
Multilingual Multiword Expression Identification Using Lateral Inhibition and Domain Adaptation

 , , , and
, , , and 
Abstract
:1. Introduction
2. Related Work
2.1. Multilingual Transformers
2.2. PARSEME 1.2 Competition
3. Methodology
3.1. Data Representation
3.2. Lateral Inhibition
3.3. Adversarial Training
3.4. Monolingual Training
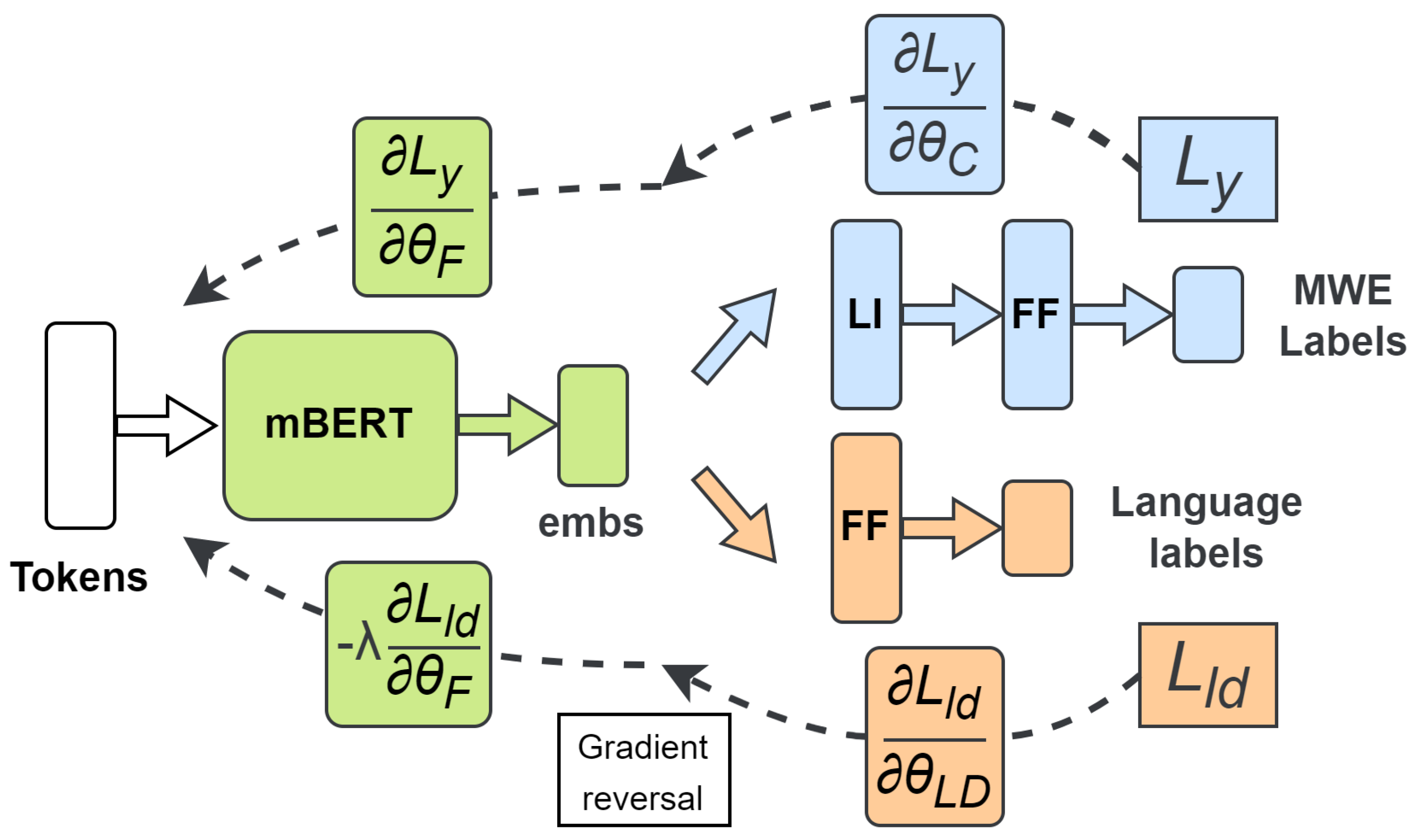
3.5. Multilingual Training
- Tokenize the using the mBERT tokenizer, obtaining the tokens (Line 1).
- Generate the multilingual embeddings for each of the above tokens using the mBERT model (Line 2).
- Apply the lateral inhibition layer on each of the embeddings (Line 3).
- Use the MWE classifier composed of lateral inhibition layer output to produce the probabilities of a token to belong to a certain MWE class (Line 4).
- Use the language discriminator on the embedding corresponding to the token [CLS] to produce the probabilities of the text to belong to a certain language (Line 5).
- Compute the loss between the predicted MWE probabilities and the ground truth MWE labels (Line 6) and the loss between the predicted language probabilities and the ground truth language labels (Line 7).
| Algorithm 1: Algorithm describing the forward pass of the multilingual training with lateral inhibition and language adversarial training. |
|
- Compute the gradients for the MWE classifier using the MWE loss (Line 1).
- Compute the gradients for the language discriminator using the language discriminator loss (Line 2).
- Compute the gradients of the mBERT model using and multiplied by (Line 3).
- Update the model parameters (i.e., , , and ) using the gradient descent algorithm (Lines 4–6).
| Algorithm 2: Algorithm describing the backward pass of the multilingual training with lateral inhibition and language adversarial training. |
|
4. Experimental Settings
4.1. Dataset
4.2. Fine-Tuning
5. Results
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shudo, K.; Kurahone, A.; Tanabe, T. A comprehensive dictionary of multiword expressions. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 161–170. [Google Scholar]
- Savary, A. Computational inflection of multi-word units: A contrastive study of lexical approaches. Linguist. Issues Lang. Technol. 2008, 1, 1–53. [Google Scholar] [CrossRef]
- Avram, A.; Mititelu, V.B.; Cercel, D.C. Romanian Multiword Expression Detection Using Multilingual Adversarial Training and Lateral Inhibition. In Proceedings of the 19th Workshop on Multiword Expressions (MWE 2023), Dubrovnik, Croatia, 2–6 May 2023; pp. 7–13. [Google Scholar]
- Zaninello, A.; Birch, A. Multiword expression aware neural machine translation. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 3816–3825. [Google Scholar]
- Najar, D.; Mesfar, S.; Ghezela, H.B. Multi-Word Expressions Annotations Effect in Document Classification Task. In Proceedings of the International Conference on Applications of Natural Language to Information Systems, Paris, France, 13–15 June 2018; pp. 238–246. [Google Scholar]
- Goyal, K.D.; Goyal, V. Development of Hybrid Algorithm for Automatic Extraction of Multiword Expressions from Monolingual and Parallel Corpus of English and Punjabi. In Proceedings of the 17th International Conference on Natural Language Processing (ICON): System Demonstrations, Patna, India, 18–21 December 2020; pp. 4–6. [Google Scholar]
- Savary, A.; Candito, M.; Mititelu, V.B.; Bejček, E.; Cap, F.; Čéplö, S.; Cordeiro, S.R.; Eryiğit, G.; Giouli, V.; van Gompel, M.; et al. PARSEME multilingual corpus of verbal multiword expressions. In Multiword Expressions at Length and in Depth: Extended Papers from the MWE 2017 Workshop; Markantonatou, S., Ramisch, C., Savary, A., Vincze, V., Eds.; Language Science Press: Berlin, Germany, 2018; pp. 87–147. [Google Scholar] [CrossRef]
- Savary, A.; Ramisch, C.; Cordeiro, S.R.; Sangati, F.; Vincze, V.; QasemiZadeh, B.; Candito, M.; Cap, F.; Giouli, V.; Stoyanova, I.; et al. Annotated Corpora and Tools of the PARSEME Shared Task on Automatic Identification of Verbal Multiword Expressions, 1.0 ed.; LINDAT/CLARIAH-CZ Digital Library at the Institute of Formal and Applied Linguistics (ÚFAL); Faculty of Mathematics and Physics, Charles University: Staré Město, Czech Republic, 2017. [Google Scholar]
- Ramisch, C.; Cordeiro, S.R.; Savary, A.; Vincze, V.; Barbu Mititelu, V.; Bhatia, A.; Buljan, M.; Candito, M.; Gantar, P.; Giouli, V.; et al. Annotated Corpora and Tools of the PARSEME Shared Task on Automatic Identification of Verbal Multiword Expressions, 1.1 ed.; LINDAT/CLARIAH-CZ Digital Library at the Institute of Formal and Applied Linguistics (ÚFAL); Faculty of Mathematics and Physics, Charles University: Staré Město, Czech Republic, 2018. [Google Scholar]
- Ramisch, C.; Guillaume, B.; Savary, A.; Waszczuk, J.; Candito, M.; Vaidya, A.; Barbu Mititelu, V.; Bhatia, A.; Iñurrieta, U.; Giouli, V.; et al. Annotated Corpora and Tools of the PARSEME Shared Task on Semi-Supervised Identification of Verbal Multiword Expressions, 1.2 ed.; LINDAT/CLARIAH-CZ Digital Library at the Institute of Formal and Applied Linguistics (ÚFAL); Faculty of Mathematics and Physics, Charles University: Staré Město, Czech Republic, 2020. [Google Scholar]
- Savary, A.; Ramisch, C.; Cordeiro, S.; Sangati, F.; Vincze, V.; QasemiZadeh, B.; Candito, M.; Cap, F.; Giouli, V.; Stoyanova, I.; et al. The PARSEME Shared Task on Automatic Identification of Verbal Multiword Expressions. In Proceedings of the 13th Workshop on Multiword Expressions (MWE 2017), Valencia, Spain, 4 April 2017; pp. 31–47. [Google Scholar] [CrossRef]
- Ramisch, C.; Cordeiro, S.R.; Savary, A.; Vincze, V.; Barbu Mititelu, V.; Bhatia, A.; Buljan, M.; Candito, M.; Gantar, P.; Giouli, V.; et al. Edition 1.1 of the PARSEME Shared Task on Automatic Identification of Verbal Multiword Expressions. In Proceedings of the Joint Workshop on Linguistic Annotation, Multiword Expressions and Constructions (LAW-MWE-CxG-2018), Santa Fe, NM, USA, 25–26 August 2018; pp. 222–240. [Google Scholar]
- Ramisch, C.; Savary, A.; Guillaume, B.; Waszczuk, J.; Candito, M.; Vaidya, A.; Barbu Mititelu, V.; Bhatia, A.; Iñurrieta, U.; Giouli, V.; et al. Edition 1.2 of the PARSEME Shared Task on Semi-supervised Identification of Verbal Multiword Expressions. In Proceedings of the Joint Workshop on Multiword Expressions and Electronic Lexicons, Online, 13 December 2020; pp. 107–118. [Google Scholar]
- Ponti, E.M.; O’horan, H.; Berzak, Y.; Vulić, I.; Reichart, R.; Poibeau, T.; Shutova, E.; Korhonen, A. Modeling language variation and universals: A survey on typological linguistics for natural language processing. Comput. Linguist. 2019, 45, 559–601. [Google Scholar] [CrossRef]
- Arroyo González, R.; Fernández-Lancho, E.; Maldonado Jurado, J.A. Learning Effect in a Multilingual Web-Based Argumentative Writing Instruction Model, Called ECM, on Metacognition, Rhetorical Moves, and Self-Efficacy for Scientific Purposes. Mathematics 2021, 9, 2119. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Conneau, A.; Lample, G. Cross-lingual language model pretraining. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 7059–7069. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, É.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8440–8451. [Google Scholar]
- Liu, Y.; Gu, J.; Goyal, N.; Li, X.; Edunov, S.; Ghazvininejad, M.; Lewis, M.; Zettlemoyer, L. Multilingual Denoising Pre-training for Neural Machine Translation. Trans. Assoc. Comput. Linguist. 2020, 8, 726–742. [Google Scholar] [CrossRef]
- Kalyan, K.S.; Rajasekharan, A.; Sangeetha, S. Ammus: A survey of transformer-based pretrained models in natural language processing. arXiv 2021, arXiv:2108.05542. [Google Scholar]
- Pais, V. RACAI at SemEval-2022 Task 11: Complex named entity recognition using a lateral inhibition mechanism. In Proceedings of the 16th International Workshop on Semantic Evaluation (SemEval-2022), Seattle, WA, USA, 14–15 July 2022; pp. 1562–1569. [Google Scholar] [CrossRef]
- Lowd, D.; Meek, C. Adversarial learning. In Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 641–647. [Google Scholar]
- Dong, X.; Zhu, Y.; Zhang, Y.; Fu, Z.; Xu, D.; Yang, S.; De Melo, G. Leveraging adversarial training in self-learning for cross-lingual text classification. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25–30 July 2020; pp. 1541–1544. [Google Scholar]
- Taslimipoor, S.; Bahaadini, S.; Kochmar, E. MTLB-STRUCT@ Parseme 2020: Capturing Unseen Multiword Expressions Using Multi-task Learning and Pre-trained Masked Language Models. In Proceedings of the Joint Workshop on Multiword Expressions and Electronic Lexicons, Online, 13 December 2020; pp. 142–148. [Google Scholar]
- Pires, T.; Schlinger, E.; Garrette, D. How Multilingual is Multilingual BERT? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4996–5001. [Google Scholar]
- Bojar, O.; Graham, Y.; Kamran, A.; Stanojević, M. Results of the wmt16 metrics shared task. In Proceedings of the First Conference on Machine Translation: Volume 2, Shared Task Papers; Association for Computational Linguistics: Cedarville, OH, USA, 2016; pp. 199–231. [Google Scholar]
- Conneau, A.; Rinott, R.; Lample, G.; Williams, A.; Bowman, S.; Schwenk, H.; Stoyanov, V. XNLI: Evaluating Cross-lingual Sentence Representations. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2475–2485. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Brussels, Belgium, 1 November 2018; pp. 353–355. [Google Scholar]
- Yirmibeşoğlu, Z.; Güngör, T. ERMI at PARSEME Shared Task 2020: Embedding-Rich Multiword Expression Identification. In Proceedings of the Joint Workshop on Multiword Expressions and Electronic Lexicons, Online, 13 December 2020; pp. 130–135. [Google Scholar]
- Gombert, S.; Bartsch, S. MultiVitaminBooster at PARSEME Shared Task 2020: Combining Window-and Dependency-Based Features with Multilingual Contextualised Word Embeddings for VMWE Detection. In Proceedings of the Joint Workshop on Multiword Expressions and Electronic Lexicons, Online, 13 December 2020; pp. 149–155. [Google Scholar]
- Kurfalı, M. TRAVIS at PARSEME Shared Task 2020: How good is (m) BERT at seeing the unseen? In Proceedings of the Joint Workshop on Multiword Expressions and Electronic Lexicons, Online, 13 December 2020; pp. 136–141. [Google Scholar]
- Pasquer, C.; Savary, A.; Ramisch, C.; Antoine, J.Y. Seen2Unseen at PARSEME Shared Task 2020: All Roads do not Lead to Unseen Verb-Noun VMWEs. In Proceedings of the Joint Workshop on Multiword Expressions and Electronic Lexicons, Online, 13 December 2020; pp. 124–129. [Google Scholar]
- Colson, J.P. HMSid and HMSid2 at PARSEME Shared Task 2020: Computational Corpus Linguistics and unseen-in-training MWEs. In Proceedings of the Joint Workshop on Multiword Expressions and Electronic Lexicons, Online, 13 December 2020; pp. 119–123. [Google Scholar]
- Rush, A. Torch-Struct: Deep structured prediction library. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Online, 5–10 July 2020; pp. 335–342. [Google Scholar]
- Martin, L.; Muller, B.; Suárez, P.J.O.; Dupont, Y.; Romary, L.; De La Clergerie, É.V.; Seddah, D.; Sagot, B. CamemBERT: A Tasty French Language Model. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Seattle, WA, USA, 5–10 July 2020; pp. 7203–7219. [Google Scholar]
- Ralethe, S. Adaptation of deep bidirectional transformers for Afrikaans language. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 2475–2478. [Google Scholar]
- Virtanen, A.; Kanerva, J.; Ilo, R.; Luoma, J.; Luotolahti, J.; Salakoski, T.; Ginter, F.; Pyysalo, S. Multilingual is not enough: BERT for Finnish. arXiv 2019, arXiv:1912.07076. [Google Scholar]
- Dumitrescu, S.; Avram, A.M.; Pyysalo, S. The birth of Romanian BERT. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 4324–4328. [Google Scholar]
- Doddapaneni, S.; Ramesh, G.; Kunchukuttan, A.; Kumar, P.; Khapra, M.M. A primer on pretrained multilingual language models. arXiv 2021, arXiv:2107.00676. [Google Scholar]
- Draskovic, D.; Zecevic, D.; Nikolic, B. Development of a Multilingual Model for Machine Sentiment Analysis in the Serbian Language. Mathematics 2022, 10, 3236. [Google Scholar] [CrossRef]
- Cohen, R.A. Lateral inhibition. Encyclopedia of Clinical Neuropsychology; Springer: New York, NY, USA, 2011; pp. 1436–1437. [Google Scholar]
- Mitrofan, M.; Pais, V. Improving Romanian BioNER Using a Biologically Inspired System. In Proceedings of the 21st Workshop on Biomedical Language Processing, Dublin, Ireland, 26 May 2022; pp. 316–322. [Google Scholar] [CrossRef]
- Wunderlich, T.C.; Pehle, C. Event-based backpropagation can compute exact gradients for spiking neural networks. Sci. Rep. 2021, 11, 12829. [Google Scholar] [CrossRef] [PubMed]
- Neftci, E.O.; Mostafa, H.; Zenke, F. Surrogate Gradient Learning in Spiking Neural Networks: Bringing the Power of Gradient-Based Optimization to Spiking Neural Networks. IEEE Signal Process. Mag. 2019, 36, 51–63. [Google Scholar] [CrossRef]
- Gui, J.; Sun, Z.; Wen, Y.; Tao, D.; Ye, J. A review on generative adversarial networks: Algorithms, theory, and applications. arXiv 2020, arXiv:2001.06937. [Google Scholar] [CrossRef]
- Wiatrak, M.; Albrecht, S.V.; Nystrom, A. Stabilizing generative adversarial networks: A survey. arXiv 2019, arXiv:1910.00927. [Google Scholar]
- Nam, S.H.; Kim, Y.H.; Choi, J.; Park, C.; Park, K.R. LCA-GAN: Low-Complexity Attention-Generative Adversarial Network for Age Estimation with Mask-Occluded Facial Images. Mathematics 2023, 11, 1925. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, J.; Cheng, N.; Xiao, J. Metasid: Singer identification with domain adaptation for metaverse. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Queensland, Australia, 18–23 June 2022; pp. 1–7. [Google Scholar]
- Joty, S.; Nakov, P.; Màrquez, L.; Jaradat, I. Cross-language Learning with Adversarial Neural Networks. In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 226–237. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Avram, A.M.; Păiș, V.; Mitrofan, M. Racai@ smm4h’22: Tweets disease mention detection using a neural lateral inhibitory mechanism. In Proceedings of the Seventh Workshop on Social Media Mining for Health Applications, Workshop & Shared Task, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 1–3. [Google Scholar]
- Straka, M.; Straková, J. Tokenizing, POS Tagging, Lemmatizing and Parsing UD 2.0 with UDPipe. In Proceedings of the CoNLL 2017 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies, Vancouver, BC, Canada, 3–4 August 2017; pp. 88–99. [Google Scholar]
- de Marneffe, M.C.; Manning, C.D.; Nivre, J.; Zeman, D. Universal Dependencies. Comput. Linguist. 2021, 47, 255–308. [Google Scholar] [CrossRef]
- Bradley, J.K.; Guestrin, C. Learning tree conditional random fields. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 127–134. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Sang, E.T.K.; De Meulder, F. Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, Edmonton, AB, Canada, 31 May–1 June 2003; pp. 142–147. [Google Scholar]
- Eisenschlos, J.; Ruder, S.; Czapla, P.; Kadras, M.; Gugger, S.; Howard, J. MultiFiT: Efficient Multi-lingual Language Model Fine-tuning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5702–5707. [Google Scholar]
- Wu, S.; Dredze, M. Are All Languages Created Equal in Multilingual BERT? In Proceedings of the 5th Workshop on Representation Learning for NLP, Online, 9 July 2020; pp. 120–130. [Google Scholar]
- Dhamecha, T.; Murthy, R.; Bharadwaj, S.; Sankaranarayanan, K.; Bhattacharyya, P. Role of Language Relatedness in Multilingual Fine-tuning of Language Models: A Case Study in Indo-Aryan Languages. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 8584–8595. [Google Scholar]

{kind=link}
{kind=link}
| Lang. | Training | Validation | Test | ||||||
|---|---|---|---|---|---|---|---|---|---|
| #Sent. | #Tok. | Len. | #Sent. | #Tok. | Len. | #Sent. | #Tok. | Len. | |
| DE | 6.5 k | 126.8 k | 19.3 | 602 | 11.7 k | 19.5 | 1.8 k | 34.9 k | 19.1 |
| EL | 17.7 k | 479.6 k | 27.0 | 909 | 23.9 k | 26.3 | 2.8 k | 75.4 k | 26.7 |
| EU | 4.4 k | 61.8 k | 13.9 | 1.4 k | 20.5 k | 14.4 | 5.3 k | 75.4 k | 14.2 |
| FR | 14.3 k | 360.0 k | 25.0 | 1.5 k | 39.5 k | 25.1 | 5.0 k | 126.4 k | 25.2 |
| GA | 257 | 6.2 k | 24.2 | 322 | 7.0 k | 21.8 | 1.1 k | 25.9 k | 23.1 |
| HE | 14.1 k | 286.2 k | 20.2 | 1.2 k | 25.3 k | 20.2 | 3.7 k | 76.8 k | 20.2 |
| HI | 282 | 5.7 k | 20.4 | 289 | 6.2 k | 21.7 | 1.1 k | 23.3 k | 21.0 |
| IT | 10.6 k | 282.0 k | 27.4 | 1.2 k | 32.6 k | 27.1 | 3.8 k | 106.0 k | 27.3 |
| PL | 17.7 k | 298.4 k | 16.8 | 1.4 k | 23.9 k | 16.8 | 4.3 k | 73.7 k | 16.7 |
| PT | 23.9 k | 542.4 k | 22.6 | 1.9 k | 43.6 k | 22.1 | 6.2 k | 142.3 k | 22.8 |
| RO | 10.9 k | 195.7 k | 17.9 | 7.7 k | 134.3 k | 17.4 | 38.0 k | 685.5 k | 18.0 |
| SV | 1.6 k | 24.9 k | 15.5 | 596 | 8.8 k | 14.9 | 2.1 k | 31.6 k | 15.0 |
| TR | 17.9 k | 267.5 k | 14.9 | 1.0 k | 15.9 k | 15.0 | 3.3 k | 48.7 k | 14.7 |
| ZH | 35.3 k | 575.5 k | 16.2 | 1.1 k | 18.2 k | 16.0 | 3.4 k | 55.7 k | 16.0 |
| Total | 175.7 k | 3512.7 k | 20.1 | 29.3 k | 522.2 k | 19.8 k | 81.9 k | 1581.6 k | 20.0 |
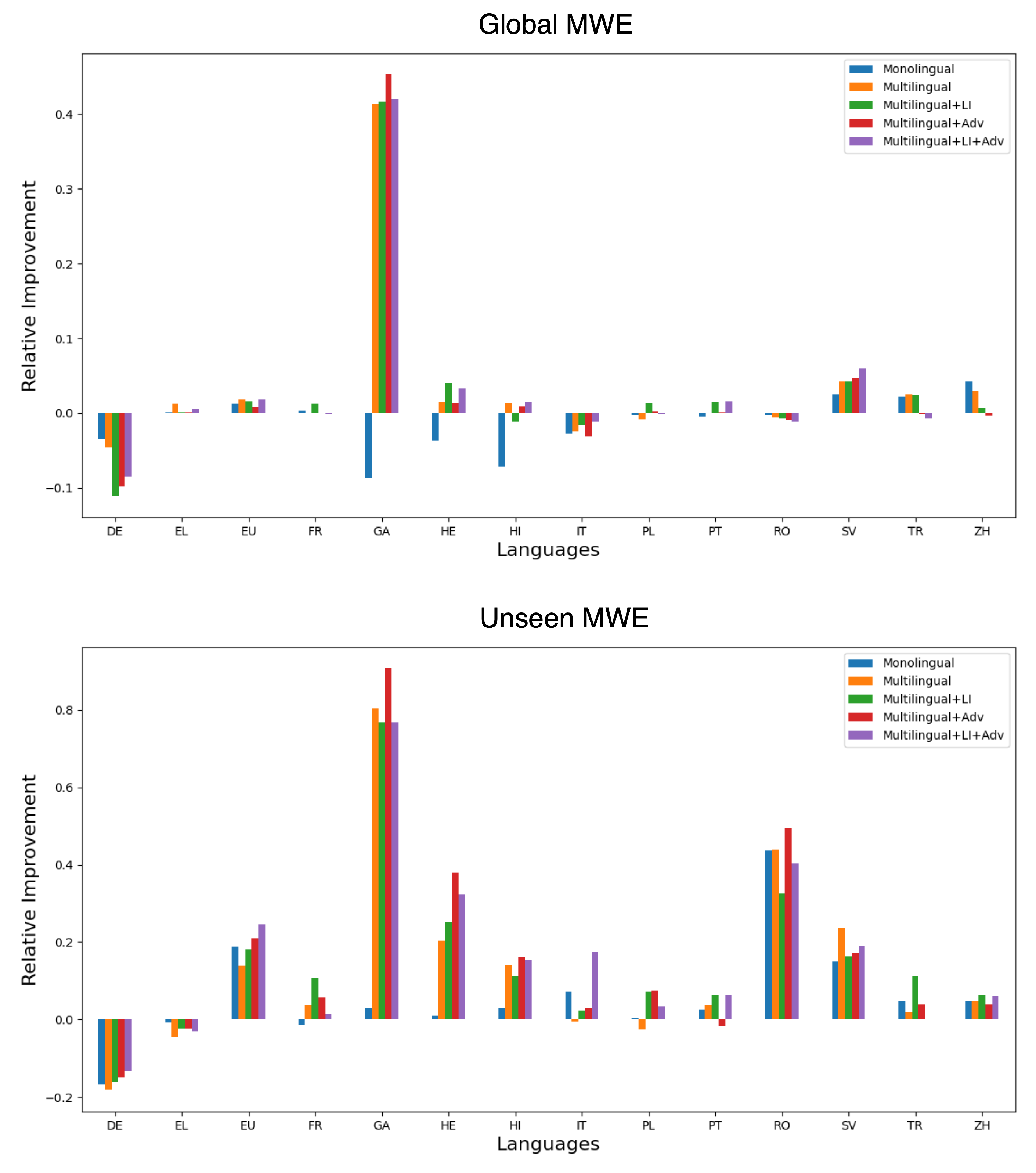
| Language | Method | Global MWE-Based | Unseen MWE-Based | ||||
|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | ||
| DE | MTLB-STRUCT [25] | 77.11 | 75.24 | 76.17 | 49.17 | 49.50 | 49.34 |
| Monolingual | 74.26 | 72.82 | 73.53 | 40.35 | 41.79 | 41.06 | |
| Multilingual | 77.26 | 68.47 | 72.60 | 37.85 | 43.22 | 40.35 | |
| Multilingual + LI | 69.07 | 66.38 | 67.70 | 39.15 | 43.85 | 41.37 | |
| Multilingual + Adv | 69.00 | 68.33 | 68.66 | 39.18 | 45.11 | 41.94 | |
| Multilingual + LI + Adv | 71.37 | 68.08 | 69.69 | 41.47 | 43.85 | 42.77 | |
| EL | MTLB-STRUCT [25] | 72.54 | 72.69 | 72.62 | 38.74 | 47.00 | 42.47 |
| Monolingual | 72.33 | 73.00 | 72.66 | 38.30 | 46.75 | 42.11 | |
| Multilingual | 74.60 | 72.38 | 73.48 | 38.92 | 42.21 | 40.50 | |
| Multilingual + LI | 72.52 | 72.90 | 72.71 | 37.90 | 45.78 | 41.47 | |
| Multilingual + Adv | 73.23 | 72.18 | 72.70 | 38.81 | 44.48 | 41.45 | |
| Multilingual + LI + Adv | 73.42 | 72.59 | 73.00 | 38.64 | 44.16 | 41.21 | |
| EU | MTLB-STRUCT [25] | 80.72 | 79.36 | 80.03 | 28.12 | 44.33 | 34.41 |
| Monolingual | 81.61 | 80.40 | 81.00 | 34.94 | 49.29 | 40.89 | |
| Multilingual | 86.49 | 77.03 | 81.49 | 33.32 | 45.04 | 39.17 | |
| Multilingual + LI | 84.07 | 78.66 | 81.28 | 37.38 | 44.48 | 40.62 | |
| Multilingual + Adv | 82.77 | 78.71 | 80.69 | 36.46 | 48.44 | 41.61 | |
| Multilingual + LI + Adv | 84.80 | 78.42 | 81.48 | 39.71 | 46.46 | 42.82 | |
| FR | MTLB-STRUCT [25] | 80.04 | 78.81 | 79.42 | 39.20 | 46.00 | 42.33 |
| Monolingual | 79.84 | 79.54 | 79.69 | 38.89 | 44.87 | 41.67 | |
| Multilingual | 81.80 | 77.04 | 79.35 | 43.17 | 44.55 | 43.85 | |
| Multilingual + LI | 81.85 | 78.96 | 80.37 | 45.48 | 48.40 | 46.89 | |
| Multilingual + Adv | 80.12 | 78.59 | 79.35 | 41.60 | 48.40 | 44.74 | |
| Multilingual + LI + Adv | 80.47 | 78.22 | 79.33 | 40.87 | 45.19 | 42.92 | |
| GA | MTLB-STRUCT [25] | 37.72 | 25.00 | 30.07 | 23.08 | 16.94 | 19.54 |
| Monolingual | 33.67 | 23.17 | 27.45 | 24.02 | 17.28 | 20.10 | |
| Multilingual | 54.91 | 34.63 | 42.48 | 45.91 | 28.61 | 35.25 | |
| Multilingual + LI | 55.31 | 34.63 | 42.60 | 45.79 | 27.76 | 34.57 | |
| Multilingual + Adv | 56.12 | 35.78 | 43.70 | 48.42 | 30.31 | 37.28 | |
| Multilingual + LI + Adv | 55.72 | 34.63 | 42.72 | 45.79 | 27.76 | 34.57 | |
| HE | MTLB-STRUCT [25] | 56.20 | 42.35 | 48.30 | 25.53 | 15.89 | 19.59 |
| Monolingual | 54.09 | 40.76 | 46.49 | 26.02 | 15.94 | 19.77 | |
| Multilingual | 61.38 | 40.76 | 48.98 | 34.76 | 17.81 | 23.55 | |
| Multilingual + LI | 61.63 | 42.54 | 50.23 | 34.46 | 19.06 | 24.55 | |
| Multilingual + Adv | 58.40 | 42.15 | 48.96 | 35.35 | 21.88 | 27.03 | |
| Multilingual + LI + Adv | 59.89 | 42.74 | 49.88 | 34.92 | 20.62 | 25.93 | |
| HI | MTLB-STRUCT [25] | 72.25 | 75.04 | 73.62 | 48.75 | 58.33 | 53.11 |
| Monolingual | 66.53 | 70.28 | 68.35 | 49.35 | 61.35 | 54.70 | |
| Multilingual | 77.78 | 71.77 | 74.65 | 62.72 | 58.65 | 60.61 | |
| Multilingual + LI | 77.08 | 68.95 | 72.78 | 61.83 | 56.49 | 59.04 | |
| Multilingual + Adv | 75.46 | 73.11 | 74.26 | 60.95 | 62.43 | 61.68 | |
| Multilingual + LI + Adv | 75.53 | 73.85 | 74.68 | 60.31 | 62.43 | 61.35 | |
| IT | MTLB-STRUCT [25] | 67.68 | 60.27 | 63.76 | 20.23 | 21.33 | 20.81 |
| Monolingual | 64.53 | 59.59 | 61.96 | 20.81 | 24.06 | 22.32 | |
| Multilingual | 69.37 | 56.40 | 62.21 | 22.22 | 19.38 | 20.70 | |
| Multilingual + LI | 71.27 | 56.01 | 62.72 | 23.02 | 20.12 | 21.28 | |
| Multilingual + Adv | 65.65 | 58.33 | 61.78 | 20.83 | 21.88 | 21.43 | |
| Multilingual + LI + Adv | 69.18 | 57.85 | 63.01 | 25.51 | 23.44 | 24.43 | |
| PL | MTLB-STRUCT [25] | 82.94 | 79.18 | 81.02 | 38.46 | 41.53 | 39.94 |
| Monolingual | 81.89 | 79.33 | 80.85 | 38.30 | 41.99 | 40.06 | |
| Multilingual | 84.02 | 77.03 | 80.37 | 40.34 | 37.50 | 38.87 | |
| Multilingual + LI | 85.14 | 79.26 | 82.09 | 44.48 | 41.33 | 42.84 | |
| Multilingual + Adv | 82.55 | 79.85 | 81.18 | 40.75 | 45.19 | 42.86 | |
| Multilingual + LI + Adv | 83.19 | 78.74 | 80.90 | 41.01 | 41.67 | 41.34 | |
| PT | MTLB-STRUCT [25] | 73.93 | 72.76 | 73.34 | 30.54 | 41.33 | 35.13 |
| Monolingual | 74.81 | 70.94 | 73.01 | 33.81 | 39.05 | 35.98 | |
| Multilingual | 75.93 | 70.94 | 73.35 | 34.06 | 39.18 | 36.44 | |
| Multilingual + LI | 77.15 | 71.89 | 74.43 | 35.61 | 39.18 | 37.31 | |
| Multilingual + Adv | 73.36 | 73.48 | 73.42 | 30.33 | 40.13 | 34.55 | |
| Multilingual + LI + Adv | 75.51 | 73.53 | 74.49 | 33.76 | 41.78 | 37.36 | |
| RO | MTLB-STRUCT [25] | 89.88 | 91.05 | 90.46 | 28.84 | 41.47 | 34.02 |
| Monolingual | 90.39 | 90.11 | 90.25 | 46.82 | 51.09 | 48.86 | |
| Multilingual | 91.34 | 88.46 | 89.88 | 49.90 | 48.12 | 48.99 | |
| Multilingual + LI | 90.78 | 88.85 | 89.81 | 45.06 | 45.15 | 45.10 | |
| Multilingual + Adv | 89.14 | 90.13 | 89.63 | 46.27 | 56.44 | 50.85 | |
| Multilingual + LI + Adv | 89.95 | 88.78 | 89.36 | 45.44 | 50.30 | 47.74 | |
| SV | MTLB-STRUCT [25] | 69.59 | 73.68 | 71.58 | 35.57 | 53.00 | 42.57 |
| Monolingual | 73.01 | 73.68 | 73.34 | 44.32 | 54.62 | 48.93 | |
| Multilingual | 78.92 | 70.79 | 74.63 | 50.78 | 54.62 | 52.63 | |
| Multilingual + LI | 75.48 | 73.68 | 74.57 | 46.77 | 52.66 | 49.54 | |
| Multilingual + Adv | 75.42 | 74.41 | 74.91 | 46.70 | 53.50 | 49.87 | |
| Multilingual + LI + Adv | 77.62 | 74.10 | 75.82 | 49.47 | 51.82 | 50.62 | |
| TR | MTLB-STRUCT [25] | 68.41 | 70.55 | 69.46 | 42.11 | 45.33 | 43.66 |
| Monolingual | 69.11 | 72.89 | 70.95 | 43.75 | 47.88 | 45.72 | |
| Multilingual | 67.52 | 73.27 | 71.18 | 41.83 | 47.56 | 44.51 | |
| Multilingual + LI | 69.92 | 72.28 | 71.08 | 47.94 | 49.19 | 48.55 | |
| Multilingual + Adv | 68.41 | 70.37 | 69.38 | 43.54 | 47.23 | 45.31 | |
| Multilingual + LI + Adv | 68.22 | 69.77 | 68.99 | 43.04 | 44.30 | 43.66 | |
| ZH | MTLB-STRUCT [25] | 68.56 | 70.74 | 69.63 | 58.97 | 53.67 | 56.20 |
| Monolingual | 72.33 | 72.88 | 72.60 | 59.74 | 58.03 | 58.87 | |
| Multilingual | 72.03 | 71.32 | 71.67 | 62.30 | 55.87 | 58.91 | |
| Multilingual + LI | 69.82 | 70.36 | 70.09 | 62.50 | 57.31 | 59.79 | |
| Multilingual + Adv | 69.29 | 69.47 | 69.38 | 62.42 | 54.73 | 58.32 | |
| Multilingual + LI + Adv | 70.64 | 68.58 | 69.59 | 65.41 | 54.73 | 59.59 | |
| Method | #Highest | #Highest |
|---|---|---|
| Global MWE | Unseen MWE | |
| MTLB-STRUCT [25] | 3 | 2 |
| Monolingual | 1 | 0 |
| Multilingual | 3 | 1 |
| Multilingual + LI | 3 | 3 |
| Multilingual + ADV | 1 | 5 |
| Multilingual + LI + ADV | 3 | 3 |
| Total (ours) | 11 | 12 |
| Method | #Lang. | Global MWE-Based | Unseen MWE-Based | ||||
|---|---|---|---|---|---|---|---|
| AP | AR | AF1 | AP | AR | AF1 | ||
| MTLB-STRUCT [25] | 14/14 | 71.26 | 69.05 | 70.14 | 36.24 | 41.12 | 38.53 |
| TRAVIS-multi [33] | 13/14 | 60.65 | 57.62 | 59.10 | 28.11 | 33.29 | 30.48 |
| TRAVIS-mono [33] | 10/14 | 49.50 | 43.48 | 46.34 | 24.33 | 28.01 | 26.04 |
| Seen2Unseen [34] | 14/14 | 63.36 | 62.69 | 63.02 | 16.14 | 11.95 | 13.73 |
| FipsCo [10] | 3/14 | 11.69 | 8.75 | 10.01 | 4.31 | 5.21 | 4.72 |
| HMSid [35] | 1/14 | 4.56 | 4.85 | 4.70 | 1.98 | 3.81 | 2.61 |
| MultiVitaminBooster [32] | 7/14 | 0.19 | 0.09 | 0.12 | 0.05 | 0.07 | 0.06 |
| Monolingual | 14/14 | 70.60 | 68.52 | 69.54 | 38.52 | 42.42 | 40.38 |
| Multilingual | 14/14 | 75.23 | 67.88 | 71.37 | 42.72 | 41.60 | 42.15 |
| Multilingual + LI | 14/14 | 74.36 | 68.24 | 71.17 | 43.48 | 42.20 | 42.78 |
| Multilingual + Adv | 14/14 | 72.78 | 68.92 | 70.80 | 42.26 | 44.30 | 43.26 |
| Multilingual + LI + Adv | 14/14 | 73.96 | 68.56 | 71.16 | 43.24 | 42.75 | 43.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Avram, A.-M.; Mititelu, V.B.; Păiș, V.; Cercel, D.-C.; Trăușan-Matu, Ș. Multilingual Multiword Expression Identification Using Lateral Inhibition and Domain Adaptation. Mathematics 2023, 11, 2548. https://doi.org/10.3390/math11112548
Avram A-M, Mititelu VB, Păiș V, Cercel D-C, Trăușan-Matu Ș. Multilingual Multiword Expression Identification Using Lateral Inhibition and Domain Adaptation. Mathematics. 2023; 11(11):2548. https://doi.org/10.3390/math11112548
Chicago/Turabian StyleAvram, Andrei-Marius, Verginica Barbu Mititelu, Vasile Păiș, Dumitru-Clementin Cercel, and Ștefan Trăușan-Matu. 2023. "Multilingual Multiword Expression Identification Using Lateral Inhibition and Domain Adaptation" Mathematics 11, no. 11: 2548. https://doi.org/10.3390/math11112548
APA StyleAvram, A.-M., Mititelu, V. B., Păiș, V., Cercel, D.-C., & Trăușan-Matu, Ș. (2023). Multilingual Multiword Expression Identification Using Lateral Inhibition and Domain Adaptation. Mathematics, 11(11), 2548. https://doi.org/10.3390/math11112548