Abstract
This research aims to explain the intrinsic difficulty of Karp’s list of twenty-one problems through the use of empirical complexity measures based on the ellipsoidal width of the polyhedron generated by the constraints of the relaxed linear programming problem. The variables used as complexity measures are the number of nodes visited by the and the CPU time spent solving the problems. The measurements used as explanatory variables correspond to the Dikin ellipse eigenvalues within the polyhedron. Other variables correspond to the constraint clearance with respect to the analytical center used as the center of the ellipse. The results of these variables in terms of the number of nodes and CPU time are particularly satisfactory. They show strong correlations, above 60%, in most cases.
MSC:
90C10
1. Introduction
The NP-completeness of Karp’s 21 problems list dates back to 1972 [1]. It is a list of classical problems that meet computational complexity characteristics. Some of the list’s problems solved in this paper included the set covering problem, the set packaging problem, the knapsack multi-demand problem, and some general integer programming problems. There were statistically significant relationships between the branching and bound tree number of nodes and the resolution time. Explanatory variables included geometric measurements corresponding to an inner Dikin ellipse that replicates the shape of the linear polyhedron. The test problems used are classics in combinatorics, computer science, and computational complexity theory.
The set covering problem, also known as SCP, is an NP-complete class problem. Solutions to these problems usually consist of finding a solution set to cover, totally or partially, a set of needs at the lowest possible cost. In many cases, the distance or the response time between customers and service delivery points is critical to customer satisfaction. For example, if a building catches fire, the fire station response time is vital; the longer the delay, the greater the building damage. In this case, the SCP model ensures that at least one fire station is at a close enough distance in order for fire engines to reach the building within a certain time. Set packing is also a classic problem. It consists of packaging sets of disjoint k subsets. The problem is visibly an NP problem because, given k subsets, subsets are disjoint 2 to 2 in polynomial time [2,3]. The optimization problem consists of finding the maximum number of sets, from 2 to 2 disjoints in a list. It is a maximization problem formulated as a packaging integer programming problem, and its dual linear problem is the set cover problem [4]. The multi-dimensional knapsack (MKP) problem involves selecting a set of items to carry in a knapsack subject to one or more restrictions. These may be the knapsack weight or volume. The objective function of this problem seeks to maximize a linear function in 0–1 variables subject to knapsack constraints. Finally, the multi-dimensional and multi-demand knapsack problem is the multi-dimensional knapsack problem to which added compliance restrictions present some demand conditions [5]. The CPU time is key when solving an MIP/BIP problem using the branch and bound () algorithm. It depends on the search tree size associated with the algorithm. finds the solution by recursively dividing the search space. The space is a tree where the root node is associated with the integer solution space. The brother nodes are a solution space partition of the parent node. At each node, the subspace is an MIP/BIP and its linear programming (LP) relaxation is solved to supply a linear solution. If the LP is not workable or better than the primary solution (the best integer value found), the procedure prunes the node. A previous article proposed complexity indices to estimate the tree size, which applies to the multi-dimensional backpack problem [6].
1.1. Tree Counting Literature Review
Knuth [7] proposed the first method to estimate the search tree size of the branch and bound () algorithm. This method works by repeatedly sampling the search tree sequence and estimating a measure of the node number to disaggregate. This calculates the tree by repeatedly following random paths from the root. As the search may prove to be extensive, Purdom [8] improved the method by following more than one path from a node. Tree size was estimated by performing a partial backtracking search. This modification exponentially improves results with the tree height. Purdom called this method Partial Backtracking. Chen [9] improved Knuth’s proposed method using heuristic sampling to estimate its efficiency. This updated version produces significantly higher efficiency estimates for tree search strategies commonly used. These are depth first, breadth first, best first, and iterative deepening. Belov et al. [10] combined Knuth’s sampling procedure with the abstract tree developed by Le Bodic and Nemhauser [11]. Knuth’s original method uses the distribution of node knowledge in a tree by reducing the variance in tree size estimates, while Le Bodic and Nemhauser provide a theoretical tree model. Belov et al. combined these two methods to obtain a significant estimation accuracy increase. According to Belov et al. and the conducted experiments, the error decreased by more than half in the a priori estimation. The abstract tree developed by Le Bodic and Nemhauser [11] is a formula based on the concept of gain by branching into any node. They use an a priori estimate of the gain obtained by branching left or right into any node. They also use what they call gap, which is the gain value that allows for obtaining the optimal integer solution via branching. Their use of the abstract tree seeks to find the best variable to branch, i.e., to obtain a tree of minimum size. Other estimation methods are the Weighted Backtrack Estimator [12], Profile Estimation [13], and the Sum of Subtree Gaps [14]. Recently, Refs. [15,16,17] developed methods based on machine learning in the context of integer programming. Fischetti in [18] proposed a classifier to predict specific points online. Finally, Hendel et al. [19] developed a new version of the old method of estimating the tree. They integrated Le Bodic and Nemhauser’s [11] theoretical tree and new measures such as "leaf frequency". A leaf in the tree is a node that does not dis-aggregate, and this may be because it delivers an integer solution, which is unfeasible or needs pruning. They then use this and other measures of algorithm progress using machine learning’s random forest model to estimate the size of the tree. Next, they integrate this technique into the SCIP constrained integer programming software [20]. The application of these methods occurs throughout the algorithm, since they require a few iterations to start with the estimate, and there are iterations for recalculations. Its accuracy also grows as the algorithm progresses, and so does the availability of information.
1.2. Our Contribution to the Problem of Estimating the B&B Tree
Our estimation of the tree research line, including the methods developed in this work, follows the conditioning concept in integer programming [21,22,23]. Vera and Derpich [24] proposed dimensions for the polyhedron width, based on m (number of constraints) and n (number of variables). The dimension used is to estimate the number of upper bounds of iterations of the algorithm and the Lenstra algorithm [25]. Vera and Derpich also proposed two measures concerning the polyhedron ellipsoidal width, which are the maximum slack and a term called the “distance to ill-posedness of the integer problem”, which Vera documented in [22]. The number of iterations of the algorithm’s proposed dimensions [25] corresponds to worst-case dimensions. They are similar when compared with those proposed by Le Bodic and Nemhauser [11], since both give values far from the real values obtained. Vera and Derpich’s [22] proposed dimensions basis includes concepts that reflect the shape and spatial orientation of the polyhedron. Earlier approaches do not capture these factors. Therefore, these dimensions also predict the tree node number and CPU time. These are the conceptual basis of this work. The indices developed in this work use a Dikin ellipse inside the polyhedron. They show a good correlation with the algorithm CPU time and the number of nodes visited. The Dikin ellipse allows for the estimation of the polyhedron ellipsoidal width, which iterates n times to estimate the tree. This enables applications to new, related geometric indices, starting with the constraints of the linear programming problem generated by relaxing the integer variables. The proposed indices’ basis is the concept of polyhedron flatness. This means that if a polyhedron is thin in some direction, the algorithm might run faster. In this article, we seek to test how much this idea influences the tree size, characterized by the number of nodes visited and the CPU time. The underlying conjecture for the proposed experimental design is that a narrower polyhedron will be faster to cross. Therefore, the tree will be smaller and vice versa, i.e., in a narrower polyhedron, the tree will be larger. These new factors are related to the dimensions of the matrices associated with the polyhedron of the relaxed problem, as well as the maximum and minimum slacks with respect to the center of the ellipse. To test the relationship between these measures and the tree’s number of nodes, we designed an experimental study and found a strong linear correlation. The empirical study included set covering, set packing, and other general problems of integer programming. Data came from the public library MIPLIB [26,27,28]. We also assessed the multi-demand multi-dimensional knapsack (MDMKP) problem. Data were taken from OR-Library [28].
Following this introduction, and because they support the proposed complexity indices, Section 2 develops the concepts related to the polyhedron ellipsoidal width. Section 3 presents the problems under study in mathematical formulations, which are set covering, set packing, and multi-demand multi-dimensional backpack. Section 4 presents the experimental design, detailing the test problems used and the results obtained. Section 5 presents a discussion in which the work is compared with others that are similar in some way, and, finally, Section 6 summarizes the main findings and future work.
2. Methods and Materials
Polyhedron Ellipsoidal Width
Let K be a convex set in which ; we define the integer width of K as follows:
If we restrict the vectors v to the Euclidean space set of unit vectors, with a unitary norm, we obtain the total width according to the coordinate axes . The integer width is a very interesting geometric measure. It is related to the existence of at least one integer point. If there is at least one integer point, this width cannot be too small. This is an important result because [29] stated that if K does not contain an integer point. Lenstra considered to be of the order of , where is a constant. The problem approach that we study in this paper is as follows.
We assume that the polyhedron given by is bounded and denotes the problem data with the letter d, so that . This is the problem-specific instance. We denote by the polyhedron, and by ,…,, the row vectors of A. Next, we analyze an application of Lenstra’s flatness theorem [30]. We obtain a dimension that depends on geometry rather than dimensional factors. As in the classical flatness theorem analysis, the basis of the estimate lies in rounding the polyhedron using inscribed and circumscribed ellipses. Ellipses are intended to interpret the polyhedron shape with certainty. Therefore, let us build a pair of ellipses with a common center .
and
so that
where Q is a definite positive matrix. The matrices have different possibilities, depending on the value of . John proposes [31] an ellipse with minimal volume by making However, computing becomes a hard problem. We use an approach based on the classic setup of interior point methods in convex linear optimization [32]. Suppose that we know a self-concordant barrier function , on a convex body, with parameter v as in Nesterov and Nemirosky [33]. Then, let
Let and E be a unit radius inner ellipse, known as a Dikin ellipse. Thus, if we take , for example, we use the traditional logarithmic barrier function
with . The point is the analytical center and the matrix Q is
with
where denotes a diagonal matrix constructed with the corresponding elements. The fact that the matrix Q naturally connects with the polyhedron’s geometric properties justifies the ellipsis construction choice. The following is the ellipses’ geometrical result.
Proposition 1.
Let Q be a positively defined symmetric real matrix by defining a pair of ellipses as in (4). Then,
Demonstration.
The term is ellipse E’s radius, according to the direction u.
2 is the ellipse E’s width, according to vector u.
Multiplying by , we obtain the expanded ellipse .
Then, 2 is ellipse ’s width, according to the vector u.
The value 2 is greater than the polyhedron ’s width, according to vector .
Proposition 2.
Let be the positive definite matrix Q orthonormal eigenvectors, and be the smallest eigenvalue of Q. Then, for any ,
Demonstration.
Since Q is symmetric and defined as positive, the result comes from the fact that
It follows that
Then, taking the minimum eigenvalue, we have
Because we use it in our analysis, we describe the result of Vera [22], which relates the matrix Q eigenvalues to the matrix eigenvalues and other data.
Proposition 3.
Let with Let and be the smallest and largest Q eigenvalues, respectively. Let and be the smallest and largest eigenvalues, respectively. Additionally, let be the highest and lowest values. Then, it fulfills
Demonstration [22,24].
Proposition 4.
Let and be the matrix Q eigenvalues and eigenvectors, respectively, Let u be a possible solution. Then, we have the following:
Demonstration.
From Proposition 1’s demonstration, we have
From Proposition 2, we have
Taking an upper bound with a norm-2 higher eigenvector, we have
Assuming that , then
Additionally, from Proposition 3, we have
In a previous paper, Ref. [34] built a disjunction to branch variables in the , based on the associated linear polyhedron ellipsoidal. This simultaneously branches various variables, as if it was a super ruler that uses ellipsoidal width . This rule proved to be more efficient than the known strong branching rule. The latter often leads to a smaller search tree, although it requires much more time to select branching variables. Figure 1 shows the ellipses used, in an exponential rounding approach, where Q is a positive definite matrix. This is a shortest vector problem version. Micciancio [35] considers it a difficult problem. We use Proposition 4 as a dimension only. Therefore, we do not solve it optimally. However, we use an upper bound of the optimal value, which captures some aspects of the original problem that reproduce the intrinsic difficulty of a particular instance. Based on Proposition 4, we propose the next dimension related to polyhedron ’s geometry.
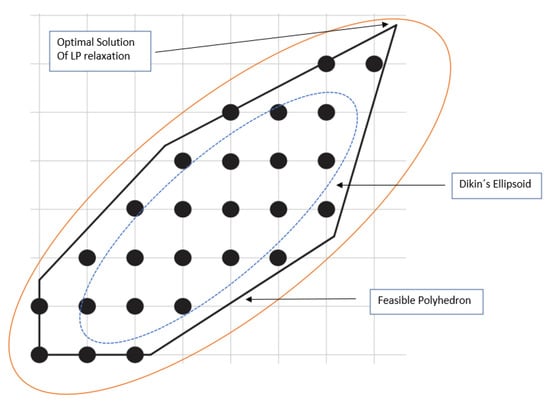
Figure 1.
Ellipsoidal rounding using a pair of Dikin ellipses.
3. Experimental Design
This section describes the experimental design and shows the mathematical structure of the test problem considered, which is part of Karp’s list. The previous section found the variables related to geometric aspects. On this basis, a linear search established relationships between these variables. Additionally, two measures were related to the tree, which were the number of explored nodes and the algorithm’s CPU time. Thus, the relationship searching work is fully experimental, and the results relate to the test problems only. They are not generalizable to other cases without re-running a similar experiment. The statistical model employed is a multiple regression model that uses the ANOVA test, using the F statistic to validate the overall model significance. The explained variables are the following:
- The solved instance CPU time, using the algorithm.
- The number of nodes scanned by the algorithm.
The explanatory variables studied were as follows:
- is the maximum eigenvalue of the matrix ;
- is the minimum eigenvalue of the matrix ;
- is the maximum eigenvalue of the matrix ;
- is the minimum eigenvalue of the matrix ;
- is the maximum slack to the center ;
- is the minimum slack to the center .
We constructed two multiple regression models, named Model 1 and Model 2. The first uses the CPU time as the explained variable. The second model uses the number of nodes as the explained variable. The models are as follows:
Model 1: Number of nodes =
Model 2: CPU time =
3.1. Used Test Problems
3.1.1. The Set Covering Problem
This problem seeks to find the minimum number of variables with which to cover all sets at least once. [35,36] provided a formal definition. Let us look at this problem through an example. Suppose that we must cover with antennas a set of geographical areas in a city. Then, we define as a binary variable, i.e., 1 if an antenna is located in the area and 0 otherwise. Installing an antenna in area j has the cost and . There are n geographical areas. Then, . Formally, the set covering problem is expressed as follows:
subject to
: areas served by an antenna located in area J.
3.1.2. The Set Packing Problem
Varizani [36] formulated the maximum set packing integer linear program as follows:
subject to
where U is the cover set.
3.1.3. The Multi-Dimensional Knapsack Problem
All coefficients are non-negative. More precisely, we can assume, without loss of generality, and Furthermore, any MKP with at least one of the parameters equal to 0 may be replaced by an equivalent MKP with positive parameters, i.e., both problems have the same feasible solutions [29].
subject to
3.1.4. The Multi-Demand Multi-Dimensional Knapsack Problem
This problem comes from OR-Library and Beasley documented it in 1990. There are nine data files: MDMKPC T1,…, MDMKPC T9. Each file has fifteen instances. In total, there are 90 test problems, which are the test problems of [29]. The MDMKP problem to solve is
subject to
MDMKP instances result from appropriately modifying the MKP instances resolved in each combination cost type (either positive or mixed), and q number of constraints = (q = 1, and , respectively). Number of test problems (), 6 cost coefficients . The first 3 correspond to the positive cost case for and constraints, respectively. The last 3 correspond to the mixed cost case for and constraints, respectively [29].
We took the test problems from two public libraries, MIPLIB and OR-Library. Table 1 shows problems from the MIPLIB library. There are binary and MIP programs, as well as other types of problems. The considered problems are knapsack, set covering, set packing, and other problems. The test problems from OR-Library correspond to the multi-dimensional knapsack problem and the multi-demand and multi-dimensional knapsack problem.

Table 1.
List of problems studied from MIPLIB library.
4. Results
Table 1 shows the problems solved using the MIPLIB library. These were inequality-type constraint problems. They included set covering, set packing, knapsack multi-dimensional, knapsack multi-dimensional and multi-demand, general integer, binary, and integer. It should be noted that some resolution times were lengthy.
4.1. MIPLIB Library Test Problem Results
Table 2 and Table 3 show the results of the nodes and CPU times obtained by solving the problems optimally with different threads for instances of the MIPLIB library. The most time-consuming problem was mas74, which took 25,447 s to solve with two threads.
Table 2.
Nodes explored vs. different threads of Cplex (nodes) of MIPLIB library.
Table 3.
CPU time explored vs. different threads of Cplex (seconds) of MIPLIB library.
High CPU times coincide with the number of highly scanned nodes, which is a sign of the consistency of the results. However, the average CPU time per node scanned is 0.017 s, with a standard deviation of 0.0631. This gives a coefficient of variation of 3.7, which indicates that these results are highly dispersed. The average number of restrictions of the instances is 5850.82 and the average number of variables is 1521.11, while the standard deviation is 8390.56 and 2711.22, respectively. This gives coefficients of variation of 1.43 and 1.78, respectively, for constraints and variables. Comparing these dispersions with the CPU time/node results, it can be concluded that the instances are less dispersed than the resolution results.
Table 4 shows the calculated predictor geometric values, which are , , , , , and . It is observed that there is a group of high values of , , and . However, no relationship is observed with the values of nodes visited, nor with CPU time.
Table 4.
Calculated predictor geometric values from MIPLIB library.
The results of Table 4 were obtained through the development of ellipses as explained in Section 2. It should be noted that the main difficulty in these calculations is found in the calculation of the analytical center (Expression 7). This is because a nonlinear problem must be solved, which was completed using Newton’s method, and it is not very efficient. Only those problems in which the calculation of these values took less than an hour were included.
Table 4 shows very high values, which coincides in instances 21 and 22 with low values of restrictions and variables.
Table 5 shows the results of the MIPLIB library Model 1 (nodes), for resolutions with different threads. When compared to other experiments with two, four, and eight threads, the correlation values were similar. When looking at the explanatory variables’ found values, the , and values were similar for all experiments. Table 5 shows that nodes versus the MIPLIB library with two, four, and eight instances of threads have a statistical F test value that shows they are statistically significant at a 95% confidence level. The experiment with 12 nodes is significant with a 90% confidence level. All threads show a good fit, with correlation coefficient values ranging from a 0.61 maximum value to a 0.541 minimum. Variables and are related to the polyhedron ellipsoid minimum width through Proposition 4. The values are similar for all threads. This is the same as with the explanatory variable coefficients. The regression coefficients show negative values for almost all variables, except for . This has positive coefficient values for all threads. We also observe that all the explanatory variables’ coefficients are negative. This shows an inverse relationship with the number of nodes. For example, the higher the value, the greater the number of nodes generated, and vice versa. Additionally, we see that the correlation between different threads’ coefficient values is slightly different. The highest value is 0.611 and the lowest is 0.541. We must note that this last value was seen in the regression with 12 threads, showing a test value of . This indicates that the experiment is not statistically significant.
Table 5.
Model 1 (node) results for resolutions with different threads in the MIPLIB library.
Figure 2 shows the CPU time results for different MIPLIB library problems. We used the Cplex software with 2, 4, 8 and 12 threads. The two-threaded resolution offered the lowest CPU time. Figure 2 data are shown in Table 2. Figure 3 shows the Cplex software results of the nodes scanned for the MIPLIB library problems with 2, 4, 8, and 12 threads. The two-thread resolution offered the fewest visited nodes in most cases. Figure 3 data are shown in Table 3. In both figures, the great dispersion of values can be observed between the different problems solved. It can also be seen that the values that give high numbers correspond to the same resolved instances and that the different threads show similar results.
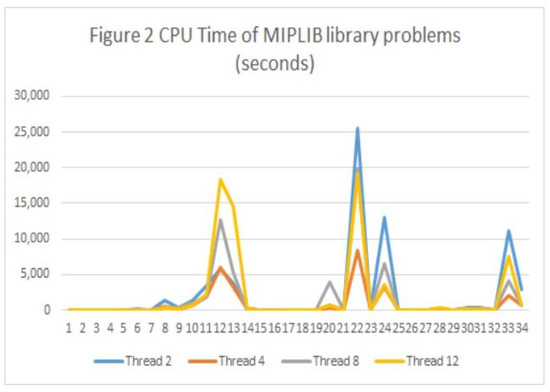
Figure 2.
CPU time for MIPLIB library problems.
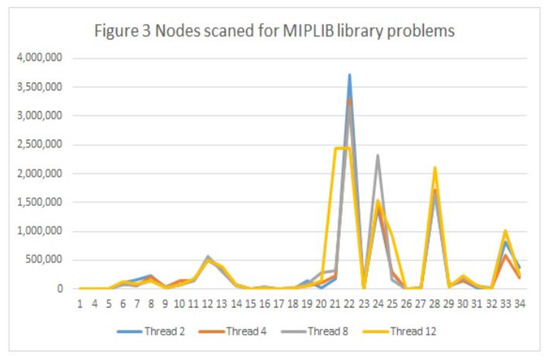
Figure 3.
Nodes scanned for MIPLIB library problems.
Table 6 shows the results of the MIPLIB library Model 2 (CPU times), for resolutions with different threads. Taking other experiments with two, four, and eight threads, the correlation values were similar, except for the runs with 12 threads, which showed a value of R = 0.38. Table 6 shows that nodes versus the MIPLIB library with two, four, and eight instances of threads had a statistical F-test value demonstrating statistical significance at a 95% confidence level. The experiment with 12 nodes was significant at a 90% confidence level. All threads show a good fit, with correlation coefficient values ranging from a 0.63 maximum value to a 0.38 minimum. When looking at the explanatory variables’ found values, the x1, x3, and x4 values are similar for all experiments. The found values are similar for all threads. The same is true for all explanatory variables, while the regression coefficients show negative values for all variables. We also observed that all the explanatory variables’ coefficients were negative. This showed an inverse relationship with the number of nodes. For example, the higher the value, the greater the CPU time, and vice versa. Additionally, we observed that the correlations between different threads’ coefficient values were slightly different. The highest value was 0.63, and the lowest was 0.38. We must note that this last value was seen in the regression with 12 threads, which showed a test value of F = 0.804. This indicates that the experiment was not statistically significant.
Table 6.
Model 2 (CPU time) results for resolutions with different threads in MIPLIB library.
The multiple linear regression model for the best coefficient F according to the data in Table 5 and Table 6 is as follows.
Model 1: Number of nodes = 244,916.2219 − 9.986 × 10− 18.197 + 1.820 × 10− 8.746 × 10 − 10,190.00 + 626,257
Model 2: CPU time = 220,408 + −4.445 × 10− 0.08 − 4.851 × 10− 5.067 × 10− 23.83 − 2828.07
4.2. OR-Library Problems with MDMKP Problem Results
We solved a set of 30 problems divided into two sets of 15 problems each. We named them and , respectively. Table 7 shows the number of nodes of each instance of the set and for different threads. Table 8 shows the CPU times in seconds for each instance of the set and for different threads.
Table 7.
Nodes vs. different Cplex threads of the multi-demand multi-dimensional knapsack problem (MDMKP OR-Library) set Ct1 and set Ct2 (nodes).
Table 8.
CPU times vs. different Cplex threads of the multi-demand multi-dimensional knapsack problem (MDMKP OR-Library) sets Ct1 and Ct2 (CPU time in seconds).
The estimation of Models 1 and 2 was performed with the 30 results obtained from the instances of Ct1 and Ct2. The regression results of Model 1 are shown in Table 9, and the results of Model 2 are shown in Table 10. The first notable result is that the set regression coefficients are values higher than 0.86 for Model 1 and 0.57 for Model 2. This is a medium–high correlation. It can be observed that in Model 1, the values of the correlation coefficient are high and that the F-test shows critical values lower than 1% for all the threads, which indicates that the experiment is statistically significant for all threads. Regarding Model 2, the experiments with two and four threads show critical values lower than 1%, while the results of experiments resolved with 8 and 12 threads present critical values higher than 5%, which makes them less reliable. This is curious since it would be expected that with more threads, the estimate would be more reliable. Finally, the most reliable model estimating the complexity of solving an integer programming model is Model 1, since the explained variable is the number of nodes visited by the , while Model 2 uses the CPU time and this depends on the computer used.
Table 9.
Model 1 OR-Library problem results with MDMKP problems. Sets Ct1 and Ct2 (nodes).
Table 10.
Model 2 OR-Library problem results with MDMKP problems. Sets Ct1 and Ct2 (CPU time).
The multiple linear regression model for the best coefficient F according to the data in Table 9 and Table 10 is as follows.
Model 1: Number of nodes = −3.5531 × 10− 8516.669 1,099,153.01 + 0.0444 +1.776 − 8197.559 − 200,762.974 .
Model 2: CPU time = − 64,363,757,062 + −1.901 + 269.798 + 9.826 × 10 + 32,181,877,396 − 2.0594 + 411.355 .
4.3. Estimated Multiple Linear Regression Model Validation
To confirm the developed models, we first calculated the determination coefficient values corresponding to the correlation coefficient square . Second, we performed an F-test value analysis of variance and obtained the corresponding critical value
where y is the observed value and . The typically used multiple correlation coefficient is = .
Table 11 summarizes the implemented regression models. Each case shows the regression coefficient and its corresponding F-test value. Table 11 shows that one model only has a linear regression coefficient above 0.5. It is Model 2 (CPU time), solved with 12 treads. Accordingly, the F-test value is low, with a high statistical type I error. Model 1 (nodes) shows linear regression values above 0.5, with nine of them above 0.6. Therefore, we conclude that the used explanatory variables are adequate to explain the algorithm’s number of nodes and CPU time.
Table 11.
Multiple correlation coefficients for problems of MIPLIB library.
4.4. Reliability and Generality Level
To estimate the experiments’ reliability and show their generality level, we conducted a reliability analysis, as shown in Table 12. We considered reliability in terms of two values: the multiple linear correlation coefficient Rho and the F-statistic. The former measures the estimate quality determined by the explanatory variables from to . The latter measures the performed experiments’ reliability. Both variables complement each other, as the experiments must be reliable and the estimation must have a high correlation. We provide Table 12 to show the Rho and F results. The first block shows the 95% and 90% confidence intervals of the MIPLIB public library problem instances for the Rho coefficient and the ANOVA test F-value. The Rho and F values are random variables, in an experimental sense, as they are the results of conducted experiments. We applied multiple linear regressions between the explained variable nodes and the explanatory variables to , and between the explained variable CPU time and the explanatory variables to .
Table 12.
Reliability of the statistical parameter estimation process.
We ran a total of 34 instances of the MIPLIB library corresponding to the set covering problem and other similar problem structures, and 30 instances of the OR-Library solving the MDMKP problem. We solved each problem set of 34 and 30 instances using RAM types with different numbers of operating system threads. Each thread generated one result, and these constituted the sample, whose size was 4. As usual, we assumed that the variables Rho and F followed an exponential distribution with unknown mean and variance. Thus, we used Student’s t-distribution to find the critical values needed to construct confidence intervals for the means of both variables, from the MIPLIB and OR-Library instances’ results. The results in Table 12 show that the average value for the Rho correlation coefficient for the explained variable nodes was 0.576 for MKIPLIB instances and 0.7776 for MDMKP instances. Both values show that the number of explanatory variables has a good capacity to estimate the number of nodes visited by the algorithm.
The 95% confidence interval for Rho in the MIPLIB library instances, when the explained variable is the number of nodes, has a width of 16.8% with respect to the mean. This implies that with 95% probability, the Rho value will be between 0.528 and 0.625. For MDMKP instances, when the explained variable is the number of nodes, the confidence interval width is 16.6% of the mean. These values show that the explanatory variables from to are good predictors for the variable nodes visited by the . The confidence interval indicates that with 95% probability, the Rho values are between 0.712 and 0.841.
The average value for the Rho correlation coefficient, when the explained variable was the CPU time, was 0.542 for MIPLIB instances and 0.639 for MDMKP instances. Both values show a good capability to estimate the CPU time variable. The confidence interval for this variable is 95%, with a width of 23.1% with respect to the mean for MIPLIB instances, and 14.9% with respect to the mean for MDKMKP instances. The 90% confidence interval shows a width of 12.8% with respect to the mean; this is narrower than the previous one and with a lower confidence level. Table 11 shows that the number of visited nodes is an explained variable with a better estimation capacity, which confirms the use of the B&B node tree as a measure of computational effort.
Regarding the F-statistical analysis, Table 12 shows that its variability is low when the explained variable is the number of nodes. The variation coefficient is 0.17 for MIPLIB instances and 0.08 for MDKP instances. When the explained variable is the CPU time, the values of the variation coefficient are 0.44 for MIPLIB and 0.54 for MDMKP instances. This analysis confirms that the number of nodes estimation, using the variables to , is highly reliable. The CPU time estimation, with the same variables, is moderately reliable.
5. Discussion
We compared this work’s results with other researchers’ findings. We found that the only comparable published result is that of Hendel et al., published in 2021 [20]. There is a substantive difference from our work. Hendel et al. presented estimation methods that drew on the results of algorithm execution, whereas our estimators are applicable before the execution of . Hendel et al.’s estimation methods implemented four predictors for the tree size using SCIP integer linear programming software [21]. These predictors estimated the gap between the number of nodes and the unknown final tree during the algorithm’s execution. The prediction used one explanatory variable only, which was the number of leaves of the tree. A leaf is an end node that no longer branches. The used estimation methods included the tree weight, leaf frequency, Weighted Backtrack Estimator (WBE), and Sum of Subtree Gaps (SSG). Each of them uses a series with double exponential smoothing (DES). They used a level value and a trend value. The software, during the algorithm’s execution, delivered the models’ data feedings. Hendel et al. [20] applied this to the MIPLIb 2017 library danoint instance. The results showed that the methods were unsuccessful until the execution was partially completed. After this point, the estimation improved, with good results after 80% execution. The prediction methods improved with greater data availability.
Our linear regression method uses geometric variables to estimate the tree size and the CPU time. It is comparable to Hendel et al.’s estimates with few iterations. Our method has 60% reliability given by the coefficient of determination. This % is higher than that of the methods in [20], for estimates up to 66% algorithm execution. In addition, our method to predict the tree and CPU time to compute the explanatory variables is mathematically simple. It implies calculating Q matrix eigenvalues and other low-complexity calculations. Therefore, these complexity measures can be embedded into available software to predict the resolution time a priori. This is a topic that has great practical importance for available software efficiency. However, few researchers have examined the area, and there is a restricted volume of scientific production. We found no more than 10 publications, and most are outdated.
Finally, this study has some limitations. The first is that the results are valid for the data obtained with the tested problems. This is a limited sample that allows us to see a trend. It is not generalizable to a larger context, without the risk of extrapolation errors. Another limitation is that, for some problems, obtaining the analytical solution presents computational complications. This is because solutions are obtained via a nonlinear method, a Newton-type method. For many problems, our algorithm to obtain the analytical center took longer than ten hours to deliver a solution. The 10-h limitation is important because this study provides problem complexity indicators, and if the analytical center calculation takes a long time, it is no longer feasible to use it for these purposes.
6. Conclusions
In this work, we investigated integer programming based on the flatness theorem and conditioning in integer programming. It was a theoretical and applied work. We developed the measures and then implemented and tested them as tree predictors. Within the integer programming context, we developed geometric measurements to estimate the CPU time and number of nodes visited by the algorithm, based on the concept of conditioning in integer programming. The results showed high values for multiple correlation coefficients. The used explanatory variables came from one of the dimensions proposed for the width of the relaxed polyhedron ellipsoid constructed with the problem’s constraints. The explanatory variables correspond to expressions associated with a Dikin ellipse matrix within the polyhedron that replicates the shape of the polyhedron. Here, the analytical center was the analytical polyhedron center. One limitation of this work is the analytical center calculation. This is because solving a nonlinear problem requires a large amount of CPU time. In some problems, results exceed the ten-hour limit. The calculation of the center of the polyhedron is typical of the interior point methods for linear programming, such as the Karmakar algorithm and the ellipsoidal method, which use analysis techniques and nonlinear programming methodology. However, this is a bottleneck when we wish to obtain effort estimation measures that need to be calculated quickly. Thus, one line of future work is to study how to speed up the calculation of these indices, so that they can be incorporated into linear optimization software. To achieve this, other centers of the polyhedron can be explored, such as the center developed by the method of the central path. This can be used directly as a feasible center of the Dikin ellipse, or it can be used to approximate the analytic center, under certain conditions. Its solution no longer requires solving a nonlinear problem, but a classic simplex.
Author Contributions
Conceptualization, I.D.; methodology, I.D. and J.V.; software, J.V.; validation, I.D. and J.V.; formal analysis, M.L.; investigation, I.D. and J.V.; writing—original draft preparation, I.D.; writing—review and editing, M.L.; visualization, M.L.; supervision, I.D.; project administration, M.L. funding acquisition, I.D. and M.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by DICYT-USACH, Grant No. 062117DC.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors gratefully acknowledge the support of the University of Santiago, Chile, and the Center of Operations Management and Operations Research CIGOMM.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Karp, R.M. Complexity of computer computation. In Reducibility among Combinatorial Problems; Springer: Berlin/Heidelberg, Germany, 1972; pp. 85–103. [Google Scholar]
- Skiena, S. The Algorithm Design Manual; Springer: New York, NY, USA, 1997; pp. 32–58. [Google Scholar]
- Crescenzi, P.; Kann, V.; Halldórsson, M.; Karpinski, M.; Woeginger, G. A compendium of NP optimization problems. Braz. J. Oper. Prod. Manag. Available online: http://www.nada.kth.se/~viggo/problemlist/compendium.html (accessed on 12 June 2023).
- Garey, M.; Johnson, D. Computers and Intractability: A Guide to the Theory of NP-Completeness; W.H. Freeman: New York, NY, USA, 1979. [Google Scholar]
- Fréville, A. The multidimensional 0–1 knapsack problem: An overview. Eur. J. Oper. Res. 2004, 155, 1–21. [Google Scholar] [CrossRef]
- Derpich, I.; Herrera, C.; Sepulveda, F.; Ubilla, H. Complexity indices for the multidimensional knapsack problem. Cent. Eur. J. Oper. Res. 2021, 29, 589–609. [Google Scholar] [CrossRef]
- Knuth, D. Estimating the efficiency of backtrack programs. Math. Comput. 1975, 29, 122–136. [Google Scholar] [CrossRef]
- Purdom, P.W. Tree size by partial backtracking. SIAM J. Comput. 1978, 7, 481–491. [Google Scholar] [CrossRef]
- Chen, P.C. Heuristic sampling: A method for predicting the performance of tree searching programs. SIAM J. Comput. 1992, 21, 295–315. [Google Scholar] [CrossRef]
- Belov, G.; Esler, S.; Fernando, D.; Le Bodic, P.; Nemhauser, G.L. Estimating the Size of Search Trees by Sampling with Domain Knowledge. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), Melbourne, Australia, 19–25 August 2017; pp. 473–479. [Google Scholar]
- Pierre Le Bodic, P.; Nemhauser, G.L. An Abstract Model for Branching and its Application to Mixed Integer Programming. Math. Program. 2015, 166, 369–405. [Google Scholar] [CrossRef]
- Lelis, L.H.; Otten, L.; Dechter, R. Predicting the size of depth-first branch and bound search trees. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 594–600. [Google Scholar]
- Ozaltın, Y.; Hunsaker, B.; Schaefer, A.J. Predicting the solution time of branch-andbound algorithms for mixed-integer programs. INFORMS J. Comput. 2011, 23, 392–403. [Google Scholar] [CrossRef]
- Alvarez, M.; Louveaux, Q.; Wehenkel, L. A Supervised Machine Learning Approach to Variable Branching in Branch-and-Bound. Technical Report, Universite de Liege. 2014. Available online: https://orbi.uliege.be/handle/2268/167559 (accessed on 12 June 2023).
- Benda, F.; Braune, R.; Doerner, K.F.; Hartl, R.F. A machine learning approach for flow shop scheduling problems with alternative resources, sequence-dependent setup times, and blocking. OR Spectr. 2019, 41, 871–893. [Google Scholar] [CrossRef]
- Lin, J.C.; Zhu, J.L.; Wang, H.G.; Zhang, T. Learning to branch with Tree-aware Branching Transformers. Knowl.-Based Syst. 2022, 252, 109455. [Google Scholar] [CrossRef]
- Kilby, P.; Slaney, J.; Sylvie Thiebaux, S.; Walsh, T. Estimating Search Tree Size. In Proceedings of the Twenty-First National Conference on Artificial Intelligence and the Eighteenth Innovative Applications of Artificial Intelligence Conference, Boston, MA, USA, 16–20 July 2006; pp. 1–7. [Google Scholar]
- Fischetti, M.; Monaci, M. Exploiting Erraticism in Search. Oper. Res. 2014, 62, 114–122. [Google Scholar] [CrossRef]
- Hendel, G.; Anderson, D.; Le Bodic, P.; Pfetschd, M.E. Estimating the Size of Branch-and-Bound Trees. INFORMS J. Comput. 2021, 34, 934–952. [Google Scholar] [CrossRef]
- Bestuzheva, K.; Besançon, M.; Wei-Kun, C.; Chmiela, A.; Donkiewicz, T.; van Doornmalen, J.; Eifler, L.; Gaul, O.; Gamrath, G.; Gleixner, A.; et al. The SCIP Optimization Suite 8.0. 2021. Available online: https://optimization-online.org/2021/12/8728/ (accessed on 12 June 2023).
- Renegar, J.; Belloni, A.; Freund, R.M. A geometric analysis of Renegar’s condition number, and its interplay with conic curvature. Math. Program. 2007, 119, 95–107. [Google Scholar]
- Vera, J. On the complexity of linear programming under finite precision arithmetic. Math. Program. 1998, 80, 91–123. [Google Scholar] [CrossRef]
- Cai, Z.; Freund, R.M. On two measures of problem instance complexity and their correlation with the performance of SeDuMi on second-order cone problems. Comput. Optim. Appl. 2006, 34, 299–319. [Google Scholar] [CrossRef]
- Vera, J.; Derpich, I. Incorporando condition measures in the context of combinatorial optimization. SIAM J. Optim. 2006, 16, 965–985. [Google Scholar] [CrossRef]
- Lenstra, H.W., Jr. Integer programming with a fixed number of variables. Math. Oper. Res. 1983, 8, 538–548. [Google Scholar] [CrossRef]
- Koch, T.; Achterberg, T.; Andersen, E.; Bastert, O.; Berthold, T.; Bixby, R.E.; Danna, E.; Gamrath, G.; Gleixner, A.M.; Heinz, S.; et al. MIPLIB 2010: Mixed Integer Programming Library version 5. Math. Prog. Comp. 2011, 3, 103–163. [Google Scholar] [CrossRef]
- Gleixner, A.; Hendel, G.; Gamrath, G.; Achterberg, T.; Bastubbe, M.; Berthold, T.; Christophel, P.; Jarck, K.; Koch, T.; Linderoth, J.; et al. Miplib 2017: Data-Driven Compilation of the 6th Mixed-Integer Programming Library. Math. Program. Comput. 2017, 13, 443–490. [Google Scholar] [CrossRef]
- Beasley, J.E. OR-Library: Distributing test problems by electronic mail. J. Oper. Res. Soc. 1990, 41, 1069–1072. [Google Scholar] [CrossRef]
- Khintcine, A. A quantitative formulation of Kronecker’theory pf approximation. Izv. Ross. Akad. Nauk. Seriya Mat. 1948, 12, 113–122. (In Russian) [Google Scholar]
- Freund, R.M.; Vera, J.R. Some characterizations and properties of the “distance to ill-posedness” and the condition measure of a conic linear system. Math. Program. 1999, 86, 225–260. [Google Scholar] [CrossRef]
- Jhon, F. Extremum problems with inequalities as subsidiary conditions. In Studies and Essays; Intersciences: New York, NY, USA, 1948; pp. 187–204. [Google Scholar]
- Schrijver, A. Chapter 14: The ellipsoid method for polyhedra more generally. In Theory of Linear and Integer Programming; Wiley Interscience Series; John Wiley & Sons: Hoboken, NJ, USA, 1986; pp. 172–189. [Google Scholar]
- Nesterov, Y.; Nemirosky, A. Acceleration and parallelization of the path-following interior point method for a linearly constrainde convex quadratic problem. Siam J. Optim. 1991, 1, 548–564. [Google Scholar] [CrossRef]
- Elhedhli, S.; Naom-Sawaya, J. Improved branching disjunctions for branch-and-bound: An analytic center approach. Eur. J. Oper. Res. 2015, 247, 37–45. [Google Scholar] [CrossRef]
- Micciancio, D. The shortest vector in a lattice is hard to approximate to within some constants. SIAM J. Comput. 2001, 30, 2008–2035. [Google Scholar] [CrossRef]
- Vazirani, V. Approximation Algorithms; Springer-Verlag: Berlin, Germany, 2001; ISBN 3-540-65367-8. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).