
DARI-Mark: Deep Learning and Attention Network for Robust Image Watermarking




Abstract
1. Introduction
- (1)
- We introduce the attention network, which makes watermark embedding focus on the edge and other areas with complex texture, and the watermark extraction pays more attention to watermarked features and suppresses noise signals. This greatly improves the imperceptibility and robustness of DARI-Mark.
- (2)
- We add the residual module to avoid gradient explosion or disappearance problems in deep neural networks.
- (3)
- We establish an end-to-end network framework and add the attack layer between watermark embedding and extraction networks to improve the robustness against multiple attacks (JPEG compression, sharpening, cropping, Gaussian noise, salt-and-pepper noise, scaling) through iterative training.
2. Related Work
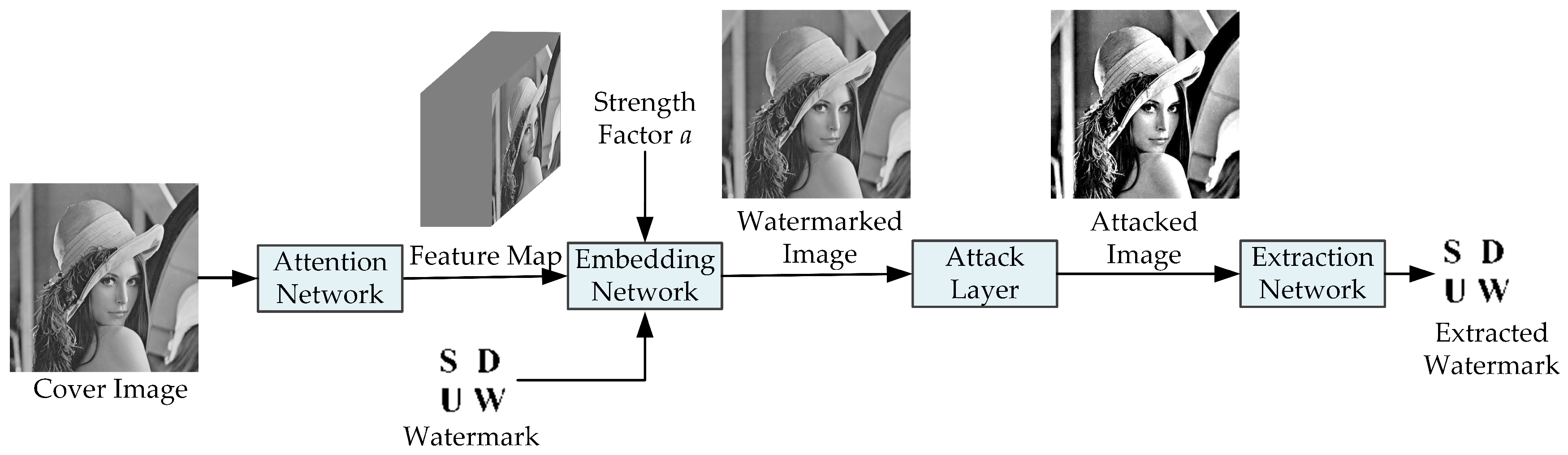
3. Proposed Framework
- (1)
- An attention network, which finds complex regions of texture that are insensitive to the human eye to embed the watermark during watermark embedding, focuses on watermark-related features, and suppresses noise signals during watermark extraction.
- (2)
- A watermark embedding network, which is responsible for embedding the watermark.
- (3)
- An attack layer, which simulates attacks that are commonly encountered in the actual communication process and improves the robustness of the framework through end-to-end training.
- (4)
- A watermark extraction network, which is responsible for the extraction of watermark information.
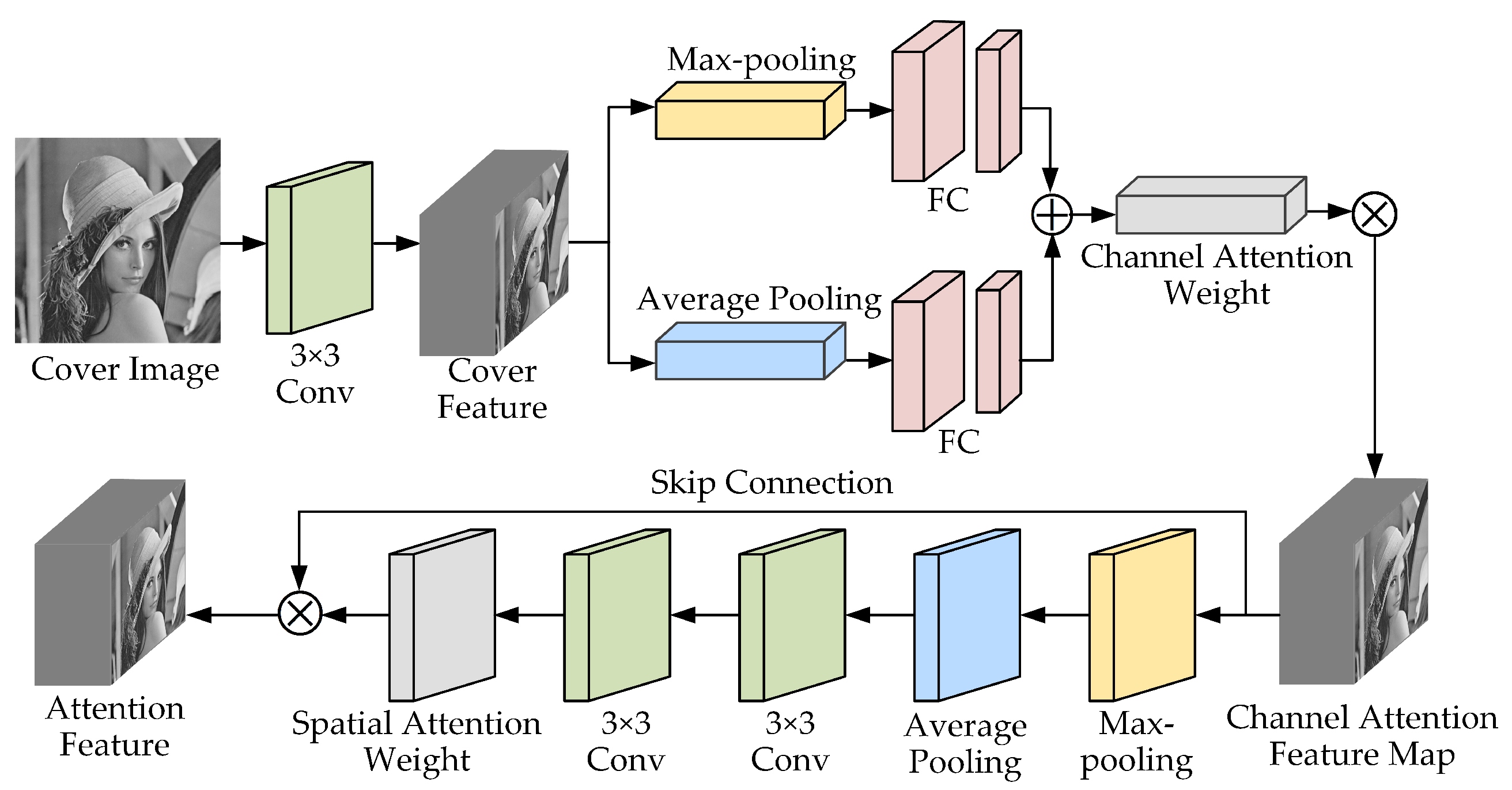
3.1. Attention Network
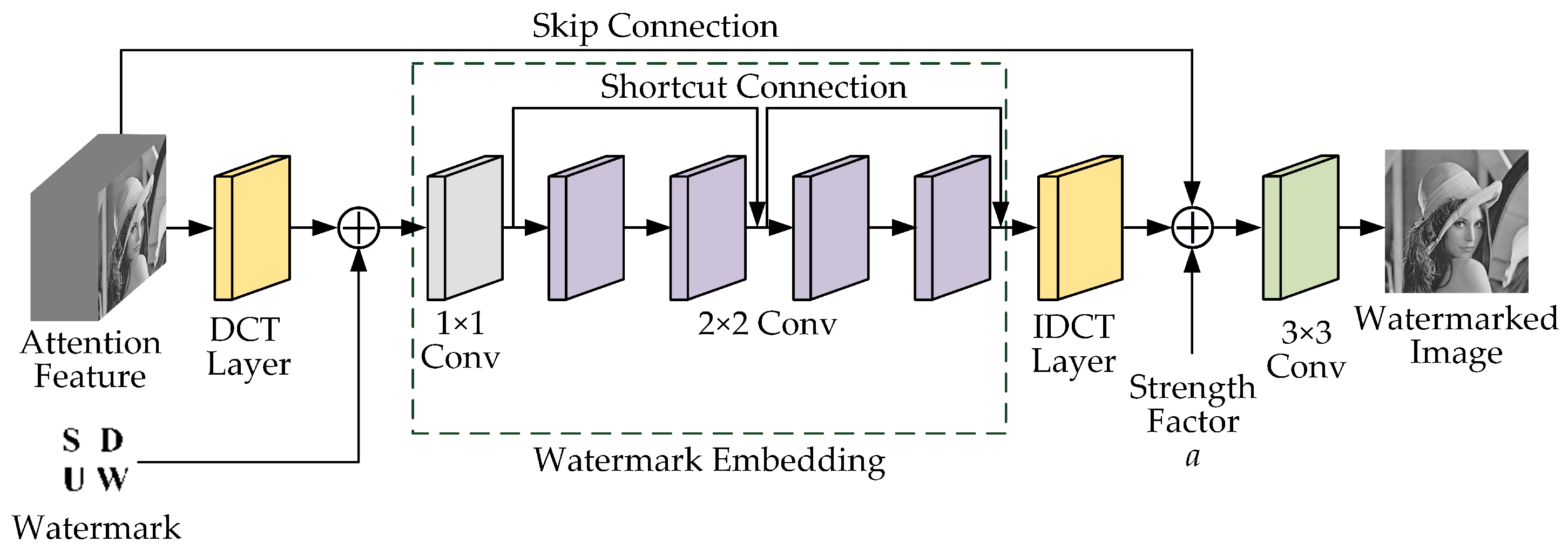
3.2. Embedding Network
- (1)
- DCT layer: A DCT is performed on the attention feature map generated by the attention network. This is because embedding the watermark in the DCT is consistent with the frequency-masking effect of the HVS, and the human eye has a large acceptable range of changes.
- (2)
- Watermark embedding: The network structure is a Conv and four Conv. Each Conv includes convolution, batch normalization, and ReLU activation functions, and the number of convolution kernels is 64. The input is the frequency-domain information after the DCT transformation and watermark information, and the output is the information after the feature fusion. The 1 × 1 convolutional layer is to change the dimension of the tensor. The 2 × 2 convolutional layers embed the watermark data into bottom features. The convolutional layers are designed as residual structures, with each residual structure corresponding to two convolutional layers, that is, a shortcut connection is added every two layers.
- (3)
- Inverse DCT (IDCT): an inverse DCT is performed on the tensor generated by the watermark embedding network to transform it from the frequency domain back to the spatial domain.
- (4)
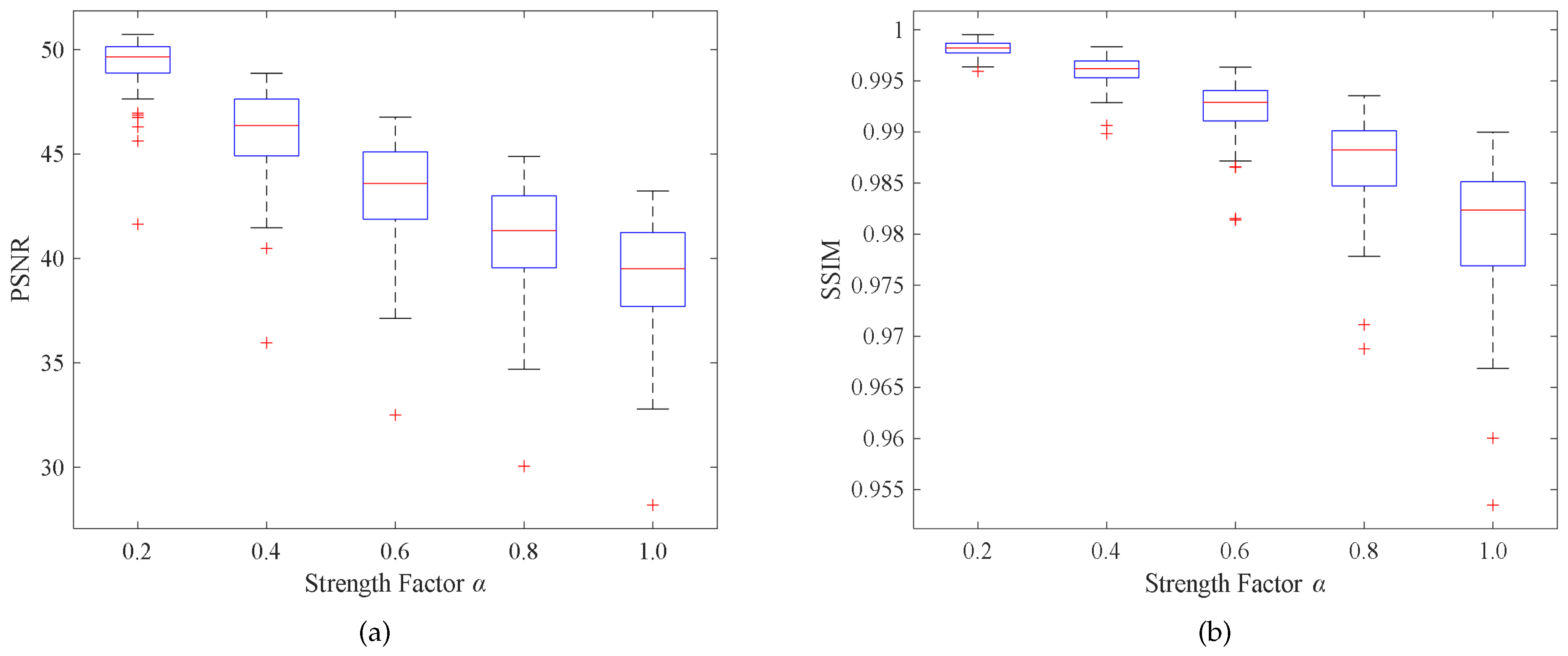
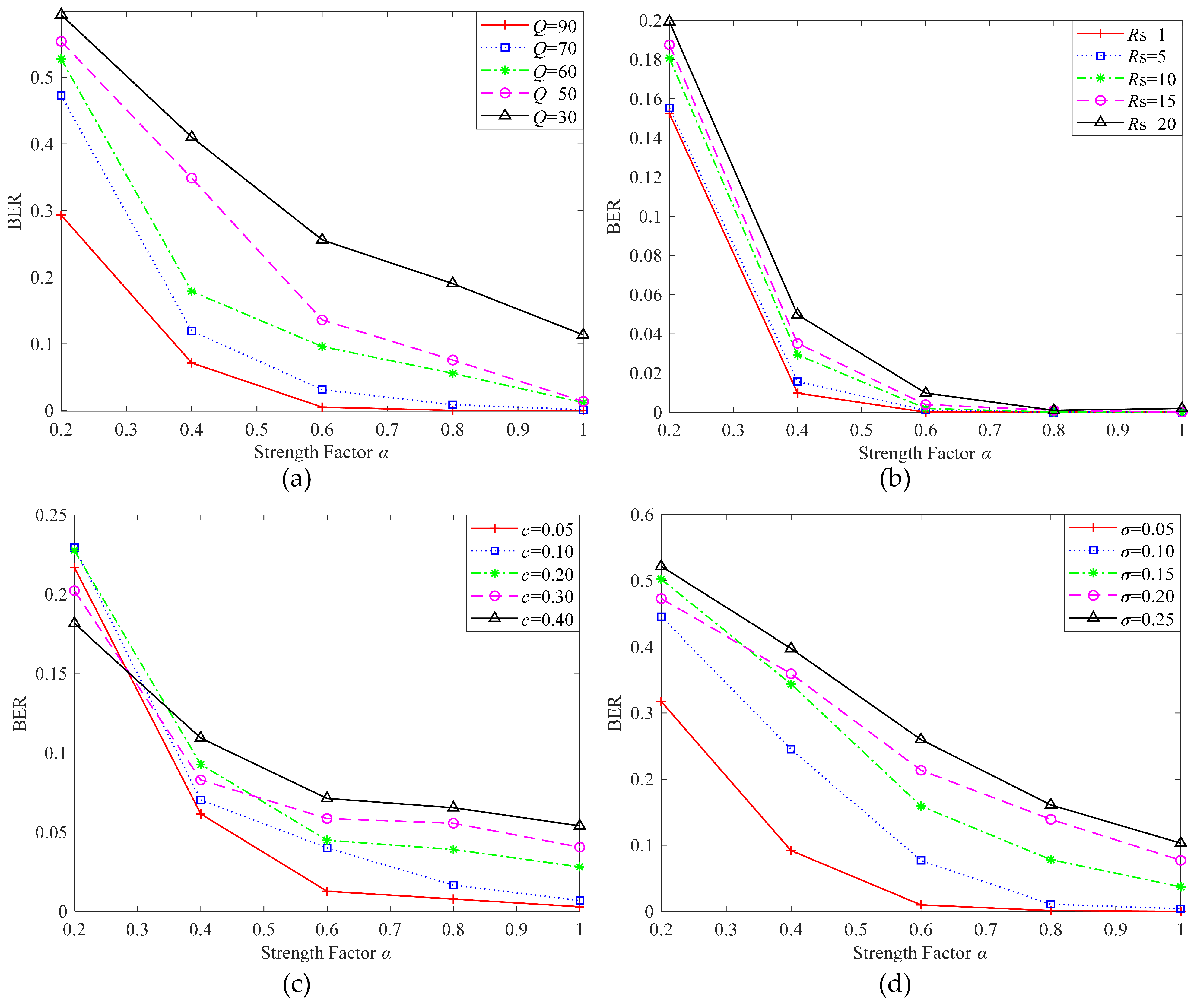
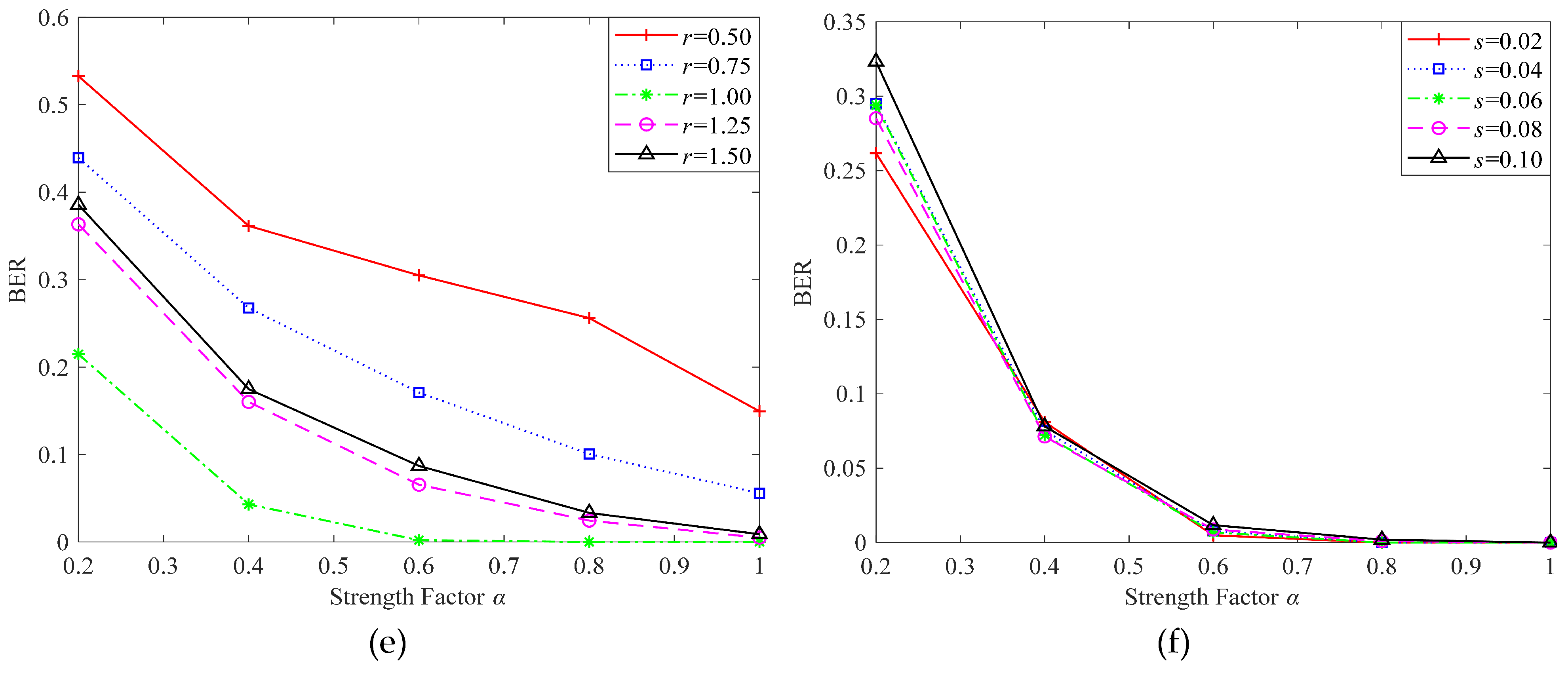
- Embedding strength factor : The embedding strength factor controls the embedding strength of the watermark, achieving the balance between imperceptibility and robustness. The tensor generated in step (3) is multiplied by and then added to the attention feature map to generate the watermarked tensor. The experimental results showed that with the increase of , the robustness was enhanced. To enhance the robustness of the algorithm, was taken as 1.0 in the training phase. In the actual application phase, can be appropriately adjusted according to application requirements.
- (5)
- A Conv: The number of convolution kernels is 1. The input is the output of step (4), and the output is the watermarked image with a size of , the same as that of the cover image.
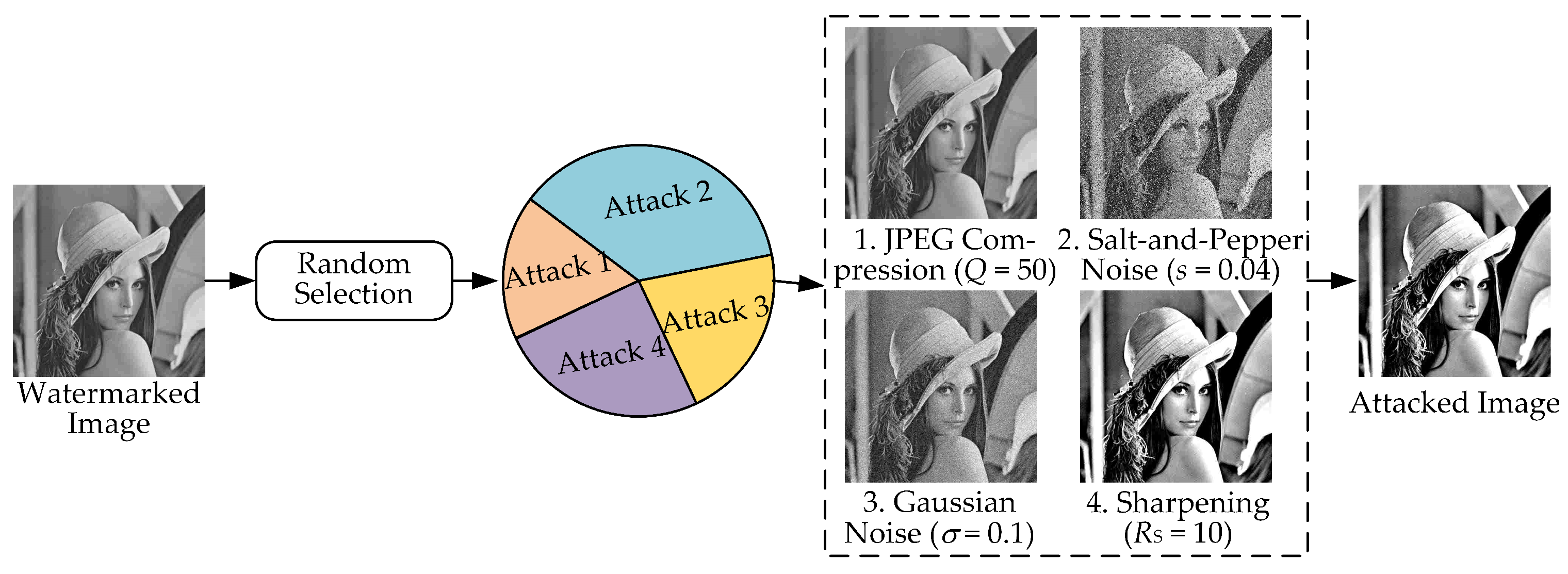
3.3. Attack Layer
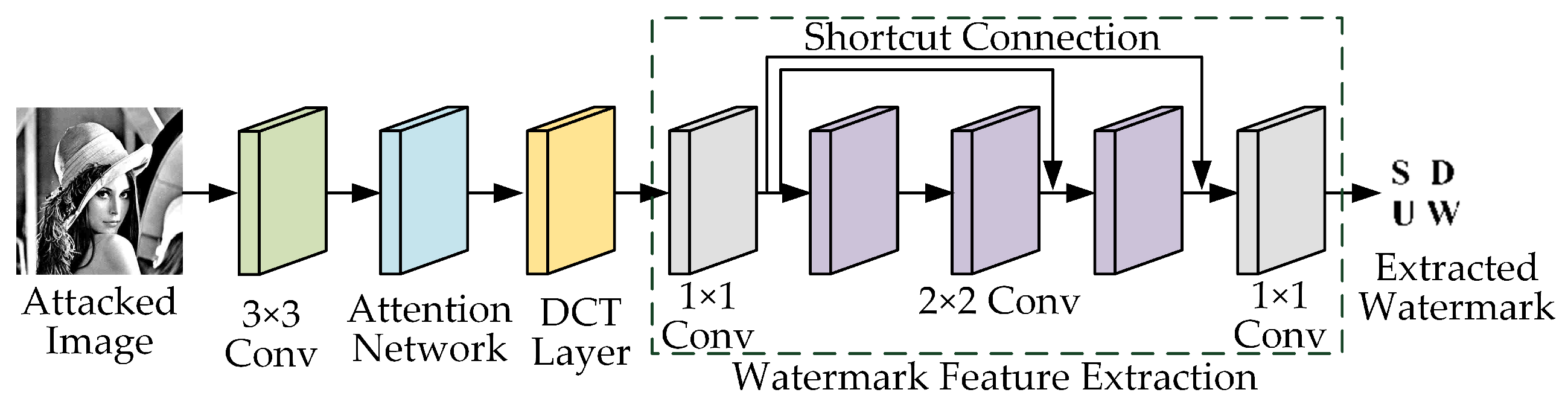
3.4. Extraction Network
- (1)
- A Conv: change the attacked image from to .
- (2)
- Attention network: The tensor with 64 channels is fed into the attention network to obtain the attention feature map. The attention feature map is used to provide the watermark feature extraction network with areas to focus on and to suppress.
- (3)
- DCT: This is the same as step (1) of the embedding network. Because the watermark information is embedded in the frequency domain, the image features are first changed from the spatial domain to the frequency domain.
- (4)
- Watermark feature extraction: The input is the DCT transformed tensor, and the output is the extracted watermark. The convolutional network parameters setting are basically consistent with the embedded network. Each Conv includes convolution, batch normalization, and ReLU activation functions. Since the final output is a watermark image with the channel number of 1, the number of convolution kernels in the last layer is set to 1. As with the watermark embedding, the convolutional layers are also designed as residual structures, and since there are only three layers of convolution, two residual structures are designed, corresponding to two and three convolutional layers, respectively.
3.5. Training Details
4. Experimental Results and Analysis
4.1. Dataset
4.2. Evaluation Metrics
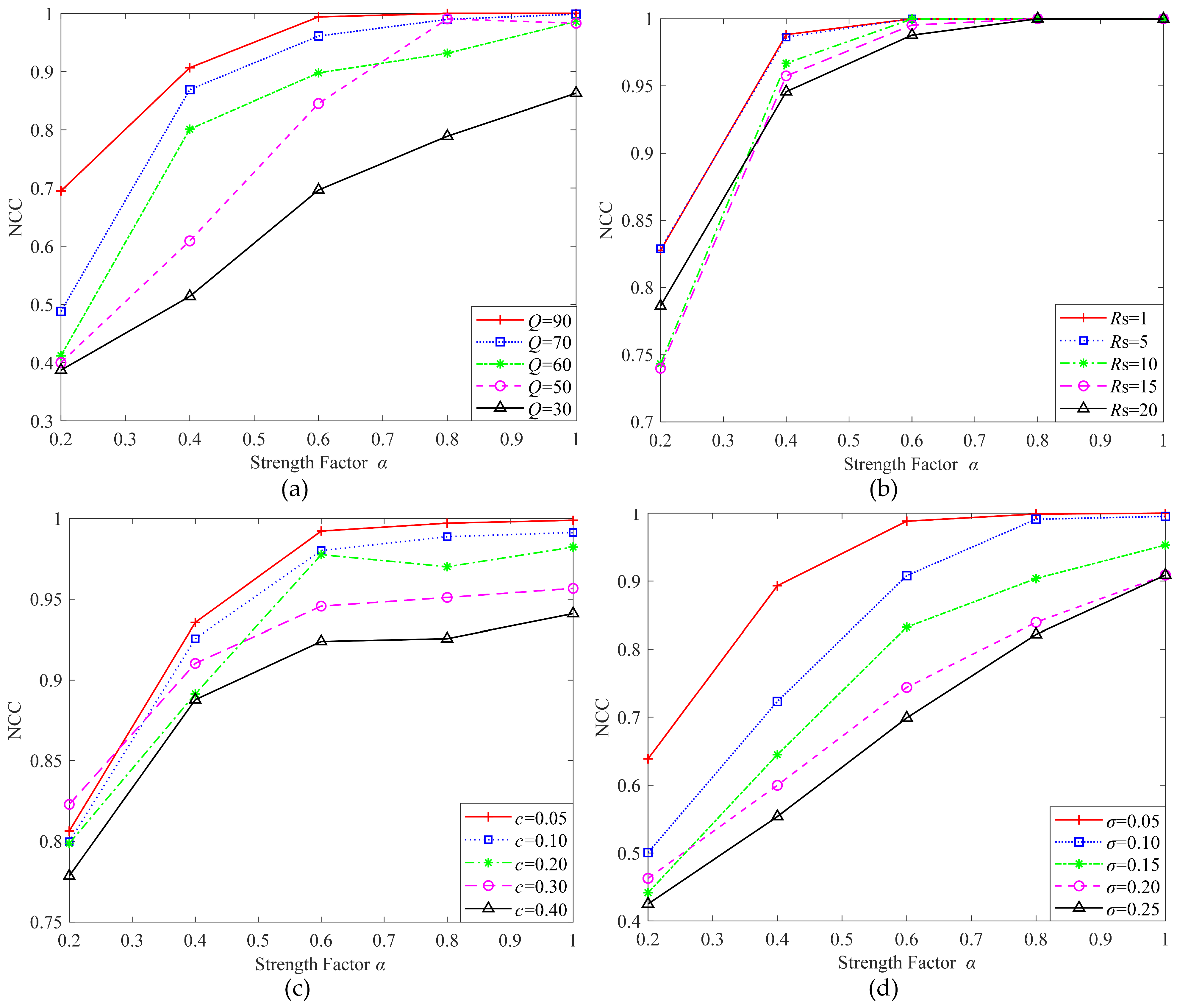
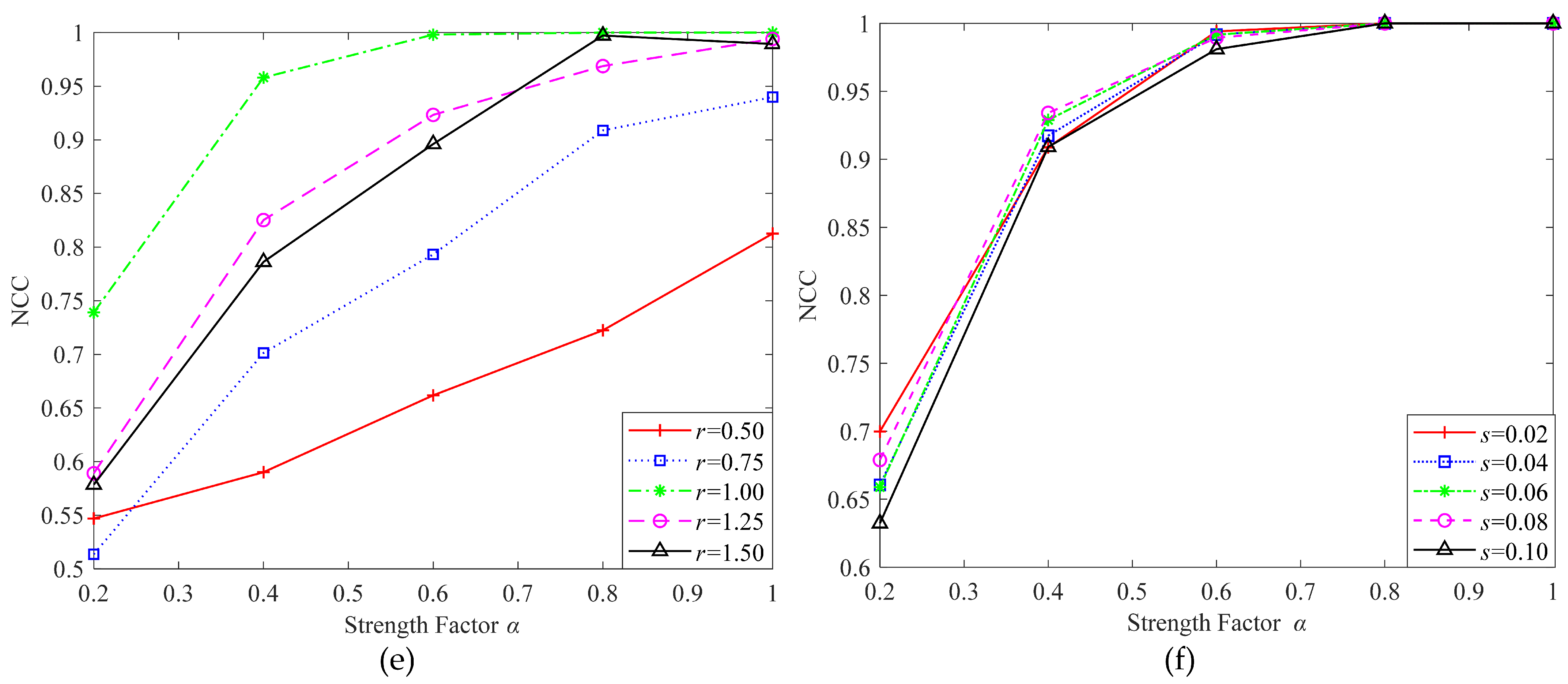
4.3. Results
4.4. Comparison with the State-of-the-Art Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zheng, Q.; Liu, N.; Wang, F. An adaptive embedding strength watermarking algorithm based on shearlets’ capture directional features. Mathematics 2020, 8, 1377. [Google Scholar] [CrossRef]
- Wu, H.Z.; Shi, Y.Q.; Wang, H.X.; Zhou, L.N. Separable reversible data hiding for encrypted palette images with color partitioning and flipping verification. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 1620–1631. [Google Scholar] [CrossRef]
- Mahto, D.K.; Singh, A. A survey of color image watermarking: State-of-the-art and research directions. Comput. Electr. Eng. 2021, 93, 107255. [Google Scholar] [CrossRef]
- Verma, V.S.; Jha, R.K. An overview of robust digital image watermarking. IETE Tech. Rev. 2015, 32, 479–496. [Google Scholar] [CrossRef]
- Faheem, Z.B.; Ali, M.; Raza, M.A.; Arslan, F.; Ali, J.; Masud, M.; Shorfuzzaman, M. Image watermarking scheme using LSB and image gradient. Appl. Sci. 2022, 12, 4202. [Google Scholar] [CrossRef]
- Li, Y.; Li, J.; Shao, C.; Bhatti, U.A.; Ma, J. Robust multi-watermarking algorithm for medical images using patchwork-DCT. In Proceedings of the 8th International Conference on Artificial Intelligence and Security, Xining, China, 15–20 July 2022; Lecture Notes in Computer Science. Springer: Berlin, Germany, 2018; Volume 13340, pp. 386–399. [Google Scholar]
- Ernawan, F.; Ariatmanto, D.; Firdaus, A. An improved image watermarking by modifying selected DWT-DCT coefficients. IEEE Access 2021, 9, 45474–45485. [Google Scholar] [CrossRef]
- Wang, B.; Zhao, P. An adaptive image watermarking method combining SVD and Wang-Landau sampling in DWT domain. Mathematics 2020, 8, 691. [Google Scholar] [CrossRef]
- Cedillo-Hernandez, M.; Cedillo-Hernandez, A.; Garcia-Ugalde, F.J. Improving DFT-based image watermarking using particle swarm optimization algorithm. Mathematics 2021, 9, 1795. [Google Scholar] [CrossRef]
- Shekhar, H.; Seal, S.; Kedia, S.; Guha, A. Survey on applications of machine learning in the field of computer vision. In Proceedings of the 1st International Conference on Emerging Technology in Modelling and Graphics, Kolkata, India, 6–7 September 2020; Volume 937, pp. 667–678. [Google Scholar]
- Rai, A.; Singh, H.V. SVM based robust watermarking for enhanced medical image security. Multimed. Tools Appl. 2017, 76, 18605–18618. [Google Scholar] [CrossRef]
- Singh, R.P.; Dabas, N.; Chaudhary, V.; Nagendra. Online sequential extreme learning machine for watermarking in DWT domain. Neurocomputing 2016, 174, 238–249. [Google Scholar] [CrossRef]
- Mehta, R.; Rajpal, N.; Vishwakarma, V.P. A robust and efficient image watermarking scheme based on Lagrangian SVR and lifting wavelet transform. Int. J. Mach. Learn. Cybern. 2017, 8, 379–395. [Google Scholar] [CrossRef]
- Abdelhakim, A.M.; Abdelhakim, M. A time-efficient optimization for robust image watermarking using machine learning. Expert Syst. Appl. 2018, 100, 197–210. [Google Scholar] [CrossRef]
- Kannan, D.; Gobi, M. An extensive research on robust digital image watermarking techniques: A review. Int. J. Signal Imaging Syst. Eng. 2015, 8, 89–104. [Google Scholar] [CrossRef]
- Hassanin, M.; Anwar, S.; Radwan, I.; Khan, F.S.; Mian, A. Visual attention methods in deep learning: An in-depth survey. arXiv 2022, arXiv:2204.07756. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Lecture Notes in Computer Science. Springer: Berlin, Germany, 2018; Volume 11211, pp. 3–19. [Google Scholar]
- Kandi, H.; Mishra, D.; Gorthi, S.R.S. Exploring the learning capabilities of convolutional neural networks for robust image watermarking. Comput. Secur. 2017, 65, 247–268. [Google Scholar] [CrossRef]
- Zhu, J.; Kaplan, R.; Johnson, J.; Fei, L.F. HiDDeN: Hiding data with deep networks. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Lecture Notes in Computer Science. Springer: Berlin, Germany, 2018; Volume 11219, pp. 682–697. [Google Scholar]
- Mun, S.M.; Nam, S.H.; Jang, H.; Kim, D.; Lee, H.K. Finding robust domain from attacks: A learning framework for blind watermarking. Neurocomputing 2019, 337, 191–202. [Google Scholar] [CrossRef]
- Liu, Y.; Guo, M.; Zhang, J.; Zhu, Y.; Xie, X. A novel two-stage separable deep learning framework for practical blind watermarking. In Proceedings of the ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1509–1517. [Google Scholar]
- Luo, X.; Zhan, R.; Chang, H.; Yang, F.; Milanfar, P. Distortion agnostic deep watermarking. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13545–13554. [Google Scholar]
- Lee, J.E.; Seo, Y.H.; Kim, D.W. Convolutional neural network-based digital image watermarking adaptive to the resolution of image and watermark. Appl. Sci. 2020, 10, 6854. [Google Scholar] [CrossRef]
- Ahmadi, M.; Norouzi, A.; Karimi, N.; Samavi, S.; Emami, A. ReDMark: Framework for residual diffusion watermarking based on deep networks. Expert Syst. Appl. 2020, 146, 113157. [Google Scholar] [CrossRef]
- Jia, Z.; Fang, H.; Zhang, W. MBRS: Enhancing robustness of DNN-based watermarking by mini-batch of real and simulated JPEG compression. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Online, China, 20–24 October 2021; pp. 41–49. [Google Scholar]
- Zhong, X.; Huang, P.C.; Mastorakis, S.; Shih, F.Y. An automated and robust image watermarking scheme based on deep neural networks. IEEE Trans. Multimed. 2021, 23, 1951–1961. [Google Scholar] [CrossRef]
- Sun, W.; Zhou, J.; Li, Y.; Cheung, M.; She, J. Robust high-capacity watermarking over online social network shared images. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 1208–1221. [Google Scholar] [CrossRef]
- Yang, Y.; Zou, T.; Huang, G.; Zhang, W. A high visual quality color image reversible data hiding scheme based on B-R-G embedding principle and CIEDE2000 assessment metric. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1860–1874. [Google Scholar] [CrossRef]
- Yu, C. Attention based data hiding with generative adversarial networks. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 1120–1128. [Google Scholar]
- Bhowmik, D.; Oakes, M.; Abhayaratne, C. Visual attention-based image watermarking. IEEE Access 2016, 4, 8002–8018. [Google Scholar] [CrossRef]
- Bas, P.; Filler, T.; Pevny, T. “Break our steganographic system”: The ins and outs of organizing BOSS. In Proceedings of the 13th International Conference on Information Hiding, Prague, Czech Republic, 18–20 May 2011; Lecture Notes in Computer Science. Springer: Berlin, Germany, 2011; Volume 6958, pp. 59–70. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2009. [Google Scholar]
- Fdez-Vidal, X.R. Dataset of Standard 512 × 512 Grayscale Test Images. 2019. Available online: https://decsai.ugr.es/cvg/CG/base.htm (accessed on 18 November 2020).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Setting |
|---|---|
| Learning rate | 0.0001 |
| Momentum | 0.98 |
| Batch size | 32 |
| Iteration | 10,000 |
| Epoch | 100 |
| Methods | PSNR (dB) |
|---|---|
| Lee et al. [24] | 35.46 |
| ReDMark [25] | 35.93 |
| DARI-Mark | 37.38 |
| Attack | Lee et al. [24] | ReDMark [25] | DARI-Mark | ||||
|---|---|---|---|---|---|---|---|
| BER (%) | NCC | BER (%) | NCC | BER (%) | NCC | ||
| JPEG compression | Q = 50 | 8.06 | 0.9055 | 3.03 | 0.9698 | 1.36 | 0.9832 |
| Q = 70 | 4.24 | 0.9601 | 1.60 | 0.9799 | 0.00 | 1.0000 | |
| Q = 90 | 0.96 | 0.9988 | 0.00 | 1.0000 | 0.00 | 1.0000 | |
| Sharpening | = 1 | 0.98 | 0.9894 | 0.95 | 0.9892 | 0.00 | 1.0000 |
| = 5 | 1.72 | 0.9799 | 1.47 | 0.9823 | 0.00 | 1.0000 | |
| = 10 | 2.01 | 0.9763 | 3.42 | 0.9599 | 0.00 | 1.0000 | |
| = 20 | 3.51 | 0.9575 | 4.98 | 0.9457 | 0.19 | 0.9998 | |
| Cropping | c = 0.10 | 4 | 0.954 | 2.14 | 0.974 | 0.68 | 0.9917 |
| c = 0.20 | 5.46 | 0.9386 | 5.33 | 0.9321 | 3.81 | 0.9499 | |
| c = 0.30 | 17.10 | 0.8216 | 8.67 | 0.9008 | 4.05 | 0.9567 | |
| Gaussian noise | = 0.05 | 5.99 | 0.9706 | 0.30 | 0.9943 | 0.09 | 0.9988 |
| = 0.15 | 27.00 | 0.6802 | 5.08 | 0.9399 | 3.71 | 0.9563 | |
| = 0.25 | 38.17 | 0.5702 | 12.73 | 0.8571 | 10.30 | 0.9088 | |
| Scaling | r = 0.50 | 10.98 | 0.8796 | 5.92 | 0.9711 | 14.47 | 0.8343 |
| r = 0.75 | 3.36 | 0.9599 | 0.00 | 1.0000 | 5.56 | 0.9399 | |
| r = 1.50 | 1.53 | 0.9832 | 0.00 | 1.0000 | 0.48 | 0.9953 | |
| Salt-and- pepper noise | s = 0.04 | 0.29 | 0.9965 | 1.45 | 0.9802 | 0.00 | 1.0000 |
| s = 0.06 | 1.53 | 0.9832 | 1.17 | 0.9858 | 0.00 | 1.0000 | |
| s = 0.10 | 3.19 | 0.9621 | 3.51 | 0.9600 | 0.00 | 1.0000 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Wang, C.; Zhou, X.; Qin, Z. DARI-Mark: Deep Learning and Attention Network for Robust Image Watermarking. Mathematics 2023, 11, 209. https://doi.org/10.3390/math11010209
Zhao Y, Wang C, Zhou X, Qin Z. DARI-Mark: Deep Learning and Attention Network for Robust Image Watermarking. Mathematics. 2023; 11(1):209. https://doi.org/10.3390/math11010209
Chicago/Turabian StyleZhao, Yimeng, Chengyou Wang, Xiao Zhou, and Zhiliang Qin. 2023. "DARI-Mark: Deep Learning and Attention Network for Robust Image Watermarking" Mathematics 11, no. 1: 209. https://doi.org/10.3390/math11010209
APA StyleZhao, Y., Wang, C., Zhou, X., & Qin, Z. (2023). DARI-Mark: Deep Learning and Attention Network for Robust Image Watermarking. Mathematics, 11(1), 209. https://doi.org/10.3390/math11010209