
AI Student: A Machine Reading Comprehension System for the Korean College Scholastic Ability Test


Abstract
:1. Introduction
- We obtained insights into the meaningful effects of our KCQA models, which assessed scholastic reading ability.
- To this end, we demonstrated the effectiveness of using various Korean and multilingual language models with four data augmentation strategies for practical learning to alleviate insufficient training data problems.
- For human performance, we employed 30 test students preparing for the CSAT with conditions identical to the PLMs. The results proved the superior performance of the proposed KCQA.
- We comprehensively conducted qualitative and quantitative analyses based on this by deriving concrete experimental results in both aspects of educational assessment and deep learning.
2. Background
3. Related Works
3.1. Pre-Trained Language Models
3.2. Adoption of Deep Learning in CSAT
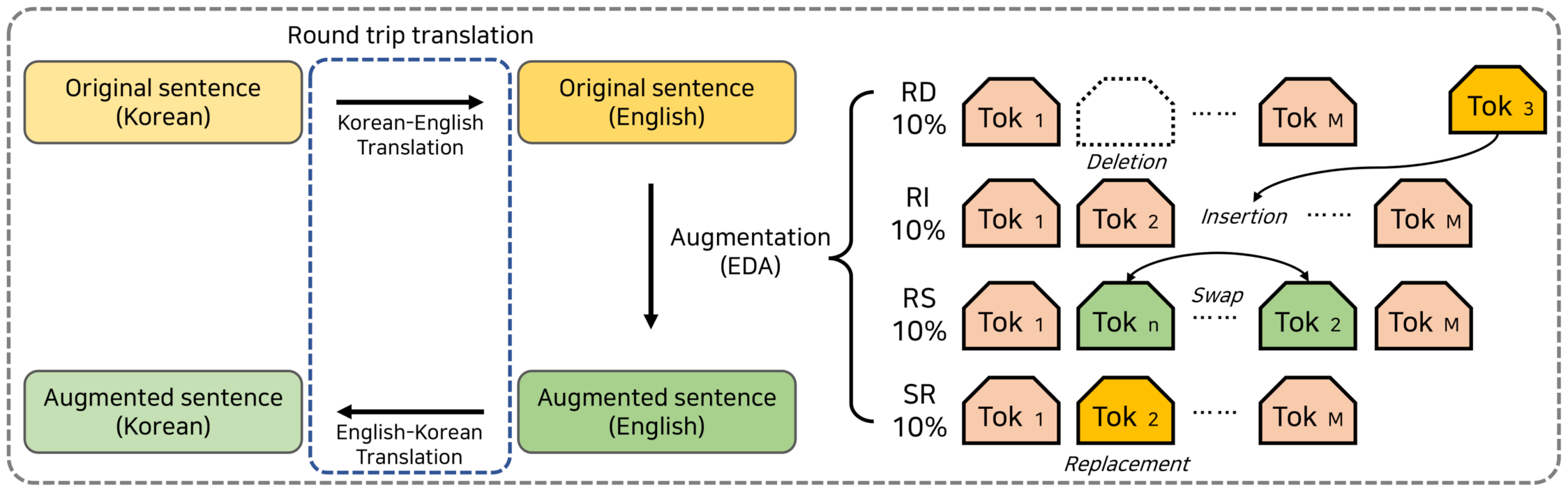
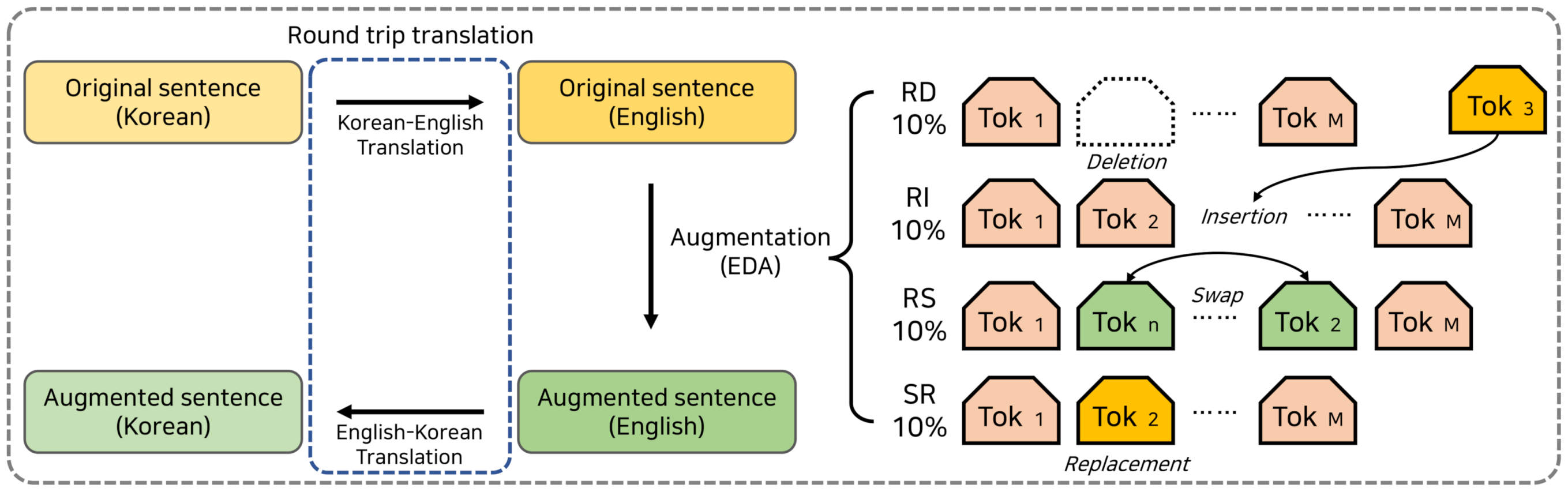
3.3. Data Augmentation Strategy
4. Enhanced Dataset Strategies for CSAT
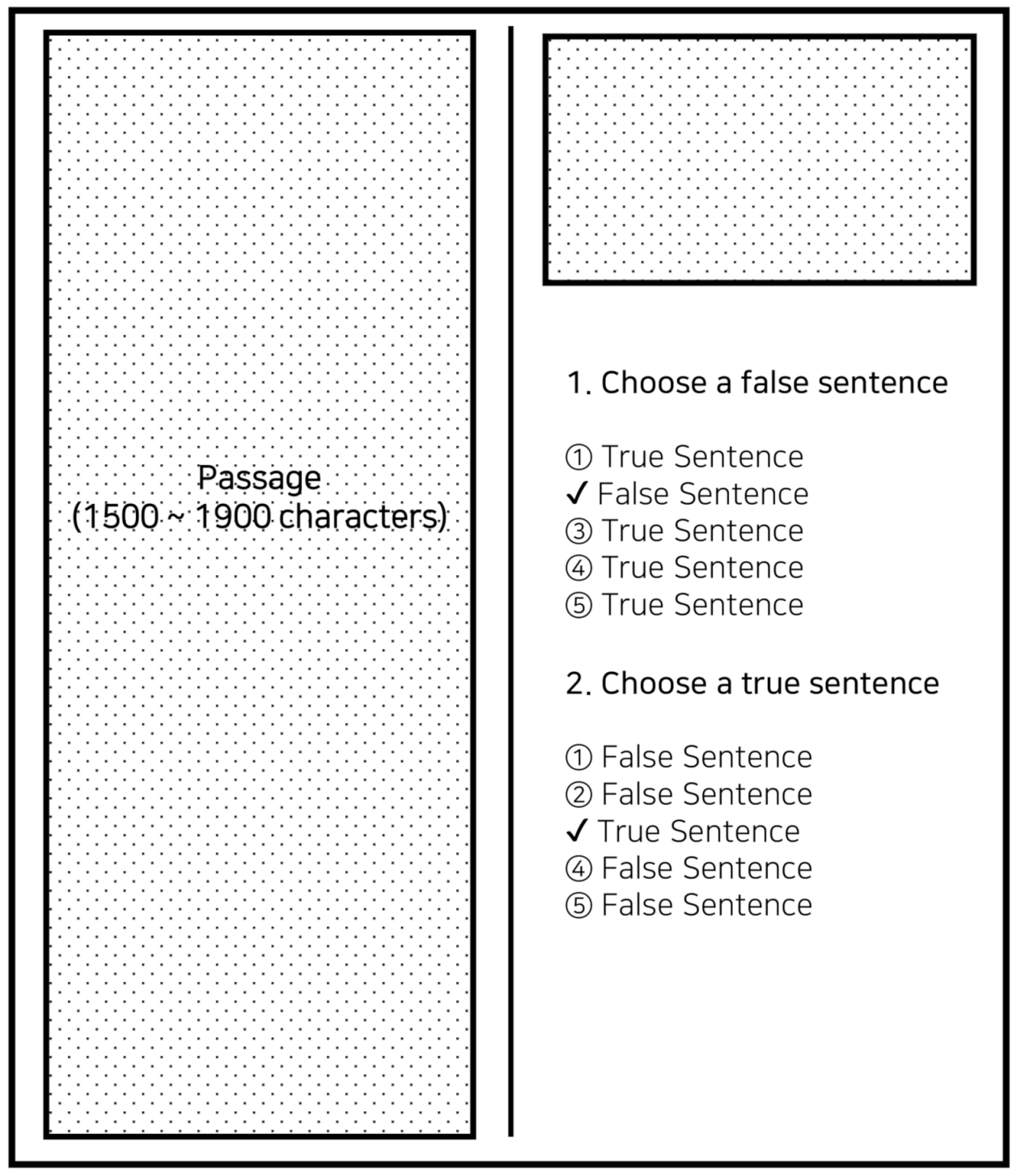
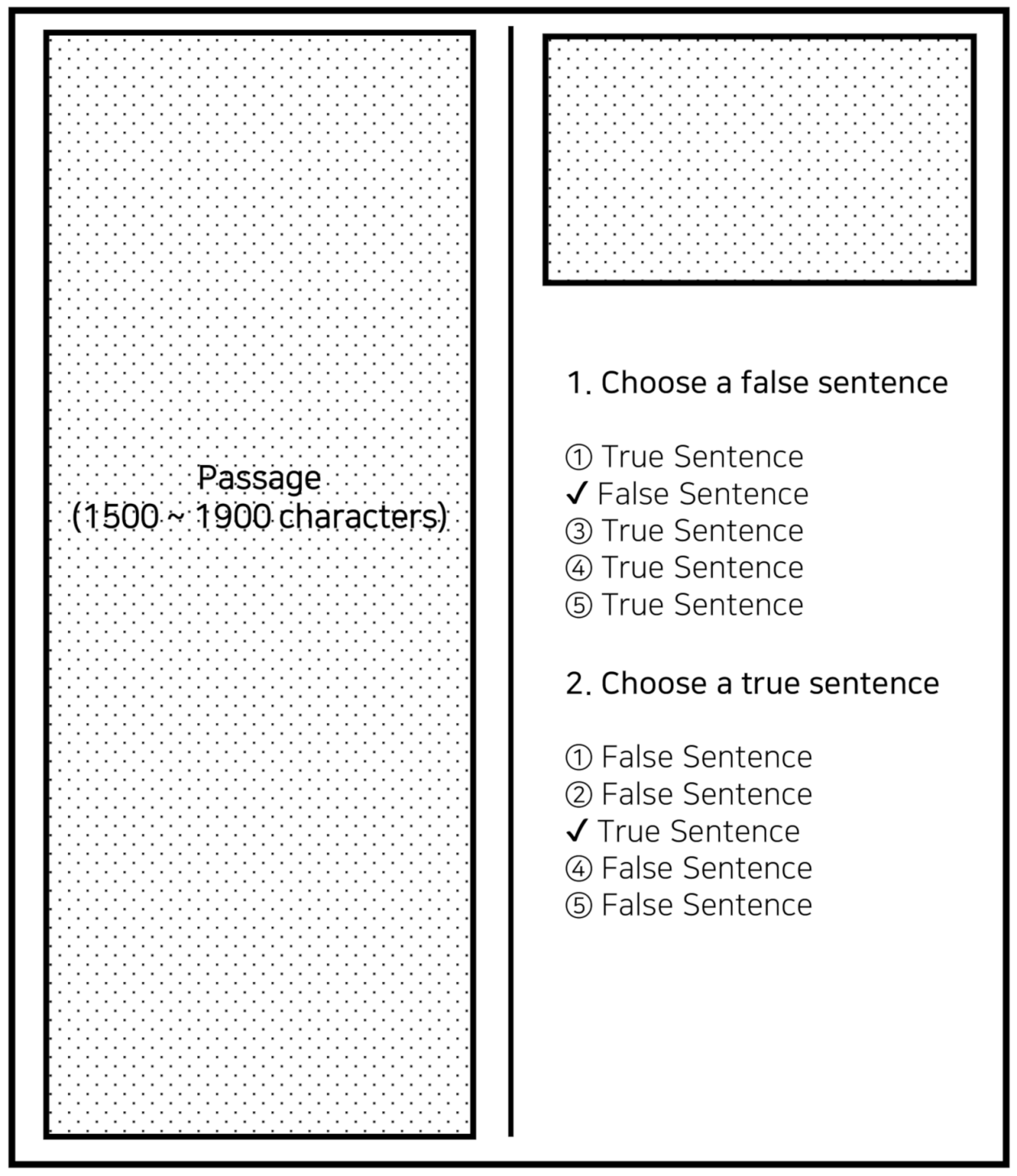
4.1. Reading Form in CSAT
4.2. Reading Section of Korean Language
4.3. Strategy for CSAT Corpus Augmentation
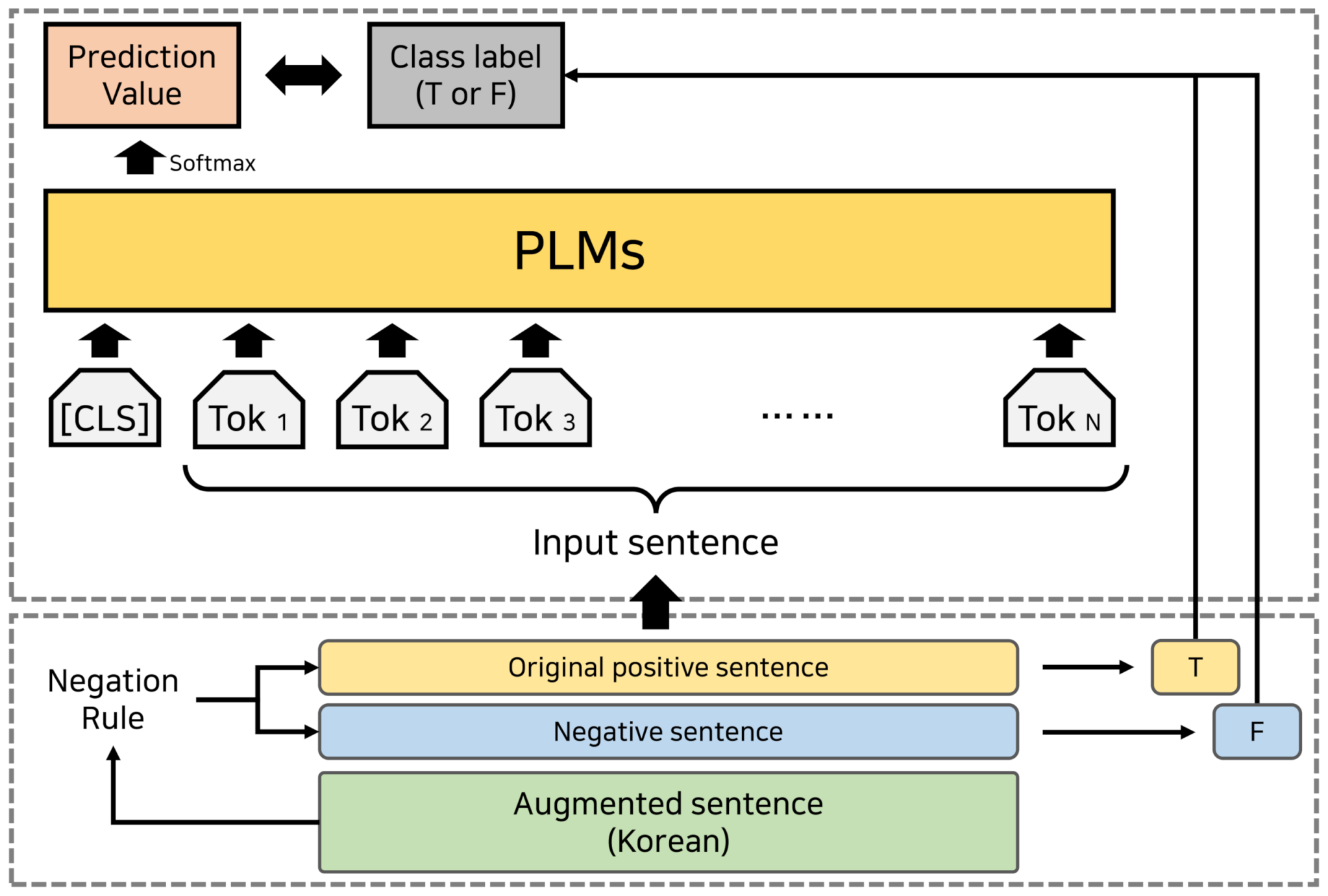
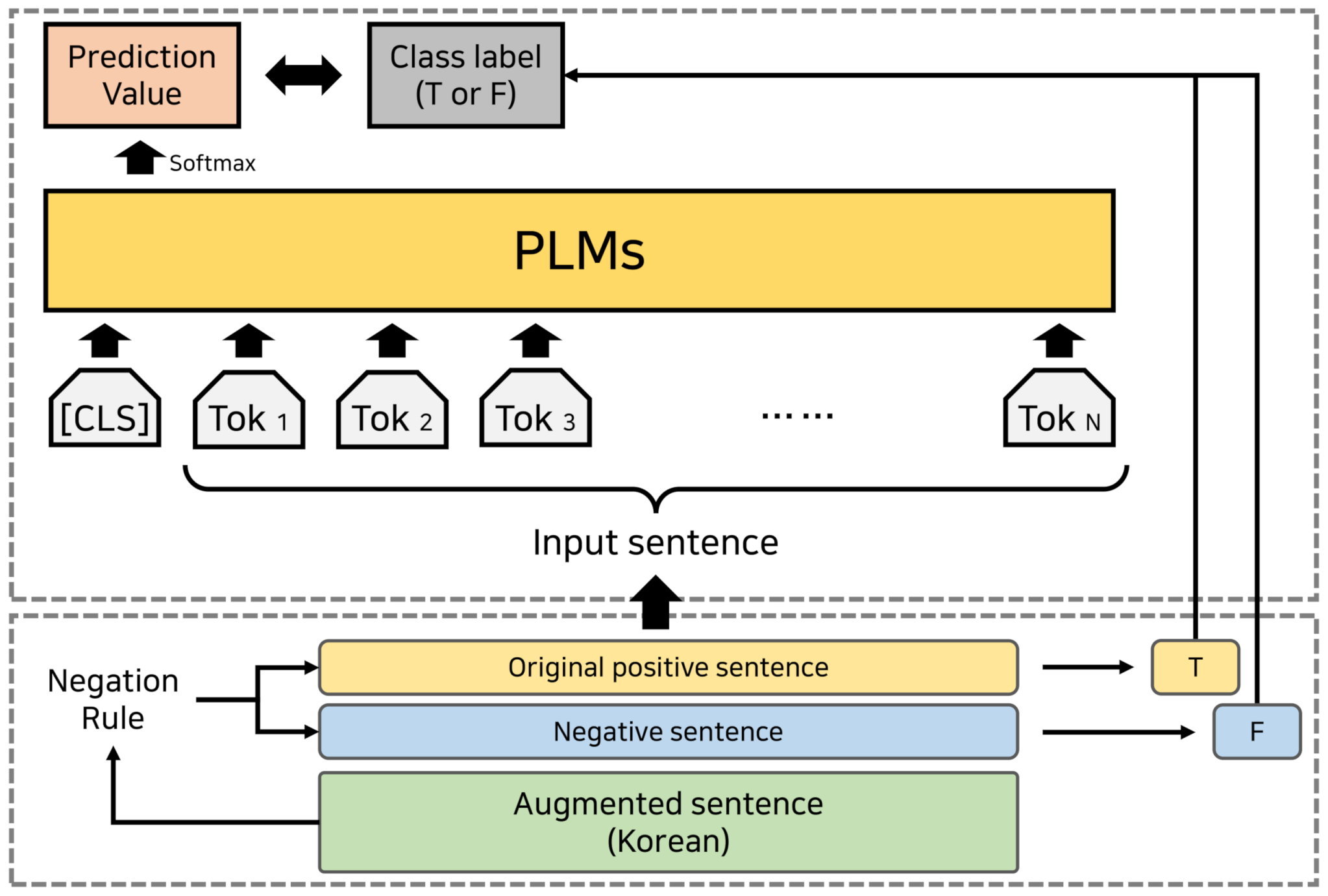
4.4. KCQA System
5. Experiments
5.1. Dataset
5.2. Metrics
5.3. Experimental Results
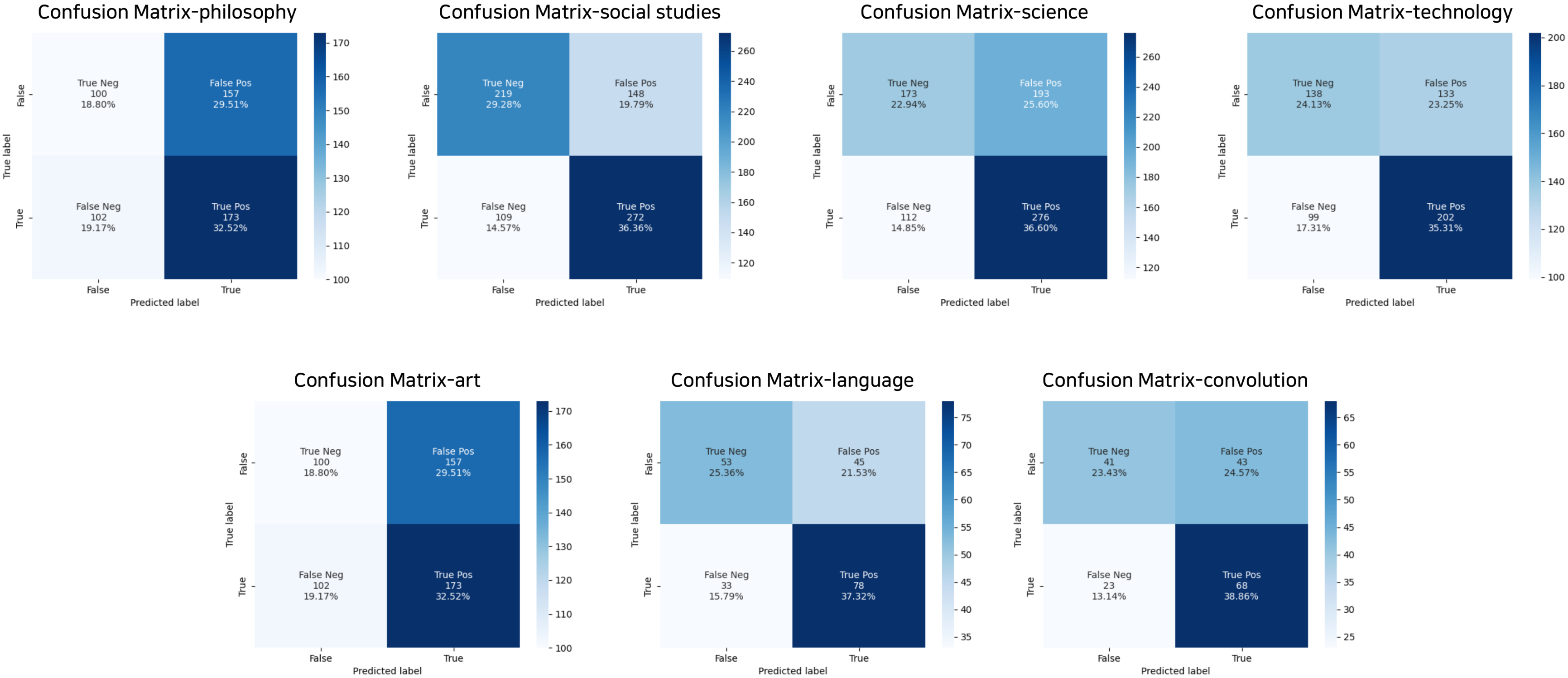
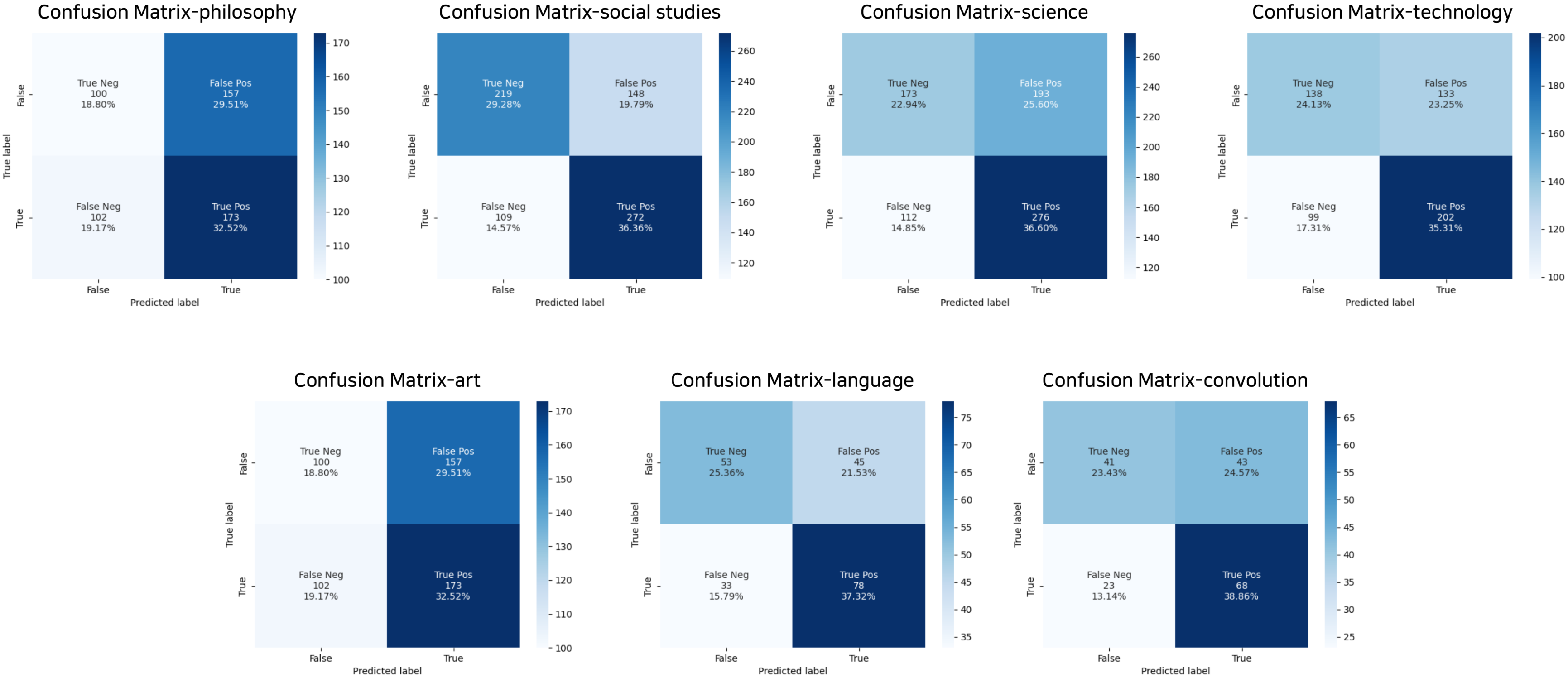
6. Analysis
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rajpurkar, P.; Jia, R.; Liang, P. Know What You Don’t Know: Unanswerable Questions for SQuAD. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 2, pp. 784–789. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Zhao, H.; Wang, R. Machine reading comprehension: The role of contextualized language models and beyond. arXiv 2020, arXiv:2005.06249. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2020, arXiv:1907.11692. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv 2019, arXiv:1910.10683. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf (accessed on 5 April 2022).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Li, D.; Hu, B.; Chen, Q.; Peng, W.; Wang, A. Towards Medical Machine Reading Comprehension with Structural Knowledge and Plain Text. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 1427–1438. [Google Scholar] [CrossRef]
- Li, J.; Zhong, S.; Chen, K. MLEC-QA: A Chinese Multi-Choice Biomedical Question Answering Dataset. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online, 7–11 November 2021; pp. 8862–8874. [Google Scholar] [CrossRef]
- Lin, G.; Miao, Y.; Hu, Y.; Shen, Z. Support Cybersecurity Risk Public Awareness with AI Machine Comprehension. Int. J. Inf. Technol. 2019, 1, 22. [Google Scholar]
- Musser, M.; Garriott, A. Machine Learning and Cybersecurity; Center for Security and Emerging Technology: Washington, DC, USA, 2021; Available online: https://cset.georgetown.edu/wp-content/uploads/Machine-Learning-and-Cybersecurity.pdf (accessed on 5 April 2022).
- Sennrich, R.; Haddow, B.; Birch, A. Improving Neural Machine Translation Models with Monolingual Data. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1, pp. 86–96. [Google Scholar] [CrossRef]
- Moon, J.; Cho, H.; Park, E.L. Revisiting Round-trip Translation for Quality Estimation. In Proceedings of the 22nd Annual Conference of the European Association for Machine Translation, Lisboa, Portugal, 3–5 November 2020; pp. 91–104. [Google Scholar]
- Wei, J.; Zou, K. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 6382–6388. [Google Scholar] [CrossRef]
- Fellbaum, C. WordNet and Wordnets; Princeton University: Princeton, NJ, USA, 2005. [Google Scholar]
- Kim, S. Analysis of Students’ Recognition of National Scholastic Aptitude Test for University Admission—With Focus on the ‘Korean Language Section’. J. Cheong Ram Korean Lang. Educ. 2014, 49, 135–164. [Google Scholar] [CrossRef]
- Kwon, S.K.; Lee, M.; Shin, D. Educational assessment in the Republic of Korea: Lights and shadows of high-stake exam-based education system. Assess. Educ. Princ. Policy Pract. 2017, 24, 60–77. [Google Scholar] [CrossRef]
- Park, K. An Analysis and Improvement of the Korean Language Section of CSAT. J. Cheong Ram Korean Lang. Educ. 2014, 49, 31–50. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Kim, G.; Lee, C.; Jo, J.; Lim, H. Automatic extraction of named entities of cyber threats using a deep Bi-LSTM-CRF network. Int. J. Mach. Learn. Cybern. 2020, 11, 2341–2355. [Google Scholar] [CrossRef]
- Kim, G.; Son, J.; Kim, J.; Lee, H.; Lim, H. Enhancing Korean Named Entity Recognition With Linguistic Tokenization Strategies. IEEE Access 2021, 9, 151814–151823. [Google Scholar] [CrossRef]
- Khashabi, D.; Min, S.; Khot, T.; Sabharwal, A.; Tafjord, O.; Clark, P.; Hajishirzi, H. UNIFIEDQA: Crossing Format Boundaries with a Single QA System. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 1896–1907. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained models for natural language processing: A survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 2383–2392. [Google Scholar] [CrossRef]
- Park, J. KoELECTRA: Pretrained ELECTRA Model for Korean. 2020. Available online: https://github.com/monologg/KoELECTRA (accessed on 5 April 2022).
- Kwon, T.; Kim, S. A Research on the Quality of ‘Speech and Writing’ Evaluation Items in College Scholastic Ability Test (CSAT). Cheong Ram Korean Lang. Educ. 2019, 71, 161–194. [Google Scholar]
- Oh, J.I.; Shin, Y. A corpus-based analysis of the linguistic complexity levels of reading passages in the Korean college entrance examination. Engl. Lang. Teach. 2020, 32, 109–126. [Google Scholar]
- Edunov, S.; Ott, M.; Auli, M.; Grangier, D. Understanding Back-Translation at Scale. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 489–500. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M.; Furht, B. Text data augmentation for deep learning. J. Big Data 2021, 8, 1–34. [Google Scholar] [CrossRef] [PubMed]
- Huang, L.; Pan, W.; Zhang, Y.; Qian, L.; Gao, N.; Wu, Y. Data augmentation for deep learning-based radio modulation classification. IEEE Access 2019, 8, 1498–1506. [Google Scholar] [CrossRef]
- Yang, Y.; Kang, S.; Seo, J. Improved machine reading comprehension using data validation for weakly labeled data. IEEE Access 2020, 8, 5667–5677. [Google Scholar] [CrossRef]
- Nam, Y. An ERP study on the processing of Syntactic and lexical negation in Korean. Korean J. Cogn. Sci. 2016, 27, 469–499. [Google Scholar]
- Lim, S.; Kim, M.; Lee, J. KorQuAD1.0: Korean QA Dataset for Machine Reading Comprehension. arXiv 2019, arXiv:cs.CL/1909.07005. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Passage | a semiconductor substrate board, which is similar to the process of making an engraving. Just as countless engravings can be made from an original plate on paper, in the case of photolithography, a single plate called a mask is made, and then the pattern of the exact same shape is repeatedly copied on the substrate using a laser to make a large number of patterns. Compared to making the original plate using an engraving knife, in the case of photolithography, the size of the mask pattern is very small, so it is made using a laser. |
| Question | The size of the pattern engraved on the mask is smaller than the size of the pattern created on the substrate board. |
| Categories (#) | Augmented Train Dataset | Test Dataset | |
|---|---|---|---|
| (True, T) | (False, F) | ||
| philosophy (58) | 120.86 | 6.16 | 5.71 |
| social studies (55) | 115.54 | 6.53 | 5.33 |
| science (53) | 120.36 | 7.36 | 6.86 |
| technology (43) | 119.00 | 6.95 | 6.31 |
| art (45) | 115.69 | 6.11 | 5.71 |
| language (23) | 109.00 | 4.83 | 4.26 |
| convolution (8) | 203.78 | 10.25 | 9.75 |
| Negation Rule | Original True Sentence | Sentence Negation |
|---|---|---|
| -이다 (V) → -이 아니다 (don’t V) | 개인적 동기가 공공성과 상충되는 현상이 나타났던 것이다. (Personal motives appear to conflict with public ones.) | 개인적 동기가 공공성과 상충되는 현상이 나타났던 것이 아니다. (Personal motives don’t appear to conflict with public ones.) |
| -할 수 있다 (can) → -할 수 없다 (can’t) | 이 교차로 표지가 과정1에 도입되었고 이 표지는 ‘b’ 까지 전달될 수 있다. (This intersecting mark was introduced in ‘process 1’ and can be delivered to ‘b’) | 이 교차로 표지가 과정1에 도입되었고 이 표지는 ’b’ 까지 전달될 수 없다. (This intersecting mark was introduced in ‘process 1’ and can’t be delivered to ‘b’) |
| -한다 (does) → -하지 않는다 (doesn’t) | 아리스토제누스는 귀로 지각된 소리를 근거로 음악의 아름다움을 판단한다. (Aristoxenus does determine the beauty of music based on the sound perceived by the ear) | 아리스토제누스는 귀로 지각된 소리를 근거로 음악의 아름다움을 판단하지 않는다. (Aristoxenus doesn’t determine the beauty of music based on the sound perceived by the ear) |
| Dataset | Data Type | Sentences | Augmented Sentences |
|---|---|---|---|
| CSAT passages (285) | Train | 24.3 | 119.55 |
| Test | 6.58 | 6.58 |
| Models (Augmented) | F1 Score | Recall | Precision |
|---|---|---|---|
| Human Performance | 58.24 | 62.31 | 59.24 |
| KoBERT | 58.46 (+0.22) | 64.08 (+1.77) | 57.24 (−2.00) |
| KoELECTRA | 61.78 (+3.54) | 67.67 (+5.36) | 59.24 (+0.00) |
| KcELECTRA | 62.10 (+3.86) | 68.22 (+5.91) | 59.10 (−0.14) |
| mBERT | 58.08 (−0.16) | 62.36 (+0.05) | 58.20 (−1.04) |
| xlm−RoBERTa | 48.48 (−9.76) | 55.71 (−6.60) | 47.63 (−11.61) |
| PLMs | Recall-Precision (Original) | Recall-Precision (Augmented) |
|---|---|---|
| KoBERT | 38.23 | 6.84 |
| KoELECTRA | 42.50 | 8.43 |
| KcELECTRA | 41.44 | 9.12 |
| mBERT | 40.54 | 4.16 |
| xlm-RoBERTa | 43.01 | 8.08 |
| Passage Index | F1 Score | Recall | Precision | Recall-Precision |
|---|---|---|---|---|
| 2013-9-tech | 100.00% | 100.00% | 100.00% | 0.00% |
| 2006-6-phil | 100.00% | 100.00% | 100.00% | 0.00% |
| 2016-9A-soc | 94.12% | 88.89% | 100.00% | −11.11% |
| 2010-9-sci | 94.12% | 100.00% | 88.89% | 11.11% |
| 2004-6-art | 94.12% | 100.00% | 88.89% | 11.11% |
| 2015-6B-phil | 93.33% | 87.50% | 100.00% | −12.50% |
| 2011-11-tech | 90.91% | 100.00% | 83.33% | 16.67% |
| 2004-6-phil | 90.91% | 100.00% | 83.33% | 16.67% |
| 2015-6A-phil | 88.89% | 100.00% | 80.00% | 20.00% |
| 2013-11-tech | 88.89% | 100.00% | 80.00% | 20.00% |
| Average | 93.53% | 97.64% | 90.44% | 7.19% |
| 2013-11-art | 20.00% | 33.33% | 14.29% | 19.05% |
| 2010-6-art | 20.00% | 20.00% | 20.00% | 0.00% |
| 2003-11-art | 20.00% | 20.00% | 20.00% | 0.00% |
| 1994-11-soc | 18.18% | 20.00% | 16.67% | 3.33% |
| 2014-5A-phil | 18.18% | 16.67% | 20.00% | −3.33% |
| 2013-11-phil | 15.38% | 20.00% | 12.50% | 7.50% |
| 2014-6A-tech | 0.00% | 0.00% | 0.00% | 0.00% |
| 2005-9-tech | 0.00% | 0.00% | 0.00% | 0.00% |
| 2009-9-phil | 0.00% | 0.00% | 0.00% | 0.00% |
| 1996-11-phil | 0.00% | 0.00% | 0.00% | 0.00% |
| Average | 11.17% | 13.00% | 10.35% | 2.65% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, G.; Lee, S.; Park, C.; Jo, J. AI Student: A Machine Reading Comprehension System for the Korean College Scholastic Ability Test. Mathematics 2022, 10, 1486. https://doi.org/10.3390/math10091486
Kim G, Lee S, Park C, Jo J. AI Student: A Machine Reading Comprehension System for the Korean College Scholastic Ability Test. Mathematics. 2022; 10(9):1486. https://doi.org/10.3390/math10091486
Chicago/Turabian StyleKim, Gyeongmin, Soomin Lee, Chanjun Park, and Jaechoon Jo. 2022. "AI Student: A Machine Reading Comprehension System for the Korean College Scholastic Ability Test" Mathematics 10, no. 9: 1486. https://doi.org/10.3390/math10091486
APA StyleKim, G., Lee, S., Park, C., & Jo, J. (2022). AI Student: A Machine Reading Comprehension System for the Korean College Scholastic Ability Test. Mathematics, 10(9), 1486. https://doi.org/10.3390/math10091486