
Spatiotemporal Adaptive Fusion Graph Network for Short-Term Traffic Flow Forecasting




Abstract
:1. Introduction
- We design the temporal adjacency matrix to effectively capture temporal distances of the traffic flow, and the adaptive matrix to exploit hidden spatial dependency in the static graph structure.
- We propose the spatial–temporal adaptive fusion graph network (STAFGN) to exploit spatial–temporal dependencies simultaneously by fusing the spatial and temporal graphs into a large adjacency matrix.
- We evaluate our model on two real-word traffic datasets with extensive experiments. The case study demonstrates that the STAFGN outperforms the state-of-the art methods.
2. Related Works
2.1. Traffic Flow Forecasting
2.2. Graph Convolution Networks
2.3. Fast-DTW
2.4. ReZero
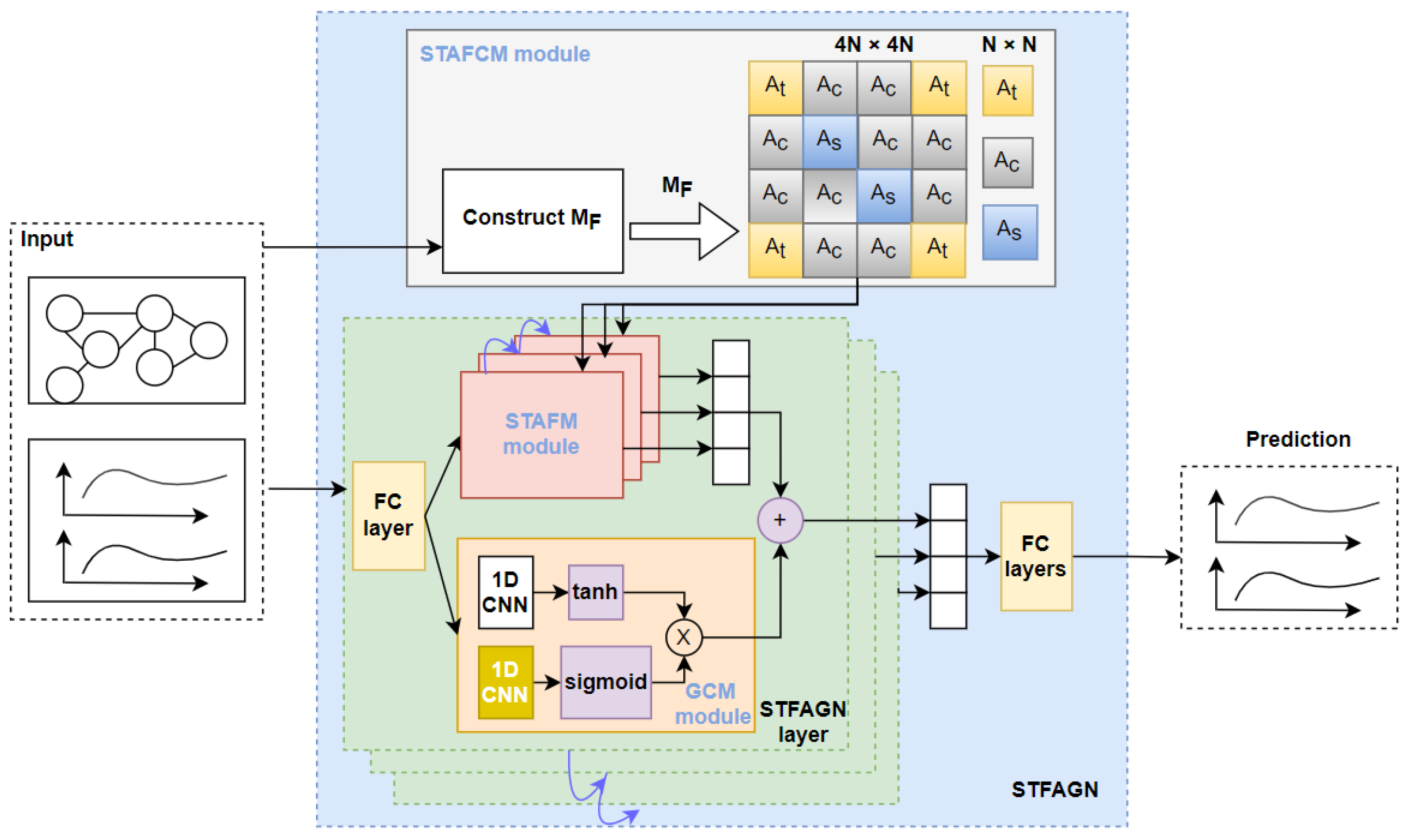
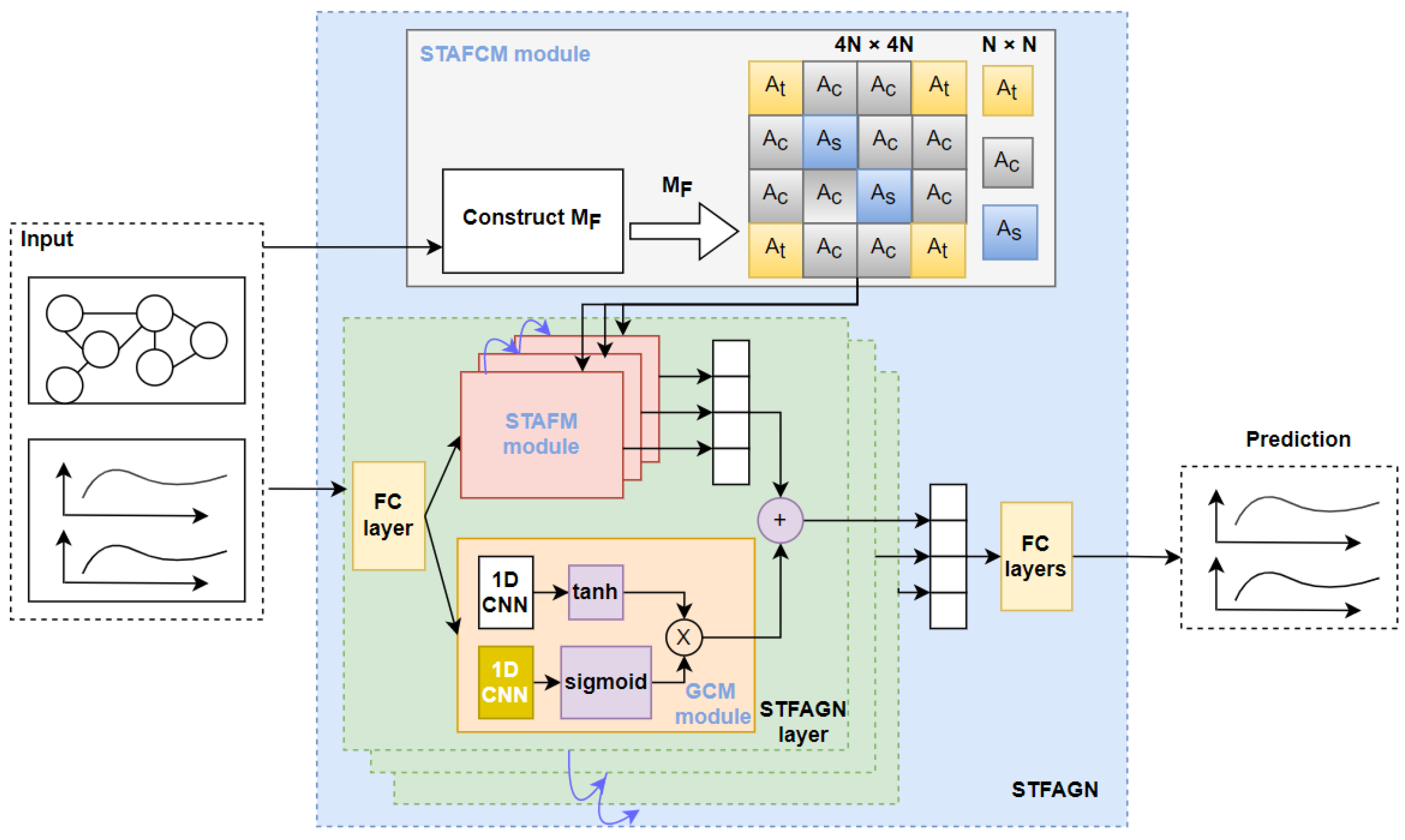
3. Methodology
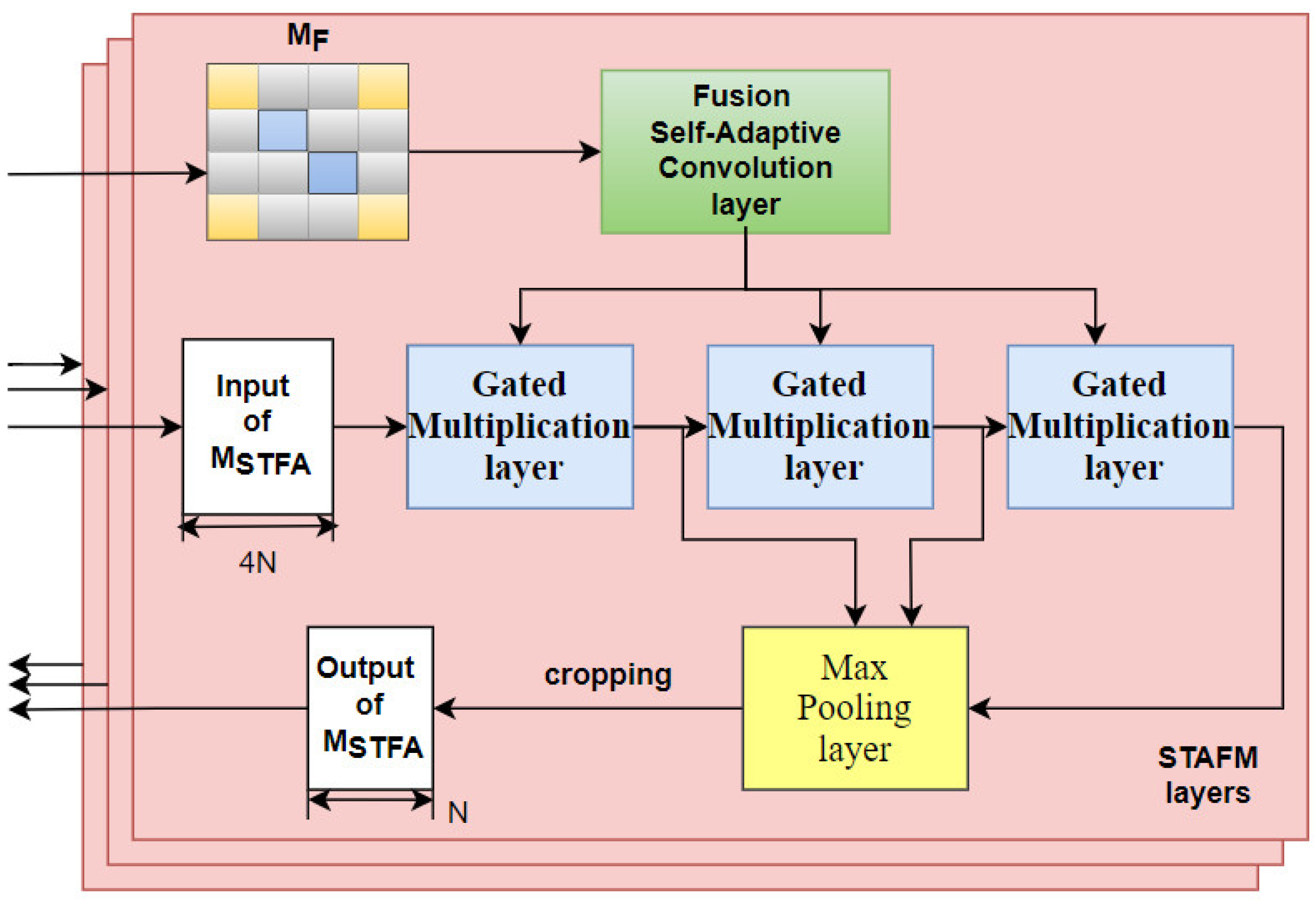
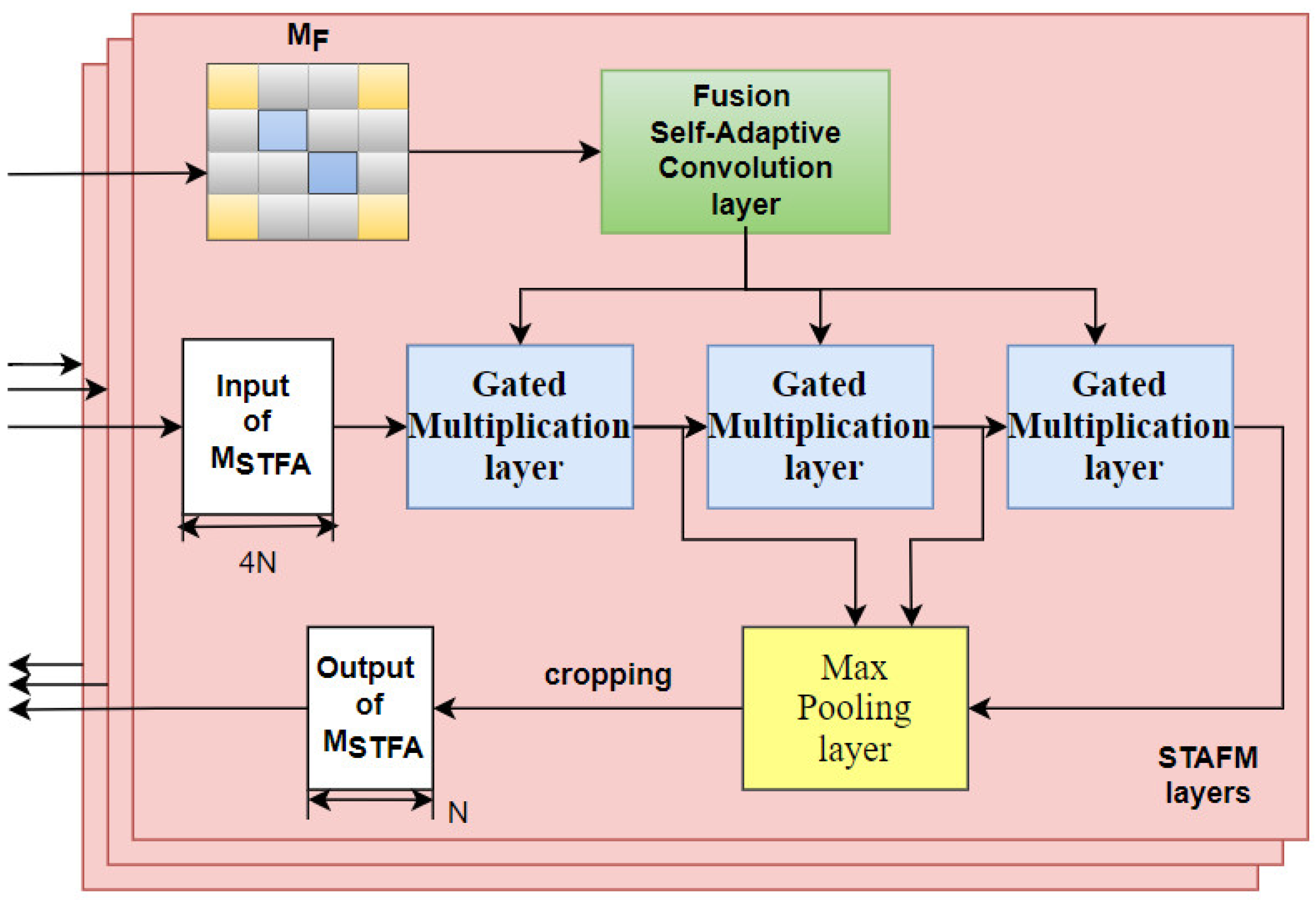
3.1. Spatial–Temporal Adaptive Fusion Convolution Layer
3.2. Spatial–Temporal Adaptive Fusion Construction Module
3.3. Gated Convolution Module
3.4. Spatial–Temporal Adaptive Fusion Graph Neural Module
4. Experiments
4.1. Datasets and Baseline
- Graph WaveNet: Graph WaveNet, a spatial–temporal graph model with a stacked dilated 1D convolution component and self-adaptive adjacency layers [24].
- STFGNN: Spatial–temporal fusion graph neural networks, with a gated dilated CNN module and spatial–temporal fusion graph module in parallel [21].
- SVR: Support vector regression, using a support vector machine to regress traffic sequence, characterized by the use of kernels, sparse solution, VC control of the margin and the number of support vectors [8].
4.2. Experiments Results and Analysis
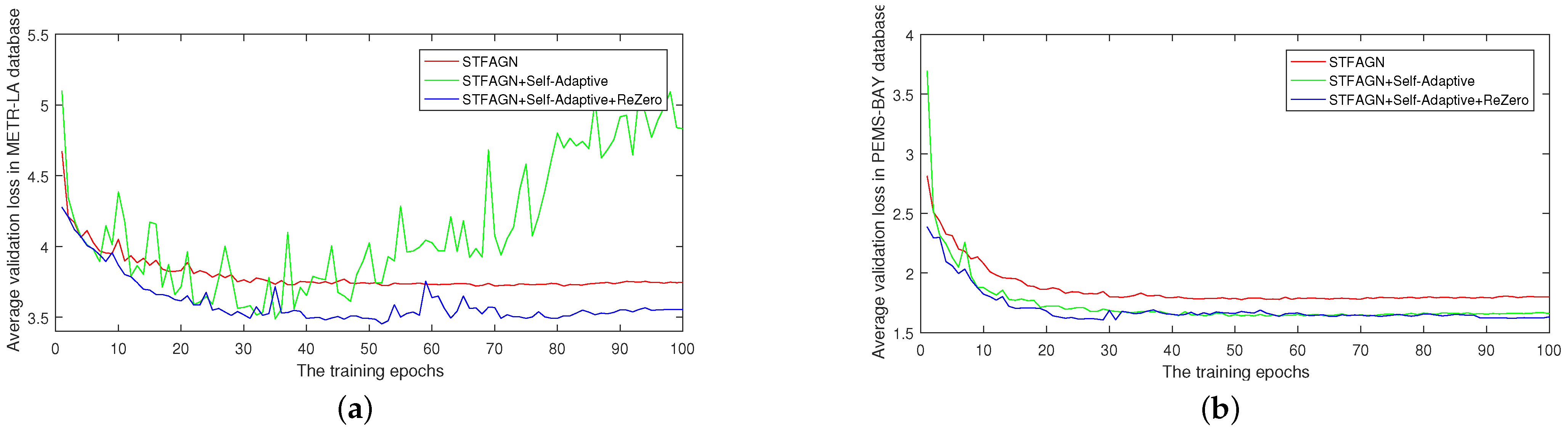
4.3. Ablation Experiments
- : STFAGN is not configured with adaptive matrix and ReZero connection.
- : STFAGN is configured with adaptive matrix without ReZero connection.
- : STFAGN is configured with adaptive matrix with ReZero connection.
- For the ingredient of , the fusion self-adaptive convolution layer is used to construct the adaptive fusion adjacency matrix, which can complete incomplete information of the adjacency matrix in the traffic network. Traffic networks based on distance do not mean that adjacent nodes have a traffic information association. The self-adaptive fusion adjacency matrix just makes up for this information and achieves a good effect of accelerating convergence.
- ReZero, a simple architectural modification, facilitates signal propagation in deep networks and helps the network maintain dynamical isometry. Applying ReZero to the STFAGN, significantly improved convergence speeds can be observed.
- STFAGN with the adaptive fusion adjacency matrix and ReZero connection not only adjusts spatiotemporal dependency, but trains efficiently. Therefore, the design of the component is reasonable.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| fast-DTW | fast dynamic time warping |
| STAFCM | spatial–temporal adaptive fusion construction module |
| STAFM | spatial–temporal adaptive fusion graph neural module |
| GCM | gated convolution module |
| STFAGN | spatial–temporal adaptive fusion graph network |
| FSAC | fusion self-adaptive convolution layer |
References
- Wei, H.; Zheng, G.; Yao, H.; Li, Z. Intellilight: A reinforcement learning approach for intelligent traffic light control. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2496–2505. [Google Scholar]
- Cai, W.; Yang, J.; Yu, Y.; Song, Y.; Zhou, T.; Qin, J. PSO-ELM: A Hybrid Learning Model for Short-term Traffic Flow Forecasting. IEEE Access 2020, 8, 6505–6514. [Google Scholar] [CrossRef]
- Cai, L.; Zhang, Z.; Yang, J.; Yu, Y.; Zhou, T.; Qin, J. A noise-immune Kalman filter for short-term traffic flow forecasting. Phys. A Stat. Mech. Its Appl. 2019, 536, 122601. [Google Scholar] [CrossRef]
- Zheng, S.; Zhang, S.; Song, Y.; Lin, Z.; Wang, F.; Zhou, T. A Noise-eliminated Gradient Boosting Model for Short-term Traffic Flow Forecasting. In Proceedings of the 8th International Conference on Digital Home, Dalian, China, 19–20 September 2020. [Google Scholar]
- Cascetta, E. Transportation Systems Engineering: Theory and Methods; Springer Science & Business Media: Cham, Switzerland, 2013; Volume 49. [Google Scholar]
- Kumar, S.V.; Vanajakshi, L. Short-term traffic flow prediction using seasonal ARIMA model with limited input data. Eur. Transp. Res. Rev. 2015, 7, 21. [Google Scholar] [CrossRef] [Green Version]
- Lippi, M.; Bertini, M.; Frasconi, P. Short-term traffic flow forecasting: An experimental comparison of time-series analysis and supervised learning. IEEE Trans. Intell. Transp. Syst. 2013, 14, 871–882. [Google Scholar] [CrossRef]
- Awad, M.; Khanna, R. Support vector regression. In Efficient Learning Machines; Springer: Berlin/Heidelberg, Germany, 2015; pp. 67–80. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Chui, C.K.; Chen, G. Kalman Filtering; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Zhou, T.; Jiang, D.; Lin, Z.; Han, G.; Xu, X.; Qin, J. Hybrid dual Kalman filtering model for short-term traffic flow forecasting. IET Intell. Transp. Syst. 2019, 13, 1023–1032. [Google Scholar] [CrossRef]
- Zheng, S.; Zhang, S.; Song, Y.; Lin, Z.; Jiang, D.; Zhou, T. A noise-immune boosting framework for short-term traffic flow forecasting. Complexity 2021, 2021, 5582974. [Google Scholar] [CrossRef]
- Connor, J.T.; Martin, R.D.; Atlas, L.E. Recurrent neural networks and robust time series prediction. IEEE Trans. Neural Netw. 1994, 5, 240–254. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Zhang, S.; Tong, H.; Xu, J.; Maciejewski, R. Graph convolutional networks: A comprehensive review. Comput. Soc. Netw. 2019, 6, 11. [Google Scholar] [CrossRef] [Green Version]
- Li, F.; Feng, J.; Yan, H.; Jin, G.; Jin, D.; Li, Y. Dynamic Graph Convolutional Recurrent Network for Traffic Prediction: Benchmark and Solution. arXiv 2021, arXiv:2104.14917. [Google Scholar]
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. arXiv 2017, arXiv:1707.01926. [Google Scholar]
- Yu, B.; Yin, H.; Zhu, Z. Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting. arXiv 2017, arXiv:1709.04875. [Google Scholar]
- Cai, L.; Lei, M.; Zhang, S.; Yu, Y.; Zhou, T.; Qin, J. A noise-immune LSTM network for short-term traffic flow forecasting. Chaos 2020, 30, 023135. [Google Scholar] [CrossRef]
- Li, M.; Zhu, Z. Spatial-temporal fusion graph neural networks for traffic flow forecasting. arXiv 2020, arXiv:2012.09641. [Google Scholar]
- Kong, X.; Zhang, J.; Wei, X.; Xing, W.; Lu, W. Adaptive spatial-temporal graph attention networks for traffic flow forecasting. Appl. Intell. 2022, 52, 4300–4316. [Google Scholar] [CrossRef]
- Guo, K.; Hu, Y.; Sun, Y.; Qian, S.; Gao, J.; Yin, B. Hierarchical graph convolution networks for traffic forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 151–159. [Google Scholar]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Zhang, C. Graph wavenet for deep spatial-temporal graph modeling. arXiv 2019, arXiv:1906.00121. [Google Scholar]
- Lu, H.; Huang, D.; Youyi, S.; Jiang, D.; Zhou, T.; Qin, J. ST-TrafficNet: A Spatial-Temporal Deep Learning Network for Traffic Forecasting. Electronics 2020, 9, 1474. [Google Scholar] [CrossRef]
- Lu, H.; Ge, Z.; Song, Y.; Jiang, D.; Zhou, T.; Qin, J. A temporal-aware lstm enhanced by loss-switch mechanism for traffic flow forecasting. Neurocomputing 2021, 427, 169–178. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Ying, R.; You, J.; Morris, C.; Ren, X.; Hamilton, W.L.; Leskovec, J. Hierarchical graph representation learning with differentiable pooling. arXiv 2018, arXiv:1806.08804. [Google Scholar]
- Zhang, M.; Chen, Y. Link prediction based on graph neural networks. Adv. Neural Inf. Process. Syst. 2018, 31, 5165–5175. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1025–1035. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Vidal, E.; Rulot, H.M.; Casacuberta, F.; Benedi, J.M. On the use of a metric-space search algorithm (AESA) for fast DTW-based recognition of isolated words. IEEE Trans. Acoust. Speech, Signal Process. 1988, 36, 651–660. [Google Scholar] [CrossRef]
- Senin, P. Dynamic time warping algorithm review. Inf. Comput. Sci. Dep. Univ. Hawaii Manoa Honol. USA 2008, 855, 40. [Google Scholar]
- Berndt, D.J.; Clifford, J. Using Dynamic Time Warping to Find Patterns in Time Series; KDD Workshop: Seattle, WA, USA, 1994; Volume 10, pp. 359–370. [Google Scholar]
- Pennington, J.; Schoenholz, S.; Ganguli, S. Resurrecting the sigmoid in deep learning through dynamical isometry: Theory and practice. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Bachlechner, T.; Majumder, B.P.; Mao, H.H.; Cottrell, G.W.; McAuley, J. Rezero is all you need: Fast convergence at large depth. arXiv 2020, arXiv:2003.04887. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- Wang, X.; Ma, Y.; Wang, Y.; Jin, W.; Wang, X.; Tang, J.; Jia, C.; Yu, J. Traffic flow prediction via spatial temporal graph neural network. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 1082–1092. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in resnet: Generalizing residual architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar]
- Zhang, G.P. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Dataset | Timestep | Nodes | Edges |
|---|---|---|---|
| METR-LA | 34,272 | 207 | 1515 |
| PEMS-BAY | 52,116 | 325 | 2691 |
| Dataset | Models | 15 min | 30 min | 60 min | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MAE | MAPE% | RMSE | MAE | MAPE% | RMSE | MAE | MAPE | RMSE | ||
| METR-LA | Graph WaveNet | 2.98± 0.00 | 7.88± 0.00 | 5.91± 0.01 | 3.59± 0.00 | 10.17± 0.00 | 7.29± 0.01 | 4.45± 0.01 | 13.66± 0.00 | 8.97± 0.02 |
| STFGNN | 2.99± 0.00 | 7.24± 0.05 | 6.72± 0.02 | 3.48± 0.00 | 8.69± 0.06 | 8.10± 0.03 | 4.27± 0.01 | 11.01± 0.08 | 10.00± 0.03 | |
| STFAGN | 2.94± 0.01 | 7.12± 0.06 | 6.62± 0.02 | 3.32± 0.06 | 8.22± 0.17 | 7.76± 0.16 | 3.96± 0.01 | 10.01± 0.08 | 9.46± 0.04 | |
| ARIMA | 3.99± 0.00 | 9.60± 0.00 | 8.21± 0.00 | 5.15± 0.00 | 12.70± 0.00 | 10.45± 0.00 | 6.90± 0.00 | 17.40± 0.00 | 13.23± 0.00 | |
| SVR | 3.99± 0.00 | 9.30± 0.00 | 8.45± 0.00 | 5.05± 0.00 | 12.10± 0.00 | 10.87± 0.00 | 6.72± 0.00 | 16.70± 0.00 | 13.76± 0.00 | |
| PEMS-BAY | GraptWaveNet | 1.39± 0.00 | 2.90± 0.00 | 3.01± 0.00 | 1.84± 0.00 | 4.16± 0.13 | 4.22± 0.01 | 2.37± 0.01 | 5.85± 0.00 | 5.45± 0.01 |
| STFGNN | 1.20± 0.01 | 2.47± 0.03 | 2.47± 0.04 | 1.47± 0.01 | 3.18± 0.05 | 3.27± 0.04 | 1.81± 0.00 | 4.17± 0.05 | 4.23± 0.04 | |
| STFAGN | 1.17± 0.00 | 2.43± 0.02 | 2.43± 0.02 | 1.41± 0.00 | 3.06± 0.02 | 3.13± 0.03 | 1.69± 0.00 | 3.85± 0.02 | 3.88± 0.03 | |
| ARIMA | 1.62± 0.00 | 3.50± 0.00 | 3.30± 0.00 | 2.33± 0.00 | 5.40± 0.00 | 4.76± 0.00 | 3.38± 0.00 | 8.30± 0.00 | 6.50± 0.00 | |
| SVR | 1.85± 0.00 | 3.80± 0.00 | 3.59± 0.00 | 2.48± 0.00 | 5.50± 0.00 | 5.18± 0.00 | 3.28± 0.00 | 8.00± 0.00 | 7.08± 0.00 | |
| Dataset | Models | 15 min | 30 min | 60 min | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Elements | MAE | MAPE% | RMSE | MAE | MAPE% | RMSE | MAE | MAPE% | RMSE | |
| METR-LA | [M,no] | 2.99± 0.00 | 7.24± 0.05 | 6.72± 0.02 | 3.48± 0.00 | 8.69± 0.06 | 8.10± 0.03 | 4.27± 0.01 | 11.01± 0.08 | 10.00± 0.03 |
| [,no] | 2.97± 0.03 | 7.14± 0.09 | 6.67± 0.09 | 3.39± 0.03 | 8.29± 0.07 | 7.90± 0.06 | 4.01± 0.03 | 10.00± 0.08 | 9.53± 0.05 | |
| [,Rezero] | 2.94± 0.01 | 7.12± 0.06 | 6.62± 0.02 | 3.32± 0.06 | 8.22± 0.17 | 7.76± 0.16 | 3.96± 0.01 | 10.01± 0.08 | 9.46± 0.04 | |
| PEMS-BAY | [M,no] | 1.20± 0.01 | 2.47± 0.03 | 2.47± 0.04 | 1.47± 0.01 | 3.18± 0.05 | 3.27± 0.04 | 1.81± 0.00 | 4.17± 0.05 | 4.23± 0.04 |
| [,no] | 1.18± 0.00 | 2.44± 0.03 | 2.53± 0.26 | 1.41± 0.00 | 3.07± 0.03 | 3.17± 0.15 | 1.69± 0.01 | 3.88± 0.04 | 3.90± 0.08 | |
| [,Rezero] | 1.18± 0.01 | 2.42± 0.02 | 2.45± 0.06 | 1.41 ±0.00 | 3.05 ±0.02 | 3.12± 0.04 | 1.68± 0.00 | 3.81± 0.02 | 3.89± 0.07 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Li, H.; Luo, Y.; Li, J.; Song, Y.; Zhou, T. Spatiotemporal Adaptive Fusion Graph Network for Short-Term Traffic Flow Forecasting. Mathematics 2022, 10, 1594. https://doi.org/10.3390/math10091594
Yang S, Li H, Luo Y, Li J, Song Y, Zhou T. Spatiotemporal Adaptive Fusion Graph Network for Short-Term Traffic Flow Forecasting. Mathematics. 2022; 10(9):1594. https://doi.org/10.3390/math10091594
Chicago/Turabian StyleYang, Shumin, Huaying Li, Yu Luo, Junchao Li, Youyi Song, and Teng Zhou. 2022. "Spatiotemporal Adaptive Fusion Graph Network for Short-Term Traffic Flow Forecasting" Mathematics 10, no. 9: 1594. https://doi.org/10.3390/math10091594
APA StyleYang, S., Li, H., Luo, Y., Li, J., Song, Y., & Zhou, T. (2022). Spatiotemporal Adaptive Fusion Graph Network for Short-Term Traffic Flow Forecasting. Mathematics, 10(9), 1594. https://doi.org/10.3390/math10091594