
Predicting Stock Price Changes Based on the Limit Order Book: A Survey



Abstract
1. Introduction
2. Overview of Strategies for Stock Prediction Based on Market Data
2.1. Introduction to the Input Data for Stock Trading
2.2. Market Data Classification Overview
2.3. Market Data-Based Trading Approaches and Their Evolution
- Input data used in these experiments;
- Models applied for the stock price prediction;
- Results achieved, their comparability and practicality assessment.
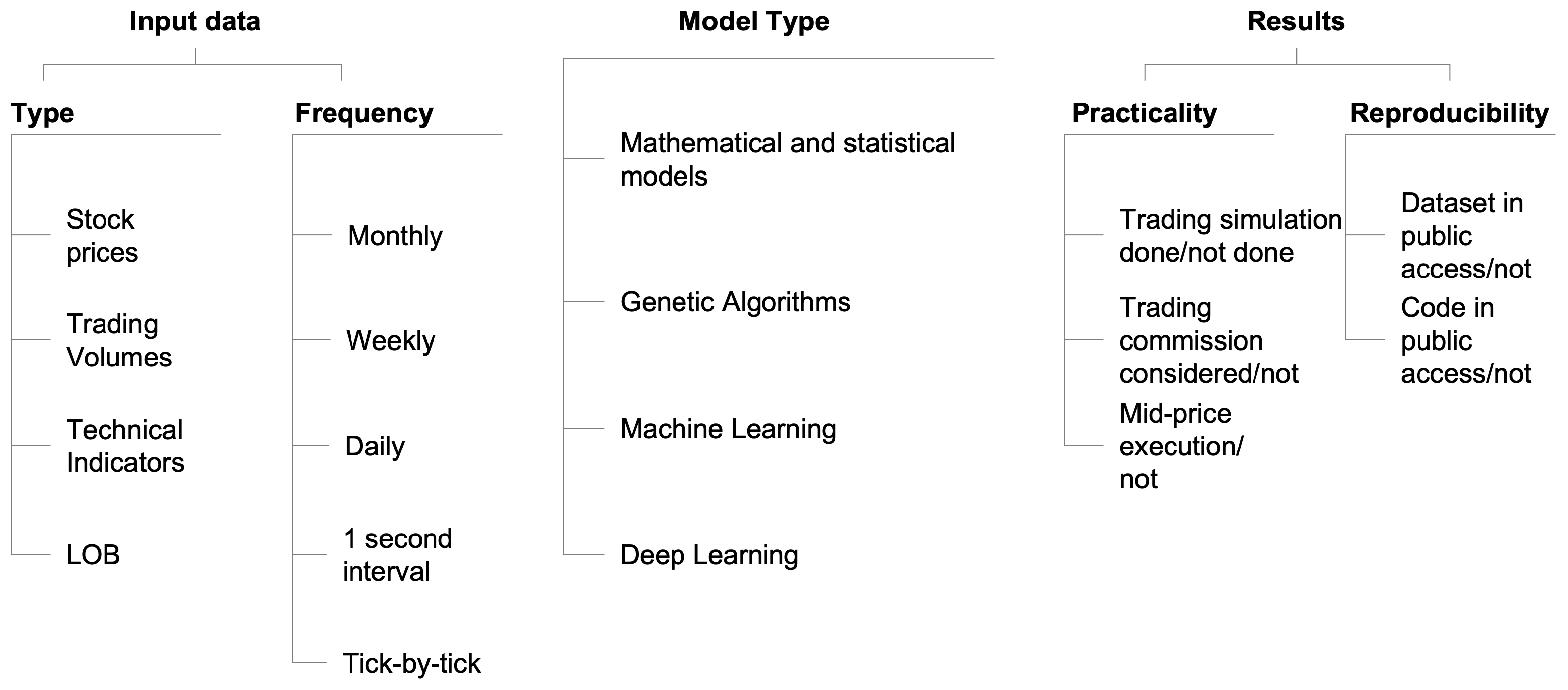
2.3.1. Model
2.3.2. Data
2.3.3. Experimental Setup, Results Comparability, Practicality and Reproducibility
2.3.4. Key Takeaways
3. Critical Review of the Experiments with the Benchmark LOB Dataset
3.1. Benchmark LOB Dataset
- The underlying order flow data provided by NASDAQ is more than ten years old, so this data may not be a good indicator of the current situation in the dynamically evolving stock markets.
- Authors combined all the five stocks data into one dataset, making them indistinguishable from each other. As a results of this, at multiple data points in the experiments, the models are learning the price movement outcome for one stock based on the LOB features of the other stock, which does not make much sense from the market operations perspective. This could introduce some bias in the models and their conclusions.
- The other potential biases could have been introduced during the processing of the raw order flow data and further data clean-ups and normalisation. Analysis of the of raw data from NASDAQ, led to the conclusion that there could be some outliers and errors in this data that need to be adjusted before feeding this to the models to avoid biased results. It is not clear if this was actually performed by the authors of the benchmark LOB dataset, since the data in the benchmark LOB dataset is normalised using three different methods: min-max, z-score, and decimal-precision) and combined for all the stocks, making it hard to identify potentially erroneous data points.
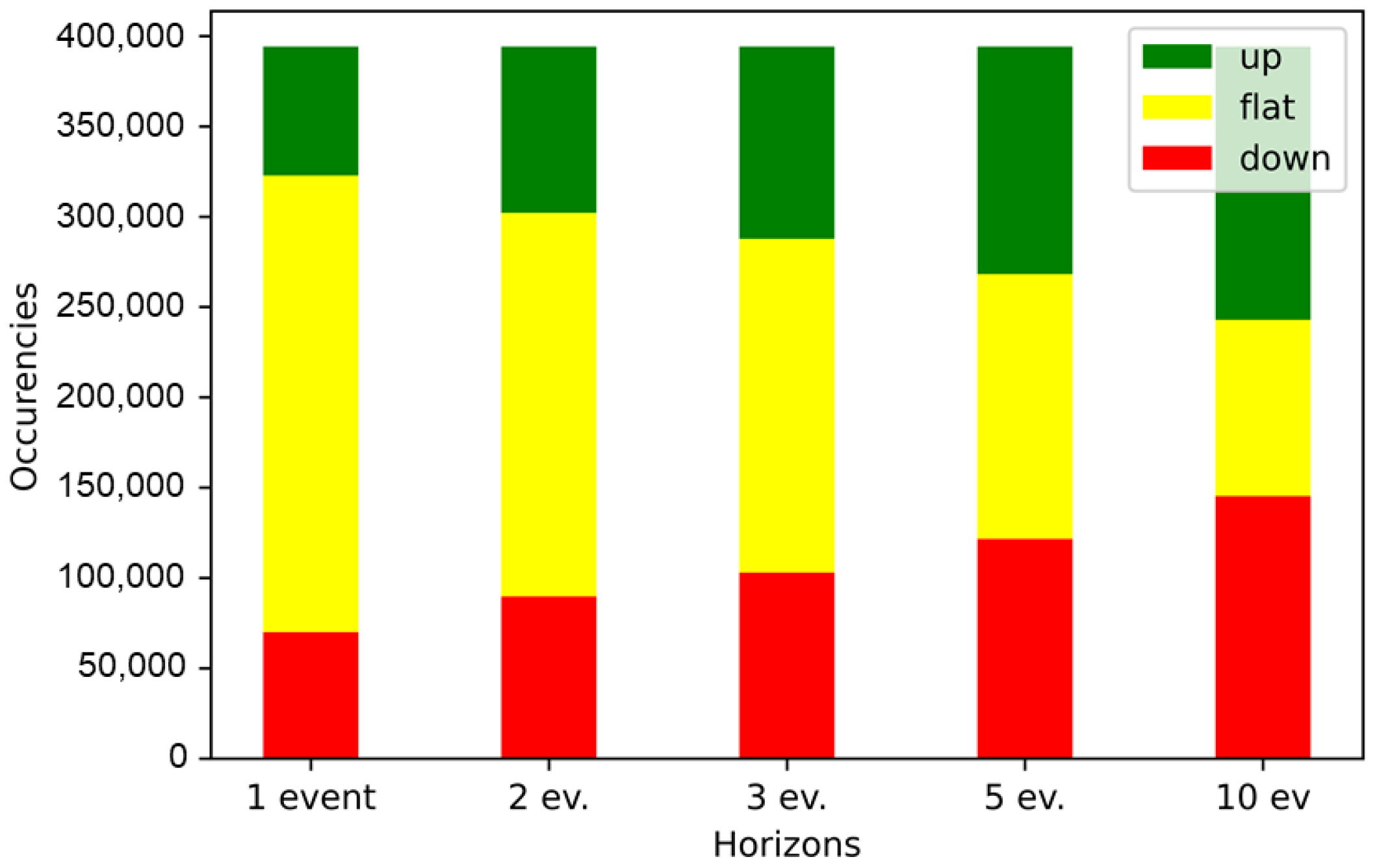
- The dataset is inherently unbalanced among its three classes of movement (“upward”, “flat”, “downward”). As we can see from Figure 3 the “flat” class is dominant for the prediction horizons of 1, 2, 3 events. With the increasing length of the prediction horizon the proportion of the “flat” class is gradually shrinking, so for the prediction horizon of 5 events the dataset is more or less balanced between the three classes, while for 10 events the “flat” class is positioned as the smallest one. This requires appropriate adjustments to the experimental setup, such as over-sampling, under-sampling and etc. Based on the review of prior studies, some of the results reported were based on experimental procedures that did not include dynamically responsive sampling of datapoints; this could have potentially biased such results.
- “upward”, “flat” and “downward” labels in this dataset are determined based on the mid-price movement, which is an average between the best bid and offer prices. This assumption could be valid if the buy or sell part of the transaction is executed using the limit orders instead of market orders. Since there is no guarantee that the limit orders would be actually executed in the required time slot, this assumption is unrealistic.
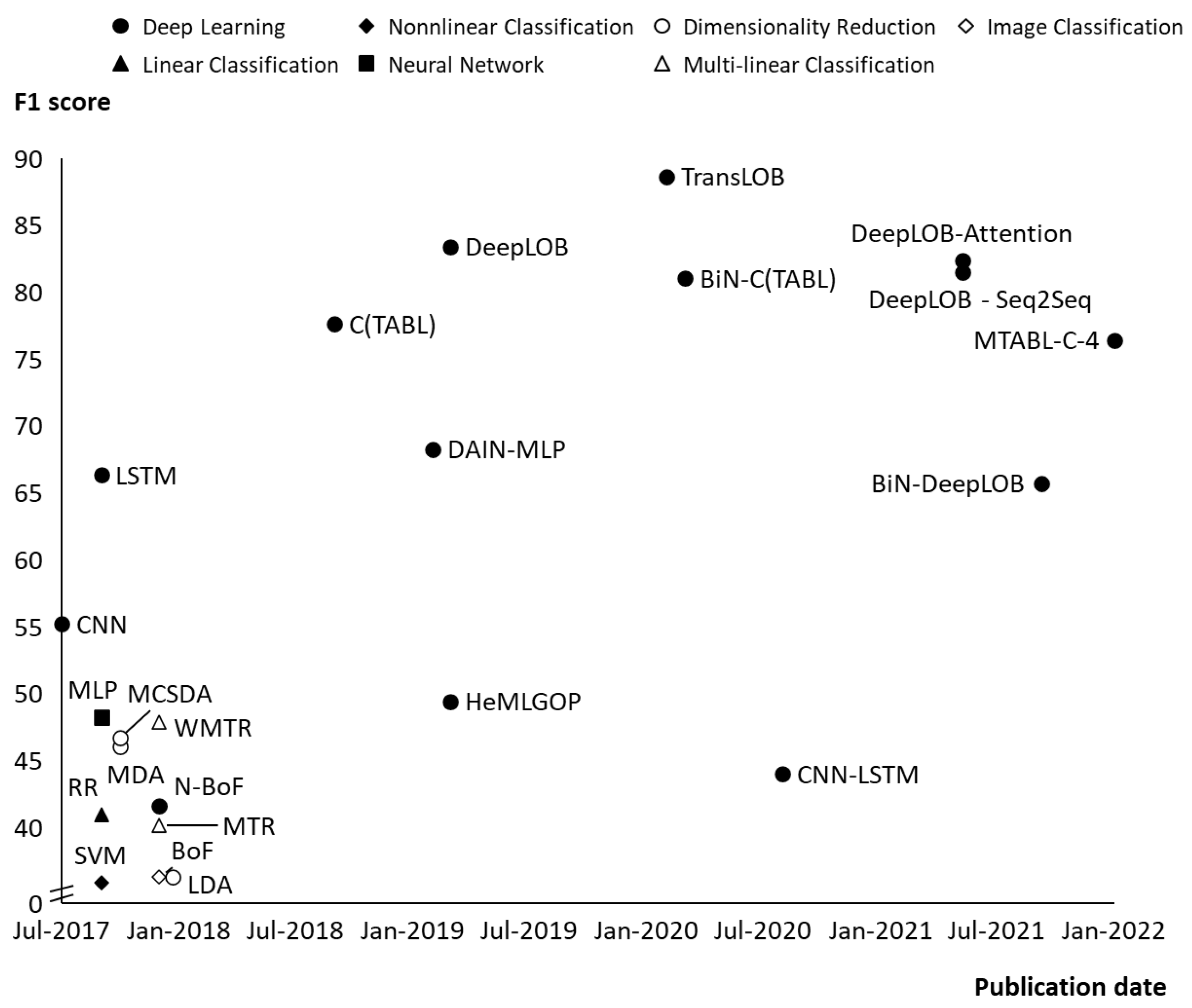
3.2. Comparison and Critical Evaluation of the ML/DL Models Based on the Benchmark LOB Dataset in Chronological Order
3.3. Reproducibility of Earlier LOB Predictions
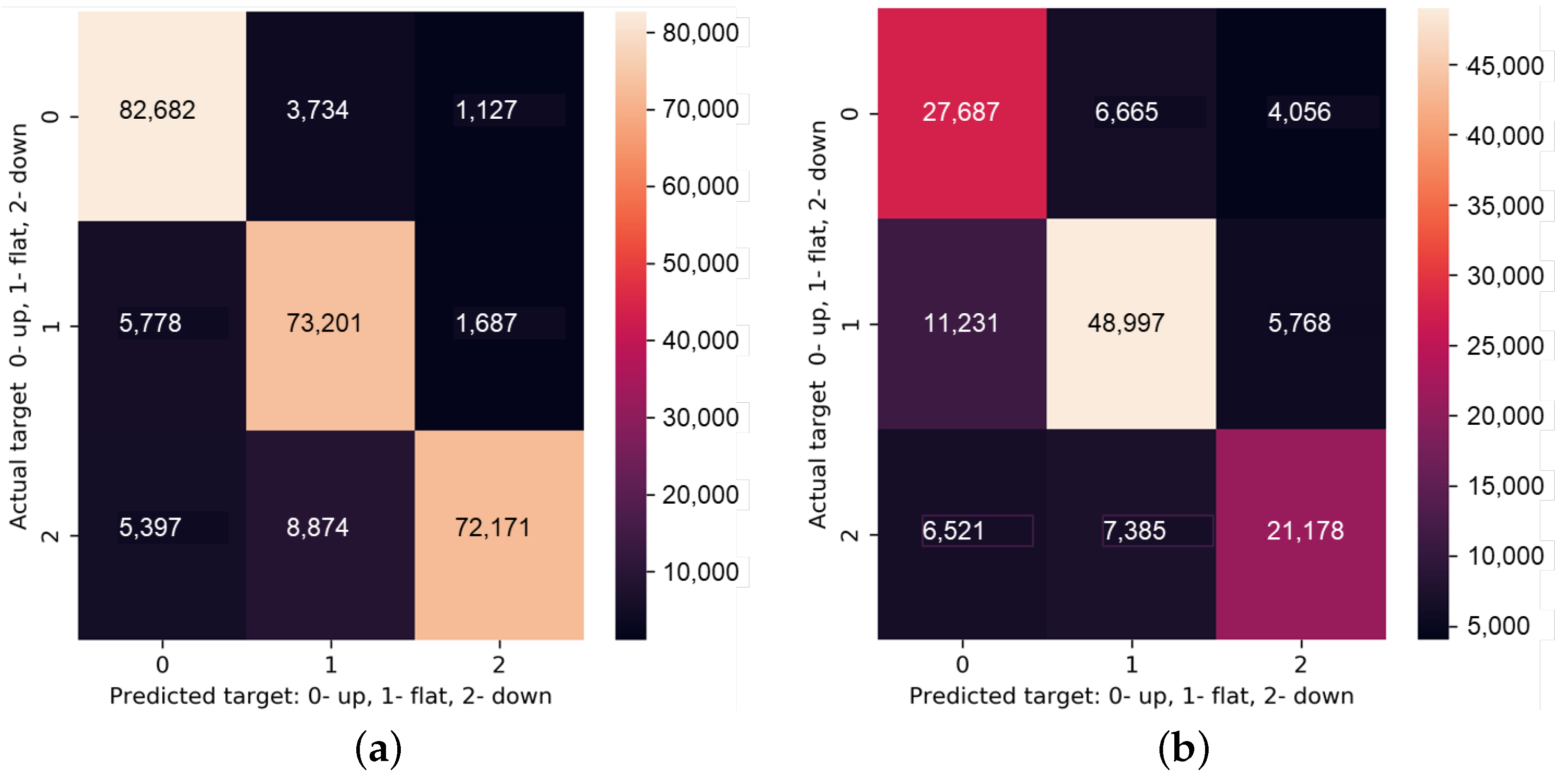
3.3.1. Model, Experimental Setup and Results Analysis
- Increase the size of the dataset. Authors of DeepLOB (recognising the over-fitting issue that can result from the fact that the LOB benchmark dataset has only LOB data for 10 consecutive days) trained their model, in addition, on the larger dataset based on the one year long data from the London Stock Exchange (LSE). Depending on the type of security and prediction horizon, accuracy for the LSE dataset is in the range of 62–70%, which is substantially lower than for the benchmark LOB dataset. This could suggest that the performance of the model on the benchmark LOB dataset was overestimated.
- Remove some of the features, optimise feature space. Authors are using price and volume data for 10 levels of the bid and ask sides of LOB, which results in 40 features. Usually, higher level orders have less effect on the future price changes, so the reduction of the number of levels from the LOB taken as an input to the model. The other aspect is the number of the latest LOB events taken into account for the price movement prediction. In the DeepLOB work, it is taken as 100, but again there could be the potential to optimise that number. The respective optimisations of the feature space could help to reduce over-fitting.
- Model simplification. The DeepLOB model consists of convolution layer with 15 filters of size ; inception module (concatenation of five convolution layers with 32 filters and max-pooling layer with stride 1 and zero padding); LSTM with 64 units. The total number of parameters of this model is around 60,000. Probably, there is potential to further optimise this complex architecture to minimise over-fitting.
- Early stopping mechanism. This was mentioned by the authors of DeepLOB model in their paper. The script is stopping the training of the model if the validation accuracy does not improve for more than 20 epochs. As a result, early stopping happens after 100 epochs. However, as was earlier mentioned, there are symptoms of over-fitting happening already after the first 50 epochs, so the early stopping mechanism could be further optimised, by reducing the allowed number of epochs without improvement.
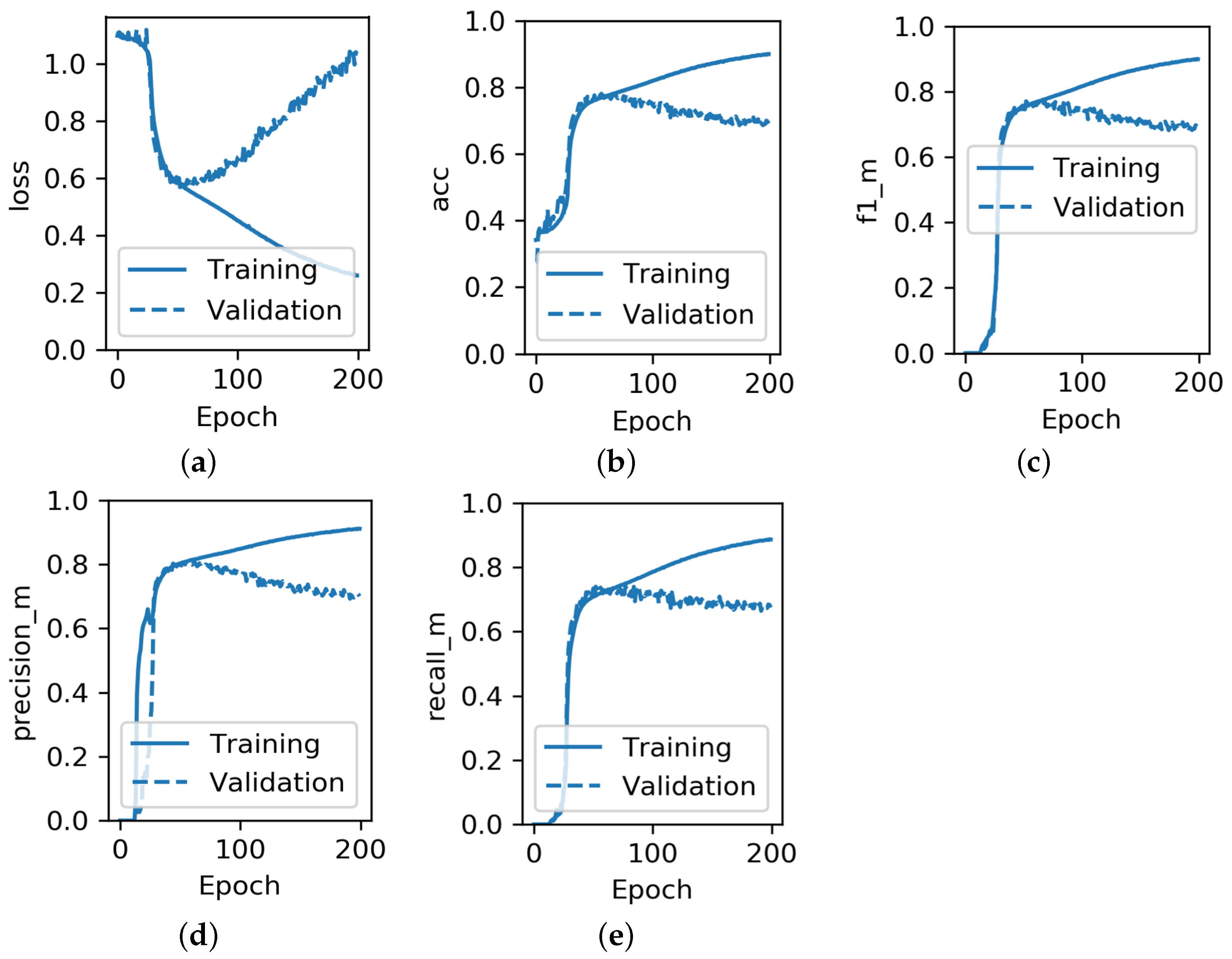
- Save the best weights of the model achieved during the training. Functionality in many Python machine learning libraries, including TensorFlow, enables the saving of the best weights of the model achieved during the training based on the selected metric performance. For example, as can be seen from Figure 6, if the condition for saving the model weights was the maximisation of the validation accuracy, the weights from somewhere around epoch 50 would be taken as the best. Thus, likewise for an early stopping mechanism the model would not suffer from over-fitting.
- Apply dropout. Dropout functionality is probabilistically removing inputs during training. This could be undertaken as an alternative to the removal of some features or in addition to that to solve the over-fitting problem.
3.3.2. Practical Value of the Model for Trading
4. Conclusions and Future Work
- Use more recent LOB data for the input features;
- Do not implicitly assume the mid-price execution;
- To properly train the deep learning models, an extensive dataset should be used, otherwise the over-fitting problem could become severe;
- Careful pre-processing of the dataset should be performed as required to filter out erroneous data;
- Data for different stocks should be distinguishable in the dataset;
- Removal of the relatively less significant features, optimisation of the feature space;
- Optimisation of the model architecture. This could be achieved by limiting the number of neurons and removing the relatively less critical layers;
- Applying the dropout functionality for probabilistically removing inputs during training
- Increasing the size of the data sample;
- Introducing the early stopping mechanism in model training;
- Saving the best weights of the model achieved during the training.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| %D | 3-day moving average of Stochastic %K. |
| ADO | Accumulation Distribution Oscillator. |
| ADX | Average Directional Index. |
| ANFIS | Adaptive Network-Based Fuzzy Inference System. |
| ANN | Artificial Neural Network. |
| ARIMA | Autoregressive Integrated Moving Average. |
| BB | Bollinger Band. |
| BFO | Bacterial foraging optimisation. |
| BiN-DeepLOB | DeepLOB model with Bilinear Input Normalization layer. |
| BiN-C(TABL) | Neural network consisting of Bilinear normalisation layer and three Temporal Attention augmented Bilinear Layers. |
| BoF | Bag-of-Features. |
| bp | Basis points. |
| BPN | Back-Propagation Networks. |
| BPNN | Back Propagation Neural Network. |
| C(TABL) | Neural network consisting of three Temporal Attention augmented Bilinear Layers. |
| C4.5 DT | C4.5 decision tree. |
| CCI | Commodity Channel Index. |
| CMF | Chaikin Money Flow. |
| CNN | Convolutional Neural Network. |
| CNN-LSTM | Deep learning architecture combining Convolutional Neural Network with Long Short-Term Memory. |
| CPACC | Closing Price Acceleration. |
| CPI | Consumer price index. |
| CV | Chaikin’s volatility. |
| CX | Convexity. |
| DAIN MLP | Neural network architecture consisting of the Deep Adaptive Input normalisation Layer and Multilayer Perceptron. |
| DAN2 | Dynamic Artificial Neural network. |
| DeepLOB | Deep neural network method with Long Short-Term Memory units. |
| DeepLOB-Attention | DeepLOB model with Attention mechanism. |
| DeepLOB-Seq2Seq | DeepLOB model with sequence-to-sequence mechanism. |
| DI | Directional Indicator. |
| DL | Deep Learning. |
| DOA | Difference of averages. |
| DPS | Dividends Per Share. |
| EMA | Exponential Moving Average. |
| Ensemble-MBO-LOB | Deep learning model combining Ensemble-MBO and Ensemble-LOB models. |
| Ensemble-MBO | Deep learning model combining MBO-LSTM and MBO-Attention models. |
| EnsembleLOB | Deep learning model combining LOB-LSTM, LOB-CNN, and LOB-DeepLOB models. |
| EPS | Earnings Per Share. |
| ESN | Recurrent neural network–Echo State Network. |
| EWO | Elliott Wave Oscillator. |
| GA | Genetic Algorithms. |
| GARCH-DAN2 | Hybrid Dynamic Artificial Neural network which use generalised Autoregressive Conditional Heteroscedasticity. |
| GARCH-MLP | Hybrid Multi-Layer Perceptron which use generalised Autoregressive Conditional Heteroscedasticity. |
| GA-SVM | Hybrid Genetic Algorithm Support Vector Machine. |
| GAIS | Genetic Algorithm approach to Instance Selection in artificial neural networks. |
| GCHP | General Compound Hawkes Processes. |
| GCL | Genetic complementary learning (GCL) fuzzy neural network. |
| GDB | Gradient Boosting Classifier. |
| GDP | Gross Domestic Product. |
| GNB | Guassian Naive Bayes. |
| GRU | Gated recurrent unit. |
| HDT-RSB | Hybrid Decision Tree-Rough Set Based trend prediction system. |
| HeMLGOP | Heterogeneous Multi-layer generalised Operational Perceptron. |
| HFT | High-Frequency Trading. |
| HMM | Hidden Markov Models. |
| HMM-FM | Combination of Hidden Markov Model and Fuzzy Model. |
| HPACC | High Price Acceleration. |
| IBCO | Improved Bacterial Chemotaxis optimisation. |
| IFFS | Improved Fractal Feature Selection. |
| IG | Information Gain. |
| IP | Industrial Production. |
| IPI | Industrial production index. |
| KNN | Kth nearest neighbour. |
| LDA | Linear Discriminant Analysis. |
| LOB | Limit Order Book. |
| LS-SVM | Least Squares Support Vector Machine. |
| LSTM | Long Short-Term Memory. |
| LW %R | Larry William’s %R. |
| M1 | Money Supply level. |
| MA | Moving Average. |
| MACD | Moving Average Convergence/Divergence. |
| MAD | Moving Average Deviation rate. |
| MAE | Mean absolute error. |
| MAP-HMM | Combination of Maximum a Posteriori Approach with Hidden Markov Model. |
| MAPE | Mean Absolute Percentage Error. |
| MBO | Market by order data. |
| MCC | Matthews Correlation Coefficient. |
| MC-fuzzy | Markov-fuzzy Combination Model. |
| MCSDA | Multilinear Class-Specific Discriminant Analysis. |
| MDA | Multilinear Discriminant Analysis. |
| MFI | Money Flow Index. |
| ML | Machine Learning. |
| MLP | Multilayer Perceptron. |
| MSE | Mean Squared Error. |
| MSM | Mathematical and Statistical models. |
| MTABL-C-4 | Multi-head Temporal Attention Bilinear Layer with 4 attention heads and topology C. |
| MTR | Multi-channel Time-series Regression. |
| N-BoF | Neural Bag-of-Features. |
| NB | Naïve Bayes. |
| NMSE | normalised mean squared error. |
| NVI | Negative volume index. |
| OBV | On Balance Volume. |
| OSCP | Price Oscillator. |
| PL | Psychological Line. |
| PPI | Producer Price Index. |
| PROC | Price Rate of Change. |
| PVI | Positive volume index. |
| PVT | Price Volume Trend. |
| QDA | Quadratic Discriminant Analysis. |
| RBFN | Radial Basis Function Networks. |
| RCI | Rank Correlation Index. |
| RCNK | Recurrent Convolutional Neural Kernel. |
| RF | Random Forest. |
| RMSE | Root-Mean-Square Error. |
| ROC | Rate Of Change. |
| RR | Ridge Regression. |
| RRS | Rate of returns of Stocks. |
| RS | Relative Strength factor. |
| RSB | Rough Set Based trend prediction system. |
| RSI | Relative Strength Index. |
| SGD | Stochastic Gradient Descent. |
| SLEMA | Short/Long Exponential Moving Average. |
| SLMA | Short/Long Moving Average. |
| STC | Schaff Trend Cycle. |
| STI | Stochastic Indicator. |
| SU | Symmetrical Uncertain. |
| SVM | Support Vector Machine. |
| SVR | Support Vector Regression. |
| T-Bill3 | 3-month Treasury bill rate. |
| TBY-1 | One year Treasury Bill Yield. |
| TR | True Range of price movements. |
| TransLOB | Deep learning architecture based on the Transformer model. |
| TRIX | Triple Exponentially Smoothed Average. |
| TSK | Takagi–Sugeno–Kang type Fuzzy Rule Based System. |
| VR | Volume Ratio. |
| VRSI | Volume Relative Strength Index. |
| W.A.S.P | Wave Analysis Stock Prediction. |
| WMTR | Weighted Multi-channel Time-series Regression. |
References
- Chang, P.C.; Liu, C.H. A TSK type fuzzy rule based system for stock price prediction. Expert Syst. Appl. 2008, 34, 135–144. [Google Scholar] [CrossRef]
- Bartov, E.; Radhakrishnan, S.; Krinsky, I. Investor sophistication and patterns in stock returns after earnings announcements. Account. Rev. 2000, 75, 43–63. [Google Scholar] [CrossRef]
- Moore, J.; Velikov, M. Oil Price Exposure, Earnings Announcements, and Stock Return Predictability. Earnings Announcements, and Stock Return Predictability (20 January 2019) 2019. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3164353 (accessed on 10 December 2021).
- Katona, Z.; Painter, M.; Patatoukas, P.N.; Zeng, J. On the capital market consequences of alternative data: Evidence from outer space. In Proceedings of the 9th Miami Behavioral Finance Conference, Coral Gables, FL, USA, 14–15 December 2018. [Google Scholar]
- Kercheval, A.N.; Zhang, Y. Modelling high-frequency limit order book dynamics with support vector machines. Quant. Financ. 2015, 15, 1315–1329. [Google Scholar] [CrossRef]
- Zhang, Z.; Zohren, S.; Roberts, S. Deeplob: Deep convolutional neural networks for limit order books. IEEE Trans. Signal Process. 2019, 67, 3001–3012. [Google Scholar] [CrossRef]
- Wallbridge, J. Transformers for limit order books. arXiv 2020, arXiv:2003.00130. [Google Scholar]
- Fu, T.C.; Chung, C.P.; Chung, F.L. Adopting genetic algorithms for technical analysis and portfolio management. Comput. Math. Appl. 2013, 66, 1743–1757. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, L. Stock market prediction of S&P 500 via combination of improved BCO approach and BP neural network. Expert Syst. Appl. 2009, 36, 8849–8854. [Google Scholar]
- Majhi, R.; Panda, G.; Sahoo, G.; Dash, P.K.; Das, D.P. Stock market prediction of S&P 500 and DJIA using bacterial foraging optimization technique. In Proceedings of the 2007 IEEE Congress on Evolutionary Computation, Singapore, 25–28 September 2007; pp. 2569–2575. [Google Scholar]
- Ntakaris, A.; Magris, M.; Kanniainen, J.; Gabbouj, M.; Iosifidis, A. Benchmark dataset for mid-price prediction of limit order book data. arXiv 2017, arXiv:1705.03233. [Google Scholar]
- Tsantekidis, A.; Passalis, N.; Tefas, A.; Kanniainen, J.; Gabbouj, M.; Iosifidis, A. Forecasting stock prices from the limit order book using convolutional neural networks. In Proceedings of the 2017 IEEE 19th Conference on Business Informatics (CBI), Thessaloniki, Greece, 24–27 July 2017; Volume 1, pp. 7–12. [Google Scholar]
- Tsantekidis, A.; Passalis, N.; Tefas, A.; Kanniainen, J.; Gabbouj, M.; Iosifidis, A. Using deep learning to detect price change indications in financial markets. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017; pp. 2511–2515. [Google Scholar]
- Tsantekidis, A.; Passalis, N.; Tefas, A.; Kanniainen, J.; Gabbouj, M.; Iosifidis, A. Using deep learning for price prediction by exploiting stationary limit order book features. Appl. Soft Comput. 2020, 93, 106401. [Google Scholar] [CrossRef]
- Armano, G.; Marchesi, M.; Murru, A. A hybrid genetic-neural architecture for stock indexes forecasting. Inf. Sci. 2005, 170, 3–33. [Google Scholar] [CrossRef]
- Klassen, M. Investigation of Some Technical Indexes inStock Forecasting Using Neural Networks. Int. J. Comput. Inf. Eng. 2007, 1, 1438–1442. [Google Scholar]
- Hassan, M.R.; Nath, B. Stock market forecasting using hidden Markov model: A new approach. In Proceedings of the 5th International Conference on Intelligent Systems Design and Applications (ISDA’05), Warsaw, Poland, 8–10 September 2005; pp. 192–196. [Google Scholar]
- Tan, T.Z.; Quek, C.; Ng, G.S. Brain-inspired genetic complementary learning for stock market prediction. In Proceedings of the 2005 IEEE Congress on Evolutionary Computation, Edinburgh, UK, 2–5 September 2005; Volume 3, pp. 2653–2660. [Google Scholar]
- Kim, K.J. Artificial neural networks with evolutionary instance selection for financial forecasting. Expert Syst. Appl. 2006, 30, 519–526. [Google Scholar] [CrossRef]
- Huang, W.; Wang, S.; Yu, L.; Bao, Y.; Wang, L. A new computational method of input selection for stock market forecasting with neural networks. In International Conference on Computational Science; Springer: Berlin/Heidelberg, Germany, 2006; pp. 308–315. [Google Scholar]
- Sheta, A. Software effort estimation and stock market prediction using takagi-sugeno fuzzy models. In Proceedings of the 2006 IEEE International Conference on Fuzzy Systems, Vancouver, BC, Canada, 16–21 July 2006; pp. 171–178. [Google Scholar]
- Ince, H.; Trafalis, T.B. Kernel principal component analysis and support vector machines for stock price prediction. Iie Trans. 2007, 39, 629–637. [Google Scholar] [CrossRef]
- Shah, V.H. Machine learning techniques for stock prediction. Found. Mach. Learn. Spring 2007, 1, 6–12. [Google Scholar]
- Tsang, P.M.; Kwok, P.; Choy, S.O.; Kwan, R.; Ng, S.C.; Mak, J.; Tsang, J.; Koong, K.; Wong, T.L. Design and implementation of NN5 for Hong Kong stock price forecasting. Eng. Appl. Artif. Intell. 2007, 20, 453–461. [Google Scholar] [CrossRef]
- Tanaka-Yamawaki, M.; Tokuoka, S. Adaptive use of technical indicators for the prediction of intra-day stock prices. Phys. A Stat. Mech. Its Appl. 2007, 383, 125–133. [Google Scholar] [CrossRef]
- Choudhry, R.; Garg, K. A hybrid machine learning system for stock market forecasting. World Acad. Sci. Eng. Technol. 2008, 39, 315–318. [Google Scholar]
- Huang, C.J.; Yang, D.X.; Chuang, Y.T. Application of wrapper approach and composite classifier to the stock trend prediction. Expert Syst. Appl. 2008, 34, 2870–2878. [Google Scholar] [CrossRef]
- Ke, J.; Liu, X. Empirical analysis of optimal hidden neurons in neural network modeling for stock prediction. In Proceedings of the 2008 IEEE Pacific-Asia Workshop on Computational Intelligence and Industrial Application, Wuhan, China, 19–20 December 2008; Volume 2, pp. 828–832. [Google Scholar]
- Lin, X.; Yang, Z.; Song, Y. Short-term stock price prediction based on echo state networks. Expert Syst. Appl. 2009, 36, 7313–7317. [Google Scholar] [CrossRef]
- Lee, M.C. Using support vector machine with a hybrid feature selection method to the stock trend prediction. Expert Syst. Appl. 2009, 36, 10896–10904. [Google Scholar] [CrossRef]
- Ou, P.; Wang, H. Prediction of stock market index movement by ten data mining techniques. Mod. Appl. Sci. 2009, 3, 28–42. [Google Scholar] [CrossRef]
- Rao, S.; Hong, J. Analysis of Hidden Markov Models and Support Vector Machines in Financial Applications; University of California at Berkeley: Berkeley, CA, USA, 2010. [Google Scholar]
- Nair, B.B.; Mohandas, V.; Sakthivel, N. A decision tree—Rough set hybrid system for stock market trend prediction. Int. J. Comput. Appl. 2010, 6, 1–6. [Google Scholar] [CrossRef]
- Naeini, M.P.; Taremian, H.; Hashemi, H.B. Stock market value prediction using neural networks. In Proceedings of the 2010 International Conference on Computer Information Systems and Industrial Management Applications (CISIM), Krakow, Poland, 8–10 October 2010; pp. 132–136. [Google Scholar]
- Boyacioglu, M.A.; Avci, D. An adaptive network-based fuzzy inference system (ANFIS) for the prediction of stock market return: The case of the Istanbul stock exchange. Expert Syst. Appl. 2010, 37, 7908–7912. [Google Scholar] [CrossRef]
- Ni, L.P.; Ni, Z.W.; Gao, Y.Z. Stock trend prediction based on fractal feature selection and support vector machine. Expert Syst. Appl. 2011, 38, 5569–5576. [Google Scholar] [CrossRef]
- Guresen, E.; Kayakutlu, G.; Daim, T.U. Using artificial neural network models in stock market index prediction. Expert Syst. Appl. 2011, 38, 10389–10397. [Google Scholar] [CrossRef]
- Atsalakis, G.S.; Dimitrakakis, E.M.; Zopounidis, C.D. Elliott Wave Theory and neuro-fuzzy systems, in stock market prediction: The WASP system. Expert Syst. Appl. 2011, 38, 9196–9206. [Google Scholar] [CrossRef]
- Enke, D.; Grauer, M.; Mehdiyev, N. Stock market prediction with multiple regression, fuzzy type-2 clustering and neural networks. Procedia Comput. Sci. 2011, 6, 201–206. [Google Scholar] [CrossRef]
- Gupta, A.; Dhingra, B. Stock market prediction using hidden markov models. In Proceedings of the 2012 Students Conference on Engineering and Systems, Allahabad, India, 16–18 March 2012; pp. 1–4. [Google Scholar]
- Bing, Y.; Hao, J.K.; Zhang, S.C. Stock market prediction using artificial neural networks. In Advanced Engineering Forum; Trans Tech Publications Ltd.: Stafa-Zurich, Switzerland, 2012; Volume 6, pp. 1055–1060. [Google Scholar]
- Cont, R.; Kukanov, A.; Stoikov, S. The price impact of order book events. J. Financ. Econom. 2014, 12, 47–88. [Google Scholar] [CrossRef]
- Palguna, D.; Pollak, I. Non-parametric prediction in a limit order book. In Proceedings of the 2013 IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013; p. 1139. [Google Scholar]
- Palguna, D.; Pollak, I. Mid-price prediction in a limit order book. IEEE J. Sel. Top. Signal Process. 2016, 10, 1083–1092. [Google Scholar] [CrossRef]
- Gould, M.D.; Bonart, J. Queue imbalance as a one-tick-ahead price predictor in a limit order book. Mark. Microstruct. Liq. 2016, 2, 1650006. [Google Scholar] [CrossRef]
- Ky, D.X.; Tuyen, L.T. A Markov-fuzzy Combination Model For Stock Market Forecasting. Int. J. Appl. Math. Stat. 2016, 55, 110–121. [Google Scholar]
- Tran, D.T.; Gabbouj, M.; Iosifidis, A. Multilinear class-specific discriminant analysis. Pattern Recognit. Lett. 2017, 100, 131–136. [Google Scholar] [CrossRef][Green Version]
- Tran, D.T.; Magris, M.; Kanniainen, J.; Gabbouj, M.; Iosifidis, A. Tensor representation in high-frequency financial data for price change prediction. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–7. [Google Scholar]
- Qureshi, F. Investigating Limit Order Book Features for Short-Term Price Prediction: A Machine Learning Approach. SSRN 3305277. 2018. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3305277 (accessed on 5 March 2022).
- Tran, D.T.; Iosifidis, A.; Kanniainen, J.; Gabbouj, M. Temporal attention-augmented bilinear network for financial time-series data analysis. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 1407–1418. [Google Scholar] [CrossRef]
- Passalis, N.; Tefas, A.; Kanniainen, J.; Gabbouj, M.; Iosifidis, A. Deep adaptive input normalization for price forecasting using limit order book data. arXiv 2019, arXiv:1902.07892. [Google Scholar]
- Thanh Tran, D.; Kanniainen, J.; Gabbouj, M.; Iosifidis, A. Data-driven Neural Architecture Learning For Financial Time-series Forecasting. arXiv 2019, arXiv:1903.06751. [Google Scholar]
- Tran, D.T.; Kanniainen, J.; Gabbouj, M.; Iosifidis, A. Data Normalization for Bilinear Structures in High-Frequency Financial Time-series. arXiv 2020, arXiv:2003.00598. [Google Scholar]
- Liu, S.; Zhang, X.; Wang, Y.; Feng, G. Recurrent convolutional neural kernel model for stock price movement prediction. PLoS ONE 2020, 15, e0234206. [Google Scholar] [CrossRef] [PubMed]
- Shahi, T.B.; Shrestha, A.; Neupane, A.; Guo, W. Stock price forecasting with deep learning: A comparative study. Mathematics 2020, 8, 1441. [Google Scholar] [CrossRef]
- Zhang, Z.; Lim, B.; Zohren, S. Deep Learning for Market by Order Data. arXiv 2021, arXiv:2102.08811. [Google Scholar] [CrossRef]
- Zhang, Z.; Zohren, S. Multi-Horizon Forecasting for Limit Order Books: Novel Deep Learning Approaches and Hardware Acceleration using Intelligent Processing Units. arXiv 2021, arXiv:2105.10430. [Google Scholar]
- Tran, D.T.; Kanniainen, J.; Gabbouj, M.; Iosifidis, A. Bilinear Input Normalization for Neural Networks in Financial Forecasting. arXiv 2021, arXiv:2109.00983. [Google Scholar]
- Sjogren, M.; DeLise, T. General Compound Hawkes Processes for Mid-Price Prediction. arXiv 2021, arXiv:2110.07075. [Google Scholar]
- Shabani, M.; Tran, D.T.; Magris, M.; Kanniainen, J.; Iosifidis, A. Multi-head Temporal Attention-Augmented Bilinear Network for Financial time series prediction. arXiv 2022, arXiv:2201.05459. [Google Scholar]
- Eaton, G.W.; Green, T.C.; Roseman, B.; Wu, Y. Zero-Commission Individual Investors, High Frequency Traders, and Stock Market Quality. High Frequency Traders, and Stock Market Quality (January 2021) 2021. Available online: https://microstructure.exchange/slides/RobinhoodSlides_TME.pdf (accessed on 5 February 2022).
- Doering, J.; Fairbank, M.; Markose, S. Convolutional neural networks applied to high-frequency market microstructure forecasting. In Proceedings of the 2017 9th Computer Science and Electronic Engineering (CEEC), Colchester, UK, 27–29 September 2017; pp. 31–36. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level 1 | Level 2 | ... | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Timestamp | Mid-Price | Ask | Bid | Ask | Bid | ... | ||||
| Price | Quantity | Price | Quantity | Price | Quantity | Price | Quantity | ... | ||
| 1275386347813 | 12.32 | 12.40 | 100 | 12.24 | 50 | 12.50 | 30 | 12.15 | 20 | ... |
| 1275386347879 | 12.30 | 12.40 | 150 | 12.20 | 100 | 12.50 | 50 | 12.15 | 10 | ... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Type | Ref. | Date | Model | Data | Results | ||||
|---|---|---|---|---|---|---|---|---|---|
| Features | Freq. | Size | Performance | Practicality | Reproducibility | ||||
| ML | [15] | 02/2005 | Feedforward Neural Network | Daily prices, indicators: DOA, CX, MA, RSI | Daily | 2000 | Outperforming the buy and hold strategy | ⊕ returns were calculated, ⊕ trading commissions were considered | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| ML | [16] | 03/2005 | Feedforward Neural Network | Daily high/low, closing prices, technical indicators: RSI, RRS, MA, EMA, MACD | Weekly | 130 | Difference 0.70–1.74% | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| MSM | [17] | 09/2005 | HMM | Opening/closing/ highest/lowest prices | Daily | <500 | Likelihood −9.4594 | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| GA | [18] | 09/2005 | GCL | Past prices | Daily | >1000 | RMSE 0.0032 | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| GA | [19] | 04/2006 | GAIS | Stochastic %K/ %D/slow%D, Momentum, ROC, A/D Oscillator, LW %R, Disparity, CCI, OSCP, RSI | Daily | 2348 | Hit rate: 65.45% | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| ML | [20] | 05/2006 | BPN, RBFN | Daily prices | Daily | >1000 | NMSE: BPN 0.09–0.39, RBFN 0.09–0.49 | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| MSM | [21] | 06/2006 | Takagi-Sugeno Fuzzy model | Weekly prices, EPS, DPS, TBY-1 | Weekly | 507 | RMSE 5.81 | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| ML | [22] | 03/2007 | SVR, MLP | EMA, RSI, BB, MACD, CMF | Daily | 2500 | MSE: SVR 0.01–57.9%, MLP 0.01–24.67% | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| ML | [23] | 05/2007 | SVM, AdaBoostM1 | Opening/closing /highest/lowest prices, volumes | Daily | >200 | Accuracy: SVM 60.20%, AdaBoostM1 64.32% | ⊖ predicting EMA instead of price, ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is in public access ⊖ Code is not in public access |
| ML | [24] | 06/2007 | BPN, SVM | Opening/closing prices, volumes | Daily | <500 | Hit rate: BPN 74.2%, SVM 64.4% | ⊕ returns were calculated, ⊕ trading commissions were considered | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| GA | [25] | 09/2007 | GA | Tick-by-tick prices, technical indicators: MA, EMA, SLMA, RSI, SLEMA, MACD, MAD, RCI, PL, Momentum | Tick-by-tick | >450,000 | Prediction rate 66% | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| GA | [10] | 09/2007 | BFO | Closing prices, technical indicators: EMA, ADO, STI, RSI, PROC, CPACC, HPACC | Daily | 3228 | MAPE 0.66–1.89, | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| GA, ML | [26] | 01/2008 | GA-SVM, SVM | Opening/closing /highest/lowest prices, volumes, Technical indexes: Momentum, LW %R, ROC, Stochastic %K, Disparity, PVT | Daily | 1386 | Hit Ratio: GA-SVM 59.534%, SVM 55.64% | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| MSM | [1] | 01/2008 | TSK, BPN, Multiple regression | Technical indexes: MA, Bias, RSI, Stochastic line, MACD, PL, volume | Daily | 614 | MAPE: TSK 2.4%, BPN 4.29%, Multiple regression 2.4% | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| ML | [27] | 05/2008 | voting, SVM, KNN, BPNN, C4.5 DT, Logistic regression | Opening/closing/ highest/lowest prices and volumes, technical indices: MA, EMA, MACD, Difference, Bias, Stochastic %K, %D, TR, Oscillator, LW %R, OBV | Daily | 365 | Accuracy: voting 76–80%, SVM 67–70%, KNN 65%, BPNN 66–69%, C4.5 DT 65–72%, Logistic regression 65–68% | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| ML | [28] | 12/2008 | BPNN | Opening prices, S&P500 index, technical indices: RSI, Stochastics (Raw-K) | Daily | <1000 | 0.96 | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| ML | [29] | 04/2009 | ESN, BPNN, Elman, RBFN | Opening/closing/ highest/lowest, Technical indicators: 5-Day high, 5-Day close MA | Daily | 1100 | Proportion of better predictions: ESN 57%, BPNN 14.87%, Elman 20.16%, RBFN 7.94% | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| GA | [9] | 07/2009 | IBCO, BPNN | Opening/closing/ highest/lowest prices and volumes | Daily | 2350 | MSE 9.93846 × 10 | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| ML | [30] | 10/2009 | SVM, BPNN | Futures contracts on commodities/foreign currencies, stock indexes: NYSE Composite, NASDAQ, PSI, UTIL, DJCOMP, TRAN, AMEX, Russell 2000, S&P 50 | Daily | >1000 | Accuracy: SVM 87.3%, BPNN 72.5% | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| ML | [31] | 10/2009 | LDA, QDA, KNN, Naïve Bayes, Logit model, Tree class., Neural Net., Gaussian proc., SVM, LS-SVM | Opening/High/Low prices, S&P 500 index, Exchange rate, HKD/USD | Daily | 1732 | Hit rate: LDA 0.84, QDA 0.85, KNN 0.80, Naïve Bayes 0.83, Logit model 0.86, Tree cl. 0.80, Neural Net. 0.85, Gaussian pr. 0.85, SVM 0.86, LS-SVM 0.86 | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| MSM | [32] | 05/2010 | HMM, SVM | High/low prices; technical indicators: MACD, RSI, ADX, Lag profits and etc. | Daily | >1000 | Accuracy: HMM 53%, SVM 70% | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| ML | [33] | 09/2010 | HDT-RSB, RSB, ANN, NB | Opening/closing/ highest/lowest prices and volumes, technical indices: MA, MACD, RSI, PVI, NVI, OBV, PVT, Momentum, Stochastic %K, Stochastic %D, CV, Acceleration, LW %R, OBV, ROC, Typical price, Median price, Weighted close, BB | Daily | 1625 | Accuracy: HDT-RSB 90.22%, RSB 88.18%, ANN 77.66%, NB 77.36% | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| ML | [34] | 10/2010 | MLP, Elman, Linear regression | Lowest/highest/ average prices | Daily | >1000 | MAPE: MLP 0.01, Elman 0.02, Linear regression 0.02 | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| ML | [35] | 12/2010 | ANFIS | Gold price, Exchange rate of USD, Interest rates on: deposits/Treasury bills, CPI, IPI, Stock indexes: DJI, DAX, BOVESPA | Mon -thly | 228 | RMSE: 0.01 | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| ML | [36] | 05/2011 | SVM+IG, SVM+SU, SVM+ReliefF, SVM+Cfs, SVM+OneR, SVM+IFFS, SVM | MACD, BB, Stochastic%K, Stochastic%D, Momentum, LW %R, PL, VR, MFI, A/B/C ratios, DI up/down, RSI, TRIX, CCI, ROC, VRSI | Daily | 2171 | Accuracy: SVM+IG 52.48, SVM+SU 52.48, SVM+ReliefF 46.69, SVM+Cfs 61.98, SVM+OneR 64.46, SVM+IFFS 64.05, SVM 62.81 | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| ML | [37] | 08/2011 | MLP, GARCH-MLP, DAN2, GARCH-DAN2 | Daily prices | Daily | <200 | MSE: MLP 2478.15, GARCH-MLP 3665.83, DAN2 1472.28, GARCH-DAN2 20,901.20 | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| ML | [38] | 08/2011 | W.A.S.P | Daily prices, MA, EWO, Oscillator lags | Daily | 400 | Hit ratio: W.A.S.P 60%, Outperforming the buy and hold strategy and coin based forecasting | ⊕ returns were calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| ML | [39] | 12/2011 | Fuzzy type-1 ANN, Fuzzy type-2 ANN | S&P 500 index, T-Bill3, M1, IP, PPI | Mon-thly | 360 | RMSE: Fuzzy type-1 ANN 0.948, Fuzzy type-2 ANN 0.909 | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| MSM, ML | [40] | 03/2012 | MAP-HMM, HMM-FM, ARIMA, ANN | Opening/closing/, highest/lowest, prices, volumes, fractional change between highest and lowest, fractional deviation between highest and lowest | Daily | >2000 | MAPE: MAP-HMM 1.51, HMM-FM 1.77, ARIMA 1.80, ANN 1.80 | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| ML | [41] | 09/2012 | ANN | Opening/closing/ highes/lowest, prices, volumes, difference between highest and lowest returns | Daily | 417 | MSE: ANN | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| MSM | [42] | 06/2013 | Linear regression model | Level 1 of LOB, Order flow imbalance | Tick-by-tick | >1,500,000 | : 65% | ⊖ returns were not calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| MSM | [43] | 12/2013 | Rule based algorithm | LOB, Order imbalance | Tick-by-tick | n.a. (One day) | Mean return: 1.9 bp, Standard error 0.7 bp | ⊕ returns were calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| GA | [8] | 12/2013 | Traditional/ Hierarchical GA | Technical indicators: MA, MACD, STC, RS and etc. | Daily | <2500 | Outperforming the buy and hold strategy | ⊕ Simulation of returns from the strategy in bearish and bullish markets, ⊕ trading commissions were considered | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| MSM | [44] | 12/2014 | Feature based prediction | LOB | Tick-by-tick | n.a. (Five-month period) | Trading cost improvement of 1 bp compared with uniform execution strategy | ⊕ trading simulations conducted, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| ML | [5] | 06/2015 | SVM | LOB, n level volumes, prices, mid-prices, bid-ask spreads, prices differences, mean prices and volumes, accumulated differences, intensity, accelerations | Tick-by-tick | 1500 | Precision: 86%, Recall: 89%, F1 score: 86.6% | ⊕ trading simulations conducted, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| MSM | [45] | 12/2015 | Logistic regression | LOB | Tick-by-tick | 25,200 | Mean squared residua 0.18–0.25 l | ⊖ returns were not calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| MSM | [46] | 12/2016 | MC-fuzzy | Closing prices | Daily | >4000 | RMSE 82.7 | ⊖ returns were not calculated, ⊖ trading commissions were ignored | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| DL | [12] | 07/2017 | CNN | LOB | Tick-by-tick | >400,000 | Precision: 65.54%, Recall: 50.98%, F1 score 55.21% | ⊖ returns were not calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| ML | [11] | 09/2017 | RR | LOB | Tick-by-tick | >400,000 | Accuracy 48% | ⊖ returns were not calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊕ Dataset is in public access ⊕ Code is in public access |
| ML | [13] | 09/2017 | SVM, MLP, LSTM | LOB | Tick-by-tick | >400,000 | F1 score (SVM 35.88%, MLP 48.27%, LSTM 66.33%) | ⊖ returns were not calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊕ Dataset is in public access ⊖ Code is not in public access |
| ML | [47] | 10/2017 | MDA, MCSDA | LOB | Tick-by-tick | >400,000 | Accuracy (MDA 71.92%, MCSDA 83.66%) | ⊖ returns were not calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊕ Dataset is in public access ⊖ Code is not in public access |
| ML, DL | [48] | 12/2017 | MTR, WMTR, LDA, N-BoF, BoF | LOB | Tick-by-tick | >400,000 | Accuracy (MTR 86.08%, WMTR 81.89%, LDA 63.82%, N-BoF 62.70%, BoF 57.59%) | ⊖ returns were not calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊕ Dataset is in public access ⊖ Code is not in public access |
| MSM, ML | [49] | 01/2018 | GNB, SGD, MLP, GDB, RF | LOB | Tick-by-tick | <=50,000 | Accuracy (GNB 38.67%, SGD 27.86%, MLP 38.96%, GDB 62.19%, RF 89.24%) | ⊖ returns were not calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊕ Dataset is in public access ⊕ Code is in public access |
| DL | [50] | 09/2018 | C(TABL) | LOB | Tick-by-tick | >400,000 | Accuracy 84.70% | ⊖ returns were not calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊕ Dataset is in public access ⊖ Code is not in public access |
| DL | [51] | 02/2019 | DAIN MLP | LOB | Tick-by-tick | >400,000 | F1 score 68.26% | ⊖ returns were not calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊕ Dataset is in public access ⊖ Code is not in public access |
| DL | [52] | 03/2019 | HeMLGOP | LOB | Tick-by-tick | >400,000 | Accuracy 83.06% | ⊖ returns were not calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊕ Dataset is in public access ⊖ Code is not in public access |
| DL | [6] | 03/2019 | DeepLOB | LOB | Tick-by-tick | > | Accuracy 84.47% | ⊕ trading simulation conducted, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊕ Dataset is in public access ⊕ Code is in public access |
| DL | [7] | 02/2020 | TransLOB | LOB | Tick-by-tick | >400,000 | Accuracy 87.66% | ⊖ returns were not calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊕ Dataset is in public access ⊖ Only part of the code is in public access |
| DL | [53] | 03/2020 | BiN-C(TABL) | LOB | Tick-by-tick | >400,000 | Accuracy 86.87% | ⊖ returns were not calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊕ Dataset is in public access ⊖ Code is not in public access |
| DL | [54] | 06/2020 | RCNK | Posts text, open/close /highest/lowest price, trading volume, technical indices: MA, ROC, RSI, | Daily | >1000 | Accuracy 66.26%, MCC 0.39 | ⊕ returns were calculated, ⊖ trading commissions were ignored | ⊕ Dataset is in public access ⊕ Code is in public access |
| DL | [55] | 07/2020 | LSTM, GRU | News text data, open/close /highest/lowest price, trading volume | Daily | Stock data: 1996, News: 42,110 | MAE (LSTM 17.69, GRU 24.47); RMSE (LSTM 23.07, GRU 29.15) | ⊕ returns were calculated, ⊖ trading commissions were ignored | ⊕ Dataset is in public access ⊕ Code is in public access |
| DL | [14] | 08/2020 | CNN-LSTM | LOB | Tick-by-tick | >400,000 | F1 score 44.00% | ⊖ returns were not calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊕ Dataset is in public access ⊖ Code is not in public access |
| DL | [56] | 02/2021 | EnsembleLOB, Ensemble-MBO, Ensemble-MBO-LOB | LOB, MBO | Tick-by-tick | >46,000,000 | F1 score (EnsembleLOB 68.31%, Ensemble-MBO 62.56%, Ensemble-MBO-LOB 69.02%) | ⊖ returns were not calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊖ Dataset is not in public access ⊖ Code is not in public access |
| DL | [57] | 05/2021 | DeepLOB-Seq2Seq, DeepLOB-Attention | LOB | Tick-by-tick | >400,000 | F1 score (DeepLOB-Seq2Seq 81.51%, DeepLOB-Attention 82.37%) | ⊖ returns were not calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊕ Dataset is in public access ⊕ Code is in public access |
| DL | [58] | 09/2021 | BiN-DeepLOB | LOB | Tick-by-tick | >400,000 | F1 score 65.73% | ⊖ returns were not calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊕ Dataset is in public access ⊖ Code is not in public access |
| MSM | [59] | 10/2021 | GCHP | LOB | 1 s interval | >500,000 | F1 score 37% | ⊖ returns were not calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊕ Dataset is in public access ⊖ Code is not in public access |
| DL | [60] | 01/2022 | MTABL-C-4 | LOB | Tick-by-tick | >400,000 | F1 score 76.42% | ⊖ returns were not calculated, ⊖ trading commissions were ignored, ⊖ mid-price assumption is unrealistic | ⊕ Dataset is in public access ⊖ Code is not in public access |
| Archetype | Model | Ref. | Date | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|---|---|
| Linear Classification | RR | [11] | 09/2017 | 48.00 | 41.80 | 43.50 | 41.00 |
| Nonlinear Classification | SVM | [13] | 09/2017 | - | 39.62 | 44.92 | 35.88 |
| Multi-linear Classification | MTR | [48] | 12/2017 | 86.08 | 51.68 | 40.81 | 40.14 |
| WMTR | [48] | 12/2017 | 81.89 | 46.25 | 51.29 | 47.87 | |
| Image Classification | BoF | [48] | 12/2017 | 57.59 | 39.26 | 51.44 | 36.28 |
| Dimensionality Reduction | LDA | [48] | 12/2017 | 63.82 | 37.93 | 45.80 | 36.28 |
| MDA | [47] | 10/2017 | 71.92 | 44.21 | 60.07 | 46.06 | |
| MCSDA | [47] | 10/2017 | 83.66 | 46.11 | 48.00 | 46.72 | |
| Neural Network | MLP | [13] | 09/2017 | - | 47.81 | 60.78 | 48.27 |
| Deep Learning | LSTM | [13] | 09/2017 | - | 60.77 | 75.92 | 66.33 |
| N-BoF | [48] | 12/2017 | 62.70 | 42.28 | 61.41 | 41.63 | |
| HeMLGOP | [52] | 03/2019 | 83.06 | 48.57 | 50.67 | 49.43 | |
| DAIN-MLP | [51] | 02/2019 | - | 65.67 | 71.58 | 68.26 | |
| CNN | [12] | 06/2017 | - | 50.98 | 65.54 | 55.21 | |
| CNN-LSTM | [14] | 08/2020 | - | 56.00 | 45.00 | 44.00 | |
| C(TABL) | [50] | 09/2018 | 84.70 | 76.95 | 78.44 | 77.63 | |
| BiN-C(TABL) | [53] | 03/2020 | 86.87 | 80.29 | 81.84 | 81.04 | |
| DeepLOB | [6] | 03/2019 | 84.47 | 84.00 | 84.47 | 83.40 | |
| TransLOB | [7] | 02/2020 | 87.66 | 91.81 | 87.66 | 88.66 |
| Model | Abbrev. | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|
| Ridge Regression | RR | 46.00 | 43.30 | 43.54 | 42.52 |
| Single hidden Layer Feed Forward Network | SLFN | 53.22 | 49.60 | 41.28 | 38.24 |
| Linear Discriminant Analysis | LDA | 63.82 | 37.93 | 45.80 | 36.28 |
| Multi-linear Discriminant Analysis | MDA | 71.92 | 44.21 | 60.07 | 46.06 |
| Multi-channel Time-series Regression | MTR | 86.08 | 51.68 | 40.81 | 40.14 |
| Weighted Multi-channel Time-series Regression | WMTR | 81.89 | 46.25 | 51.29 | 47.87 |
| Bag-of-Features | BoF | 57.59 | 39.26 | 51.44 | 36.28 |
| Neural Bag-of-Features | N-BoF | 62.70 | 42.28 | 61.41 | 41.63 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zaznov, I.; Kunkel, J.; Dufour, A.; Badii, A. Predicting Stock Price Changes Based on the Limit Order Book: A Survey. Mathematics 2022, 10, 1234. https://doi.org/10.3390/math10081234
Zaznov I, Kunkel J, Dufour A, Badii A. Predicting Stock Price Changes Based on the Limit Order Book: A Survey. Mathematics. 2022; 10(8):1234. https://doi.org/10.3390/math10081234
Chicago/Turabian StyleZaznov, Ilia, Julian Kunkel, Alfonso Dufour, and Atta Badii. 2022. "Predicting Stock Price Changes Based on the Limit Order Book: A Survey" Mathematics 10, no. 8: 1234. https://doi.org/10.3390/math10081234
APA StyleZaznov, I., Kunkel, J., Dufour, A., & Badii, A. (2022). Predicting Stock Price Changes Based on the Limit Order Book: A Survey. Mathematics, 10(8), 1234. https://doi.org/10.3390/math10081234