Since our MILP model is computationally difficult, we consider two approximate algorithms and compare them with each other. First, the algorithm constructs a schedule for each department separately, and after that, it changes some surgeries to more optimal solutions. In the second algorithm, we construct a decomposition graph to divide departments into groups and solve the MILP problem for each group.
4.1. Vertex Decomposition with Balanced Distribution
Vertex decomposition with balanced distribution further in the text will be called Algorithm 1. The main idea of this algorithm is to assign patients to ORs in their departments at first. This is the first stage. After this distribution, we have a schedule without guest surgeries and some patients remained on the waiting list. Next, at the second stage, we check if the patients from the waiting list can be assigned to any OR on any day of the week. Next, at the third stage, our algorithm checks if it is possible to assign patients from the waiting list to the OR if the surgery with the minimum duration is removed from it. Removed surgeries are added back to the waiting list and all steps of the algorithm are repeated for these surgeries. The third stage of the algorithm may be repeated several times. We look at the maximum value of the following values for all operation rooms and for all days: the remaining hours in the operating room if we remove the surgery with the minimum duration. Furthermore, this value is compared to the duration of the minimal surgeries on the waiting list; if it is more than the duration of two or one surgeries, we repeat the third stage twice or once, respectively. In our case, we always get one repetition of the third stage. As a reminder, our main goal is to minimize gaps in all ORs during the week. At first, we need to set a problem for the first step, whereby we construct a schedule without guest surgeries. It is a MILP model with the following parameters, objective functions, and constraints:
—processing time of surgery j, ;
D—set of days when you can perform the surgery. In our case it is (Monday, Tuesday, Wednesday, Thursday);
A—operating room hours per day (11 h).
The variables of the model are:
The solution of this MILP model presents an optimal weekly schedule for one department if there are no guest surgeries. We solve this problem 10 times for each department (for each OR) and put all unassigned patients in the general waiting list. For a better understanding, we present the pseudocode of our Algorithm 1.
In our first experiment, we constructed a schedule for two weeks. Now we need to construct a schedule for two weeks for this algorithm. To achieve this, it is necessary to use the algorithm twice, but the second time the waiting list will not be empty, it will remain from the previous week. Furthermore, we can construct a schedule for
N weeks, we just need to perform this algorithm
N times and add unscheduled surgeries from previous weeks to the waiting list.
| Algorithm 1: pseudocode |
![Mathematics 10 00784 i001]() |
Remark 1. At the third stage, we have restriction , which means that we consider only ORs with more than T hours left for surgeries. Here, we took h, but in future works, we will find the cost of an operational hour and the cost of one guest surgery, and then calculate T based on these considerations, because T affects gap hours and the number of guest surgeries.
4.3. Complexity of the Algorithms
In general, the upper bound of the efficiency of our MILP problem using the exact approach is brute force:
. In our case,
n is equal to the number of binary variables
,
, where
N—the number of the surgeries,
M—the number of the operation rooms, and
D—the number of workdays in a week. Let the efficiency estimate of the algorithm for solving a discrete optimization problem with
n binary variables be:
Furthermore, let there be a tree that divides the problem into
r blocks. It is argued that when decomposing the problem into blocks, the efficiency estimate of the entire problem will be equal to:
where
.
Property 1. The estimate (8) is better than (7).
Proof. Using the well-known inequality
,
we can write the following chain of inequalities:
As a result, we observe that the decomposition increases the efficiency of the algorithm. □
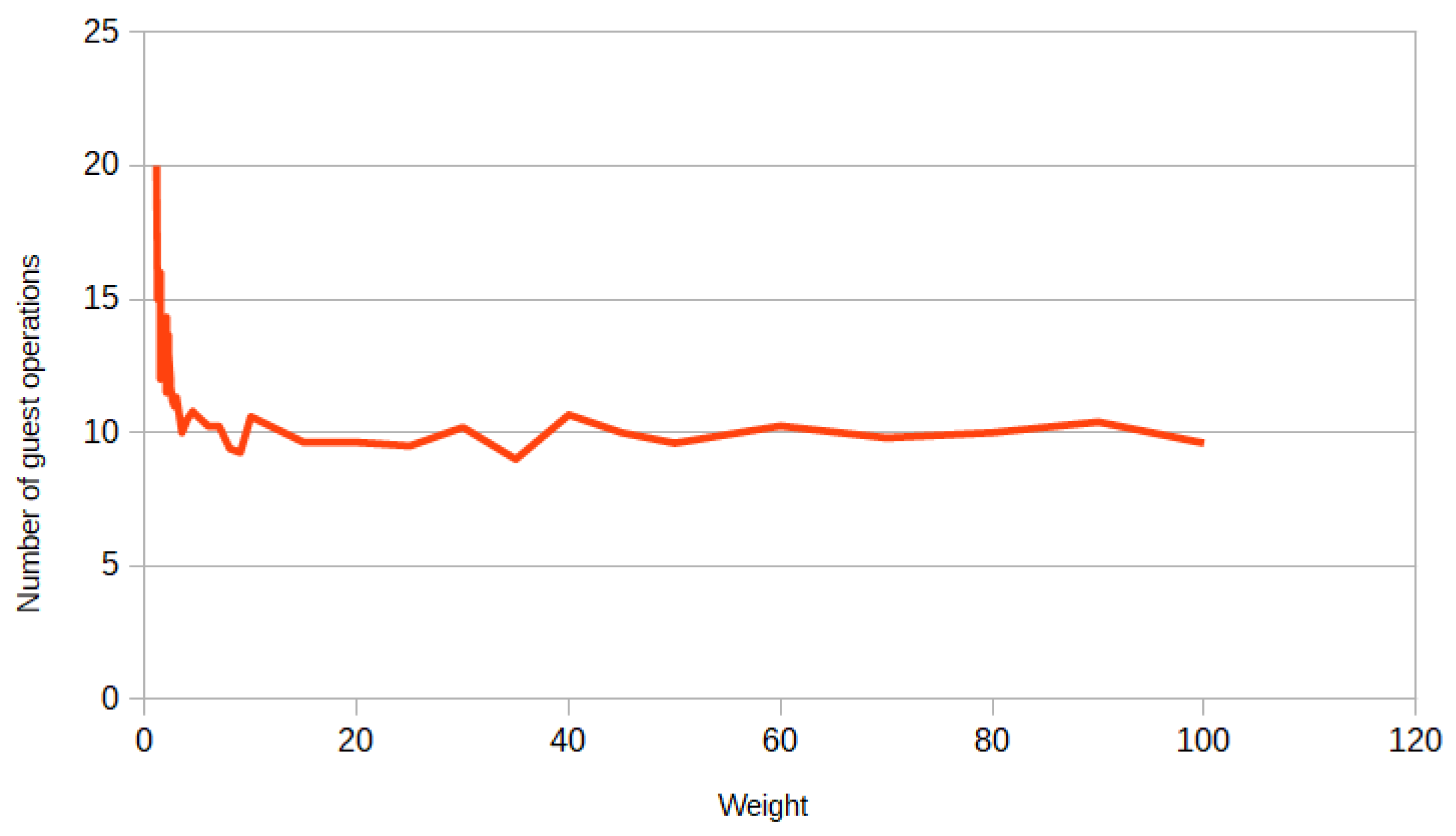
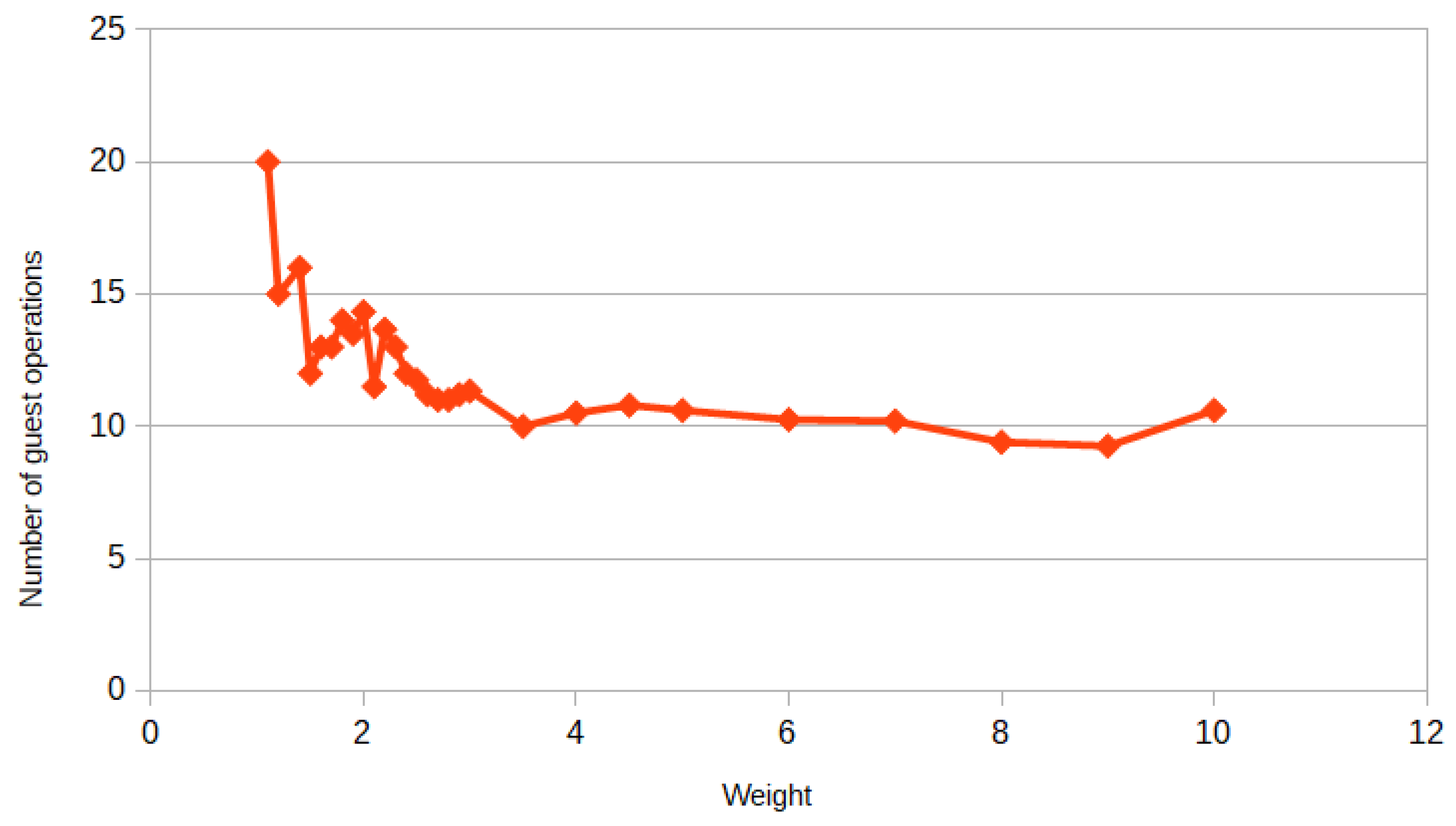
In Algorithm 2, we decompose our problem into four subproblems: . Furthermore, the MILP problem becomes much easier, because the efficiency estimate now is equal to , and with Property 1, it is better than . In Algorithm 1, we decompose the problem into 10 subproblems , but in each subproblem the dimension of the variable is reduced by one: . , , …, , where is the number of surgeries in i-th department and . So let us find the complexity of Algorithm 1 exclusive of the complexity of Gurobi. At the first stage, we solve the MILP problem by Gurobi for each department. At the second stage, we check for each surgery on the waiting list to see if it can be placed in an operating room on any given day. In the worst case, the number of surgeries on the waiting list can be N, then the complexity of the second stage is . At the third stage, we check for each surgery on the waiting list to see if it can be changed with the scheduled surgery with a minimum duration in an operating room on any given day. Furthermore, the complexity of this stage is the same as the second stage. The complexity of Algorithm 1, exclusive of the complexity of Gurobi, is and it is less than . Therefore, the efficiency estimate of Algorithm 1 is equal and with Property 1, it is better than .
4.4. Algorithms Accuracy Estimation
Now, let consider evaluating the accuracy of our algorithms. Let us discuss this question using the following examples:
Example 1. To illustrate the accuracy of Algorithm 1, consider a simple example. Let , , , and , where is the processing time in hours of surgeries that are related to department i. There are a total of four departments and four operating rooms. Let each operating room work only 9 h and only one day. The total duration of all surgeries is 36 h. The optimal solution of this problem using model (1)–(3) constructs the schedule without gaps, all operations are scheduled, all 36 of the 36 h of operating time is used, and the number of guest surgeries is equal to three. To use Algorithm 1 for this example, we construct a schedule for each department using model (4)–(6) and then rearrange some surgeries if they will increase the objective function, according to Algorithm 1. We get the following results: 33 of the 36 h of operating time is used and only one guest surgery. Thus, the relative error of the objective function of Algorithm 1 for this example is 8.3%.
Example 2. To illustrate the accuracy of Algorithm 1, consider the same example as for the Algorithm 1. To use Algorithm 2 for this example, we break down the departments into groups and solve model (1)–(3) for each group. In this example, the total processing time of the surgeries for each department are 9 h, 11 h, 10 h, and 6 h, respectively. Thus, in the worst case we can divide the departments into the following groups: and . Let me remind you that this means that surgeries can only be transferred from one department to another within its group. After scheduling each group using model (1)–(3), we get the following results: only 32 of the 36 h of operating time were used and the number of guest surgeries is equal to two. Since our main criterion is the total duration of surgeries, Algorithm 2 gives a relative error equal to 11.1% of the optimal solution in this example.
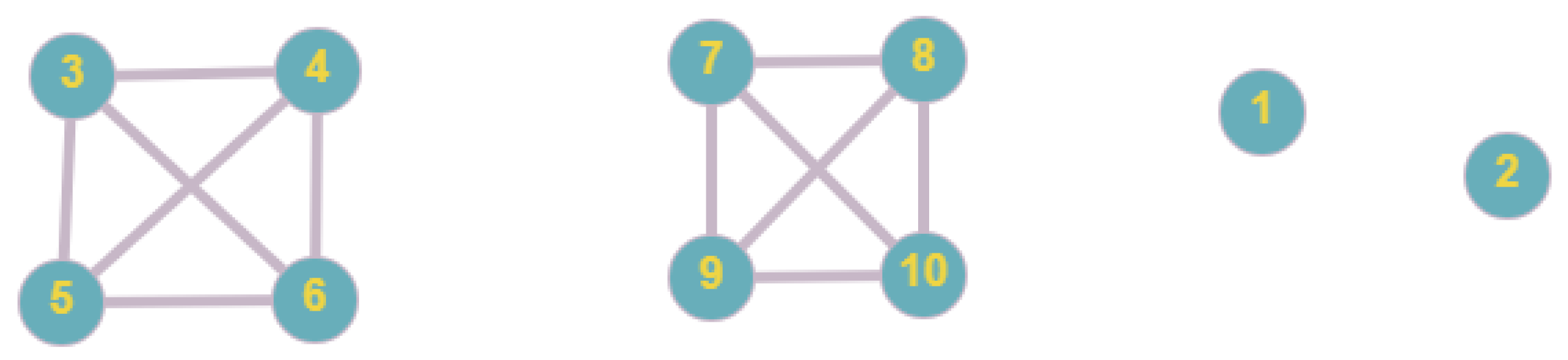
In order to measure the accuracy of Algorithm 2, it is necessary to take the model (1)–(3), and according to the decomposition in
Figure 5, construct a special example using additional parameters. These parameters must be related to the number of generated operations N described in the beginning of
Section 3. It is necessary to describe these parameters in such a way that this special case is the worst case for the Algorithm 2. The estimate of the accuracy in the worst case will be the accuracy of the algorithm. For Algorithm 1, everything is done similarly, but instead of a decomposition graph, each operation is considered separately and then there is a balancing process according to Steps 2 and 3 of Algorithm 1.
Worst case of Algorithm 1. The problem of calculating the absolute error for the NP-hard problem is quite time consuming. The study of this problem is planned to be covered in future papers. However, let us show a rough estimation of the algorithm accuracy without taking into account some restrictions existing in practice. Let us neglect the restriction on the total number of operations and the number of operations that are assigned to each operation to construct the worst case of the problem. The exact algorithm allows for an even distribution of operations between operations, so we will construct the worst-case example so that the distribution of operations is unequal. Furthermore, the exact algorithm allows you to go through all possible combinations, to construct the worst case so that the approximate algorithm works least accurately due to the order of operations of the different durations. To increase the error of the approximate algorithm we will use only the minimum and maximum operations. In our case, the minimum duration of the operation is h, and the maximum is h. We took these durations based on historical data. Furthermore, we use the restriction on the size of one day in the operating room– h of work. We construct the jobs in such a way that by using the largest duration of the surgery in each working day we get the gaps of a maximum size. Let the next set of surgeries be assigned to the first department for this week: eight surgeries with a duration of h, 180 surgeries with a duration of h hours, and 36 surgeries with a duration of H hours. Furthermore, the rest of the departments are empty. Following the exact approach, the schedule will be constructed as follows: all surgeries of h will be assigned to the first operating room (two surgeries for each day). Furthermore, the rest of the operating rooms will have one surgery of a duration of H and five surgeries of a duration of h on each day. Thus, there will be no gaps in the schedule at all. Applying the first algorithm to this example yields the following results: Since at the first step of the algorithm we construct the schedule for all departments separately, all surgeries of h will be assigned to the first operating room, but then all other surgeries will be on the waiting list. According to the second and third steps of Algorithm 1 on page 9, the operations from the waiting list will be distributed as follows: operating rooms number 2, 3, 4, and 5 will be “packed” with surgeries of a duration of h, this will require surgeries, where days. The remaining four surgeries of a duration of h will be assigned to OR six on the first day. Finally, one surgery of a duration of H will be assigned to operating room numbers 6, 7, 8, 9, and 10 for each day. So, it turns out that the number of gap hours is equal to h, where it is the number of not-fully-filled operating rooms. As a result, we obtain that a rough estimate of the absolute error of Algorithm 1 is 96 h.
Worst case of Algorithm 2. To construct the worst case for Algorithm 2, we introduce an additional restriction: 10 to 20 patients must be admitted to each department. Without this restriction, Algorithm 2 does not make much sense for extreme cases. To construct the worst case, we distribute the surgeries as follows: In each department of the first subgraph of the decomposition graph in
Figure 5, we place 10 surgeries of duration
h. Furthermore, in each department of the second subgraph we place 10 surgeries of duration
h. We also place 10 surgeries of duration
hours and 10 surgeries of duration
H hours, respectively, in department one and two. Thus, the exact approach would give an optimal solution with the number of gap hours equal to zero: each operating room would have one surgery of duration
and one surgery of duration
H on each day. Furthermore, following Algorithm 2, we obtain that half of the operating rooms for each day have one surgery of duration
H, and the other half of the operating rooms for each day have two surgeries of duration
. We get the following estimate of the absolute error of gap hours for Algorithm 2:
where M = 10—the number of operating rooms.
The result is that a rough estimate of the absolute error of Algorithm 2 is 120 h. However, although Algorithm 2 has a worse accuracy estimate, Algorithm 1 performs worse on average, as will be shown in the results below.
Our problem is a generalization of the 0–1 multiple knapsack problem. This problem is NP-hard, and it is shown in [
15], where our problem is called LEGAP—a special case of the generalized assignment problem. Since it is NP-hard, it is not possible to obtain theoretical estimates for these algorithms. To estimate the practical accuracy of the algorithms, the extreme cases of the examples were constructed. In the first case, the surgeries with the minimum variation in the duration of surgeries were taken, and in the second case, with the maximum variation. As shown in [
16,
17], for examples with a large scatter of surgery duration, the core-type algorithms work badly, and for examples with a small scatter of surgery duration, the graphical-type algorithms work badly. For this experiment, the data were divided into two types. In the first case, the duration of the surgeries varies from 1.5 h to 9 h, with a uniform distribution. That is, the duration of surgeries has a very large scatter. In the second case, the duration of surgeries varies from 4.5 to 5.5 h, also with a uniform distribution. Using this experiment, we analyze the accuracy estimate of our algorithms depending on the width of the range of the duration of the surgeries. The other parameters of data remained the same as for the previous experiments. The assignment of surgeries to each of the 10 departments for each case is the same. However, in this experiment, half of the working week was taken, i.e., 2 days. Accordingly, half as many surgeries were taken. This was done so that the MILP solver could solve all the examples in a reasonable time. For each type, 100 examples were generated and tested for each of our approaches.
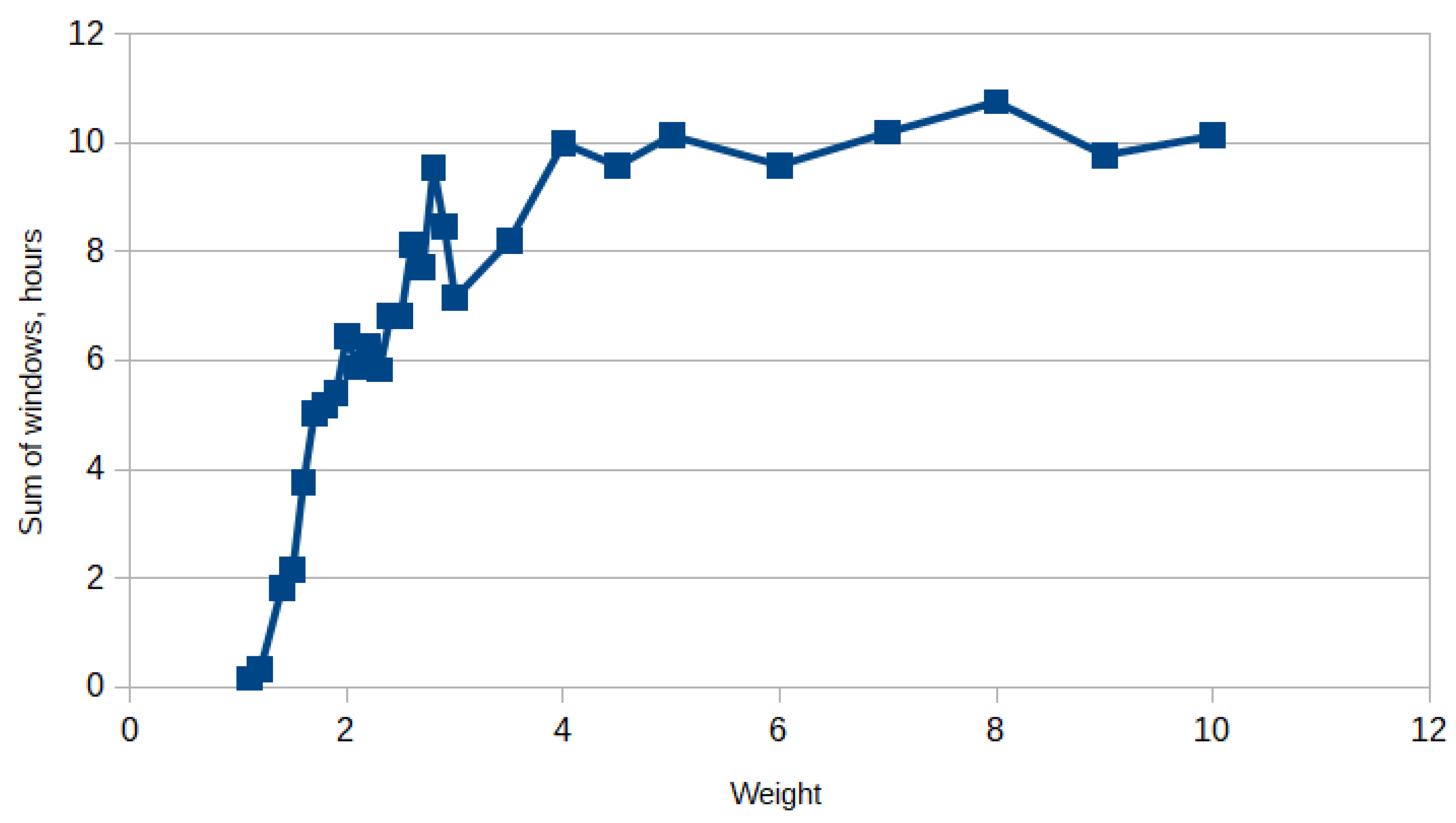
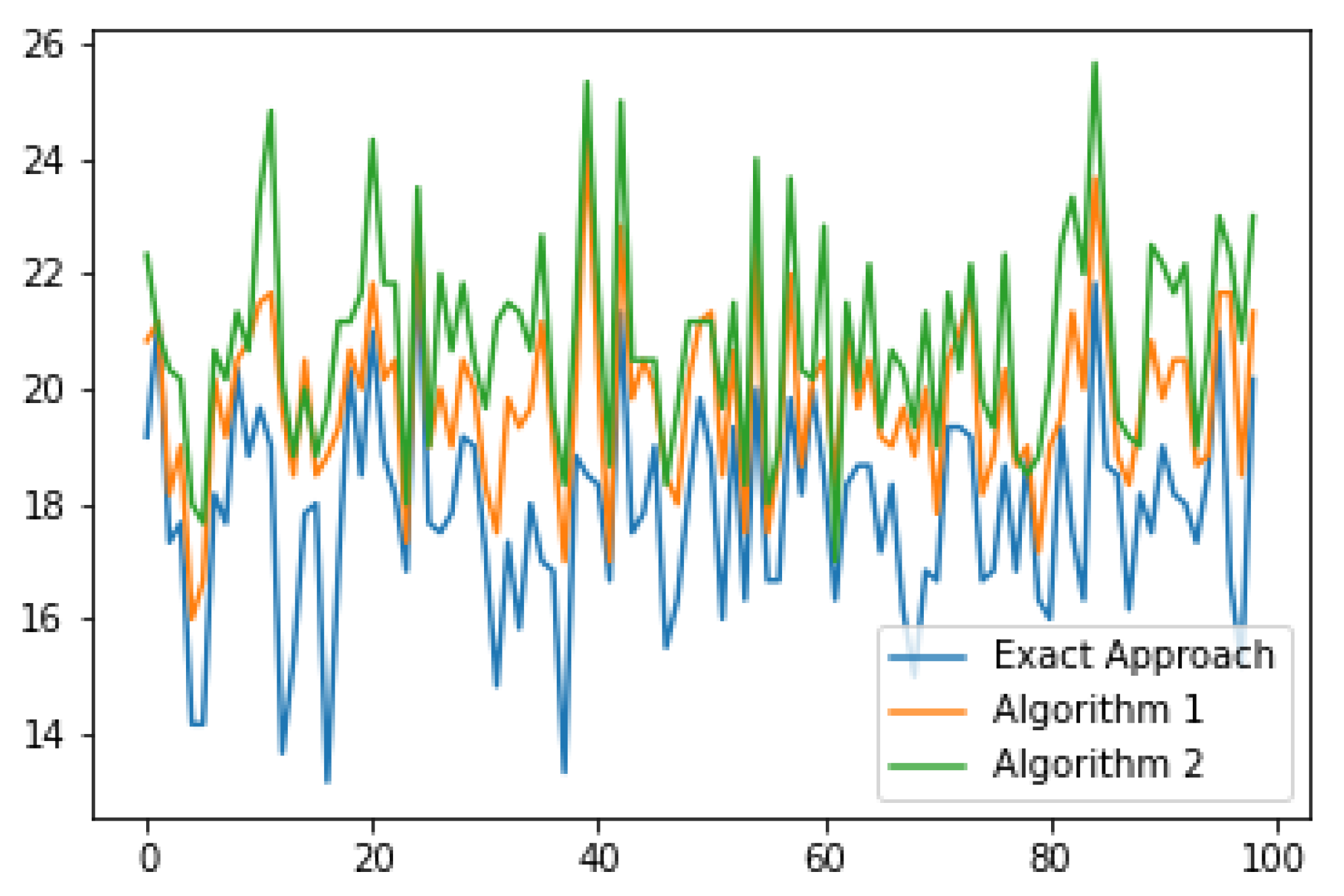
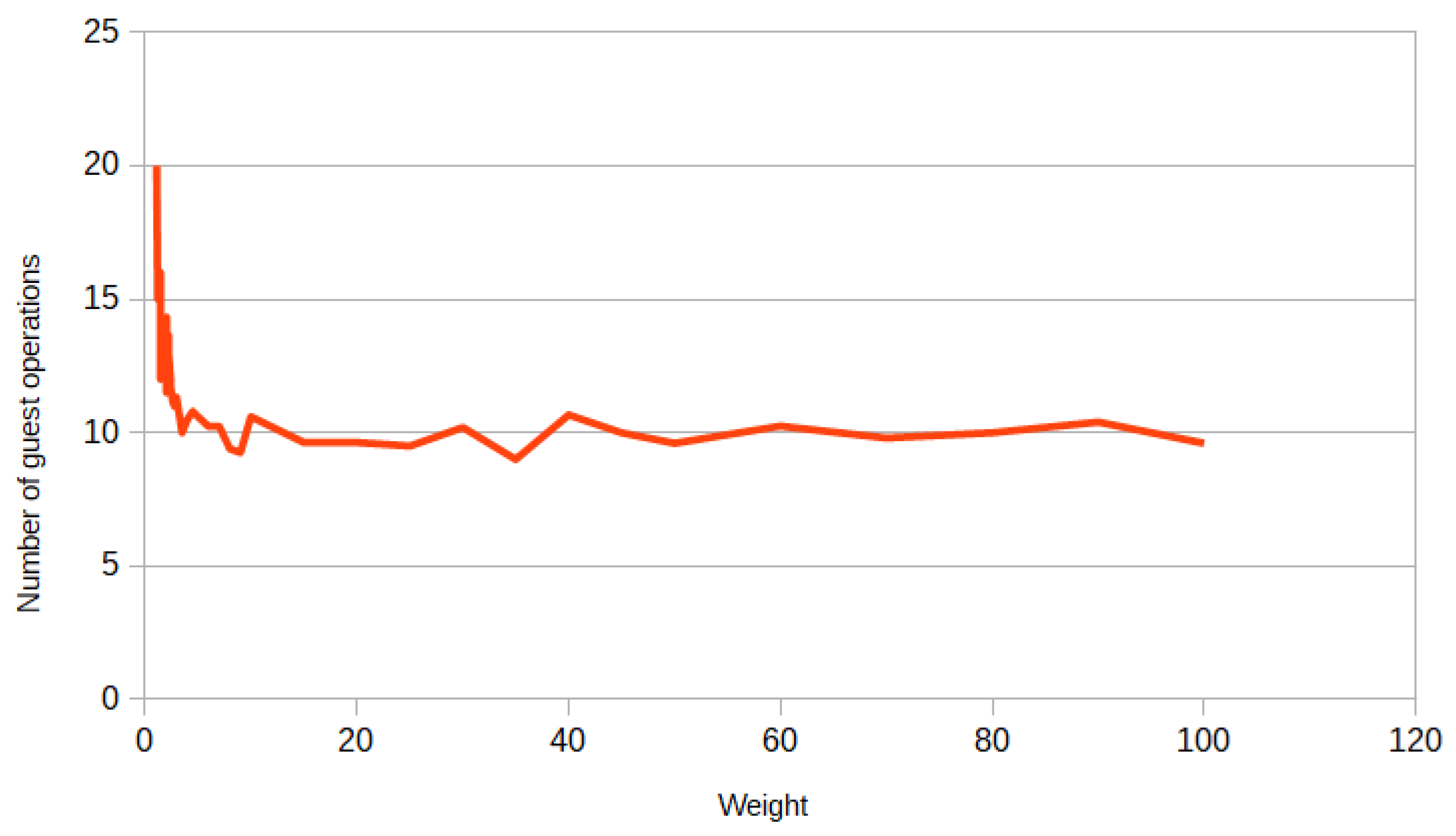
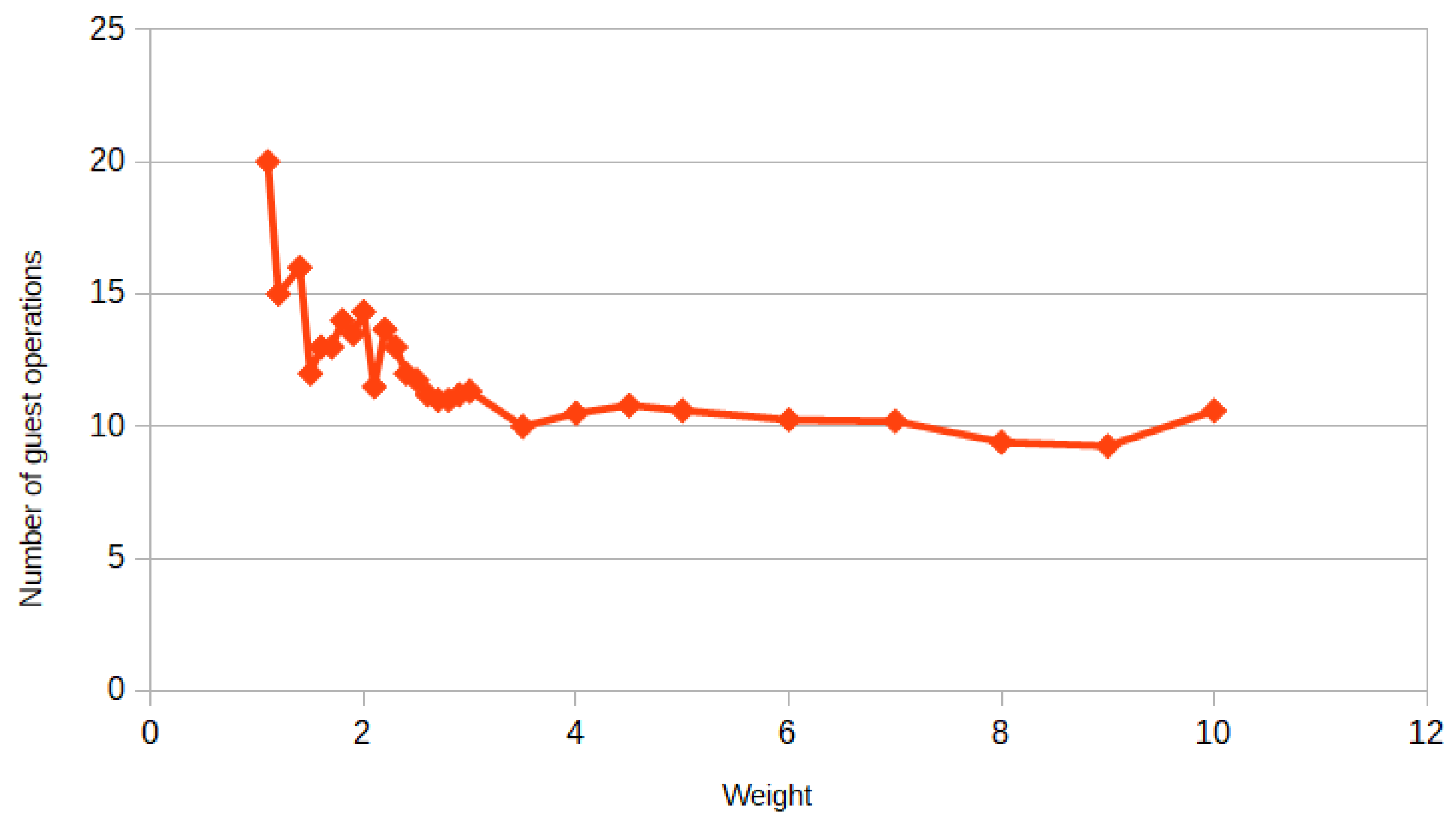
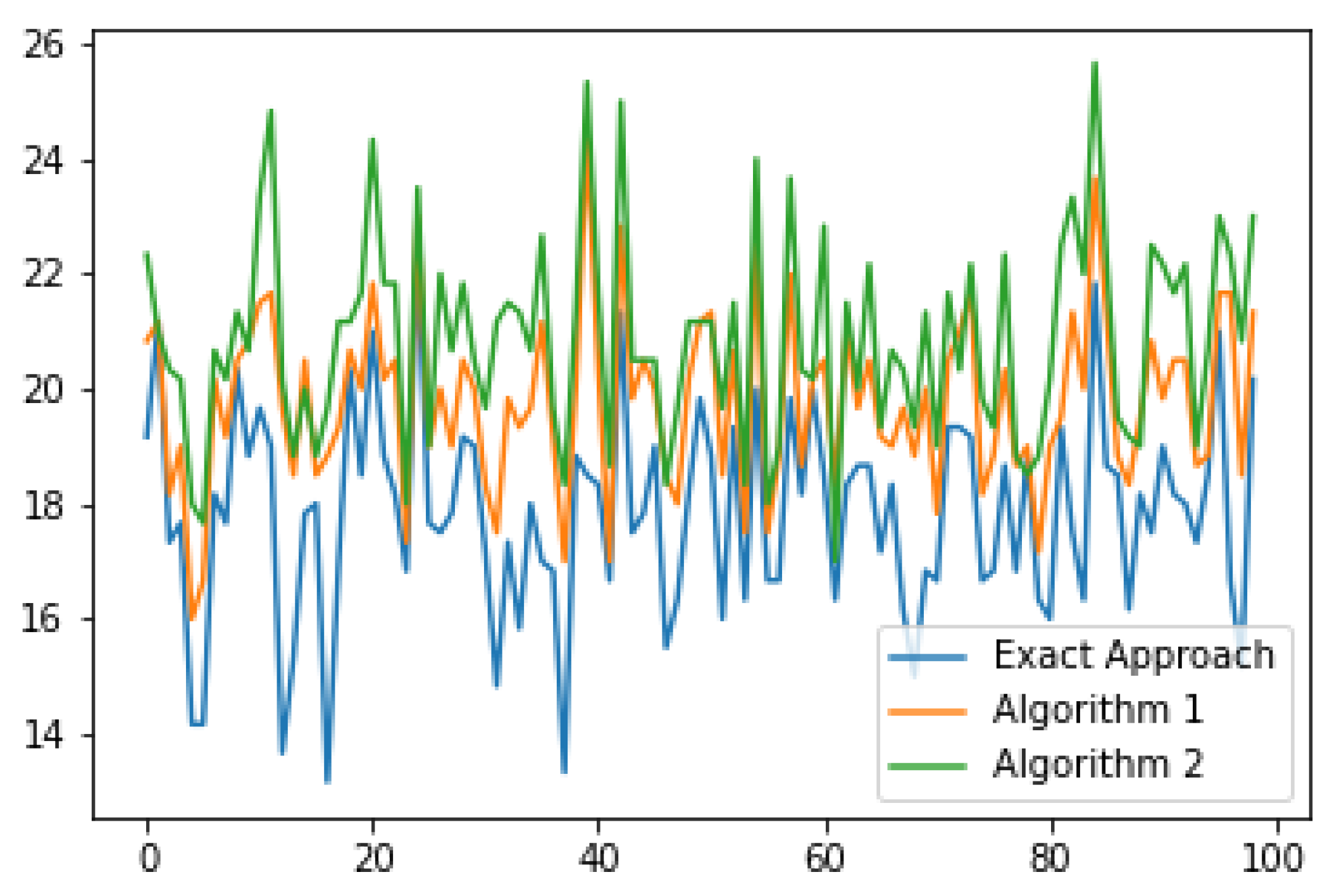
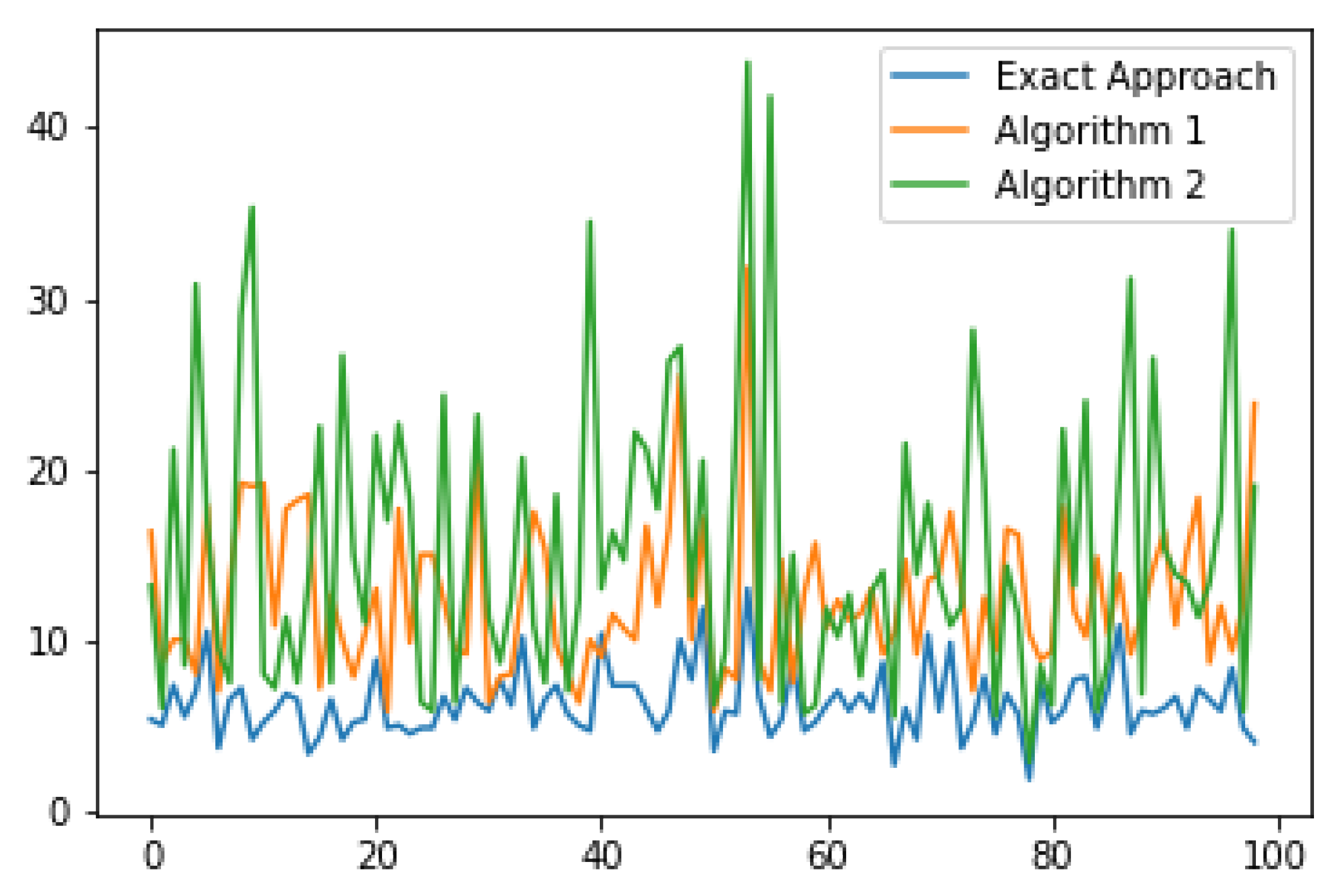
Figure 6 and
Figure 7 show a graph of the dependence of the gap hours in the examples with a small variation of the duration of surgeries and on the examples with a large variation of the duration, accordingly. In
Figure 6, it can be seen that Algorithm 1 performs better in almost all examples compared to Algorithm 2. The absolute error of the algorithms compared to the exact approach is not very large for surgeries with a small scatter, while it is already significantly larger for surgeries with a large scatter. Furthermore, it can be noticed that the scatter of the gap hours in
Figure 6 is smaller than in
Figure 7, which is quite logical, since the examples in
Figure 6 are close to each other.
The average values of the objective function and the number of guest surgeries are shown in
Table 1. In the case of surgeries with a wide variation of duration, the absolute error of the gap hours for Algorithm 1 is
h, and for Algorithm 2 it is
h, while the number of guest surgeries for each approach is about the same. Now consider the case of surgeries with a small variation of duration. The absolute error of the gap hours for Algorithm 1 is only
h, and for Algorithm 2 it is
h. However, the average number of guest surgeries is different for each approach. For the exact approach, the average number of guest surgeries is equal to one. This can be explained by the fact that in each department the duration of the surgeries is almost the same. In Algorithm 2, the number of guest surgeries is not too large either, but Algorithm 1 has an average of 12 guest surgeries. This is due to the fact that in the second and third steps of Algorithm 1, surgeries are transferred from one department to another, even with a small improvement in the objective function. To summarize, our approaches work better for surgeries with a wide range of duration. This is a good factor for us, since in real life, the durations of surgeries are very different.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}