
Contextual Semantic-Guided Entity-Centric GCN for Relation Extraction

Abstract
:1. Introduction
- We propose a self-attention enhanced neural network that captures long-distance dependency and concentrates on the importance and relevance of different words in a sentence to obtain semantic-guided contextual information;
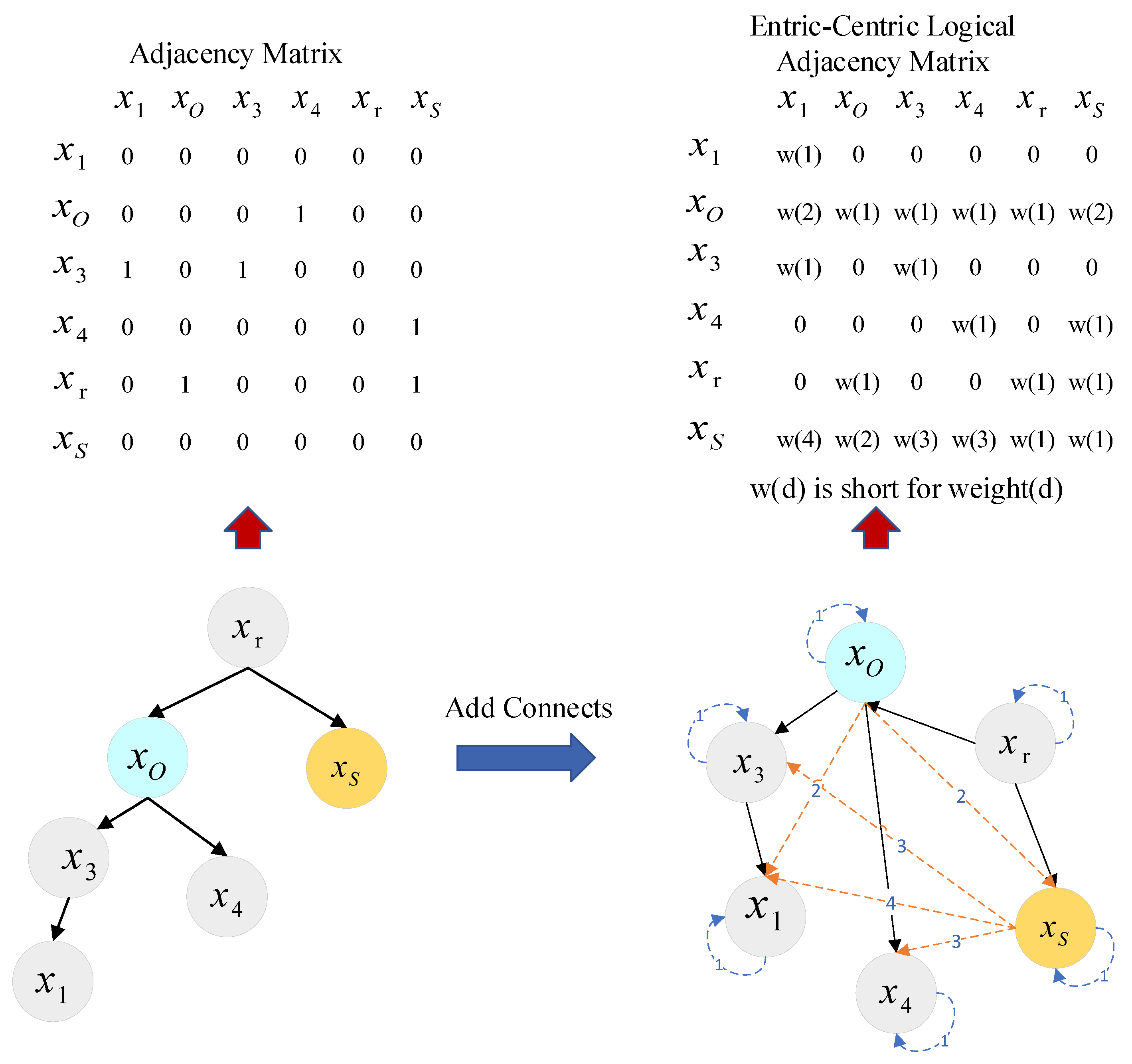
- We propose a novel entity-centric logical adjacency matrix that enables entities to aggregate contextual semantic information with a one-layer GCN calculation.
- Finally, we analyze the complementary semantic-feature-capturing effect of the extended LSTM, GCN, and multi-head self-attention mechanisms.
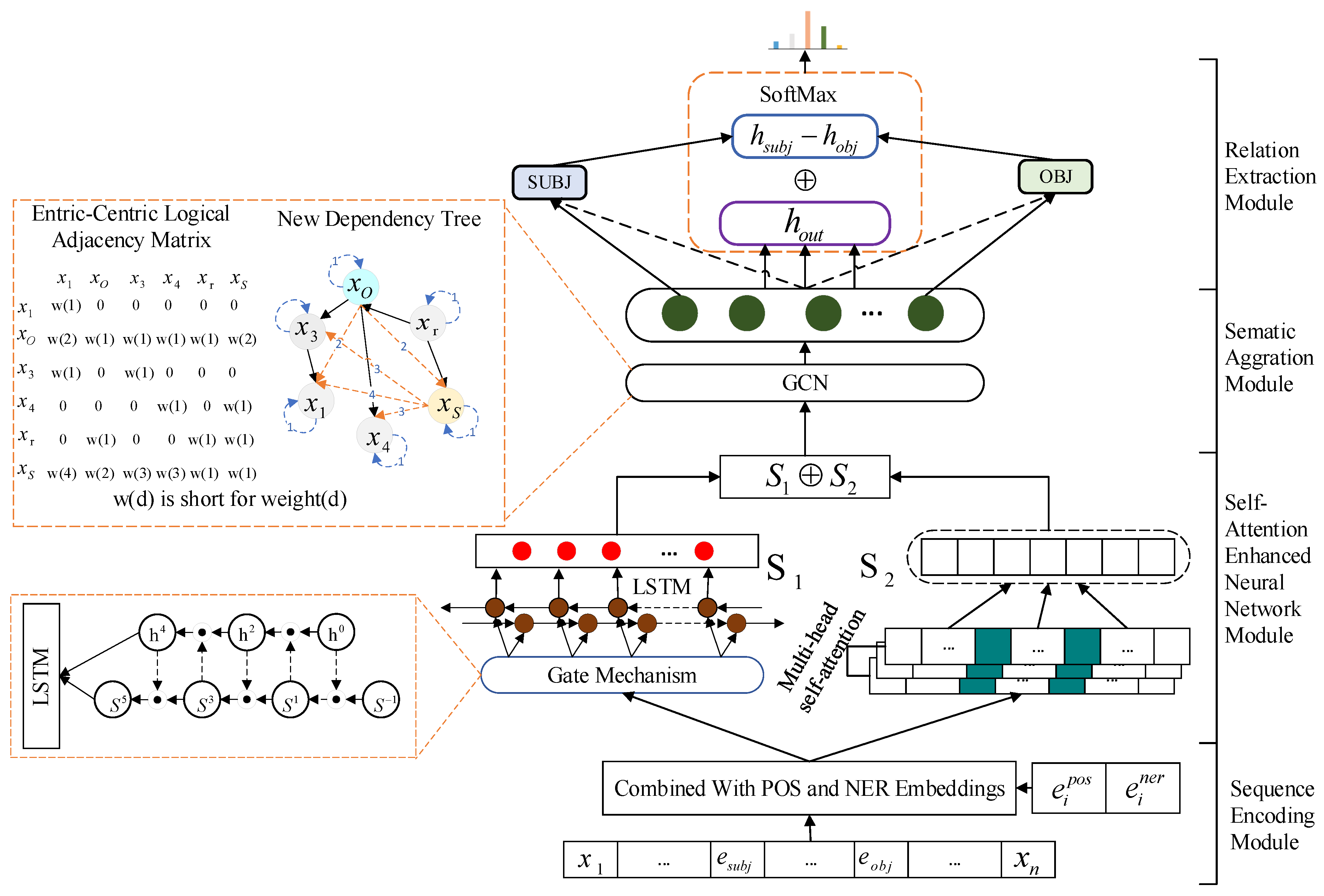
2. Materials and Methods
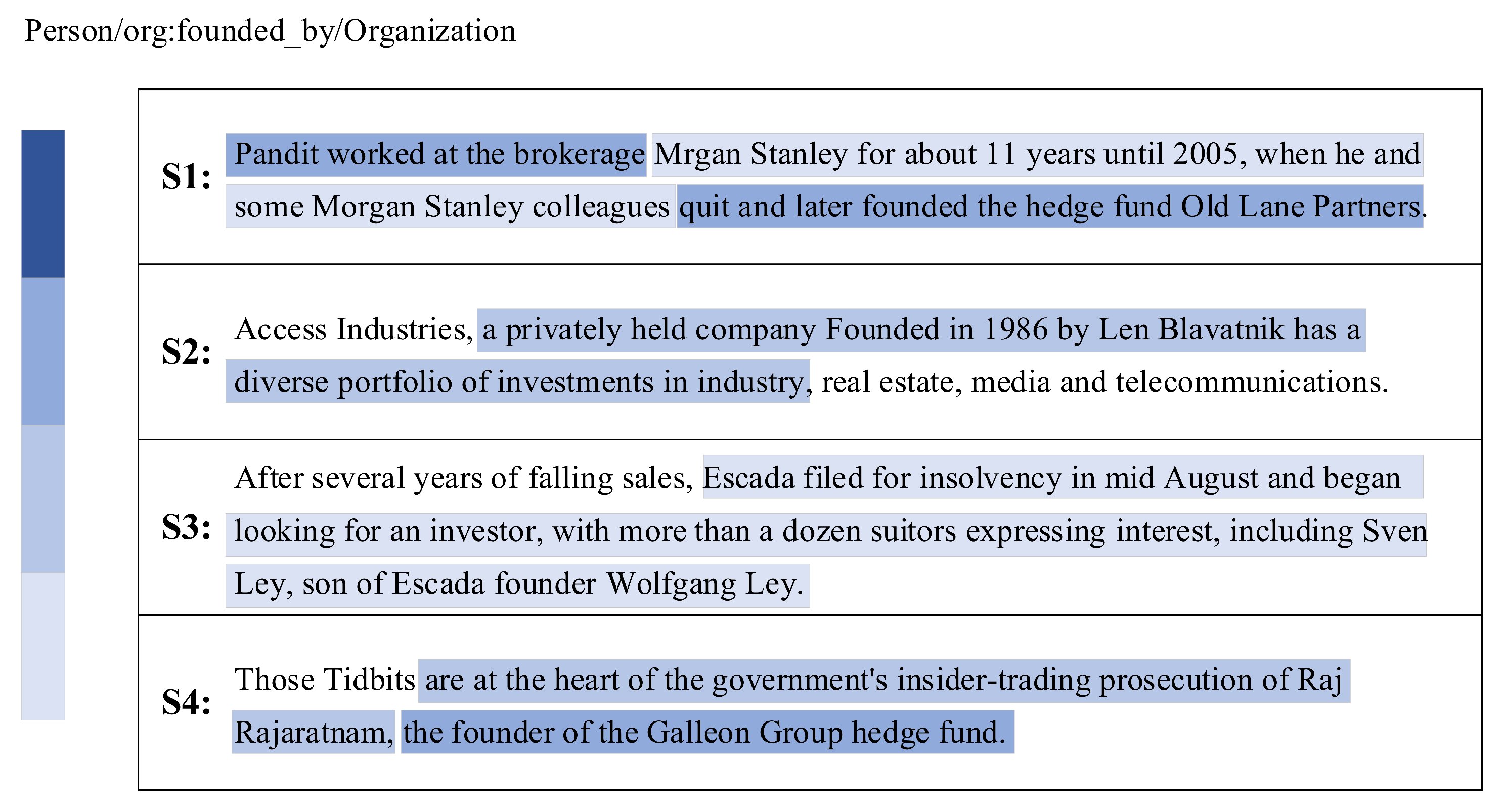
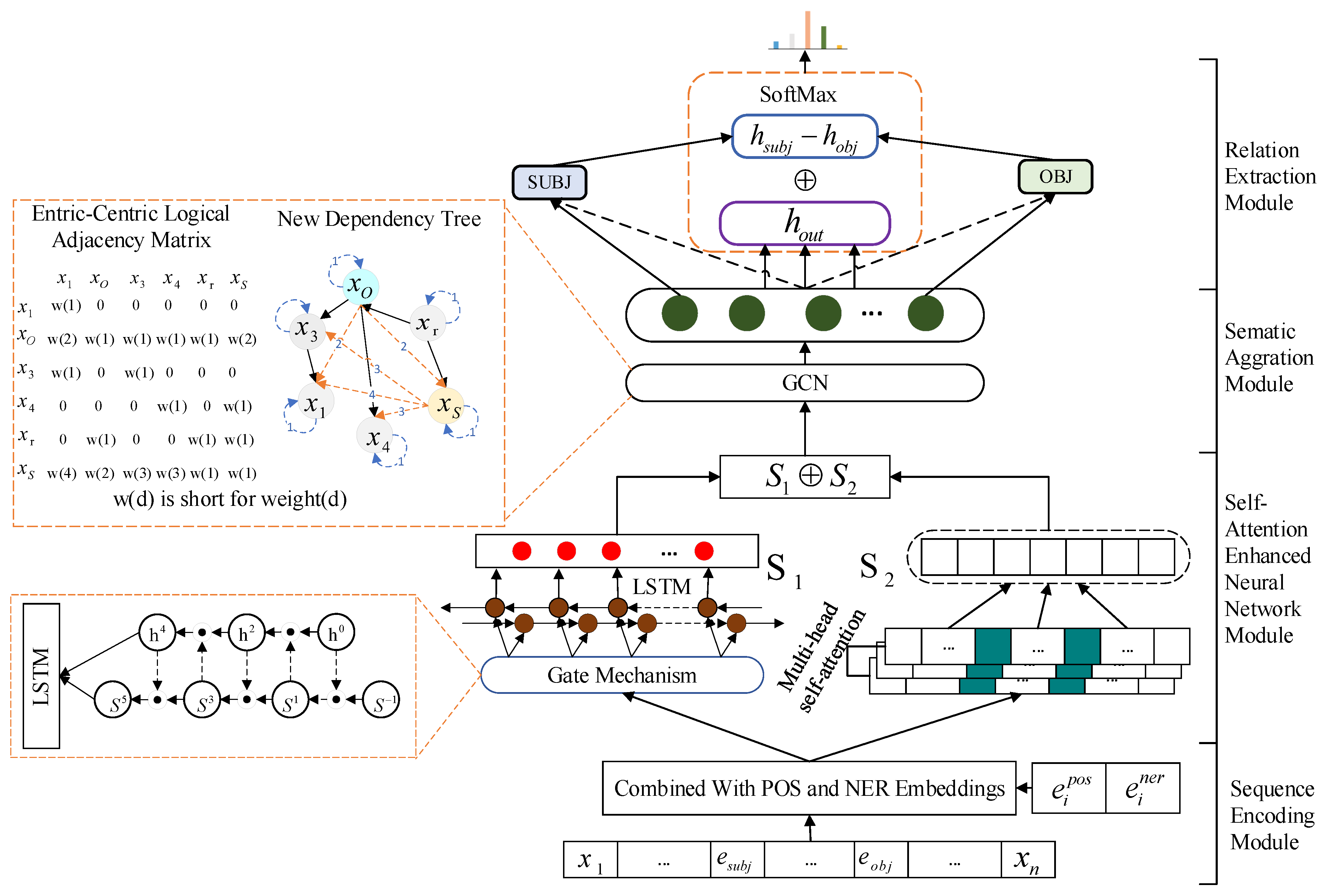
2.1. Sequence Encoding Module
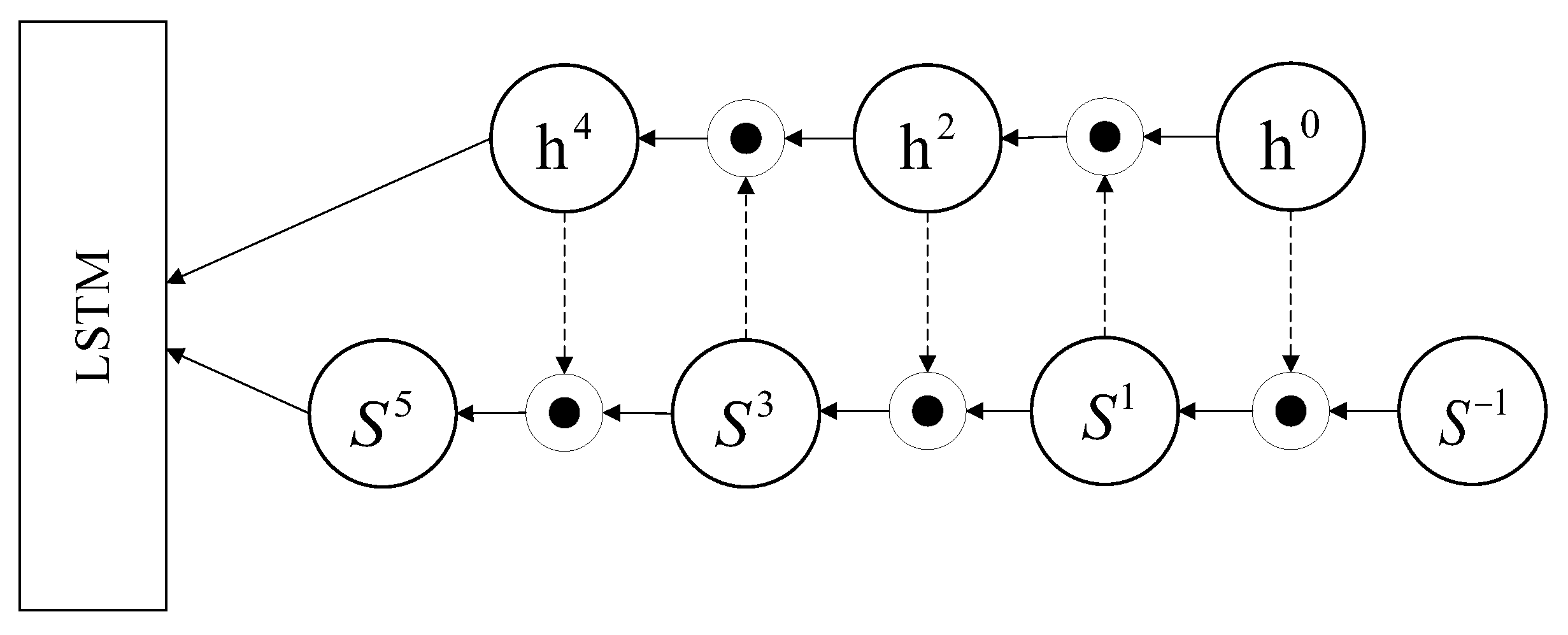
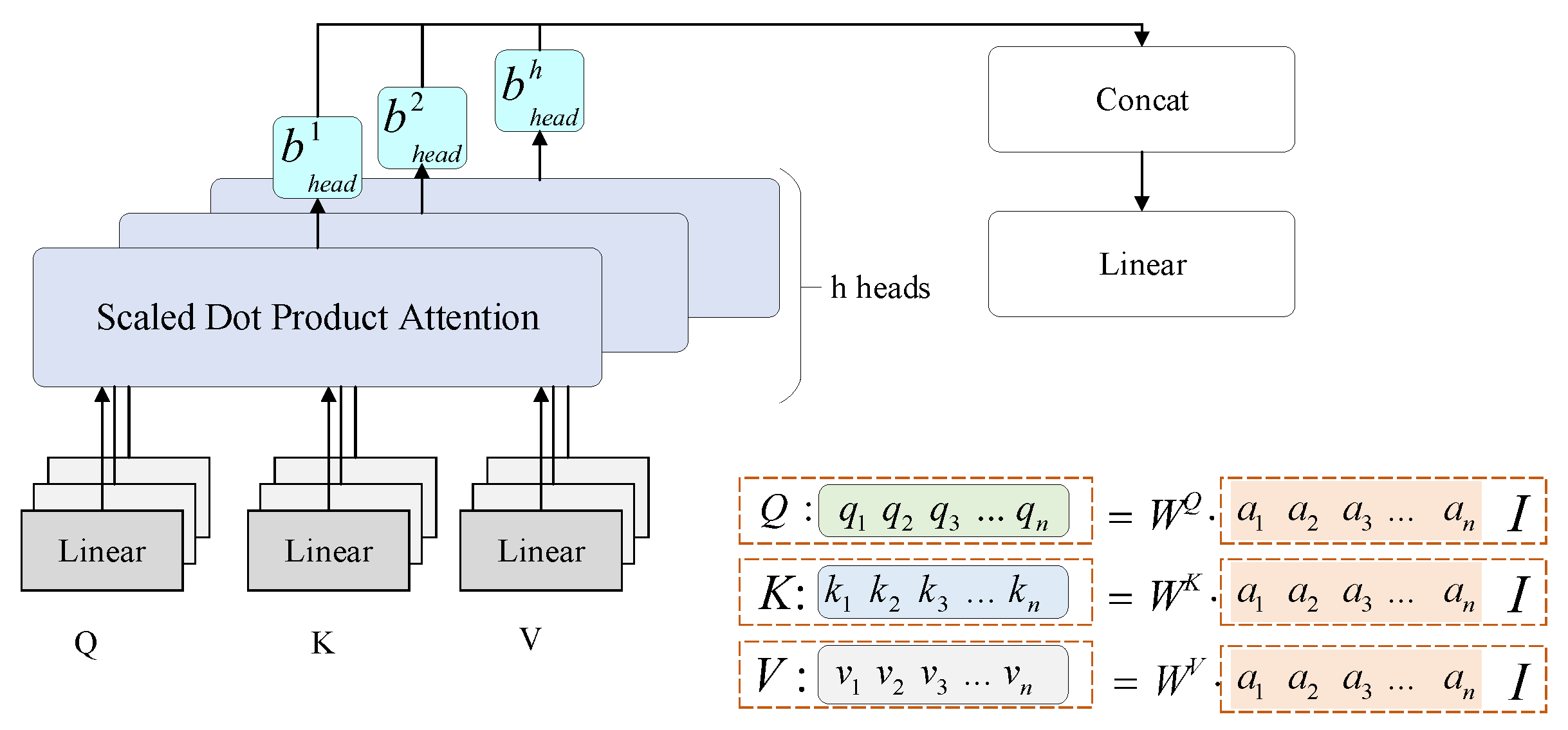
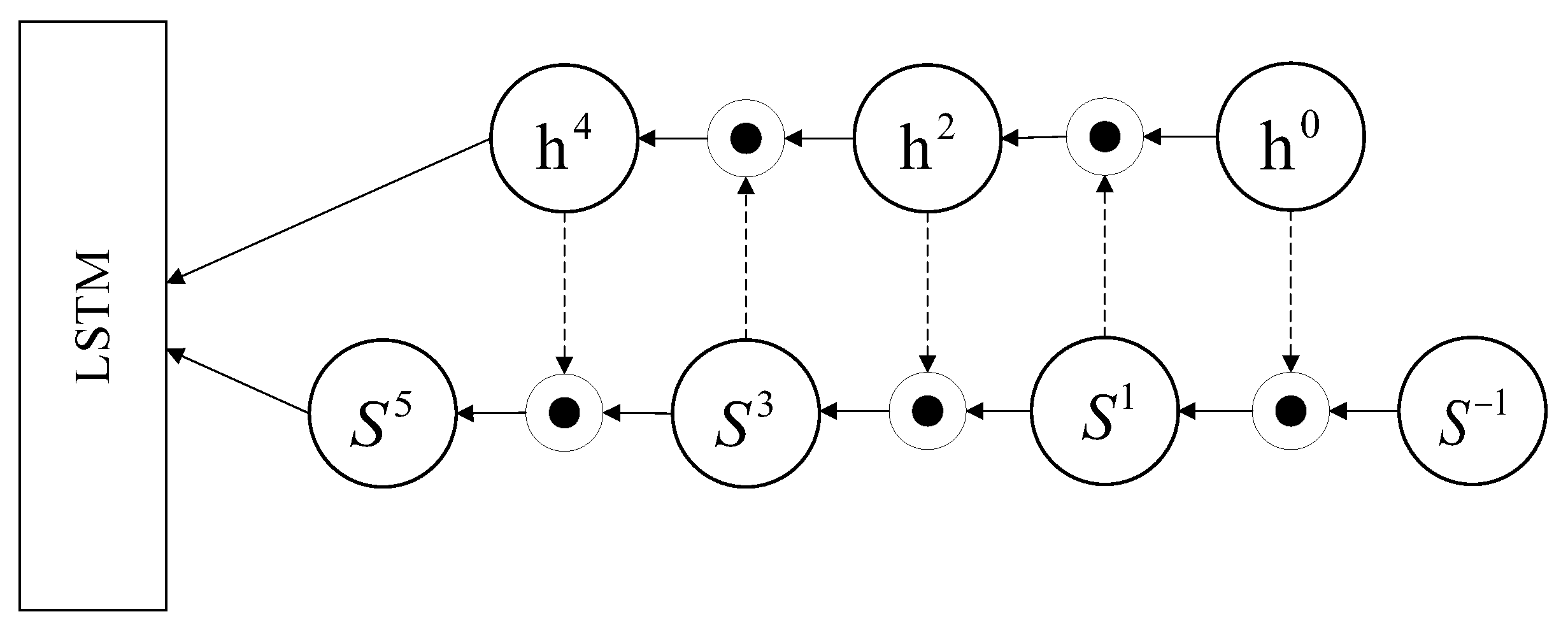
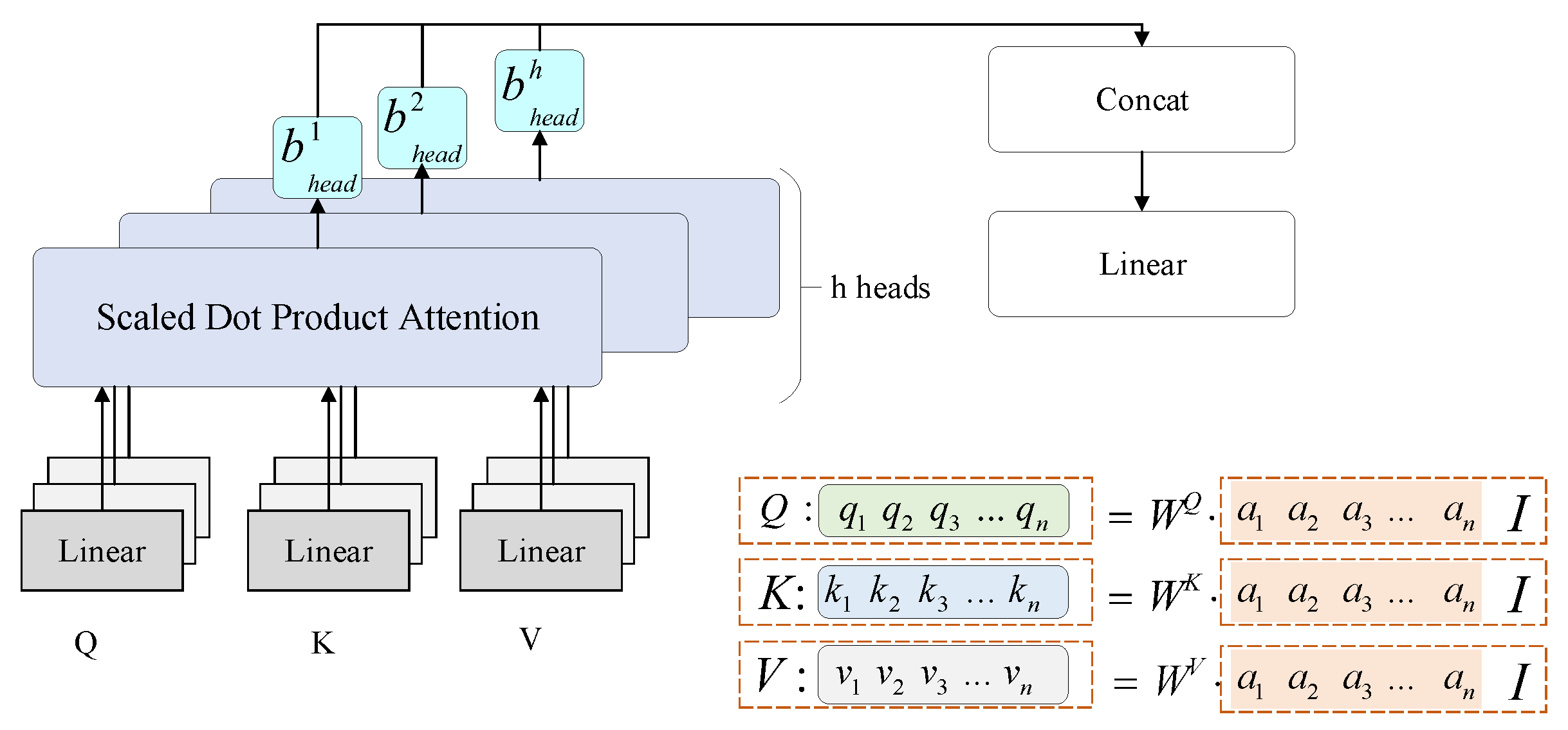
2.2. Self-Attention Enhanced Neural Network Module
2.3. Semantic Aggregation Module
| Algorithm 1 Contruction of the entity-centric logical adjacency matrix (ELAM). |
Input: P: entity position in sentence; N: sentence length; S: target sequence. Output: Entity-centric logical adjacency matrix (ELAM);
|
2.4. Relation Extraction Module
3. Experiment
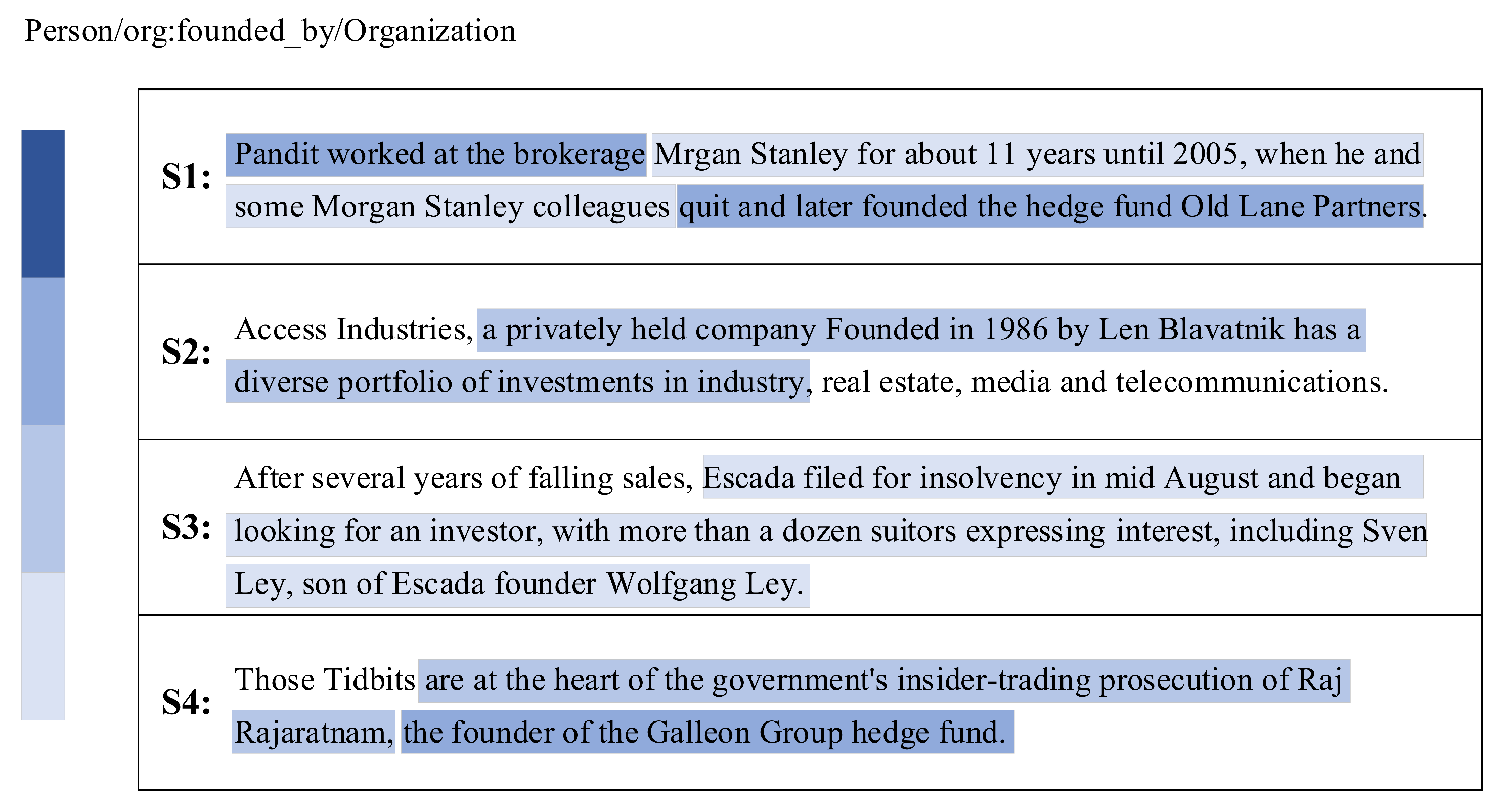
3.1. Datesets
3.2. Performance Comparison
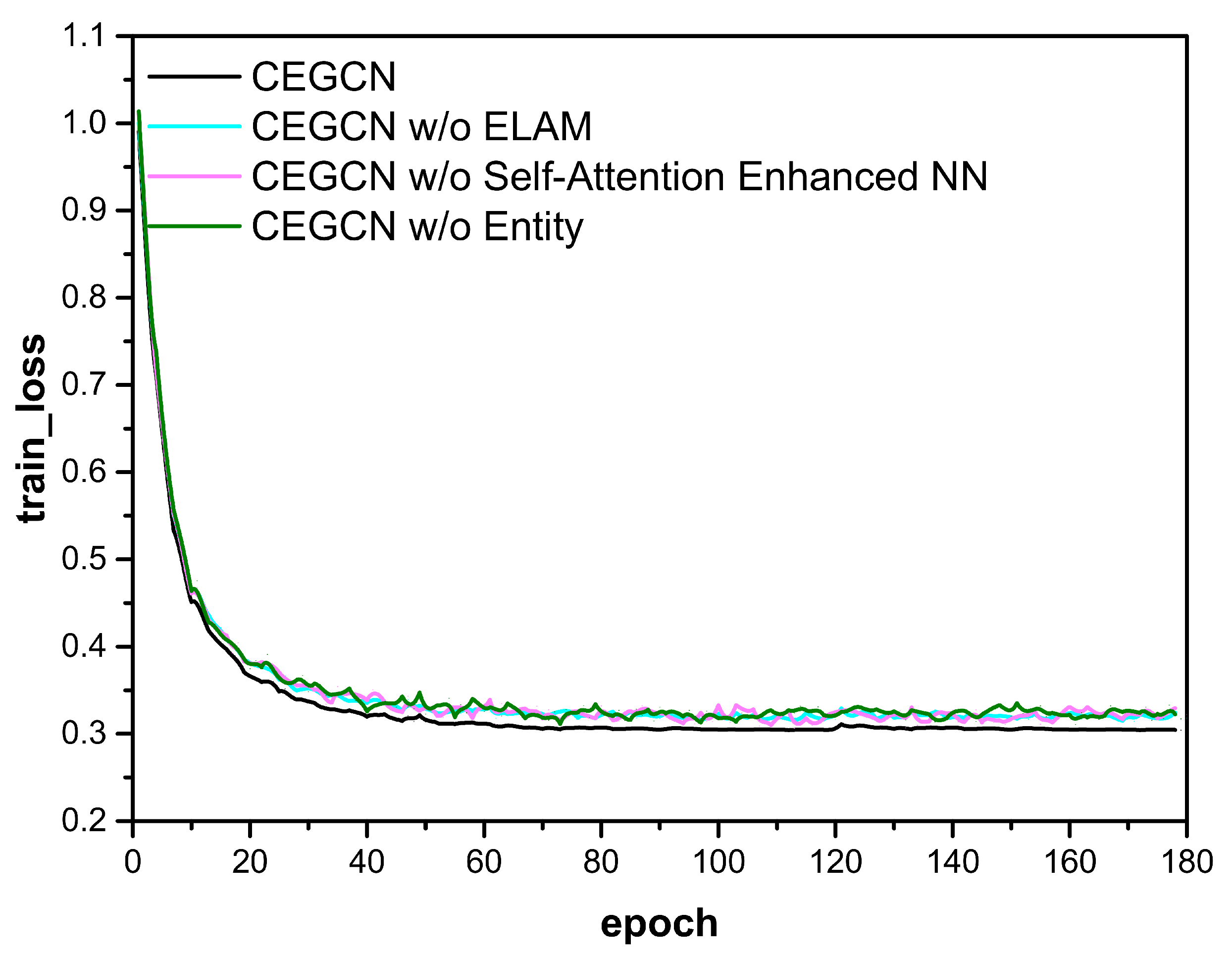
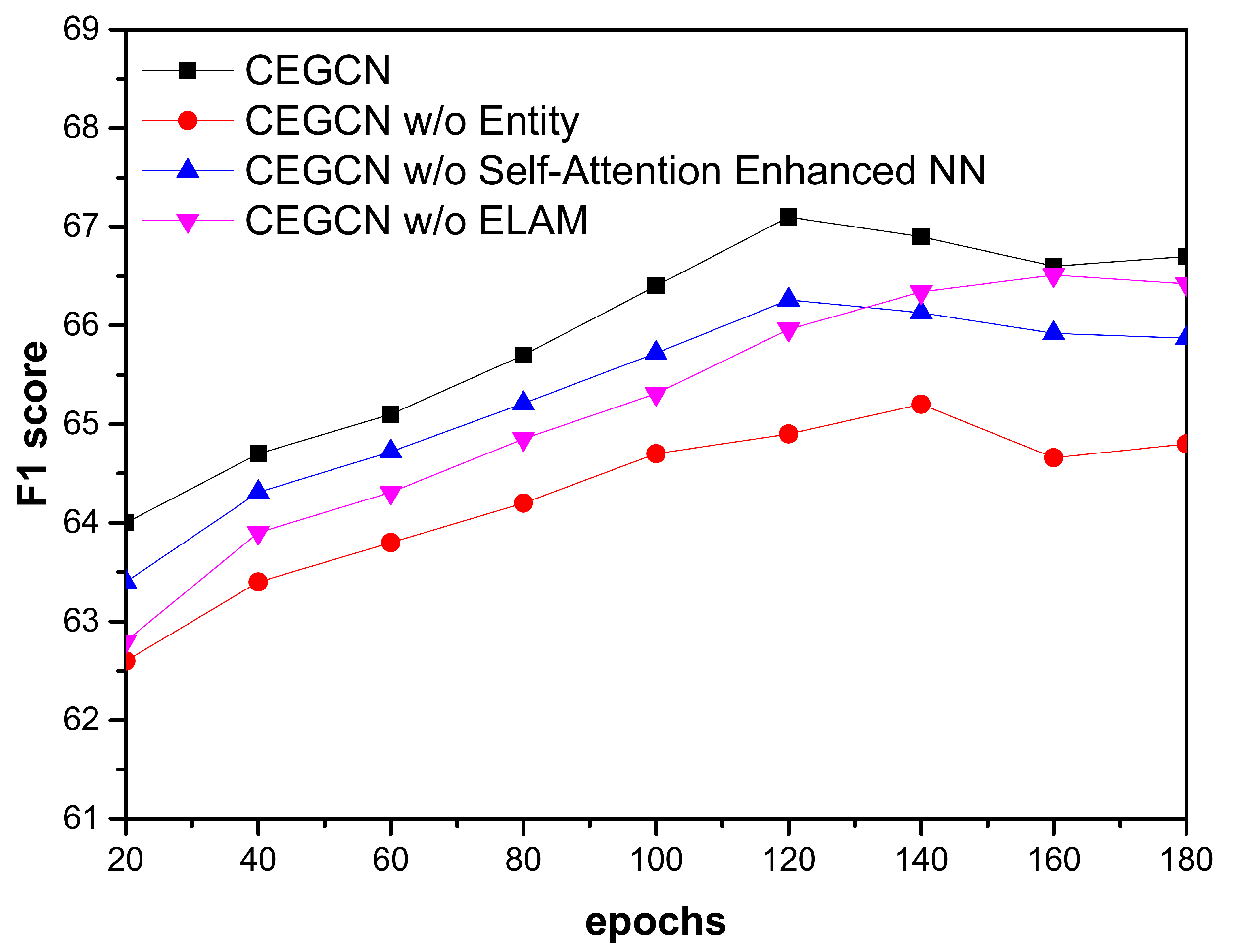
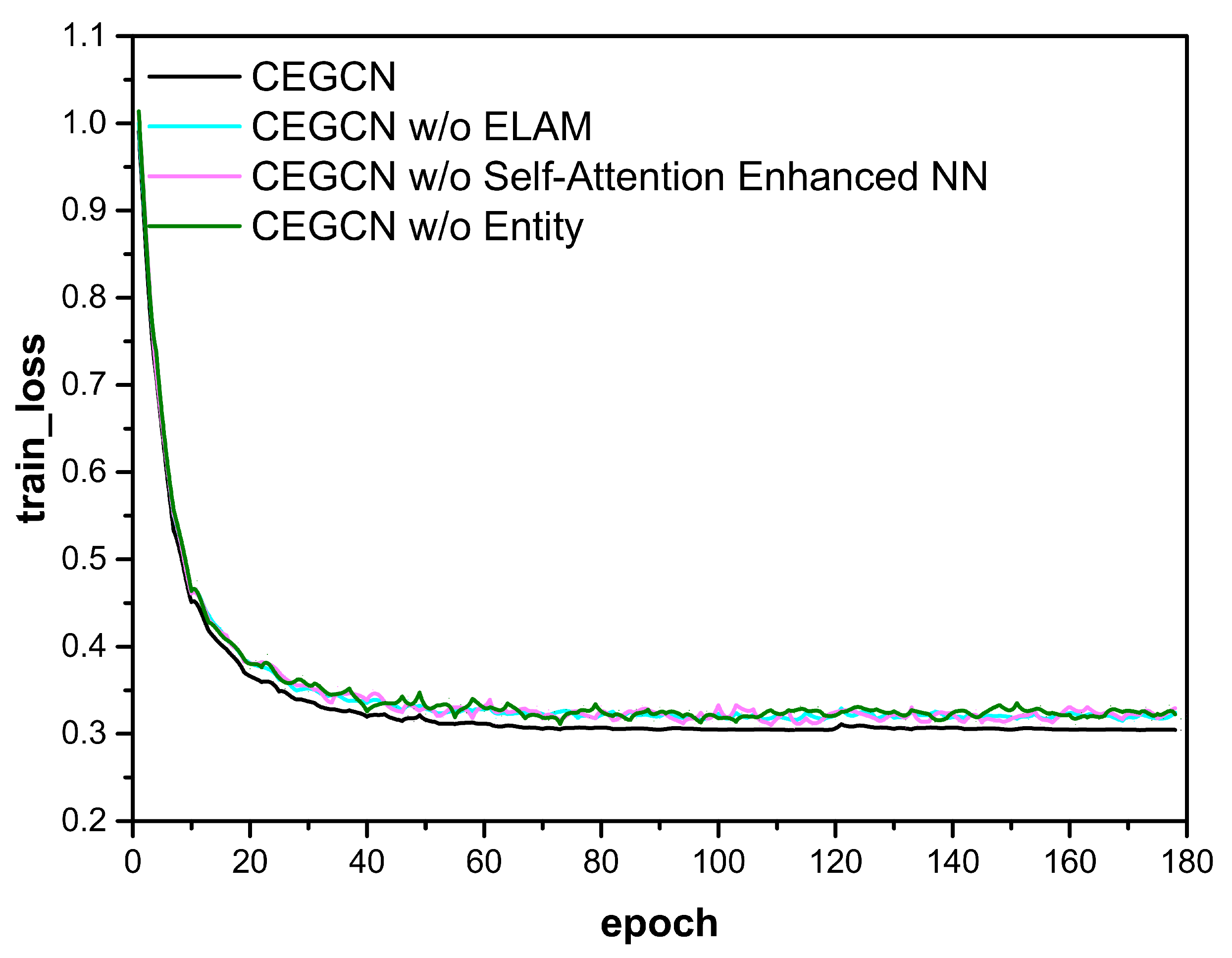
3.3. Ablation Study
- “CEGCN w/o Entity” means that we mask the entities with random tokens in the proposed model;
- “CEGCN w/o Self-Attention Enhanced NN” means that the self-attention enhanced neural network is removed;
- “CEGCN w/o ELAM” means that the entity-centric logical adjacency matrix is replaced by the ordinary adjacency matrix.
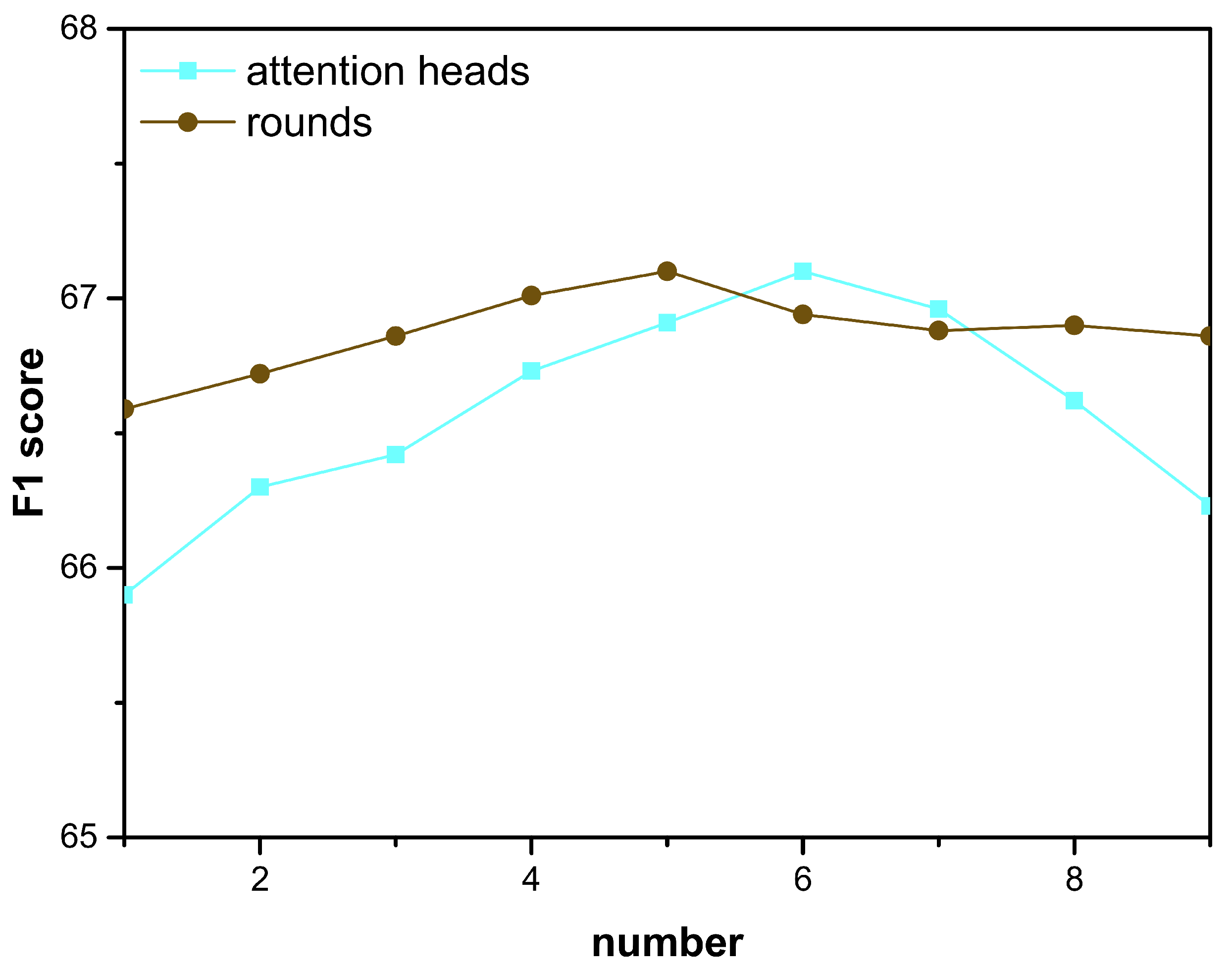
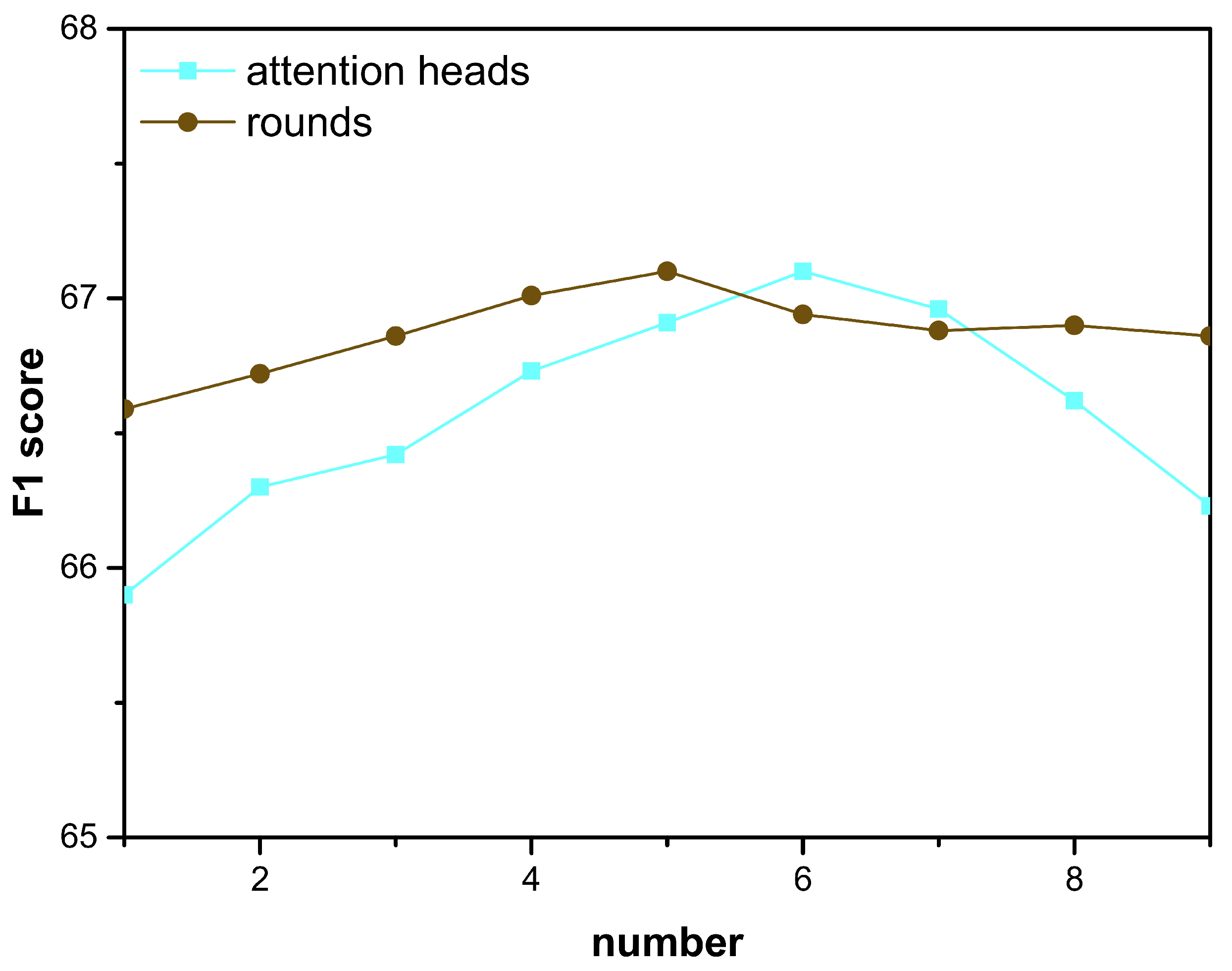
3.4. Effect of Hyper-Parameters
4. Related Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional neural network |
| LSTM | Long short-term memory |
| GCN | Graph convolutional network |
| RNN | Recurrent neural network |
References
- Fader, A.; Soderland, S.; Etzioni, O. Identifying relations for open information extraction. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 1535–1545. [Google Scholar]
- Hobbs, J.R.; Riloff, E. Information Extraction. In Handbook of Natural Language Processing; Chapman & Hall/CRC Press: London, UK, 2010. [Google Scholar]
- Aviv, R.; Erlich, Z.; Ravid, G.; Geva, A. Network analysis of knowledge construction in asynchronous learning networks. J. Asynchronous Learn. Netw. 2003, 7, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Li, H.; Kong, S.C.; Xu, Q. An analytic knowledge network process for construction entrepreneurship education. J. Manag. Dev. 2006, 25, 11–27. [Google Scholar] [CrossRef]
- Yih, S.W.t.; Chang, M.W.; He, X.; Gao, J. Semantic parsing via staged query graph generation: Question answering with knowledge base. In Proceedings of the Joint Conference of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015. [Google Scholar]
- Dong, J.; Wu, R.; Pan, Y. A Low-Profile Broadband Metasurface Antenna with Polarization Conversion Based on Characteristic Mode Analysis. Front. Phys. 2022, 10, 860606. [Google Scholar] [CrossRef]
- Hashimoto, K.; Miwa, M.; Tsuruoka, Y.; Chikayama, T. Simple customization of recursive neural networks for semantic relation classification. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1372–1376. [Google Scholar]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation classification via convolutional deep neural network. In Proceedings of the 25th International Conference on Computational Linguistics (COLING 2014), Dublin, Ireland, 23–29 August 2014; pp. 2335–2344. [Google Scholar]
- Dong, J.; Qin, W.; Wang, M. Fast multi-objective optimization of multi-parameter antenna structures based on improved BPNN surrogate model. IEEE Access 2019, 7, 77692–77701. [Google Scholar] [CrossRef]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 207–212. [Google Scholar]
- Xu, Y.; Mou, L.; Li, G.; Chen, Y.; Peng, H.; Jin, Z. Classifying relations via long short term memory networks along shortest dependency paths. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP), Lisbon, Portugal, 17–21 September 2015; pp. 1785–1794. [Google Scholar]
- Zhang, Y.; Qi, P.; Manning, C.D. Graph convolution over pruned dependency trees improves relation extraction. arXiv 2018, arXiv:1809.10185. [Google Scholar]
- Chen, Z.M.; Wei, X.S.; Wang, P.; Guo, Y. Multi-label image recognition with graph cosnvolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5177–5186. [Google Scholar]
- Li, L.; Gan, Z.; Cheng, Y.; Liu, J. Relation-aware graph attention network for visual question answering. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 10313–10322. [Google Scholar]
- Babič, M.; Mihelič, J.; Calì, M. Complex network characterization using graph theory and fractal geometry: The case study of lung cancer DNA sequences. Appl. Sci. 2020, 10, 3037. [Google Scholar] [CrossRef]
- Hendrickx, I.; Kim, S.N.; Kozareva, Z.; Nakov, P.; Séaghdha, D.O.; Padó, S.; Pennacchiotti, M.; Romano, L.; Szpakowicz, S. Semeval-2010 task 8: Multi-way classification of semantic relations between pairs of nominals. arXiv 2019, arXiv:1911.10422. [Google Scholar]
- Zhang, Y.; Zhong, V.; Chen, D.; Angeli, G.; Manning, C.D. Position-aware attention and supervised data improve slot filling. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017. [Google Scholar]
- Santoro, A.; Raposo, D.; Barrett, D.G.; Malinowski, M.; Pascanu, R.; Battaglia, P.; Lillicrap, T. A simple neural network module for relational reasoning. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Melis, G.; Kočiskỳ, T.; Blunsom, P. Mogrifier LSTM. arXiv 2019, arXiv:1909.01792. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Kim, M.; Park, S.; Lee, W. A robust energy saving data dissemination protocol for IoT-WSNs. KSII Trans. Internet Inf. Syst. 2018, 12, 5744–5764. [Google Scholar]
- Guo, Z.; Zhang, Y.; Lu, W. Attention guided graph convolutional networks for relation extraction. arXiv 2019, arXiv:1906.07510. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Tsukimoto, H. Logical regression analysis: From mathematical formulas to linguistic rules. In Foundations and Advances in Data Mining; Springer: Berlin/Heidelberg, Germany, 2005; pp. 21–61. [Google Scholar]
- Xu, K.; Feng, Y.; Huang, S.; Zhao, D. Semantic relation classification via convolutional neural networks with simple negative sampling. arXiv 2015, arXiv:1506.07650. [Google Scholar]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved semantic representations from tree-structured long short-term memory networks. arXiv 2015, arXiv:1503.00075. [Google Scholar]
- Chen, F.; Pan, S.; Jiang, J.; Huo, H.; Long, G. DAGCN: Dual Attention Graph Convolutional Networks. In Proceedings of the International Joint Conference on Neural Networks (IJCNN 2019), Budapest, Hungary, 14–19 July 2019. [Google Scholar]
- Hong, Y.; Liu, Y.; Yang, S.; Zhang, K.; Wen, A.; Hu, J. Improving graph convolutional networks based on relation-aware attention for end-to-end relation extraction. IEEE Access 2020, 8, 51315–51323. [Google Scholar] [CrossRef]
- Shi, P.; Lin, J. Simple bert models for relation extraction and semantic role labeling. arXiv 2019, arXiv:1904.05255. [Google Scholar]
- Nguyen, T.H.; Grishman, R. Relation extraction: Perspective from convolutional neural networks. In Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing, Denver, CO, USA, 5 June 2015; pp. 39–48. [Google Scholar]
- Hu, Y.; Shen, H.; Liu, W.; Min, F.; Qiao, X.; Jin, K. A Graph Convolutional Network With Multiple Dependency Representations for Relation Extraction. IEEE Access 2021, 9, 81575–81587. [Google Scholar] [CrossRef]
- Yu, M.; Yin, W.; Hasan, K.S.; Santos, C.D.; Xiang, B.; Zhou, B. Improved neural relation detection for knowledge base question answering. arXiv 2017, arXiv:1704.06194. [Google Scholar]
- Kong, Q.; Cao, Y.; Iqbal, T.; Wang, Y.; Wang, W.; Plumbley, M.D. PANNs: Large-scale pretrained audio neural networks for audio pattern recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2880–2894. [Google Scholar] [CrossRef]
- Shi, H.; Zhao, X.; Wan, H.; Wang, H.; Dong, J.; Tang, K.; Liu, A. Multi-model induced network for participatory-sensing-based classification tasks in intelligent and connected transportation systems. Comput. Networks 2018, 141, 157–165. [Google Scholar] [CrossRef]
- Huang, W.; Mao, Y.; Yang, Z.; Zhu, L.; Long, J. Relation classification via knowledge graph enhanced transformer encoder. Knowl.-Based Syst. 2020, 206, 106321. [Google Scholar] [CrossRef]
- Huang, W.; Mao, Y.; Yang, L.; Yang, Z.; Long, J. Local-to-global GCN with knowledge-aware representation for distantly supervised relation extraction. Knowl.-Based Syst. 2021, 234, 107565. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Description | Value |
|---|---|---|
| word embedding | 300 | |
| POS embedding | 30 | |
| NER embedding | 30 | |
| LSTM hidden size | 100 | |
| GCN hidden size | 200 | |
| CEGCN layers | 3 | |
| h | attention heads | 6 |
| r | interaction rounds | 5 |
| batch | batch size | 50 |
| Model | P | R | F1 |
|---|---|---|---|
| LR [24] | 73.5 | 49.9 | 59.4 |
| CNN [30] | 75.6 | 47.5 | 58.3 |
| SDP-LSTM [11] | 66.3 | 52.7 | 58.7 |
| PA-LSTM [17] | 66.0 | 59.2 | 62.4 |
| C-GCN [12] | 65.7 | 63.3 | 66.4 |
| AGGCN [22] | 69.9 | 60.9 | 65.1 |
| DAGCN [27] | 70.1 | 63.5 | 66.8 |
| CEGCN (our model) | 73.4 | 61.8 | 67.2 |
| Model | F1 |
|---|---|
| LR [24] | 82.2 |
| CNN [30] | 83.7 |
| SDP-LSTM [11] | 84.4 |
| PA-LSTM (2017) [17] | 84.8 |
| C-GCN (2018) [12] | 84.8 |
| C-AGGCN (2020) [22] | 85.7 |
| C-MDR-GCN (2021) [31] | 84.9 |
| CEGCN (our model) | 86.1 |
| Model | Dev F1 |
|---|---|
| CEGCN (our model) | 67.2 |
| CEGCN w/o Entity | 65.4 |
| CEGCN w/o Self-Attention Enhanced NN | 66.3 |
| CEGCN w/o ELAM | 66.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Long, J.; Liu, L.; Fei, H.; Xiang, Y.; Li, H.; Huang, W.; Yang, L. Contextual Semantic-Guided Entity-Centric GCN for Relation Extraction. Mathematics 2022, 10, 1344. https://doi.org/10.3390/math10081344
Long J, Liu L, Fei H, Xiang Y, Li H, Huang W, Yang L. Contextual Semantic-Guided Entity-Centric GCN for Relation Extraction. Mathematics. 2022; 10(8):1344. https://doi.org/10.3390/math10081344
Chicago/Turabian StyleLong, Jun, Lei Liu, Hongxiao Fei, Yiping Xiang, Haoran Li, Wenti Huang, and Liu Yang. 2022. "Contextual Semantic-Guided Entity-Centric GCN for Relation Extraction" Mathematics 10, no. 8: 1344. https://doi.org/10.3390/math10081344
APA StyleLong, J., Liu, L., Fei, H., Xiang, Y., Li, H., Huang, W., & Yang, L. (2022). Contextual Semantic-Guided Entity-Centric GCN for Relation Extraction. Mathematics, 10(8), 1344. https://doi.org/10.3390/math10081344