1. Introduction
The modern financial sector requires high security standards due to rapid technological progress [
1,
2]. Banks utilize many security measures for transactions, including artificial intelligence (AI), neural networks, and machine learning [
3,
4,
5,
6]. The use of these techniques allows advanced technological problems to be solved. The most common types of financial frauds are money laundering, identity fraud, and credit and debit card frauds [
1].
The key role in securing financial systems is anti-money-laundering (AML), while identifying illegal transactions [
7,
8,
9]. The launch of Bitcoin (BTC) has created a paradox: the anonymity allows criminals to remain unknown; however, forensic or AML analysis can be performed with access to the BTC transaction database. The goal of AML analytics is to identify fraudulent transactions in massive, ever-growing datasets. Semi-automatic or manual transaction analysis produces a large number of errors while the success of machine learning methods shows great potential in AML analysis [
10,
11,
12].
Current AI methods are not sufficient to process the online transaction data stream. To analyze different security methods, a set of transactions filtered by specially created rules needs to be used. All transactions passing through the filter are considered legitimate and do not get analyzed further. The filter parameters include the direct characteristics of the transaction or its parties with the exclusion of any indirect characteristics. The results of this process can be invalid; thus, the most important obstacles in AML are [
1] the inability to make real-time online selections of parameters that are unique to specific financial activities, the lack of a centralized transaction analysis tool, a large volume of false positives for fraudulent transactions, and the high cost of manual analysis.
The current task is to develop a system to identify suspicious transactions. Such a system would help speed up and simplify data processing, decrease the risks of transactions, store information and data about criminals, provide credit score verification, and trace the users involved in money laundering. Due to the high cost of these systems, only large financial institutions can afford them. In 24 h, large companies process up to 20 million transactions [
13]. Unfortunately, manual analysis identifying suspicious activities often produces false results and requires extra time and resources in order for it to be performed correctly. Therefore, the development and implementation of an antifraud system is essential [
14,
15,
16,
17].
In past studies, the identification of fraudulent transactions using machine learning algorithms has been primarily accomplished via classification [
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28]; however, traditional algorithms are unreliable and inadequate for precise classifications. This study describes the development of a reliable machine learning model to detect fraudulent bank transactions. We use the CreditCardFraud dataset [
29], which contains more than 200,000 credit card transactions.
In this article, the model is used to identify fraudulent transactions using the following algorithms: linear regression, logistic regression, quadratic regression, naive Bayes classifier, k-nearest neighbors algorithm, multi-layer perceptron (MLP), discriminant function analysis, quadratic discriminant analysis (QDA), decision trees, random forest, support vector machine (SVM), and adaboost. The article describes the optimization methods of hyperparameters for machine learning algorithms to increase classification reliability.
Imbalanced classification is an important machine learning problem. Class imbalance is primarily used in fraud detection, medical diagnostics, pollution detection, and remote sensing. Class imbalance emerges due to the few examples gathered from the minority class, or by a natural imbalance in the underlying probability distribution of the data. Most classification algorithms are based on the balanced distribution of class labels.
Our goal is to maximize the percentage of fraudulent transactions detected (the recall for the fraud class) while potentially sacrificing the percentage of predicted frauds that turn out to be actual frauds (the precision for the fraud class) and to maximize the percentage of correctly classified transactions (the accuracy).
The CreditCardFraud dataset is imbalanced (492 are fraudulent and 284,315 are legitimate) [
29]. Including the Tomek links resampling algorithm increased the classification reliability of fraudulent BTC transactions in the imbalanced class condition [
30].
The main contributions of this article are insights into machine learning methods which can provide the reliable classification of fraudulent bank transactions and an improvement in the classification of fraudulent bank transactions by using data preprocessing, hyperparameter optimization, and a resampling algorithm.
The remainder of this article is organized as follows:
Section 2 discusses the requirements of the proposed model,
Section 3 provides a detailed description of the model,
Section 4 describes the evaluation process,
Section 5 discusses the proposed model, and
Section 6 concludes.
2. Related Work
It is important for banks to identify suspicious transactions before fraud happens. As an example the Nilson report states that cumulative damages from credit card fraud were USD 22.8 billion in 2016 and USD 28.7 in 2019 [
31].
All international credit card payment systems use their own fraud detection methods. Often, all of the transactions are checked using antifraud rules, lists, and filters. In Russia these systems are also used to identify cyber criminals; however, the first priority is to find the illegal exchange of goods and services.
Bank transaction security has been improved due to the addition of a built-in EMV chip to credit and debit cards and the client authentication process, by means of two-step authentication. Despite this, the number of fraudulent bank transactions has not reduced: credit card fraud totals EUR 1.5 billion a year [
14]. Experts agree that to reduce credit card fraud using authentication methods—the development and implementation of the fraud identification systems based on data analysis—is required.
Experts classify credit card fraud into different forms, for example, fraud with false identity or using behavioral biometrics. In the first case, a criminal applies for a credit card with false identification, while in the case of behavioral biometrics, a criminal obtains and uses the cardholder’s existing credit card credentials. Fraudulent bank transactions are divided into six categories [
14]: lost or stolen card fraud, fake card fraud, online fraud, bankruptcy fraud, retailer fraud, and stolen in transit card fraud. In addition, bank transaction fraud can be classified by three categories: bankcard fraud, retail fraud, and Internet fraud.
Recently, it has been suggested to distinguish two categories of fraud: fraud with a card (face-to-face) and fraud without a card (e-commerce fraud). Bank transaction fraud can be categorized into five different types [
14]:
Lost and stolen cards (<1% of all fraudulent transactions). Most of the time elderly people are the victims in this category; fraudsters get the PIN by “shoulder-reading” and subsequently steal the card. In this case, the fraudster is the thief and the credit card does not go through an organized crime resale network.
Cards that do not reach their destination (<1% of all fraudulent transactions). In this case the credit card may have been stolen during production or upon delivery by mail. To avoid this type of fraud, banks ask customers to obtain and activate the card at their office.
Identity theft. A card obtained by using fake or stolen documents.
Counterfeit cards (>10% of all fraudulent transactions). The card is copied using a genuine card or during database hacking, and then reproduced on a counterfeit plastic card by international organized crime groups. The criminal obtains and reproduces the magnetic stripe data of the cards. This type of fraud had been prevalent in the past but has been partially solved by EMV technology as magnetic stripe terminals are no longer used in the EU; however, they remain in Asia and America. This kind of non-contact payment is not appealing for criminals, since only small value payments are processed.
Fraud without a card makes up over 90% of all fraudulent transactions. Most credit card fraud occurs during electronic transactions. The card number, expiration date, and CVC are extracted during database hacks, then these credentials are sold. The value of the credentials depends on the re-sale capabilities (the first digits of the card numbers represent the bank and, accordingly, the blocking policies they have). Many retailers (90%) use 3-D Secure. This technology protects the cardholder through two-step authentication; however, some large retailers, such as Ebay or Amazon, do not protect their users’ transactions with 3-D Secure. Another problem hindering the fight against cardless fraud is that companies do not report attacks that result in a data breach since it can cause bad publicity, which might lead to financial losses.
Typical fraud detection systems have several control levels. Each level can be automated or managed manually. Part of the automated approach consists of machine learning algorithms. These algorithms are used to create predictive models based on annotated bank transactions. Over the past ten years regular credit card fraud research has made it possible to develop models based on supervised or unsupervised machine learning, and partial machine learning [
17].
The authors analyze methods of money laundering detection based on Big Data [
32]. Big Data is represented in complex systems that perform tasks to prevent legalization and laundering of money that has been obtained illegally (the SAS Anti-Money Laundering System, SAS AML).
Machine learning methods for binary classification to predict fraudulent transactions using multilayer perceptrons, random forest, logistic regression, and convoluted network graphs are used to detect anomalous BTC transactions [
10]. Convoluted network diagrams have emerged as a potential tool for AML analysis, and they are particularly attractive as a new way to capture and analyze transactions. The results reflect the advantage of the random forest method of classification, though the F1 score of 0.796 is not sufficiently reliable for classifying abnormal BTC transactions.
Recent studies built deep neural networks for the detection of irregularities either by discriminatively mapping normal samples and abnormal samples to different regions of the feature space, or by fitting multiple different distributions [
33,
34,
35,
36,
37].
The effect of high cardinality attributes on credit card fraud detection has been investigated, and the Value Clustering for Categorical Attributes algorithm was used to reduce the cardinality of their domains while preserving fraud-detection capabilities [
38].
Using machine learning to predict fraudulent financial transactions without balancing data, as in real life there are usually many more honest than fraudulent ones, an accurate and reliable method is proposed. Additional fraudulent transaction samples were generated using a conditional generative adversarial network for tabular data (CTGAN) to make the classifier more robust and accurate [
39].
By combining a nature-inspired hyperparameter setting with several supervised classifier models implemented in a modified version of the XGBoost algorithm, a unique hybrid technique for financial payment fraud detection is presented [
40]. Using machine learning and domain data to identify fraudulent payments, a modified XGBoost model can be created and tested by tuning. Experiments showed that the model successfully classified with 99.64% accuracy.
An AE-PRF fraud detection method has been proposed which uses AE to reduce the dimensionality of the data and extract the features of the data [
23]. In addition, the method uses RF with a probabilistic classification to classify the data as fraudulent together with the corresponding probability. AE-PRF outputs a final classification as fraudulent if the corresponding probability exceeds a predefined probability threshold.
An AED-LGB algorithm has been proposed to solve bank credit card fraud [
24]. The AED-LGB algorithm first extracts the feature data using an autoencoder. The features are then fed into the LightGBM algorithm for classification and prediction.
3. The Proposed Model
Figure 1 presents a flowchart of the proposed model. First, the CreditCardFraud data are preprocessed using outlier reduction, missing value reduction, repetition reduction, data normalization, imbalance resampling, and data splitting. The preprocessed data are divided into a training set and a test set. The training set data are used for model training by machine learning and, during training, the hyperparameters are constantly optimized to obtain the trained model. Afterward, the testing data are used to evaluate the trained model by classifying the data into fraudulent data or legitimate data.
3.1. The CreditCardFraud Data
We use the CreditCardFraud dataset [
29], which is imbalanced (492 transactions are fraudulent and 284,315 are legitimate). The experiment consisted of a resampling algorithm, which increased the classification reliability of fraudulent bank transactions in an imbalanced class condition [
29].
To train the model to detect fraudulent transactions, it is necessary to prepare a large dataset. The analysis should be carried out with bank transaction data; however, there are no suitable datasets available in the public domain. The only option is the CreditCardFraud dataset containing transactions made by European credit card holders in the fall of 2013. This dataset contains bank transaction over the course of two days. During this period 492 fraudulent credit card transactions were recorded out of 284,807 transactions. The positive class (fraud) is 0.172% of total transactions, so the dataset is imbalanced.
The CreditCardFraud dataset contains only numeric features. These features are the result of converting the original values using the principal component method. The original functions and additional information could not be obtained to maintain confidentiality.
Table 1 shows some of the features of the dataset used in this experiment. Features
are the main components obtained using the method of principal components. Attributes “Time” and “Amount” are the only ones publicly available. “Time” of dataset contains seconds between the first and all of the following transactions. “Amount” lists the summary of transactions. The correct answer is tagged as “Class”, and this attribute equals 1 in a case of fraudulent transaction and 0 in a legitimate transaction case.
3.2. Data Preprocessing
The most important step for machine learning is data preprocessing, because the models are based on machine learning algorithms which increase the dataset reliability. Since the parameters have a different range of values and units of measurement, they need to be normalized before the training of the model to make sure that all the parameters inside the model contain all of the appropriate values.
The following normalization, standardization, and scaling aggregators from the SciKit-Learn library were used [
41]: Normalizer, StandardScaler, MinMaxScaler, MaxAbsScaler, RobustScaler, PowerTransformer QuantileTransformer, and PolynomialFeatures. The StandardScaler normalization algorithm scales each feature to a specified range. The normalization is represented as:
where
x is the sample value,
and
are the minimum and maximum values of all samples, respectively, and
y is the normalized value of feature.
The data were initially partitioned at random into two parts: the training dataset (70%) and the test dataset (30%). Additionally, 20% of the training dataset was used for validation.
3.3. Machine Learning Model of Fraudulent Credit Card Transactions
Detection of fraudulent credit card transactions can be based on supervised machine learning [
42,
43,
44]. In supervised machine learning, the objective function
f is determined using labeled training data
, where
x is a vector of input features and
y is an output label. To correctly determine the label of a new example, the learning algorithm generalizes the correlation between the vector of features and the label in the training data.
Assume that is the training dataset, where for , which is a vector of features for and is its relevant label. Using the training dataset, the goal of supervised learning is to learn an objective function for a set of class labels. Assume that are independent and equally distributed. Based on the test data, the predictive ability of the objective function can be estimated. The machine learning model is a classification model when the labels are discrete states or symbols.
One of the main machine learning goals is the search of the objective function , where X are input data and Y is an output variable. The supervised learning or building of the model is the process of finding the objective function f. It can be detected only if there are enough tag data and all of the records are labeled in the current dataset.
The dataset, M, of the fraudulent credit card transactions model dataset consists of n = 284,807 transactions. An answer label on the dataset indicates whether this transaction is fraudulent or legitimate. The objective function f: is introduced to determine whether a definite example m is “fraudulent” 1 or “legitimate” 0. Function f: can be determined by one of the machine learning algorithms for a set of n labeled examples , where and for .
Each transaction is associated with a feature vector, which consists of 30 values. For the objective function f it is required to determine whether transaction m is fraudulent (represented as 1) or legitimate (represented as 0). The function f can be detected using one of the machine learning algorithms for the dataset of n marked transactions.
The following machine learning algorithms are used to detect fraudulent bank transactions: linear regression, logistic regression, quadratic regression, k-nearest neighbors algorithm, support vector machine (SVM), multi-layer perceptron (MLP), discriminant function analysis, quadratic discriminant analysis (QDA), decision trees, random forest, naive Bayes classifier, and adaboost.
Our experiments with models involve testing various combinations of hyperparameters to find the optimal response. We used the GridSearchCV algorithm from the SKlearn library [
41] to automate finding the best combination of hyperparameters. The GridSearchCV algorithm exhaustively generates candidates from a grid of parameter values specified. When performing hyperparameter optimization, we first need to define a region or parameter grid in which we include a set of possible values of hyperparameters that can be used to build the model. The grid search method is then used to place these hyperparameters into the matrix and the model is trained on each combination of hyperparameter values. The model with the best performance is then selected. Some algorithms can lead to overfitting, especially tree-based methods; therefore, we used regularization and early stopping to avoid overfitting.
3.4. Imbalanced Classification
If a certain class of the dataset is too small, the class is called a minority and the opposite class that is strongly represented is called the majority. There are several approaches to solve the problem of the dataset being imbalanced. One is to utilize different resampling strategies. Class balance restoration can be achieved by using one of the two methods. The first method consists in removing some transactions of the majority class (undersampling) and the second method is to use artificial data to increase some numbers of the minority (oversampling).
The oversampling approach is not as straightforward as the duplicated minority class, so samples are redistributed into multiple training batches. This approach is not practical because we are not trying to learn the spatial distribution of the database of credit card frauds with chosen features.
To solve the problem of an imbalanced dataset, the Tomek links algorithm was used [
30]. All of the majority records included in Tomek links must be removed. Tomek links can be defined as follows: consider
and
are two class instances, where
, and
is the range between
and
, so pair
is called the Tomek link, if there is no case
, where
or
. The Tomek links algorithm is good for removal of the records that can be considered fraudulent [
45].
The Tomek links algorithm is used to clean the data followed by random undersampling as an option for data cleaning.
3.5. Model Evaluation
Some evaluation criteria have been used to estimate the performance of the models represented in this study for imbalanced classification of fraudulent bank transactions.
In this study, we used
Accuracy,
Precision,
Recall,
F1 Score, and Index of Balanced Accuracy (
IBA) as measures to evaluate the model quality. The accuracy is a ratio of how often a classifier gives a correct prediction and is equal to
where
is the number of true positive results when the example of a positive class is correctly predicted by the model as belonging to the positive class;
is the number of true negative results when the example of a negative class is correctly predicted as belonging to the negative class;
is the number of false positive results, where the example of a negative class is a false prediction of the model;
is the number of false negative results, where the example of a positive class is incorrectly predicted as belonging to the negative class.
Precision is the ratio which measures the frequency of classifier correctness, where it correctly predicts a positive class mark for the positive class.
Recall is the ratio which estimates the ability of a classifier to correctly predict the positive class, i.e., how often the classifier predicts a mark of the positive class dataset, when the data truly belongs to this class.
F1 Score is the harmonic average of Precision and Recall:
F1 Score’s best value is 1 and worst is 0.
The geometric mean (Gmean) is a parameter used to maximize the and classifications while maintaining the balance between them. Gmean minimizes the negative impact of class distribution errors, although it is unable to define the contribution of each class to the overall index, giving the same result for different combinations of and .
To estimate the binary classifier in cases of imbalanced data, the Index of Balanced Accuracy (
IBA) was proposed [
46]
where
Dominance can be defined as
, which is used to estimate the relationship between
and
. Replacing
Dominance and
Gmean in the final equation provides useful information to better understand how IBA supports a compromise between
Dominance and
Gmean.
4. Experimental Evaluation
The following steps were used for model training: data preprocessing (outlier reduction, missing value reduction, repetition reduction, and data normalization), resampling, and splitting into training and test datasets.
Before proceeding to the learning step, it is essential to check the original dataset for missing values. We initially checked all of the spaces in the tables, and verified that all values were set and that all of the records were unique. In total, 283,726 records were unique.
Initially, the dataset with 492 minority records was highly imbalanced and the percentage of these unique records was around 96%. As a result, it was decided to exclude non-unique records from the dataset and to work with the remaining 283,726 rows. The training accuracy was slightly better using this dataset. The Tomek links algorithm was used on the resulting dataset to solve the imbalanced dataset problem. Using this algorithm, 248 records were removed from the dominant class and this algorithm increased the learning accuracy percentage.
Using different combinations of machine learning algorithms from ready-made libraries is required to classify the transactions. The original dataset uses different functional transformation methods to classify the data. These methods are valuable for machine learning, since different metrics can be measured in different ranges or the values of the same metric are too strong. The functional transformation is divided into the normalization and standardization of data. Data normalization changes the data ranges without changing the data into a uniform format. Data standardization involves changes within a uniform format. Data standardization is applicable when using algorithms based on distance measurements, for example, k-nearest neighbors or support vector machine (SVM).
For the test and training samples we selected legitimate and fraudulent transactions in a ratio of 3:7. The fraudulent bank transaction model uses manually selected algorithms. To evaluate the reliability of learning models we use the following metrics: Precision, Accuracy, F1 Score, Recall and IBA.
The following variations of training the model for detecting fraudulent bank transactions were analyzed, including 440 different combinations in total:
- 1.
With and without the removal of duplicate source data (two options);
- 2.
With and without data optimization using the Tomek links algorithm (two options);
- 3.
With and without the data normalization algorithms: MinMaxScaler, MaxAbsScaler, StandardScaler, PowerTransformer, QuantileTransfomer, Normalizer, FunctionTransformer, PolynomialFeatures, and RobustScaler (10 options);
- 4.
With different machine learning algorithms: RandomForest, AdaBoost, K-Neighbors, DecisionTree, LogisticRegression, SVC, CatBoost, XGBoost, LGBM, TPOT, and AutoSklearn (11 options).
Based on the RandomForest machine learning method, it was concluded that using the Tomek links algorithm increases the built model accuracy by 0.0001; therefore, this data optimization was used for the each successive method. Deleting the duplicated initial data did not affect the model accuracy.
Figure 2 contains the results of the RandomForest machine learning method with various data normalizers. The best scaling functions are Normalizer, PowerTransformer, StandardScaler, and QuantileTransformer. Whitening, as a data preprocessing step, is used to remove correlation or dependencies between features in a dataset. These normalizers demonstrated the same accuracy; however, due to
IBA, the best scaling method is the QuantileTransformer. This confirmed the theoretical assumptions that this scaler was developed for classification problems.
Additionally, the TPOT algorithm was used for the ready-made library of automated machine learning which optimizes the machine learning capabilities using genetic programming [
47], and the AutoSklearn was used for the automated machine learning with the enumeration of machine learning algorithms and their hyperparameters [
48].
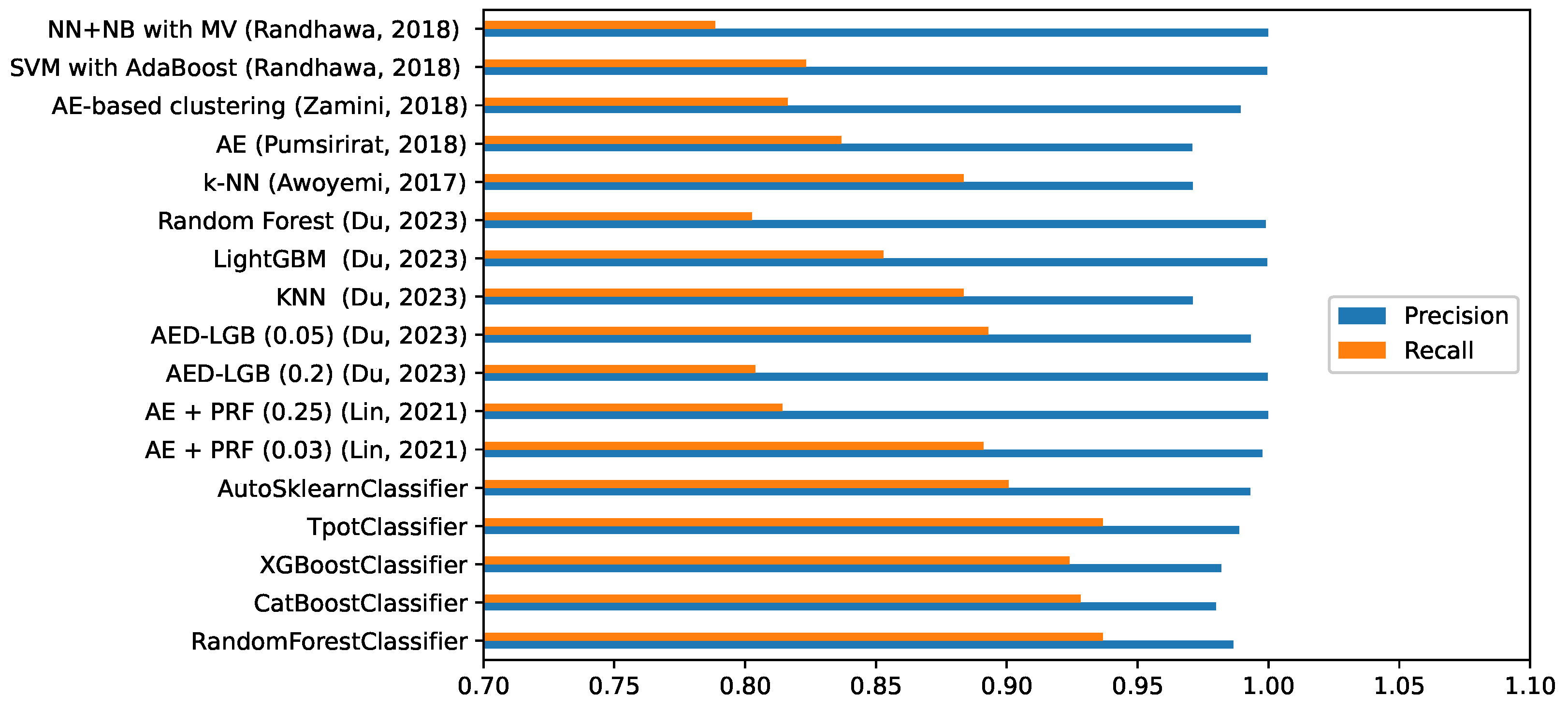
Figure 3 shows the best results for the each machine learning method. Metrics
Recall,
F1 Score, and
Precision are calculated separately for each transaction.
Figure 3 shows the best results specifically for fraudulent bank transactions, since it is important to perform an error correction of the fraudulent transaction class to fully understand the effectiveness of detecting such transactions. Based on the results from
Figure 3 we concluded that the best accuracy rates were achieved by CatBoost, AutoSklearn, XGBoost, and RandomForest.
Since TPOT and AutoSklearn are automated and choose the best hyperparameters and training methods,
Figure 3 lists the methods and their variations with the best results. For TPOT, it was XGBClassifier with the following parameters: learning_rate = 0.5, max_depth = 7, min_child_weight = 1, n_estimators = 100, n_jobs = 1, subsample = 0.8; for AutoSklearn it was the RandomForest method with the following parameters: learning_rate = 0.5, max_depth = 10, min_child_weight = 1, n_estimators = 100, n_thread = 1, subsample = 0.7.
Since the parameters are approximately the same, the models were trained using different methods with the same hyperparameters, instead of using brute force in order to get these hyperparameters.
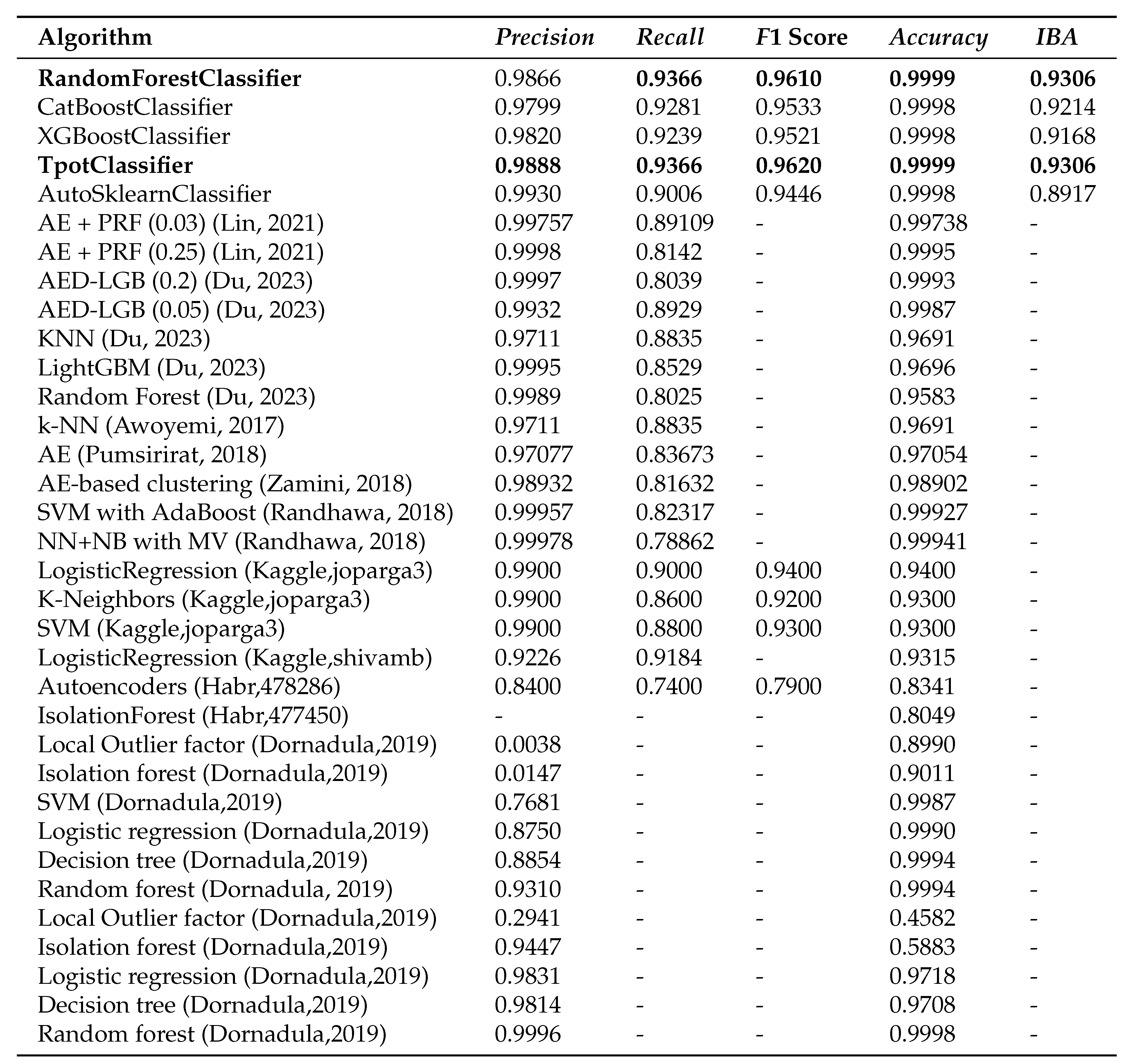
Figure 4 lists the best results achieved in this study and a comparison with the other studies [
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28], which also built models for detecting fraudulent bank transactions on the same dataset. For the fraudulent bank transactions the metrics are
Precision,
Recall,
F1 Score, and
IBA. If their values add up, then they get listed as a dash. The results obtained in this study were more accurate than the ones previously obtained.
The proposed model based on the TPOT and RandomForest algorithms provided the best results with a Recall of 0.9366 on the testing dataset. Recall demonstrates the ability of the algorithm to detect the class at all while the models [
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28] provide poor results. However, the accuracy of the models is high here, because the CreditCardFraud dataset is highly imbalanced. Thus, we can conclude that the model based on the TPOT and RandomForest algorithms performed better than the other models [
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28]. The created models are open and accessible to the research community [
49].
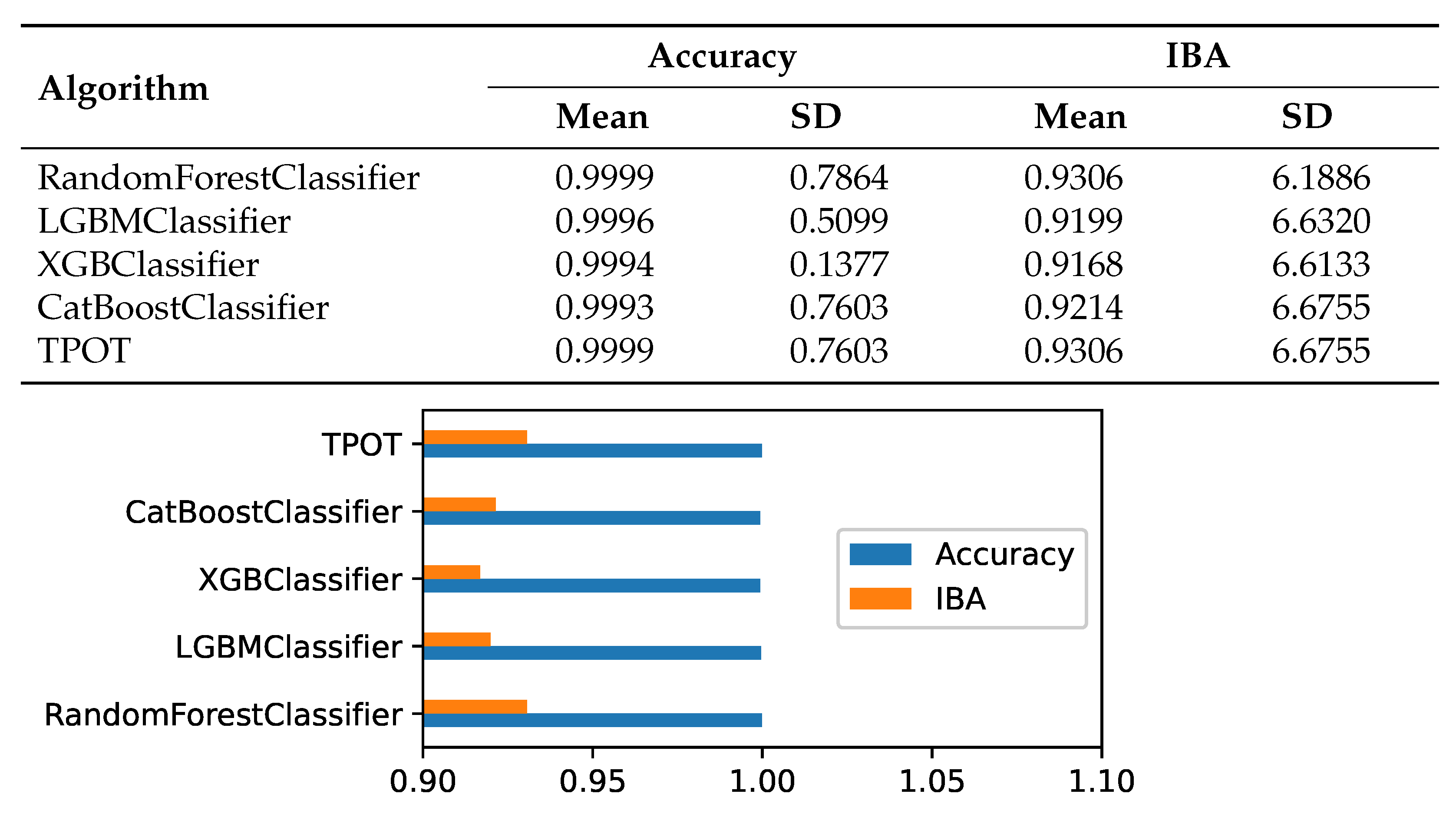
IBA and
Precision are verified with 10-fold cross-validation. For the test and training samples we have selected legitimate and fraudulent transactions in a ratio of 3:7. The result of this analysis is shown in
Figure 5 for the following top models: CatBoostClassifier, TPOT, RandomForestClassifier, XGBClassifier, and LGBMClassifier. The metric values remain almost the same for all ten iterations. Consequently, the TPOT and RandomForest models are stable when fraudulent bank transactions are detected.
5. Discussion
When credit card fraud is detected, the costs of incorrectly identifying the class label are limited. The costs associated with overdetection of fraudulent transactions must be issued as quickly as possible after these transactions occur. In addition, there are costs associated with inaccurately identifying a legitimate transaction as fraudulent, but these tend to be lower and easier to manage. If a transaction is classified as fraudulent, a finance company may freeze the account and contact the owner. If the transaction proves to be legitimate, the finance company can unfreeze the account and the owner can generally proceed with using the account as if nothing happened. A finance company hiring someone to research and develop strategies to detect fraudsters can have a deterrent effect and even prevent certain cases of fraud.
Imbalanced data, without any adjustments, have a dramatic effect on the performance of classification algorithms. Several methods have been proposed for adjusting the standard classification process when there are imbalanced data [
45]. Many experiments were conducted with different methods of adjustment; however, conclusions were inconclusive. Some researchers present the idea of the superiority of sampling techniques while others recommend cost-sensitive and ensemble methods as optimal solutions [
45].
The benefits of sampling techniques include simplicity and portability; however, they have some limitations such as information loss, class overlapping, overfitting and a prediction bias towards the minority class. In addition, it is difficult to differentiate between the minority class and noise. The Tomek links algorithm can solve this problem by removing noise; however, the problem of imbalanced class distribution is still present. In this article, we recommend the use of the Tomek links algorithm as a method of data cleaning followed by random undersampling as an option for data cleaning. This improves the performance of the classification algorithm because removing noise from the majority class, followed by random sampling, reduces the chance of information loss. Our conclusion supports the finding of Elhassan et al., where the authors expressed this idea using the same approach [
45].
6. Conclusions
We proposed a model for detecting fraudulent bank transactions based on machine learning. In the training we used a dataset consisting of 284,807 credit card transactions, of which 492 were classified as fraudulent and 284,315 as legitimate. The model was assessed based on Accuracy, F1 score, Recall, Precision, and IBA. The model for detecting of fraudulent bank transactions uses different machine learning algorithms with hyperparameters.
The majority class usually dominates in cases of imbalanced classification, meaning examples of the minority class can be misclassified. The data presented in this study were severely imbalanced. Our main objective was to demonstrate that an improvement in the classification performance of the classification algorithms towards prediction of a positive rare class using a resampling algorithm can be achieved. The undersampling algorithm demonstrated superior performance.
The majority class usually dominates in cases of imbalanced classification, so examples of the minority class are misclassified. The data presented in this study were severely imbalanced. Our main objective was to demonstrate that an improvement in the classification performance of the classification algorithms towards prediction of a positive rare class using a resampling algorithm can be achieved. The undersampling algorithm demonstrated superior performance.
Using the Tomek links resampling algorithm, the classification reliability of fraudulent bank transactions was increased in comparison to the best result of the imbalanced CreditCardFraud dataset. This result bettered those in [
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28]. As a result the accuracy of the model is 0.9999 based on the TPOT and the RandomForest algorithms, which was confirmed using 10-fold cross-validation.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}