
All-to-All Broadcast Algorithm in Galaxyfly Networks †



Abstract
1. Introduction
- We design four basic routing algorithms by utilizing recursion and breadth-first traversal.
- Based on basic routing algorithms, we propose two different all-to-all broadcast algorithms. The supernode-first all-to-all broadcast algorithm can achieve a higher utilization of network resources used in the routing process, while the router-first all-to-all broadcast algorithm delivers packets to all routers within the same supernode in priority.
- We implement the proposed algorithms to show their effectiveness and performance.
2. Preliminaries
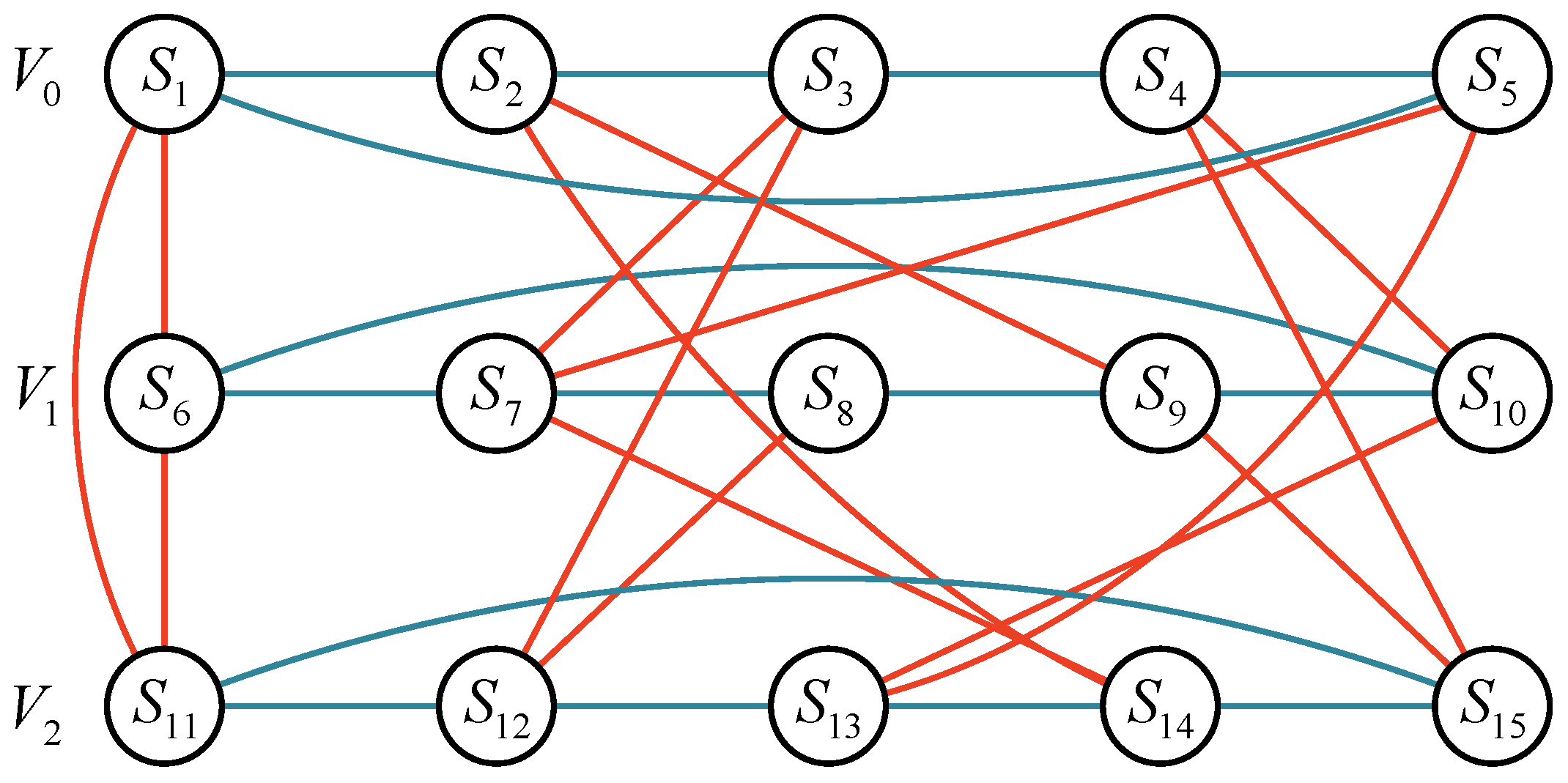
2.1. Galaxy Graph
- Intra-cluster edges: The construction of intra-cluster edges requires some basic knowledge on algebraic graphs over finite fields. We present only the basic results necessary to understand the construction process. Intra-cluster edges connecting nodes in the same cluster are constructed as in Definition 1.
- Inter-cluster edges: The construction of inter-cluster edges is determined by an isomorphic function H. First, we introduce a definition on the generator graphs (i.e., Theorem 1), then we introduce the definition of the isomorphic function H and a theorem on it (i.e., Definition 2 and Theorem 2). Inter-cluster edges connect nodes in two different clusters, constructed as in Theorem 1, Definition 2, and Theorem 2.
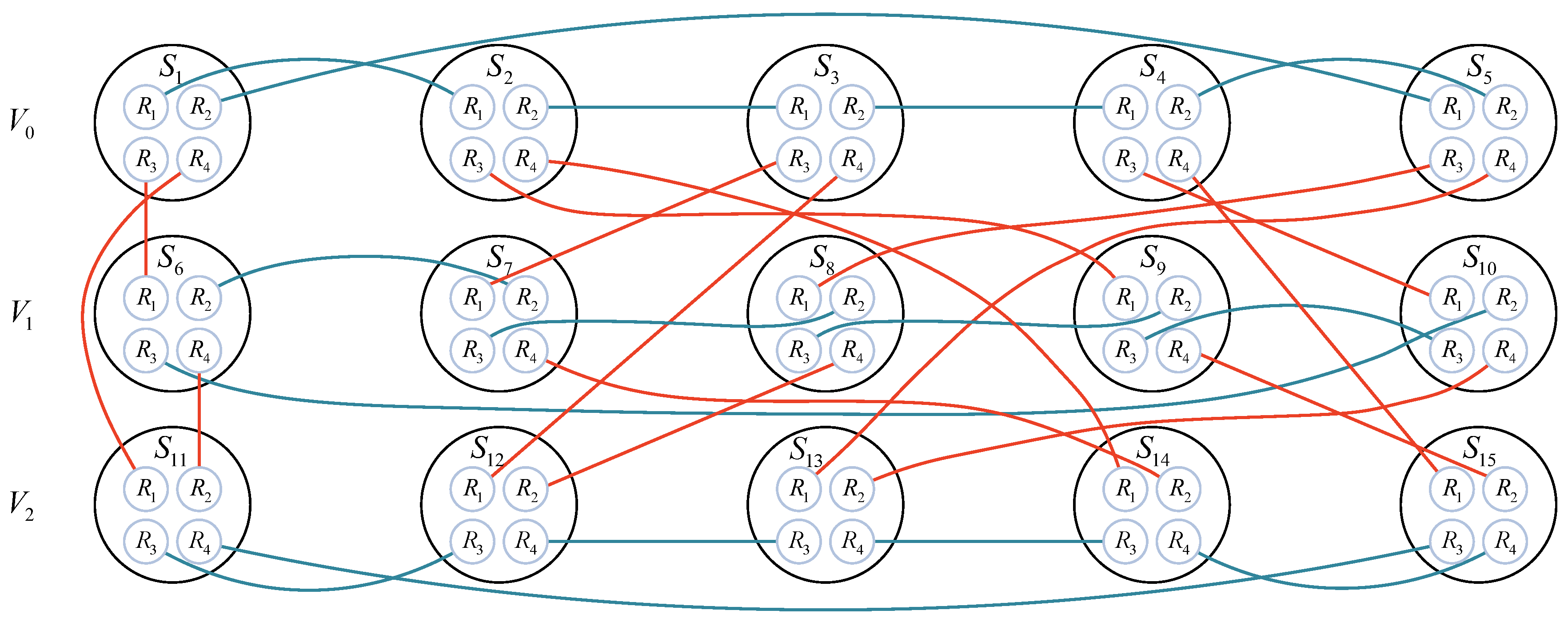
2.2. Galaxyfly Network
3. Basic Algorithm
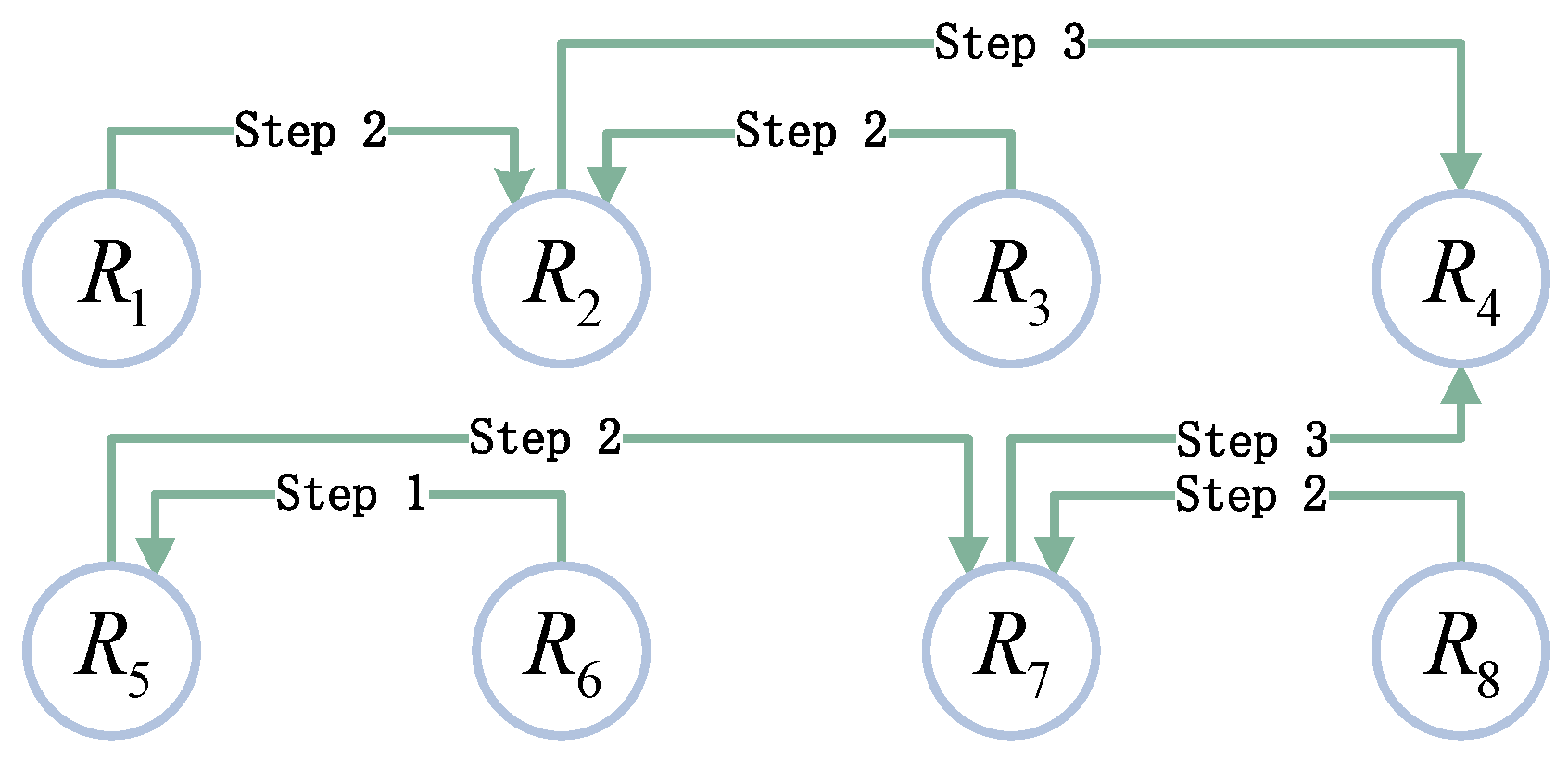
3.1. Algorithms: Router-Packet-Collection (RPC) and Router-Packet-Distribution (RPD)
| Algorithm 1: Router-Packet-Collection (RPC). |
 |
3.2. Algorithms: Supernode-Packet-Collection (SPC) and Supernode-Packet-Distribution (SPD)
| Algorithm 2: Supernode-Packet-Collection (SPC). |
 |
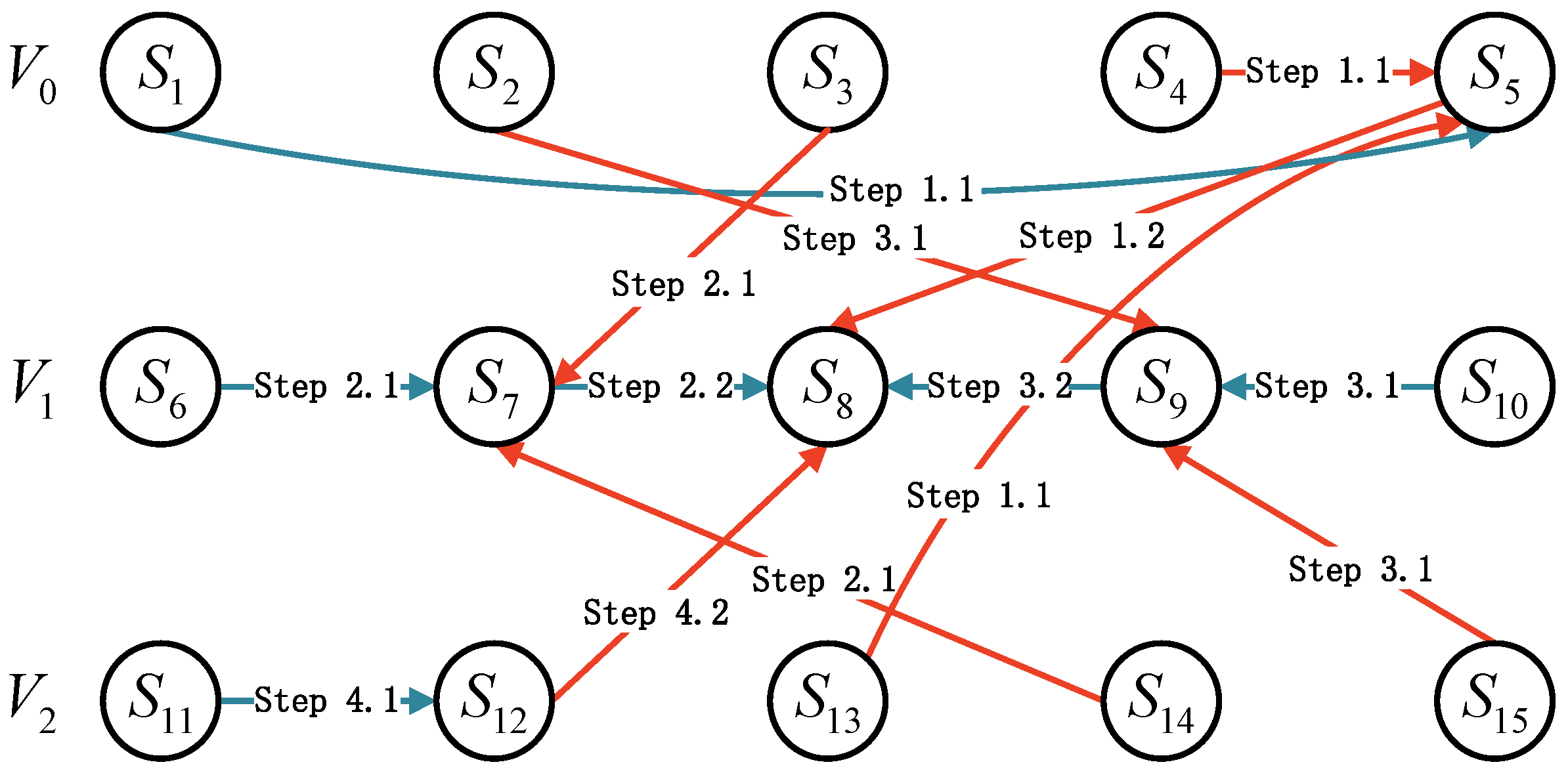
4. All-to-All Broadcast Algorithm
4.1. Supernode-First All-to-All (SFATA) Broadcast Algorithm
- All routers accept and send packets through the shortest feasible path.
- Each router does not receive redundant packets.
| Algorithm 3: Supernode-first all-to-all broadcast algorithm (SFATA). |
| Input: U: the set of all supernodes; A: a supernode; Output: All routers within all supernodes receive all packets under the rule of supernode-first; SPC; SPD; return; |
4.2. Router-First All-to-All Broadcast Algorithm (RFATA)
- All routers receive and send packets through the shortest feasible path.
- The routers in the supernode will receive packets in priority.
| Algorithm 4: Router-First All-to-All Broadcast Algorithm (RFATA). |
 |
5. Simulation Results
5.1. Validation
- : the total number of routers in the network.
- : the number of routers that successfully received packets from all routers.
- : the number of routers that failed to receive packets from all routers.
- SuccessRate: the ratio of the number of routers receiving all packets successfully to the total number of routers, calculated by
- FailureRate: the ratio of the number of routers failing to receive all packets to the total number of routers, calculated by
5.2. Performance Analysis
- AvgTime: the average time for all packets to be received by all routers in the network.
- MaxTime: the maximum time for all routers in the network to receive all packets, i.e., the running time of the whole all-to-all broadcast algorithm.
- MinTime: the minimum time for all packets to be received by the routers in the network.
- AvgPacket: the average redundant packets, which is the ratio of the total number of redundant packets to the total number of routers in the network.
- RouterTime: the average time for the router to collect packets from the supernode.
- AvgChannel: the average channel utilization, which is the ratio of the average time spent on all channels in the network to the total routing time (i.e., MaxTime).
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fan, W.; Xiao, F.; Fan, J.; Han, Z.; Sun, L.; Wang, R. Fault-tolerant routing with load balancing in LeTQ networks. IEEE Trans. Dependable Secur. Comput. 2023, 20, 68–82. [Google Scholar] [CrossRef]
- Liao, X.; Shen, Y.; Li, S.; Lu, Y.; Du, Y.; Chen, Z. Optimizing data query performance of Bi-cluster for large-scale scientific data in supercomputers. J. Supercomput. 2022, 78, 2417–2441. [Google Scholar] [CrossRef]
- Mavroidis, I.; Papaefstathiou, I.; Lavagno, L.; Nikolopoulos, D.S.; Koch, D.; Goodacre, J.; Sourdis, I.; Papaefstathiou, P.; Coppola, M.; Palomino, M. Ecoscale: Reconfigurable computing and runtime system for future exascale systems. In Proceedings of the 2016 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 14–18 March 2016; pp. 696–701. [Google Scholar]
- Sedova, A.; Davidson, R.; Taillefumier, M.; Elwasif, W. HPC Molecular Simulation Tries Out a New GPU: Experiences on Early AMD Test Systems for the Frontier Supercomputer; Oak Ridge National Lab: Oak Ridge, TN, USA, 2022. [Google Scholar]
- Bharadwaj, S.; Yin, J.; Beckmann, B.; Krishna, T. Kite: A family of heterogeneous interposer topologies enabled via accurate interconnect modeling. In Proceedings of the 2020 57th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 20–24 July 2020; pp. 1–6. [Google Scholar]
- Cicconetti, C.; Conti, M.; Passarella, A. Low-latency distributed computation offloading for pervasive environments. In Proceedings of the 2019 IEEE International Conference on Pervasive Computing and Communications (PerCom), Kyoto, Japan, 11–15 March 2019; pp. 1–10. [Google Scholar]
- ORNL’s Exaflop Machine Frontier Keeps Top Spot, New Competitor Leonardo Breaks the Top10. 2022. Available online: https://www.top500.org/news/ornls-exaflop-machine-frontier-keeps-top-spot-new-competitor-leonardo-breaks-the-top10 (accessed on 23 March 2023).
- Zahid, F.; Taherkordi, A.; Gran, E.G.; Skeie, T.; Johnsen, B.D. A self-adaptive network for HPC clouds: Architecture, framework, and implementation. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 2658–2671. [Google Scholar] [CrossRef]
- Sensi, D.D.; Girolamo, S.D.; McMahon, K.H.; Roweth, D.; Hoefler, T. An in-depth analysis of the slingshot interconnect. In Proceedings of the SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, Atlanta, GA, USA, 9–19 November 2020; pp. 1–14. [Google Scholar]
- Kim, J.; Dally, W.J.; Abts, D. Flattened butterfly: A cost-efficient topology for high-radix networks. SIGARCH Comput. Archit. News 2007, 35, 126–137. [Google Scholar] [CrossRef]
- Faanes, G.; Bataineh, A.; Roweth, D.; Court, T.; Froese, E.; Alverson, B.; Johnson, T.; Kopnick, J.; Higgins, M.; Reinhard, J. Cray cascade: A scalable HPC system based on a Dragonfly network. In Proceedings of the SC ’12: Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, Salt Lake City, UT, USA, 10–16 November 2012; pp. 1–9. [Google Scholar]
- Maglione-Mathey, G.; Yebenes, P.; Escudero-Sahuquillo, J.; Garcia, P.J.; Quiles, F.J.; Zahavi, E. Scalable deadlock-free deterministic minimal-path routing engine for infiniband-based dragonfly networks. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 183–197. [Google Scholar] [CrossRef]
- Jiang, N.; Dennison, L.; Dally, W.J. Network endpoint congestion control for fine-grained communication. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Austin, TX, USA, 15–20 November 2015; pp. 1–12. [Google Scholar]
- Xiang, D.; Li, B.; Fu, Y. Fault-tolerant adaptive routing in dragonfly networks. IEEE Trans. Dependable Secur. Comput. 2019, 16, 259–271. [Google Scholar] [CrossRef]
- Ahn, J.H.; Binkert, N.; Davis, A.; McLaren, M.; Schreiber, R.S. HyperX: Topology, routing, and packaging of efficient large-scale networks. In Proceedings of the Conference on High Performance Computing Networking, Storage and Analysis, Portland, OR, USA, 14–20 November 2009; pp. 1–11. [Google Scholar]
- Fujiwara, I.; Koibuchi, M.; Matsutani, H.; Casanova, H. Skywalk: A topology for HPC networks with low-delay switches. In Proceedings of the 2014 IEEE 28th International Parallel and Distributed Processing Symposium, Phoenix, AZ, USA, 19–23 May 2014; pp. 263–272. [Google Scholar]
- Besta, M.; Hoefler, T. Slim fly: A cost effective low-diameter network topology. In Proceedings of the SC ’14: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, New Orleans, LA, USA, 16–21 November 2014; pp. 348–359. [Google Scholar]
- Dai, Y.; Lu, K.; Xiao, L.; Su, J. A cost-efficient router architecture for HPC inter-connection networks: Design and implementation. IEEE Trans. Parallel Distrib. Syst. 2018, 30, 738–753. [Google Scholar] [CrossRef]
- Cao, J.; Lai, M.; Luo, Z.; Pang, Z. Efficient management and intelligent fault tolerance for HPC interconnect networks. In Proceedings of the 2019 IEEE 25th International Conference on Parallel and Distributed Systems (ICPADS), Tianjin, China, 4–6 December 2019; pp. 343–351. [Google Scholar]
- Lei, F.; Dong, D.; Liao, X. Exploring the galaxyfly family to build flexible-scale interconnection networks. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 1054–1068. [Google Scholar] [CrossRef]
- Joardar, B.K.; Duraisamy, K.; Pande, P.P. High performance collective communication-aware 3D network-on-chip architectures. In Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 1351–1356. [Google Scholar]
- Xiang, D.; Liu, X. Deadlock-free broadcast routing in dragonfly networks without virtual channels. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 2520–2532. [Google Scholar] [CrossRef]
- Xiang, D.; Chakrabarty, K.; Fujiwara, H. Multicast-based testing and thermal-aware test scheduling for 3D ICs with a stacked network-on-chip. IEEE Trans. Comput. 2016, 65, 2767–2779. [Google Scholar] [CrossRef]
- Lin, X.; Ni, L.M. Multicast communication in multicomputer networks. IEEE Trans. Parallel Distrib. Syst. 1993, 4, 1105–1117. [Google Scholar] [CrossRef]
- Lin, X.; McKinley, P.K.; Ni, L.M. Deadlock-free multicast wormhole routing in 2-D mesh multicomputers. IEEE Trans. Parallel Distrib. Syst. 1994, 5, 793–804. [Google Scholar]
- Panda, D.K.; Singal, S.; Kesavan, R. Multidestination message passing in wormhole k-ary n-cube networks with base routing conformed paths. IEEE Trans. Parallel Distrib. Syst. 1999, 10, 76–96. [Google Scholar] [CrossRef]
- Boppana, R.V.; Chalasani, S.; Raghavendra, C.S. Resource deadlocks and performance of wormhole multicast routing algorithms. IEEE Trans. Parallel Distrib. Syst. 1998, 9, 535–549. [Google Scholar] [CrossRef]
- McKinley, P.K.; Xu, H.; Esfahanian, A.-H.; Ni, L.M. Unicast-based multicast communication in wormhole-routed networks. IEEE Trans. Parallel Distrib. Syst. 1994, 5, 1252–1265. [Google Scholar] [CrossRef]
- Suh, Y.; Valamanchili, S. All to-all communication with minimum start-up costs in 2D/3D tori and meshes. IEEE Trans. Parallel Distrib. Syst. 1998, 9, 442–458. [Google Scholar]
- Jiang, N.; Kim, J.; Dally, W.J. Gossiping on meshes and tori. IEEE Trans. Parallel Distrib. Syst. 1998, 9, 513–525. [Google Scholar]
- Hafner, P.R. Geometric realisation of the graphs of McKay–Miller–Širáň. J. Comb. Theory Ser. B 2004, 90, 223–232. [Google Scholar] [CrossRef]
- Xiang, D.; Ju, Y. All-to-All Broadcast in Dragonfly Networks. In Computing and Combinatorics. COCOON 2021; Springer: Cham, Switzerland, 2021; pp. 13–24. [Google Scholar]
- Fu, H.; Liao, J.; Yang, J.; Wang, L.; Song, Z.; Huang, X.; Yang, C.; Xue, W.; Liu, F.; Qiao, F.; et al. The Sunway TaihuLight supercomputer: System and applications. Sci. China Inf. Sci. 2016, 59, 072001. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning |
|---|---|
| n | Number of clusters in Galaxyfly network. |
| q | Number of supernodes per cluster. |
| a | Number of routers per supernode. |
| p | Number of links per router to terminals. |
| h | Number of links per router to other supernodes. |
| The supernode . | |
| The router . | |
| U | The set of all supernodes. |
| Number of elements in the set X. |
| PS | 160B | 320B | 640B | 1280B |
|---|---|---|---|---|
| SFATA.SuccessRate | 100% | 100% | 100% | 100% |
| SFATA.FailureRate | 0% | 0% | 0% | 0% |
| RFATA.SuccessRate | 100% | 100% | 100% | 100% |
| RFATA.FailureRate | 0% | 0% | 0% | 0% |
| AvgTime | |||||
| MaxTime | |||||
| MinTime | 8500 | 9700 | |||
| AvgPacket | |||||
| RouterTime | |||||
| AvgChannel |
| AvgTime | |||||
| MaxTime | |||||
| MinTime | |||||
| AvgPacket | |||||
| RouterTime | 2440 | 2310 | 3160 | ||
| AvgChannel |
| AvgTime | |||||
| MaxTime | |||||
| MinTime | 1800 | 1800 | 2200 | 2500 | 3800 |
| AvgPacket | |||||
| AvgChannel |
| SFATA | RFATA | |
|---|---|---|
| Rule | Supernode-first | Router-first |
| Lower execution time | ||
| Advantages | AvgPacket equals to zero | Lower RouterTime |
| Higher AvgChannel | ||
| Higher execution time | ||
| Disadvantages | Higher RouterTime | Higher AvgPacket |
| Lower AvgChannel | ||
| Application Scopes | Applications that require completion of the whole broadcast as soon as possible | Applications that require prioritization of packet delivery to all routers in the same supernode |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhuang, H.; Chang, J.-M.; Li, X.-Y.; Song, F.; Lin, Q. All-to-All Broadcast Algorithm in Galaxyfly Networks. Mathematics 2023, 11, 2459. https://doi.org/10.3390/math11112459
Zhuang H, Chang J-M, Li X-Y, Song F, Lin Q. All-to-All Broadcast Algorithm in Galaxyfly Networks. Mathematics. 2023; 11(11):2459. https://doi.org/10.3390/math11112459
Chicago/Turabian StyleZhuang, Hongbin, Jou-Ming Chang, Xiao-Yan Li, Fangying Song, and Qinying Lin. 2023. "All-to-All Broadcast Algorithm in Galaxyfly Networks" Mathematics 11, no. 11: 2459. https://doi.org/10.3390/math11112459
APA StyleZhuang, H., Chang, J.-M., Li, X.-Y., Song, F., & Lin, Q. (2023). All-to-All Broadcast Algorithm in Galaxyfly Networks. Mathematics, 11(11), 2459. https://doi.org/10.3390/math11112459