

Research on Medical Problems Based on Mathematical Models


Abstract
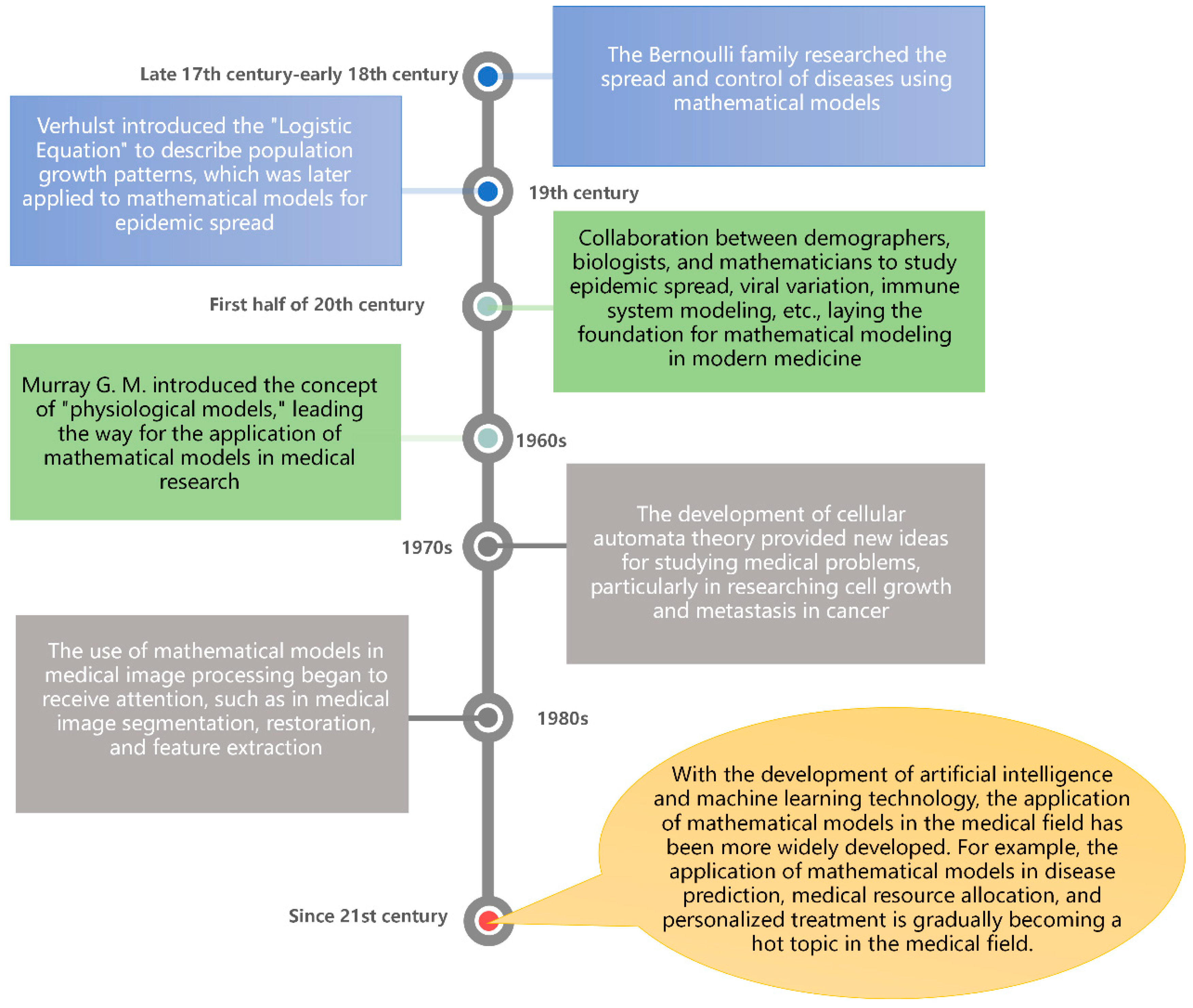
1. Introduction
2. Basic Concepts and Methods of Mathematical Modeling
2.1. Definition and Classification of Mathematical Modeling
2.2. Common Mathematical Models and Mathematical Modeling Methods
- (1)
- Differential equation model [24]: This model is based on the physical laws and kinetic principles of biological processes, such as chemical reactions, cell growth, and signal transmission. By establishing differential equations to describe the changes in these biological processes, it is possible to simulate and predict the behavior of biological systems, such as drug metabolism, tumor growth, nervous system activity, etc. This type of model often requires the use of numerical calculation methods to solve differential equations and the calibration and validation of model parameters.
- (2)
- Statistical model [25]: This model is based on collected medical data, such as patient clinical characteristics, disease incidence, and drug efficacy, and analyzes the relationship between the data through statistical models and hypothesis testing. These models can be used for disease risk assessment, diagnostic accuracy evaluation, and treatment effectiveness evaluation. Common statistical models include linear regression models, logistic regression models, and survival analysis models.
- (3)
- Machine learning model [26]: This model can learn and automatically discover patterns and associations between large-scale medical data. Medical models based on machine learning can be used for tasks such as diagnosis, disease prediction, drug discovery, and image analysis. Common machine learning algorithms include decision tree, support vector machine, neural network, and random forest.
- (4)
- Network science model [27]: This model describes the topological structure and interaction mode of biological system by building a biological network. Networks can represent protein interactions, gene regulation, disease transmission, and more. Medical models based on network science can be used to reveal the pathogenesis of diseases, identify important biomarkers, and predict drug targets. Common network analysis methods include graph theory, complex network analysis, and community detection.
- (5)
- Optimization models [28]: Optimization models are often used to help healthcare organizations manage their resources to obtain the best possible medical outcomes. For example, optimization models can be used to determine how to allocate the work time of doctors and nurses to achieve optimal treatment outcomes.
3. The Application of Mathematical Models in Medical Problems
3.1. Differential-Equation-Based Biomedical Models
3.1.1. Growth and Development Model
3.1.2. Tumor Growth Model
3.1.3. Cardiovascular System Model
3.2. Statistical Medical Model
3.2.1. Survival Analysis Model
3.2.2. Risk-Assessment Model
3.3. Machine-Learning-Based Medical Models
3.3.1. Medical Image Analysis Model
3.3.2. Pathology Diagnostic Model
- Data Acquisition and Processing
- Feature extraction and selection
- Model Training and Evaluation
3.4. Network-Science-Based Medical Models
4. Summary and Outlook
4.1. Problems and Challenges
- Data quality: Data quality is critical for building reliable survival analysis models. If historical data are incomplete or inaccurate, the model built may be compromised, leading to inaccurate assessment results.
- Sample size: For building risk assessment models, sample size is also a very important factor. Since statistical methods are based on probability, the sample size determines how much information can be taken into account when the model is built, and thus the accuracy of the model. If the sample is too small, the model will lose some of its predictive power, so it is necessary to ensure that the sample is large enough.
- Model selection: When building a machine learning model, a suitable machine learning algorithm should be selected according to the specific situation. Different types of models are suitable for different types of data sets and problems, so they need to be chosen according to the actual needs to achieve the best prediction results.
- With the continuous development of medical technology, new discoveries and theories may change the understanding of disease mechanisms and treatment methods. It is necessary to timely incorporate new medical knowledge and theories to update the model and ensure that the model reflects the latest scientific insights through continuous learning and attention to the latest developments in medical research.
4.2. Future Application Prospects
- High-performance computing is a computing technology capable of processing data on a large scale, and it has been widely used in various fields in recent years, such as weather forecasting, climate simulation, and risk assessment. In the medical field, the application of high-performance computing is still relatively small, but in the future, with the improvement in computer processing power, high-performance computing will be able to help medical research explore human physiology and disease mechanisms more deeply and accurately. Large-scale data analysis technology based on high-performance computing can help medical researchers discover potential causes and treatments to improve the diagnosis and treatment of diseases; by analyzing large-scale genetic data sets, medical researchers can discover the mechanisms of cancer occurrence and development and thus develop more effective cancer treatments; through the computing power of high-performance computing, medical researchers can process and analyze image data more rapidly, thus improving the accuracy and speed of medical diagnosis; high-performance computing can also help medical researchers simulate and analyze the functions of human organs and disease mechanisms. Through mathematical models based on high-performance computing, medical researchers can more accurately study human physiology and disease mechanisms and develop more effective treatments.
- Deep learning is a neural-network-based machine learning technique that automatically extracts useful features from massive amounts of data for applications in a variety of fields. In particular, deep learning techniques have started to play an important role in the medical field. Deep learning technology can be applied to the diagnosis and treatment of diseases: deep learning technology can be used to analyze medical images to automatically detect and identify signs of diseases, thus improving the early diagnosis rate and treatment effectiveness of diseases; deep learning can also be applied to genomics and drug development, helping scientists to discover more accurate and effective treatment solutions; and deep learning technology can be used to predict disease epidemics. The use of deep learning technology to predict disease trends can help medical institutions and government departments better respond to the outbreak and spread of diseases, thereby better protecting public health. In addition, with the development of artificial intelligence technology, deep learning technology is also expected to achieve more accurate and personalized treatment in the medical field, making medical services more inclusive and close to people’s needs. In the future, with the continuous development of and improvement in the application of deep learning technology in mathematical models, we can foresee that it will play an even more important role in the medical field.
- Virtual reality is a technology that allows users to interact with and immerse themselves in a computer-generated digital environment. Currently, virtual reality technology is widely used in entertainment and education, and its application in the medical field is starting to receive more and more attention. On the one hand, virtual reality technology can be used for medical simulation, simulating surgical procedures, and operational skills training. Through virtual reality technology, medical professionals can simulate various surgical scenarios, allowing medical students and doctors to operate and practice in a virtual environment, thus improving surgical skills and reducing surgical risks. Virtual reality technology can also be used to simulate and predict disease progression and treatment outcomes, helping doctors make more accurate treatment decisions. On the other hand, virtual reality technology can also be used to treat psychological disorders and pain management. Through virtual reality technology, patients can enter a virtual environment to relieve pain and anxiety through immersion and relaxation. For example, virtual reality technology can be used to relieve symptoms such as chronic pain, post-surgical pain, and nausea and vomiting caused by cancer treatment. In addition, virtual reality technology can be used to treat psychological disorders such as anxiety disorders, post-traumatic stress disorder, and phobias. Virtual reality technology can provide patients with a safe virtual environment in which they can gradually adapt and overcome their psychological disorders. At present, the collection of virtual reality technology and mathematical modeling is not close enough, but it has shown a wide range of application prospects and potential. In the future, virtual reality technology combined with mathematical modeling will play a more important role in the medical field, helping doctors and patients to better treat and recover.
- Gene editing technology is a biotechnology that uses tools such as CRISPR/Cas9 to precisely edit gene sequences. This technology can target specific genes in hereditary diseases and modify them to help patients restore normal function. In addition, gene editing technology can be used to treat other types of diseases, such as cancer, cardiovascular disease, and immune system disorders. As the technology continues to evolve, gene editing technology can also be used in the future to develop more precise mathematical modeling applications. Most current treatments are designed based on average outcomes and cannot be individually tailored to each patient’s unique situation. By using mathematical models and machine learning algorithms, individualized treatment plans can be tailored to achieve the best possible outcome based on each patient’s genetic information, medical history, and other clinical data, which would be an important advance. However, there are some challenges and risks associated with gene editing technology. Some people are concerned that gene editing may lead to unknown side effects and consequences and may even result in the permanent alteration of human genes. Therefore, we need strict ethical review and regulatory mechanisms to ensure the safety and reliability of gene editing technology.
- Blockchain technology is a database technology based on a distributed network of nodes, whose most important features are decentralization and security. The blockchain can distribute the modification and verification of data to multiple nodes throughout the network, ensuring the integrity and trustworthiness of data. The application of blockchain technology in healthcare can make medical data-sharing platforms more secure and reliable and help improve the quality and efficiency of medical services. Blockchain technology combines medical data with mathematical models to better analyze and predict disease occurrence and prevalence trends. The collection and analysis of medical data can help doctors and researchers better understand the development and treatment process of diseases and help improve the accuracy and effectiveness of treatment. At the same time, the analysis of medical data can also provide valuable information to public health departments to help them better control the spread of diseases. In disease prevention and control in the post-epidemic era, blockchain technology can prevent the spread of diseases by tracking the movement routes of infected people. By recording the movement trajectories of infected people on the blockchain, the public can be kept informed of their environment and risks, so they can take appropriate measures to protect themselves. Public health departments can also analyze these data to develop more scientific and precise prevention and control strategies to enhance the control and management of the epidemic.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Migliori, G.B.; Kurhasani, X.; van den Boom, M.; Visca, D.; D’Ambrosio, L.; Centis, R.; Tiberi, S. History of prevention, diagnosis, treatment and rehabilitation of pulmonary sequelae of tuberculosis. La Presse Médicale 2022, 51, 104112. [Google Scholar] [CrossRef] [PubMed]
- Bienenstock, J.; Collins, S. 99th Dahlem conference on infection, inflammation and chronic inflammatory disorders: Psycho-neuroimmunology and the intestinal microbiota: Clinical observations and basic mechanisms. Clin. Exp. Immunol. 2010, 160, 85–91. [Google Scholar] [CrossRef] [PubMed]
- Usak, M.; Kubiatko, M.; Shabbir, M.S.; Viktorovna Dudnik, O.; Jermsittiparsert, K.; Rajabion, L. Health care service delivery based on the Internet of things: A systematic and comprehensive study. Int. J. Commun. Syst. 2020, 33, e4179. [Google Scholar] [CrossRef]
- Pan, Y.; Fu, M.; Cheng, B.; Tao, X.; Guo, J. Enhanced deep learning assisted convolutional neural network for heart disease prediction on the internet of medical things platform. IEEE Access 2020, 8, 189503–189512. [Google Scholar] [CrossRef]
- Yasnitsky, L.N.; Dumler, A.A.; Poleshchuk, A.N.; Bogdanov, C.V.; Cherepanov, F.M. Artificial neural networks for obtaining new medical knowledge: Diagnostics and prediction of cardiovascular disease progression. Biol. Med. (Aligarh) 2015, 7, 095. [Google Scholar]
- Jang, H.J.; Cho, K.O. Applications of deep learning for the analysis of medical data. Arch. Pharmacal Res. 2019, 42, 492–504. [Google Scholar] [CrossRef]
- Zhang, H.; Ye, Y.; Diggle, P.; Shi, J. Joint modeling of time series measures and recurrent events and analysis of the effects of air quality on respiratory symptoms. J. Am. Stat. Assoc. 2008, 103, 48–60. [Google Scholar] [CrossRef]
- Huang, Q.; Zhou, Y.; Tao, L.; Yu, W.; Zhang, Y.; Huo, L.; He, Z. A Chan-Vese model based on the Markov chain for unsupervised medical image segmentation. Tsinghua Sci. Technol. 2021, 26, 833–844. [Google Scholar] [CrossRef]
- Salgia, R.; Mambetsariev, I.; Hewelt, B.; Achuthan, S.; Li, H.; Poroyko, V.; Wang, Y.; Sattler, M. Modeling small cell lung cancer (SCLC) biology through deterministic and stochastic mathematical models. Oncotarget 2018, 9, 26226–26242. [Google Scholar] [CrossRef]
- Li, H.; Slone, J.; Fei, L.; Huang, T. Mitochondrial DNA variants and common diseases: A mathematical model for the diversity of age-related mtDNA mutations. Cells 2019, 8, 608. [Google Scholar] [CrossRef]
- Liu, M.; Zhang, D. A dynamic logistics model for medical resources allocation in an epidemic control with demand forecast updating. J. Oper. Res. Soc. 2016, 67, 841–852. [Google Scholar] [CrossRef]
- Ordu, M.; Demir, E.; Tofallis, C.; Gunal, M.M. A novel healthcare resource allocation decision support tool: A forecasting-simulation-optimization approach. J. Oper. Res. Soc. 2021, 72, 485–500. [Google Scholar] [CrossRef]
- McGillen, J.B.; Anderson, S.J.; Dybul, M.R.; Hallett, T.B. Optimum resource allocation to reduce HIV incidence across sub-Saharan Africa: A mathematical modelling study. Lancet HIV 2016, 3, e441–e448. [Google Scholar] [CrossRef]
- Moore, S.; Hill, E.M.; Tildesley, M.J.; Dyson, L.; Keeling, M.J. Vaccination and non-pharmaceutical interventions for COVID-19: A mathematical modelling study. Lancet Infect. Dis. 2021, 21, 793–802. [Google Scholar] [CrossRef] [PubMed]
- Johnson, M.; Albizri, A.; Simsek, S. Artificial intelligence in healthcare operations to enhance treatment outcomes: A framework to predict lung cancer prognosis. Ann. Oper. Res. 2022, 308, 275–305. [Google Scholar] [CrossRef]
- Alsina, Á.; Salgado, M. Understanding early mathematical modelling: First steps in the process of translation between real-world contexts and mathematics. Int. J. Sci. Math. Educ. 2022, 20, 1719–1742. [Google Scholar] [CrossRef]
- Osaba, E.; Villar-Rodriguez, E.; Del Ser, J.; Nebro, A.J.; Molina, D.; LaTorre, A.; Suganthan, P.N.; Coello, C.A.C.; Herrera, F. A tutorial on the design, experimentation and application of metaheuristic algorithms to real-world optimization problems. Swarm Evol. Comput. 2021, 64, 100888. [Google Scholar] [CrossRef]
- Ahmad, S.; Ullah, A.; Al-Mdallal, Q.M.; Khan, H.; Shah, K.; Khan, A. Fractional order mathematical modeling of COVID-19 transmission. Chaos Solitons Fractals 2020, 139, 110256. [Google Scholar] [CrossRef]
- Pannu, A. Artificial intelligence and its application in different areas. Artif. Intell. 2015, 4, 79–84. [Google Scholar]
- Blum, W. Quality teaching of mathematical modelling: What do we know, what can we do? In Proceedings of the 12th International Congress on Mathematical Education: Intellectual and Attitudinal Challenges; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 73–96. [Google Scholar]
- Bossaerts, P.; Murawski, C. Computational complexity and human decision-making. Trends Cogn. Sci. 2017, 21, 917–929. [Google Scholar] [CrossRef] [PubMed]
- Chambers, J.M.; Hastie, T.J. Statistical models. In Statistical Models; Routledge: Oxfordshire, UK, 2017; pp. 13–44. [Google Scholar]
- Hastie, T.J.; Pregibon, D. Generalized linear models. In tatistical Models in S; Routledge: Oxfordshire, UK, 2017; pp. 195–247. [Google Scholar]
- Kidger, P. On neural differential equations. arXiv 2022, arXiv:2202.02435. [Google Scholar]
- Chen, Y.; Li, N.; Lourenço, J.; Wang, L.; Cazelles, B.; Dong, L.; Li, B.; Liu, Y.; Jit, M.; Bosse, N.I.; et al. Measuring the effects of COVID-19-related disruption on dengue transmission in southeast Asia and Latin America: A statistical modelling study. Lancet Infect. Dis. 2022, 22, 657–667. [Google Scholar] [CrossRef]
- Shehab, M.; Abualigah, L.; Shambour, Q.; Abu-Hashem, M.A.; Shambour, M.K.Y.; Alsalibi, A.I.; Gandomi, A.H. Machine learning in medical applications: A review of state-of-the-art methods. Comput. Biol. Med. 2022, 145, 105458. [Google Scholar] [CrossRef]
- Sridhar, C.; Pareek, P.K.; Kalidoss, R.; Jamal, S.S.; Shukla, P.K.; Nuagah, S.J. Optimal medical image size reduction model creation using recurrent neural network and GenPSOWVQ. J. Healthc. Eng. 2022, 2022, 2354866. [Google Scholar] [CrossRef]
- Hart, W.E.; Laird, C.D.; Watson, J.P.; Woodruff, D.L.; Hackebeil, G.A.; Nicholson, B.L.; Siirola, J.D. Pyomo-Optimization Modeling in Python; Springer: Berlin, Germany, 2017; Volume 67, p. 277. [Google Scholar]
- Koivunen, M.; Saranto, K. Nursing professionals’ experiences of the facilitators and barriers to the use of telehealth applications: A systematic review of qualitative studies. Scand. J. Caring Sci. 2018, 32, 24–44. [Google Scholar] [CrossRef]
- Dash, S.; Shakyawar, S.K.; Sharma, M.; Kaushik, S. Big data in healthcare: Management, analysis and future prospects. J. Big Data 2019, 6, 54. [Google Scholar] [CrossRef]
- Beerenwinkel, N.; Schwarz, R.F.; Gerstung, M.; Markowetz, F. Cancer evolution: Mathematical models and computational inference. Syst. Biol. 2015, 64, e1–e25. [Google Scholar] [CrossRef] [PubMed]
- Narin, A.; Kaya, C.; Pamuk, Z. Automatic detection of coronavirus disease (COVID-19) using x-ray images and deep convolutional neural networks. Pattern Anal. Appl. 2021, 24, 1207–1220. [Google Scholar] [CrossRef] [PubMed]
- Zimmer, A.; Katzir, I.; Dekel, E.; Mayo, A.E.; Alon, U. Prediction of multidimensional drug dose responses based on measurements of drug pairs. Proc. Natl. Acad. Sci. USA 2016, 113, 10442–10447. [Google Scholar] [CrossRef] [PubMed]
- Inoue, J.; Sato, Y.; Sinclair, R.; Tsukamoto, K.; Nishida, M. Rapid genome reshaping by multiple-gene loss after whole-genome duplication in teleost fish suggested by mathematical modeling. Proc. Natl. Acad. Sci. USA 2015, 112, 14918–14923. [Google Scholar] [CrossRef]
- Alber, M.; Buganza Tepole, A.; Cannon, W.R.; De, S.; Dura-Bernal, S.; Garikipati, K.; Karniadakis, G.; Lytton, W.W.; Perdikaris, P.; Petzold, L.; et al. Integrating machine learning and multiscale modeling—Perspectives, challenges, and opportunities in the biological, biomedical, and behavioral sciences. NPJ Digit. Med. 2019, 2, 115. [Google Scholar] [CrossRef]
- Ionescu, C.; Lopes, A.; Copot, D.; Machado, J.T.; Bates, J.H. The role of fractional calculus in modeling biological phenomena: A review. Commun. Nonlinear Sci. Numer. Simul. 2017, 51, 141–159. [Google Scholar] [CrossRef]
- Neftci, E.O.; Averbeck, B.B. Reinforcement learning in artificial and biological systems. Nat. Mach. Intell. 2019, 1, 133–143. [Google Scholar] [CrossRef]
- Breakspear, M. Dynamic models of large-scale brain activity. Nat. Neurosci. 2017, 20, 340–352. [Google Scholar] [CrossRef]
- Sharma, S.; Samanta, G.P. Analysis of the dynamics of a tumor–immune system with chemotherapy and immunotherapy and quadratic optimal control. Differ. Equ. Dyn. Syst. 2016, 24, 149–171. [Google Scholar] [CrossRef]
- Ibrahim, R.W.; Jalab, H.A.; Karim, F.K.; Alabdulkreem, E.; Ayub, M.N. A medical image enhancement based on generalized class of fractional partial differential equations. Quant. Imaging Med. Surg. 2022, 12, 172. [Google Scholar] [CrossRef]
- Luzyanina, T.Y.B.; Bocharov, G.A. Markov chain Monte Carlo parameter estimation of the ODE compartmental cell growth model. Математическая Биoлoгия И Биoинфoрматика 2018, 13, 376–391. [Google Scholar] [CrossRef]
- Miranville, A.; Rocca, E.; Schimperna, G. On the long time behavior of a tumor growth model. J. Differ. Equ. 2019, 267, 2616–2642. [Google Scholar] [CrossRef]
- Zhang, Y.; Barocas, V.H.; Berceli, S.A.; Clancy, C.E.; Eckmann, D.M.; Garbey, M.; Kassab, G.S.; Lochner, D.R.; McCulloch, A.D.; Tran-Son-Tay, R.; et al. Multi-scale modeling of the cardiovascular system: Disease development, progression, and clinical intervention. Ann. Biomed. Eng. 2016, 44, 2642–2660. [Google Scholar] [CrossRef]
- Lunney, J.K.; Van Goor, A.; Walker, K.E.; Hailstock, T.; Franklin, J.; Dai, C. Importance of the pig as a human biomedical model. Sci. Transl. Med. 2021, 13, eabd5758. [Google Scholar] [CrossRef]
- Barucca, G.; Santecchia, E.; Majni, G.; Girardin, E.; Bassoli, E.; Denti, L.; Gatto, A.; Iuliano, L.; Moskalewicz, T.; Mengucci, P. Structural characterization of biomedical Co–Cr–Mo components produced by direct metal laser sintering. Mater. Sci. Eng. C 2015, 48, 263–269. [Google Scholar] [CrossRef]
- Gupta, S.; Sharaff, A.; Nagwani, N.K. Frequent item-set mining and clustering based ranked biomedical text summarization. J. Supercomput. 2023, 79, 139–159. [Google Scholar] [CrossRef]
- Bolton, L.; Cloot, A.H.; Schoombie, S.W.; Slabbert, J.P. A proposed fractional-order Gompertz model and its application to tumour growth data. Math. Med. Biol. A J. IMA 2015, 32, 187–209. [Google Scholar] [CrossRef]
- Kühleitner, M.; Brunner, N.; Nowak, W.G.; Renner-Martin, K.; Scheicher, K. Best fitting tumor growth models of the von Bertalanffy-PütterType. BMC Cancer 2019, 19, 683. [Google Scholar] [CrossRef] [PubMed]
- Lima, E.A.B.F.; Oden, J.T.; Hormuth, D.A.; Yankeelov, T.E.; Almeida, R.C. Selection, calibration, and validation of models of tumor growth. Math. Model. Methods Appl. Sci. 2016, 26, 2341–2368. [Google Scholar] [CrossRef] [PubMed]
- Holdt, L.M.; Kohlmaier, A.; Teupser, D. Molecular functions and specific roles of circRNAs in the cardiovascular system. Non-Coding RNA Res. 2018, 3, 75–98. [Google Scholar] [CrossRef] [PubMed]
- Femminò, S.; Penna, C.; Margarita, S.; Comità, S.; Brizzi, M.F.; Pagliaro, P. Extracellular vesicles and cardiovascular system: Biomarkers and Cardioprotective Effectors. Vasc. Pharmacol. 2020, 135, 106790. [Google Scholar] [CrossRef]
- Patel, B.; Sengupta, P. Machine learning for predicting cardiac events: What does the future hold? Expert Rev. Cardiovasc. Ther. 2020, 18, 77–84. [Google Scholar] [CrossRef]
- Allenbach, Y.; Saadoun, D.; Maalouf, G.; Vieira, M.; Hellio, A.; Boddaert, J.; Gros, H.; Salem, J.E.; Resche Rigon, M.; Menyssa, C.; et al. Development of a multivariate prediction model of intensive care unit transfer or death: A French prospective cohort study of hospitalized COVID-19 patients. PLoS ONE 2020, 15, e0240711. [Google Scholar] [CrossRef]
- Liu, A.; Wang, Z.; Yang, Y.; Wang, J.; Dai, X.; Wang, L.; Lu, Y.; Xue, F. Preoperative diagnosis of malignant pulmonary nodules in lung cancer screening with a radiomics nomogram. Cancer Commun. 2020, 40, 16–24. [Google Scholar] [CrossRef]
- Zyout, I.; Togneri, R. Empirical mode decomposition of digital mammograms for the statistical based characterization of architectural distortion. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 109–112. [Google Scholar]
- Azbeg, K.; Boudhane, M.; Ouchetto, O.; Jai Andaloussi, S. Diabetes emergency cases identification based on a statistical predictive model. J. Big Data 2022, 9, 31. [Google Scholar] [CrossRef]
- Austin, P.C. A tutorial on multilevel survival analysis: Methods, models and applications. Int. Stat. Rev. 2017, 85, 185–203. [Google Scholar] [CrossRef]
- Jing, B.; Zhang, T.; Wang, Z.; Jin, Y.; Liu, K.; Qiu, W.; Ke, L.; Sun, Y.; He, C.; Hou, D.; et al. A deep survival analysis method based on ranking. Artif. Intell. Med. 2019, 98, 1–9. [Google Scholar] [CrossRef]
- Peláez, R.; Cao, R.; Vilar, J.M. Nonparametric estimation of the conditional survival function with double smoothing. J. Nonparametr. Stat. 2022, 34, 1063–1090. [Google Scholar] [CrossRef]
- Barakat, A.; Mittal, A.; Ricketts, D.; Rogers, B.A. Understanding survival analysis: Actuarial life tables and the Kaplan–Meier plot. Br. J. Hosp. Med. 2019, 80, 642–646. [Google Scholar] [CrossRef] [PubMed]
- Liu, N.; Zhou, Y.; Lee, J.J. IPDfromKM: Reconstruct individual patient data from published Kaplan-Meier survival curves. BMC Med. Res. Methodol. 2021, 21, 111. [Google Scholar] [CrossRef]
- Benza, R.L.; Gomberg-Maitland, M.; Elliott, C.G.; Farber, H.W.; Foreman, A.J.; Frost, A.E.; McGoon, M.D.; Pasta, D.J.; Selej, M.; Burger, C.D.; et al. Predicting survival in patients with pulmonary arterial hypertension: The REVEAL risk score calculator 2.0 and comparison with ESC/ERS-based risk assessment strategies. Chest 2019, 156, 323–337. [Google Scholar] [CrossRef]
- Gupta, S.; Provenzale, D.; Llor, X.; Halverson, A.L.; Grady, W.; Chung, D.C.; Haraldsdottir, S.; Markowitz, A.J.; Slavin, T.P., Jr.; Hampel, H.; et al. NCCN guidelines insights: Genetic/familial high-risk assessment: Colorectal, version 2.2019: Featured updates to the NCCN guidelines. J. Natl. Compr. Cancer Netw. 2019, 17, 1032–1041. [Google Scholar] [CrossRef] [PubMed]
- Sargent, R.G. Verification and validation of simulation models. In Proceedings of the 2010 IEEE Winter Simulation Conference, Baltimore, MD, USA, 5–8 December 2010; pp. 166–183. [Google Scholar]
- Lwakatare, L.E.; Rånge, E.; Crnkovic, I.; Bosch, J. On the experiences of adopting automated data validation in an industrial machine learning project. In Proceedings of the 2021 IEEE/ACM 43rd International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), Madrid, Spain, 25–28 May 2021; pp. 248–257. [Google Scholar]
- Cybulska, B.; Kłosiewicz-Latoszek, L. Landmark studies in coronary heart disease epidemiology. The Framingham Heart Study after 70 years and the Seven Countries Study after 60 years. Kardiol. Pol. (Pol. Heart J. ) 2019, 77, 173–180. [Google Scholar] [CrossRef] [PubMed]
- Mahmood, S.S.; Levy, D.; Vasan, R.S.; Wang, T.J. The Framingham Heart Study and the epidemiology of cardiovascular disease: A historical perspective. Lancet 2014, 383, 999–1008. [Google Scholar] [CrossRef] [PubMed]
- Charlson, M.E.; Carrozzino, D.; Guidi, J.; Patierno, C. Charlson comorbidity index: A critical review of clinimetric properties. Psychother. Psychosom. 2022, 91, 8–35. [Google Scholar] [CrossRef]
- Beigmohammadi, M.T.; Amoozadeh, L.; Motlagh, F.R.; Rahimi, M.; Maghsoudloo, M.; Jafarnejad, B.; Eslami, B.; Salehi, M.R.; Zendehdel, K. Charlson comorbidity index and a composite of poor outcomes in COVID-19 patients: A systematic review and meta-analysis. Diabetes Metab. Syndr. Clin. Res. Rev. 2020, 14, 2103–2109. [Google Scholar]
- Beigmohammadi, M.T.; Amoozadeh, L.; Rezaei Motlagh, F.; Rahimi, M.; Maghsoudloo, M.; Jafarnejad, B.; Eslami, B.; Salehi, M.R.; Zendehdel, K. Mortality predictive value of APACHE II and SOFA scores in COVID-19 patients in the intensive care unit. Can. Respir. J. 2022, 2022, 5129314. [Google Scholar] [CrossRef]
- Rahmatinejad, Z.; Tohidinezhad, F.; Reihani, H.; Rahmatinejad, F.; Pourmand, A.; Abu-Hanna, A.; Eslami, S. Prognostic utilization of models based on the APACHE II, APACHE IV, and SAPS II scores for predicting in-hospital mortality in emergency department. Am. J. Emerg. Med. 2020, 38, 1841–1846. [Google Scholar] [CrossRef] [PubMed]
- Horby, P.W.; Mafham, M.; Bell, J.L.; Linsell, L.; Staplin, N.; Emberson, J.; Palfreeman, A.; Raw, J.; Elmahi, E.; Prudon, B.; et al. Lopinavir–ritonavir in patients admitted to hospital with COVID-19 (RECOVERY): A randomised, controlled, open-label, platform trial. Lancet 2020, 396, 1345–1352. [Google Scholar] [CrossRef]
- Linzey, J.R.; Foshee, R.L.; Srinivasan, S.; Fiestan, G.O.; Mossner, J.M.; Gemmete, J.J.; Burke, J.F.; Sheehan, K.M.; Rajajee, V.; Pandey, A.S. The predictive value of the hospital score and Lace Index for an adult neurosurgical population: A prospective analysis. World Neurosurg. 2020, 137, e166–e175. [Google Scholar] [CrossRef] [PubMed]
- Garg, A.; Mago, V. Role of machine learning in medical research: A survey. Comput. Sci. Rev. 2021, 40, 100370. [Google Scholar] [CrossRef]
- Gopal, V.N.; Al-Turjman, F.; Kumar, R.; Anand, L.; Rajesh, M. Feature selection and classification in breast cancer prediction using IoT and machine learning. Measurement 2021, 178, 109442. [Google Scholar] [CrossRef]
- Sachdev, N.; Rishi, N.; Jain, R. Breast Cancer Prediction Using Supervised Machine Learning Techniques. Int. J. Comput. Biol. Bioinform. 2021, 7, 8–13. [Google Scholar]
- Sun, J.; Yang, Y.; Wang, Y.; Wang, L.; Song, X.; Zhao, X. Survival risk prediction of esophageal cancer based on self-organizing maps clustering and support vector machine ensembles. IEEE Access 2020, 8, 131449–131460. [Google Scholar] [CrossRef]
- Daoud, M.; Mayo, M. A survey of neural network-based cancer prediction models from microarray data. Artif. Intell. Med. 2019, 97, 204–214. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Wang, S.; Wu, Q.; Azim, R.; Li, W. Predicting potential miRNA-disease associations by combining gradient boosting decision tree with logistic regression. Comput. Biol. Chem. 2020, 85, 107200. [Google Scholar] [CrossRef] [PubMed]
- Al-Azzam, N.; Shatnawi, I. Comparing supervised and semi-supervised machine learning models on diagnosing breast cancer. Ann. Med. Surg. 2021, 62, 53–64. [Google Scholar] [CrossRef]
- Kabiraj, S.; Raihan, M.; Alvi, N.; Afrin, M.; Akter, L.; Sohagi, S.A.; Podder, E. Breast cancer risk prediction using XGBoost and random forest algorithm. In Proceedings of the 2020 11th International Conference on Computing, Communication and NETWORKING Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020; pp. 1–4. [Google Scholar]
- Morais-Rodrigues, F.; Silv́erio-Machado, R.; Kato, R.B.; Rodrigues, D.L.N.; Valdez-Baez, J.; Fonseca, V.; San, E.J.; Gomes, L.G.R.; Dos Santos, R.G.; Viana, M.V.C.; et al. Analysis of the microarray gene expression for breast cancer progression after the application modified logistic regression. Gene 2020, 726, 144168. [Google Scholar] [CrossRef] [PubMed]
- Kamel, H.; Abdulah, D.; Al-Tuwaijari, J.M. Cancer classification using gaussian naive bayes algorithm. In Proceedings of the 2019 International Engineering Conference (IEC), Erbil, Iraq, 23–25 June 2019; pp. 165–170. [Google Scholar]
- Ray, S. A quick review of machine learning algorithms. In Proceedings of the 2019 International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon), Faridabad, India, 14–16 February 2019; pp. 35–39. [Google Scholar]
- Shakeel, P.M.; Burhanuddin, M.A.; Desa, M.I. Lung cancer detection from CT image using improved profuse clustering and deep learning instantaneously trained neural networks. Measurement 2019, 145, 702–712. [Google Scholar] [CrossRef]
- Vougas, K.; Sakellaropoulos, T.; Kotsinas, A.; Foukas, G.R.P.; Ntargaras, A.; Koinis, F.; Polyzos, A.; Myrianthopoulos, V.; Zhou, H.; Narang, S.; et al. Machine learning and data mining frameworks for predicting drug response in cancer: An overview and a novel in silico screening process based on association rule mining. Pharmacol. Ther. 2019, 203, 107395. [Google Scholar] [CrossRef]
- Schneider, L.; Laiouar-Pedari, S.; Kuntz, S.; Krieghoff-Henning, E.; Hekler, A.; Kather, J.N.; Gaiser, T.; Fröhling, S.; Brinker, T.J. Integration of deep learning-based image analysis and genomic data in cancer pathology: A systematic review. Eur. J. Cancer 2022, 160, 80–91. [Google Scholar] [CrossRef]
- Latif, J.; Xiao, C.; Imran, A.; Tu, S. Medical imaging using machine learning and deep learning algorithms: A review. In Proceedings of the 2019 2nd International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 30–31 January 2019; pp. 1–5. [Google Scholar]
- Lundervold, A.S.; Lundervold, A. An overview of deep learning in medical imaging focusing on MRI. Z. Für Med. Phys. 2019, 29, 102–127. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, Y.; Wu, Q.; Xia, Y. Medical image classification using synergic deep learning. Med. Image Anal. 2019, 54, 10–19. [Google Scholar] [CrossRef]
- Li, Q.; Cai, W.; Wang, X.; Zhou, Y.; Feng, D.D.; Chen, M. Medical image classification with convolutional neural network. In Proceedings of the 2014 IEEE 13th International Conference on Control Automation Robotics & Vision (ICARCV), Singapore, 10–12 December 2014; pp. 844–848. [Google Scholar]
- Nour, M.; Cömert, Z.; Polat, K. A novel medical diagnosis model for COVID-19 infection detection based on deep features and Bayesian optimization. Appl. Soft Comput. 2020, 97, 106580. [Google Scholar] [CrossRef]
- Yadav, S.S.; Jadhav, S.M. Deep convolutional neural network based medical image classification for disease diagnosis. J. Big Data 2019, 6, 113. [Google Scholar] [CrossRef]
- Stam, C.J. Modern network science of neurological disorders. Nat. Rev. Neurosci. 2014, 15, 683–695. [Google Scholar] [CrossRef]
- Gysi, D.M.; Valle, Í.D.; Zitnik, M.; Ameli, A.; Gan, X.; Varol, O.; Ghiassian, S.D.; Patten, J.J.; Davey, R.A.; Loscalzo, J.; et al. Network medicine framework for identifying drug-repurposing opportunities for COVID-19. Proc. Natl. Acad. Sci. USA 2021, 118, e2025581118. [Google Scholar] [CrossRef] [PubMed]
- Mezei, T.; Horváth, A.; Nagy, Z.; Czigléczki, G.; Banczerowski, P.; Báskay, J.; Pollner, P. A Novel Prognostication System for Spinal Metastasis Patients Based on Network Science and Correlation Analysis. Clin. Oncol. 2023, 35, e20–e29. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Hu, Z.; Jiang, R.; Zhou, M. DeepCDR: A hybrid graph convolutional network for predicting cancer drug response. Bioinformatics 2020, 36 (Suppl. S2), i911–i918. [Google Scholar] [CrossRef]
- Ding, K.; Zhou, M.; Wang, Z.; Liu, Q.; Arnold, C.W.; Zhang, S.; Metaxas, D.N. Graph Convolutional Networks for Multi-modality Medical Imaging: Methods, Architectures, and Clinical Applications. arXiv 2022, arXiv:2202.08916. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modeling Process | Basic Concepts |
|---|---|
| Problem Abstraction | The process of translating practical problems into mathematical language. This includes identifying key variables, establishing mathematical descriptions of the problem, and setting goals for the problem. |
| Mathematical Model | A mathematical model is an abstract representation of practical problems. It usually includes components such as variables, equations, constraints, and initial conditions. Mathematical models can be deterministic or probabilistic and can be continuous or discrete. |
| Modeling Methods | Modeling methods are techniques and strategies used to construct mathematical models. Common modeling methods include mathematical analysis, optimization theory, probability and statistics, calculus, and differential equations. The choice of modeling method depends on the nature and requirements of the problem. |
| Model Validation | Model validation is the process of confirming whether a mathematical model can accurately reflect actual problems. This can be achieved by comparing the predicted results of the model with actual data. If the model’s predictions match well with actual observations, then the effectiveness of the model is verified. |
| Model Solution | Model solving is the process of analyzing and calculating established mathematical models using mathematical tools and techniques. This can involve methods such as symbolic computation, numerical computation, and optimization algorithms to obtain the solution or optimal solution of the problem. |
| Model Evaluation | Model evaluation is the process of evaluating the quality of model results and solutions. This includes evaluating the feasibility, stability, accuracy, and practicality of the solution. The purpose of model evaluation is to determine the effectiveness and reliability of the model in solving practical problems. |
| Applications | Content | Cases |
|---|---|---|
| Disease Prediction | Predict whether patients will develop a certain disease and assess their risk level. | Logistic regression models are used to assess the risk factors for having diabetes and thus guide patients to better prevention and management strategies. |
| Diagnosis and Treatment | Quickly and accurately diagnose patients and provide the best treatment plan. | Data such as tumor markers and CT scans are used to diagnose cancer and to develop individualized treatment plans based on a patient’s specific situation. |
| Drug Development | Determine the optimal drug dosage, develop an effective drug trial plan, and evaluate the efficacy of a drug in different populations. | Multiple linear regression models were used to assess the relationship between drug dose and patient physiological parameters to determine the optimal drug dose. |
| Clinical Decision Support | Provide more scientific basis for decision-making. | Use survival analysis models to evaluate the patient’s survival time or the risk of event occurrence in order to complete clinical treatment decisions. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Wu, R.; Yang, A. Research on Medical Problems Based on Mathematical Models. Mathematics 2023, 11, 2842. https://doi.org/10.3390/math11132842
Liu Y, Wu R, Yang A. Research on Medical Problems Based on Mathematical Models. Mathematics. 2023; 11(13):2842. https://doi.org/10.3390/math11132842
Chicago/Turabian StyleLiu, Yikai, Ruozheng Wu, and Aimin Yang. 2023. "Research on Medical Problems Based on Mathematical Models" Mathematics 11, no. 13: 2842. https://doi.org/10.3390/math11132842
APA StyleLiu, Y., Wu, R., & Yang, A. (2023). Research on Medical Problems Based on Mathematical Models. Mathematics, 11(13), 2842. https://doi.org/10.3390/math11132842