
Performance Analysis and Assessment of Type 2 Diabetes Screening Scores in Patients with Non-Alcoholic Fatty Liver Disease

 , ,
, ,  ,
,  , ,
, , 
Abstract
1. Introduction
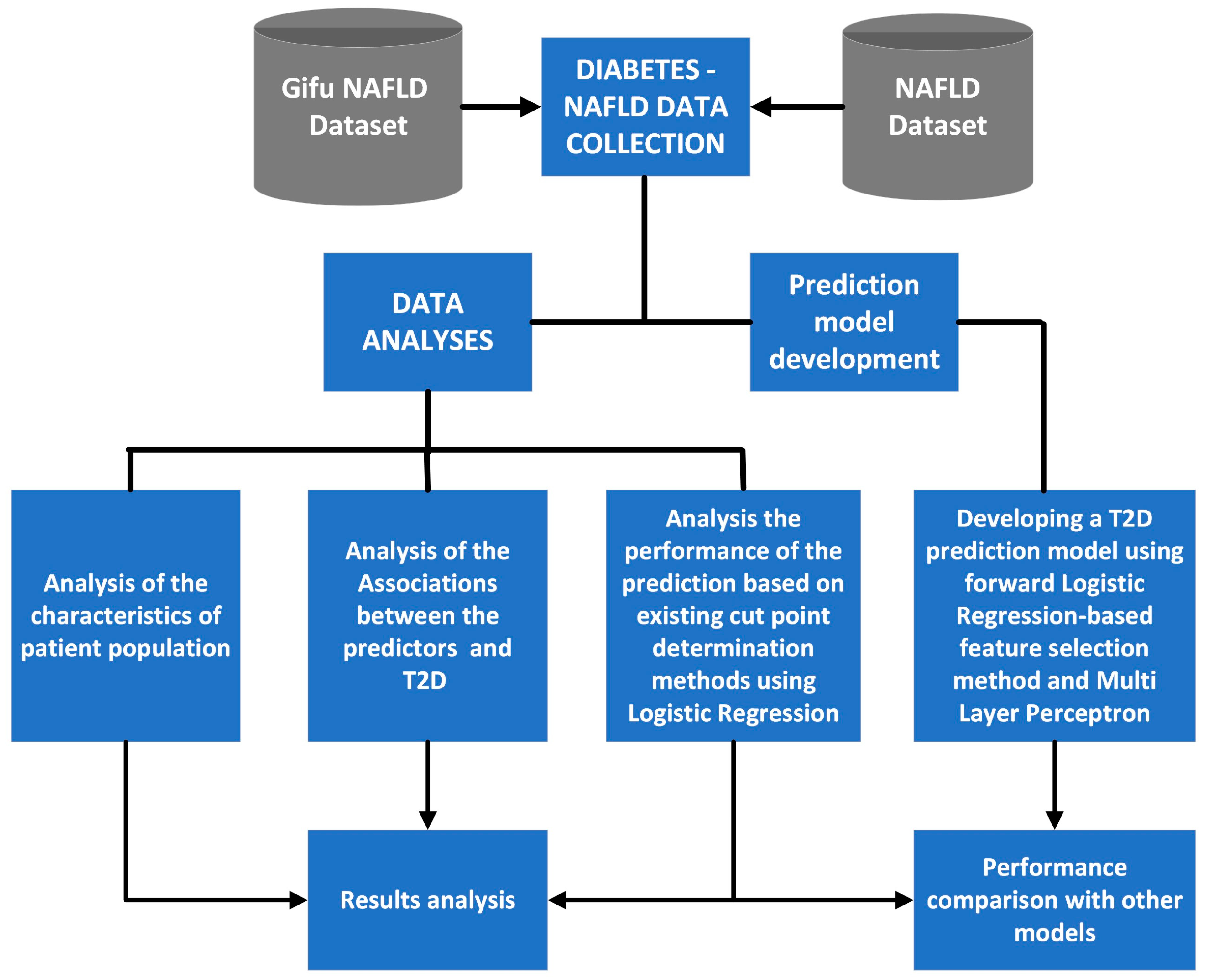
2. Materials and Methods
2.1. Data Sources and Study Population
- The first dataset is NAFLD in the Gifu area longitudinal analysis dataset (Gifu NAFLD). The Gifu NAFLD dataset is an investigation of medical examination program data from Murakami Memorial Hospital in Gifu, Japan, using a population-based longitudinal approach [35]. The participants consist of 15,464 in all, ranging in age from 22 to 70. In this dataset, none of the subjects have fasting blood glucose (FBG) greater than 125 mg/dL or glycated hemoglobin (HbA1c) greater than 6.5%, which is categorized as diabetes. However, the T2D cases are in the range of 100 to 125 mg/dL for FBG and 5.7 to 6.4% for HbA1c, which means that the subjects who were diagnosed with T2D in this dataset were subjects with prediabetes. In order to analyze the T2D scores among patients with NAFLD, we modified the dataset by selecting data where the patient is diagnosed with NAFLD; thus, the final data used is from 2741 patients, consisting of 2255 men and 486 women. We used all available data for the analysis, with 30 features with some classes included.
- The second dataset is NAFLD [36] dataset which is a population-based longitudinal data collection gathered from a program for patients with NAFLD who were undergoing medical examinations. This dataset has a total of 605 participants, including 321 males and 284 women. The patients who took part in this medical examination program ranged in age from 18 to 71, and the majority of them had the severe form of NAFLD known as NASH, which affected 537 individuals, or 88.76% of the total. In this dataset, according to FBG and HbA1c data, the T2D cases are in the stage of prediabetes and diabetes stages. 62 features with some classes make up the whole dataset.
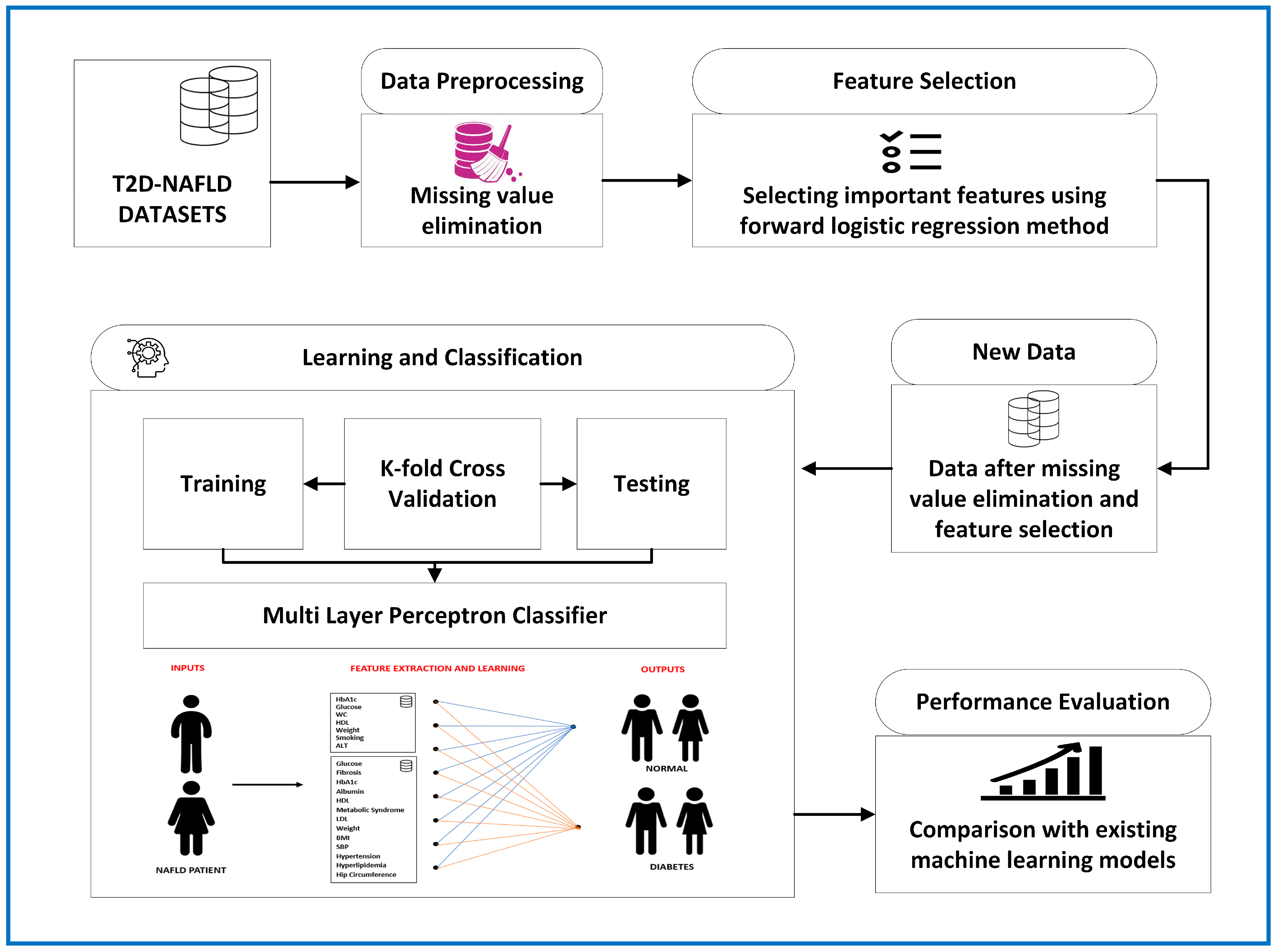
2.2. Study Design and Implementation
2.3. Forward Logistic Regression-based Feature Selection Method
| Algorithm 1: A forward logistic regression-based feature selection method |
|
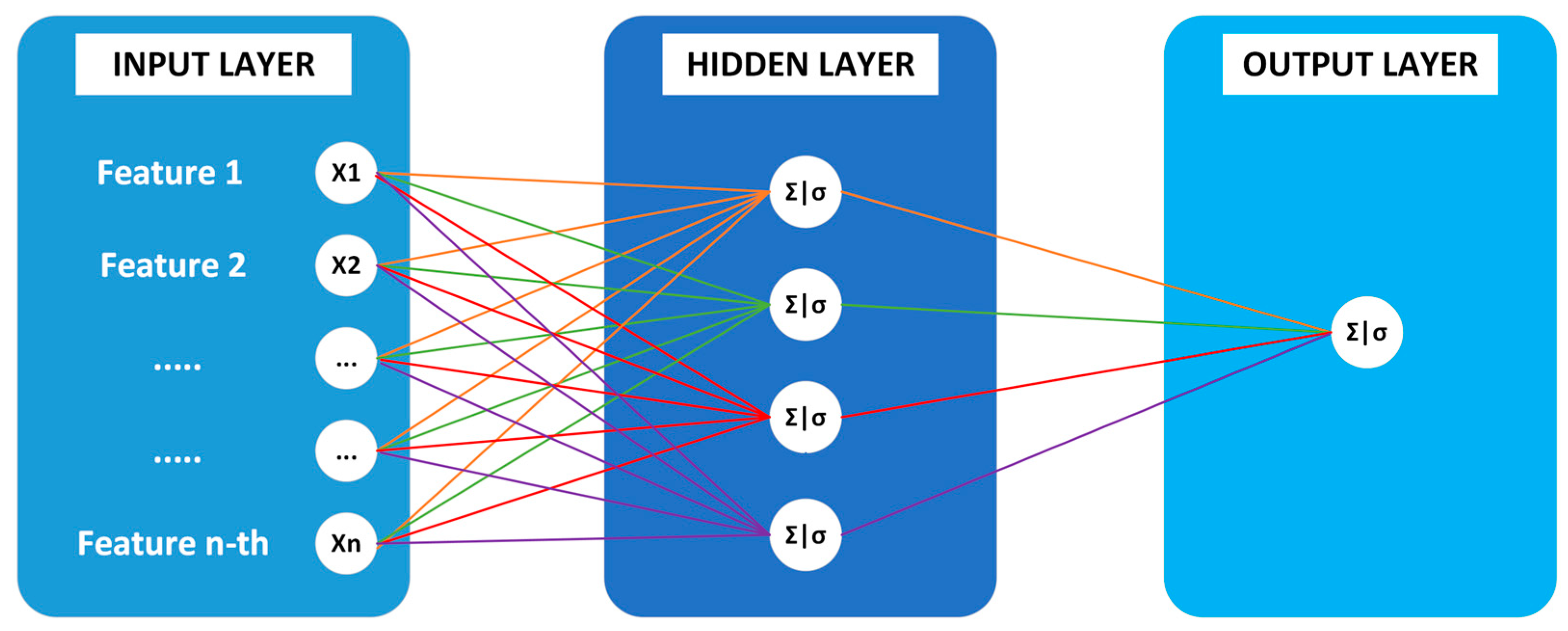
2.4. Multi-Layer Perceptron
2.5. Evaluation of the Model’s Performance
3. Results
3.1. Characteristics of Patient Population
3.2. Measure of Associations
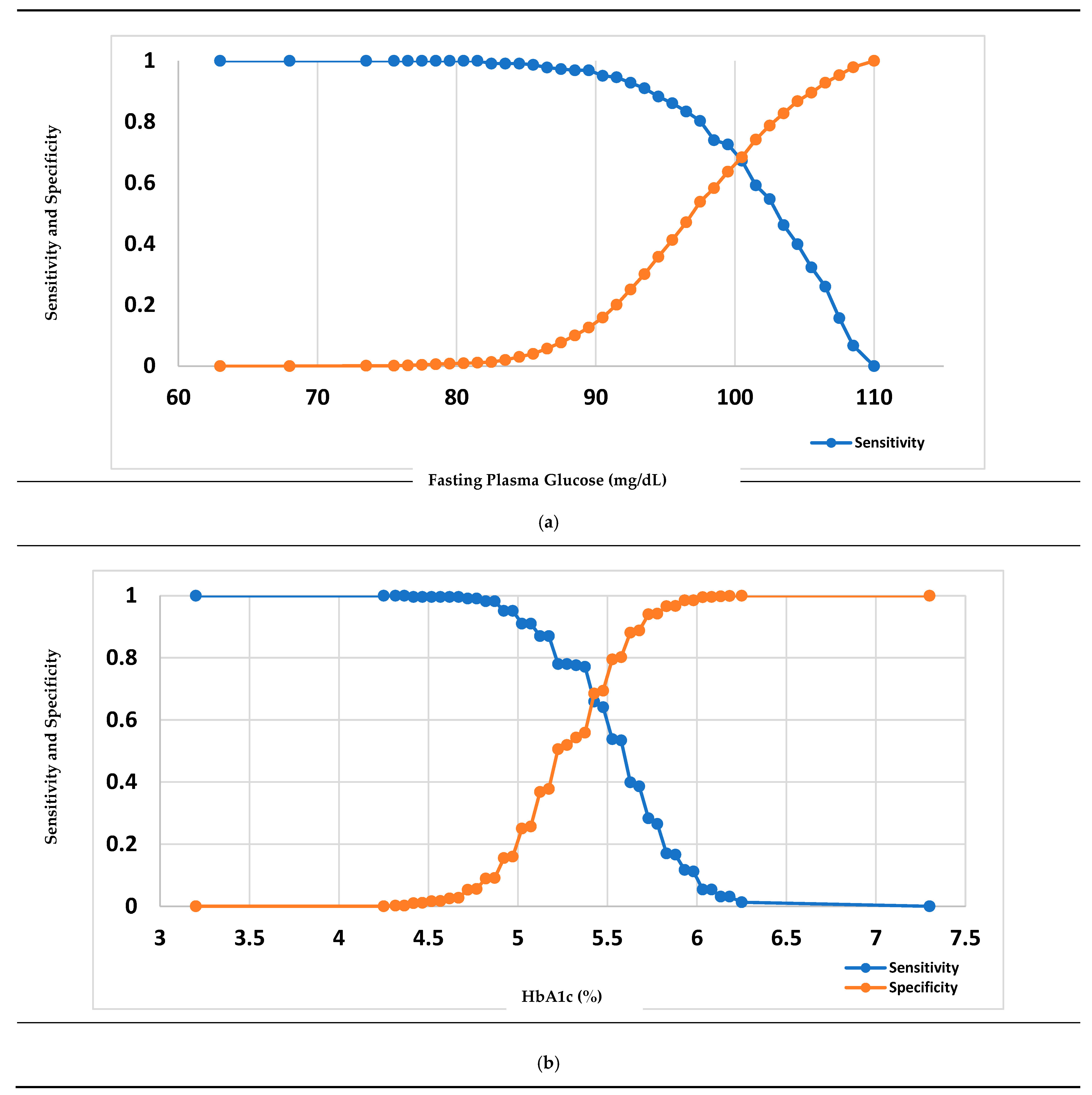
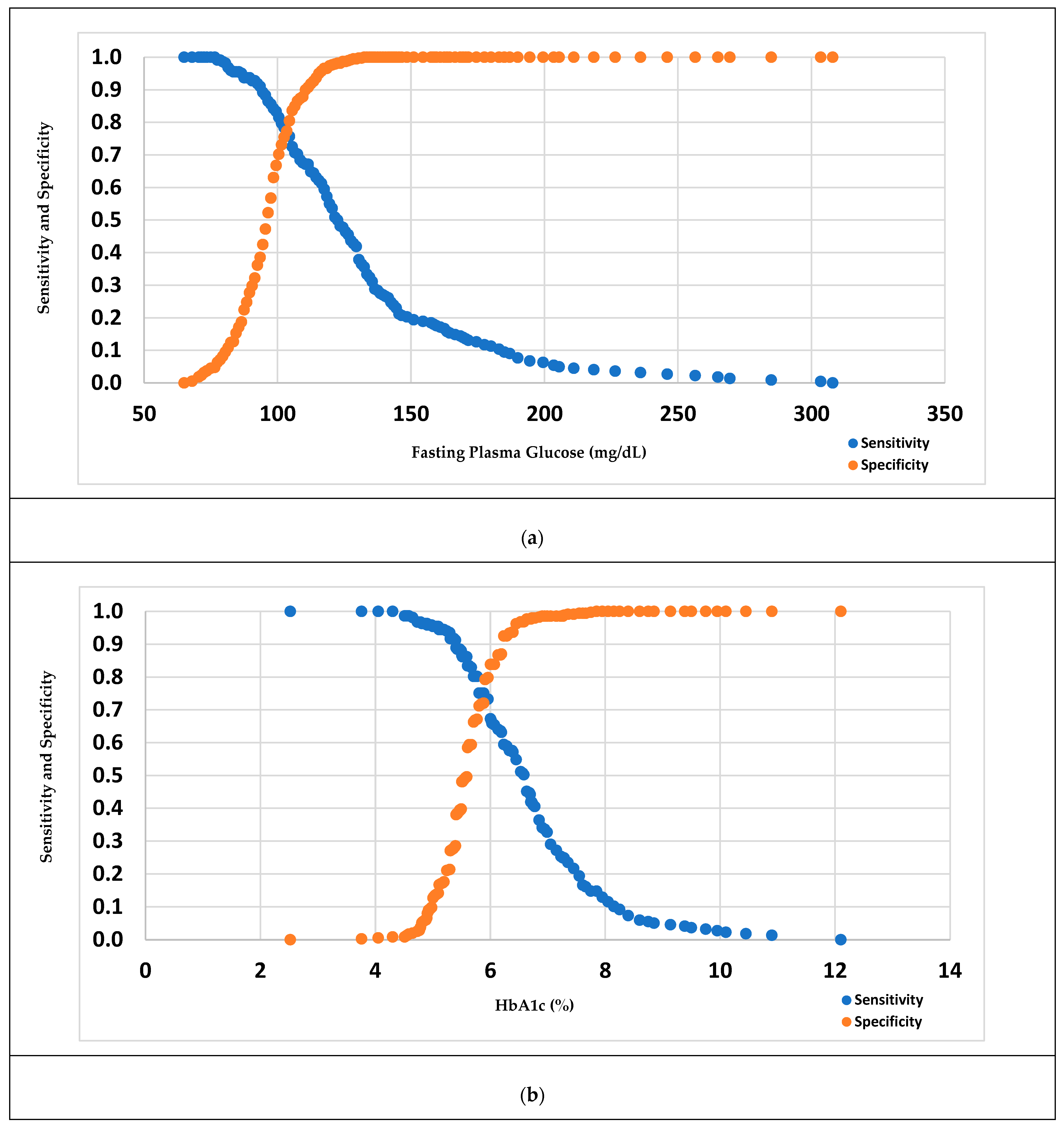
3.3. Measure of the Performance of Diabetes Diagnostic Tests
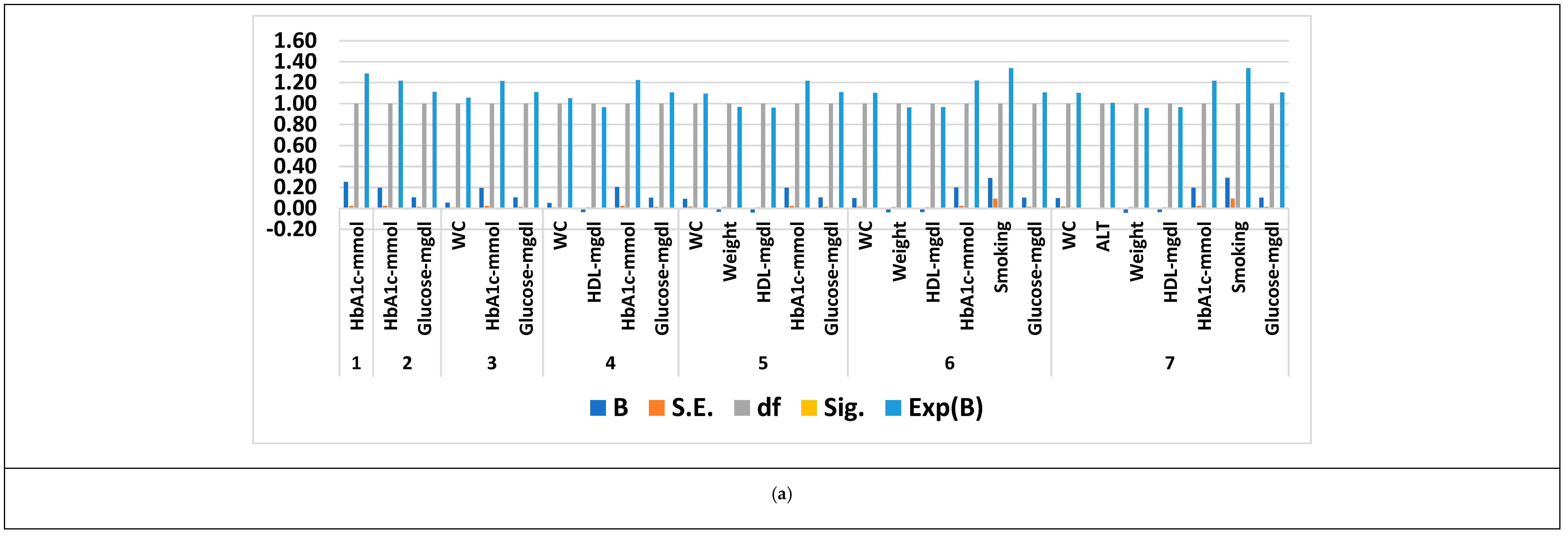
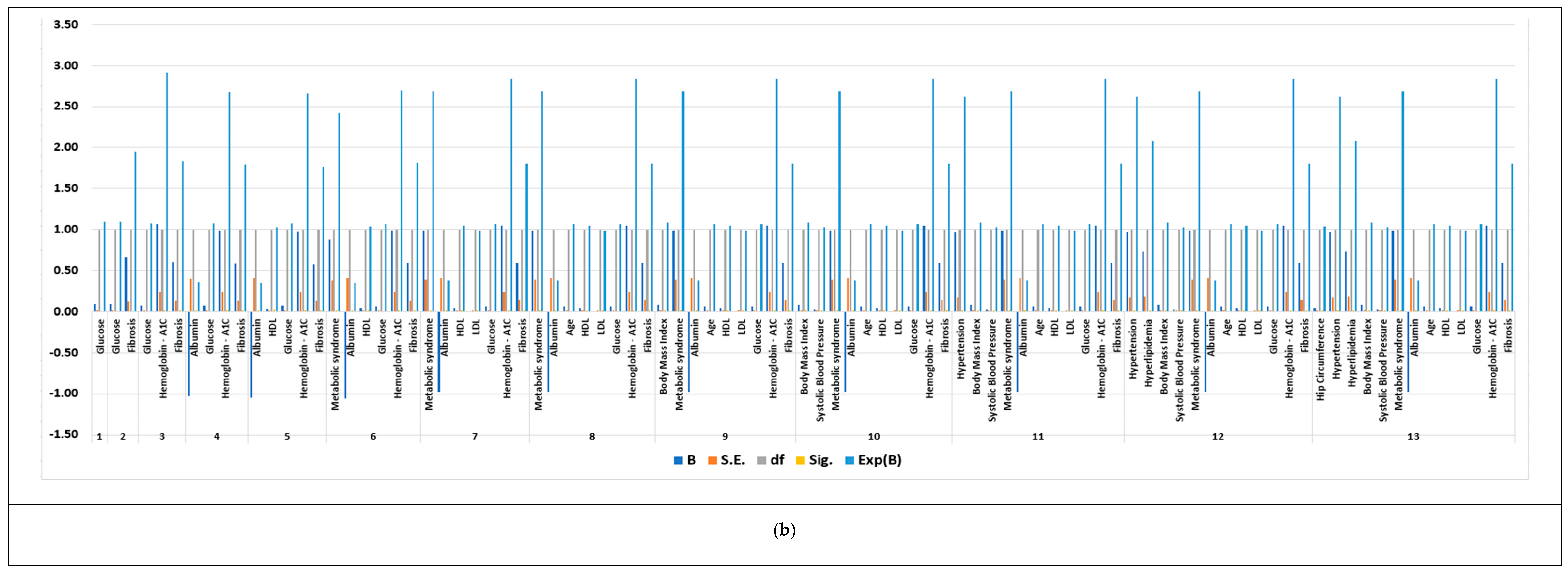
3.4. Feature Selection Results Based on Forward Logistic Regression Method
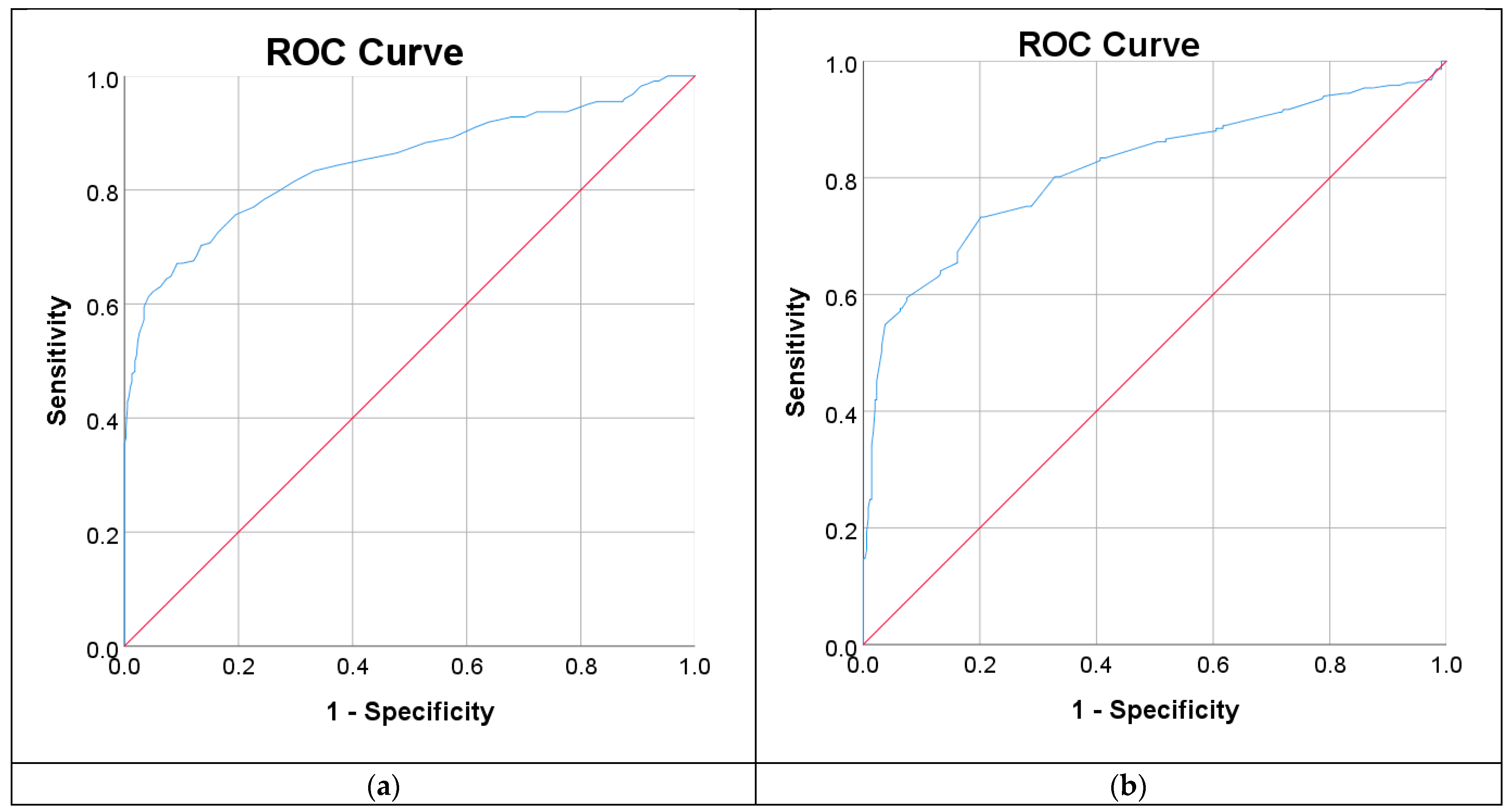
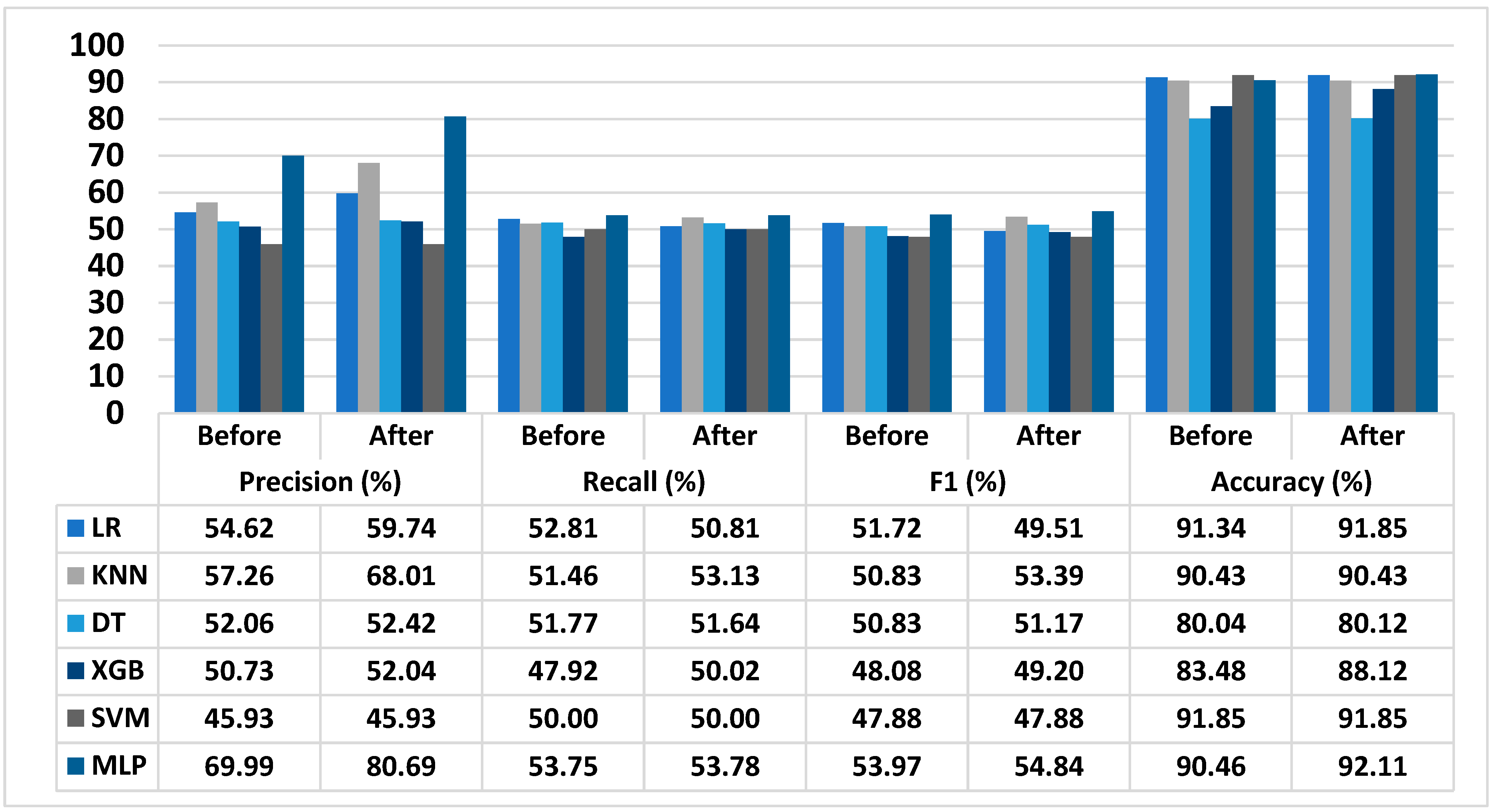
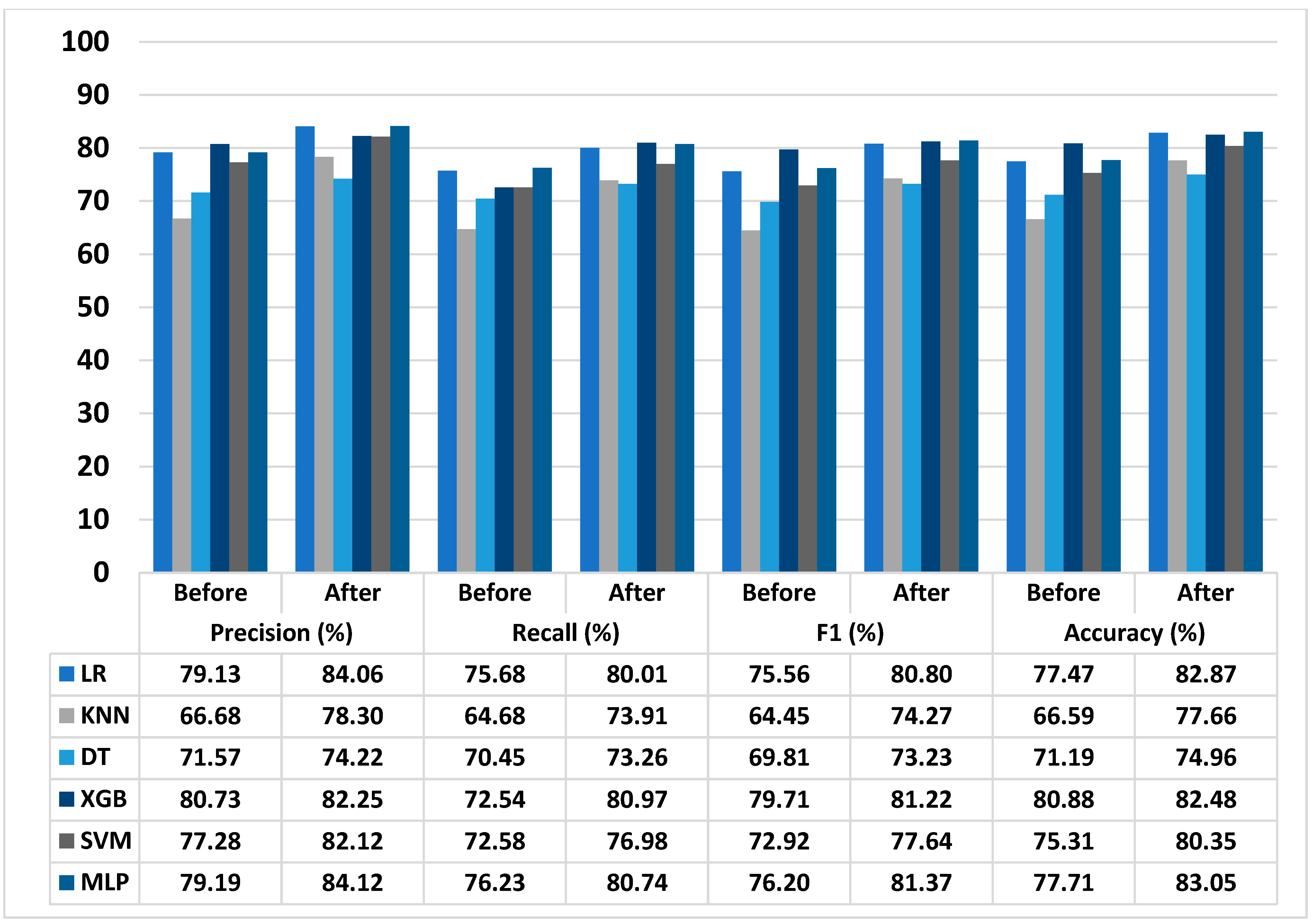
3.5. Performance of Proposed T2D Prediction Model
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Physical Inactivity Leading Cause of Disease and Disability, Warn WHO. Available online: https://www.who.int/news/item/04-04-2002-physical-inactivity-a-leading-cause-of-disease-and-disability-warns-who (accessed on 5 January 2023).
- Reddy, S.; Sethi, N.; Rajender, R.; Mahesh, G. Forecasting Diabetes Correlated Non-Alcoholic Fatty Liver Disease by Exploiting Naïve Bayes Tree. EAI Endorsed Trans. Scalable Inf. Syst. 2023, 10, e2. [Google Scholar] [CrossRef]
- Garg, K.; Reinicke, T.; Garg, S.K. NAFLD and NASH and Diabetes. Diabetes Technol. Ther. 2021, 23, S-198–S-205. [Google Scholar] [CrossRef] [PubMed]
- Liver Fat Directly Raises Risk of Type 2 Diabetes. Available online: https://www.diabetes.org.uk/about_us/news/liver-fat-risk-type-2-diabetes (accessed on 5 January 2023).
- Curry, A. Fatty Liver and Type 2 Diabetes. Available online: https://diabetes.ufl.edu/news-events/fatty-liver-and-type-2-diabetes/ (accessed on 5 January 2023).
- Dharmalingam, M.; Yamasandhi, P.G. Nonalcoholic Fatty Liver Disease and Type 2 Diabetes Mellitus. Indian J. Endocrinol. Metab. 2018, 22, 421–428. [Google Scholar] [CrossRef] [PubMed]
- Ng, C.H.; Chan, K.E.; Chin, Y.H.; Zeng, R.W.; Tsai, P.C.; Lim, W.H.; Tan, D.J.H.; Khoo, C.M.; Goh, L.H.; Ling, Z.J.; et al. The Effect of Diabetes and Prediabetes on the Prevalence, Complications and Mortality in Nonalcoholic Fatty Liver Disease. Clin. Mol. Hepatol. 2022, 28, 565–574. [Google Scholar] [CrossRef] [PubMed]
- Sun, H.; Saeedi, P.; Karuranga, S.; Pinkepank, M.; Ogurtsova, K.; Duncan, B.B.; Stein, C.; Basit, A.; Chan, J.C.N.; Mbanya, J.C.; et al. IDF Diabetes Atlas: Global, Regional and Country-Level Diabetes Prevalence Estimates for 2021 and Projections for 2045. Diabetes Res. Clin. Pract. 2022, 183, 109119. [Google Scholar] [CrossRef]
- Yan, Y.; Wu, T.; Zhang, M.; Li, C.; Liu, Q.; Li, F. Prevalence, Awareness and Control of Type 2 Diabetes Mellitus and Risk Factors in Chinese Elderly Population. BMC Public Health 2022, 22, 1382. [Google Scholar] [CrossRef]
- Younossi, Z.M. Non-Alcoholic Fatty Liver Disease—A Global Public Health Perspective. J. Hepatol. 2019, 70, 531–544. [Google Scholar] [CrossRef]
- Kianpour, F.; Fararouei, M.; Hassanzadeh, J.; Mohammadi, M.; Dianatinasab, M. Performance of Diabetes Screening Tests: An Evaluation Study of Iranian Diabetes Screening Program. Diabetol. Metab. Syndr. 2021, 13, 13. [Google Scholar] [CrossRef]
- Meng, L.; Kwon, K.-S.; Kim, D.J.; Lee, Y.; Kim, J.; Kshirsagar, A.V.; Bang, H. Performance of Diabetes and Kidney Disease Screening Scores in Contemporary United States and Korean Populations. Diabetes Metab. J. 2022, 46, 273–285. [Google Scholar] [CrossRef] [PubMed]
- Addressing the Specific Behavioral Health Needs of Men. Available online: https://www.ncbi.nlm.nih.gov/books/NBK144289/ (accessed on 5 January 2023).
- Lee, Y.; Bang, H.; Kim, H.C.; Kim, H.M.; Park, S.W.; Kim, D.J. A Simple Screening Score for Diabetes for the Korean Population. Diabetes Care 2012, 35, 1723–1730. [Google Scholar] [CrossRef]
- Mao, T.; Chen, J.; Guo, H.; Qu, C.; He, C.; Xu, X.; Yang, G.; Zhen, S.; Li, X. The Efficacy of New Chinese Diabetes Risk Score in Screening Undiagnosed Type 2 Diabetes and Prediabetes: A Community-Based Cross-Sectional Study in Eastern China. J. Diabetes Res. 2020, 2020, 7463082. [Google Scholar] [CrossRef] [PubMed]
- Fitriyani, N.L.; Syafrudin, M.; Ulyah, S.M.; Alfian, G.; Qolbiyani, S.L.; Anshari, M. A Comprehensive Analysis of Chinese, Japanese, Korean, US-PIMA Indian, and Trinidadian Screening Scores for Diabetes Risk Assessment and Prediction. Mathematics 2022, 10, 4027. [Google Scholar] [CrossRef]
- Lee, S.M.; Hwangbo, S.; Norwitz, E.R.; Koo, J.N.; Oh, I.H.; Choi, E.S.; Jung, Y.M.; Kim, S.M.; Kim, B.J.; Kim, S.Y.; et al. Nonalcoholic Fatty Liver Disease and Early Prediction of Gestational Diabetes Mellitus Using Machine Learning Methods. Clin. Mol. Hepatol. 2022, 28, 105–116. [Google Scholar] [CrossRef] [PubMed]
- Oh, T.; Kim, D.; Lee, S.; Won, C.; Kim, S.; Yang, J.; Yu, J.; Kim, B.; Lee, J. Machine Learning-Based Diagnosis and Risk Factor Analysis of Cardiocerebrovascular Disease Based on KNHANES. Sci. Rep. 2022, 12, 2250. [Google Scholar] [CrossRef]
- Ahsan, M.M.; Luna, S.A.; Siddique, Z. Machine-Learning-Based Disease Diagnosis: A Comprehensive Review. Healthcare 2022, 10, 541. [Google Scholar] [CrossRef] [PubMed]
- Alfian, G.; Syafrudin, M.; Fahrurrozi, I.; Fitriyani, N.L.; Atmaji, F.T.D.; Widodo, T.; Bahiyah, N.; Benes, F.; Rhee, J. Predicting Breast Cancer from Risk Factors Using SVM and Extra-Trees-Based Feature Selection Method. Computers 2022, 11, 136. [Google Scholar] [CrossRef]
- Syafrudin, M.; Alfian, G.; Fitriyani, N.L.; Hadibarata, T.; Rhee, J.; Anshari, M. Future Glycemic Events Prediction Model Based On Artificial Neural Network. In Proceedings of the 2022 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT), Sakheer, Bahrain, 20–21 November 2022; pp. 151–155. [Google Scholar]
- Siddiqui, S.; Arifeen, M.; Hopgood, A.; Good, A.; Gegov, A.; Hossain, E.; Rahman, W.; Hossain, S.; Al Jannat, S.; Ferdous, R.; et al. Deep Learning Models for the Diagnosis and Screening of COVID-19: A Systematic Review. SN Comput. Sci. 2022, 3, 397. [Google Scholar] [CrossRef]
- Choi, S.B.; Kim, W.J.; Yoo, T.K.; Park, J.S.; Chung, J.W.; Lee, Y.; Kang, E.S.; Kim, D.W. Screening for Prediabetes Using Machine Learning Models. Comput. Math. Methods Med. 2014, 2014, 618976. [Google Scholar] [CrossRef]
- Prananda, A.R.; Frannita, E.L.; Hutami, A.H.T.; Maarif, M.R.; Fitriyani, N.L.; Syafrudin, M. Retinal Nerve Fiber Layer Analysis Using Deep Learning to Improve Glaucoma Detection in Eye Disease Assessment. Appl. Sci. 2022, 13, 37. [Google Scholar] [CrossRef]
- Dutta, A.; Hasan, M.K.; Ahmad, M.; Awal, M.A.; Islam, M.A.; Masud, M.; Meshref, H. Early Prediction of Diabetes Using an Ensemble of Machine Learning Models. Int. J. Environ. Res. Public Health 2022, 19, 12378. [Google Scholar] [CrossRef]
- Fitriyani, N.L.; Syafrudin, M.; Alfian, G.; Rhee, J. Development of Disease Prediction Model Based on Ensemble Learning Approach for Diabetes and Hypertension. IEEE Access 2019, 7, 144777–144789. [Google Scholar] [CrossRef]
- Fitriyani, N.L.; Syafrudin, M.; Alfian, G.; Yang, C.; Rhee, J.; Ulyah, S.M. Chronic Disease Prediction Model Using Integration of DBSCAN, SMOTE-ENN, and Random Forest. In Proceedings of the 2022 ASU International Conference in Emerging Technologies for Sustainability and Intelligent Systems (ICETSIS), Manama, Bahrain, 22–23 June 2022; pp. 289–294. [Google Scholar]
- Al Bataineh, A.; Manacek, S. MLP-PSO Hybrid Algorithm for Heart Disease Prediction. JPM 2022, 12, 1208. [Google Scholar] [CrossRef] [PubMed]
- Pal, M.; Parija, S.; Panda, G.; Dhama, K.; Mohapatra, R.K. Risk Prediction of Cardiovascular Disease Using Machine Learning Classifiers. Open Med. 2022, 17, 1100–1113. [Google Scholar] [CrossRef]
- Bikku, T. Multi-Layered Deep Learning Perceptron Approach for Health Risk Prediction. J. Big Data 2020, 7, 50. [Google Scholar] [CrossRef]
- Sivaranjani, R.; Yuvaraj, N. Artificial Intelligence Model for Earlier Prediction of Cardiac Functionalities Using Multilayer Perceptron. J. Phys. Conf. Ser. 2019, 1362, 012062. [Google Scholar] [CrossRef]
- Zhang, Z. Variable Selection with Stepwise and Best Subset Approaches. Ann. Transl. Med. 2016, 4, 136. [Google Scholar] [CrossRef]
- Sanchez-Pinto, L.N.; Venable, L.R.; Fahrenbach, J.; Churpek, M.M. Comparison of Variable Selection Methods for Clinical Predictive Modeling. Int. J. Med. Inform. 2018, 116, 10–17. [Google Scholar] [CrossRef]
- Soroush, A.; Bahreininejad, A.; van den Berg, J. A Hybrid Customer Prediction System Based on Multiple Forward Stepwise Logistic Regression Mode. IDA 2012, 16, 265–278. [Google Scholar] [CrossRef]
- Ectopic Fat Obesity Presents the Greatest Risk for Incident Type 2 Diabetes: A Population-Based Longitudinal Study. Available online: https://datadryad.org/stash/dataset/doi:10.5061/dryad.8q0p192 (accessed on 7 November 2022).
- Fatty Liver Disease Dataset. Available online: https://www.kaggle.com/datasets/tourdeglobe/fatty-liver-disease (accessed on 7 November 2022).
- Singhal, R.; Rana, R. Chi-Square Test and Its Application in Hypothesis Testing. J. Pract. Cardiovasc. Sci. 2015, 1, 69–71. [Google Scholar] [CrossRef]
- Guidelines for the Prevention, Management, and Care of Diabetes Mellitus. Available online: https://applications.emro.who.int/dsaf/dsa664.pdf (accessed on 26 August 2022).
- Diagnosis and Management of Type 2 Diabetes. Available online: https://apps.who.int/iris/rest/bitstreams/1274478/retrieve (accessed on 26 August 2022).
- Diabetes Risk Factors. Available online: https://www.cdc.gov/diabetes/basics/risk-factors.html (accessed on 26 August 2022).
- Classification and Diagnosis of Diabetes: Standard of Care in Diabetes-2023. Available online: https://diabetesjournals.org/care/article/46/Supplement_1/S19/148056/2-Classification-and-Diagnosis-of-Diabetes (accessed on 26 August 2022).
- Zhao, T.; Zheng, Y.; Wu, Z. Feature Selection-Based Machine Learning Modeling for Distributed Model Predictive Control of Nonlinear Processes. Comput. Chem. Eng. 2023, 169, 108074. [Google Scholar] [CrossRef]
- Abirami, S.; Chitra, P. Energy-Efficient Edge Based Real-Time Healthcare Support System. In Advances in Computers; Elsevier: Amsterdam, The Netherlands, 2020; Volume 117, pp. 339–368. ISBN 978-0-12-818756-2. [Google Scholar]
- Menzies, T.; Kocagüneli, E.; Minku, L.; Peters, F.; Turhan, B. Using Goals in Model-Based Reasoning. In Sharing Data and Models in Software Engineering; Elsevier: Amsterdam, The Netherlands, 2015; pp. 321–353. ISBN 978-0-12-417295-1. [Google Scholar]
- Trevethan, R. Sensitivity, Specificity, and Predictive Values: Foundations, Pliabilities, and Pitfalls in Research and Practice. Front. Public Health 2017, 5, 307. [Google Scholar] [CrossRef] [PubMed]
- Fitriyani, N.L.; Syafrudin, M.; Alfian, G.; Rhee, J. HDPM: An Effective Heart Disease Prediction Model for a Clinical Decision Support System. IEEE Access 2020, 8, 133034–133050. [Google Scholar] [CrossRef]
- Bolboacă, S.D. Medical Diagnostic Tests: A Review of Test Anatomy, Phases, and Statistical Treatment of Data. Comput. Math. Methods Med. 2019, 1748-670X. [Google Scholar] [CrossRef] [PubMed]
- Alfian, G.; Syafrudin, M.; Ijaz, M.F.; Syaekhoni, M.A.; Fitriyani, N.L.; Rhee, J. A Personalized Healthcare Monitoring System for Diabetic Patients by Utilizing BLE-Based Sensors and Real-Time Data Processing. Sensors 2018, 18, 2183. [Google Scholar] [CrossRef]
- Gerstein, H.C.; Ramasundarahettige, C.; Bangdiwala, S.I. Creating Composite Indices From Continuous Variables for Research: The Geometric Mean. Diabetes Care 2021, 44, e85–e86. [Google Scholar] [CrossRef]
- Sacks, D.B. A1C versus glucose testing: A comparison. Diabetes Care 2011, 34, 518–523. [Google Scholar] [CrossRef] [PubMed]
- Tonyushkina, K.; Nichols, J.H. Glucose meters: A review of technical challenges to obtaining accurate results. J. Diabetes Sci. Technol. 2009, 3, 971–980. [Google Scholar] [CrossRef] [PubMed]
- Fitriyani, N.L.; Syafrudin, M.; Alfian, G.; Fatwanto, A.; Qolbiyani, S.L.; Rhee, J. Prediction Model for Type 2 Diabetes Using Stacked Ensemble Classifiers. In Proceedings of the 2020 International Conference on Decision Aid Sciences and Application (DASA), Sakheer, Bahrain, 8–9 November 2020; pp. 399–402. [Google Scholar] [CrossRef]
- Goel, G.; Maguire, L.; Li, Y.; McLoone, S. Evaluation of sampling methods for learning from imbalanced data. Intell. Comput. Theor. 2013, 7995, 392–401. [Google Scholar] [CrossRef]
- Batista, G.E.A.P.A.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Deberneh, H.M.; Kim, I. Prediction of Type 2 Diabetes Based on Machine Learning Algorithm. Int. J. Environ. Res. Public Health 2021, 18, 3317. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | Gifu NAFLD Dataset (n = 2741) | NAFLD Dataset (n = 605) |
|---|---|---|
| Sex, Men/Women, n (%) | 2255 (82.24)/486 (17.72) | 321 (53.06)/284 (46.94) |
| Age, year | 44.00 ± 13.00 | 47.00 ± 16.00 |
| Weight, kg | 71.40 ± 13.90 | 85.00 ± 16.00 |
| BMI, kg/m2 | 25.08 ± 3.78 | 31.21 ± 5.91 |
| Normal (18.5 ≤ MI < 23), n (%) | 544 (19.84) | 3 (0.50) |
| Overweight (23 ≤ BMI < 25), n (%) | 789 (28.77) | 36 (5.95) |
| Obese I (25 ≤ BMI < 30), n (%) | 1185 (43.22) | 188 (31.07) |
| Obese II (BM ≥ 30), n (%) | 219 (7.99) | 377 (62.31) |
| WC, Men/Women, cm | 86.00 ± 9.00/82.00 ± 12.00 | 106.00 ± 10.00/112.00 ± 16.00 |
| HC, Men/Women, cm | - | 104.00 ± 12.00/104.00 ± 15.75 |
| ALT, U/L | 27.00 ± 19.00 | 66.00 ± 54.00 |
| AST, U/L | 21.00 ± 9.00 | 42.00 ± 25.00 |
| ALP, U/L | - | 89.50 ± 46.00 |
| GGT, U/L | 23.00 ± 18.00 | 49.00 ± 43.75 |
| LDH, U/L | - | 215.00 ± 101.00 |
| HDL, mg/dL | 44.00 ± 13.50 | 44.00 ± 13.00 |
| LDL, mg/dL | - | 134.00 ± 53.00 |
| Total Cholesterol, mg/dL | 210.00 ± 44.00 | 211.00 ± 56.00 |
| Triglyceride, mg/dL | 111.00 ± 83.00 | 164.50 ± 114.25 |
| HbA1c in general, % | 5.30 ± 0.40 | 5.80 ± 1.00 |
| FBG, mg/dL | 97.00 ± 9.00 | 100.00 ± 25.00 |
| SBP, mmHg | 122.50 ± 19.00 | 121.00 ± 15.00 |
| DBP, mmHg | 77.50 ± 15.50 | 80.00 ± 10.00 |
| Ethanol, mg/dL | 50.89 ± 86.474 | - |
| Alcohol, n (%) | ||
| Level 1 | 2088 (76.15) | - |
| Level 2 | 286 (10.43) | - |
| Level 3 | 250 (9.12) | - |
| Level 4 | 117 (4.27) | - |
| Smoking, n (%) | ||
| Level 1 (Never Smoking) | 1226 (44.71) | 267 (44.13) |
| Level 2 (Left Smoking) | 726 (26.48) | 206 (34.05) |
| Level 3 (Smoking) | 789 (28.77) | 104 (17.19) |
| Physical Inactive, n (%) | 2340 (85.38) | - |
| Hypertension, n (%) | - | 214 (35.37) |
| Hyperlipidemia, n (%) | - | 351 (58.02) |
| Metabolic Syndrom, n (%) | - | 392 (64.79) |
| NASH, n (%) | - | 537 (88.76) |
| Diabetes and NASH, n (%) | - | 207 (34.21) |
| Diabetes, n (%) | 223 (8.13) | 225 (37.19) |
| Predictor (Assigned Score) | Gifu NAFLD Dataset (T2D: Prediabetes Stage) (T2D Cases = 223, n = 2741) | NAFLD Dataset (T2D: Prediabetes + Diabetes Stages) (T2D Cases = 225, n = 605) | ||
|---|---|---|---|---|
| OR (95% CI) | p-Value | OR (95% CI) | p-Value | |
| Sex, Women | 1.05 (0.74–1.50) | 0.79 | 2.19 (1.57–3.07) | <0.001 |
| Age, year | ||||
| 35 ≤ Age < 45 | 1.68 (0.80–3.53) | 0.17 | 3.75 (1.84–7.62) | <0.001 |
| 45 ≤ Age < 60 | 2.03 (0.97–4.23) | 0.06 | 5.58 (2.85–10.91) | <0.001 |
| Age ≥ 60 | 2.13 (0.83–5.48) | 0.11 | 14.18 (6.23–32.26) | <0.001 |
| BMI, kg/m2 | ||||
| Overweight (23 ≤ BMI < 25) | 0.91 (0.57–1.44) | 0.68 | 1.15 (0.11–12.44) | 0.91 |
| Obese I (25 ≤ BMI < 30) | 1.53 (1.03–2.29) | 0.03 | 1.18 (0.12–11.58) | 0.89 |
| Obese II (BM ≥ 30) | 2.76 (1.66–4.56) | <0.001 | 2.24 (0.23–21.70) | 0.48 |
| WC ≥ 90 (Men), cm | 2.27 (1.67–3.09) | <0.001 | 1.63 (0.18–14.76) | 0.66 |
| ALT, U/L | 1.91 (1.31–2.78) | <0.001 | 0.50 (0.36–0.70) | <0.001 |
| AST, U/L | 1.50 (0.68–3.35) | <0.001 | 0.99 (0.36–1.40) | <0.001 |
| ALP, U/L | - | 0.77 (0.51–1.17) | <0.001 | |
| GGT, U/L | 1.52 (0.96–2.40) | <0.001 | 1.39 (0.99–1.96) | <0.001 |
| HDL, mg/dL | ||||
| Elevated in Men (40 ≤ HDL < 59) | 2.80 (1.01–7.72) | <0.001 | 0.78 (0.26–2.40) | 0.67 |
| Low in Men (HDL < 40) | 4.55 (1.64–12.60) | <0.001 | 0.81 (0.26–2.55) | 0.72 |
| Elevated in Women (50 ≤ HDL < 59) | 4.92 (1.39–17.41) | <0.001 | 0.88 (0.41–1.90) | 0.75 |
| Low in women (HDL < 50) | 5.54 (1.60–18.52) | <0.001 | 0.71 (0.36–1.42) | 0.34 |
| Total Cholesterol ≥ 240 (High), mg/dL | 1.65 (1.13–2.40) | 0.01 | 0.87 (0.57–1.32) | 0.51 |
| Triglyceride ≥ 240 (High), mg/dL | 2.19 (1.55–3.08) | <0.001 | 1.12 (0.77–1.64) | 0.55 |
| SBP ≥ 240 (High), mmHg | 4.53 (3.10–6.63) | <0.001 | 2.74 (1.63–4.61) | <0.001 |
| DBP ≥ 90 (High), mmHg | 1.41 (0.94–2.12) | <0.001 | 1.30 (0.81–2.06) | 0.26 |
| Alcohol Intake | ||||
| Level 2 | 1.11 (0.72–1.72) | 0.62 | - | - |
| Level 3 | 0.76 (0.45–1.29) | 0.31 | - | - |
| Level 4 | 0.93 (0.46–1.87) | 0.04 | - | - |
| Smoking | ||||
| Level 2 | 1.07 (0.74–1.55) | 0.70 | 0.97 (0.67–1.41) | 0.87 |
| Level 3 | 1.94 (1.44–2.69) | <0.001 | 0.92 (0.57–1.47) | 0.72 |
| Physical Inactive | 1.62 (1.03–2.55) | 0.04 | - | - |
| Hypertension, n (%) | - | - | 2.62 (1.85–3.70) | <0.001 |
| Hyperlipidemia, n (%) | - | - | 2.08 (1.47–2.94) | <0.001 |
| Metabolic Syndrom, n (%) | - | - | 4.38 (2.52–6.58) | <0.001 |
| Type of Disease = Severe Illness, n (%) | - | - | 1.83 (1.00–3.38) | 0.05 |
| NASH, n (%) | - | - | 1.74 (0.99–3.07) | 0.05 |
| Model Population | Gifu NAFLD Dataset (T2D: Prediabetes Stage) (T2D Cases = 223, n = 2741) | NAFLD Dataset (T2D: Prediabetes + Diabetes Stages) (T2D Cases = 225, n = 605) | ||
|---|---|---|---|---|
| Diagnostic Test | FPG | HbA1c | FPG | HbA1c |
| Cut point as recommended by WHO or ADA (a) | 100 | 5.7 | 100 | 5.7 |
| Youden Index-based optimal cut point (b) | 99.50 | 5.426 | 111.50 | 5.960 |
| Sensitivity and Specificity-based optimal cut point (c) | 100.50 | 5.426 | 103.50 | 5.885 |
| Percentage of high risk based on a/b/c | 5.91/5.91/5.47 | 3.14/5.36/5.36 | 51.75/30.62/42.67 | 56.91/40.60/46.10 |
| Sensitivity, based on a/b/c (%) | 72.65/72.65/67.26 | 38.57/65.92/65.92 | 83.33/67.12/77.03 | 82.95/73.27/75.12 |
| Specificity, based on a/b/c (%) | 63.66/63.66/68.39 | 88.80/68.51/68.51 | 66.75/90.77/77.31 | 59.37/79.83/72.05 |
| PPV, based on a/b/c (%) | 15.04/15.04/15.86 | 23.37/15.64/15.64 | 59.49/80.98/66.54 | 56.07/69.43/62.69 |
| NPV, based on a/b/c (%) | 96.33/96.33/95.93 | 94.23/95.78/95.78 | 87.24/82.49/85.17 | 84.77/82.69/82.24 |
| LR+, based on a/b/c (%) | 2.00/2.00/2.13 | 3.44/2.09/2.09 | 2.51/7.27/3.39 | 2.04/3.63/2.69 |
| LR−, based on a/b/c (%) | 0.43/0.43/0.48 | 0.69/0.50/0.50 | 0.25/0.36/0.30 | 0.29/0.33/0.35 |
| Accuracy, based on a/b/c (%) | 64.39/64.39/68.30 | 84.71/68.30/68.30 | 72.88/82.03/77.20 | 68.44/53.10/73.23 |
| Youden Index, based on a/b/c (%) | 36.31/36.31/35.65 | 27.37/34.43/34.43 | 50.09/57.88/54.34 | 42.32/53.10/47.16 |
| Standard error | 0.018 | 0.018 | 0.018 | 0.020 |
| p-value (CST, HLT) | <0.001, 0.514 | <0.001, 0.214 | <0.001, 0.000 | <0.001, 0.000 |
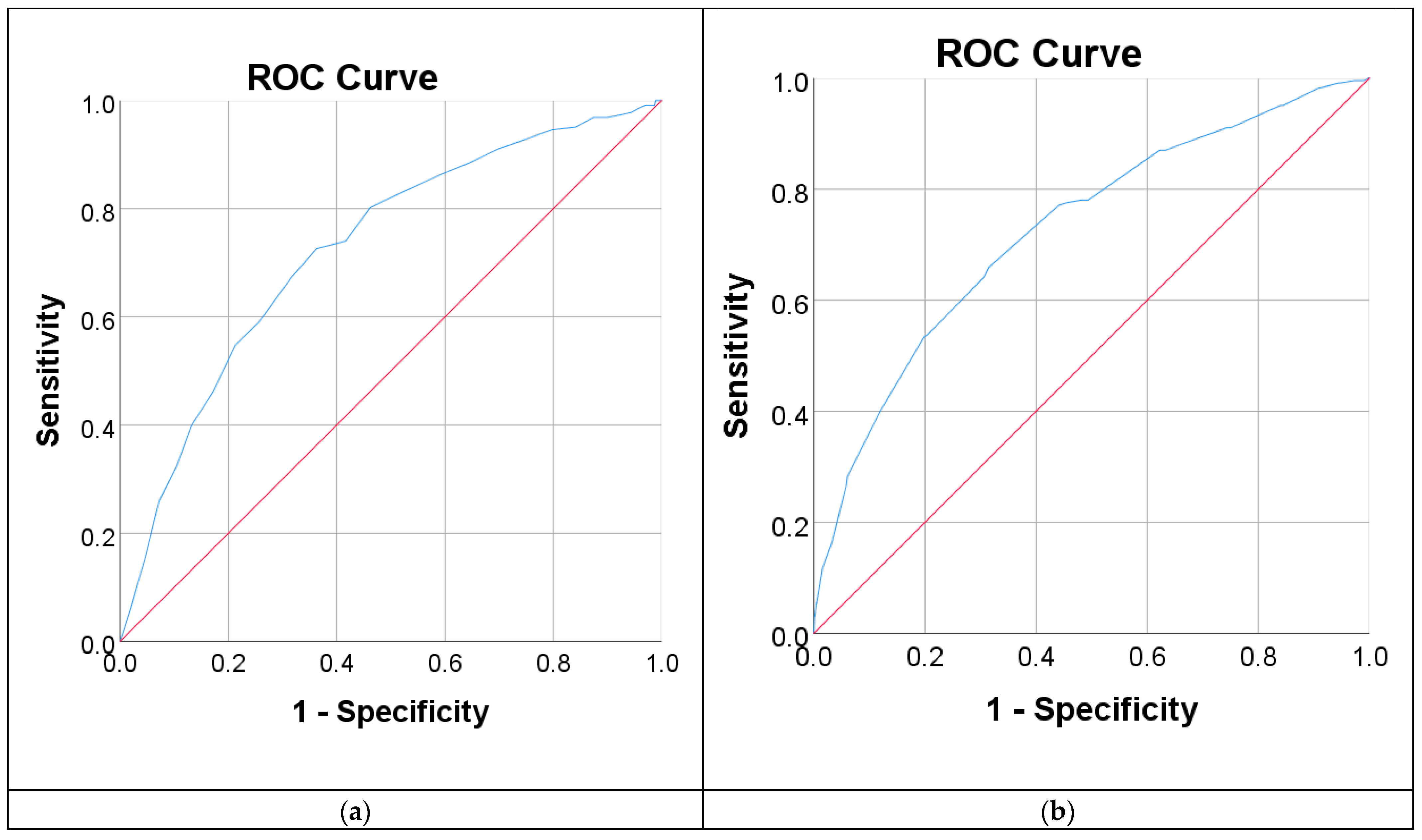
| 95% CI of AUC | 0.69–0.76 | 0.69–0.76 | 0.81–0.89 | 0.78–0.87 |
| AUC | 0.73 | 0.73 | 0.85 | 0.82 |
| RMSE | 0.998 | 0.999 | 0.856 | 0.849 |
| 0.990 | 0.806 | |||
| GM ± SD | 1.89 ± 1.273 | 1.53 ± 0.487 | ||
| Dataset | Characteristics | |||
|---|---|---|---|---|
| Size | Number of Original Features | Number of Class | Number of Selected Features | |
| Gifu NAFLD dataset | 2741 | 30 | 2 | 7 |
| NAFLD dataset | 605 | 62 | 11 | 13 |
| Model | 95% CI of Precision (%) | 95% CI of Recall (%) | 95% CI of F1 (%) | 95% CI of Accuracy (%) | ||||
|---|---|---|---|---|---|---|---|---|
| Before FS | After FS | Before FS | After FS | Before FS | After FS | Before FS | After FS | |
| LR | 49.81–59.89 | 54.38–65.62 | 48.16–57.91 | 46.25–55.81 | 45.40–58.92 | 43.35–56.54 | 83.12–100.00 | 83.44–100.00 |
| KNN | 52.22–62.79 | 61.91–74.71 | 46.93–56.43 | 48.37–58.37 | 44.51–58.05 | 46.75–60.98 | 82.29–99.37 | 82.15–99.55 |
| DT | 47.48–57.09 | 47.81–57.48 | 47.21–56.77 | 48.37–58.37 | 45.40–58.92 | 44.80–58.44 | 72.84–87.95 | 72.78–88.20 |
| XGB | 46.26–55.63 | 47.38–47.17 | 43.60–52.55 | 45–53–54.95 | 42.20–54.77 | 43.07–56.19 | 75.97–91.73 | 80.05–97.00 |
| SVM | 41.89–50.36 | 41.81–50.45 | 45.60–54.83 | 47.15–56.67 | 42.03–54.54 | 47.13–56.67 | 83.59–100.00 | 83.44–100.00 |
| MLP | 47.38–61.48 | 73.45–88.64 | 49.02–58.94 | 48.96–59.10 | 48.14–62.47 | 48.14–62.47 | 82.32–99.40 | 83.68–100.00 |
| Model | 95% CI of Precision (%) | 95% CI of Recall (%) | 95% CI of F1 (%) | 95% CI of Accuracy (%) | ||||
|---|---|---|---|---|---|---|---|---|
| Before FS | After FS | Before FS | After FS | Before FS | After FS | Before FS | After FS | |
| LR | 73.29–85.43 | 78.02–90.56 | 70.10–81.71 | 79.10–83.73 | 67.80–84.21 | 72.72–89.78 | 70.64–84.96 | 75.70–90.71 |
| KNN | 61.76–71.99 | 72.68–69.83 | 59.91–69.83 | 68.60–79.63 | 58.00–71.61 | 67.02–82.75 | 60.72–73.03 | 71.95–85.01 |
| DT | 66.29–77.27 | 68.74–80.13 | 65.25–76.06 | 67.99–78.93 | 62.64–77.80 | 65.90–81.37 | 64.92–78.07 | 68.49–82.05 |
| XGB | 74.77–87.16 | 76.34–88.61 | 67.19–78.32 | 75.15–87.23 | 71.52–88.83 | 73.09–90.02 | 73.75–88.69 | 75.34–90.28 |
| SVM | 71.58–83.43 | 76.22–88.47 | 67.22–88.69 | 71.30–83.11 | 65.43–81.26 | 69.87–86.27 | 68.67–82.59 | 73.40–87.95 |
| MLP | 68.37–84.92 | 78.08–90.63 | 70.61–82.30 | 74.94–86.99 | 68.37–84.92 | 72.99–90.65 | 70.86–85.22 | 75.87–90.91 |
| Dataset | Improvement Score (%) | |||
|---|---|---|---|---|
| Precision | Recall | F1 | Accuracy | |
| Gifu NAFLD dataset | 10.40 | 0.04 | 0.89 | 1.65 |
| NAFLD dataset | 4.94 | 4.51 | 5.17 | 5.35 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fitriyani, N.L.; Syafrudin, M.; Ulyah, S.M.; Alfian, G.; Qolbiyani, S.L.; Yang, C.-K.; Rhee, J.; Anshari, M. Performance Analysis and Assessment of Type 2 Diabetes Screening Scores in Patients with Non-Alcoholic Fatty Liver Disease. Mathematics 2023, 11, 2266. https://doi.org/10.3390/math11102266
Fitriyani NL, Syafrudin M, Ulyah SM, Alfian G, Qolbiyani SL, Yang C-K, Rhee J, Anshari M. Performance Analysis and Assessment of Type 2 Diabetes Screening Scores in Patients with Non-Alcoholic Fatty Liver Disease. Mathematics. 2023; 11(10):2266. https://doi.org/10.3390/math11102266
Chicago/Turabian StyleFitriyani, Norma Latif, Muhammad Syafrudin, Siti Maghfirotul Ulyah, Ganjar Alfian, Syifa Latif Qolbiyani, Chuan-Kai Yang, Jongtae Rhee, and Muhammad Anshari. 2023. "Performance Analysis and Assessment of Type 2 Diabetes Screening Scores in Patients with Non-Alcoholic Fatty Liver Disease" Mathematics 11, no. 10: 2266. https://doi.org/10.3390/math11102266
APA StyleFitriyani, N. L., Syafrudin, M., Ulyah, S. M., Alfian, G., Qolbiyani, S. L., Yang, C.-K., Rhee, J., & Anshari, M. (2023). Performance Analysis and Assessment of Type 2 Diabetes Screening Scores in Patients with Non-Alcoholic Fatty Liver Disease. Mathematics, 11(10), 2266. https://doi.org/10.3390/math11102266