
Gaussian Perturbations in ReLU Networks and the Arrangement of Activation Regions


Abstract
:1. Introduction
2. Related Results
- We suggest a measure, tangent sensitivity, which characterises, in a way, both the geometrical properties of the function and the original data distribution without the target, meanwhile capturing how the model handled injecting noise at each layer per sample. In comparison to [34], our measure operates on directional derivatives.
- We derive several easily computable bounds and measures for feed-forward ReLU multi-layer perceptrons based either only on the state of the network or on the data as well. Throughout these measures we connect tangent sensitivity to the structure of the network and particularly to the input–output paths inside the network, the norm of the parameters and the distribution of the linear regions in the input space. The bounds are closely related to path-sgd [35], the margin distribution [14,25,36] and the narrowness estimation of linear regions [37] albeit primarily to the distribution of non zero volume activation patterns.
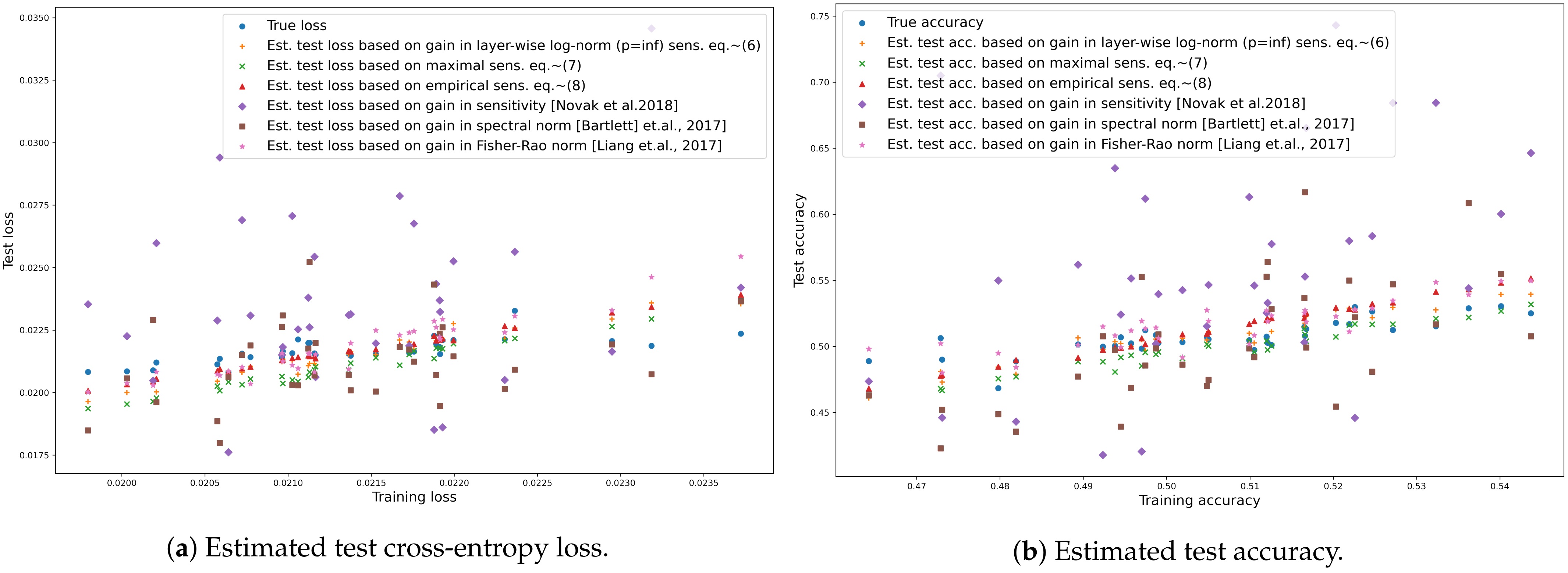
- Finally, we experiment on the CIFAR-10 [38] dataset and observe that even simple upper bounds of tangent sensitivity are connected to the empirical generalisation gap, the performance difference between the training set and test set.
3. Methods
3.1. Preliminaries
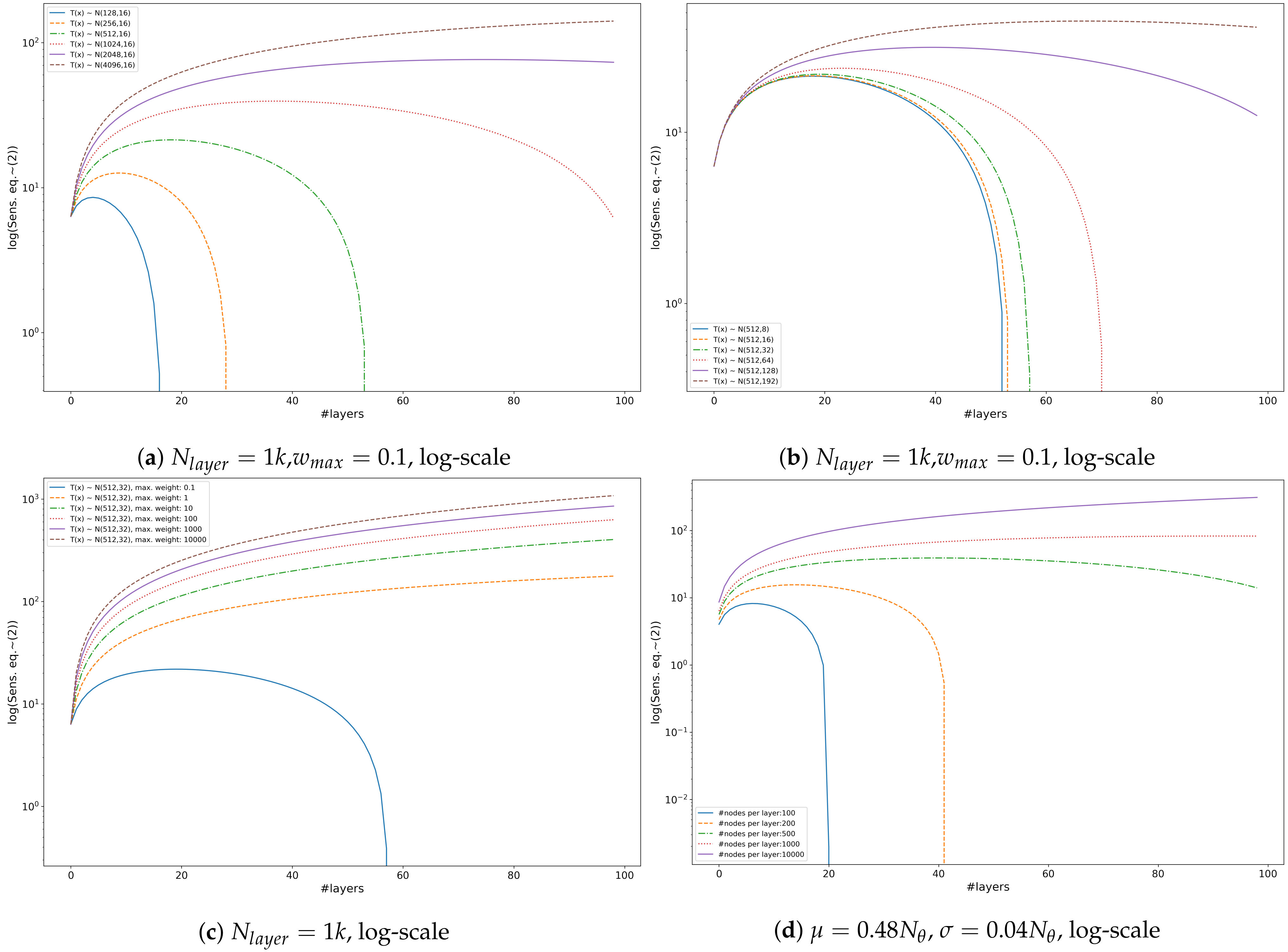
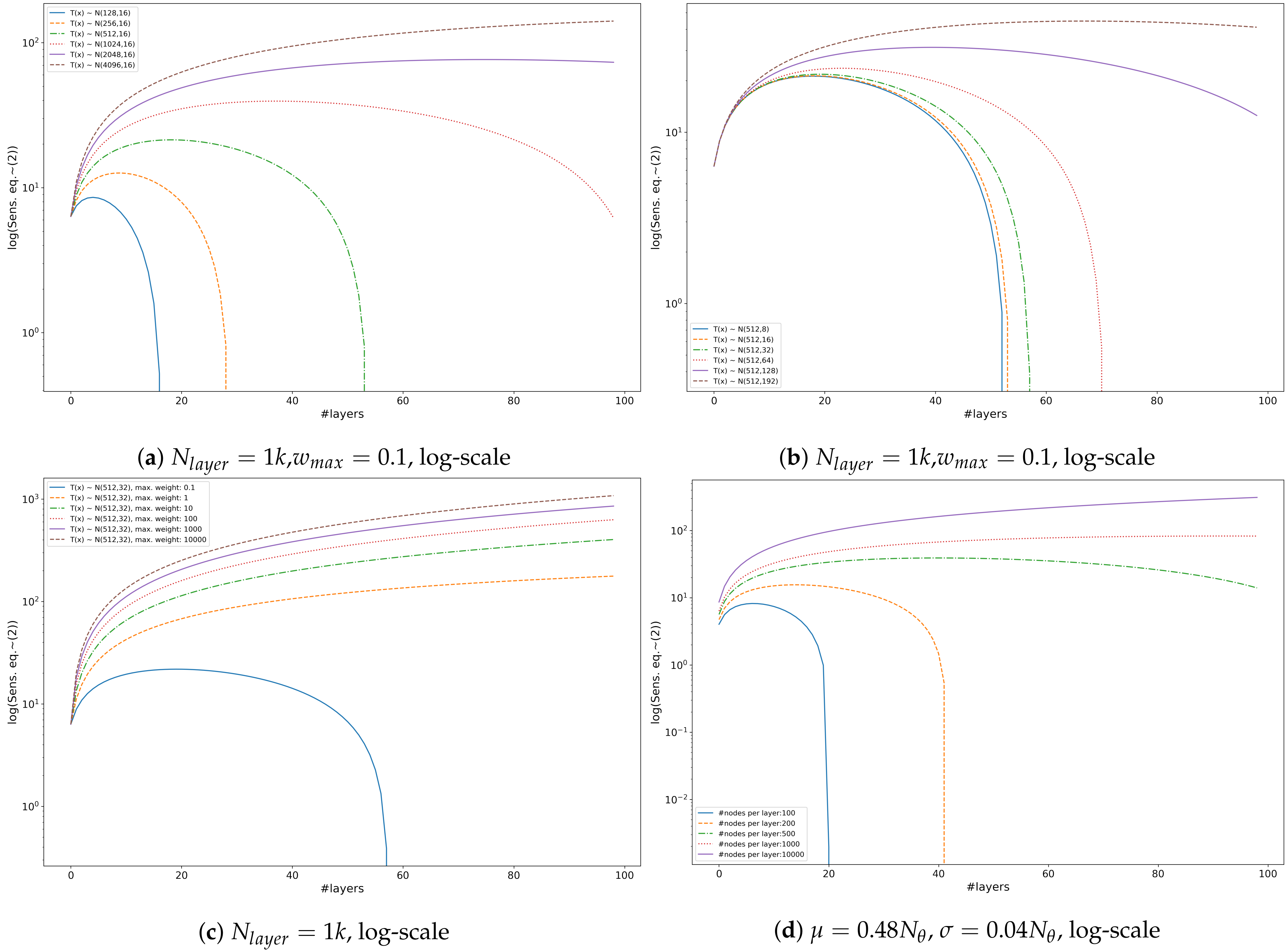
3.2. Tangent Space Sensitivity
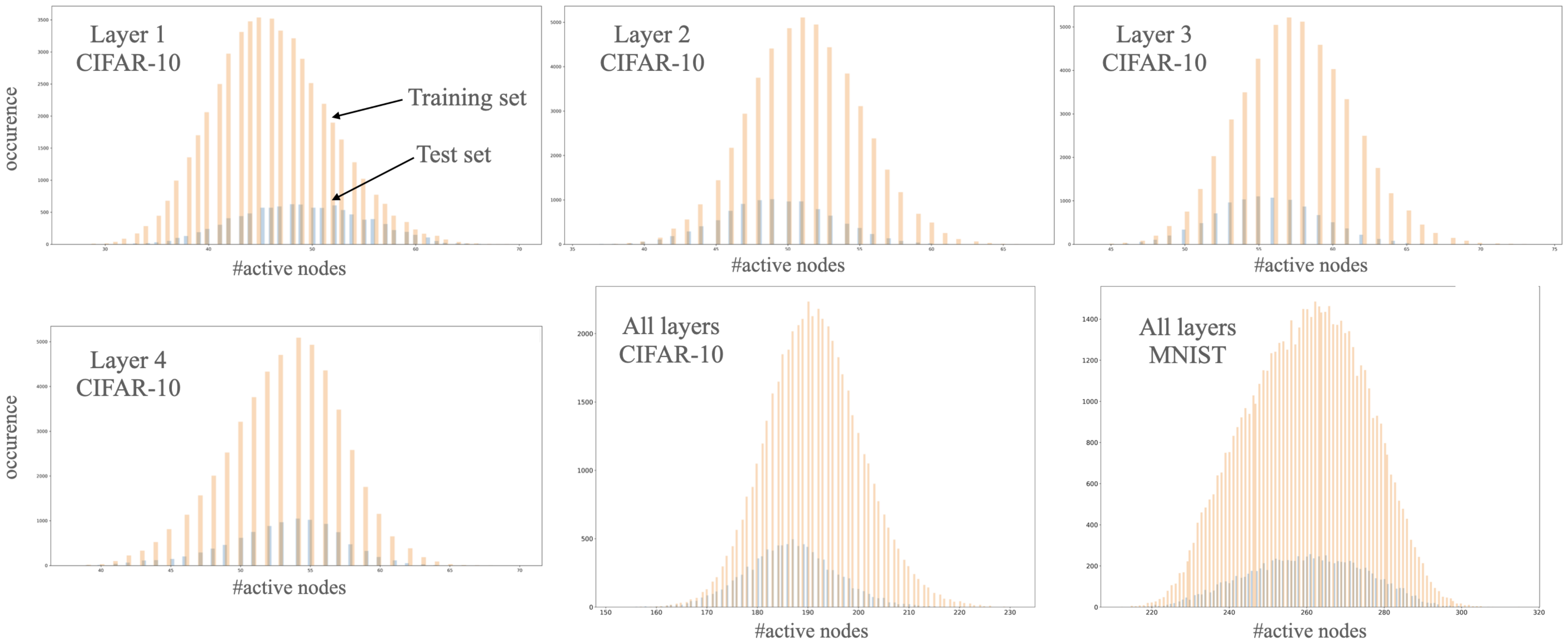
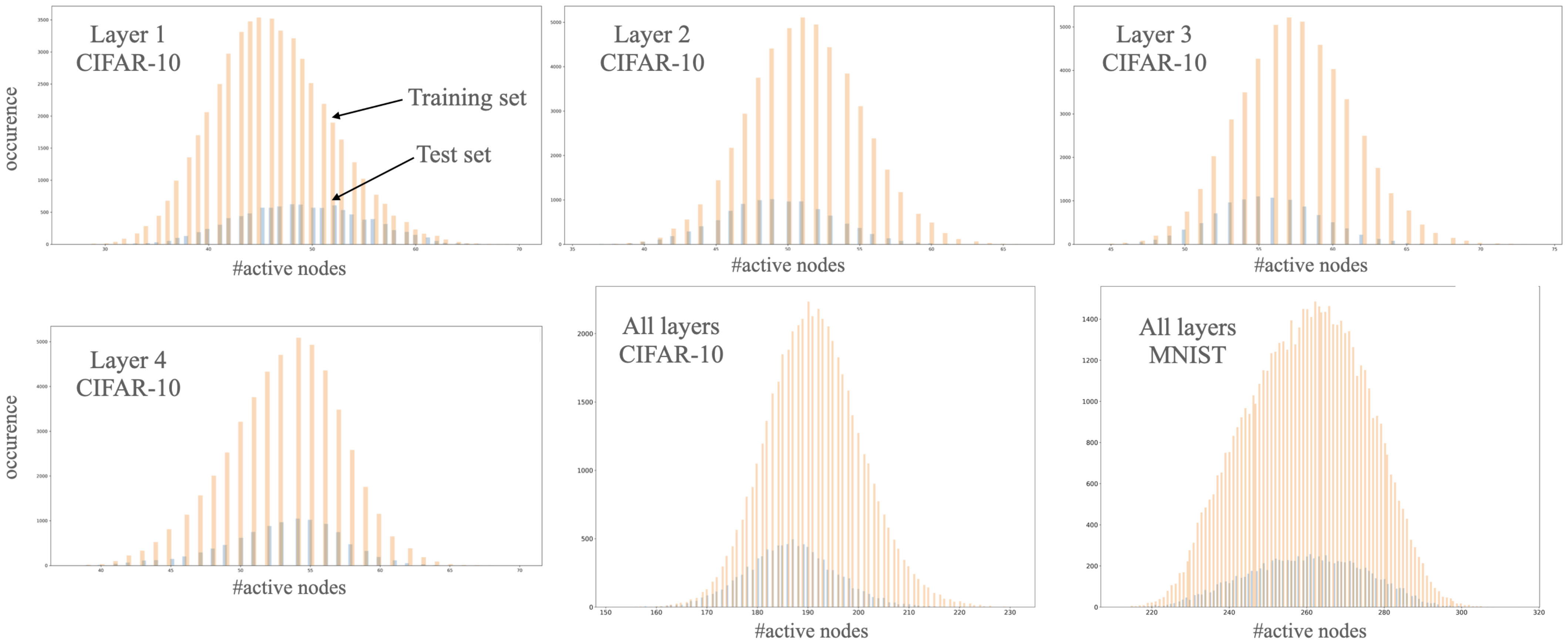
3.3. Distribution of Linear Regions
3.4. Tangent Space Sensitivity and Generalisation
- Layer-wise norm sensitivity, (Equation (1)): the bound does not depend on input, however the layer-wise norm of the parameters changes throughout learning therefore we may estimate the loss at time t (learning step t) based on the inverse change in maximal sensitivity (Equation (1)) and loss measured on the training set at time t:where is norm in the i-th layer at time t. The missing parts of (Equation (1)) are invariable throughout learning.
- Maximal sensitivity, (Equation (2)): similarly, we may estimate test loss based on the distribution of the number of active nodes:where and the corresponding normal distributions are and for the training and the test sets, respectively. Note that the missing parts of (Equation (2)) are invariable if the graph of the network is fixed. At any state of the network, the difference between the estimated sensitivity is based only on how the distribution of the number of active neurons differs in the two sets and the depth of the network while concealing the difference in activation patterns given the sets.
- Empirical sensitivity, (Equation (3)): assuming the empirical estimation of in (Equations (2) and (5)) we define empirical tangent sensitivity as:The corresponding estimation of test loss:
4. Experiments
- Input-output sensitivity [1]: In case of binary classification and for an input set X, input sensitivity is defined astherefore we may estimate the loss at time t (learning step t) based on the sensitivity on the training and the test set and the loss measured on the training set at time t:
- Fisher-Rao norm [23]: The authors proposed a measure (Theorem 3.1) in case of smooth loss with known labeling asThe measure depends on the input labels therefore we need a slight modification with replacing the loss with the sum of loss over all ten classes:We are only interested in the change of the measure therefore we also remove the constant part. We may estimate the loss on the test set by
- Spectral norm [14]: the authors suggest spectrally normalised margin complexity to measure generalisation in case of multiclass classification aswhere represents the margin of a sample with as the y-th output of the network and with zero matrices as reference matrices (Equation (1.2) in [14])As the measure depends on the input label we modified the measure by removing the margin motivated by the fact that on the training set the margin can be misleading as the models may reach high accuracy fast. Additionally, we are only interested in the change of the measure therefore we also remove the norm of the input as it is constant throughout our experiments. The final estimation is similarly to the layer-wise norm:
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix B
Appendix C

{kind=link}
{kind=link}
{kind=link}
| Layer | #Nodes | #Parameters | Variants |
|---|---|---|---|
| Input layer | 3072 | 0 | |
| Hidden layer 1 | 100 | -/BN | |
| Hidden layer 1 | 100 | -/BN/DO | |
| Hidden layer 1 | 100 | -/BN/DO | |
| Hidden layer 1 | 100 | -/BN/DO | |
| Output layer | 10 |
References
- Novak, R.; Bahri, Y.; Abolafia, D.A.; Pennington, J.; Sohl-Dickstein, J. Sensitivity and generalisation in neural networks: An empirical study. In Proceedings of the ICLR’18, Vancouver, BC, Canada, 20 April–3 May 2018. [Google Scholar]
- Sontag, E.D. VC dimension of neural networks. NATO ASI Ser. F Comput. Syst. Sci. 1998, 168, 69–96. [Google Scholar]
- Bartlett, P.L.; Maass, W. Vapnik-Chervonenkis dimension of neural nets. In The Handbook of Brain Theory and Neural Networks; MIT Press: Cambridge, MA, USA, 2003; pp. 1188–1192. [Google Scholar]
- Liu, T.; Lugosi, G.; Neu, G.; Tao, D. Algorithmic stability and hypothesis complexity. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 2159–2167. [Google Scholar]
- Rolnick, D.; Tegmark, M. The power of deeper networks for expressing natural functions. arXiv 2017, arXiv:1705.05502. [Google Scholar]
- Lin, H.W.; Tegmark, M. Why does deep and cheap learning work so well? arXiv 2016, arXiv:1608.08225. [Google Scholar] [CrossRef] [Green Version]
- Stoudenmire, E.; Schwab, D.J. Supervised learning with tensor networks. In Advances in Neural Information Processing Systems, Proceedings of the NIPS 2016, Barcelona, Spain, 5–10 December 2016; Curran Associates Inc.: North Adams, MA, USA, 2016; pp. 4799–4807. [Google Scholar]
- Amari, S.I. Neural learning in structured parameter spaces-natural Riemannian gradient. In Advances in Neural Information Processing Systems, Proceedings of the NIPS 1996, Denver, CO, USA, 3–5 December 1996; MIT Press: Cambridge, MA, USA, 1996; pp. 127–133. [Google Scholar]
- Kanwal, M.; Grochow, J.; Ay, N. Comparing information-theoretic measures of complexity in Boltzmann machines. Entropy 2017, 19, 310. [Google Scholar] [CrossRef]
- Jacot, A.; Gabriel, F.; Hongler, C. Neural tangent kernel: Convergence and generalisation in neural networks. In Advances in Neural Information Processing Systems, Proceedings of the NIPS 2018, Montreal, QC, USA, 3–8 December 2018; MIT Press: Cambridge, MA, USA, 2018; pp. 8571–8580. [Google Scholar]
- Ay, N.; Jost, J.; Vân Lê, H.; Schwachhöfer, L. Information Geometry; Springer: Berlin/Heidelberg, Germany, 2017; Volume 64. [Google Scholar]
- Neyshabur, B.; Li, Z.; Bhojanapalli, S.; LeCun, Y.; Srebro, N. Towards understanding the role of over-parametrisation in generalisation of neural networks. In Proceedings of the ICLR 2018, Vancouver, BC, USA, 30 April–3 May 2018. [Google Scholar]
- Du, S.S.; Zhai, X.; Poczos, B.; Singh, A. Gradient descent provably optimises over-parameterised neural networks. arXiv 2018, arXiv:1810.02054. [Google Scholar]
- Bartlett, P.L.; Foster, D.J.; Telgarsky, M.J. Spectrally-normalised margin bounds for neural networks. In Advances in Neural Information Processing Systems 30, Proceedings of the NIPS 2017, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: North Adams, MA, USA, 2017; pp. 6240–6249. [Google Scholar]
- Krogh, A.; Hertz, J.A. A simple weight decay can improve generalisation. In Advances in Neural Information Processing Systems, Proceedings of the NIPS 1992, Denver, CO, USA, 2–5 December 1992; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1992; pp. 950–957. [Google Scholar]
- Neyshabur, B.; Tomioka, R.; Srebro, N. In search of the real inductive bias: On the role of implicit regularisation in deep learning. In Proceedings of the ICLR’14, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning requires rethinking generalisation. arXiv 2016, arXiv:1611.03530. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Cao, Y.; Gu, Q. Generalisation bounds of stochastic gradient descent for wide and deep neural networks. In Advances in Neural Information Processing Systems 32, Proceedings of the NIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates Inc.: North Adams, MA, USA, 2019; pp. 10835–10845. [Google Scholar]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Wilson, A.C.; Roelofs, R.; Stern, M.; Srebro, N.; Recht, B. The marginal value of adaptive gradient methods in machine learning. In Advances in Neural Information Processing Systems 30, Proceedings of the NIPS 2017, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: North Adams, MA, USA, 2017; pp. 4148–4158. [Google Scholar]
- Keskar, N.S.; Socher, R. Improving generalisation performance by switching from adam to sgd. arXiv 2017, arXiv:1712.07628. [Google Scholar]
- Liang, T.; Poggio, T.; Rakhlin, A.; Stokes, J. Fisher-rao metric, geometry, and complexity of neural networks. arXiv 2017, arXiv:1711.01530. [Google Scholar]
- Dinh, L.; Pascanu, R.; Bengio, S.; Bengio, Y. Sharp minima can generalise for deep nets. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 1019–1028. [Google Scholar]
- Jiang, Y.; Krishnan, D.; Mobahi, H.; Bengio, S. Predicting the generalisation gap in deep networks with margin distributions. In Proceedings of the ICLR’19, New Orleasns, LA, USA, 6–9 May 2019. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Nagarajan, V.; Kolter, J.Z. Uniform convergence may be unable to explain generalisation in deep learning. In Advances in Neural Information Processing Systems 32, Proceedings of the NIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: North Adams, MA, USA, 2019; pp. 11615–11626. [Google Scholar]
- Werpachowski, R.; György, A.; Szepesvári, C. Detecting overfitting via adversarial examples. In Advances in Neural Information Processing Systems 32, Proceedings of the NIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates, Inc.: North Adams, MA, USA, 2019; pp. 7856–7866. [Google Scholar]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning (still) requires rethinking generalisation. Commun. ACM 2021, 64, 107–115. [Google Scholar] [CrossRef]
- Beritelli, F.; Capizzi, G.; Sciuto, G.L.; Napoli, C.; Scaglione, F. Rainfall estimation based on the intensity of the received signal in a LTE/4G mobile terminal by using a probabilistic neural network. IEEE Access 2018, 6, 30865–30873. [Google Scholar] [CrossRef]
- Sciuto, G.L.; Napoli, C.; Capizzi, G.; Shikler, R. Organic solar cells defects detection by means of an elliptical basis neural network and a new feature extraction technique. Optik 2019, 194, 163038. [Google Scholar] [CrossRef]
- Hanin, B.; Rolnick, D. Deep relu networks have surprisingly few activation patterns. In Advances in Neural Information Processing Systems 32, Proceedings of the NIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates, Inc.: North Adams, MA, USA, 2019; pp. 359–368. [Google Scholar]
- Raghu, M.; Poole, B.; Kleinberg, J.; Ganguli, S.; Dickstein, J.S. On the expressive power of deep neural networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 2847–2854. [Google Scholar]
- Arora, S.; Ge, R.; Neyshabur, B.; Zhang, Y. Stronger generalisation bounds for deep nets via a compression approach. arXiv 2018, arXiv:1802.05296. [Google Scholar]
- Neyshabur, B.; Salakhutdinov, R.R.; Srebro, N. Path-SGD: Path-Normalised Optimisation in Deep Neural Networks. In Advances in Neural Information Processing Systems, Proceedings of the NIPS 2015, Montreal, QC, Canada, 7–12 December 2015; Curran Associates, Inc.: North Adams, MA, USA, 2015. [Google Scholar]
- Neyshabur, B.; Bhojanapalli, S.; McAllester, D.; Srebro, N. Exploring generalisation in deep learning. In Advances in Neural Information Processing Systems 30, Proceedings of the NIPS 2017, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: North Adams, MA, USA, 2017; pp. 5947–5956. [Google Scholar]
- Zhang, X.; Wu, D. Empirical Studies on the Properties of Linear Regions in Deep Neural Networks. arXiv 2020, arXiv:2001.01072. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; MIT Press: Cambridge, MA, USA; NYU: New York, NY, USA, 2009. [Google Scholar]
- Devroye, L.; Györfi, L.; Lugosi, G. A Probabilistic Theory of Pattern Recognition; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013; Volume 31. [Google Scholar]
- Carlini, N.; Wagner, D. Adversarial examples are not easily detected: Bypassing ten detection methods. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 3–14. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Montufar, G.F.; Pascanu, R.; Cho, K.; Bengio, Y. On the number of linear regions of deep neural networks. In Advances in Neural Information Processing Systems, Proceedings of the NIPS 2014, Montreal, QA, Canada, 8–13 December 2014; Curran Associates Inc.: North Adams, MA, USA, 2014. [Google Scholar]
- Lovász, L.; Vempala, S. Simulated annealing in convex bodies and an O*(n4) volume algorithm. J. Comput. Syst. Sci. 2006, 72, 392–417. [Google Scholar] [CrossRef] [Green Version]
- Cousins, B.; Vempala, S. A practical volume algorithm. Math. Program. Comput. 2016, 8, 133–160. [Google Scholar] [CrossRef]
- Chakrabarti, S.; Childs, A.M.; Hung, S.H.; Li, T.; Wang, C.; Wu, X. Quantum algorithm for estimating volumes of convex bodies. arXiv 2019, arXiv:1908.03903. [Google Scholar]
- Hoeffding, W. Probability inequalities for sums of bounded random variables. In The Collected Works of Wassily Hoeffding; Springer: Berlin/Heidelberg, Germany, 1994; pp. 409–426. [Google Scholar]
- Russo, D.; Zou, J. Controlling bias in adaptive data analysis using information theory. In Artificial Intelligence and Statistics, Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; PMLR: Westminster, UK, 2016; pp. 1232–1240. [Google Scholar]
- Russo, D.; Zou, J. How much does your data exploration overfit? Controlling bias via information usage. IEEE Trans. Inf. Theory 2019, 66, 302–323. [Google Scholar] [CrossRef] [Green Version]
- Xu, A.; Raginsky, M. Information-theoretic analysis of generalisation capability of learning algorithms. In Advances in Neural Information Processing Systems 30, Proceedings of the NIPS 2017, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: North Adams, MA, USA, 2017. [Google Scholar]
- Neu, G.; Lugosi, G. Generalisation Bounds via Convex Analysis. arXiv 2022, arXiv:2202.04985. [Google Scholar]
- Winkelbauer, A. Moments and absolute moments of the normal distribution. arXiv 2012, arXiv:1209.4340. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalisation: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimisation. arXiv 2014, arXiv:1412.6980. [Google Scholar]
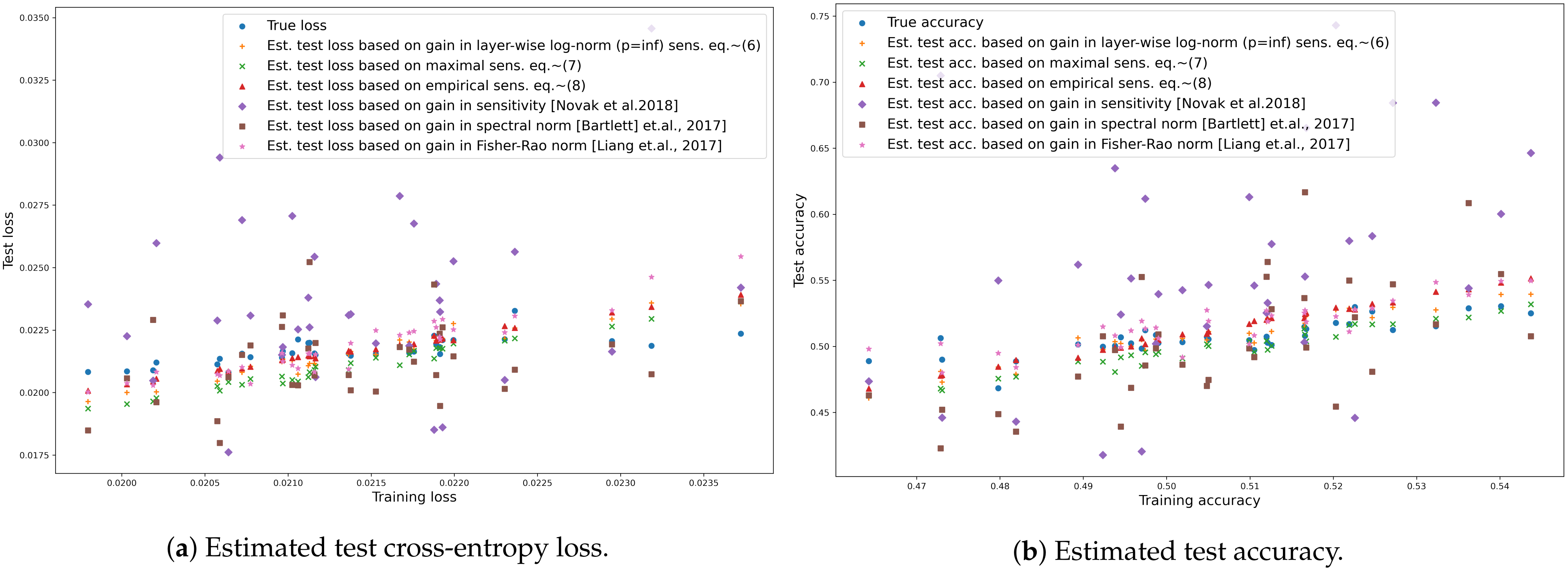
| Estimation | Cross-Entropy | Accuracy |
|---|---|---|
| Layer-wise log-norm (p = inf) sens. (Equation (6)) | ||
| Maximal sens. (Equation (7)) | ||
| Empirical sens. (Equation (8)) | ||
| Change in sens. (Equation (9)) | ||
| Change in spectral norm (Equation (11)) | ||
| Change in Fisher-Rao norm (Equation (10)) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Daróczy, B. Gaussian Perturbations in ReLU Networks and the Arrangement of Activation Regions. Mathematics 2022, 10, 1123. https://doi.org/10.3390/math10071123
Daróczy B. Gaussian Perturbations in ReLU Networks and the Arrangement of Activation Regions. Mathematics. 2022; 10(7):1123. https://doi.org/10.3390/math10071123
Chicago/Turabian StyleDaróczy, Bálint. 2022. "Gaussian Perturbations in ReLU Networks and the Arrangement of Activation Regions" Mathematics 10, no. 7: 1123. https://doi.org/10.3390/math10071123
APA StyleDaróczy, B. (2022). Gaussian Perturbations in ReLU Networks and the Arrangement of Activation Regions. Mathematics, 10(7), 1123. https://doi.org/10.3390/math10071123