1. Introduction
In the application of some statistical methods, such as clinical trials, the results are, usually, described in terms of the values taken by classical estimators, such as the sample mean and sample variance. These results are combined, in a second stage, as a weighted mean in a meta analysis. The same occurs in its alternative, Mendelian Randomization, one of the main topics in causal inference.
Moreover, in many applied studies, their results have been described in these terms, i.e., as summary data, not knowing the individual observations, to compute robust estimators with them, replacing the classical non-robust estimations with robust ones.
In this paper, a solution to this problem is proposed, correcting, if necessary, the given classical estimations because, although the individual observations are unknown, the mechanism that generates the data is known because it is the model.
Focusing on the mean estimation problem, the optimal estimator (uniformly minimum variance unbiased estimator) is the sample mean, when no outliers exist in the sample, and the normal distribution
is assumed as the model, with
and
being the usual parameters of the normal distribution, population mean, and variance. Assume that a proportion
of outliers exists in the sample, i.e., a contaminated normal model (see [
1], p. 2)
where most of the data are from a
, and a small part of them,
, are from a normal model with more dispersion and a different location,
, where
is a contamination parameter that affects the location, and
is a contamination parameter that affects the scale. The optimality of the sample mean is lost because the optimal procedure and its properties heavily depend on the assumed probability model ([
2], p. 2). This is the reason why classical statistics rests, basically, on the normal model and on the sample mean.
Additionally, under a contaminated normal model, the robustness of the sample mean is lost [
1,
3]. Under this model, the sample mean is not the maximum likelihood estimator [
4], and even the normality of the sample mean is not guaranteed [
5].
In this paper, a new estimator for a location–scale contaminated normal model is proposed, avoiding the extreme sensitivity of the sample mean but coinciding with it when no outliers are present in the data. The median of the distribution of the sample mean is proposed as a new estimator, where the parameters of are estimated with the classical estimations described in previous studies. This estimator is called the median of the distribution of the mean, .
The two reasons why this new estimator relies on the distribution of the sample mean are that, first, the classical estimations are given in terms of the classical mean (and classical variance) and, second, this new procedure extends the classical one in the sense that if no outliers are present, this new estimator is the classical sample mean, i.e., with this method, the classical estimation is extended to the case in which outliers are present.
Another estimator somewhat related to
is the
median of the means estimator
. However, this estimator is, finally, one of the sample means and, hence, is not robust (see [
6]).
With the , robustness and optimality are obtained if there are no outliers. Hence, with this approach, a new vision of the dilemma between optimality and robustness is provided.
Because the exact sample distribution of
under a mixture distribution is not known, here it is estimated in a closed form with the von Mises (VOM) plus saddlepoint (SAD) method, a technique used by the author in several studies (see, for instance, [
7,
8]) but in another context. With this approximation, the estimator introduced in this paper can also be extended to other more general models than the normal mixture considered here.
The rest of the paper is structured as follows. In
Section 2, the VOM+SAD approximation for the distribution of the sample mean is obtained under a location–scale contaminated normal model. The definition and some properties of this new location estimator are considered in
Section 3, and a scale estimator, based on these ideas, is defined in
Section 4, and an example of the application of this new estimator is considered in
Section 5. These ideas are applied to Mendelian randomization in
Section 6. Some conclusions are outlined in
Section 7.
2. VOM+SAD Approximation of Sample Mean Distribution
Because the new estimator depends on the distribution of the sample mean, the distribution of the sample mean must be very precise, especially when the considered sample sizes are very small. For this situation, using a von Mises expansion ([
9], p. 215, or [
10], p. 578) that depends on Hampel’s influence function [
11] is highly recommended.
Although, in the end, the obtained results are be applied to the mixture of normals model considered previously, these refer to more general models, F, G, and H, which indicate future extensions of this method.
The final approximation is called VOM+SAD and was previously obtained by the author in the context of spatial data (see [
7,
8]). Following the ideas developed in those two papers, considering the tail probability functional, initially, the approximation obtained is
which allows the approximation of the distribution of
when the observations follow model
F by the distribution of
when the variables of
follow model
G (pivotal distribution).
This approximation depends on the tail area influence function, TAIF, defined in [
12].
Restricting this approximation to
M estimators with a monotonic decreasing score function
(see [
1], p. 46) and using the Lugannani and Rice formula ([
13], or [
14] p. 77, or [
1] p. 314) to obtain a saddlepoint approximation for the TAIF, as the approximation given in [
15] (p. 94), for
M estimators, the VOM+SAD approximation obtained is
In the case of a location–scale mixture normal model, the framework that it is considered in this paper, i.e., assuming that
, the VOM+SAD approximation is
where
, and
.
VOM-SAD Approximation for the Distribution of the Sample Mean
In the particular case of the sample mean, the score function is
. Remember that in the VOM+SAD approximation, the saddlepoint is computed under
. Under this pivotal distribution, it is
Hence, from the saddlepoint equation
the saddlepoint
is obtained.
Additionally,
,
,
, and
. The leading term is
, and the quotient in last term in the right side of (
1) is
Hence, the VOM+SAD approximation (
1) is
If distributions
F and
G are not close enough, intermediate distributions can be considered, as in [
16,
17,
18], to obtain a more accurate approximation.
3. Estimator Median of the Distribution of the Mean
If the previous distribution of the mean is
the median of this distribution, i.e.,
, is called
the median of the distribution of the mean,
, i.e., this estimator is the solution of
The parameters of are estimated with the classical estimations, the sample mean and the sample variance .
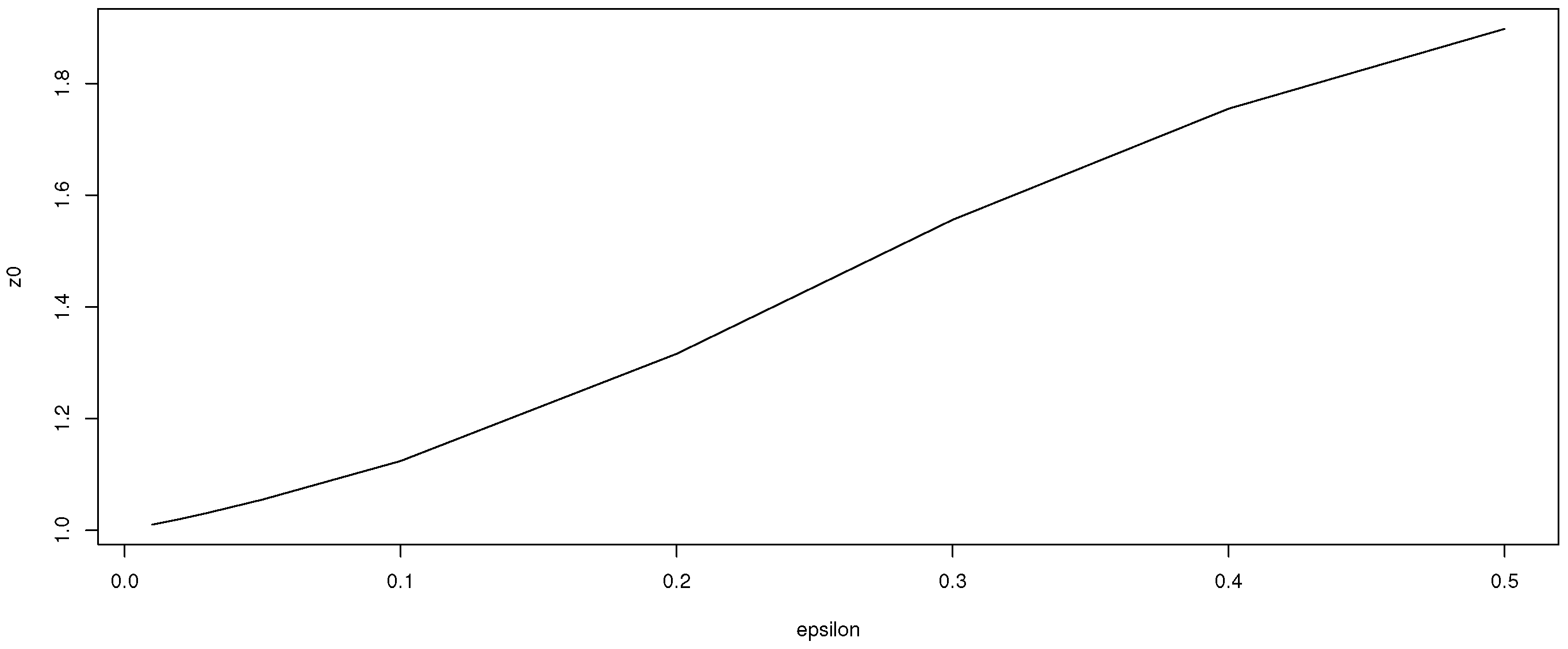
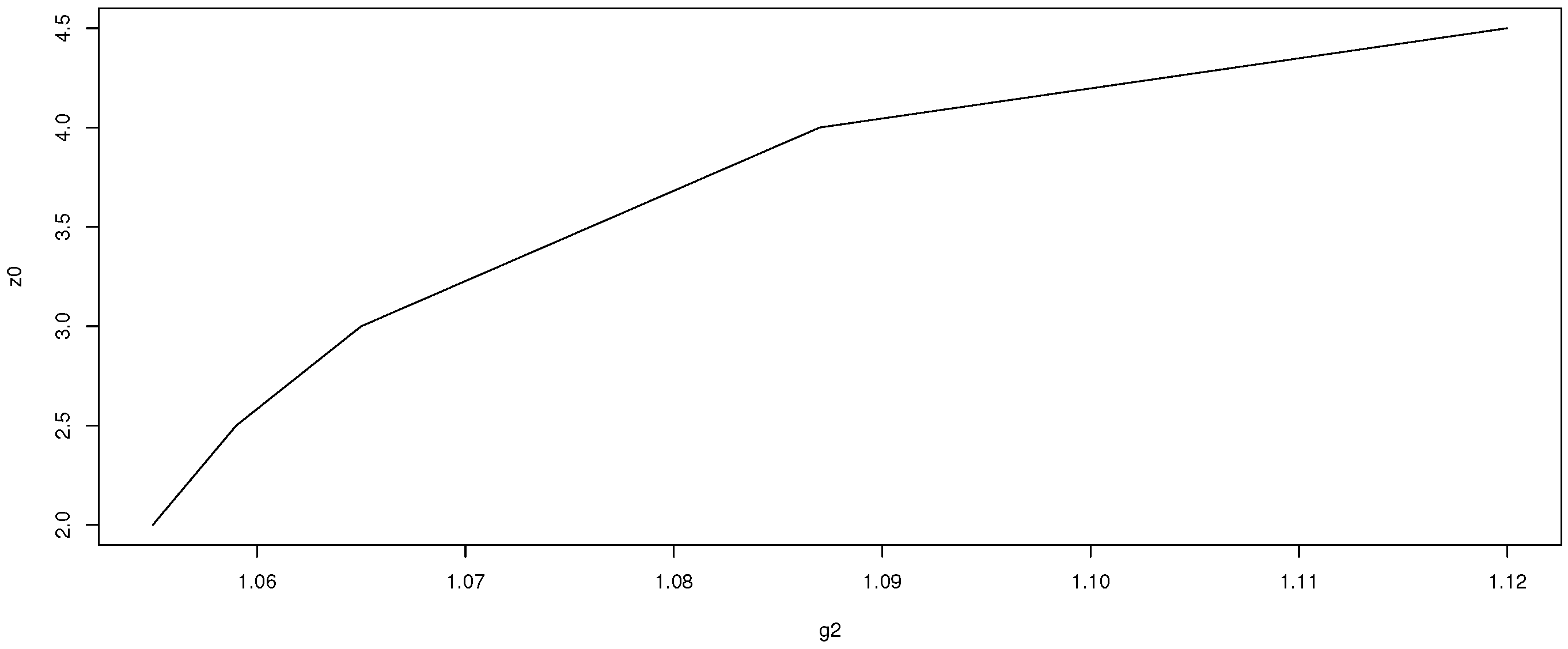
Figure 1,
Figure 2 and
Figure 3 show that as contamination parameters
,
, or
increase, the difference between
and
, i.e.,
, increases.
The main reason for the definition of is that the median is more robust than the sample mean and, hence, the influence of possible outliers, not knowing the individual observations, as assumed here, should be lower with the median of the distribution of the mean than with the sample mean, used in this distribution as an estimator of the location parameter. Furthermore, in the case without outliers, this estimator is equal to the classical sample mean.
As a limitation, observe that is also sensitive if outliers already affect the sample mean or sample variance used in the estimation of the location or scale parameter or . Nevertheless, with , this sensitivity is lower.
One way to check the behavior of with respect to in a simple numerical example is to run the R sentences
- >
x<-0.80*rnorm(11,2,1)+0.2*rnorm(11,3*2,1)
- >
mean(x)
- >
median(x)
in which we consider a random sample of sample data from a mixture normal , i.e., a sample where and .
Finally, in future research, other robust estimators could be considered, such as the trimmed mean of the distribution of the sample mean.
4. Dispersion Estimator
With the ideas developed in this paper, a dispersion estimator should be
5. Example
In most application papers, only the final values of the estimators used on them are given. Additionally, these estimators are usually the classical sample mean and sample variance and do not include the individual observations from which these estimators are obtained and, therefore, not providing the opportunity to robustify these values using robust techniques.
For this reason, a large number of examples could serve as an illustration of the estimator defined in this paper. Next, let us consider just one.
Example 1. One of these studies is [19], where some vertebral column and thorax of Neanderthals fossils were re-evaluated using their vertebrae because, probably, as stated by the author, errors occurred in the reconstruction and the samples were wrongly classified. He mentions ([19], p. 23) a misclassification of 7/33, which can be considered as the value of the contamination parameter ϵ. Because modern humans and Neanderthals have very similar vertebrae, no difference in the mean is assumed, using, hence a distortion factor . On the other hand, Neanderthals are slightly more stockier than modern humans, with the dispersion of the latter being larger, assuming that .
In Table 2 in [19], classical acceptance confidence intervals are provided for several vertebrae of 28 modern humans. They are based on the classical mean and variance, as the author says in this table. From the table, with respect vertebra T1, the remains of Kebara 2 and La Ferrassie can be considered as modern humans instead of Neanderthals, because they are inside of the confidence interval. The same happens with vertebra T7 but not with vertebra T5.
From these classical intervals, for vertebra T1, the classical sample mean and standard deviation are and , respectively. In this case, the estimator median of the distribution of the mean takes the value , obtaining the new robust acceptance confidence interval equal to , which does not contain the remains, concluding then, that these remains are Neanderthals and not modern humans, as they were wrongly considered with the classical estimators.
With respect to vertebra T5, , and the new robust acceptance confidence interval is , with neither the classical nor the robust interval not including the remains, confirming that they are Neanderthals.
Finally, for vertebra T7, , and the new robust acceptance confidence interval , both this robust and the previous classical confidence interval including the remains of the La Ferrassie, hence being modern humans and not Neanderthals.
6. Robust Inverse-Weighted Estimator RIVW in Mendelian Randomization
Another field for the class of problems considered in this paper is randomized clinical trials (CTs). In each of these CTs, the sample mean and sample variance are the usual final result. These are usually combined, in a classical way, as a weighted mean in a meta-analysis. In CTs, the relationship of a variable X (called cause) with another variable Y (called effect) is analyzed, but reverse causality may exist or a lack complete randomization or, more importantly, confounders may be present.
Moreover, CTs are expensive and take a long time. With Mendelian randomization (MR), a method that has received a renewed interest in recent years, CTs are imitated because, in any person, all genetic material is randomized allocated from their parents, including DNA markers. Randomly, some people receive more DNA markers related with variable X and, for others, fewer. MR uses genetic variants (usually single-nucleotide polymorphisms (SNPs)) as instrumental variables Z.
Mathematically, MR is used to avoid possible biases in the regression of
Y on
X due to these three causes just mentioned. Formally, MR leads us to a two-step linear regression process; first, for every genetic variant
, a linear regression of
X on
is performed, where, for individuals,
is
from which the fitted values
are obtained and used in a second regression of
Y on these
, obtaining finally [
20]
where
and
represent the association of
with the exposure and the outcome (only through
X), respectively. The parameter
represents the effect of
on
Y through
X, where
is the causal effect of
X on
Y that is being estimated. Moreover,
represents the association between
and
Y not through the exposure of interest. Finally, the errors terms
and
are assumed to be independent because independent samples are assumed to be used to fit the two previous regression models.
In MR, the standard estimator of the parameter of interest
, the slope in the linear regression of
Y on
X, is the classical
two-stage least squares estimator
which is the quotient of the slope of the regression of
Y on
,
, and the slope estimator of the regression of
X on
,
. These classical estimations, one for each value of the instrumental variable
, are combined with the classical inverse-variance weighted (IVW) estimator
where
, which is used to weight the
estimators, assuming that the
L genetic variants are mutually independent. In this way, a single causal effect estimate from
L genetic instruments is obtained.
This classic and widely used estimator is not robust because it has a
breakdown point because it is a weighted mean, see, for instance, [
21].
In this section, the robustification of the classical estimator IVW is obtained, first, by replacing estimators
with the
median of the distribution of the mean,
estimators and, second, by replacing the weights
with
, the inverse of the new dispersion estimator,
defining the new estimator, based on the
distribution, as
6.1. Distribution of Estimator
In this section, an approximation for the distribution of is obtained for each genetic variant , i.e, j is fixed. Moreover, because of the usual regression assumptions, is not random in the two previous linear regressions, i.e., in the estimator .
Hence, with
denoting the constant
avoiding the
j in the notation of
to simplify it, and with
being the constant
and assuming no outliers in the sample, the variable
follows a normal distribution
and
The estimator
is equal to
and, considering standardized data, i.e., that
is computed as a correlations quotient,
its tail distribution is
Letting
(removing the
j if there is no risk of confusion) denote the random variable
,
, where
a and
are not random, the aim is to compute the distribution of the sample mean of the variables
at 0, i.e.,
where
is independent but not identically distributed because
where
and
which depends on
and
. The values of these parameters are given from previous studies following the median of the distribution the mean method.
If the data contain no outliers, it will be
but, as usual, a proportion
of outliers in the data is assumed, i.e., as a model for the observations
the following
where the
contamination constants and
are assumed to depend on
.
To compute the distribution of under models , assuming that the sample sizes are small, a von Mises approximation (VOM), based on a von Mises expansion, is used to obtain an accurate approximation with small sample sizes.
6.2. VOM Approximation of the Distribution
In general, to approximate the tail probability of statistic
under a vector of model distributions
, knowing its tail distribution under the vector of model distributions
(called
pivotal distributions), the von Mises expansion of the tail probability of
at
is used ([
10],
Section 2, or [
22], Theorem 2.1, or [
17], Corollary 2),
where the sample space
,
where
is the second derivative of the tail probability functional at the mixture distribution
, for some
; and
is the
ith (multivariate)
partial tail area influence function of
at
in relation to
,
, introduced in [
17], Definition 1,
in those
where the right-hand side exists. In the computation of
, only
is contaminated; the other distributions remain fixed,
.
In general,
is close to 0, and the
von Mises approximation (VOM) is defined as
Moreover, if
is a mixture distribution,
,
([
23], p. 77). Additionally, because of the partial influence functions properties ([
22], p. 3) that are valid for the partial tail area influence functions defined in [
17], for any
it will be
i.e., the integral with respect a given model of the
that depends on this model is equal to 0. Hence,
i.e., the VOM approximation is
Moreover, because of Proposition 1 in [
17],
and the VOM approximation of the tail probability
can also be expressed as
which allows an approximation of the tail probability
under models
, knowing the value of this tail probability under near models
.
In the particular case that
, the VOM approximation for the tail of
can be expressed as (see (
2) with
and
now)
or, see (
4),
or
If it is assumed as model for the observations
and it is denoted by
, and by
the pivotal distribution,
, i.e.,
the generic component of this last equation is
where
is the cumulative distribution function of a standard normal distribution,
and
Because
is a normal mixture
the VOM approximation (
5) is
Moreover, because of property (
3) for the partial influence functions mentioned before, it is
or
Hence, making the change of variable
, it is
where
and
Then, the VOM approximation to the distribution of
is
Example 2. In a study [24], whether low-density lipoprotein cholesterol (LDL-C) is a cause of coronary artery disease (CAD) was analyzed considering 28 DNA markers DNA markers X Y
SNP exposure.beta exposure.se outcome.beta outcome.se
1 snp_1 0.0260 0.004 0.0677 0.0286
2 snp_2 -0.0440 0.004 -0.1625 0.0300
..............................................................
27 snp_27 0.0090 0.003 0.0000 0.0255
28 snp_28 -0.0360 0.007 0.0198 0.0647
Usually, is assumed to be an instrumental variable to mimic biallelic SNPs in Hardy–Weinberg equilibrium. A valuewas obtained. With the method proposed in this paper, considering sample sizes of , , , and , and contamination parameters , , and , for the first DNA marker is obtainedand For all the 28 DNA markers, we havewhich are combined in the new robust estimate 7. Conclusions
In this paper, a new method for estimating the parameters in a location–scale contamination model is introduced, in the case where individual observations are not available and, therefore, applying the usual robust methods is not possible, i.e., in summary data problems.
For the location problem, a new estimator was defined that is equal to the usual sample mean when no outliers exist and correcting classical estimations when outliers exist.
This new estimator was applied to one of the most used estimators in Mendelian randomization, the inverse-variance weighted estimator (IVW), defining a new estimator robust inverse weighted estimator (RIVW).


{kind=link}
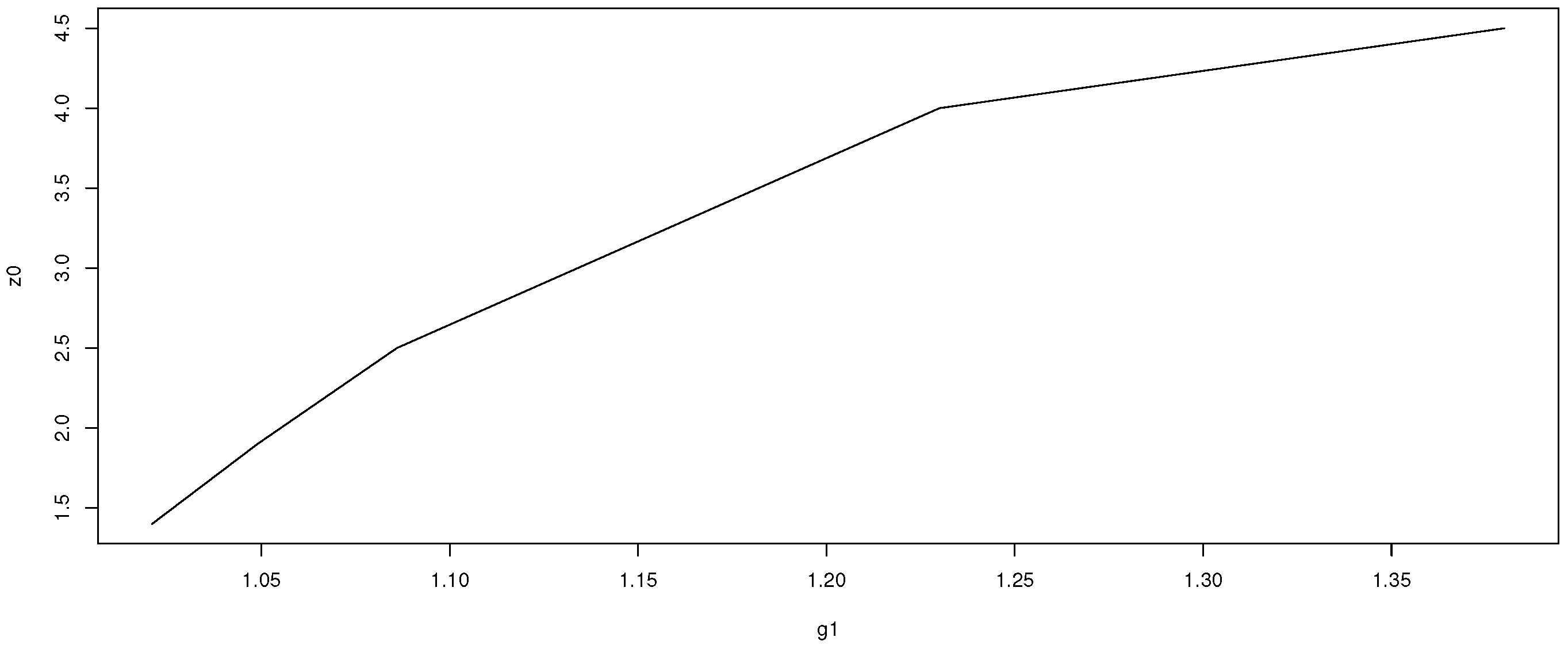{kind=link}
{kind=link}


