Abstract
Many stream ciphers employ linear feedback shift registers (LFSRs) to generate pseudorandom sequences. Many recent LFSRs are defined in to take advantage of the n-bit processors, instead of using the classic binary field. In this way, the bit generation rate increases at the expense of a higher complexity in computations. For this reason, only certain primitive polynomials in are used as feedback polynomials in real ciphers. In this article, we present an efficient implementation of the LFSRs defined in . The efficiency is achieved by using equivalent binary LFSRs in combination with binary n-bit grouped operations, n being the processor word’s length. This improvement affects the general considerations about the security of cryptographic systems that uses LFSR. The model also allows the development of a faster method to test the primitiveness of polynomials in .
Keywords:
LFSR; stream cipher; m-sequence; primitive polynomial; extended Galois field; symmetric encryption MSC:
3304; 05C31; 90C23; 46B85; 6804
1. Introduction
The symmetric cryptographic systems known as stream ciphers base their operation on the generation of binary sequences that are combined with the message to be encrypted by binary addition (XOR operation). The sequence used in the transmitter must also be generated in the receiver to recover the message by applying the XOR operation to the received ciphertext [1]. The concept of perfect secrecy defined by Shannon [2] establishes as a condition that the binary sequences used to encrypt the message (ciphering sequences) are random, have a length greater than or equal to the message, and are one time use. Although excellent random generators exist, the need to reproduce the sequence in the receiver makes it necessary to use pseudo-random sequences instead of true random ones. Therefore, pseudorandom number generators (PRNGs) constitute the fundamental part of any stream cipher.
One of the simplest and most widely used methods to generate cryptographic pseudorandom sequences is the linear feedback shift register (LFSR) [3]. This generator stands out for its simplicity and for the good statistical properties of the generated sequences. In addition, the behavior of the LFSR is completely characterized by the polynomial that defines the applied feedback. Thus, if the polynomial is primitive, the generated sequence reaches the maximum length, which is known as the m-sequence. However, these sequences are easily predictable from known elements of the sequence generated by an L-stage LFSR. This makes the sequences obtained from an LFSR not directly usable. Instead, non-linear filtering or non-linear combinations of various LFSRs have to be applied to ensure the cryptographic security of stream ciphers, such as those used in mobile and wireless communication systems, e.g., Bluetooth [4], wireless area networks [5], or GSM [6]. On the other hand, although LFSRs are generically defined on a finite field , practical implementations of these ciphers are carried out on to integrate with bitwise operations. Nevertheless, these operations are clearly inefficient when using current processors that work with 16-, 32-, or 64-bit words. For this reason, the extended Galois fields , where matches the processor word length, have been analyzed to substitute in cryptographic applications [7,8,9]. In the particular case of LFSR-based stream ciphers, the SNOW 3G algorithm [10] is currently used in 3G and 4G mobile communication systems, and several proposals have recently appeared to be applied to 5G communications [11,12,13]. However, computations on an extended field are time consuming, much more than in the base field [14]. Although the bit generation rate improves n times the binary case, the overall performance of the system does not, sometimes being even lower. In fact, several methods have been developed to reduce computational time, such as precomputed tables, optimized algorithms for multiplication [15], or the use of representations of the elements in terms of elements with . In contrast to binary case, where any primitive polynomial guarantees a sequence of maximum length, only certain primitive polynomials that facilitate its implementation are used in extended fields. This means that they do not require excessive resource consumption, as the SNOW 3G case does, defined to work on devices with 32-bit processors by combining operations with 32-bit and 8-bit arguments. On the other hand, the identification of primitive polynomials in requires a much higher computational effort than in the binary case.
This article presents two methods that reduce the execution time for the implementation of an LFSR and the search for primitive polynomials in the extended filed . These methods are based on the model that establishes a direct relationship between the m-sequence generated by an LFSR in and the interleaving of n m-sequences generated by n LFSRs in . This relationship was used by Komo and Lam [16] to build primitive polynomials in in terms of primitive polynomials in , establishing the relationships that must hold between both polynomials. We propose to use these relationships in the opposite direction; that is, we propose to represent the primitive polynomial over in terms of binary LFSRs. In this way, the same sequences will be generated using only binary operations (XOR). However, moving from n-bit word operations to bit operations would be back to square one, since the main reason for using LFSR on extended fields is to take advantage of the capabilities of n-bit processors where bit operations are inefficient. Taking into account that the n binary LFSRs that allow generating the same sequence as the LFSR in have all the same primitive feedback polynomial in , the previous obstacle can be easily overcame. Thus, the calculation of the bit operations of the n binary LFSRs can be performed jointly, giving rise to XOR operations between n-bit words and eliminating the inefficiency generated by single-bit operations in this type of processor. The efficiency improvement provided by the proposed implementation turns it into a method especially suitable for cryptanalysis tasks where any execution time reduction in the systems under analysis is very appreciated. Therefore, security assessments performed to cryptosystems based on LFSR in extended fields must take into account the proposed implementation to report a more realistic security level. Additionally, the proposed method allows any primitive polynomial in to be used as feedback polynomial of an LFSR, thus overcoming the current limitations.
The rest of the paper is organized as follows. In Section 2, the mathematical background and notation are introduced, with special emphasis on the LFSR fundamentals and the relationships between the m-sequences generated in extended and base fields, and . Section 3 describes the proposed implementation for the particular case of LFSRs defined in through a different and more efficient way. Section 4 contains the algorithm proposed to test the primitiveness of polynomials making use of the same relationships. Finally, discussion about security and efficiency of the implementations and conclusion are included in Section 5 and Section 6, respectively.
2. Mathematical Background
Let be the finite field of q elements, q being a prime, and the set of all polynomials with coefficients in . Equivalently, let be the finite field of elements, and the set of all polynomials with coefficients from . A generator of the cyclic group of a finite field is called a primitive element of that field. Hence, a polynomial of degree is called primitive over if it is the minimal polynomial over of a primitive element . A primitive polynomial of degree n allows one to construct in such a way that:
The addition and multiplication in are the ones in , but performing the module reduction, as all the elements in can be represented as polynomials of degree less than n with coefficients in . On the other hand, any element can be expressed in terms of a basis , being a root of in . Consequently, any element can be written as the vector where:
For , it is very common to use the hexadecimal notation as a compact representation of the elements in . Thus, if we use to construct , being a root of , as any element in can be represented as a power of , we can write the element as or and the element as or . Note that the powers of correspond to the vector components in descending order, beginning from the left, to facilitate the conversion to and from hexadecimal values.
2.1. Linear Feedback Shift Registers
An LFSR defined over is a collection of L memory cells , , whose contents belong to that field and are updated synchronously by a master clock, by the following equations:
giving rise to the sequence , which is completely determined by the initial state of the cells, named seed, and the feedback coefficients , according to the linear recurrence:
where correspond to the seed (see Figure 1). The length of the sequence D can be analyzed in terms of the connection polynomial composed with the feedback coefficients:
in such a way that the maximal sequence length is achieved when is primitive. In such a case, the sequence is called m-sequence and is independent from the chosen seed.
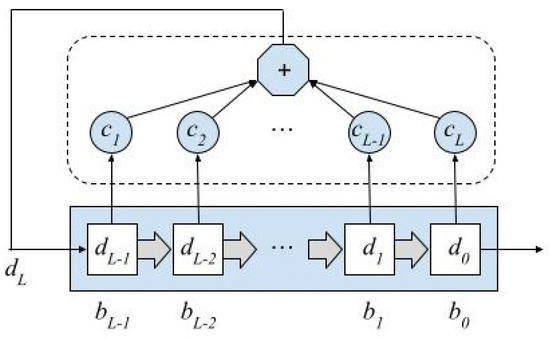
Figure 1.
Linear feedback shift register.
Stream ciphers are mainly based on LFSRs defined over finite fields with [1]. Hence, the cell content is one bit, and the addition and multiplication correspond to XOR and AND operations, respectively. However, for efficiency reasons, in the generation process, LFSRs defined in are also being used in current communication systems. When LFSR is defined in this extension field, the cells contain n-bit words, where n matches the processor’s word length. Although the equations that govern the LFSR are the same, as described above, addition and multiplication are defined as polynomial addition and multiplication modulus , the polynomial used to construct the . From now on, we shall use the notation to refer to an LFSR with L cells in and connection polynomial of degree L. The form is for an LFSR of L cells in and connection polynomial of degree L.
2.2. Binary Equivalent Model
Komo and Lam [16] proposed a method to generate primitive polynomials in using primitive polynomials in based on the relationship previously discovered by Park and Komo [17] between the m-sequences produced in and , in such a way that an m-sequence in can be decomposed into n m-sequences in . More precisely:
Theorem 1
(cf. [17], th 7). Let be a primitive polynomial of degree in . Let be one of the n primitive polynomials of degree m in into which factors when viewed in . Let be an m-sequence over generated by . If
where is a basis for over , then the sequence is an m-sequence of length over .
As one can observe, the sequence is composed by the j-th component of each element in the sequence D. Equivalently, the sequence can be considered as a decimation sequence obtained from D giving rise to the following set of decimated sequences, as it is shown in Figure 2:
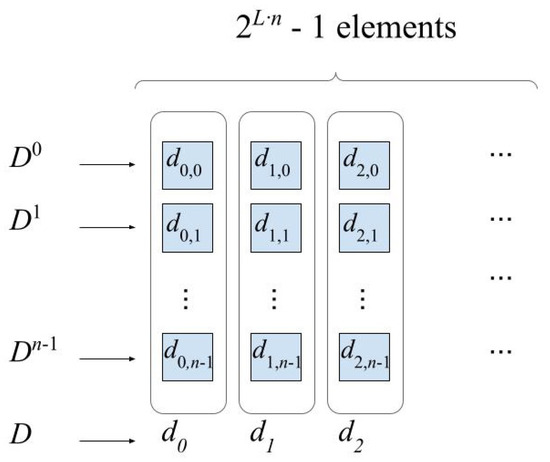
Figure 2.
Relationship between m-sequences in the extended and base fields.
Furthermore, as it is stated in [16], since the sequences , for , are generated by the same polynomial , all of them are shifted versions of the same m-sequence. Hence, taking as the reference, we can define as the shift of respect to . In [16], a method to obtain a primitive polynomial in terms of a given primitive polynomial is proposed by means of the computation of the shifts that satisfy the relationship between the m-sequences in the extended and base fields.
3. Efficient LFSR Implementation
The relationship between the m-sequences on and the m-sequences on , as described in the previous section, also allows us to establish an equivalence between the LFSRs that generate them. This section presents a practical and efficient method to obtain such LFSRs, i.e., to obtain the feedback polynomial and the seeds of each LFSR that allow us to generate the same sequence as the LFSR from a given seed. Note that, according to the equivalent model, the n LFSRs in have the same connection polynomial but different seeds, all of them related to the seed in . Hence, in order to efficiently implement the LFSR using the equivalent model, it is necessary to solve three main questions: the computation of , the computation of the seeds, and how to speed up the performance of the binary LFSRs.
Since the connection polynomial is primitive, the minimal polynomial of the decimated sequences is also primitive and unique for . Hence, can be obtained analyzing a decimated sequence using the Massey–Berlekamp algorithm [18]. Consequently, the following Algorithm 1 is defined.
| Algorithm 1: Computation of connection polynomial . |
| input : LFSR output: in LFSR
|
Once has been determined, we can construct the n LFSRs , but we need their respective seeds in order to generate the same sequence as that generated from the initial seed in the extended field. As it is derived from the equivalent model, the L known elements in that compose the initial seed only provide us with bits, while bits are needed to complete the n seeds in (see Figure 3). Thus, the seed of can be partially written in terms of the seed s of D as:
where are unknown for . However, the shifts that relate the binary sequences to each other allow us to obtain the seeds completely. The following subsections describes the computation of and .
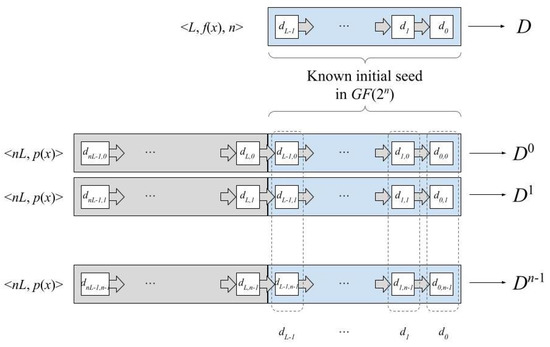
Figure 3.
LFSR seeds in the binary equivalent model.
3.1. Computation of Shifts
All decimated sequences have the same primitive minimal polynomial , obtained using Algorithm 1. Hence, all of them are shifted versions of the others. The shift of with respect to allows one to obtain the state of the j-th LFSR (the one that generates ) from the state of the 0-th LFSR as follows:
where A is the connection matrix of , that is:
The computation of is not an easy task. Furthermore, the computation of is time-consuming. Instead, we can obtain the matrix solving the linear equation system of Equation (9). Note that we have n matrices to compute and thus n linear systems to solve. The linear system in Equation (9), stated using the first element, the seed, has equations and unknowns. Each new element of the sequence defines new equations with the same unknowns. Hence, the elements of the m-sequence in generated in Algorithm 1 to obtain provide enough equations to solve the systems. As an example, we consider a 3-stage LFSR defined in , that is, the LFSR , where is primitive over and the primitive polynomial has been used to construct . From the initial seed or, equivalently, , being a root of , the LFSR generates the following sequence:
where the elements of are represented in columns with the least significant bit at the top. The four decimated sequences are all generated by the same primitive polynomial and, hence, all of them are shifted versions of the same m-sequence. Solving the system in Equation (9), we obtain the matrices :
Since the decimated sequences have a small period of , we have also compared them to obtain the shifts , , and . In a real scenario, is not going to be computed. It is important to point out that the calculation of the matrices can be performed prior to the normal operation of the LFSR since they do not depend on the seeds.
3.2. Computation of Seeds
Let us consider that the shift matrices have already been precomputed. For any given seed , the seeds of the binary LFSRs can be represented as:
where are unknowns for every . The values can be obtained solving the linear system composed with the equations with the known values for , i.e.:
where are the components of the matrix . The remaining seeds , with , are calculated using Equation (13). Considering the precomputed matrices in Equation (12) of the previous example, the Equation (13) can be written as:
Solving for , we obtained the complete seed for the sequence , that is, . Next, using the matrices , and , the complete seeds of the sequences , , and are obtained. Hence, we have:
3.3. Grouped Operations
Once the n binary LFSRs have been constructed, it is time to generate the sequence. Instead of running n independent instances of the binary LFSR, which require 1-bit operations with an n-bit processor, we propose to group the n LFSRs into a unique LFSR with connection polynomial but using n-bit cells. The result is not an LFSR over but a parallel implementation of n LFSR over using only one processor. Since the addition and multiplication in the binary LFSRs correspond to the XOR and AND bitwise operations, respectively, instead of applying the XOR to 1-bit values, we apply it over n-bit values. The processor takes the same time to perform the XOR operation with 1-bit values than with n-bit values because the word length is n, thus saving a lot of execution time. Hence, Equation (4) can be redefined as follows:
in such a way that the n sequences stated in Equation (7) are simultaneously generated using a unique polynomial (see Equation (5)).
From the practical implementation perspective, there is no difference at all with respect to preforming a classical binary LFSR, which includes coding and execution, since the 1-bit XOR operation is actually performed taking n-bit operands. Hence, the n-bit grouped operation proposed in this paper is a way of not wasting the capacity of the operations of the n-bit processors. As a consequence, this implementation method increases the bit generation net rate by n because the generation of a new element of a 32-bit m-sequence takes the same amount of time as a new element of a 1-bit m-sequence.
4. Primitiveness Test
As mentioned in Section 2.2, the m-sequences generated by an LFSR in can be decomposed into n m-sequences generated by n LFSRs in , so that when the feedback polynomial of the LFSR in the extended field is primitive, all LFSRs in have the same feedback polynomial, and it is also primitive. This relationship is what allows us to propose an algorithm to check if a polynomial is primitive over .
In general terms, to check if a polynomial over is primitive, we propose to build an LFSR whose feedback polynomial is and generate elements, at least. The sequence generated by concatenating all generated elements is decomposed into n binary sequences by decimating by n, as it is stated in Equation (7). Next, the n sequences are processed to obtain the minimal polynomials of the binary LFSRs that generate them (This can be achieved using the Berlekamp–Massey algorithm). If all the n sequences are generated by the same polynomial and it is also primitive, then is primitive over . Algorithm 1 can be extended including one more step (step 5) to perform the check, resulting in Algorithm 2.
| Algorithm 2: Primitiveness test. |
 |
As an example, let us consider the degree 6 polynomial , where the primitive polynomial has been used to construct . In order to check if is primitive, we consider as the feedback polynomial of an LFSR in the of 6 cells. For a random seed , we generate elements, giving rise to the following decimated sequences:
The same minimal polynomial is obtained for each sequence by means of the Massey–Berlekamp algorithm [18]. The polynomial is the following:
Since is primitive over , we can conclude that is primitive over .
5. Efficiency and Security
The implementation presented in Section 3 considerably reduces the execution time of the LFSRs defined in . Specifically, an implementation of the LFSR used in the SNOW 3G stream cipher has been performed and compared with the implementation provided in the technical specification of the protocol [10]. This is an LFSR . Hence, the equivalent model is based on 32 LFSRs . The polynomial is built from 1024 elements generated using the official implementation [10] following the steps established in Algorithm 1. The result is that the 32 decimated sequences have the same minimal polynomial of degree 512, whose coefficients are represented below in compact hexadecimal format:
Despite the fact that has 250 non-zero coefficients, and therefore 250 XOR operations are required to generate the next element in the sequence, the execution time is 3.3 times lower than the original implementation. The computation of the matrices is not considered, since this is performed prior to the normal operating of the LFSR. The times have been calculated by taking the average of 10 repetitions of each generation of 1000, 10,000, 20,000, 50,000, and 100,000 elements. Both implementations have been made in Python 3.9 language and have been executed on an Intel(R) Core(TM) i7-10510U 64-bit processor with 16 GB of RAM. Although the SNOW 3G algorithm has been designed to be executed on 32-bit platforms, the tests carried out on a 64-bit processor are completely valid since the greater word length of the processor compared to the algorithm does not affect the normal execution of our implementation. Note that the goal is to achieve an implementation of an algorithm defined in using n-bit operations. The case of working with processors of more than n bits offers the possibility of developing new faster implementations to make the most of their capacity, but requires adapting the algorithms to the new processor architecture. This is outside the scope of this work.
As mentioned in the Section 3, the net bit generation rate is increased by n when compared to a single binary LFSR implementation, that is, to a binary LFSR using the same connection polynomial. However, the improvement observed in the tests on SNOW 3G does not reach the net rate. This is mainly due to the number of non-zero coefficients in that slow down the computation. Therefore, in the case of equivalent binary polynomials with a few nonzero coefficients, the real rate will reach the net rate. In the general case, the fewer non-zero coefficients in , the greater the improvement to the generation rate.
The efficiency of the proposed implementations, shown in Section 3 affects the security of the cryptosystems used by these LFSRs, although, in general, they are not intended to replace those currently used by most devices, such as smartphones, but rather for use in mobile devices without any type of restriction, such as personal computers or servers. Using the equivalent model implies multiplying by n, the number of bits needed to generate a new element of the m-sequence over , that is, to generate n bits. In the case of SNOW 3G, it goes from 512 to 16,384 bits. Therefore, the theoretical improvement of the execution time by a factor n is associated with an increase in the same factor n in the amount of memory needed to generate the same number of bits. As a consequence, this implementation provides a substantial improvement for the calculation of m-sequences that, although it could not be deployed on some devices, could always be used for cryptanalysis tasks. Regarding the cost of our proposal, an increment in the memory cells must be taken in mind, rising from to bits.
Regarding the algorithm for primitiveness testing, we can conclude that it has a better performance than O’Connor’s algorithm, one of the most used ones. The main advantage is that the proposed algorithm has to generate elements instead of the whole sequence or alternatively to perform as many divisions as elements in the maximal sequence over the extended field. The validation and comparison tests have been performed using Mathematica software, version , on a 64-bits Microsoft Windows platform running on a Intel(R) Core (TM) processor with i7-4510U CPU @ GHz and 16 GB RAM. The processor’s temperature and the amount of simultaneous running processes have been taken into account for the execution time comparison. Figure 4 shows the behavior of the algorithm with respect to O’Connor’s in and , respectively.
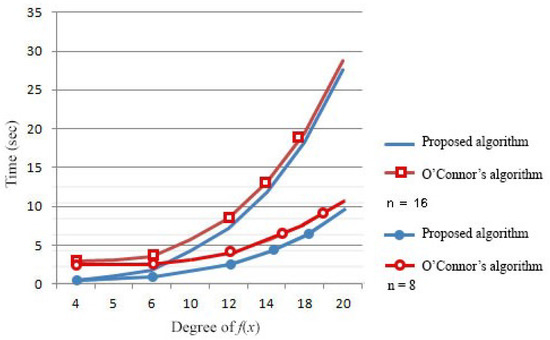
Figure 4.
Execution time in and .
6. Conclusions
In this article, we have presented two real applications of the relationships between the m-sequences in and . The first one is a new algorithm designed to verify the primitiveness of polynomials with coefficients in that improves the execution times of existing methods. The second one is the support of an efficient implementation of the LFSRs defined over the extended field , which improves the other implementations. It enables better performance of the LFSR-based stream ciphers, often used in high speed communication systems. The improvement is achieved by a combination of the binary equivalent model of LFSRs in the extended field, which uses only binary operations, and the n-bit grouped operation that take advantage of the n-bit processors. The feasibility of the implementation has been shown by applying it to the SNOW 3G stream cipher, whose execution time has been reduced by a factor of 3.3 with respect to the code provided in the technical specification of the protocol. These results can also be extended to cryptanalysis, making use of not only the grouped operations but of the underlying binary structure that may facilitate the parallelization of the operations. On the other hand, the proposed implementation is software-oriented, although the binary operations also allow hardware implementations. In this way, we provide a complete method to efficiently increase the bit generation rate.
Author Contributions
Writing of original draft and writing—review and editing, J.E.G., G.C., A.P. and A.O. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the research group BIOSIP (TIC-251) and by the Spanish State Research Agency (AEI) of the Ministry of Science and Innovation (MICINN), project P2QProMeTe (PID2020-112586RB-I00/AEI/10.13039/501100011033) co-funded by the European Regional Development Fund (ERDF, EU).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Menezes, A.J.; Van Oorschot, P.C.; Vanstone, S.A. Handbook of Applied Cryptography; CRC Press: Boca Ratón, FL, USA, 2020. [Google Scholar]
- Shannon, C. Communication Theory of Secrecy Systems. Bell Syst. Tech. J. 1949, 28, 656–715. [Google Scholar] [CrossRef]
- Golomb, S.W. Shift Register Sequences, 3rd Revised ed.; Aegean Park Press: Laguna Hills, CA, USA, 2017. [Google Scholar]
- Padgette, J.; Bahr, J.; Batra, M.; Holtmann, M.; Smithbey, R.; Lily, C.; Scarfone, K. Guide to Bluetooth Security; NIST: Gaithersburg, MD, USA, 2017. [Google Scholar]
- Jindal, P.; Singh, B. RC4 Encryption-A Literature Survey. Procedia Comput. Sci. 2015, 46, 697–705. [Google Scholar] [CrossRef] [Green Version]
- Biham, E.; Dunkelman, O. Cryptanalysis of the A5/1 GSM stream cipher. In Proceedings of the International Conference on Cryptology in India, Calcutta, India, 10–13 December 2000; pp. 43–51. [Google Scholar]
- Kiyomoto, S.; Tanaka, T.; Sakurai, K. K2: A stream cipher algorithm using dynamic feedback control. In Proceedings of the International Conference on Security and Cryptography, SECRYPT, Barcelona, Spain, 28–13 July 2007; Hernando, J., Fernández-Medina, E., Malek, M., Eds.; INSTICC Press: Lisboa, Portugal, 2007; pp. 204–213. [Google Scholar]
- George, K.; Michaels, A.J. Designing a Block Cipher in Galois Extension Fields for IoT Security. IoT 2021, 2, 669–687. [Google Scholar] [CrossRef]
- Panario, D.; Reis, L. The functional graph of linear maps over finite fields and applications. Des. Codes Cryptogr. 2019, 87, 437–453. [Google Scholar] [CrossRef]
- ETSI/SAGE. Specification of the 3GPP, Confidentiality and Integrity Algorithm UEA2 and UIA2; Document 2: SNOW 3G Specification; ETSI: Sophia Antipolis, France, 2006. [Google Scholar]
- Caforio, A.; Balli, F.; Banik, S. Melting SNOW-V: Improved lightweight architectures. J. Cryptogr. Eng. 2020, 12, 53–73. [Google Scholar] [CrossRef]
- Ekdahl, P.; Johansson, T.; Maximov, A.; Yang, J. A new SNOW stream cipher called SNOW-V. IACR Trans. Symmetr. Cryptol. 2019, 3, 1–42. [Google Scholar] [CrossRef]
- Ekdahl, P.; Maximov, A. SNOW-Vi: An Extreme Performance Variant of SNOW-V for Lower Grade CPUs. In Proceedings of the 14th ACM Conference on Security and Privacy in Wireless and Mobile Networks, WiSec ’21, Abu Dhabi, United Arab Emirates, 28 June–2 July 2021; pp. 261–272. [Google Scholar]
- Avanzi, R.; Theriault, N. Effects of optimization for software implementations of small binary field arithmetic. In International Workshop on the Arithmetic of Finite Fields; Springer: Berlin/Heidelberg, Germany, 2007; pp. 69–84. [Google Scholar]
- Delgado-Mohatar, O.; Fúster-Sabater, A.; Sierra, J.M. Performance evaluation of highly efficient techniques for software implementation of LFSR. Comput. Electr. Eng. 2011, 37, 1222–1231. [Google Scholar] [CrossRef]
- Komo, J.J.; Lam, M.S. Primitive Polynomials and m-sequences over GF(qm). IEEE Trans. Inf. Theory 1993, 39, 643–647. [Google Scholar] [CrossRef]
- Park, W.J.; Komo, J.J. Relationships Between m-Sequences over GF(q) and GF(qm). IEEE Trans. Inf. Theory 1989, 35, 183–186. [Google Scholar] [CrossRef]
- Massey, J.L. Shift register synthesis and BCH decoding. IEEE Trans. Inf. Theory 1969, 15, 122–127. [Google Scholar] [CrossRef] [Green Version]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).