GCN | 78.4 | 94.8 |
| Scene Fusion | NBA | Volleyball |
|---|---|---|
| w/o | 78.0 | 94.0 |
| Early | 77.6 | 93.6 |
| Middle | 78.1 | 94.1 |
| Late | 78.4 | 94.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, F.; Tian, C.; Wang, J.; Jin, Y.; Cui, L.; Lee, I. STAB-GCN: A Spatio-Temporal Attention-Based Graph Convolutional Network for Group Activity Recognition. Mathematics 2023, 11, 3074. https://doi.org/10.3390/math11143074
Liu F, Tian C, Wang J, Jin Y, Cui L, Lee I. STAB-GCN: A Spatio-Temporal Attention-Based Graph Convolutional Network for Group Activity Recognition. Mathematics. 2023; 11(14):3074. https://doi.org/10.3390/math11143074
Chicago/Turabian StyleLiu, Fang, Chunhua Tian, Jinzhong Wang, Youwei Jin, Luxiang Cui, and Ivan Lee. 2023. "STAB-GCN: A Spatio-Temporal Attention-Based Graph Convolutional Network for Group Activity Recognition" Mathematics 11, no. 14: 3074. https://doi.org/10.3390/math11143074
APA StyleLiu, F., Tian, C., Wang, J., Jin, Y., Cui, L., & Lee, I. (2023). STAB-GCN: A Spatio-Temporal Attention-Based Graph Convolutional Network for Group Activity Recognition. Mathematics, 11(14), 3074. https://doi.org/10.3390/math11143074