1. Introduction
Over the past few years, metaheuristic methods have emerged as powerful tools in addressing complex problems, particularly those pertaining to the realm of combinatorial challenges. A wide array of applications across various fields, including biology [
1,
2], logistics [
3], civil engineering [
4,
5], machine learning [
6], and many more, serve as compelling evidence of their effectiveness in problem-solving.
These methods have garnered considerable attention owing to their capacity to effectively navigate extensive search spaces and identify near-optimal solutions within relatively brief timeframes. This characteristic has demonstrated its particular value in addressing the immense scale and complexity inherent in numerous combinatorial problems. The ability to find satisfactory solutions for complex problems in a time-efficient manner has solidified the importance of these methods in the field of optimization.
However, as the intricacy of such problems continues to grow, the challenges associated with efficiently solving them also intensify. Consequently, there is a pressing need for innovative techniques and strategies that can enhance the performance of these methods, ensuring that they remain relevant and effective when confronted with increasingly complex optimization tasks. The development of advanced algorithms and the integration of novel approaches in the initialization process can contribute to overcoming these obstacles, ultimately bolstering the performance and reliability of these methods in tackling large-scale, intricate combinatorial problems.
In response to these challenges, researchers have focused on the development and application of diverse approaches aimed at enhancing and fortifying metaheuristic algorithms. One notable example involves hybrid techniques, which amalgamate the strengths of various metaheuristic algorithms. By integrating complementary methods and harnessing their synergies, these hybrid techniques have demonstrated success in augmenting the overall performance, accuracy, and efficiency of the underlying metaheuristic algorithms. Another intriguing aspect to explore is the examination of the forms and parameters of solution initialization.
The significance of initialization operators lies in the fact that the diversity and nature of the initial population have an impact on the algorithm’s performance, potentially leading to enhanced solutions and improved convergence rates. Furthermore, the sensitivity of the algorithms is problem-dependent, signifying that the choice of an initialization method can have a substantial influence on the performance for certain problems. In addition, the population size and the number of iterations also play a role in the algorithms’ performance, necessitating an appropriate population size and a sufficient number of iterations to achieve optimal solutions. Lastly, the effectiveness of initialization methods varies depending on the specific metaheuristic optimizer employed, making it crucial to comprehend the relationship between initialization methods and optimizers in order to select the most suitable combination for specific problems. In summary, good population diversity and an adequate number of iterations, combined with an appropriate initialization method, are likely to lead to optimal solutions.
In the literature exploration, it has been observed that studies such as [
7] compare the effects of population size, maximum iterations, and eleven initialization methods on the convergence and accuracy of metaheuristic optimizers. Results have indicated that sensitivity to initialization schemes varies among algorithms and is problem-dependent. Furthermore, performance has been found to rely on population size and the number of iterations, with greater diversity and a suitable quantity of iterations being more likely to produce optimal solutions. In a study by [
8], a systematic comparison of 22 initialization methods was conducted, analyzing their impact on the convergence and accuracy of five optimizers: DE, PSO, CS, ABC, and GA. The findings revealed that 43.37% of DE functions and 73.68% of PSO and CS functions were significantly affected by initialization methods. Population size, number of iterations, and certain probability distributions also influenced performance.
In the study by [
9], a reliability-analysis-based structural shape optimization formulation was proposed, incorporating Latin hypercube sampling (LHS) as the initialization scheme. The investigation focused on the relationship between geometry and fatigue life in structural component design. The extended finite element method (XFEM) and level set description were utilized, and nature-inspired optimization techniques were employed to solve the problems. Results indicated that proper shape changes can enhance the service life of structural components subjected to fatigue loads, with the location and orientation of initial imperfections significantly affecting optimal shapes. Finally, in [
10], the authors provided an extensive review of diverse initialization strategies designed to improve the performance of metaheuristic optimization algorithms. Emphasizing the crucial role of initialization, various distribution schemes, population sizes, and iteration numbers have been investigated by researchers in pursuit of optimal solutions. Notable schemes encompass random numbers, quasirandom sequences, chaos theory, probability distributions, hybrid algorithms, Lévy flights, and more. Additionally, the paper evaluated the influence of population size, maximum iterations, and ten distinct initialization methods on three prominent population-based metaheuristic optimizers: bat algorithm (BA), grey wolf optimizer (GWO), and butterfly optimization algorithm (BOA).
Aligning with the process of solution initialization, this paper proposes various strategies for initializing solutions, incorporating these strategies into a discrete hybrid algorithm detailed in [
11]. This algorithm merges the concept of k-means with metaheuristics and is applied to the set union knapsack problem (SUKP). The SUKP [
12] is an extended version of the traditional knapsack problem and has attracted considerable research interest in recent years [
13,
14,
15]. This attention is primarily due to its intriguing applications [
16,
17], coupled with the complexity and challenge involved in solving it efficiently.
In the context of the SUKP, an assortment of items is identified, each with a specific profit value attributed. Additionally, a correspondence is established between each item and a group of elements, with each carrying a weight that impacts the knapsack constraint. A scrutiny of the existing body of literature reveals that the SUKP is predominantly addressed using advanced metaheuristics, with outcomes provided within acceptable time limits. However, when conventional metaheuristics are utilized in the SUKP, issues including instability and diminished effectiveness are exposed as the instance size increases. For instance, a variety of transfer functions were deployed and evaluated within small to medium SUKP instances, as documented in [
18]. A reduction in effectiveness was noted when these algorithms were applied to standard SUKP instances. Adding to the complexity, a new series of benchmark problems have been recently introduced, as noted in [
19].
Given these considerations, it becomes imperative to explore solution initialization techniques to assess the algorithm’s performance. The following are the significant contributions of this study:
The structure of this paper is organized as follows:
Section 2 delivers a comprehensive examination of the set-union knapsack problem and its related applications. In
Section 3, the k-means sine cosine search algorithm and the initialization operator are thoroughly described.
Section 4 expounds on the numerical experiments undertaken and the resulting comparisons. Finally,
Section 6 presents concluding insights and explores potential directions for future research.
2. Advancements in Solving the Set-Union Knapsack Problem
The SUKP represents an extended model of a knapsack, which is defined as follows. A set of
n elements, denoted as
U, is assumed to exist, with each element
possessing a positive weight
. Assumed also is a set of
m items, named
V, where each item
is a subset of elements
and holds a profit
. Given the presence of a knapsack with a capacity
C, the aim of SUKP is to identify a subset of items
that allows the maximization of the total profit of
S, while ensuring that the combined weight of the components belonging to
S does not exceed the capacity
C of the knapsack. The decision variables of the problem are identified as the elements belonging to the set
S. It is noteworthy that an element’s weight is considered only once, even if it corresponds to multiple chosen items in
S. The mathematical depiction of SUKP is presented subsequently:
subject to:
In the research work, interesting applications of SUKP are identified, such as the one introduced in [
16]. The aim of this application is the enhancement of robustness and scalability within cybernetic systems. The consideration is given to a centralized cyber system with a fixed memory capacity, which hosts an assortment of profit-generating services (or requests), each inclusive of a set of data objects. The activation of a data object consumes a particular amount of memory; however, recurring utilization of the same data object does not incur additional memory consumption (a pivotal condition of SUKP). The objective involves the selection of a service subset from the pool of available candidates, with the intention to maximize the total profit of these services, whilst keeping the total memory required by the linked data objects within the cyber system’s memory capacity. The SUKP model, in which an item symbolizes a service with its profit and an element represents a data object with its memory usage (element weight), fittingly structures this application. Consequently, the determination of the optimal solution to the resulting SUKP problem parallels the resolution of the data allocation problem.
An additional application worth mentioning relates to the real-time rendering of animated crowds, as noted in [
21]. In this study, a method is introduced by the authors to hasten the visualization process for large gatherings of animated characters. A caching system is implemented that permits the reuse of skinned key-poses (elements) in multi-pass rendering, across multiple agents and frames, while endorsing an interpolative approach for key-pose blending. Within this context, each item symbolizes a member of the crowd. More applications are evident in data stream compression using bloom filters, as reported in [
17].
SUKP is an
-hard problem [
12], and various methods have been employed to address it. Theoretical studies using greedy approaches or dynamic programming are presented in [
12,
22]. In [
23], an integer linear programming model was developed and applied to small instances comprising 85 and 100 items, yielding optimal solutions.
Metaheuristic algorithms have been employed to tackle SUKP in various studies. In [
24], the authors utilize an artificial bee colony technique to address SUKP, integrating a greedy operator to manage infeasible solutions. An enhanced moth search algorithm is developed in [
25], incorporating a differential mutation operator to boost efficiency. The Jaya algorithm, along with a differential evolution technique, is applied in [
26] to enhance exploration capability. A Cauchy mutation is used to improve exploitation ability, while an enhanced repair operator is designed to rectify infeasible solutions.
In [
18], the efficacy of various transfer functions is examined for binarizing moth metaheuristics. A local search operator is devised in [
27] and applied to large-scale instances of SUKP. The study proposes three strategies in line with the adaptive tabu search framework, enabling efficient solutions for new SUKP instances. In [
28], the grey wolf optimizer (GWO) algorithm is adapted to tackle binary problems. Instead of traditional binarization methods, the study employs a multiple parent crossover with two distinct dominance tactics, replicating GWO’s leadership hierarchy technique. Furthermore, an adaptive mutation featuring an exponentially decreasing step size is employed, aiming to inhibit premature convergence and establish a balance between intensification and diversification.
In [
29], the authors merge machine learning and metaheuristics to devise a Q-learning reinforcement strategy for binary optimization problems, using PSO, genetic algorithm, and gbPSO as optimizers. Enhanced optimizers incorporate initial solution generation and a random immigrants mechanism, while a mutation procedure fosters intensified search. This approach is applied to the set-union knapsack problem, producing promising outcomes. Meanwhile, [
30] investigates the impact of integrating a backtracking strategy into population-based approaches for the same problem. The proposed method features swarm optimization, an iterative search operator, and a path-relinking strategy for obtaining high-quality solutions. Performance evaluation using benchmark instances demonstrates promising results when compared to existing methods.
3. Initialization, Metaheuristic, and Search Operators
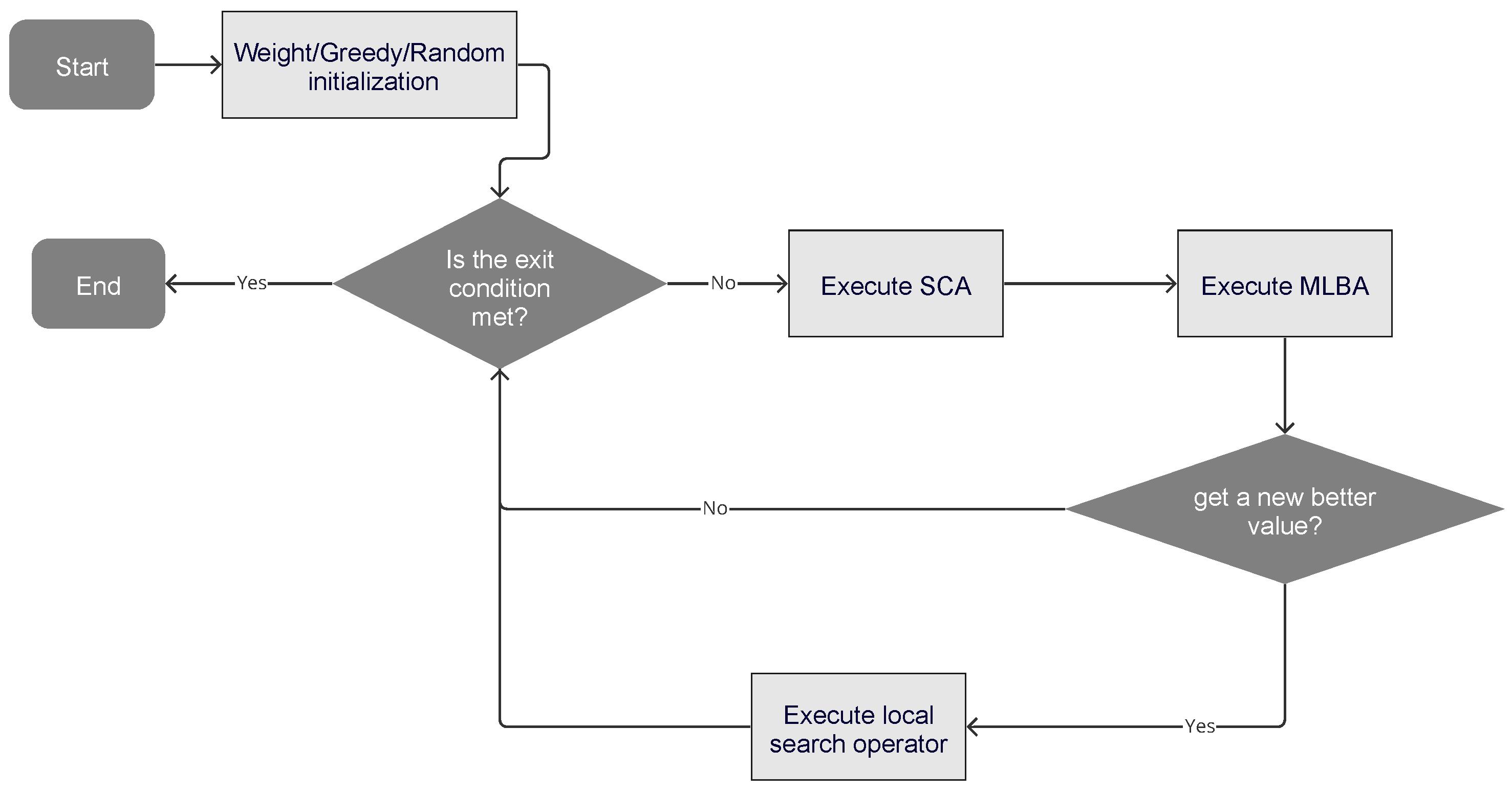
This section outlines a comparison of three distinct initialization operators: a random operator, a greedy operator, and a weighted operator based on a specific indicator. The overall functioning of the proposed algorithm is depicted in
Figure 1, with subsequent sections delving into detailed descriptions of each operator. These initialization operators are further elaborated in
Section 3.1. Additionally, we discuss the hybrid operator, a unique blend of machine learning techniques and metaheuristics, which is tasked with executing movements. For this study, we implemented a hybrid SCA, as detailed in
Section 3.2. Finally, we examine the local search operator, which is utilized to refine the results obtained. This operator is discussed in
Section 3.3.
3.1. Initialization Operators
The aim of these operators is to construct the initial solutions that will initiate the search process. To achieve this, items are sorted according to the ratio defined in Equation (
3). The operators take
as input, which consists of elements arranged in descending order based on their
r values. The output is a valid solution, denoted as
Sol.
In the case of the greedy operator, Algorithm 1, at line 4,
is initialized with a random element, and this element is removed from the
list. Subsequently, at line 6, the knapsack constraint is checked; if the condition is met, the while loop is entered. Within the loop, a new item is assigned based on Equation (
3), and it is removed again from
. Once the knapsack is full, the solution requires cleaning in line 10, as its weight is greater than or equal to
. If the weights are equal, no action is taken. However, if the weight is greater, the items in
must be sorted using the r value defined in Equation (
3), and removed in ascending order while checking the constraint after each removal. Once the constraint is satisfied, the procedure halts, and the solution
is returned.
In the context of the random operator, Algorithm 2, at line 4, a random item is used to initialize
, and this item is subsequently removed from the
list. Following this, the knapsack constraint is evaluated at line 6. If the condition is fulfilled, the program enters the while loop. Within this loop, a new item is randomly selected without considering the greedy condition and is promptly removed from
. When the knapsack is filled, the solution requires adjustment at line 10 as its weight equals or exceeds
. If the weights are identical, no action is required. However, if the weight of
surpasses
, the items in
G must be arranged in accordance with the
r-value defined in Equation (
3) and are removed in ascending order, with the constraint being evaluated after each removal. The procedure concludes once the constraint is met, returning the solution
as the output.
| Algorithm 1 Greedy initialization operator. |
- 1:
Function initGreedySolutions() - 2:
Input - 3:
Output - 4:
getRandom() - 5:
) - 6:
while (weightSol < knapsackSize) do - 7:
) - 8:
) - 9:
end while - 10:
cleanSol() - 11:
return =0
|
| Algorithm 2 Random initial operator. |
- 1:
Function initRandomSolutions() - 2:
Input - 3:
Output - 4:
getRandom() - 5:
) - 6:
while (weightSol < knapsackSize) do - 7:
) - 8:
) - 9:
end while - 10:
cleanSol() - 11:
return
|
In the case of the weighted operator, Algorithm 3, the selection process differs in that items are chosen randomly but with a probability governed by Equation (
3). In this approach, a normalized probability is constructed for each item, where the sum of all probabilities equals 1. Subsequently, the random selection of items is performed, taking into account the probability assigned to each of them.
| Algorithm 3 Weighted initial operator. |
- 1:
Function initWeightedSolutions() - 2:
Input - 3:
Output - 4:
getRandom() - 5:
) - 6:
while (weightSol < knapsackSize) do - 7:
) - 8:
) - 9:
end while - 10:
cleanSol() - 11:
return
|
3.2. Machine Learning Binarization Operator
The binarization process relies heavily on the machine learning binarization algorithm (MLBA). This algorithm receives the list of solutions
from the prior iteration, the metaheuristic (
)—in this scenario, SCA, the optimal solution achieved thus far (
), and the transition probability for each cluster,
, as input. In line 4, the metaheuristic
is utilized on the list
; in this specific situation, it corresponds to SCA. The absolute values of velocities
are extracted from the result of applying
to
. These velocities symbolize the transition vector obtained through the application of the metaheuristic to the solution list. In line 5, k-means is used to cluster the entire set of velocities (getKmeansClustering); in this particular instance,
K is designated as 5. It should be emphasized that the Algorithm 4 in conjunction with Algorithm 5 were proposed in the context of [
11].
| Algorithm 4 Machine learning binarization operator (MLBA). |
- 1:
Function MLBA(, , , ) - 2:
Input , , - 3:
Output , - 4:
getAbsValueVelocities(, ) - 5:
getKmeansClustering(, K) - 6:
for (each in ) do - 7:
for (each in ) do - 8:
= getClusterProbability(, ) - 9:
if then - 10:
Update considering the best. - 11:
else - 12:
Do not update the item in - 13:
end if - 14:
end for - 15:
cleanSol() - 16:
end for - 17:
getBest() - 18:
if > then - 19:
execLocalSearch() - 20:
- 21:
end if - 22:
return ,
|
| Algorithm 5 Local search. |
- 1:
Function LocalSearch() - 2:
Input - 3:
Output - 4:
getItems() - 5:
i = 0 - 6:
while (i < T) do - 7:
swap(, ) - 8:
if and then - 9:
- 10:
end if - 11:
i += 1 - 12:
end while - 13:
return =0
|
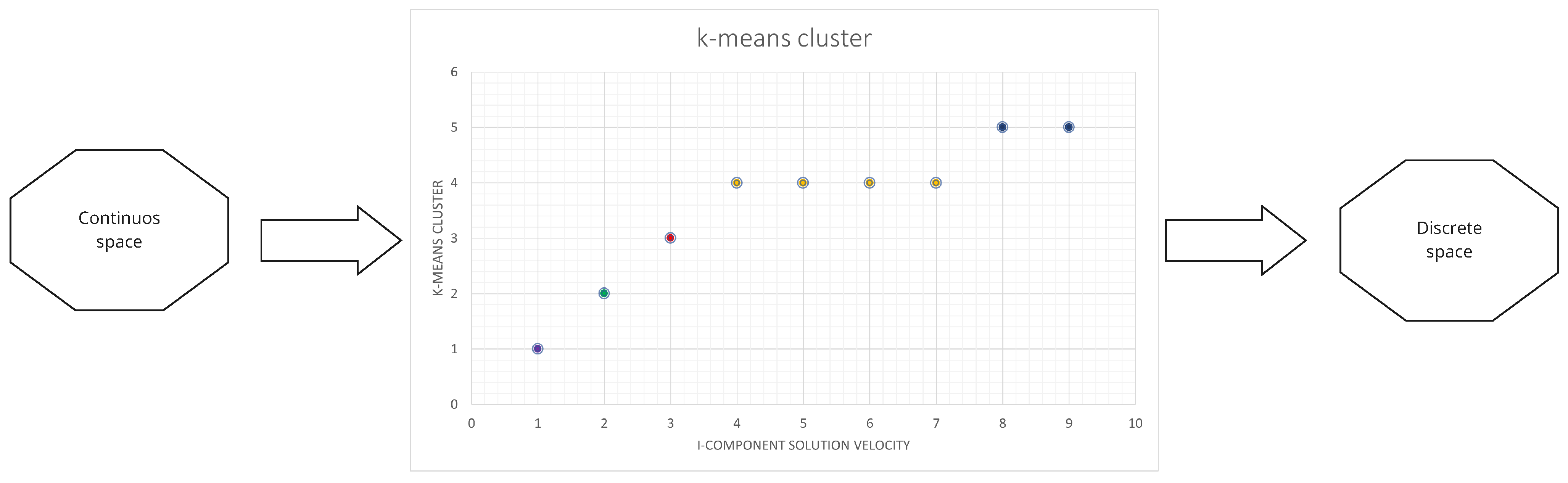
For each solution
and dimension
j, a cluster assignment is made, and every cluster is linked with a transition probability (
), organized based on the value of the cluster centroid. In this situation, the transition probabilities employed are [0.1, 0.2, 0.4, 0.5, 0.9]. The set of points that belongs to the cluster with the smallest centroid, depicted by the green color in
Figure 2, is connected with a transition probability of 0.1. For the collection of blue points with the highest centroid value, a transition probability of 0.9 is associated. The smaller the value of the centroid, the lower the related
.
In line 8, for each
, a transition probability
is allocated and subsequently contrasted with a random number
in line 9. If
, the solution undergoes an update considering the best value in line 10; otherwise, no update occurs, as indicated in line 12. After all solutions have been refreshed, a cleanup process, explained in
Section 3.1, is applied. If a new best value emerges, a local search operator is executed in line 19. The details of this local search operator are provided in the following section. Ultimately, the revised list of solutions
and the optimal solution
are returned.
3.3. Local Search Operator
The local search operator is invoked whenever a new best value is uncovered by the metaheuristic. This operator accepts the new best values () as input and, for its initial step, leverages them to ascertain the items that are included and excluded from , as displayed in line 4 of Algorithm 5. These two lists of items undergo an iteration times, effectuating a nonrepetitive swap, as exhibited in line 7 of Algorithm 5. Upon the completion of the swap, two conditions are assessed: whether the profit has improved and if the weight of the knapsack is less than or equal to . If both conditions are met, is updated with , and, ultimately, the refreshed is returned.
4. Results
This section introduces the experiments performed using MLBA in combination with the sine cosine metaheuristic, aiming to assess the efficacy and contribution of the proposed algorithms when deployed for an -hard combinatorial problem. This specific variant of MLBA, which employs the sine cosine algorithm, will be referred to as MLSCABA. The SUKP was elected as a benchmark problem due to its extensive addressal by numerous algorithms and its presentation of nontrivial challenges when it comes to resolving small, medium, and large instances. It should be emphasized that the MLBA binarization technique is highly adaptable to other optimization algorithms. The optimization algorithm of choice was SCA, given its absence of a requirement for parameter tuning and its wide use in solving a variety of optimization problems.
The algorithm was implemented using Python 3.8 and executed on a Windows 10 PC equipped with a Core i7 processor and 32 GB of RAM. To evaluate the statistical significance of the differences, the Wilcoxon signed-rank test was applied with a significance level of 0.05. This test was selected following the methodology delineated in [
31]. The Shapiro–Wilk normality test is utilized first in this process. If one of the populations does not adhere to a normal distribution and both populations have an identical number of points, the Wilcoxon signed-rank test is suggested for identifying the difference. In the experiments, the Wilcoxon test was employed to contrast the MLSCABA results with other variants or algorithms used in pairs. A comprehensive list of results was consistently employed for comparisons. The tests were constructed using the statsmodels and scipy libraries in Python. Each instance was solved 30 times to gather the best value and average indicators. Moreover, the average time (in seconds) necessary for the algorithm to discover the optimal solution is documented for each instance.
The initial set of instances, employed during the first phase of this study, were introduced in [
32]. These instances encompass between 85 and 500 items and elements. They are distinguished by two parameters. The first parameter,
, signifies the density in the matrix, where
denotes that item
i is included in element
j. The second parameter,
, denotes the capacity ratio
C over the total weight of the elements. As a result, an SUKP instance is labeled as
. The secondary group of instances was proposed in [
19] and ranges between 585 and 1000 items and elements. These instances were assembled following the same framework as the preceding set.
4.1. Parameter Setting
The parameter selection was guided by the methodology delineated in [
20,
33]. This technique draws upon four metrics, encapsulated in Equations (
4)–(
7), to facilitate judicious parameter selection. We generated values through instances 100_85_0.10_0.75, 100_100_0.15_0.85, and 85_100_0.10_0.75, with each parameter combination undergoing a tenfold validation. The parameters examined and subsequently chosen are documented in
Table 1. To identify the optimal configuration, the polygonal area derived from the four-metric radar chart was computed for each setting. The configuration yielding the most expansive area was subsequently selected. Regarding transition probabilities, variation was exclusively confined to the probability of the fourth cluster, assessed at values of [0.5, 0.6, 0.7], while maintaining the rest at a constant level.
The percentage difference between the best value achieved and the best known value:
The percentage difference between the worst value achieved and the best known value:
The percentage deviation of the obtained average value from the best known value:
The convergence time utilized during the execution:
4.2. Insight into Binary Algorithm
The objective of this section is to have the performance of various initialization operators assessed and compared, specifically random, weighted, and greedy, when applied to two sets of data. In order to carry out this comparison, several key performance indicators were considered, including best value achieved, average value, average execution time, and standard deviation. Valuable insights into the efficiency, effectiveness, and consistency of each initialization operator can be offered by these metrics. To ensure the reliability of the findings, each instance was executed 30 times, providing a more comprehensive evaluation of the performance of the operators across multiple runs.
For the analysis of the results, comparative tables are generated to present quantitative data, box plots are created to facilitate visual comparisons of the performance distributions of the operators, and convergence graphs for selected instances are illustrated to depict the progress of each operator over time. By utilizing these various data visualization techniques, a thorough understanding of the strengths and weaknesses of each initialization operator can be provided, enabling more informed decisions when selecting the most suitable operator for a specific problem or dataset.
The findings from an experimental study on medium-sized instances of the set-union knapsack problem are delineated in
Table 2, with accompanying visualizations depicted in
Figure 3 and
Figure 4. Three distinct initialization operators—random, greedy, and weighted—were examined in this study. We investigated three different initialization operators, namely, random, greedy, and weighted. The table is formatted in such a way that the first column provides the designation of the instance being analyzed, followed by the column depicting the optimum known solutions for the respective instances. The subsequent four columns illustrate the findings associated with the random initialization operator, including the best-found solution, the average solution, computational time measured in seconds, and the standard deviation of obtained values. In a similar format, the next four columns present the results derived from the weighted operator, while the final quartet of columns elaborate on the outcomes resulting from the application of the greedy operator.
From
Table 2, it can be inferred that the best values obtained are associated with the weighted operator, both in terms of best value and average. Additionally, it can be observed that the average convergence times are quite similar among the three operators. The exact number of instances in which the weighted operator outperformed the other two operators in terms of best value was counted, and it was found to be superior in five instances, the random operator in one instance, and the greedy operator in three instances. When the average indicator was analyzed, the weighted initialization operator was observed to outperform the others in 16 instances, while the random operator excelled in seven instances and the greedy operator in seven instances. This further demonstrated the consistent superiority of the weighted operator compared to the others. In the significance analysis, the weighted operator was indicated to be significantly superior to the other two initialization operators, both in terms of best value and average.
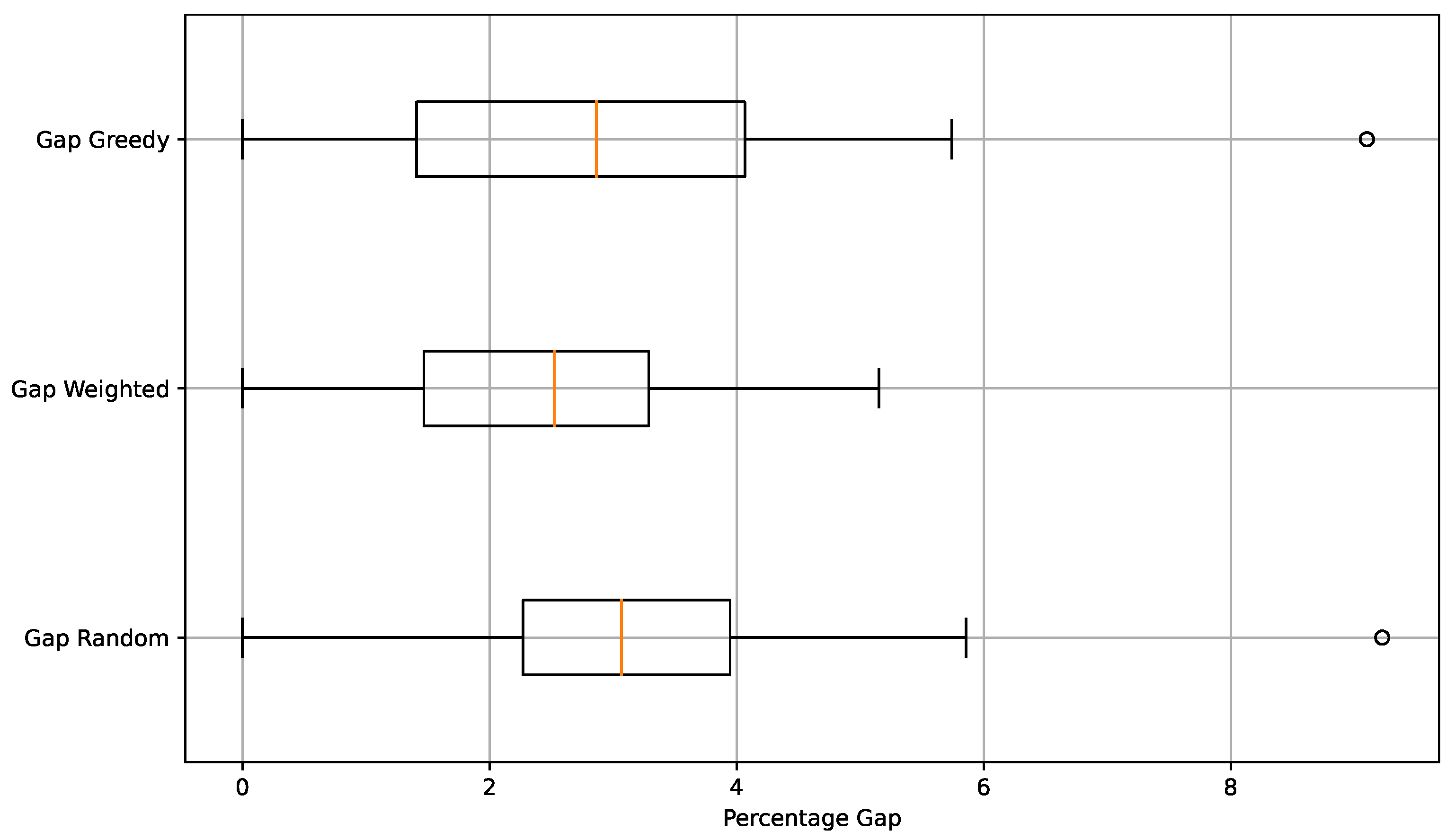
In
Figure 3, the % gap of average value, defined in Equation (
8), is compared with respect to the best-known value for the different variants developed in this experiment. The comparison is made through box plots. In the figure, it can be observed that visually, the three box plots are similar; however, the median is relatively better for the weighted operator. On the other hand, it is observed that both random and weighted operators have one outlier each. In both cases, it occurred for the same instance, sukp-200-185-0.15-0.85. The dispersion in the case of the greedy operator was greater than that of the other two, even though it is not apparent in the average.
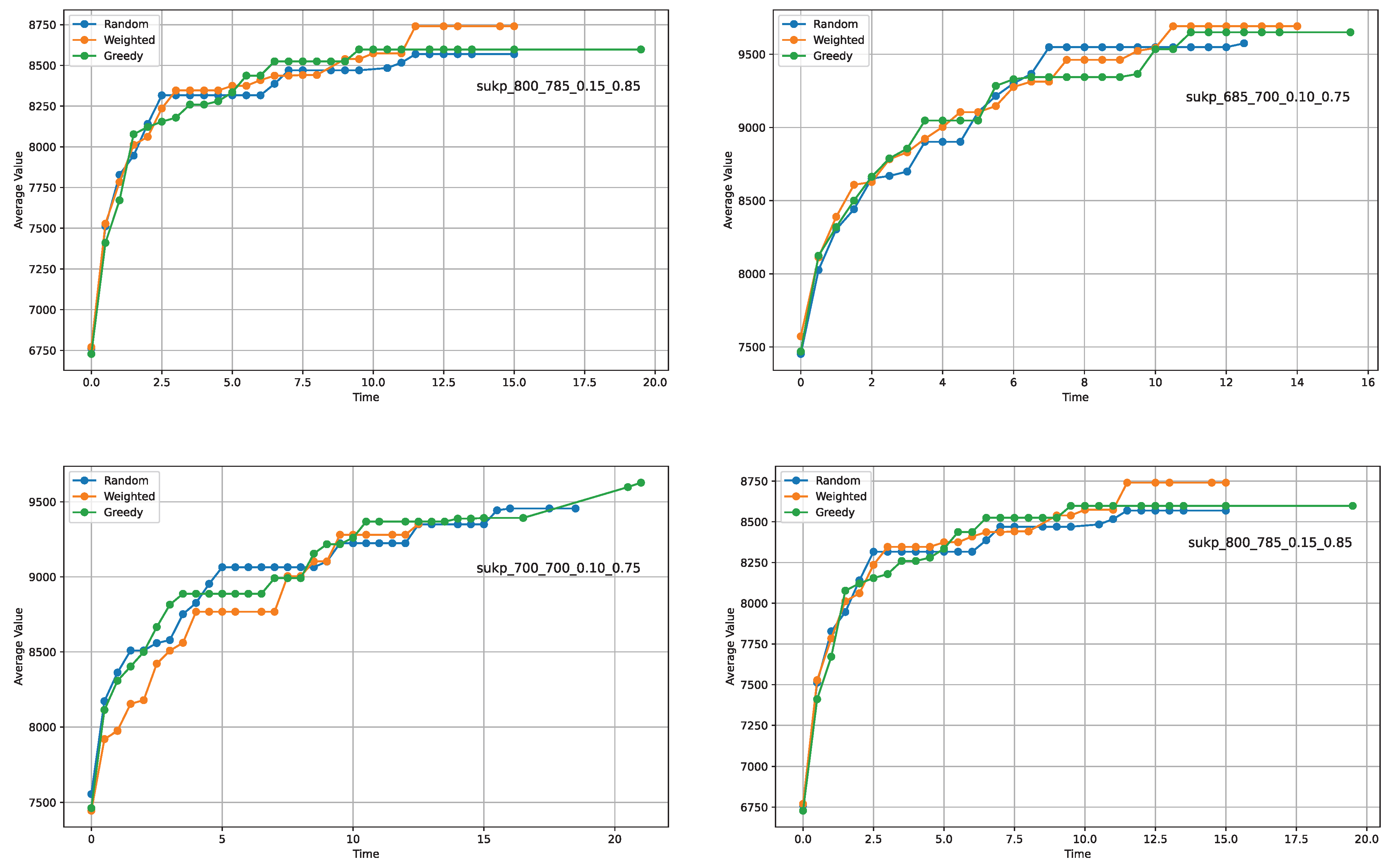
The convergence patterns for four instances are delineated in
Figure 4. On initial observation, all plots exhibit analogous trends of convergence, yet certain distinctions arise when delving into the specifics. Notably, the greedy operator demonstrates slower convergence rates in the cases of graphs ’a’ and ’c’ compared to the other two operators. However, this pattern is intriguingly inverted in the context of graph ’d’. Such variations indicate that, on average, the performance disparities among the operators tend to counterbalance across different instances.
Experimental findings derived from large-sized instances of the set-union knapsack problem are presented in
Table 3 and further elucidated by the illustrative graphics in
Figure 5 and
Figure 6. From the data in
Table 3, it can be seen that superior results for both average and best value metrics were achieved on average by ’weighted’. Upon detailed inspection of individual instances, it was found that 14 ’best values’ were obtained by the ’weighted’ initialization operator, followed by ’random’ and ’greedy’, each achieving three. In terms of ’average’ values, a similar pattern was seen, with 19 optimal averages being obtained by ’weighted’, followed by ’greedy’ with six, and ’random’ with five. These observations suggest that the final outcome of the optimization process can be influenced by the method used for initializing the solutions. This is further confirmed by significance tests, which indicate a statistically significant difference.
Upon examining the box plots, a favorable trend towards better values for the ’weighted’ initialization operator is also discernible within the interquartile range. The dispersion of results appears more controlled, and the median value also demonstrates superior performance. Furthermore, when analyzing convergence times in conjunction with the graphs, it is observed that there is generally no significant difference among them, with very similar timings being recorded across all three operators. The convergence graphs, likewise, exhibit a comparable pattern.
Based on the findings from the experimental study, it can be concluded that superior performance was exhibited by the weighted initialization operator when compared to the random and greedy operators in solving medium to large-sized instances of the set-union knapsack problem. Although the average convergence times were found to be similar across all three operators, the most optimal solutions were consistently achieved by the weighted operator, along with superior average performance. These assertions were further corroborated by the significance analysis, in which superior performance in terms of best value and average was shown by the weighted operator. However, it must be noted that in certain instances, superior performance was achieved by the random and greedy operators over the weighted operator, indicating that the choice of initialization operator may be contingent upon the unique characteristics of each problem instance.
4.3. Comparisons
This section endeavors to contrast the proposed algorithm with a variety of optimization strategies, particularly focusing on BABC [
24], binDE [
24], gPSO [
14], intAgents [
34], and DH-Jaya [
26]. The gPSO algorithm commences by creating a randomly populated binary set. By employing crossover and gene selection mechanisms, it generates new particles based on the current, personal, and globally optimal solutions. After the solutions are evaluated and updated accordingly, the algorithm perpetuates iterations until a designated termination criterion is reached. Furthermore, an optional mutation procedure is integrated as needed to preclude premature convergence. The binary artificial bee colony (BABC) is an optimization algorithm that draws inspiration from the foraging practices of honeybees. It incorporates three categories of bees: employed, onlooker, and scout bees. The employed bees actively seek food sources and relay their discoveries to the onlooker bees. Subsequently, the onlookers choose a food source predicated upon its perceived quality. Meanwhile, scout bees traverse uncharted territories in search of superior food sources. The algorithm operates in an iterative manner, continuously refining the food sources until it satisfies a predetermined stopping criterion.
The binary differential evolution (BinDE) algorithm is a population-based optimization strategy. It employs the differential evolution operator to generate novel candidate solutions. The algorithm sustains a population of potential solutions, iteratively updating them by crafting new ones via the differential evolution operator. This operator constructs a new solution by amalgamating two existing solutions with a third, randomly chosen one. Subsequently, the algorithm opts for the superior solution from among the new and existing ones to revamp the population. The algorithm culminates upon reaching a termination criterion, such as attaining a maximum number of iterations or a minimal enhancement in the objective function. The IntAgents algorithm is a swarm-based optimization strategy tailored to solve binary optimization problems. It comprises artificial search agents, each possessing unique cognitive intelligence that enables individual learning within the problem space. While these agents display varied search characteristics, they periodically share information about promising regions. Guided by a central swarm intelligence, these independent agents make use of adaptive information-sharing techniques. These techniques allow the search agents to learn across generations, mitigating the issues of premature convergence and local optima as effectively as possible.
The results are presented in
Table 4. The table indicates that MLSCABA uniquely achieved the optimal values in 19 instances, underscoring its robust performance. Nevertheless, in other situations, at least two algorithms jointly attained the best values, highlighting a competitive landscape. When considering average values, both DH-Jaya and MLSCABA exhibited superior results, with DH-Jaya outperforming in 7 instances and MLSCABA in 23. Notably, while MLSCABA generally yields commendable outcomes, its performance is influenced by the process of solution initialization, indicating that its robustness may be tempered by these initial conditions.
5. Discussion
The findings of this study indicate that the weighted initialization operator tends to outperform the random and greedy operators in most instances of the medium- and large-sized SUKP. This is evident both in terms of the best value obtained and the average value. In particular, the weighted operator achieved the best value in more instances than the other two operators in both datasets. Furthermore, the weighted operator also outperformed the other two operators in terms of the average value in most instances. These results suggest that the weighted operator is more efficient and effective in initializing solutions for this problem.
However, it is important to note that the average execution time was similar among the three operators. This suggests that, although the weighted operator may produce higher-quality solutions, it does not necessarily do so faster than the other operators. Additionally, the convergence plots show that, although all three operators tend to converge to a solution over time, there are some differences in their convergence patterns. For instance, the greedy operator showed a slower convergence rate in some cases, but in other cases, its convergence rate was faster. These differences may be due to the specific characteristics of the problem instances.
In summary, the results suggest that the weighted initialization operator is generally the most effective for the set-union knapsack problem. However, it is also important to consider other factors, such as execution time and the specific characteristics of the problem, when selecting an initialization operator. The results obtained from the comparison of the gPSO, BABC, binDE, intAgents, DH-Jaya, and MLSCABA algorithms in solving the SUKP reveal a variety of strengths and weaknesses in each approach.
The gPSO algorithm, which uses a swarm optimization approach and an iterative process of crossover and gene selection, proved capable of finding optimal solutions in several instances. However, its average performance was surpassed by MLSCABA and DH-Jaya, suggesting it may struggle to maintain consistent performance across multiple iterations. On the other hand, BABC, which draws inspiration from the behavior of bees to search for and improve solutions, achieved the best value in some instances, but its average performance was inferior to that of MLSCABA and DH-Jaya. This may indicate that, although BABC’s approach can be effective in finding optimal solutions, it may not be as effective in maintaining consistent performance across multiple iterations.
The intAgents algorithm, which uses a swarm-based optimization strategy with artificial search agents, achieved the best value in several instances, but its average results were inferior to those of MLSCABA and DH-Jaya. This may indicate that, although intAgents’ approach can be effective in finding optimal solutions, it may struggle to maintain consistent performance across multiple iterations.
DH-Jaya showed solid performance both in terms of the best values and average results. Although it did not achieve the best value in as many instances as MLSCABA, it surpassed MLSCABA in terms of average results in several instances. This suggests that DH-Jaya may be a viable option for this problem, especially in situations where the average quality of the solution is more important than achieving the best possible value. Finally, the proposed algorithm, MLSCABA, achieved the best value in most instances and also showed solid performance in terms of average results. However, its performance may be affected by the initial conditions of the solution, suggesting that the selection of a good initialization operator may be crucial for its performance.
6. Conclusions
In the context of this research, three solution initialization methods were developed and evaluated: random, greedy, and weighted. These methods were integrated and tested in relation to a sine cosine algorithm that uses k-means as a binarization procedure. Tests were conducted with medium- and large-sized instances, and the results show that the solution initialization method significantly impacts the performance of the algorithm.
Specifically, it was observed that the weighted method, which introduces some control over the weight of each item while also incorporating a random component, exhibits superior performance compared to the greedy method. The latter focuses its attention on the quality of items based on a specific heuristic, but does not introduce random elements into the process.
In addition, the weighted method was proven to perform better than the completely random method (random), which does not consider any heuristic for the construction of functions. Regarding convergence times, no significant differences were observed among the methods. However, an improvement in terms of the quality of the solutions obtained was noted, which reiterates the importance of the initialization strategy on the effectiveness of the algorithm.
This study, while concentrating on the set union knapsack problem, unveils initialization methods with potentially broader applicability to a diverse range of combinatorial problems. These might encompass challenges as varied as the traveling salesman problem (TSP), vehicle routing problem (VRP), job shop scheduling problem (JSSP), and quadratic assignment problem (QAP). Each of these problems presents its own unique set of challenges, thus creating a plethora of opportunities for more in-depth examination and investigation in future studies.
Moreover, we believe that there is an opportunity to enhance the solution initialization process further. In this regard, one promising avenue for future research involves the development of adaptive initialization methods. Such methods, with the ability to modulate their behavior based on either the specific characteristics of the problem instance or the algorithm’s progress, could potentially contribute to a more refined, efficient, and effective problem-solving approach.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}