
Survey of Optimization Algorithms in Modern Neural Networks



Abstract
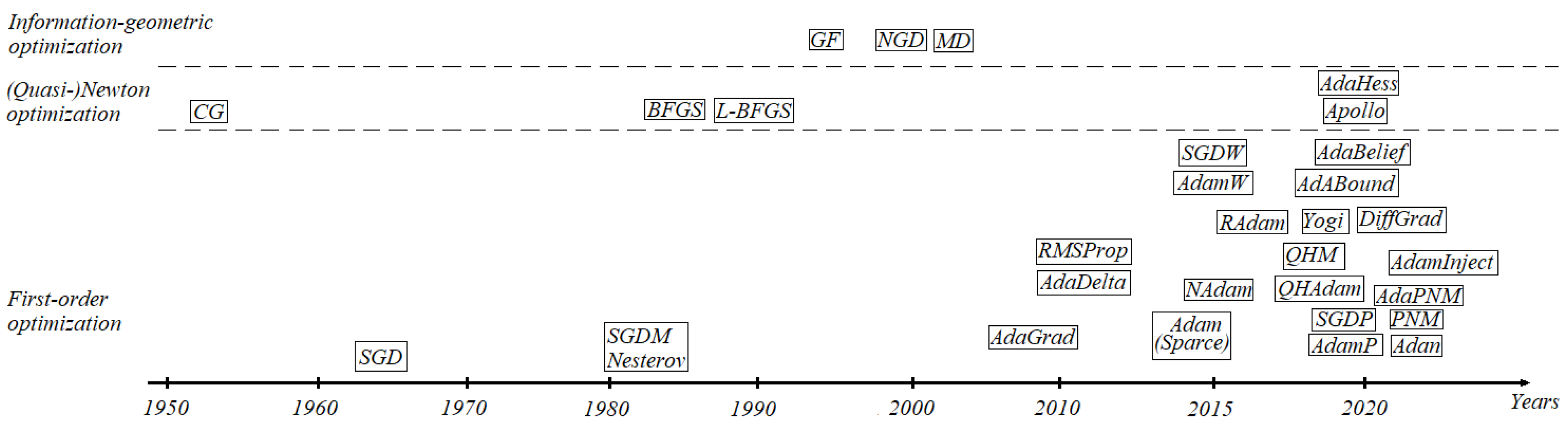
1. Introduction
2. First-Order Optimization Algorithms
2.1. SGD-Type Algorithms
2.2. Adam-Type Algorithms
2.3. Positive–Negative Momentum
3. Second-Order Optimization Algorithms
3.1. Newton Algorithms
3.2. Quasi-Newton Algorithms
4. Information-Geometric Optimization Methods
4.1. Natural Gradient Descent
4.2. Mirror Descent
5. Application of Optimization Methods in Modern Neural Networks
6. Challenges and Potential Research
6.1. Promising Approaches in Optimization
6.2. Open Problems in the Modern Theory of Neural Network
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Notations
| weight | |
| learning rate | |
| loss function | |
| gradient | |
| weight decay parameter, regularization factor | |
| momentum | |
| sum of gradients | |
| exponential moving average of | |
| horizontal direction converging, exponential moving average of | |
| running average , where is a | |
| decay rate | |
| schedule multiplier | |
| immediate discount factor | |
| momentum buffer’s discount factor | |
| moments | |
| variance | |
| variance rectification | |
| DiffGrad friction coefficient (DFC) | |
| Hessian matrix | |
| inverse BFGS Hessian approximation | |
| curvature pairs | |
| Hessian diagonal matrix | |
| Hessian diagonal matrix with momentum | |
| Riemannian manifold with n-dimensional topological space and | |
| metric g | |
| ∇ | affine connection, gradient |
| tangent bundle | |
| proximity function | |
| Bregman |
References
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Qian, K.; Pawar, A.; Liao, A.; Anitescu, C.; Webster-Wood, V.; Feinberg, A.W.; Rabczuk, T.; Zhang, Y.J. Modeling neuron growth using isogeometric collocation based phase field method. Sci. Rep. 2022, 12, 8120. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Shi, Y.; Mu, F.; Cheng, J.; Li, C.; Chen, X. Multimodal MRI Volumetric Data Fusion With Convolutional Neural Networks. IEEE Trans. Instrum. Meas. 2022, 71, 1–15. [Google Scholar] [CrossRef]
- Li, Q.; Xiong, D.; Shang, M. Adjusted stochastic gradient descent for latent factor analysis. Inf. Sci. 2022, 588, 196–213. [Google Scholar] [CrossRef]
- Dogo, E.M.; Afolabi, O.J.; Nwulu, N.I.; Twala, B.; Aigbavboa, C.O. A Comparative Analysis of Gradient Descent-Based Optimization Algorithms on Convolutional Neural Networks. In Proceedings of the 2018 International Conference on Computational Techniques, Electronics and Mechanical Systems (CTEMS), Belgaum, India, 21–22 December 2018; pp. 92–99. [Google Scholar]
- Ward, R.; Wu, X.; Bottou, L. AdaGrad stepsizes: Sharp convergence over nonconvex landscapes. J. Mach. Learn. Res. 2020, 21, 9047–9076. [Google Scholar]
- Xu, D.; Zhang, S.; Zhang, H.; Mandic, D.P. Convergence of the RMSProp deep learning method with penalty for nonconvex optimization. Neural Netw. 2021, 139, 17–23. [Google Scholar] [CrossRef] [PubMed]
- Zeiler, M.D. Adadelta: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Singarimbun, R.N.; Nababan, E.B.; Sitompul, O.S. Adaptive Moment Estimation To Minimize Square Error In Backpropagation Algorithm. In Proceedings of the 2019 International Conference of Computer Science and Information Technology (ICoSNIKOM), Medan, Indonesia, 28–29 November 2019; pp. 1–7. [Google Scholar]
- Seredynski, F.; Zomaya, A.Y.; Bouvry, P. Function Optimization with Coevolutionary Algorithms. Intell. Inf. Process. Web Min. Adv. Soft Comput. 2003, 22, 13–22. [Google Scholar]
- Osowski, S.; Bojarczak, P.; Stodolskia, M. Fast Second Order Learning Algorithm for Feedforward Multilayer Neural Networks and its Applications. Neural Netw. 1996, 9, 1583–1596. [Google Scholar] [CrossRef]
- Tyagi, K.; Rane, C.; Irie, B.; Manry, M. Multistage Newton’s Approach for Training Radial Basis Function Neural Networks. SN Comput. Sci. 2021, 2, 366. [Google Scholar] [CrossRef]
- Likas, A.; Stafylopatis, A. Training the random neural network using quasi-Newton methods. Eur. J. Oper. Res. 2000, 126, 331–339. [Google Scholar] [CrossRef]
- Arbel, M.; Korba, A.; Salim, A.; Gretton, A. Maximum Mean Discrepancy Gradient Flow. arXiv 2019, arXiv:1906.04370. [Google Scholar]
- Ay, N.; Jost, N.J.; Lê, H.V.; Schwachhöfe, L. Information Geometry; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Gattone, S.A.; Sanctis, A.D.; Russo, T.; Pulcini, D. A shape distance based on the Fisher–Rao metric and its application for shapes clustering. Phys. A Stat. Mech. Its Appl. 2017, 487, 93–102. [Google Scholar] [CrossRef]
- Hua, X.; Fan, H.; Cheng, Y.; Wang, H.; Qin, Y. Information Geometry for Radar Target Detection with Total Jensen–Bregman Divergence. Entropy 2018, 20, 256. [Google Scholar] [CrossRef] [PubMed]
- Osawa, K.; Tsuji, Y.; Ueno, Y.; Naruse, A.; Foo, C.-S.; Yokota, R. Scalable and Practical Natural Gradient for Large-Scale Deep Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 404–415. [Google Scholar] [CrossRef] [PubMed]
- Orabona, F.; Crammer, K.; Cesa-Bianchi, N. A generalized online mirror descent with applications to classification and regression. Mach. Learn. 2015, 99, 411–435. [Google Scholar] [CrossRef]
- Lu, L.; Pestourie, R.; Yao, W.; Wang, Z.; Verdugo, F.; Johnson, S.G. Physics-Informed Neural Networks with Hard Constraints for Inverse Design. SIAM J. Sci. Comput. 2021, 43, 1105–1132. [Google Scholar] [CrossRef]
- Gousia, H.; Shaima, Q. Optimization and acceleration of convolutional neural networks: A survey. J. King Saud Univ.–Comput. Inf. Sci. 2022, 34, 4244–4268. [Google Scholar]
- Teodoro, G.S.; Machado, J.A.T.; De Oliveira, E.C. A review of definitions of fractional derivatives and other operators. J. Comput. Phys. 2019, 388, 195–208. [Google Scholar] [CrossRef]
- Joshi, M.; Bhosale, S.; Vyawahare, V.A. A survey of fractional calculus applications in artificial neural networks. Artif. Intell. Rev. 2023; accepted paper. [Google Scholar]
- Nielsen, F. The Many Faces of Information Geometry. Not. Am. Math. Soc. 2022, 69, 36–45. [Google Scholar] [CrossRef]
- Abualigah, L.; Diabat, A. A comprehensive survey of the Grasshopper optimization algorithm: Results, variants, and applications. Neural Comput. Appl. 2020, 32, 15533–15556. [Google Scholar] [CrossRef]
- Huisman, M.; van Rijn, J.N.; Plaat, A. A survey of deep meta-learning. Artif. Intell. Rev. 2021, 54, 4483–4541. [Google Scholar] [CrossRef]
- Magris, M.; Iosifidis, A. Bayesian learning for neural networks: An algorithmic survey. Artif. Intell. Rev. 2023; accepted paper. [Google Scholar]
- Nanni, L.; Paci, M.; Brahnam, S.; Lumini, A. Comparison of Different Image Data Augmentation Approaches. J. Imaging 2021, 7, 254. [Google Scholar] [CrossRef] [PubMed]
- Hacker, C.; Aizenberg, I.; Wilson, J. Gpu simulator of multilayer neural network based on multi-valued neurons. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 4125–4132. [Google Scholar]
- Traore, C.; Pauwels, E. Sequential convergence of AdaGrad algorithm for smooth convex optimization. Oper. Res. Lett. 2021, 49, 452–458. [Google Scholar] [CrossRef]
- Mustapha, A.; Mohamed, L.; Ali, K. Comparative study of optimization techniques in deep learning: Application in the ophthalmology field. J. Phys. Conf. Ser. 2020, 1743, 012002. [Google Scholar] [CrossRef]
- Chen, S.; McLaughlin, S.; Mulgrew, B. Complex-valued radial basis function network, part i: Network architecture and learning algorithms. Signal Process. 1994, 35, 19–31. [Google Scholar] [CrossRef]
- Suzuki, Y.; Kobayashi, M. Complex-valued bidirectional auto-associative memory. In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–7. [Google Scholar]
- Gu, P.; Tian, S.; Chen, Y. Iterative Learning Control Based on Nesterov Accelerated Gradient Method. IEEE Access 2019, 7, 115836–115842. [Google Scholar] [CrossRef]
- Van Laarhoven, T. L2 Regularization versus Batch and Weight Normalization. arXiv 2017, arXiv:1706.05350. [Google Scholar]
- Byrd, J.; Lipton, Z.C. What is the Effect of Importance Weighting in Deep Learning? In Proceedings of the 36th International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 872–881. [Google Scholar]
- Vrbančič, G.; Podgorelec, V. Efficient ensemble for image-based identification of Pneumonia utilizing deep CNN and SGD with warm restarts. Expert Syst. Appl. 2022, 187, 115834. [Google Scholar] [CrossRef]
- Heo, B.; Chun, S.; Oh, S.J.; Han, D.; Yun, S.; Kim, G.; Uh, Y.; Ha, J.-W. AdamP: Slowing Down the Slowdown for Momentum Optimizers on Scale-invariant Weights. arXiv 2021, arXiv:2006.08217. [Google Scholar]
- Sun, J.; Yang, Y.; Xun, G.; Zhang, A. Scheduling Hyperparameters to Improve Generalization: From Centralized SGD to Asynchronous SGD. ACM Trans. Knowl. Discov. Data 2023, 17, 1–37. [Google Scholar] [CrossRef]
- Wu, S.; Li, G.; Deng, L.; Liu, L.; Wu, D.; Xie, Y.; Shi, L. L1-Norm Batch Normalization for Efficient Training of Deep Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2043–2051. [Google Scholar] [CrossRef] [PubMed]
- Novik, N. Pytorch-Optimizer. Available online: https//github.com/jettify/pytorch-optimizer (accessed on 20 May 2023).
- Yu, Z.; Sun, G.; Lv, J. A fractional-order momentum optimization approach of deep neural networks. Neural Comput. Appl. 2022, 34, 7091–7111. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Kalfaoglu, M.E.; Kalkan, S.; Alatan, A.A. Late Temporal Modeling in 3D CNN Architectures with BERT for Action Recognition. In Computer Vision—ECCV 2020 Workshops, Proceedings of the European Conference on Computer Vision (ECCV 2020), Glasgow, UK, 23–28 August 2020; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2020; Volume 12539, pp. 731–747. [Google Scholar]
- Herrera-Alcántara, O. Fractional Derivative Gradient-Based Optimizers for Neural Networks and Human Activity Recognition. Appl. Sci. 2022, 12, 9264. [Google Scholar] [CrossRef]
- Jia, X.; Feng, X.; Yong, H.; Meng, D. Weight Decay With Tailored Adam on Scale-Invariant Weights for Better Generalization. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–12. [Google Scholar] [CrossRef]
- Bai, Z.; Liu, T.; Zou, D.; Zhang, M.; Zhou, A.; Li, Y. Image-based reinforced concrete component mechanical damage recognition and structural safety rapid assessment using deep learning with frequency information. Autom. Constr. 2023, 150, 104839. [Google Scholar] [CrossRef]
- Ma, J.; Yarats, D. Quasi-hyperbolic momentum and Adam for deep learning. arXiv 2019, arXiv:1810.06801v4. [Google Scholar]
- Tang, S.; Shen, C.; Wang, D.; Li, S.; Huang, W.; Zhu, Z. Adaptive deep feature learning network with Nesterov momentum and its application to rotating machinery fault diagnosis. Neurocomputing 2018, 305, 1–14. [Google Scholar] [CrossRef]
- Li, L.; Xu, W.; Yu, H. Character-level neural network model based on Nadam optimization and its application in clinical concept extraction. Neurocomputing 2020, 414, 182–190. [Google Scholar] [CrossRef]
- Melinte, D.O.; Vladareanu, L. Facial Expressions Recognition for Human–Robot Interaction Using Deep Convolutional Neural Networks with Rectified Adam Optimizer. Sensors 2020, 20, 2393. [Google Scholar] [CrossRef] [PubMed]
- Gholamalinejad, H.; Khosravi, H. Whitened gradient descent, a new updating method for optimizers in deep neural networks. J. AI Data Min. 2022, 10, 467–477. [Google Scholar]
- Shanthi, T.; Sabeenian, R.S. Modified Alexnet architecture for classification of diabetic retinopathy images. Comput. Electr. Eng. 2019, 76, 56–64. [Google Scholar] [CrossRef]
- Wu, Z.; Shen, C.; Van Den Hengel, A. Wider or Deeper: Revisiting the ResNet Model for Visual Recognition. Pattern Recognit. 2019, 90, 119–133. [Google Scholar] [CrossRef]
- Das, D.; Santosh, K.C.; Pal, U. Truncated inception net: COVID-19 outbreak screening using chest X-rays. Phys. Eng. Sci. Med. 2020, 43, 915–925. [Google Scholar] [CrossRef]
- Tang, P.; Wang, H.; Kwong, S. G-MS2F: GoogLeNet based multi-stage feature fusion of deep CNN for scene recognition. Neurocomputing 2017, 225, 188–197. [Google Scholar] [CrossRef]
- Lin, L.; Liang, L.; Jin, L. R2-ResNeXt: A ResNeXt-Based Regression Model with Relative Ranking for Facial Beauty Prediction. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 85–90. [Google Scholar]
- Dubey, S.R.; Chakraborty, S.; Roy, S.K.; Mukherjee, S.; Singh, S.K.; Chaudhuri, B.B. diffGrad: An Optimization Method for Convolutional Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4500–4511. [Google Scholar] [CrossRef]
- Sun, W.; Wang, Y.; Chang, K.; Meng, K. IdiffGrad: A Gradient Descent Algorithm for Intrusion Detection Based on diffGrad. In Proceedings of the 2021 IEEE 20th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Shenyang, China, 20–22 October 2021; pp. 1583–1590. [Google Scholar]
- Panait, L.; Luke, S. A comparison of two competitive fitness functions. In Proceedings of the 4th Annual Conference on Genetic and Evolutionary Computation, New York, NY, USA, 9–13 July 2002; pp. 503–511. [Google Scholar]
- Khan, W.; Ali, S.; Muhammad, U.S.K.; Jawad, M.; Ali, M.; Nawaz, R. AdaDiffGrad: An Adaptive Batch Size Implementation Technique for DiffGrad Optimization Method. In Proceedings of the 2020 14th International Conference on Innovations in Information Technology (IIT), Al Ain, United Arab Emirates, 17–18 November 2020; pp. 209–214. [Google Scholar]
- Valova, I.; Harris, C.; Mai, T.; Gueorguieva, N. Optimization of Convolutional Neural Networks for Imbalanced Set Classification. Procedia Comput. Sci. 2020, 176, 660–669. [Google Scholar] [CrossRef]
- Zaheer, M.; Reddi, S.; Sachan, D.; Kale, S.; Kumar, S. Adaptive Methods for Nonconvex Optimization. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Zhuang, J.; Tang, T.; Ding, Y.; Tatikonda, S.C.; Dvornek, N.; Papademetris, X.; Duncan, J. AdaBelief Optimizer: Adapting Stepsizes by the Belief in Observed Gradients. Adv. Neural Inf. Process. Syst. 2020, 33. [Google Scholar]
- Liu, J.; Kong, J.; Xu, D.; Qi, M.; Lu, Y. Convergence analysis of AdaBound with relaxed bound functions for non-convex optimization. Neural Netw. 2022, 145, 300–307. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Liu, J.; Chang, X.; Wang, J.; Rodríguez, R.J. AB-FGSM: AdaBelief optimizer and FGSM-based approach to generate adversarial examples. J. Inf. Secur. Appl. 2022, 68, 103227. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, J.; Chang, X. Generalizing Adversarial Examples by AdaBelief Optimizer. arXiv 2021, arXiv:2101.09930v1. [Google Scholar]
- Dubey, S.R.; Basha, S.H.S.; Singh, S.K.; Chaudhuri, B.B. AdaInject: Injection Based Adaptive Gradient Descent Optimizers for Convolutional Neural Networks. IEEE Trans. Artif. Intell. 2022, 1–10. [Google Scholar] [CrossRef]
- Li, G. A Memory Enhancement Adjustment Method Based on Stochastic Gradients. In Proceedings of the 2022 41st Chinese Control Conference (CCC), Hefei, China, 25–27 July 2022; pp. 7448–7453. [Google Scholar]
- Xie, Z.; Yuan, L.; Zhu, Z.; Sugiyama, M. Positive-Negative Momentum: Manipulating Stochastic Gradient Noise to Improve Generalization. Int. Conf. Mach. Learn. PMLR 2021, 139, 11448–11458. [Google Scholar]
- Zavriev, S.; Kostyuk, F. Heavy-ball method in nonconvex optimization problems. Comput. Math. Model. 1993, 4, 336–341. [Google Scholar] [CrossRef]
- Wright, L.; Demeure, N. Ranger21: A synergistic deep learning optimizer. arXiv 2021, arXiv:2106.13731v2. [Google Scholar]
- Xie, X.; Zhou, P.; Li, H.; Lin, Z.; Yan, S. Adan: Adaptive Nesterov Momentum Algorithm for Faster Optimizing Deep Models. arXiv 2022, arXiv:2208.06677v3. [Google Scholar]
- Burke, J.V.; Ferris, M.C. A Gauss—Newton method for convex composite optimization. Math. Program. 1995, 71, 179–194. [Google Scholar] [CrossRef]
- Berahas, A.S.; Bollapragada, R.; Nocedal, J. An investigation of Newton-Sketch and subsampled Newton methods. Optim. Methods Softw. 2020, 35, 661–680. [Google Scholar] [CrossRef]
- Hartmann, W.M.; Hartwig, R.E. Computing the Moore–Penrose Inverse for the Covariance Matrix in Constrained Nonlinear Estimation. SIAM J. Optim. 1996, 6, 727–747. [Google Scholar] [CrossRef]
- Gupta, V.; Kadhe, S.; Courtade, T.; Mahoney, M.W.; Ramchandran, K. OverSketched Newton: Fast Convex Optimization for Serverless Systems. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 288–297. [Google Scholar]
- Yang, Z. Adaptive stochastic conjugate gradient for machine learning. Expert Syst. Appl. 2022, 206, 117719. [Google Scholar] [CrossRef]
- Faber, V.; Joubert, W.; Knill, E.; Manteuffel, T. Minimal Residual Method Stronger than Polynomial Preconditioning. SIAM J. Matrix Anal. Appl. 1996, 17, 707–729. [Google Scholar] [CrossRef]
- Jia, Z.; Ng, M.K. Structure Preserving Quaternion Generalized Minimal Residual Method. SIAM J. Matrix Anal. Appl. 2021, 42, 616–634. [Google Scholar] [CrossRef]
- Mang, A.; Biros, G. An Inexact Newton–Krylov Algorithm for Constrained Diffeomorphic Image Registration. SIAM J. Imaging Sci. 2015, 8, 1030–1069. [Google Scholar] [CrossRef]
- Hestenes, M.R.; Stiefel, E.L. Methods of conjugate gradients for solving linear systems. J. Res. Nat. Bur. Stand. 1952, 49, 409–436. [Google Scholar] [CrossRef]
- Fletcher, R.; Reeves, C. Function minimization by conjugate gradients. Comput. J. 1964, 7, 149–154. [Google Scholar] [CrossRef]
- Daniel, J.W. The conjugate gradient method for linear and nonlinear operator equations. SIAM J. Numer. Anal. 1967, 4, 10–26. [Google Scholar] [CrossRef]
- Polak, E.; Ribiere, G. Note sur la convergence de directions conjuge’es. Rev. FrançAise D’Informatique Rech. OpéRationnelle 1969, 3, 35–43. [Google Scholar]
- Polyak, B.T. The conjugate gradient method in extreme problems. USSR Comp. Math. Math. Phys. 1969, 9, 94–112. [Google Scholar] [CrossRef]
- Fletcher, R. Practical Methods of Optimization Vol. 1: Unconstrained Optimization; John Wiley and Sons: New York, NY, USA, 1987. [Google Scholar]
- Liu, Y.; Storey, C. Efficient generalized conjugate gradient algorithms. J. Optim. Theory Appl. 1991, 69, 129–137. [Google Scholar] [CrossRef]
- Dai, Y.H.; Yuan, Y. A nonlinear conjugate gradient method with a strong global convergence property. SIAM J. Optim. 1999, 10, 177–182. [Google Scholar] [CrossRef]
- Hager, W.W.; Zhang, H. A new conjugate gradient method with guaranteed descent and an efficient line search. SIAM J. Optim. 2005, 16, 170–192. [Google Scholar] [CrossRef]
- Dai, Y.-H. Convergence Properties of the BFGS Algoritm. SIAM J. Optim. 2002, 13, 693–701. [Google Scholar] [CrossRef]
- Liu, D.C.; Nocedal, J. On the limited memory BFGS method for large scale optimization. Math. Program. 1989, 45, 503–528. [Google Scholar] [CrossRef]
- Shi, H.-J.M.; Xie, Y.; Byrd, R.; Nocedal, J. A Noise-Tolerant Quasi-Newton Algorithm for Unconstrained Optimization. SIAM J. Optim. 2022, 32, 29–55. [Google Scholar] [CrossRef]
- Byrd, R.H.; Khalfan, H.F.; Schnabel, R.B. Analysis of a Symmetric Rank-One Trust Region Method. SIAM J. Optim. 1996, 6, 1025–1039. [Google Scholar] [CrossRef]
- Rafati, J.; Marcia, R.F. Improving L-BFGS Initialization for Trust-Region Methods in Deep Learning. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 501–508. [Google Scholar]
- Ma, X. Apollo: An Adaptive Parameter-wise Diagonal Quasi-Newton Method for Nonconvex Stochastic Optimization. arXiv 2021, arXiv:2009.13586v6. [Google Scholar]
- Yao, Z.; Gholami, A.; Shen, S.; Mustafa, M.; Keutzer, K.; Mahoney, M. ADAHESSIAN: An Adaptive Second Order Optimizer for Machine Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 10665–10673. [Google Scholar]
- Shen, J.; Wang, C.; Wang, X.; Wise, S.M. Second-order Convex Splitting Schemes for Gradient Flows with Ehrlich–Schwoebel Type Energy: Application to Thin Film Epitaxy. SIAM J. Numer. Anal. 2012, 50, 105–125. [Google Scholar] [CrossRef]
- Martens, J. New insights and perspectives on the natural gradient method. J. Mach. Learn. Res. 2020, 21, 5776–5851. [Google Scholar]
- Amari, S. Information geometry in optimization, machine learning and statistical inference. Front. Electr. Electron. Eng. China 2010, 5, 241–260. [Google Scholar] [CrossRef]
- Wang, S.; Teng, Y.; Perdikaris, P. Understanding and Mitigating Gradient Flow Pathologies in Physics-Informed Neural Networks. SIAM J. Sci. Comput. 2021, 43, 3055–3081. [Google Scholar] [CrossRef]
- Nielsen, F. An Elementary Introduction to Information Geometry. Entropy 2020, 22, 1100. [Google Scholar] [CrossRef]
- Wald, A. Statistical decision functions. Ann. Math. Stat. 1949, 165–205. [Google Scholar] [CrossRef]
- Wald, A. Statistical Decision Functions; Wiley: Chichester, UK, 1950. [Google Scholar]
- Rattray, M.; Saad, D.; Amari, S. Natural Gradient Descent for OnLine Learning. Phys. Rev. Lett. 1998, 81, 5461–5464. [Google Scholar] [CrossRef]
- Duchi, J.C.; Agarwal, A.; Johansson, M.; Jordan, M.I. Ergodic Mirror Descent. SIAM J. Optim. 2012, 22, 1549–1578. [Google Scholar] [CrossRef]
- Wang, Y.; Li, W. Accelerated Information Gradient Flow. J. Sci. Comput. 2022, 90, 11. [Google Scholar] [CrossRef]
- Goldberger, J.; Gordon, S.; Greenspan, H. An efficient image similarity measure based on approximations of KL-divergence between two gaussian mixtures. Proc. Ninth IEEE Int. Conf. Comput. Vis. 2003, 1, 487–493. [Google Scholar]
- Joyce, J.M. Kullback-Leibler Divergence. In International Encyclopedia of Statistical Science; Lovric, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Nielsen, F. Statistical Divergences between Densities of Truncated Exponential Families with Nested Supports: Duo Bregman and Duo Jensen Divergences. Entropy 2022, 24, 421. [Google Scholar] [CrossRef]
- Stokes, J.; Izaac, J.; Killoran, N.; Carleo, G. Quantum Natural Gradient. Open J. Quantum Sci. 2020, 4, 269–284. [Google Scholar] [CrossRef]
- Abdulkadirov, R.; Lyakhov, P.; Nagornov, N. Accelerating Extreme Search of Multidimensional Functions Based on Natural Gradient Descent with Dirichlet Distributions. Mathematics 2022, 10, 3556. [Google Scholar] [CrossRef]
- Abdulkadirov, R.I.; Lyakhov, P.A. A new approach to training neural networks using natural gradient descent with momentum based on Dirichlet distributions. Comput. Opt. 2023, 47, 160–170. [Google Scholar]
- Lyakhov, P.; Abdulkadirov, R. Accelerating Extreme Search Based on Natural Gradient Descent with Beta Distribution. In Proceedings of the 2021 International Conference Engineering and Telecommunication (En&T), Dolgoprudny, Russia, 24–25 November 2021; pp. 1–5. [Google Scholar]
- Abdulkadirov, R.I.; Lyakhov, P.A. Improving Extreme Search with Natural Gradient Descent Using Dirichlet Distribution. In Proceedings of the Mathematical Applications and New Computational Systems, Online, 1–5 March 2021; Volume 424, pp. 19–28. [Google Scholar]
- Kesten, H.; Morse, N. A Property of the Multinomial Distribution. Ann. Math. Stat. 1959, 30, 120–127. [Google Scholar] [CrossRef]
- D’Orazio, R.; Loizou, N.; Laradji, I.; Mitliagkas, I. Stochastic Mirror Descent: Convergence Analysis and Adaptive Variants via the Mirror Stochastic Polyak Stepsize. arXiv 2021, arXiv:2110.15412v2. [Google Scholar]
- Gessert, N.; Nielsen, M.; Shaikh, M.; Werner, R.; Schlaefer, A. Skin lesion classification using ensembles of multi-resolution EfficientNets with meta data. MethodsX 2020, 7, 100864. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360v4. [Google Scholar]
- Ke, H.; Chen, D.; Li, X.; Tang, Y.; Shah, T.; Ranjan, R. Towards Brain Big Data Classification: Epileptic EEG Identification With a Lightweight VGGNet on Global MIC. IEEE Access 2018, 6, 14722–14733. [Google Scholar] [CrossRef]
- Zhu, Y.; Newsam, S. DenseNet for dense flow. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 790–794. [Google Scholar]
- Chollet, F. Xception: Deep Learning With Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Paoletti, M.E.; Haut, J.M.; Pereira, N.S.; Plaza, J.; Plaza, A. Ghostnet for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10378–10393. [Google Scholar] [CrossRef]
- Liu, Y. Novel volatility forecasting using deep learning–Long Short Term Memory Recurrent Neural Networks. Expert Syst. Appl. 2019, 132, 99–109. [Google Scholar] [CrossRef]
- Lai, C.H.; Liu, D.R.; Lien, K.S. A hybrid of XGBoost and aspect-based review mining with attention neural network for user preference prediction. Int. J. Mach. Learn. Cyber. 2021, 12, 1203–1217. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Lynn, H.H.; Pan, S.B.; Kim, P. A Deep Bidirectional GRU Network Model for Biometric Electrocardiogram Classification Based on Recurrent Neural Networks. IEEE Access 2019, 7, 145395–145405. [Google Scholar] [CrossRef]
- Kim, T.Y.; Cho, S.B. Predicting residential energy consumption using CNN-LSTM neural networks. Energy 2019, 182, 72–81. [Google Scholar] [CrossRef]
- Sajjad, M.; Khan, Z.A.; Ullah, A.; Hussain, T.; Ullah, W.; Lee, M.Y.; Baik, S.W. A Novel CNN-GRU-Based Hybrid Approach for Short-Term Residential Load Forecasting. IEEE Access 2020, 8, 143759–143768. [Google Scholar] [CrossRef]
- Hu, C.; Cheng, F.; Ma, L.; Li, B. State of Charge Estimation for Lithium-Ion Batteries Based on TCN-LSTM Neural Networks. J. Electrochem. Soc. 2022, 169, 0305544. [Google Scholar] [CrossRef]
- Lu, L.; Jin, P.; Pang, G.; Zhang, Z.; Karniadakis, G.E. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators. Nat. Mach. Intell. 2021, 3, 218–229. [Google Scholar] [CrossRef]
- Meng, X.; Karniadakis, G.T. A composite neural network that learns from multi-fidelity data: Application to function approximation and inverse PDE problems. J. Comput. Phys. 2020, 401, 109020. [Google Scholar] [CrossRef]
- Gao, C.; Lui, W.; Yang, X. Convolutional neural network and riemannian geometry hybrid approach for motor imagery classification. Neurocomputing 2022, 507, 180–190. [Google Scholar] [CrossRef]
- Li, J.; Chen, J.; Li, B. Gradient-optimized physics-informed neural networks (GOPINNs): A deep learning method for solving the complex modified KdV equation. Nonlinear Dyn. 2022, 107, 781–792. [Google Scholar] [CrossRef]
- Volinski, A.; Zaidel, Y.; Shalumov, A.; DeWolf, T.; Supic, L.; Tsur, E.E. Data-driven artificial and spiking neural networks for inverse kinematics in neurorobotics. Patterns 2022, 3, 100391. [Google Scholar] [CrossRef]
- Wang, R.; Liu, Z.; Zhang, B.; Guo, G.; Doermann, D. Few-Shot Learning with Complex-Valued Neural Networks and Dependable Learning. Int. J. Comput. Vis. 2023, 131, 385–404. [Google Scholar] [CrossRef]
- Chen, M.; Shi, X.; Zhang, Y.; Wu, D.; Guizani, M. Deep Feature Learning for Medical Image Analysis with Convolutional Autoencoder Neural Network. IEEE Trans. Big Data 2021, 7, 750–758. [Google Scholar] [CrossRef]
- Taqi, A.M.; Awad, A.; Al-Azzo, F.; Milanova, M. The Impact of Multi-Optimizers and Data Augmentation on TensorFlow Convolutional Neural Network Performance. In Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 140–145. [Google Scholar]
- Qu, Z.; Yuan, S.; Chi, R.; Chang, L.; Zhao, L. Genetic Optimization Method of Pantograph and Catenary Comprehensive Monitor Status Prediction Model Based on Adadelta Deep Neural Network. IEEE Access 2019, 7, 23210–23221. [Google Scholar] [CrossRef]
- Huang, Y.; Peng, H.; Liu, Q.; Yang, Q.; Wang, J.; Orellana-Martin, D.; Perez-Jimenez, M.J. Attention-enabled gated spiking neural P model for aspect-level sentiment classification. Neural Netw. 2023, 157, 437–443. [Google Scholar] [CrossRef]
- Sharma, S.; Gupta, S.; Kumar, N. Holistic Approach Employing Different Optimizers for the Recognition of District Names Using CNN Model. Ann. Rom. Soc. Cell Biol. 2021, 25, 3294–3306. [Google Scholar]
- Huk, M. Stochastic Optimization of Contextual Neural Networks with RMSprop. Lect. Notes Comput. Sci. 2020, 12034, 343–352. [Google Scholar]
- Gautam, A.; Singh, V. CLR-based deep convolutional spiking neural network with validation based stopping for time series classification. Appl. Intell. 2020, 50, 830–848. [Google Scholar] [CrossRef]
- Liu, B.; Zhang, Y.; He, D.; Li, Y. Identification of Apple Leaf Diseases Based on Deep Convolutional Neural Networks. Symmetry 2018, 10, 11. [Google Scholar] [CrossRef]
- Kisvari, A.; Lin, Z.; Liu, X. Wind power forecasting—A data-driven method along with gated recurrent neural network. Renew. Energy 2021, 163, 1895–1909. [Google Scholar] [CrossRef]
- Kim, K.-S.; Choi, Y.-S. HyAdamC: A New Adam-Based Hybrid Optimization Algorithm for Convolution Neural Networks. Sensors 2021, 21, 4054. [Google Scholar] [CrossRef] [PubMed]
- Shankar, K.; Kumar, S.; Dutta, A.K.; Alkhayyat, A.; Jawad, A.J.M.; Abbas, A.H.; Yousif, Y.K. An Automated Hyperparameter Tuning Recurrent Neural Network Model for Fruit Classification. Mathematics 2022, 10, 2358. [Google Scholar] [CrossRef]
- Wu, J.; Chua, Y.; Zhang, M.; Yang, Q.; Li, G.; Li, H. Deep Spiking Neural Network with Spike Count based Learning Rule. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–6. [Google Scholar]
- Bararnia, H.; Esmaeilpour, M. On the application of physics informed neural networks (PINN) to solve boundary layer thermal-fluid problems. Int. Commun. Heat Mass Transf. 2022, 132, 105890. [Google Scholar] [CrossRef]
- Lu, S.; Sengupta, A. Exploring the Connection Between Binary and Spiking Neural Networks. Front. Neurosci. 2020, 14, 535. [Google Scholar] [CrossRef] [PubMed]
- Freire, P.J.; Neskornuik, V.; Napoli, A.; Spinnler, B.; Costa, N.; Khanna, G.; Riccardi, E.; Prilepsky, J.E.; Turitsyn, S.K. Complex-Valued Neural Network Design for Mitigation of Signal Distortions in Optical Links. J. Light. Technol. 2021, 39, 1696–1705. [Google Scholar] [CrossRef]
- Khan, M.U.S.; Jawad, M.; Khan, S.U. Adadb: Adaptive Diff-Batch Optimization Technique for Gradient Descent. IEEE Access 2021, 9, 99581–99588. [Google Scholar] [CrossRef]
- Roy, S.K.; Manna, S.; Dubey, S.R.; Chaudhuri, B.B. LiSHT: Non-parametric linearly scaled hyperbolic tangent activation function for neural networks. arXiv 2022, arXiv:1901.05894v3. [Google Scholar]
- Roshan, S.E.; Asadi, S. Improvement of Bagging performance for classification of imbalanced datasets using evolutionary multi-objective optimization. Eng. Appl. Artif. Intell. 2020, 87, 103319. [Google Scholar] [CrossRef]
- Yogi, S.C.; Tripathi, V.K.; Behera, L. Adaptive Integral Sliding Mode Control Using Fully Connected Recurrent Neural Network for Position and Attitude Control of Quadrotor. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 5595–5609. [Google Scholar] [CrossRef]
- Shi, H.; Wang, L.; Scherer, R.; Woźniak, M.; Zhang, P.; Wei, W. Short-Term Load Forecasting Based on Adabelief Optimized Temporal Convolutional Network and Gated Recurrent Unit Hybrid Neural Network. IEEE Access 2021, 9, 66965–66981. [Google Scholar] [CrossRef]
- Guo, J.; Liu, Q.; Guo, H.; Lu, X. Ligandformer: A Graph Neural Network for Predicting Ligand Property with Robust Interpretation. arXiv 2022, arXiv:2202.10873v3. [Google Scholar]
- Wu, D.; Yuan, Y.; Huang, J.; Tan, Y. Optimize TSK Fuzzy Systems for Regression Problems: Minibatch Gradient Descent With Regularization, DropRule, and AdaBound (MBGD-RDA). IEEE Trans. Fuzzy Syst. 2020, 28, 1003–1015. [Google Scholar] [CrossRef]
- Demertzis, K.; Iliadis, L.; Pimenidis, E. Large-Scale Geospatial Data Analysis: Geographic Object-Based Scene Classification in Remote Sensing Images by GIS and Deep Residual Learning. In International Conference on Engineering Applications of Neural Networks, Proceedings of the 21st EANN (Engineering Applications of Neural Networks) 2020 Conference, Halkidiki, Greece, 5–7 June 2020; Springer: Berlin, Germany, 2020. [Google Scholar]
- Wang, C.C.; Tan, K.L.; Chen, C.T.; Lin, Y.H.; Keerthi, S.S.; Mahajan, D.; Sundararajan, S.; Lin, C.J. Distributed Newton Methods for Deep Neural Networks. Neural Comput. 2018, 30, 1673–1724. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.; Wang, C.; Byun, H.; Hu, W.; Kim, S.; Jiao, Q.; Lee, T.H. Variable three-term conjugate gradient method for training artificial neural networks. Neural Netw. 2022, 159, 125–136. [Google Scholar] [CrossRef]
- Peng, C.-C.; Magoulas, G.D. Adaptive Nonmonotone Conjugate Gradient Training Algorithm for Recurrent Neural Networks. In Proceedings of the 19th IEEE International Conference on Tools with Artificial Intelligence (ICTAI 2007), Patras, Greece, 29–31 October 2007; pp. 374–381. [Google Scholar]
- Franklin, T.S.; Souza, L.S.; Fontes, R.M.; Martins, M.A.F. A Physics-Informed Neural Networks (PINN) oriented approach to flow metering in oil wells: An ESP lifted oil well system as a case study. Digit. Chem. Eng. 2022, 5, 100056. [Google Scholar] [CrossRef]
- Koshimizu, H.; Kojima, R.; Kario, K.; Okuno, Y. Prediction of blood pressure variability using deep neural networks. Int. J. Med. Inform. 2020, 136, 104067. [Google Scholar] [CrossRef]
- Wierichs, D.; Gogolin, C.; Kastoryano, M. Avoiding local minima in variational quantum eigensolvers with the natural gradient optimizer. Phys. Rev. Res. 2020, 2, 043246. [Google Scholar] [CrossRef]
- Sun, F.; Sun, J.; Zhao, Q. A deep learning method for predicting metabolite–disease associations via graph neural network. Briefings Bioinform. 2022, 23, bbac266. [Google Scholar] [CrossRef]
- Boso, F.; Tartakovsky, D.M. Information geometry of physics-informed statistical manifolds and its use in data assimilation. J. Comput. Phys. 2022, 467, 111438. [Google Scholar] [CrossRef]
- You, J.-K.; Cheng, H.-C.; Li, Y.-H. Minimizing Quantum Rényi Divergences via Mirror Descent with Polyak Step Size. In Proceedings of the 2022 IEEE International Symposium on Information Theory (ISIT), Espoo, Finland, 26 June–1 July 2022; pp. 252–257. [Google Scholar]
- Chen, Y.; Chang, H.; Meng, J.; Zhang, D. Ensemble Neural Networks (ENN): A gradient-free stochastic method. Neural Netw. 2019, 110, 170–185. [Google Scholar] [CrossRef] [PubMed]
- Han, D.; Yuan, X. A Note on the Alternating Direction Method of Multipliers. J. Optim. Theory Appl. 2012, 155, 227–238. [Google Scholar] [CrossRef]
- Zhang, S.; Liu, M.; Yan, J. The Diversified Ensemble Neural Network. Adv. Neural Inf. Process. Syst. 2020, 33, 16001–16011. [Google Scholar]
- Dominic, S.; Das, R.; Whitley, D.; Anderson, C. Genetic reinforcement learning for neural networks. In Proceedings of the IJCNN-91-Seattle International Joint Conference on Neural Networks, Seattle, WA, USA, 8–12 July 1991; Volume 2, pp. 71–76. [Google Scholar]
- Kanwar, S.; Awasthi, L.K.; Shrivastava, V. Feature Selection with Stochastic Hill-Climbing Algorithm in Cross Project Defect Prediction. In Proceedings of the 2022 2nd International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 28–29 April 2022; pp. 632–635. [Google Scholar]
- Sexton, R.S.; Dorsey, R.E.; Johnson, J.D. Optimization of neural networks: A comparative analysis of the genetic algorithm and simulated annealing. Eur. J. Oper. Res. 1999, 114, 589–601. [Google Scholar] [CrossRef]
- Maehara, N.; Shimoda, Y. Application of the genetic algorithm and downhill simplex methods (Nelder–Mead methods) in the search for the optimum chiller configuration. Appl. Therm. Eng. 2013, 61, 433–442. [Google Scholar] [CrossRef]
- Huang, G.B.; Chen, L. Enhanced random search based incremental extreme learning machine. Neurocomputing 2008, 71, 3460–3468. [Google Scholar] [CrossRef]
- Pontes, F.J.; Amorim, G.F.; Balestrassi, P.P.; Paiva, A.P.; Ferreira, J.R. Design of experiments and focused grid search for neural network parameter optimization. Neurocomputing 2016, 186, 22–34. [Google Scholar] [CrossRef]
- Farfán, J.F.; Cea, L. Improving the predictive skills of hydrological models using a combinatorial optimization algorithm and artificial neural networks. Model. Earth Syst. Environ. 2022, 9, 1103–1118. [Google Scholar] [CrossRef]
- Zerubia, J.; Chellappa, R. Mean field annealing using compound Gauss-Markov random fields for edge detection and image estimation. IEEE Trans. Neural Netw. 1993, 4, 703–709. [Google Scholar] [CrossRef]
- Ihme, M.; Marsden, A.L.; Pitsch, H. Generation of Optimal Artificial Neural Networks Using a Pattern Search Algorithm: Application to Approximation of Chemical Systems. Neural Comput. 2008, 20, 573–601. [Google Scholar] [CrossRef]
- Vilovic, I.; Burum, N.; Sipus, Z. Design of an Indoor Wireless Network with Neural Prediction Model. In Proceedings of the Second European Conference on Antennas and Propagation, EuCAP 2007, Edinburgh, UK, 11–16 November 2007; pp. 1–5. [Google Scholar]
- Bagherbeik, M.; Ashtari, P.; Mousavi, S.F.; Kanda, K.; Tamura, H.; Sheikholeslami, A. A Permutational Boltzmann Machine with Parallel Tempering for Solving Combinatorial Optimization Problems. Lect. Notes Comput. Sci. 2020, 12269, 317–331. [Google Scholar]
- Poli, R.; Kennedy, J.; Blackwell, T. Particle swarm optimization. Swarm Intell. 2007, 1, 33–57. [Google Scholar] [CrossRef]
- Wang, Q.; Perc, M.; Duan, Z.; Chen, G. Delay-enhanced coherence of spiral waves in noisy Hodgkin–Huxley neuronal networks. Phys. Lett. A 2008, 372, 5681–5687. [Google Scholar] [CrossRef]
- Fernandes, F.E., Jr.; Yen, G.G. Pruning deep convolutional neural networks architectures with evolution strategy. Inf. Sci. 2021, 552, 29–47. [Google Scholar] [CrossRef]
- Cho, H.; Kim, Y.; Lee, E.; Choi, D.; Lee, Y.; Rhee, W. Basic Enhancement Strategies When Using Bayesian Optimization for Hyperparameter Tuning of Deep Neural Networks. IEEE Access 2020, 8, 52588–52608. [Google Scholar] [CrossRef]
- Pauli, P.; Koch, A.; Berberich, J.; Kohler, P.; Allgöwer, F. Training Robust Neural Networks Using Lipschitz Bounds. IEEE Control Syst. Lett. 2022, 6, 121–126. [Google Scholar] [CrossRef]
- Rong, G.; Li, K.; Su, Y.; Tong, Z.; Liu, X.; Zhang, J.; Zhang, Y.; Li, T. Comparison of Tree-Structured Parzen Estimator Optimization in Three Typical Neural Network Models for Landslide Susceptibility Assessment. Remote Sens. 2021, 13, 4694. [Google Scholar] [CrossRef]
- He, Y.; Xue, G.; Chen, W.; Tian, Z. Three-Dimensional Inversion of Semi-Airborne Transient Electromagnetic Data Based on a Particle Swarm Optimization-Gradient Descent Algorithm. Appl. Sci. 2022, 12, 3042. [Google Scholar] [CrossRef]
- Landa, P.; Aringhieri, R.; Soriano, P.; Tànfani, E.; Testi, A. A hybrid optimization algorithm for surgeries scheduling. Oper. Res. Health Care 2016, 8, 103–114. [Google Scholar] [CrossRef]
- Chaparro, B.M.; Thuillier, S.; Menezes, L.F.; Manach, P.Y.; Fernandes, J.V. Material parameters identification: Gradient-based, genetic and hybrid optimization algorithms. Comput. Mater. Sci. 2008, 44, 339–346. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, D. Theory-guided deep-learning for electrical load forecasting (TgDLF) via ensemble long short-term memory. Adv. Appl. Energy 2021, 1, 100004. [Google Scholar] [CrossRef]
- Yang, X.-J. General Fractional Derivatives. Theory, Methods and Applications; CRC Press, Taylor and Francis Group: Boca Raton, FL, USA, 2019. [Google Scholar]
- Wang, J.; Wen, Y.; Gou, Y.; Ye, Z.; Chen, H. Fractional-order gradient descent learning of BP neural networks with Caputo derivative. Neural Netw. 2017, 89, 19–30. [Google Scholar] [CrossRef] [PubMed]
- Garrappa, R.; Kaslik, E.; Popolizio, M. Evaluation of Fractional Integrals and Derivatives of Elementary Functions: Overview and Tutorial. Mathematics 2019, 7, 407. [Google Scholar] [CrossRef]
- Louati, H.; Bechikh, S.; Louati, A.; Hung, C.C.; Said, L.B. Deep convolutional neural network architecture design as a bi-level optimization problem. Neurocomputing 2021, 439, 44–62. [Google Scholar] [CrossRef]
- Yang, J.; Ji, K.; Liang, Y. Provably Faster Algorithms for Bilevel Optimization. Adv. Neural Inf. Process. Syst. 2021, 34, 13670–13682. [Google Scholar]
- Hong, M.; Wai, H.T.; Wang, Z.; Yang, Z. A two-timescale framework for bilevel optimization: Complexity analysis and application to actor-critic. arXiv 2020, arXiv:2007.05170. [Google Scholar] [CrossRef]
- Khanduri, P.; Zeng, S.; Hong, M.; Wai, H.-T.; Wang, Z.; Yang, Z. A Near-Optimal Algorithm for Stochastic Bilevel Optimization via Double-Momentum. Adv. Neural Inf. Process. Syst. 2021, 34, 30271–30283. [Google Scholar]
- Grazzi, R.; Franceschi, L.; Pontil, M.; Salzo, S. On the iteration complexity of hypergradient computation. In Proceedings of the International Conference on Machine Learning (ICML), Virtual Event, 13–18 July 2020; pp. 3748–3758. [Google Scholar]
- Sow, D.; Ji, K.; Liang, Y. Es-based jacobian enables faster bilevel optimization. arXiv 2021, arXiv:2110.07004. [Google Scholar]
- Ji, K.; Yang, J.; Liang, Y. Bilevel Optimization: Convergence Analysis and Enhanced Design. Int. Conf. Mach. Learn. PMLR 2021, 139, 4882–4892. [Google Scholar]
- Supriya, Y; Thippa R.G. A Survey on Soft Computing Techniques for Federated Learning-Applications, Challenges and Future Directions. J. Data Inf. Qual. 2023; accepted paper.
- Kandati, D.R.; Gadekallu, T.R. Federated Learning Approach for Early Detection of Chest Lesion Caused by COVID-19 Infection Using Particle Swarm Optimization. Electronics 2023, 12, 710. [Google Scholar] [CrossRef]
- Pang, G.; Lu, L.; Karniadakis, G.E. fPINNs: Fractional physics-informed neural networks. SIAM J. Sci. Comput. 2019, 41, 2603–2626. [Google Scholar] [CrossRef]
- Gupta, V.; Koren, T.; Singer, Y. Shampoo: Preconditioned Stochastic Tensor Optimization. Proc. Mach. Learn. Res. 2018, 80, 1842–1850. [Google Scholar]
- Henderson, M.; Shakya, S.; Pradhan, S.; Cook, T. Quanvolutional neural networks: Powering image recognition with quantum circuits. Quantum Mach. Intell. 2020, 2, 2. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, M.; Yang, T.; Rosing, T. Improved Schemes for Episodic Memory-based Lifelong Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 1023–1035. [Google Scholar]
- Zhang, D.; Liu, L.; Wei, Q.; Yang, Y.; Yang, P.; Liu, Q. Neighborhood Aggregation Collaborative Filtering Based on Knowledge Graph. Appl. Sci. 2020, 10, 3818. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Wang, G.; Deb, S.; Cui, Z. Monarch butterfly optimization. Neural Comput. Appl. 2019, 31, 1995–2014. [Google Scholar] [CrossRef]
- Yuan, C.; Agaian, S.S. A comprehensive review of Binary Neural Network. Artif. Intell. Rev. 2023; accepted paper. [Google Scholar]


{kind=link}
| Reference | Summary of Work | Limitations |
|---|---|---|
| [21] | A survey demonstrating first-order optimization algorithms in convolutional neural networks. | This survey presents only gradient-based optimization algorithms. They are well known and do not give any novel ideas for neural networks of different architecture. |
| [25] | A study reviewing the Grasshopper optimization algorithm, which is used for various problems in machine learning, image processing, wireless networking, engineering design, and control systems. | Regardless of the good presentation of the local, evolutionary, and swarm optimization algorithms, the author does not present global optimizers, which can improve the work of gradient-free neural networks, or other models in machine learning. |
| [26] | A survey studying various models, datasets, and gradient-based optimization techniques in deep meta-learning. | There are only stochastic gradient and adaptive moment estimation approaches, customized under conditions of meta-learning systems. |
| [27] | This survey describes the information-geometric optimization approach from probabilistic and geometrical points of view. There are new type manifolds with described Riemannian metrics and connections. | This review does not give exact application domains and lacks the mirror descent, which is a duality of the natural gradient descent. |
| [23] | This survey describes fractional optimization. There are are implied mathematical formulations of fractional error backpropagation. | This review mentions only Riemann–Liouville, Caputo, and Grunwald–Letnikov derivatives. |
| [28] | This review studies fractional, gradient-free, and information-geometric optimization algorithms. The author shows new types of manifolds with implied Riemannian metrics and connections. | Such a review does not mention other types of fractional derivatives. It considers only particle swarm optimization algorithms from gradient-free approaches and briefly describes the natural gradient descent with Fisher matrix approximation. |
| CG Update Parameter | Authors | Year |
|---|---|---|
| Hestenes and Stiefel [83] | 1952 | |
| Fletcher and Reeves [84] | 1964 | |
| Daniel [85] | 1967 | |
| Polak and Ribière [86] and Polyak [87] | 1969 | |
| Fletcher [88], CD stands for “Conjugate Descent” | 1987 | |
| Liu and Storey [89] | 1991 | |
| Dai and Yuan [90] | 1999 | |
| Hager and Zhang [91] | 2005 |
| Probability Density Function | Fisher Information Matrix | Probability Distribution |
|---|---|---|
| Gauss [115] | ||
| Multinomial [116] | ||
| Dirichlet [113,117] | ||
| for | Generalized Dirichlet [113] | |
| and | -zero matrix |
| Potential Function | Bregman Divergence | Algorithm |
|---|---|---|
| Gradient Descent | ||
| Exponentiated Gradient Descent |
| Type of Optimization Algorithm | Optimizer | Application | Advantages | Disadvantages |
|---|---|---|---|---|
| SGD-type | SGD | PINN [136], SNN [137], CVNN [138], AE [139] | These optimizers are fast and can easily be customized. They still meet in many modern neural networks. The convergence rate is from to | These optimizers cannot reach the global minimum of the loss function. As the consequence, the training accuracy is decreasing. The majority do not have regret bound estimation. |
| AdaGrad | CNN [140] | |||
| AdaDelta | CNN [141], RNN [141], SNN [142] | |||
| RMSProp | CNN [143], RNN [144], SNN [145] | |||
| SGDW | CNN [37] | |||
| SGDP | CNN [38] | |||
| QHM | CNN [39] | |||
| NAG | CNN [146], RNN [147] | |||
| Adam-type | Adam | CNN [148], RNN [149], SNN [150], PINN [151], GNN [152] CVNN [153] | ADue to exponential moving averages and their modification, the optimization process is more accurate and rapid. The convergence rate can be improved from to . The number of parame ters is extended, which makes the optimization more controllable. | AOnly DiffGrad, Yogi, AdaBelief, AdaBound, and AdamInject can reach the global minimum of the loss function. They are appropriate for CNN and RNN. |
| AdamW | CNN [44] | |||
| AdamP | CNN [46] | |||
| QHAdam | CNN [49] | |||
| Nadam | CNN [51] | |||
| Radam | CNN [52] | |||
| DiffGrad | CNN [154], RNN [60], GNN [155] | |||
| Yogi | CNN [156], RNN [157] | |||
| AdaBelief | CNN [158], RNN [158], GNN [159] | |||
| AdaBound | CNN [160], RNN [161] | |||
| AdamInject | CNN [69] | |||
| PNM-type | PNM | CNN [73] | These optimizers are improved by positive–negative moment estimations, which help to reach the global extreme. | They are appropriate only for CNN. |
| AdaPNM | CNN [73] | |||
| Adan | CNN [74] | |||
| Newton | Newton approach | CNN [162] | These optimizers can reach the global minimum using less iterations. They can be extended on non-Euclidean domains. | They are appropriate only for
deep CNN, GNN, and PINN. The optimization process is too long. |
| CG | CNN [163], GNN [164] | |||
| Quasi-Newton | (L-)BFGS | PINN [165] | These optimzers are faster than Newton approaches. Their main ability is to achieve the global minimum in a short time. | These algorithms are not fast as first-order approaches. They are not useful for deep CNN. Only Apollo has a regret bound. |
| SR1 | CNN [166] | |||
| Apollo | CNN [97] | |||
| AdaHessian | CNN [98] | |||
| Information geometry | NGD | CNN [167], RNN [114], GNN [168], PINN [169], QNN [169] | These optimizers are novel and can be useful in neural networks of any type. The set of hyperparameters is controllable and wider than that in first-order approaches. | The mathematical model of these optimization methods is too complex for customization. Not many probability distributions and potential functions have been investigated for NGD and MD, respectively. |
| MD | CNN, RNN [170] |
| Type of Optimization Algorithm | Optimizer |
|---|---|
| Local optimization | Hill Climbing [174], |
| Stochastic Hill Climbing [175], | |
| Simulated Annealing [176], | |
| Downhill Simplex Optimization [177] | |
| Global optimization | Random Search [178], |
| Grid Search [179], | |
| Random Restart Hill Climbing [180], | |
| Random Annealing [181], | |
| Pattern Search [182], | |
| Powell’s Method [183] | |
| Population-based optimization | Parallel Tempering [184], |
| Particle Swarm Optimization [185], | |
| Spiral Optimization [186], | |
| Evolution Strategy [187] | |
| Sequential model-based optimization | Bayesian Optimization [188], |
| Lipschitz Optimization [189], | |
| Tree of Parzen Estimators [190] |
| Type of Fractional Derivatives | Formulas |
|---|---|
| Riemann–Liouville | , |
| , | |
| where | |
| Liouville–Sonine–Caputo | , |
| , | |
| where and | |
| Tarasov | , |
| , | |
| where and , | |
| Hadamard | , |
| , | |
| where , and | |
| Marchaud | , |
| , | |
| where | |
| Liouville–Weyl | , |
| , | |
| where and | |
| Sabzikar–Meerschaert–Chen | , |
| , | |
| where and | |
| Katugampola | , |
| , | |
| where and |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdulkadirov, R.; Lyakhov, P.; Nagornov, N. Survey of Optimization Algorithms in Modern Neural Networks. Mathematics 2023, 11, 2466. https://doi.org/10.3390/math11112466
Abdulkadirov R, Lyakhov P, Nagornov N. Survey of Optimization Algorithms in Modern Neural Networks. Mathematics. 2023; 11(11):2466. https://doi.org/10.3390/math11112466
Chicago/Turabian StyleAbdulkadirov, Ruslan, Pavel Lyakhov, and Nikolay Nagornov. 2023. "Survey of Optimization Algorithms in Modern Neural Networks" Mathematics 11, no. 11: 2466. https://doi.org/10.3390/math11112466
APA StyleAbdulkadirov, R., Lyakhov, P., & Nagornov, N. (2023). Survey of Optimization Algorithms in Modern Neural Networks. Mathematics, 11(11), 2466. https://doi.org/10.3390/math11112466