
Unsupervised and Supervised Methods to Estimate Temporal-Aware Contradictions in Online Course Reviews


Abstract
:1. Introduction
- (C1). In this paper, we give the definition of the subjective contradiction occurring in reviews, around aspects. Four research questions were raised by this definition:
- –
- RQ1: How do we define the notion of subjective contradiction around an aspect? The definition of the notion of subjective contradiction is based on the notion of sentiment diversity with respect to aspects. We considered, in this article, the notion of diversity as the dispersion of sentiments (sentiment polarity);
- –
- RQ2: How can the strength (intensity) of a contradiction occurring in reviews be estimated? This was performed by computing the degree of dispersion of sentiment polarity around an aspect of a web resource;
- –
- RQ3: How do we balance the sentiment polarity around an aspect and the global rating of a review leading to the underlying question, when computing the intensity of a contradiction? What is the weight of the global rating of a review in the expression of feelings around an aspect?
- –
- RQ4: Freshness and temporality are essential in Web 2.0; it is therefore necessary to take into account the temporality of the reviews when computing contradiction intensity;
- (C2). We present the development of a data collection that allows the evaluation of the contradiction intensity estimation. The evaluation was based on a user study;
- (C3). We performed an experimental comparison, over our corpus, of the unsupervised method based on our definition of subjective contradiction with supervised methods with automatic feature selection.
2. Background and Related Work
2.1. Contradiction Detection Approaches
2.2. Methods for Aspect Detection
2.3. Methods for Sentiment Analysis
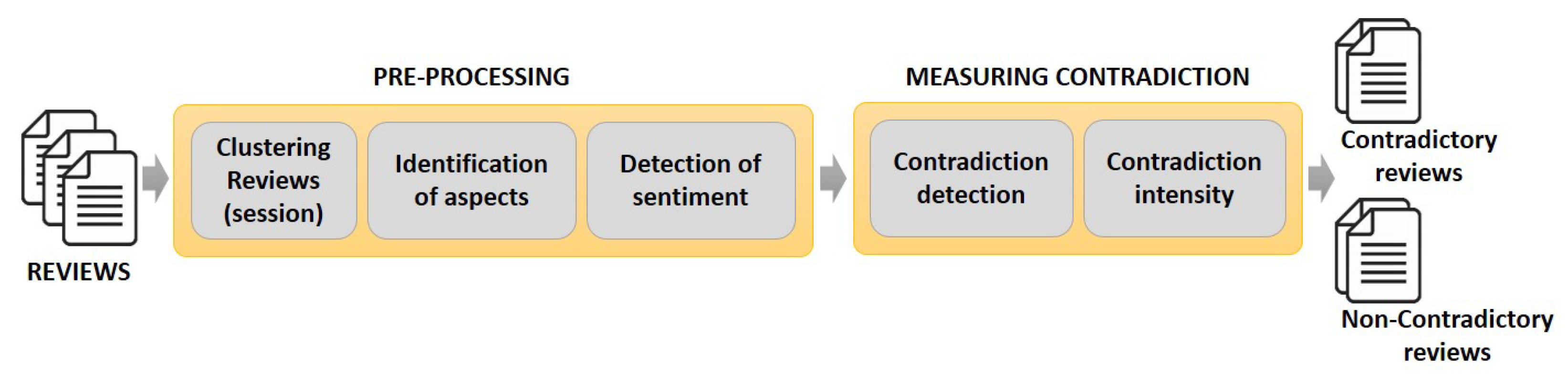
3. Time-Aware Contradiction Intensity
3.1. Preprocessing
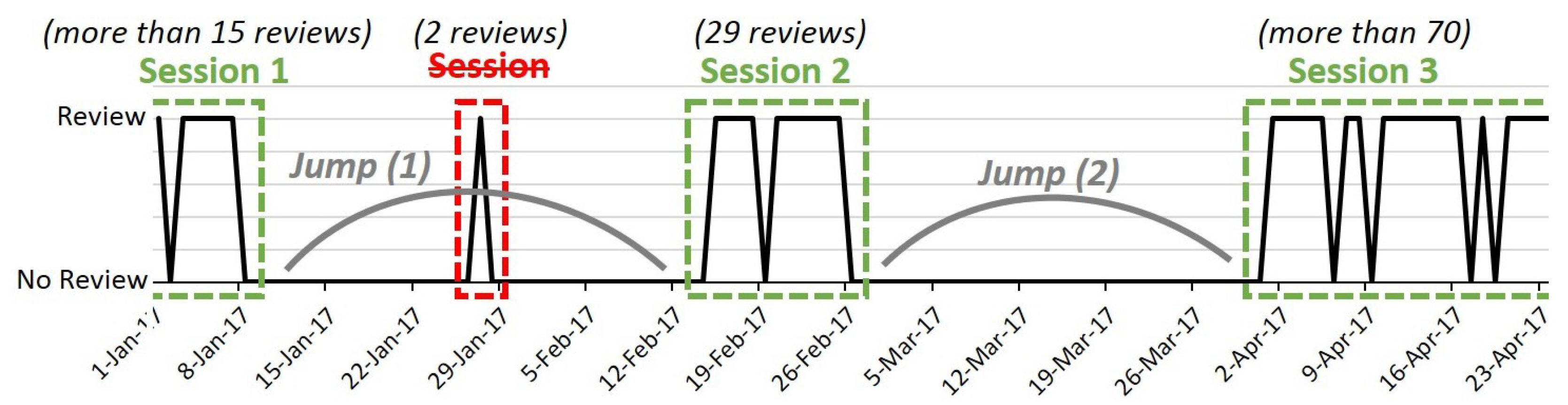
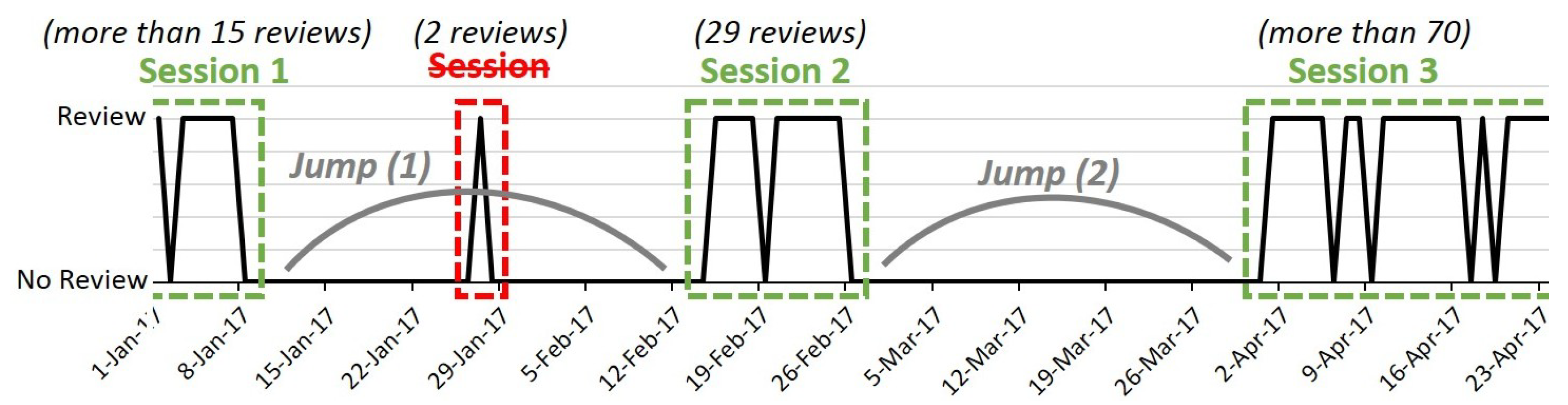
3.1.1. Clustering Reviews Based on Sessions
- We computed a threshold that corresponds to the duration of the jump. This was performed on a per course basis and was based on the average time gaps between reviews (for instance, there was a gap of 35 d for the “Engagement and Nurture Marketing Strategies” lecture);
- We grouped the reviews with respect to the above-mentioned threshold, on a per course basis;
- We kept only the important sessions by suppressing the so-called “false sessions” (sessions that contained only a very low number of reviews).
3.1.2. Aspect Extraction
- The reviews corpus’ term frequency was calculated;
- The Stanford Parser https://nlp.stanford.edu:8080/parser/(accessed on 5 January 2022) was used for the parts-of-speech labeling of reviews;
- Nominal category (NN, NNS) https://cs.nyu.edu/grishman/jet/guide/PennPOS.html (accessed on 5 January 2022) terms were chosen;
- Nouns having emotive terms in a five-term context window were considered (using the SentiWordNet https://sentiwordnet.isti.cnr.it/ (accessed on 5 January 2022) dictionary);
- The extraction of the most common terms from the corpus was performed (the candidates for this step issued from the previous step). The aspects are represented by the before-mentioned terms.
| Algorithm 1: The reviews of a resource are grouped according to the time period (session) in which they were written. |
 |
3.1.3. Sentiment Analysis
3.2. Contradiction Detection and Contradiction Intensity
- is positive or zero; if , there is no dispersion = ;
- increases as moves away from . (when there is increasing dispersion).
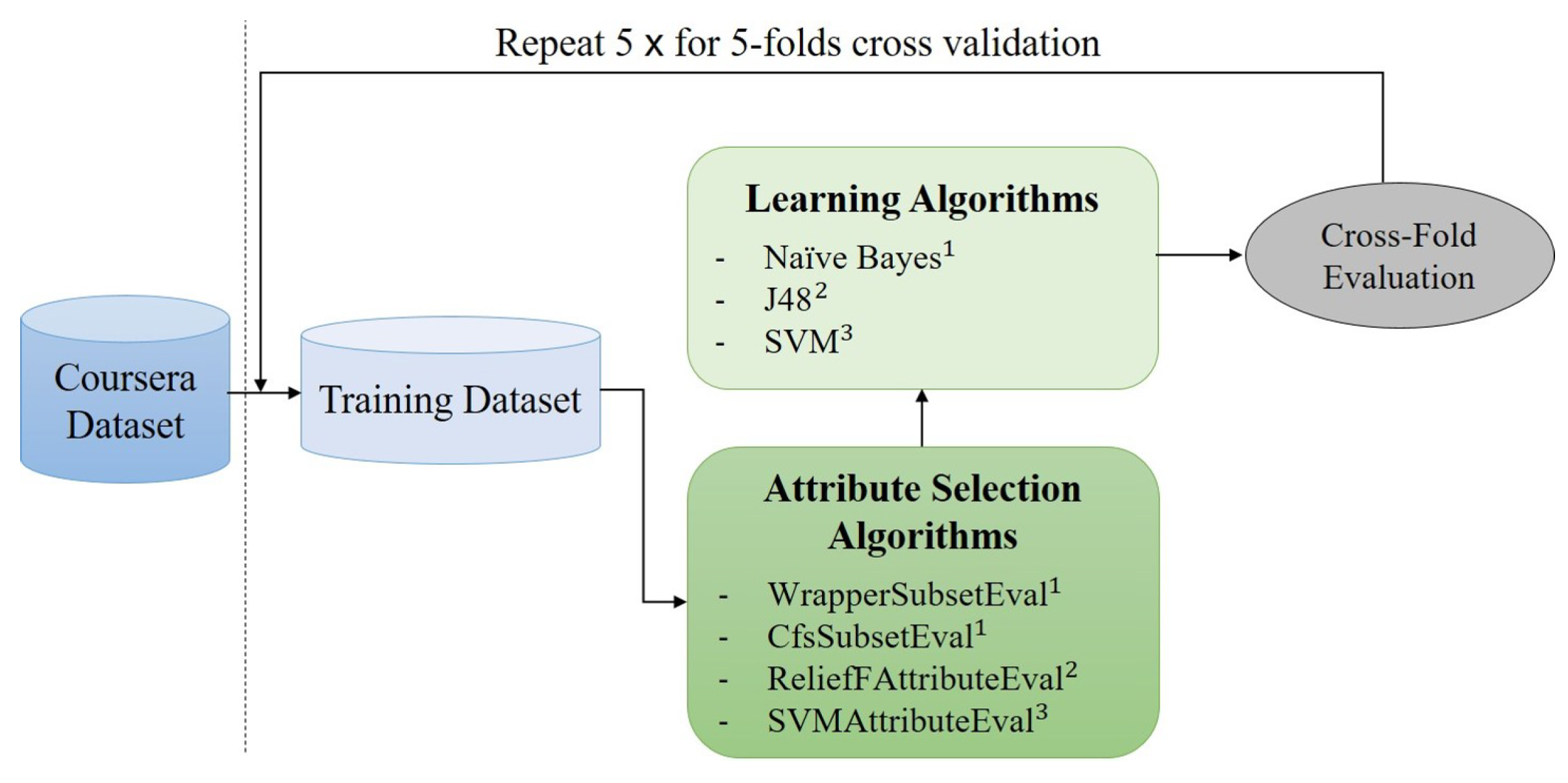
3.3. Predicting Contradiction Intensity
4. Experimental Evaluation
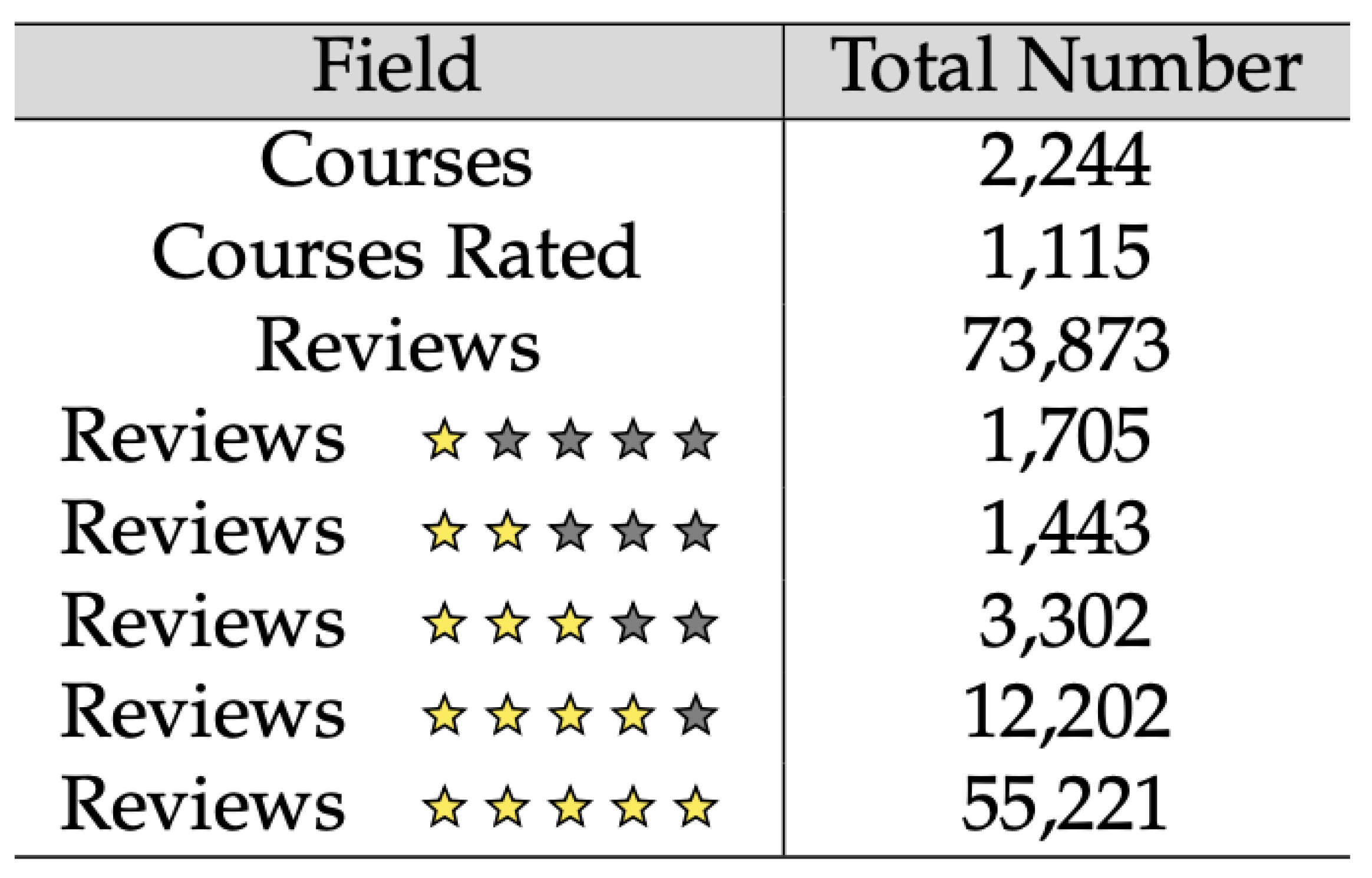
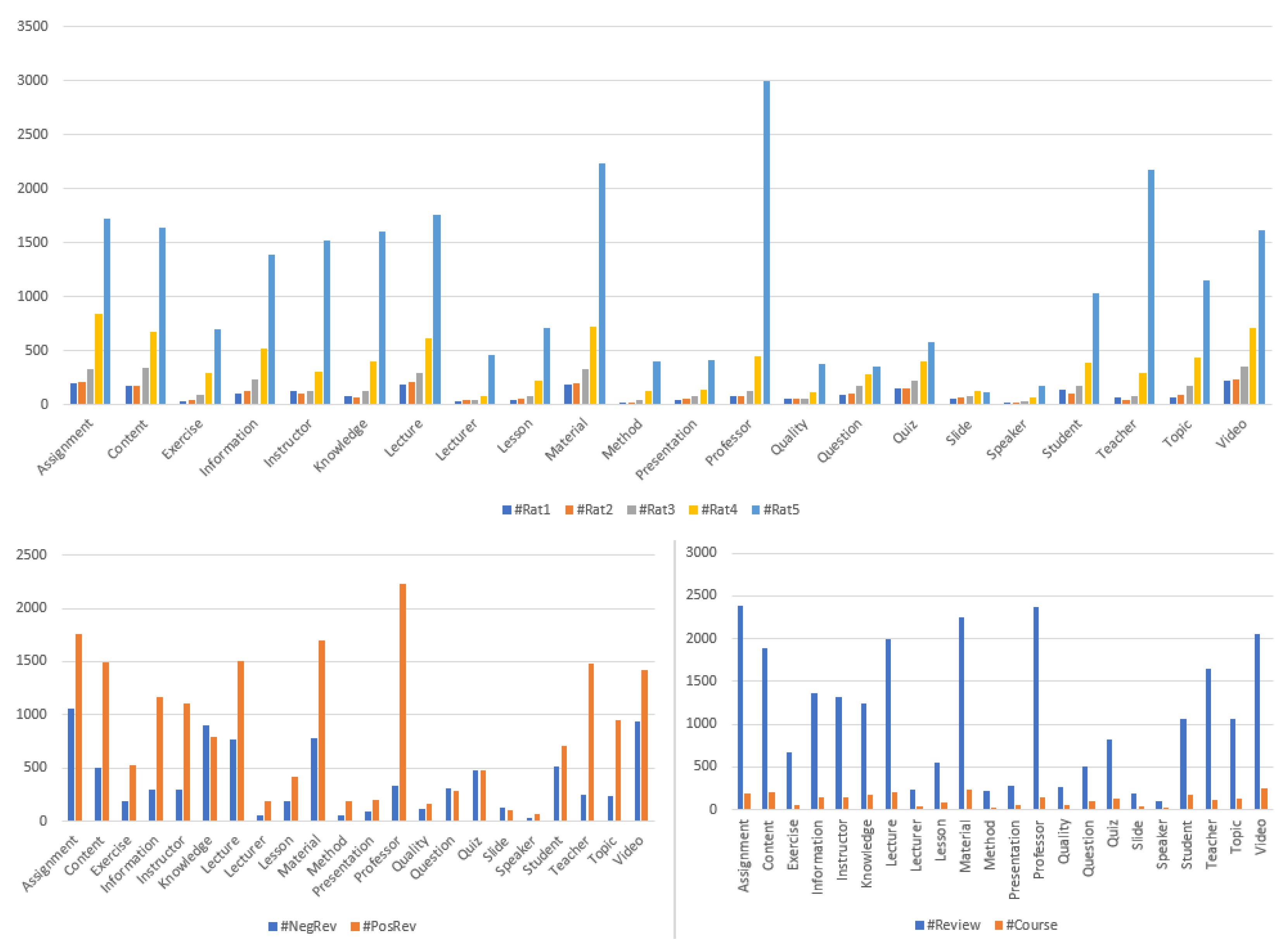
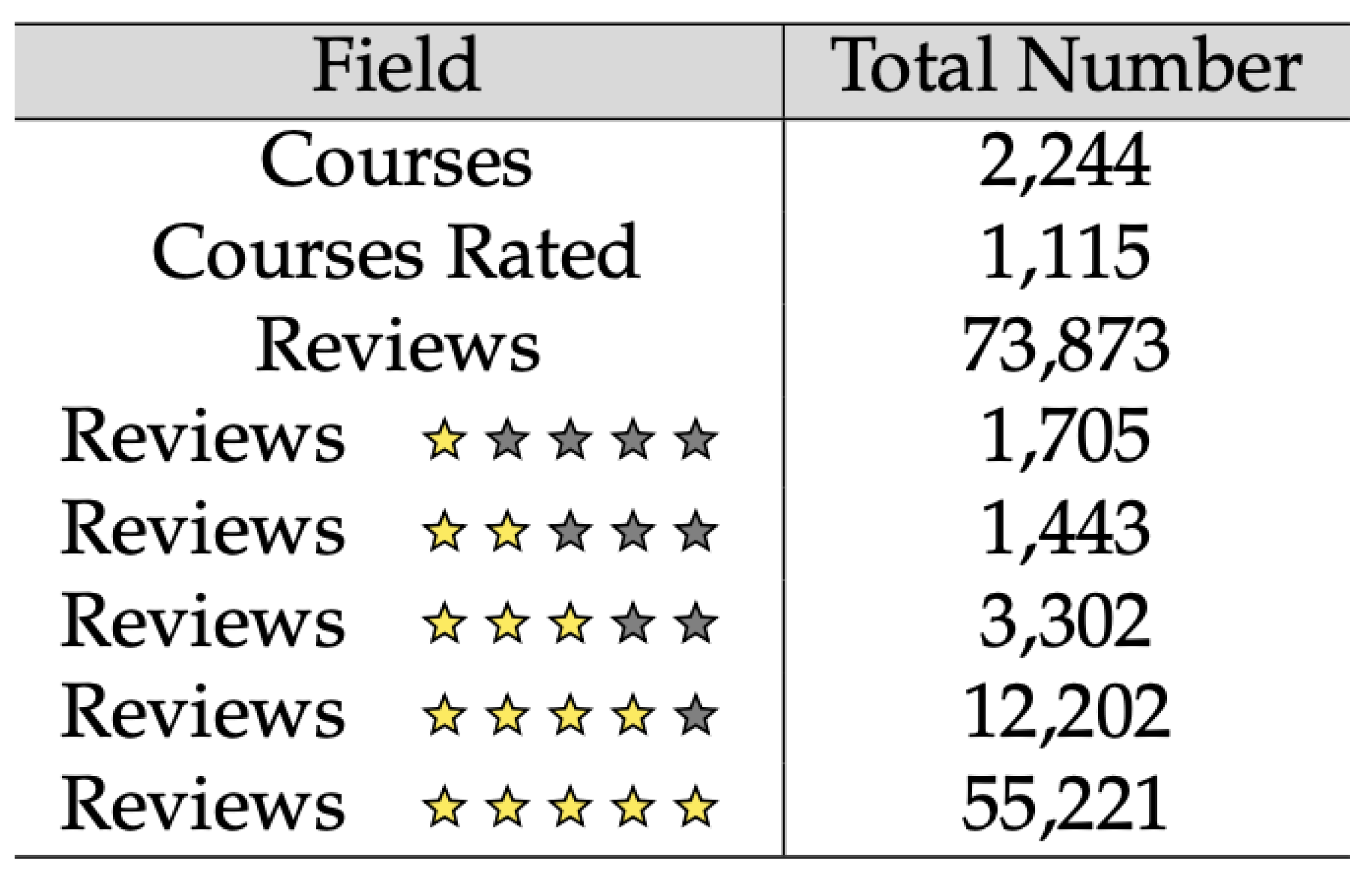
4.1. Description of the Test Dataset
4.1.1. Data
4.1.2. User Study
- The sentiment class for each review-aspect of 1100 courses was assessed by 3 users (assessors). Users must only judge the polarity of the involved sentiment class;
- The degree of contradiction between these review-aspects (see Figure 6) was assessed by 3 new users.
4.2. Results and Discussion
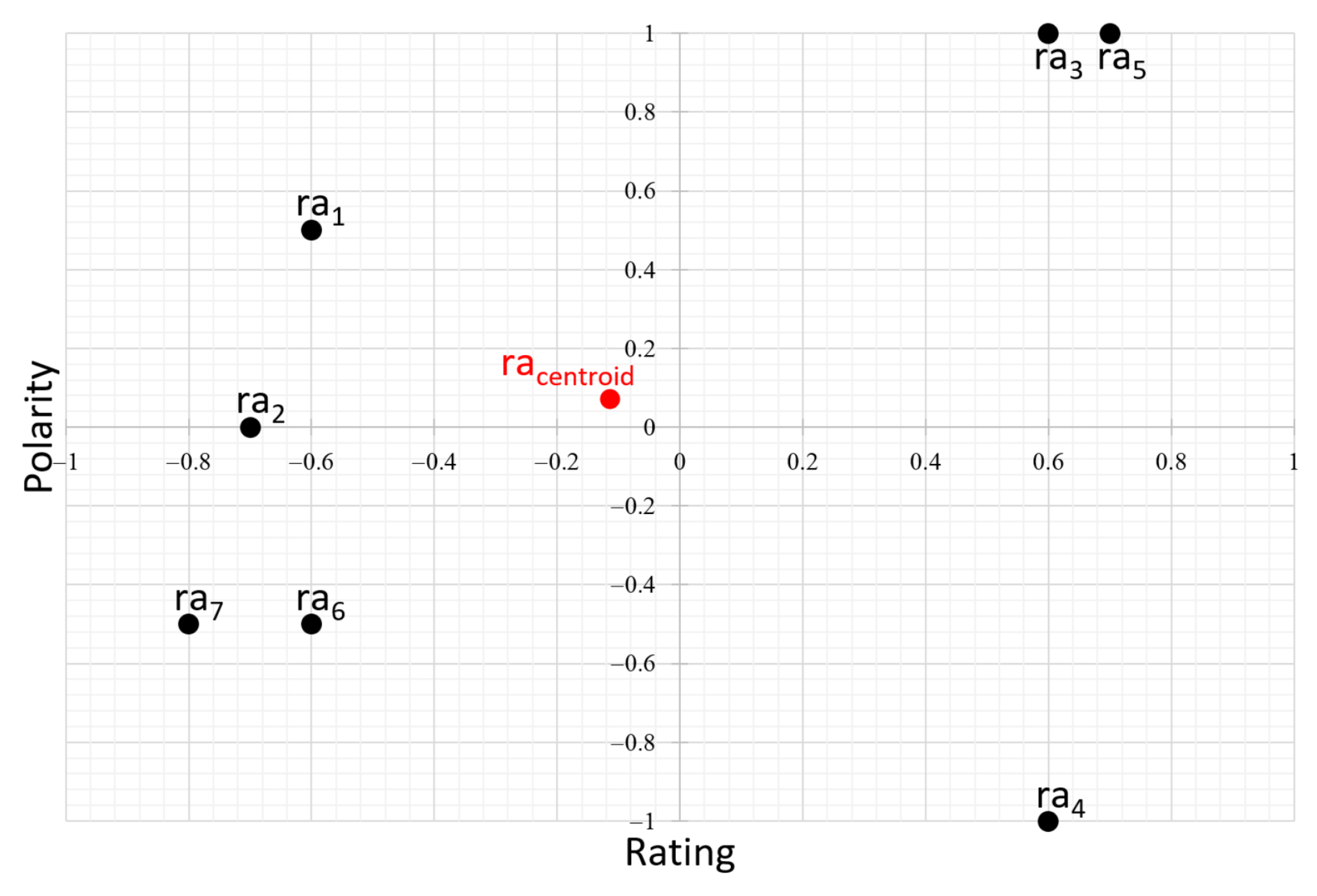
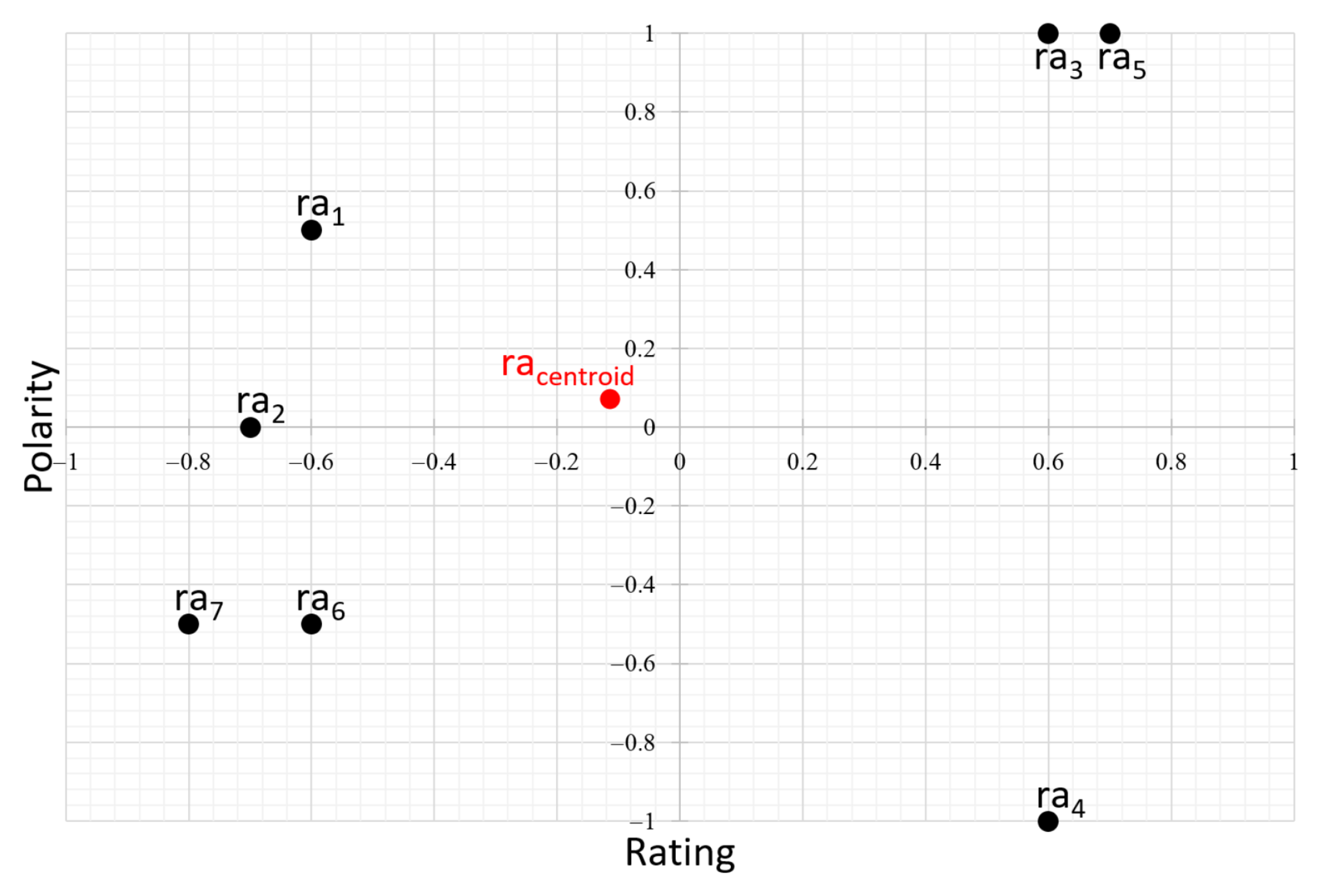
4.2.1. Averaged and Weighted Centroid
- The training phase for the sentiment analysis was performed over 50 k reviews issued from the IMDb movie database https://ai.stanford.edu/~amaas/data/sentiment/ (the vocabulary used in the movie reviews is similar to the vocabulary used in our dataset);
- The accuracy of the sentiment analysis rose to ;
- The assessed sentiment judgments were considered as the ground truth, thus yielding 100% in terms of accuracy.
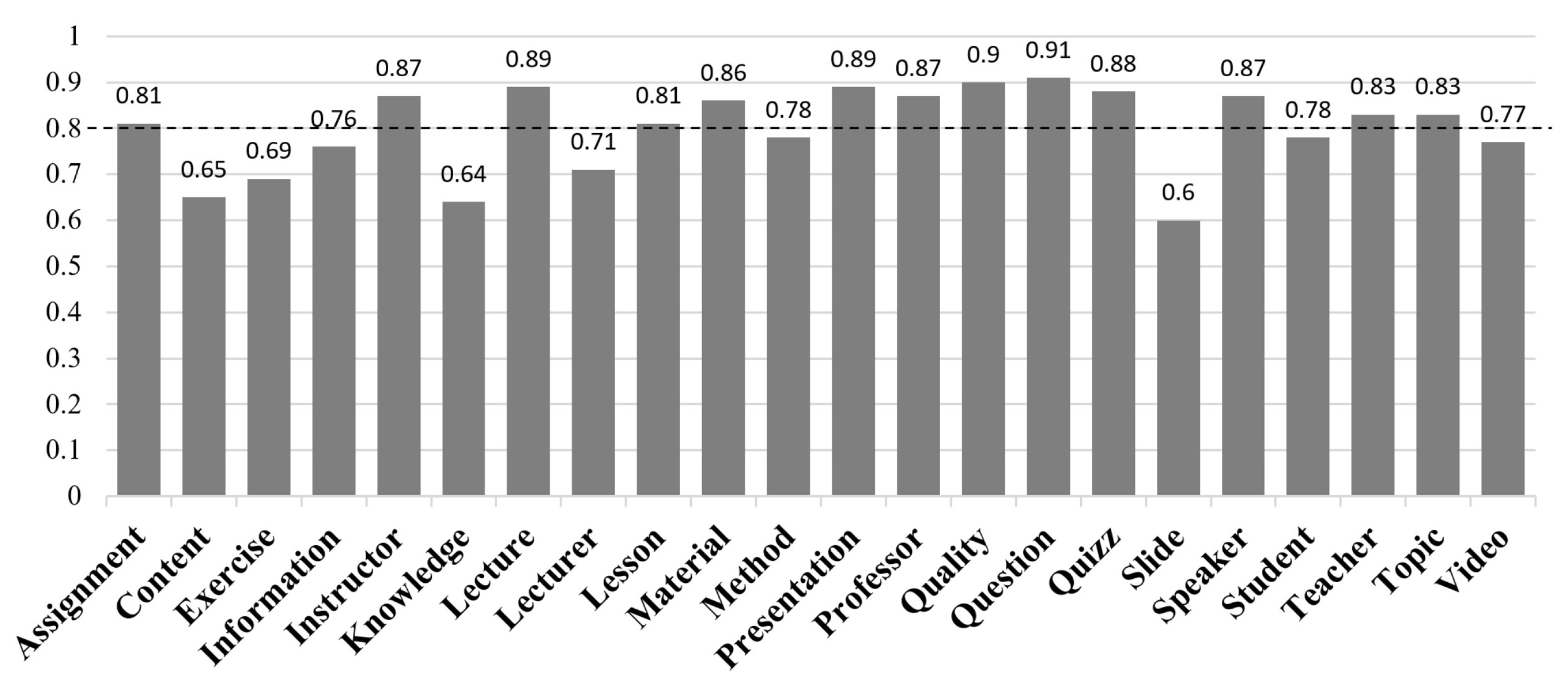
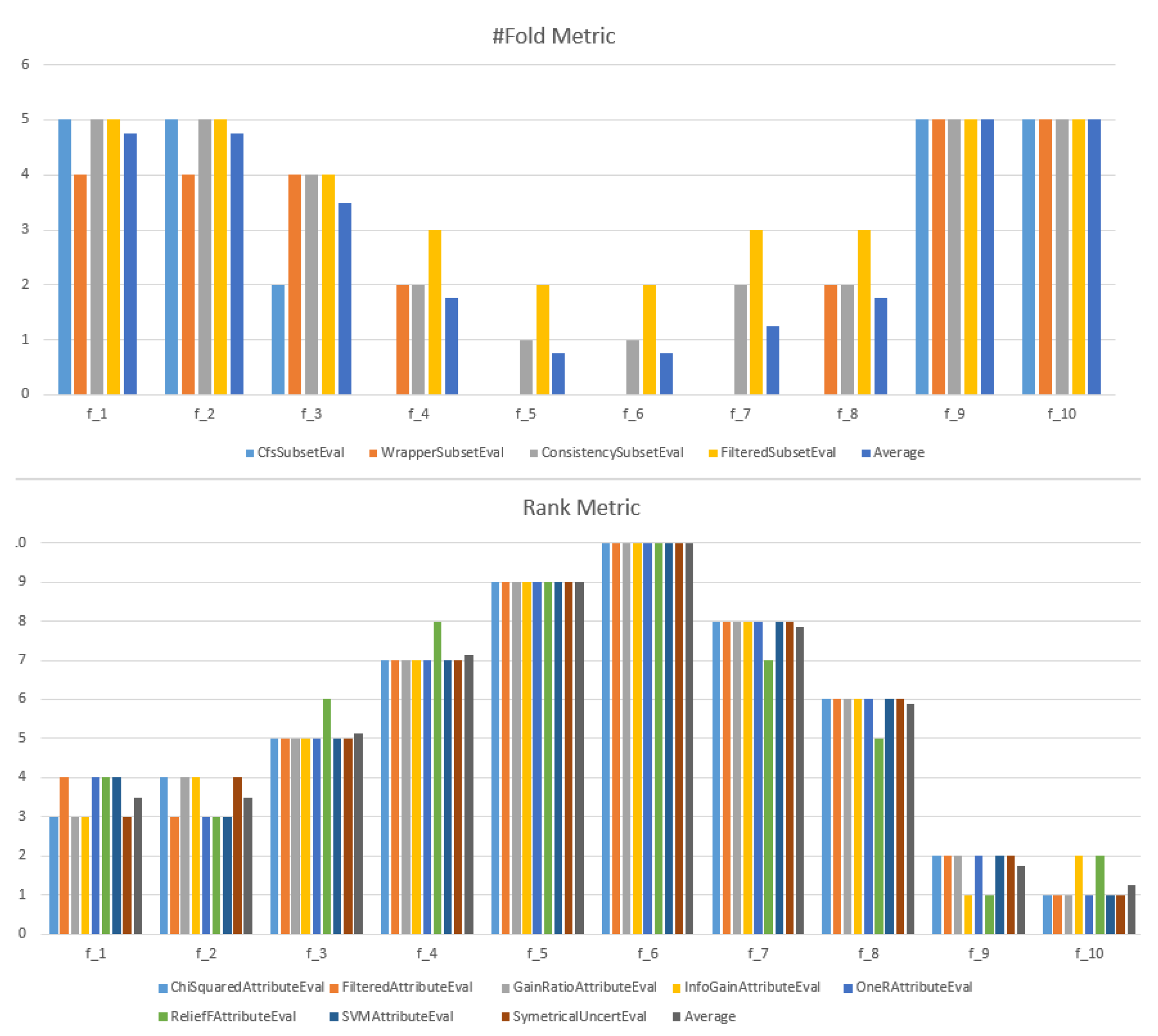
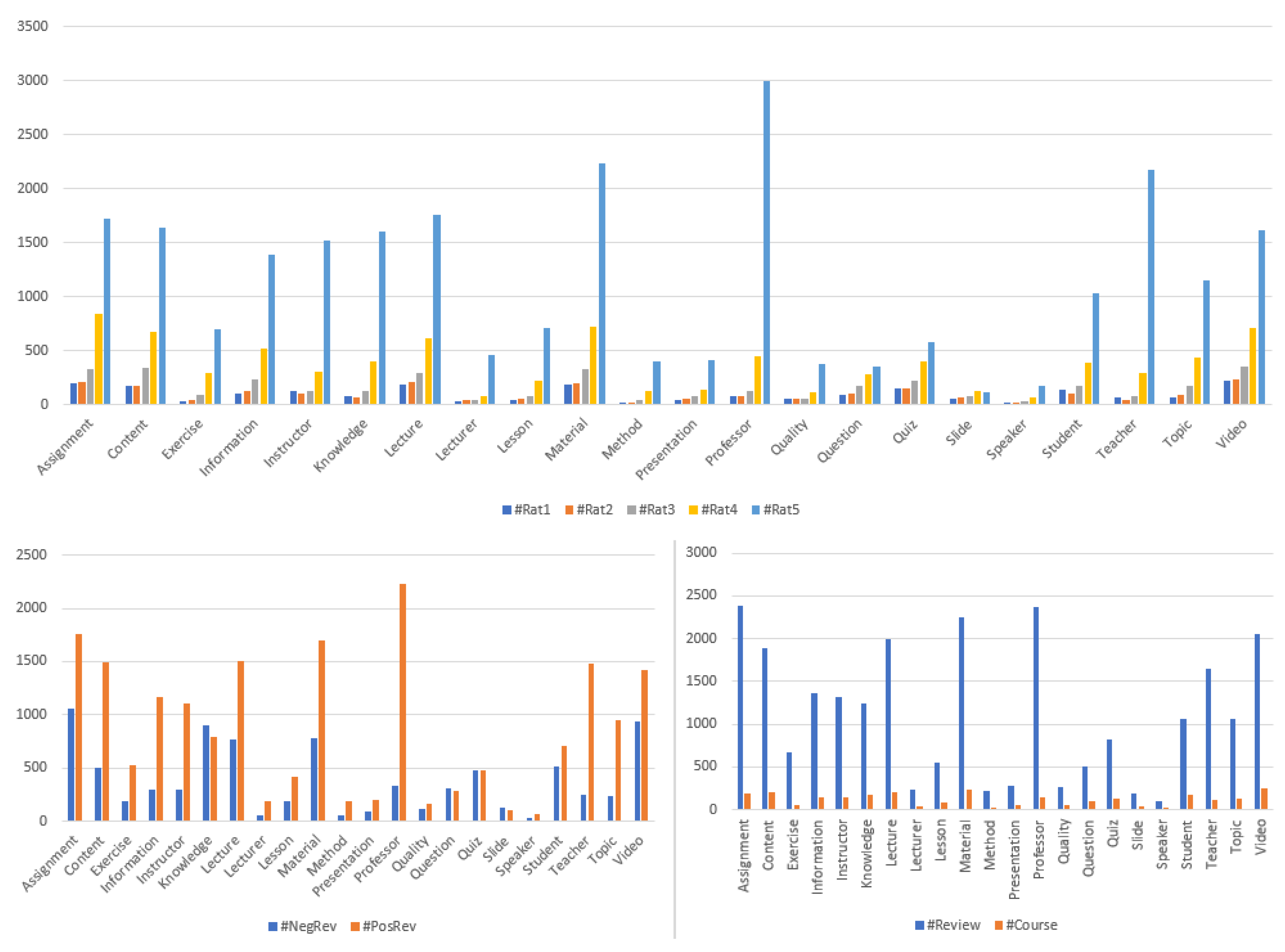
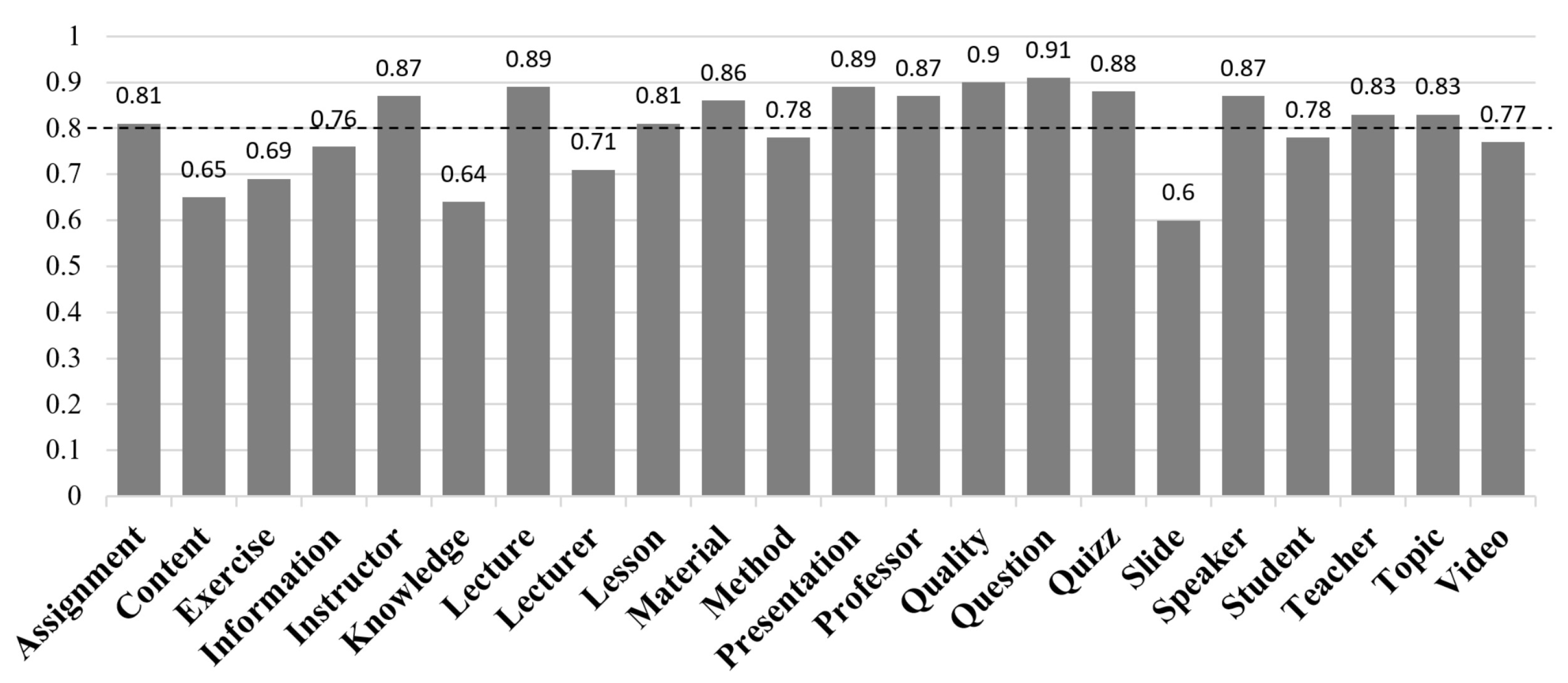
4.2.2. Best Feature Identification
- Based on ranking metrics to sort the features (marked by Rank in the figure);
- Based on the occurrence frequency during the cross-validation step (marked by #Folds in the figure).
4.2.3. Feature Learning Process for Contradiction Intensity Prediction
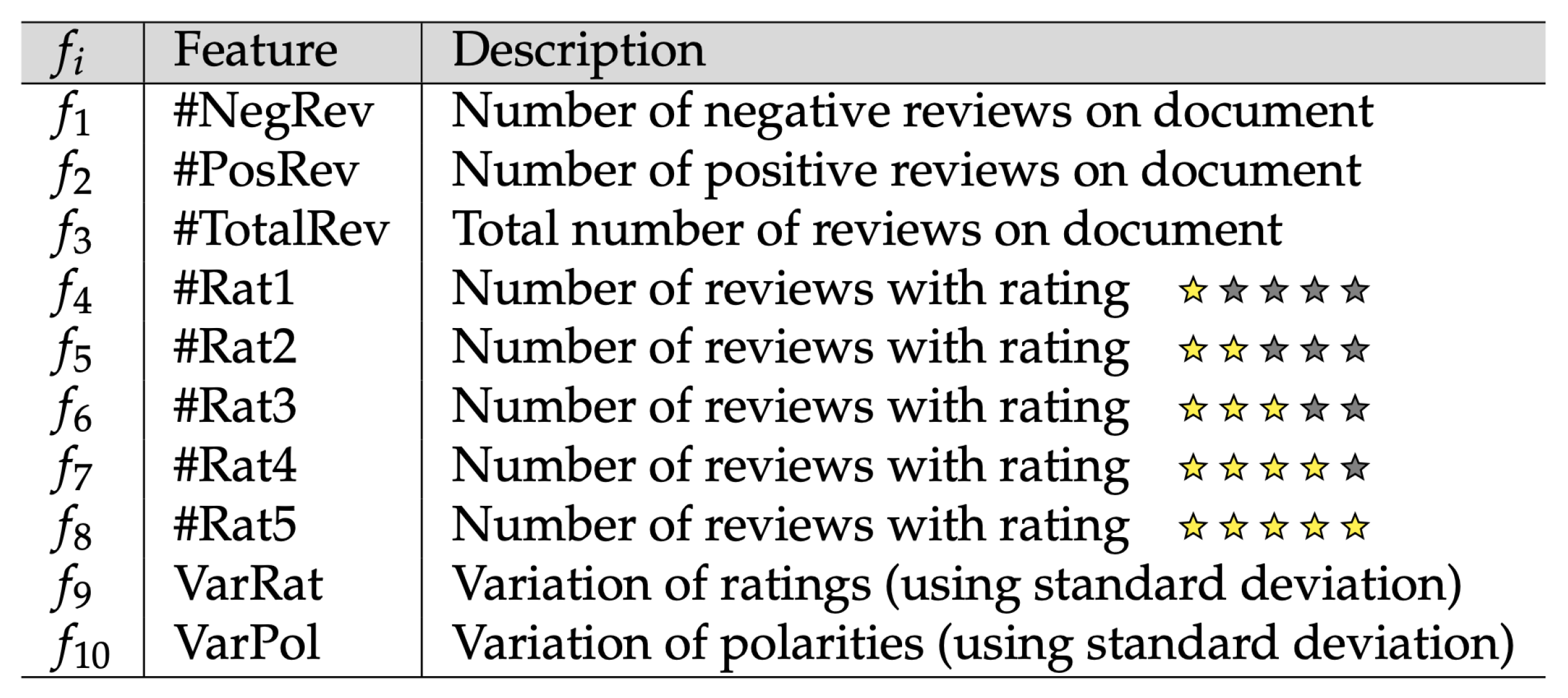
- For the CfsSubsetEval and the WrapperSubsetEval algorithms, the selected features were: : #NegRev, : #PosRev, : #TotalRev, : VarRat, and : VarPol;
- For CfsSubsetEval, the selected features were: , , , , and ;
- For the CfsSubsetEval and the WrapperSubsetEval algorithms, the selected features were: , , , , and ;
- For the other algorithms, all the features were selected: : #NegRev, : #PosRev, : #TotalRev, : #Rat1, : #Rat2, : #Rat3, : #Rat4, : #Rat5, : VarRat, and : VarPol.
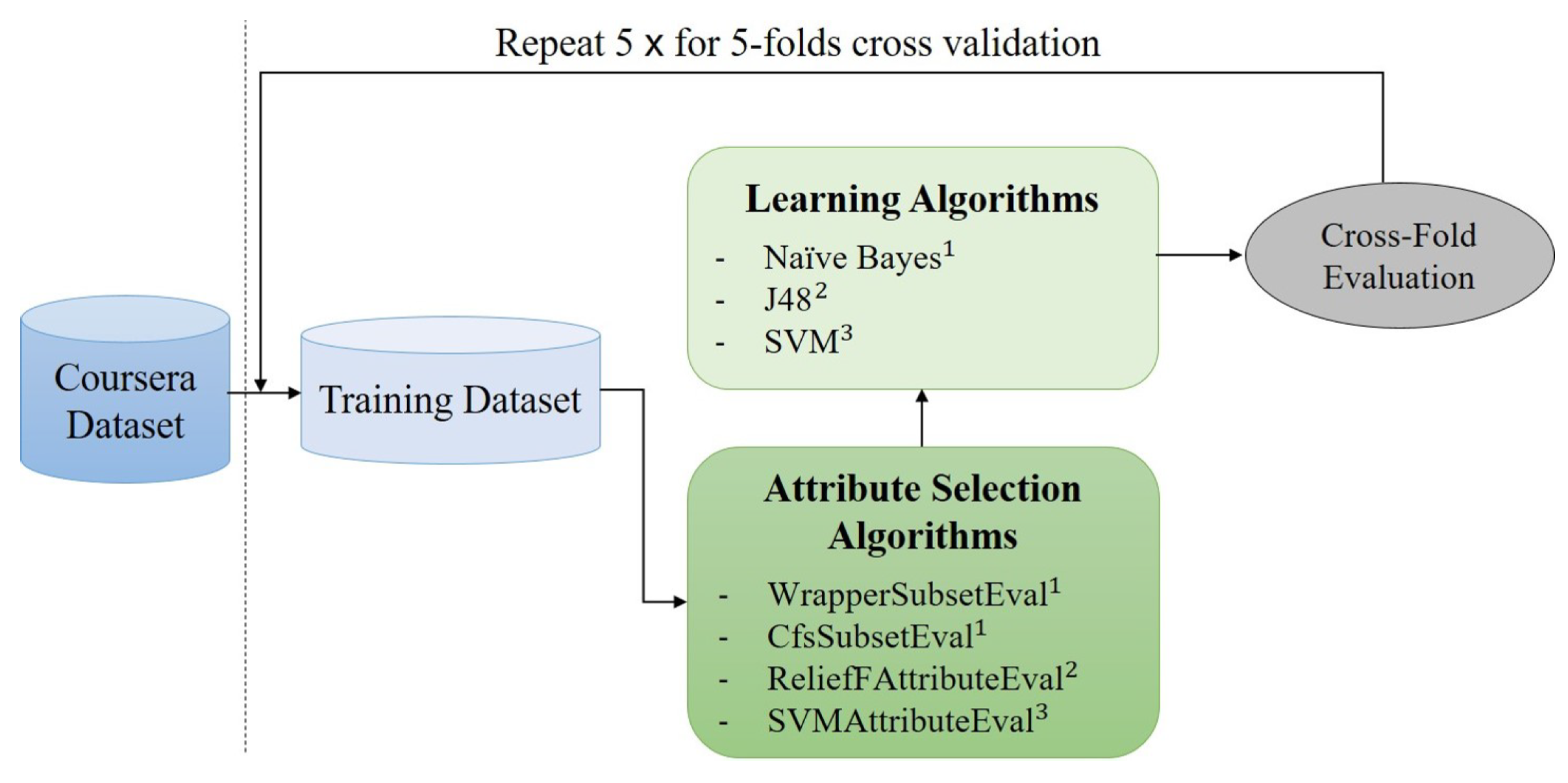
- Feature selection: CfsSubsetEval (CFS) and WrapperSubsetEval (WRP); machine learning algorithm: naive Bayes;
- Feature selection: ReliefFAttributeEval (RLF); machine learning algorithm: J48 (the C4.5 implementation);
- Feature selection: SVMAttributeEval (SVM); machine learning algorithm: multi-class SVM (SMO function on Weka).
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Badache, I.; Boughanem, M. Harnessing Social Signals to Enhance a Search. IEEE/WIC/ACM 2014, 1, 303–309. [Google Scholar]
- Badache, I.; Boughanem, M. Emotional social signals for search ranking. SIGIR 2017, 3, 1053–1056. [Google Scholar]
- Badache, I.; Boughanem, M. Fresh and Diverse Social Signals: Any impacts on search? In Proceedings of the CHIIR ’17: Proceedings of the 2017 Conference on Conference Human Information Interaction and Retrieval, Oslo, Norway, 7–11 March 2017; pp. 155–164. [Google Scholar]
- Kim, S.; Zhang, J.; Chen, Z.; Oh, A.H.; Liu, S. A Hierarchical Aspect-Sentiment Model for Online Reviews. In Proceedings of the Twenty-Seventh AAAI Conference on Artificial Intelligence, Bellevue, WA, USA, 14–18 July 2013. [Google Scholar]
- Poria, S.; Cambria, E.; Ku, L.; Gui, C.; Gelbukh, A.F. A Rule-Based Approach to Aspect Extraction from Product Reviews. In Proceedings of the Second Workshop on Natural Language Processing for Social Media, SocialNLP@COLING 2014, Dublin, Ireland, 24 August 2014; pp. 28–37. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Cardie, C. A Piece of My Mind: A Sentiment Analysis Approach for Online Dispute Detection. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, ACL 2014, Baltimore, MD, USA, 22–27 June 2014; Short Papers. Volume 2, pp. 693–699. [Google Scholar]
- Harabagiu, S.M.; Hickl, A.; Lacatusu, V.F. Negation, Contrast and Contradiction in Text Processing. In Proceedings of the Twenty-First National Conference on Artificial Intelligence and the Eighteenth Innovative Applications of Artificial Intelligence Conference, Boston, MA, USA, 16–20 July 2006; pp. 755–762. [Google Scholar]
- de Marneffe, M.; Rafferty, A.N.; Manning, C.D. Finding Contradictions in Text. In Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics, Columbus, OH, USA, 15–20 June 2008; pp. 1039–1047. [Google Scholar]
- Tsytsarau, M.; Palpanas, T.; Denecke, K. Scalable discovery of contradictions on the web. In Proceedings of the 19th International Conference on World Wide Web, WWW 2010, Raleigh, NC, USA, 26–30 April 2010; pp. 1195–1196. [Google Scholar] [CrossRef] [Green Version]
- Tsytsarau, M.; Palpanas, T.; Denecke, K. Scalable detection of sentiment-based contradictions. DiversiWeb WWW 2011, 11, 105–112. [Google Scholar]
- Yazi, F.S.; Vong, W.T.; Raman, V.; Then, P.H.H.; Lunia, M.J. Towards Automated Detection of Contradictory Research Claims in Medical Literature Using Deep Learning Approach. In Proceedings of the 2021 Fifth International Conference on Information Retrieval and Knowledge Management (CAMP), Pahang, Malaysia, 15–16 June 2021; pp. 116–121. [Google Scholar] [CrossRef]
- Hsu, C.; Li, C.; Sáez-Trumper, D.; Hsu, Y. WikiContradiction: Detecting Self-Contradiction Articles on Wikipedia. In Proceedings of the IEEE International Conference on Big Data (IEEE BigData 2021), Orlando, FL, USA, 15–18 December 2021. [Google Scholar]
- Sepúlveda-Torres, R. Automatic Contradiction Detection in Spanish. In Proceedings of the Doctoral Symposium on Natural Language Processing from the PLN.net Network, Baeza, Spain, 19–20 October 2021. [Google Scholar]
- Rahimi, Z.; Shamsfard, M. Contradiction Detection in Persian Text. arXiv 2021, arXiv:2107.01987. [Google Scholar]
- Pielka, M.; Sifa, R.; Hillebrand, L.P.; Biesner, D.; Ramamurthy, R.; Ladi, A.; Bauckhage, C. Tackling Contradiction Detection in German Using Machine Translation and End-to-End Recurrent Neural Networks. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 6696–6701. [Google Scholar] [CrossRef]
- Păvăloaia, V.D.; Teodor, E.M.; Fotache, D.; Danileţ, M. Opinion Mining on Social Media Data: Sentiment Analysis of User Preferences. Sustainability 2019, 11, 4459. [Google Scholar] [CrossRef] [Green Version]
- Mohammad, S.M.; Turney, P.D. Crowdsourcing a word–Emotion association lexicon. Comput. Intell. 2013, 29, 436–465. [Google Scholar] [CrossRef] [Green Version]
- Al-Ayyoub, M.; Rabab’ah, A.; Jararweh, Y.; Al-Kabi, M.N.; Gupta, B.B. Studying the controversy in online crowds’ interactions. Appl. Soft Comput. 2018, 66, 557–563. [Google Scholar] [CrossRef]
- Popescu, A.M.; Pennacchiotti, M. Detecting controversial events from twitter. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, Toronto, ON, Canada, 26–30 October 2010; pp. 1873–1876. [Google Scholar]
- Balasubramanyan, R.; Cohen, W.W.; Pierce, D.; Redlawsk, D.P. Modeling polarizing topics: When do different political communities respond differently to the same news? In Proceedings of the Sixth International AAAI Conference on Weblogs and Social Media, Dublin, Ireland, 4–8 June 2012.
- Dori-Hacohen, S.; Allan, J. Detecting controversy on the web. In Proceedings of the 22nd ACM international conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 1845–1848. [Google Scholar]
- Dori-Hacohen, S.; Allan, J. Automated Controversy Detection on the Web. In Advances in Information Retrieval; Hanbury, A., Kazai, G., Rauber, A., Fuhr, N., Eds.; Springer International Publishing: Cham, Germany, 2015; pp. 423–434. [Google Scholar]
- Garimella, K.; Morales, G.D.F.; Gionis, A.; Mathioudakis, M. Quantifying Controversy in Social Media. In Proceedings of the Ninth ACM International Conference on Web Search and Data Mining, San Francisco, CA, USA, 22–25 February 2016; pp. 33–42. [Google Scholar] [CrossRef] [Green Version]
- Guerra, P.C.; Meira, W., Jr.; Cardie, C.; Kleinberg, R. A measure of polarization on social media networks based on community boundaries. In Proceedings of the Seventh International AAAI Conference on Weblogs and Social Media, Cambridge, MA, USA, 8–11 July 2013. [Google Scholar]
- Jang, M.; Allan, J. Improving Automated Controversy Detection on the Web. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2016, Pisa, Italy, 17–21 July 2016; pp. 865–868. [Google Scholar] [CrossRef] [Green Version]
- Lin, W.H.; Hauptmann, A. Are these documents written from different perspectives? A test of different perspectives based on statistical distribution divergence. In Proceedings of the 21st International Conference on Computational Linguistics and the 44th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Sydney, Australia, 6–8 July 2006; pp. 1057–1064. [Google Scholar]
- Sriteja, A.; Pandey, P.; Pudi, V. Controversy Detection Using Reactions on Social Media. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 884–889. [Google Scholar]
- Morales, A.; Borondo, J.; Losada, J.C.; Benito, R.M. Measuring political polarization: Twitter shows the two sides of Venezuela. Chaos Interdiscip. J. Nonlinear Sci. 2015, 25, 033114. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Garimella, K.; Morales, G.D.F.; Gionis, A.; Mathioudakis, M. Quantifying Controversy on Social Media. Trans. Soc. Comput. 2018, 1. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, A.; Xing, E.P. Staying informed: Supervised and semi-supervised multi-view topical analysis of ideological perspective. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Stroudsburg, PA, USA, 9–11 October 2010; pp. 1140–1150. [Google Scholar]
- Cohen, R.; Ruths, D. Classifying political orientation on Twitter: It’s not easy! In Proceedings of the Seventh International AAAI Conference on Weblogs and Social Media, Cambridge, MA, USA, 8–11 July 2013.
- Conover, M.D.; Gonçalves, B.; Ratkiewicz, J.; Flammini, A.; Menczer, F. Predicting the political alignment of twitter users. In Proceedings of the 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust and 2011 IEEE Third International Conference on Social Computing, Boston, MA, USA, 9–11 October 2011; pp. 192–199. [Google Scholar]
- Paul, M.; Girju, R. A Two-Dimensional Topic-Aspect Model for Discovering Multi-Faceted Topics. In Proceedings of the AAAI’10: Twenty-Fourth AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010; AAAI Press: Atlanta, GA, USA, 2010; pp. 545–550. [Google Scholar]
- Qiu, M.; Jiang, J. A Latent Variable Model for Viewpoint Discovery from Threaded Forum Posts. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, Georgia, 9–14 June 2013; Association for Computational Linguistics: Atlanta, GA, USA, 2013; pp. 1031–1040. [Google Scholar]
- Trabelsi, A.; Zaiane, O.R. Mining contentious documents using an unsupervised topic model based approach. In Proceedings of the 2014 IEEE International Conference on Data Mining, Shenzhen, China, 14–17 December 2014; pp. 550–559. [Google Scholar]
- Thonet, T.; Cabanac, G.; Boughanem, M.; Pinel-Sauvagnat, K. VODUM: A topic model unifying viewpoint, topic and opinion discovery. In European Conference on Information Retrieval; Spring: Berlin/Heidelberg, Germany, 2016; pp. 533–545. [Google Scholar]
- Galley, M.; McKeown, K.; Hirschberg, J.; Shriberg, E. Identifying agreement and disagreement in conversational speech: Use of bayesian networks to model pragmatic dependencies. In Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics, Stroudsburg, PA, USA, 21–26 July 2004; p. 669. [Google Scholar]
- Menini, S.; Tonelli, S. Agreement and disagreement: Comparison of points of view in the political domain. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics, Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2461–2470. [Google Scholar]
- Mukherjee, A.; Liu, B. Mining contentions from discussions and debates. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 841–849. [Google Scholar]
- Mohammad, S.; Kiritchenko, S.; Zhu, X. NRC-Canada: Building the State-of-the-Art in Sentiment Analysis of Tweets. In Proceedings of the 7th International Workshop on Semantic Evaluation, SemEval@NAACL-HLT 2013, Atlanta, GA, USA, 14–15 June 2013; pp. 321–327. [Google Scholar]
- Mohammad, S.; Kiritchenko, S.; Sobhani, P.; Zhu, X.; Cherry, C. SemEval-2016 Task 6: Detecting Stance in Tweets. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 10–11 June 2016; Association for Computational Linguistics: San Diego, CA, USA; pp. 31–41. [Google Scholar] [CrossRef]
- Augenstein, I.; Rocktäschel, T.; Vlachos, A.; Bontcheva, K. Stance detection with bidirectional conditional encoding. arXiv 2016, arXiv:1606.05464. [Google Scholar]
- Gottipati, S.; Qiu, M.; Sim, Y.; Jiang, J.; Smith, N. Learning topics and positions from debatepedia. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1858–1868. [Google Scholar]
- Johnson, K.; Goldwasser, D. “All I know about politics is what I read in Twitter”: Weakly Supervised Models for Extracting Politicians’ Stances From Twitter. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics, Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2966–2977. [Google Scholar]
- Qiu, M.; Sim, Y.; Smith, N.A.; Jiang, J. Modeling user arguments, interactions, and attributes for stance prediction in online debate forums. In Proceedings of the 2015 SIAM International Conference on Data Mining, SIAM, Vancouver, BC, Canada, 30 April–2 May 2015; pp. 855–863. [Google Scholar]
- Somasundaran, S.; Wiebe, J. Recognizing stances in ideological on-line debates. In Proceedings of the NAACL HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, Los Angeles, CA, USA, 10–12 June 2010; pp. 116–124. [Google Scholar]
- Küçük, D.; Can, F. Stance detection: A survey. ACM Comput. Surv. (CSUR) 2020, 53, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177. [Google Scholar] [CrossRef] [Green Version]
- Hamdan, H.; Bellot, P.; Béchet, F. Lsislif: CRF and Logistic Regression for Opinion Target Extraction and Sentiment Polarity Analysis. In Proceedings of the 9th International Workshop on Semantic Evaluation, SemEval@NAACL-HLT 2015, Denver, CO, USA, 4–5 June 2015; pp. 753–758. [Google Scholar]
- Titov, I.; McDonald, R.T. Modeling online reviews with multi-grain topic models. In Proceedings of the 17th International Conference on World Wide Web, WWW 2008, Beijing, China, 21–25 April 2008; pp. 111–120. [Google Scholar] [CrossRef]
- Tulkens, S.; van Cranenburgh, A. Embarrassingly Simple Unsupervised Aspect Extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3182–3187. [Google Scholar] [CrossRef]
- Turney, P.D. Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 417–424. [Google Scholar]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment Classification using Machine Learning Techniques. In Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing, EMNLP 2002, Philadelphia, PA, USA, 6–7 July 2002. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, EMNLP 2013, Seattle, WA, USA, 18–21 October 2013; A Meeting of SIGDAT, a Special Interest Group of the ACL. Grand Hyatt Seattle: Seattle, WA, USA, 2013; pp. 1631–1642. [Google Scholar]
- Radford, A.; Józefowicz, R.; Sutskever, I. Learning to Generate Reviews and Discovering Sentiment. arXiv 2017, arXiv:1704.01444. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the fifth Berkeley symposium on mathematical statistics and probability, Berkeley, CA, USA, 21 June–18 July 1965. [Google Scholar]
- McAuley, J.J.; Pandey, R.; Leskovec, J. Inferring Networks of Substitutable and Complementary Products. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Looks, M.; Herreshoff, M.; Hutchins, D.; Norvig, P. Deep Learning with Dynamic Computation Graphs. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Hall, M.A.; Holmes, G. Benchmarking Attribute Selection Techniques for Discrete Class Data Mining. IEEE Trans. Knowl. Data Eng. 2003, 15, 1437–1447. [Google Scholar] [CrossRef] [Green Version]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Pearson, E.S.; Stephens, M.A. The Ratio of Range to Standard Deviation in the Same Normal Sample. Biometrika 1964, 51, 484–487. [Google Scholar] [CrossRef]
- Vosecky, J.; Leung, K.W.; Ng, W. Searching for Quality Microblog Posts: Filtering and Ranking Based on Content Analysis and Implicit Links. In Proceedings of the Database Systems for Advanced Applications—17th International Conference, DASFAA 2012, Busan, Korea, 15–19 April 2012; pp. 397–413. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann: Burlington, MA, USA, 1993. [Google Scholar]
- Yuan, Q.; Cong, G.; Magnenat-Thalmann, N. Enhancing naive bayes with various smoothing methods for short text classification. In Proceedings of the 21st World Wide Web Conference, WWW 2012, Lyon, France, 16–20 April 2012; pp. 645–646. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Text on the Left | Aspect | Text on the Right | Pol. | Rat. |
|---|---|---|---|---|---|
| Course | I thought the | Lesson | were really boring, never enjoyable | −0.9 | 2 |
| I enjoyed very much the | Lesson | and I had a very good time | +0.9 | 5 |
| Step Number | Step Detail |
|---|---|
| 1 | course: 44,219, material: 3286, assignment: 3118, content: 2947,......., lecturer: 2705, lesson: 1251, presentation: 591, slide: 512, teaching: 119, image: 11, Michael: 2,……term |
| 2 | Michael/NN is/VBZ a/DT wonderful/JJ he/DT lecturer/NN delivering/VBG the/DT lessons/NNS in/IN an/DT easy/JJ to/TO understand/VB manner/NN ./.The/DT whole/JJ presentation/NN was/VBD easy/JJ to/TO follow/VB ./. I/PRP do/VBP n’t/RB recall/VB any/DT ambiguity/NN in/IN his/PRP$ teachings/NNS and/CChis/PRP$ slide/NN was/VBD clear/JJ ./. I/PRP also/RB enjoy/VBP some/DT of/IN the/DT assignments/NNS because/IN I/PRP surprise/VB myself/PRP by/IN producing/VBG some/DT great/JJ images/NNS ./. My/PRP$ main/JJ problem/NN is/VBZ the/DT instructions/NNS of/IN the/DT assignments/NNS that/WDT causes/VBZ a/DT lot/NN of/IN students/NNS to/TO be/VB confused/JJ (/-LRB- there/EX are/VBP many/JJ complaints/NNS expressed/VBN in/IN the/DT Discussion/NN forum/NN)/-RRB- ./. |
| 3 | Michael, lecturer, job, lesson, manner, presentation, ambiguity, teachings, slide, assignments, images, problem, instructions, students, complaints, discussion, forum |
| 4 | Michael, lecturer, lesson, presentation, teachings, slide, assignments, images |
| 5 | lecturer, lesson, presentation, slide, assignments |
| Measure | Config (1): Averaged Centroid | Config (2): Weighted Centroid |
|---|---|---|
| (Baseline) Sentiment analysis: accuracy (naive Bayes) | ||
| Pearson | 0.45 | 0.51 |
| Precision | 0.61 | 0.70 |
| (a) Sentiment analysis: accuracy (SentiNeuron) | ||
| Pearson | 0.61 | 0.80 |
| Precision | 0.75 | 0.88 |
| (b) Sentiment analysis: accuracy (User judgments) | ||
| Pearson | 0.68 | 0.87 |
| Precision | 0.82 | 0.91 |
| Measure | Config (1): Averaged Centroid | Config (2): Weighted Centroid |
|---|---|---|
| (Baseline) Sentiment analysis: accuracy (naive Bayes) | ||
| Pearson | 0.61 | 0.71 |
| Precision | 0.69 | 0.77 |
| (a) Sentiment analysis: accuracy (SentiNeuron) | ||
| Pearson | 0.69 | 0.82 |
| Precision | 0.80 | 0.87 |
| (b) Sentiment analysis: accuracy (User judgments) | ||
| Pearson | 0.73 | 0.91 |
| Precision | 0.83 | 0.92 |
| Algorithm | Features |
|---|---|
| CfsSubsetEval | , , , , |
| WrapperSubsetEval | , , , , , , |
| Other algorithms | , , , , , , , , , |
| Models | Intensity Class | Feature Selection Method | All the Features |
|---|---|---|---|
| Very Low | 0.81 (CFS) | 0.71 | |
| Low | 0.38 (CFS) | 0.34 | |
| Strong | 0.75 (CFS) | 0.66 | |
| Very Strong | 0.78 (CFS) | 0.69 | |
| Naive Bayes | Average | 0.68 (CFS) | 0.60 |
| Very Low | 0.86 (WRP) | 0.72 | |
| Low | 0.46 (WRP) | 0.38 | |
| Strong | 0.76 (WRP) | 0.63 | |
| Very Strong | 0.80 (WRP) | 0.67 | |
| Average | 0.72 (WRP) | 0.60 | |
| Very Low | 0.88 (SVM) | 0.88 | |
| Low | 0.72 (SVM) | 0.72 | |
| SVM | Strong | 0.78 (SVM) | 0.78 |
| Very Strong | 0.90 (SVM) | 0.90 | |
| Average | 0.82 (SVM) | 0.82 | |
| Very Low | 0.97 (RLF) | 0.97 | |
| Low | 0.92 (RLF) | 0.92 | |
| J48 | Strong | 0.97 (RLF) | 0.97 |
| Very Strong | 0.98 (RLF) | 0.98 | |
| Average | 0.96 (RLF) | 0.96 |
| Best Solution | The Different Configurations | Improvement Rate |
|---|---|---|
| Decision trees J48 Average Precision: 0.96 | WITHOUT Considering Review Session | |
| Sentiment Analysis: 79% accuracy (naive Bayes) | ||
| Averaged Centroid | 57% | |
| Weighted Centroid | 37% | |
| Sentiment Analysis: 93% accuracy (SentiNeuron) | ||
| Averaged Centroid | 28% | |
| Weighted Centroid | 9% | |
| Sentiment Analysis: 100% accuracy (user judgments) | ||
| Averaged Centroid | 17% | |
| Weighted Centroid | 5% | |
| WITH Considering Review Session | ||
| Sentiment Analysis: 79% accuracy (naive Bayes) | ||
| Averaged Centroid | 40% | |
| Weighted Centroid | 25% | |
| Sentiment Analysis: 93% accuracy (SentiNeuron) | ||
| Averaged Centroid | 20% | |
| Weighted Centroid | 10% | |
| Sentiment Analysis: 100% accuracy (user judgments) | ||
| Averaged Centroid | 15% | |
| Weighted Centroid | 4% | |
| Machine Learning Techniques | ||
| Naive Bayes (CFS) | ||
| Very Low Low Strong Very Strong Average | 18.5% 153% 28% 23% 41% | |
| Naive Bayes (WRP) | ||
| Very Low Low Strong Very Strong Average | 12% 109% 26% 20% 33% | |
| SVM | ||
| Very Low Low Strong Very Strong Average | 9% 33% 23% 7% 17% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Badache, I.; Chifu, A.-G.; Fournier, S. Unsupervised and Supervised Methods to Estimate Temporal-Aware Contradictions in Online Course Reviews. Mathematics 2022, 10, 809. https://doi.org/10.3390/math10050809
Badache I, Chifu A-G, Fournier S. Unsupervised and Supervised Methods to Estimate Temporal-Aware Contradictions in Online Course Reviews. Mathematics. 2022; 10(5):809. https://doi.org/10.3390/math10050809
Chicago/Turabian StyleBadache, Ismail, Adrian-Gabriel Chifu, and Sébastien Fournier. 2022. "Unsupervised and Supervised Methods to Estimate Temporal-Aware Contradictions in Online Course Reviews" Mathematics 10, no. 5: 809. https://doi.org/10.3390/math10050809
APA StyleBadache, I., Chifu, A.-G., & Fournier, S. (2022). Unsupervised and Supervised Methods to Estimate Temporal-Aware Contradictions in Online Course Reviews. Mathematics, 10(5), 809. https://doi.org/10.3390/math10050809